

«Требуются цитаты»
Генетик и лауреат нобелевской премии Оливер Смитис, умерший в январе 2017-го в возрасте 91 года, был скромным и предпочитающим держаться в тени изобретателем. Для него было типичным рассказывать историю о его крупнейшем фиаско: работе по измерению осмотического давления, опубликованной в 1953 году [Smithies, O. Biochem. J. 55, 57–67 (1953)], которая, как он выражался, «имела сомнительное достижение в виде отсутствия ссылок на неё».
«На неё никто ни разу не сослался и никто никогда не использовал этот метод», — рассказал он студентам на встрече в г. Линдау в Германии в 2014 году.
На самом-то деле работа Смитиса привлекла гораздо больше внимания, чем он думал: за десять лет с момента её публикации на неё сослались девять работ. Но ошибка понятна — многие учёные неправильно воспринимают нецитируемость работ, как с точки зрения масштаба этого явления, так и по его влиянию на мир науки.
Одна часто повторяемая оценка, упомянутая в спорной статье, опубликованной в журнале Science в 1990, утверждает, что более половины всех научных статей остаются без ссылок на них в течение пяти лет после их опубликования. И учёные сильно беспокоятся по этому поводу, говорит Джевин Уэст [Jevin West], специалист по теории информации из Вашингтонского университета в Сиэтле, изучающий крупномасштабные закономерности исследовательской литературы. Ведь цитирование является общепризнанной мерой академического влияния: маркером того, что работу не просто прочитали, но и сочли полезной для последующих исследований. Исследователи беспокоятся, что большое количество нецитируемых работ указывает на появление горы бесполезных или несущественных исследований. «И не сосчитать, сколько раз люди спрашивали меня за ужином: „Какая часть литературы остаётся совсем без ссылок?“ — говорит Уэст.
На самом деле исследование без ссылок на него не всегда бесполезно. Более того, таких исследований довольно мало, говорит Винсент Ларивьер [Vincent Lariviere], специалист по теории информации из Монреальского университета в Канаде.
Чтобы лучше разобраться в этом тёмном, всеми забытом углу опубликованных работ, журнал Nature погрузился в цифры с намерением выяснить, сколько работ на самом деле остаются без упоминания. Наверняка это узнать невозможно, поскольку базы данных по цитированию неполны. Но ясно, что, по крайней мере у костяка из 12000 журналов в Web of Science, крупной базе данных от компании Clarivate Analytics, работы без упоминаний встречаются гораздо реже, чем принято считать.
Записи Web of Science говорят о том, что менее 10% научных работ остаются без ссылок на них. Настоящая цифра должна быть ещё ниже поскольку большое количество работ, помеченных в базе, как не имеющие упоминаний, на самом деле где-то кем-то упомянуты.
Это не обязательно значит, что низкокачественных работ существует меньше: тысячи журналов не индексируются базой Web of Science, и беспокойство насчёт того, что учёные набивают свои резюме бессмысленными работами, остаётся реальным.
Но новые цифры могут успокоить людей, напуганных рассказами об океанах заброшенных работ. Кроме того, при ближайшем рассмотрении некоторых работ, которые никто не упоминал, оказывается, что у них есть польза — и их читают — несмотря на кажущееся игнорирование. „Отсутствие цитат нельзя интерпретировать как бесполезность или никчёмность статей“, — говорит Дэвид Пендлбюри [David Pendlebury], главный аналитик цитат из Clarivate.
Мифы об отсутствии упоминаний
Представление о том, что научная литература переполнена неупоминаемыми исследованиями, восходит к паре статей в журнале Science, от 1990 и 1991 [Pendlebury, D. A. Science 251,1410–1411 (1991)] годов. Отчёт от 1990 года сообщает, что 55% статей, опубликованных с 1981 по 1985 года не упоминались нигде в течение пяти лет после их выхода. Но эти анализы вводят в заблуждение, в основном, поскольку они учитывали такие виды публикаций, как письма, исправления, протоколы заседаний и другой редактурный материал, который обычно не цитируется. Если удалить это всё, оставив только исследовательские работы и обзорные статьи, проценты неупомянутых статей рухнут. А если продлить срок ожидания свыше пяти лет, эти проценты упадут ещё сильнее.
В 2008 году Ларивьер с коллегами по-новому взглянули на Web of Science и сообщили не только о том, что количество совсем не процитированных работ меньше, чем считалось, но и о том, что процент работ без упоминаний уменьшается уже несколько десятилетий. Журнал Nature попросил Ларивьера совместно с Кэссиди Сугимото [Cassidy Sugimoto] из Индианского университета в Блумингтоне обновить свой анализ и прокомментировать его для этой статьи.
Новые цифры, подсчитывающие исследовательские статьи и обзоры, говорят о том, что в большинстве областей количество работ, совсем не привлекающих ссылок, выравнивается на сроке от пяти до десяти лет после публикации, хотя у каждой области эти пропорции свои. Из всех работ по биомедицине, опубликованных в 2006 году, на сегодня не цитируются лишь 4%; по химии это число равно 8%, а по физике — ближе к 11%. Если убрать случаи самоцитат, эти цифры возрастают — и в некоторых дисциплинах в полтора раза. В инженерных и технологических областях процент работ 2006 года без ссылок равен 24%, гораздо выше естественных наук. Это может быть связано с технической природой этих статей, решающих специфические проблемы, вместо того, чтобы предоставлять другим учёным основу для продолжения работы — так считает Ларивьер.
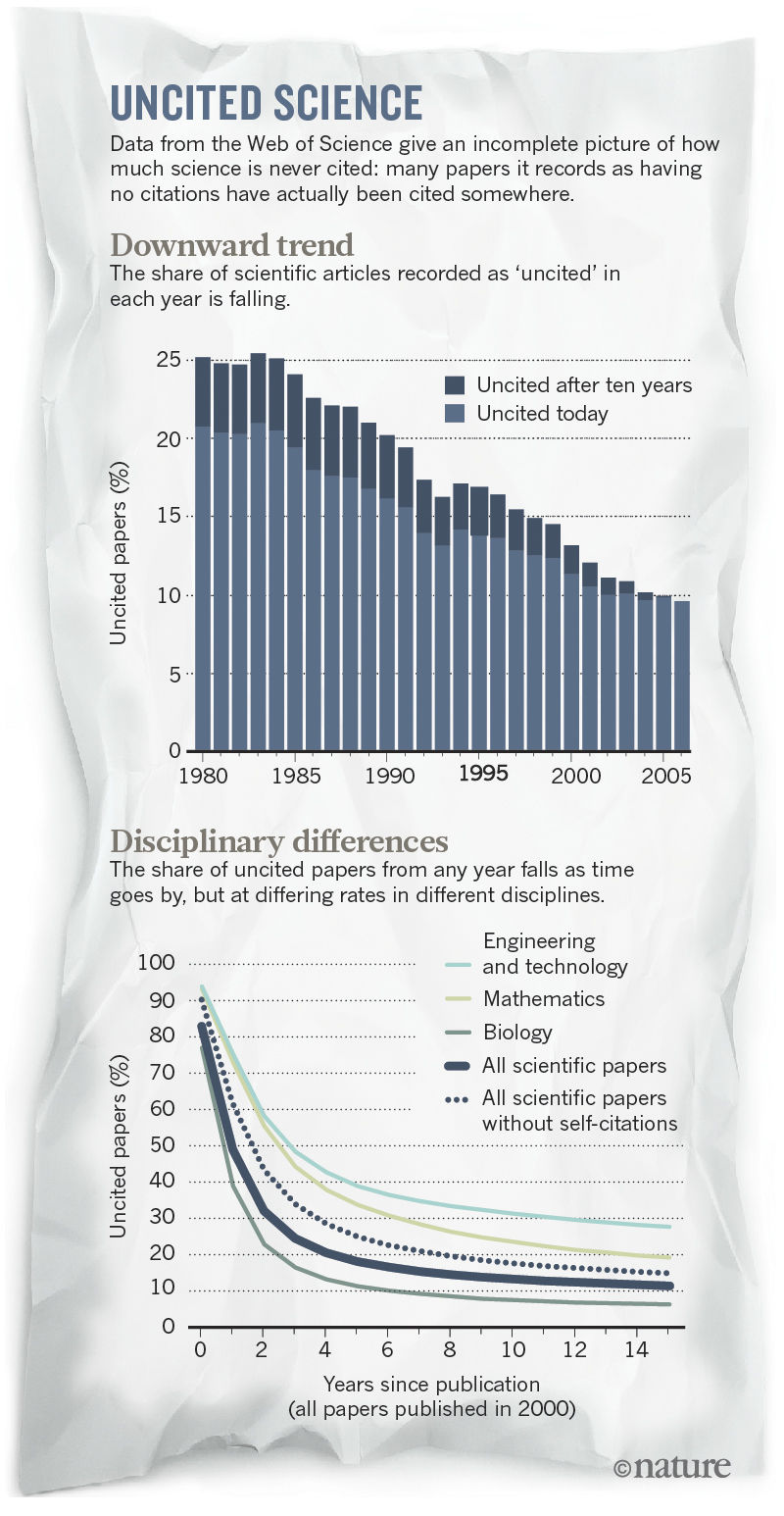
Верхний график — распределение количества работ без ссылок по годам.
Нижний — различия в разных областях науки; пунктиром обозначен общий график для всех областей.
Если взять все статьи в целом — 39 миллионов исследовательских работ по всем областям, записанных в Web of Science с 1900 года по конец 2015 — то из них 21% остался без упоминания. Что неудивительно, большая часть работ без ссылок на них появлялись в малоизвестных журналах. Почти все работы в известных журналах впоследствии цитируют.
Невозможные измерения
Эти данные дают лишь часть картины. Но заполнить всю недостающую информацию по научной литературе — задача практически невыполнимая.
Проверка небольшого количества работ уже получается достаточно сложной задачей. К примеру, в 2012 году Петр Хенеберг, биолог из Карлова Университета в Праге, решил проверить записи Web of Science, относящиеся к 13 нобелевским лауреатам, чтобы проверить дико звучавшие заявления другой статьи, утверждавшей, что примерно на 10% исследований нобелевских лауреатов никто не ссылается. Его первое исследование Web of Science выявило число близкое к 1,6%. Но затем, используя сервис Google Scholar, Хенеберг обнаружил, что на многие из оставшихся работ всё-таки были ссылки, но они оказались неучтёнными из-за ошибок при вводе данных и опечаток в работах. Кроме того, в журналах и книгах, которые не индексировал Web of Science, существовали дополнительные цитаты. К тому времени, как Хенеберг прекратил свои поиски, проведя за этим порядка 20 часов, он уменьшил количество работ без упоминания ещё в пять раз, до 0,3%.
Такие недостатки и приводят к тому, что настоящее количество ни разу не цитировавшихся работ узнать невозможно: на повторение ручной проверки вслед за Хенебергом в больших масштабах уйдёт слишком много времени. На Web of Science указано, к примеру, что 65% работ по гуманитарным работам, опубликованные в 2006 году, ещё никто ни разу не упоминал. И это на самом деле так — довольно много гуманитарных работ остаются без упоминания, в частности, потому что новые исследования в этой области не так сильно зависят от накопленных предыдущих знаний. Но Web of Science неправильно отображает ситуацию в этой области, поскольку пренебрегает многими журналами и книгами.
Те же самые причины подрывают надёжность сравнений разных народов. Web of Science показывает, что работы, написанные учёными из Китая, Индии и России, будут проигнорированы с большей вероятностью, чем те, что написаны в США или Европе. Но база данных вообще не отслеживает многие местные журналы, которые уменьшили бы этот разрыв, говорит Ларивьер.
Несмотря на проблемы с абсолютным количеством, уменьшение работ без упоминаний в Web of Science соблюдается строго, говорит Ларивьер. Интернет серьёзно облегчил задачу нахождения и цитирования нужных работ, говорит он. Возможно, что этому способствует также стремление открыть доступ к статьям. Но Ларивьер предупреждает, что эту тенденцию не стоит переоценивать. В его исследовании от 2009 года [Wallace, M. L., Lariviere. V. & Gingras, Y. J. Informetrics 3, 296–303 (2009)] утверждается, что количество работ без цитат падает потому, что учёные публикуют всё больше работ, и пихают в них всё больше упоминаний других работ. Специалист в области библиометрии [статистический анализ научной литературы / прим. перев.] Людо Уолтмэн [Ludo Waltman] из Лейденского университета в Нидерландах соглашается с этим. „Я бы не стал интерпретировать эти цифры как гарантию того, что всё больше научных работ становятся полезными“.
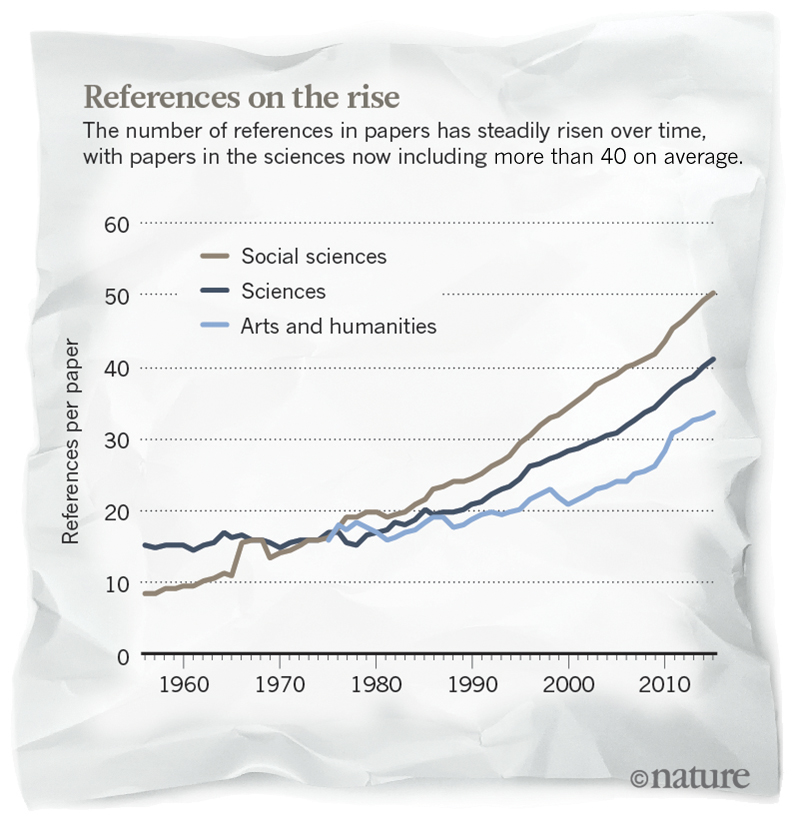
Количество ссылок на работы постепенно растёт
Уолтман говорит, что многие работы едва избегают судьбы нецитируемых: независимые подсчёты Уолтмана и Ларивьера показывают, что на Web of Science работ, упомянутых один-два раза, больше, чем тех, у кого вообще нет упоминаний. „А нам известно, что многие ссылки на самом деле делаются формально, для галочки“, — говорит он. Или они могут быть признаком системы „ты — мне, я — тебе“ у учёных, говорит Далия Ремлер [Dahlia Remler], специалист по экономике здравоохранения из Школы общественных и международных отношений им. Марксе в Нью-Йорке. „Даже исследования с большой цитируемостью могут быть частью игры, в которую учёные играют вместе, не идущей никому на пользу“, — говорит она.
Не совсем бессмысленно
Некоторые исследователи могут поддаться искушению отбросить работы без упоминаний как неважные. Ведь если бы они имели хоть какое-то значение, разве не сослался бы кто-нибудь на них?
Вероятно, но не обязательно. На учёных влияет гораздо больше статей, чем они потом упоминают, говорит Майкл Макробертс, ботаник из Луизианского университета в Шревепорте. В статье от 2010 года, посвящённой недостатку анализа цитирования, Макробертс сослался на свою собственную работу 1995 года, посвящённую открытию плауна поникшего (Palhinhaea cernua) в Техасе. Это был первый и единственный раз, когда кто-то сослался на эту работу, но упомянутая в ней информация при этом попала в атласы растений и крупные базы данных. Люди, использующие эти базы, полагаются на эту работу и тысячи других ботанических отчётов. „Информация в этих, так называемых нецитируемых статьях, используется; их просто не цитируют“, — говорит он.
Кроме того, статьи, которые не цитируют, всё же читают. В 2010 году исследователи из Нью-йоркского департамента здравоохранения и психологической гигиены опубликовали исследование, с анализом недостатков работы набора для теста слюны на ВИЧ, проделанным при помощи специальных программ [Egger, J. R., Konty, K. J., Borrelli, J. M., Cummiskey, J. & Blank, S. PLoS ONE 5, e12231 (2010)]. За несколько лет до этого использование набора было приостановлено в клиниках, а потом снова возобновлено. Авторы хотели использовать опыт клиник для изучения вопроса о том, может ли софт анализировать качество работы наборов в случае возникновения проблем.
Их работу, опубликованную в журнале PLoS ONE, ни разу не упоминали. Но её просмотрели более 1500 раз, а скачали более 500 раз, отмечает Джо Эггер, соавтор работы, сейчас работающий в Институте всемирного здравоохранения Дьюка в Дарэме, Северная Каролина. „Цель этой статьи — улучшить практики, направленные на поддержку здравоохранения, а не продвинуть вперёд науку“, — говорит он.
Другие статьи могут оставаться без упоминаний, поскольку закрывают непродуктивные области исследований, говорит Никлаас Бююрма, химик из Университета в Кардифе, Британия. В 2003 году Бююрма с коллегами опубликовали работу по „изохорическому спору“ — о том, будет ли полезным пытаться сдержать расширение или сжатие растворителя во время реакции, происходящие при изменении температур. В теории этот технически сложный эксперимент мог бы привести к новым знаниям о том, как растворители влияют на скорость химических реакций. Но проверки Бююрмы показали, что химики не узнают ничего нового из подобных экспериментов. „Мы решили доказать, что нечто делать не стоит — и показали, — говорит он. — Я горжусь этой работой, как не подразумевающей упоминания“, — добавляет он.
Оливер Смитис, выступая на встрече в Линдау, сказал, что признаёт важность работы 1953 года, несмотря на то, что он думал, что её не упоминают. Он рассказал публике, что проведённая работа помогла ему заработать учёную степень и стать полноправным учёным. По сути, это было ученичество будущего лауреата нобелевской премии. „Мне очень нравилось ею заниматься, — сказал он, — и я научился правильно заниматься наукой“. У Смитиса на самом деле есть по меньшей мере одна работа без всяких упоминаний: статья 1976 года, где было показано, что определённый ген, связанный с иммунной системой, расположен на человеческой хромосоме. Но и это было важно, по другим причинам, говорит генетик Раджу Кучерлапати из Медицинской школы Гарварда в Бостоне, Массачусетс, один из авторов работы. Он говорит, что статья стала началом долгого сотрудничества с лабораторией Смитиса, кульминацией которого стала работа по генетике мышей, которая принесла Смитису нобелевскую премию 2007 года по физиологии или медицине. „Для меня, — говорит Кучерлапати, — важность этой работы заключалась в том, что я узнал Оливера“.
Истории нецитируемых работ
Долгое ожидание
Для каждого исследователя, желающего, чтобы его работу кто-нибудь упомянул, есть надежда, если учесть историю Альберта Пека, работу которого от 1926 года, описывающую одну из разновидностей дефектов стекла, впервые процитировали в 2014-м году. В 1950-х работа потеряла полезность, поскольку производители придумали, как делать гладкое стекло без описанных дефектов. Но в 2014 году исследователь материалов Кевин Ноулс из Кембриджского университета в Британии наткнулся в Google на эту работу во время написания обзора этой области — он занимался использованием таких дефектов для рассеивания света. Теперь он процитировал её уже в четырёх статьях. „Мне нравится писать работы, в которых я могу упоминать малоизвестные статьи“.
Упущенная волна
Докторант Франциско Пина-Мартинс из Лиссабонского университета в 2016 опубликовал году работу по интерпретации данных генетического секвенирования, будучи уверенным, что её точно никто не будет упоминать, поскольку описываемая в ней технология, разработанная фирмой 454 Life Sciences, устарела и не используется. Он загрузил своё ПО для анализа данных на GitHub, сайт, где люди делятся исходным кодом, в 2012 году — и это было упомянуто в нескольких работах. Но публикация самого исследования заняла четыре года, поскольку, по его словам, оно связано с редкой проблемой, которую специалисты, предварительно изучавшие статью, просто не поняли.
Тупик
Множество историй о работах без упоминания получаются грустными. В 2010 году нейробиолог Адриано Чеккарелли опубликовал в журнале PLoS ONE статью о регуляции генов у слизевиков Dictyostelium. Его просьбы о грантах на продолжение исследований остались без ответа, и работу никогда не цитировали. „Ну, вы знаете, как бывает с исследованиями — оказывается, что работа завела в тупик, — говорит он. — Мои идеи не представляют ценности для финансирования. Теперь я просто преподаю и жду пенсии. Но с радостью принялся бы за работу, если бы завтра получил финансирование“.
Комментарии (19)
Lissov
24.12.2017 18:30Все эти тренды основаны в первую очередь на техническом прогрессе.
Когда я писал магистерский диплом (интернет уже был, но научных работ там было мало), публикации приходилось искать вручную в библиотеках, потому внимание обращали на известных и уже «раскрученных» авторов и большие журналы, ссылок было мало. Ко времени моей диссертации научные работы уже все попали в интернет, плюс полнотекстовый поиск, соответственно стало элементарно просто найти релевантную информацию из мелких журналов от неизвестных мне авторов. Теперь можно быстрее найти нужные абзацы в сотнях публикаций со всего мира, чем перечитать пару статей в библиотеке.
А ещё стоит вспомнить автоматическую нумерацию ссылок (в противовес адовому процессу упорядочивания номеров ссылок 30 лет назад), и понятно, почему в моей работе гораздо больше ссылок чем у авторов десять лет до меня. А значит и большое количество работ получили ссылки.
Я считаю что это очень хороший тренд, что знания становятся гораздо более доступны глобально.
kolipass
25.12.2017 09:19Особенно большим прорывом стала киберленинка и гугл шкляр, которые в один клик предоставляют выходные данные по статье в ГОСТ-формате. Обзорные статьи стало писать на порядок приятнее и интереснее.

inferrna
25.12.2017 10:02Ещё большим прорывом было бы полное избавление от необходимости вычитывать тексты. Например, с помощью разработки некоего метаязыка описания статей, где можно было бы в машинно-усвояемом виде задать, зависимость чего, от чего, с учётом каких условий, исследуется — и какие результаты были получены. Потом на это дело даже можно было бы натравить некий алгоритм/ИИ, который, изучив имеющиеся результаты исследований, и сам сделал бы пару научных открытий, и показал бы, куда ещё можно рыть.

DistortNeo
25.12.2017 13:07+1Выдача ссылок в формате ГОСТ — далеко не главное преимущество Google Scholar, тем более, что нормальные люди используют BibTeX. Главное преимущество — индексация всех статей и ссылок на них.
qbertych
25.12.2017 13:29Вообще Google Scholar сильно переоценен. Его единственное отличие от Webofknowledge/Scopus — открытость. Только зачем она вам, если вы и так работаете в академической среде и у вас есть подписка на Scopus?
При этом багов у гугла не счесть:
- нельзя искать статьи конкретного автора в хронологическом порядке более, чем за год
- массу журналов он не индексирует (я когда писал про китайский спутник, там самая мякотка была в китайских журналах, о которых гугл понятия не имеет)
- про OrcIDы (уникальные идентификаторы авторов) он вообще ни сном ни духом
- вместе с бредовой релевантностью выдачи по фамилии это делает поиск по китайцам-однофамильцам бесполезным чуть менее, чем полностью.
DistortNeo
25.12.2017 14:36Только зачем она вам, если вы и так работаете в академической среде и у вас есть подписка на Scopus?
Потому что поиск через Google Scholar я считаю более качественным.
Во-первых, Google Scholar имеет полноценный полнотекстовый поиск. Найти что-то реальное полезное через WoS/Scopus довольно сложно. Ну и ссылка на PDF будет приятным бонусом.
Во-вторых, WoS/Scopus индексируют только журналы и некоторые конференции, да и то не сразу. То есть между опубликованием автором препринта на арихве и его индексацией в WoS/Scopus может пройти год-два. А может и не пройти. Так, есть статьи на архиве с 1000 цитирований и выше. По каким-то причинам, работу автора не взяли в журнал, но она оказалась признана научным сообществом.
Несмотря на отсутствие китайских журналов, охват Google Scholar я считаю более широким.
вместе с бредовой релевантностью выдачи по фамилии это делает поиск по китайцам-однофамильцам бесполезным чуть менее, чем полностью.
Да и хрен с ними. Релевантные статьи я ищу не по автору, а по цитированиям: смотрю, кто ссылается на работу и смотрю ссылки из самой работы. Собственно, это тот случай, когда самоцитирования идут на пользу: самоцитирования позволяют связать релевантные работы друг с другом.
qbertych
25.12.2017 15:07А зачем вам полнотектовый поиск? Если работа по теме, то тема будет упомянута в названии/абстракте. Поэтому поисковые движки, скажем, топовых физических издательств (APS, NPG, AIP и т.д.) полнотекстового поиска и не имеют. Исключение — Science, но там цели другие, там половина издания — это научпоп.
Ссылками на arXiv гугл рвет всех, это факт. Но проблема с "тысячей цитирований", очевидно, надумана — при таком раскладе остаться непринятым в нормальный журнал просто невозможно. Если автор статьи этого не понимает/не хочет менять — то он ССЗБ.
DistortNeo
25.12.2017 15:53А зачем вам полнотектовый поиск?
Потому что мне важно содержание — я много статей находил именно так.
У меня не естественно-научная тематика. В отличие от медицинских статьей, где в аннотации — выводы, а внутри статьи — обоснования выводов, в случае обработки изображений по одной аннотации сложно определить, является ли статья полезной или нет.
Поэтому поисковые движки, скажем, топовых физических издательств (APS, NPG, AIP и т.д.) полнотекстового поиска и не имеют.
Они его не имеют по другой причине: нет коммерческого интереса.
Ссылками на arXiv гугл рвет всех, это факт. Но проблема с "тысячей цитирований", очевидно, надумана — при таком раскладе остаться непринятым в нормальный журнал просто невозможно. Если автор статьи этого не понимает/не хочет менять — то он ССЗБ.
Потому что не всегда хочется связываться с журналами: за время между подачей статьи и её фактическим выходом она может потерять актуальность.
В моей области конкуренция огромна: если твоя работа плохо индексируется, то и ссылаться на тебя не будут. Поэтому если автор хочет, чтобы его цитировали, то он должен сам позаботиться о том, чтобы текст его работы находился в открытом доступе.
А почему сразу ССЗБ? Если автор не принимает правил игры и другие авторы, которые на него ссылаются, от этих правил тоже отходят, почему вы считаете это проблемой?
qbertych
26.12.2017 14:51Вы сейчас довольно смело обвинили APS в коммерческом интересе.
Публикация занимает много времени, зато без нее (в отличие от arXiv'а) нельзя ни грант получить, ни карьеру нормально продолжить. Автор можно сколько угодно рассуждать про правила игры, но при дичайшей конкуренции в науке забивать на заведомо цитируемые публикации — это самоубийственная блажь.
DistortNeo
26.12.2017 15:22Вы сейчас довольно смело обвинили APS в коммерческом интересе.
Даже у некоммерческих обществ есть бюджет, и создание системы полнотекстового поиска может приведёт к выходу за рамки бюджета.
Публикация занимает много времени, зато без нее (в отличие от arXiv'а) нельзя ни грант получить, ни карьеру нормально продолжить. Автор можно сколько угодно рассуждать про правила игры, но при дичайшей конкуренции в науке забивать на заведомо цитируемые публикации — это самоубийственная блажь.
Вы всё смешали в кучу. Хорошая публикация на архиве — это и есть получение конкурентного преимущества. Да, для грантов она не подойдёт, но если у автора есть высокоцитируемая работа на архиве, то и остальные его работы будут заведомо цитируемы.
Собственно, что мешает делать и публикации для грантов, и публикации для получения конкуретного преимущества?
qbertych
26.12.2017 15:50если у автора есть высокоцитируемая работа на архиве, то и остальные его работы будут заведомо цитируемы
Боже, какой бред. Вам знакомо понятие "группа одного хита"?
что мешает делать и публикации для грантов, и публикации для получения конкуретного преимущества
А в чем проблема залить препринт статьи на arXiv, после чего опубликовать ее же в нормальном журнале, чем сразу убить двух зайцев? (На arXiv'е — сюрпрайз, сюрпрайз — даже специальное поле для ссылки на версию статьи в журнале есть.)
Не публиковать популярный текст на arXiv'е — это душить курицу, несущую золотые яйца. В здравом уме и здравом научном сообществе это попросту невозможно.
DistortNeo
26.12.2017 17:43Боже, какой бред. Вам знакомо понятие "группа одного хита"?
И, собственно, что? Есть как хорошие группы, играющие хорошую музыку, но не имеющие популярности, так и популярные группы с посредственным репертуаром. В том то и проблема, что качество работ не очень хорошо коррелирует с их цитируемостью.
А в чем проблема залить препринт статьи на arXiv, после чего опубликовать ее же в нормальном журнале, чем сразу убить двух зайцев?
Ничто не мешает. Так делать можно и даже нужно. Просто журнал её в итоге может так и не принять.
Не публиковать популярный текст на arXiv'е — это душить курицу, несущую золотые яйца. В здравом уме и здравом научном сообществе это попросту невозможно.
В математике, IT если твоя работа отсутствует в открытом доступе, то на неё ссылаться попросту не будут — сошлются на конкурента. Для того и нужен архив. Но вот в той же биологии или медицине выкадывание препринтов и работ в открытый доступ почему-то не принято.
maslyaev
24.12.2017 18:55Интересно, а каков процент ни разу не упомянутых публикаций на Гиктаймс? И можно ли это трактовать как признак тупиковости?
super-guest
24.12.2017 19:47Цитируемость как мерило значимости учёного — плюсы, минусы, альтернативы?
vassabi
25.12.2017 04:02Но в 2014 году исследователь материалов Кевин Ноулс из Кембриджского университета в Британии наткнулся в Google на эту работу во время написания обзора этой области
Мне иногда кажется, что это присущее любому человеку ограничение (ну, вот как со спектром фотонов — мы глазами умеем видеть весьма узкий диапазон)
А именно — непонимание сути этой конкретной научной работы.
во-первых своими коллегами. Не все ученые пишут ясным и понятным языком. И еще, чтобы много цитироваться, ученый должен быть социальным, посещать мероприятия и заводить знакомства, а иначе его работой будет интересоваться гораздо меньшее число людей.
во-вторых — самим автором. Например, когда пишет только об ему одним интересном аспекте (вот как с теми дефектами стекла: ученый писал об дефектах, теории появления и как с ними бороться, а исследователь материалов его нашел для того, чтобы гарантированно и побольше такие дефекты получать).
Хорошо, что есть гугл с его полнотекстовым (а не только ключевые слова из аннотации статьи) поиском для решения таких проблем.
Tyusha
По-честному, надо бы выкинуть большую часть ссылок самоцитирования автором своих предыдущих работ, а также работ своих ближайших коллег, друзей и научного руководителя. Картина резко ухудшится.
Nik_sav
Обычно и не учитывают. По крайней мере, не могу вспомнить ни одного рейтинга, отчета и т.п., где было бы допустимо учитывать самоцитирование.
qbertych
Пардон, а как вы это себе представляете? LIGO не будет ссылаться на первые статьи по открытию гравитационных волн, потому что они написаны LIGO? ;)
То же самое касается конкретных людей. Ушел человек в другую группу родственной тематики, — а его там в соавторы не включают. Ибо во введении к статье не упомянуть его предыдущие работы ну никак нельзя, а если упомянуть — не дадут грант из-за самоцитирования.