
Сегодня мы поговорим о том,
- Как делать тестирование сложными зависимостями?
- Как добиться большого тестового покрытия?
- Как тесты влияют на дизайн?
- Что делать, когда много логики в базе?
- Как соблюсти компромисс между дизайном и «не дизайном».
О спикере: Андрей Коломенский — Agile Coach в компании OnAgile, пишет код уже более 10 лет, работал как над сложными доменными моделями — такими, как платежные системы, так и над разработкой сложных legacy кодов, когда их приходилось спасать и восстанавливать продуктивность работы над ними.
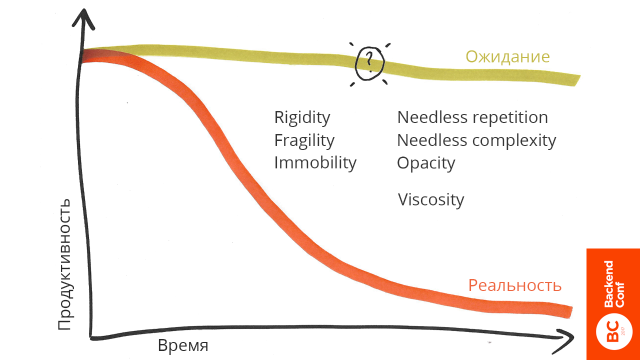
За все время своей работы я заметил следующую проблему. Когда мы только начинаем проект или уже работаем над ним, мы всегда ожидаем, что будем двигаться с постоянной скоростью (как на заглавном рисунке). Но на самом деле реальность с нами не согласна.
Все мы очень часто скатываемся в дикую непродуктивность. Вначале бизнес радуется, что мы, как программисты, реализуем очень много фич, а в конце жалуется на то, что мы поставляем мало фич. В результате в средней зоне, примерно там, где поставлен знак вопроса, у нас возникает сильное желание все переписать или провести крупный рефакторинг.
Ситуация, когда мы хотим выкинуть код, меня сильно раздражает. Это очень близкая мне тема. Я разрабатывал банковское кошельковое решение полтора года. Все это время мы не выходили в продакшн, а когда у нас почти все было готово, у банка отзывают лицензию.
Бизнес решает не бросать код и сделать другой продукт: платежный агрегатор, вместо кошелькового решения. Предметная область очень похожа: мы берем деньги от пользователей, забираем себе комиссию, отдаем деньги магазину.
Мы выкинули весь наш код, потому что мы не смогли сделать такой pivot, даже на близкую по смыслу предметную область. Для этого было несколько причин.
- Наш код был слишком жестким. Жесткость (rigidity) говорит о том, что система сопротивляется внесению изменений. Чтобы внести изменения в систему, мы должны затронуть очень много компонент.
- Наша система была хрупкой (fragility). Это тенденция системы ломаться в самых различных местах при внесении, казалось бы, небольших изменений.
- Наша система была непереносима — immobility. Это качество системы, которое говорит о том, что мы не можем повторно использовать код из одной системы в другой. Точнее, можем, но затраты на извлечение будут дороже, чем затраты на написание кода с самого начала.
- Наша система содержала ненужные дупликации (needless repetition) и избыточную сложность ( needless complexity).
- Ясность (opacity) выражения намерений у нас была достаточно низкой, хоть мы на ней и фокусировались. Частая ошибка программистов — когда мы запускаем новый продукт и долго не выходим в продакшн, мы делаем задел на будущее с целью экономии. Из-за этого мы не понимали, как именно должны быть устроены те части системы, которые были заглушками, что конкретно те элементы должны из себя представлять, и какими поведениями и зависимостями обладать. Дисфункции которые я перечислил выше мешали достижению ясности и в остальных частях системы.
- Последний параметр viscosity я вынес отдельно. Это атрибут качества, который говорит о том, насколько система сопротивляется применению качественных архитектурных решений. Допустим, если тесты проходят час и ни о каком TDD речи быть не может, — это система с огромным показателем viscosity.
Вопрос: как узнать, как должна выглядеть наша система в точке максимально высокой продуктивности?
Тот код, который мы выкинули, был покрыт тестами. Мы заботились о его качестве, рефакторили, но в результате выкинули почти весь.
Нам нужен какой-то инструмент получения обратной связи от системы, который помогал бы понимать, как мы должны проектировать нашу систему. Знаний, которые у нас есть в голове, может оказаться недостаточно для того, чтобы в каждый конкретный момент знать, как вообще в целом наша система должна выглядеть.
Юнит-тесты — основной инструмент получения обратной связи от системы
Когда мы пишем юнит-тесты, мы как минимум можем гарантировать корректность системы и какое-то небольшое качество ее тестопригодности.
Давайте посмотрим на один тест.

Есть пример в вакууме BuyProductsAction — мы покупаем какие-то продукты. К этому тесту у меня есть вопросы, главный из которых: что я могу узнать о качестве системы из этого теста? Практически ничего: я могу перебирать входные параметры, добавить больше ассертов, каким-то образом обеспечить дополнительные проверки. Причем проверять нужно достаточно много, потому что у нас слишком большое количество характеристик продукта и пользователя и слишком большое количество параметров в базе данных.
О дизайне системы я не узнаю здесь ничего. Это причина, почему мы выкинули весь код — потому что то, что мы узнавали из наших тестов, не позволяло обоснованно улучшать дизайн нашей системы.
Что может делать BuyProductsAction внутри себя? Создавать заказ, отсылать уведомления, списывать деньги со счета, начислять процентные бонусы — он может внутри себя делать очень многое.
Что такое интегрированний тест?
Я сейчас уйду от понятия Юнит-тест, потому это оно слишком расплывчато, каждый его понимает по-своему.
Интегрированные тесты — это тесты, прохождение или падение которых
зависит более чем от одной единицы нетривиального поведения.
То есть мы не можем конкретно показать на точку, почему этот тест упал. Когда мы видим, что где-то находится ошибка, что какой-то компонент из области тестирования упал, а не конкретное одно место, тогда этот тест интегрированный.
Изолированные тесты — это тесты на одну единицу нетривиального
поведения, прохождение или падение которого зависит только от этого
поведения.
Фактически это тест на один метод или на один участок системы, а остальное нетривиальное поведение подменено на моки.
Предположим, что будет, если мы попробуем тест на метод BuyProductsAction сделать изолированным — так, чтобы не тестировать все целиком, а выполнить исключительно метод run, который будет изолирован от любого нетривиального поведения зависимостей, которые он содержит.
Скорее всего, мы этого сделать не сможем, потому что системы, которые пишутся с подобными тестами, не оказывают на дизайн системы такого сильного воздействия, чтобы мы могли сразу написать изолированные тесты. Даже если мы можем это сделать, скорее всего, там будет треш:

Мы начинаем с того, что у нас есть какой-то AnaliticsComponent, куда передаются входные параметры. Мы это дело засовываем в сервис-локатор. У нас есть еще какие-то компоненты, поведение которых мы задаем.




Количество зависимостей, которые мы видим в изолированном тесте, когда мы их явно прописываем, обычно достаточно велико, если практики написания изолированных тестов в компании нет. Даже если мы можем написать изолированный тест, обычно ситуация выглядит так.

Первое, что я делаю, когда провожу рефакторинг системы в тестопригодное состояние, я начинаю распихивать зависимости по классам и явно их инжектить в конструктор.
Главный вопрос, который можно задать, глядя на этот тест, —что я узнаю о качестве системы из этого теста?
Я вижу, что у меня явно нарушается принцип единственной ответственности. Здесь уже не отвертеться субъективными рассуждениями о «понятности». Я вижу, что мне этот тест тяжело писать и читать. Я вижу, что этот тест будет постоянно падать, потому что любое изменение у меня будет вноситься в этот класс. Мне этот вымышленный тест было тяжело готовить даже для презентации.
Если бы мы писали так продакшн код, мы бы просто сошли с ума.
Я использую изолированные тесты для повышения качества дизайна системы и её обоснованного рефакторинга.
Они дают максимально полную обратную связь о моей системе.

Если интегрированные тесты мне не дают практически ничего, кроме базового понимания, что часть моей системы работает корректно на части входных параметров, то изолированные тесты позволяют мне ясно видеть, что происходит в моей системе. Та степень дискомфорта, с которой я пишу изолированные тесты, будет соответствовать степени тестопригодности моей системы.
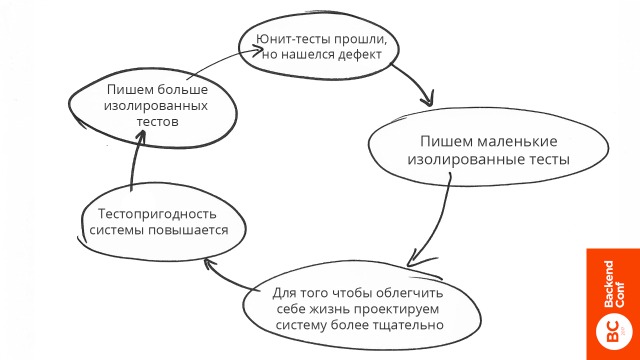
Загнивание системы
У нас прошли все юнит-тесты, но QA отдел обнаружил какой-то дефект. Мы понимаем, что проблема находится на стыке двух компонентов, и решаем написать интегрированный тест, потому что так проще, и потому что должны проверить реальную работу — как конкретно работает наша система, потому что все-таки у нас был баг.
Кстати, не рекомендую использовать слово баг. Это мушка, которая
залетела в серваки на заре нашей индустрии. Пример бага из IT
разработки — это когда я скопировал из скайпа SQL запрос, вставил его в код, и он там не работает, потому что скайп вместо пробела вставил
неразрывный пробел. Когда такое происходит — это баг. В остальных
случаях я предпочитаю использовать слово дефект, так
как некорректное поведение программы — это не случайность, а прямая ответственность программистов. Дефект гораздо более мощная формулировка
чем снимающий ответственность «баг». Конкретных пруфов нет, но одна
команда умудрилась просто за счет того, что перешла от слова баг на слово дефект, увеличить качество, просто за счет повышения осознанности и ответственности.
Так как мы написали интегрированный тест, он оказывает меньше воздействия на дизайн нашей системы. Мы, когда пишем интегрированный тест, можем написать его реализацию по-разному: вставить кучу зависимостей, сделать вызов статичных методов, которые меняют поведение системы, вызвать из сервис-локатора просто пелену вызовов — абсолютно, что угодно — у нас полная свобода.
Поэтому от легкой жизни мы начинаем проектировать систему менее тщательно. Нам все равно, как будет устроена наша система — только на нашем собственном чувстве внутренней красоты мы смотрим на систему, и думаем, как лучше. Но никакого давления со стороны теста не происходит.
Это приводит к тому, что тестопригодность нашей системы понижается, и теперь мы не можем написать маленький изолированный тест. По крайней мере, если даже можем написать, то это стало сложнее сделать.
В связи с этим у нас возникает больший риск возникновения дефектов, потому что тестировать нашу систему становится сложнее. У нас остается меньше времени на написание качественных маленьких изолированных юнит-тестов.

Мы возвращаемся на круг и в итоге приходим к решению писать только интегрированные тесты, потому что изолированные тесты писать сложно. В результате мы получаем ситуацию, когда на дизайн нашей системы не влияет ничего, только мы сами — как хотим, так и пишем.
Альтернативный вариант.
Та же самая ситуация — прошли юнит тест, но нашелся дефект. Что же будет, если мы напишем маленький изолированный тест. Мы столкнемся с кучей проблем с тем, что система мешает нам писать эти маленькие изолированные тесты.
Для того, чтобы облегчить себе жизнь и просто начать писать эти изолированные тесты качественно, чтобы мы понимали, что там происходит, мы начинаем проектировать систему более тщательно для того, чтобы нам не приходилось писать огромные тесты.
Чтобы тесты были маленькими, нужно очень сильно постараться сделать систему качественной и соответствующей принципу единственной ответственности. Это ведет к тому, что тестопригодность нашей системы повышается. Мы стараемся сделать нашу систему максимально тестопригодной, чтобы нам было легче писать изолированные юнит-тесты.
В результате с тестопригодной системой у нас есть больше времени для написания маленьких изолированных юнит-тестов, что приводит к качественному дизайну системы и уменьшает риск возникновения дефектов. Что насчет того что не производится «реальная работа»? Прежде чем я раскрою эту тему я хочу затронуть еще один момент. Моя точка зрения в том, что:
Непрерывно поддерживать высокую продуктивность возможно только
практикуя дисциплину Test Driven Development.
Хотя противоположное мнение тоже довольно распространено (например, видео на это тему).
Test Driven Development
Test Driven Development — это дисциплина. Дисциплина подразумевает ограничение, которое мы на себя накладываем, применяя ее. Это не Red-Green-Refactoring, а ряд конкретных правил:
- Пока у вас нет падающего юнит-теста, вы не можете писать продакшн-код.
- Вам запрещается писать больше кода юнит-теста, чем достаточно для его падения. Любая ошибка компиляции — это падение. Вы сразу останавливаетесь писать юнит-тест, как только он упал, даже с ошибкой компиляции.
- Вам запрещается писать больше продакшн кода, чем достаточно для прохождения одного падающего юнит-теста, и вы не можете писать тот продакшн код, который не относится к конкретному падающему юнит-тесту.
Мы не просто пишем тест, а потом реализацию — не просто Red-Green-Refactoring, это дополнительные ограничения. Это — Test Driven Development — то, что позволяет поддерживать нашу систему в качественном состоянии и поддерживать максимально высокую продуктивность на протяжении длительного периода времени.
Легаси код
Согласно определению, данному Michaels C. Feathers, легаси-код — это код без юнит-тестов. Все просто. Я в своей практике замечаю прямую зависимость между отсутствием тестов и наличием огромнейшего числа проблем с дизайном системы, а также наличием интегрированных тестов и примерно такой же зависимостью с проблемами дизайна системы. Чем меньше маленьких изолированных тестов, тем больше проблем с дизайном системы.

Когда тестов нет, это легаси.
Мне нравится другое определение, которое менее точное, но отражает действительность.
Легаси код — это код, который страшно изменять.
Дейв Томас как-то сказал примерно следующее: «Я в некоторых случаях вообще не пишу тесты, я и так могу хорошо спроектировать качественную систему.»
Во-первых, у него за плечами огромное количество опыта юнит-тестирования. Во-вторых, когда я буду работать с такой системой без тестов, для меня эта система будет легаси, потому что мне будет страшно вносить в нее изменения. Страх внесения изменений — основная причина загнивания кода. Дисциплина Test Driven Development — лекарство. При приверженном использовании этой дисциплины страх внесения изменений уходит, так как вы получаете обратную связь по каждой строчке вашего кода.
Роберт Мартин предлагает, чтобы в нашей профессии мы давали клятву, аналогичную клятве Гиппократа для врачей. Я привожу ее здесь для того, чтобы наглядно продемонстрировать, почему юнит-тесты, как минимум, важны для нашей индустрии, и, как максимум, Test Driven Development, как дисциплина, важна для нас, как программистов.
Клятва программиста
С целью защитить и сохранить честь профессии программистов, я обещаю, что в меру своих возможностей и суждений:
1. Я не буду создавать вредоносный код.
Это относится не только к вирусам, но и к коду, который создает убытки для нашей компании. Если мы написали код, который принес компании убытки — это вредоносный код.
2. Код, который я создаю, всегда будет моей лучшей работой.
Я не буду сознательно допускать, чтобы мой код был дефектен, как в поведении, так и в структуре. В поведении, понятное дело, мы не можем гарантировать его корректность, если у нас нет какой-то проверки. В структуре, если нет маленьких изолированных юнит-тестов, мы не можем гарантировать, что дизайн нашей системы тестопригоден и качественен.
3. Я буду предоставлять с каждым релизом быстрое, надежное и повторяемое доказательство того, что каждый элемент кода работает так, как должен.
Важность этого пункта особенно заметна если увидеть сколько денег тратят многие компании на ручное тестирование, на то что можно и автоматизировать, и одновременно использовать для повышения качества кода, и как следствие для ускорения разработки.
4. Я буду делать частые, небольшие релизы, чтобы не мешать прогрессу других.
Для того, чтобы поставлять быстро, нам нужно делать маленькие релизы. Делать маленькие релизы с достаточной степенью качества без тестов лично я не могу.
5. Я буду бесстрашно и неустанно улучшать свой код при каждой возможности. Я никогда не буду снижать его качество.
Для того, чтобы рефакторить код, нам нужно не бояться его изменять. Мой старый паттерн выглядел следующим образом: я вижу место в системе и 2 способа внести изменения в эту систему: легкий способ («костыль») и сложный способ, когда мне нужно провести серьезный рефакторинг.
Если у меня нет тестов, я серьезно менять структуру предметную область не стану, потому что я могу что-то сломать. А я не хочу что-то ломать, поэтому я выбираю легкий способ.
С юнит-тестами у меня такой проблемы нет. Практикуя Test Driven Development, проблем нет вообще — у меня код всегда корректен. Если там что-то ломается, это боль для меня как для профессионала, потому что я чувствую, что я где-то облажался, так как ситуация была под моим полным контролем. Лично для меня возникновение дефектов — это прямо серьезный вызов.
6. Я сделаю всё что смогу, для того чтобы сохранять продуктивность самого себя и других как можно выше. Я не буду делать ничего, что снижает эту продуктивность
Часто говорят, что Test Driven Development снижает продуктивность, или повышает ее, когда мы его долго практикуем. На самом деле он сохраняет продуктивность на постоянном уровне.
Наша задача не в том, чтобы двигаться быстрее, наша задача — двигаться с постоянной скоростью и сделать так, чтобы мы избавились от потерь, связанных со слабыми архитектурными решениями.
Test Driven Development позволяет нам это делать.
7. Я буду постоянно следить за тем, чтобы другие могли подменить меня, а я мог бы подменить их
Если я вижу код другого человека, и там нет тестов, для меня это проблема. Я могу разобраться, что там происходит, но мне страшно вносить туда изменения, так как я могу что-нибудь не учесть. Если у нас в команде практикуется парное программирование и полное покрытие юнит-тестами, нам очень легко друг друга подменять и работать над разными частями системы — все в безопасности.
8. Я буду давать оценки, которые являются честными как в их правильности, так и в точности. Я не буду давать обещания без уверенности в том, что смогу их сдержать
Если у нас есть страшное легаси, и мы говорим, что это займет неделю, а потом мы откапываем место с плохим кодом, эта неделя превращается в три — очень частое явление с легаси-кодом.
9. Я никогда не перестану изучать свое ремесло
Маленькое упражнение
Предлагаю вам проверить утверждение, что Test Driven Development позволяет держать продуктивность на максимальном постоянном уровне. Я хочу, чтобы вы попробовали у себя в продукте найти часть системы, которую вы считаете хорошо спроектированной, на которую, может быть, есть тесты, но они интегрированые, и попробовать написать на эту часть системы маленький изолированный юнит-тест. Дальше я покажу, как я их лично пишу.
Степень дискомфорта, который вы будете испытывать, соответствует степени качества этой системы. Маленький изолированный тест даст вам понимание того, насколько ваша система хорошо или плохо спроектирована.
Если вы поймете, что система спроектирована не очень, это повод задуматься о том, чтобы начать применять Test Driven Development.
Простейший пример

Есть клиент, который зависит от сервера. Клиент контекстно независим, тестировать его очень легко. Мы просто вызываем методы и смотрим на выходящий результат. Тестировать сервер сложнее, сейчас он гвоздями связан с клиентом. Для того, чтобы протестировать его независимо, нам нужно их разделить.
Мы посередине должны вставить интерфейс. Теперь мы можем тестировать сервер, независимо от клиента. Наверное, многие слышали совет программировать на основе интерфейса, а не реализации, но не понимали, почему этот совет хорош.
Это демонстрация того, почему это так. Если мы хотим писать маленькие изолированные юнит-тесты, которые помогают нам с проектированием нашей системы, мы должны как-то разделять наши компоненты. Для того, чтобы их разделять, нам нужно посередине что-то вставлять. В данном случае это интерфейс.
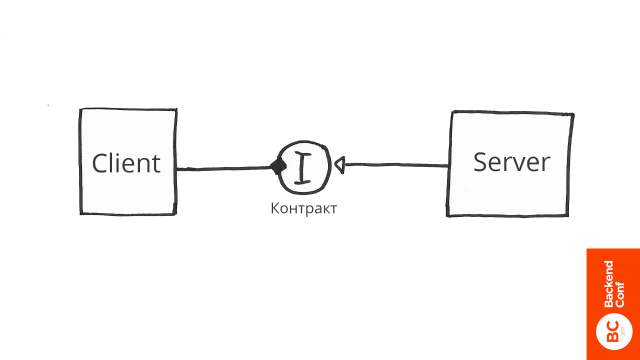
Интерфейс — это не просто набор методов и сигнатур входящих и выходящих параметров. Интерфейс — это также контракт, то есть то ожидание клиента, которое должно быть удовлетворено, когда он что-то спрашивает у интерфейса.
Допустим, мы просим интерфейс, вернуть активных пользователей. Не достаточно просто проверить, что у нас в выходящем параметре массив пользователей. Нам нужны именно активные. Поэтому мы пишем тест, в котором мы спрашиваем: «Интерфейс, пожалуйста, дай нам активных пользователей!»
И имитируем реальную работу — потому что нам реальную работу делать не нужно, мы пишем изолированный тест.

Stub-ом возвращаем какое-то значение:
- Пустой массив —значит, пользователей нет.
- 1 пользователь — сразу вводим в профиль одного пользователя.
- Если пользователей много, выводим список таблиц.
Все — мы написали три теста. Теперь наша задача сделать так, чтобы контракт выполнялся в какой-то реализации. Мы реально лезем в базу данных, что-то достаем и проверяем, что мы действительно достаем активных пользователей. Действуем в соответствии с контрактом интерфейса.
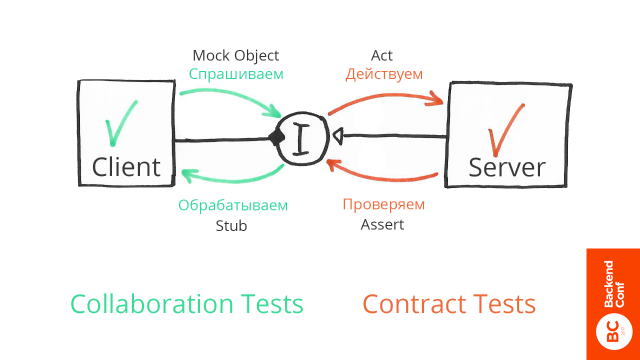
Таким образом, слева мы конкретно задаем, как ведет себя наша система при различном результате работы интерфейса, справа — что система действительно исполняет ожидания, в результате получаем, что у нас все вместе работает.
Нам не нужно тестировать клиент и сервер вместе для того, чтобы проверить их корректность. Достаточно того, что мы:
- правильно спрашиваем,
- правильно обрабатываем,
- правильно действуем,
- правильно проверяем.
Этого достаточно.
The 4 Rules of Simple Design
Эта концепцию придумал Кент Бек. В порядке приоритета система может считаться простой, если она проходит все тесты.
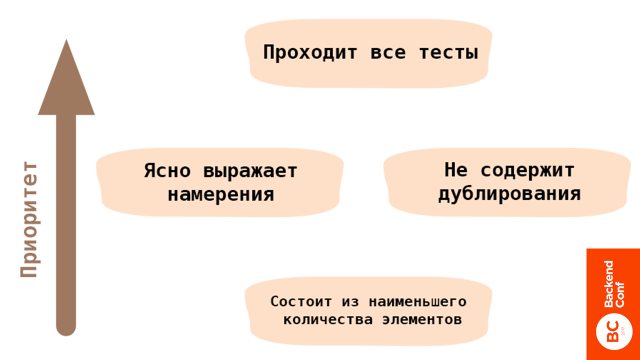
Если тестов в системе нет или код не проходит тесты, он простым считаться не может, как минимум, потому что вязкость системы очень большая. Такой код страшно изменять и это — проблема, потому что система начнет загнивать. В итоге продуктивность будет падать.
Тесты — обязательное условие для того, чтобы код считался простым.
Дальше мы можем сконцентрироваться на прояснении наших намерений. Не помню, кто сказал, что код должен читаться, как хорошо написанная проза. После того, как у нас работают все тесты, мы можем позаботиться о том, чтобы наш код читается, как хорошо написанная проза, и удалить ненужное дублирование.
В самом конце мы можем уже подумать о том, чтобы наша система состояла из наименьшего количества элементов.

Я советую вам добавить этих ребят в друзья в соц. сетях:
- Kent Beck — основатель движения экстремального программирования и дисциплины Test Driven Development.
- J. B. Rainsberger — основатель компании JetBrains.
- Robert Martin — уверен, вы про него знаете, если нет — дайте максимальный приоритет чтению его блога и книг.
Подпишитесь на них, берите с них пример, читайте блоги, изучайте то, что они пишут.
Что дальше?
Я хочу бросить вам вызов. Возвращаюсь к маленькому упражнению: попробуйте взять часть системы, которую вы считаете хорошо спроектированной, и написать на нее маленький изолированный юнит-тест.
Скорее всего, вы столкнетесь с тем, что вы это сделать не можете, и если вы решите что-то с этим сделать, то советую вам посмотреть на эти ресурсы:
https://cleancoders.com
https://online-training.jbrains.ca/p/wbitdd-01
Спасибо вам за приверженность в прочтении этой статьи.
Вы можете написать Андрею в телеграмм https://t.me/akolomensky для того чтобы задать вопросы или спросить совета по инженерным, процессным или продуктовым кейсам, он обещал всем ответить, поэтому не стесняйтесь.
Хотим заметить, разве не для того, чтобы соответствовать пункту клятвы «Я никогда не перестану изучать свое ремесло», и непрерывно совершенствоваться, мы с вами встречаемся на конференциях. Ведь интенсивный поток идей и случаев из практики, получаемый на конференциях, дает толчок к самосовершенствованию, как минимум на полгода. А чтобы, график развития не выглядел, как плохой график продуктивности, пора получить новый заряд — фестиваль РИТ++ будет 28 и 29 мая, а Highload++ Siberia 25 и 26 июня в Новосибирске. На последнюю до 30 апреля можно успеть подать заявки.
Программу РИТ++ по направлениям, в том числе BackendConf, мы уже начали формировать и можно начинать прикидывать, что вам будет особенно полезно, и бронировать билеты. Например, в тему этой статьи заявка Юрия Бадальянца из 2ГИС на тему «Интеграционное тестирование микросервисов на Scala». Он тоже считает, что одного юнит-тестирования часто недостаточно, и необходимо применять и интеграционное тестирование.
Комментарии (48)
Druu
12.04.2018 03:56+2> Нам нужен какой-то инструмент получения обратной связи от системы, который помогал бы понимать, как мы должны проектировать нашу систему.
Называется «мозг». Мозг позволяет проверять систему на соответствие архитектуры тем или иным свойствам, а вот юнит-тесты — нет.
ApeCoder
12.04.2018 11:10+2Называется «мозг».
Мозг ошибается. Именно по этому люди придумали тестирование, типы, компиляторы и прочее. Время мозга дорого. Именно поэтому люди используют языки высокого уровня, IDE и прочее.
Мозг позволяет проверять систему на соответствие архитектуры тем или иным свойствам, а вот юнит-тесты — нет.
А слабо привести аргументы?

onedev_link
12.04.2018 11:16Юнит–тесты, написанные через TDD, позволяют моему мозгу принимать более качественные архитектурные решения, а также улучшать дизайн системы. Без них — анрил, особенно в командной разработке сложной системы.
Druu
12.04.2018 11:31+1> Юнит–тесты, написанные через TDD, позволяют моему мозгу принимать более качественные архитектурные решения, а также улучшать дизайн системы.
А каким, собственно, образом? Смотрите, вы привели ряд параметров:
rigidity, fragility, immobility, needless repetition, needless complexity, opacity, viscosity
которые определяют качество вашей системы.
Из них всего один (viscosity) связан с тестами. Это выделение viscosity как параметра в принципе выглядит весьма искусственно, не правда ли? Нужны какие-то более конкретные соображения в пользу того, что архитектура, позволяющая простое юнит-тестирование — это хорошая архитектура (а не наоборот). Ведь кто гарантирует, что, снижая viscosity, вы не ухудшаете все остальные показатели? Архитектура должна строиться исходя и ряда конкретных требований. Простота юнит-тестирования _может_ быть _одним из_ таких требований (и уж точно никогда она не будет в ряду основных).onedev_link
12.04.2018 11:59+1Юнит-тесты являются основой, на которой строится качественная архитектура.
Как вы будете производить рефакторинг, не имея уверенности что вы не внесете дефект? Как ваша команда будет безопасно интегрировать изменения и без страха устранять любые моменты плохо выражающие требования? Что позволит вам набраться храбрости на серьезное изменение структуры, если вы вдруг обнаружите что она не оптимальна?
Я уверен, существуют исключения, но как правило в среде, где рефакторинг означает «я поменяю структуру системы без изменения поведения, и возможно внесу в систему явные и скрытые дефекты» вынуждает разработчиков обходить проблемные места стороной, особенно под давлением сроков. Результат — загнивание системы и замедление разработки.
Проверьте, попробуйте написать юнит-тест на ваш текущий модуль, с полной изоляцией зависимостей. Любые сложности с которыми вы столкнетесь, будут связаны с одним из этих свойств. Обычно жесткость (сильная связанность) будет основной проблемой.Druu
12.04.2018 12:21> Юнит-тесты являются основой, на которой строится качественная архитектура.
Это утверждение, которое как раз и следует доказать. Каким именно образом простота юнит -тестирования приводит к улучшению (а не к ухудшению, например) архитектуры? Вы же сами привели 7 параметров качества архитектуры. И лишь один из этих параметров у вас с юнит-тестами улучшается. Как на счет остальных 6?
> Как вы будете производить рефакторинг, не имея уверенности что вы не внесете дефект? Как ваша команда будет безопасно интегрировать изменения и без страха устранять любые моменты плохо выражающие требования?
Ну вот, признаюсь вам как на духу — при наличии одного нормального интеграционного теста моя уверенность при рефакторинге гораздо выше, чем при наличии десятка-другого юнит-тестов, которые ничего не тестируют.
> Что позволит вам набраться храбрости на серьезное изменение структуры, если вы вдруг обнаружите что она не оптимальна?
Берешь и меняешь. Мы тут обсуждаем работу взрослых людей, профессионалов, или выезд детсада на пикник? Что это еще за «набраться храбрости»? «Не могу фичу внедрить, мне страшно»? Инфантилизм какой-то возведенный в абсолют, уж простите.
> Любые сложности с которыми вы столкнетесь, будут связаны с одним из этих свойств.
Ну слушайте, сложность по факту одна — куча зависимостей. Эта сложность принципиальная — ее невозможно устранить. И все попытки устранения, которые я видел, приводили лишь к общему снижению качеству архитектуры. Хотя, да, юнит-тесты в итоге писать было проще.
Видите, в чем проблема: тесты (в общем, и юнит-тесты даже в бОльшей степени) есть лишь обслуживающий элемент системы. И лучший обслуживающий элемент — это тот, который выполняет свои задачи максимально незаметно. Если вам тесты начинают диктовать архитектурные решения, то это сродни тому, что уборщица начнет диктовать распорядок дня работникам офиса, в котором она убирается. Что с такой работницей будет? Она пойдет на мороз. То же следует делать и с тестами. Если какой-то подход к тестированию плохо ложится на вашу систему — это проблема подхода. Не системы.onedev_link
12.04.2018 12:41> Берешь и меняешь. Мы тут обсуждаем работу взрослых людей, профессионалов, или выезд детсада на пикник? Что это еще за «набраться храбрости»? «Не могу фичу внедрить, мне страшно»? Инфантилизм какой-то возведенный в абсолют, уж простите.
Обычно так: «Для того чтобы правильно имплементировать это требование нужно изменить структуру 2х модулей. Один модуль связан с адресацией, второй с контрактами. Есть интеграционные тесты, но они тестируют только ограниченное количество вариаций. Если я где-то накосячу, а QA не обнаружит дефект то у компани из-за меня будут проблемы, очень вероятно финансовые, а мне это не нужно. Сделаю-ка я чуть-чуть по-другому.»
Альтернативное мышление в виде «Я проведу рефакторинг, а QA пусть ищет дефекты» не лучше.
>> И все попытки устранения, которые я видел, приводили лишь к общему снижению качеству архитектуры. Хотя, да, юнит-тесты в итоге писать было проще.
Если стало проще писать тесты, значит стало проще поддерживать систему в корректном состоянии и обеспечивать безопасный рефакторинг. Единственное исключение, при котором это не является преимуществом — ранняя валидация бизнес–модели.
В западных странах в нормальную компанию на позицию Senior бекэнд разработки не возьмут без навыков написания юнит-тестов. В Silicon Valley это ~99% компаний практикующие гибкие подходы к разработке, большая часть также использует TDD.Druu
12.04.2018 12:45+1> Обычно так:
Замечательно. Человек осознает все риски и даже предлагает варианты решения проблемы. А какую альтернативу предлагаете вы? Самообмануться и убедить себя в том, что «если я где-то накосячу, а QA не обнаружит дефект, то у компани из-за меня не будет проблем, ведь волшебные юнит-тесты не дадут мне накосячить!11!»?
> Если стало проще писать тесты, значит стало проще поддерживать систему в корректном состоянии и обеспечивать безопасный рефакторинг.
Есть какие-то аргументы в пользу этой точки зрения? Потому что обратные есть.
> В западных странах в нормальную компанию на позицию Senior бекэнд разработки не возьмут без навыков написания юнит-тестов.
Тут начать надо с того, что само понимание юнит-тестов у всех разное. Примерно в 50% случаев под юнит-тестами подразумеваются тесты вполне себе интеграционные.onedev_link
12.04.2018 12:51Да, именно. Я предлагаю жесткую дисциплину: ни одной строчки кода без быстрой, автоматизированной проверки его поведения. Я предлагаю писать код так чтобы QA обнаруживал 0 дефектов. TDD — единственная дисциплина которая может позволить реализовать это.
Это тяжело. Это очень тяжело. И это профессионально.
> Есть какие-то аргументы в пользу этой точки зрения?
Опыт индустрии за последние 25 лет. Попробуйте пройти bowling kata game, это будет как один из примеров как это работает.Druu
12.04.2018 12:59> TDD — единственная дисциплина которая может позволить реализовать это.
Но она не позволяет. Как минимум потому, что подавляющее большинство ошибок — интеграционные и юнит-тестами не могут быть пойманы by design. После разговора с вами у меня появилась абсолютно четкая уверенность в том, что TDD — исключительно вред. Потому что дает программисту чувство ложной уверенности в корректности тогда, когда для этой уверенности нет ровно никаких причин.
> Опыт индустрии за последние 25 лет.
То есть, никаких логических соображений нет? Хорошо, давайте обратимся к опыту. Можно с ним как-то ознакомиться?onedev_link
12.04.2018 13:11Логические соображения описаны мастерами в книгах и выступлениях, я привел их в статье, а также привел свои аргументы. Могу сконтачить с J.B.Rainsberger, Кент Беку можно написать в фейсбук.
Druu
12.04.2018 13:17+1> Логические соображения описаны мастерами в книгах и выступлениях, я привел их в статье, а также привел свои аргументы.
В статье? Это замечательно, я, видимо, пропустил. Можно уточнить, где и в каком конкретном месте были описаны соображения о том, как и за счет чего внесение изменений в архитектуру для упрощения юнит-тестирования приводит к улучшению этой архитектуры? Я нашел только что-то вида: «хорошая архитектура — это та, в которой просто писать юнит-тесты, по-этому архитектура, в которой просто писать юнит-тесты — хорошая». Меня лично подобный вид рассуждений по очевидным причинам не устраивает.
Я могу даже конкретный вопрос задать — каким образом вы обеспечите переработку графа зависимостей, сохранив семантику и разделение ответственностей модулей системы?onedev_link
12.04.2018 13:50Работа с Legacy это отдельный большой топик. Если тестов нет, то обычно применяется Golden Master и верхнеуровневые Acceptance тесты. Далее в зависимости от стратегии, самый простой вариант — писать новые классы с явным контролем зависимостей, изменяемые части системы постепенно выносить в отдельные классы и покрывать тестами.
Если есть тесты, но они интегрированные, коротко алгоритм следующий:
Вижу что не могу написать изолированный тест — слишком много зависимостей. Просто беру и повышаю уровень абстракции, одновременно лучше выражая намерения за счет качественного подбора имени и названий методов. Зависимостей становится меньше, становится возможным написать изолированный тест.
Если в модуле больше 3-4 зависимостей, очень вероятно нарушение SRP. Наиболее вероятный алгоритм действий — прояснять выражаемые зависимостями намерения благодаря объединению нескольких раздельных зависимостей под одним понятием.
Тем самым мы:
- Увеличили количество элементов в системе
- Повысили количество абстракции
- Лучше прояснили намерения
- Вероятней всего обеспечили SRP и OCP
- Сделали возможным написание изолированных тестов с разделением на тесты контракта и коллаборации
Иногда, особенно если используется сервис-локатор, происходит просто взрыв новых, самых разнообразных классов. Просто аккуратно распихиваем ответственности по своим местам для SRP и OCP.
Есть много нюансов. В частности DDD помогает лучше сформировать выражения намерений, а также еще хочется добавить что наибольший результат этот подход дает для продуктов которые уже нашли свою бизнес–модель. Стартапам не нужно поддерживать продуктивность разработки на постоянном уровне.Druu
12.04.2018 15:43> Вижу что не могу написать изолированный тест — слишком много зависимостей. Просто беру и повышаю уровень абстракции, одновременно лучше выражая намерения за счет качественного подбора имени и названий методов. Зависимостей становится меньше, становится возможным написать изолированный тест.
Извините, но:
1. не становится
2. попытка подобрать более хорошие имена и названия привет, скорее, к обратному результату.
Вы, видимо, не можете понять проблему, о которой речь. Я подробнее объясню. Вот вам дан граф зависимостей. Не обязательно это легаси система — может быть этот граф является просто условным иделаьным выражением требований к системе. Вы понимаете, что вот для такой системы вам будут нужны модули X, Y, и так далее, каждый из которых имеет определенную ответственность и, в силу этой ответственности, требует связи с некоторыми другими модулями.
Потом оказывается, что данный граф плох для тестов (чисто математическое свойство, никак не связанное с устройством, назначением, функционированием вашей системы) и вам надо сделать из него другой граф, который этим свойством обладать не будет (чисто математическое преобразование).
И вот тут-то и возникает проблема — после данного преобразования все ответственности окажутся размыты совершенно случайным образом, модули утратят всю семантику (вы даже не сможете дать им никаких названий, кроме условных foo42 или bar100500, так как ни один из модулей не будет делать ничего осмысленного) и в принципе это все превратится в невменяемый хаос. Естественно, что _чисто случайно_ данное преобразование может перевести ваш граф в некую так же осмысленную форму. Но, подчеркиваю — чисто случайно. Да, полученную систему будет легко тестировать. Но называть ворох бессмысленных модулей с именами вида foo42 «хорошей архитектурой» у меня язык не поворачивается, уж извините.ApeCoder
12.04.2018 16:39+1Вы понимаете, что вот для такой системы вам будут нужны модули X, Y, и так далее, каждый из которых имеет определенную ответственность и, в силу этой ответственности, требует связи с некоторыми другими модулями.
Потом оказывается, что данный граф плох для тестов (чисто математическое свойство, никак не связанное с устройством, назначением, функционированием вашей системы)С чего вы решили что оно никак не связанное?
Druu
13.04.2018 03:08> С чего вы решили что оно никак не связанное?
А с чего ему быть связанным? Есть какие-то причины?ApeCoder
13.04.2018 08:07Разщумеется. Тесты это выражение требований. Структура программы — это язык на котором вы их выражаете. Если выражать требования на составленном вам языке неудобно, то язык неадекватен.
Вы же не пишете тесты с названиями типа
"Если на вход подать 2 функция должна возарвтить 3"?
onedev_link
12.04.2018 16:44Если граф плох для быстрой, автоматизированной проверки, это является явным маркером сильного связывания. Что приводит к жесткости, хрупкости, непереносимости, нарушению SRP и OCP.
Название должны ясно выражать намерения. Вы можете привести пример из класса, состоящего из 3-4-5 зависимостей, я сделаю из него класс с 1-2 зависимостями, причем они будут лучше выражать намерения чем те зависимости. Есть исключения, многопоточность, Observer-ы, но в целом задача решается.Druu
13.04.2018 03:19> Если граф плох для быстрой, автоматизированной проверки, это является явным маркером сильного связывания.
Смотрите, допустим у нас есть уже идеальная структура модулей. Естественно, в ней будут модули с большим количеством зависимостей. При этом если вы переработаете структуру так, чтобы в ней не было модулей с большим количеством зависимостей — станет только хуже просто по определению.
> Название должны ясно выражать намерения.
Но если у модуля нет намерений, то и выразить их не выйдет. Кроме того, если вы увеличиваете количество модулей, то и количество зависимостей, в общем случае, будет расти. Собственно, большое количество мелких модулей — как раз и есть причина роста количества зависимостей.
> Вы можете привести пример из класса, состоящего из 3-4-5 зависимостей, я сделаю из него класс с 1-2 зависимостями
Ну допустим у вас есть модуль, в нем требуется получить данные из базы (1 зависимость), провести некий расчет согласно определенным требованиям (вторая зависимость), заапдейтить состояние базы согласно результату расчета (третья зависимость), согласно определенным настройкам (которые можно получить через четвертую зависимость) отправить какое-нибудь оповещение (пятая зависимость) и что-нибудь залогировать (шестая зависимость) по ходу выполнения всего этого. Чтобы уменьшить количество зависимостей надо либо исключить какие-то действия в принципе (что делать нельзя), либо включить зависимость в текущий модуль (что тоже делать нельзя), либо выделить несколько действий в отдельный модуль (например, сгруппировав действия по два вы получите модуль с тремя зависимостями), что приведет к существованию огромного количества бессмысленных искусственных модулей, структура которых к тому же будет прибита к деталям реализации.ApeCoder
13.04.2018 08:25Чтобы уменьшить количество зависимостей надо либо исключить какие-то действия в принципе (что делать нельзя),
Почему нельзя? Зачем тесту проверяющему правильность расчета (или интеграции расчетного модуля) проверять сразу и базу и логгирование.
Вообще говоря если задача модуля интеграция других модулей то его можно покрыть интеграционными тестами см focused integration tests
VolCh
13.04.2018 11:20Можно разбить модуль, например так:
- переносим получение из базы, расчёт и апдейт в отдельный модуль с тремя зависимостями, у оригинального становится четыре зависимости, да ещё он становится в идеале persistence ignorance.
- переносим условие оповещения и оповещение в отдельный модуль с двумя зависимостями, оригинальный становится с тремя зависимостями.
Вместо одного модуля с 6 зависимостями получаем 3 модуля с 2-3 зависимостями, причём юнит-тесты оригинального сводятся к проверке что результаты вызовов двух стабов (даже не моков) логируются.
VolCh
12.04.2018 13:40+1Видите, в чем проблема: тесты (в общем, и юнит-тесты даже в бОльшей степени) есть лишь обслуживающий элемент системы. И лучший обслуживающий элемент — это тот, который выполняет свои задачи максимально незаметно.
С одной стороны, тесты, да, — обслуживающая система. С другой — они такой же клиент системы под тестом, как её целевые клиенты. Если код ещё не написан даже, а нам уже сложно написать тест к нему, работающий с кодом так же как целевой клиент, то есть подозрение, что целевой клиент ещё сложнее чем тест будет писать.
Druu
12.04.2018 15:48Это верно для интеграционных тестов, но не для модульных. Смотрите — клиент о вашей системе всегда знает только апи, и проблемы клиента — это проблемы плохого апи.
Модульные тесты же — это особый клиент, который знает не только об апи, но и о реализации, и в этом-то и состоит проблема данного особенного клиента. Другие клиенты такой проблемы иметь просто не могут от слова никак.VolCh
12.04.2018 18:37Знания этого особого клиента о реализации, имхо, применять нужно в исключительных случаях. И чисто оценочно таких случаев быть не должно, если приложение строится по TDD.
Грубо говоря, наи не нужно проверять в тестах, что после вызова сеттера записалось значение в приватное свойство, нам нужно проверять хотя бы, что геттер соответствующий возвращает это значение.
В целом, модульные тесты не должны знать деталей реализации, они должны знать контракт модуля и проверять как модуль его соблюдает, что его поведение соответствует тому поведению, которое от него ожидают клиенты. По хорошему, даже мокать зависимости и проверять, что модуль их вызывает в определенных ситуациях — это уже интеграционные тесты, в модульных должны быть тупые стабы, которые просто дают вызвать себя и возвращают конкретное значение, игнорируя параметры и не фиксируя факт вызова. Исключение, разве что, модули, основная ответственность которых преобразовывать свой вызов в вызовы зависимостей по правилам которые диктует клиент. Не знаю, декораторы, например. Декорируемые ими модули для них не просто инструментальные зависимости, а основной объект ответственности. Модульный тест на декоратор должен использовать умный мок, который не просто не даст модулю закрашится, но и даст возможность проверить, что до декорируемого объекта вызов дошёл, если клиент не получил ошибки.
Druu
13.04.2018 03:25> В целом, модульные тесты не должны знать деталей реализации
Не знать детали реализации = не использовать моки и стабы. Это два эквивалентных требования. Конечно, если моков и стабов нет, то все ок. Но тогда:
1. Либо ваш тест не модульный
2. Либо в нем нет зависимостей в принципе
На практике 90% модульных тестов содержат зависимости и, с-но, моки и стабы. А значит, они прибиты к своей реализации. Ну и это, в общем, главная причина, по которой ТДД подход и критикуется.
> в модульных должны быть тупые стабы, которые просто дают вызвать себя и возвращают конкретное значение, игнорируя параметры и не фиксируя факт вызова
Что работает исключительно в тех случаях, когда смысл вызова метода не состоит в исполнении эффектов. Всегда почему-то при обсуждении тестов рассматриваются наиболее простые и удобные кейсы. Но, видите ли в чем дело, в простых и удобных кейсах, откровенно говоря, и обсуждать-то нечего. Там все тестируется элементарно любым способом, хоть стоя на голове и жонглируя шариками в процессе. Интересно рассмотреть как раз кейсы сложные.ApeCoder
13.04.2018 08:31Завивит от того, что вы называете моком. Если SUT требует ILogger то передать ему InMemoryLogger а потом узнать у InMemoryLogger что в нем лежит — не будет прибитостью к реализации
VolCh
13.04.2018 11:30Это будет прибитостью к контракту ILogger. Причём в общем случае в изолированных юнит-тестах даже не нужно узнавать у InMemoryLogger что там лежит, достаточно NullLogger. InMemoryLogger приберечь для интеграционных тестов, проверяющих правильно ли SUT интегрируется с ILogger.
ApeCoder
13.04.2018 11:38ILogger это часть интерфейса SUT, а не реализация. Так что прибитость к ILogger это ok.
SUT не может интегрироваться с ILogger так как он интерфейс. А не другой юнит — это просто описание контракта и все.
VolCh
13.04.2018 13:30У меня дополнение было, а не опровержение :)
Модуль зависит от ILogger, он ничего больше не знает и взаимодействует именно с ним. Тестирование того, что он правильно взаимодействует с ILogger, дергает нужные методы, передаёт им нужные параметры, или ноборот не дергает в каких-то кейсах — это не интеграционное тестирование?
ApeCoder
13.04.2018 14:29Интеграционный тест — это тест который проверяет, как части работают вместе. То что часть X вместе с Y делает что-то полезное. Если мы заменяем часть Y на тестовый сабкласс тест очевидно не тестирует интеграцию частей нашей системы а только то, что часть X соблюдает свой контракт.
Так как Y не является частью системы.
А вот, например шор определяет так:
James Shore
Focused Integration Tests
Unit tests aren't enough. At some point, your code has to talk to the outside world. You can use TDD for that code, too.
A test that causes your code to talk to a database, communicate across the network, touch the file system, or otherwise leave the bounds of its own process is an integration test. The best integration tests are focused integration tests that test just one interaction with the outside world.VolCh
13.04.2018 18:07Не только то, что X соблюдает свой контракт, но и то, что при работе X использует Y его в соответствии с контрактом последнего.
И как тогда назвать тесты, которые проверяют взаимодействие модулей друг с другом в рамках одного процесса?
ApeCoder
13.04.2018 18:29В юнит тесте мы проверяем X на то, что если мы передали IY, то он делает то, что должен. IY это что-то, соблюдающее контракт IY, в частности Y.
Если мы кладем двигатель на стенд и подаем туда топливо из тестового стенда — это юнит тест двигателя.
Если мы подсоединяем двигатель к бензобаку это уже проверка интеграции двигателя и бензобака (хотя это может быть и тест двигателя, просто бензобак достаточно прост, чтобы быть жлементом тестового стенда).
И как тогда назвать тесты, которые проверяют взаимодействие модулей друг с другом в рамках одного процесса?
Фаулер считает что эти понятия размытые
Sociable and Solitary
Some argue that all collaborators (e.g. other classes that are called by your class under test) of your subject under test should be substituted with mocks or stubs to come up with perfect isolation and to avoid side-effects and a complicated test setup. Others argue that only collaborators that are slow or have bigger side effects (e.g. classes that access databases or make network calls) should be stubbed or mocked.
Occasionally people label these two sorts of tests as solitary unit tests for tests that stub all collaborators and sociable unit tests for tests that allow talking to real collaborators (Jay Fields' Working Effectively with Unit Tests coined these terms). If you have some spare time you can go down the rabbit hole and read more about the pros and cons of the different schools of thought.Я иногда называю и тесты которые тестирую интеграцию со внешними системами интеграционными, и тесты, которые тестируют какие-то связки модулей интеграционными. Так же юнит тест может использовать production реализацию зависимости, если она проста для употребления, но это будет юнит тест.
Talking about different test classifications is always difficult. What I mean when I talk about unit tests can be slightly different from your understanding. With integration tests it's even worse. For some people integration testing is a very broad activity that tests through a lot of different parts of your entire system. For me it's a rather narrow thing, only testing the integration with one external part at a time. Some call them integration tests, some refer to them as component tests, some prefer the term service test. Even others will argue, that all of these three terms are totally different things. There's no right or wrong. The software development community simply hasn't managed to settle on well-defined terms around testing.
Don't get too hung up on sticking to ambiguous terms. It doesn't matter if you call it end-to-end or broad stack test or functional test. It doesn't matter if your integration tests mean something different to you than to the folks at another company. Yes, it would be really nice if our profession could settle on some well-defined terms and all stick to it. Unfortunately this hasn't happened yet. And since there are many nuances when it comes to writing tests it's really more of a spectrum than a bunch of discrete buckets anyways, which makes consistent naming even harder.
VolCh
13.04.2018 11:27Чтобы использовать моки и стабы зависимостей тестируемого модуля не нужно знать детали его реализации в общем случае. Нужно знать контракт зависимостей, замокать/застабить его для проверяемых кейсов и передать тестируемому модулю (подразумевается, что модуль спроектирован с соблюдением DI и передача зависимостей входит в его публичный контракт для клиентов). Если в контракт модуля не входит делегирование вызовов зависимостям, то даже полноценные моки не нужны, просто тупые стабы.
ApeCoder
12.04.2018 14:29+1Если код трудно тестировать, он сильно связан. Сильно связанный код трудно менять и понимать. TDD стимулирует разбить систему на менее связанные части.
Druu
12.04.2018 16:37> Сильно связанный код трудно менять и понимать.
Это распространенное заблуждение. Верно будет, что труднее менять и понимать код, который плохо соответствует структуре предметной области. Если предметная область не предполагает сложных взаимосвязей — то и в вашей системе их не должно быть. Но если предполагает — они быть как раз должны, скорее всего.
Понимаете, в чем дело? Структура взаимосвязей между модулями должна определяться нуждами предметной области, а не неким абстрактным математическим свойством. Если вы сформировали хорошую, годно мапающуюся на предметную область структуру, а потом видоизменяете ее, чтобы было «проще тестировать» — это неправильно. Правильно выгнать эту уборщицу на ветер и выбрать другую, которая будет удовлетворять вашим требованиям.ApeCoder
12.04.2018 16:47+1Взаимосвязи есть наш способ видеть предметную область, а не только свойство предметной области. Тесты говорят "делай менее связано".
Вы можете их слушать и не слушать. Практика показывает что слушать имеет смысл. То есть если вам трудно тестировать надо понять почему а не тупо делать очередной мок. Сделать проще часто возможно, если подумать.
Если вы сформировали хорошую, годно мапающуюся на предметную область структуру, а потом видоизменяете ее, чтобы было «проще тестировать» — это неправильно.
Вот тут хотелось бы пример
Druu
13.04.2018 03:31> Вы можете их слушать и не слушать.
Уборщицу, которая вам указывает, когда приходить на работу, а когда — уходить, тоже можно слушать либо нет.
> То есть если вам трудно тестировать надо понять почему
Ответ простой — используемый подход к тестированию плохо согласуется с архитектурой вашей системы. Надо данный подход выкинуть (а не тупо лепить очередной мок, конечно же) и применить вместо него тот, который согласуется лучше (нанять уборщицу, которую устраивает установленный распорядок).ApeCoder
13.04.2018 08:05+1Уборщицу, которая вам указывает, когда приходить на работу, а когда — уходить, тоже можно слушать либо нет.
Я скорее всего пришлушаюсь к совету уборщицы. Потому, что я не работаю в говноконторе, где она советует это делать просто так. Если она мне посоветует не приходить на работу, скорее всего там какая-нибудь дератизация или что-то еще.
Ответ простой — используемый подход к тестированию плохо согласуется с архитектурой вашей системы.
Тут хотелось бы пример: может быть это вы просто не видите возможностей упростить систему, так же как не увидели возможность, что уборщица дает стоящий совет.
VolCh
12.04.2018 19:15+1Сильносвязанный код трудно менять. Это не заблуждение, а факт. Код, моделирующий сложную предметную область, трудно менять просто потму что предметная область сложная. Связанность кода не может быть меньше связанности в предметной области. Но кроме этой связанности есть ещё "паразитная" техническая, о которой эксперты предметной области не догадываются. Они говорят "вот теперь нужно, чтобы эта сложная штука взаимодействовала новым образом с вот этой новой сложной штукой, а не с той", но не догадываются, например, что старое взаимодействие в большой степени обеспечивалось тем, что состояние штук хранились в одной SQL-базе, что позволяло часть взаимодействия вынести в неё, а новая штука хранится в монго или файлах. Разработчики, осознанно (например в целях оптимизации) или не очень сделали сильную техническую связь. Ещё пример: есть абстрактный заказ и абстрактный счёт на него, примерно одинаковые — товары/услуги, единица измерения, цена, количество, стоимость и итого. Когда-то эксперт предметной области сказал "все пункты заказа должны переноситься в чек" и разработчики не мудрствуя лукаво сделали пункты заказа по совместительству и пунктами чека, банально сохраняя в чеке ссылку на заказ и выводя под видом пунктов чека пункты заказа, чем создали более сильную техническую связанность чем есть в предметной области — их никто не просил даже хранить связь чека и заказа. Потом, например, оказалось, что заказ может редактироваться задним числом, а чек — нет. Или в чек надо включать уже не всё. Или ещё что-то добавлять.
Стремление к простым тестам мешало бы вводить подобные технические связи. В идеале связанность кода должна быть равна связанности предметной области, но на практике она выше. Стремление к простым тестам позволяет снизить разницу в пределе к нулю.
Druu
13.04.2018 03:37> Сильносвязанный код трудно менять. Это не заблуждение, а факт. Код, моделирующий сложную предметную область, трудно менять просто потму что предметная область сложная. Связанность кода не может быть меньше связанности в предметной области.
Все так. Однако — тесты тут лишние. Надо просто стремиться к тому, чтобы код как можно лучше моделировал предметную область, то есть — достаточно полно и без лишнего. Зачем при решении данной задачи делать отсылку к тестам?
То есть:
> Стремление к простым тестам мешало бы вводить подобные технические связи.
Надо стремиться к простым связям (где это позволительно с точки зрения требований предметной области), а не к простым тестам. Напрямую.ApeCoder
13.04.2018 08:34+1Все так. Однако — тесты тут лишние. Надо просто стремиться к тому, чтобы код как можно лучше моделировал предметную область, то есть — достаточно полно и без лишнего. Зачем при решении данной задачи делать отсылку к тестам?
Это способ проверить на достаточно ли независимые части мы разбили систему. Это как предупреждение при компиляции — его можно игнорировать, но в большинстве случаев не стоит.
Зачем вообще тестировать? "Надо просто тремиться к тому", чтобы код был безошибочный.
Зачем видеть ошибки комплияции? "Надо просто тремиться к тому", чтобы код был сразу правильный.
VolCh
13.04.2018 11:41Тесты, их сложность служат индикатором количества "паразитических" зависимостей. Если открываем тест взаимодействия одной сложной штуки с другой сложной штукой и видим что там мокается (а то и подключается реальная) база, то это сигнал, что зависимость гораздо сильнее, чем описана экспертом. Если для тестирования подсчёта суммы в чеке нам нужно создавать заказ, а чек создаётся автоматически, то это тоже сигнальчик, если эксперт не заявлял, что чек должен создаваться только на основании заказа, а говорил, что на определенном этапе на базе заказа должен создаваться чек. Мы на пустом месте создали связь 1:1 чека и ордера вместо, хотя бы, 0..1:0..1
velvetcat
Не смог понять, в чем цель поста… Ну да ладно, допустим, я тупой.
Но вот конкретный вопрос (иду с конца).
Серьезно? 99,9% разработчиков ужаснутся при мысли о том, что им надо серьезно переделать код, намертво (если код плохой) или более-менее приемлемо (если код ок) склееный юнит- и интеграционными тестами.
Весь смысл в том, чтобы оптимизировать код еще при написании тестов, когда видно, что тест не складывается (например, слишком много дублирования в самих тестах).
onedev_link
4 Rules of Simple Design рассказывает о приоритизации. Без тестов безопасный рефакторинг невозможен, следовательно невозможно устранение дублирования и прояснение намерений.
Вы правильно говорите, нужно двигаться по циклу Red — Green — Refactor.
VolCh
В TDD при написании тестов мы не можем оптимизировать код, потому что его ещё нет. Максимум, что у нас есть к моменту когда упадёт тест не по синтаксическим причинам — это интерфейсы (в широком смысле слова). Вот их мы и можем оптимизировать пока реального кода нет.
zloddey
Тогда смотрите на две картинки с замкнутыми циклами ("Загнивание системы" и "Альтернативный вариант"). Вспомните собственный опыт: как вёл себя код при доработках, какие проблемы вылезали в тестах, какими способами их решали разработчики, какие последствия это вызывало.
В этих картинках и есть самый смак. Остальное — подсказки, каким образом с пути загнивания перейти на путь стабильного и быстрого развития.