
Каждый программист старается писать хороший код. Читабельность — один из главных признаков такого кода. О ней написано достаточно много книг, но всё же в теме есть пробелы. Например, те самые книги сфокусированы больше на советах КАК написать читабельный код, а не на причинах того, почему один код является хорошо читабельным, а другой — нет. Книга говорит нам «используйте подходящие названия переменных» — но что делает одно название более подходящим, чем другое? Работает ли это для всех примеров подобного кода? Работает ли это для всех программистов, которым попадётся на глаза этот код? Как раз о последнем я и хотел бы поговорить чуть детальнее. Давайте погрузимся немного в человеческую психику. Наш мозг — главный наш инструмент, хорошо бы изучить специфику его работы.
Психологическое основание
Каждый программист знает, что возможности нашего мозга не безграничны. Есть ограничение на количество вещей, о которых мы можем думать. Это наш рабочий лимит памяти. Есть старый миф о том, что человек может держать в памяти одновременно 7±2 объектов. Это называется "Магическое число семь" и оно на самом деле не очень точное. Последние исследования говорят о числе 4±1, а то и меньше. В любом случае — количество идей, которые мы можем держать одновременно в голове, весьма ограниченно.
Некоторые люди скажут, что способны легко оперировать одновременно более, чем четырьмя объектами в памяти. Это так: к счастью, есть ещё один процесс, который постоянно происходит в нашей голове — это группировка. Мы объединяем схожие мелкие сущности в чуть большие и оперируем уже ими. Вспомните, как вы называете даты или номера телефонов — не по одной цифре, а группами по две, три или четыре. При этом каждая группа цифр является самостоятельной сущностью. Более того, все цифры вместе формируют «дату» или «номер телефона» — тоже отдельные сущности.
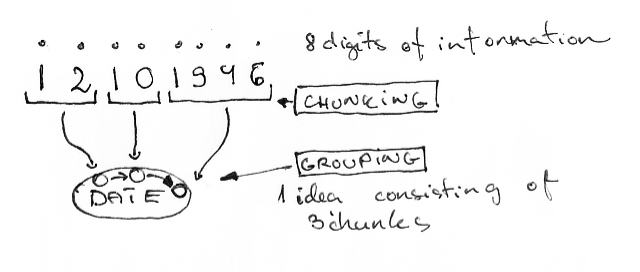
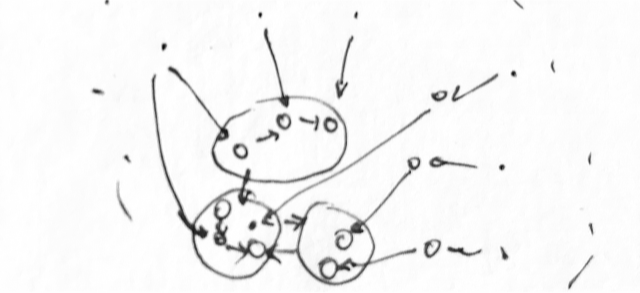
Из этих групп мы строим нашу долговременную память. Я представляю её как большую паутину из таких вот группок и их последовательностей.
Исходя из данной картинки, вам может показаться, что перемещение из одной части памяти в другую происходит достаточно медленно. И это действительно так. В науке проектирования пользовательских интерфейсов есть концепция «единого фокуса внимания». Название говорит само за себя — мы можем фокусироваться в каждый момент времени только на чём-то одном. Более того, кроме фокуса, есть ещё и «локус» — ограниченность внимания в пространстве.
Вы можете подумать, что это то же самое, что и упомянутый выше рабочий лимит памяти, но есть важное отличие. Рабочий лимит памяти говорит о том, сколько всего сущностей мы можем держать в памяти. Фокус и локус внимания говорят о том, что для выполнение какой-то полезной мыслительной работы данные сущности ещё и должны «находиться рядом», быть чем-то связанными.
О фокусе и локусе внимания важно знать, поскольку переключение между идеями — весьма затратный процесс. И ещё более затратным он становится, когда нам на ходу нужно осмысливать незнакомые сущности и группировать их. К счастью, это работает и в обратную сторону — чем что-то нам лучше знакомо, тем меньше времени требуется, чтобы переключить на него внимание и осмыслить. Это называется опытом.
Также мы по-разному запоминаем вещи в зависимости от контекста. Однажды проводился следующий эксперимент: группе дайверов читали набор слов, а затем, через некоторое время, просили их воспроизвести. И первоначальное чтение, и воспроизведение проводилось как на суше, так и в воде. Лучше всего обстояло дело со случаем, когда слова и читались и воспроизводились на суше. Но на втором месте неожиданно оказалась комбинация с чтением и воспроизведением в воде. Люди запоминали слова в контексте окружающей обстановки и аналогичная окружающая обстановка помогала лучше вспоминать.
Из контекстов и сгруппированных по ячейкам памяти сущностей мы и строим ментальные представления и ментальные модели. Ментальные модели играют ключевую роль для нашей способности находить решения проблем. Для одной и той же проблемы можно построить разные ментальные модели, и каждая будет иметь свои плюсы и минусы. Есть и главная проблема в их построении и применении: наш мозг. О, у нашего мозга есть целая куча разных недостатков.
Во-первых, ему сложновато работать с абстракциями. Когда некоторые сущности кажутся схожыми, они располагаются в мозгу «рядом», являются связанными. Это приводит к тому, что мозг иногда ошибается какую из них следует извлечь и использовать в каждом конкретном случае. Пример: путаница между l и 1, 0 и О. Ещё один пример — двусмысленность. «Ключ» — это мы сейчас о предмете для открывания замков, построении стаи птиц или инструменте для работы с гайками?
Неуверенность в правильности найденной абстракции замедляет процесс мышления. На какую-то долю секунды — но и этого может хватить для потери фокуса внимания. Нас вообще много чего может сбить, но, если крупные отвлекающие факторы мы способны понять, локализовать и отфильтровать, то «всякую мелочь» можем и не осознавать. Если кто-то будет называть случайные числа, пока вы что-то считаете — считать станет существенно сложнее. Это может происходить и с визуальными факторами: если на экране есть несколько важных в текущей ситуации объектов и пару десятков не важных — вам будет сложнее выделить и осознать лишь важное.
Всё вышеуказанное создаёт когнитивную нагрузку. Это количество ментальных усилий, которые необходимы для решения некоторой задачи. Наша «операционная мощность» падает по ходу работы и возрастает после отдыха. Если вы не даёте своей голове осознанного отдыха — природу вы всё-равно не обманете и через какое-то время ваш мозг начнёт «витать в облаках».
Давайте теперь перейдём ближе к делу и подумаем, как всё это касается написание хорошего кода. Дальше будет несколько рекомендаций, эмпирических правил и парадигм, которые могут так или иначе вам помочь с точки зрения психологии. Это, конечно, не фундаментальное руководство, но, я надеюсь, вы уловите основные идеи и дальше сможете их применять для оценки других известных вам правил, советов и парадигм.
Именование сущностей
Давайте взглянем на простенький цикл for:
- A. for(i=0 to N)
- B. for(theElementIndex=0 to theNumberOfElementsInTheList)
Какой вариант нравится вам больше? Большинство программистов порекомендуют вариант А. Почему? А потому, что вариант B использует слишком длинные имена переменных, что мешает нам с одного взгляда увидеть единый (и хорошо знакомый) паттерн. Кроме того, в данном случае столь длинные имена и не помогают создать более качественный контекст, они просто добавляют шум.
Теперь давайте посмотрим на различные способы формирования пространств имён (это могут быть пакеты, модули или что-то ещё в вашем языке программирования):
- A. strings.IndexOf(x, y)
- B. s.IndexOf(x, y)
- C. std.utils.strings.IndexOf(x, y)
- D. IndexOf(x, y)
Вариант В плох, поскольку «s» — слишком короткое название и не помогает нам понять, что «это, наверное, строка».
Вариант С плох, поскольку std.utils.strings — слишком длинное название, мы и так поняли, что это строка, не нужно каждый раз напоминать о том, где она находится.
Вариант D плох, поскольку без пространств имён мы вообще не очень хорошо понимаем, что за функцию вызываем, откуда она и над какими объектами будет работать.
Важно заметить, что если уж речь в коде зашла о строках, то логичным будет предположить, что вызов IndexOf для строки выполняет какую-то работу именно на строке. В таком случае, даже упоминание пространства имён «strings» будет излишним, как, например, операция сложения на целых числах более понятна в виде a + b, а не в виде int16.Add(a, b).
Состояние переменной
Некоторые парадигмы программирования говорят, что любая модификация переменной является плохой вещью, ведь «становится трудно понять, что и когда изменилось». Но давайте посмотрим вот на эти примеры:
// A.
func foo() (int, int) {
sum, sumOfSquares := 0, 0
for _, v := range values {
sum += v
sumOfSquares += v * v
}
return sum, sumOfSquares
}// B.
func GCD(a, b int) int {
for b != 0 {
a, b = b, a % b
}
return a
}// C.
func GCD(a, b int) int {
if b == 0 {
return a
}
return GCD(b, a % b)
}Здесь первую функцию (foo), наверное, легче всего понять. Почему? Потому, что проблема не в модификации переменных, а в том, как именно они модифицируются. Пример А не содержит никаких сложных вычислений, в отличии от B и С.
// D.
sum = sum + v.x
sum = sum + v.y
sum = sum + v.z
sum = sum + v.w// E.
sum1 = v.x
sum2 := sum1 + v.y
sum3 := sum2 + v.z
sum4 := sum3 + v.wВот ещё один пример кода, где версия с модификацией значения переменной (D) читается проще. Вариант Е не модифицирует существующие переменные, но добавляет 3 новых сущности для описания той же идеи. Больше шума — сложнее понимание.
Идиомы
Давайте посмотрим ещё на несколько циклов:
- A. for(i = 0; i < N; i++)
- B. for(i = 0; N > i; i++)
- D. for(i = 0; i <= N-1; i += 1)
- C. for(i = 0; N-1 >= i; i += 1)
Насколько долго у вас заняло понять, что делает каждый из них? Бьюсь об заклад, вариант А вы восприняли на лету. Остальные три варианта пришлось читать и понимать. Главная причина — опыт. Вариант А у многих программистов лежит в отдельной, быстро-доступной ячейке памяти. Остальные три — нет. Для них нужно строить в голове новые временные модели.
Но для новичка все четыре варианта будут выглядеть одинаково — их сложность действительно примерно равна и ни один из них не покажется человеку «со стороны» лучше другого. Опытный программист с первого взгляда скажет «а, ну это проход по массиву». Новичок же расскажет о том, что «здесь мы обнуляем переменную i, потом сравниваем её с N, выполняем код внутри тела цикла, увеличиваем i и снова сравниваем и т.д.».
Вариант А — это «идиоматический способ» написания цикла. Он не лучше остальных с точки зрения вычислительной сложности, но значительно лучше с точки зрения читабельности кода, ведь он входит в «базовый словарь профессии».
Большинство языков программирования имеют идиоматический способ написания тех или иных вещей. Есть классические документы и книги, типа APL idioms, C++ idioms а также более высокоуровневые вещи вроде паттернов Банды Четырёх. Используя идиомы из подобных классических книг, мы можем строить более сложные программы, отдельные куски которых будут понятны остальным программистам (ведь они, наверное, читали те же книги).
У всего этого есть и негативный аспект. Чем больше идиом мы используем, тем больший вокабуляр требуется запоминать для их понимания. Динамические языки подвержены данной проблеме больше остальных — программисты чувствуют возможность изобрести новые гибкие идиомы для хитрого решения своей текущей проблемы (и это даже работает), но каждый следующий читатель данного кода будет вынужден замедляться, пытаясь понять неожиданные подходы автора.
Консистентность
Хорошим примером консистентности могут быть названия сущностей типа «модель» и «контроллер». Выучив однажды что это и как они связаны друг с другом, вы навсегда приобретаете в своей голове ценную пару идиом. Теперь в любом коде, увидев класс со словом Model или Controller в названии, вы будете понимать, для чего он создан и с чем связан.
Такие вещи как фреймворки или игровые движки всегда пытаются действовать подобным образом: дать нам понимание базовых сущностей, связей между ними и способов манипуляции ими. Выучив структуру одного проекта на каком-то фреймворке или движке, программист может очень быстро вникнуть в суть другого проекта на нём же.
Важным фактором здесь является и консистентность оформления кода. Чем более в коде консистентны имена переменных, классов, методов, форматирование кода, подходы к решению одинаковых проблем в разных местах кодовой базы — тем легче читатель понимает проект, тем быстрее начинает «доверять» ему.
Неопределённость
Неопределённость может замедлить как написание, так и понимание кода. В качестве примера можно рассмотреть двусмысленность. Например, вот такой код:
[1,2,3].filter(v => v >= 2)при всей своей простоте всё-же оставляет открытым вопрос, что же будет получено в итоге «2 и 3» или «1»? То есть мы здесь «фильтруем» или «отфильтровываем»? Скорее всего вы быстро найдёте ответ в документации вашей платформы или используемой библиотеки — но вам придётся отвлечься, а потом ещё и запомнить найденную информацию. Правда, было бы лучше, если бы название и синтаксис говорили сами за себя? Значительно лучше подошли бы названия функций типа select, discard или keep.
Мы также можем по-разному понимать значение той или иной сущности. Например, функция GetUser(string) одними людьми может быть воспринята как поиск пользователя по имени, а другие посчитают, что это поиск по уникальному ключу пользователя. Из этой ситуации можно легко выйти, создав специальный тип CustomerID (пусть даже он будет алиасом на ту же строку) и использовав его в прототипе функции GetUser(CustomerID), а вот поиск пользователя по имени можно назвать GetUserByName(string). Здесь уже нет никакой неопределённости.
Подобие — ещё одна распространённая причина ошибок. Если у вас есть переменные типа total1, total2, total3 — очень легко скопировать-вставить кусок кода и забыть исправить индекс. Код скомпилируется, а ошибка будет найдена (если будет) намного позже. Назвать эти переменные именами вроде sum, sum_of_squares, total_error — намного безопаснее.
Ещё одна беда — именование одной и той же сущности разными именами в разных модулях вашего кода. Это кажется не такой большой проблемой: «я назвал это так, в базу его другой программист положил под вот таким именем, а в UI его назвали вот так». Всё хорошо, пока всё хорошо. А потом что-то ломается и какой-то другой программист, чертыхаясь, пытается понять как связаны эти, совершенно не совпадающие по именам, вещи.
Проблемы двусмысленности и подобия присущи не только написанию исходного кода. В разных контекстах одни и те же слова могут означать разные вещи. Например, слово «заказчик» означает совершенно разные вещи в отделах закупок и продаж одной и той же компании. Таким образом, никогда не стоит бояться показаться смешным или неуместным, лишний раз переспросив всех вокруг, одинаково ли вы понимаете какие-то термины вашей предметной области.
Комментарии
Все мы видели примеры глупых комментариев новичков, типа:
// увеличиваем в цикле переменную i от 0 до 99
for(var i = 0; i < 100; i++) {
// присваиваем переменной а значение 4
var a = 4;Да, выглядит немного туповато. Но даже у таких комментариев может быть смысл. Подумайте об изучении второго (или третьего) языка программирования. У вас уже есть знание синтаксиса одного языка, понимание всех этих условных переходов, циклов, функций — и вот вы изучаете то же самое в другом языке. Вам не нужно заново изучать данные понятия в новом языке, а лишь привязать у себя в голове вот такой формат цикла или присвоения к абстрактной идиоме «цикла» или «присвоения» — вот здесь могут и подобные комментарии пригодиться.
Как только эта привязка произошла — эти комментарии станут ненужным мусором, поскольку объяснение происходящего будет возникать у вас в голове уже при взгляде на сам код. По ходу того, как программист набирается опыта, его комментарии несут всё меньше информации о том, ЧТО делает код и всё больше о том ПОЧЕМУ и В КАКОМ КОНТЕКСТЕ он это делает. «Подход Х был выбран потому, что альтернативные подходы Y и Z не подошли по таким-то причинам», «при модификации данного кода следует помнить о том, что ...».
Хорошие комментарии дополяют ментальную модель понимания кода.
Контексты
Ограниченность рабочего лимита памяти приводит нас к необходимости декомозиции кода. Мы разбиваем сложный (или длинный) код на части, оперирующие ограниченным числом объектов. Но разбивать и декомпозировать тоже можно по-разному. Представьте себе, например, класс, лежащий очень глубоко в дереве наследования. И вот вы пишете в нём какой-то метод, который вызывает несколько других методов — один из того же класса, другой из «родителя», третий из «дедушки». Вроде бы ваш класс совсем прост — пара методов, строк по 5 в каждом. Но читать его код трудно, ведь даже чтение этих 10 строк требует создать в голове (и держать всё время чтения!) всё дерево наследования. Это трудно. Каждый новый слой наследования — это ещё одна идиома, занимающая и истощающая наш рабочий лимит памяти.
То же самое и с отслеживаем вызовов функций. Каждый шаг вглубь стека вызовов — шаг к лимиту наших ментальных возможностей.
Один из способов уменьшить глубину нашей ментальной модели контекстов — чётко разделить их. Одним из примеров может служать концепция раннего возврата («early return»):
public void SomeFunction(int age)
{
if (age >= 0) {
// сделать что-то
} else {
System.out.println("Не верный возраст");
}
}
public void SomeFunction(int age)
{
if (age < 0){
System.out.println("Не верный возраст");
return;
}
// сделать что-то
}В первой версии при чтении кода мы доходим до части «сделать что-то» и ещё помним, что эта часть выполняется только при условии, указанном выше. Однако, когда мы доходим до части «else» мы уже достаточно далеко мысленно удалились от изначального условия и для понимания к чему-же относится это «else» нам нужно, во-первых, выбросить из головы только что прочитанную часть «сделать что-то», во-вторых вернуться назад к условию и осознать его и, в третьих, снова перейти к блоку «else» уже будучи в контексте условий, при которых мы в него попадём. Достаточно длинный путь.
Вторая версия кода применяет концепцию раннего возврата и поэтому является лучшей альтернативой. Мы сначала проверяем граничные условия и адекватно на них реагируем. Затем мы переходим к основному блоку кода и выполняем его. Никаких мысленных прыжков туда-обратно, никакой лишней смены контекстов.
Эмпирические правила
Одно из фундаментальных правил программирования гласит «Избегайте использования глобальных переменных». Но как на счёт случая, когда значение такой переменной присваивается лишь раз при инициализации и никогда не меняется в дальнейшем — это тоже проблема? Да, проблема. Дело здесь даже не в «переменности» или «глобальности». Мы вводим сущность, которая доступна отовсюду, а значит она явно или неявно будет присутствовать в любой ментальной модели кода, которую вы будете строить у себя в голове. Даже если это константа, даже если в данной функции она не используется — само по себе знание того, что есть нечто, что по своей воле (а не по воле данной функции) является видимым и доступным — уже даёт ему право претендовать на место в голове читателя данного кода. Конечно, мы не пишем «программы в вакууме», все они работают в каком-то окружении, и даже некоторые «допустимые» идиомы вроде Singleton обладают теми же свойствами. Так почему же они считаются лучшим вариантом, чем глобальные переменные?
Всё дело здесь в принципе единственной ответственности. Его предназначение — гарантировать, что каждая сущность в вашем коде служит одной цели. Не нулю, не двум — ровно одной. Это ограничение часто приводит к разбиению на более мелкие части. Это не всегда хорошо — подобным дроблением можно дойти до столь мелких частей, что собрать из них что-то реально полезное будет требовать серьёзных усилий. Кроме того, эти мелкие части могут быть настолько завязаны друг на друга, что от этого потеряется весь смысл принципа единственной ответственности.
Хорошим примером на эту тему может быть комментарий Кармака. Он показал вот эти три куска кода:
// A
void MinorFunction1( void ) {
}
void MinorFunction2( void ) {
}
void MinorFunction3( void ) {
}
void MajorFunction( void ) {
MinorFunction1();
MinorFunction2();
MinorFunction3();
}
// B
void MajorFunction( void ) {
MinorFunction1();
MinorFunction2();
MinorFunction3();
}
void MinorFunction1( void ) {
}
void MinorFunction2( void ) {
}
void MinorFunction3( void ) {
}
// C.
void MajorFunction( void ) {
{ // MinorFunction1
}
{ // MinorFunction2
}
{ // MinorFunction3
}
}
Делая части кода меньшего размера, мы можем лучше добиться соответствия их содержимого их идее и названию. Однако, понимание кода от этого не становится лучше. Мы не можем читать код в линейном порядке (сверху вниз) и понимать его — вместо этого нам приходится перескакивать к коду вызываемых функций и обратно. Вериант С предлагает решение данной проблемы — выделение частей кода в логические области видимости, что, с одной стороны, сохраняет их целостность и разделение, а с другой — позволяет читать код последовательно и не терять контекст его выполнения.
На практике не существует идеального способа организации кода, поскольку кроме читабельности, о которой мы говорили выше, есть не менее важные вещи, такие как надёжность, поддерживаемость, производительность, скорость создания минимально рабочего прототипа и т.д. Некоторые из этих ценностей дополняют друг друга, но некоторые — прямо противоречат друг другу. В каждом отдельном случае важно понимать, что является ценностью данного конкретного проекта и на чём стоит сфокусировать усилия здесь и сейчас.
Комментарии (44)

TimTowdy
29.05.2018 18:34+1Очень годно, думаю к аналогичным выводам приходят многие программисты спустя N лет опыта.
Вставлю свои пять копеек:
Преобразование GetUser(string) в GetUser(CustomerID) + GetUserByName(string) тоже зависит от контекста. Пока ваша условная библиотека невелика по размерам, GetUserByName по сравнению с GetUser будет казаться тем самым шумом, который вы описали раньше. По мере же роста кодовой базы будет возрастать вероятность неоднозначного восприятия, и, следовательно, потребность в более «явной типизации».
Хотя, на мой взгляд, энтерпрайзное тяготение к излишней типизации и длиннющим именам методов является попыткой решить проблемы некачественной ментальной модели средствами языка. Следует стремиться строить такие модели, в которых
users.find(first_name, last_name)несет тот же смысл что иUserDAOSingleton().FindUserByFirstNameAndLastName(String FirstName, String LastName). Неоднозначность должна устраняться самой моделью, а не более длинным специализированным именем метода. В GetUserByName(string) до сих пор присутствует много неоднозначности, например возникает ли исключение если юзер не найден? А если найдено более одного юзера? Возвращает ли метод одного юзера, или их список, или итерируемый курсор? Ответы на такие вопросы должны быть в самой модели, а не в имени метода/комментариях.
К слову, построение «правильной» (легкой, непротиворечивой, расширяемой, etc), ментальной модели это и есть основная сложность в программировании. Имея ментальную модель, написание кода становится просто рутиной. А код, написанный без четкой ментальной модели неизбежно превращается в набор костылей и говнокода. Грубо говоря, код это функция от ментальной модели и набора правил (языка программирования, стандартов, ограничений). При развитии почти любого проекта обычно меняется как ментальная модель, так и некоторые стандарты/ограничения. И когда этих изменений накапливается достаточно много, у программиста возникает желание «все переписать с нуля».
Как следствие, при передаче кода, написании документации, или onboarding, в первую очередь нужно описывать именно ментальную модель, а не структуры данных и всякие API.mad_nazgul
30.05.2018 05:36Так код и есть воплощение ментальной модели!
Но как «красота в глазах смотрящих», так и понимание ментальной модели зависит от читающего.
А вот что он увидит…
И никак не проконтролируешь.
Процесс передачи понимания асинхронный.
Поэтому мне нравиться концепция ТДД.
Как минимум машине проще объяснить чего ты хочешь, чем человеку. :-)
Comdiv
29.05.2018 19:56Одним из примеров может служать концепция раннего возврата («early return»):
…
public void SomeFunction(int age) { if (age < 0){ System.out.println("Не верный возраст"); return; } // сделать что-то }
В контексте статьи это плохой пример, так как если после «сделать что-то» понадобится добавить код, обязательно выполняющийся в конце функции, то нужно будет учитывать, что где-то ранее может быть сделан преждевременный выход из функции — нужно учитывать больше контекста. С точки зрения читаемости такой код лучше:public void SomeFunction(int age) { if (age < 0){ System.out.println("Неправильный возраст"); } else { // сделать что-то } }
Структурность и форматирование кода делает поток вычислений более очевидным в противовес выравненным неструктурным переходам.TimTowdy
29.05.2018 20:39Пример с SomeFunction слишком абстрактен, но думаю автор подразумевает что код самодостаточен и завершен: функция решает только одну задачу, и задачи «добавить код выполняющийся в конце функции» попросту возникнуть не может. Что в данном примере вполне логично, т.к. это что-то вроде исключения на невалидных данных, и сложно придумать кейс где один и тот же код должен выполняться как в обычной, так и в исключительной ситуации.
Может появиться задача делать что-то на каждом вызове SomeFunction, напрямую не относящееся к решаемой ею задаче (допустим считать время выполнения функции). Но раз это не имеет отношения к самой задаче, то и код должен находиться вне функции (например обернуть функцию декоратором, либо использовать какую-нибудь cross-cutting библиотеку).
Либо же возникнет задача сделать что-то после вызова SomeFunction — но и делаться в таком случае это будет делаться отдельной функцией. И если последовательность вызовов этих двух функций несет смысловую нагрузку, тогда их можно объединить в третью функцию:
public void SomeComplexAction(age){ SomeFunction(age) SomeOtherFunction() }Comdiv
29.05.2018 21:04Пример с SomeFunction слишком абстрактен
Да, абстрактен. Я это называю проблемой восприятия маленьких примеров, когда выводы делаются на основе заведомо суженных рамок, за которыми не видно проблем промышленного кода, которые можно наблюдать, например, регулярно анализируя сообщения об уязвимостях.
думаю автор подразумевает что код самодостаточен и завершен: функция решает только одну задачу, и задачи «добавить код выполняющийся в конце функции» попросту возникнуть не может.
А это ещё одна нагрузка мозг — нужно воспринимать не только текущий, но и предсказывать будущий контекст, что ещё хуже.TimTowdy
29.05.2018 21:43Попробуйте привести контрпример, где нужно именно «добавить код выполняющийся в конце функции», особенно с учетом что early return здесь используется в качестве исключения. Я попытался привести два примера, где у, очевидного на первый взгляд, подхода «добавить код в конце функции» есть более удачные альтернативы.
К слову, сама ваша формулировка «понадобится добавить код, обязательно выполняющийся в конце функции» для меня звучит порочно.
Если следовать правилу, которое я привел раньше:
source_code = F(mental_model, rules_and_restrictions)
то есть всего три причины для изменения кода:
1. Изменилась F (другими словами код не соответствует ментальной модели, т.е. в коде найден баг)
2. Изменилась ментальная модель (например добавляем новую фичу)
3. Изменились правила/ограничения (меняем ЯП, разбиваем монолит на (микро)сервисы, меняем фреймворк, применяем style guidelines, etc)
Задача «добавить код» сама по себе в принципе не возникает.Comdiv
29.05.2018 22:22Не поверю, что Вы не можете придумать примеры сами. Я же не буду придумывать, а покажу функцию от Apple, где есть код, который должен выполнится в конце habr.com/post/213525. Кстати, эта конкретная ошибка могла произойти и с return.
Добавить код может понадобиться, когда, к примеру, расширяются коды проверки или изначально что-то забыто, или происходит рефакторинг или ещё по тысяче причин.
Задача «добавить код» сама по себе в принципе не возникает.
Как и задача писать код сама по себе в принципе не возникает. Но мы же и пишем, и добавляем?TimTowdy
30.05.2018 01:03Вот я и постарался придумать в том контексте: early return в качестве исключения. Придумать ситуацию когда один и тот же код должен выполняться в случае исключения и в случае его отсутствия мне сложно.
Но мы видимо друг друга не понимаем. В приведенном вами коде Apple задача «очистить память перед выходом» стояла изначально. Вы же, как мне показалось, утверждали что подобная потребность может появиться внезапно.
Так или иначе, вот на мой взгляд более наглядный пример, демонстрирующий преимущество early return:
def func1(): results = None user = get_user() if user: orders = get_orders(user) if orders: transactions = get_transactions(orders): if transactions: results = [execute(t) for t in transactions] else: print('no transactions') else: print('no orders') else: print('no user') return results def func2(): user = get_user() if not user: print('no user') return None orders = get_orders(user) if not orders: print('no orders') return None transactions = get_transactions(orders) if not transactions: print('no transactions') return None return [execute(t) for t in transactions]
Я думаю большинство согласится, что ментальная нагрузка в func2 гораздо ниже. Ментальный стек не переполняется, взгляду не нужно прыгать по if/else блокам, читать и поддерживать такой код гораздо проще.
Естественно, если изначально стоит задача делать нечто перед выходом из функции, и язык не поддерживает try-finally либо RAII/contextmanager, то early return будет неуместен.Comdiv
30.05.2018 02:34В приведенном вами коде Apple задача «очистить память перед выходом» стояла изначально
А если я скажу, что изначально шла работа с локальными буферами и освобождать не нужно было, но в процессе обновления библиотеки понадобилось, то это что-то изменит? Если не стоит запрет на преждевременный выход и я привык его применять, это не увеличит нагрузку на распознавание ситуации, что дальше есть необходимые действия и так поступать нельзя?
Читать и поддерживать такой код гораздо проще.
Вот я из большинства поверил Вам, взял этот код и в процессе его более простого сопровождения он стал таким.
def func2(): user = get_user() if not user: print('no user') orders = get_orders(user) if not orders: return 'no orders', None transactions = get_transactions(orders) if not transactions: return 'no transactions', None return 'OK', [execute(t) for t in transactions]
Уменьшилась ли от этого ментальная нагрузка на работу с этой функцией по сравнению со структурным потоком исполнения?
И, кстати, почему 1-й вариант Вы записали не так?
def func1(): results = None user = get_user() if not user: print('no user') else orders = get_orders(user) if not orders: print('no orders') else transactions = get_transactions(orders): if not transactions: print('no transactions') else: results = [execute(t) for t in transactions] return results
Ведь он же ближе ко 2-му? И что значит прыгать по if/else? Вы действительно прыгаете, затрачивая энергию, а не читаете наглядное ветвление? Может, с непривычки?TimTowdy
30.05.2018 04:19Если не стоит запрет на преждевременный выход и я привык его применять, это не увеличит нагрузку на распознавание ситуации, что дальше есть необходимые действия и так поступать нельзя?
Безусловно увеличит. Но, как я уже сказал, проблема возникает лишь в тех средах, где нет возможности использовать try-finally или его аналоги, т.е. ничтожно редко.
Уменьшилась ли от этого ментальная нагрузка на работу с этой функцией по сравнению со структурным потоком исполнения?
Не совсем понял вопрос. В любом случае, этот вариант меня так же устраивает (за исключением опечаток), т.к. основная работа метода все так же выполняется на первом уровне вложенности.
И, кстати, почему 1-й вариант Вы записали не так?
Можно и так. Читается лучше, но все равно плохо — каждый вложенный if грузит мой ментальный стек. Если у вас десяток таких проверок будет — вы десять вложенных if-блоков будете делать?
Плюс, в таком стиле пишут крайне редко, т.к. он противоречит естественному (позитивному) ходу мыслей. В if обычно пишут позитивное условие, в else — негативное, а не наоборот. Начинать if с отрицания, при наличии else, часто считается code smell.
т.е. вместо
if not condition: # something bad else: # something good
практически всегда будет
if condition: # something good else: # something badComdiv
30.05.2018 20:58Не совсем понял вопрос. В любом случае, этот вариант меня так же устраивает (за исключением опечаток)
Дело именно в «опечатках». Статья, напомню, о психологии читабельности, и Ваш комментарий о более лёгком сопровождении.
Плюс, в таком стиле пишут крайне редко, т.к. он противоречит естественному (позитивному) ходу мыслей. В if обычно пишут позитивное условие, в else — негативное, а не наоборот. Начинать if с отрицания, при наличии else, часто считается code smell.
А это, тогда что такое?
if not user: print('no user') return None
От того, что в таком случае else неявный, делает только хуже в контексте статьи.
Comdiv
30.05.2018 21:21проблема возникает лишь в тех средах, где нет возможности использовать try-finally или его аналоги
Отнюдь. Освобождение ресурсов это лишь один из примеров, где важна последовательность действий. Растаскивание же порядка действий по defer, try finally и им подобным совсем не улучшает читаемость. А ведь статья об этом. Уменьшения разнообразия переходов положительно сказывается на понятности. Это давно заметили ещё на goto, но этим оператором дело ограничивается.
VolCh
30.05.2018 19:33func2() у вас может упасть, если get_orders(user) не воспринимает нормально get_orders(false) или что там проверяется в not user.
В коде func1() надо тщательно читать каждое условие, чтобы понимать где success path, а где ошибки, плюс следить за значением results. Может это можно отреглировать на уровне соглашений команды/проекта, что success path идёт исключительно в else и состояния меняются исключительно в ней, но, субъективно, это сложнее чем принцип early return «exception». За ним, кстати, тоже нужно следить, чтобы не нарушали.Comdiv
30.05.2018 20:52func2() у вас может упасть
В этом и суть. Статья о чём? О читабельности. Что читабельней: наличие всех return очевидный поток исполнения?
В коде func1() надо тщательно читать каждое условие, чтобы понимать где success path
Не более внимательно, чем в раннем выходе.
плюс следить за значением results
Питон это отдельная песня, но при использовании более ошибкоустойчивых языков(+анализатор), корректность работы с result отслеживается. Попробуйте отследить пропущенный return.TimTowdy
30.05.2018 22:55Попробуйте отследить пропущенный return.
Весьма странный аргумент.
Но в любом случае, вот вам аналогичная опечатка в вашем коде, попробуйте ее отследить. Не думаю что отсутствие early return вам хоть как-то поможет.
def func1(): results = None user = get_user() if not user: print('no user') else orders = get_orders(user) if not user: print('no orders') else transactions = get_transactions(orders): if not transactions: print('no transactions') else: results = [execute(t) for t in transactions] return resultsComdiv
31.05.2018 12:23Весьма странный аргумент.
Напоминаю, что речь в статье о читабельности.
Но в любом случае, вот вам аналогичная опечатка в вашем коде
Во-первых, код не мой, а переделанный Ваш, так как мне было непонятно, почему Вы не записали 1-й вариант так. Во-вторых, ошибка не аналогичная, но тоже отслеживается, хотя и не стандартными средствами Python. Как я уже писал, Python — это отдельная песня.
Чтобы ошибка была, действительно, аналогичной, она должна была бы выглядеть так:
Как и прежде не видите разницы в читаемости структурного потока и выравненного неструктурного?def func1(): results = None user = get_user() if not user: print('no user') orders = get_orders(user) if not orders: print('no orders') else: transactions = get_transactions(orders): if not transactions: print('no transactions') else: results = [execute(t) for t in transactions] return resultsTimTowdy
31.05.2018 14:23Напоминаю, что речь в статье о читабельности.
Вот именно. А не о случайных опечатках, они из другой оперы.
Во-вторых, ошибка не аналогичная, но тоже отслеживается
Как я понял, ваш аргумент состоит в том, что если в функции несколько return, то сложно отследить когда один из них из-за опечатки удалят и это приведет к runtime error. На мой взгляд этот аргумент очень слаб — ведь аналогичных ошибок можно придумать бесконечное множество, и защищать себя от одной ошибки из бесконечности довольно бесполезно. Поэтому и привел аналогичный, на мой взгляд пример: опечатка, не бросающаяся в глаз, приводящая к runtime error.
Если я неправильно понял класс опечаток, от которых вы пытаетесь защититься — тогда поясните о каком именно классе идет речь.
И вы до сих пор не ответили: вместо 10 return вы тоже предпочтете сделать 10 уровней вложенных if/else?Comdiv
31.05.2018 23:55Вот именно. А не о случайных опечатках
Отчего же, если в одном случае читаемость потока исполнения выше настолько, что случайная опечатка не сможет пройти незамеченной?
Как я понял, ваш аргумент состоит в том, что если в функции несколько return, то сложно отследить когда один из них из-за опечатки удалят и это приведет к runtime error
Нет, речь об очевидности структурного потока. Пример от Apple, приведший к серьёзной уязвимости, был о том же, за тем исключением, что там использовался goto, но это не так принципиально. Ошибка оставалась незамеченной, несмотря на то, что Вы и другие мои критики, считают что неструктурный преждевременный выход лучше читается. В то же время со строго структурным потоком такую ошибку не только было бы сложно допустить, но и была бы она намного очевидней.
На мой взгляд этот аргумент очень слаб — ведь аналогичных ошибок можно придумать бесконечное множество, и защищать себя от одной ошибки из бесконечности довольно бесполезно
Мы рассмотрели отдельный аспект, и было бы странно, если бы нам удалось охватить все случаи. Это не защита от одной ошибки, где Вы это увидели? От защиты от ошибок памяти и арифметического переполнения Вы тоже будете открещиваться на том основании, что ошибок можно придумать бесконечное множество?
И вы до сих пор не ответили: вместо 10 return вы тоже предпочтете сделать 10 уровней вложенных if/else?
Похоже, я просто не обратил внимание на этот вопрос. Это зависит от задачи. Если в коде встречается виртуальная лесенка из 10 return (а не switch), то скорее всего, там проблема на архитектурном уровне, и надо не потакать ей неструктурными подходами, а решать. Впрочем, всегда надо смотреть на конкретику, для универсального ответа недостаточно данных.TimTowdy
01.06.2018 02:07Отчего же, если в одном случае читаемость потока исполнения выше настолько, что случайная опечатка не сможет пройти незамеченной?
Стоп, а почему вы решили что не может? На мой взгляд все ровно наоборот: в вашем примере заметить опечатку гораздо сложнее. Пропущенный return резко выбивается из общего стиля, а вот отсутствие else выглядит вполне органично.
Если в коде встречается виртуальная лесенка из 10 return (а не switch), то скорее всего, там проблема на архитектурном уровне
То же самое можно сказать о двух goto в коде Apple, да и в принципе о любой проблеме. У вас получается нефальсифицируемая теория: любой недостаток вы списываете на внешние причины. Моя теория работает везде, а там где она не работает — это у вас плохая архитектура. Неконструктивно.Comdiv
01.06.2018 02:25Стоп, а почему вы решили что не может? На мой взгляд все ровно наоборот: в вашем примере заметить опечатку гораздо сложнее
А Вы попробуйте 1. совершить эту ошибку. 2. не заметить сместившийся блок. 3. Сопоставьте это с изменением потока управления из-за наличия или отсутствия линейного оператора.
То же самое можно сказать о двух goto в коде Apple
О том и речь, и это напрямую связано с наличием неструктурных переходов.
У вас получается нефальсифицируемая теория
Какая теория? О том, что в заданном вопросе недостаточно информации, для универсального ответа? Или Вас удивляет, что наличие «потребности» в большом количестве неструктурных переходов свидетельствует о проблемах проектирования? Об этом пишут ещё с 70-х. Вы знакомы с классикой Дейкстры? Знакомы с рекомендациями MISRA C для критического к корректности ПО и им подобным? Моя «нефальсифицируемая теория» написана практикой задолго до меня. Но сообщество, к сожалению, ходит по кругу.TimTowdy
01.06.2018 04:31А Вы попробуйте
Попробовал, получилось довольно легко, т.к. код выглядит валидно. В обоих вариантах это выглядит не как exception, а как warning, вот и все.
Или Вас удивляет, что наличие «потребности» в большом количестве неструктурных переходов свидетельствует о проблемах проектирования? Об этом пишут ещё с 70-х. Вы знакомы с классикой Дейкстры?
Представьте себе, знаком. Вот только сейчас не 70-е. При фанатичном следовании «классике» Дейкстры придется отказаться не только от multiple return, но и от break/continue в циклах, и от try/catch/finally в языках с исключениями. К счастью, фанатиков нынче не много, да и сам Дейкстра сегодня вряд ли бы поддержал фанатиков.
Знакомы с рекомендациями MISRA C для критического к корректности ПО и им подобным?
А вас не смущает что 'эти рекомендации официально допускают отклонения? И что они написаны для конкретной индустрии (embedded), конкретно для С (где памятью приходится управлять вручную), и вовсе не претендуют применение в других сферах? А может даже вообще ни на что не претендуют.
Обсуждению на самом деле сто лет в обед, люди давно пришли к консенсусу:
stackoverflow.com/questions/36707/should-a-function-have-only-one-return-statement
eugenebb
29.05.2018 20:45Как мне кажется «early return» более надёжная конструкция. Несколько раз встречал ошибки что в начинают добавлять код после закрывающего блока для else, а на самом деле этот код должен быть использован внутри else.
Плюс часто встречается необходимость обработать несколько условий. Предложенный способ неудобен для вложенных конструкций, лучше иметь один способ и «early return» более универсален (конечно IMHO).
public void SomeFunction(int age) { if (age < 0){ System.out.println("Не верный возраст"); return; } if (age > 100){ System.out.println("Подумай ещё"); return; } if (age < 18){ System.out.println("Не продаём малолетним"); return; } // сделать что-то }Comdiv
29.05.2018 21:09Несколько раз встречал ошибки что в начинают добавлять код после закрывающего блока для else, а на самом деле этот код должен быть использован внутри else.
К сожалению, не понял, что имеется ввиду.
А пример хорошо переписывается в многоветочный if, Java не имеет встроенной поддержки, но благодаря статическим анализаторам это не так критично
public void SomeFunction(int age) { if (age < 0) { System.out.println("Не верный возраст"); } else if (age > 100) { System.out.println("Подумай ещё"); } else if (age < 18) { System.out.println("Не продаём малолетним"); } else { // сделать что-то } }
С преждевременным выходом же появляется дополнительная возможность ошибки пропуска return и диагностировать это сложней в общем случаеeugenebb
29.05.2018 21:25Что-то типа
public void SomeFunction(int age) { if (age < 0){ System.out.println("Неправильный возраст"); } else { // сделать что-то } // добавили что то, что должно быть в "сделать что-то" }
Про «else if» пример был для самых простых случаях. Обычно это что-то типа
public void SomeFunction(int age) { if (condition1){ System.out.println("Не верный возраст"); return; } // сходили в базу, что-то посчитали if (condition2){ System.out.println("Подумай ещё"); return; } // получили данные от сервиса, что-то ещё посчитали if (condition3){ System.out.println("Не продаём малолетним"); return; } // сделать что-то }Comdiv
29.05.2018 22:34Про «else if» пример был для самых простых случаях. Обычно это что-то типа
Тогда нужно разбивать на шаги. Ибо иначе огромные функции так и растут. Из-за усеянности неструктурными переходами разбивать функцию становится всё сложней.
Как-то, читая новость об исправлении уязвимости в NGINX, случайно обнаружил в нём другую ошибку переполнения. Оцените исправление этой ошибки hg.nginx.org/nginx/rev/e3723f2a11b7 Она была продублирована в большом количестве мест, и общий код не мог быть так просто вынесен в отдельную оттестированную функцию, а был повсюду в большущих функциях, потому что использовалась логика неструктурных переходов, усложняющая декомпозицию.eugenebb
29.05.2018 22:49Поэтому я и написал свой первоначальный комментарий, потому что наш реальный проект пестрит подобными конструкциями. Создаётся новый метод и после нескольких итераций изменений превращается в головоломку вложенных if-ов.
Если бы сразу использовали подход «early return» то скорее всего последующие изменения поддерживали бы этот стиль.
В идеальном мире можно было бы конечно надеяться на refactoring, но обычно реальность отличается от мечты и принцип: «работает — не трогай» перевешивает любые доводы о внутренней красоте кода.Comdiv
30.05.2018 00:11Если он состоит из вложенных if-ов, то он поддаётся декомпозиции. Ранний выход провоцирует на дальнейшее разрастание.
Про неидеальный мир согласен, но в контекст статьи это не вписывается. Тут, всё-таки, о правильном подходе даже с учётом психологии.striver
30.05.2018 10:05Один раз сделал конструкцию, очень красиво получалось, пока не начал заполнять «пробелы» между элс-ифами. Думал по бырому сделаю копированием, чтоб проверить что будет на выходе… получилось овер 5к строк для печати одной формы… естественно, ужалось всё это в 500.
Comdiv
01.06.2018 00:00А можете рассказать чуть подробней? Если Вам удалось ужать 5000 строк до 500, то хотелось понять как.
striver
01.06.2018 12:02Я там вообще всю логику переделал, методы переписал (я же говорю, изначально хотел по бырому копи-пастом заполнить и проверить как работает...). Проблема в том, что уже полгода никому это не нужно. Было сказано, что для пользователей сложно, пуская пишут вручную. И недельные потуги пришлось умножить на «0».
GeekberryFinn
29.05.2018 22:15} else if (age > 100) {
System.out.println(«Подумай ещё»);
Вообще-то люди старше ста лет существуют.
Так что код так же неверно построен, как и база данных в которой у всех людей есть фамилия, имя и отчество — и каждое поле не длиннее 16 символов, никак не учитывающая то, что клиент может оказаться иностранцем.eugenebb
29.05.2018 22:25Надо смотреть где это используется, чаще гораздо логичнее предположить что папа/мама вводя дату рождения ребёнка, вместо 2008, напишут например 1908, а не то что столетний аксакал захочет поиспользовать нашу замечательную систему.
Antervis
30.05.2018 09:23С точки зрения читаемости такой код лучше:
не согласен, категорически. Early return/throw — такой же шаблон восприятия, что и обычный for, его назначение интуитивно понятно, а позитивный и негативный сценарии выполнения легко отличимы при беглом осмотре. И уже бонусом к этому идет уменьшение уровней вложенности.
Leg3nd
29.05.2018 23:22public void SomeFunction(int age) { if (age >= 0) { // сделать что-то } else { System.out.println("Не верный возраст"); } } public void SomeFunction(int age) { if (age < 0){ System.out.println("Не верный возраст"); return; } // сделать что-то }
Лично мне первый вариант является более приемлемым. Так как при большем количестве параметров функции возникает комбинаторный взрыв количества возможных значений и сочетаний этих параметров. И на много проще оказывается очертить множество подходящих значений, а все остальное по умолчанию считать мусором и выбрасывать ошибку (ну или как-то по другому обрабатывать эту ситуацию). По опыту так меньше ошибок вылазит в итоге.
striver
30.05.2018 10:18По поводу комментариев.
Чем проще функция или метод — тем проще комментарий, но бывает и переизбыток, А при усложнении — их недостаток. Да, нужно комментировать. Написан код, а про комменты все забыли. Вот и начинается
а + б // а+б
а+б*с/г // какая-то формула
20 строк кода // метод делает то, потому что это вот так вот
50 строк кода // метод делает то
100 строк кода // метод
500 строк кода // магия, потому что по другому никак.
exehoo
30.05.2018 14:03Порой комментарии напоминают
интимную перепискунадписи, нацарапанные гвоздем на стенах камеры =)
MalinaAlina
30.05.2018 11:02Возможно, концепцию раннего возврата стоит расширить до «при множественном выборе ставьте крупные блоки вниз, мелкие — наверх».
Прекрасная статья!
amarao
30.05.2018 13:14Вопросы красоты записи обычных структур — наверное. Хотя, условный питон по удобности циклов трудно превзойти. Куда важнее, чтобы язык программирования давал возможности для добавления семантики через синтаксис.
Каждый раз, когда у вас в коде появляется осмысленное имя внутри синтаксической конструкции, код становится понятнее.
Начинаем с имён переменных (вместо номеров ячеек). Имя — смысл, номер ячейки — синтаксис. Добавили имена — получили семантику. Потом метки вместо адресов. Тоже семантика. Потом функции. Имя? Семантика! Лямбды? Минус семантика.
Дальше — группа функций и переменных, делающих что-то. Модуль. имя? Семантика.
Группа переменных? Структура. Имя? Семантика! И дальше по той же линии. Классы, трейты, синтаксические макросы, typeclass'ы, namespace'ы, lifetime'ы. Каждый раз, когда мы что-то новое называем — это улучшает понимание кода. Но мы не можем называть те штуки, которые не уменьшают его размер. Это означает, что нам нужен всё более и более выразительный синтаксис. Как только синтаксис уменьшает размер кода, код становится выразительнее. Как только синтаксис требует идентификаторов, код становится понятнее.
Направление развития языков программирования — выразительность синтаксиса, подкрепляющаяся семантикой именования.VolCh
30.05.2018 19:57Тут главное, именовать так, чтобы понятней было, а не наоборот. Вот в посте упомянуто про Model и Controller. На практике 91,35456(6)% знакомых разработчиков видя class UserModel или class User extends Model думают не о модели в смысле MVC, не о модели в смысле объектной модели какой-то сущности предметной области, а о де-факто RowTableGateway «де-юре» именующемся ActiveRecord.
ov7a
30.05.2018 13:50Пример про состояние переменной считаю некорректным, т.к. там сравниваются разные функции.
Кроме того, вычисление НОД через хвостовую рекурсию, на мой взгляд, более понятная реализация, чем циклом. По крайней мере она 1 в 1 отражает запись НОД(a,b) = HОД(b, a%b).
Parondzhanov
01.06.2018 08:53Спасибо автору Владимиру tangro за интересный материал.
Жаль, что автор ограничился текстовым программированием и не рассмотрел визуальное.
AlexPancho
Здорово когда простым языком объяснят то, что воспринимаешь интуитивно. Теперь можно не просто сказать «так надо», а «так надо, потому что твой мозговой процессор так работает»
sasha1024
И это будет неправдой.