
С момента выпуска консоли Dreamcast и появления модемного адаптера разработчики игр получили возможность собирать данные от игроков об их поведении в естественной среде обитания. На самом деле история игровой аналитики началась со старых PC-игр наподобие EverQuest, выпущенной в 1999 году. Игровые серверы были необходимы для авторизации пользователей и заполнения миров, но в то же время обеспечивали возможность записи данных об игровом процессе.
С 1999 года ситуация со сбором и анализом данных существенно изменилась. Вместо хранения данных локально в виде log-файлов, современные системы могут отслеживать действия и применять машинное обучение практически в реальном времени. Я расскажу о четырёх этапах развития игровой аналитики, которые выделил за время своего пребывания в игровой индустрии:
- Обычные файлы: данные сохраняются локально на игровых серверах
- Базы данных: данные получаются как простые файлы и загружаются в базу данных
- «Озёра данных» (Data Lakes): данные сохраняются в Hadoop/S3, а затем загружаются в базу данных
- Бессерверный этап: для хранения и выполнения запросов используются услуги с удалённым управлением (managed services)
Каждый из этих этапов эволюции поддерживал всё больший объём собираемых данных и снижал задержку между сбором данных и выполнением анализа. В этом посте я представлю примеры систем каждой из этих эпох и расскажу о плюсах и минусах каждого подхода.
Игровая аналитика начала набирать обороты примерно с 2009 года. Георг Зоеллер из Bioware создал систему для сбора игровой телеметрии в процессе разработки игр. Он представил эту систему на GDC 2010. Вскоре после этого Electronic Arts начала собирать данные из игр после разработки, чтобы отслеживать поведение настоящих игроков. Кроме того, постоянно возрастал научный интерес к применению аналитики в игровой телеметрии. Такие исследователи этой области, как Бен Медлер, предложили использовать игровую аналитику для персонализации игрового процесса.
Хотя за последние два десятилетия произошла общая эволюция конвейеров аналитики геймплея, чёткого разграничения между разными эрами нет. Некоторые игровые команды до сих пор используют системы из более ранних эпох, и, может быть, они лучше подходят для их целей. Кроме того, существует большое количество готовых систем игровой аналитики, но их мы в этом посте рассматривать не будем. Я расскажу о коллективах разработчиков игр, собирающих телеметрию и использующих для этого собственный конвейер данных.
Эра простых файлов

Компоненты архитектуры аналитики до эпохи баз данных
Я начал заниматься игровой аналитикой в Electronic Arts в 2010 году, ещё до того, как EA создала организацию для работы с этими данными. Хотя многие игровые компании уже собирали огромные объёмы данных о геймплее, бОльшая часть телеметрии хранилась в форме log-файлов или других простых форматов файлов, сохранявшихся локально на игровых серверах. Ни к каким данным невозможно было осуществить запрос напрямую, и вычисление основных метрик, например, количество ежемесячных активных пользователей (monthly active users, MAU) требовало значительных усилий.
Electronic Arts встроила в Madden NFL 11 функцию реплея, обеспечившую неожиданный источник игровой телеметрии. После каждого матча на игровой сервер передавалась сводка игры в формате XML, в которой перечислялись стратегии игры, движения, сделанные во время игры и результаты даунов. В результате появились миллионы файлов, которые можно было проанализировать, чтобы узнать больше о взаимодействии игроков с Madden в естественной среде обитания. Проходя интернатуру в EA осенью 2010 года, я создал регрессионную модель, анализировавшую те функции, которые сильнее всего влияли на удержание интереса пользователей к игре.

Влияние соотношения побед на удерживание игроков в Madden NFL 11 на основании предпочитаемого режима игры.
Примерно за десять лет до моей интернатуры в EA компания Sony Online Entertainment уже использовала игровую аналитику, собирая данные геймплея с помощью сохраняемых на серверах log-файлов. Эти наборы данных стали использовать для анализа и моделирования только несколько лет спустя, но, тем не менее, они оказались одними из первых примеров игровой аналитики. Такие исследователи, как Дмитри Уильямс и Ник И, опубликовали работы, основанные на проанализированных данных франшизы EverQuest.
Локальное хранение данных — это, без сомнения, самый простой подход к сбору геймплейных данных. Например, я написал туториал по использованию PHP для сохранения данных, сгенерированных Infinite Mario. Но у такого подхода есть значительные недостатки. Вот перечень компромиссов, на которые приходится идти при таком подходе:
Плюсы
— Простота: сохраняем любые нужные нам данные в любом нужном формате.
Минусы
— Нет отказоустойчивости.
— Данные не хранятся в центральном хранилище.
— Высокая задержка доступа к данным.
— Отсутствие стандартного инструментария или экосистемы для анализа.
Обычные файлы вполне подходят, если у вас всего несколько серверов, но на самом деле такой подход не является конвейером аналитики, если вы не перемещаете файлы в центральное хранилище. Работая в EA, я написал скрипт для передачи файлов XML с десятков серверов на единый сервер, который парсил файлы и сохранял игровые события в базе данных Postgres. Это означало, что мы могли выполнять анализ геймплея Madden, но набор данных был неполным и имел значительные задержки. Эта система была предшественником следующей эры игровой аналитики.
Ещё одним подходом, который использовался в ту эру, был скрэппинг веб-сайтов для сбора геймплейных данных с последующим анализом. Во время выполнения моей аспирантской исследовательской работы я скрэппил веб-сайты наподобие TeamLiquid и GosuGamers для создания набора данных реплеев профессиональных игроков в StarCraft. Затем я создал прогнозирующую модель для определения порядка строительства. Другими примерами аналитических проектов той эры был скрэппинг веб-сайтов наподобие WoW Armory. Более современный пример — это SteamSpy.
Эра баз данных

Компоненты аналитической архитектуры на основе ETL
Удобство сбора игровой телеметрии в центральном хранилище стало очевидным примерно в 2010 году, и многие игровые компании начали сохранять телеметрию в базах данных. Для передачи данных событий в базу данных, которую могли использовать аналитики, использовалось множество различных подходов.
Когда я работал в Sony Online Entertainment, у нас были игровые серверы, сохранявшие файлы событий на центральный файловый сервер через каждую пару минут. Затем файловый сервер примерно раз в час запускал процесс ETL, который быстро загружал эти файлы событий в аналитическую базу данных (в то время это была Vertica). Этот процесс имел разумную задержку, примерно около часа от момента передачи игровым клиентом события до возможности осуществления запросов к нашей аналитической базе данных. Кроме того, она масштабировалась до больших объёмов данных, но при этом данные событий должны были иметь неизменную схему.
Работая в Twitch, мы использовали похожий процесс для одной из наших аналитических баз данных. Основное отличие от решения Sony заключалось в том, что вместо передачи файлов scp с игровых серверов в центральное хранилище, мы использовали Amazon Kinesis для потоковой передачи событий от серверов в область индексирования S3. Затем мы применяли процесс ETL для быстрой загрузки данных в Redshift для анализа. С тех пор Twitch перешёл к системе «озёр данных» (data lake), чтобы иметь возможность масштабирования под бОльшие объёмы данных и обеспечивать различные варианты выполнения запросов наборов данных.
Использованные в Sony и Twitch базы данных чрезвычайно ценны для обеих компаний, но при увеличении масштаба объёмов хранимых данных у нас начали возникать проблемы. Когда мы стали собирать более подробную информацию о геймплее, мы больше не могли хранить полную историю событий в таблицах и нам приходилось обрезать данные, хранящиеся дольше нескольких месяцев. Это нормально, если можно создать итоговые таблицы, содержащие самые важные подробности этих событий, но такая ситуация неидеальна.
Одна из проблем такого подхода заключалась в том, что промежуточный сервер становится основной точкой сбоя. Также возможно возникновение «бутылочных горлышек», когда одна игра отправляет слишком много событий, что приводит к потере событий всех игр. Ещё одна проблема заключается в скорости выполнения запросов при увеличении количества работающих с базой данных аналитиков. Команда из нескольких аналитиков, работающая над несколькими месяцами геймплейных данных вполне справляется с работой, но после многолетнего сбора данных и увеличения количества аналитиков скорость выполнения запросов может стать серьёзной проблемой, из-за которой на выполнение некоторых запросов требуется несколько часов.
Плюсы
— Все данные хранятся в одном месте и доступ к ним возможен через запросы SQL.
— Имеется хороший инструментарий, например, Tableau и DataGrip.
Минусы
— Хранение всех данных в базе данных наподобие Vertica или Redshift оказывается дорогостоящим.
— События должны иметь постоянную схему.
— Может потребоваться усечение таблиц.
Ещё одна проблема с использованием базы данных в качестве основного интерфейса данных геймплея заключается в том, что в них невозможно эффективно применять инструменты машинного обучения, например MLlib Spark, поскольку перед началом работы из базы данных необходимо выгрузить все значимые данные. Один из способов преодоления этого ограничения — хранение данных геймплея в формате и слое хранения, хорошо работающем с инструментами Big Data, например, сохранять события как файлы Parquet в S3. Такой тип конфигурации стал популярным в следующей эре. Он позволил избавиться от необходимости усечения таблиц и снизил затраты на хранение всех данных.
Эра «озёр данных»

Компоненты аналитической архитектуры озера данных
Наиболее популярным паттерном хранения данных во время моей работы специалистом по анализу данных в игровой индустрии был паттерн озёр данных. Общий паттерн заключается в хранении полуструктурированных данных в распределённой базе данных и в выполнении процессорв ETL для извлечения наиболее важных данных в аналитические базы данных. Для распределённой базы данных можно использовать множество различных инструментов: в Electronic Arts мы использовали Hadoop, в Microsoft Studios — Cosmos, а в Twitch — S3.
Такой подход позволяет командам масштабироваться до огромных объёмов данных, а также предоставляет дополнительную защиту от сбоев. Основной его недостаток в том, что он повышает сложность и может привести к тому, что аналитики будут иметь доступ к меньшему количеству данных, чем при традиционном подходе с базами данных, из-за нехватки инструментария или политик доступа. Большинство аналитиков будет взаимодействовать с данными в этой модели таким же образом, используя аналитическую базу данных, заполненную из ETL озера данных.
Один из преимуществ такого подхода в том, что он поддерживает множество различных схем событий, и в нём можно изменять атрибуты события, не влияя на аналитическую базу данных. Ещё одно преимущество заключается в том, что команды аналитиков могут использовать такие инструменты, как Spark SQL для непосредственной работы с озером данных. Однако в большинстве мест моей работы доступ к озеру данных ограничивался, что не позволяло использовать большинство преимуществ такой модели.
Плюсы
— Масштабируемость до огромных объёмов данных.
— Поддержка гибких схем событий.
— Затратные запросы можно перенести в озеро данных.
Минусы
— Значительные издержки при работе.
— Процессы ETL могут создавать значительные задержки.
— В некоторых озёрах данных не хватает полноценного инструментария.
Основной недостаток озёр данных заключается в том, что обычно для функционирования системы требуется целая команда. Это имеет смысл для больших организаций, но для мелких компаний может быть перебором. Один из способов использования преимуществ озёр данных без затрат на издержки — применение услуг удалённого управления (managed services).
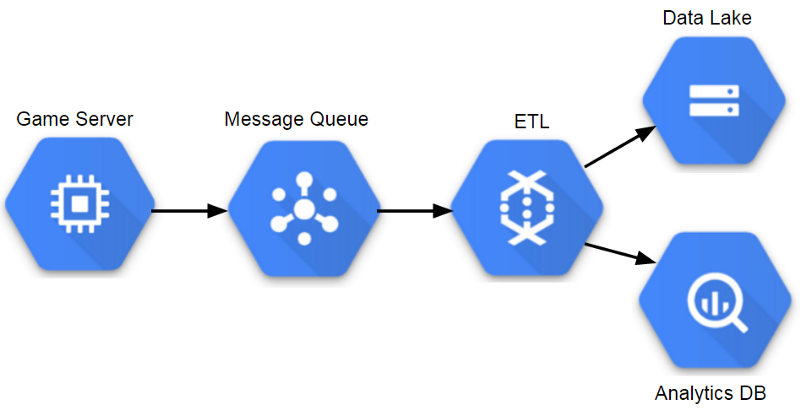
Бессерверная эра
Компоненты управляемой аналитической архитектуры (GCP)
В нынешнюю эру на платформах игровой аналитики используется множество услуг управления сетью, позволяющих командам работать с данными практически в реальном времени, при необходимости масштабировать системы и снижать издержки на поддержку серверов. Мне не приходилось работать в этой эре, когда я был в игровой индустрии, но я видел признаки такого перехода. Riot Games использует Spark для процессов ETL и машинного обучения, поэтому ей нужна была возможность масштабирования инфраструктуры по запросу. Некоторые игровые команды используют для игровых сервисов адаптивные методы, поэтому логично применять этот подход и для аналитики.
После GDC 2018 я решил попробовать построить образец конвейера. На своей нынешней работе я использовал Google Cloud Platform, и, похоже, у неё есть хороший инструментарий для управляемого озера данных и среды выполнения запросов. Результат превратился в этот туториал, в котором для построения масштабируемого конвейера используется DataFlow.
Плюсы
— Те же преимущества, что и у использования озера данных.
— Автоматическое масштабирование на основе потребностей в хранилище и запросах.
— Минимальные издержки на работу.
Минусы
— Услуги удалённого управления могут быть дорогостоящими.
— Многие услуги привязаны к платформе и их портирование может быть невозможно.
В своей карьере наибольшего успеха я достигал, работая с подходом эры баз данных, поскольку она давала команде аналитиков доступ ко всем важным данным. Однако такая схема не может продолжать масштабироваться, и большинство команд с тех пор перешла на окружения с озёрами данных. Чтобы окружение с озером данных было успешным, команды аналитиков должны иметь доступ к лежащим в основе данным и иметь готовый инструментарий для поддержки своих рабочих процессов. Если бы я строил конвейер сегодня, я бы совершенно точно начал с бессерверного подхода.
Бен Вебер — ведущий специалист по анализу данных в Windfall Data, занимающейся созданием наиболее точной и исчерпывающей модели чистой стоимости активов.
a-l-e-x
не очень хорошо это понял, пока не прочитал в оригинале «a staging area on S3»