
Успокойтесь, начальство всё равно не даст ничего переписать. Остаётся рефакторить. На что лучше всего потратить свои невеликие ресурсы? Как именно рефакторить, где проводить чистки?
Название этой статьи — в том числе отсылка к книге Дяди Боба «Чистая Архитектура», а сделана она на основе замечательного доклада Victor Rentea (твиттер, сайт) на JPoint (под катом он начнёт говорить от первого лица, но пока дочитайте вводную). Чтения умных книжек эта статья не заменит, но для такого короткого описания изложено весьма хорошо.
Идея в том, что популярные в народе вещи вроде «Clean Architecture» действительно являются полезными. Сюрприз. Если нужно решить вполне конкретную задачу, простой изящный код не требует сверхусилий и оверинжиниринга. Чистая архитектура говорит, что нужно защищать свою доменную модель от внешних эффектов, и подсказывает, как именно это можно сделать. Эволюционный подход к наращиванию объема микросервисов. Тесты, которые делают рефакторинг менее страшным. Вы ведь уже знаете всё это? Или знаете, но боитесь даже подумать об этом, ведь это же ужас что тогда делать придётся?
Кто хочет получить волшебную анти-прокрастинационную таблетку, которая поможет перестать трястись и начать рефакторить — добро пожаловать на видеозапись доклада или под кат.
Меня зовут Виктор, я из Румынии. Формально я являюсь консультантом, техлидом и ведущим архитектором в Румынском IBM. Но если бы меня попросили самому дать определение своей деятельности, то я евангелист чистого кода. Обожаю создавать красивый, чистый, поддерживаемый код — об этом, как правило, и рассказываю на докладах. Даже больше, меня вдохновляет преподавание: обучение разработчиков в областях Java EE, Spring, Dojo, Test Driven Development, Java Performance, а также в области упомянутого евангелизма — принципов чистоты паттернов кода и их разработки.
Опыт, на котором строится моя теория — в основном разработка корпоративных приложений для крупнейшего клиента IBM в Румынии — банковского сектора.
План на эту статью таков:
- Моделирование данных: структуры данных не должны становиться нашими врагами;
- Организация логики: принцип «декомпозиции кода, которого слишком много»;
- «Onion» — самая чистая архитектура философии Transaction Script;
- Тестирование как способ борьбы со страхами разработчика.
Но сначала давайте вспомним те главные принципы, о которых мы, как разработчики, должны помнить всегда.
Принцип единственной ответственности

Иначе говоря, количество vs качество. Как правило, чем больше функциональности содержит ваш класс, тем хуже она оказывается в качественном отношении. Разрабатывая большие классы, программист начинает путаться, ошибаться в построении зависимостей, а большой код, помимо всего прочего, сложнее отладить. Лучше разбить такой класс на несколько более мелких, каждый из которых будет отвечать за некоторую подзадачу. Пусть лучше у вас будет несколько сильносвязанных модулей, чем один — крупный и неповоротливый. Модульность также даёт возможность повторного использования логики.
Слабое связывание модулей

Степень связывания — это характеристика того, насколько тесно взаимодействуют друг с другом ваши модули. Она показывает то, насколько широко способен распространиться эффект от изменений, вносимых вами в какой-то одной точке системы. Чем выше связывание, тем сложней осуществлять модификации: вы меняете что-то в одном модуле, а эффект распространяется далеко и не всегда ожидаемым образом. Поэтому показатель связывания должен быть как можно ниже — этим вы обеспечите больший контроль над системой, подвергающейся модификациям.
Не повторяйтесь

Ваши собственные реализации могут быть хороши сегодня, но уже не так хороши завтра. Не разрешайте себе копировать свои собственные наработки и таким образом распространять их по кодовой базе. Вы можете копировать со StackOverflow, из книг — с любых авторитетных источников, которые (как вы точно знаете) предлагают идеальную (или близкую к тому) реализацию. Дорабатывать же свою собственную реализацию, встречающуюся не один раз, а размноженную по всей кодовой базе, может быть очень утомительно.
Простота и лаконичность

На мой взгляд, это главный принцип, который нужно соблюдать в инженерных и программных разработках. «Преждевременная инкапсуляция — корень зла», — говорил Адам Биен. Иначе говоря, корень зла заключается в «пере-инженерии». Автор цитаты Адам Биен одно время занимался тем, что брал легаси-приложения и, полностью переписывая их код, получал кодовую базу объемом в 2-3 раза меньше исходного. Откуда берётся столько лишнего кода? Он ведь возникает не просто так. Его порождают испытываемые нами страхи. Нам кажется, что, нагромождая в большом количестве паттерны, плодя косвенность и абстракции, мы обеспечиваем нашему коду защиту — защиту от неизвестностей завтрашнего дня и завтрашних требований. Ведь на самом-то деле сегодня ничего из этого нам не нужно, изобретаем мы всё это только ради каких-то «будущих нужд». И не исключено, что эти структуры данных впоследствии будут мешать. Скажу честно, когда ко мне подходит какой-нибудь мой разработчик и озвучивает, что он придумал кое-что интересное, что можно добавить в продакшн-код, я отвечаю всегда одинаково: «Парень, тебе это не пригодится».
Кода не должно быть много, а тот, что есть, должен быть простым — только так с ним можно будет нормально работать. Это забота о ваших разработчиках. Вы должны помнить, что именно они являются ключевыми фигурами для вашей системы. Постарайтесь снизить их энергозатраты, уменьшить те риски, с которыми им придётся работать. Это не значит, что вам придётся создать свой собственный фреймворк, более того, я бы не советовал вам это делать: в своём фреймворке всегда будут баги, всем нужно будет его изучать и т.д. Лучше пустите в ход существующие средства, коих сегодня имеется масса. Это должны быть простые решения. Пропишите глобальные обработчики ошибок, примените технологию аспектов, генераторы кода, расширения Spring или CDI, настройте области действия Request/Thread, используйте манипуляцию и генерацию на лету байткода и пр. Всё это будет вашим вкладом в поистине важнейшую вещь — в комфорт вашего разработчика.
В частности, я бы хотел продемонстрировать вам применение областей Request/Thread. Я не раз наблюдал, как эта вещь невероятным образом упрощала корпоративные приложения. Суть в том, что она даёт вам возможность, будучи залогиненным пользователем, сохранять данные RequestContext. Таким образом, RequestContext будет в компактном виде хранить данные о пользователе.

Как видите, реализация занимает всего пару строк кода. Прописав запрос в нужную аннотацию (несложно делается, если вы используете Spring или CDI), вы навсегда освободите себя от необходимости передавать методам пользовательский логин и что бы то ни было ещё: хранимые внутри контекста метаданные запроса будут прозрачным образом перемещаться по приложению. Scoped proxy же позволит вам в любой момент получить доступ к метаданным текущего запроса.
Регрессионные тесты

Обновляющихся требований разработчики боятся потому, что боятся процедуры рефакторинга (модификации кода). И самый простой способ помочь им — создать надёжный набор тестов для регрессионного тестирования. С помощью него разработчик будет иметь возможность в любой момент протестировать свою наработку — убедиться, что она не поломает систему.
Разработчик не должен бояться ничего сломать. Вы должны сделать всё, чтобы рефакторинг воспринимался как что-то хорошее.
Рефакторинг — важнейший аспект разработки. Помните, ровно в тот момент, когда ваши разработчики испугаются рефакторинга, приложение можно считать перешедшим в разряд «легаси».
Где реализовывать бизнес-логику?
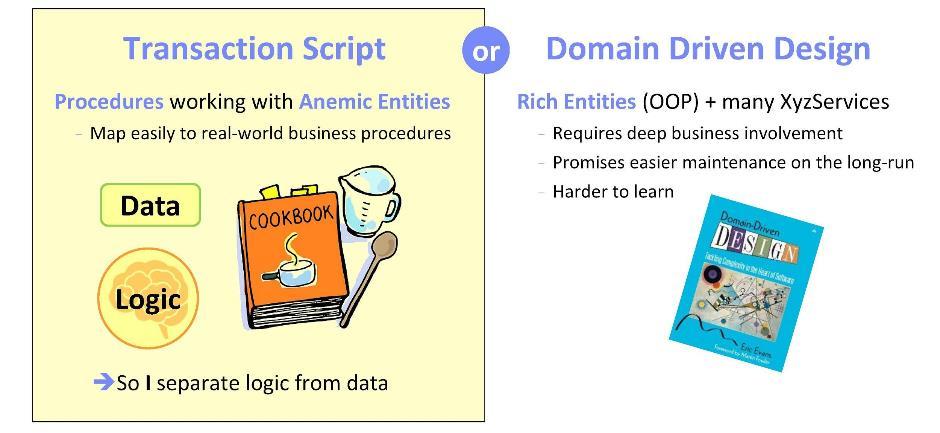
Начиная реализацию любой системы (или компоненты системы), мы задаём себе вопрос: где лучше реализовать логику предметной области, то есть функциональные аспекты нашего приложения? Есть два противоположных подхода.
Первый из них основывается на философии Transaction Script. Здесь логика реализуется в процедурах, работающих с анемичными сущностями (то есть со структурами данных). Такой подход хорош тем, что в ходе его реализации можно опираться на сформулированные бизнес-задачи. Работая над приложениями для банковского сектора, я не раз наблюдал перевод бизнес-процедур в софт. Могу сказать, что это действительно очень естественно — соотносить сценарии с софтом.
Альтернативный подход — использовать принципы Domain-Driven Design. Здесь вам потребуется соотнести спецификации и требования с объектно-ориентированной методологией. Важно и тщательно продумать объекты, и обеспечить хорошую вовлеченность со стороны бизнеса. Плюс спроектированных таким образом систем в том, что в дальнейшем они легко поддерживаются. Однако по моему опыту, осваивать данную методологию достаточно непросто: более-менее смело вы почувствуете себя не раньше, чем через полгода её изучения.
Для своих разработок я всегда выбирал первый подход. Могу заверить, что в моем случае он работал идеально.
Моделирование данных
Сущности
Как же нам моделировать данные? Как только приложение принимает более-менее приличные размеры, обязательно появляются персистентные данные. Это такие данные, которые вам требуется хранить дольше остальных — они являются доменными сущностями (domain entities) вашей системы. Где их хранить — в базе данных ли, в файле или напрямую управляя памятью — не имеет значения. Важно то, как вы будете их хранить — в каких структурах данных.

Вам как разработчику дан этот выбор, и только от вас зависит, будут ли эти структуры данных работать на вас или против вас при реализации функциональных требований в будущем. Чтобы всё было хорошо, вы должны реализовывать сущности, закладывая в них крупицы переиспользуемой доменной логики. Как конкретно? Продемонстрирую несколько способов на примере.

Давайте посмотрим, чем я снабдил сущность Customer. Во-первых, я реализовал синтетический геттер
getFullName(), который будет возвращать мне конкатенацию firstName и lastName. Также я реализовал метод activate() — для контроля состояния моей сущности, таким образом инкапсулируя его. В этот метод я поместил, во-первых, операцию по валидации, и, во-вторых, присвоение значений полям status и activatedBy, благодаря чему не нужно прописывать для них сеттеры. Также я добавил в сущность Customer методы isActive() и canPlaceOrders(), осуществляющие внутри себя лямбда-валидацию. Это так называемая инкапсуляция предикатов. Такие предикаты пригодятся, если вы используете фильтры Java 8: можно передавать их в качестве аргументов фильтрам. Этими хелперами советую пользоваться.Возможно, вы используете какой-нибудь ORM вроде Hibernate. Предположим, у вас имеется две сущности с двусторонней связью. Инициализацию необходимо выполнять с обеих сторон, иначе, как вы понимаете, у вас возникнут проблемы при обращении к этим данным в дальнейшем. Но разработчики зачастую забывают проинициализировать объект с какой-нибудь одной из сторон. Вы же, разрабатывая эти сущности, можете предусмотреть специальные методы, которые будут гарантировать двустороннюю инициализацию. Посмотрите на
addAddress().
Как видите, это вполне обычная сущность. Но внутрь неё заложена доменная логика. Такие сущности не должны быть скудными и поверхностными, но и не должны быть переполненными логикой. Переполненность логикой возникает чаще: если уж вы решили реализовать всю логику в домене, то для каждого use-case возникнет соблазн реализовать какой-нибудь специфический метод. А use-case-ов, как правило, бывает много. Вы получите не сущность, а одну большую кучу всевозможной логики. Старайтесь соблюдать здесь меру: в домен помещается только переиспользуемая логика и только в небольшом количестве.
Объекты-значения
Помимо сущностей вам, скорее всего, также понадобятся объекты-значения (object values). Это не что иное, как способ сгруппировать доменные данные, чтобы потом вместе перемещать их по системе.
Объект-значение должен быть:
- Небольшим. Никаких
floatдля денежных переменных! Крайне осторожно подходите к выбору типов данных. Чем компактнее ваш объект, тем легче в нём разберётся новый разработчик. Это основа основ для комфортной жизни.
- Неизменяемым. Если объект действительно иммутабельный, то разработчик может быть спокоен, что ваш объект не изменит своего значения и не сломается после создания. Это закладывает основу для спокойной, уверенной работы.

А если добавить в конструктор вызов метода
validate(), то разработчик сможет быть спокоен за валидность созданной сущности (при передаче, скажем, несуществующей валюты или отрицательной денежной суммы конструктор не отработает).Отличие сущности от объекта-значения
Объекты-значения отличаются от сущностей тем, что у них нет постоянного ID. В сущностях всегда будут поля, связанные с внешним ключом какой-нибудь таблицы (или другого хранилища). У объектов-значений таких полей нет. Возникает вопрос: отличаются ли процедуры проверки на равенство двух объектов-значений и двух сущностей? Поскольку у объектов-значений нет поля ID, чтобы заключить, что два таких объекта равны, придётся попарно сравнить значения всех их полей (то есть осмотреть всё содержимое). При сравнении же сущностей достаточно провести одно единственное сравнение — по полю ID. Именно в процедуре сравнения заключается главное отличие сущностей от объектов-значений.
Data Transfer Objects (DTOs)

В чём заключается взаимодействие с пользовательским интерфейсом (UI)? Ему вы должны передать данные для отображения. Неужели понадобится ещё одна структура? Так и есть. А всё потому, что пользовательский интерфейс вам совсем не друг. У него свои запросы: ему нужно, чтобы данные хранились в соответствии с тем, как они должны отображаться. Это так чудно — что именно порой требуют от нас пользовательские интерфейсы и их разработчики. То им нужно достать данные для пяти строк; то им приходит в голову завести для объекта булево поле
isDeletable (может ли в принципе у объекта быть такое поле?), чтобы знать, делать ли активной кнопку «Удалить» или нет. Но возмущаться нечего. У пользовательских интерфейсов попросту другие требования.Вопрос в том, можно ли вверить им в пользование наши сущности? Вероятней всего, они их изменят, причем самым нежелательным для нас образом. Поэтому предоставим им кое-что другое — Data Transfer Objects (DTO). Они будут приспособлены специально под внешние требования и под логику, отличную от нашей. Некоторые примеры структур DTO: Form/Request (поступают из UI), View/Response (отправляются в UI), SearchCriteria/SearchResult и пр. Можно в некотором смысле назвать это API-моделью.
Первый важный принцип: DTO должно содержать минимум логики.
Перед вами пример реализации
CustomerDto.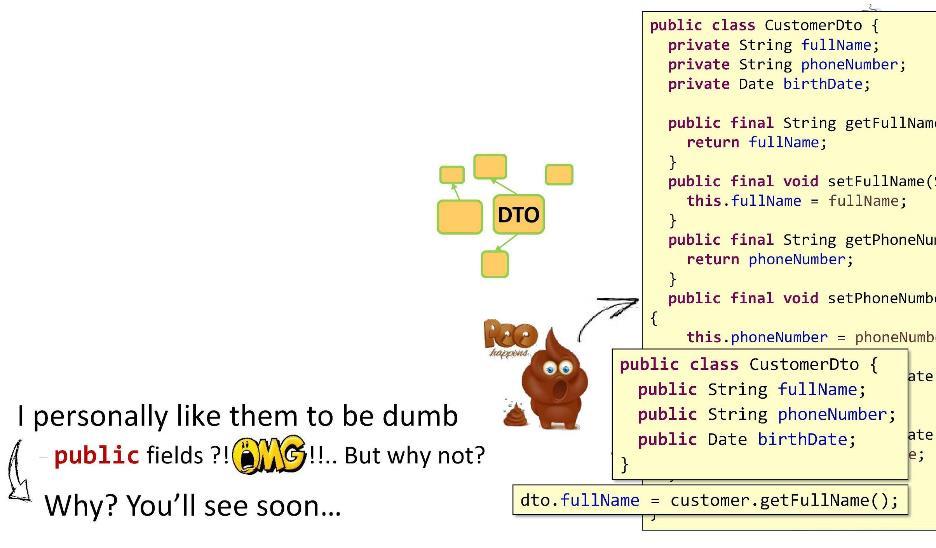
Содержимое: private-поля, public-геттеры и сеттеры для них. Вроде бы всё супер. ООП во всей красе. Но одно плохо: в виде геттеров и сеттеров я реализовал слишком большое количество методов. В DTO же логики должно быть как можно меньше. И тогда какой мой выход? Я делаю поля публичными! Вы скажете, что такое плохо работает с method references из Java 8, что возникнут ограничения и пр. Но верите или нет, все свои проекты (10-11 штук) я делал вот с такими DTO. Брат жив. Теперь, поскольку мои поля — публичные, я имею возможность запросто присваивать значение
dto.fullName, просто ставя знак равно. Что может быть прекраснее и проще?Организация логики
Маппинг
Итак, у нас есть задача: нам нужно преобразовать наши сущности в DTO. Реализуем преобразование так:
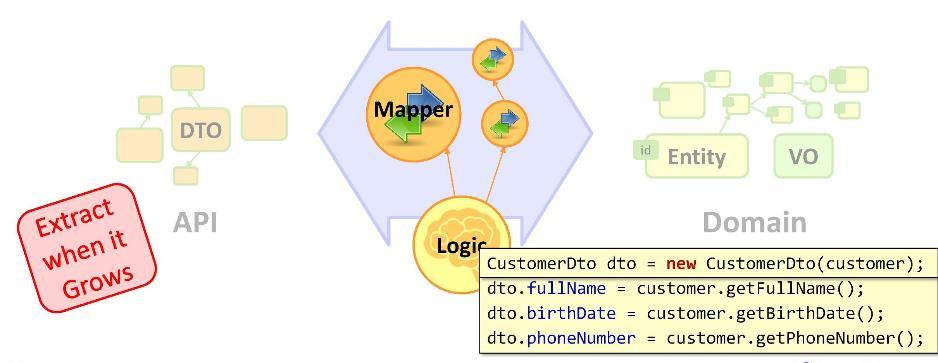
Как видите, объявив DTO, мы переходим к операциям маппинга (присвоения значений). Нужно ли быть senior developer, чтобы писать в таком количестве обычные присвоения? Для некоторых это настолько непривычно, что они начинают переобуваться на ходу: например, копировать данные при помощи какого-нибудь фреймворка для маппинга, используя рефлекшн. Но они упускают главное — то, что рано или поздно произойдёт взаимодействие UI с DTO, в результате которого сущность и DTO разойдутся в своих значениях.
Можно было бы, скажем, поместить операции маппинга в конструктор. Но такое возможно не для любого маппинга; в частности, в конструкторе нельзя осуществить доступ к базе данных.
Таким образом, мы вынуждены оставить операции маппинга в бизнес-логике. И если они имеют компактный вид, то в этом ничего страшного нет. Если же маппинг занимает не пару строк, а больше, то лучше вынести его в так называемый маппер. Маппер — это класс, специально предназначенный для копирования данных. Это, в общем-то, допотопная вещь и бойлерплейт. Но зато за ними можно скрыть наши многочисленные присвоения — сделать код чище и стройнее.
Запомните: код, который слишком разросся, нужно выносить в отдельную структуру. В нашем случае операций маппинга было действительно многовато, поэтому мы вынесли их в отдельный класс — в маппер.
Разрешать ли мапперам доступ в базу данных? Можете по умолчанию разрешить — так часто поступают из соображений простоты и прагматики. Но это подвергает вас определённым рискам.
Проиллюстрирую на примере. Создадим на основе имеющегося DTO сущность
Customer.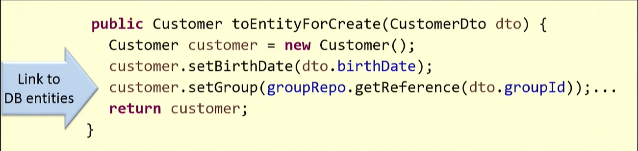
Для маппинга нам необходимо добыть из базы данных ссылку на группу покупателя. Поэтому я запускаю метод
getReference(), и он возвращает мне некоторую сущность. Запрос, скорей всего, уйдёт в базу данных (в некоторых случаях этого не происходит, и отрабатывает функция-заглушка).Но неприятность нас ожидает не здесь, а в методе, выполняющем обратную операцию — преобразование сущности в DTO.

При помощи цикла мы проходим все адреса, ассоциированные с имеющимся Customer, и преобразуем их в адреса DTO. Если вы используете ORM, то, вероятно, при вызове метода
getAddresses() выполнится ленивая загрузка. Если вы не используете ORM, то это будет открытый запрос ко всем детям данного родителя. И здесь вы рискуете вляпаться в «проблему N+1». Почему?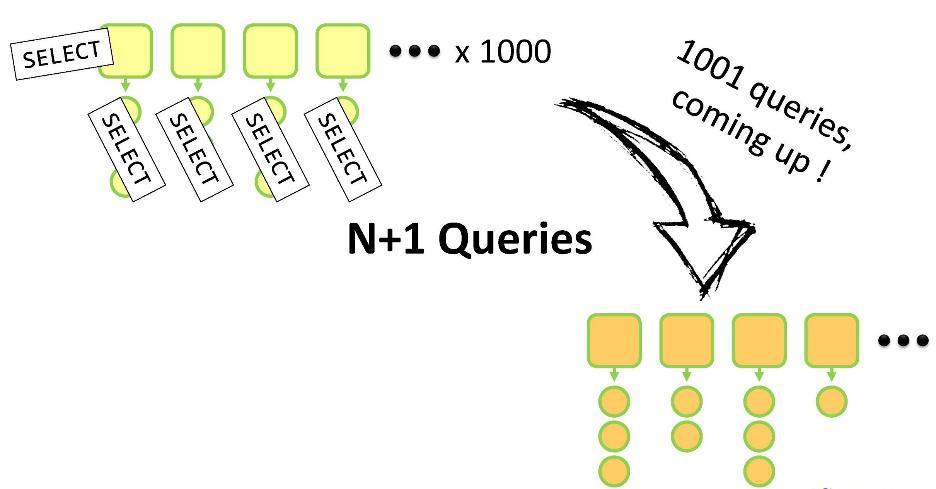
У вас есть набор родителей, у каждого из которых есть дети. Для всего этого вам нужно создать свои аналоги внутри DTO. Вам понадобится выполнить один
SELECT-запрос для обхода N родительских сущностей и далее — ещё N SELECT-запросов, чтобы обойти детей каждой из них. Итого N+1 запрос. Для 1000 родительских сущностей Customer такая операция займёт 5-10 секунд, что, конечно, долго.Предположим, что, всё же, наш метод
CustomerDto() вызывается внутри цикла, преобразуя список объектов Customer в список CustomerDto.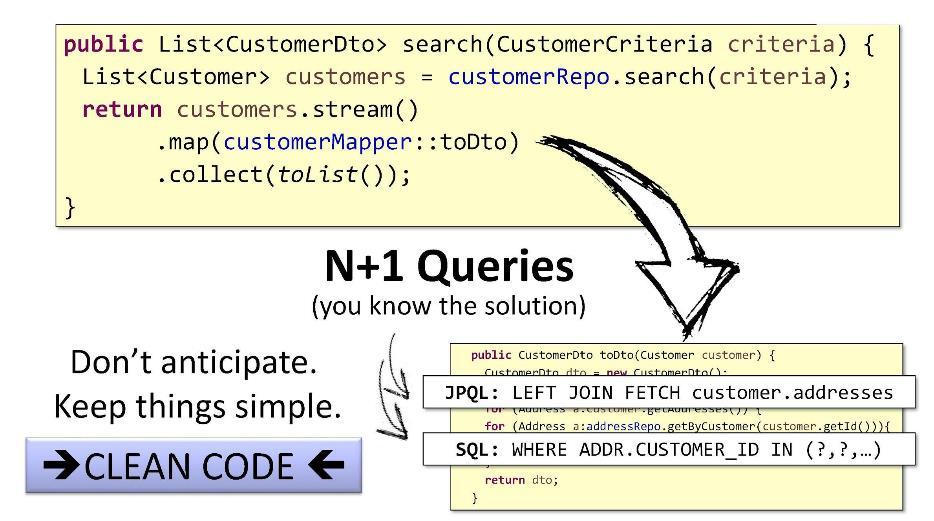
У проблемы с N+1 запросами есть простые типовые решения: в JPQL для извлечения детей вы можете воспользоваться
FETCH по customer.addresses и затем соединить их при помощи JOIN, а в SQL вы можете применить обход IN и оператор WHERE.Но я бы сделал по-другому. Можно узнать, какова максимальная длина списка детей (это можно сделать, например, на основе поиска с пагинацией). Если в списке всего 15 сущностей, то нам потребуется всего 16 запросов. Вместо 5мс мы потратим на всё, скажем, 15мс — пользователь не заметит разницы.
Об оптимизации
Я бы не советовал вам оглядываться на производительность системы уже на начальном этапе разработки. Как сказал Дональд Кнуд: «Преждевременная оптимизация — корень зла». Нельзя оптимизировать с самого начала. Это именно то, что нужно оставить на потом. И что особенно важно: никаких предположений — только измерения и оценка измерений!
Так ли вы уверены, что вы компетентны, что вы настоящий эксперт? Будьте скромны в оценке себя. Не думайте, что поняли работу JVM, пока не прочтёте хотя бы пару книг о JIT-компиляции. Бывает, лучшие программисты из нашей команды подходят ко мне и говорят, что, как им кажется, они нашли более эффективную реализацию. Оказывается же, что они снова изобрели что-то, что только усложняет код. Поэтому я раз за разом отвечаю: YAGNI. Нам это не понадобится.
Зачастую для корпоративных приложений вообще не требуется никакой оптимизации алгоритмов. Узким местом для них, как правило, является не компиляция и не то, что касается работы процессора, а всевозможные операции ввода-вывода. Например, считывание миллиона строк из базы данных, объёмные записи в файл, взаимодействие с сокетами.
Со временем начинаешь понимать, какие узкие места содержит система, и, подкрепив всё измерениями, начнешь понемногу оптимизировать. А до этого момента сохраняйте код как можно более чистым. Вы обнаружите, что такой код гораздо легче поддаётся дальнейшей оптимизации.
Предпочитайте композицию наследованию
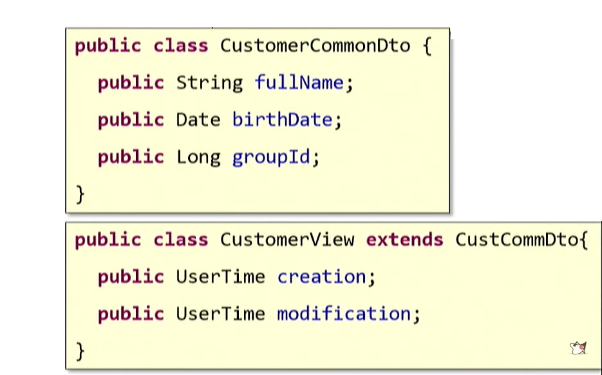
Вернёмся к нашим DTO. Предположим, мы определили такую DTO:

Она может понадобиться нам во множестве рабочих потоков. Но эти потоки разные и, вероятней всего, каждый use-case будет предполагать различную степень заполненности полей. Например, создать DTO нам явно нужно будет раньше, чем когда у нас будет полная информация о пользователе. Можно временно оставлять поля пустыми. Но чем больше полей будете игнорироваться, тем больше вам будет хотеться создать новое более строгое DTO для данного use-case.
Как вариант, можно создать копии избыточно большого DTO (в количестве имеющихся use-case-ов) и далее убрать из каждой копии лишние для неё поля. Но многим программистам, в силу ума и грамотности, действительно больно нажимать Ctrl+V. Аксиома гласит, что копипастить — плохо.
Можно прибегнуть к известному в теории ООП принципу наследования: просто определим некий базовый DTO и для каждого use-case создадим наследника.
Известный принцип гласит: «Предпочитайте композицию наследованию». Прочитайте, что там написано: «extends». Вроде бы мы должны были «расширить» исходный класс. Но если вдуматься, то, что мы сейчас понаделали — вовсе не «расширение». Это самое настоящее «повторение» — тот же копипаст, вид сбоку. Поэтому наследование мы использовать не будем.
Но как же тогда нам быть? Как перейти к композиции? Сделаем так: пропишем в CustomerView поле, которое будет указывать на объект базового DTO.
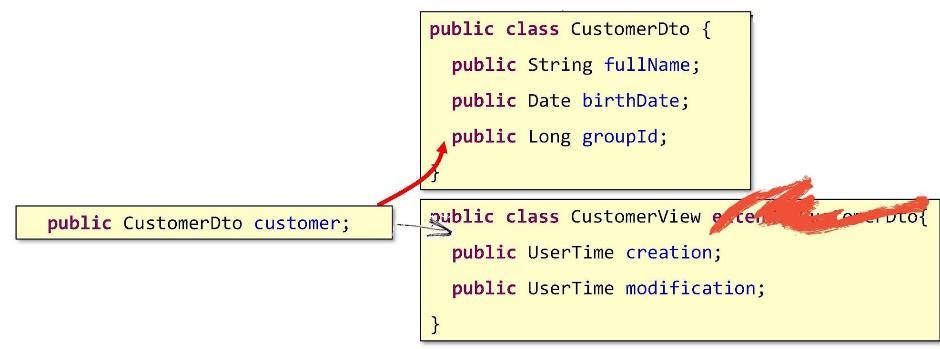
Таким образом наша базовая структура будет вложена внутрь. Вот так выйдет настоящая композиция.
Используем ли мы наследование или решаем вопрос композицией — это всё частности, тонкости, возникшие глубоко в ходе нашей реализации. Они очень хрупкие. Что значит хрупкие? Посмотрите внимательно на этот код:

Большинство разработчиков, которым я это показал, сразу выпалили, что число «2» повторяется, поэтому его нужно вынести в виде константы. Они не обратили внимание, что двойка во всех трёх случаях имеет совершенно разный смысл (или «бизнес-значение») и что её повторение — не более чем совпадение. Вынести двойку в константу — правомерное решение, однако очень хрупкое. Старайтесь не допускать в домен хрупкую логику. Никогда не работайте из него со внешними структурами данных, в частности, с DTO.
Итак, почему же работа по ликвидации наследования и введению композиции оказывается бесполезной? Именно потому, что DTO мы создаем не для себя, а для внешнего клиента. А как клиентское приложение будет парсить полученные от вас DTO — вам остаётся только догадываться. Но очевидно, что это будет иметь мало общего с вашей реализацией. Разработчики с той стороны могут и не сделать различия для базовых и небазовых DTO, которые вы так старательно продумали; наверняка они используют наследование, а возможно и тупо копипастят вот это всё.
Фасады

Вернёмся к общей картине приложения. Я бы советовал вам реализовывать доменную логику через паттерн Facade, расширяя фасады доменными сервисами по необходимости. Доменный сервис создаётся тогда, когда в фасаде накапливается слишком большое количество логики, и удобнее её вынести в отдельный класс.
Ваши доменные сервисы должны обязательно говорить на языке вашей доменной модели (её сущностей и объектов-значений). Они ни в коем случае не должны работать с DTO, потому как DTO, как вы помните, — это структуры, постоянно изменяемые с клиентской стороны, слишком хрупкие для домена.
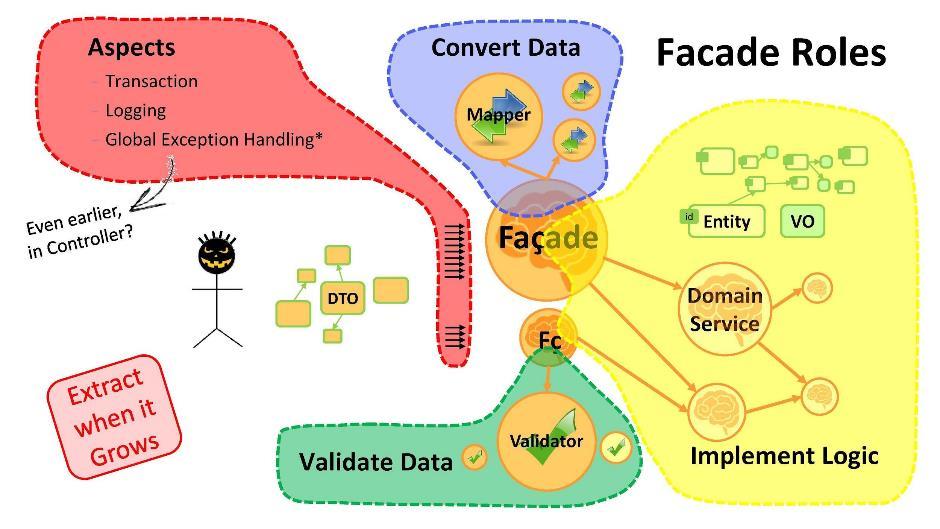
Каково назначение фасада?
- Преобразование данных. Если мы имеем сущности с одного конца и DTO с другого, необходимо проводить преобразования из одного в другое. И это первое, для чего нужны фасады. Если процедура преобразования разрослась в объёме — применяйте классы-мапперы.
- Реализация логики. В фасаде вы начнёте писать основную логику приложения. Как только её становится много — выносите части в доменный сервис.
- Валидация данных. Помните, что любые поступающие от пользователя данные по определению являются некорректными (содержащими ошибки). В фасаде есть возможность провести валидацию данных. Эти процедуры при превышении объёма принято выносить в валидаторы.
- Аспекты. Можно пойти дальше и сделать так, чтобы каждый use-case проходил через свой фасад. Тогда получится надстроить на методы фасада такие вещи, как транзакции, логирование, глобальные обработчики исключений и др. Отмечу, очень важно иметь в любом приложении глобальные обработчики исключений, которые бы ловили все ошибки, не пойманные другими обработчиками. Они очень помогут вашим программистам — дадут им спокойствие и свободу действий.
Декомпозиция кода, которого много
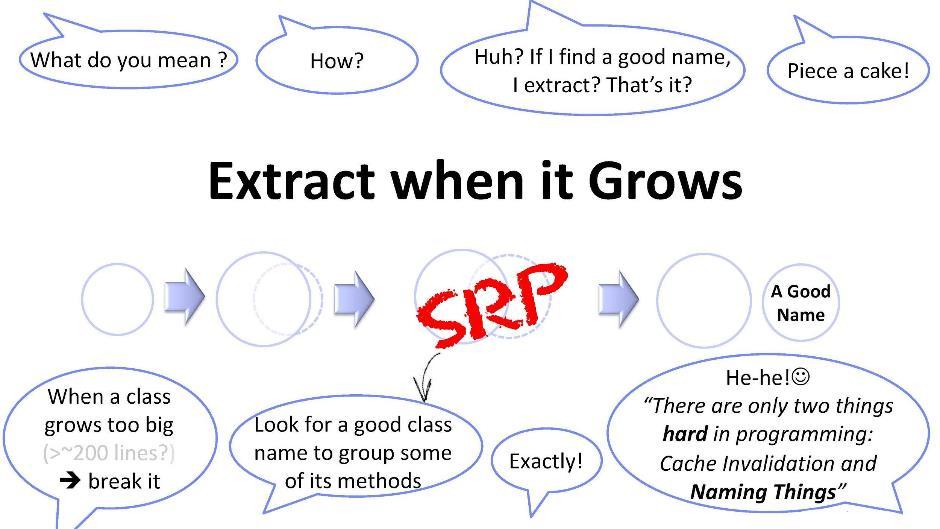
Ещё пара слов об этом принципе. Если класс достиг некоторого неудобного для меня размера (скажем, 200 строк), то я должен попробовать разбить его на части. Но выделить новый класс из существующего не всегда просто. Нужны придумать какие-то универсальные способы. Один из таких способов состоит в поиске имён: вы пробуете подобрать название для какого-нибудь подмножества методов вашего класса. Как только у вас получилось найти имя — смело создавайте новый класс. Но и это не так просто. В программировании, как известно, всего две сложные вещи: это инвалидация кэша и придумывание имен. В данном случае, придумывание названия сопряжено с выявлением подзадачи — скрывающейся и потому ранее никем не выявленной.
Пример:
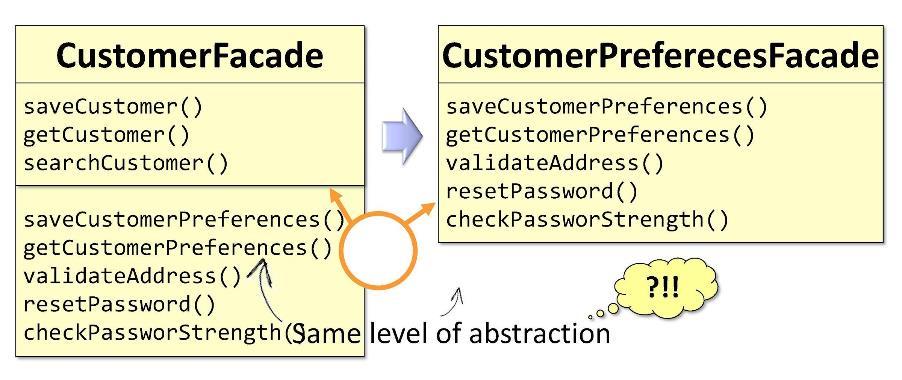
В исходном фасаде
CustomerFacade часть методов связана непосредственно с покупателем, некоторые же — с предпочтениями покупателя. На основе этого я смогу расколоть класс на две части, когда он достигнет критических размеров. Получу два фасада: CustomerFacade и CustomerPreferencesFacade. Плохо только то, что оба этих фасада принадлежат одному уровню абстракции. Разделение же по уровням абстракции предполагает несколько другое.Ещё один пример:

Предположим, в нашей системе есть класс
OrderService, в котором мы реализовали механизм уведомлений по электронной почте. Теперь мы создаём DeliveryService и хотели бы использовать здесь тот же самый механизм уведомлений. Копипаст — исключён. Сделаем так: извлечём функциональность уведомлений в новый класс AlertService и пропишем его в качестве зависимости для классов DeliveryService и OrderService. Здесь, в отличие от предыдущего примера, разделение произошло именно по уровням абстракции. DeliveryService более абстрактен, чем AlertService, так как использует его как составляющую своего рабочего потока.Разделение по уровням абстракции всегда предполагает, что извлекаемый класс становится зависимостью, а извлечение осуществляется для переиспользования.
Задача извлечения не всегда даётся просто. Она также может повлечь за собой некоторые сложности и потребовать какого-нибудь рефакторинга unit-тестов. Тем не менее, по моим наблюдениям, искать какой бы то ни было функционал по огромной монолитной кодовой базе приложения разработчикам ещё тяжелее.
Парное программирование
Многие консультанты расскажут про парное программирование, про то, что это универсальное решение любых проблем IT-разработки на сегодняшний день. В ходе него программисты развивают свои технические навыки и функциональные знания. Кроме того, интересен сам процесс, он сплачивает команду.
Если говорить не как консультанты, а по-человечески, самое важное здесь вот что: парное программирование улучшает «фактор автобуса». Суть же «фактора автобуса» в том, что людей, обладающих знаниями об устройстве системы, должно быть как можно больше. Потерять этих людей означает потерять последние ключи к этим знаниям.
Рефакторинг в формате парного программирования — искусство, требующее опыта и тренировки. Здесь полезны, например, практики агрессивного рефакторинга, проведение хакатонов, катов, Coding Dojos и др.
Парное программирование хорошо работает в случаях, когда нужно решать задачи высокой сложности. Сам процесс работы вдвоём не всегда прост. Зато он гарантирует вам, что вы избежите «переинженерии» — напротив, получите реализацию, которая адресует поставленные требования с минимальной сложностью.

Организация удобного формата работы — одна из ваших главных обязанностей перед командой. Вы должны не переставая заботиться об условиях труда разработчика — обеспечивать им полный комфорт и свободу творчества, особенно, если от них требуется наращивать проектную архитектуру и её сложность.
«Я архитектор. По определению, я всегда прав».
Эту глупость периодически выражают гласно или негласно. В сегодняшней практике архитекторы как таковые встречаются всё меньше. С приходом Agile эта роль постепенно перешла к старшим разработчикам, потому как обычно вся работа, так или иначе, строится вокруг них. Размер реализации постепенно растёт, и вместе с этим появляется потребность в рефакторинге и разрабатывается новая функциональность.
Архитектура «луковица»
«Луковица» — самая чистая архитектура философии Transaction Script. Строя её, мы руководствуемся целью обеспечить защиту того кода, который считаем критичным, и для этого перемещаем его в доменный модуль.

В нашем приложении самыми важными являются доменные сервисы: они реализуют самые критичные потоки. Переместим их в доменный модуль. Безусловно, сюда же стоит перенести все свои доменные объекты — сущности и объекты-значения. Всё остальное, что мы с вами сегодня накодили — DTO, мапперы, валидаторы и пр. — становится, так сказать, первой линией обороны от пользователя. Потому как пользователь, увы, нам не друг, и необходимо защищать от него систему.
Внимание вот на эту зависимость:

Модуль приложения будет зависеть от доменного модуля — именно так, а не наоборот. Прописывая связь такой, мы гарантируем, что DTO никогда не ворвутся на святую территорию доменного модуля: они попросту не видны и недоступны из доменного модуля. Получается, что мы в некотором смысле огородили территорию домена — ограничили к ней доступ посторонних.
Тем не менее, домену может понадобиться взаимодействовать с каким-нибудь внешним сервисом. С внешним — значит, с недружественным, потому что он снабжён своими DTO. Какие наши варианты?
Первый: пропустить недруга внутрь модуля.
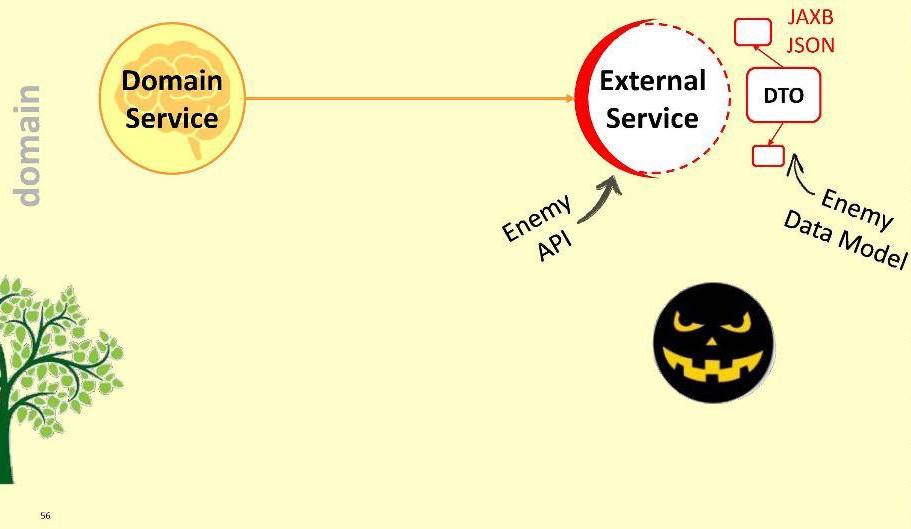
Очевидно, что это плохой вариант: не исключено, что завтра внешний сервис не выполнит апгрейд на версию 2.0, и нам придётся перекраивать наш домен. Нельзя пускать врага внутрь домена!
Предлагаю другой подход: для взаимодействия создадим специальный адаптер.
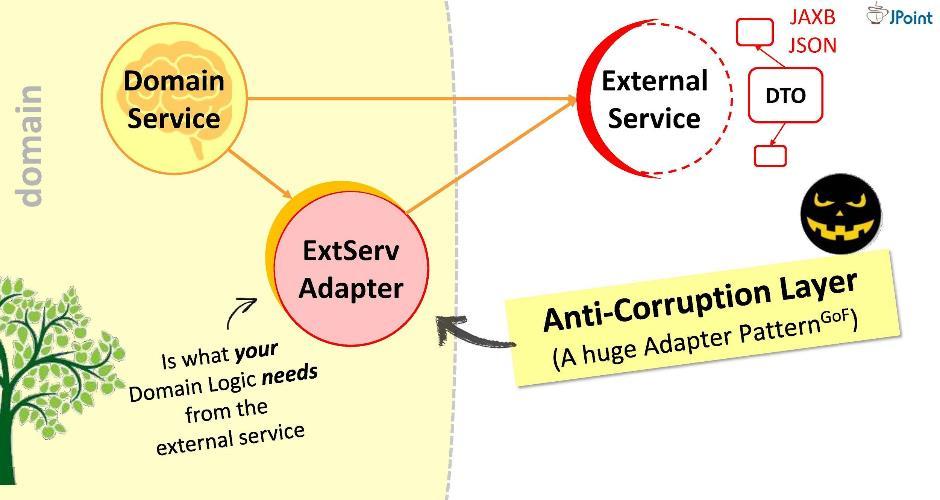
Адаптер будет получать данные от внешнего сервиса, извлекать те из них, которые нужны нашему домену, и преобразовывать их в требуемые виды структур. В таком случае всё, что от нас требуется при разработке — соотнести вызовы к внешней системе с требованиями домена. Думайте об этом как об огромном таком адаптере. Я называю такой слой «антикоррупционным».
Например, нам может понадобиться выполнять из домена запросы LDAP. Для этого мы реализуем «антикоррупционный модуль»
LDAPUserServiceAdapter.
В адаптере мы можем:
- Скрыть некрасивые вызовы API (в нашем случае скрываем метод, принимающий массив Object);
- Упаковать исключения в наши собственные реализации;
- Преобразовать чужие структуры данных в свои собственные (в наши доменные объекты);
- Проверить валидность поступающих данных.
Таково назначение адаптера. По хорошему, на стыке с каждой внешней системой, с которой вам необходимо взаимодействовать, должен быть заведён свой адаптер.

Таким образом, домен будет направлять вызов не к внешнему сервису, а к адаптеру. Для этого в домене должна быть прописана соответствующая зависимость (от адаптера либо от того инфраструктурного модуля, в котором он находится). Но безопасна ли такая зависимость? Если её установить вот так, к нам в домен могут попасть DTO внешнего сервиса. Такого мы допускать не должны. Поэтому предлагаю вам другой способ моделирования зависимостей.
Принцип инверсии зависимостей
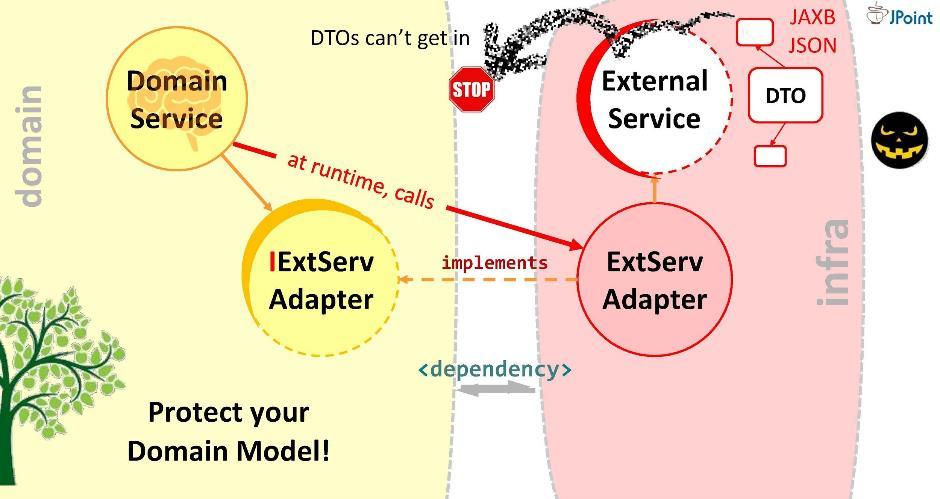
Создадим интерфейс, пропишем в нём сигнатуру нужных методов и поместим его внутрь нашего домена. Задача адаптера — реализовать этот интерфейс. Получается, интерфейс находится внутри домена, а адаптер — снаружи, в инфраструктурном модуле, который импортирует интерфейс. Таким образом, мы развернули направление зависимости в обратную сторону. Во время исполнения доменная система будет вызывать любой класс через интерфейсы.
Как видите, всего-навсего введя в архитектуру интерфейсы, мы сумели развернуть зависимости и тем самым обезопасить наш домен от попадания в него чужеродных структур и API. Такой подход называется инверсией зависимостей.
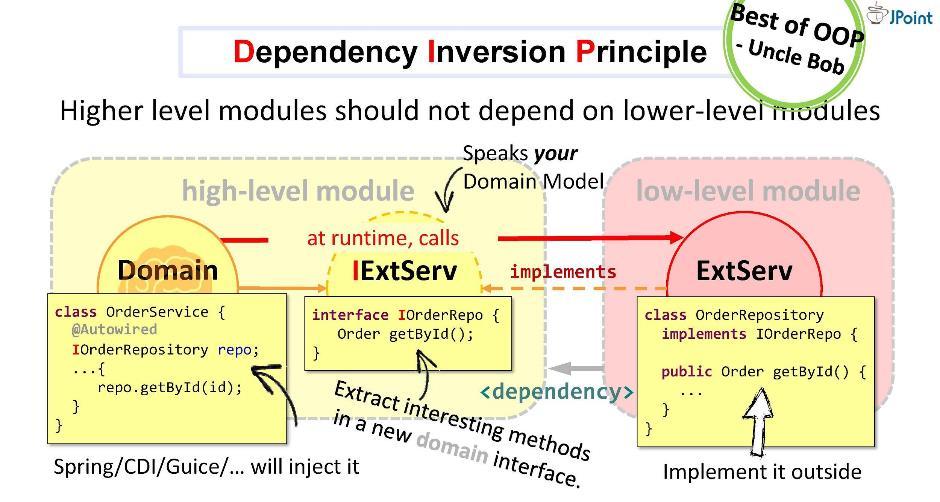
В общем случае, инверсия зависимостей предполагает, что вы размещаете интересующие вас методы в интерфейсе внутри вашего высокоуровневого модуля (в домене), а реализуете этот интерфейс снаружи — в том или ином низкоуровневом (инфраструктурном) некрасивом модуле.
Интерфейс, реализуемый внутри доменного модуля, должен говорить на языке домена, то есть он будет оперировать его сущностями, его параметрами и возвращаемыми типами. Во время исполнения домен будет вызывать любой класс посредством полиморфного вызова к интерфейсу. Фреймворки, предназначенные для внедрения зависимостей (например, Spring и CDI), снабдят нас конкретным экземпляром класса прямо в рантайме.
Но главное то, что во время компиляции доменный модуль не будет видеть содержимого внешнего модуля. Именно это нам и нужно. Никакая внешняя сущность не должна попасть в домен.
Как считает Дядя Боб, принцип инверсии управления (или, как он её называет, «архитектура плагинов») — это, возможно, лучшее, что вообще предлагает парадигма ООП.
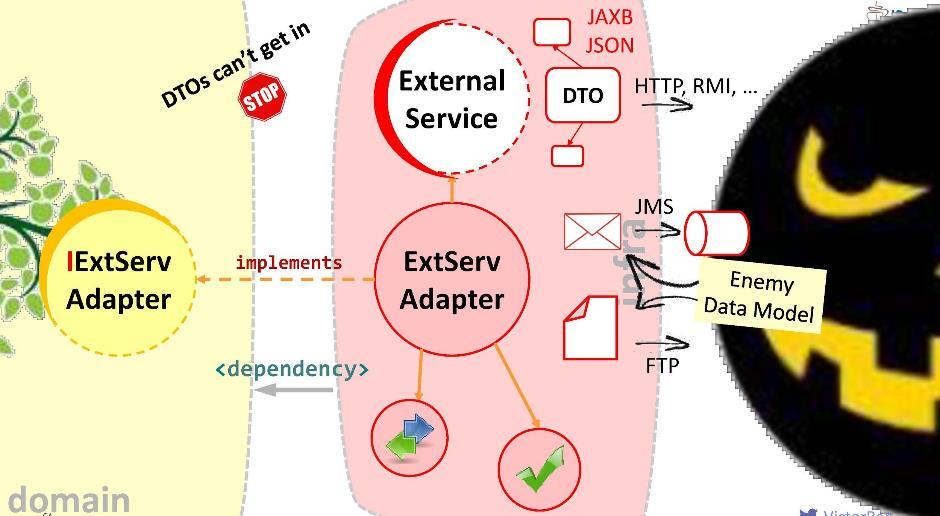
Данную стратегию можно использовать для интеграции с любыми системами, для синхронных и асинхронных вызовов и сообщений, для отсылки файлов и т. д.
Обзор «луковицы»

Итак, мы решили, что защищать будем доменный модуль. Внутри него размещается доменный сервис, сущности, объекты-значения, а теперь и интерфейсы для внешних сервисов, плюс интерфейсы для репозитория (для взаимодействия с базой данных).
Структура выглядит так:
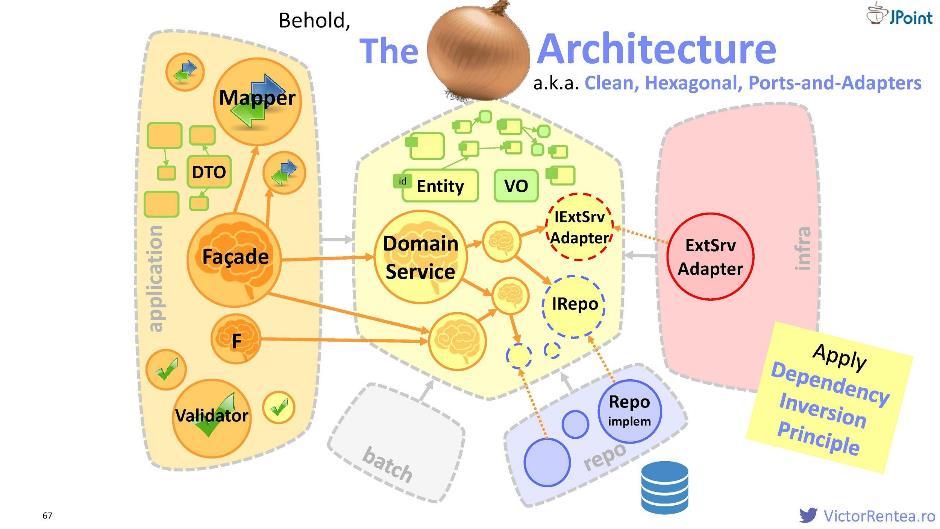
В качестве зависимостей для домена объявлены модуль приложения, инфраструктурный модуль (посредством инверсии зависимостей), модуль репозитория (базу данных мы тоже считаем внешней системой), batch-модуль и, возможно, некоторые другие модули. Такая архитектура носит название «луковицы»; также её называют «чистой», «шестиугольной» и «порты и адаптеры».
Модуль репозитория
Вкратце расскажу о модуле репозитория. Выносить ли его из домена — это вопрос. Задача репозитория — сделать логику чище, скрыв от нас ужас работы с персистентными данными. Вариант для олдскульных ребят — использовать для взаимодействия с базой данных JDBC:

Также можно использовать Spring и его JdbcTemplate:
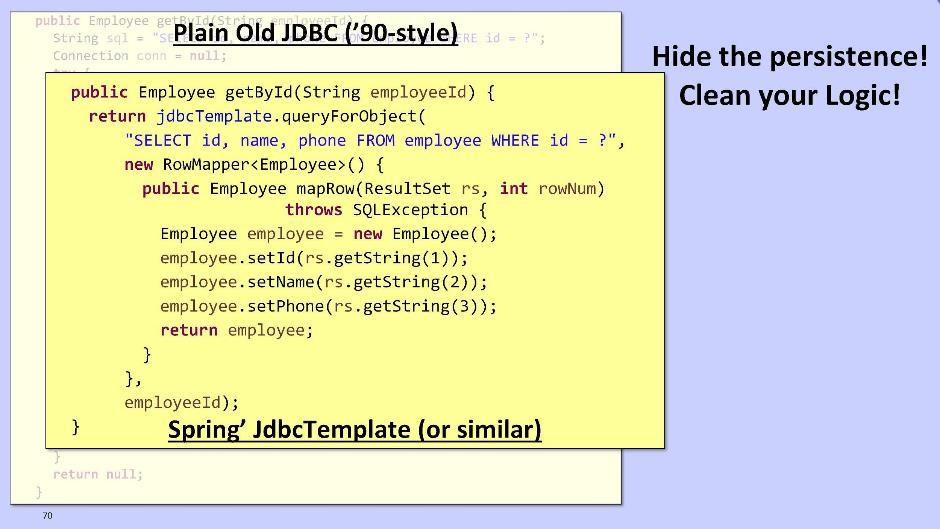
Или же MyBatis DataMapper:

Но это до того сложно и некрасиво, что отбивает всякое желание делать что-то дальше. Поэтому предлагаю использовать JPA/Hibernate либо Spring Data JPA. Они дадут нам возможность отправлять запросы, построенные не на схеме БД, а непосредственно на основе модели наших сущностей.
Реализация для JPA/Hibernate:

В случае же со Spring Data JPA:
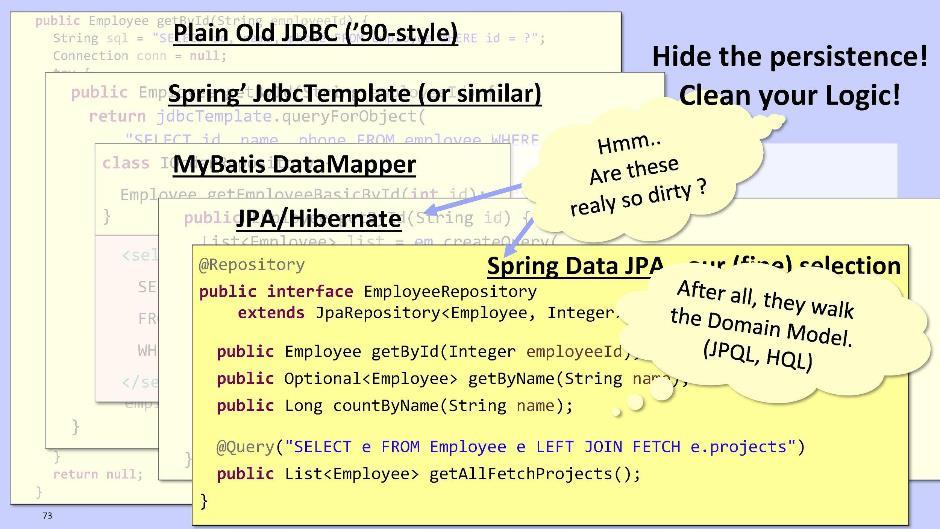
Spring Data JPA умеет автоматически генерировать методы во время исполнения, такие, как, например, getById(), getByName(). Также он позволяет при необходимости выполнять JPQL-запросы — и не к БД, а к вашей собственной модели сущностей.
Код Hibernate JPA и Spring Data JPA действительно выглядит очень неплохо. Нужно ли нам вообще извлекать его из домена? По моему мнению, это не так-то и обязательно. Скорей всего, код будет даже чище, если оставить данный фрагмент внутри домена. Так что действуйте по ситуации.

Если вы всё же создаёте модуль репозитория, то для организации зависимостей лучше точно так же воспользоваться принципом инверсии управления. Для этого разместите в домене интерфейс и реализуйте его в модуле репозитория. Что касается логики репозитория, то лучше перенести её в домен. Это делает удобным тестирование, так как в домене вы сможете использовать Mock-объекты. Они позволят протестировать логику быстро и многократно.
Традиционно для репозитория в домене создаётся всего одна сущность. Разбивают на части её только тогда, когда она становится чересчур объёмной. Не забывайте о том, что классы должны быть компактными.
API
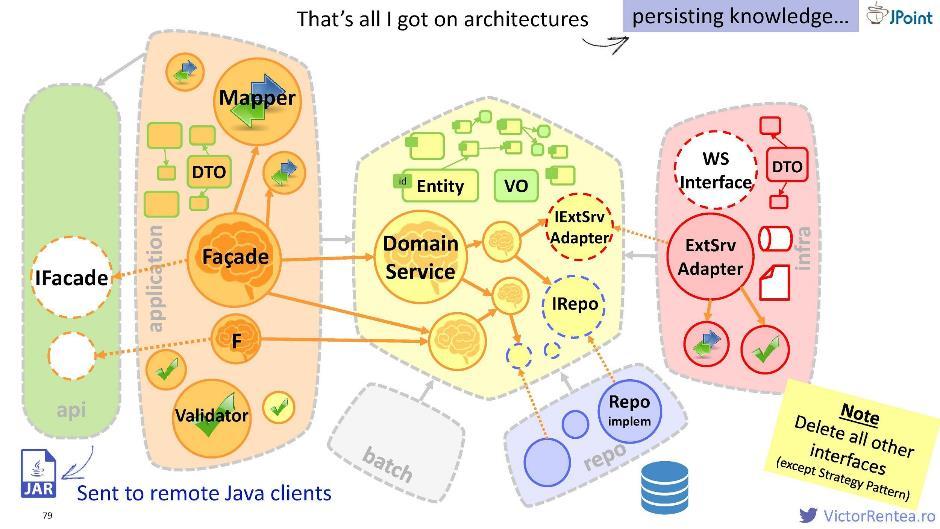
Можно создать отдельный модуль, поместить в него извлечённый из фасада интерфейс и полагающиеся к нему DTO, затем упаковать в JAR, и в таком виде передавать своим Java-клиентам. Имея этот файл, они получат возможность направлять запросы к фасадам.
«Прагматичная Луковица»
Помимо тех наших «врагов», которым мы поставляем функциональность, то есть клиентов, у нас есть враги и с другой стороны — те модули, от которых зависим мы сами. От этих модулей нам тоже необходимо защищаться. И для этого предлагаю вам несколько модифицированную «луковицу» — в ней вся инфраструктура объединяется в один модуль.
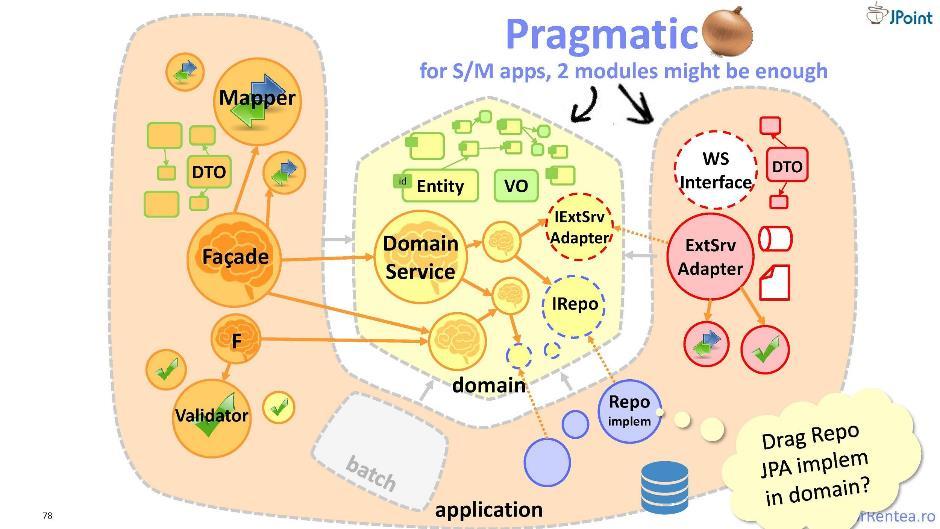
Я называю такую архитектуру «прагматичной луковицей». Здесь разделение компонент проходит по принципу «моё» и «интегрируемое»: отдельно хранится то, что относится к моему домену, и отдельно — то, что относится к интеграции с внешними коллаборационистами. Таким образом, получается всего два модуля: домен и приложение. Такая архитектура очень хороша, но только тогда, когда модуль приложений имеет небольшие размеры. В противном случае вам лучше вернуться к традиционной «луковице».
Тесты
Как я уже говорил ранее, если вашего приложения все боятся, считайте, что оно пополнило ряды легаси.

А вот тесты — это хорошо. Они дают нам чувство уверенности, благодаря которому можно продолжать работы по рефакторингу. Но к сожалению, эта уверенность спокойно может оказаться неоправданной. Объясню почему. TDD (разработка через тестирование) предполагает, что вы одновременно выступаете и автором кода, и автором тест-кейсов: читаете спецификации, реализуете функциональность и сразу же пишете для неё набор тестов. Тесты, предположим, выполнятся успешно. Но что, если вы неверно поняли требования спецификаций? Тогда тесты проверят не то, что нужно. А значит, ваша уверенность ничего не стоит. И всё оттого, что вы писали и код, и тесты единолично.
Но попробуем закрыть на это глаза. Тесты всё же необходимы, и в любом случае они дают нам уверенность. Больше всего мы, конечно же, любим функциональные тесты: они не подразумевают никаких побочных эффектов, никаких зависимостей — только входные и выходные данные. Для тестирования домена вам нужно воспользоваться mock-объектами: они позволят тестировать классы изолированно.
Что касается запросов к БД, то тестировать их неприятно. Эти тесты хрупкие, они требуют, чтобы сначала вы добавили в базу тестовые данные — и только после этого вы сможете перейти к тестированию функциональности. Но как вы понимаете, эти тесты также необходимы, даже если вы используйте JPA.
Unit-тесты

Я бы сказал, что сила unit-тестов не в возможности их запуска, а в том, что заключает в себе процесс их написания. Пока вы пишете тест, вы заново осмысливаете и прорабатываете код — уменьшаете связанность, разбиваете на классы — словом, осуществляете очередной рефакторинг. Тестируемый код — это чистый код; он проще, в нём уменьшена связанность; в общем-то, он ещё и задокументирован (хорошо написанный unit-тест прекрасно описывает то, как работает класс). Неудивительно, что писать unit-тесты — трудно, особенно первые несколько штук.
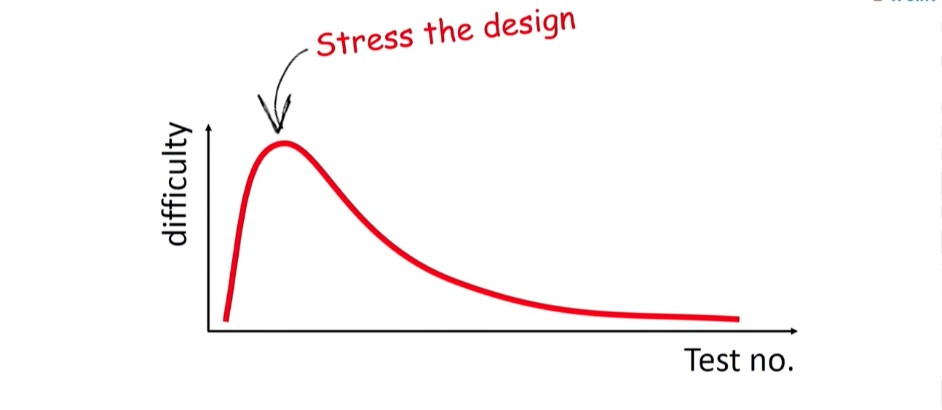
На этапе первых unit-тестов многие действительно пугаются перспективы, что действительно придётся что-то протестировать. Почему же они даются так сложно?
Потому что эти тесты являются первой нагрузкой на ваш класс. Это первый удар по системе, который, возможно, покажет, что она хрупкая и хлипкая. Но надо понимать, что эти несколько тестов — самые важные для вашей разработки. Они, в сущности, ваши лучшие друзья, потому что скажут всё как есть о качестве вашего кода. Если бояться этого этапа, то далеко уйти не получится. Вы должны запустить для своей системы тестирование. После этого сложность спадёт, тесты будут писаться быстрее. Добавляя их один за другим, вы создадите для вашей системы надёжную базу регрессионного тестирования. А это невероятно важно для дальнейшей работы ваших разработчиков. Им будет проще заниматься рефакторингом; Они будут понимать, что система может быть в любой момент регрессионно протестирована, что поэтому работать с кодовой базой — безопасно. И, уверяю вас, они займутся рефакторингом гораздо охотнее.

Мой вам совет: если вы чувствуете, что сегодня у вас много сил и энергии — посвятите себя написанию unit-тестов. И сделайте так, чтобы каждый из них был чистым, быстрым, имел свой вес и не повторял другие.
Советы
Резюмируя всё сказанное сегодня, я бы хотел напутствовать вас следующими советами:
- Как можно дольше (и чего бы это ни стоило) соблюдайте простоту: избегайте «переинженерии» и запоздалой оптимизации, не перегружайте приложение;
- Заботьтесь о своих разработчиках, предпринимайте меры в защиту их самих и того, что они делают;
- Идентифицируйте «вражеские» структуры данных и держите их на безопасном расстоянии от домена — внешние структуры должны обязательно оставаться снаружи;
- Если вы считаете, что логика разрослась и занимает много места — декомпозируйте: формулируйте названия подзадач и реализуйте их в отдельном классе;
- Помните об архитектуре «луковицы», а точнее, об её главной идее — размещении в домене только критичного кода и недоступности для домена внешних структур;
- Не бойтесь тестов: дайте им возможность повалить вашу систему, ощутите всю их пользу — в конце концов, они потому ваши друзья, что способны честно указать на проблемы.
Делая эти вещи, вы поможете и своей команде, и себе. И тогда, когда наступит день поставки продукта, — вы будете к нему готовы.
Что почитать

- 7 Virtues of a Good Object
- NULL is the worst mistake in Computer Science
- The Clean Architecture
- New Programming Jargon
- Code quality: WTFs/minute
- Why every single element of SOLID is wrong!
- Good software is written 3 times
Минутка рекламы. Если вам понравился этот доклад с конференции JPoint — обратите внимание, что 19-20 октября в Санкт-Петербурге пройдет Joker 2018 — крупнейшая в России Java-конференция. В его программе тоже будет много интересного. На сайте уже есть первые спикеры и доклады.
Комментарии (24)

ookami_kb
06.08.2018 15:19Они не обратили внимание, что двойка во всех трёх случаях имеет совершенно разный смысл
Нет же:
double START_PRICE = 2; int MIN_DURATION = 2; double DAY_PRICE_MULTIPLIER = 1.5; double price = START_PRICE; if (daysRented > MIN_DURATION) { price += (daysRented - MIN_DURATION) * DAY_PRICE_MULTIPLIER; } return price;
И тогда сразу понятно, что здесь 2 сущности.
rjhdby
07.08.2018 13:24Здесь 3 сущности.
DAY_PRICE_MULTIPLIER,MIN_DURATIONиNOT_COUNTED_DAYSookami_kb
07.08.2018 13:31Это что тогда за use-case? "Если арендуете больше, чем на 5 дней, то будете доплачивать за каждый день, начиная с третьего дня..." Так, что ли?
Все-таки стандартный случай будет: "200 руб. за первые 2 дня + 50 руб. за каждый следующий день".
Если же это действительно какой-то странный случай, то тем более надо убирать magic numbers, добавлять пояснение, ну и проверку усиливать, чтобы цена в минус не ушла.
rjhdby
07.08.2018 13:46В докладе речь была не про то, что выносить в константы не нужно, а про преждевременную оптимизацию.
Объединить все двойки под одной константой — красиво, но совершенно не корректно.
Объединить две двойки(которые про количество дней) — уже лучше, но ТАКЖЕ не корректно. Это такая же преждевременная оптимизация, которая может в последствии выйти боком.ookami_kb
07.08.2018 13:52При чем тут оптимизация? Тут magic numbers, в которых путаются их программисты, и совершенно непонятно, что менять, если условия аренды изменились. Две здесь сущности или три – это вопрос к их бизнес-логике, но это совершенно точно не должны быть просто какие-то числа.
И уж совсем непонятно, что этот пример (который неудачный даже для объяснения DRY) делает в пункте "Предпочитайте композицию наследованию".
rjhdby
07.08.2018 14:06Пример не очень удачный, согласен. Но давайте, на минутку, представим, что докладчик представил просто идеальный пример, на пять страниц кода, с неочевидными зависимостями и сложной логикой. Выиграл бы от этого доклад? Очевидно, что нет.
Формат доклада со слайдами диктует свои ограничения, причем довольно жесткие.
— А вон в этом примере надо было использовать не ArrayList, а LinkedList!
— Ээээ? Ну наверное да, но пример-то про Dependency Injection, а не про правильное использование коллекций…
— Вы не увиливайте! В коллекциях не разобрались, а все туда же — учить лезете!
muhaa
06.08.2018 19:00Об этих DTO… Когда-то нужно было быстро написать Enterprise-подобное приложение для одного предприятия. Взял AngularJS + некий Breeze js и обошелся без этих самых DTO вообще. Breeze js позволял прямо из js запрашивать объекты из базы (с ORM на клиенте), редактировать эти объекты в js, коммитить на сервер дельту и автоматически применять ее к базе.
В итоге на не сервере изначально не было кода вообще и все работало. Потом появился код для проверки прав пользователя на доступ и изменения. Потом код для очень сложных запросов групп доменных объектов, которые тормозили при реализации на клиенте.
На клиенте же Angular прекрасно показывал доменные объекты и их же менял.
Обычно вроде так не пишут (не могу понять почему), но для меня это была архитектура, позволяющая в одиночку написать максимальное количество юз-кейзов в минимальные сроки практически при полном отсутствии кода или логики не относящихся непосредственно к решению основных задач приложения.muhaa
09.08.2018 14:56И этот комментарий я разместил потому, что заголовок статьи «Чистая прагматичная архитектура» и мне интересно делал ли еще кто-то так как я, а не потому что я считаю эту схему пригодной для больших проектов.
arturpanteleev
07.08.2018 12:14+1Спасибо за перевод, но сама по себе статья выглядит несколько сомнительно. Основной тезис «Т.к сложно освоить нормальную доменную модель, то можно фигачить проекты на анемичной, юзая некоторые паттерны нормлаьной разработки чтобы было не так уж паршиво». Ну и некоторые тезисы вообще смотрятся как то печально. В частности автор дает неверное определение SRP, предлагает сувать «немного логики в DTO» и т.д. А в конце автор перечисляет основне идеи архитектуры Порты и Адаптеры, но подаёт их под именованием «Прагматичная луковица». Вобщем, статья, конечно прочиталась легко, тем боолее в условиях дифицита материалов об архитектуре ПО на хабре, но вот читать ее надо с повышенным уровнем критичности, особенно новичкам.
rjhdby
07.08.2018 13:31По большому счету, выбор между DDD и Transaction Script определяется габаритами предметной области. Если она мала (и таковой и останется), то особого смысла в DDD нет.
Собственно основной посыл, как я понял
Как можно дольше (и чего бы это ни стоило) соблюдайте простоту: избегайте «переинженерии» и запоздалой(wtf? подозреваю, что это баг перевода и должно было быть "преждевременной") оптимизации, не перегружайте приложение;
rjhdby
07.08.2018 13:34А вот определение DRY автором подано как-то очень странно. Мне всегда казалось, что это как раз про переиспользование, а не про "каждый раз пиши заново".
AndrewMayorov
08.08.2018 11:40+1Хорошее выступление. Хотя не понравилось традиционное упоминание «композиции вместо наследования». Почему бы не использовать этот тезис в его правильной трактовке: иногда вместо наследования лучше применять композицию?
Еще момент: разбиение фасада на кусочки пройдет легче, если вообще не делать фасадов из нескольких методов. Пиши каждый метод в отдельном классе и будет щасте.olegchir Автор
08.08.2018 14:40Сейчас очень популярно говорить, что наследование вообще нигде не нужно. Особенно, налседование реализации. Возможно, просто дань моде.
bores
09.08.2018 09:52Скорее всего потому что наследование в смысле расширения функциональности (интерфейса) противоречит принципу подстановки.
poxvuibr
09.08.2018 11:45+1Почему бы не использовать этот тезис в его правильной трактовке: иногда вместо наследования лучше применять композицию?
Потому что тогда надо будет рассказать как отличить случаи когда вместо наследования лучше применять композицию от случаев, когда можно применять наследование. Плюс, когда вы говорите о правильной трактовке, надо иметь в виду, что многие считают правильной трактовкой следующую: иногда вместо композиции лучше применять наследование.
poxvuibr
Логика в Entity, пусть даже немного, это как-то стрёмно. Вообще интересно, что автор доклада имел в виду под Entity. Если то, что использует JPA, то есть вопрос. Как я понял, он собирается эти Entity использовать в слое, который описывает бизнес логику. Что делать, если нужно порефакторить структуру БД? Править код во всех местах, которые используют Entity?
Leg3nd
Править код во всех местах вам придется, если вы используете паттерн Active Record, дяд Боб же в своей книге рекомендует отделять зависимости бизнес-логики от деталей (БД или что вы там используете для персистентности) и юзать паттерн Data Mapper, таким образом вам не придется править код во всех местах, если поправите структуру БД или вообще решите сменить какой-нибудь MySql на Mongo, это затронет только имплементацию модуля доступа к данным.
Не скажу что имел ввиду автор статьи, но Роберт Мартин в своей книге разделяет бизнес логику на две:
1. application-specific business rules — они же юз кейсы, они же интеракторы.
2. application independent business rules — они же entities — это соединение в одной сущности критических бизнес данных и критических бизнес правил, которые оперируют на этими данными. Как он сказал: «мы называем эти правила так, потому что они критические непосредственно по отношению к самому бизнесу и будут существовать даже если не будет никакой системы автоматизирующей их». С критическими бизнес данными тоже самое, они будут существовать в бизнесе, даже если не будет автоматизирующей системы для этого бизнеса.
poxvuibr
Если использовать JPA, то тоже придётся, хотя это не Active Record. Код придётся рефакторить если поля классов, которые используются в системе один в один соответствуют полям таблиц БД. Я думаю, именно это вы и хотели сказать.
У меня сложилось впечатление, что автор доклада не советует.
Это не те Entity, в которых поля один в один соответствуют полям таблиц в БД, да?
Leg3nd
Я не Java разработчик, по этому не знаю что там в JPA и как.
Не, не те. Они вообще не имеют никакого отношения к способу хранения информации в постоянной памяти. Вы их можете сохранять хоть в обычном файле вместо БД. Код бизнес логики это вообще никак не затронет.
Leg3nd
Да дело даже не в том соответствуют они один в один или нет, а дело в направлении зависимости. Если ваша бизнес логика зависит от БД, то еще как придется менять. А если ваша бизнес логика скажем использует всего лишь интерфейс, что-то вроде такого IOrderDataAccess и у этого интерфейса есть допустим методы: saveOrder(Order o), findOrdersByDate(Date d), где Order — это как раз и есть entity, то какая разница как имплементация этого интерфейса хранит данные Order — в одной таблице, в 10-ти, в обычном файле или вообще на марсе через http api third party сервиса какого нибудь. Тут как раз направление зависимости другое — имплементация IOrderDataAccess зависит от вашей бизнес логики, а не наоборот.
bores
Entity здесь из мира DDD. По сути это идентифицируемый объект, который можно сохранить и восстановить из БД. В JPA Entity он превращается только в Repository. В простейших случаях Entity равно JPA Entity по хранимым данным.
В последнее время я склоняюсь к тому, что не нужно лениться разделять Entity и JPA Entity, чтобы не было больно рефакторить БД. Но об этом же говорится и в статье. БД — это внешние данные для домена :)