
Всем привет.
С середины 2016 года мы проектируем и разрабатываем новое поколение платформы. Принципиальное отличие от первого поколения — поддержка API "тонкого" клиента. Если старая платформа предполагает, что на клиента при запуске загружается метаинформация о всем контенте, который доступен для абонента, то новая платформа должна отдавать срезы данных отфильтрованные и отсортированы для отображения на каждом экране/странице.
Высокоуровневая архитектура на уровне хранения данных внутри системы — постоянное хранение всех данных в централизованном реляционном SQL хранилище. Выбор пал на Postgres, тут никаких откровений. В качестве основного языка для разработки — выбрал golang.
У системы порядка 10м пользователей. Мы посчитали, что с учетом профиля теле-смотрения, 10М пользователей может дать сотни тысяч RPS на всю систему.

Это означает, что запросы от клиентов и близко не стоит подпускать к реляционной SQL БД без кэширования, а между SQL БД и клиентами должен быть хороший кэш.
Посмотрели на существующие решения — погоняли прототипы. Данных, по современным меркам у нас немного, но параметры фильтрации (читай бизнес-логика) — сложные, и главное персонализированные — зависящие от сессии пользователя, т.е. использовать параметры запроса как ключ кэширования в K-V кэше будет очень накладно, тем более пейджинг и богатый набор сортировок никто не отменял. По сути, под каждый запрос от пользователя формируется полностью уникальный набор отфильтрованных записей.
По итогам отсмотра готовых решений ничего не подошло. Простые K-V базы типа Redis отбросили практически сразу: не подходит по функционалу — всю фильтрацию и объединение придётся реализовывать на Application Level, а это накладно. Посмотрел на Tarantool. тоже не подошел функционально
Смотрели на Elastic — функционально подошел. Но производительность выдачи контента по требованиям бизнес-логики вышла в районе 300-500 RPS.
При ожидаемой нагрузке даже в 100К RPS — под эластик впритык нужно 200-300 серверов. В деньгах — это несколько миллионов долларов.
Когда это посчитали, у меня в голове уже практически созрел план — написать свой велик, in-memory движок кэша на C++ и провести наши тесты на нем. Сказано — сделано. Прототип был реализован практически за пару недель. Запустили тесты.
Вау! Получили 15к RPS на том же железе, с теми же условиями, где Elastic давал 500.
Разница в 20 раз. Больше чем на порядок, Карл!
Первая, уже не Proof-Of-Concept версия бэкенда со своим in-memory кэшем появилась в конце 2016 года. К середине 2017 Reindexer уже оформился во вполне полноценную БД, обзавелся собственным хранилищем и движком полнотекстового поиска, в это же время мы опубликовали ее на github.

Технические детали
Reindexer — это NoSQL in-memory БД общего назначения. По структуре хранения данных Reindexer сочетает все основные подходы:
- оптимизированное бинарное представление JSON с дополнением из табличной строки с индексируемыми полями
- опциональное колоночное хранение выбранных индексных полей
Такое сочетание позволяет добиться максимальной скорости доступа к значениям полей, а с другой стороны не требовать от приложения определения жесткой схемы данных.
Индексы
Для выполнения запросов есть 4 типа индекса:
- хэш таблица, самый быстрый индекс, для выборки по значению
- бинарное дерево, с возможностью быстрых выборок по условиям '<', '>' и сортировкой по полю
- колонка, минимальный оверхед по памяти, но поиск медленнее, чем у бинарного дерева и хэша
- полнотекстовый индекс, а точнее даже два: быстрый, не требовательный к памяти, и продвинутый на базе триграмм
При вставке записей в таблицы используется методика "ленивого" построения индексов т.е. вне зависимости от количества индексов, вставка происходит практически мгновенно, а индексы достраиваются только в тот момент, когда они требуются для выполнения запроса.
Дисковое хранилище
Вообще, Reindexer — полностью in-memory база данных, то есть, все данные с которыми работает Reindexer должны находиться в оперативной памяти. Поэтому, основное назначение дискового хранилища — загрузка данных на старте.
При добавлении записей в Reindexer данные в фоновом режиме пишутся на диск, практически не внося задержек на процесс вставки.
В качестве бэкенда дискового хранилища Reindexer использует leveldb.
Полнотекстовый поиск
Для полнотекстового поиска в Reindexer есть два собственных движка:
fast, с минимальными требованиями по памяти, на базе suffixarray, c поддержкой морфологии и опечаток.fuzzy, триграммный — дает лучшее качество поиска, но конечно требует больше памяти и работает медленнее. Пока он в экспериментальном статусе.
В обоих движках есть поддержка поиска транслитом и поиска с неверной раскладкой клавиатуры. Ранжирование результатов поиска происходит с учетом статистических вероятностей (BM25), точности совпадения и еще примерно 5 параметров. Формулу ранжирования можно гибко настроить в зависимости от решаемых задач.
Так же, есть возможность полнотекстового поиска по нескольким таблицам, с выдачей результатов отсортированных по релевантности.
Для формирования запросов к полнотекстовому поиску используется специальный DSL.
Join
Reindexer умеет делать Join. Если быть точным, в мире NoSQL, как правило, нет операции Join в чистом виде, а есть функционал, позволяющий вставить в каждый результат ответа поле, содержащее сущности из присоединяемой таблицы. Например, в Elastic этот функционал называется nested queries, в mongo — lookup aggregation.
В Reindexer этот функционал называется Join. Поддерживается механика left join и inner join.
Кэш десериализованных объектов
Данные в Reindexer хранятся в области памяти управляемой C++, и при получении выборки в golang приложении происходит десериализация результатов в golang структуру. Вообще, между прочим, у golang части Reindexer очень быстрый десериализатор: примерно в 3-4 раза быстрее JSON, и раза в 2 быстрее BSON. Но даже с учетом этого, десериализация — относительно медленная операция, которая создает новые объекты на куче и нагружает GC.
Object cache в golang части Reindexer-а решает задачу пере использования уже десериализованных объектов, не тратя лишнее время на медленную повторную десериализацию.
Использование Reindexer в Golang приложении
Пора перейти от слов к делу, и посмотреть как использовать Reindexer в golang приложении.
Интерфейс для Reindexer реализован в виде Query builder, например запросы в таблицы пишутся таким способом:
db := reindexer.NewReindex("builtin")
db.OpenNamespace("items", reindexer.DefaultNamespaceOptions(), Item{})
it := db.Query ("media_items").WhereInt ("year",reindexer.GT,100).WhereString ("genre",reindexer.SET,"action","comedy").Sort ("ratings")
for it.Next() {
fmt.Println (it.Object())
}Как видно из примера, можно конструировать сложные выборки по многим условиям фильтрации и с произвольными сортировками.
package main
// Импортируем пакеты
import (
"fmt"
"math/rand"
"github.com/restream/reindexer"
// Выбор способа подключения Reindexer к приложения (в этом случае `builtin`, означает линковку в виде статической библиотеки)
_ "github.com/restream/reindexer/bindings/builtin"
)
// Определяем структуру с индексными полями, которые помечаем тэгом 'reindex'
type Item struct {
ID int64 `reindex:"id,,pk"` // 'id' первичный ключ
Name string `reindex:"name"` // Добавляем хэш индекс по полю 'name'
Articles []int `reindex:"articles"` // Добавляем хэш индекс по массиву 'articles'
Year int `reindex:"year,tree"` // Добавляем btree индекс по полю 'year'
Descript string // Просто поле в структуре, не индексируется
}
func main() {
// Инициализируем БД, и выбираем биндинг 'builtin'
db := reindexer.NewReindex("builtin")
// Включаем дисковое хранилище (опциональный шаг)
db.EnableStorage("/tmp/reindex/")
// Создаем новую таблицу (namespace) с названием 'items', в которой будут храниться записи типа 'Item'
db.OpenNamespace("items", reindexer.DefaultNamespaceOptions(), Item{})
// Генерируем рандомный датасет
for i := 0; i < 100000; i++ {
err := db.Upsert("items", &Item{
ID: int64(i),
Name: "Vasya",
Articles: []int{rand.Int() % 100, rand.Int() % 100},
Year: 2000 + rand.Int()%50,
Descript: "Description",
})
if err != nil {
panic(err)
}
}
// Делаем запрос к таблице 'items' - получаем 1 элемент, у которого поле id == 40
elem, found := db.Query("items").
Where("id", reindexer.EQ, 40).
Get()
if found {
item := elem.(*Item)
fmt.Println("Found document:", *item)
}
// Далеам запрос к таблице 'items' - получаем выборку элементов
query := db.Query("items").
Sort("year", false). // Сортировка по полю 'year' в порядке возрастания
WhereString("name", reindexer.EQ, "Vasya"). // В поле 'name' ищем значение 'Vasya'
WhereInt("year", reindexer.GT, 2020). // В поле 'year' должно быть значение больше 2020
WhereInt("articles", reindexer.SET, 6, 1, 8). // В массиве 'articles' должно быть хотя одно из значений [6,1,8]
Limit(10). // Вернуть не более 10-ти записей
Offset(0). // с 0 позиции
ReqTotal() // Запрос подсчета общего количества записей в таблице, удовлетворяющих условиям выборки
// Выполнить запрос с БД
iterator := query.Exec()
// Не забыть закрыть Iterator
defer iterator.Close()
// Проверить, была ли ошибка в запросе
if err := iterator.Error(); err != nil {
panic(err)
}
fmt.Println("Found", iterator.TotalCount(), "total documents, first", iterator.Count(), "documents:")
// Итерируемся по результатам запроса
for iterator.Next() {
// Получить следующий результат выборки и привести тип
elem := iterator.Object().(*Item)
fmt.Println(*elem)
}
}Кроме Query Builder в Reindexer-е есть встроенная поддержка запросов в SQL формате.
Производительность
Одной из главных мотивирующих причин появления Reindexer-а — была разработка самого производительного решения, существенно превосходящего существующие решения. Поэтому статья была бы не полной без конкретных цифр — замеров производительности.
Мы провели сравнительное нагрузочное тестирование производительности Reindexer и других популярных SQL и NoSQL БД. Основным объектом сравнения исторически выступает Elastic и MongoDB, которые функционально наиболее близки к Reindexer.
Так же в тестах участвуют Tarantool и Redis, которые функционально скромнее, но тем не менее так же часто используются в качестве кэша горячих данных между SQL DB и клиент API.
Для полноты картины в список тестируемых БД включили пару SQL решений — Mysql и Sqlite.
В Reindexer есть полнотекстовый поиск, поэтому мы не смогли отказать себе в соблазне сравнить производительность со Sphinx
И последний участник — Clickhouse. Вообще, Clickhouse — БД заточенная под другие задачи, но тем не менее, к нам периодически прилетают вопросы, 'а почему не Clickhouse', поэтому решили добавить в тесты и его.
Бенчмарки и их результаты
Начнем с результатов, а технические детали тестов, описание методики и датасет сразу после графиков.
- Получить запись по первичному ключу. Эта функциональность есть во всех БД участвующих в тесте.
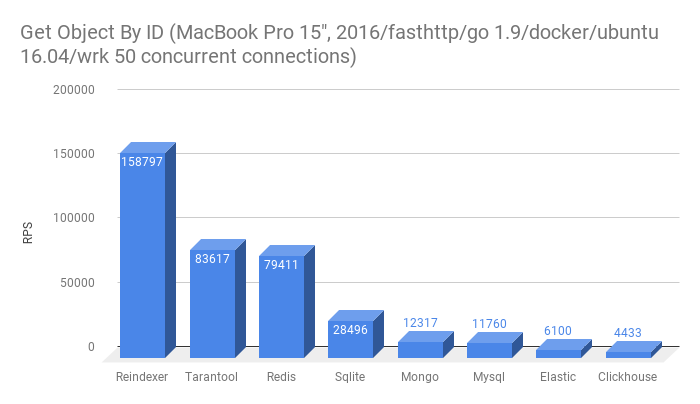
- Получить список из 10-ти сущностей с фильтрацией по одному полю, не primary key
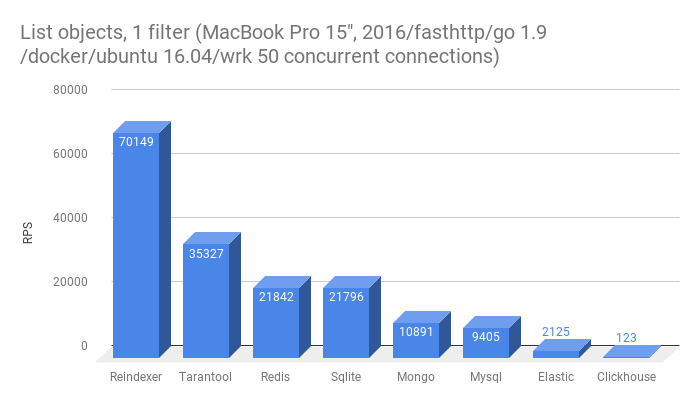
- Получить список из 10-ти сущностей с фильтрацией по двум полям
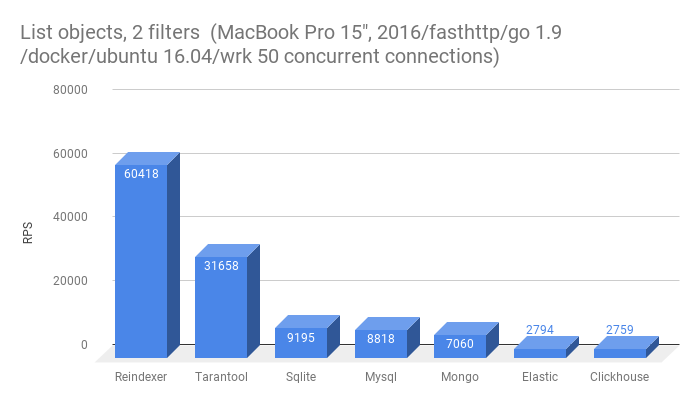
Из этого теста выбыл Redis, да в нем есть возможность эмуляции secondary index, однако это требует от приложения дополнительных действий при сохранении/загрузки записей в Redis.
- Перезаписать сущность в БД
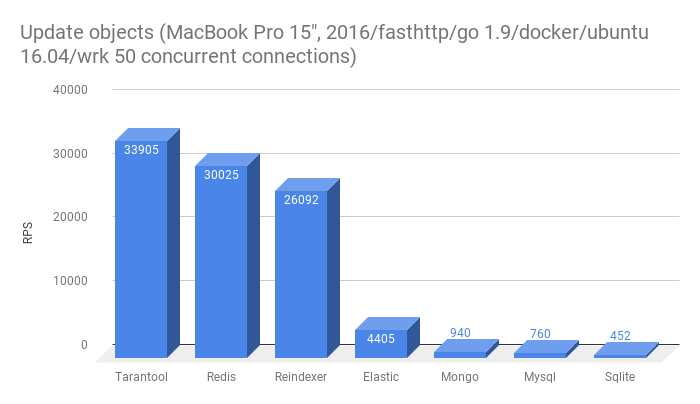
Из этого теста выбыл Clickhouse, т.к. в нем нет поддержки Update. Низкая скорость перезаписи в многие базы — скорее всего результат наличия полнотекстового индекса в таблице, в которую вставляются данные. У Tarantool и Redis нет полнотекстого поиска.
- Полнотекстовый поиск точных словоформ
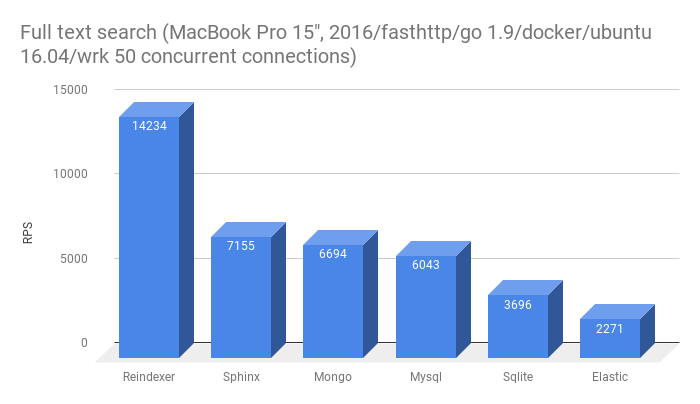
- Полнотекстовый поиск неточных словоформ (префиксы и опечатки)
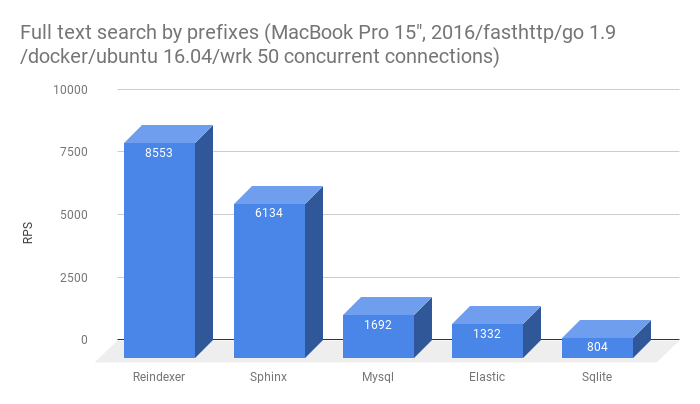
Среда тестирования
Все тесты проводились в docker контейнере, запущенном на MacBookPro 15", 2016. Гостевая ОС — Ubuntu 16.04 LTS. Чтобы минимизировать влияние сетевого стека, все БД, тестовый микро-бэкенд и обстрел запускались внутри общего контейнера и все сетевые соединения были на localhost.
На контейнер выделено 8GB ОЗУ и все 8 ядер CPU.
Тестовый бэкенд
Для проведения тестов мы сделали микро-бэкенд на golang, обрабатывающий запрос на url-ы вида: http://127.0.0.1:8080/<название теста>/<название БД>
Структура микро-бэкенда хоть и очень простая, но повторяет структуру реального приложения: есть слой репозитория с коннекторами к тестируемым БД и слой http API, отдающий ответы клиенту в JSON формате.
Для обработки http запросов используется пакет fasthttp, для сериализации ответов — штатный пакет encoding/json.
Работа с SQL БД через пакет sqlx. Connection Pool — 8 соединений. Немного забегая вперед, это число получено экспериментально — с такими настройками SQL базы дали лучший результат.
Для работы с Elastic использован gopkg.in/olivere/elastic.v5 — с ним пришлось немного поколдовать. Штатно он никак не хотел работать в режиме keep alive — проблему удалось решить только передав ему http.Client с настройкой MaxIdleConnsPerHost:100.
Коннекторы Tarantool, Redis, Mongo не доставили хлопот — они из коробки эффективно работают в многопоточном режиме и не нашлось никаких настроек, позволяющих существенно их ускорить.
Больше всего хлопот доставил коннектор Sphinx github.com/yunge/sphinx — он не поддерживает много поточность. А тестировать в 1 поток — заведомо не корректный тест.
Поэтому нам ничего не оставалось делать, как реализовать свой connection pool для этого коннектора.
Тестовые данные
В тестовом сете данных 100к записей. В записи 4 поля:
idуникальный идентификатор записи, число от 0 до 99999nameимя. строка из двух случайных имен. ~1000 уникальных ключейyearгод. целое число от 2000 до 2050descriptionслучайный текст 50 слов из словаря в 100к слов
Размер каждой записи в формате Json ~ 500 байт. Пример записи
{
"id": 73,
"name": "welcome ibex",
"description": "cheatingly ... compunction ",
"year": 2015
}Обстрел
Обстрел велся утилитой wrk в 50 конкурирующих соединений. На каждый тест каждой базы проводилось 10 обстрелов и выбирался лучший результат. Между тестами пауза в несколько секунд, чтобы не дать процессору перегреться и уйти в throttling.
Итоги тестов
В рамках тестов было важно собрать решение, по структуре аналогичное продакшн решению, без 'триков', `хаков' и в равных условиях для всех БД входящих в тест.
Бенчмарки не претендуют на 100% полноту, но в них отражен основной набор кейсов работы с базой.
Исходники микробэкенда и Dockerfile тестов я разместил на github, и при желании их не сложно воспроизвести.
Что дальше
Сейчас основная функциональность Reindexer стабилизирована и Production Ready. Golang API стабилизирован, и в нем не ожидается breaking changes в обозримом будущеем.
Однако, Reindexer пока еще очень молодой проект, ему чуть больше года, в нем пока не все реализовано. Он активно развивается и улучшается и, как следствие, внутренний C++ API еще не зафиксирован и иногда он меняется.
Сейчас доступно три варианта подключения Reindexer-а к проекту:
- библиотекой к Golang
- библиотекой к C++
- standalone server, работающий по http протоколу
В планах есть реализация биндинга для Python и реализация бинарного протокола в сервере.
Также, в настоящий момент не реализована репликации данных между нодами на уровне Reindex-а. Для основного кейса использования Reindexer, как быстрого кэша между SQL и клиентами — это не критично. Ноды реплицируют данные с SQL на уровне Application, и этого кажется вполне хватает.
Вместо заключения
Кажется, получилось реализовать красивое и, не побоюсь этого слова, уникальное решение, которое сочетает в себе функциональность сложных БД и производительность в разы, а то и на порядок превосходящее существующее решения.
Что самое важное — Reindexer позволяет сэкономить миллионы долларов на железе уже сейчас, при этом не увеличивая затраты на разработку Application Level — ведь Reindexer обладает высокоуровневым API, использование которого не сложнее обычного SQL или ORM.
PS. В комментариях попросили добавить ссылку на github в конце статьи. Вот она:
Репозиторий Reindexer на github.
Комментарии (102)


pil0t
18.01.2018 07:13А какой StorageEngine в mongodb использовался? InMemory docs.mongodb.com/manual/core/inmemory?
olegator99 Автор
18.01.2018 08:37Обычный дисковый. Похоже, у MongoDB In-memory движок есть только в Enterprise редакции, поэтому сходу его опробовать не удалось.
Так же, в комментарии выше написал результаты тестов с базой в tmpfs. Результаты принципиально не изменились.
svetasmirnova
18.01.2018 18:39В Перконовском форке InMemory открыт: www.percona.com/doc/percona-server-for-mongodb/LATEST/inmemory.html
olegator99 Автор
19.01.2018 11:25Спасибо. Прогнал с ним тесты:
mongo byid -> 14748.92
mongo 1cond -> 12661.20
mongo 2cond -> 7703.52
mongo update -> 1158.17
mongo text -> 876.09
В целом стало на ~20% быстрее. Однако, полнотекстовый поиск — в 10 раз медленнее. Предполагаю, что это связано с версией монги — где то между 3.4 и 3.6 они его существенно разогнали.

bosom
18.01.2018 08:38Всё отлично, но есть один минус, в библиотеке «github.com/restream/reindexer» 66% С/С++ кода, а это значит что используется cgo с постоянным переключением между golang и C вызывающие соответствующие этому проблемы. Если таких переключений мало, то с этим можно кое как жить, но данный вопрос требует изучения.
Было бы идеально если бы вы избавились от С/С++ кода в библиотеке для golang и полностью её написали бы на Go.
Лично меня, с моим перфекционизмом, наличие cgo всегда напрягает, прежде чем использовать такое творение придётся смотреть количество вызовов переключения go -> c, c->go и только потом решать стоит ли…
Подумайте об этом, избавление от cgo добавит значительную часть производительности reindexer и снимет проблему переключения миров c <-> go!olegator99 Автор
18.01.2018 08:52Я ждал этого вопроса. Наверно стоит начать с того, что переключение между go и c++ действительно не бесплатно, но весьма легковесно. Например, у меня на ноутбуке это порядка 100нс. Это время сопоставимо со временем обращения к map, и на остальном фоне практически не заметно — возможно, что-то в районе <1% от общей загрузки.
В Reindexer количество переключений go — с минимально: 1-ин раз на Query.Exec(), 2-рой раз на iterator.Close().
Решение на C++ выбрано сознательно по двум основным причинам:
- Для эффективной реализации индексов активно используются "generics", которых в golang, увы нет. В golang для этого пришлось бы либо существенно раздувать кодовую базу, копипастой реализаций индексов под каждый тип, либо использовать рантайм interface{}, который бы существенно ударил по производительности.
- В golang есть GC. Если данные хранить в Go (например 5м записей, в каждой из которых есть по 10 строчек), это как минимум 50М объектов на куче. Расплатой за это станут заметные паузы на GC, и как следствие общее замедление работы. В C++ нет GC, и как следствие проблемы с GC нет, как класс.

JekaMas
18.01.2018 11:59Корректно ли говорить о цифрах, если тестирование велось в далёкой от prod среде?
olegator99 Автор
18.01.2018 13:22Специально проверил. В данном случае корректно:
Если говорить о c <-> cgo, то вот цифры с прод сервера:
root@90b6ed8da107:/build/tst# go test -bench . -benchmem goos: linux goarch: amd64 BenchmarkCGO-24 20000000 109 ns/op 0 B/op 0 allocs/op
Если про остальные тесты, выборочно запустил несколько бенчмарков на prod сервере. Соотношение результатов ± аналогичное.
JekaMas
18.01.2018 17:23Я так понимаю, в вашем случае нет передачи данных между go и C?
olegator99 Автор
18.01.2018 18:57В Reindexer-е все параметры на переходе go<->c пакуются в общий линейный буфер, который передается в cgo.
В таком кейсе получается 140 нс, или даже 115 нс если включитьGODEBUG=cgocheck=0

dmbreaker
18.01.2018 12:46interface{}, который бы существенно ударил по производительности
Откуда информация?
Приведение interface{} к типу в Go вроде бы довольно быстро работает.olegator99 Автор
18.01.2018 13:05Согласен, приведение interface{} не очень затратная операция.
Однако, каждое приведение interface{} к конкретному типу, это как минимум лишнее ветвление, и дополнительные затраты по памяти на хранение информации о типе каждой переменной. Когда данных много, и индекс активно используется — даже незначительный оверхед на приведении типа заметно ударит по производительности.JekaMas
18.01.2018 17:24Все так, существенная разница. Могу подтвердить, напарывался на это делая кэш на go.

kafeman
18.01.2018 17:14Наверно стоит начать с того, что переключение между go и c++ действительно не бесплатно, но весьма легковесно. Например, у меня на ноутбуке это порядка 100нс.
Я не очень знаком с компилятором Go, но может мне кто-нибудь объяснить, что вообще представляет собой природа этих задержек? Как я себе это представляю: есть загруженная в память программа на Go, есть загруженная ею в свою память библиотека на Си. Программа на Go кладет свой адрес в стек и передает управление какому-то адресу библиотеки, библиотека что-то считает, кладет сам результат или ссылку на него, например, в регистр, достает из стека адрес Go программы и возвращает ему управление. О каких переключениях идет речь? Тут разве что небольшой cache miss может быть, но это не страшно. Чем это отличается от обычного вызова процедуры?JekaMas
18.01.2018 17:27Вот тут подробно рассказано — github.com/tschottdorf/goplay/tree/master/cgobench
Если коротко, то каждый вызов C из Go может приводить к созданию нового thread с копированием стэка соответственно, плюс нужно передавать данные между C и Go частями, для этого в Go есть отдельные типы данных и возможность преобразования стандартных типов в них и из них, что влечет и еще задержки.
Фактически есть две вселенные Go и C и они общаются мало и нехотя с существенными задержками, которые тем выше, чем более активно эти вселенные должны общаться.kafeman
18.01.2018 17:35Спасибо за объяснение. Фига себе у них заморочки…
JekaMas
18.01.2018 18:15Там некоторая печаль… Сначала кажется, что ничего страшного, но однажды оно приходит большое и страшное.
Оно круто только как временное решение для старта проекта с legacy C или какими-то библиотеками, которых нет на Go.
andreylartsev
19.01.2018 08:47На самом деле GC не только зло но и добро. В управляемой куче память для новых объектов выделяется быстрее, почти так же быстро как на стеке так как выделение памяти в управляемой куче означает просто перестановку указателя. Другой момент то что с долгоживущими большими объектами у GC идеологическая проблема. Неуправляемая куча с другой стороны со временем фрагментируется и начинает тормозить выделение памяти. Но для того чтобы получить такой эффект требуется значительный uptime и на коротких тестах его разумеется заметно не будет.

Elufimov
18.01.2018 08:45А как тюнили и настраивали эластик когда рассматривали его?
olegator99 Автор
18.01.2018 08:59Пробовали разное. Если мне не изменяет память, варьировали количество шард, использовали наиболее подходящие mappings. Делали разнообразные sysctl, увеличивали до беспредела размер памяти под JVM...

ggo
18.01.2018 10:04эластик, игнит, монго и прочие решения всегда проиграют данному решению в данном контексте.
эластик, игнит, монго рассчитаны на большой объем данных, размазанных по куче нод.
в приведенном решении самих данных мало, они на одной ноде, но нужно очень быстро по ним выполнять обработку.
наверно, можно было бы сравнивать с тарантул, в случае нормализации данных. но как я понял автору важна денормализация и вложенные структуры.olegator99 Автор
18.01.2018 10:39Мы рассматривали тарантул как один из вариантов, но он не подошел функционально. Как минимум, хватало индексов по полям массивам и полнотекстового поиска.
А в тестах производительности, которые есть в этой статье, мы с тарантулом очень даже сравниваемся.
olegator99 Автор
18.01.2018 09:13Если честно, то пока руки не дошли. Да и Ignite в golang очень скудно представлен — нагуглиась только одна либа https://github.com/amsokol/go-ignite-client

ainu
18.01.2018 09:42Хех, сам уже год пишу такое же с такими же входными задачами (кроме полнотекстового индекса) =)
У полнотекстового индекса есть морфология?
Есть аггрегации как у эластика? Уточню кейс — есть некий фильтр а-ля яндекс маркет. Списки галочек — свойств, по которым идет фильтрация, для галочки надо вывести число — количество элементов с этим свойством без учета галочек этой группы. Вот такое делается?
Может ли свойство иметь несколько значений? ({«year»: [2001, 2017]})?olegator99 Автор
18.01.2018 09:58+1Да уж!
У полнотекстового поиска морфология реализована на уровне поиска по корням слов и возможных опечаток. Например, если в документе есть слово "задачами", то документ найдется по запросам "задача", "зодачей" и даже "zadacha". Это в быстром движке. В продвинутом -триграммы, он допускает еще больший разброс словоформ.
Аггрегация тоже есть — вот описание
Свойства массивы — есть. Они нам потребовались в бизнеслогике с самого начала, и кстати сильно ограничили набор готовых решений, которые мы рассматривали.

comerc
18.01.2018 10:09Но у Tarantool есть быстрый старт после падения, не надо ожидать разогрев кэша.
olegator99 Автор
18.01.2018 10:32Reindexer сразу после запуска считывает весь кэш с диска в память. Скорость загрузки мы специально не измеряли, но в среднем, база в ~800MB считывается в память где то за 5-7 секунд.
То есть, в нашем случае, через 7 секунд после запуска получаем полностью прогретый кэш.digore
18.01.2018 21:48+1У вас база всего 800MB?
Тогда я не понял, зачем для Elastic нужно 200-300 серверов. Поясните, пожалуйста.olegator99 Автор
18.01.2018 22:45800MB это компактный бинарный формат, сверху пожатый snappy. В эластике эти данные занимают на диске существенно больше (точной цифры сейчас уже не скажу, но кажется коэффициент быть 1:10). А по памяти, что бы с ними нормально работать эластику требовалось минимально 16GB RAM.
Но главная проблема все же не в объеме данных, а в правилах фильтрации. С одной машины с эластиком получали всего лишь сотни RPS, а на всю систему нужно 100к RPS
ikirin
18.01.2018 11:57Из java-проекта не получиться подключиться к инстенсу?
P.S. Почему не выложили Ваши красивые графики в документацию git-проекта?olegator99 Автор
18.01.2018 12:13Из Java проекта пока можно только по http подключиться, но с ним будет конечно, большой overhead. В не очень далеких планах есть реализация бинарного протокола, тогда и можно будет сделать хороший коннектор для Java
А эти графики с пылу-жару — для хабра сделали, еще не успели оформить и выложить в документации git проекта.
Zebradil
18.01.2018 12:38Выглядит здорово. А что с отказоустойчивостью? Сколько памяти потребляет (у вас в тестах сам датасет 0.5Гб, а реально сколько требуется для работы)?
olegator99 Автор
18.01.2018 13:36По отказо-устойчивости хранилища Reindexer зависит от storage backend-а, сейчас это leveldb со всеми ее плюсами и минусами. Если окажется, что leveldb не устраивает, легко можно перейти на любой другой. Но пока устраивает.
Сами данные хранятся с минимальными накладными расходами (+~32 байта на одну запись)
Потребление памяти сильнее всего зависит от количества и типов индексов, которые используются. Наиболее прожорливый — полнотекстовый индекс.
Если говорить в среднем, то потребление ОЗУ получается 2-3х от размера исходных данных (но зависит от большого количества факторов)
lega
18.01.2018 15:47Reindexer — это NoSQL in-memory БД общего назначения.
Не указали очень важный момент — «here is no standalone server mode. Only embeded (builtin) binding is supported for now.», отсюда и скорость. В добавок можете сравнить со встроеным map из Go для теста выборки по значению.olegator99 Автор
18.01.2018 16:31Отчего же, не указали. Еще как указали:
Сейчас доступно три варианта подключения Reindexer-а к проекту:
библиотекой к Golang
библиотекой к C++
standalone server, работающий по http протоколуКонечно, сеть скорости не прибавляет. Но и подключение либой — не серебряная пуля.
К примеру, sqlite, подключается либой, без сети, однако цифры у нее — так себе.
Сеть заметно накидывает на Latency. Примерно ~30мкс на запрос, это правда. Но Latency мы в этой статье не сравниваем.
А на RPS, которые мы сравниваем — влияние не так велико. Точные цифры сказать сложно, но по ощущениям на Get By ID ~20%-30%, на остальных более тяжелых запросах — способ подключения базы влияет еще меньше.

z3apa3a
18.01.2018 18:01Reindexer вы тестировали как in-app библиотеку, а все прочие — как внешний сервер BD и сами ниже пишете, что использование Reindexer'а как внешнего сервера сильно влияет на производительность, т.е. такое сравнение очевидно не корректно.
Не пробовали сравнить по производительности конечного приложения tarantool+lua с go+reindexer?olegator99 Автор
18.01.2018 18:25В рамках этих тестов — не сравнивали, но раньше сталкивались.
Несколько месяцев назад проводился Mailru Highload Сup. https://highloadcup.ru/rating/. Пользуясь случаем, кстати, огромное спасибо организаторам :)
Решение но основе Reindexer/C++ прошло в финал, а решение на основе Tarantool+lua — нет.
arcman
19.01.2018 09:47В итоге вы сравнивали не корректно.
В синхронном режиме Latency имеет решающее значение на RPS.
Тут нужно либо Reindexer поставить в те же условия (отдельным процессом запускать) либо для остальных использовать pipelining (https://redis.io/topics/pipelining) и тогда у вас Redis быстро уйдет за 1M RPS.
TicSo
18.01.2018 15:59fuzzy, триграммный — … он в экспериментальном статусе
_
про полнотекстовый поиск понятно.
_
Что-то ещё по функционалу в планах есть?
Интересно узнать Ваше мнение чего не хватает. Разработка коллективная? Спасибо.olegator99 Автор
18.01.2018 16:45В планах — встроенный Web интерфейс для просмотра и редактирования данных в БД, а так же консольная утилиты для дампа/рестора БД.
Еще в обозримых планах бинарный протокол для сервера и коннекторы к другим ЯП.
Из функционала движка задумываемся об R-Tree, оптимизация операция записи, и еще некоторый ряд оптимизаций.
Начинал сам, а сейчас уже разработка коллективная — в проекте участвует несколько человек.

olegator99 Автор
18.01.2018 16:54Каждый тест 10раз x 5 секунд.
Объем данных 100К записей x 0.5кб. Увеличение объема в 10 раз существенно результаты не меняло, однако со всеми запущенными базами контейнер переставал помещаться в память, что сильно усложняло тесты.
melon
18.01.2018 17:17Добавьте ссылку на github в конец статьи! А-то если бы не комментарий со ссылкой, я бы подумал, что вы так это никуда и не выложили.
melon
18.01.2018 17:19а сравнивали с rocksdb? Были ли идеи сделать её форк и добавить туда нужный функционал? Или есть какие-то причины, почему она не подходит в этой задаче как отправная точка?
olegator99 Автор
18.01.2018 18:33Rocksdb функционально ближе к Leveldb, от которой она и произошла. Добавить к ней функционал выборок по N произвольным индексам, Join и произвольные сортировки — задача возможно даже сложнее, чем написать с нуля, т.к. Архитектурно RocksDB это все же продвинутая дисковая K-V
Смотрел на нее, как на дисковый backend вместо leveldb, но большого профита по отношению к leveldb в этом разрезе не нашел.
arcman
19.01.2018 10:00«RocksDB is an embeddable persistent key-value store for fast storage.»
Учитывая, что RocksDB так-же встраиваемая, то ее стоило добавить в сравнение.
web_whale
18.01.2018 18:57Что происходит, если данных так много, что заканчивается место в оперативной памяти?
Почему не хотите сделать gRPC вместо бинарного протокола?olegator99 Автор
18.01.2018 19:15Если данные не перестают влезать в память, то будет либо уход в swap либо отказ в операции с ошибкой, или даже OOM killer на уровне ядра. Зависит от настройки конкретной системы.
gRPC кажется тяжеловатым для нашей задачи. Нашел такие бенчмарки: 50мкс wall clock, 30мкс cpu clock — это очень медленно.
FyvaOldj
18.01.2018 19:45Выбор пал на Postgres, тут никаких откровений
10М пользователей может дать сотни тысяч RPS на всю систему.
Это означает, что запросы от клиентов и близко не стоит подпускать к реляционной SQL БД без кэширования, а между SQL БД и клиентами должен быть хороший кэшПостгрес даже по записи держит 100 000 при включенной отложенной записи. Не то что по чтению.
Кэширование в любом случае применять стоит на всякий случай.
Но вот это ваше "нагрузку в 100к даже близко нельзя подпускать к Постгрес" — откровенно коробит и выдает в вас специалистов, не вникающих в инструменты с которыми работаете
olegator99 Автор
18.01.2018 20:25Конечно, можно подпускать — всего лишь увеличив количество железа в 10, а то и больше раз.
FyvaOldj
18.01.2018 19:54Вау! Получили 15к RPS на том же железе, с теми же условиями, где Elastic давал 500.
Все тормоза Эластика — от автоматического распределения данных по кластеру.
Без этого — есть уже быстрое решение на C написанное. Sphinx называется.
На конференции Highload был доклад Ivi. Почему они перешли с Sphinx на ElasticShearch. Там рассказано что производительность у Elastic ниже чем у Сфинкса. Но они решели это уменьшением размера ответа — в терминах SQL это limit в запросе в 200 строк. При 1500 строках Сфинкс существенно шустрее Эластика
olegator99 Автор
18.01.2018 20:30У Sphinx по состоянию на год назад не было хранилища и для него требовалось еще SQL хранилище рядом, как для индексации, так и для отдачи контента.
Сейчас, говорят, уже появилось. Но коннекторов Golang для Sphinx 3.x с поддержкой хранилища я еще не встречал.
FyvaOldj
18.01.2018 21:25+1На год назад Сфинкс 2 было актуальным. И с коннекторами под Go — порядок.
SQL хранилище там не требуется для отдачи вообще. Для индексации SQL хранилище опционально.
Ну то есть вам очень хотелось сделать свой велосипед, вы даже не вникнули в аналоги. Ни в Сфинкс ни в Эластик. Ограничились дефолтными настройками?
olegator99 Автор
19.01.2018 00:38С коннекторами в гошке, к сожалению, у сфинкса — грусно.
Нативный не поддерживает многопотчку и падает при конкурентных запросах из нескольких потоков (казалось бы, что в 2017 году это базовый фунционал), не говоря уж об коннекшн пулинге…
Коннектор через протокол MySQL — просто отказался работать с ошибкой
С эластиком, как бы цифры бенчей (даже после тюнига коннектора и рекомендованных sysctl), уступающие на порядок и Reindexer и Tarantool, говорят сами за себя.
FyvaOldj
20.01.2018 09:32С Эластиком — вполне ожидаемая плата за хорошую работу распределенки. Жаль что вы этого не понимаете, хотя и пытаетесь что то для черьезных вещей разрабатывать
FyvaOldj
20.01.2018 17:34С коннекторами в гошке, к сожалению, у сфинкса — грусно.
Нативный не поддерживает многопотчку и падает при конкурентных запросах из нескольких потоков (казалось бы, что в 2017 году это базовый фунционал), не говоря уж об коннекшн пулинге…
Коннектор через протокол MySQL — просто отказался работать с ошибкойБД можете сделать а коннектор починить нет?
И вместо этого соорудили новую БД, не разобравшишь ни со Сфинксом ни с Эластиком?
Как программист я вас понимаю.
Но менеджеру за вашу не эффективность я бы всыпал люлей

fls_welvet
18.01.2018 19:59+2Было бы хорошо, если бы помимо «Reindexer — полностью in-memory база данных» вы бы указали что Reindexer в тестах был в embedded режиме и что флаш данных на диск происходит асинхронно.
Это важные особенности — так как отсутствие слоя сети существенно увеличивает рпс быстрых однотипных операций (оптимизации компилятором всего бенчмарка, меньше вытеснений кешлайнов и тп), а асинхронная запись на диск не только ничего не блокирует, но еще и может приводить к потере данных. С этими уточнениями будет понятно откуда такой выигрыш в производительности и не будет нужды смотреть в код.olegator99 Автор
18.01.2018 20:44Слой сети существенно увеличивает latancy, однако на RPS он влияет не так существенно. Порядка 20-30% процентов.
В нашем случае — развернута линейная структура из нод, каждая из которых работает со своим инстансом кэша. Один сервер — одна нода. В этом случае сеть между Reindexer и Golang бэком технически избыточна и вносит дополнительный оверхед.arcman
19.01.2018 09:38Из ваших цифр видно что вы работали с Redis в синхронном режиме, и latancy в данном случае имеет решающее значение.
Если использовать pipeline запросы (сразу по 100 — 1000 штук), то Redis легко улетает за 1М RPS.olegator99 Автор
19.01.2018 11:32Latency влияет на RPS далеко не линейно: пока один процесс ждет сети — работает другой процесс и процессор не простаивает. Конечно, какой то, оверхед на context switch есть.
В тестах я привел бенчмарки методов, аналогичных реальной задаче: "в методе http API сходить в кэш -> сфорировать JSON -> отдать клиенту"
Pipelining, это конечно хорошо, но к данной, и что не маловажно весьма типовой задаче, он не применим.

dj1m
18.01.2018 20:44А in-memory data grid Oracle Coherence не рассматривали? Там и индексы, и кластеризация, и быстрая PoF сериализация и много чего собственно.
mmm_corp
18.01.2018 20:451. написано что standalone только в планах на github-е, насколько они далеки?
2. нормально ли поддерживается кирилица?
3. есть ранжирование результатов?
4. активно занялся разработкой под Odoo, вопрос с эффективным поиском не решон до сих пор, тут случайно наткнулся на ваш пост, (elastic, solr колупал, но привести его до вменямеого состояния с анализом морфолии, транслитом и т.д. не удалось). Плачевность ситуации что в Odoo кроме как Postgres FTS больше ничего нет из коробки. Готов реализовать такой модуль с вашей разработкой (конечно под OpenSource), и вам хорошо и нам хорошо) Как вы на это смотрите? Или может кто предлагал или уже делает бинды для питона (хотя более нужнее всетаки Stand Alone)?olegator99 Автор
18.01.2018 20:52- standalone режим уже реализован, но пока поддерживается только http протокол.
- кириллица в utf8 поддерживается полностью, включая транслит и "неверную" раскладку клавиатуры. 8-ми битные кодировки типа koi-8r/win1251 — нет.
- ранжирование результатов полнотекстового поиска — есть по достаточно большому количеству критериев. Можно настроить через API.
- мы только за :) бинд для питона у нас есть в производственных планах, но пока не с самым большим приоритетом.
cybernik
18.01.2018 20:53+1Планируете ли перевести разработку полностью в опенсорс?
Есть ли планы по горизонтальному масштабированию для отказоустойчивости?olegator99 Автор
18.01.2018 21:12Спасибо. Очень актуальные вопросы.
У нас внутри развернута система CI с автотестами Reindexer, включая автотесты MR в Reindexer в составе нашего гошного бэкенда. Если честно, пока не знаю, как собрать конструкцию с разработкой на github и с автотестами, которым требуется доступ ко внутренним ресурсам.
Сейчас горизонтальное масштабирование реализовано уровнем выше. В системе есть входной балансировщик, который знает про статус нод и отправляет на клиентов на живые ноды. В случае аварии и потери данных в кэше, нода загружает данные из Постгресс.
Как реализовать горизонтальное масштабирование на уровне Reindexer думаем.
erwins22
18.01.2018 21:49а не думали привязать компиляцию скл кода?
в gcc есть для этого библиотека и у LLVMolegator99 Автор
18.01.2018 22:21Вот не уловил мысль…
erwins22
18.01.2018 22:48+1libgccjit
т.е. формировать код запроса на с++ и компилировать, скомпилированную функцию исполнять.ivan2kh
18.01.2018 23:19За jit компиляцией движков баз данных будущее. Это позволит значительно оптимизировать запросы на выборку данных. С удовольствием бы глянул на существующие проекты.
olegator99 Автор
19.01.2018 00:55Ох ) Были такие идеи когда участвовали в Mailru Highload Cup. Но практическая реализация, которую можно было бы хотя бы запрототипировать, пока вызывает больше вопросов, чем понимания, как ее сделать.
digore
18.01.2018 21:59Полнотектовый поиск у вас реализован на уровне поиска одиночного слова? Можно ли искать фразу, слова на расстоянии нескольких слов и т.д.
В Elastic, например, этот функционал есть.olegator99 Автор
18.01.2018 22:15У нас можно искать фразу, в том числе с учетом расстояния между словами, и полей в которых эти фразы встречаются и т.д.
примеры поисковых запросов
hhblaze
18.01.2018 22:21А, для общего развития, есть ещё такая быстрая опен-соурс .NET БД с неплохими характеристиками DBreeze database, но не распределённая.
sm0g
18.01.2018 23:52Здравствуйте. В Эластике есть автоматическое добавление индексов/маппингов, но удалить их нельзя, только полный реиндекс. Как у вас реализована работа с маппингами? Пожалуйста, выложите образ на докер хаб + краткое руководство по HTTP API. Очень бы хотелось потестировать ваш проект. Голосую за Java драйвер =)
olegator99 Автор
19.01.2018 00:46Удалять индексы без переиндексации всей таблички Reindexer тоже не умеет. Технически задача не сложная, но я, если честно, сходу не вижу практический кейс, в котором такой функционал был бы критичен.
Документация по HTTP API будет, но чуточку попозже.
А какой образ хотелось бы видеть на докерхабе? )

kxl
19.01.2018 01:08Наверное, такой, который позволит протестировать по HTTP, и не заморачиваться с установкой c++ и go
sm0g
19.01.2018 01:42Как верно заметил kxl, самодостаточный образ для теста REST API и общего функционала. Кстати, что такое «namespace» и какое максимальное количество маппингов на сущность?
olegator99 Автор
19.01.2018 12:09Хорошая идея, спасибо! Сделаем такой образ.
namespace — табличка.
Сейчас ограничение — 64 индекса на сущность.
olegator99 Автор
19.01.2018 21:06Выложил образ на Dockerhub:
Запускать такой командой:
docker run -p9088:9088 -it reindexer/reindexer
Дальше, в браузере можно зайти на http://<ip докера>:9088/doc — откроется свагер дока REST API

bro-dev
19.01.2018 06:01Может быть тогда вообще не нужно плодить сущности и просто хранить данные в переменной, тоже самое будет всё в оперативке и работать должно быстрее.
andreylartsev
19.01.2018 08:56+1К сожалению не нашёл информации о том как устроена транзакционная модель (
Поддерживается ли ACID?
Что вообще происходит при конкурентной записи в таблицы? Поддерживается ли read consistency?olegator99 Автор
19.01.2018 11:47ACID только на уровне документа, насколько я понимаю примерно так-же, как у монги.
При записи происходит короткий lock всей таблицы.
Так же есть механизм Lock Free атомарного bulk обновления таблицы.
emacsway
19.01.2018 19:57> ACID только на уровне документа, насколько я понимаю примерно так-же, как у монги.
Тогда, боюсь, что это не ACID, а «Transactions at the single-document level are known as
atomic transactions». Есть еще термин BASE (Basically Available, Soft state, Eventual
consistency) в противовес ACID.
Проблему согласованности и атомарности данных Монга выносит на уровень приложения в виде «Two Phase Commits», как об этом говорит документация.
Блокировать всю таблицу ради atomic transactions не нужно, оптимистической блокировки более чем достаточно. Все-таки пессимистическая блокировка существенно влияет на уровень параллелизма.
Но если Вы замахнулись на поддержку JOIN, тогда ACID будет уместным. Но при этом вы поставите крест на возможностях шардинга (CAP-теорема). Есть небольшая книжечка, всего в 150 страниц, «NoSQL Distilled» by M.Fowler, которая кратко и очень доходчиво рассматривает все эти вопросы. Только не читайте русский перевод этой книги, он ужасен, и нередко искажает смысл оригинала.olegator99 Автор
19.01.2018 21:42Согласен, честный ACID нам будет дорого стоить. Возможно лучше сменим терминологию, и назовем функционал не Join, а например 'Nested queries', что бы не вводить людей в заблуждение )
Все-таки пессимистическая блокировка существенно влияет на уровень параллелизма.
Все так, но реализация индексов внутри не thread safe, и требует наличия блокировки на запись.
Что бы запустить запись во много потоков еще потребуется порефакторить индексы — они требуют блокировки. Прямо сейчас производительность на запись нас устраивает, если станет проблемой — то да, пойдем именно этим путем.
emacsway
19.01.2018 11:47+1> Если быть точным, в мире NoSQL, как правило, нет операции Join в чистом виде
Ну, в этом и заключается смысл NoSQL хранилищ. Они ориентированны для работы в условиях шардинга (за исключением некоторых, например, графовых). А поскольку в условиях шардинга невозможно обеспечить ACID (в силу CAP-теоремы), то возник вопрос организации транзакций. Поэтому границами транзакций в NoSQL стали границы агрегата (композитной структуры объектов), что вписывается в распределенную модель хранения информации (и удовлетворяет DDD). Джойны по этой же причине обычно не поддерживаются (что компенсируется поддержкой вложенных объектов).
Кстати, я не заметил, как автор решает проблему параллельного доступа к данных (транзакций). Возможно я этот момент упустил, поэтому пробежался по статье повторно, но так и не нашел. А этот момент очень важный в условиях «100К RPS».
Поскольку в NoSQL границы транзакции совпадают с границами агрегата, там достаточно оптимистической блокировки. Совсем другое дело возникает при поддержке JOIN. В таком случае, следует как-то предотвратить чтение несогласованных данных. А способ реализации транзакций существенно влияет на уровень параллелизма (потому и существует четыре уровня ACID транзакций).
Я не хочу затрагивать вопрос о том, что это влечет за собой способ организации клиентского кода (двухфазные транзакции и т.д.).
Отдельно хочу затронуть тему самого термина NoSQL.
«The original call [NoSQL Meetup] for the meetup asked for “open-source,
distributed, nonrelational databases.» (NoSQL Distilled by M.Fowler)
Одним из критериев NoSQL является "Designed to run on large clusters".
Автор решал совсем другую задачу, нежели решают NoSQL. И хотя термин NoSQL использовать можно в порядке исключения, как это делают, например, графовые БД, но этот термин заметно искажает назначение БД. По этой причине, например, вы не встретите термина NoSQL в документации IndexedDB.
Интересно было бы услышать характеристики используемого диска. И, в целях чистоты эксперимента, было бы интересно рассмотреть вариант монтирования файловой системы тестируемых БД в RAM.olegator99 Автор
19.01.2018 11:57Кстати, я не заметил, как автор решает проблему параллельного доступа к данных (транзакций). Возможно я этот момент упустил, поэтому пробежался по статье повторно, но так и не нашел. А этот момент очень важный в условиях «100К RPS».
Реализовано на уровне rwlock табличек, с гарантией конситености на уровне документов.
Интересно было бы услышать характеристики используемого диска. И, в целях чистоты эксперимента, было бы интересно рассмотреть вариант монтирования файловой системы тестируемых БД в RAM.
Тесты запускались на MacBook Pro 15" 2016. Диск — штатный SSD
Выше в комментариях повторил тесты MySQL и Mongo в вариантах с монтированием файловой системы в tmpfs и там же привел цифры.
mikhailf
19.01.2018 21:42Относительно сравнений: ещё интересно как будет выглядеть на фоне Aerospike, Riak, Couchbase.

stychos
20.01.2018 03:09Хотелось бы увидеть примеры использования по HTTP.
olegator99 Автор
20.01.2018 15:26Пока http API в статусе драфта, и будет немного меняться. Как финализируется сделаем подробную документацию.
По просьбе в комментарии выше, выложил на docker hub образ, который можно запустить, и в браузере подергать методы API через Swagger UI.
Выглядит вот так:


Juralis
Было бы ещё интересно сравнить в аналогичных условиях какой-нибудь inmemory-вариант использования mongodb. Percona, или даже просто что-то простое, на базе tempfs
olegator99 Автор
Согласен.
Прогнал тесты mysql с in-memory mysql (ENGINE=MEMORY) — пришлось оторвать полнотекстовый поиск, т.к. ENGINE=MEMORY его не умеет. Результаты такие:
mysql byid -> 12917.17
mysql 1cond -> 10845.16
mysql 2cond -> 10114.12
mysql update -> 8447.82 (вырос в 10 раз, скорее всего, за счет отказа от полнотекстового индекса)
Судя по всему, mongo умеет in-memory только в enterprise редакции. Поэтому удалось проверить только на tmpfs:
mongo byid -> 12808.25
mongo 1cond -> 11279.45
mongo 2cond -> 7895.26
mongo text -> 7258.60
mongo update -> 809.77
Итого, выигрыш получился не принципиальный...
Juralis
Спасибо!
andreylartsev
In-memory MySQL это engine=ndb или MySQL Cluster. Это то с чем по идее надо сравнивать.