
Путь к постижению Дзена начинается с разработки приложений, которые могут мониторить сами себя — это позволяет проще и дешевле чинить проблемы на продакшне. В этой статье мы увидим, как современные Windows-приложения могут делать самомониторинг, самодиагностику, и возможно — даже самовосстановление, и всё это — без необходимости иметь внешний агент или тупо перезапускать приложение. Обуздав мощь ETW для точного низкоуровневого мониторинга, счетчики производительности Windows для получения бесплатной по ресурсам статистики и библиотеку CLRMD для анализа собственных потоков, объектов в куче и локов, можно продвинуться по пути достижения самосознания. Всё это будет продемонстрировано на серии демок: автоматический профайлинг CPU, исследование загруженных тредов и стеков, автоматический мониторинг GC (включая выделения объектов), автоматический анализ кучи в целях поиска утечек памяти и многое другое. Дочитав статью до конца, вы получите набор инструментов и техник для реализации самомониторинга в своих собственных приложениях.
Основой статьи является доклад Дины Гольдштейн «Self-aware applications: automatic production monitoring» на DotNext 2017 Moscow. Слайды можно скачать по ссылке.
Дина, с недавнего времени, — разработчик в Google, до этого работала в Riverbed. Riverbed занимается разработкой инструментов для мониторинга производительности, которые работают на миллионах компьютеров и мобильных девайсов. Дина была в команде, ответственной за центральный механизм сборки информации, который использует низкоуровневые события Windows, собирая из различных источников информацию о производительности. Работая в Riverbed, она много занималась мониторингом производительности, занималась поиском узких мест в процессе загрузки Windows и мониторингом user experience в вебе.
Для начала обсудим, зачем именно нужно заниматься мониторингом. Уверена, у вас есть об этом свое представление, но я хотела бы добавить несколько наблюдений, которые, по моему опыту, не всегда очевидны для людей. Во-первых, очевидно, что когда мы разрабатываем что-либо масштабное, мониторинг необходим. Ситуация должна находиться под контролем, чтобы не принести убытка клиентам. Обычно у нас одновременно работает слишком много экземпляров приложений, чтобы следить за ними всеми, и поэтому задачу приходится автоматизировать. Но этот случай как раз очевидный, в отличие от того, о чем я буду говорить далее.
На мой взгляд, мониторинг настолько же важен в простых пользовательских приложениях. В определенном смысле здесь ситуация значительно хуже, чем с приложениями, работающими на серверах. Как правило, сервер, для которого пишется приложение, находится под полным контролем разработчика: известна версия операционной системы, патчи, какие программы установлены. Ничего этого мы не знаем о среде, в которой будут работать написанные нами пользовательские приложения. Вы не знаете, какие средства безопасности установлены на компьютере потребителя, что, по моему опыту, достаточно часто может мешать нормальной работе приложения. Как правило, о проблеме мы узнаем, когда клиенты звонят и сообщают, что у них произошла катастрофа и продлевать лицензию на следующий год они не собираются. И узнать, чем именно была вызвана эта катастрофа, вам очень сложно. У вас может даже не быть связи через интернет со средой, в которой запущено ваше приложение у клиента.
Зачем заниматься разработкой собственных средств профилирования и мониторинга, если существует множество сторонних инструментов? Начну с того, что, по моему личному мнению, заниматься исследованиями производительности крайне интересно, и для меня уже этой причины достаточно. Но если подходить к вопросу с практической точки зрения, разработанные вами средства профилирования и мониторинга будут лучше отвечать специфическим потребностям вашего бизнеса. Вы можете заниматься наблюдением не только общих вещей вроде CPU, памяти, доступа к диску, но и отдельных компонентов, имеющих прямое коммерческое значение для вас. Например, вы можете отслеживать время запуска, размеры очередей, отдельные запросы, время выполнения отдельных компонентов, критичных для вашего бизнеса. Как правило, этого достаточно сложно достичь, пользуясь сторонними средствами профилирования.
Другая причина, по которой стоит заниматься разработкой собственных средств профилирования, заключается в том, что данные диагностики в этом случае идут снизу вверх. Я имею в виду, что вам не нужно после сбора данных отправлять их на внешнюю панель мониторинга, ждать, пока там завершится их анализ, после чего вас посреди ночи разбудит оповещение. Напротив, при предлагаемом мною подходе приложение само занимается сбором данных. Оно, как и сказано в названии статьи, обретает самосознание. Оно может даже предпринимать действия на основе этих данных. Позже я покажу примеры того, что именно можно предпринять, когда приложение обнаружило проблему.
Наконец, именно такой подход, судя по всему, является сегодня «последним писком». Под влиянием принципов DevOps сообщество приходит к выводу о необходимости автоматизации мониторинга, да и вообще всего, что только можно. Сам по себе факт, что все так делают, еще, конечно, не значит, что нужно подражать, но в данном случае обоснования для этих общепринятых практик есть (их я только что перечислила). Надеюсь, вместе эти аргументы вас убедят.
Как именно нам создавать свою систему мониторинга? Очевидно, в работающем приложении не может быть постоянно запущен профилировщик или отладчик. Это потребует слишком большого количества ресурсов, и масштабировать такой подход нельзя. Мое предложение не отличается особенной новизной: использовать ту или иную иерархическую систему мониторинга. Мы будем пользоваться наиболее легковесными из доступных средств для мониторинга наиболее базовых вещей — CPU, память, отдельные запросы, короче говоря, все, что так или иначе потребляет какие-то ресурсы. Это можно достаточно легко делать при помощи Performance Counters API под Windows. Он обеспечивает доступ к поставщикам данных, распределенных по всей системе, и обеспечивает информацию связанную как с базовыми показателями (CPU, память), так и с вещами, имеющими отношение к .NET (время сборки мусора, поколения и т. д.). К этим данным можно получить доступ как на уровне системы, так и на уровне нашего процесса. Если вам не нравятся Performance Counters — никаких проблем, вы можете пользоваться Win32 API. По большому счету, это одно и тоже, источник у информации один.
Для более редких событий или ситуаций, где нам нужна более подробная информация, мы можем потратить больше времени и ресурсов при сборе данных. Самое интересное начинается именно здесь. Есть инструменты, которые позволяют осуществлять диагностику и анализировать ситуацию непосредственно в работающем приложении, и затем отправлять данные разработчикам, то есть вам, для решения возникших проблем. Ситуации, о которых идет речь, — это редкие исключения, взаимоблокировки (deadlock), замедления работы приложений. Для этой цели существует, к примеру, ETW (Event Tracing for Windows, трассировка событий под Windows). Этот инструмент похож на Performance Counters. Это API, обеспечивающий доступ к поставщикам данных в системе. В отличие от Performance Counters, здесь информация не только количественная. У каждого из его событий есть множество метаданных, есть стеки вызовов, что уже весьма неплохо. К примеру, о событиях сборки мусора сообщается тип сборки мусора, почему она была вызвана, какой именно тип был выделен. Позже я продемонстрирую это на примерах. Ресурсоемкость ETW в основном зависит от частоты событий, которые мы отслеживаем, и от количества собираемых данных.
Полезный инструмент, который может дополнить ETW — ClrMD. Это опенсорсная библиотека, существующая уже несколько лет. Она доступна на NuGet, исходный код есть на GitHub. Ее поддержку обеспечивает Microsoft. Это API, предоставляющий множество действий, связанных с отладкой: исследование стеков вызовов, обход памяти .NET, доступ к журналам, механизмам синхронизации, и многое другие. Некоторые из этих операций доступны также для нативных приложений (приложений и библиотек, написанных на C/C++), что может быть необходимо, если в вашем приложении несколько уровней, в т. ч. системный. Ресурсоемкость, опять-таки, зависит от частоты использования и от конкретных выполняемых операций. К примеру, получить стеки вызовов нескольких тредов можно достаточно быстро, а вот для обхода 64 гигабайт памяти придется подождать. Как и вообще все в программировании, применять этот инструмент нужно с умом.
Наконец, в действительно критических ситуациях можно выкатывать тяжелую артиллерию отладки и профилирования. Речь идет о CLR Profiling API, CLR Debugging API, у них есть все доступные профилировщикам и отладчикам функции, в т. ч. они могут приостанавливать работу приложения, пользоваться точками останова и многое другое. Очевидно, регулярно к таким средствам прибегать не стоит. Даже в документации к этим библиотекам указывается, что их не рекомендуется использовать в коде, выполнение которого зависит от скорости. Но знать о существовании этих инструментов полезно. Здесь прилагаются ссылки на них. Сегодня мы о них говорить не будем, поскольку, положа руку на сердце, сама я ими не пользовалась.
Наконец, если вас интересуют определенные низкоуровневые API, можно пользоваться ими. Я их тоже отношу к категории наиболее ресурсоемких и громоздких средств, потому что правильно ими пользоваться достаточно сложно. По моему опыту, многие средства безопасности также пользуются точками перехвата. Когда несколько инструментов делают это по отношению к одному API, а при этом один из них делает это неправильно, последствия могут быть кошмарными. При возможности, стоит пытаться получать данные другими способами. Ресурсоемкость, опять-таки, зависит от характера выполняемых действий.
Со вступительной частью на этом все, перейдем к делу. Посмотрим на примерах, что можно узнать о работе ваших приложений. Начать я хотела бы с профилирования CPU. Несмотря на то, что пример достаточно простой, и не подогнан под чье-либо конкретное приложение, уже он демонстрирует выгоды, которые можно получить. В основном докладе конференции Андрей говорил о перформанс-тестировании на стадии разработки. Но, я думаю, со всеми вами случалось, что на этой стадии все было в порядке, а в продакшне выяснялось, что все работает совсем не так, как задумано. Возможно, клиент что-то делает не так, или у него установлена не та версия Windows — опять-таки, я говорю здесь о пользовательских приложениях, которые должны функционировать в разных средах у разных клиентов. Может быть неясно, как воспроизвести проблемы, они могут возникать нерегулярно. К примеру, раз в три дня загрузка CPU подскакивает в течение 10 секунд, а ваши клиенты этим крайне недовольны, потому что они очень важные люди, и эти 10 секунд все им испортили. Как с такими проблемами бороться? Представьте, что можно было бы собирать данные о текущем состоянии вашего работающего приложения, записывать их в журнал и отправлять разработчикам. Именно такой подход я сейчас и продемонстрирую.
Как я уже говорила, для достижения этой цели нужно будет реализовать иерархическую систему мониторинга. Для начала, проблему необходимо обнаружить. Это несложно, мы будем отслеживать использование CPU при помощи Performance Counters. Это займет самый минимум ресурсов, поэтому делать это можно достаточно часто. Затем нужно будет определить некоторые правила работы приложения, например, оно не должно занимать более 80% CPU в течение более чем 10 секунд непрерывной работы. Какие именно это будут правила вы должны решить сами, или спросить ваших клиентов.
Как только мы определили, что в данный момент мы находимся в проблемной ситуации, можно вложить больше ресурсов, чтобы определить источник проблемы: провести диагностику, получить стеки вызовов. Это мы будем делать при помощи ETW, который, как вы помните, предоставляет стеки вызовов тех событий, отслеживанием которых он занимается. В случае с CPU, ETW может просто сэмплировать CPU, к примеру, каждую миллисекунду (то есть, 1000 сэмплов в секунду — это значение по умолчанию). Таким образом мы получим тот же результат, который мы бы получили, если бы прикрепили к приложению профилировщик и провели сэмплирование. В реальном времени с ETW мы будем это делать при помощи опенсорсной библиотеки LiveStacks, которая переводит сделанные ETW выборки циклов в имена функций. Благодаря этому мы сможем восстановить деревья стеков вызовов, найти стеки, потребляющие больше всего ресурсов CPU, вывести данные в виде флеймграфов (flame graphs) или любой другой удобной форме. Больше того, можно даже сделать рекомендации относительно действий, которые приложение может сразу же при обнаружении проблемы. Я приведу несколько примеров, но, уверена, вы сами можете придумать конкретные решения, более подходящие для сферы вашего бизнеса.
Предположим, ваш AuthenticationController вдруг начинает занимать слишком много ресурсов CPU. Возможно, на вас идет DDoS-атака? Это предположение уже позволяет принять какие-то меры, какие именно — мне сказать сложно, поскольку я не веб-эксперт. Наверное, можно закрыть каналы коммуникаций, попробовать фильтровать определенные IP. Другой пример: какой-то механизм обработки вдруг оказывается перегружен. Если он находится на сервере, то, возможно, пришло время масштабирования. И будет особенно здорово, если это масштабирование можно осуществить автоматически. Наконец, если ничего умного придумать не получается, можно попросту записать всю доступную информацию в журнал и отправить его разработчикам. Уже за это они будут очень благодарны.
Посмотрим демонстрацию такого подхода. У меня сервер на ASP.NET, называется «Los Gatos». Все демонстрации у меня записаны на видео, поскольку я не хотела, чтобы возникли какие-либо помехи во время доклада. На экране слева виден сайт, а справа — perfmon, UI для Performance Counters. Я настроила его на отслеживание времени использования процессора. Мы видим, что когда я захожу на сайт, в течение нескольких секунд процессор оказывается перегружен, после чего загрузка снова падает. В этой ситуации клиент не успеет позвать вас, чтобы вы решили эту проблему с помощью профилировщика. Было бы неплохо получить данные о ней в реальном времени. Посмотрим, как это можно сделать.
Хочу сделать оговорку: я не уверена, что с точки зрения дизайна и архитектуры в этом коде наилучшим образом реализованы классы и наследование. Он написан специально для демонстрации, так что копировать его в чистом виде в вашу систему, наверное, не стоит. Кроме того, мы не будем слишком сильно вдаваться в детали — я уверена, вы можете самостоятельно прочитать документацию API. Моя задача — продемонстрировать, чего именно можно достичь, и каким образом.
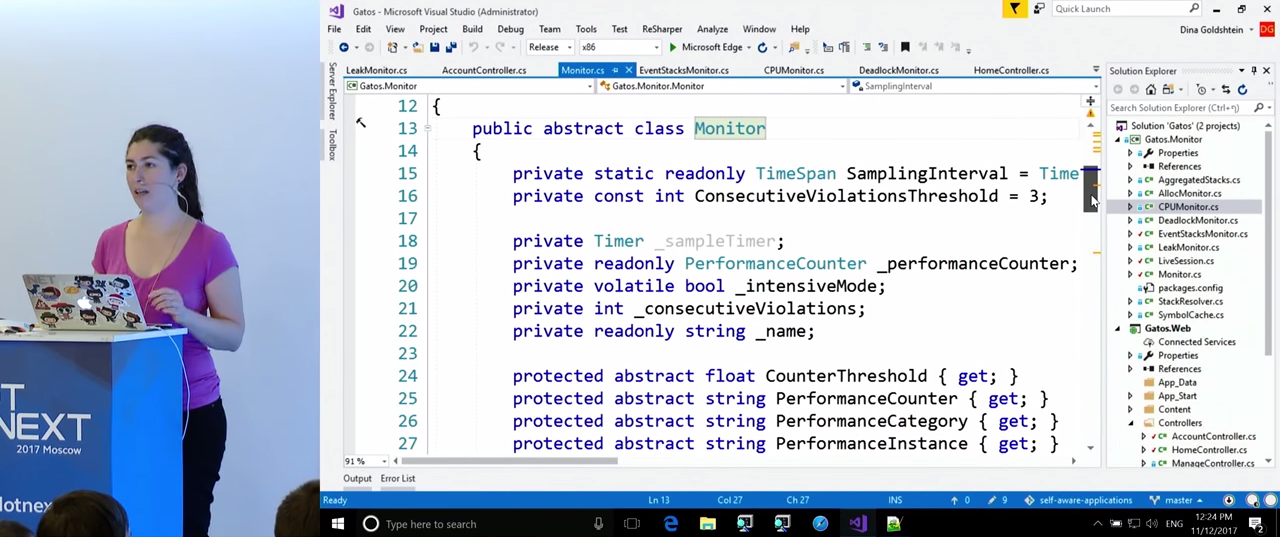
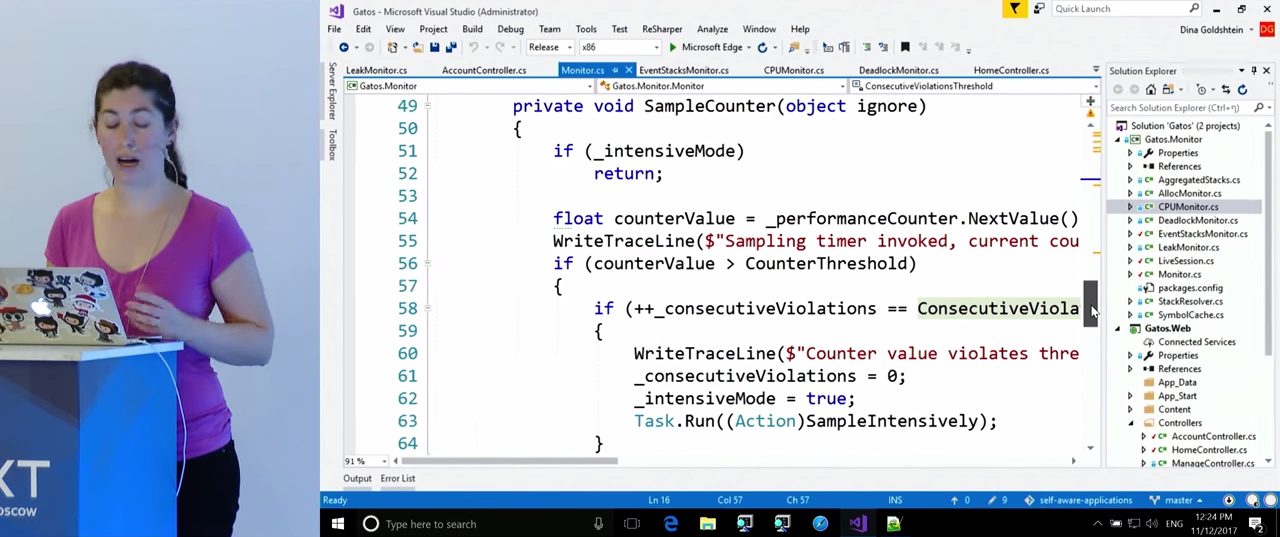
Посмотрим на класс CPUMonitor, который наследует от классаEventStacksMonitor, который, в свою очередь, наследует от Monitor. ВMonitor присутствует наиболее базовый функционал. С некоторой частотой (в данном случае — раз в секунду) он сэмплирует Performance Counters и отслеживает нарушения заданных нами правил. Если Monitor обнаруживает три нарушения подряд, он вызывает то, что я назвала «интенсивным режимом»,SampleIntensively. Реализуется жеSampleIntensively` в дочерних классах в зависимости от того, что именно они отслеживают.
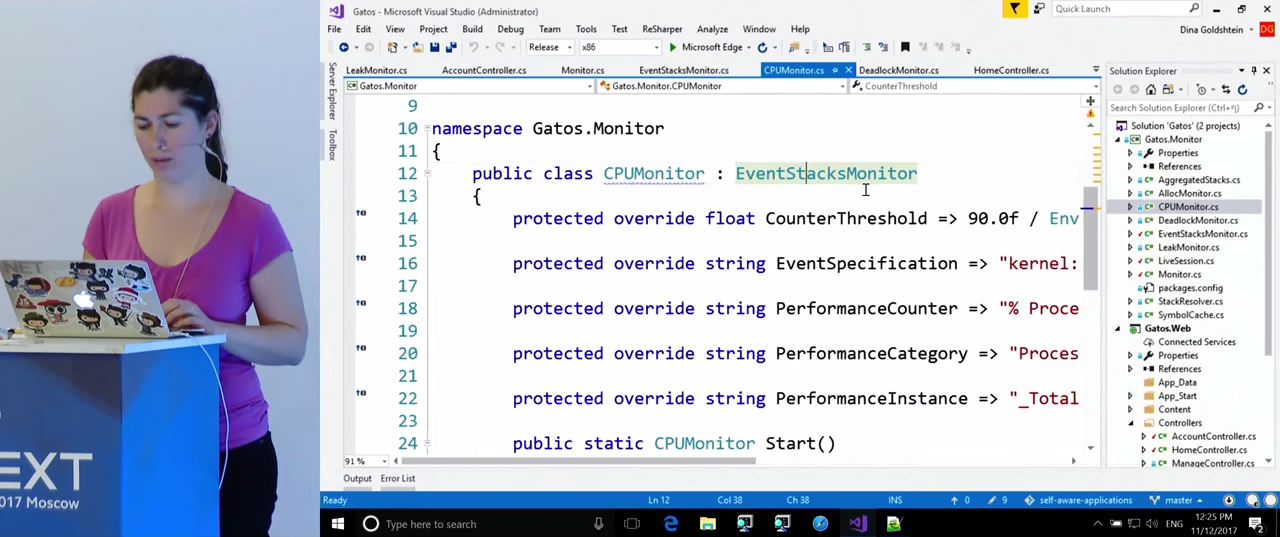
Взглянем более внимательно на CPUMonitor. В переменных здесь заданы правила, нарушения которых мы будем отслеживать: CounterThreshold — 90%, PerformanceCounter — "% Processor Time", PerformanceInstance — "_Total". В случае с мониторингом CPU нам будут необходимы стеки вызовов. Их получением занимается клас EventStacksMonitor.
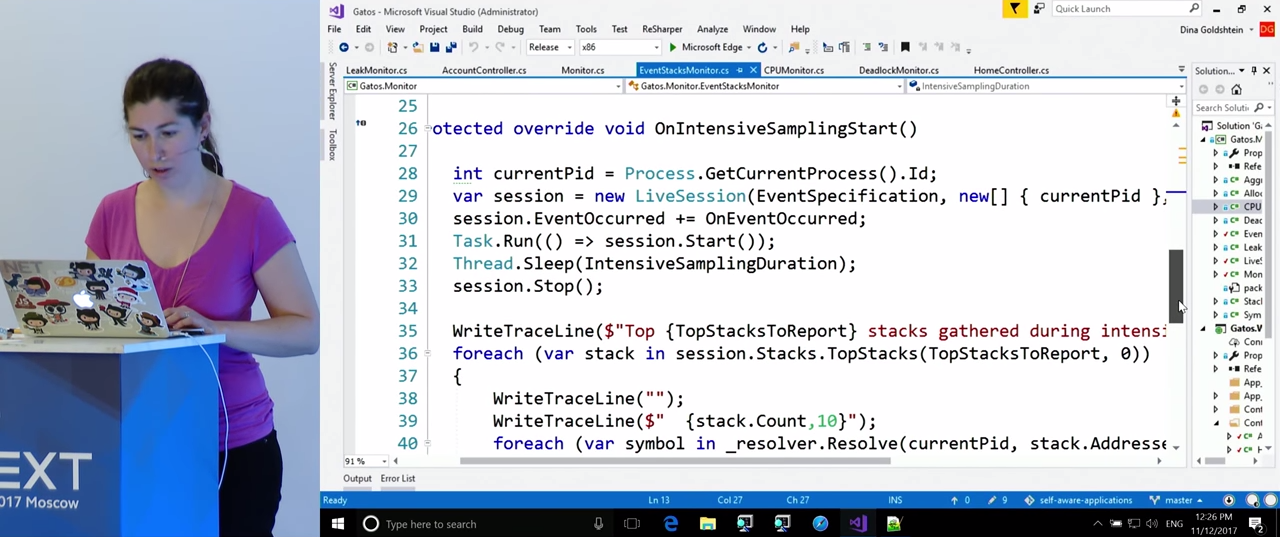

Здесь мы видим реализацию «интенсивного режима» в функции OnIntensiveSamplingStart(). В ней мы получаем текущий процесс и создаем LiveSession. О LiveSession подробнее я скажу позже, она служит оболочкой для ETW, что позволяет нам получить стеки вызовов. Мы начинаем сессию, ждем в течение некоторого времени (кажется, 5 секунд), останавливаем ее, и, после того, как завершена сборка данных, обращаемся к ее свойству Stacks.TopStacks. Там мы получаем стеки, больше всего загружавшие процессор в ходе этой сессии, и записываем их в журнал. Если интересно, метод .Resolve() переводит адреса функций в памяти в имена функций, чтобы разработчики позже могли установить источник проблемы.
Вернемся к классу LiveSession. Я не буду заходить в него, он скопирован с репозитория LiveStacks на GitHub. Это просто оболочка для ETW, которая занимается настройкой событий, сборка которых будет происходить для получения информации о сэмплировании CPU. Только что был показан общий принцип ее работы. Давайте взглянем теперь на журнал, получившийся в результате нашей попытки зайти в приложение.
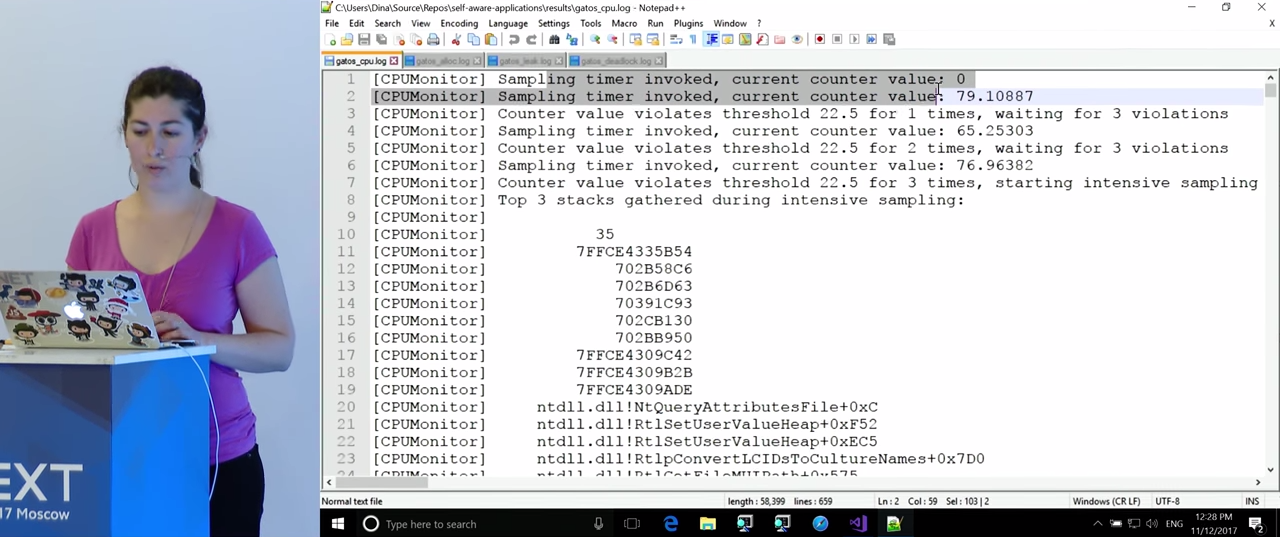
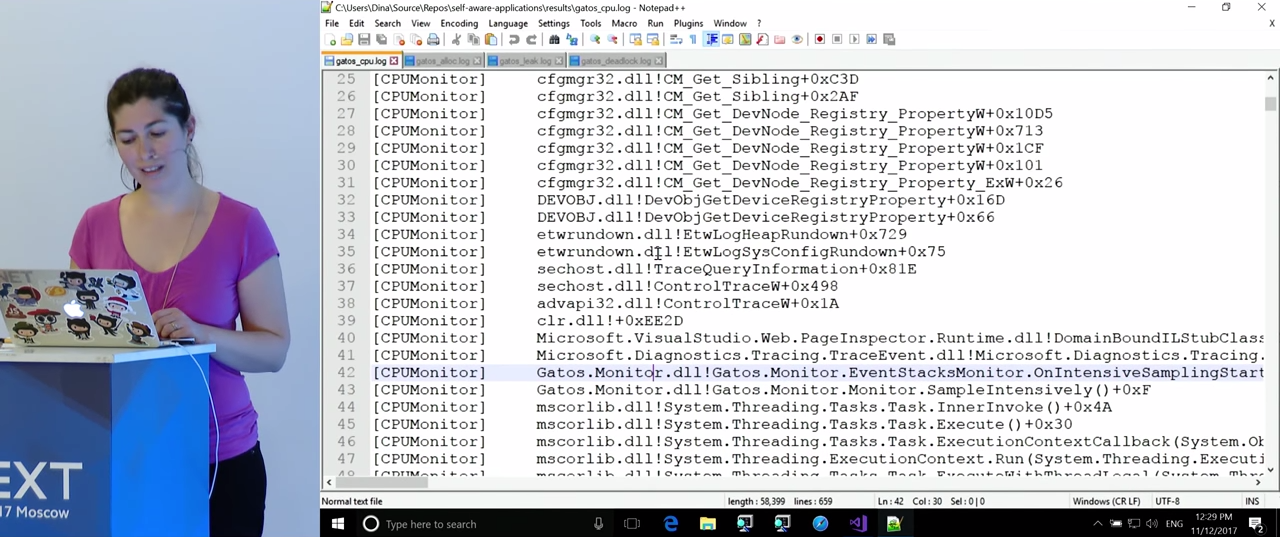
Мы видим, что поначалу все выглядит хорошо, загрузка CPU низкая. Через какое-то время обнаруживаются три нарушения, включается режим сэмплирования CPU. Через 5 или 10 секунд работы было собрано достаточно данных и в журнал были записаны три стека вызовов, поглощающих наибольшее количество времени процессора. К сожалению, некоторые из адресов перевести не удалось — возможно, для этого не было соответствующих символов, у Microsoft их иногда нет. Результат несколько разочаровывает (и я вернусь к этому вопросу позже): по-видимому, первый стек вызовов — это собственно код мониторинга. Однако он попал сюда в результате уже возникшего пика загрузки процессора, из-за включения интенсивного режима, в обычных условиях он не потребляет столько мощностей. Перейдем к следующему стеку вызовов. Тут мы видим много вызовов, связанных с ASP.NET. Поскольку я не эксперт в ASP.NET, я не могу сказать наверняка, что тут можно сделать, но, по-моему, это полезная информация. Наконец, третий стек вызовов. Перед нами метод Login() нашего приложения — у нас это не должно вызывать удивления, поскольку мы видели, что проблема возникла непосредственно после входа в приложение. Стоит, однако, помнить, что, когда разработчики читают журнал, они могут не знать, какие именно действия выполнялись во время пика загрузки процессора. Если взглянуть на стек вызовов более подробно, мы увидим функцию, занимающуюся вычислением хэша.
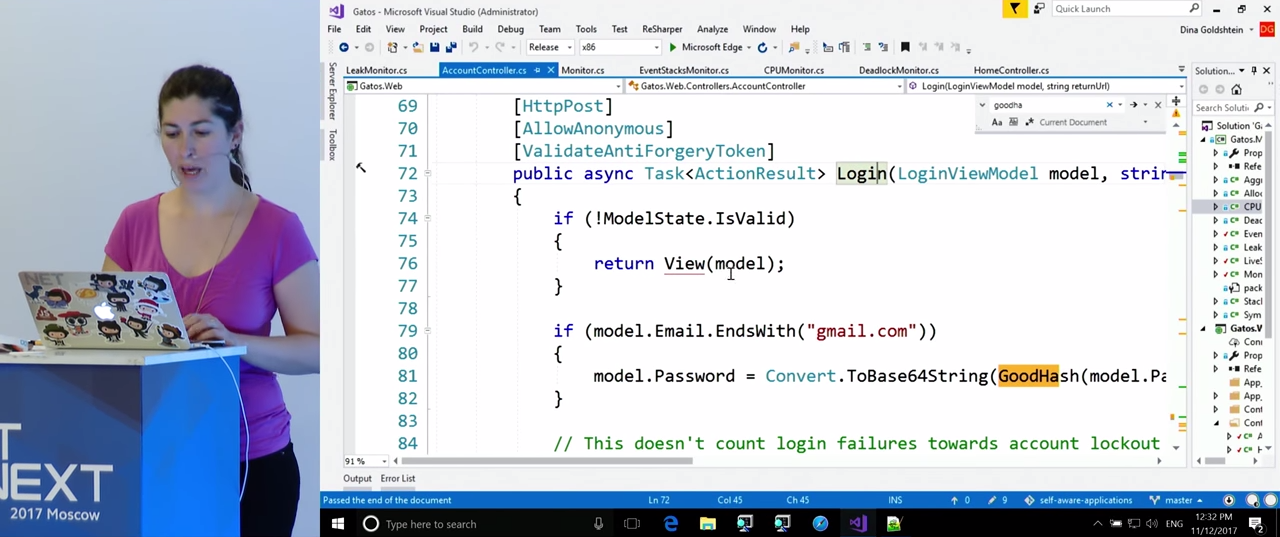
Теперь мы можем вернуться к коду. Находим функцию по ее имени, и видим, что она занимается вычислением хэша каждый раз, когда адрес электронной почты заканчивается на «gmail.com». Именно эти подсчеты загружают процессор. Итак, мы обнаружили в реальном времени проблему с использованием CPU, и в результате профилирования нашли ту функцию в коде, которая эту проблему вызывала. По-моему, это весьма неплохой результат.
Следующий пример взят из реальной жизни.

На экране — скриншот, в котором мы видим открытые Visual Studio и Process Explorer, и в Process Explorer выделен процесс devenv. Все это вы можете проверить на своих компьютерах. У процесса devenv есть дочерний процесс,perfwatson2, и «perf» в названии тут явно указывает на перформанс. Далее, мы видим, чтоperfwatson2` создает сессию ETW с четырьмя поставщиками. Мне не удалось точно установить, что именно они записывают, но известно, что этот процесс занимается профилированием Visual Studio. Разработчики Visual Studio сочли, что им необходима телеметрия того, что происходит внутри программы во время ее использования. И они воспользовались тем же способом, который я продемонстрировала вам в предыдущем примере. Он уже входит в практику некоторых компаний. Мне не удалось добраться до файла, в который записывались данные этой телеметрии, возникли какие-то странные ошибки, но не в этом суть. Мониторинг Visual Studio самой себя при помощи ETW является частью ее функциональности (хотя в общем случае, это неясно — Microsoft описывает PerfWatson, но он не является частью публичной документации на VisualStudio). Как видим, не я изобрела этот способ, он уже входит в практику некоторых компаний. Следующие примеры, о которых я буду говорить, тоже связаны с реальной практикой.
Поговорим о мониторинге сборки мусора, вернее, о проблемах, которые могут повлиять на ее эффективность. Речь пойдет о ситуациях с большим количеством выделений памяти. Очевидно, что паузы GC при обработке запросов — это плохо.

Но, опять-таки, не стоит забывать о ситуации с пользовательскими приложениями. Если у пользователей будут возникать сбои и замедления в работе UI из-за длинных остановок в сборке мусора, им это, очевидно, не понравится. Я хочу еще раз подчеркнуть, что вещи, которые мы здесь обсуждаем, касаются всех типов приложений, не только серверных.
Принцип здесь будет тот же, что и в прошлом примере, но в этот раз мы будем иметь дело с памятью, а не с процессором. При помощи счетчиков производительности мы будем отслеживать скорость выделения памяти, и, как только заметим скачок производительности, можно будет начать более интенсивное профилирование. В данном случае это будет значить получение данных о выделении памяти: на какие именно типы уходит память, и где это происходит. Кроме того, можно выяснить, сколько времени занимает сборка мусора, получить информацию о поколениях, о том, сколько памяти было высвобождено, сколько осталось занято. Можно даже прикрепить ClrMD и увидеть в целом, что находится в нашей куче (позже мы это и сделаем): сегменты, поколения, типы объектов, количество объектов. Все это может помочь нам понять, что происходит в приложении и где именно локализована проблема.
Итак, перед нами приложение, в котором мы отслеживаем скорость выделения. При выходе на "About" мы наблюдаем внезапный пик выделений. Это не значит, что у нас непременно возникнет проблема со сборкой мусора, но она становится весьма вероятной.
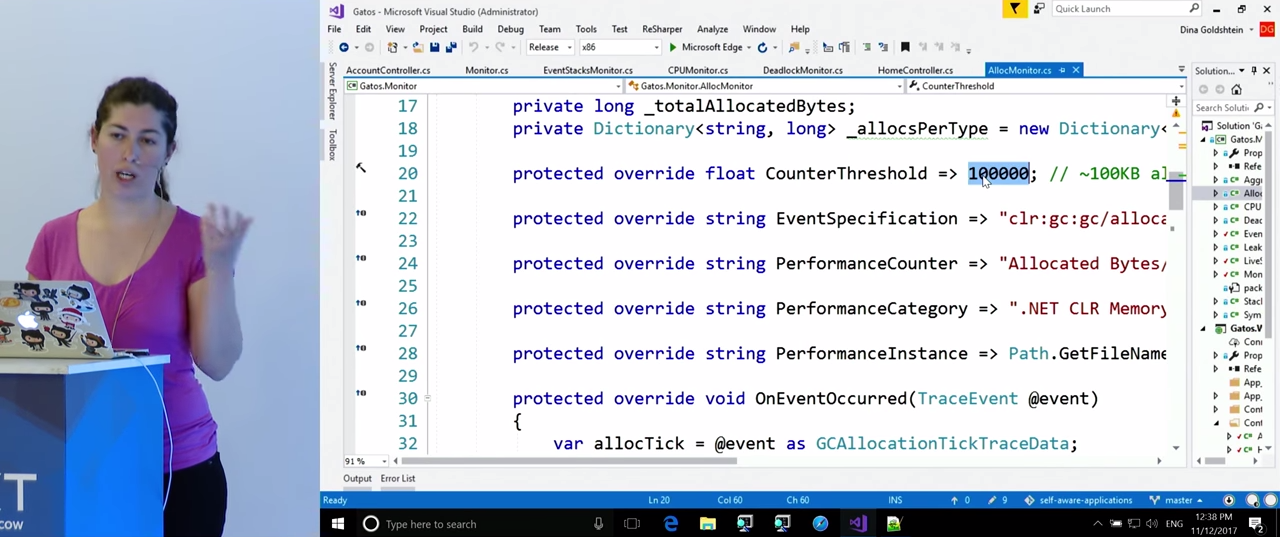
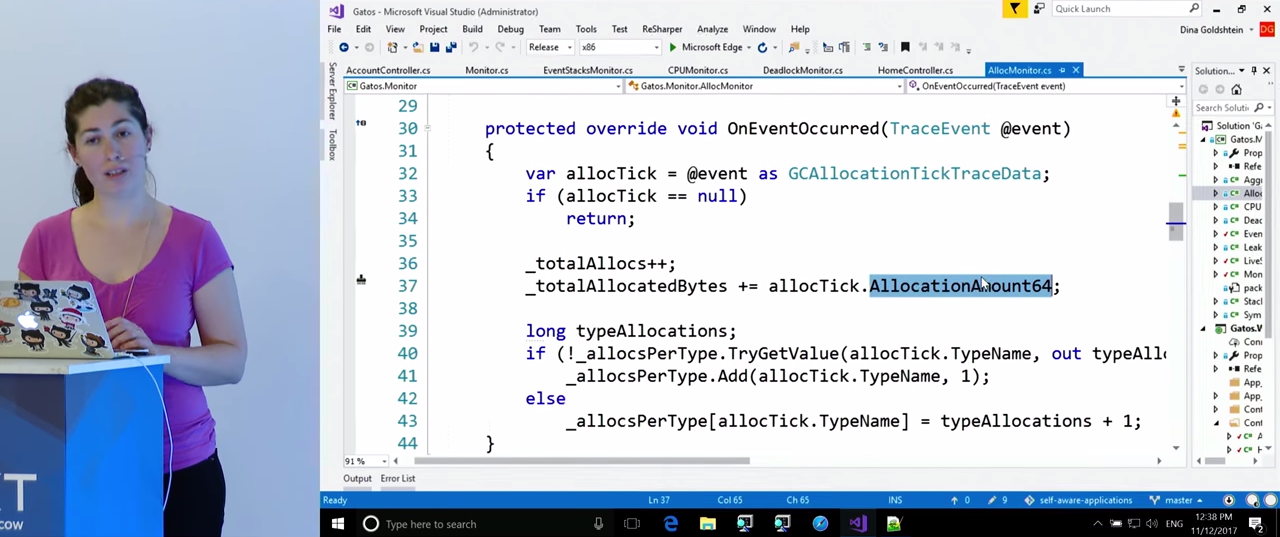
Чтобы узнать больше, посмотрим на наш код, а именно — на класс AllocMonitor. Он также наследует от EventStacksMonitor, потому что, как и в случае с отслеживанием чрезмерной загрузки процессора, нас будут интересовать стеки вызовов, в которых происходят выделения. Для этого нам понадобится ETW. Как и в прошлый раз, здесь в переменных уточняются правила, по которым мы будем следить за Performance Counters, например, CounterThreshold равен 100000 (очевидно, в своем приложении вы выставите его исходя из ваших потребностей). Событие ETW, которое мы будем ожидать, и от которого мы получим стеки вызовов, называется clr:gc:gc/allocationtick. Это событие даст нам информацию о типе создаваемого объекта, и о том, где происходит выделение памяти. Функция OnEventOccurred() ловит это событие. У структуры данныхGCAllocationTickTraceData есть свойство, которое сообщает, сколько памяти было выделено, и есть информация о типе созданного объекта. Пока нам понадобятся именно эти данные, хотя там есть много других. Во время режима интенсивного сэмплирования эти данные будут храниться в словаре, и мы будем знать, сколько за время этого режима было выделено объектов каждого типа. Кроме того, мы получим стеки вызовов, в которых эти выделения памяти происходили.
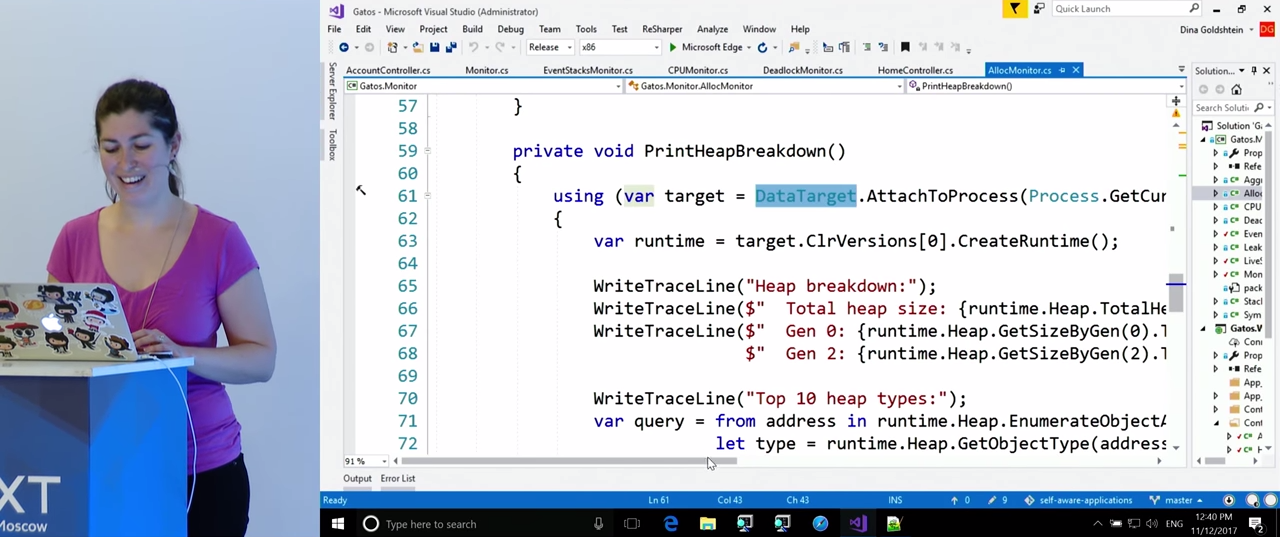
После этого мы в течение некоторого времени будем собирать статистику о том, что происходит в куче. Делать это мы будем при помощи библиотеки ClrMD. Кода здесь достаточно много, но он очень простой. Главный API, который нам понадобится — AttachToProcess. Мы получаем среду выполнения CLR, у нее нам нужно будет свойство `runtime.Heap, благодаря ему мы сможем совершать обход кучи. В нем также есть общий размер кучи, размеры поколений. Однако самое важное, что при помощи этого свойства мы можем пронумеровать всю кучу и получить для каждого объекта тип, имя и размер. Все эти данные помещаются в словарь, и мы теперь знаем, что в куче такое-то количество строк, такое-то количество массивов и т. д.
Взглянем на журнал. Поначалу в нем все в порядке, но затем начинаются выделения памяти, и возникает три нарушения. Как вы помните, мы собирали стеки вызовов, в которых происходили выделения. Здесь перед нами те стеки, в которых произошло наибольшее количество выделений. На этот раз мы сразу же находим нужный нам результат: стек с методом About(). Опять-таки, это не удивительно, поскольку мы знаем, что выделения начались, когда мы вышли на страницу "About". Если посмотреть более подробно, то выяснится, что выделения происходят при объединении строк. Чтобы прояснить ситуацию, вернемся к коду.
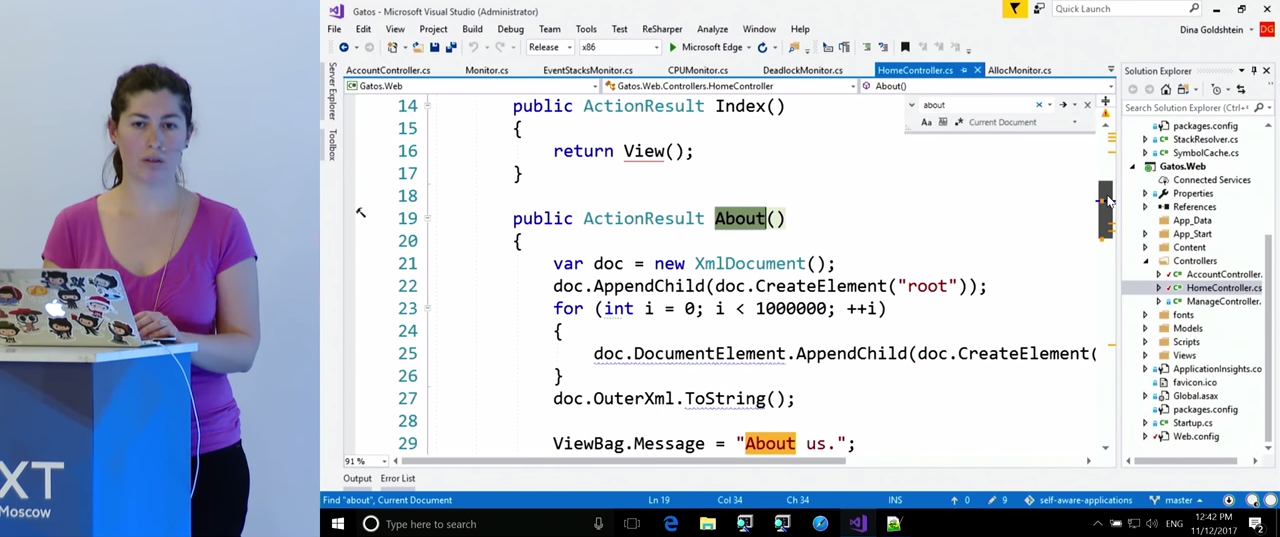
Мы видим, что метод About() анализирует большое количество XML. Вызываются некие функции .append, отсюда возникает большое количество строк, промежуточных объектов, объединений, записи и прочего. Все это вызывает проблему с выделениями. Чтобы подтвердить источник проблемы, можно взглянуть, какая еще информация есть в журнале, ведь туда была записана статистика по куче. Вполне ожидаемо, мы там находим большое количество строковых объектов. Это подтверждает наш изначальный диагноз проблемы.
В следующем примере мы будем исследовать проблему, доставляющую всем большое количество неприятностей: утечки памяти. Здесь уже нет смысла собирать стеки вызовов. Мы будем следовать все тому же общему принципу отслеживания использования памяти. В качестве одного из симптомов можно следить за скачками использования памяти, но сами по себе они не дают уверенности, что произошла утечка. Помимо этого, можно указать, что приложение не должно использовать больше, например, 100 мегабайт памяти. Если этот порог превышен, ситуация требует нашего внимания, даже если это не утечка. Здесь можно применить ClrMD, по тому же принципу, что и в предыдущем примере, и выяснить, что именно занимает необычно большой объем памяти. Если все-таки есть вероятность утечки, мы, как разработчики, можем автоматизировать реакцию приложения. Можно сделать несколько снапшотов кучи, и попытаться их сравнить. Так мы выясним, какие объекты были выделены, какая память освобождена, какая нет и почему. Все это можно сделать при помощи ClrMD, а затем можно сравнить эту информацию с полученной от ETW, если мы готовы потратить на это дополнительные усилия.
Взглянем на демонстрацию. На этот раз я отслеживаю байты во всех кучах, это наша управляемая память. Я регистрируюсь на сайте, и пока я ввожу данные, состояние памяти не меняется. Как только я нажимаю на кнопку регистрации, происходит скачок использования памяти. Даже если мы не опасаемся утечки, следует выяснить, что именно является причиной скачка.


Для этого обратимся к классу LeakMonitor. Поскольку стеки вызовов нам на этот раз не нужны (нет события ETW, которое можно было бы использовать для анализа данной ситуации с памятью), он наследует не от EventStacksMonitor, а напрямую от Monitor. Как и в предыдущих примерах, в переменных указан порог, троекратное превышение которого вызывает интенсивный режим, и указан отслеживаемый параметр. Посмотрим, что именно происходит при обнаружении чрезмерного использования памяти. Я попытаюсь показать, что именно здесь можно автоматизировать на стадии разработки. Мы сделаем три снапшота пространства памяти. Обратите внимание, что перед каждым снапшотом делается вызов сборщика мусора, поскольку я хочу, чтобы статистика была как можно более чистой. Позже, я сравню, что именно освободилось, а что — нет. После сборки мусора я подключаюсь к процессу, получаю снапшот кучи, жду несколько секунд, затем повторяю цикл. После завершения цикла я сравниваю снапшоты и записываю результаты в файл.
Взглянем на снапшот кучи. Он достаточно примитивен, в нем не будет статистики по отдельным объектам. Это, очевидно, заняло бы значительно больше времени, а его не всегда хочется тратить. Собраны только данные о количестве объектов каждого типа и об общем размере всех объектов определенного типа. Это делается абсолютно таким же способом, как и в предыдущем примере: делается обход кучи, извлекаются данные о размере, имени и типе, и добавляются в два словаря, размер в зависимости от типа, и количество в зависимости от типа. Эти два словаря сравниваются даже не с помощью ClrMD, а простой функцией, сверяющей данные в словарях разных снапшотов. Наконец, все это записывается в журнал.
В журнале поначалу нет ничего необычного, но ниже мы видим, что программа обнаруживает нарушение заданных нами правил. Благодаря сделанным снапшотам мы видим, что значительно возросло количество массивов байтов. Очевидно, здесь есть проблема. Сложность в том, что массивы байтов могут возникать где угодно. В оптимальном сценарии вам удастся найти специфичный для вашего приложения тип, в котором создаются эти массивы. В рассматриваемом примере мы знаем, что проблема возникла при регистрации, поэтому мы можем найти соответствующий код.

Функция регистрации проверяет пароль, и при этом добавляет данные в некоторый статический список. А создание этих данных вызывает выделение достаточно большого массива байтов. Очевидно, пример не слишком реалистичен, тем не менее, я думаю, в вашей практике все равно была бы та или иная структура данных, которую можно было бы обнаружить в подобном случае. Но даже если речь идет о массивах байтов, вы, наверное, знаете, где именно в вашем коде происходит выделение этих массивов. Либо можно соотнести эти данные с данными по выделениям памяти из ETW, и обнаружить, что именно в этой ветви кода происходит их значительное количество.
На сладкое сегодня будет пример об обнаружении взаимоблокировок (англ. deadlock). Тут есть отличие от других рассмотренных нами примеров, поскольку нет простого численного показателя, по которому можно было бы определить, что возникла взаимоблокировка. Можно только обозначить некоторые симптомы. Одним из них может быть ситуация, когда загрузка процессора вдруг становится необычно низкой, и приложение ничего не делает. Или если запросы не возвращаются по истечении времени их ожидания, это может значить, что треды, которые должны отвечать на эти запросы, оказались подвешены. А может быть и обратная ситуация, ваш пул тредов открывает все больше и больше тредов, потому что другие находятся во взаимоблокировке, а на запросы отвечать надо. Но точно определить список симптомов вам необходимо самим исходя из потребностей вашего бизнеса.
Если есть подозрение, что возникла взаимоблокировка, то для ее обнаружения мы прикрепим ClrMD и взглянем на стеки вызовов. Я не уверена, есть ли что-то, что можно предпринять для разрешения взаимоблокировки в таком случае, но, по крайней мере, проблема будет занесена в журнал, который будет отправлен разработчикам.
Перейдем непосредственно к примеру. Я пытаюсь выйти на страницу контактов, и выясняется, что она подвисла. Загрузка процессора почти нулевая, страница не загружается. Возможно, возникла взаимоблокировка. Взглянем на код, класс DeadlockMonitor. В данном примере я не реализовала обнаружение взаимоблокировки, поскольку тут может быть много решений, и мы уже видели достаточно их примеров. Я хочу просто показать, насколько просто можно получить доступ к стекам вызовов при помощи ClrMD и проверить, присутствует ли цикл в графе ожидания тредов.
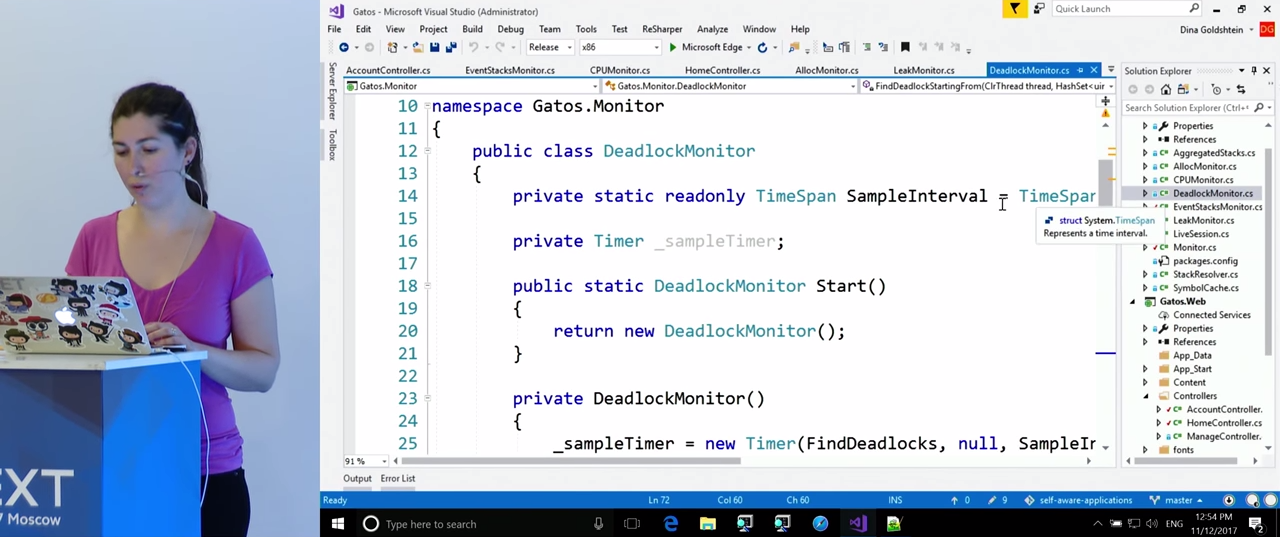

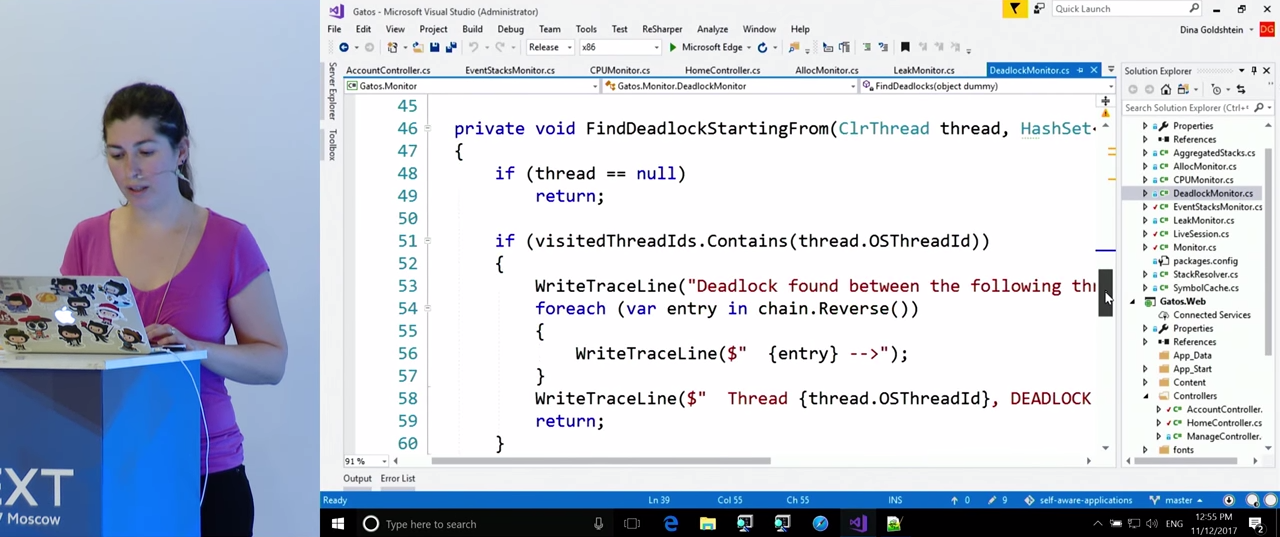
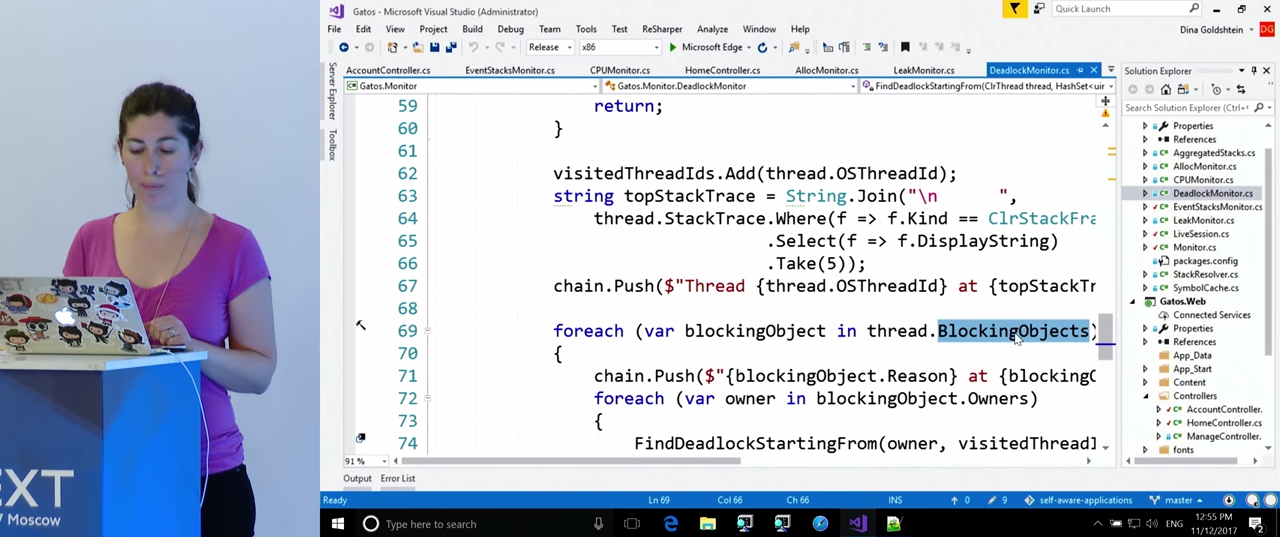
Каждые несколько секунд мы будем запускать достаточно простой рекурсивный метод FindDeadlocks(). Он проходит все треды, которые мы получили от ClrMD, и для каждого из тредов обходит все объекты, которые этот тред ожидает. Их можно найти при помощи свойства треда thread.BlockingObjects. У каждого из этих объектов есть свойство Owners, которое отсылает к другому треду, владельцу этого объекта. Все вместе это позволяет нам построить граф того, что происходит в приложении, и посмотреть, есть ли в графе цикл. Если есть, можно будет получить стек вызовов, в котором он происходит, и записать его в журнал.
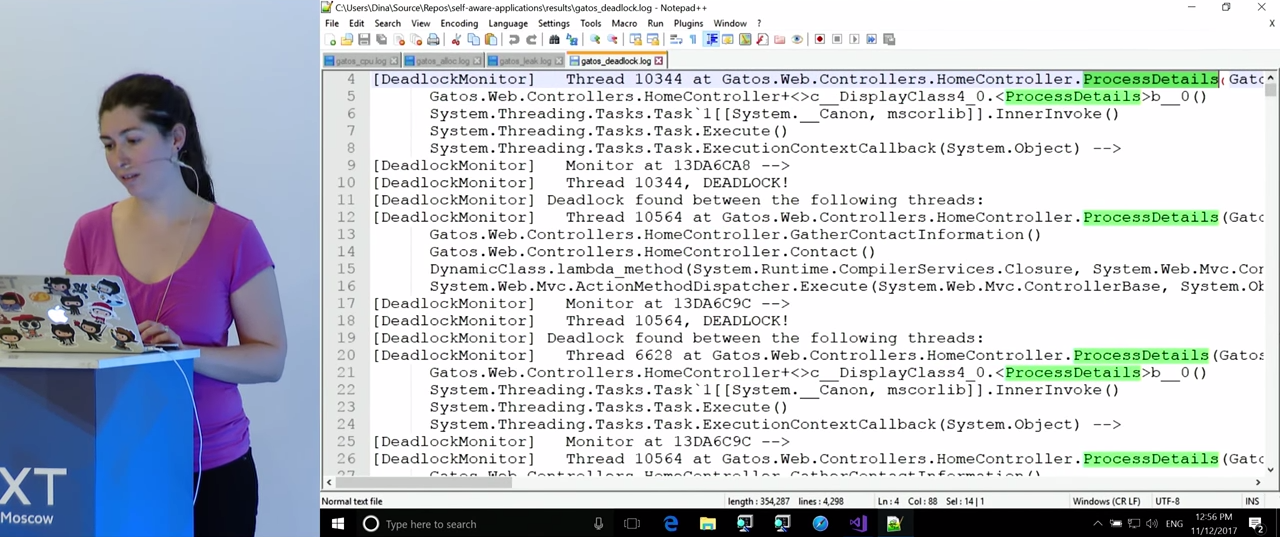
Обращаясь к журналу, мы видим, что, действительно, в HomeController.ProcessDetails() была обнаружена взаимоблокировка.
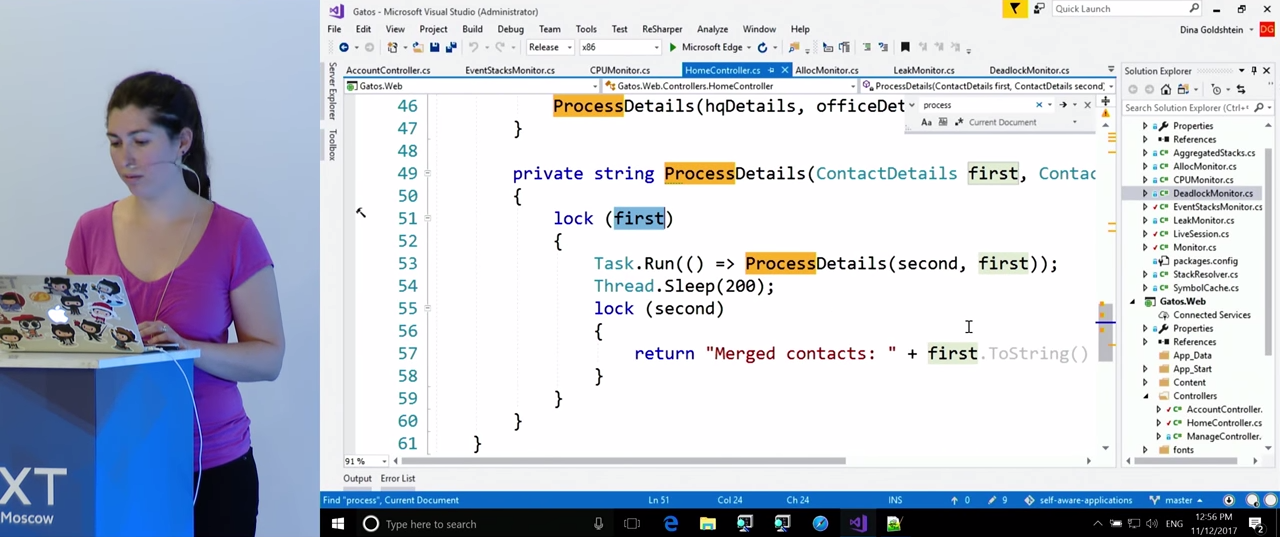
Если вернуться в код и найти там эту функцию, мы увидим две блокировки и вызов функцией самой себя, классический пример взаимоблокировки. Итак, функцию удалось обнаружить, что, по-моему, весьма неплохо.
В оставшееся время я хотела бы сказать несколько общих вещей. Очевидно, примеров предлагаемого подхода можно приводить множество и на все времени не хватит, но я упомяну некоторые. Можно заниматься мониторингом фрагментации кучи. CLR не будет сжимать крупные объекты в куче, если вы специально этого не укажете, поскольку это занимает много времени. Если вы осуществляете мониторинг фрагментации, то у вас есть информация, чтобы решить, хотите вы тратить это время или нет. Другая возможность, о которой я хотела упомянуть, заключается в использовании ETW для анализа утечек памяти на системном уровне. Есть возможность получать стектрейсы. Для этого в ETW можно получать события с указанием источника. Имеются в виду стектрейсы, сгенерированные нативными приложениями, написанными на C/C++ и использующими неуправляемую Win32 кучу.
В качестве небольшого отступления хочу заметить, что ClrMD может работать не только с запущенными процессами, его можно подключить к аварийному дампу и автоматизировать анализ дампа (просмотр стеков вызовов, поиск неисправных компонентов). В этом случае было бы оптимальным агрегировать все аварийные завершения одного типа, и, возможно, даже автоматизировать создание отчетов об ошибках для разработчиков.
Наконец, хочу заметить, что у описанного подхода помимо очевидных достоинств есть и недостатки. Достоинство заключается в том, что у вас есть видимость внутри вашего приложения, но при этом нет необходимости расширять команду при масштабировании приложения. Один из недостатков в том, что происходит увеличение сложности приложения. Больше кода значит больше потенциальных проблем. Риск можно сократить, выполняя все операции, которые я демонстрировала, в отдельном процессе. В приведенных примерах все выполнялось в одном процессе, но серьезных препятствий для того, чтобы вынести мониторинг в отдельный процесс, нет. Данные от ETW и счетчиков производительности все равно собираются по всей системе, ClrMD может подключаться к любому процессу.
Другой недостаток в увеличении ресурсоемкости. На это я уже обращала внимание в связи с первым примером, где самый большой по загрузке процессора стек вызовов был от самого ETW. Ту же проблему, судя по всему, испытывают некоторые пользователи Visual Studio: если вы наберете в поисковике «perfwatson2», вы увидите множество вопросов о том, как этот процесс можно отключить.
Наконец, дополнительный код требует времени разработчиков. Стоит ли его тратить — решение, которое должны принимать вы или ваши менеджеры.
На этом статья подходит к концу. Мы увидели, почему важна диагностика в продакшне, независимо от типа создаваемого приложения. Увидели, как ее можно осуществить при помощи иерархической системы мониторинга: легковесный мониторинг для обнаружения проблемы, больше ресурсов для диагностики. Наконец, были приведены четыре примера, демонстрирующих весьма неплохие результаты, которые может дать описанный подход: обнаружение в коде реальных проблем, связанных с загрузкой процессора, памяти, и с взаимоблокировками. Все демки доступны в сети.
Минутка рекламы. Как вы, наверное, знаете, мы делаем конференции. Ближайшая конференция по .NET — DotNext 2018 Piter. Она пройдет 22-23 апреля 2018 года в Санкт-Петербурге. Какие доклады там бывают — можно посмотреть в нашем архиве на YouTube. На конференции можно будет вживую пообщаться с докладчиками и лучшими экспертами по .NET в специальных дискуссионных зонах после каждого доклада. Короче, заходите, мы вас ждём.
jetcar
мониторинг написать можно всегда, важнее решить другие задачи, как это сделать так чтоб не тратить на это много времени, чтоб мониторинг не занимал своей работой слишком много процессорного времени и чтоб выдавал максимум полезной информации? и если начинать всё делать хорошо может получиться что мониторинг будет важнее самого приложения, хочется вовсе не этого, а библиотеку или плагин подключив который всё само начнёт работать :)