
Все мы встречались со сложными ошибками на продакшне, которые сложно поймать обычными средствами мониторинга. BPF — это технология ядра Linux, которая позволяет делать быструю и безопасную динамическую отладку прямо на запущенной работающей системе, без необходимости готовиться к этому заранее. JVM сама по себе имеет множество точек мониторинга для отслеживания сборки мусора, выделения объектов, вызовов JNI, даже вызовов методов — и всё это без необходимости в дополнительном инструментировании. Когда этих точек мониторинга недостаточно, ядро Linux и всевозможные бибилиотеки позволяют отслеживать системные вызовы, сетевые пакеты, события планировщика, время потраченное на доступ к диску, и даже запросы к базам данных.
В этом хабрапосте мы сделали текстовую расшифровку доклада Sasha Goldshtein, посвященного тому, как инструменты BPF можно использовать для мониторинга JVM-приложений на GNU/Linux, и чеклисту проверки производительности с использованием классических инструментов, таких как fileslower, opensnoop, strace — но всё это с использованием неинвазивной, быстрой и безопасной технологии BPF.
После ката будет множество картинок со слайдами. Осторожно, трафик! Картинки ужаты насколько можно, но не более того. Все они действительно нужны.
Сегодня мы поговорим о мониторинге посредством некоторых новых и наиболее продвинутых инструментов под Linux. Меня зовут Саша Гольдштейн и я занимаюсь многими вещами, связанными с .NET для Microsoft. В течение нескольких лет я занимался инструментами мониторинга и трассировки под Linux, и, в целом, моя работа на протяжении последних примерно двенадцати лет была связана с производительностью. Оказывается, те же инструменты под Linux, которые используются для мониторинга приложений на C++ (я это делаю довольно часто), под Python (это я делаю иногда), можно использовать для мониторинга, улучшения производительности, трассировки и решения важных проблем Java-приложений под Linux. Некоторые вещи, которыми я занимаюсь, полезны также и разработчикам на Java.
Доклад будет посвящен экспертным инструментам трассировки под Linux и тому, как их можно использовать в приложениях на Java. Это значит, что я покажу вам только верхушку айсберга, это инструменты системного уровня, которые можно использовать с другими языками и средами. Так что если вам иногда приходится заниматься отладкой или профилированием приложений, написанных не только на Java, эти инструменты вам пригодятся, в отличие многих Java-профилировщиков, которые могут работать только с кодом на Java, а C++ или Python они не поддерживают.
В ходе доклада я освещу четыре главных пункта, которые, я надеюсь, будут полезны вам. Во-первых, вы узнаете, какие именно готовые к эксплуатации инструменты трассировки можно использовать с JVM-приложениями. Об этом я расскажу совсем немного. Во-вторых, и это будет одной из ключевых тем, речь пойдет о BPF (это технология системного уровня), и о том, насколько она может поменять многое в современных инструментах трассировки под Linux, поскольку она позволяет то, чего раньше было крайне сложно достичь в продакшне под Linux. В-третьих, я продемонстрирую своего рода чеклист инструментов для оценки производительности, при помощи которых можно легко и быстро получить некоторые предварительные данные. Наконец, я покажу примеры узконаправленных исследований, которые решают определенные проблемы при помощи более сложных и утонченных инструментов.
Если при развертывании вы иногда пользуетесь чем-либо помимо Linux, на других системах есть аналоги этим инструментам. Под Windows некоторые вещи, о которых я буду говорить, может выполнять ETW. Под FreeBSD и MacOS можно пользоваться DTrace; BPF — это, можно сказать, DTrace для Linux, хоть ее и не любят так называть.
Сейчас я представлю вам общую картину инструментов трассировки под Linux в виде графика.

Горизонтальная ось — это степень детализации, т. е. насколько подробную информацию может выдать инструмент. Вертикальная ось — это простота использования. Отдельными цветами представлены новые инструменты, стабильные инструменты и вышедшие из использования инструменты, на которые не стоит тратить свое время.
Очень часто люди незнакомы с ftrace, в особенности это касается разработчиков, не работающих на системном уровне. Поднимите руки, кто из вас слышал об ftrace? Совсем немногие. Ftrace — это встроенный механизм, он с незапамятных времен входит в Linux, это инструмент для трассировки проблем с производительностью, багов во время продакшна. Однако он не предназначен для работы с Java. Его нельзя использовать для трассировки многих интересных Java-событий, как, например, сборки мусора, загрузки классов, выделения объектов.
Перейдем к perf. Достаточно полезный инструмент, кто из вас пользовался им? Уже значительно больше людей. Следующий за мной докладчик будет говорить о том, как адаптировать perf к работе с приложениями на Java. В моем докладе я не буду пользоваться perf и позже объясню, почему именно. Но скажу, что он применим к значительно более широкому спектру приложений.
Далее, SystemTap. Кто из вас пользовался им или слышал о нем? Вновь совсем немногие, причем, кажется, те же люди, что поднимали руки раньше. SystemTap весьма низкоуровневый инструмент, который может выполнять трассировку cобытий ядра и высокоуровневых cобытий в юзерспейсе (в т. ч. Java-событий). Главная проблема, с которой многие сталкиваются в SystemTap, заключается в том, что для работы с этим инструментом нужно во время его выполнения скомпилировать модуль ядра и загрузить его в ядро. Некоторые готовы это делать, у других загрузка динамически компилируемых модулей ядра не вызывает особого энтузиазма. Создатели SystemTap занимаются разработкой бэкенда к BPF, чтобы можно было не компилировать новый модуль ядра для каждой программы трассировки, однако пока что это остается проблемой.
На противоположном конце спектра — максимальная доступность и удобство, но меньший функционал, это SysDig. Кто из вас пользовался им? Еще меньше людей. SysDig — замечательный инструмент, с особенным упором на отслеживание производительности в контейнерах, но он может работать только с системными вызовами. Он делает это хорошо, но больше ничего не умеет. Не совсем то, что нужно для приложений на Java.
Сегодня я в основном буду говорить об инструментах на базе BPF, но к самому BPF я перейду позже. У BPF есть несколько фронтендов, инструменты на его основе можно писать на C, на Python, вариантов много. Те, о которых пойдет речь в докладе — новые, не такие стабильные, как другие, но крайне мощные. Из-за новизны ими иногда бывает не совсем просто пользоваться, но они того стоят — по крайней мере, я надеюсь это сегодня доказать.
Есть и другие инструменты. Например, некоторые, вышедшие из употребления, в т.ч. DTrace под Linux. Это был достаточно амбициозный проект, но в итоге он умер. Как я уже говорил, в своем роде BPF — это и есть тот самый DTrace под Linux, которого нам так нехватало.
Поскольку сегодня в фокусе нашего внимания Java, поговорим о точках мониторинга в JVM. Что можно трассировать в работающем Java-приложении специфичного для JVM, т.е. помимо вещей, выполняемых операционной системой (системные вызовы, сетевые события)? Оказывается, в большинстве последних версий Java в JVM встроено достаточно много статичных точек трассировки, которые можно включить во время выполнения, т. е. их не обязательно включать предварительно. Затем к этим точкам можно подключить программы трассировки, которые дадут нужную вам информацию.
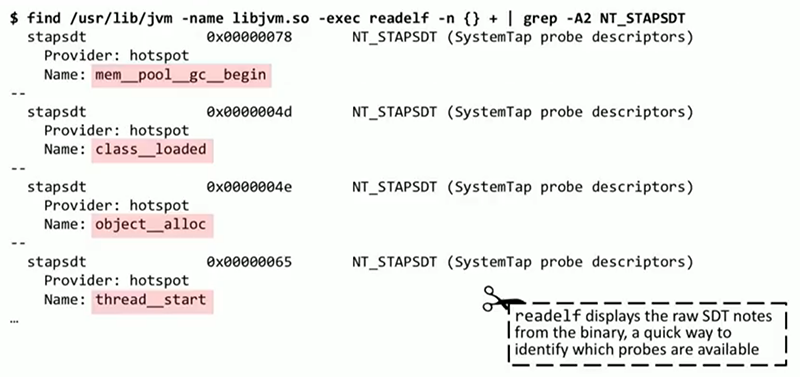
Опишу один из способов, которым можно получить список этих точек трассировки. На Linux есть инструмент readelf, который занимается анализом заголовков ELF и может выдавать примечания. В них описаны те самые точки трассировки, которые встроены в любое Java-приложение на вашей системе. Мы видим высокоуровневые Java-события: class_loaded, thread_start, object_alloc, их трассировку можно осуществлять через эти точки.

Есть другой инструмент, tplist, он несколько проще в использовании, я его написал сам. С ним не нужно анализировать примечания, поскольку он создает простой список. Примеров точек трассировки тут много десятков: сборка мусора, занятие и покидание мониторов, события JNI (они на слайде не показаны).

У этих событий также есть аргументы. В интересах экономии времени я не буду сейчас рассказывать, как эта информация была добыта, но у tplist есть флажок, который позволяет выводить аргументы каждой из этих точек наблюдаемости. К примеру, основываясь на здравом смысле можно сказать, что событие monitor__waited скорее всего обладает какой-то информацией о мониторе, который мы ожидали, возможно, там есть идентификатор потока. Однако напрямую тут ничего не говорится о том, что именно эти аргументы значат. Оказывается, здесь нам могут помочь прилагающиеся к JVM текстовые файлы, в которых эти точки трассировки описываются. По сути дела, файлы трассировки SystemTap. В них можно, например, узнать, что у события monitor__waited несколько аргументов, это идентификатор потока, идентификатор монитора, имя класса ожидаемого объекта. Даже предлагается вариант формата, в котором это можно представить для трассировки, для показа.
Итак, вопрос: идет ли речь об OpenJDK, Oracle JDK, каких-то конкретных дистрибутивах? Насколько я знаю, эти точки трассировки есть во всех JDK, хоть я и сильно сомневаюсь, что к этому принуждает спецификация. Когда именно они возникли, я точно сказать не могу. Я помню статью Oracle, кажется, 2008 года, в которой они были описаны, так что это не новое явление.
(После этого доклада мы проверили: на Linux в OracleJDK этих точек мониторинга нет. Есть на Solaris и возможно на Oracle Linux. Эти точки есть в исходнике, но они не компилируются по-умолчанию. А вот во всех OpenJDK они присутствуют!).
Вначале я хотел бы показать, как их можно использовать, а потом перейду к описанию BPF и его работы с ними. Вот несерьезный пример: приложение на Java печатает на консоль сообщения, по всей видимости важные, но мы не знаем, откуда они исходят. Причем узнать, какой код отправляет эти сообщения, мы хотим именно в продакшне. Возможно, при помощи отладчика эту проблему можно было бы решить через точки останова, но мы так делать не будем. Нам понадобится флаг PreserveFramePointer, который также используется многими Java-профилировщиками для прохождения стека. Этот флаг уже присутствовал в JDK 8u60, о нем пойдет речь и в следующем докладе, который использует perf. Флаг необходим для хождения по стеку. Этот флаг включает проверку, что frame register (один из регистров CPU) не используется для обычных вычислений, как любой другой регистр. Он должен использоваться только для обработки цепочки вызовов, в том числе для хождения по стеку.
Оценочная стоимость использования этого флага составляет где-то 3%. Если загрузка процессора не сверхвысокая и не вызываются миллионы методов в секунду — может быть и 0%, это скромная оценка. На экране вы видите вывод программы, которую мы пытаемся трассировать.

Предупреждения выглядят достаточно серьезно, поэтому нужно понять, откуда они исходят. Попробуем применить инструмент trace, написанный, опять-таки, мной. Он занимается трассировкой событий системного уровня, и попутно получает стек вызовов Java из этих событий. При этом не возникает необходимости перезапускать Java-приложение, перекомпилировать, собственно же, trace — крайне легковесный инструмент, который можно запустить в продакшн. По ходу слайдов размещены ссылки, к концу доклада вы будете знать, где достать все эти инструменты.

trace основан на BPF. На слайде вы видите обращение к нему. Для начала, обратите внимание: мне необходимо запускать код от имени привилегированного пользователя. Как мы потом увидим, этого требует BPF, как и perf, как и многие другие инструменты. Затем надо определить, к чему именно прикрепить trace. Мне нужна трассировка вывода на экран, но в данном конкретном случае я работаю на системном уровне, поэтому я буду искать определенный системный вызов, который, помимо прочего, осуществляет стандартный вывод. Кроме того, я добавлю условие, согласно которому первый аргумент должен быть единицей. Какой, по-вашему, будет первый аргумент у нужного системного вызова?
Правильно, дескриптор файла, а единица — это условие, благодаря которому я буду осуществлять трассировку выводов на stdout. Затем мы видим сообщение, которое будет напечатано, оно в стиле printf; arg2 же — это буфер, непосредственно находящийся в процессе печати (в том случае, если в нем текст, что наиболее вероятно). За ним следует флаг -U, который обозначает стек вызовов в юзерспейсе. В самом конце мы ставим фильтр, который оставляет только Java-процесс, поскольку нас интересует только он. Если вы разберетесь в синтаксисе, я надеюсь, это все станет понятным.
Посмотрим на вывод trace. Он почти такой, как мы хотели. Первые несколько строк — это заголовок, там обозначаются идентификаторы процесса и потока. Дальше идет то сообщение, которое нас интересует — «ошибка в получении данных, происходит очистка». Стек вызовов почти такой, какой нам нужен, в его начале все в порядке, но он не показывает нам наиболее интересную часть, например, то, что происходит до java_io_FileOutputStream. И с этой проблемой мы столкнемся при работе со многими инструментами, которые пытаются проходить стеки Java и строить соответствия с символами, именами функций и методами в вашем коде.

Здесь, как в perf и многих других инструментах, необходим будет небольшой агент, который будет печатать соответствия между адресами в памяти JIT-компилированного кода и собственно именами методов. Если необходимо, он также может печатать сведения об источнике, поскольку он имеет к ним доступ. В данном случае я использую достаточно часто встречающийся и очень простой агент, perf-map-agent, который можно найти на GitHub. Он будет отправлять свой вывод в папку /tmp, это будут файлы в очень простом формате с адресом кода, указанием конкретного метода и размером этого метода. Эти соответствия нужны для разрешения стеков вызовов java. Если профилировщик изначально не умеет работать с фреймами стеков Java, без такой операции не обойтись.
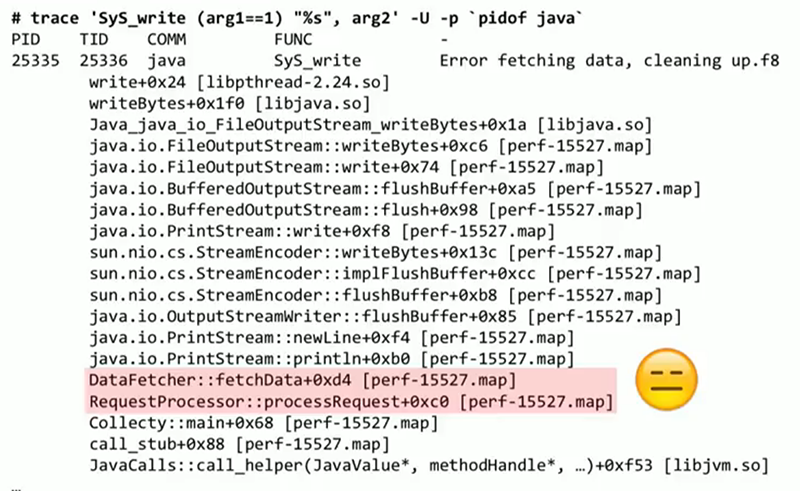
На слайде новый результат с применением агента, в нем приемлемо выглядят стеки, разрешены названия функций, которые все добываются из только что сгенерированного нами файла .map. На слайде выделена часть кода моего приложения (DataFetcher::fetchData), которая и осуществляет тот вывод на консоль, который нас тревожил. Источник найден, и теперь уже зависит от ситуации, что мы с этим кодом будем делать. Мне кажется, это пример тех возможностей, которые у нас должны присутствовать: извлечь данные из уже запущенной системы при помощи простых, не ресурсоемких, готовых к продакшну инструментов. Это может происходить на уровне Java, на уровне системы, на уровне ядра — не имеет значения.
Прежде, чем мы займемся сутью вопроса, рассмотрим еще один похожий пример. Приложение Java, которое вызывает много сборки мусора. Из журнала сборщика мусора я знаю, что оно вызывает System.gc() напрямую, и необходимо понять, где именно. Приложение огромное, библиотек множество, какой именно код совершает эти вызовы, неизвестно. Я не начал с этого примера, поскольку здесь нам будет необходим флаг, требующий достаточно много ресурсов. Это своего рода режим супер-отладки, называется ExtendedDTraceProbes, и он позволяет присоединить программу трассировки ко входу и выходу любого Java-метода. Очевидно, для это потребуется больше ресурсов, чем для других способов, о которых я говорил, поэтому этим флажком стоит пользоваться только когда необходимо решить конкретную проблему.

Перед нами журнал сборщика мусора, в котором мы видим прямые вызовы к System.gc(). Здесь мы снова воспользуемся trace, но несколько иным образом, поскольку немного другой будет цель прикрепления.

Ею будет точка внутри JVM под названием method__entry, и при помощи нее можно осуществлять трассировку любого Java-метода. Чтобы указать, какой именно метод нас интересует, мы подставляем условие, которое требует, чтобы arg4 (это имя метода) был равен gc. Вероятно, мне следовало бы также добавить проверку на имя класса, которое должно быть System. Затем я печатаю сообщение, и после него стек вызовов. Наконец, все это должно выполняться только с процессами на Java. Дальше перед нами вывод, в котором есть трассировки вызова и стека на каждый вызов System.gc() в этом приложении. Мы видим, что это тот же код, что и в прошлый раз, DataFetcher::fetchData, вызванные по запросу RequestProcessor::processRequest и т.д.
Это честный полный стек, в нём есть и java-фреймы, и нативные фреймы из JVM, и он ведёт нас вдоль всего-всего пути, вплоть до корневого треда в Linux. Совершенно всё можно здесь посмотреть. Такой вот вышел пример того, что нужно преодалеть, чтобы добраться до подобных данных.
Ещё несколько примеров мотивации, которая стоит за такой работой… Давайте перейдем от примеров к уже упомянутой проблеме — что не так с perf? Об этом инструменте упоминается в каждом докладе о мониторинге или трассировке Java-приложений в продакшне на Linux. Как я уже упоминал, следующий после моего будет доклад о новом и оригинальном способе применения perf для выборки циклов CPU в приложениях Java.
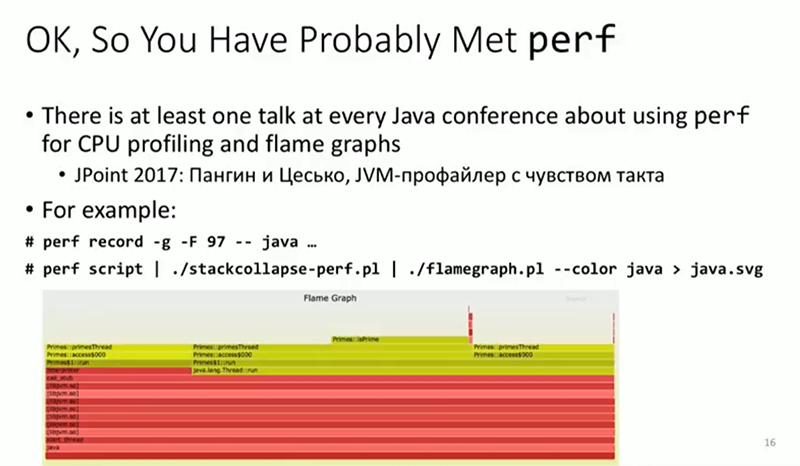
С perf мы действуем просто — вначале записываем, затем обрабатываем запись, получаем, к примеру, флеймграф. Скорее всего, некоторые знают о таком применении perf. Проблема, о которой я буду говорить, связана с BPF и с той мыслью, которую я больше всего хотел бы до вас донести. Для своей работы perf передает большой объем данных в юзерспейс через файл для последующего анализа. Я поставил эксперимент: создал виртуальную машину на некоем облаке, подключился к этой машине и скачал файл со скоростью примерно 1 Гбит/сек. Дома у меня такого подключения нет, почему я и сказал, что речь идет о виртуальной машине на облаке. В результате у меня получилось примерно 90 тыс. событий netif_receive_skb. Я мог бы сделать запись этого при помощи perf, чтобы осуществить трассировку данных, которые получает моя система, трассировку задержек и размеров пакетов. Но при этом на выход будет поступать 90 тыс. событий в секунду, и при записи стеков вызовов это 20 мегабайт данных в секунду, записываемых в файл. Очевидно, в продакшн так, как правило, не делается, и больше чем минуту выполнять такую работу явно нежелательно, поскольку попросту закончится место на жестком диске. При этом нас может интересовать только 5 байт из этих 20 мегабайт в секунду, например, средний размер пакета, или средняя задержка между получением пакета и доставкой его в приложение Java, или нечто подобное. 20 мегабайт в секунду нам не нужны, но это именно то, как работает perf — события отгружаются в файл, и затем запускается программа в юзерспейсе, которая этот файл анализирует. Это именно та проблема, которую мы пытаемся разрешить. Мы пытаемся переместить обработку ближе к непосредственной сборке данных, к программе трассировки, и избежать создания каких-либо файлов, если нам самим они не нужны.

И здесь я хочу вас познакомить с BPF, расшифровывается как «Berkley Packet Filter». Инструмент существует с начала 90-х гг. Я не хотел бы, чтобы доклад превратился в урок истории, просто пытаюсь показать, что основание тут весьма зрелое. BPF был создан для фильтрации пакетов, для трассировки входящих в систему пакетов и принятия решения о том, пропускать их или нет. tcpdump, Wireshark или похожие инструменты слежения используют его, когда вы указываете, с каких именно IP-адресов вы хотите получать пакеты, с какими именно протоколами. И tcpdump, и Wireshark в таких случаях создают небольшую программу BPF с собственным набором инструкций, передают ее в ваше ядро, и оно затем выполняет эту программу для каждого входящего пакета, чтобы решить, удалить этот пакет или трассировать его. На слайде перед нами этот набор инструкций, который представляет из себя очередной ассемблер. В 90-е этот набор инструкций был крайне простым. Но за последние 3-4 года стало прилагаться много усилий к тому, чтобы BPF можно было использовать не только для сетевых целей, не только для фильтрации пакетов. Сегодня в его функции входит трассировка, и мое основное внимание будет сосредоточено на ней. Инструмент trace, который я демонстрировал выше, использует BPF. Но у BPF есть и другие функции. Кроме того, как и у Java, у BPF теперь есть JIT-компилятор. Упомянутый набор инструкций теперь не интерпретируется ядром, вместо этого оно компилирует их в машинный код, в инструкции процессора, и затем выполняет их.
Выше я говорил, что у SystemTap есть проблема, которая заключается в том, что он загружает динамически компилируемый модуль ядра. Это не то же самое, что делает BPF. В последнем случае набор инструкций не произвольный, он специально отбирался, чтобы избежать проблем с безопасностью. Плохая программа BPF не сможет уронить или подвесить ядро. Программы BPF не занимаются выделением памяти, и поэтому не могут привести к утечке памяти в ядре. Все функции этих программ жестко ограничены, чтобы они не нанесли вреда продакшну.
Расскажу коротко о некоторых сценариях, прежде чем перейти к главной теме, трассировке. Одно из крайне важных использований BPF сегодня, о котором можно услышать на конференциях по сетям — XDP (eXpress Data Path). Предположим, вы занимаетесь созданием службы защиты от DDoS-атак (в качестве примера можно назвать Cloudflare). Вам необходимо удалять пакеты максимально быстро, не обрабатывая их и не передавая. В этом случае прежде, чем пакет попадает в ядро, в стек TCP или в любое приложение, выполняется программа BPF, которая решает, нужно ли удалить пакет, передать его кому-либо еще или отправить наверх приложению. Это — один из примеров настройки динамических правил вашей системы при помощи BPF.
Другой пример такого же рода — seccomp. В Linux сегодня можно установить программу BPF для фильтрации системных вызовов конкретного приложения. Приложению можно запретить доступ к определенному файлу, при этом позволяя совершать вызовы к другим файлам. Можно запретить запись на жесткий диск, при этом позволяя читать с него. Благодаря такому фильтру взаимодействий с системой программа BPF создает своего рода песочницу.
Мы же будет в основном говорить об использовании BPF для трассировки событий в вашей системе, к примеру, сборки мусора, а также трассировки вызовов методов, о которой я уже говорил, когда демонстрировал trace. В системе есть разные точки прикрепления, на уровне приложений это сборки мусора, выделения объектов, загрузки классов в Java-приложениях. Кроме того, есть много точек прикрепления на уровне ядра, к примеру, получение пакетов, системные вызовы write и read. В юзерспейсе есть контролирующая программа, которая устанавливает в ядре программу на BPF, и затем прикрепляет ее к интересующим нас событиям. Когда эти события происходят, программа в ядре выполняется, при этом она может делать одно из двух. Она может передавать информацию в юзерспейс, и при этом она в сущности работает как средство трассировки. Это то, как работает моя программа, она печатает свой вывод через скрипт в юзерспейсе. Либо программа может обновлять находящуюся в памяти структуру данных, которая выполняет агрегирование. Вместо передачи данных в юзерспейс для последующего анализа можно совершать агрегирования прямо в ядре, получать средние, максимумы, минимумы, гистограммы и т.п. там, где работает трассировщик, не занимаясь при этом передачей миллионов событий. Именно в этом ключевое отличие BPF, делающее его таким ценным и дающее ему преимущество перед perf.
Когда программа в ядре отработала, ваш скрипт в юзерспейсе читает данные из буфера или из структуры данных, и делает с ними то, что вам нужно: выдает сообщения на экран, строит графики, гистограммы и т.п. В отличие от perf, нигде не создаются файлы, если они вам не нужны.
Почему этот инструмент не общепринят? В первую очередь потому что он совсем новый. Для использования любых программ BPF, занимающихся трейсингом и мониторингом производительности, нужно ядро Linux версии минимум 4.1, которой всего несколько лет. В Ubuntu 14 или CentOS 5 её нет. Для наиболее полезных вещей нужно еще более новое ядро. Посмотрим на примере Fedora и Ubuntu. В Ubuntu 16 LTS можно пользоваться многими возможностями BPF, в Ubuntu 16.10 — практически всеми. Новейший функционал, добавленный BPF, требует версии ядра 4.9, которая вышла всего несколько месяцев назад. Поэтому многое может не работать непосредственно сегодня, или работать только на определенных системах с достаточно новым ядром. Но будущее трассировки под Linux именно за BPF. Это касается и Java, и Python, и C++ — любого языка, работающего под Linux. Причина именно в способности выполнять программу трассировки в ядре и совершать там сложные действия вроде обновления таблиц соответствий и гистограмм, вместо того, чтобы передавать все данные в юзерспейс для последующего анализа.
Сравним старый и новый методы. Как правило, при использовании perf происходит отгрузка данных в файл, затем происходит обработка и анализ этого файла. В случае же с BPF анализ и агрегация происходят в ядре, обновляется небольшая таблица соответствия. Инструменту трассировки затем нужно лишь произвести чтение из этой таблицы и вывести результат. Таким образом, происходит значительная разгрузка каналов между ядром и пользовательским пространством, потребляется значительно меньше ресурсов.
Взглянем на некоторые примеры. Для того, чтобы их продемонстрировать, нам понадобится оболочка для набора инструкций BPF, поскольку самостоятельно писать эти инструкции мы не будем. В качестве нее мы будем использовать полезный и весьма продвинутый опенсорсный проект BCC. Его поддержкой занимается много людей, в т.ч. Брендан Грегг, о котором некоторые из вас, возможно, слышали, очень известный перфоманс-архитектор Linux. В этом наборе средств многие разработаны мной. Все они бесплатные и просты в использовании.

В BCC есть следующие инструменты. Каждая строчка на слайде — это отдельный инструмент с документацией, с примерами и руководствами пользования. Эти инструменты не были написаны кое-как за выходные, с точки зрения документации и зрелости они достаточно развитые. С их помощью можно осуществлять трассировку системы на разных уровнях, начиная, если нужно, с низкоуровневых вещей вроде аппаратных прерываний, и заканчивая Java, MySQL, Postgres и многими другими базами данных и средами, у которых есть инструменты именно для этого сценария. Я продемонстрирую, как пользоваться этими инструментами и некоторыми другими, более общего назначения, с помощью которых вы сможете создавать собственные сценарии трассировки, при этом не задаваясь вопросами о всех тонкостях внутренней работы BPF.

На слайде в виде чеклиста перечислены некоторые из элементов, которые я хотел бы продемонстрировать. Все их запоминать, конечно, не надо, но может быть полезно пройтись по этому списку, если вы пытаетесь решить проблему с производительностью системы, понять, в какой области проблема локализована. Здесь есть инструменты для трассировки доступа к жесткому диску, к файлам, если ваше приложение ограничено IO. Также есть инструменты для работы с сетями, для трассировки подключений TCP и активности TCP. Есть даже инструмент для отслеживания медленных запросов DNS. Также есть инструмент для приложений, ограниченных возможностями процессора. Его можно использовать, когда необходимо проследить, что именно загружает процессор — именно этим мы займемся в следующем примере. Конечно же, все эти инструменты работают с приложениями Java.
Пользуясь этими средствами, проведем наше первое исследование. У меня запущено приложение, которое достаточно сильно загружает процессор. Я хочу провести самую обычную профилировку. Для этого уже есть множество инструментов, но давайте посмотрим, как с этой задачей справится BPF.
Я запускаю top и вижу, что использование процессора почти достигает 100%. Процессор явно не справляется с работой приложения, необходимо разобраться, что происходит. Применим инструмент из набора BCC — uthreads. Его можно запустить, прикрепить к Java-приложению, и при каждом создании или уничтожении потока он будет печатать сообщение. По столбцу с указанием времени сообщений видно, что потоки создаются и уничтожаются очень часто. Скорее всего, в этом процессе у нас одновременно работает множество потоков. Теперь применим инструмент profile, созданный для профилирования процессора (в этой области он может заменить perf). Прикрепляем profile к процессу Java, указываем частоту, с которой необходимо производить выборку циклов СPU, и продолжительность работы в секундах. Для экономии места значительную часть вывода я убрал, оставил только самый нагруженный стек. Это стек Java, с Java-фреймами, методами — и с нативными фреймами. Получается та же точность информации, которую молжно получить от perf или других аналогичных инструментов — полный стек вызовов, включая java-фреймы, и как видим — это самый горячий участок в этом приложении.

Если вам нравятся инструменты визуализации, всю эту информацию можно представить в виде флеймграфа. Специальная утилита может выдавать данные в формате, специально предназначенном для создания флеймграфа. Сам флеймграф здесь рисует скрипт Брендана Грегга, но можно пользоваться и другими средствами. Коротко о том, как читать флеймграф. Чем шире прямоугольник, тем больше времени и ресурсов процессора занимает соответствующая сущность. Если прямоугольники располагаются друг над другом, то это стек вызовов, вызывающий метод располагается под вызываемым. Наконец, здесь нет шкалы времени, сортировка идет в алфавитном порядке. Мы видим на флеймграфе фоновый процесс dd, затем dnf, потом Java и инструмент stress. Конечно, при запуске профилировщика можно было указать, что данные нужно выдавать только по Java. В процессе Java доминируют те же методы, которые мы видели на предыдущем слайде — Prime::isPrime, приложение, которое занимается вычислением простых чисел. В чем тут отличие от других инструментов? Главное в том, что профилировщик выводит только сводку стека вызовов, а не выборки отдельных стеков. Если функция isPrime встречается миллион раз, не происходит передача миллиона событий в юзерспейс, передается только одно событие, которое сообщает, что isPrime выполнена миллион раз. Я надеюсь, что разница в требованиях к производительности очевидна. Происходит значительно меньше обработки данных и передачи их в юзерспейс, поскольку агрегация происходит в ядре, которое в любом случае занимается обработкой этих событий. Ядро — это код, который, собственно, и занимается выборкой циклов CPU, разумно осуществлять эти агрегации именно в нем. Итак, можно создавать флеймграф событий процессора, можно профилировать процессор при помощи BPF, таким образом, я закрываю один из пунктов в нашем чеклисте по производительности.

Давайте перейдем к более интересному вопросу. Наблюдая за тем приложением, которое занимается вычислением простых чисел, я обнаруживаю в исходном коде следующий отрывок: если обнаруживается простое число, создается блокировка, и число добавляется в список (функция if(isPrime(i)) на слайде). Меня беспокоит, не является ли эта блокировка узким местом? Насколько часто она используется? Может быть, стоит применить одну из тех мудреных Java-коллекций без блокировок, о которых вы все наверняка знаете? Попробуем разобраться при помощи другого инструмента BCC, argdist. В данном случае он используется только для подсчета событий, он не слишком мудреный. Я указал, какое именно событие меня интересует: monitor__contended__enter(), событие от JVM. Argdist теперь будет сообщать каждые 5 секунд, сколько раз это событие произошло. Мы видим, что оно происходит не часто — 3 раза, 9 раз. Это не из-за того, что обнаруживается только 3 или 9 простых чисел за 5 секунд, такая производительность была бы крайне низкой. Причина в том, что это событие происходит только когда вход осуществляется при состязании, когда монитор уже заблокирован. Если монитор свободен, его получение не требует большого количества ресурсов. Эту информацию мы получили без дополнительного инструментирования, просто наблюдая за существующими событиями, являющимися частью JVM.
Многие доклады о профилировании слишком большое внимание уделяют CPU, может сложиться впечатление, что все Java-приложения занимаются вычислением простых чисел, что, конечно, не так. Рассмотрим другое Java-приложение, написанное мной, которое осуществляет доступ к базе данных MySQL. Некоторые из запросов выполняются особенно медленно, иногда по нескольку секунд. Я хочу разобраться, какие именно это запросы, и из какого именно места в исходном коде они отправляются. Я уверен, что многие из вас пользуются крайне сложными абстракциями поверх доступа к базе данных, между вашим кодом и непосредственным контактом с базой данных может быть порядка 50 функций, и в такой ситуации возможность проследить источник вызова может быть крайне ценной.
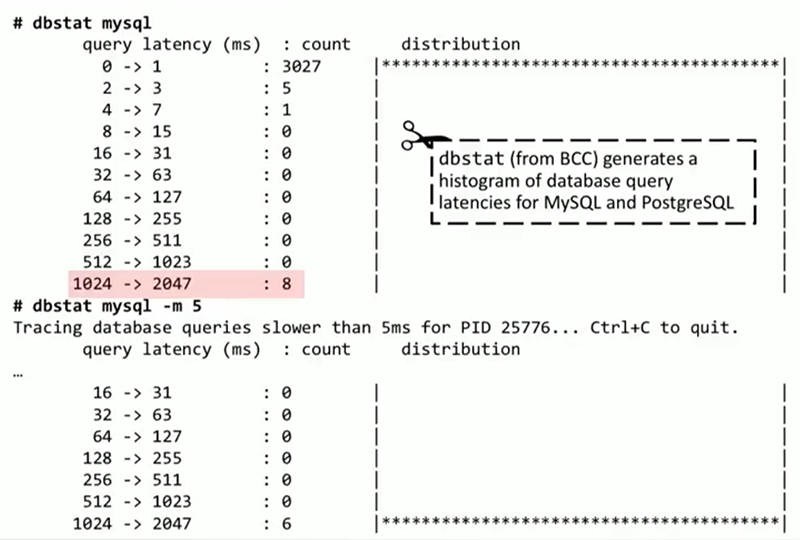
Для начала, запустим небольшой инструмент под названием dbstat из BCC. На данный момент он поддерживает MySQL и PostgreSQL. В них есть статичные метрики, под которые проще написать такой инструмент, но в теории его можно адаптировать к любой базе данных. Он прикрепляется к MySQL и выдает ASCII-гистограмму времени выполнения запросов (она не похожа на гистограмму потому, что в ней только один доминирующий промежуток). 3000 запросов заняли от 0 до 1 миллисекунды, при этом 8 запросов заняли от 1 до 2 секунд, что достаточно медленно. Получение этих данных не требует реконфигурации базы данных или проведения подробного расследования в ее внутреннем механизме. Эти метрики встроены в MySQL. dbstat может также фильтровать запросы по скорости, например, выводить только те, которые выполняются дольше 5 миллисекунд. Тогда лучше будут видны те запросы, которые занимают больше 2 секунд, а именно они нас и интересуют.
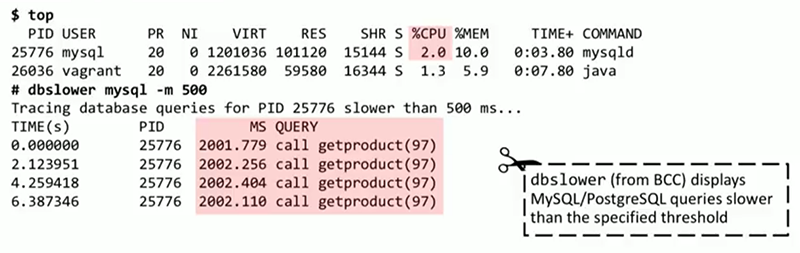
Возможно, системе не хватает ресурсов для работы MySQL. Но из вывода top ясно, что база данных потребляет 2% мощности процессора, скорее всего он не перегружен запросами. Чтобы найти причину задержек, воспользуемся инструментом BCC dbslower. Он прикрепляется к MySQL и просматривает запросы, выполняющиеся дольше определенного количества миллисекунд — в данном случае 500. Из вывода dbslower ясно, что в каждом случае это один и тот же запрос, call getproduct(97). Можно ли получить больше данных о том, что происходит внутри этой функции?

Встроенного инструмента для этого нет, нам понадобится программа trace, с которой я начал свой доклад. Она прикрепляется к статичной точке трассировки в MySQL query__exec__start и будет оповещаться как при внешних, так и при внутренних вызовах базы данных. На выводе trace мы видим, что после вызова call getproduct(97)`` база данных выполняет функциюsleep(2)`. Очевидно, это проблема была искусственно создана мной, и ее решение достаточно простое — избавиться от вызова sleep(2). Но главное, что у нас есть полная видимость того, что происходит внутри базы данных.

Но предположим, что вы не можете оптимизировать запрос таким простым способом. Придется обратиться к Java-приложению, попробовать сделать кэширование или избавиться от вызова конкретной процедуры. Рассмотрим эту ситуацию более подробно. Со стороны Java может возникнуть больше проблем, поэтому мне пришлось написать инструмент специально для этого доклада, mysqlsniff. У него достаточно интересное устройство. Он использует BPF и прикрепляется ко всем исходящим вызовам процесса Java на уровне сети, как, например, socket.send(). Там он анализирует пакеты в поисках пакетов протокола MySQL. Этот протокол достаточно простой, в основном текстовый, достаточно легко анализируется. Следующим шагом я могу отфильтровать все, кроме определенных вызовов, и при помощи флажка сделать вывод стека вызовов. В отслеживании вызова мы видим, где именно происходит обращение к call getproduct(97). В данном случае его найти просто, поскольку нет hibernate, beans и проч., простой вызов JDBC, достаточно короткий стек. В конце этого стека — код моего приложения, Product::load, User::loadProducts, Databaseey::main и т.д. Этим инструментом можно пользоваться, если вы готовы к тому, что нужно будет приложить определенное усилие. Работа инструмента отличается от применения анализатора сетевых пакетов, Wireshark, от поиска пакетов вручную, поскольку эти пакеты нигде не регистрируются. Их обработка осуществляется ядром во время выполнения программы, моя программа BPF анализирует пакеты, ищет протокол MySQL и, когда находит, записывает стек вызовов и передает его в юзерспейс. Пакет нигде не сохраняется и моментально удаляется, поскольку все, что нам нужно — это стек вызовов.
Итак, в этом примере мы взглянули на обе стороны запроса. Со стороны MySQL мы использовали инструменты для трассировки запросов к базе данных, в которых не было Java. Со стороны Java у меня была весьма специфичная проблема, для решения которой нет подходящего инструмента в BCC, поэтому мне пришлось написать такой инструмент самому.
Надеюсь, моих примеров было достаточно, чтобы вас заинтересовать. Возможно, не всеми описанными инструментами можно пользоваться каждый день в каждом приложении, но есть вещи, на которые стоит обратить внимание.

Пока осталось время, я приведу еще несколько примеров и отвечу на вопросы, если они есть. Рассмотрим Java-приложение, которое перегружено сборкой мусора. Я с такой ситуацией сталкиваюсь постоянно и на .NET, что, наверное, неудивительно. Для начала я запущу top, чтобы убедиться, что это приложение ограничено возможностями процессора, а после него специальный инструмент BCC ustat. Это даст мне полезную статистику о процессах Java, в том числе количество сборок мусора в секунду. Их происходит 800, что, наверное, не оптимально, хотя, возможно, эти сборки очень короткие. Затем я запускаю уже виденное нами средство profile, чтобы понять, на что тратится время работы процессора. Наиболее частым вызовом оказывается ResponseBuilder::addLine, который каждый раз создает новый массив, происходит выделение памяти и это занимает большую часть моих ресурсов.
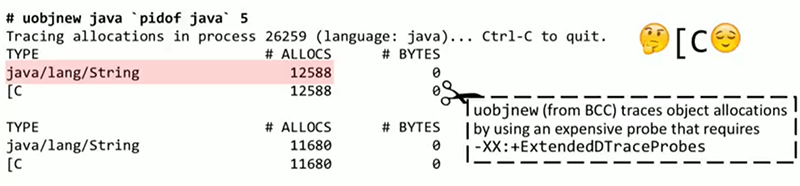
Чтобы убедиться в этом, в BCC есть инструмент для трассировки выделения объектов в Java, Ruby и некоторых других языках — uobjnew. Из всех перечисленных средств оно единственное, которое требует ресурсоемкого флага ExtendedDTraceProbes. Как правило, этот флаг не стоит включать по умолчанию, но здесь мы это сделаем, поскольку уже исследуем проблему, для которой он необходим. Каждые 5 секунд мы будем получать сводку о типах, выделение которых происходит наиболее часто в процессе Java. Все это происходит и выводится на консоль в реальном времени, нет необходимости ждать завершения работы профилировщика и анализа его отчета другим инструментом. По выводу uobjnew мы видим, что происходит выделение строк и, как следствие, массивов символов. При желании можно найти, где в исходном коде это выделение происходит, и здесь может помочь еще один новый инструмент — stackcount. Его мы прикрепляем к точке трассировки object__alloc внутри JVM, и он будет выводить стеки вызовов, в которых эти выделения происходят чаще всего. Это похоже на профилировку, но выполняется по отношению к выделениям объектов, а не к использованию процессора. Перед нами тот же стек, который мы видели раньше: _new_array_Java, вызываемый ResponseBuilder::AddLine. Фреймы, расположенные на слайде над этим вызовом — реализация JVM, из них вызов SharedRuntime::dtrace_object_alloc — это местонахождение нашей точки трассировки.
Итак, мы разобрались, какой именно код совершает эти выделения. Для этого мы отследили частоту, с которой осуществляется сборка мусора, затем выяснили, какие именно объекты выделяются и где это выделение происходит. Опять-таки, все это мы делали в ходе работы программы, а не во время разработки, и без сложного визуального профилировщика.

Еще несколько примеров. Попробуем разобраться, почему приложение не инициализируется, и при этом выдает странное сообщение — «Открывается файл конфигурации». Кто из вас сталкивался с такой проблемой, когда есть только подозрение о причинах ошибки, но понять, почему именно она происходит, не удается? Для этого случая есть написанный Бренданом Греггом инструмент opensnoop, который выполняет трассировку любых неудачных попыток вашего приложения открыть файлы и выводит на консоль сообщение с путем к файлу. Параметр -x означает неудачные попытки. Мы видим, что наше приложение пытается открыть файл конфигурации в папке /etc, а код ошибки — 2, что в Linux значит «путь не найден», файл не существует. Возможно, нас интересует, где именно в исходном коде осуществляется вызов к этому файлу. Здесь может помочь trace. Его необходимо прикрепить к системному вызову open, и найти вызовы с возвращаемым значением «-2». При этом нас интересует только процесс Java. При каждом таком вызове нам нужен вывод стека вызовов. При необходимости, можно было бы добавить фильтр по имени файла, например, если ошибок происходит большое количество с разными файлами. Таким образом, мы получаем контекст этой ошибки в Java.
Последний пример, о котором я хотел сегодня рассказать. HTTP-клиент в определенном сценарии делает очень медленные запросы. Этот сценарий я буду сравнивать с другим, в котором все происходит как нужно. В обоих сценариях выполняется обход контента, скачиваются сайты, и там, где все работает правильно, каждый запрос занимает 1.4-2 секунды. В медленном же сценарии они занимают около 6 секунд — очевидно, что-то не в порядке. В правильном сценарии один из сайтов — facebook.com, в медленном — i-dont-exist-at-all.com, т. е. несуществующий сайт. Но чтобы понять, что он не существует, не требуется 5 секунд.
Кроме того, в идеале, разрешив DNS несуществующего сайта один раз, программа должна сохранить этот результат в кэш. Но в реальности она выполняет разрешение каждый раз заново. В BCC есть инструмент для трассировки разрешения DNS. Для каждого разрешения DNS он выводит сообщение с именем хоста и длительностью разрешения. Как видим, во времени выполнения программы доминируют разрешения DNS одного и того же несуществующего имени хоста, в то время как разрешения существующих сайтов сохраняются в кэш и не повторяются. Однако это все лишь симптомы. Какая именно ошибка возникает, когда не удается разрешение? При помощи trace мы выясняем, что это ошибка «-2», «имя хоста не существует», что неудивительно.
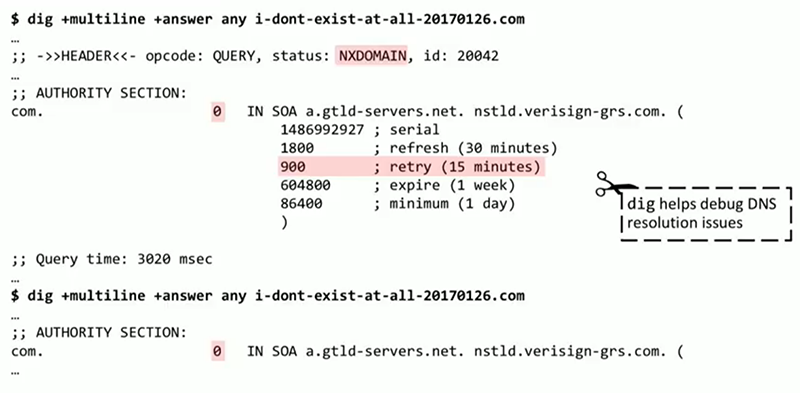
Затем я запускаю dig — простой, встроенный инструмент, который, в отличие от других перечисленных, не входит в BCC. При попытке разрешить DNS для i-dont-exist-at-all.com dig выводит интересное сообщение: как и ожидалось, он не находит хост, а в одном из полей указывается, что после 15 минут необходимо повторить попытку, т. е. в течение этого времени информация должна находиться в кэше. Но при этом в поле «срок жизни» мы видим 0, то есть сразу же требуется новое разрешение. Тот же результат показывается при повторном запуске dig. Тут явно проблема с конфигурацией DNS.
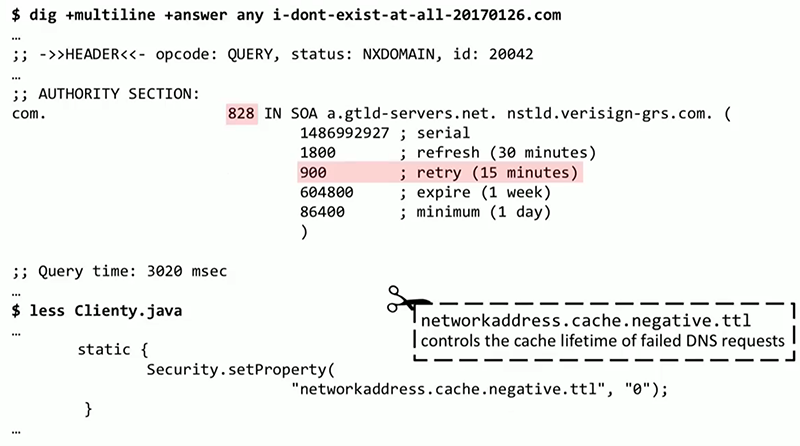
Все это основано на реально произошедшем со мной сценарии. После того, как я отладил мой DNS-сервер, результаты стали лучше, срок жизни стал 800 с чем-то секунд. И тем не менее приложение по-прежнему работало очень медленно. Выяснилось, что в определенном месте в коде срок жизни для неудавшихся разрешений DNS выставлялся равным 0. Поэтому, независимо от информации на сервере, клиентское приложение на Java продолжало повторять неудавшиеся разрешения DNS при каждой встрече с ними. Это проблема была как на уровне системы, так и на уровне приложения, и ее удалось решить с помощью BPF, осуществляя трассировку DNS.
Напоследок хочу сказать, что мы смогли пройти по всем сценариям, о которых я хотел рассказать: инструменты трассировки в продакшн, которые можно использовать с JVM-приложениями; как BPF можно использовать для трассировки под Linux; контрольный список приложений; и некоторые исследования конкретных проблем. Спасибо большое за внимание.


Минутка рекламы. Как вы, наверное, знаете, мы делаем конференции. Ближайшие — JBreak 2018 и JPoint 2018. Можно туда прийти и вживую пообщаться с разработчиками разных моднейших технологий, например там будет Simon Ritter — Deputy CTO из Azul Systems. Там же можно встретиться c Виктором Гамовым из "Разбора Полётов" и кучей других интересных людей. С бездельниками типа меня (olegchir) тоже можно пересечься. Короче, заходите, мы вас ждём.
unix_junkie
Мне кажется, стоило бы ещё упомянуть goldshtn/linux-tracing-workshop.