
Двоичный поиск — один из самых базовых известных мне алгоритмов. Имея отсортированный список сравнимых элементов и целевой элемент, двоичный поиск смотрит в середину списка и сравнивает значение с целевым элементом. Если цель больше, мы повторяем с меньшей половиной списка, и наоборот.
При каждом сравнении алгоритм двоичного поиска разбиваем пространство поиска пополам. Благодаря этому всегда будет не более сравнений со временем выполнения . Красиво, эффективно, полезно.
Но всегда можно посмотреть под другим углом.
Что, если попробовать выполнить двоичный поиск по графу? Большинство алгоритмов поиска по графам, такие как поиск в ширину или поиск в глубину, требуют линейного времени и были придуманы довольно умными людьми. Поэтому если двоичный поиск по графу будет иметь какой-то смысл, то он должен использовать больше информации, чем та, к которой имеют доступ обычные алгоритмы поиска.
Для двоичного поиска по списку этой информацией является факт отсортированности списка, и для управления поиском мы можем сравнивать числа с искомым элементом. Но на самом деле важнейшая информация не связана со сравнимостью элементов. Она заключается в том, что мы можем избавляться на каждом этапе от половины пространства поиска. Этап «сравнение с целевым значением» можно воспринимать как чёрный ящик, отвечающий на запросы типа «То ли это значение, которое я искал?» ответами «Да» или «Нет, но посмотри лучше вот здесь»

Если ответы на наши запросы достаточно полезны, то есть они позволяют нам разделять на каждом этапе большие объёмы пространства поиска, то, похоже, мы получили хороший алгоритм. На самом деле, существует естественная модель графов, определённая в статье Эмамджоме-Заде, Кемпе и Сингала 2015 году следующим образом.
Мы получаем в качестве входных данных неориентированный взвешенный граф с весами при . Мы видим весь граф и можем задавать вопросы в форме «Является ли вершина нужной нам?» Ответами могут двух варианта:
- Да (мы победили!)
- Нет, но является ребром из на кратчайшем пути от до нужной вершины.
Наша цель — найти нужную вершину за минимальное количество запросов.
Очевидно, что это работает только если является связанным графом, но небольшие вариации изложенного в статье будут работать и для несвязанных графов. (В общем случае это неверно для ориентированных графов.)
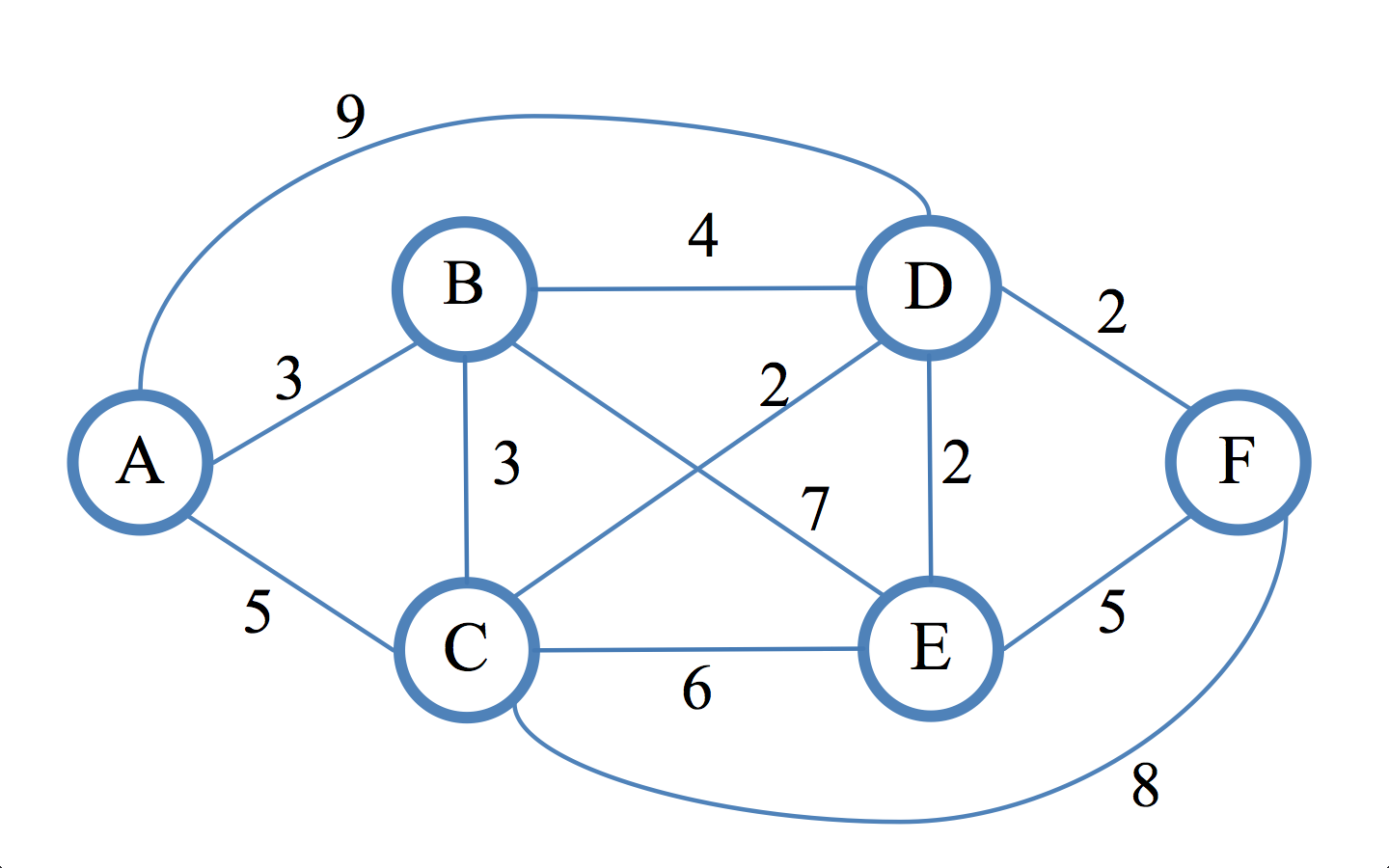
Когда граф является линией, то задача «редуцируется» до двоичного поиска в том смысле, что используется та же базовая идея, что и в двоичном поиске: начинаем с середины графа, и ребро, которое мы получаем в ответ на запрос, говорит нам, в какой половине графа продолжать поиск.
И если мы сделаем этот пример всего немного более сложным, то обобщение станет очевидным:
Здесь мы снова начинаем с «центральной вершины» и ответ на наш запрос избавит нас от одной из двух половин. Но как тогда нам выбрать следующую вершину, ведь теперь у нас нет линейного порядка? Это должно быть очевидно — выбрать «центральную вершину» любой половины, в которой мы оказались. Этот выбор можно формализировать в правило, которое будет работать даже при отсутствии очевидной симметрии, и как оказывается, этот выбор всегда будет правильным.
Определение: медианой взвешенного графа относительно подмножества вершин является вершина (необязательно находящаяся в ), которая минимизирует сумму расстояний между вершинами в >. Более формально, она минимизирует
где — сумма весов рёбер вдоль кратчайшего пути от до .
Обобщение двоичного поиска до такой модели с запросами на графе приводит нас к следующему алгоритму, ограничивающему пространство поиска, запрашивая на каждом шаге медиану.
Алгоритм: двоичный поиск в графах. В качестве входных данных используется граф .
- Начинаем с множества кандидатов .
- Пока мы не нашли нужную вершину и :
- Запрашиваем медиану множества и останавливаемся, если найдём нужную вершину.
- В противном случае пусть будет ребром, полученным в ответ на запрос; вычисляем множество всех вершин , для которых является кратчайшим путём из в . Назовём это множество .
- Заменим на .
- Выводим единственную оставшуюся вершину в
И в самом деле, как мы скоро увидим, реализация на Python будет почти столь же проста. Самая важная часть работы заключается в вычислении медианы и множества . Обе эти операции являются небольшими разновидностями алгоритма Дейкстры для вычисления кратчайших путей.
Теорема, которая проста и отлично сформулирована Эмамджоме-Заде с коллегами (всего около половины страницы на стр. 5) заключается в том, что алгоритму требуется всего запросов — столько же, сколько и в двоичном поиске.
Прежде чем мы углубимся в реализацию, стоит рассмотреть одну хитрость. Даже несмотря на то, что у нас гарантированно будет не больше запросов, из-за нашей реализации алгоритма Дейкстры, у нас точно не получится алгоритм логарифмического времени. Что в такой ситуации будет нам полезно?
Здесь мы воспользуется «теорией» — создадим вымышленную задачу, для которой позже найдём применение (что достаточно успешно используется в информатике). В этом случае мы будем обращаться с механизмом запросов как с чёрным ящиком. Естественно будет представить, что запросы затратны по времени и являются ресурсом, который нужно оптимизировать. Например, как авторы написали в дополнительной статье, граф может быть множеством группировок множества данных, а при запросах требуется вмешательство человека, смотрящего на данные и сообщающего, какой класер должен быть разделён, или какие два кластера должны быть объединены. Разумеется, граф оказывается слишком большим для обработки при группировании, поэтому алгоритм поиска медианы должен быть определён неявно. Но самое важное ясно: иногда запрос является самой затратной частью алгоритма.
Ну ладно, давайте всё это реализуем! Полный код, как всегда находится на Github.
Реализуем алгоритм
Мы начнём с небольшой вариации алгоритма Дейкстры. Здесь нам задана в качестве входных данных «начальная» точка, а в качестве выходных данных мы создаём список всех кратчайших путей до всех возможных конечных вершин.
Мы начнём с голой структуры данных графа.
from collections import defaultdict
from collections import namedtuple
Edge = namedtuple('Edge', ('source', 'target', 'weight'))
class Graph:
# Голая реализация взвешенного неориентированного графа
def __init__(self, vertices, edges=tuple()):
self.vertices = vertices
self.incident_edges = defaultdict(list)
for edge in edges:
self.add_edge(
edge[0],
edge[1],
1 if len(edge) == 2 else edge[2] # дополнительный вес
)
def add_edge(self, u, v, weight=1):
self.incident_edges[u].append(Edge(u, v, weight))
self.incident_edges[v].append(Edge(v, u, weight))
def edge(self, u, v):
return [e for e in self.incident_edges[u] if e.target == v][0]Теперь, поскольку бо?льшая часть работы в алгоритме Дейкстры заключается в отслеживании информации, накапливаемой при поиске по графу, мы определим «выходную» структуру данных — словарь с весами рёбер вместе с обратными указателями на обнаруженные кратчайшие пути.
class DijkstraOutput:
def __init__(self, graph, start):
self.start = start
self.graph = graph
# наименьшее расстояние от начала до конечной точки v
self.distance_from_start = {v: math.inf for v in graph.vertices}
self.distance_from_start[start] = 0
# список предшествующих рёбер для каждой конечной точки
# для отслеживания списка возможного множества кратчайших путей
self.predecessor_edges = {v: [] for v in graph.vertices}
def found_shorter_path(self, vertex, edge, new_distance):
# обновление решения новым найденным более коротким путём
self.distance_from_start[vertex] = new_distance
if new_distance < self.distance_from_start[vertex]:
self.predecessor_edges[vertex] = [edge]
else: # "ничья" для нескольких кратчайших путей
self.predecessor_edges[vertex].append(edge)
def path_to_destination_contains_edge(self, destination, edge):
predecessors = self.predecessor_edges[destination]
if edge in predecessors:
return True
return any(self.path_to_destination_contains_edge(e.source, edge)
for e in predecessors)
def sum_of_distances(self, subset=None):
subset = subset or self.graph.vertices
return sum(self.distance_from_start[x] for x in subset)Настоящий алгоритм Дейкстры затем выполняет поиск в ширину (управляемый очередью с приоритетами) по , обновляя метаданные при нахождении более коротких путей.
def single_source_shortest_paths(graph, start):
'''
Вычисляем кратчайшие пути и расстояния от начальной вершины до всех
возможных конечных вершин. Возвращаем экземпляр DijkstraOutput.
'''
output = DijkstraOutput(graph, start)
visit_queue = [(0, start)]
while len(visit_queue) > 0:
priority, current = heapq.heappop(visit_queue)
for incident_edge in graph.incident_edges[current]:
v = incident_edge.target
weight = incident_edge.weight
distance_from_current = output.distance_from_start[current] + weight
if distance_from_current <= output.distance_from_start[v]:
output.found_shorter_path(v, incident_edge, distance_from_current)
heapq.heappush(visit_queue, (distance_from_current, v))
return outputНаконец, мы реализуем подпрограммы нахождения медианы и вычисления :
def possible_targets(graph, start, edge):
'''
Имея заданный неориентированный граф G = (V,E), входную вершину v в V и ребро e,
инцидентное v, вычисляем множество вершин w, такое, что e находится на кратчайшем
пути от v к w.
'''
dijkstra_output = dijkstra.single_source_shortest_paths(graph, start)
return set(v for v in graph.vertices
if dijkstra_output.path_to_destination_contains_edge(v, edge))
def find_median(graph, vertices):
'''
Вычисляем в качестве output вершину во входном графе, которая минимизирует сумму
расстояний к входному множеству вершин
'''
best_dijkstra_run = min(
(single_source_shortest_paths(graph, v) for v in graph.vertices),
key=lambda run: run.sum_of_distances(vertices)
)
return best_dijkstra_run.startА теперь ядро алгоритма
QueryResult = namedtuple('QueryResult', ('found_target', 'feedback_edge'))
def binary_search(graph, query):
'''
Находим нужный узел в графе с помощью запросов вида "Является ли x нужной вершиной?"
и даём ответ - или "Мы нашли нужный узел!", или "Вот ребро на кратчайшем пути к нужному узлу".
'''
candidate_nodes = set(x for x in graph.vertices) # копируем
while len(candidate_nodes) > 1:
median = find_median(graph, candidate_nodes)
query_result = query(median)
if query_result.found_target:
return median
else:
edge = query_result.feedback_edge
legal_targets = possible_targets(graph, median, edge)
candidate_nodes = candidate_nodes.intersection(legal_targets)
return candidate_nodes.pop()Вот пример выполнения скрипта на образце графа, который мы использовали выше в посте:
'''
Граф выглядит как дерево с равномерными весами
a k
b j
cfghi
d l
e m
'''
G = Graph(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i',
'j', 'k', 'l', 'm'],
[
('a', 'b'),
('b', 'c'),
('c', 'd'),
('d', 'e'),
('c', 'f'),
('f', 'g'),
('g', 'h'),
('h', 'i'),
('i', 'j'),
('j', 'k'),
('i', 'l'),
('l', 'm'),
])
def simple_query(v):
ans = input("Является ли '%s' нужной вершиной? [y/N] " % v)
if ans and ans.lower()[0] == 'y':
return QueryResult(True, None)
else:
print("Введите вершину на кратчайшем пути между"
" '%s' и нужной вершиной. Граф: " % v)
for w in G.incident_edges:
print("%s: %s" % (w, G.incident_edges[w]))
target = None
while target not in G.vertices:
target = input("Введите соседнюю вершину '%s': " % v)
return QueryResult(
False,
G.edge(v, target)
)
output = binary_search(G, simple_query)
print("Найдена нужная вершина: %s" % output)Функция запроса просто выводит напоминание о структуре графа и просит пользователя ответить (да/нет) и сообщить соответствующее ребро, если в случае отрицательного ответа.
Пример выполнения:
Является ли 'g' нужной вершиной? [y/N] n
Введите вершину на кратчайшем пути между 'g' и нужной вершиной. Граф:
e: [Edge(source='e', target='d', weight=1)]
i: [Edge(source='i', target='h', weight=1), Edge(source='i', target='j', weight=1), Edge(source='i', target='l', weight=1)]
g: [Edge(source='g', target='f', weight=1), Edge(source='g', target='h', weight=1)]
l: [Edge(source='l', target='i', weight=1), Edge(source='l', target='m', weight=1)]
k: [Edge(source='k', target='j', weight=1)]
j: [Edge(source='j', target='i', weight=1), Edge(source='j', target='k', weight=1)]
c: [Edge(source='c', target='b', weight=1), Edge(source='c', target='d', weight=1), Edge(source='c', target='f', weight=1)]
f: [Edge(source='f', target='c', weight=1), Edge(source='f', target='g', weight=1)]
m: [Edge(source='m', target='l', weight=1)]
d: [Edge(source='d', target='c', weight=1), Edge(source='d', target='e', weight=1)]
h: [Edge(source='h', target='g', weight=1), Edge(source='h', target='i', weight=1)]
b: [Edge(source='b', target='a', weight=1), Edge(source='b', target='c', weight=1)]
a: [Edge(source='a', target='b', weight=1)]
Введите соседнюю вершину 'g': f
Является ли 'c' нужной вершиной? [y/N] n
Введите вершину на кратчайшем пути между 'c' и нужной вершиной. Граф:
[...]
Введите соседнюю вершину 'c': d
Является ли 'd' нужной вершиной? [y/N] n
Введите вершину на кратчайшем пути между 'd' и нужной вершиной. Граф:
[...]
Введите соседнюю вершину 'd': e
Найдена нужная вершина: eВероятностная история
Реализованный нами в этом посте двоичный поиск довольно минималистичен. На самом деле, более интересной частью работы Эмамджоме-Заде с коллегами является часть, в которой ответ на запрос может быть неверным с неизвестной вероятностью.
В таком случае может быть множество кратчайших путей, являющихся правильным ответом на запрос, в дополнение ко всем неверным ответам. В частности, это исключает стратегию передачи одного и того же запроса несколько раз и выбора самого популярного ответа. Если частота ошибки равна 1/3, и к нужной вершине есть два кратчайших пути, то мы можем получить ситуацию, в которой мы с равной частотой увидим три ответа и не сможем выяснить, какой из них лжив.
Вместо этого Эмамджоме-Заде с соавторами использует технику, основанную на алгоритме обновления мультипликативных весов (он снова в деле!). Каждый запрос даёт мультипликативное увеличение (или уменьшение) для множества узлов, являющихся постоянными нужными вершинами при условии, что ответ на запрос верен. Есть ещё некоторые детали и постобработка для избежания невероятных результатов, но в целом основная идея такова. Её реализация будет отличным упражнением для читателей, заинтересованных в глубоком изучении этой недавней статьи (или в том, чтобы поразмять свои математические мышцы)
Но если смотреть ещё глубже, то эта модель «запроса и получения совета о том, как улучшить результат» является классической моделью обучения, впервые формально изученной Даной Энглуин. В её модели проектируется алгоритм для обучения классификатора. Допустимыми запросами являются запросы о принадлежности и об эквивалентности. Принадлежность — это, в сущности, вопрос «Какая метка у этого элемента?», а запрос эквивалентности имеет вид «Верный ли это классификатор?» Если ответ «нет», то передаётся пример с неправильной меткой.
Это отличается от обычного предположения машинного обучения, потому что алгоритм обучения должен создать пример, о котором он хочет получить больше информации, а не просто полагаться на случайно сгенерированное подмножество данных. Цель заключается в минимизации количества запросов, пока алгоритм точно не обучится нужной гипотезе. И на самом деле — как мы увидели в этом посте, если у нас будет немного лишнего времени на изучение пространства задачи, то мы можем создать запросы, получающие достаточно много информации.
Представленная здесь нами модель двоичного поиска по графам является естественным аналогом запроса эквивалентности в задаче поиска: вместо контрпримера с неверной меткой мы получаем «толчок» в правильном направлении к цели. Довольно неплохо!
Здесь мы можем пойти различными путями: (1) реализовать версию алгоритма с мультипликативными весами, (2) применить эту технику к задаче ранжирования или группирования, или (3) подробнее рассмотреть теоретические модели обучения типа принадлежности и эквивалентности.
Комментарии (12)

MikailBag
13.12.2017 15:57сложность по времени не менее чем n log n, но запросов всего log. Если граф небольшой, а запрос выполняется долго, то это эффективно.

slonopotamus
14.12.2017 09:33Подвох здесь чувствую я. Вы собрались в множестве из N элементов искать нужный за более чем O(n) операций???
Also, зачем вы говорите об ограничении снизу когда вас спрашивают об ограничении сверху?
alexeykuzmin0
14.12.2017 16:15У нас поиск медианы на каждом шаге долгий. Так что да, если запрос выполняется за константное время, быстрее будет перебрать все вершины графа
slonopotamus
14.12.2017 16:55Расскажите сценарий в котором запрос будет выполняться за время зависящее от N.
alexeykuzmin0
14.12.2017 17:02Я вам синтетических примеров могу сколько угодно придумать — например, запрос, который n! считает прежде, чем ответ выдать.
А вот реальной применимости здесь не видно.slonopotamus
14.12.2017 20:59После еще нескольких перечитываний статьи я кажется начал понимать что хотел сказать автор.
Вот есть git bisect, который ищет между "хорошей" и "плохой" вершиной в DAG самую раннюю плохую. И минимизирует количество вопросов "является ли эта вершина плохой", т.к. время на получение ответа (который вообще может считаться вручную) непредсказуемо и предполагается много бОльшим чем обходы графа.
Автор хочет сделать что-то похожее, только в более общем виде — на произвольном графе.
slonopotamus
14.12.2017 21:38Но по постановке задачи автора, тот кто отвечает на вопросы (и чьё время мы хотим сэкономить) сразу знает точный ответ и становится непонятно зачем выяснять его таким странным способом. Надо подумать как видоизменить задачу так, чтобы изначально ни у одной из сторон ответа не было.
slonopotamus
14.12.2017 11:54В противном случае пусть e=(v,w) будет ребром, полученным в ответ на запрос; вычисляем множество всех вершин x?V, для которых e является кратчайшим путём из v в x. Назовём это множество T.
И что вот здесь вот с big-O происходит?

slonopotamus
14.12.2017 09:05self.distance_from_start[vertex] = new_distance
if new_distance < self.distance_from_start[vertex]:Здесь ошибка. Присвоение, а потом сравнение с тем же самым значением.

vba
14.12.2017 15:44Граф выглядит как дерево с равномерными весами
Хм тавтология какая то… Дерево это связный ациклический граф, следовательно выходит: граф выглядит как граф. Если смотреть оригинал:
Graph looks like this tree, with uniform weights
То тоже немного тавтологией отдает, но не так.
slavenski
Спасибо за статью, читал с интересом. Скажите мне, может я просто не вник, а сложность остается та же O(logN)? Я так понял, что на каждой итерации мы, по сути, задействуем поиск кратчайших путей, для определения медианы (а это тоже вносит свой вклад). В общем, вопрос сложности. Извините, если задаю глупые вопросы =)