
А началось все с чего? А началось все одним домашним, зимним, субботним вечером… Ну и конечно же с проблемы, для которой искалось решение)
На днях, по своей же глупости, я потерял навеки всю свою коллекцию музыки (Я — DJ, музыкант). Было очень жалко, ведь коллекция была идеально рассортирована, проанализирована на битрейт, тональность и т.д.
Смирился, думаю ладно, буду заново качать все треки. Качать буду с сайта promodj.com
Почему «промоднище», а не какой нибудь soundcloud? Первая причина — я сижу на этом сайте гораздо чаще, чем на остальных музыкальных порталах. Вторая причина — там есть очень удобный поиск с фильтрами а-ля «Топовое за январь 2017 с качеством 320kbps, длиной не больше 10 минут и не является мэшапом».
Как вы сами понимаете, совсем скоро мне настое… надоело нажимать руками кнопочку «Скачать». И тут и началось самое интересное).
Про то, как посмотреть исходный код элемента страницы, я говорить не буду. Не думаю что здесь есть люди настолько глупенькие.
Сообственно DIV для каждой композиции выглядит вот так:
А вот код для даного DIV'а:
Интересует нас, на первый взгляд, данная строка:
Именно под эту строку я и начал разрабатывать регулярное выражение, которое будет вырезать ссылку на аудио-файл. Но это оказалось неверное решение!
Кроме листа запроса с треками, на promodj.com так же есть реклама музыкальных треков. И в каждой такой рекламе точно такой же ссылкой выводится кнопка «Скачать». Это значит, что кроме нужных мне треков, так же будут скачиваться композиции из рекламы.
Вначале я даже хотел плюнуть, ну и хрен с ним, будет у меня в подарок еще овердохера рекламных треков. Но, посчитав, сколько лишнего рекламного мусора у меня будет, я резко отказался от этой идеи.
Далее меня напрягло то, как называется класс ссылки. «bigdownloadbutton», возможно это и разработчик сайта так красиво все называет в свой жизни, а возможно есть кнопочка поменьше…
Так и есть! Вспомнив, про маленькую, неприметную кнопку загрузки под треком, я начал искать ее код для парсинга. Вот он:
Судя по названия класса, сразу понятно, что этот элемент изначально предназначался как счетчик скачиваний. Но нас интересует другое — внутри него есть ссылка!!! На всякий случай проверил как визуально, так и с помощью поиска в коде, есть ли еще элементы с таким классом на странице. Нету! Идеально!!!
Пара-тройка минут ушла на составление простейшей регулярки:
С помощью данной регулярки мы получим все ссылки на странице, находящиеся внутри SPAN'а «downloads_count». Отлично! Второй этап.
Так как пополнять свою коллекцию я хотел треками разных жанров, да еще и только топовых, я сконструировал для себя точную цель.
Для каждого, из интересных мне стилей, парсить первые 2 страницы, выдаваемых по запросам с фильтрами: "Сортировка по рейтингу, за 2017 год, за каждый месяц, с качеством не менее 320kbps, длинной трека не более 10 минут, не является мэшапом" (Мэшапы это стремно, фу, хочу авторскую музыку!).
Теперь мне необходимо было сгенерировать несколько ссылок на страницы по заданным критериям.
При обычном запросе из браузера мы имеем следующий URL и параметры:
Догадаться, что к чему, не сложно. Тем более все параметры передаются с помощью метода GET. Дело остается за малым — сгенерировать несколько урлов по моему запросу! Я решил не заниматься извращением и не печатать все эти урлы вручную.
Мы же прогеры! Давайте напишем скрипт, который нам сгенерирует эти URL'ы!!! Да без б:
И на выходе мы получаем аккуратненькие ссылочки для парсинга!

Ну-с, ссылки страниц для парсинга у нас есть. Регулярку мы уже сделали. Давайте парсить господа!
А как парсить? Чем парсить? Конечно же чистым PHP! Мы ведь у мамы КУЛХАЦКЕРЫ и ТЫЖПРОГРАММИСТЫ!
Переходим во все тяжкие. Поиск подстроки по регулярному выражению в PHP реализовать достаточно просто. Для этого есть функция preg_match_all(). Но нам нужно для начала получить HTML код страницы, что бы его парсить.
И нет, мы не будем использовать DOM, и даже не будем использовать для этого Curl!!! Мы будем юзать функцию стандартного PHP — file_get_contents()! Вдруг кто не знал, с помощью данной функции можно читать не только локальный текстовый файл, но и скомпилированый сервером HTML код, если подать в аргументе URL!
ЦЕЛЫХ 8 СТРОК занимает наш цикл парсинга с учетом форматирования. ЦЕЛЫХ 8 СТРОК, КАРЛ!!!
Вот кстати и код:
Объяснить, что здесь к чему? Ну на всякий случай обьясню. В цикл кидаем массив URL'ов, сгенерированных ранее, затем для каждого URL'а получаем его HTML код с помощью file_get_contents(). Далее имеем строку с регулярным выражением, полученным на первом шаге.
После выполняем функцию preg_match_all с аргументами HTML кода, строки с регуляркой и переменной-массивом, куда будут записываться все найденые строки. PREG_SET_ORDER
Упорядочивает результаты так, что элемент $matches[0] содержит первый набор вхождений, элемент $matches[1] содержит второй набор вхождений, и так далее. И в конце у нас уже прописан цикл, в котором мы выводим на экран все спарсеные ссылки!
«АЛИЛУЯ!» случайно проорал я вслух. А потом пошел курить и думать, что делать дальше то…
По простейшим расчетам, на выходе я получал 11(кол-во стилей для поиска)*20(кол-во результатов на странице поиска)*12(месяцы)*2(страниц поиска) = 5,280 аудиофайлов. Плюс нужно учитывать, что загрузка каждой страницы для парсинга так же занимает время, да и сама работа регулярки тоже занимает время.
Сначала было решение все таки использовать Curl для скачивания файлов. Но минуту спустя я снова улыбался от радости).
Есть прекрасная программа — Download Master (не реклама)! Последний раз я ее видел в далеком 2010 году, времена, когда я лишь познавал uTorrent.
Фишка программы в том, что она может принимать на вход список URL файлов для закачки!!!
Вторая проблема. Если я сейчас возьму все ссылки разом, пихну их в Download Master и уйду пить чай/курить/спать, то в итоге у меня вся музыка будет в одной папке!!! Ну то есть не рассортированая по стилям.
Решение простое и логическое — буду парсить по очереди каждый стиль и кидать в Download Master. Только я начал копировать полученные URL'ы, как вежливый загрузчик предложил мне начать их загрузку!

Более того, сразу же спросил, куда сохранить эти файлы и применять ли те же настройки для всех остальных файлов в списке!
Ну и теперь я наконец то расплылся в улыбке и пошел пить чай/курить/спать!)
Если кому-нибудь это будет необходимо — вот полный PHP код для парсера:
UPD: Если кому-нибудь интересно — на выходе я получил 3350+ композиций общим весом 36,5 Гб. Не думаю, что справился бы просто руками))
На днях, по своей же глупости, я потерял навеки всю свою коллекцию музыки (Я — DJ, музыкант). Было очень жалко, ведь коллекция была идеально рассортирована, проанализирована на битрейт, тональность и т.д.
Смирился, думаю ладно, буду заново качать все треки. Качать буду с сайта promodj.com
Почему «промоднище», а не какой нибудь soundcloud? Первая причина — я сижу на этом сайте гораздо чаще, чем на остальных музыкальных порталах. Вторая причина — там есть очень удобный поиск с фильтрами а-ля «Топовое за январь 2017 с качеством 320kbps, длиной не больше 10 минут и не является мэшапом».
Как вы сами понимаете, совсем скоро мне настое… надоело нажимать руками кнопочку «Скачать». И тут и началось самое интересное).
Задача первая: определить регулярку для ссылки!
Про то, как посмотреть исходный код элемента страницы, я говорить не буду. Не думаю что здесь есть люди настолько глупенькие.
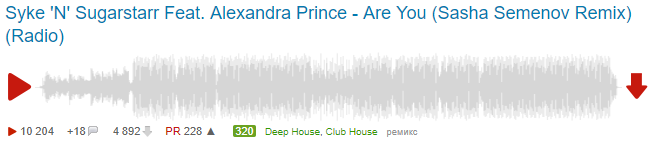
Сообственно DIV для каждой композиции выглядит вот так:
А вот код для даного DIV'а:
Заголовок спойлера
<div class="track2 track2_no_avatar">
<div class="title">
<a amba="file:6224428" onclick="return cb(event);" href="http://promodj.com/sashasemenov/remixes/6224428/Syke_N_Sugarstarr_Feat_Alexandra_Prince_Are_You_Sasha_Semenov_Remix_Radio" class="invert">Syke 'N' Sugarstarr Feat. Alexandra Prince - Are You (Sasha Semenov Remix) (Radio)</a>
</div>
<div class="aftertitle">
<div id="fpp6224428" class="player">
<div class="playerr_standalone playerr __rototype_destructable" style="min-height: 70px;">
<div class="playerr_bigplaybutton"><img class="playerr_bigplaybutton" style="width: 30px; height: 30px; visibility: visible; margin-top: 20px;" src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAB4AAAAeCAYAAAA7MK6iAAABzklEQVRIS8XWS0sCURQH8P8ZKzdlEBiMfY2oHCVo37pdO1dCILhtUyD4AYS2UhAELWslFNGDNkHbQGgz6sTQY0bDDPWELxot05m52mxn5v7O3Dn3nEP4p4us7m1gJlwHnYBRZuDQ++HZXXx9NUYRWxd8LfsuCQhbIJ2BeKhgHojGu+Ab2fcMYO4HQnxWB6LhfPFBVADdcMD3BsZsn8U/QUhCMpOKirLbAOzALYuRlSSKruSNjBvcPtzWmHE0WavFlvR3zUkAjuEmRmhk/LaSN1N2cXfwt3bHkhQJ5d7uhw1AFNzwagBSlap3e03XS4MCEAl3LI2IYsG8cfQXPgq4nfzIkAdRRTWzvwUwMriFUZmARLBgJHrxEcOdo4+9UMGMWvGxwA2wyvX5Va2kd/BxwbpaMOWNVua3S4Dl+2/+rtWDTki/+yVwfV3RShfj22rCqadGW8tPxuOYkotyzIiFNOO43zaI/sdDVy+RsK167R522KFcwW56sjNYwBRiFxY2dw0NM3DFxBFRk2bPeDurArzQc/ZeiDke1Ippp6VrcFuUffsANjsPMiFNEuKKar6IRJsN07rgud8/PTVR2QFQhiQd25mh7AbWBdt92c3zX1dq6x88MV4BAAAAAElFTkSuQmCC"></div>
<div class="playerr_bigdownloadbutton"><a class="playerr_bigdownloadbutton" href="http://promodj.com/download/6224428/Syke%20%27N%27%20Sugarstarr%20Feat.%20Alexandra%20Prince%20-%20Are%20You%20%28Sasha%20Semenov%20Remix%29%20%28Radio%29%20%28promodj.com%29.mp3" target="_self" style="width: 30px; height: 30px; margin-top: 19px;"><img style="visibility: visible; width: 30px; height: 30px;" src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAB4AAAAeCAYAAAA7MK6iAAAB2klEQVRIS+2WQUsbURSFz80MAYmZLIo4o910LXZTsOaBi4qb4EIQcdFFKQh1KbQ/QOgPKP0BgS4KLbSLQldiN6I4EtGVqBvBLqITkAbmRZDSJldGoQ0xmXcnCm4y23vu+d673HcYwj19dE9ciMC+5xyKDsg4URU9JdFKwSwxA1BVgX4g0d41+KcK9KMeuN0EeqNuuxe+50i3urdcHV9Wb7ngD2ZGYdnT4EZTAtErSRoBqAH8+b+WLhjYPQn0p3mg3uxxY9S+5+wAeCIESWUFFeiVePBQdgFMRamjUcc4gq0fqzIuYsFR0fdyRYAXjKYmASFMNRpqvHJ+0Cptu9X7I0iHv5w1EPIm77g6Ec/kT2vfE2X19kDG/WvbOwAPdwVnLKuKftupN/Yd+64zBsIGgHQyOH1TQTgbOw2T4ZabfclEH0y6f3Wivd9/0urZ2dn5rcDXy+a8B7AkgFdh4akq6yOTVhSZXwDr4VB2FUyTMYb1FFFh/DT8YYJGdRE4Eq67/QM2pUoA2v5TEfhNPqi9k0ATga9GHsVpyi4B3NcC+KgC/UIKTQyOGjbd3BwRf22C7MLSE63JZDqEeNTNRr7nPAfwGuBjWLSoyrpqAomSK6lJN/qubtwNqLXnEj6wph9Ln/rvAAAAAElFTkSuQmCC"></a></div>
<div style="padding-left: 30px; padding-right: 30px;">
<div class="playerr_waveformview" style="position: relative; width: 100%; height: 70px;">
<div style="position: absolute; width: 100%; height: 70px; clip: auto;">
<canvas style="width: 100%; height: 70px; opacity: 0.8;"></canvas>
</div>
<div style="position: absolute; width: 100%; height: 70px; clip: auto;">
<canvas style="width: 100%; height: 70px; opacity: 0.8;"></canvas>
</div>
<div style="position: absolute; width: 100%; height: 70px; clip: auto;">
<canvas style="width: 100%; height: 70px; opacity: 0.8; visibility: visible;" width="500" height="100"></canvas>
</div>
<div style="position: absolute; display: none; left: 0px; top: 0px; width: 1px; height: 70px; background-color: rgb(39, 39, 39);"></div>
<div style="position: absolute; left: 0px; top: 0px; width: 100%; height: 70px; cursor: pointer; display: block; background-image: url("//cdn.promodj.com/core/i/playerr/playerr_0.gif"); background-position: 50% 50%; background-repeat: no-repeat;"></div>
</div>
</div>
<div></div>
</div>
<div class="rbtify"></div>
</div>
<script> CORE.Player('fpp6224428', 'standalone.big', 6224428, { omitTitle: true, replace: true }); </script>
<div class="notizer"></div>
<div class="icons">
<span class="play_button" style="margin-left: 3px;"><a href="http://promodj.com/sashasemenov/remixes/6224428/Syke_N_Sugarstarr_Feat_Alexandra_Prince_Are_You_Sasha_Semenov_Remix_Radio?play=1" ambatitle="Послушать">10 204</a></span>
<span class="comments_count"><a onclick="return cb(event);" href="http://promodj.com/sashasemenov/remixes/6224428/Syke_N_Sugarstarr_Feat_Alexandra_Prince_Are_You_Sasha_Semenov_Remix_Radio#comments" ambatitle="Комментарии"><span class="cc17607699"><span class="newc">+18</span></span></a></span>
<span class="downloads_count"><a onclick="return cb(event);" href="http://promodj.com/download/6224428/Syke%20%27N%27%20Sugarstarr%20Feat.%20Alexandra%20Prince%20-%20Are%20You%20%28Sasha%20Semenov%20Remix%29%20%28Radio%29%20%28promodj.com%29.mp3" ambatitle="Скачать">4 892</a></span>
<span class="balls_count">PR <a href="#" id="fv7_6224428" ambatitle="Голосовать за ремикс" onclick="Vote('file',6224428,this,'550cb446865f60595506b16fc51a35fd'); cb(event); return false;">228 ^</a></span>
<a class="bitrate" onclick="return cb(event);" href="http://promodj.com/source/6224428/Syke%20%27N%27%20Sugarstarr%20Feat.%20Alexandra%20Prince%20-%20Are%20You%20%28Sasha%20Semenov%20Remix%29%20%28Radio%29%20%28promodj.com%29.mp3">320</a>
<span class="styles_list styles"><span class="styles"><b><a href="/music/deep_house?sortby=rating&bitrate=high&no_junk=1&period=date&duration=10m&year=2017&month=2">Deep House</a></b>, <b><a href="/music/club_house?sortby=rating&bitrate=high&no_junk=1&period=date&duration=10m&year=2017&month=2">Club House</a></b></span></span>
<span class="small" style="margin-left: 6px;">ремикс</span>
</div>
</div>
</div>
Интересует нас, на первый взгляд, данная строка:
<a class="playerr_bigdownloadbutton" href="http://promodj.com/download/6224428/Syke%20%27N%27%20Sugarstarr%20Feat.%20Alexandra%20Prince%20-%20Are%20You%20%28Sasha%20Semenov%20Remix%29%20%28Radio%29%20%28promodj.com%29.mp3" target="_self" style="width: 30px; height: 30px; margin-top: 19px;">
Именно под эту строку я и начал разрабатывать регулярное выражение, которое будет вырезать ссылку на аудио-файл. Но это оказалось неверное решение!
Кроме листа запроса с треками, на promodj.com так же есть реклама музыкальных треков. И в каждой такой рекламе точно такой же ссылкой выводится кнопка «Скачать». Это значит, что кроме нужных мне треков, так же будут скачиваться композиции из рекламы.
Вначале я даже хотел плюнуть, ну и хрен с ним, будет у меня в подарок еще овердохера рекламных треков. Но, посчитав, сколько лишнего рекламного мусора у меня будет, я резко отказался от этой идеи.
Далее меня напрягло то, как называется класс ссылки. «bigdownloadbutton», возможно это и разработчик сайта так красиво все называет в свой жизни, а возможно есть кнопочка поменьше…
Так и есть! Вспомнив, про маленькую, неприметную кнопку загрузки под треком, я начал искать ее код для парсинга. Вот он:
<span class="downloads_count"><a onclick="return cb(event);" href="http://promodj.com/download/6224428/Syke%20%27N%27%20Sugarstarr%20Feat.%20Alexandra%20Prince%20-%20Are%20You%20%28Sasha%20Semenov%20Remix%29%20%28Radio%29%20%28promodj.com%29.mp3" ambatitle="Скачать">4 892</a></span>
Судя по названия класса, сразу понятно, что этот элемент изначально предназначался как счетчик скачиваний. Но нас интересует другое — внутри него есть ссылка!!! На всякий случай проверил как визуально, так и с помощью поиска в коде, есть ли еще элементы с таким классом на странице. Нету! Идеально!!!
Пара-тройка минут ушла на составление простейшей регулярки:
/<span class="downloads_count"><a onClick="return cb(event);" href="(.*)" ambatitle="Download">/im
С помощью данной регулярки мы получим все ссылки на странице, находящиеся внутри SPAN'а «downloads_count». Отлично! Второй этап.
Задача вторая: сгенерировать ссылки на страницы для парсинга
Так как пополнять свою коллекцию я хотел треками разных жанров, да еще и только топовых, я сконструировал для себя точную цель.
Для каждого, из интересных мне стилей, парсить первые 2 страницы, выдаваемых по запросам с фильтрами: "Сортировка по рейтингу, за 2017 год, за каждый месяц, с качеством не менее 320kbps, длинной трека не более 10 минут, не является мэшапом" (Мэшапы это стремно, фу, хочу авторскую музыку!).
Теперь мне необходимо было сгенерировать несколько ссылок на страницы по заданным критериям.
При обычном запросе из браузера мы имеем следующий URL и параметры:
Protocol: http:
Hostname: promodj.com
Path name: /music/club_house
Arguments:
sortby = rating
bitrate = high
no_junk = 1
period = date
duration = 10m
year = 2017
month = 2
page = 2
Догадаться, что к чему, не сложно. Тем более все параметры передаются с помощью метода GET. Дело остается за малым — сгенерировать несколько урлов по моему запросу! Я решил не заниматься извращением и не печатать все эти урлы вручную.
Мы же прогеры! Давайте напишем скрипт, который нам сгенерирует эти URL'ы!!! Да без б:
$styles = array(
'big_room_house',
'club_house',
'dance_pop',
'deep_house',
'electrohouse',
'future_house',
'g_house',
'pop',
'progressive_housee House',
'russian_pop',
'techhouse',
);
$urls = array();
foreach ($styles as $style) {
for ($m=1; $m < 12; $m++) {
$urls[] = "http://promodj.com/music/$style/?sortby=rating&bitrate=high&no_junk=1&period=date&duration=10m&year=2017&month=$m&page=1";
$urls[] = "http://promodj.com/music/$style/?sortby=rating&bitrate=high&no_junk=1&period=date&duration=10m&year=2017&month=$m&page=2";
}
}
foreach ($urls as $url) {
echo $url."\r\n";
}
И на выходе мы получаем аккуратненькие ссылочки для парсинга!
Задача третья: парсинг ссылок
Ну-с, ссылки страниц для парсинга у нас есть. Регулярку мы уже сделали. Давайте парсить господа!
А как парсить? Чем парсить? Конечно же чистым PHP! Мы ведь у мамы КУЛХАЦКЕРЫ и ТЫЖПРОГРАММИСТЫ!
Переходим во все тяжкие. Поиск подстроки по регулярному выражению в PHP реализовать достаточно просто. Для этого есть функция preg_match_all(). Но нам нужно для начала получить HTML код страницы, что бы его парсить.
И нет, мы не будем использовать DOM, и даже не будем использовать для этого Curl!!! Мы будем юзать функцию стандартного PHP — file_get_contents()! Вдруг кто не знал, с помощью данной функции можно читать не только локальный текстовый файл, но и скомпилированый сервером HTML код, если подать в аргументе URL!
ЦЕЛЫХ 8 СТРОК занимает наш цикл парсинга с учетом форматирования. ЦЕЛЫХ 8 СТРОК, КАРЛ!!!
Вот кстати и код:
foreach ($urls as $url) {
$html = file_get_contents($url);
$re = '/<span class="downloads_count"><a onclick="return cb\(event\);" href="(.*)" ambatitle="Download">/im';
preg_match_all($re, $html, $matches, PREG_SET_ORDER, 0);
foreach ($matches as $key => $value) {
echo $value[1]."\r\n";
}
}
Объяснить, что здесь к чему? Ну на всякий случай обьясню. В цикл кидаем массив URL'ов, сгенерированных ранее, затем для каждого URL'а получаем его HTML код с помощью file_get_contents(). Далее имеем строку с регулярным выражением, полученным на первом шаге.
После выполняем функцию preg_match_all с аргументами HTML кода, строки с регуляркой и переменной-массивом, куда будут записываться все найденые строки. PREG_SET_ORDER
Упорядочивает результаты так, что элемент $matches[0] содержит первый набор вхождений, элемент $matches[1] содержит второй набор вхождений, и так далее. И в конце у нас уже прописан цикл, в котором мы выводим на экран все спарсеные ссылки!
«АЛИЛУЯ!» случайно проорал я вслух. А потом пошел курить и думать, что делать дальше то…
Задача четвертая: скачивание множества файлов
По простейшим расчетам, на выходе я получал 11(кол-во стилей для поиска)*20(кол-во результатов на странице поиска)*12(месяцы)*2(страниц поиска) = 5,280 аудиофайлов. Плюс нужно учитывать, что загрузка каждой страницы для парсинга так же занимает время, да и сама работа регулярки тоже занимает время.
Сначала было решение все таки использовать Curl для скачивания файлов. Но минуту спустя я снова улыбался от радости).
Есть прекрасная программа — Download Master (не реклама)! Последний раз я ее видел в далеком 2010 году, времена, когда я лишь познавал uTorrent.
Фишка программы в том, что она может принимать на вход список URL файлов для закачки!!!
Вторая проблема. Если я сейчас возьму все ссылки разом, пихну их в Download Master и уйду пить чай/курить/спать, то в итоге у меня вся музыка будет в одной папке!!! Ну то есть не рассортированая по стилям.
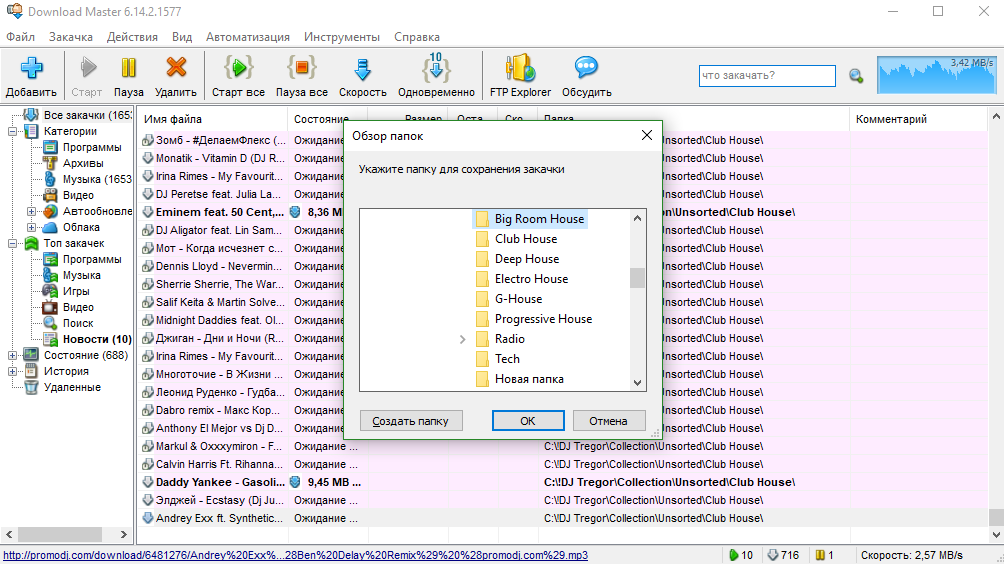
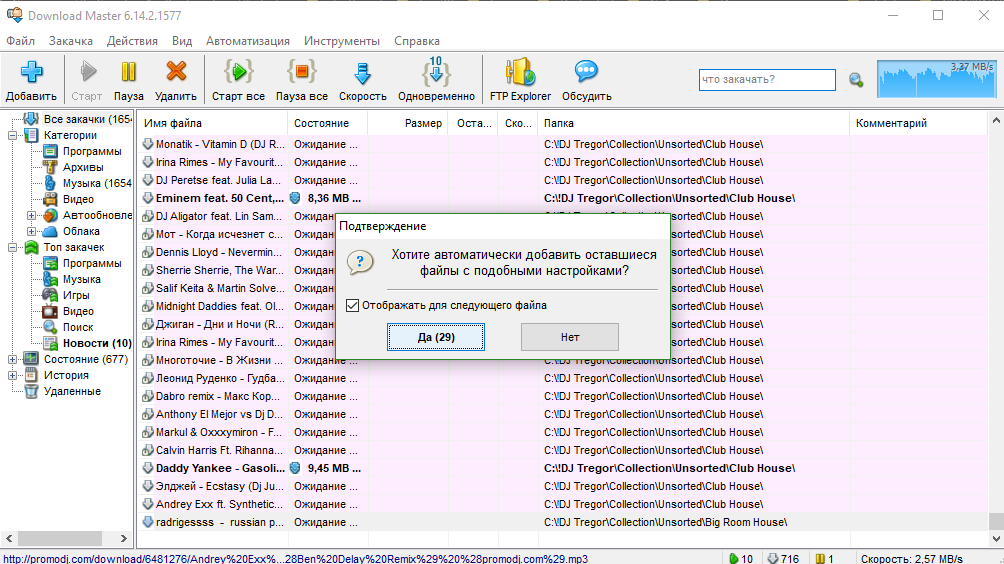
Решение простое и логическое — буду парсить по очереди каждый стиль и кидать в Download Master. Только я начал копировать полученные URL'ы, как вежливый загрузчик предложил мне начать их загрузку!
Более того, сразу же спросил, куда сохранить эти файлы и применять ли те же настройки для всех остальных файлов в списке!
Ну и теперь я наконец то расплылся в улыбке и пошел пить чай/курить/спать!)
Если кому-нибудь это будет необходимо — вот полный PHP код для парсера:
promodj_parser.php
<?php
$styles = array(
'big_room_house',
'club_house',
'dance_pop',
'deep_house',
'electrohouse',
'future_house',
'g_house',
'pop',
'progressive_housee',
'russian_pop',
'techhouse',
);
$styles = array(
'techhouse',
);
$urls = array();
foreach ($styles as $style) {
for ($m=1; $m < 12; $m++) {
$urls[] = "http://promodj.com/music/$style/?sortby=rating&bitrate=high&no_junk=1&period=date&duration=10m&year=2017&month=$m&page=1";
$urls[] = "http://promodj.com/music/$style/?sortby=rating&bitrate=high&no_junk=1&period=date&duration=10m&year=2017&month=$m&page=2";
}
}
foreach ($urls as $url) {
$html = file_get_contents($url);
$re = '/<span class="downloads_count"><a onclick="return cb\(event\);" href="(.*)" ambatitle="Download">/im';
preg_match_all($re, $html, $matches, PREG_SET_ORDER, 0);
foreach ($matches as $key => $value) {
echo $value[1]."\r\n";
}
}
?>
UPD: Если кому-нибудь интересно — на выходе я получил 3350+ композиций общим весом 36,5 Гб. Не думаю, что справился бы просто руками))
Комментарии (11)


vmm86
27.11.2017 20:40по своей же глупости, я потерял навеки всю свою коллекцию музыки
Первым делом я бы приложил максимум усилий к восстановлению потерянных данных, насколько это возможно. У меня был подобный крайне неприятный опыт, но восстановить удалось почти 100% потерянного.

Asikk
28.11.2017 12:12Простите, но здесь
[code]
for ($m=1; $m < 12; $m++) {
[/code]
Счетчик m будет от 1 до
т.е декабрь Вам не нужен?

endorphinUA
28.11.2017 19:50а почему бы не взять github.com/Imangazaliev/DiDOM?
очень удобная тулза для разбора html файлов с использованием селекторов из jQuery )
регулярки это плохая практика сейчас и плохой тон для парсинга html.
и почему процедурный стиль? )

andrew_tch
Ждем постов «как подключиться к mysql5.4 в php 5.6».