
Сегодня мы поговорим о производительности в C#, о способах прокачать её до неузнаваемости. Задача этой статьи — продемонстрировать такие способы повышения производительности, которые, при необходимости, вы смогли бы использовать самостоятельно. Однако эти методики не являются универсальными — вы не сможете использовать их в качестве общего решения любой задачи. Они хороши при наличии вполне конкретных сценариев использования, о которых пойдет речь ниже.
В качестве прототипа статьи был выбран доклад Федерико Луиса, основателя компании Corvalius (они занимаются R&D). Работая над движком базы данных для одного из клиентов, они посвятили около четырёх лет задачам оптимизации. Такое количество времени требуется для того, чтобы применить разного рода техники и достичь хороших показателей оптимизации. Требуется выявить все проблемы и узкие места, проследить поведение софта в соответствии со всеми имеющимися метриками и так далее. Примеры из этой статьи основаны на работе над RavenDB 4.0 (известная NoSQL база для .NET), которую компания Федерико тюнила до уровня наносекунд во всевозможных сложных кейсах.
Все примеры, которые встретятся вам в ходе рассказа (плюс некоторые дополнительные), доступны в специальном репозитории на GitHub.
Осторожно, трафик! В этом посте присутствует огромное количество картинок — слайдов и скриншотов с видео в формате 720p. На слайдах присутствует важный для понимания статьи код.
Немного математики
Представьте, что вы вернулись с очередного DotNext или обчитались Хабры в рабочее время, и ваш босс, полагая, что вы качественно прокачались в вопросах производительности, предлагает разработать систему, которая бы выполняла 20 миллиардов операций в день. Вдумайтесь в это число! Очевидно, идея безумная — реализовать нереально. Однако попробуем копнуть глубже и поймём одну важную вещь: 20 миллиардов операций должны выполняться в течение 24 часов непрерывной работы узла. Высокая или нет, но наша производительность обязательным образом будет устойчивой. Этот факт позволяет нам перейти к другим цифрам: 20000000000 / 24 = 833333333 операций в час. Легче ли нам? По правде, нет. Но мы можем продолжить разбивать наш показатель и далее. Получим, что требуемое количество операций в минуту: 833333333 / 60 = 13888888. Такое число уже более-менее поддаётся счёту. На следующем шаге получим количество операций в секунду — 13888888 / 60 = 231481. На практике, дальнейшее решение задачи, как правило, очень простое: мы берем, скажем, 40 серверов, каждый из которых обладал бы производительностью 231481 / 40 = 5787 операций в секунду. А ещё лучше, если возьмём 1500 серверов производительностью 231481 / 1500 = 154 операций в секунду. С такими цифрами уже можно работать. Получается, что число, вначале казавшееся нам неимоверно большим, уже не производит такого ужаса. На выполнение одной операции будет предоставлен целый узел и целых 5 миллисекунд его работы. Более того, в данном случае мы с уверенностью можем говорить о быстродействии нашей системы. Для сравнения, компьютерные игры выпускаются на рынок с отметкой в 13 миллисекунд.
Порядок чисел
Большинство продаваемых высокопроизводительных систем характеризуется способностью одного узла обрабатывать около 600 запросов в секунду в непрерывном режиме. Как такое возможно? Разумеется, показатель во многом зависит от того бенчмарка, который предъявлен системе: выполняем ли мы попросту серию повторяющихся операций, возвращающих каждый раз одно и то же, или же мы рассылаем сообщения по всему миру и вообще делаем невесть что. Но дело в том, что если наша цель — добиться выполнения узлом 600 запросов в секунду в непрерывном режиме, то в изначальный проект системы мы должны закладывать показатель в 10 раз больший и ориентироваться на него. А 6000 запросов — задача, требующая иного рода усилий с инженерной точки зрения. 6000 операций в секунду — показатель, требующий планирования. Необходимо, чтобы кто-то постоянно контролировал свежий код, который дописывают в кодовую базу, и не пропускал бы ничего, что ставит показатель в 6000 операций под удар. И в конечном счёте вы добьетесь этой цели. А вот чтобы достигнуть производительности, которая была бы выше не на один, а на два порядка, то есть 60000 операций в секунду, те же самые методики уже не подойдут. Здесь нам потребуются серьёзные изощрения. Сегодня я хотел бы поделиться с вами теми секретами, которые используем в работе мы.
Обсуждать не будем, но примем за аксиомы
- Интероп — постоянный источник накладных расходов ресурсов:
- Перфоманс убивает высокая частота маршалинга;
- Сборка мусора — основной источник проблем с производительностью;
- Нельзя использовать try-catch и LINQ:
- Эпилог и пролог для исключений — не бесплатные;
- Вызовы методов LINQ ведут к выделению памяти;
- При высокой частоте выполнения коротких операций — всё пропало;
- Любой доступ до значений через интерфейсы приводит к выделению памяти в куче (иначе говоря, будет боксинг;
- Типы-значения нужно оптимизировать особым образом;
unsafeназывается небезопасным не просто так;- GC pinning (явная блокировка объектов, запрещающая их перемещение в памяти сборщиком мусора) обходится очень дорого.
Всё, что нужно знать об инлайнинге
- Директивы компилятора — не более чем подсказки;
- Применяя инлайнинг, мы снижаем:
- количество промахов кэша инструкций;
- количество операций Push/Pop и обработку параметров;
- количество переключений контекста на уровне процессора;
- Применяя инлайнинг, мы увеличиваем:
- размер (в байтах) вызывающей функции;
- область локальности ссылки;
- Связанные эффекты:
- Dead Code Elimination;
- Constant propagation;
- Код может ускориться или замедлиться (нужно всё измерять!).
Даже зная обо всём этом, всё равно можно находить оптимизирующие решения. То, что будет дальше, полностью основано на нашем рабочем опыте. Никаких публикаций, отчетов об этом вы не найдёте. Выводы сделаны нами скорее эмпирически, на основе наших собственных наблюдений.
Порядковая оценка и Парето-классификация узких мест
Знаменитый закон Парето говорит нам о том, что 20% кода использует 80% ресурсов. Оценка, как мы считаем, вполне реалистичная. Возведем эту пропорцию в квадрат и уменьшим масштаб значений в 100 раз. Получим квадрат закона Парето: 4.0% кода использует 64% (около ?) ресурсов. Если же возведем пропорцию в куб и уменьшим масштаб в 10000 раз, получим куб закона Парето: 0.8% кода использует приблизительно 51% (около половины) ресурсов. То есть имея кодовую базу в 1 миллион строк, мы вынуждены отвести примерно половину ресурсов на выполнение всего 5000 строк. Закон Парето первого, второго и третьего порядка — это то, что поможет нам классифицировать техники оптимизации. Проведём любимую работу программиста и разложим наши техники по группам:
- В первую группу поместим техники оптимизации, работающие по закону Парето I порядка. Это техники про архитектуру системы, сетевое окружение, порядковую сложность используемых алгоритмов (пока что в терминах «большого О»).
- Во вторую группу пойдут техники, для которых применим закон Парето II порядка. Они подразумевают работу над оптимизацией времени исполнения алгоритмов. Возможно ли, например, не допустить многократное выполнение того алгоритма, который может быть выполнен однократно?
- Третья группа — это закон Парето III порядка, и здесь мы сталкиваемся с поистине непростыми вещами, требующими настоящей изобретательности. Это так называемые техники микрооптимизации.
Надо сказать, что, как правило, исходная производительность вашей системы будет требовать применения техник первой группы. Если уровень оптимизированности системы находится ниже некоторого порогового значения, то задумываться о техниках второй и третьей группы вам пока рано.
Работая над RavenDB
Сейчас я продемонстрирую вам те проблемы, с которыми мы имели дело в работе над продуктом RavenDB пару версий назад. RavenDB — полностью управляемая документо-ориентированная база данных. Во времена версии RavenDB 2.0 мы использовали систему хранения Microsoft ESE (известную также как Esent). Продукт хороший. Но скоро выявилась проблема: каждый раз при сохранении данных выполнялся вызов интероп, который, как мы знаем, является достаточно ресурсозатратным. Другие проблемы производительности возникали, в частности, из-за использования криптографического хеширования, из-за обработки JSON. Также мы выполняли недостаточно батчинга и теряли производительность, используя Write Locks при записи данных. Итак, мы решили оптимизировать кодовую базу RavenDB 2.0. Мы создали своё собственное хранилище, которое было призвано решить проблему с интеропами. И что же, взамен мы получили две новых дыры! Точно так же мы обнаружили новые проблемы после того, как оптимизировали обработку JSON и стали выполнять больше батчинга. Устраняя имеющиеся узкие места, мы получали взамен всё новые и новые. Но уже к тому моменту предпринятые нами действия дали десятикратное увеличение производительности на критических ответвлениях кода, что само по себе достаточно существенно.
На пути от версии 3.0 к версии 4.0 RavenDB мы решили использовать кардинально другой подход — «Performance first». Мы отнесли клиентские требования на второй план, а во главу угла поставили производительность. Мы принялись работать с локальным распределением памяти, создали свой собственный строковый тип. Чтобы избежать копирования данных и добиться полного контроля над памятью, мы создали свой собственный формат бинарной сериализации. Мы разрабатывали собственные алгоритмы сжатия, заточенные специально под виды хранимых данных. Также мы бросили усилия на то, чтобы обеспечить полный контроль доступа к IO и памяти (к примеру, необходимо было иметь возможность напрямую указывать ядру, какие страницы выгружать и подгружать). Крайне важно было попытаться очистить код от виртуальных вызовов. Об эффективности такого рода методик заранее судить невозможно, они оцениваются лишь на практике. А каждая удачная оптимизация —это не просто величина, это новый множитель в формуле. Увеличение производительности — это всегда её умножение. Из всех тех ботлнеков, которые присутствовали в RavenDB 3.0, я бы хотел рассмотреть с вами три:
- проблему обработки JSON;
- проблемы управления памятью;
- большое число виртуальных вызовов.
Работа с памятью
Так или иначе, мы всё время имеем дело с запросами. Запрос некоторым образом начинается и завершается. Выделение памяти — это тоже запрос. Вначале память необходимо предоставить, а по окончании использования её необходимо вернуть. Как показала наша практика, приблизительно 90% случаев выделение памяти происходит для строк (такова специфика баз данных, ведь они в основном хранят строки). Далее в порядке убывания идут коллекции, объекты поколения Gen0, попадающие под сборку мусора (так называемые объекты «fire & forget»), асинхронные операции, объекты Context лямбда-функций. Если вы разрабатываете высокопроизводительный софт, от использования сборщика мусора вам придётся отказаться. А значит, освобождение памяти вы также будете осуществлять вручную. Мы создали такие строки, которыми бы управляла не среда, а мы лично (в буквальном смысле обращаясь к диску). Для краткости будем называть такие строки «неуправляемыми».
Теперь мы будем иметь дело с вопросами типа: кому принадлежит тот или иной участок памяти, как быстро может быть выделена память, возможно ли обеспечить высокую скорость выделения памяти, если речь идет о короткой строке? Если в ходе работы нам понадобится (в рамках того же потока) выполнить ещё один запрос на память, то, поскольку свободный сегмент будет располагаться по соседству с уже используемыми, он с большой долей вероятности окажется уже подгруженным в кэш. Но наличие в вашем коде ботлнеков может не дать вам возможности вести подобную ювелирную работу. Чтобы вы могли успешно заниматься таким видом оптимизации, ваш код должен быть скроен уже в достаточной мере бережливо. Тем не менее, данный подход относится к методикам закона Парето I порядка, поскольку пронизывает всю архитектуру системы. Решиться на подобные преобразования, как правило, нелегко. Вы должны быть готовы практически начать с чистого листа. Ваши версии не будут обладать двоичной программной совместимостью, что проблематично.
Анатомия ByteString
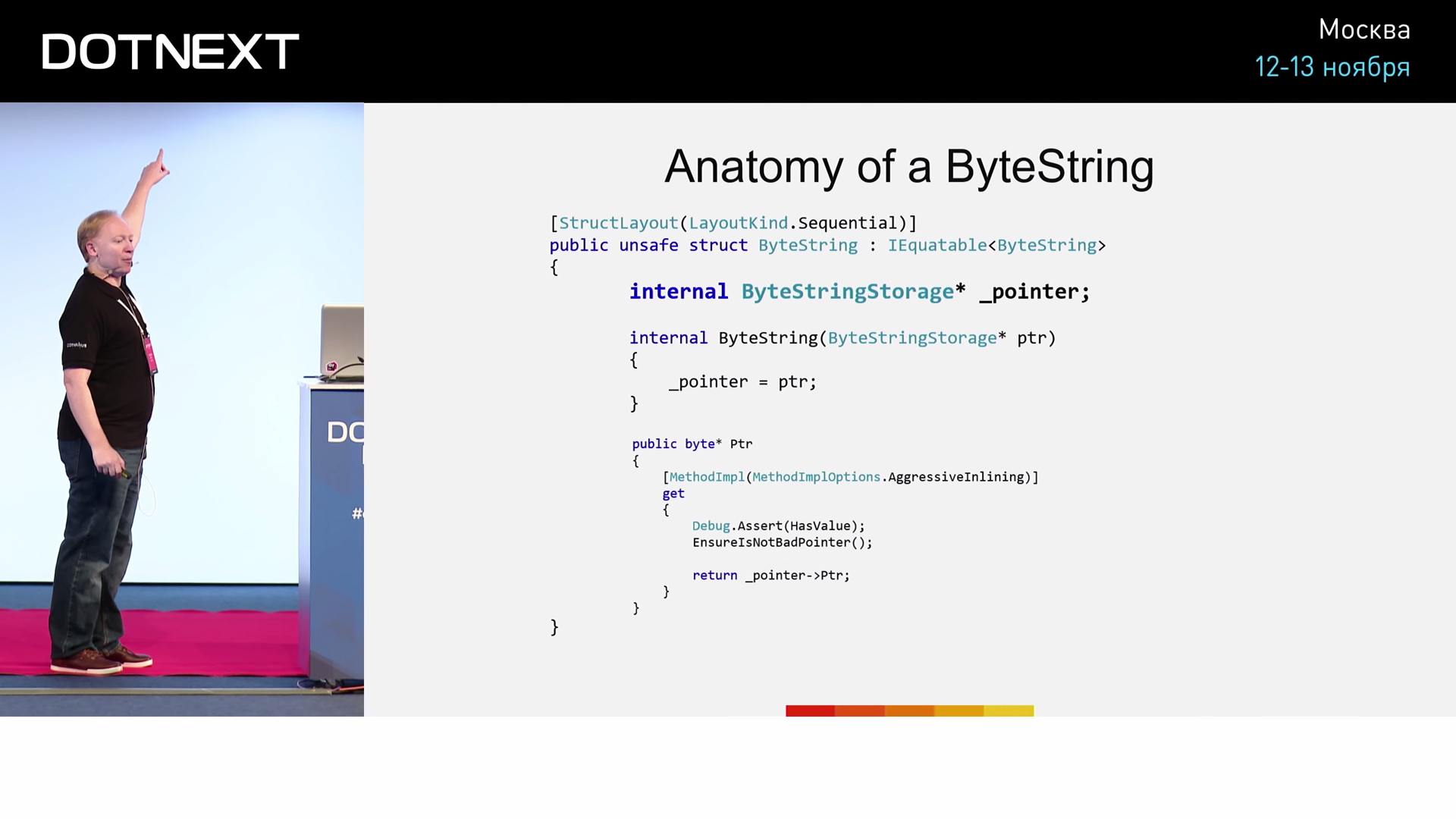
Что такое ByteString? Его реализация выглядит примерно так:

Несколько флагов, длина ByteString, указатель на сегмент памяти, в котором он хранится, а также размер этого сегмента (на тот случай, если мы решим освободить его с возможностью переиспользования кем-то другим). Не сильно отличается от строкового типа плюсов, верно? Данная реализация ByteString напоминает нам и кое-что другое — Span библиотеки CoreCLR.

Span был впервые представлен в начале 2016 года, а сейчас вошел в мейнстрим. Внутри себя Span хранит ссылку на тип. А что такое ссылка? Это не что иное, как указатель, тщательно скрытый от нас за своей прекрасной реализацией. Второе поле Span хранит длину. Сам по себе Span нам не подойдёт, поскольку не поддерживает работы с неуправляемой памятью. Итак, ByteString — структура по типу Span, притом вполне законная для C#. Она прекрасно решает проблему управления памятью. Однако ByteString имеет одну большую проблему — она занимает целых 36 байт. Размер регистра данных позволяет нам хранить всего 8 байт, в лучшем случае — 32 байта. Передавать такую структуру в качестве параметра или возвращаемого значения будет крайне проблематично. И вся та производительность, которую мы выиграли за счёт концепции ByteString, будет потеряна при его передаче. Но такого рода проблема, как правило, находит решение в сообществе любого языка. Решат её так же, как и любую другую проблему в информатике: добавлением ещё одного уровня косвенности.

Создадим указатель на наш ByteString.
И теперь наш ByteString занимает 8 байт. Круто ведь! Но хочется задать вопрос: и всё же, как дорого нам обходится передача ByteString в качестве параметра на самом деле? Лучший способ выяснить — провести эксперимент. Экспериментировать специалист по производительности вынужден постоянно.

Пусть ByteString "a" задан внутри метода UsingByteString. Не будем выполнять никаких операций, метод должен просто вернуть "а". Компилятору необходимо указать, что метод «холодный». «Горячий» метод всегда отработает быстрее — чистота эксперимента будет нарушена, показатель производительности окажется искажен в лучшую сторону. Напомню, что ByteString, в соответствии с нашей реализацией, должен занимать 8 байт. Ниже реализуем метод UsingLong, который выполнит те же самые действия (возврат значения) над 8-байтной переменной типа long. Если упраление ByteString через указатель окажется не сложней, чем управление переменной типа long, то методы UsingByteString и UsingLong отработают за равное время. В качестве реализации ByteString возьмём такую:

Реализация упрощена до минимума, но вполне подходит для нашего эксперимента. Создавая экземпляр структуры, мы выполняем присваивание значения именно указателю. Итак, сначала протестируем на переменной long. Отправная точка нашей программы:

Значение переменной long добудем из статической глобальной переменной. Затем запустим наш метод, возвращенное значение сохраним в переменную "a". И, чтобы не дать компилятору вмешаться и оптимизировать здесь что-либо (а он делает это только тогда, когда все действия кода строго детерминированы, в частности, в нем отсутствуют побочные эффекты), добавим операцию с побочным эффектом — выполним вывод "a" в консоль. Запустим программу и получим такой результат:
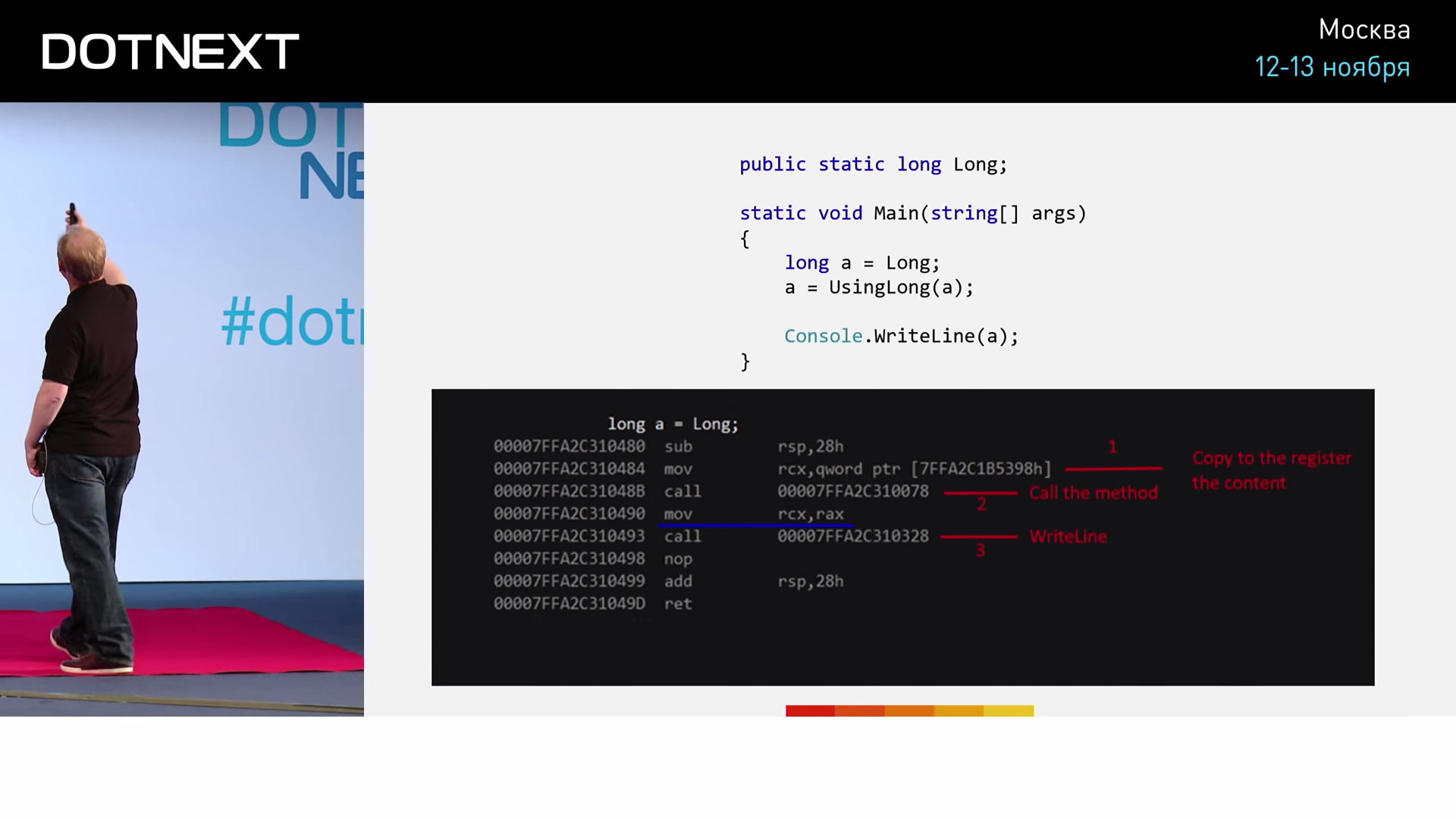
Итак, первая операция mov перемещает в регистр RCX первый параметр метода. Далее следует операция call — вызов функции, после чего происходит копирование значения из регистра RAX в регистр RCX — запись значения, которое вернула функция, в переменную "a". Следующий далее call — это вызов метода WriteLine. Теперь повторим то же самое, но с ByteString. Код для запуска:

Объявляем статическую глобальную переменную-указатель. Код Main аналогичен: инициализируем новый ByteString, вызываем метод UsingByteString, возвращенное значение сохраняем в переменную "a" и выводим её значение в консоль; во избежание каких-либо проблем с Console.WriteLine, добавим сюда явное приведение к типу long. Результаты выполнения программы:

Точно так же выполняется сохранение в регистр RCX, точно так же выполняется вызов метода, точно так же полученное значение копируется из регистра RAX в регистр RCX, и точно так же происходит вызов WriteLine. Результаты одинаковы!
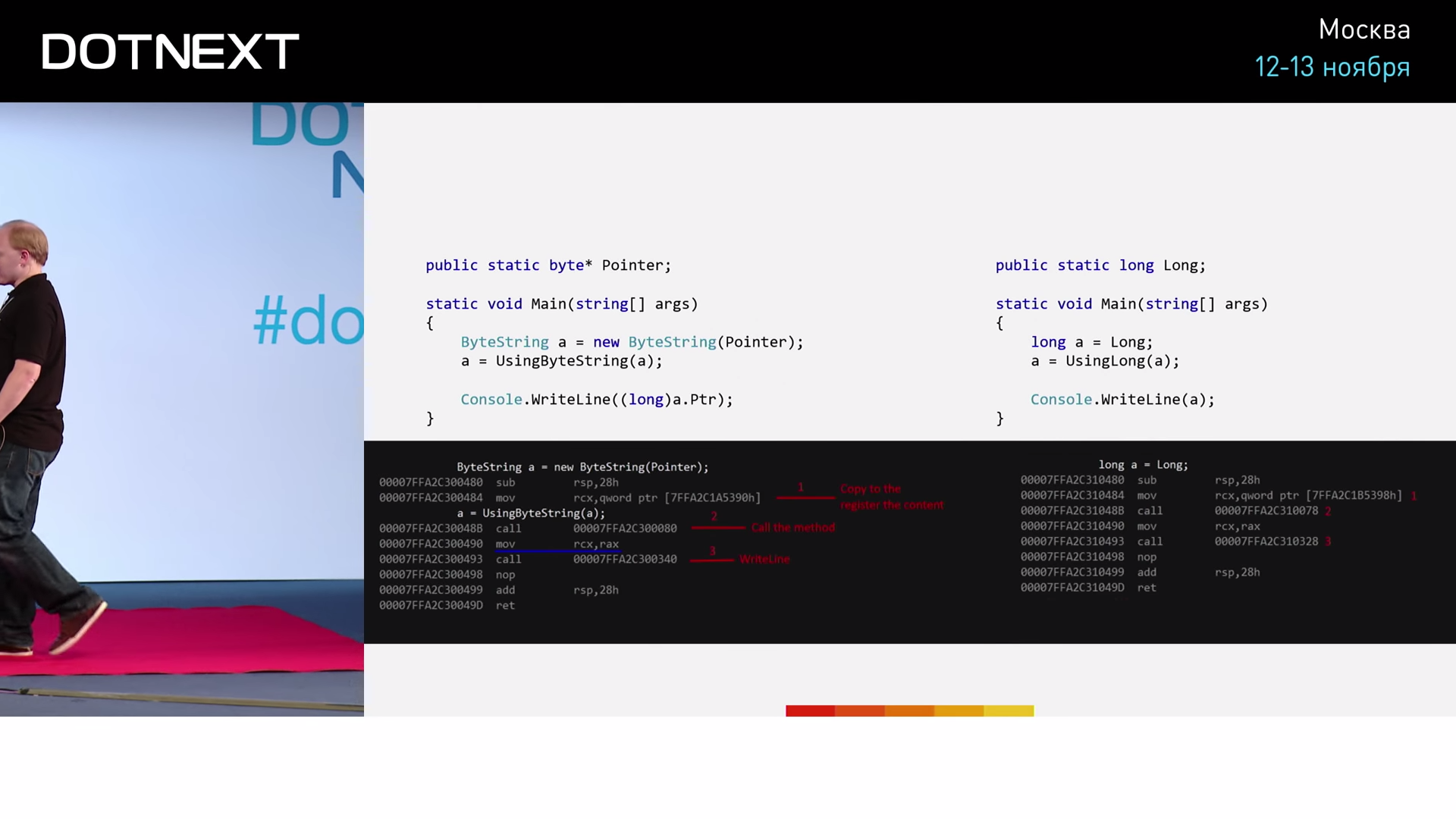
Получается, что, несмотря на явное семантические отличие, на уровне JIT-компилятора эти два куска кода отрабатывают идентично. Возможно, вы кое о чём догадываетесь. Однако потерпите немного, вторая часть истории впереди.
Ликвидация ветвлений
Втихаря от нас JIT-компилятор кое-что оптимизировал. Проиллюстрируем на другом примере:

Предположим, у нас есть пустой интерфейс IMarker и две его реализации — MarkerI и MarkerJ. Однако, что важно, объявим MarkerI и MarkerJ структурами, а не классами, как обычно. Ниже определим метод Method, для которого: — параметр типа, принадлежащий интерфейсу IMarker; i и j — входные параметры типа int. Внутри метода выполним простую операцию: если T равен MarkerI, то вернём значение i; если же T равен MarkerJ — вернём j. Запустим метод с параметром MarkerI.

Как именно будет обрабатывать такой вызов JIT-компилятор? Он увидит метод Method и параметр MarkerI, который ему передан. Затем он выполнит проверку принадлежности MarkerI интерфейсу IMarker, и, посчитав, что условие выполнено, приступит к выполнению тела метода. И далее, анализируя условие оператора if, компилятор выполнит довольно интересную операцию: он проверит, равен ли тип MarkerI типу MarkerI и, разумеется, получит значение true. Однако, поскольку MarkerI является структурой, а не классом, компилятор сочтет, что true в данном случае является константой и решит изъять из кода оператор if (а заодно и то, что следует после него), оставив только команды тела if. Код примет такой вид:

Теперь запустим метод с параметром MarkerJ.

В этот раз анализ условия оператора if даст значение false (переданный тип MarkerJ не равен типу MarkerI). Точно так же компилятор посчитает, что в данном случае false является константой, а значит можно изъять конструкцию if целиком вместе с содержимым. Таким образом, мы наблюдали генерацию JIT-компилятором кода для двух различных ветвей.
Зачем нам нужно обобщённое метапрограммирование?
Для программистов на C++ скажу: по тем же самым причинам, что и у вас. Для всех остальных оно позволяет:
- избегать частых виртуальных вызовов;
- адаптировать алгоритмы с учётом того, как именно мы планируем их использовать (например, того как часто);
- использовать возможности JIT-компилятора (определение значений констант и простых выражений) — получать улучшенный, «уплотненный» код;
- избегать инвариантных условий (мы не можем предугадывать ветвь исполнения, но мы можем свести к минимуму количество ветвлений).
Для более наглядного представления я приведу вам пример применения обобщенного метапрограммирования. Поговорим об пулах объектов.
Объектные пулы

В сущности, мы имеем некоторый тип и имеем набор объектов этого типа — получается пул. Но объект ведь имеет жизненный цикл: однажды он создаётся, а рано или поздно нам нужно будет удалить его из памяти (связавшись с неуправляемой памятью, удаление мы вынуждены делать буквально руками). Есть и другой нюанс. Возможно, мы хотим сделать объект специально заточенным под тот или иной процессор. Если в последний раз некоторый объект был получен нами от процессора №1, то нам бы хотелось, чтобы дальнейшая работа с этим объектом произошла как можно скорее и на том же самом процессоре №1. Типичная реализация аллокатора на сегодняшний день выглядит примерно так:

Имеем объектный пул с NonThreadAwareBehavior. На вход конструктору мы передаем функцию factory, которая умеет создавать нужный нам объект. Фокус же состоит в том, что мы будем корректировать типы данных.

Сравним две реализации:

Первая использует классический подход, представленный только что. Во второй использован явный аллокатор, представленный обыкновенной структурой. Для создания же нового объекта пула, в данном случае нам достаточно использовать оператор New. Теперь протестируем и сравним эти две реализации.
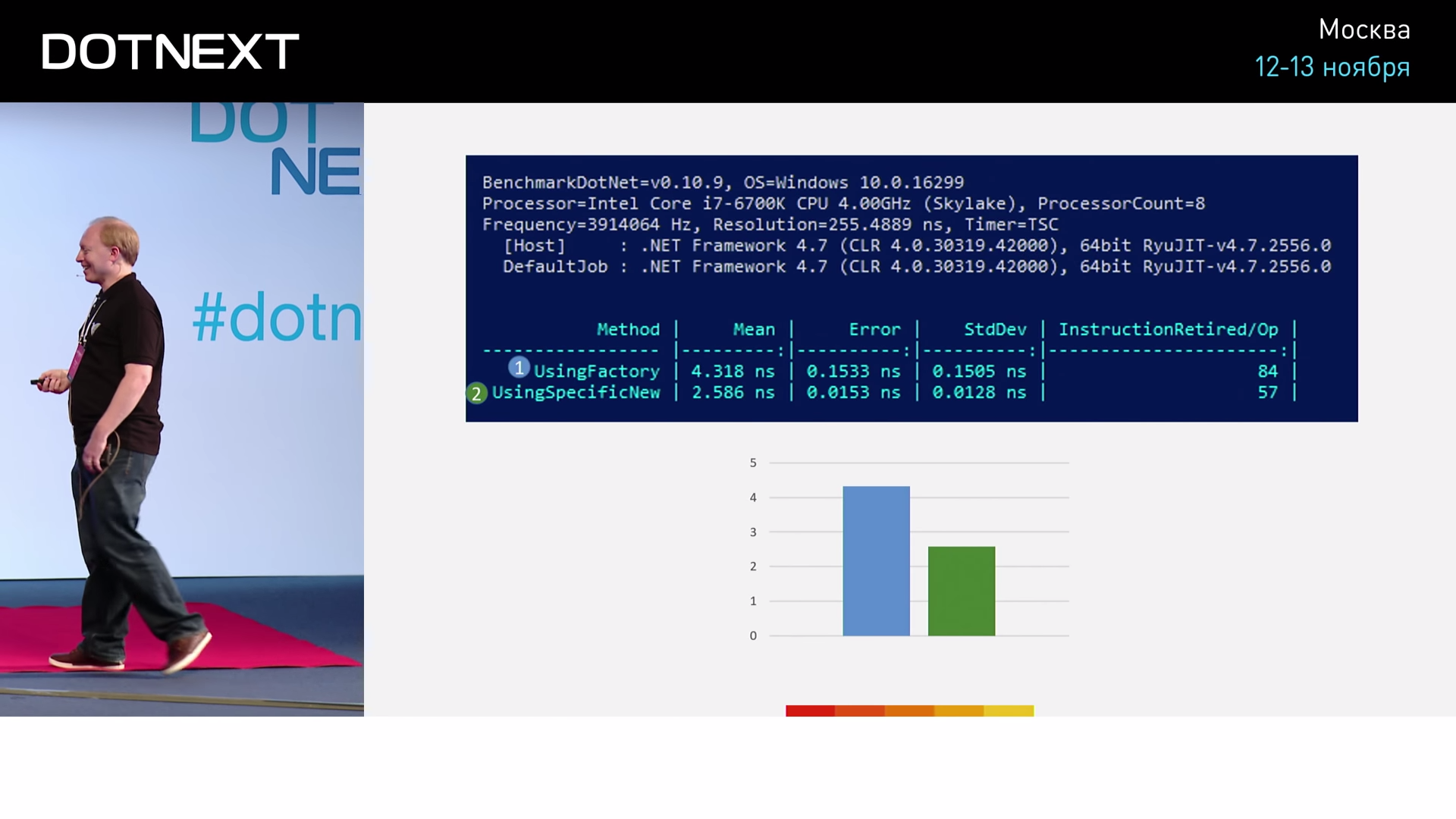
Мы можем видеть, что реализация с factory задействовала 84 ассемблерные команды, а реализация с New — всего 57. То есть вариант с использованием New оказывается эффективнее в 1.7 раз. Насколько существенно для нас такое различие? Попробуем кое-что более интересное — реализуем ассоциативный массив (Dictionary).

Вдобавок к привычным двум аргументам ключа и значения, объявим третий — компаратор. Классическая реализация, соответствующая нашим пожеланиям, будет выглядеть примерно так:

В качестве компаратора указываем интерфейс IEqualityComparer. Реализация NumericEqualityComparer достаточно проста:

В данном случае NumericEqualityComparer представляет собой структуру, реализующую интерфейс IEqualityComparer для типа long. Метод Equals попросту возвращает результат проверки на равенство двух переданных ему значений типа long. Обратите внимание на особое указание к реализации метода — AgressiveInlining, увидев которое, JIT-компилятор будет по возможности выполнять метод как встроенный. Тестировать будем три разных варианта реализаций:
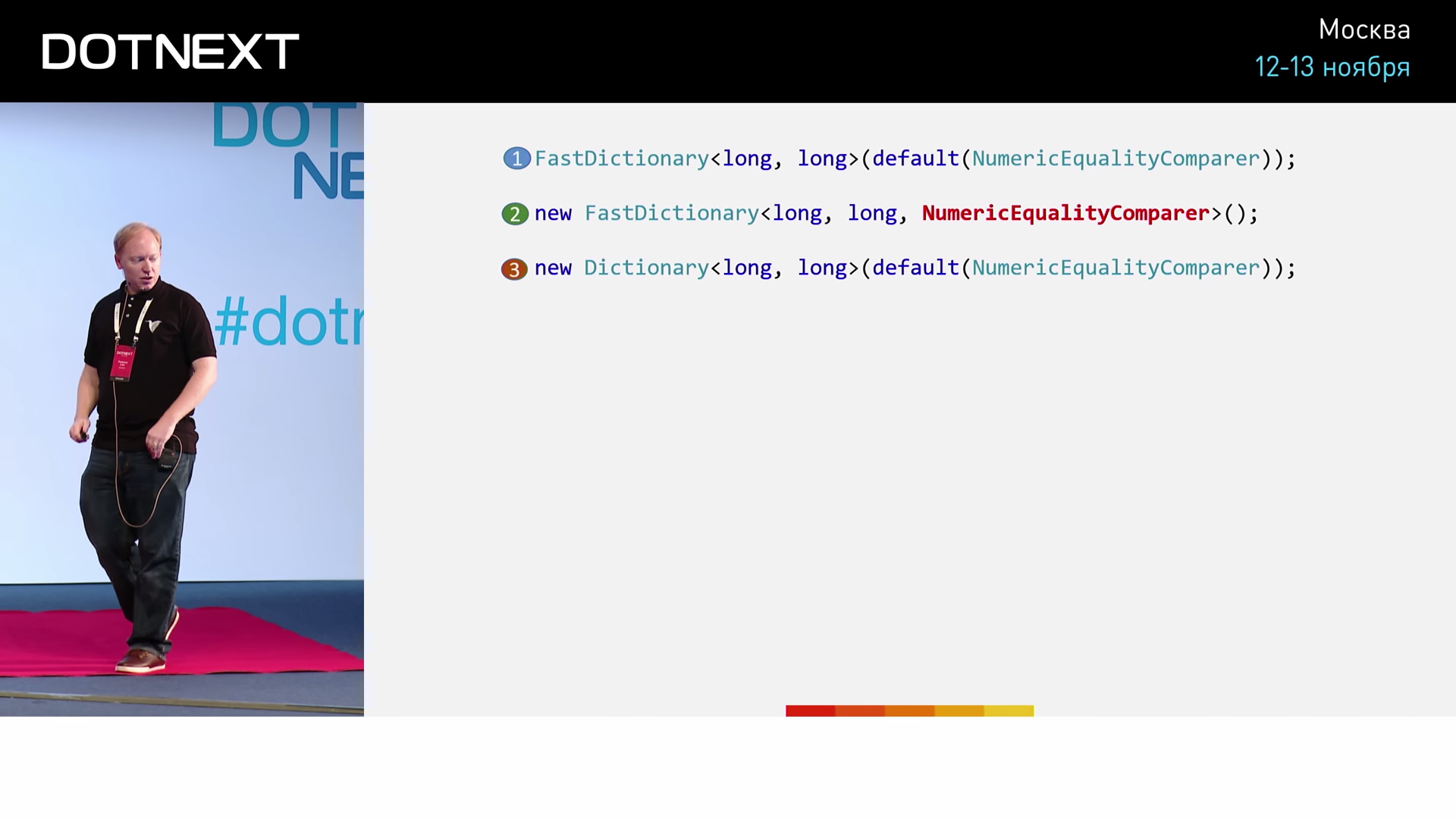
В первом случае осуществляем типичное для .NET использование ассоциативного массива с применением интерфейса. Во втором случае, минуя использование интерфейса, пробуем передать наш NumericEqualityComparer непосредственно в качестве типа. Третий вариант нужен нам для полноты картины. Здесь мы выполним то же самое с использованием ассоциативного массива CoreCLR. Результаты тестирования дают:
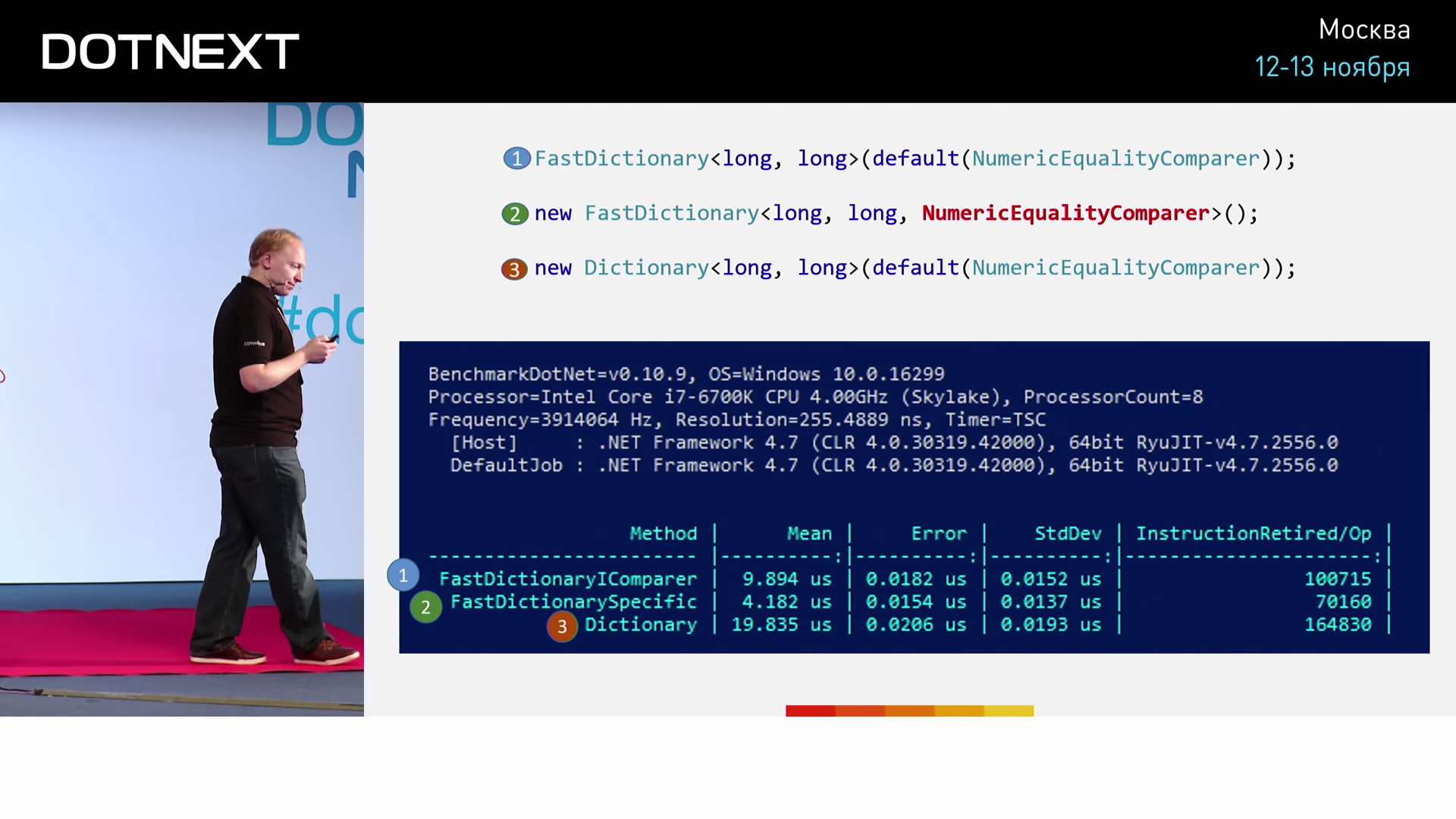

Очевидно, что алгоритмы FastDictionary работают быстрее. Но кроме того, мы видим, что прямое использование типа NumericEqualityComparer эффективнее использования интерфейса более чем в два раза. Я представил вам несколько примеров. Объективно ли использовать их в качестве бенчмарков? Ответ: нет. Нам необходимо провести реальное тестирование.
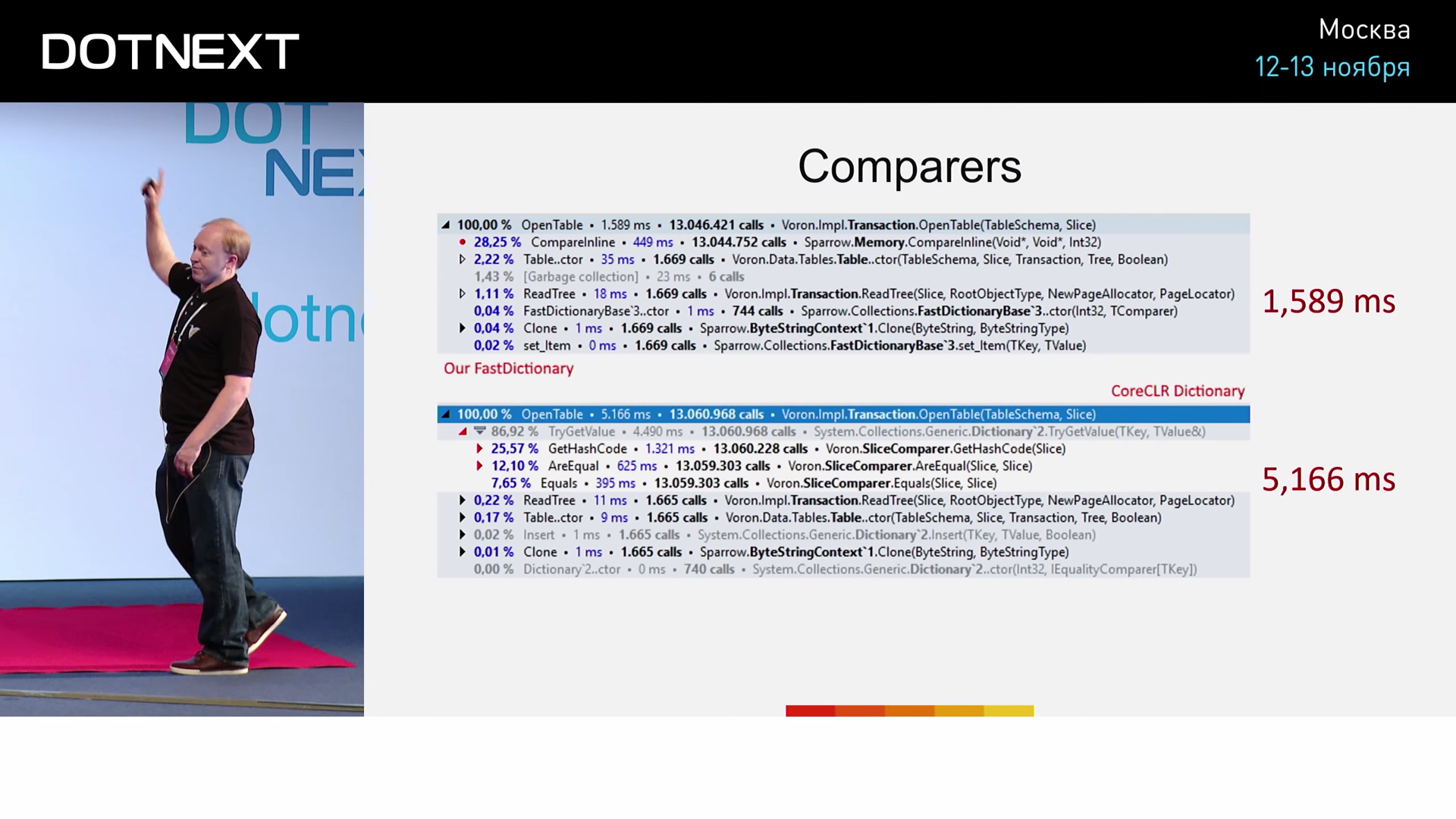
Отсюда мы видим, что на самом деле компараторы встроены не были: они оказались слишком большими. И тем не менее, использование FastDictionary уже повышает нашу производительность в 3,25 раз. Не любое использование FastDictionary даст нам подобный результат, поэтому важно разобраться в том, что же обусловило его в данном конкретном случае. Оптимизации, проводимые JIT-компиляторами, далеко не так просты, как кажутся.
Константы
Ещё один пример:

Флагу doDispose присваивается некоторое вычисляемое значение. В момент реализации JIT-компилятор не может определить, является ли это значение константным (напомню, если в качестве параметра будет передана, например, структура, то выражение будет расценено как константа). Однако, в силу неопределённости, скомпилированный ассемблерный код будет вынужден хранить две возможные ветви. Попробуем ввести упрощения. Тот тип техники, который я вам покажу, важно применять с большой осторожностью, иначе он может иметь неожиданный эффект на клиентской стороне. Упрощать будем следующее:

(На слайде ошибка: вместо TEvictionStrategy нужно использовать TEviction)
Реализован метод Clear, который умеет очищать память от того или иного объекта. Но как нам определять какой объект удалить, а какой оставить? Можно назначить условия искусственно: пусть объект удаляется по прошествии определенного периода времени с момента последнего использования (скажем, 15 минут или часа). Но сейчас я воспользуюсь другим подходом.

Пусть IEviction — интерфейс критерия. А реализующие его AlwaysEvictStrategy и NeverEvictStrategy, предлагают две противоположные стратегии соответственно: «удалять можно» и «удалять нельзя». Технически, и AlwaysEvictStrategy, и NeverEvictStrategy содержат метод под названием CanEvict, который просто возвращает true и false соответственно. Код Clear будет выглядеть так:

В bucket хранятся некоторые объекты. Если имеется хоть один, мы бы хотели использовать CanEvict, чтобы понять, можно ли его удалить или нет. Нужно только указать используемую стратегию. А в зависимости от выбора (удалять или нет), скомпилированный код будет иметь разный вид. Если будет использована AlwaysEvictStrategy, компилятор видит следующее:

Обратите внимание на то, что теперь параметр типа при методе отсутствует, а в качестве второго параметра мы теперь имеем ссылку на AlwaysEvictStrategy.

Вызов CanEvict вернет значение true и будет заменен на константу. Конструкция if будет упрощена следующим образом:

В случае, если будет использована NeverEvictStrategy, наблюдаемая компилятором картина:

В условие оператора if попадёт константа false, возвращенная CanEvict.

Компилятор сочтет, что данная ветвь не будет исполнена никогда, а значит, if-конструкция будет полностью удалена:

А зачем в таком случае добывать значение inst? Компилятор не станет этого делать и удалит строку:

А зачем нужен вызов пустого метода?

Компилятор удалит вызов Clear из кода. У такого кода есть очевидная проблема:

Компилятор должен удалить цикл for, однако пока что он не может этого сделать.
Zero Cost Facade
Поговорим о другой реализации тех же самых техник. Предположим, у нас есть интерфейс ILimitedOutputDirective, реализованный структурами NotLimited и LimitedOutput. Также объявим интерфейс ITableTypeDirective и реализуем его структурами ByU32 и ByU16.

Так будет выглядеть сигнатура метода:

Тело метода:

Если в качестве типа сжатия был указан ByU16, то выполнится первая ветвь if. Если был указан ByU32 — выполнится вторая ветвь if. Если же указанный тип не является ни ByU32, ни ByU16, то бросим исключение. Можно адаптировать код под различные варианты использования. А можно применить методику, называемую «Zero Cost Facade». Её и рассмотрим.

Мы создали интерфейс IUnmanagedWriteBuffer и две его реализации: структура UnmanagedStreamBuffer (для потоков, которые, как правило, работают медленно, так как оперируют большим числом виртуальных вызовов) и структура UnmanagedWriteBuffer (для агрегирования и вывода данных). Что интересно, теперь вы можете конструировать новые типы путем надстройки над имеющимися. Сами структуры генерируются на лету.

Если необходимо, например, параметризировать создание BlittableWriter — вы просто добавите конструктор с соответствующими параметрами, внутри которого будет вызываться конструктор TWriter. Теперь мы можем написать, к примеру, такой код:

Это реализация метода WriteNumber, уже подверженная ряду оптимизаций. Обратите внимание на указание к AgressiveInlining. Причём неважно, добываем ли мы данные, выполняя виртуальный вызов или собирая по частям байты памяти — данный код абстрагирован от такой информации. JIT-компилятор поймет, что ему предложен эффективный код, и выполнит его. Как это использовать? При помощи такого подхода мы можем, к примеру, маскировать указатели и ссылки структурами.

Мы можем индексировать множество объектов пула, сопоставив каждому из них структуру, которая будет содержать две вещи: ссылку на пул и индекс на соответствующий объект.
Стоит ли вложиться во всё это?
Около 6 месяцев назад мы занимались микрооптимизацией JSON-парсера, исходные скорости которого были уже не так-то плохи. На тот момент для одного из наших тестов общее время парсинга составило 500 секунд (около 8 минут). Совершив первый двухнедельный заход и применив ряд озвученных сегодня методик оптимизации, мы достигли исполнения того же теста за 3 минуты. Спустя неделю мы приблизились к отметке в 2 минуты, а через пару дней тратили на тест уже менее 2-х минут. Таким образом, имея продукт далеко не низкой исходной производительности, мы сумели достичь дополнительной оптимизации его работы в 6,6 раз. А теперь представьте, что мы запускаем такое ПО на устройстве с маломощным процессором, таком как, например, Raspberry Pi. В данном случае оптимизация окажется абсолютно спасительной. Подумайте обо всех тех ресурсах, которые вы сэкономите, запуская такое ПО на огромном кластере из 1000 машин. Когда речь идёт о суперкомпьютерах, отказ от оптимизации производительности означает финансовый расход — реальный и при том каждодневный.
Подводя итог
Что подразумевать под оптимизацией? Во-первых, это обобщенное метапрограммирование, использующее упаковку типов в структуры. Это мощнейшее средство, открывающее большой простор для оптимизации.
В частности, обобщённое программирование позволяет:
- специализировать обобщённый код под конкретные условия;
- бесплатно делать фасады:
- создаем интерфейсные структуры над типами;
- создаем в интерфейсных типах обобщенные методы;
- профит!
- (как говорят в Rust, это «трейты для бедных» — другими словами, бесплатные абстракции);
- (а в C# это похоже на shapes and extensions);
- избавляться от виртуальных методов (даже в сложных ситуациях).
Сообщество C#-программистов постоянно ищет новые решения. К примеру, они пробуют определить кое-что, именуемое идиомой «shapes & extensions». Реализации напоминают то, что я продемонстрировал вам сегодня, при этом код становится всё меньше похож на привычный C#.
- Cокрытие указателей и ссылок за структурами:
- позволяет иметь бесплатные дженерики над указателями;
- дает использовать структуры вместо последовательностей заранее подготовленных данных:
- позволяет относиться к ним как к прозрачным индексам;
- улучшает локализацию памяти;
- дает возможность работать с управляемой и неуправляемой памятью одинаковым способом;
- помогает избежать расходования лишней памяти при захвате контекста в лямбдах.
Методика скрытия за структурами открывает много возможностей. Но вы должны иметь в виду, что она делает код более сложным для понимания. Есть риск, что программисты, читающие ваш код спустя полгода, не смогут понять вашего подхода (мы сталкивались с подобной проблемой в Corvalius).
Заключительная мысль
Любой специалист по производительности должен понимать одну важную вещь: узкие места не могут исчезнуть, вместо этого они видоизменяются, становясь всё более трудноустранимыми. В борьбе с такими проблемами мы постепенно дошли до проблем уровня элементарной нехватки процессорного кэша. А ведь наша система способна за 6 минут загрузить в базу данных 64 Гб, используя при этом всего 17% ресурса процессора. То есть чем глубже залегают раскапываемые вами ботлнеки, чем сложнее задачи, для которых вы ищете решения — тем большей производительности вы уже достигли. К чему мы в итоге приходим? К необходимости оптимизации работы с I/O, к вопросам того, как обеспечить наличие свободной памяти каждый раз, когда она нам нужна. Работы много! Я думаю, что мы с вами ещё встретимся в будущем и обсудим найденные решения.
Что дальше?
Смело знакомьтесь материалами моего репозитория, а также с моей подборкой лучших учебных материалов!
- Исходники RavenDB 4.0: коммиты автора этой статьи, Federico Lois;
- Local (arena) Memory Allocators — John Lakos [ACCU 2017];
- Carl Cook «When a Microsecond Is an Eternity: High Performance Trading Systems in C++»;
- An Overview of Program Optimization Techniques — Mathias Gaunard [ACCU 2017];
- MIT 6.172 Performance Engineering of Software Systems, Fall 2010 — BTree Write Cliff;
- Understanding Flash: The Write Cliff (SSD);
- Блог Oren Eini — технические статьи о базах данных (Federico Lois иногда пишет туда статьи);
- Баги CoreCLR по темам перформанса и оптимизаций;
- BenchmarkDotNet.
Минутка рекламы. Как вы, наверное, знаете, мы делаем конференции. Ближайшая конференция по .NET — DotNext 2018 Piter. Она пройдет 22-23 апреля 2018 года в Санкт-Петербурге. Какие доклады там бывают — можно посмотреть в нашем архиве на YouTube. На конференции можно будет вживую пообщаться с докладчиками и лучшими экспертами по .NET в специальных дискуссионных зонах после каждого доклада. Короче, заходите, мы вас ждём.