
Это первый пост от лица нашей компании на Хабре и в нём мы хотим вам немного рассказать об архитектуре нашего облачного сервиса мониторинга серверов и веб сайтов CloudStats.me, с которым мы в данный момент проходим акселерацию во ФРИИ в Москве. Мы также хотим поделиться с вами нашей текущей статистикой и рассказать о планах на ближайшее будущее, но обо всём по порядку.
1. Архитектура системы
Наша платформа нацелена на системных администраторов, которым не хочется долго возиться с настройкой Nagios или Zabbix, а просто нужно отслеживать основные параметры серверов, не тратя много времени и ресурсов на мониторинг. Мы стараемся не перегружать интерфейс системы количеством настроек, поэтому всё построено по принципу KISS (keep it simple stupid).
Почти вся система написана на Ruby on Rails (за исключением python агента, которого мы скоро также заменим на агента на Ruby), с использованием RactiveJS. Front-end работает на Tomcat, нагрузка на которые распределяется с помощью Haproxy. В качестве CDN мы используем CloudFlare, через которую проходят только статичные файлы JS, CSS, PNG и т.д. Тем не менее, даже для такого достаточно простого и пока что не очень большого сервиса, нам уже приходится применять балансировку нагрузки на всех частях платформы для избежания перегрузок.
Архитектура сервиса на конец июня:
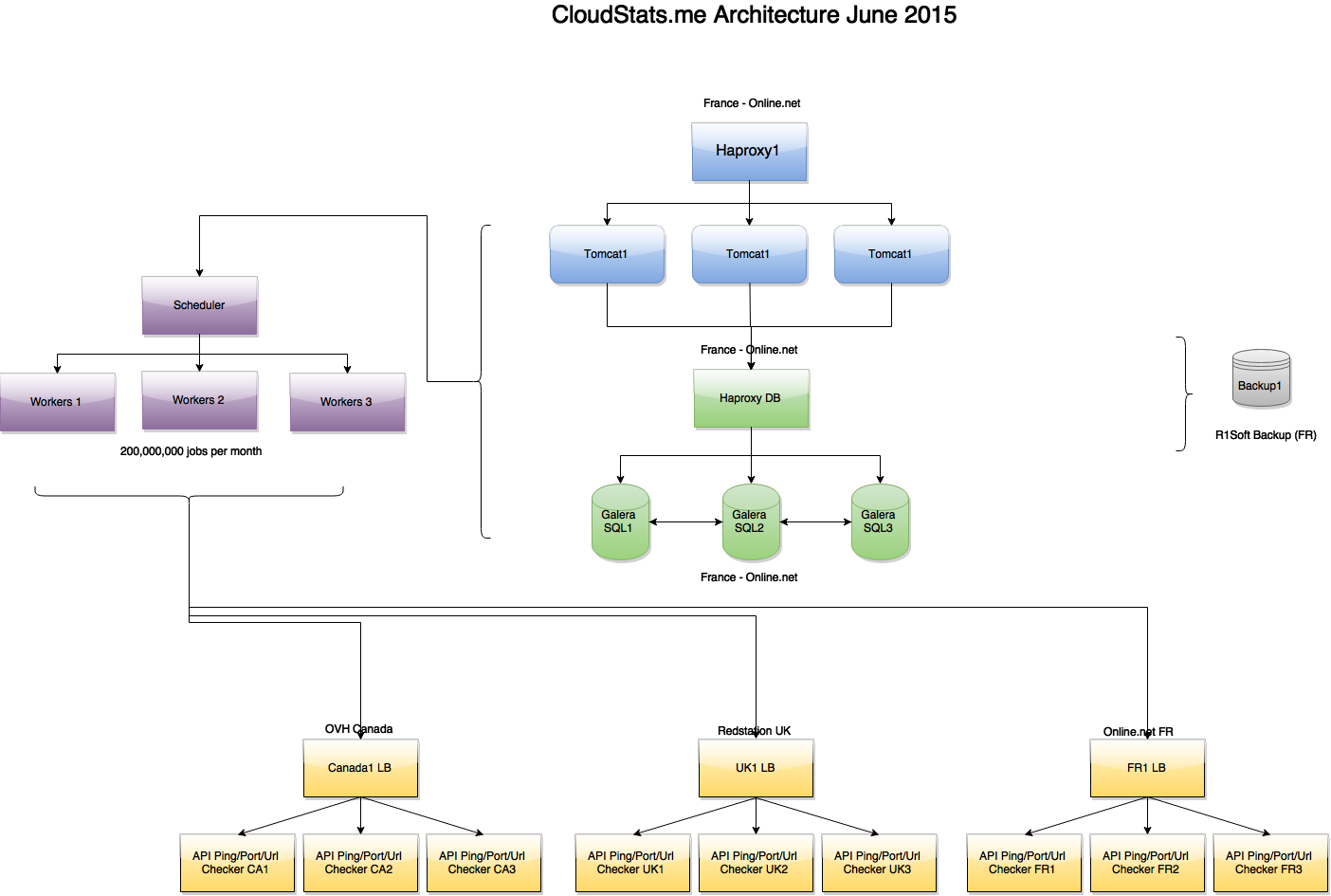
(большая картинка)
Как видно на картинке, задачи создаются отдельным нодом Scheduler и обрабатываются несколькими Worker нодами, которые в свою очередь связываются по API с серверами проверок Ping/Port/URL, расположенными в 3х зонах — France, UK, USA. Если один из серверов проверок вернул «Ping Failed» статус для какого-либо IP, то осуществляются дополнительные проверки в двух других зонах, чтобы исключить false positives. В будущем мы планируем вывести всё это во front-end чтобы вы смогли видеть, из каких локаций ваш IP недоступен (допустим, в ситуации с DDoS или routing issues).
Как мы писали ранее, мы используем master-master репликацию кластера Galera MariaDB и Haproxy перед ним. Haproxy установлены на всех участках нашей архитектуры, что позволяет нам как выкатывать новые версии продукта без ущерба для пользователей, так и обновлять backend системы без ухудшения сервиса. В дальнейшем мы планируем начать использовать партицирование.
2. Инфраструктура

Из датацентров, наш выбор пал на 3 достаточно распространённых ДЦ, которые нам позволяют держать затраты на инфраструктуру под контролем, а уровень сервиса на должном уровне.
Мы используем Online.net для наших серверов во Франции, где находится основной front-end системы. Выбор пал на Online.net, т.к. там присутствует удобная панель управления серверами, позволяющая быстро переносить IP адреса с одного сервера на другой, наличие удалённой консоли iDRAC, а также отсутствие ограничений по трафику и защита от DDoS атак. В Online.net мы использовали порядка 11 Tb трафика за июнь и за это не было никаких переплат, что удобно.
Дополнительные серверы, производящие проверки URL, Ping, и Ports, находятся в OVH Canada и Redstation UK, что даёт нам необходимый географический охват. Тем не менее, уже в июле мы завершим переезд на платформу Microsoft Azure, которая предоставит нам доступ к 15 датацентрам по всему миру. Это позволит увеличить количество локаций, откуда мы будем производить проверки серверов и сайтов, а также повысит отказоустойчивость платформы в целом (об этом мы напишем отдельно).
В данный момент мы уже производим порядка 200 миллионов проверок в месяц, что включает в себя пинги всех серверов (1352 сервера x 2 пинга в минуту x 60 минут x 24 часа x 31 день = ~120 млн. «ping jobs» в месяц), проверки URLs, а также проверки портов, сбор и обработку статистики по серверам и т.д.
3. Немного статистики:
В данный момент в нашу систему добавлено 1352 сервера, на которых установлен наш агент и которые каждые 4 минуты отправляют нам свою статистику. Вдобавок, мы проверяем каждый добавленный сервер с помощью внешнего ping'a 2 раза в минуту.
Серверы, добавленные в систему, в пиковый день 10 Июня 2015 генерировали до 1,6 Терабита трафика в сек. (Tb/s). Это включает в себя как входящий, так и исходящий трафик. Исходящего трафика немного больше, чем входящего, но это довольно предсказуемо.
Использование канала по дням за Июнь 2015 года. Пиковый день — 10 Июня.
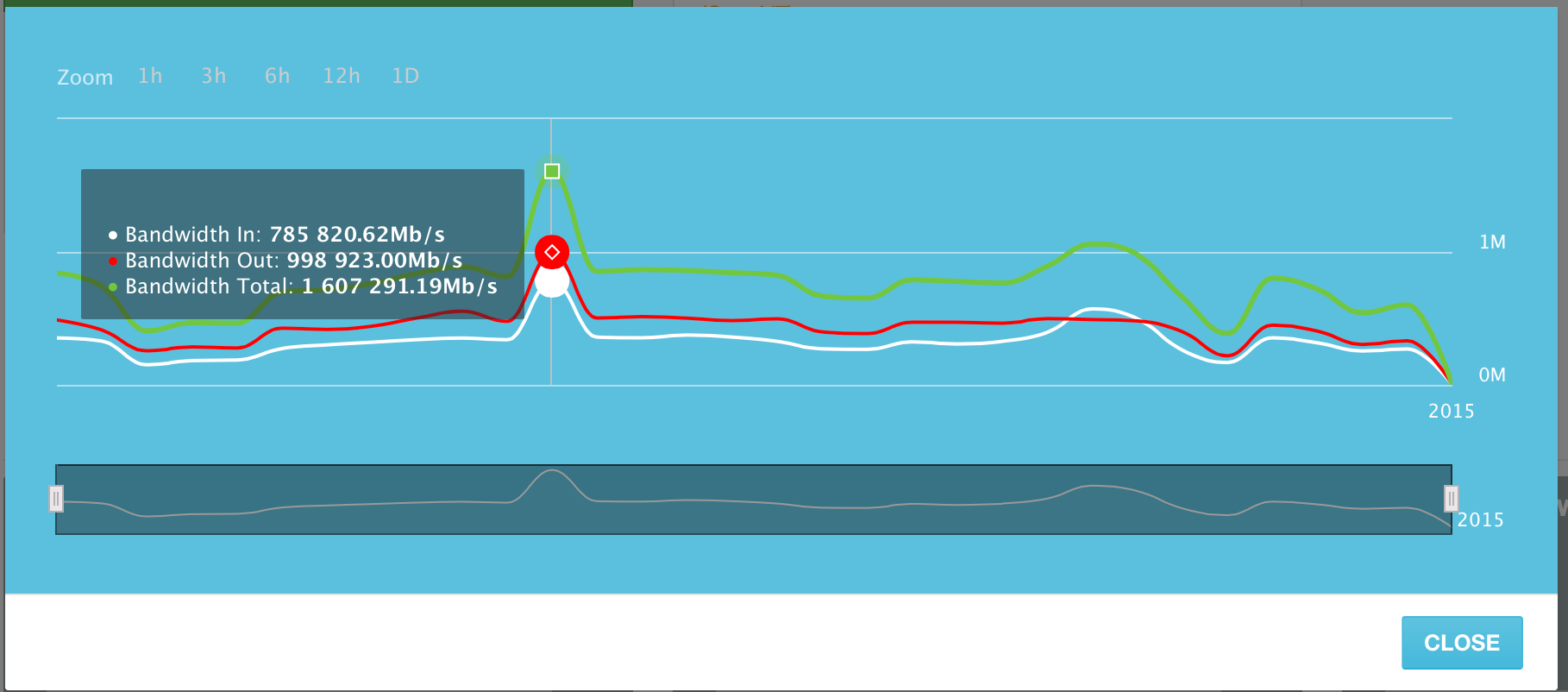
Среднее использование канала всех серверов в системе — в районе 500 Гигабит в секунду.
При небольшом пересчете, эти «средние» 500 Гигабит трафика в секунду выливаются примерно в 5 273 Терабайт переданных данных в день. И это объем данных, передаваемый только лишь ~1300 серверами в нашей системе!
Конечно, мы пока что еще молодой сервис мониторинга, но мы прилагаем все усилия для создания удобной и простой платформы, которую можно использовать как внутри компании, так и показывать клиентам и давать им доступ.
Впрочем, мы не идем по моделе конкурентов и не создаем «отечественный New Relic». Напротив, мы хотим создать платформу, в которой будет присутствовать не только мониторинг серверов, но также элементы безопасности — сканирование серверов и сайтов на уязвимости; возможность управления серверами из одной платформы, а также резервное копирование данных (backups) в облачный storage.
Следите за обновлениями!
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (42)

akamajoris
01.07.2015 10:40При небольшом пересчете, эти «средние» 500 Гигабит трафика в секунду выливаются примерно в 5 273 Терабайт переданных данных в день. И это объем данных, передаваемый только лишь ~1300 серверами в нашей системе!
Вы гигабайтный файл с серверов передаете каждые четыре минуты? Откуда такие цифры?
aquanet Автор
01.07.2015 11:01Считается использование каналов всех серверов в системе. Каждую секунду, среднее значение по всем сервервам — 500 Gbit/s.

exdee
01.07.2015 16:59то есть каждый из 1300 клиентских серверов, ради мониторинга и статистики дополнительно постоянно нагружает свой канал в среднем на 400mbit/s (это только обмен данными с вашим сервисом, без учета их основных нагрузок)?
aquanet Автор
01.07.2015 17:01нет, они ни в коем случае не нагружают ничего ради нас — это лишь «общая» статистика использования их каналов, только ради цифр.


nucleusv
01.07.2015 10:42А MaxScale перед Galera попробовать не хотите mariadb.com/products/mariadb-maxscale?
aquanet Автор
01.07.2015 11:14Да, у нас бывают мелкие накладки с haproxy и другими видами LB. Вы пробовали MaxScale в production'e? Так ли всё хорошо, как там пишут?
nucleusv
01.07.2015 11:27Нет не пробовал, у меня мускульного кластера. Дал как новодку родное решение от MariaDB.
Там просто на уровне запросов можно маршрутизацию делать.

achekalin
01.07.2015 16:01New Relic много что мониторит, кроме как пинг серверов. У вас насколько близок к ним продукт?
Они интересны тем, что мониторят все от и до. И скрипты, и замедления от общения с sql, и какие запросы в sql вызвали замедления. За это и деньги просят.
P.S. И таки да, мониторить uptime — это одно, а вот делать тест портов, а потом еще и бекап в облако — ой, совсем другое!aquanet Автор
01.07.2015 16:15Основной фокус New Relic'a это мониторинг приложений, как инструмент для разработчиков. Мы же — это больше платформа для системных администраторов и хостинг провайдеров, которые используют нас как «white label» решение, предоставляя доступ своим клиентам и сотрудникам технической поддержки, которым в первую очередь нужен мониторинг ресурсов и доступности серверов. Таким компаниям не приходится создавать свою платформу, они выдают нашу систему за свою.

brozen_zwork
01.07.2015 22:14> You can then add more servers for just $5 per server
Вот мне было всегда интересно, почему так дорого? Всего лишь «CPU, RAM, Disk Space, Network, etc». Например, у меня 20 виртуалок на DO по $5 каждая и мне теперь умножать цену за виртуалки вдвое ради ваших 20 проверок?aquanet Автор
02.07.2015 08:21Привет, на самом деле вы правы и это лишь общая цена, т.к. большинство мелких клиентов добавляют 1-2 сервера и всё. Нам с них просто нет смысла по доллару собирать. В данный момент всем кто имеет больше 5 серверов, мы опускаем цену, возможно добавим это на сайт.
brozen_zwork
02.07.2015 10:30А вы не задумывались об альтернативной модели биллинга? Например мне бы было удобно подписываться на что-то вроде «100.000» проверок в месяц за $x. Можно пойти еще дальше и сделать дневную или даже почасовую тарификацию. Да, это потребует дополнительных человеко-часов на разработку, но люди будут охотнее пользоваться вашим сервисом.
aquanet Автор
02.07.2015 12:29У нас сейчас как раз почасово высчитывается, тоесть каждый час мы смотрим сколько у вас добавлено веб сайтов, серверов и т.д. и считаем биллинг.

rudenkovk
А чем вызвано переписывание агента с python на ruby?
aquanet Автор
Это вызвано тем, что у нас все программисты используют Ruby, а python агент был написан достаточно давно и мы посчитали, что удобнее будет иметь все части системы на одном языке. P.s. мы были на Zabbix meetup в эту субботу, и Алексей Владышев из Zabbix подтвердил такую же проблему с их системой, которая написана на C, но имеет php frontend.
rudenkovk
legacy, я понимаю. Но не могу не посочувствовать.
Из моего опыта, было дешевле освоить python, чем бороться с утечками и размером памяти у ruby. Еще хороший вариант на Go, и быстро и все можно в один бинарник влить, и не мучатся с зависимостями.
У Zabbix, как я понимаю, c наследием вообще жутко.
В моем случае, мы отказываемся от заббикса, как не справившегося.
drakmail
Сейчас у ruby с памятью ситуация потихоньку исправляется. Хотя go тут подошел бы идеально, на мой взгляд.
rudenkovk
Ага, сорри за оффтоп, но то-то папет переписывают на clojure :)
Собтвенно ключеое тут «потихоньку», а потоки данных/задач растут как на дрожжах в теплый день!
nucleusv
Расскажите, чем не справился?
rudenkovk
1. Порядка терабайта метрик в месяц
2. Слабые возможности по составлению графиков, например две оси Y (на разные метрики), молчу про возможности визуализации
3. Нельзя отдать возможность написания шаблонов в «народ», слишком сложно и неявно
nucleusv
Да это серьезно.
А NVPS в такой системе сколько?
Терабайт это объем данных истории или кол-во метрик?
До плагина графаны досидели?
На что планируете менять?
rudenkovk
Мы не считали детали, прикидка общая. Терабайт — это размер базы за месяц, метрики мы пока не жмем, храним все, что есть.
NVPS — тут то же сложно. У нас есть метрики раз в секунду, раз в 10 сек и так далее, до раз в 10 минут. Количество метрик варьируется (иногда сильно) в зависимости от сервера/сервиса.
Grafana — это сейчас наше все. :) Zabbix планируем выпилить, и судя по всему, как страшный сон.
На текущий момент пришли к следующему:
— хранение данных opentsdb
— визуализация grafana
— сбор данных collectd (так же рассматриваем diamond)
— алертинг, выбираем между shinken и bosun. Очень вероятно, что будем совместно использовать.
— прогностика — kale
nucleusv
NVPS — что у вас показывает, график на элементе zabbix[wcache,values]?
плагин Zabbix для Grafana — вы про это github.com/alexanderzobnin/grafana-zabbix?
а дайте плиз ссылку на kale?
rudenkovk
У меня нет метрик в заббиксе, на основании своего старого опыта, я просто не стал туда это все вносить. Зачем мне так нагружать РСУБД, которая просто не предназначена для такой работы, при условии приближенном к realtime?! Чтобы предупредить дальнейшие вопросы: у меня сейчас заббикс это наследие, причин его оставлять, я не вижу. Заббикс работает сейчас как алертинг, и не более.
habrahabr.ru/post/219377
nucleusv
Ну как бы без цифирей трудно говорить, где у вас там риалтайм, выставляете в в заббиксе большие кеши мегов на 512 или больше и у вас in-memory db :)
За kale thanks!
rudenkovk
Ага, и начинаем все дальше и все толще делать серваки, все больше наворачивать на них решений по оптимизации. Тут архитектурная проблема. Если угодно, то не в самом заббиксе, а в том, что он использует рсубд.
Вот сейчас у меня тестеры просят иметь возможность просмотра набора метрик (достаточно сложный набор, и не только простые mean на шкале фремени) за 1-2 месяца, причем в реалтайме. На обычной рсубд это будет огромный набор джоинов и не последовательного чтения. На time series базе, чтение будет почти линейным. А в случае opentsdb, еще и распределенным, и мне не надо думать не о шардинге, не о бекапах.
Дальше математика: 2 месяца, это 2 Терабайта данных. Сейчас у меня на 1ТБ базе запрос около 40 метрик за 30 дней грузит сервак с (2 новых ксеончика, средних, 64 ГБ ram, ssd sas raid10) на секунд 15-20 с LA ~7-8, то есть горлышко в диске. Если сюда вставить рсубд, то по нагрузке все будет куда печальнее.
nucleusv
За 1-2 месяца у вас просто кол-во точек не уместится на графике (если у вас еще интервалы по 10 сек), поэтому там используется тренды.
Не подумайте, что я вас отговариваю, Яндекс давно отказался от Zabbix.
Нам он удобен именно с точки зрения легкости его скрещивать со всем ,)
rudenkovk
За 1-2 мес я получу графики (некоторые с двумя осями Y), где аномалии будет заметны, соответсвенно в той же grafana я могу выделить фрагмент и изучить его более внимательно. И при этом мне не надо будет дергать данные из разных точек. Например, у меня сейчас аномалия, и я хочу посмотреть за N-дней назад, были ли аномалии. С исторической БД такое не возможно (так, чтобы было удобно).
По поводу легкости скрешивания, ну у меня тут есть вопросы то же. На мой взгляд, описание шаблонов nagios-like куда удобнее.
nucleusv
По поводу RDMS — Алексей обещает, что сделают плагинабл архитектуру для Zabbix, чтобы можно было разные БД использовать. Но боюсь это будет не скоро.
alexvl
На митапе я лишь указал на различие в культуре разработки C и PHP, не более того. У каждого проекта с солидной историей есть определенный технический долг, в нашем случае этот долг сконцентрирован на стороне интерфейса, PHP. С этим мы активно работаем.
Eсли говорить о цифрах. Наши пользователи и клиенты подтвердят, что 70-80 миллиардов (!) проверок в месяц не являются пределом для Zabbix. И это не только простые пинги, но и тяжелые проверки уровня приложений, мониторинг лог файлов, VMWare и прочее.
rudenkovk
Моя проблема с zabbix не в проверках, а в невозможности хранить нормально time series и гибко их отрисовывать.
nucleusv
Сделайте партиционирование, разделите установки на операционный заббикс который алертинг, историю за неделю.
Остальные данные перекладывайте в историческую-аналитическую базу, в тот же opentsdи можно раз в час переливать.
С отрисовкой мне кажется вопрос полностью решен плагином на который дал выше.
Просто менять заббикс это когда она реально считать триггеры не может. То есть у вас дикий NVPS и вы уже все разнесли по проксям.
rudenkovk
У меня вопрос — а зачем мне этим всем заниматься, когда проблема решается куда более простыми средствами?
Вот простой юзкейз: у меня есть логи, скажем gunicorn (php-fpm & etc), за сутки, есть метрики в zabbix, есть алгоритм (формула), которая дает возможность проанализировать запросы и его взаимоотношение с метриками. Как это реализовать в заббикс?
Будет большой набор костылей, скриптов и тд. В моем случае, я по курлу дергаю апишечки и все.
nucleusv
С логами соглашусь на 100% в заббиксе это слабое место — мы идем по пути, что логи льем в elasticsearch, graylog2 и оттуда дергаем агрегированную метрику. Например вернуть кол-во вхождений слова error за последнею минуту и вешаем на нее триггер.
rudenkovk
Ага, мы уже кажется обсуждали. На каком количестве логов начинает ложиться ES? Все таки его основная функция индексация и поиск, а не хранение.
И это не решает, без костылей, проблему поиска совпадений между метриками и логами. И совместных отчетов.
nucleusv
Вы логи куда льете?
Для меня сейчас это очень актуальная задача. Ну в graylog2 он в монгу льет, а еластик как раз для индексации.
rudenkovk
В моем наследии — в ES, сейчас переходим на hadoop. Там файлами будем класть, на начальном этапе, с RF=3. В перспективе возможно hbase/cassandra, тут будем смотреть на объемы и запросы от бизнеса.
nucleusv
Индексировать через, через еластик?
Как метрики из логов делать собираетесь?
rudenkovk
Да, ES.
Метрики из логов, мы еще тут прорабатываем архитектуру.
Для начала, будет дублирование, из приложения будем по udp класть в statsd, он уже будет класть в opentsdb.
И видимо на кластере хадупа, запустим несколько паучков, которые будут в ленивом режиме класть инфу в timeseries. Возможно по мере реализации придем к другим решениям.