
И вот мы дошли до темы QoS.
Знаете почему только сейчас и почему это будет закрывающая статья всего курса СДСМ? Потому что QoS необычайно сложен. Сложнее всего, что было прежде в цикле.
Это не какой-то магический архиватор, который ловко сожмёт трафик на лету и пропихнёт ваш гигабит в стомегабитный аплинк. QoS это про то как пожертвовать чем-то ненужным, впихивая невпихуемое в рамки дозволенного.
QoS настолько опутан аурой шаманизма и недоступности, что все молодые (и не только) инженеры стараются тщательно игнорировать его существование, считая, что достаточно закидать проблемы деньгами, и бесконечно расширяя линки. Правда пока они не осознают, что при таком подходе их неизбежно ждёт провал. Или бизнес начнёт задавать неудобные вопросы, или возникнет масса проблем, почти не связанных с шириной канала, зато прямо зависящих от эффективности его использования. Ага, VoIP активно машет ручкой из-за кулис, а мультикастовый трафик ехидно поглаживает вас по спинке.
Поэтому давайте просто осознаем, что QoS это обязательно, познать его придётся так или иначе, и почему-бы не начать сейчас, в спокойной обстановке.

Содержание
1. Чем определяется QoS?
- Потери
- Задержки
- Джиттер
2. Три модели обеспечения QoS
- Best Effort
- Integrated Services
- Differentiated Services
3. Механизмы DiffServ
4. Классификация и маркировка
- Behavior Aggregate
- Multi-Field
- Interface-Based
5. Очереди
6. Предотвращение перегрузок (Congestion Avoidance)
- Tail Drop и Head Drop
- RED
- WRED
7. Управление перегрузками (Congestion Management)
- First In, First Out
- Priority Queuing
- Fair Queuing
- Round Robin
8. Ограничение скорости
- Shaping
- Policing
- Механизмы Leaky Bucket и Token Bucket
9. Аппаратная реализация QoS
До того как читатель нырнёт в эту нору, я заложу в него три установки:
- Не все проблемы можно решить расширением полосы.
- QoS не расширяет полосу.
- QoS про управление ограниченными ресурсами.
1. Чем определяется QoS?
Бизнес ожидает от сетевого стека того, что он будет просто хорошо выполнять свою несложную функцию — доставлять битовый поток от одного хоста до другого: без потерь и за предсказуемое время.
Из этого короткого предложения можно вывести все метрики качества сети:
- Потери
- Задержки
- Джиттер
Эти три характеристики определяют качество сети независимо от её природы: пакетная, канальная, IP, MPLS, радио, голуби.
Потери
Эта метрика говорит о том, сколько из отправленных источником пакетов дошло до адресата.
Причиной потерь может быть проблема в интерфейсе/кабеле, перегрузка сети, битовые ошибки, блокирующие правила ACL.
Что делать в случае потерь решает приложение. Оно может проигнорировать их, как в случае с телефонным разговором, где запоздавший пакет уже не нужен, или перезапросить его отправку — так делает TCP, чтобы гарантировать точную доставку исходных данных.

Как управлять потерями, если они неизбежны, в главе Управление перегрузками.
Как использовать потери во благо в главе Предотвращение перегрузок.
Задержки
Это время, которое необходимо данным, чтобы добраться от источника до получателя.

Совокупная задержка складывается из следующих компонентов.
- Задержка сериализации (Serialization Delay) — время, за которое узел разложит пакет в биты и поместит в линк к следующему узлу. Она определяется скоростью интерфейса. Так, например, передача пакета размером 1500 байтов через интерфейс 100Мб/с займёт 0,0001 с, а на 56 кб/с — 0,2 с.
- Задержка передачи сигнала в среде (Propagation Delay) — результат печально известного ограничения скорости распространения электромагнитных волн. Физика не позволяет добраться из Нью-Йорка до Томска по поверхности планеты быстрее чем за 30 мс (фактически порядка 70 мс).
- Задержки, вносимые QoS — это томление пакетов в очередях (Queuing Delay) и последствия шейпинга (Shaping Delay). Об этом мы сегодня будем говорить много и нудно в главе Управление скоростью.
- Задержка обработки пакетов (Processing Delay) — время на принятие решения, что делать с пакетом: lookup, ACL, NAT, DPI — и доставку его от входного интерфейса до выходного. Но в день, когда Juniper в своём M40 разделил Control и Data Plane, задержкой обработки стало можно пренебречь.
Задержки не так страшны приложениям, где не требуется спешка: обмен файлами, сёрфинг, VoD, интернет-радиостанции итд. И напротив, они критичны для интерактивных: 200мс уже неприятны на слух при телефонном разговоре.
Связанный с задержкой термин, но не являющийся синонимом — RTT (Round Trip Time) — это путь туда-обратно. При пинге и трассировке вы видите именно RTT, а не одностороннюю задержку, хотя величины и имеют корреляцию.
Джиттер
Разница в задержках между доставкой последовательных пакетов называется джиттером.
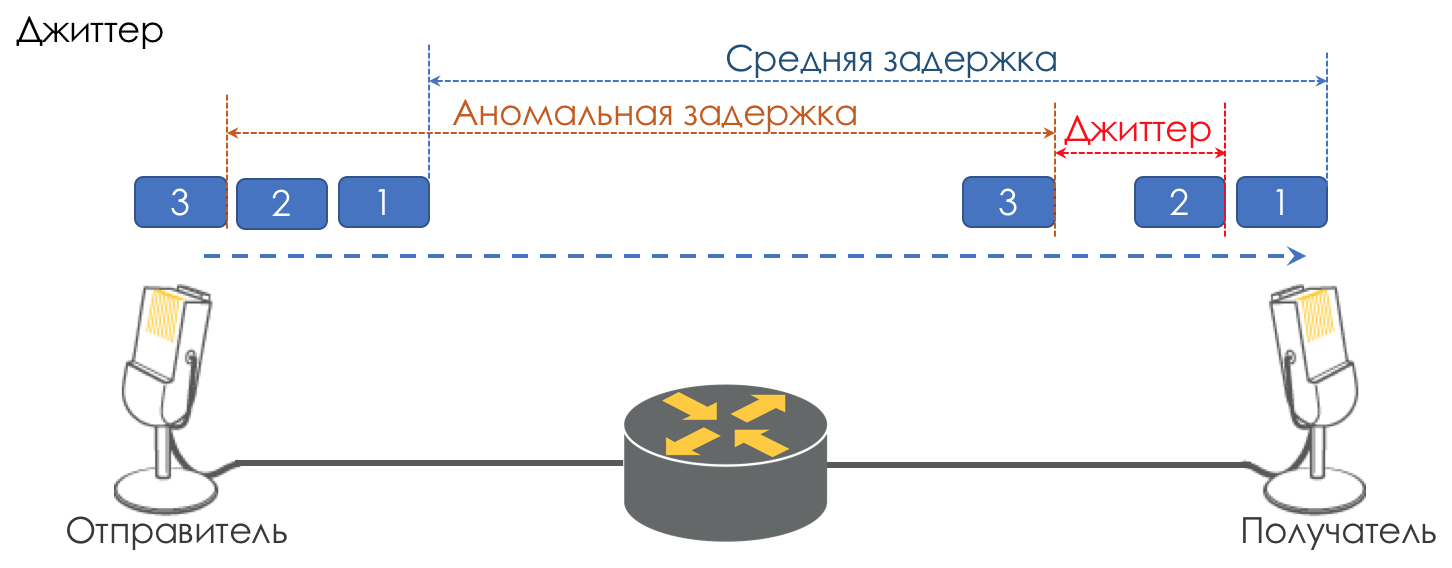
Как и задержка, джиттер для многих приложений не имеет значения. И даже, казалось бы, какая разница — пакет доставлен, чего же боле?
Однако для интерактивных сервисов он важен.
Возьмём в качестве примера ту же телефонию. По сути она является оцифровкой аналоговых сигналов с разбиением на отдельные чанки данных. На выходе получается достаточно равномерный поток пакетов. На принимающей стороне есть небольшой буфер фиксированного размера, в который укладываются последовательно поступающие пакеты. Для восстановление аналогового сигнала необходимо определённое их количество. В условиях плавающих задержек следующий чанк данных может не прийти вовремя, что равносильно потере, и сигнал не удаётся восстановить.
Наибольший вклад в вариативность задержки вносит как раз QoS. Об этом тоже много и нудно в тех же главах Ограничение скорости.
Это три основные характеристики качества сети, но есть две другие, которые тоже играют не последнюю роль.
Неупорядоченная доставка
Ряд приложений, таких как телефония, NAS, CES экстремально чувствительны к неупорядоченной доставке пакетов, когда они приходят к получателю не в том порядке, в котором были отправлены. Это может приводить к потере связности, ошибкам, повреждению файловой системы.
И хотя неупорядоченная доставка не является формально характеристикой QoS, но определённо относится к качеству сети.
Даже в случае TCP, толерантного к этому виду проблем, происходят дублирующиеся ACK'и и ретрансмиты.

Полоса пропускания
Её не выделяют, как метрику качества сети, поскольку фактически её недостаток выливается в три указанные выше. Однако в наших реалиях, когда некоторым приложениям она должна быть гарантирована или, наоборот, по договору должна быть ограничена, а например MPLS TE её резервирует на всём протяжении LSP, упомянуть её, хотя бы как слабую метрику, стоит.
Механизмы управления скоростью рассмотрим в главах Ограничение скорости.
Почему характеристики могут портиться?
Итак, начнём мы с очень примитивного представления, что сетевое устройство (будь то коммутатор, маршрутизатор, файрвол, да что угодно) — это просто ещё один кусочек трубы под названием канал связи, такой же, как медный провод или оптический кабель.

Тогда все пакеты пролетают насквозь в том же порядке, в котором они пришли и не испытывают никаких дополнительных задержек — негде задерживаться.
Но на самом деле каждый маршрутизатор восстанавливает из сигнала биты и пакеты, что-то с ними делает (об этом пока не думаем) и потом обратно преобразует пакеты в сигнал.
Появляется задержка сериализации. Но в целом это не страшно поскольку она постоянна. Не страшно до тех пор, пока ширина выходного интерфейса больше, чем входного.
Например, на входе в устройство гигабитный порт, а на выходе радио-релейная линия 620 Мб/с, подключенная в такой же гигабитный порт?
Никто не запретит пулять через формально гигабитный линк гигабит трафика.
Ничего тут не поделаешь — 380 Мб/с будут проливаться на пол.
Вот они — потери.
Но при этом очень бы хотелось, чтобы проливалась худшая его часть — видео с youtube, а телефонный разговор исполнительного директора с директором завода не прерывался и даже не квакал.
Хотелось бы, чтобы у голоса была выделенная линия.
Или входных интерфейсов пять, а выходной один, и одновременно пять узлов начали пытаться влить трафик одному получателю.
Добавим щепотку теории VoIP (статью, про который никто так и не написал) — он весьма чувствителен к задержкам и их вариации.
Если для TCP-потока видео с youtube (на момент написания статьи QUIC — ещё остаётся экспериментом) задержки даже в секунды ровным счётом ничего не стоят благодаря буферизации, то директор после первого же такого разговора с камчаткой призовёт к себе руководителя тех.отдела.
В более старые времена, когда автор цикла ещё делал уроки по вечерам, проблема стояла особенно остро. Модемные соединения имели скорость 56к.
И когда в такое соединение приходил полуторакилобайтный пакет, он оккупировал всю линию на 200 мс. Никто другой в этот момент пройти не мог. Голос? Не, не слышал.
Поэтому таким важным является вопрос MTU — пакет не должен слишком надолго оккупировать интерфейс. Чем менее он скоростной, тем меньший MTU необходим.
Вот они — задержки.
Сейчас канал свободен и задержка низкая, через секунду кто-то начал качать большой файл и задержки выросли. Вот он — джиттер.
Таким образом нужно, чтобы голосовые пакеты пролетали через трубу с минимальными задержками, а youtube подождёт.
Имеющиеся 620 Мб/с нужно использовать и для голоса, и для видео, и для B2B клиентов, покупающих VPN. Хотелось бы, чтобы один трафик не притеснял другой, значит нужна гарантия полосы.
Все вышеуказанные характеристики универсальны относительно природы сети. Однако существует три разных подхода к их обеспечению.
2. Три модели обеспечения QoS
- Best Effort — никакой гарантии качества. Все равны.
- IntServ — гарантия качества для каждого потока. Резервирование ресурсов от источника до получателя.
- DiffServ — нет никакого резервирования. Каждый узел сам определяет, как обеспечить нужное качество.
Best Effort (BE)
Никаких гарантий.
Самый простой подход к реализации QoS, с которого начинались IP-сети и который практикуется и по сей день — иногда потому что его достаточно, но чаще из-за того, что никто и не думал о QoS.
Кстати, когда вы отправляете трафик в Интернет, то он там будет обрабатываться как BestEffort. Поэтому через VPN, прокинутые поверх Интернета (в противовес VPN, предоставляемому провайдером), может не очень уверенно ходить важный трафик, вроде телефонного разговора.
В случае BE — все категории трафика равны, никакому не отдаётся предпочтение. Соответственно, нет гарантий ни задержки/джиттера, ни полосы.
Этот подход носит несколько контринтуитивное название — Best Effort, которое новичка вводит в заблуждение словом «лучший».
Однако фраза «I will do my best» означает, что говорящий постарается сделать всё, что может, но не гарантирует ничего.
Для реализации BE не требуется ничего — это поведение по умолчанию. Это дёшево в производстве, персоналу не нужны глубокие специфические знания, QoS в этом случае не поддаётся никакой настройке.
Однако эта простота и статичность не приводят к тому, что подход Best Effort нигде не используется. Он находит применение в сетях с высокой пропускной способностью и отсутствием перегрузок и всплесков.
Например, на трансконтинентальных линиях или в сетях некоторых ЦОДов, где нет переподписки.
Иными словами в сетях без перегрузок и где нет необходимости особенным образом относиться к какому-либо трафик (например, телефонии), BE вполне уместен.
IntServ
Заблаговременное резервирование ресурсов для потока на всём протяжении от источника до получателя.
В растущий бессистемно Интернет отцы сетей MIT, Xerox, ISI решили добавить элемент предсказуемости, сохранив его работоспособность и гибкость.
Так в 1994 году родилась идея IntServ в ответ на стремительный рост реал-тайм трафика и развитие мультикаста. Сокращалась она тогда до IS.
Название отражает стремление в одной сети одновременно предоставлять услуги для реал-тайм и не-реал-тайм типов трафика, предоставив, при этом первым приоритетное право использования ресурсов через резервирование полосы. Возможность переиспользования полосы, на которой все и зарабатывают, и благодаря чему IP выстрелил, при этом сохранялась.
Миссию по резервированию возложили на протокол RSVP, который для каждого потока резервирует полосу на каждом сетевом устройстве.
Грубо говоря, до установки A Single Rate Three Color MarkerP сессии или начала обменом данными, конечные хосты отправляют RSVP Path с указанием требуемой полосы. И если обоим вернулся RSVP Resv — они могут начать коммуницировать. При этом, если доступных ресурсов нет, то RSVP возвращает ошибку и хосты не могут общаться или пойдут по BE.
Пусть теперь храбрейшие из читателей представят, что для любого потока в интернете сегодня будет сигнализироваться канал заранее. Учтём, что это требует ненулевых затрат CPU и памяти на каждом транзитном узле, откладывает фактическое взаимодействие на некоторое время, становится понятно, почему IntServ оказался фактически мертворожденной идеей — нулевая масштабируемость.
В некотором смысле современная инкарнация IntServ — это MPLS TE с адаптированной под передачу меток версией RSVP — RSVP TE. Хотя здесь, конечно же не End-to-End и не per-flow.
IntServ описан в RFC 1633.
Документ в принципе любопытен, чтобы оценить, насколько можно быть наивным в прогнозах.
DiffServ
DiffServ сложный.
Когда в конце 90-х стало понятно, что End-to-End подход IntServ в IP провалился, в IETF созвали в 1997 рабочую группу «Differentiated Services», которая выработала следующие требования к новой модели QoS:
- Никакой сигнализации (Адьёс, RSVP!).
- Основан на агрегированной классификации трафика, вместо акцента на потоках, клиентах итд.
- Имеет ограниченный и детерминированный набор действий по обработке трафика данных классов.
В результате в 1998 родились эпохальные RFC 2474 (Definition of the Differentiated Services Field (DS Field) in the IPv4 and IPv6 Headers) и RFC 2475 (An Architecture for Differentiated Services).
И дальше всю дорогу мы будем говорить только о DiffServ.
Стоит обратить внимание, что название DiffServ — это не антитеза IntServ. Оно отражает, что мы дифференцируем сервисы, предоставляемые различным приложениям, а точнее их трафику, иными словами разделяем/дифференцируем эти типы трафика.
IntServ делает то же самое — он различает типы трафика BE и Real-Time, передающиеся на одной сети. Оба: и IntServ и DiffServ — относятся к способам дифференциации сервисов.
3. Механизмы DiffServ
Что же собой являет DiffServ и почему он выигрывает у IntServ?
Если очень просто, то трафик делится на классы. Пакет на входе в каждый узел классифицируется и к нему применяется набор инструментов, который по-разному обрабатывает пакеты разных классов, таким образом обеспечивая им разный уровень сервиса.
Но просто не будет.
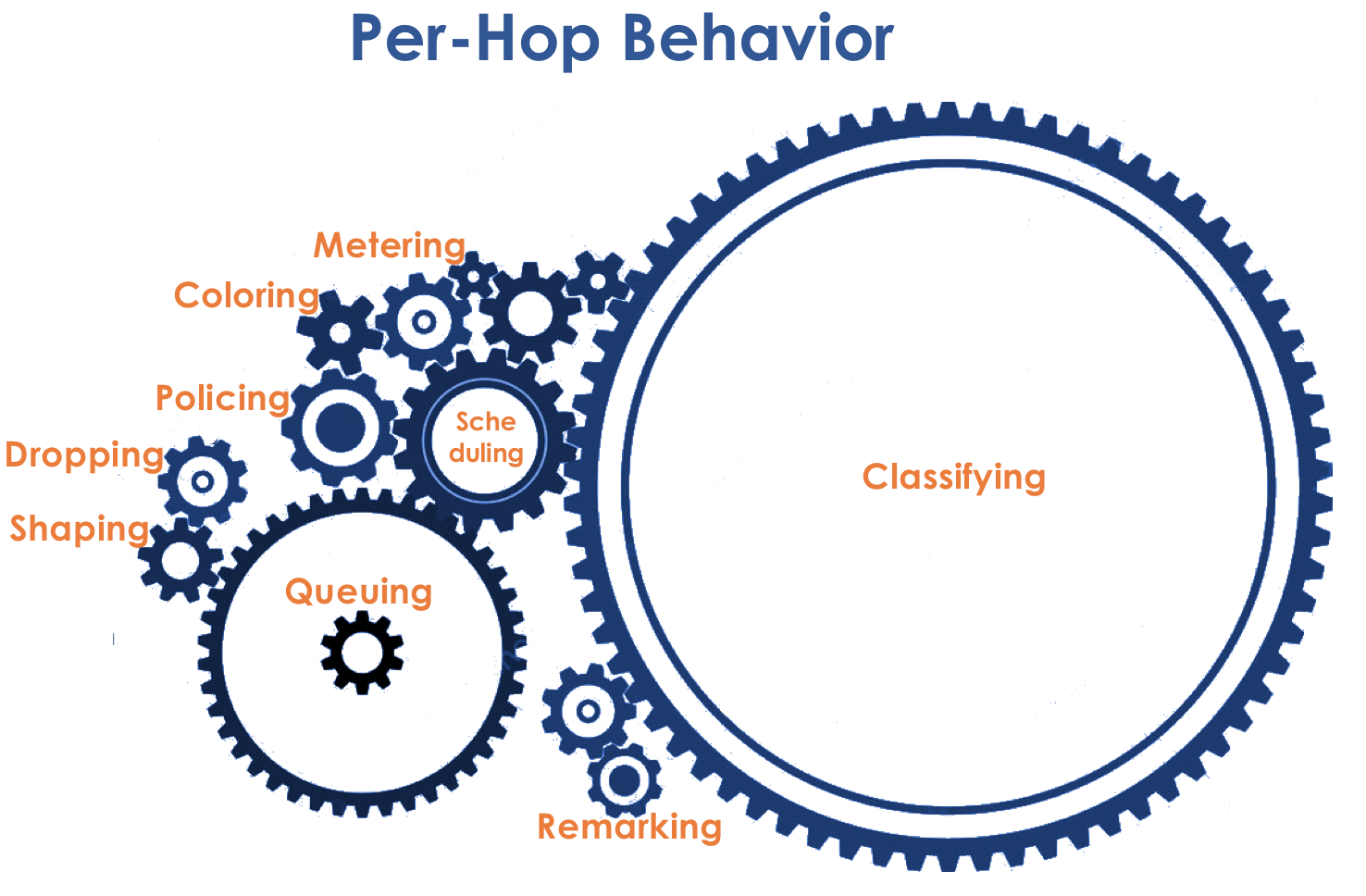
В основе DiffServ лежит идеологически выдержанная в традициях IP концепция PHB — Per-Hop Behavior. Каждый узел по пути трафика самостоятельно принимает решение о том, как вести себя относительно пришедшего пакета, на основе его заголовков.
Действия маршрутизатора с пакетом назовём моделью поведения (Behavior). Количество таких моделей детерминировано и ограничено. На разных устройствах модели поведения по отношению к одному и тому же трафику могут отличаться, поэтому они и per-hop.
Понятия Behavior и PHB я буду использовать в статье как синонимы.
Тут есть лёгкая путаница. PHB — это с одной стороны общая концепция независимого поведения каждого узла, с другой — конкретная модель на конкретном узле. С этим мы ещё разберёмся.

Модель поведения определяется набором инструментов и их параметров: Policing, Dropping, Queuing, Scheduling, Shaping.
Используя имеющиеся модели поведения, сеть может предоставлять различные классы сервиса (Class of Service).
То есть разные категории трафика могут получить разный уровень сервиса в сети путём применения к ним разных PHB.
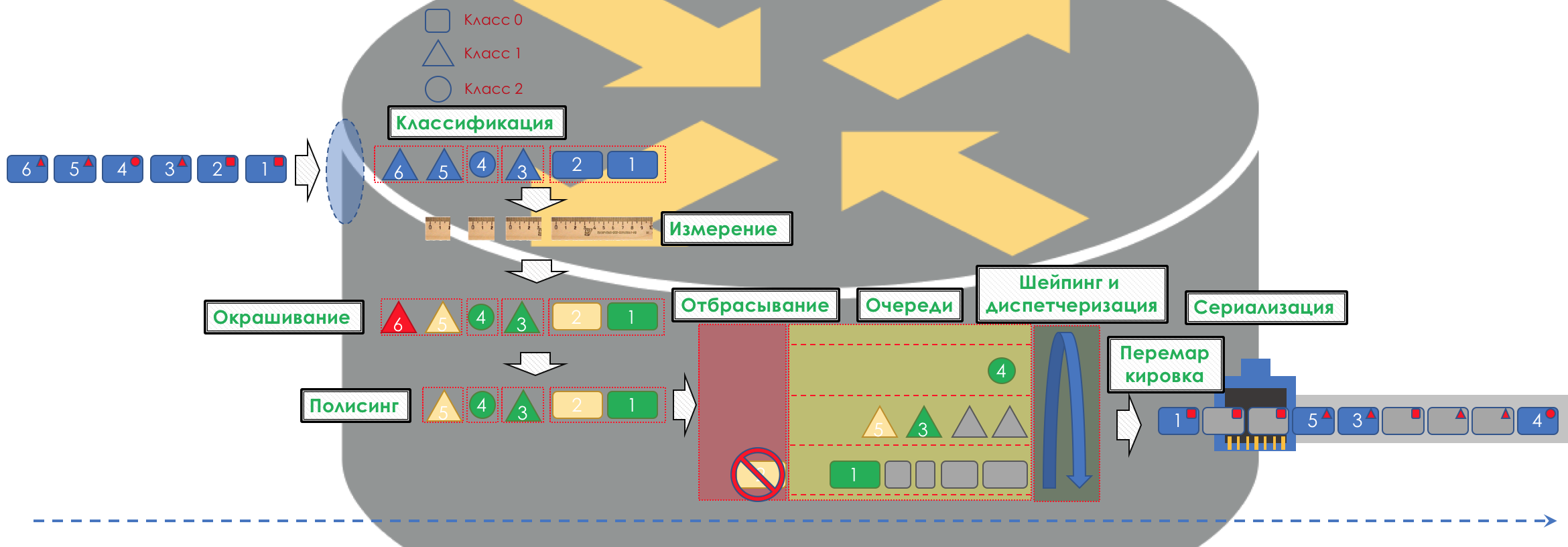
Соответственно прежде всего нужно определить к какому классу сервиса относится трафик — классификация (Classification).
Каждый узел самостоятельно классифицирует поступающие пакеты.

После классификации происходит измерение (Metering) — сколько битов/байтов трафика данного класса пришло на маршрутизатор.
На основе результатов пакеты могут окрашиваться (Coloring): зелёный (в рамках установленного лимита), жёлтый (вне лимита), красный (совсем берега попутал).
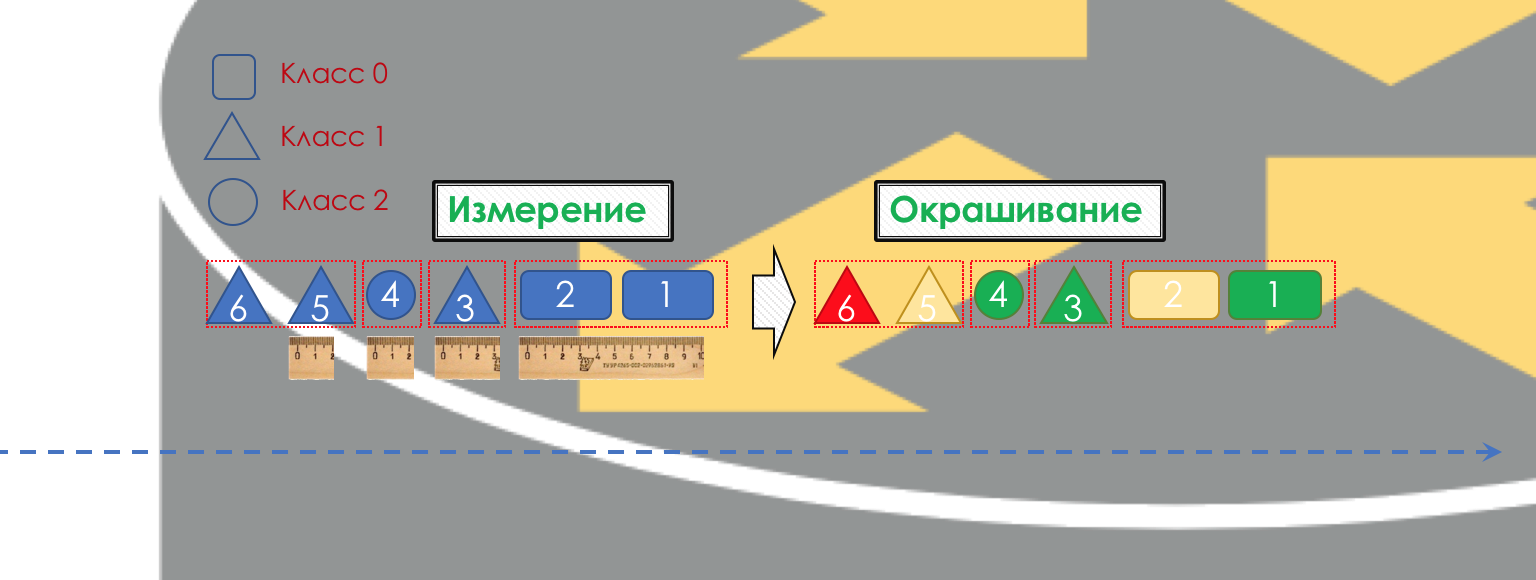
Если необходимо, далее происходит полисинг (Policing) (уж простите за такую кальку, есть вариант лучше — пишите, я поменяю). Полисер на основе цвета пакета назначает действие по отношению к пакету — передать, отбросить или перемаркировать.
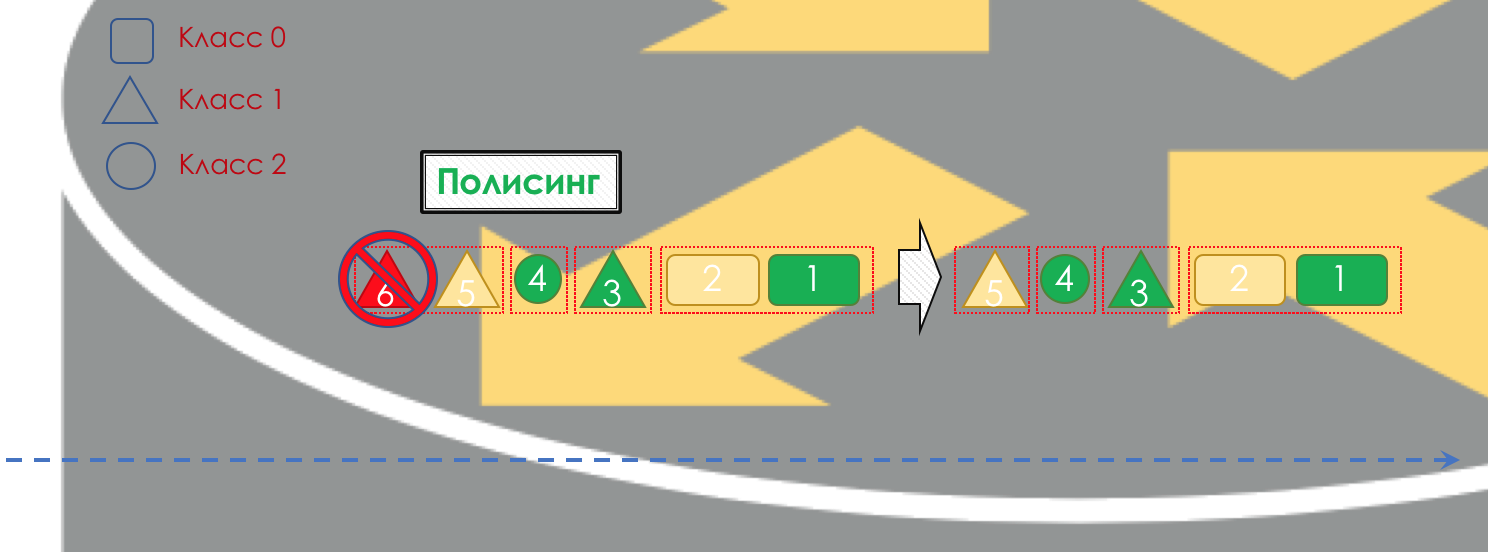
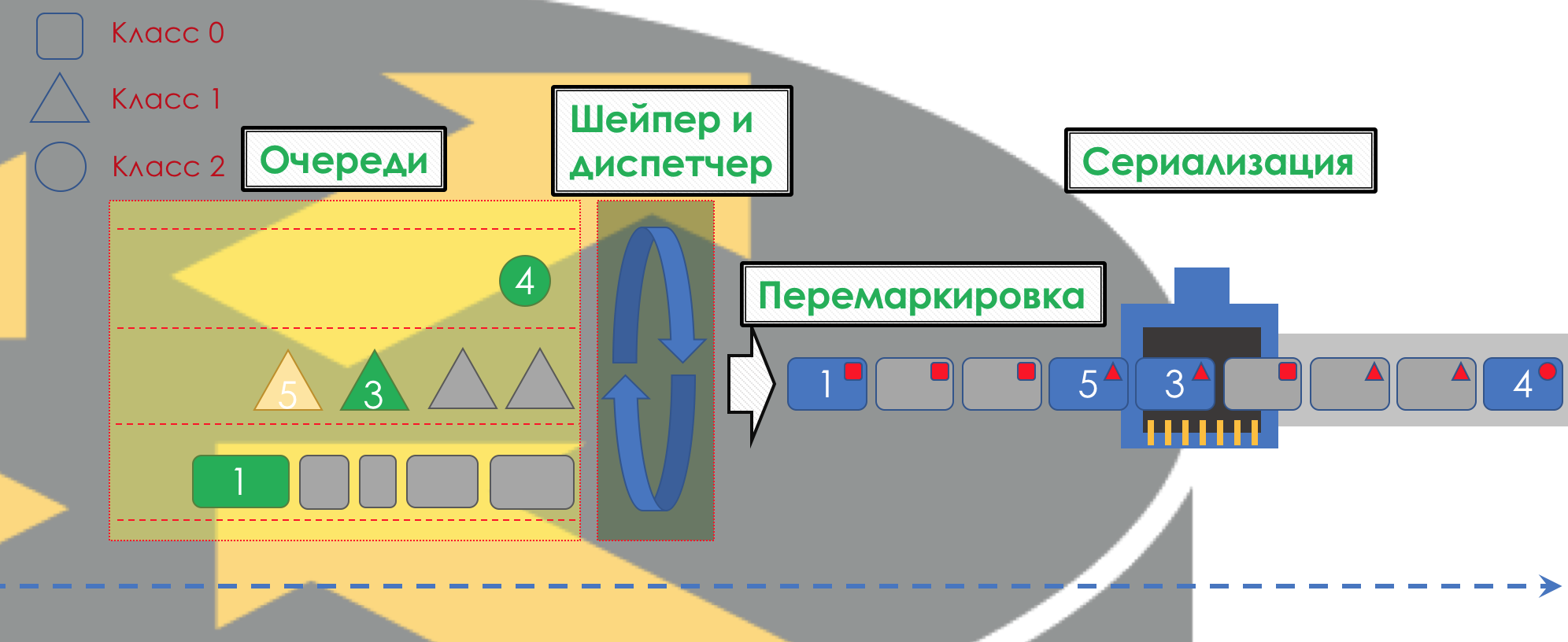
После этого пакет должен попасть в одну из очередей (Queuing). Для каждого класса сервиса выделена отдельная очередь, что и позволяет их дифференцировать, применяя разные PHB.
Но ещё до того, как пакет попадёт в очередь, он может быть отброшен (Dropper), если очередь заполнена.
Если он зелёный, то он пройдёт, если жёлтый, то его вполне вероятно, отбросят, если очередь полна, а если красный — это верный смертник. Условно, вероятность отбрасывания зависит от цвета пакета и наполненности очереди, куда он собирается попасть.
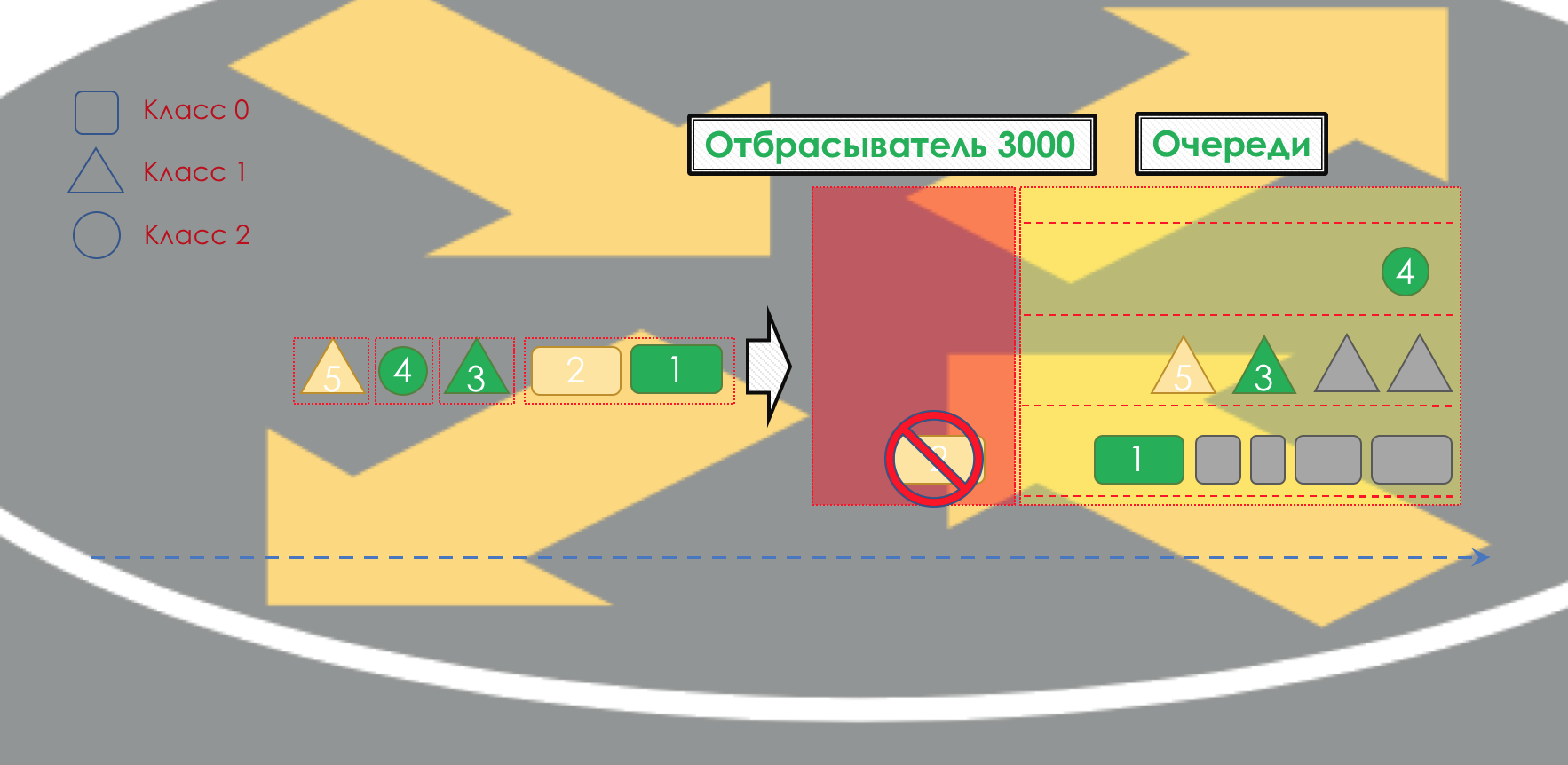
На выходе из очереди работает шейпер (Shaper), задача которого очень похожа на задачу полисера — ограничить трафик до заданного значения.
Можно настроить произвольные шейперы для отдельных очередей или даже внутри очередей.
Об отличии шейпера от полисера в главе Ограничение скорости.
Все очереди в итоге должны слиться в единый выходной интерфейс.
Вспомните ситуацию, когда на дороге 8 полос сливаются в 3. Без регулировщика это превращается в хаос. Разделение по очередям не имело бы смысла, если бы на выходе мы имели то же, что на входе.
Поэтому есть специальный диспетчер (Scheduler), который циклически вынимает пакеты из разных очередей и отправляет в интерфейс (Scheduling).
На самом деле связка набора очередей и диспетчера — самый главный механизм QoS, который позволяет применять разные правила к разным классам трафика, одним обеспечивая широкую полосу, другим низкие задержки, третьим отсутствие дропов.
Далее пакеты уже выходят на интерфейс, где происходит преобразование пакетов в поток битов — сериализация (Serialization) и далее сигнал среды.
В DiffServ поведение каждого узла независимо от остальных, нет протоколов сигнализации, которые бы сообщили, какая на сети политика QoS. При этом в пределах сети хотелось бы, чтобы трафик обрабатывался одинаково. Если всего лишь один узел будет вести себя иначе, вся политика QoS псу под хвост.
Для этого, во-первых, на всех маршрутизаторах, настраиваются одинаковые классы и PHB для них, а во-вторых, используется маркировка (Marking) пакета — его принадлежность определённому классу записывается в заголовок (IP, MPLS, 802.1q).
И красота DiffServ в том, что следующий узел может довериться этой маркировке при классификации.
Такая зона доверия, в которой действуют одинаковые правила классификации трафика и одни модели поведения, называется домен DiffServ (DiffServ-Domain).

Таким образом на входе в домен DiffServ мы можем классифицировать пакет на основе 5-Tuple или интерфейса, промаркировать (Remark/Rewrite) его согласно правилам домена, и дальнейшие узлы будут доверять этой маркировке и не делать сложную классификацию.
То есть явной сигнализации в DiffServ нет, но узел может сообщить всем следующим, какой класс нужно обеспечить этому пакету, ожидая, что тот доверится.
На стыках между DiffServ-доменами нужно согласовывать политики QoS (или не нужно).
Целиком картина будет выглядеть примерно так:
Чтобы было понятно, приведу аналог из реальной жизни.Как вы могли уже заметить, DiffServ предельно (или беспредельно) сложен. Но всё описанное выше, мы разберём. При этом в статье я не буду вдаваться в нюансы физической реализации (они могут различаться даже на двух платах одного маршрутизатора), не буду рассказывать про HQoS и MPLS DS-TE.
Перелёт на самолёте (не Победой).
Есть три класса сервиса (CoS): Эконом, Бизнес, Первый.
При покупке билета происходит классификация (Classification) — пассажир получает определённый класс сервиса на основе цены.
В аэропорту происходит маркировка (Remark) — выдаётся билет с указанием класса.
Есть две модели поведения (PHB): Best Effort и Premium.
Есть механизмы, реализующие модели поведения: Общий зал ожидания или VIP Lounge, микроавтобус или общий автобус, удобные большие сиденья или плотностоящие ряды, количество пассажиров на одну борт-проводницу, возможность заказать алкоголь.
В зависимости от класса назначаются модели поведения — эконому Best Effort, Бизнесу — Premium базовый, а Первому — Premium SUPER-POWER-NINJA-TURBO-NEO-ULTRA-HYPER-MEGA-MULTI-ALPHA-META-EXTRA-UBER-PREFIX!
При этом два Premium отличаются тем что, в одном дают бокал полусладкого, а в другом безлимит Бакарди.
Далее по приезду в аэропорт все заходят через одни двери. Тех, кто попытался провезти с собой оружие или не имеет билета, не пускают (Drop). Бизнес и эконом попадают в разные залы ожидания и разный транспорт (Queuing). Сначала на борт пускают Первый класс, потом бизнес, потом эконом (Scheduling), однако потом они в пункт назначения все летят одним самолётом (интерфейс).
В этом же примере перелёт на самолёте — это задержка передачи (Propagation), посадка — задержка сериализации (Serialization), ожидание самолёта в залах — Queuing, а паспортный контроль — Processing. Заметьте, что и тут Processing Delay обычно пренебрежимо мал в масштабах общего времени.
Следующий аэропорт может обойтись с пассажирами совсем иначе — его PHB отличается. Но при этом если пассажир не меняет авиакомпанию, то, скорее всего, отношение к нему не поменяется, потому что одна компания — один DiffServ-domain.
Порог входа в круг инженеров, понимающих технологию, для QoS значительно выше, чем для протоколов маршрутизации, MPLS, или, прости меня Радья, STP.
И несмотря на это DiffServ заслужил признание и внедрение на сетях по всему миру, потому что, как говорится, хайли скэлэбл.
Всю дальнейшую часть статьи я буду разбирать только DiffServ.
Ниже мы разберём все инструменты и процессы, указанные на иллюстрации.
По ходу раскрытия темы некоторые вещи я буду показывать на практике.
Работать мы будем вот с такой сетью:
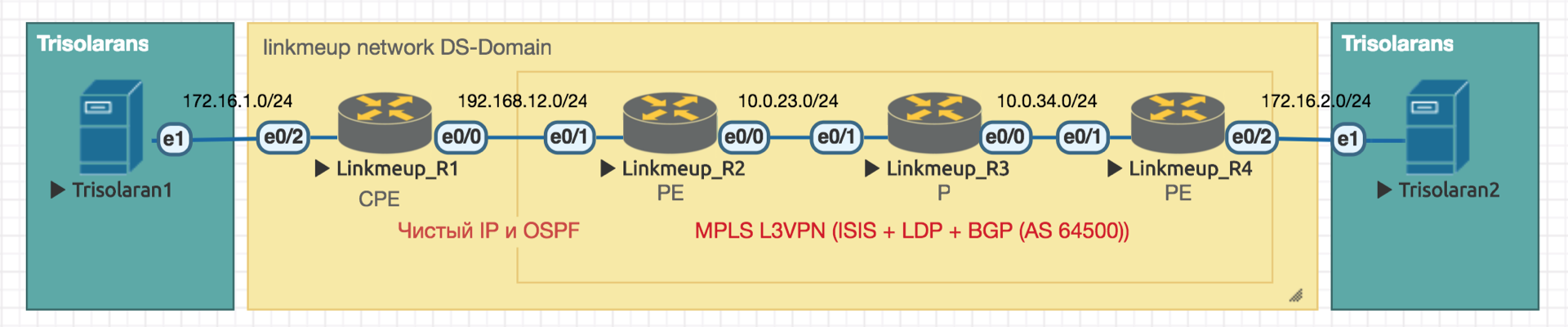
Trisolarans — это клиент провайдера linkmeup с двумя точками подключения.
Жёлтая область — это DiffServ-домен сети linkmeup, где действует единая политика QoS.
Linkmeup_R1 — это CPE устройство, которое находится под управлением провайдера, а потому в доверенной зоне. С ним поднят OSPF и взаимодействие происходит через чистый IP.
В пределах ядра сети MPLS+LDP+MP-BGP с L3VPN, растянутый от Linkmeup_R2 до Linkmeup_R4.
Все остальные комментарии я буду давать по мере необходимости.
Файл начальной конфигурации.
4. Классификация и маркировка
Внутри своей сети администратор определяет классы сервиса, которые он может предоставлять трафику.
Поэтому первое, что делает каждый узел при получении пакета, проводит его классификацию.
Существует три способа:
- Behavior Aggregate (BA)
Просто довериться имеющейся маркировке пакета в его заголовке. Например, полю IP DSCP.
Называется он так, потому что под одной меткой в поле DSCP агрегированы различные категории трафика, которые ожидают одинакового по отношению к себе поведения. Например, все SIP-сессии будут агрегированы в один класс.
Количество возможных классов сервиса, а значит и моделей поведения, ограничено. Соответственно нельзя каждой категории (или тем более потоку) выделить отдельный класс — приходится агрегировать. - Interface-based
Всё, что приходит на конкретный интерфейс, помещать в один класс трафика. Например, мы точно знаем, что в этот порт подключен сервер БД и больше ничего. А в другой рабочая станция сотрудника. - MultiField (MF)
Проанализировать поля заголовков пакета — IP-адреса, порты, MAC-адреса. Вообще говоря, произвольные поля.
Например, весь трафик, который идёт в подсеть 10.127.721.0/24 по порту 5000, нужно маркировать как трафик, условно, требующий 5-й класс сервиса.
Администратор определяет набор классов сервиса, которые сеть может предоставлять, и сопоставляет им некоторое цифровое значение.
На входе в DS-домен мы никому не доверяем, поэтому проводится классификация вторым или третьим способом: на основе адресов, протоколов или интерфейсов определяется класс сервиса и соответствующее цифровое значение.
На выходе из первого узла эта цифра кодируется в поле DSCP заголовка IP (или другое поле Traffic Class: MPLS Traffic Class, IPv6 Traffic Class, Ethernet 802.1p) — происходит ремаркировка.
Внутри DS-домена принято доверять этой маркировке, поэтому транзитные узлы используют первый способ классификации (BA) — наиболее простой. Никакого сложного анализа заголовков, смотрим только записанную цифру.
На стыке двух доменов можно классифицировать на основе интерфейса или MF, как я описал выше, а можно довериться маркировке BA с оговорками.
Например, доверять всем значениям, кроме 6 и 7, а 6 и 7 перемаркировывать в 5.
Такая ситуация возможна в случае, когда провайдер подключает юрлицо, у которого есть своя политика маркировки. Провайдер не возражает сохранить её, но при этом не хочет, чтобы трафик попадал в класс, в котором у него передаются пакеты сетевых протоколов.
Behavior Aggregate
В BA используется очень простая классификация — вижу цифру — понимаю класс.
Так что же за цифра? И в какое поле она записывается?
- IPv6 Traffic Class
- MPLS Traffic Class
- Ethernet 802.1p
В основном классификация происходит по коммутирующему заголовку.
Коммутирующим я называю заголовок, на основе которого устройство определяет, куда отправить пакет, чтобы он стал ближе к получателю.
То есть если на маршрутизатор пришёл IP-пакет, анализируется заголовок IP и поле DSCP. Если пришёл MPLS, анализируется — MPLS Traffic Class.
Если на обычный L2-коммутатор пришёл пакет Ethernet+VLAN+MPLS+IP, то анализироваться будет 802.1p (хотя это можно и поменять).
IPv4 TOS
Поле QoS сопутствует нам ровно столько же, сколько и IP. Восьмибитовое поле TOS — Type Of Service — по задумке должно было нести приоритет пакета.
Ещё до появления DiffServ RFC 791 (INTERNET PROTOCOL) описывал поле так:
IP Precedence (IPP) + DTR + 00.
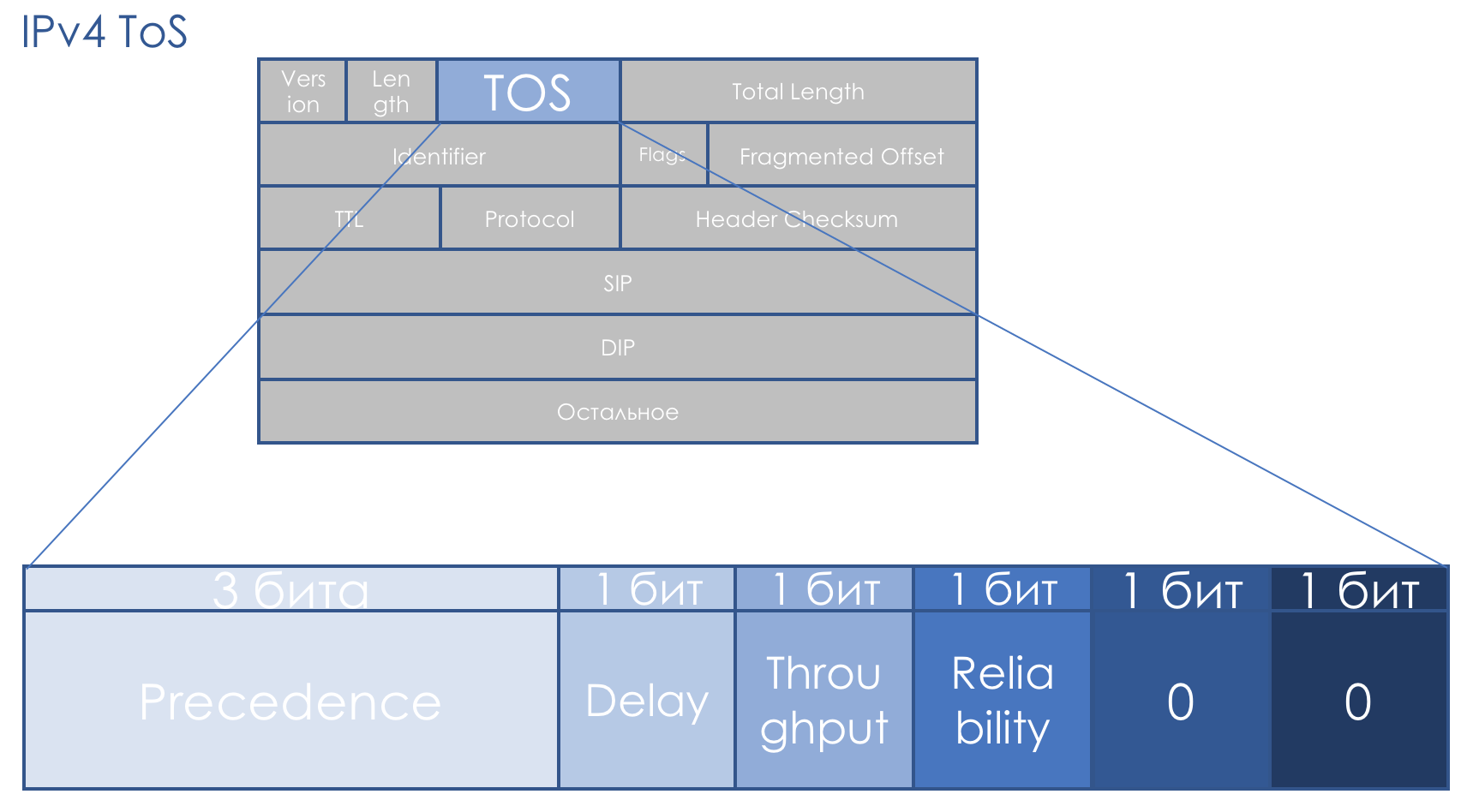
То есть идёт приоритет пакета, далее биты требовательности к Delay, Throughput, Reliability (0 — без требований, 1 — с требованиями).
Последние два бита должны быть нулём.
110 — Internetwork Control
101 — CRITIC/ECP
100 — Flash Override
011 — Flash
010 — Immediate
001 — Priority
000 — Routine
Чуть позже в RFC 1349 (Type of Service in the Internet Protocol Suite) поле TOS немного переопределили:
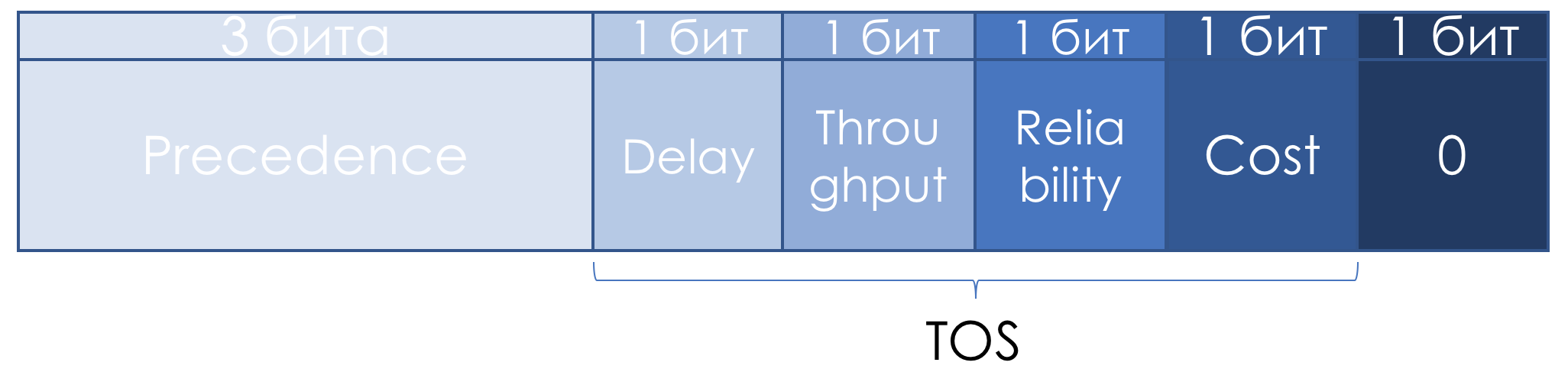
Левые три бита остались IP Precedence, четыре следующих превратились в TOS после добавления бита Cost.
Вот как следовало читать единицы в этих битах TOS:
- D — «minimize delay»,
- T — «maximize throughput»,
- R — «maximize reliability»,
- C — «minimize cost».
Туманные описания не способствовали популярности этого подхода.
Системный подход к QoS на всём протяжении пути отсутствовал, чётких рекомендаций, как использовать поле приоритета тоже не было, описание битов Delay, Throughput и Reliability было крайне туманным.
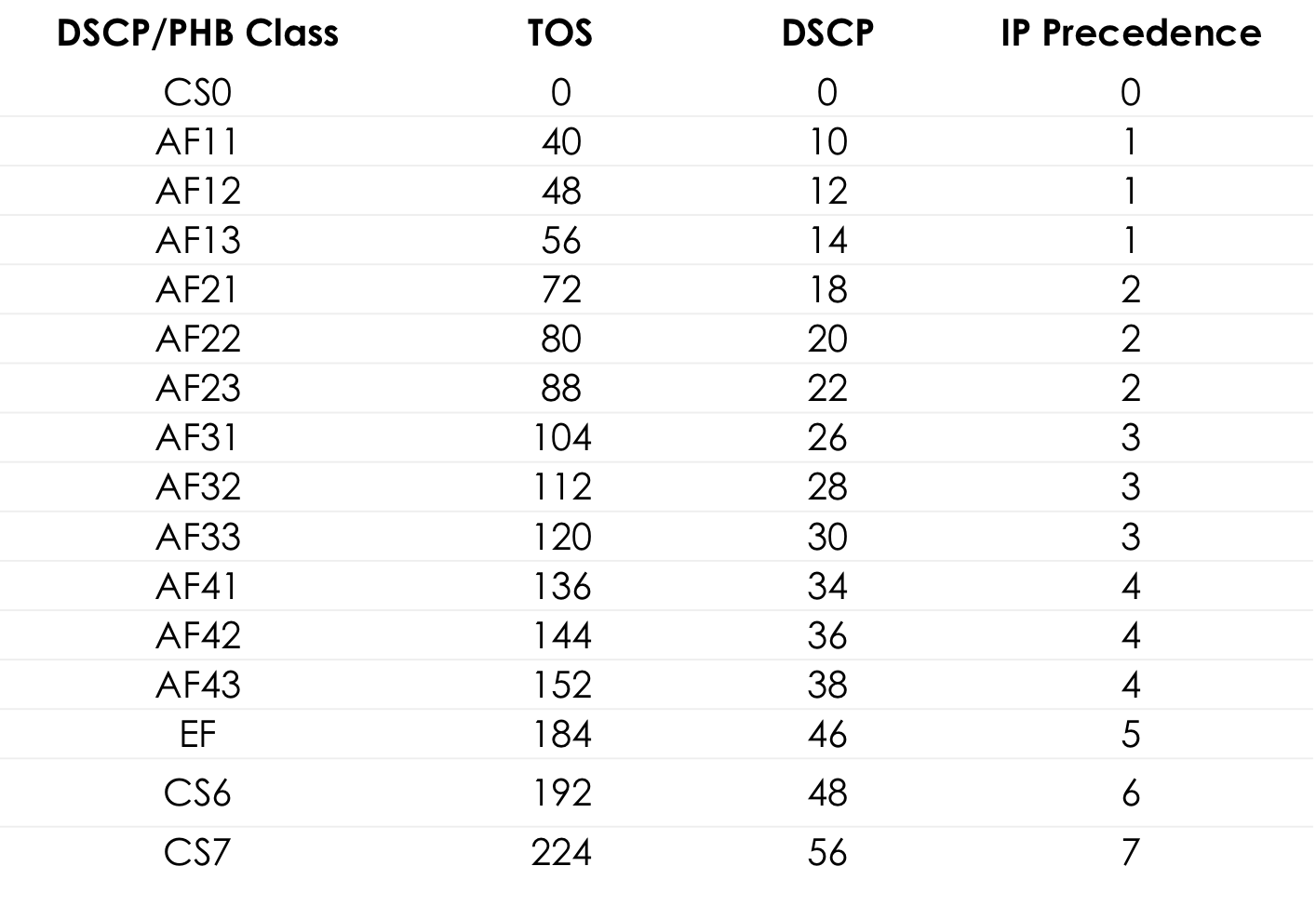
Поэтому в контексте DiffServ поле TOS ещё раз переопределили в RFC 2474 (Definition of the Differentiated Services Field (DS Field) in the IPv4 and IPv6 Headers):

Вместо битов IPP и DTRC ввели шестибитовое поле DSCP — Differentiated Services Code Point, два правых бита не были использованы.
С этого момента именно поле DSCP должно было стать главной маркировкой DiffServ: в него записывается определённое значение (код), которое в пределах данного DS-домена характеризует конкретный класс сервиса, необходимый пакету и его приоритет отбрасывания. Это та самая цифра.
Все 6 бит DSCP администратор может использовать, как ему заблагорассудится, разделяя максимум до 64 классов сервиса.
Однако в угоду совместимости с IP Precedence за первыми тремя битами сохранили роль Class Selector.
То есть, как и в IPP, 3 бита Class Selector позволяют определить 8 классов.

Однако это всё же не более, чем договорённость, которую в пределах своего DS-домена, администратор может легко игнорировать и использовать все 6 бит по усмотрению.
Далее также замечу, что согласно рекомендациям IETF, чем выше значение, записанное в CS, тем требовательнее этот трафик к сервису.
Но и это не стоит воспринимать как неоспоримую истину.
Если первые три бита определяют класс трафика, то следующие три используются для указания приоритета отбрасывания пакета (Drop Precedence или Packet Loss Priority — PLP).
Восемь классов — это много или мало? На первый взгляд мало — ведь так много разного трафика ходит в сети, что так и хочется каждому протоколу выделить по классу. Однако оказывается, что восьми достаточно для всех возможных сценариев.
Для каждого класса нужно определять PHB, который будет обрабатывать его как-то отлично от других классов.
Да и при увеличении делителя, делимое (ресурс) не увеличивается.
Я намеренно не говорю о том, какие значения какой именно класс трафика описывают, поскольку здесь нет стандартов и формально их можно использовать по своему усмотрению. Ниже я расскажу, какие классы и соответствующие им значения рекомендованы.
Например, когда в очередях маршрутизатора задерживаются пакеты надолго и заполняют их, например, на 85%, он меняет значение ECN, сообщая конечному хосту, что нужно помедленнее — что-то вроде Pause Frames в Ethernet.
В этом случае отправитель должен уменьшить скорость передачи и снизить нагрузку на страдающий узел.
При этом теоретически поддержка этого поля всеми транзитными узлами не обязательна. То есть использование ECN не ломает не поддерживающую его сеть.
Цель благая, но прежде применения в жизни ECN особо не находил. В наше время мега- и гиперскейлов на эти два бита смотрят с новым интересом.
ECN является одним из механизмов предотвращения перегрузок, о которых ниже.
Практика классификации DSCP
Не помешает немного практики.
Схема та же.
Для начала просто отправим запрос ICMP:
Linkmeup_R1#ping ip 172.16.2.2 source 172.16.1.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds:
Packet sent with a source address of 172.16.1.1
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 msLinkmeup_R1. E0/0.

pcapng
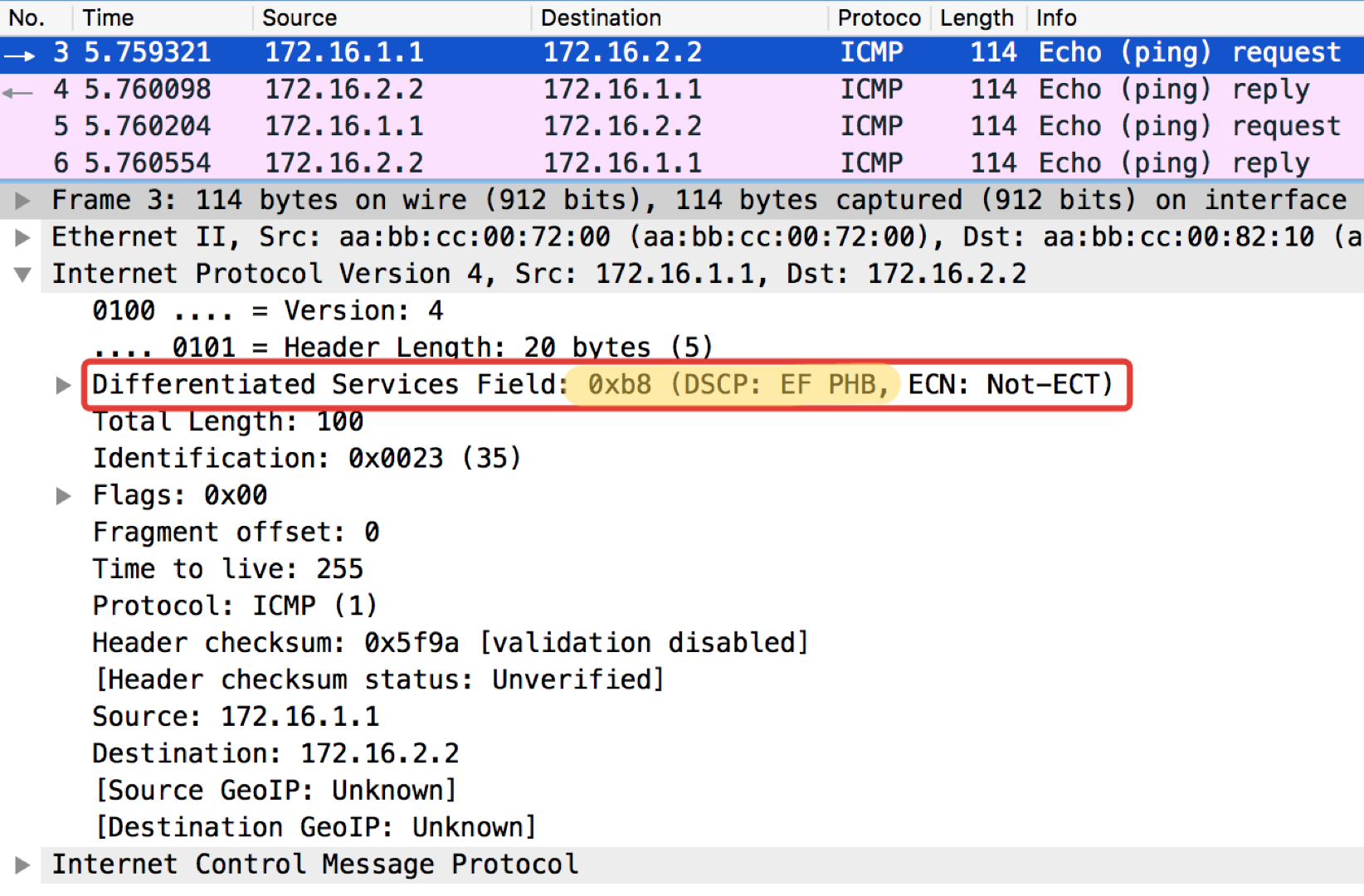
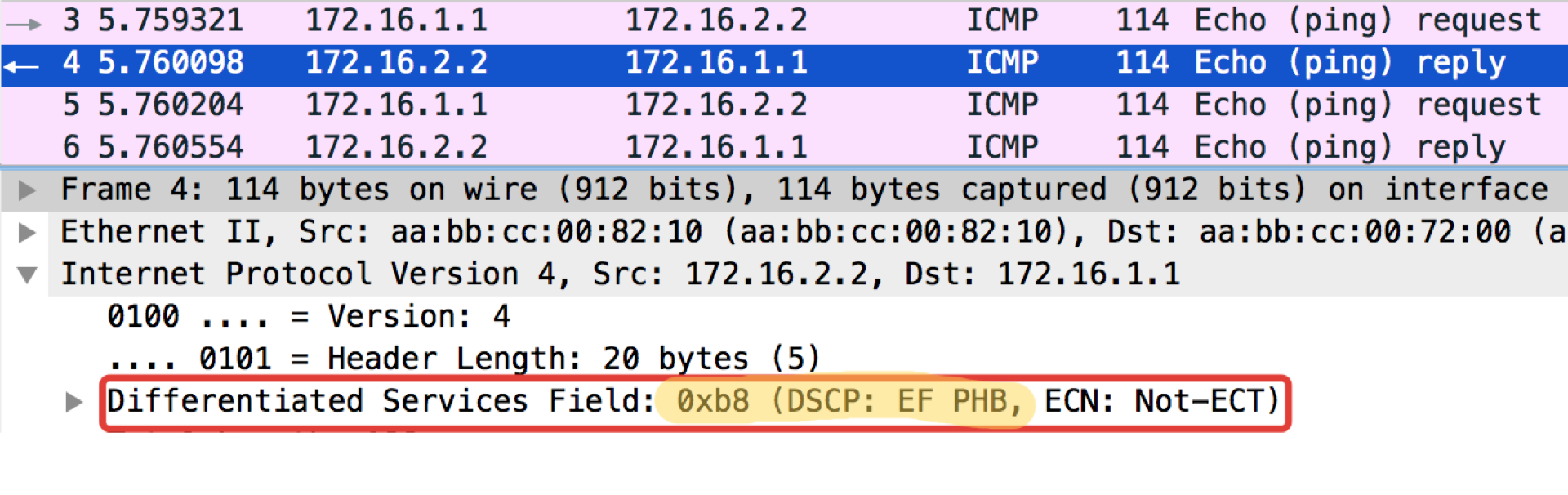
А теперь с установленным значением DSCP.
Linkmeup_R1#ping ip 172.16.2.2 source 172.16.1.1 tos 184
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds:
Packet sent with a source address of 172.16.1.1
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 msЗначение 184 — это десятичное представление двоичного 10111000. Из них первые 6 бит — это 101110, то есть десятичные 46, а это класс EF.
Подробнее
Ниже по тексту в главе Рекомендации IETF я расскажу, откуда взялись и эти цифры и названия.
Linkmeup_R2. E0/0
pcapng
Любопытное замечание: адресат попингушек в ICMP Echo reply устанавливает такое же значение класса, как было в Echo Request. Это логично — если отправитель послал пакет с определённым уровнем важности, то, очевидно, он хочет получить его гарантировано назад.
Linkmeup_R2. E0/0
Файл конфигурации DSCP классификации.
IPv6 Traffic Class
IPv6 мало чем в вопросе QoS отличается от IPv4. Восьмибитовое поле, называемое Traffic Class, также разбито на две части. Первые 6 бит — DSCP — играют ровно ту же роль.

Да, появился Flow Label. Говорят, что его можно было бы использовать для дополнительной дифференциации классов. Но применения в жизни эта идея пока нигде не нашла.
MPLS Traffic Class
Концепция DiffServ была ориентирована на IP-сети с маршрутизацией на основе IP-заголовка. Вот только незадача — через 3 года опубликовали RFC 3031 (Multiprotocol Label Switching Architecture). И MPLS начал захватывать сети провайдеров.
DiffServ нельзя было не распространить на него.
По счастливой случайности в MPLS заложили трёхбитовое поле EXP на всякий экспериментальный случай. И несмотря на то, что уже давным-давно в RFC 5462 («EXP» Field Renamed to «Traffic Class» Field) официально стало полем Traffic Class, по инерции его называют ИЭксПи.
С ним есть одна проблема — его длина три бита, что ограничивает число возможных значений до 9. Это не просто мало, это на 3 двоичных порядка меньше, чем у DSCP.

Учитывая, что часто MPLS Traffic Class наследуется из DSCP IP-пакета, имеем архивацию с потерей. Или же… Нет, вы не хотите этого знать… L-LSP. Использует комбинацию Traffic Class + значение метки.
Вообще согласитесь, ситуация странная — MPLS разрабатывался как помощь IP для быстрого принятия решения — метка MPLS мгновенно обнаруживается в CAM по Full Match, вместо традиционного Longest Prefix Match. То есть и про IP знали, и в коммутации участие принимает, а нормальное поле приоритета не предусмотрели.На самом деле выше мы уже увидели, что для определения класса трафика используется только первые три бита DSCP, а три другие — Drop Precedence (или PLP — Packet Loss Priority).
Поэтому в плане классов сервиса всё же имеем соответствие 1:1, теряя только информацию о Drop Precedence.
В случае MPLS классификация так же как и в IP может быть на основе интерфейса, MF, значения DSCP IP или Traffic Class MPLS.
Маркировка означает запись значения в поле Traffic Class заголовка MPLS.
Пакет может содержать несколько заголовков MPLS. Для целей DiffServ используется только верхний.
Существуют три разных сценария перемаркировки при продвижении пакета из одного чистого IP-сегмента в другой через MPLS-домен: (это просто выдержка из статьи).
- Uniform Mode
- Pipe Mode
- Short-Pipe Mode
Uniform Mode
Это плоская модель End-to-End.
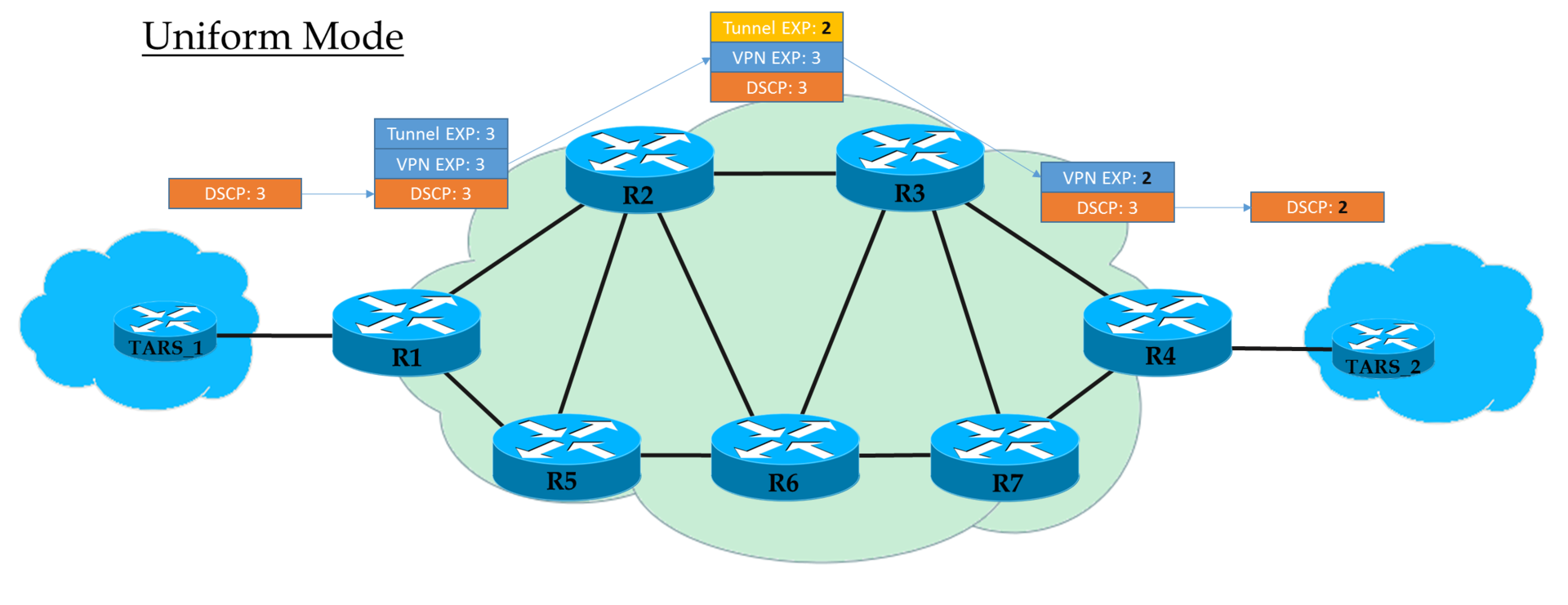
На Ingress PE мы доверяем IP DSCP и копируем (строго говоря, отображаем, но для простоты будем говорить «копируем») его значение в MPLS EXP (как туннельный, так и VPN заголовки). На выходе с Ingress PE пакет уже обрабатывается в соответствии со значением поля EXP верхнего заголовка MPLS.
Каждый транзитный P тоже обрабатывает пакеты на основе верхнего EXP. Но при этом он может его поменять, если того хочет оператор.
Предпоследний узел снимает транспортную метку (PHP) и копирует значение EXP в VPN-заголовок. Не важно, что там стояло — в режиме Uniform, происходит копирование.
Egress PE снимая метку VPN, тоже копирует значение EXP в IP DSCP, даже если там записано другое.
То есть если где-то в середине значение метки EXP в туннельном заголовке изменилось, то это изменение будет унаследовано IP-пакетом.
Pipe Mode
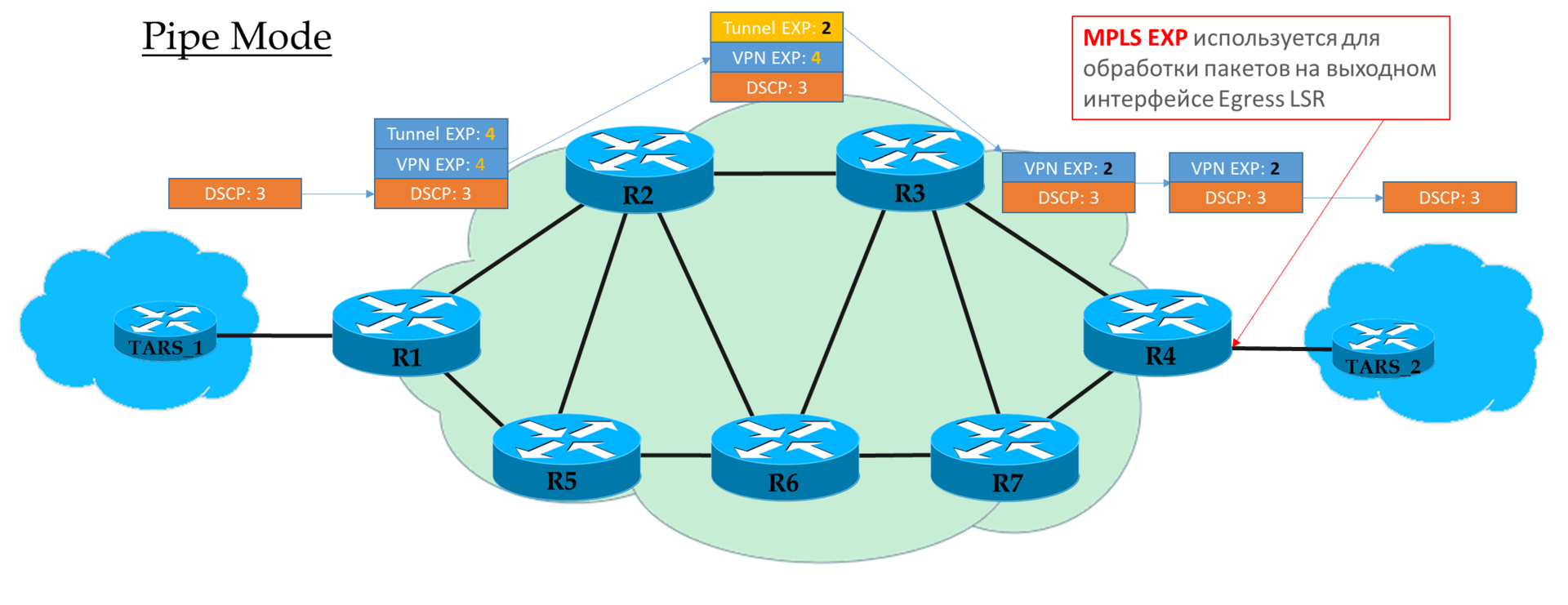
Если же на Ingress PE мы решили не доверять значению DSCP, то в заголовки MPLS вставляется то значение EXP, которое пожелает оператор.
Но допустимо и копировать те, что были в DSCP. Например, можно переопределять значения — копировать всё, вплоть до EF, а CS6 и CS7 маппировать в EF.
Каждый транзитный P смотрит только на EXP верхнего MPLS-заголовка.
Предпоследний узел снимает транспортную метку (PHP) и копирует значение EXP в заголовок VPN.
Egress PE сначала производит обработку пакета, опираясь на поле EXP в заголовке MPLS, и только потом его снимает, при этом не копирует значение в DSCP.
То есть независимо от того, что происходило с полем EXP в заголовках MPLS, IP DSCP остаётся неизменным.
Такой сценарий можно применять, когда у оператора свой домен Diff-Serv, и он не хочет, чтобы клиентский трафик как-то мог на него влиять.
Short-Pipe Mode
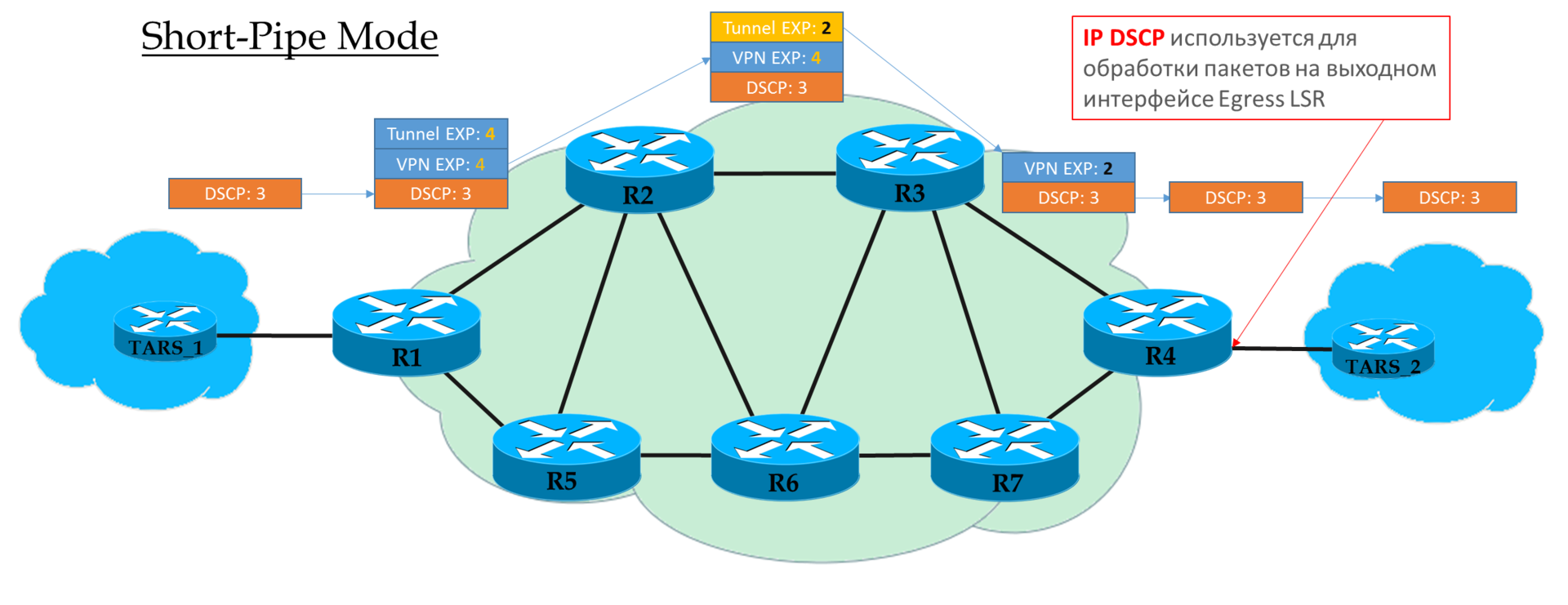
Этот режим вы можете рассматривать вариацией Pipe-mode. Разница лишь в том, что на выходе из MPLS-сети пакет обрабатывается в соответствие с его полем IP DSCP, а не MPLS EXP.
Это означает, что приоритет пакета на выходе определяется клиентом, а не оператором.
Ingress PE не доверяет IP DSCP входящих пакетов
Транзитные P смотрят в поле EXP верхнего заголовка.
Предпоследний P снимает транспортную метку и копирует значение в VPN-метку.
Egress PE сначала снимает метку MPLS, потом обрабатывает пакет в очередях.
Объяснение от cisco.
Практика классификации MPLS Traffic Class
Схема та же:
Файл конфигурации тот же.
В схеме сети linkmeup есть переход из IP в MPLS на Linkmeup_R2.
Посмотрим, что происходит с маркировкой при пинге ping ip 172.16.2.2 source 172.16.1.1 tos 184.
Linkmeup_R2. E0/0.

pcapng
Итак, мы видим, что изначальная метка EF в IP DSCP трансформировалась в значение 5 поля EXP MPLS (оно же Traffic Class, помним это) как VPN-заголовка, так и транспортного.
Тут мы являемся свидетелями режима работы Uniform.
Ethernet 802.1p
Отсутствие поля приоритета в 802.3 (Ethernet) находит своё объяснение в том, что Ethernet изначально планировался исключительно как решение для LAN-сегмента. За скромные деньги можно получить избыточную пропускную способность, и узким местом всегда будет аплинк — не за чем беспокоиться о приоритизации.
Однако очень скоро стало ясно, что финансовая привлекательность Ethernet+IP выводит эту связку на уровень магистрали и WAN. Да и сожительство в одном LAN-сегменте торрентов и телефонии нужно разруливать.
По счастью к этому моменту подоспел 802.1q (VLAN), в котором выделили 3-битовое (опять) поле под приоритеты.
В плане DiffServ это поле позволяет определить те же 8 классов трафика.
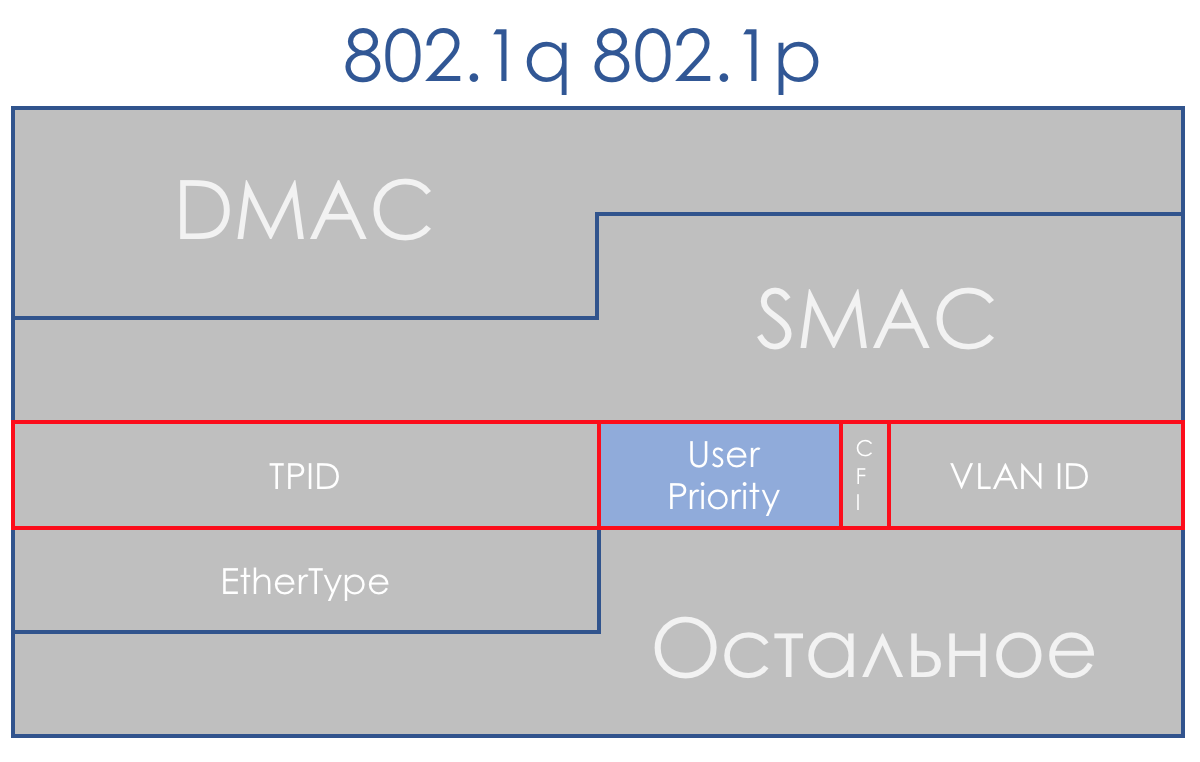
При получении пакета сетевое устройство DS-домена в большинстве случаев берёт в рассмотрение тот заголовок, который оно использует для коммутации:
- Ethernet-коммутатор — 802.1p
- MPLS-узел — MPLS Traffic Class
- IP-маршрутизатор — IP DSCP
Хотя это поведение можно и изменить: Interface-Based и Multi-Field классификация. А можно иногда даже явно сказать, в поле CoS какого заголовка смотреть.
Interface-based
Это наиболее простой способ классифицировать пакеты в лоб. Всё, что насыпалось в указанный интерфейс, помечается определённым классом.
В некоторых случаях такой гранулярности хватает, поэтому Interface-based находит применение в жизни.
Практика по Interface-based классификации
Схема та же:
Настройка политик QoS в оборудовании большинства вендоров делится на этапы.
- Сначала определяется классификатор:
class-map match-all TRISOLARANS_INTERFACE_CM
match input-interface Ethernet0/2
Всё, что приходит на интерфейс Ethernet0/2.
- Далее создаётся политика, где связываются классификатор и необходимое действие.
policy-map TRISOLARANS_REMARK class TRISOLARANS_INTERFACE_CM set ip dscp cs7
Если пакет удовлетворяет классификатору TRISOLARANS_INTERFACE_CM, записать в поле DSCP значение CS7.
Здесь я забегаю вперёд, используя непонятные CS7, а далее EF, AF. Ниже можно прочитать про эти аббревиатуры и принятые договорённости. Пока же достаточно знать, что это разные классы с разным уровнем сервиса.
- И последним шагом применить политику на интерфейс:
interface Ethernet0/2 service-policy input TRISOLARANS_REMARK
Здесь немного избыточен классификатор, который проверят что пакет пришёл на интерфейс e0/2, куда мы потом и применяем политику. Можно было бы написать match any:
class-map match-all TRISOLARANS_INTERFACE_CM match any
Однако политика на самом деле может быть применена на vlanif или на выходной интерфейс, поэтому можно.
Пускаем обычный пинг на 172.16.2.2 (Trisolaran2) с Trisolaran1:
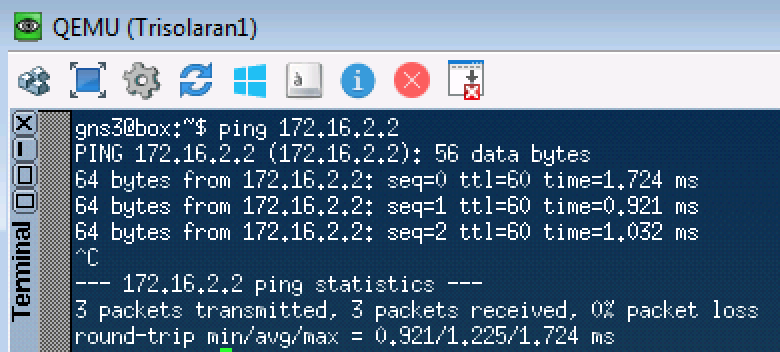
И в дампе между Linkmeup_R1 и Linkmeup_R2 увидим следующее:
pcapng
Файл конфигурации Interface-Based классификации.
Multi-Field
Наиболее часто встречающийся тип классификации на входе в DS-домен. Не доверяем имеющейся маркировке, а на основе заголовков пакета присваиваем класс.
Зачастую это способ вообще «включить» QoS, в случае, когда отправители не проставляют маркировку.
Достаточно гибкий инструмент, но в то же время громоздкий — нужно создавать непростые правила для каждого класса. Поэтому внутри DS-домена актуальнее BA.
Практика по MF классификации
Схема та же:
Из практических примеров выше видно, что устройства сети по умолчанию доверяют маркировке приходящих пакетов.
Это прекрасно внутри DS-домена, но неприемлемо в точке входа.
А давайте теперь не будем слепо доверять? На Linkmeup_R2 ICMP будем метить как EF (исключительно для примера), TCP как AF12, а всё остальное CS0.
Это будет MF (Multi-Field) классификация.
- Процедура та же, но теперь матчить будем по ACL, которые выцепляют нужные категории трафика, поэтому сначала создаём их.
На Linkmeup_R2:
ip access-list extended TRISOLARANS_ICMP_ACL permit icmp any any ip access-list extended TRISOLARANS_TCP_ACL permit tcp any any ip access-list extended TRISOLARANS_OTHER_ACL permit ip any any
- Далее определяем классификаторы:
class-map match-all TRISOLARANS_TCP_CM match access-group name TRISOLARANS_TCP_ACL class-map match-all TRISOLARANS_OTHER_CM match access-group name TRISOLARANS_OTHER_ACL class-map match-all TRISOLARANS_ICMP_CM match access-group name TRISOLARANS_ICMP_ACL
- А теперь определяем правила перемаркировки в политике:
policy-map TRISOLARANS_ADMISSION_CONTROL class TRISOLARANS_ICMP_CM set ip dscp ef class TRISOLARANS_TCP_CM set ip dscp af11 class TRISOLARANS_OTHER_CM set ip dscp default
- И вешаем политику на интерфейс. На input, соответственно, потому что решение нужно принять на входе в сеть.
interface Ethernet0/1 service-policy input TRISOLARANS_ADMISSION_CONTROL
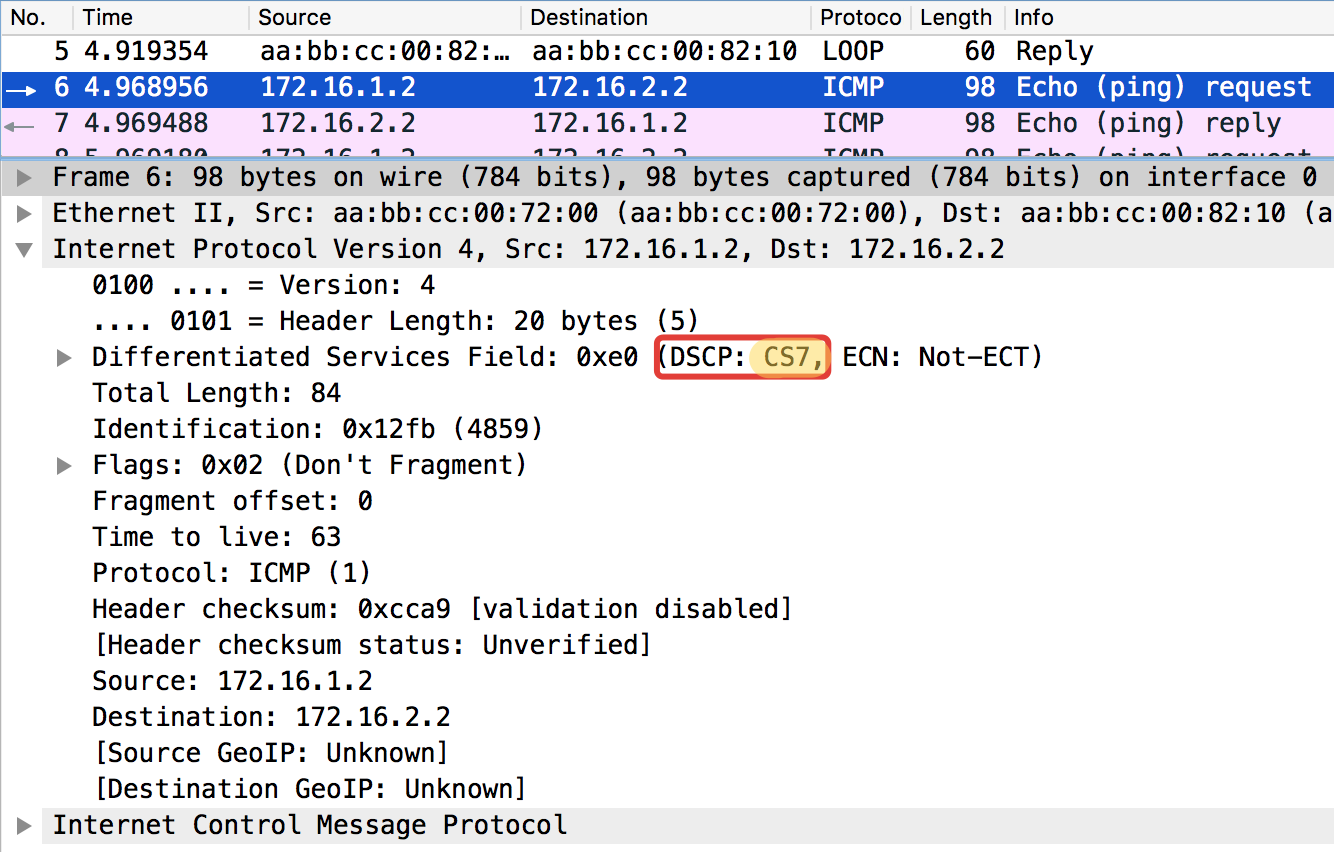
ICMP-тест с конечного хоста Trisolaran1. Никак сознательно не указываем класс — по умолчанию 0.
Политику с Linkmeup_R1 я уже убрал, поэтому трафик приходит с маркировкой CS0, а не CS7.
Вот два дампа рядом, с Linkmeup_R1 и с Linkmeup_R2:
Linkmeup_R1. E0/0.
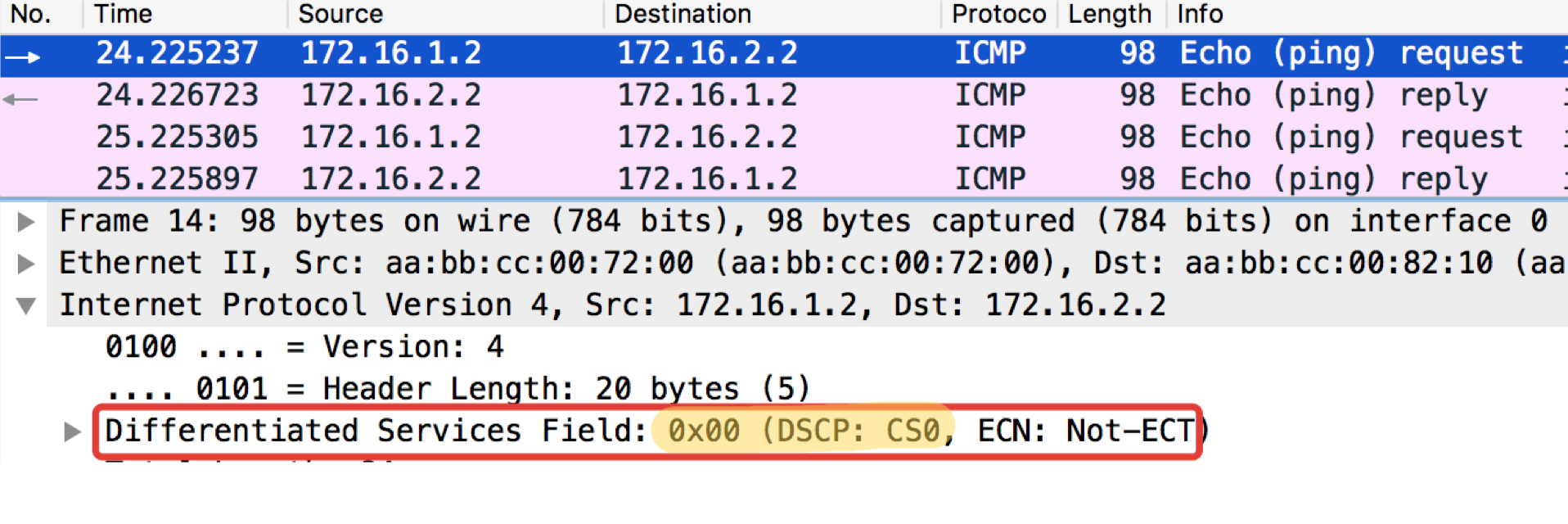
pcapng
Linkmeup_R2. E0/0.
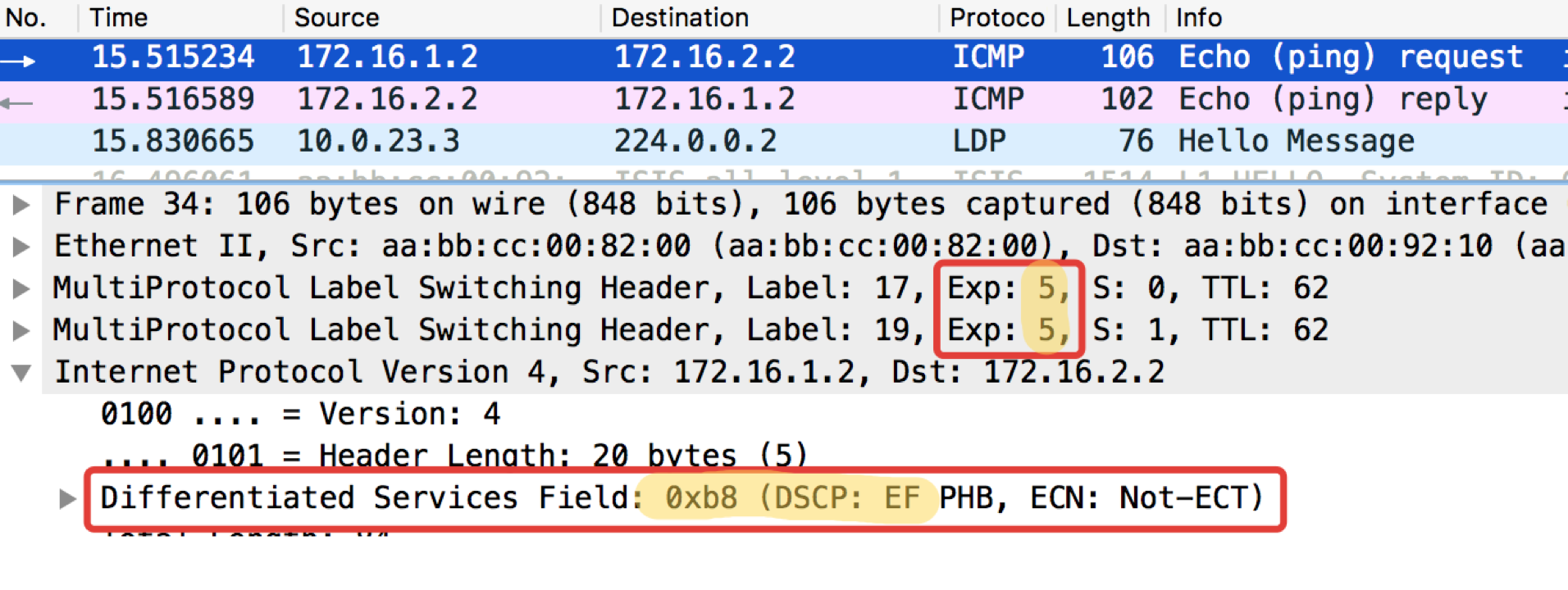
pcapng
Видно, что после классификаторов и перемаркировки на Linkmeup_R2 на ICMP-пакетах не только DSCP поменялся на EF, но и MPLS Traffic Class стал равным 5.
Аналогичный тест с telnet 172.16.2.2. 80 — так проверим TCP:
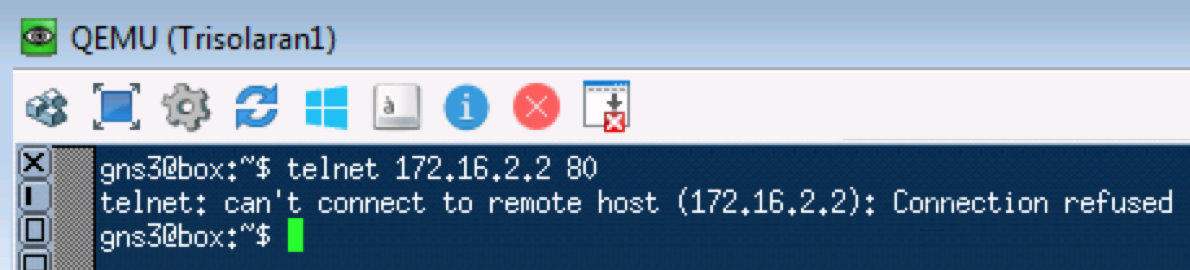
Linkmeup_R1. E0/0.

pcapng
Linkmeup_R2. E0/0.
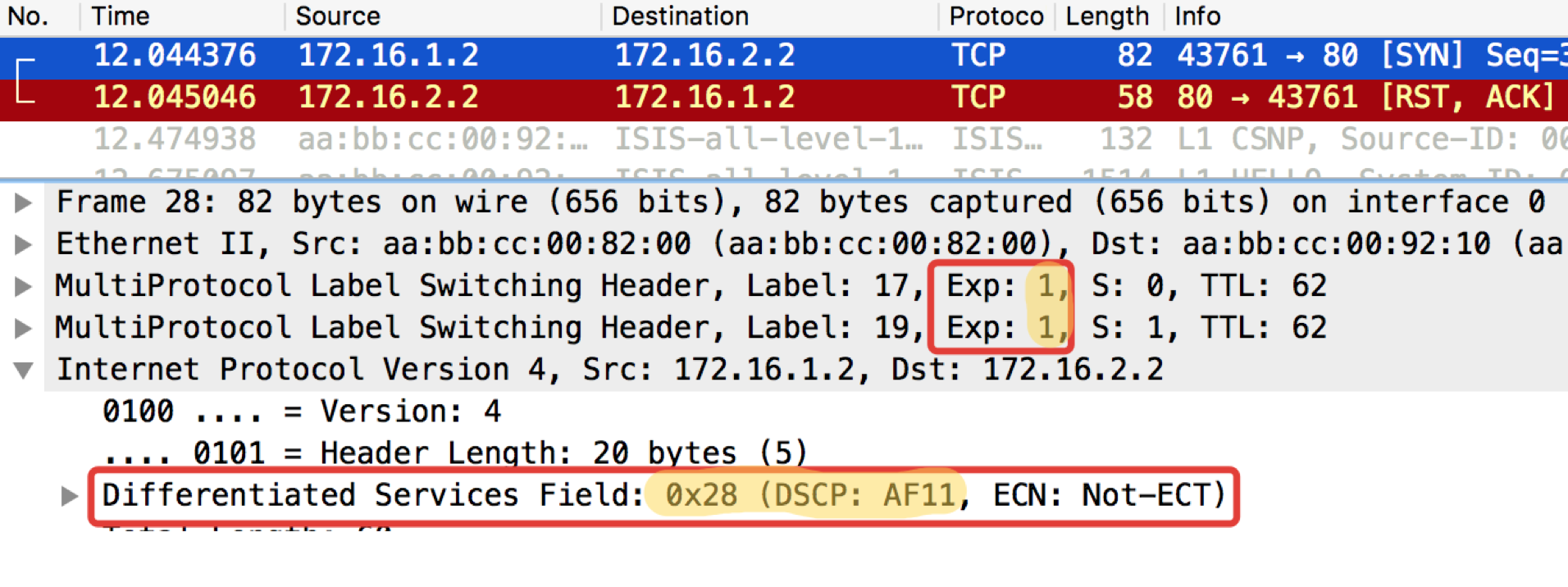
pcapng
ЧИТО — Что И Требовалось Ожидать. TCP передаётся как AF11.
Следующим тестом проверим UDP, который должен попасть в CS0 согласно нашим классификаторам. Для этого воспользуемся iperf (привезти его в Linux Tiny Core изи через Apps). На удалённой стороне iperf3 -s — запускаем сервер, на локальной iperf3 -c -u -t1 — клиент (-c), протокол UDP (-u), тест в течение 1 секунды (-t1).
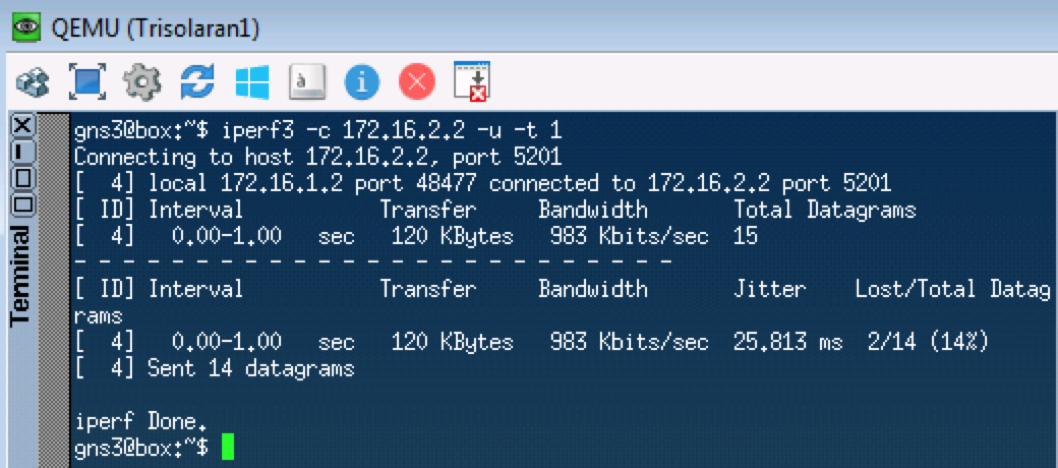
Linkmeup_R1. E0/0.
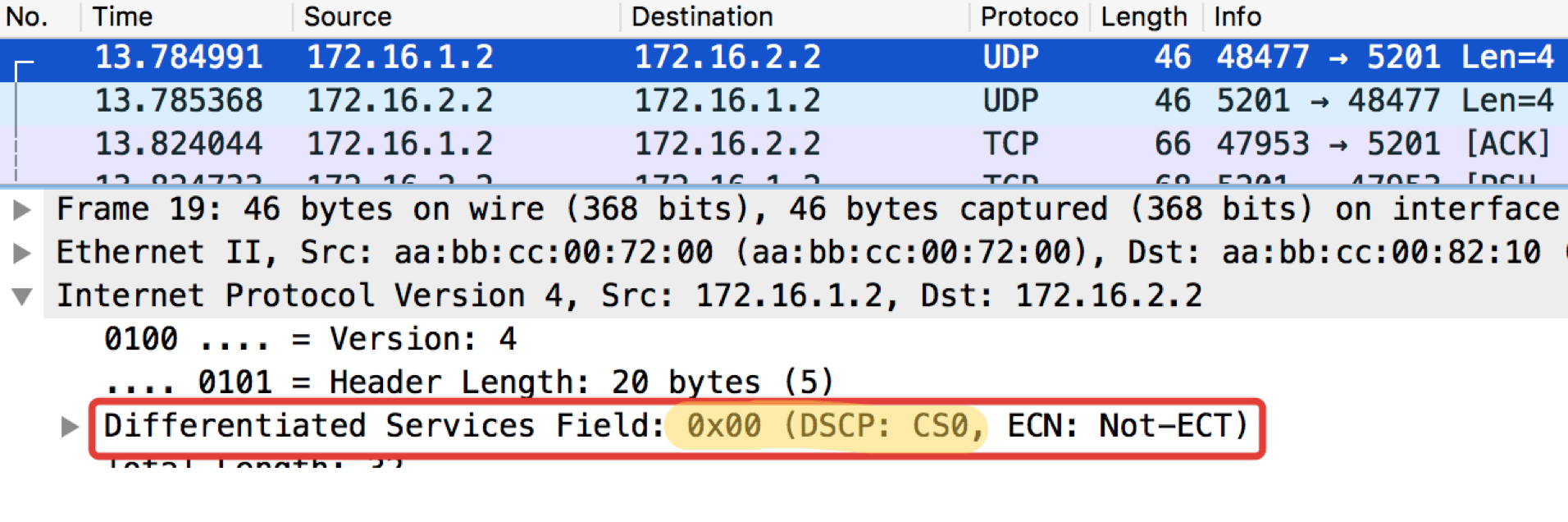
pcapng
Linkmeup_R2. E0/0

pcapng
С этого момента всё, что приходит в этот интерфейс, будет классифицировано согласно настроенным правилам.
Маркировка внутри устройства
Ещё раз: на входе в DS-домен может происходить классификация MF, Interface-based или BA.
Между узлами DS-домена пакет в заголовке несёт знак о необходимом ему классе сервиса и классифицируется по BA.
Независимо от способа классификации после неё пакету присваивается внутренний класс в пределах устройства, в соответствии с которым он и обрабатывается. Заголовок при этом снимается, и голый (нет) пакет путешествует к выходу.
А на выходе внутренний класс преобразуется в поле CoS нового заголовка.
То есть Заголовок 1 ? Классификация ? Внутренний класс сервиса ? Заголовок 2.
В некоторых случаях нужно отобразить поле заголовка одного протокола в поле заголовка другого, например, DSCP в Traffic Class.
Происходит это как раз через промежуточную внутреннюю маркировку.
Например, Заголовок DSCP ? Классификация ? Внутренний класс сервиса ? Заголовок Traffic Class.
Формально, внутренние классы могут называться как угодно или просто нумероваться, а им в соответствие только ставится определённая очередь.
На глубине, до которой мы погружаемся в этой статье, не важно, как они называются, важно, что конкретным значениям полей QoS ставится в соответствие определённая модель поведения.
Если мы говорим о конкретных реализациях QoS, то количество классов сервиса, которое устройство может обеспечить, не больше, чем количество доступных очередей. Зачастую их восемь (не то под влиянием IPP, не то по неписанной договорённости). Однако в зависимости от вендора, устройства, платы, их может быть как больше, так и меньше.
То есть если очередей 4, то классов сервиса просто нет смысла делать больше четырёх.
Чуть поподробнее об этом поговорим в аппаратной главе.
Таблицы ниже могут показаться удобными для первого взгляда на соотношение между полями QoS и внутренними классами, однако вводят несколько в заблуждение, называя классы именами PHB. Всё-таки PHB — это то, какая модель поведения назначается трафику определённого класса, имя которого, грубо говоря, произвольно.
Поэтому относитесь к таблицам ниже с долей скепсиса (поэтому и под спойлером).
На примере Huawei. Здесь Service-Class — это тот самый внутренний класс пакета.
То есть, если на входе происходит классификация BA, то значения DSCP будут транслироваться в соответствующие им значения Service-Class и Color.

Здесь стоит обратить внимание на то, что многие значения DSCP не используются, и пакеты с такой маркировкой фактически обрабатываются, как BE.
Вот таблица обратного соответствия, которая показывает, какие значения DSCP будут установлены трафику при перемаркировке на выходе.

Обратите внимание, что только у AF есть градация по цветам. BE, EF, CS6, CS7 — все только Green.
Это таблица преобразования полей IPP, MPLS Traffic Class и Ethernet 802.1p во внутренние классы сервиса.

И обратно.

Заметьте, что здесь вообще теряется какая-либо информация о приоритете отбрасывания.
Следует повториться — это только конкретный пример соответствий по умолчанию от наугад выбранного вендора. У других это может отличаться. На своей сети администраторы могут настроить совершенно отличные классы сервисов и PHB.
В плане PHB нет абсолютно никакой разницы что используется для классификации — DSCP, Traffic Class, 802.1p.
Внутри устройства они превращаются в классы трафика, определённые администратором сети.
То есть все эти маркировки — это способ сообщить соседям, какой класс сервиса им следует назначить этому пакету. Это примерно, как BGP Community, которые не значат ничего сами по себе, пока на сети не определена политика их интерпретации.
Рекомендации IETF (категории трафика, классы сервиса и модели поведения)
Стандарты вообще не нормируют, какие именно классы сервиса должны существовать, как их классифицировать и маркировать, какие PHB к ним применять.
Это отдано на откуп вендорам и администраторам сетей.
Имеем только 3 бита — используем, как хотим.
Это хорошо:
- Каждая железка (вендор) самостоятельно выбирает, какие механизмы использовать для PHB — нет сигнализации, нет проблем совместимости.
- Администратор каждой сети может гибко распределять трафик по разным классам, выбирать сами классы и соответствующий им PHB.
Это плохо:
- На границах DS-доменов возникают вопросы преобразования.
- В условиях полной свободой действий — кто в лес, кто бес.
Поэтому IETF в 2006 выпустила методичку, как следует подходить к дифференциации сервисов: RFC 4594 (Configuration Guidelines for DiffServ Service Classes).
Далее коротко суть этого RFC.
Модели поведения (PHB)
DF — Default Forwarding
Стандартная пересылка.
Если классу трафика не назначена модель поведения специально, он будет обрабатываться именно по Default Forwarding.
Это Best Effort — устройство сделает всё возможное, но ничего не гарантирует. Возможны отбрасывания, разупорядочивание, непредсказуемые задержки и плавающий джиттер, но это не точно.
Такая модель подходит для нетребовательных приложений, вроде почты или загрузки файлов.
Есть, кстати, PHB и ещё менее определённый — A Lower Effort.
AF — Assured Forwarding
Гарантированная пересылка.
Это улучшенный BE. Здесь появляются некоторые гарантии, например, полосы. Отбрасывания и плавающие задержки всё ещё возможны, но уже в гораздо меньшей степени.
Модель подходит для мультимедии: Streaming, видео-конференц-связь, онлайн-игры.
RFC 2597 (Assured Forwarding PHB Group).
EF — Expedited Forwarding
Экстренная пересылка.
Все ресурсы и приоритеты бросаются сюда. Это модель для приложений, которым нужны отсутствие потерь, короткие задержки, стабильный джиттер, но они не жадные до полосы. Как, например, телефония или сервис эмуляции провода (CES — Circuit Emulation Service).
Потери, разупорядочивание и плавающие задержки в EF крайне маловероятны.
RFC 3246 (An Expedited Forwarding PHB).
CS — Class Selector
Это модели поведения, призванные сохранить обратную совместимость с IP-Precedence в сетях, умеющих в DS.
В IPP существуют следующие классы CS0, CS1, CS2, CS3, CS4, CS5, CS6, CS7.
Не всегда для всех них существует отдельный PHB, обычно их два-три, а остальные просто транслируются в ближайший DSCP класс и получают соответствующий ему PHB.
Так например, пакет, помеченный CS 011000, может классифицироваться как 011010.
Из CS наверняка в оборудовании сохранились только CS6, CS7, которые рекомендованы для NCP — Network Control Protocol и требуют отдельного PHB.
Как и EF, PHB CS6,7 предназначены для тех классов, что имеют очень высокие требования к задержкам и потерям, однако до некоторой степени толерантны к дискриминации по полосе.
Задача PHB для CS6,7 обеспечить уровень сервиса, который исключит дропы и задержки даже в случае экстремальной перегрузки интерфейса, чипа и очередей.
Важно понимать, что PHB — это абстрактное понятие — и на самом деле реализуются они через механизмы, доступные на реальном оборудовании.
Таким образом один и тот же PHB, определённый в DS-домене, может различаться на Juniper и Huawei.
Более того, один PHB — это не статический набор действий, PHB AF, например, может состоять из нескольких вариантов, которые различаются уровнем гарантий (полосой, допустимыми задержками).
Классы сервиса
В IETF позаботились об администраторах и определили основные категории приложений и агрегирующие их классы сервиса.
Я здесь не буду многословен, просто вставлю пару табличек из этого Guideline RFC.
Категории приложений:

Требования в характеристикам сети:
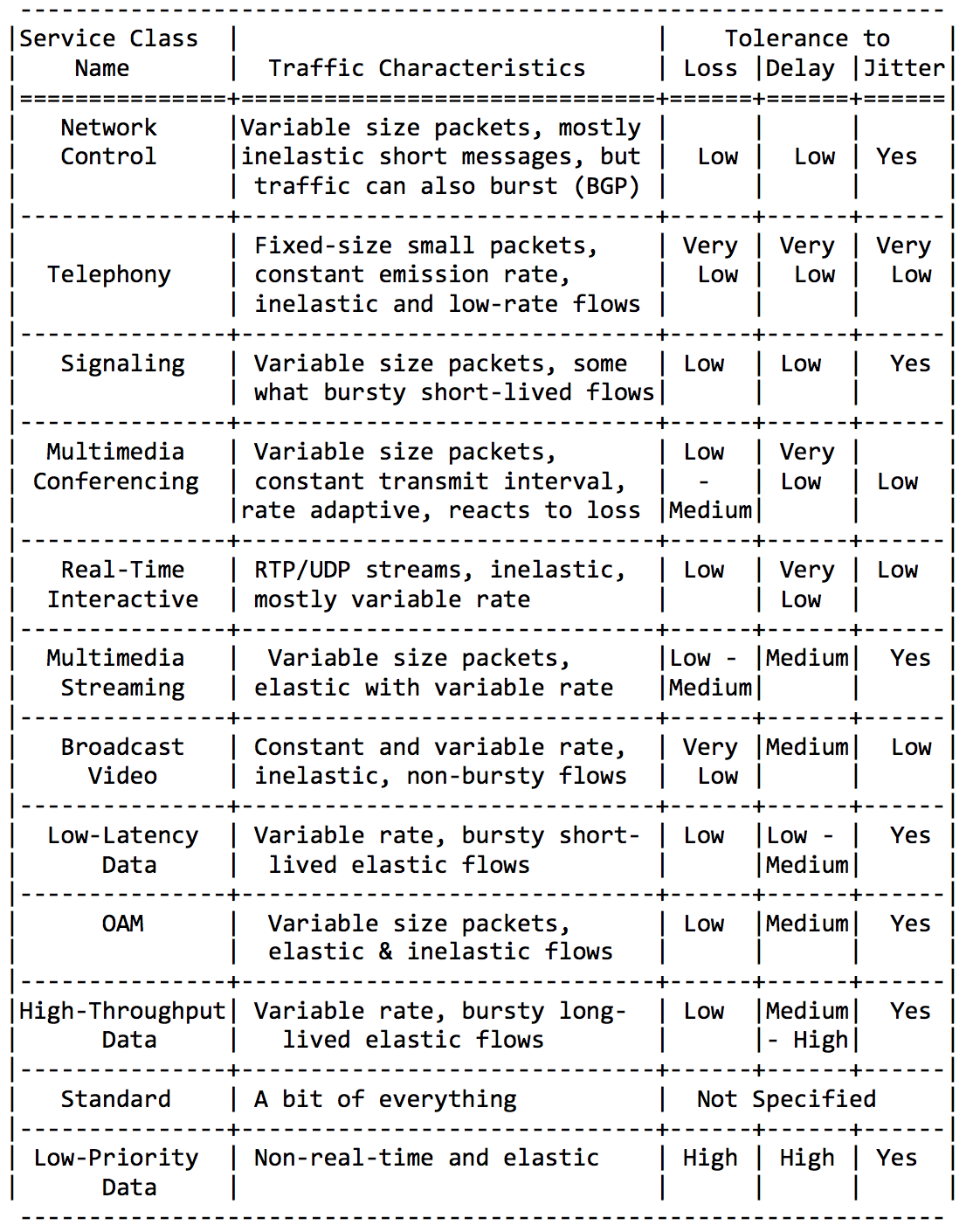
И наконец рекомендованные имена классов и соответствующие значения DSCP:

Комбинируя вышеуказанные классы различным образом (чтобы уложиться в 8 имеющихся), можно получить решения QoS для разных сетей.
Наиболее частым является, пожалуй, такое:

Классом DF (или BE) маркируется абсолютно нетребовательный трафик — он получает внимание по остаточному принципу.
PHB AF обслуживает классы AF1, AF2, AF3, AF4. Им всем нужно обеспечить полосу, в ущерб задержкам и потерям. Потери управляются битами Drop Precedence, поэтому они и называются AFxy, где x — класс сервиса, а y — Drop Precedence.
EF нужна некая минимальная гарантия полосы, но что важнее — гарантия задержек, джиттера и отсутствия потерь.
CS6, CS7 требуют ещё меньше полосы, потому что это ручеёк служебных пакетов, в котором всё же возможны всплески (BGP Update, например), но в ней недопустимы потери и задержки — какая польза от BFD с таймером в 10 мс, если Hello вялится в очереди по 100 мс?
То есть 4 класса из 8 доступных отдали под AF.
И несмотря на то, что фактически обычно так и делают, повторюсь, что это только рекомендации, и ничто не мешает в вашем DS-домене трём классам назначить EF и только двум — AF.
Короткий итог по классификации
На входе в узел пакет классифицируется на основе интерфейса, MF или его маркировки (BA).
Маркировка — это значение полей DSCP в IPv4, Traffic Class в IPv6 и в MPLS или 802.1p в 802.1q.
Выделяют 8 классов сервиса, которые агрегируют в себе различные категории трафика. Каждому классу назначается свой PHB, удовлетворяющий требованиям класса.
Согласно рекомендациям IETF, выделяются следующие классы сервисов, это CS1, CS0, AF11, AF12, AF13, AF21, CS2, AF22, AF23, CS3, AF31, AF32, AF33, CS4, AF41, AF42, AF43, CS5, EF, CS6, CS7 в порядке возрастания важности трафика.
Из них можно выбрать комбинацию из 8, которые реально можно закодировать в поля CoS.
Наиболее распространённая комбинация: CS0, AF1, AF2, AF3, AF4, EF, CS6, CS7 с 3 градациями цвета для AF.
Каждому классу ставится в соответствие PHB, которых существует 3 — Default Forwarding, Assured Forwarding, Expedited Forwarding в порядке возрастания строгости. Немного в стороне стоит PHB Class Selector. Каждый PHB может варьироваться параметрами инструментов, но об этом дальше.
В незагруженной сети QoS не нужен, говорили они. Любые вопросы QoS решаются расширением линков, говорили они. С Ethernet и DWDM нам никогда не грозят перегрузки линий, говорили они.
Они — те, кто не понимает, что такое QoS.
Но реальность бьёт VPN-ом по РКНу.
- Не везде есть оптика. РРЛ — наша реальность. Иногда в момент аварии (да и не только) в узкий радио-линк хочет пролезть весь трафик сети.
- Всплески трафика — наша реальность. Кратковременные всплески трафика легко забивают очереди, заставляя отбрасывать очень нужные пакеты.
- Телефония, ВКС, онлайн-игры — наша реальность. Если очередь хоть на сколько-то занята, задержки начинают плясать.
В моей практике были примеры, когда телефония превращалась в азбуку морзе на сети, загруженной не более чем на 40%. Всего лишь перемаркировка её в EF решила проблема сиюминутно.Пришло время разобраться с инструментами, которые позволяют обеспечить разный сервис разным классам.
Инструменты PHB
Существует на самом деле всего лишь три группы инструментов обеспечения QoS, которые активно манипулируют пакетами:
- Предотвращение перегрузок (Congestion Avoidance) — что делать, чтобы не было плохо.
- Управление перегрузками (Congestion Management) — что делать, когда уже плохо.
- Ограничение скорости (Rate Limiting) — как не пустить в сеть больше, чем положено, и не выпустить столько, сколько не смогут принять.
Но все они по большому счёту были бы бесполезны, если бы не очереди.
5. Очереди
В парке аттракционов нельзя отдать кому-то приоритет, если не организовать отдельную очередь для тех, кто заплатил больше.
Такая же ситуация в сетях.
Если весь трафик в одной очереди, не получится выдёргивать из её середины важные пакеты, чтобы дать им приоритет.
Именно поэтому после классификации пакеты помещаются в соответствующую данному классу очередь.
А далее одна очередь (с голосовыми данными) будет двигаться быстро, но с ограниченной полосой, другая помедленнее (потоковое вещание), зато с широкой полосой, а какой-то ресурсы достанутся по остаточному принципу.
Но в пределах каждой отдельной очереди действует то же правило — нельзя выдернуть пакет из середины — только из его изголовья.
Каждая очередь обладает определённой ограниченной длиной. С одной стороны это диктуется аппаратными ограничениями, а с другой тем, что нет смысла держать пакеты в очереди слишком долго. VoIP пакет не нужен, если он задержался на 200мс. TCP запросит переотправку, условно, после истечения RTT (настраивается в sysctl). Поэтому отбрасывание — не всегда плохо.
Разработчикам и дизайнерам сетевого оборудования приходится находить компромисс между попытками сохранить пакет как можно дольше и напротив не допустить бесполезной траты полосы, пытаясь доставить уже никому не нужный пакет.
В нормальной ситуации, когда интерфейс/чип не перегружен, утилизация буферов около нуля. Они амортизируют кратковременные всплески, но это не вызывает их продолжительного заполнения.
Если же трафика приходит больше, чем может обработать чип коммутации или выходной интерфейс, очереди начинают заполняться. И хроническая утилизация выше 20-30% — это уже ситуация, к которой нужно принимать меры.
6. Предотвращение перегрузок (Congestion Avoidance)
В жизни любого маршрутизатора наступает момент, когда очередь переполняется. Куда положить пакет, если положить его решительно некуда — всё, буфер кончился, совсем, и не будет, даже если хорошо поискать, даже если доплатить.
Тут есть два путя: отбросить либо этот пакет, либо те, что уже очередь забили.
Если те, что уже в очереди, то считай, что пропало.
А если этот, то считай, что и не приходил он.
Эти два подхода называются Tail Drop и Head Drop.
Tail Drop и Head Drop
Tail Drop — наиболее простой механизм управления очередью — отбрасываем все вновь пришедшие пакеты, не помещающиеся в буфер.

Head Drop отбрасывает пакеты, которые стоят в очереди уже очень долго. Их уже лучше выбросить, чем пытаться спасти, потому что они, скорее всего, бесполезны. Зато у более актуальных пакетов, пришедших в конец очереди, будет больше шансов прийти вовремя. Плюс к этому Head Drop позволит не загружать сеть ненужными пакетами. Естественным образом самыми старыми пакетами оказываются те, что в самой голове очереди, откуда и название подхода.

У Head Drop есть и ещё одно неочевидное преимущество — если пакет отбросить в начале очереди, то получатель быстрее узнает о перегрузке на сети и сообщит отправителю. В случае Tail Drop информация об отброшенном пакете дойдёт, возможно, на сотни миллисекунд позже — пока будет добираться с хвоста очереди до её головы.
Оба механизма работают с дифференциацией по очередям. То есть на самом деле не обязательно, чтобы весь буфер переполнился. Если 2-ая очередь пустая, а нулевая под завязку, то отбрасываться буду только пакеты из нулевой.

Tail Drop и Head Drop могут работать одновременно.
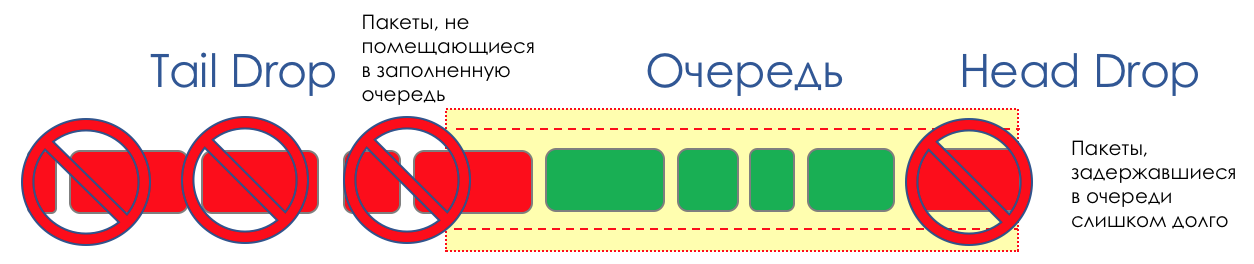
Tail и Head Drop — это Congestion Avoidance «в лоб». Даже можно сказать — это его отсутствие.
Ничего не предпринимаем, пока очередь не заполнится на 100%. А после этого все вновь прибывшие (или надолго задержавшиеся) пакеты начинаем отбрасывать.
Если для достижения цели не нужно ничего делать, значит где-то есть нюанс.
И этот нюанс — TCP.
Вспомним (поглубже и экстремально глубоко), как работает TCP — речь про современные реализации.
Есть Скользящее окно(Sliding Window или rwnd — Reciever's Advertised Window), которым управляет получатель, сообщая отправителю, сколько можно посылать.
А есть окно перегрузки (CWND — Congestion Window), которое реагирует на проблемы в сети и управляется отправителем.
Процесс передачи данных начинается с медленного старта (Slow Start) с экспоненциальным ростом CWND. С каждым подтверждённым сегментом к CWND прибавляется 1 размер MSS, то есть фактически оно удваивается за время, равное RTT (туда данные, обратно ACK) (Речь про Reno/NewReno).
Например,

Экспоненциальный рост продолжается до значения, называемого ssthreshold (Slow Start Threshold), которое указывается в конфигурации TCP на хосте.
Далее начинается линейный рост по 1/CWND на каждый подтверждённый сегмент до тех пор, пока либо не упрётся в RWND, либо не начнутся потери (о потерях свидетельсв повторное подтверждение (Duplicated ACK) или вообще отсутствие подтверждения).
Как только зафиксирована потеря сегмента, происходит TCP Backoff — TCP резко уменьшает окно, фактически снижая скорость отправки, — и запускается механизм Fast Recovery:
- отправляются потерянные сегменты (Fast Retransmission),
- окно скукоживается в два раза,
- значение ssthreshold тоже становится равным половине достигнутого окна,
- снова начинается линейный рост до первой потери,
- Повторить.
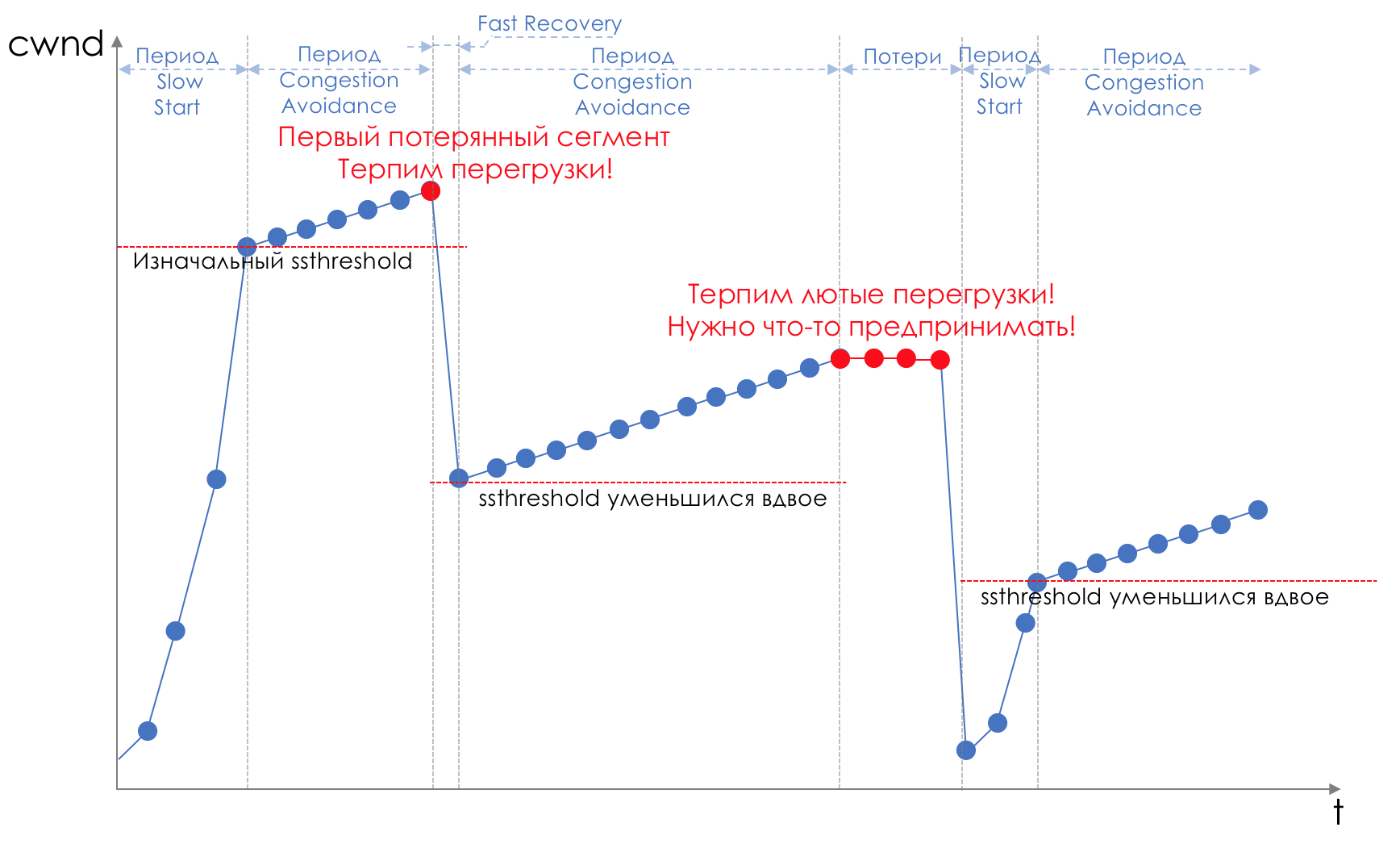
Потеря может означать либо полный развал какого-то сегмента сети и тогда считай, что пропало, либо перегрузку на линии (читай переполнение буфера и отбрасывание сегмента данной сессии).
Таков у TCP метод максимальной утилизации доступной полосы и борьбы с перегрузками. И он достаточно эффективен.
Однако к чему приводит Tail Drop?
- Допустим через маршрутизатор лежит путь тысячи TCP-сессий. В какой-то момент трафик сессий достиг 1,1 Гб/с, скорость выходного интерфейса — 1Гб/с.
- Трафик приходит быстрее, чем отправляется, буферы заполняются всклянь.
- Включается Tail Drop, пока диспетчер не выгребет из очереди немного пакетов.
- Одновременно десятки или сотни сессий фиксируют потери и уходят в Fast Recovery (а то и в Slow Start).
- Объём трафика резко падает, буферы прочищаются, Tail Drop выключается.
- Окна затронутых TCP-сессий начинают расти, и вместе с ними скорость поступления трафика на узкое место.
- Буферы переполняются.
- Fast Recovery/Slow Start.
- Повторить.
Подробнее об изменениях в механизмах TCP в RFC 2001 (TCP Slow Start, Congestion Avoidance, Fast Retransmit, and Fast Recovery Algorithms).
Это характерная иллюстрация ситуации, называемой глобальной синхронизацией TCP (Global TCP Synchronization):

Глобальная — потому что страдают много сессий, установленных через этот узел.
Синхронизация, потому что страдают они одновременно. И ситуация будет повторяться до тех пор, пока имеет место перегрузка.
TCP — потому что UDP, не имеющий механизмов контроля перегрузки, ей не подвержен.
Ничего плохого в этой ситуации не было бы, если бы она не вызывала неоптимальное использование полосы — промежутки между зубцами пилы — потраченные зря деньги.
Вторая проблема — это TCP Starvation — истощение TCP. В то время, как TCP сбавляет свою скорость для снижения нагрузки (не будем лукавить — в первую очередь, чтобы наверняка передать свои данные), UDP эти все моральные страдания вообще по датаграмме — шлёт сколько может.
Итак, количество трафика TCP снижается, а UDP растёт (возможно), следующий цикл Потеря — Fast Recovery случается на более низком пороге. UDP занимает освободившееся место. Общее количество TCP-трафика падает.
Чем решать проблему, лучше её избежать. Давайте попробуем снизить нагрузку до того, как она заполнит очередь, воспользовавшись Fast Recovery/Slow Start, который только что был против нас.
RED — Random Early Detection
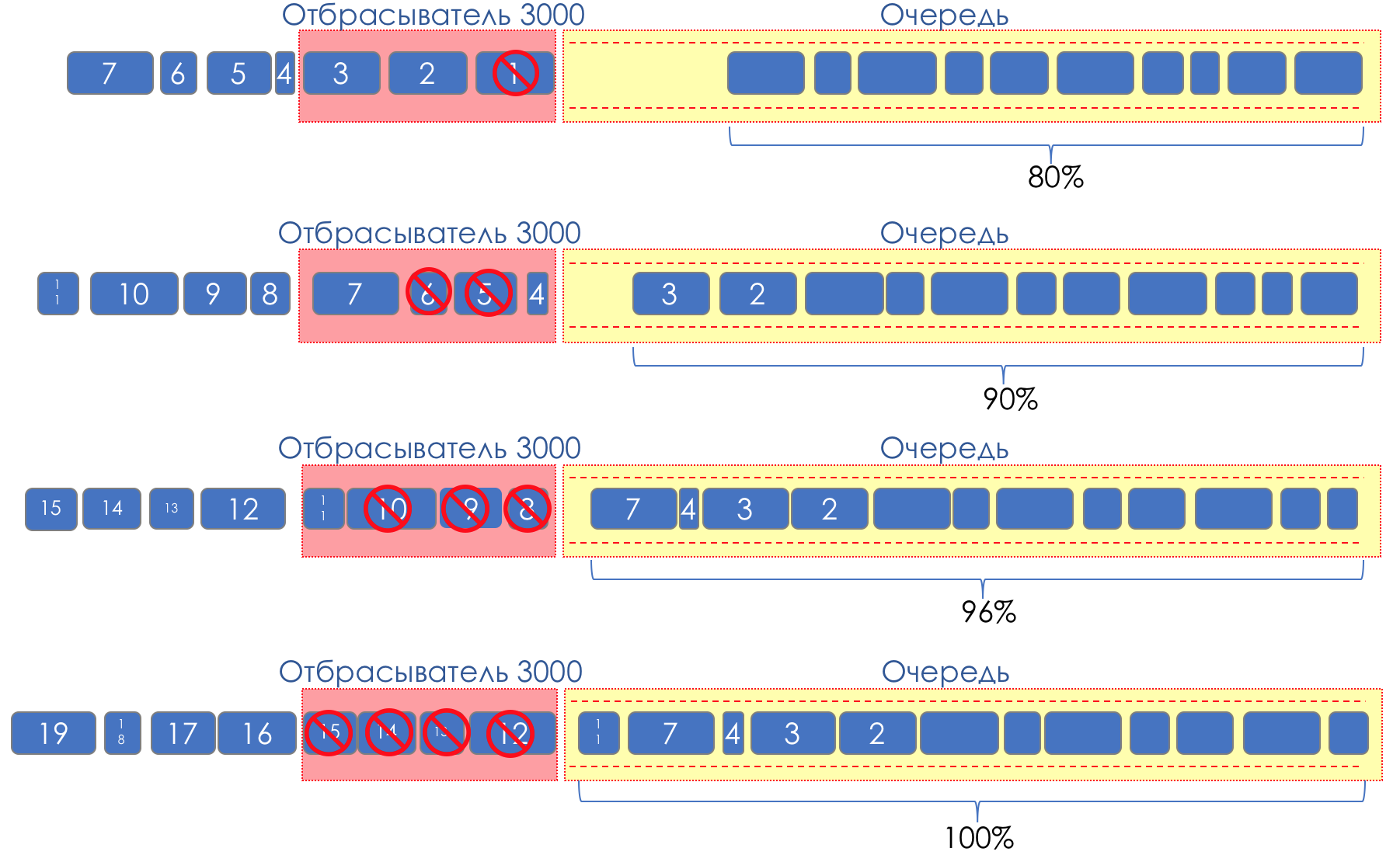
А что если взять и дропы размазать по некоторой части буфера?
Условно говоря, начинать отбрасывать случайные пакеты, когда очередь заполняется на 80%, заставляя некоторые TCP-сессии уменьшить окно и соответственно, скорость.
А если очередь заполнена на 90%, начинаем отбрасывать случайным образом 50% пакетов.
90% — вероятность растёт вплоть до Tail Drop (100% новых пакетов отбрасывается).
Механизмы, реализующие такое управление очередью называются AQM — Adaptive (или Active) Queue Management
Именно так и работает RED.
Early Detection — фиксируем потенциальную перегрузку;
Random — отбрасываем пакеты в случайном порядке.
Иногда расшифровывают RED (на мой взгляд семантически более корректно), как Random Early Discard.
Графически это выглядит так:
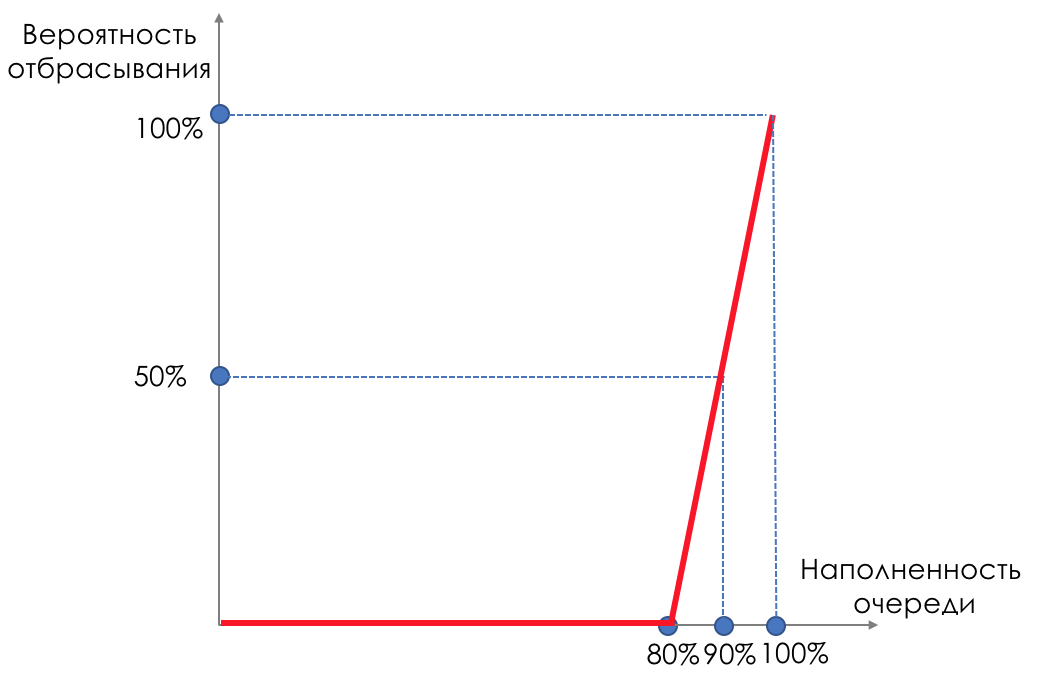
До заполнения буфера на 80% пакеты не отбрасываются совсем — вероятность 0%.
От 80 до 100 пакеты начинают отбрасываться, и тем больше, чем выше заполнение очереди.
Так процент растёт от 0 до 30.
Побочным эффектом RED является и то, что агрессивные TCP-сессии скорее начнут притормаживать, просто потому что их пакетов много и они с бо?льшей вероятностью будут отброшены.
Неэффективность использования полосы RED решает тем, что притупляет гораздо меньшую часть сессий, не вызывая такую серьёзную просадку между зубьями.
Ровно по этой же причине UDP не может оккупировать всё.
WRED — Weighted Random Early Detection
Но на слуху у всех, наверно, всё-таки WRED. Проницательный читатель linkmeup уже предположил, что это тот же RED, но взвешенный по очередям. И оказался не совсем прав.
RED работает в пределах одной очереди. Нет смысла оглядываться на EF, если переполнилась BE. Соответственно и взвешивание по очередям ничего не принесёт.
Здесь как раз работает Drop Precedence.
И в пределах одной очереди у пакетов с разным приоритетом отбрасывания будут разные кривые. Чем ниже приоритет, тем больше вероятность того, что его прихлопнут.

Здесь есть три кривые:
Красная — менее приоритетный трафик (с точки зрения отбрасывания), жёлтая — более, зелёная — максимально.
Красный трафик начинает отбрасываться уже при заполнении буфера на 20%, с 20 до 40 он дропается вплоть до 20%, далее — Tail Drop.
Жёлтый стартует попозже — с 30 до 50 он отбрасывается вплоть до 10%, далее — Tail Drop.
Зелёный наименее подвержен: с 50 до 100 плавно растёт до 5 %. Далее — Tail Drop.
В случае с DSCP это могли бы быть AF11, AF12 и AF13, соответственно зелёная, жёлтая и красная.

Очень важно здесь то, что это работает с TCP и это абсолютно неприменимо к UDP.
Либо приложение использующее UDP игнорирует потери, как в случае телефонии или потокового видео, и это отрицательно сказывается на том, что видит пользователь.
Либо приложение само осуществляет контроль доставки и попросит повторно отправить тот же самый пакет. При этом оно совсем не обязано просить источник снизить скорость передачи. И вместо уменьшения нагрузки получается увеличение из-за ретрансмитов.
Именно поэтому для EF применяется только Tail Drop.
Для CS6, CS7 тоже применяется Tail Drop, поскольку там не предполагается больших скоростей и WRED ничего не решит.
Для AF применяется WRED. AFxy, где x — класс сервиса, то есть очередь, в которую он попадает, а y — приоритет отбрасывания — тот самый цвет.
Для BE решение принимается на основе преобладающего в этой очереди трафика.
В пределах одного маршрутизатора используются специальная внутренняя маркировка пакетов, отличная от той, что несут заголовки. Поэтому MPLS и 802.1q, где нет возможности кодировать Drop Precedence, в очередях могут обрабатываться с различными приоритетами отбрасывания.
Например, MPLS пакет пришёл на узел, он не несёт маркировки Drop Precedence, однако по результатам полисинга оказался жёлтым и перед помещением в очередь (которая может определяться полем Traffic Class), может быть отброшен.
При этом стоит помнить, что вся эта радуга существует только внутри узла. В линии между соседями нет понятия цвета.
Хотя закодировать цвет в Drop Precedence-часть DSCP, конечно, возможно.
Отбрасывания могут появиться и в незагруженной сети, где казалось бы никакого переполнения очередей быть не должно. Как?
Причиной этому могут быть кратковременные всплески — бёрсты — трафика. Самый простой пример — 5 приложений одновременно решили передать трафик на один конечный хост.
Пример посложнее — отправитель подключен через интерфейс 10 Гб/с, а получатель — 1 Гб/с. Сама среда позволяет крафтить пакеты быстрее на отправителе. Ethernet Flow Control получателя просит ближайший узел притормозить, и пакеты начинают скапливаться в буферах.
Ну а что же делать, когда плохо всё-таки стало?
7. Управление перегрузками (Congestion Management)
Когда всё плохо, приоритет обработки следует отдать более важному трафику. Важность каждого пакета определяется на этапе классификации.
Но что такое плохо?
Необязательно все буферы должны быть забиты, чтобы приложения начали испытывать проблемы.
Самый простой пример — голосовые пакетики, которые толпятся за большими пачками крупных пакетов приложения, скачивающего файл.
Это увеличит задержку, испортит джиттер и, возможно, вызовет отбрасывания.
То есть мы имеем проблемы с обеспечением качественных услуг при фактическом отсутствии перегрузок.
Эту проблему призван решить механизм управления перегрузками (Congestion Management).
Трафик разных приложений разделяется по очередям, как мы уже видели выше.
Вот только в результате всё снова должно слиться в один интерфейс. Сериализация всё равно происходит последовательно.
Каким же образом разным очередям удаётся предоставлять различный уровень сервисов?
По-разному изымать пакеты из разных очередей.
Занимается этим диспетчер.
Мы рассмотрим большинство существующих сегодня диспетчеров, начиная с самого простого:
- FIFO — только одна очередь, все в BE, С — несправедливость.
- PQ — дорогу олигархам, холопы уступают.
- FQ — все равны.
- DWRR — все равны, но некоторые ровнее.
FIFO — First In, First Out
Простейший случай, по сути отсутствие QoS, — весь трафик обрабатывается одинаково — в одной очереди.
Пакеты уходят из очереди ровно в том порядке, в котором они туда попали, отсюда и название: первым вошёл — первым и вышел.
FIFO не является ни диспетчером в полном смысле этого слова, ни вообще механизмом DiffServ, поскольку фактически никак классы не разделяет.
Если очередь начинает заполняться, задержки и джиттер начинают расти, управлять ими нельзя, потому что нельзя выдернуть важный пакет из середины очереди.
Агрессивные TCP-сессии с размером пакетов по 1500 байтов могут оккупировать всю очередь, заставляя страдать мелкие голосовые пакеты.
В FIFO все классы сливаются в CS0.

Однако несмотря на все эти недостатки именно так работает сейчас Интернет.
У большинства вендоров FIFO и сейчас является диспетчером по умолчанию с одной очередью для всего транзитного трафика и ещё одной для локально-сгенерированных служебных пакетов.
Это просто, это крайне дёшево. Если каналы широкие, а трафика мало — всё отлично.
Квинтэссенция мысли о том, что QoS — для бедных — расширяй полосу, и заказчики будут довольны, а зарплата твоя будет расти кратно.
Только так когда-то и работало сетевое оборудование.
Но очень скоро мир столкнулся с тем, что так просто не получится.
С тенденцией в сторону конвергентных сетей стало понятно, что у разных типов трафика (служебные, голосовые, мультимедиа, интернет-сёрфинг, файлообмен) принципиально разные требования к сети.
FIFO стало недостаточно, поэтому создали несколько очередей и начали плодить схемы диспетчеризации трафика.
Однако FIFO никогда не уходит из нашей жизни: внутри каждой из очередей пакеты всегда обрабатываются по принципу FIFO.
PQ — Priority Queuing
Второй по сложности механизм и попытка разделить сервис по классам — приоритетная очередь.
Трафик теперь раскладывается в несколько очередей согласно своему классу — приоритету (например, хотя не обязательно, те же BE, AF1-4, EF, CS6-7). Диспетчер перебирает одну очередь за другой.
Сначала он пропускает все пакеты из самой приоритетной очереди, потом из менее, потом из менее. И так по кругу.
Диспетчер не начинает изымать пакеты низкого приоритета, пока не пуста высокоприоритетная очередь.

Если в момент обработки низкоприоритетных пакетов приходит пакет в более высокоприоритетную очередь, диспетчер переключаются на неё и только опустошив её, возвращается к другим.
PQ работает почти так же в лоб, как FIFO.
Он отлично подходит для таких видов трафика, как протокольные пакеты и голос, где задержки имеют критическое значение, а общий объём не очень большой.
Ну, согласитесь, не стоит придерживать BFD Hello из-за того, что пришли несколько больших видео-чанков с ютуба?
Но тут и кроется недостаток PQ — если приоритетная очередь нагружена трафиком, диспетчер вообще никогда не переключится на другие.
И если какой-то Доктор ЗЛО в поисках методов завоевания мира решит помечать весь свой злодейский трафик наивысшей чёрной меткой, все другие будут покорно ждать, а потом отбрасываться.
О гарантированной полосе для каждой очереди говорить тоже не приходится.
Высокоприоритетные очереди можно прирезать по скорости обрабатываемого в них трафика. Тогда другие не будут голодать. Однако контролировать это непросто.
Следующие механизмы ходят по всем очередям по очереди, забирая из них некое количество данных, тем самым предоставляя более честные условия. Но делают они это по-разному.
FQ-Fair Queuing
Следующий претендент на роль идеального диспетчера — механизмы честных очередей.
FQ — Fair Queuing
История его началась в 1985, когда Джон Нейгл предложил создавать очередь на каждый поток данных. По духу это близко к подходу IntServ и это легко объяснимо тем, что идеи классов сервиса, как и DiffServ тогда ещё не было.
FQ извлекал одинаковый объём данных из каждой очереди по порядку.
Честность заключается в том, что диспетчер оперирует числом не пакетов, а числом битов, которые можно передать из каждой очереди.
Так агрессивный TCP-поток не может затопить интерфейс, и все получают равные возможности.
В теории. FQ так и не был реализован на практике как механизм диспетчеризации очередей в сетевом оборудовании.
Недостатка тут три:
Первый — очевидный — это очень дорого — заводить очередь под каждый поток, считать вес каждого пакета и всегда беспокоиться о пропускаемых битах и размере пакета.
Второй — менее очевидный — все потоки получают равные возможности в плане пропускной способности. А если я хочу неравные?
Третий — неочевидный — честность FQ абсолютная: задержки у всех тоже равные, но есть потоки которым задержка важнее, чем полоса.
Например, среди 256 потоков присутствуют голосовые, это значит, что до каждого из них дело будет доходить только раз из 256-и.
И что делать с ними непонятно.
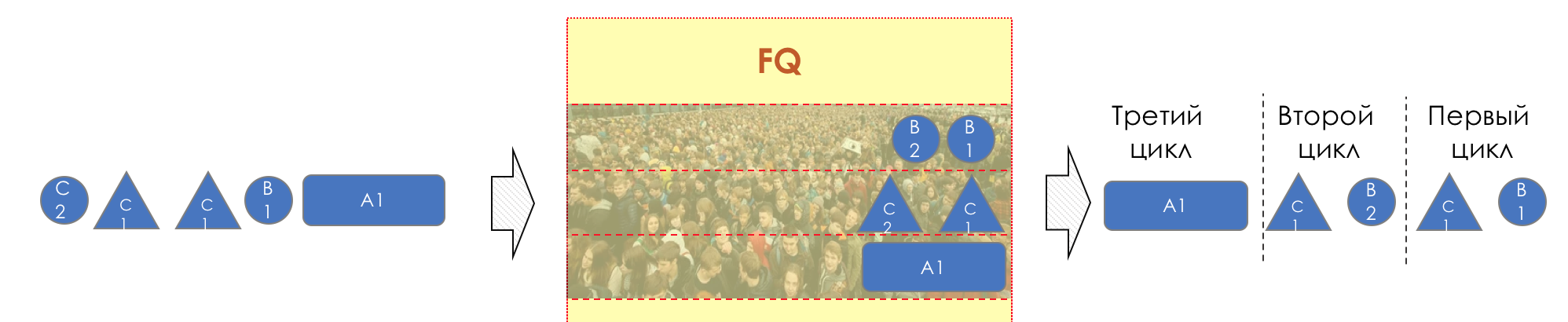
Здесь вы можете видеть, что из-за большого размера пакета в 3-ей очереди, в первые два цикла обработали по одному пакету из первых двух.
Описание механизмов bit-by-bit Round Robin и GPS уже за пределами этой статьи, и я отсылаю читателя к самостоятельному изучению.
WFQ — Weighted Fair Queuing
Второй и отчасти третий недостатки FQ попытался закрыть WFQ, обнародованный в 1989 году.
Каждая очередь наделялась весом и соответственно правом за один цикл отдавать трафика кратно весу.
Вес высчитывался на основе двух параметров: ещё актуальном тогда IP Precedence и длине пакета.
В контексте WFQ чем больше вес, тем хуже.
Поэтому чем выше IP Precedence, тем меньше вес пакета.
Чем меньше размер пакета, тем меньше и его вес.
Таким образом высокоприоритетные пакеты небольшого размера получают больше всего ресурсов, тогда как, низкоприоритетные гиганты ждут.
На иллюстрации ниже пакеты получили такие веса, что сначала пропускается один пакет из первой очереди, потом два из второй, снова из первой и только потом обрабатывается третья. Так, например, могло сложиться, если размер пакетов во второй очереди сравнительно маленький.

Про суровую машинерию WFQ, с её packet finish time, виртуальным временем и Теоремой Парика можно почитать в любопытном цветном документе.
Впрочем первую и третью проблемы это никак не решало. Flow Based подход был так же неудобен, а потоки, нуждающиеся в коротких задержках и стабильных джиттерах, их не получали.
Это, впрочем, не помешало WFQ найти применение в некоторых (преимущественно старых) устройствах Cisco. Там имелось до 256 очередей, в которые потоки помещались на основе хэша от своих заголовков. Этакий компромисс между Flow-Based парадигмой и ограниченными ресурсами.
CBWFQ — Class-Based WFQ
Заход на проблему сложности сделал CBWFQ с приходом DiffServ. Behavior Aggregate классифицировал все категории трафика в 8 классов и, соответственно, очередей. Это дало ему имя и значительно упростило обслуживание очередей.
Weight в CBWFQ приобрел уже другой смысл. Вес назначался классам (не потокам) вручную в конфигурации по желанию администратора, потому что поле DSCP уже использовалось для классификации.
То есть DSCP определял в какую очередь помещать, а настроенный вес — сколько полосы доступно данной очереди.
Самое главное, что это косвенно немного облегчило жизнь и low-latency потокам, которые теперь были агрегированы в одну (две-три-…) очереди и получали свой звёздный час заметно чаще. Жить стало лучше, но ещё не хорошо — гарантий никаких так и нет — в целом в WFQ все по-прежнему равны в плане задержек.
Да и необходимость постоянного слежения за размером пакетов, их фрагментации и дефрагментации, никуда не делась.
CBWFQ+LLQ — Low-Latency Queue
Последний заход, кульминация бит-по-биту подхода, — это объединение CBWFQ с PQ.
Одна из очередей становится так называемой LLQ (очередь с низими задержками), и в то время, пока все остальные очереди обрабатываются диспетчером CBWFQ, между LLQ и остальными работает диспетчер PQ.
То есть пока в LLQ есть пакеты, остальные очереди ждут, растят свои задержки. Как только пакеты в LLQ кончились — пошли обрабатывать остальные. Появились пакеты в LLQ — про остальные забыли, вернулись к нему.
Внутри LLQ работает также FIFO, поэтому не стоит туда пихать всё, что ни попадя, увеличивая утилизацию буфера и заодно задержки.
И всё-таки чтобы неприоритетные очереди не голодали, в LLQ стоит ставить ограничение по полосе.

Вот так и овцы сыты и волки целы.
RR — Round-Robin
Рука об руку с FQ шёл и RR.
Один был честен, но не прост. Другой совсем наоборот.

RR перебирал очереди, извлекая из них равное число пакетов. Подход более примитивный, чем FQ, и оттого нечестный по отношению к различным потокам. Агрессивные источники легко могли затопить полосу пакетами размером в 1500 байтов.
Однако он очень просто реализовывался — не нужно знать размер пакета в очереди, фрагментировать его и собирать потом обратно.
Однако его несправедливость в распределении полосы перекрыла ему путь в мир — в мире сетей чистый Round-Robin не был реализован.
WRR — Weighted Round Robin
Та же судьба и у WRR, который придавал очередям вес на основе IP Precedence. В WRR вынималось не равное число пакетов, а кратное весу очереди.
Можно было бы давать больший вес очередям с более мелкими пакетами, но делать это динамически не представлялось возможным.

DWRR — Deficit Weighted Round Robin
И вдруг, крайне любопытный подход в 1995-м году предложили M. Shreedhar and G. Varghese.
Каждая очередь имеет отдельную кредитную линию в битах.
При проходе из очереди выпускается столько пакетов, на сколько хватает кредита.
Из суммы кредита вычитается размер того пакета, что в голове очереди.
Если разность больше нуля, этот пакет изымается, и проверяется следующий. Так до тех пор, пока разность не окажется меньше нуля.
Если даже первому пакету не хватает кредита, что ж, увы-селявы, он остаётся в очереди.
Перед следующим проходом кредит каждой очереди увеличивается на определённую сумму, называемую квант.
Для разных очередей квант разный — чем большую полосу нужно дать, тем больше квант.
Таким образом все очереди получают гарантированную полосу, независимо от размера пакетов в ней.
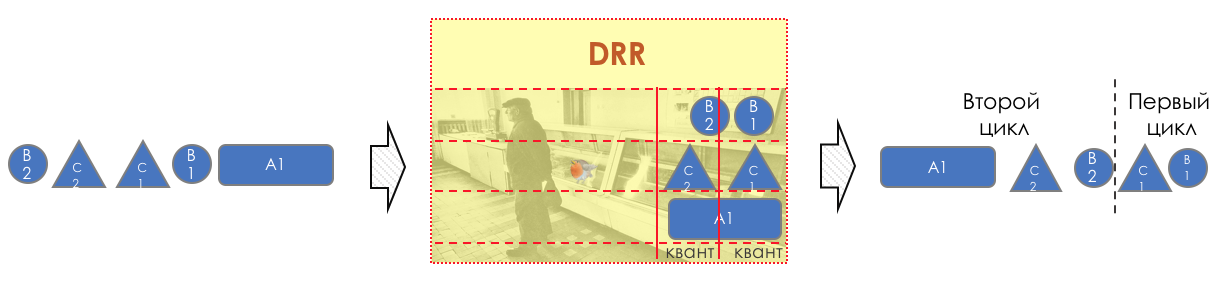
Мне бы из объяснения выше не было понятно, как это работает.
- DRR (без W),
- 4 очереди,
- в 0-й все пакеты по 500 байтов,
- В 1-й — по 1000,
- Во 2-й по 1500,
- А в 3-й лежит одна колбаса на 4000,
- Квант — 1600 байтов.

Цикл 1
Цикл 1. Очередь 0
Начинается первый цикл, каждой очереди выделяется по 1600 байтов (квант)
Обработка начинается с 0-й очереди. Диспетчер считает:
Первый пакет в очереди проходит — Пропускаем (1600 — 500 = 1100).
Второй — проходит — пропускаем (1100 — 500 = 600).
Третий — проходит — пропускаем (600 — 500 = 100).
Четвёртый — уже не проходит (100 — 500 = -400). Переходим к следующей очереди.
Финальный кредит — 100 байтов.
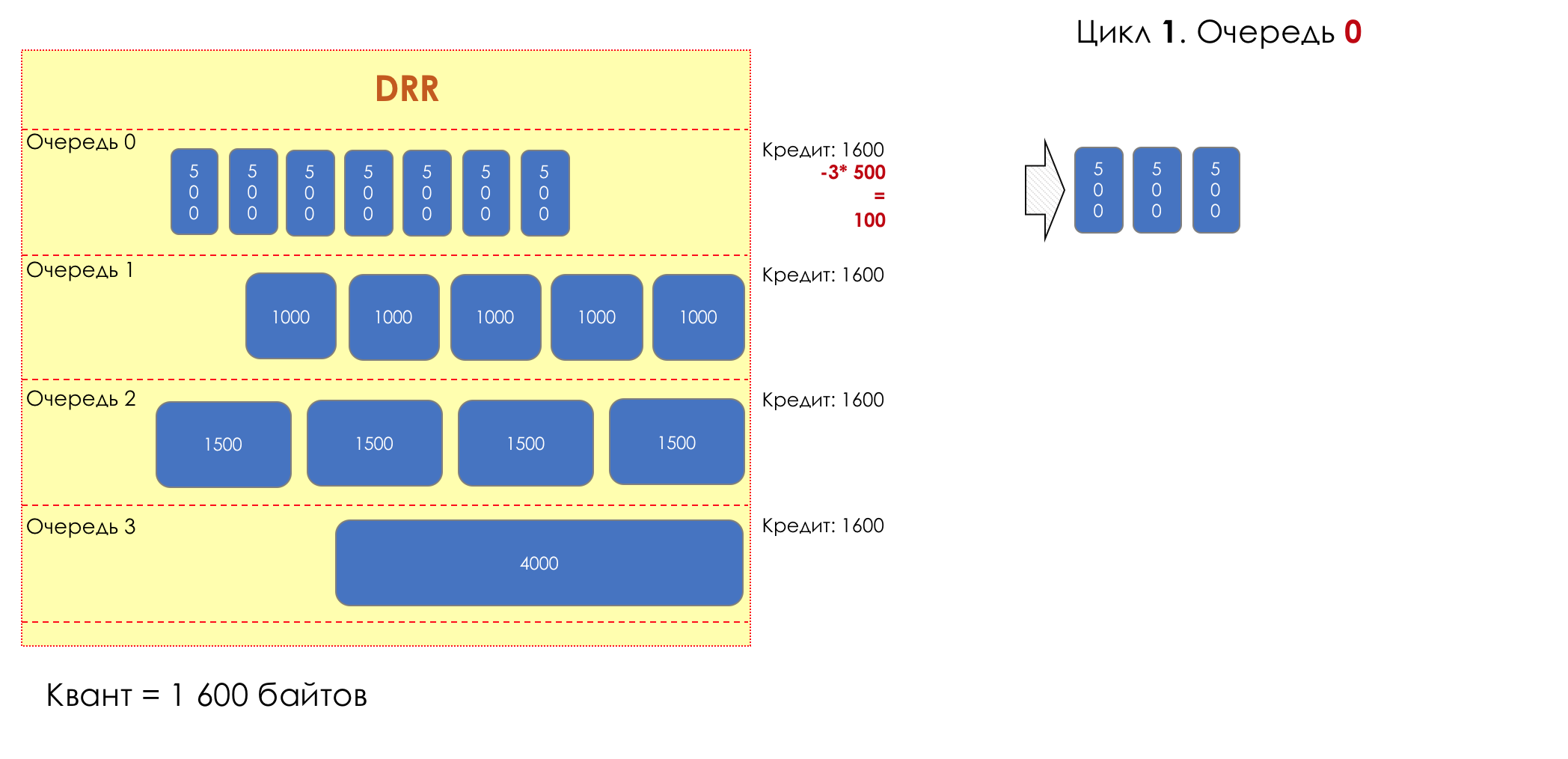
Цикл 1. Очередь 1
Первый пакет проходит — пропускаем (1600 — 1000 = 600).
Второй не проходит (600 — 1000 = -400). Переходим к следующей очереди.
Финальный кредит — 600 байтов.
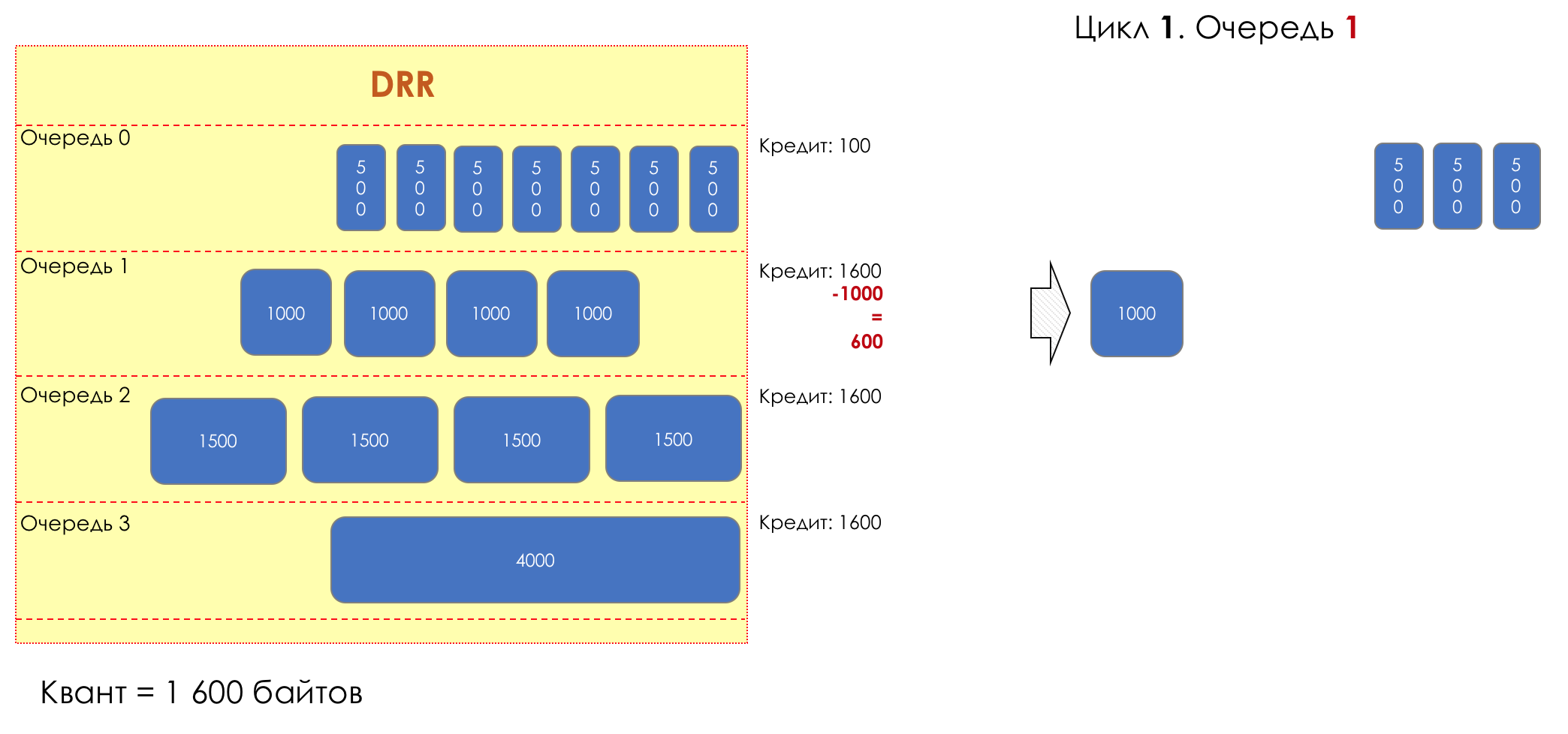
Цикл 1. Очередь 2
Первый пакет проходит — пропускаем (1600 — 1500 = 100).
Второй не проходит (100 — 1000 = -900). Переходим к следующей очереди.
Финальный кредит — 100 байтов.

Цикл 1. Очередь 3
Первый пакет уже не проходит. (1600 — 4000 = -2400).
Переходим к следующей очереди.
Финальный кредит — те же 1600 байтов.
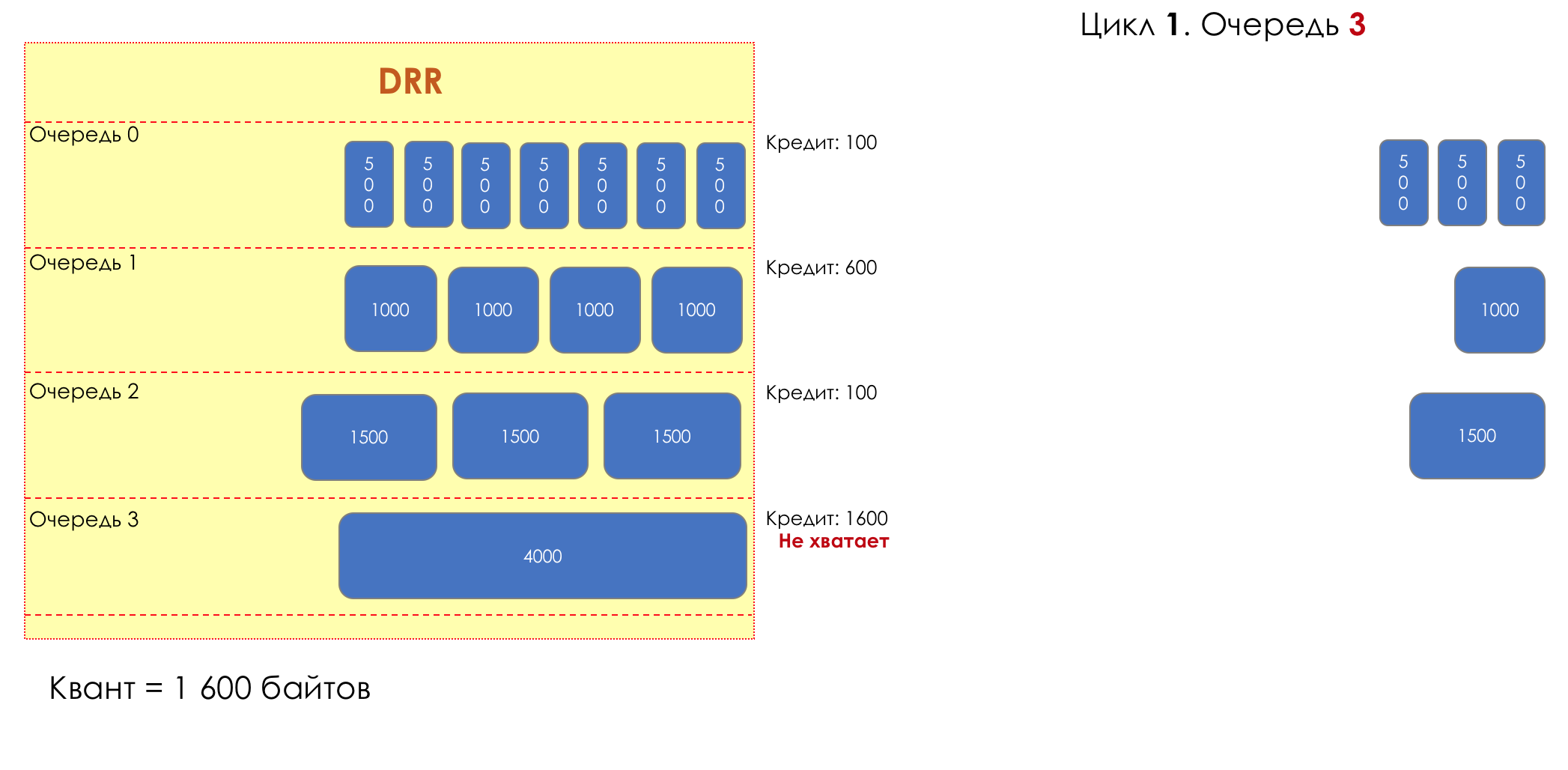
Итак, по окончании первого цикла работы диспетчера пропустили:
- Очередь 0 — 1500
- Очередь 1 — 1000
- Очередь 2 — 1500
- Очередь 3 — 0
Имеющийся кредит:
- Очередь 0 — 100
- Очередь 1 — 600
- Очередь 2 — 100
- Очередь 3 — 1600
Цикл 2
В начале цикла к кредиту очереди прибавляется заданный квант — то есть 1600 байтов.
Цикл 2. Очередь 0
Кредит увеличивается до 1700 (100 + 1600).
Первые три пакета в очереди проходят — пропускаем их (1700 — 3*500 = 200).
Четвёртому уже не хватает кредита.
Финальный кредит — 200 байтов.
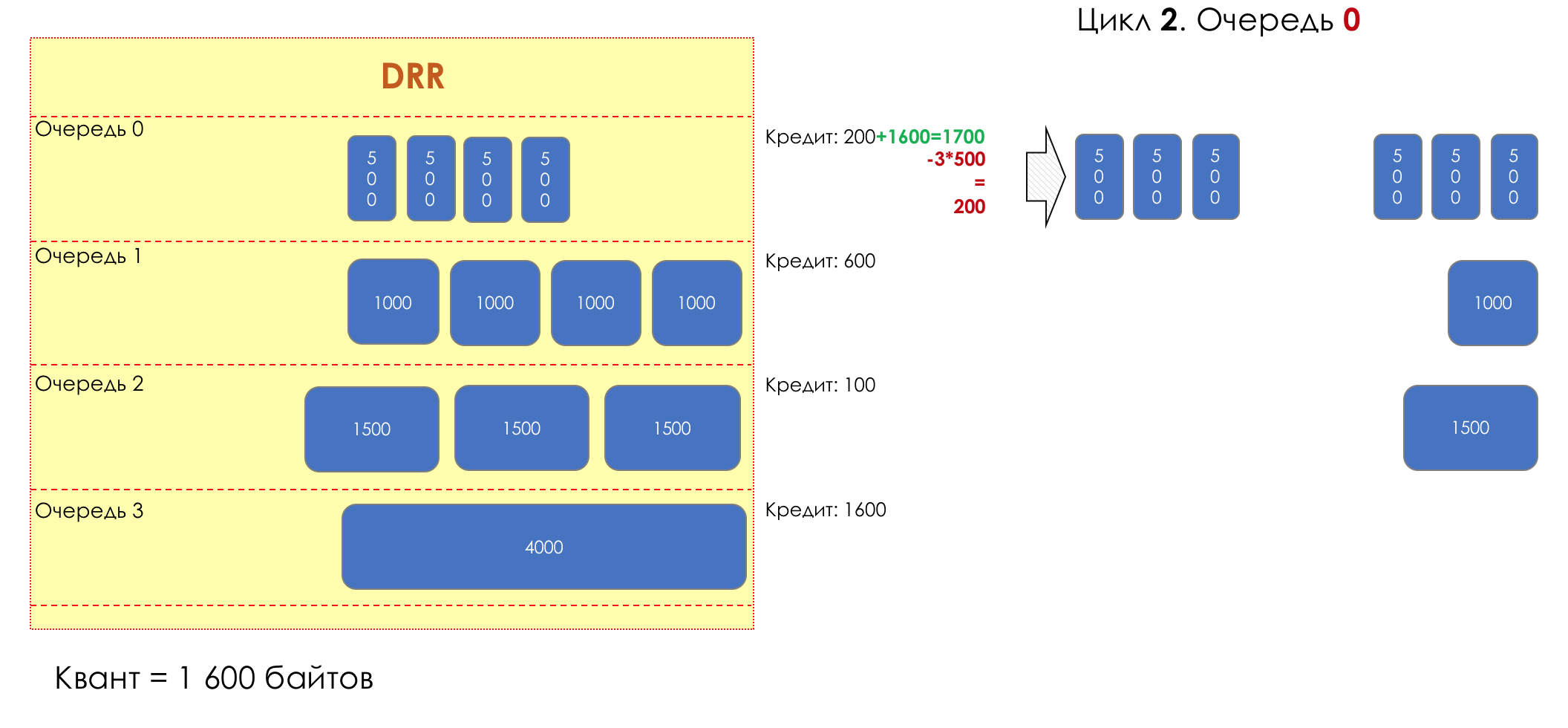
Цикл 2. Очередь 1
Кредит увеличивается до 2200 (600 + 1600).
Первые два пакета в очереди проходят — пропускаем их (2200 — 2*1000 = 200).
Третий уже не проходит.
Финальный кредит — 200 байтов.
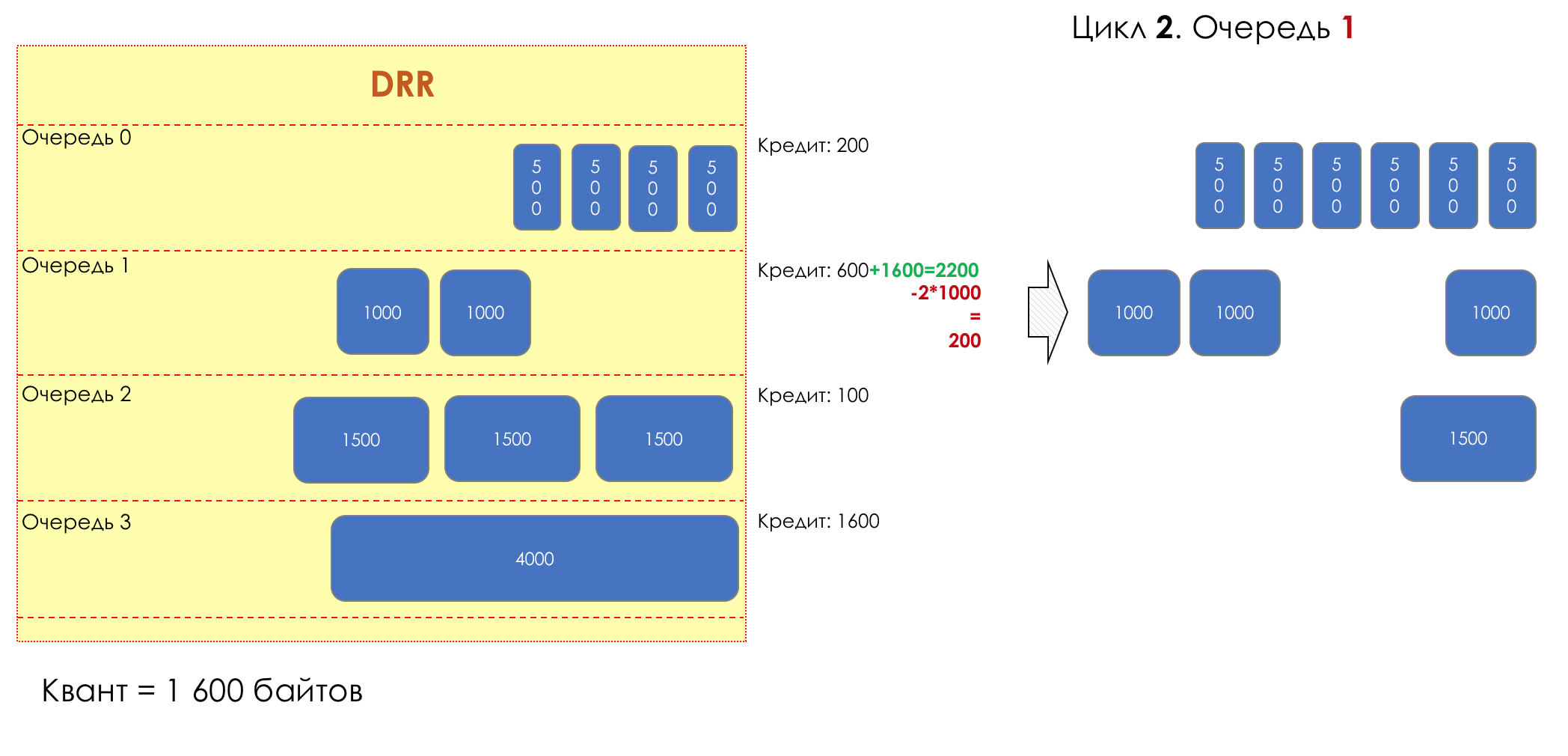
Цикл 2. Очередь 2
Кредит увеличивается до 1700 (100 + 1600).
Первый пакет в очереди проходит — пропускаем его (2200 — 1500 = 200).
А второй — уже нет.
Финальный кредит — 200 байтов.
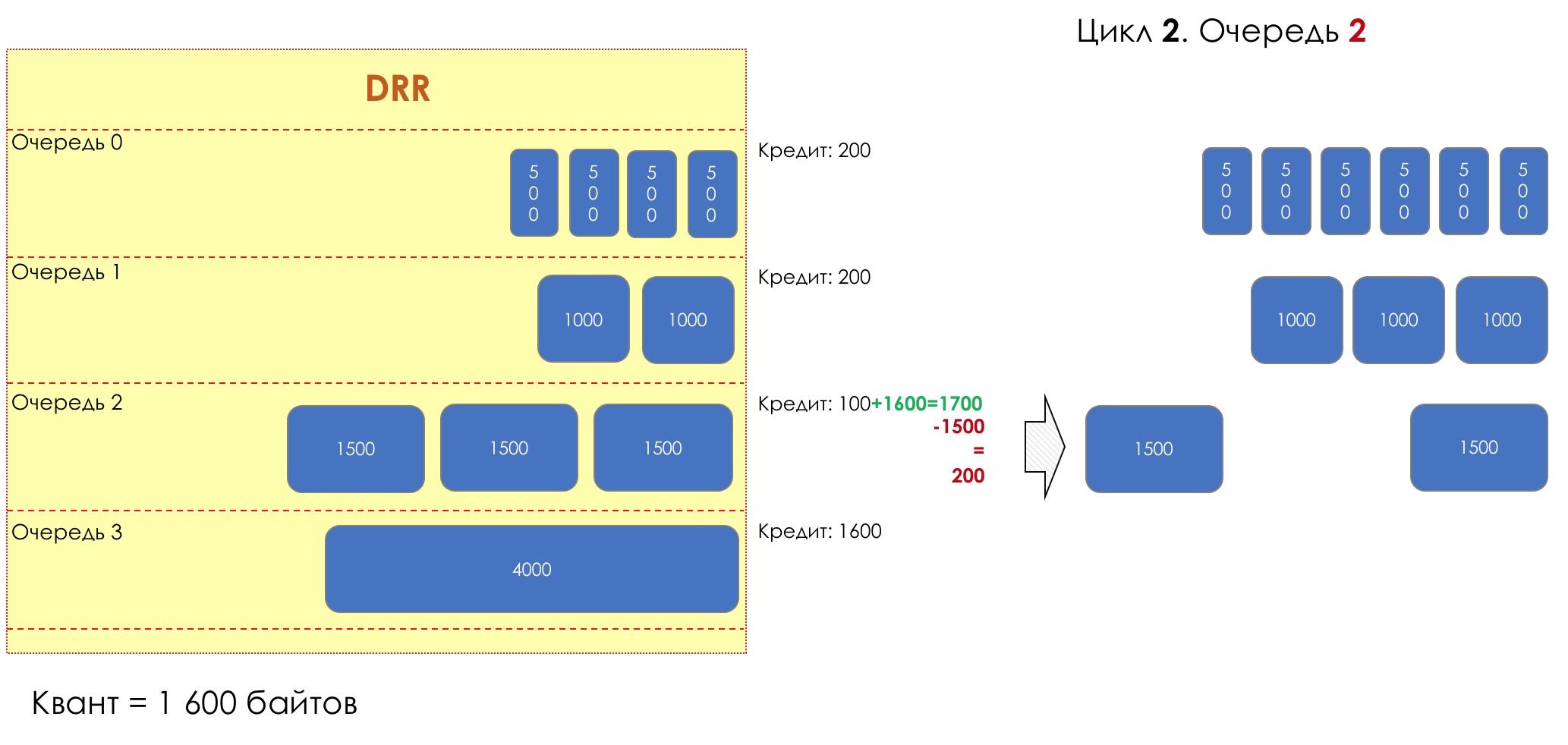
Цикл 2. Очередь 3
Кредит увеличивается до 3200 (1600 + 1600).
Но она всё равно в пролёте (3200 — 4000 = -800)
Финальный кредит — 3200 байтов.
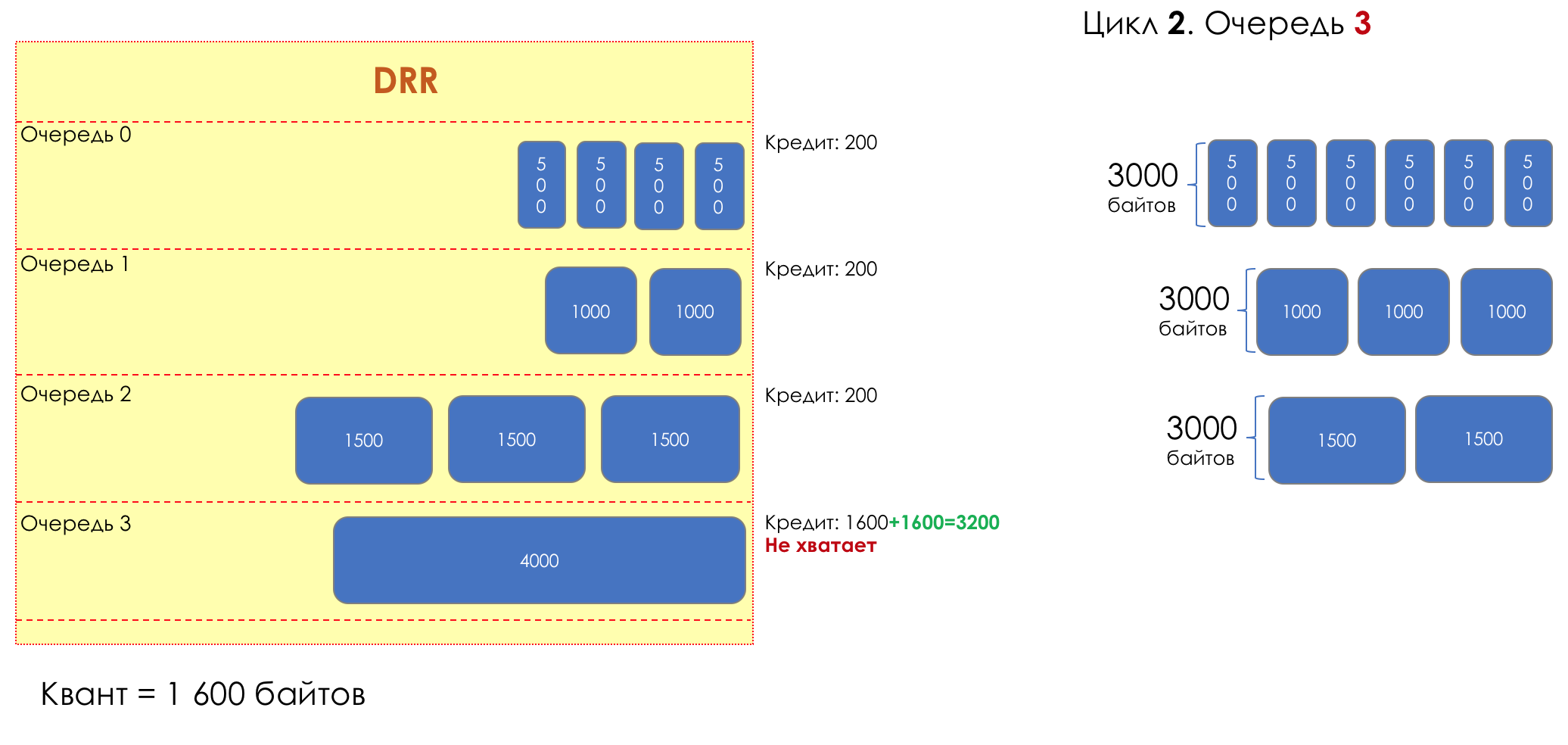
Итак, по окончании второго цикла работы диспетчера пропустили:
- Очередь 0 — 3000
- Очередь 1 — 3000
- Очередь 2 — 3000
- Очередь 3 — 0
Имеющийся кредит:
- Очередь 0 — 200
- Очередь 1 — 200
- Очередь 2 — 200
- Очередь 3 — 3200
Цикл 3
В начале каждого цикла к кредиту очереди прибавляется квант — 1600 байтов.
Цикл 3. Очередь 0
Кредит увеличивается до 1800 (200 + 1600).
И снова три пакета в очереди проходят — пропускаем их (1800 — 3*500 = 300).
Четвёртому опять не хватает кредита.
Финальный кредит — 300 байтов.
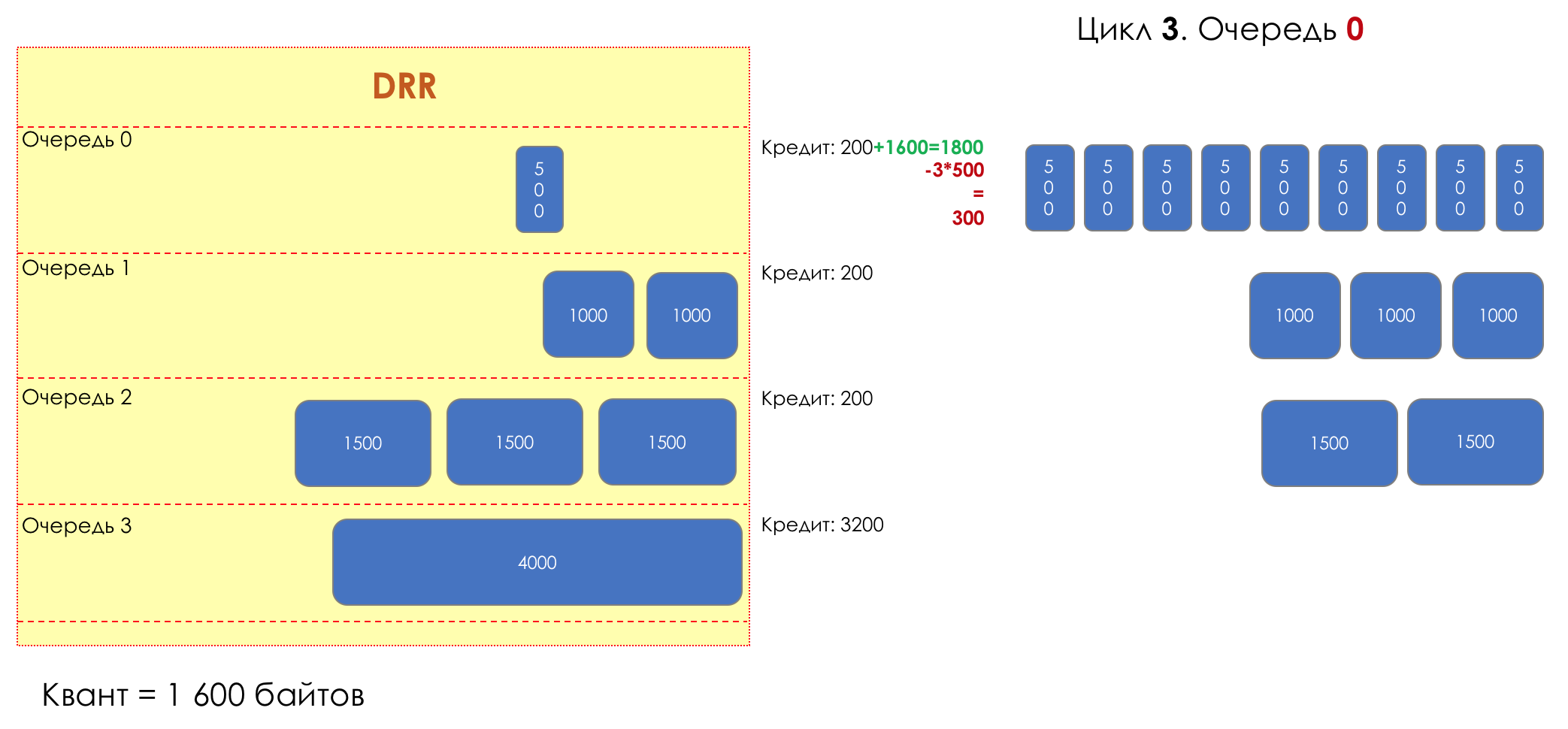
Цикл 3. Очередь 1
Кредит увеличивается до 1800 (200 + 1600).
Один пакет проходит — пропускаем (1800 — 1000 = 800).
Финальный кредит — 800 байтов.
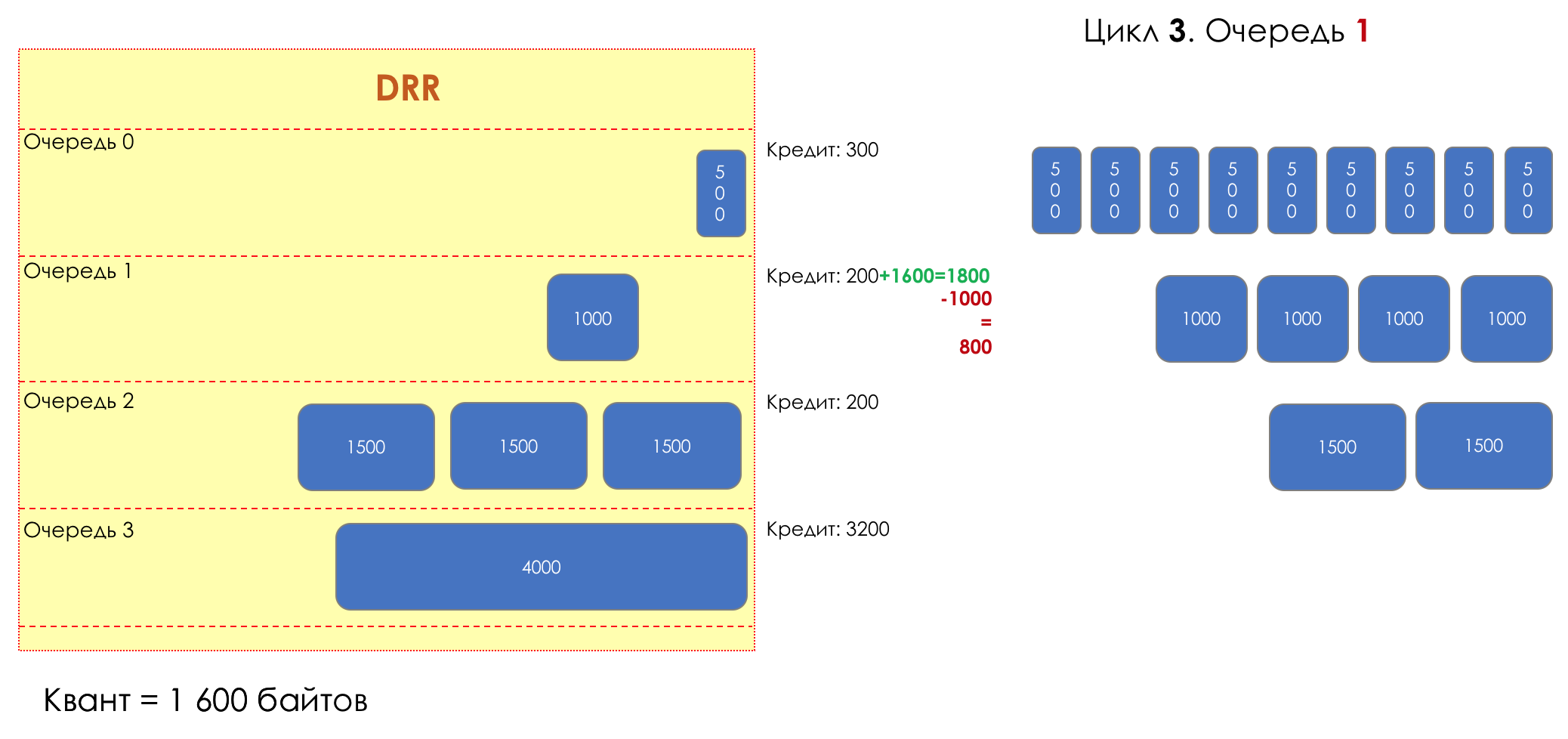
Цикл 3. Очередь 2
Кредит увеличивается до 1800 (200 + 1600).
Один пакет проходит — пропускаем (1800 — 1500 = 300).
Финальный кредит — 300 байтов.

Цикл 3. Очередь 3
Будет и в 3-й очереди праздник!
Кредит увеличивается до 4800 (3200 + 1600).
Пакет наконец проходит — пропускаем (4800 — 4000 = 800).
Финальный кредит — 800 байтов.
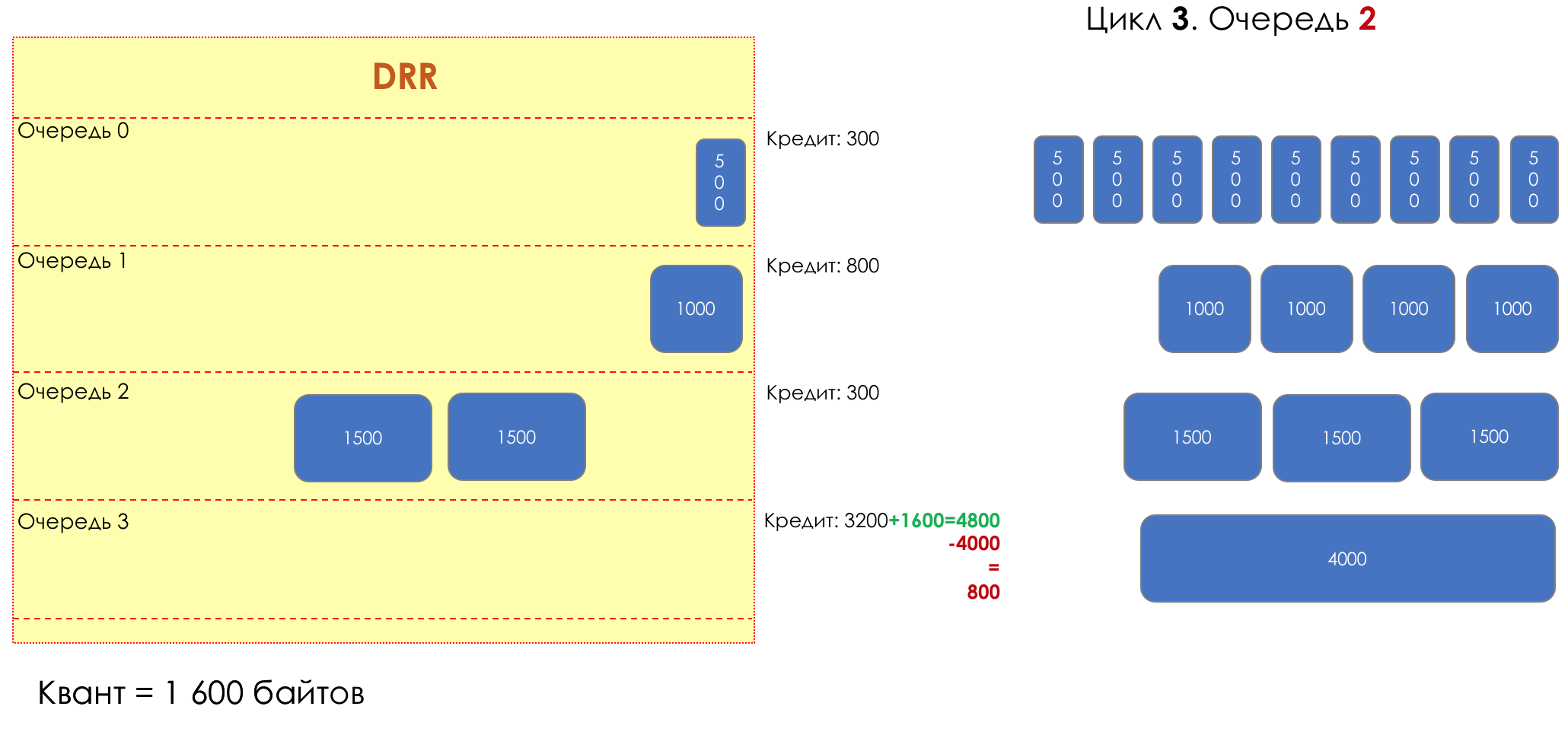
Итак, по окончании третьего цикла работы диспетчера пропустили:
- Очередь 0 — 4500
- Очередь 1 — 4000
- Очередь 2 — 4500
- Очередь 3 — 4000
Имеющийся кредит:
- Очередь 0 — 300
- Очередь 1 — 800
- Очередь 2 — 300
- Очередь 3 — 800
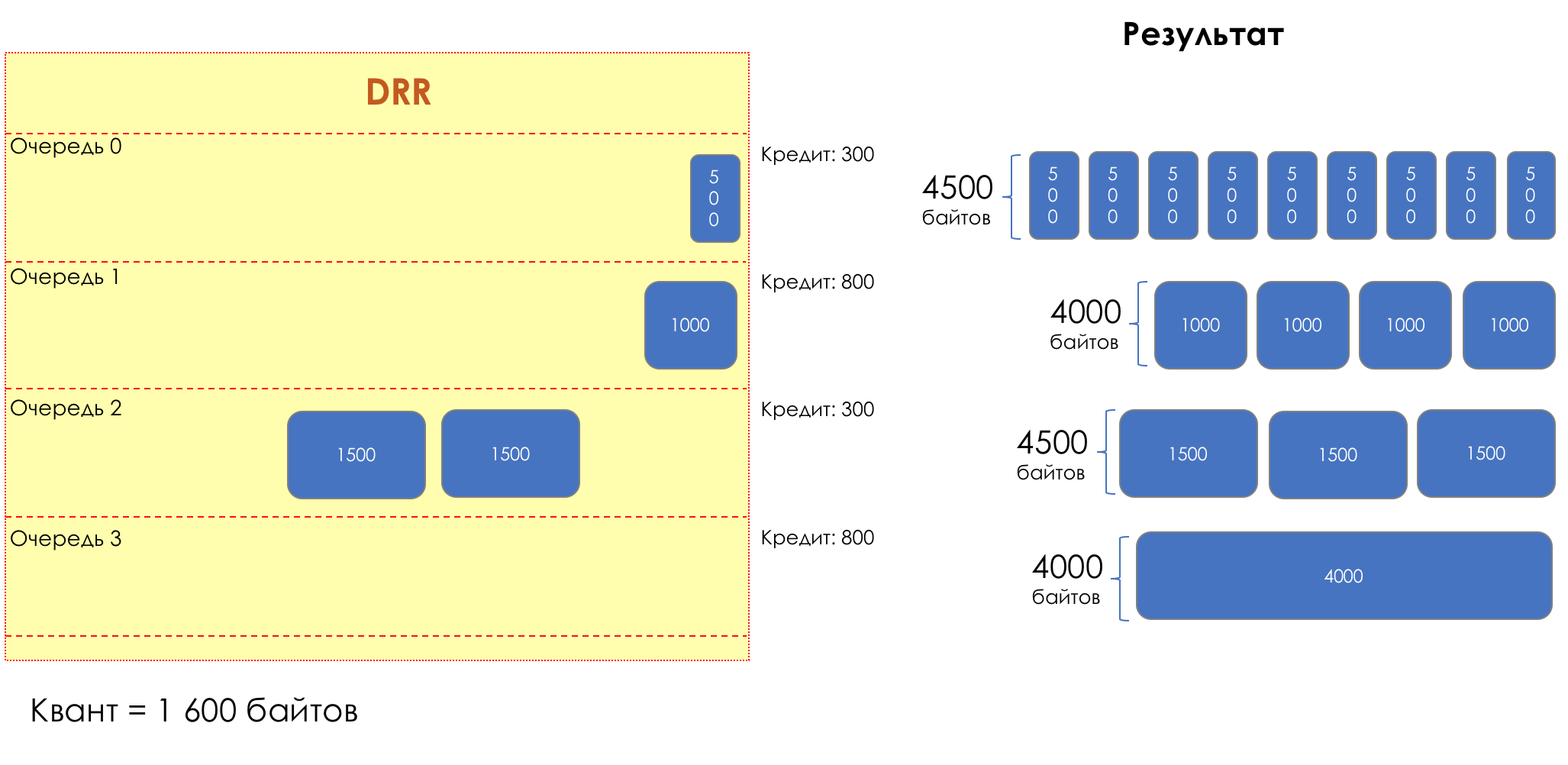
Достаточно наглядна здесь работа DRR. В масштабах многих итераций все очереди получат причитающуюся часть полосы.
Если кому не лень, смотрите анимации.
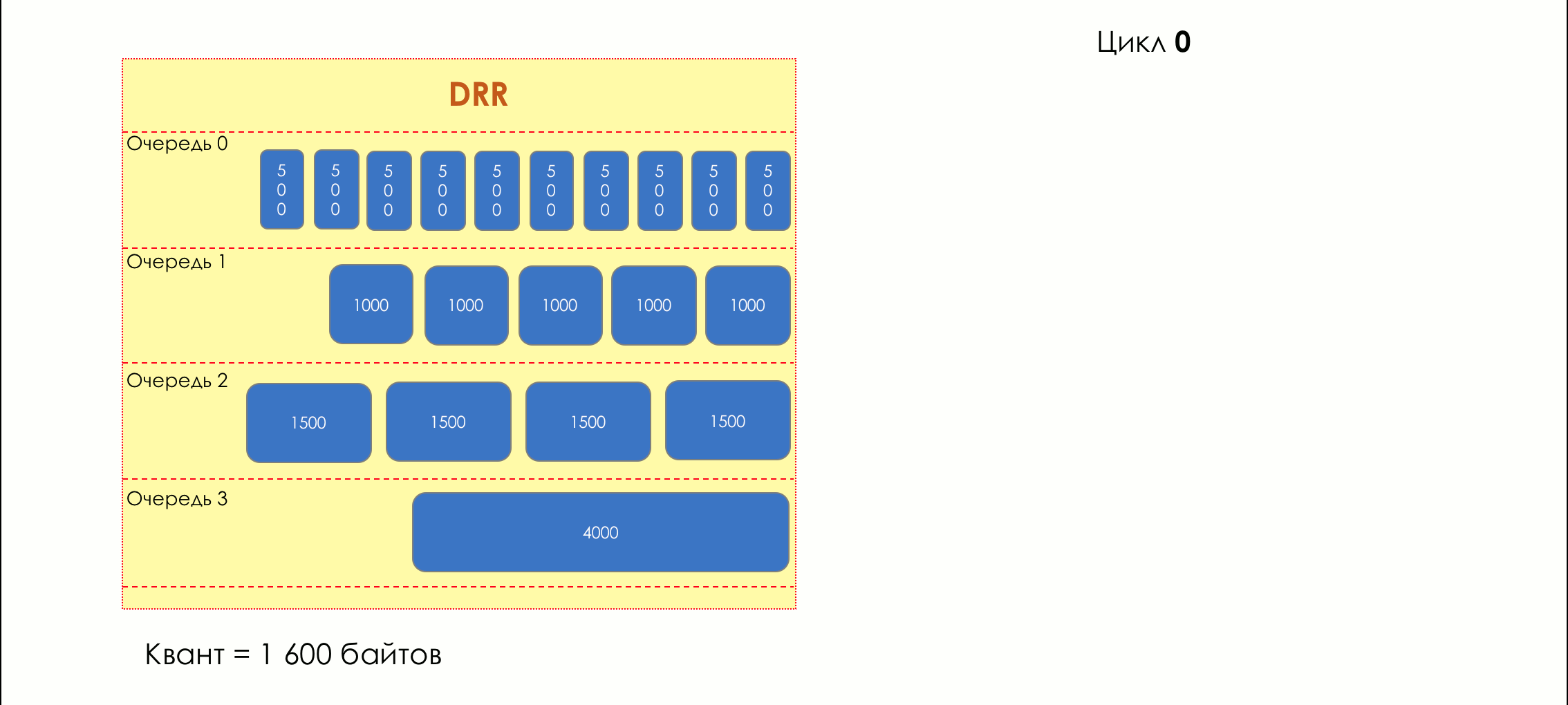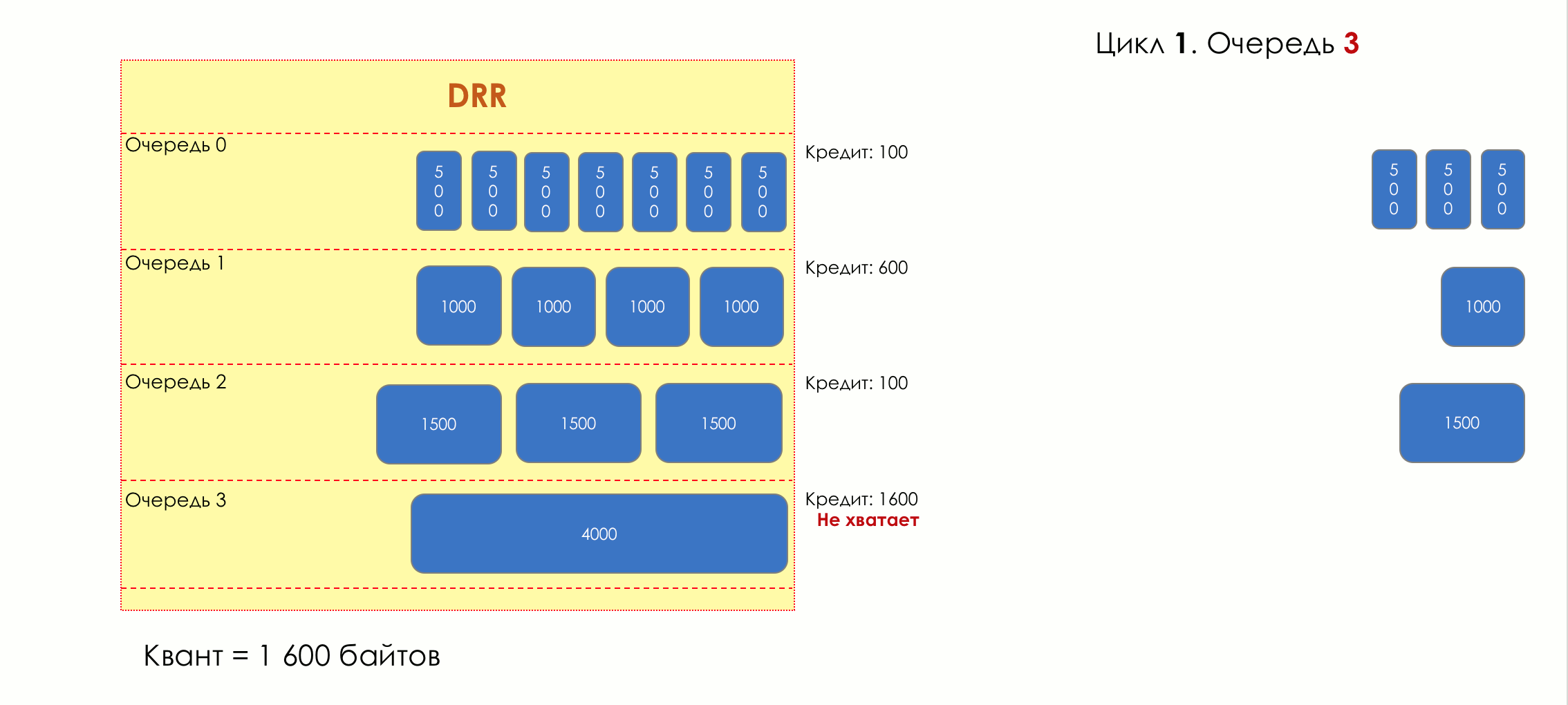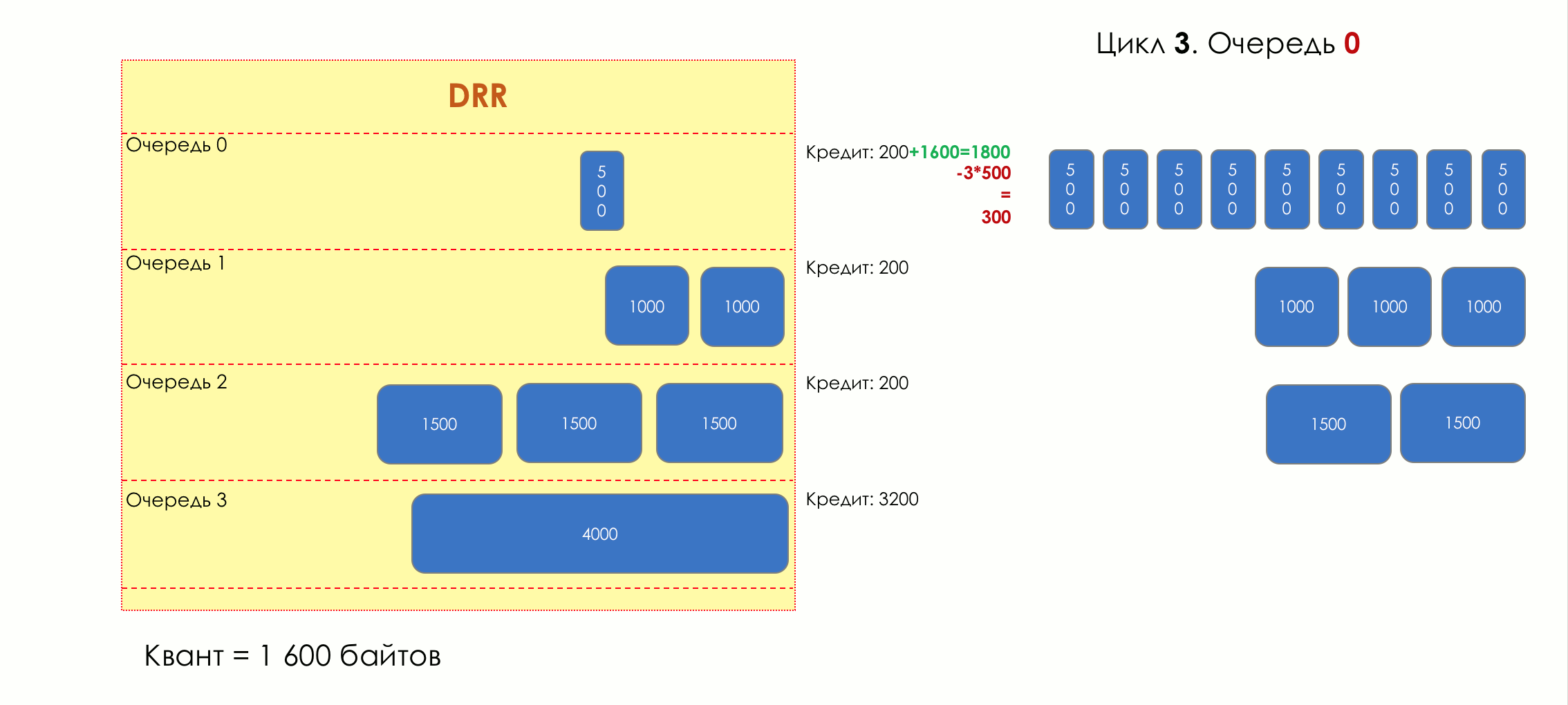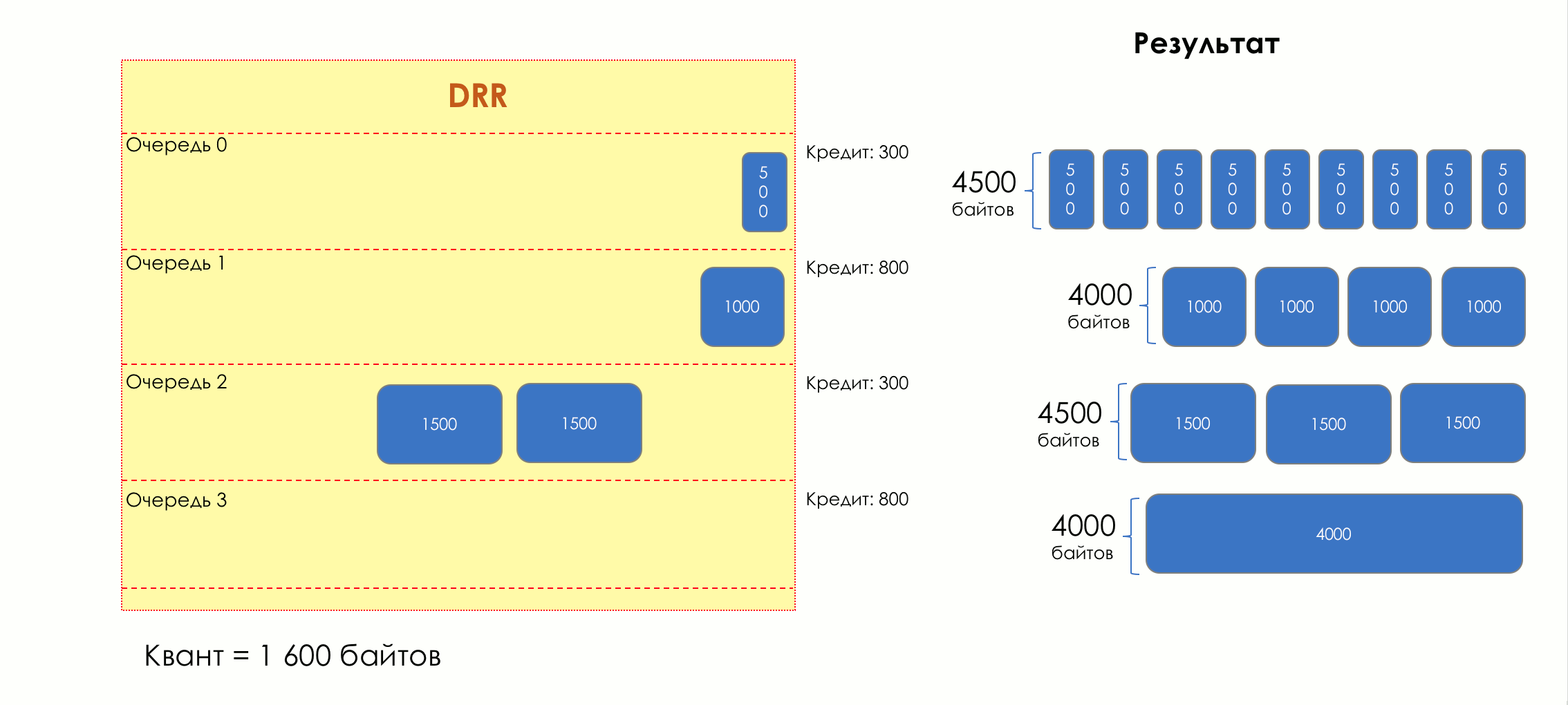
Отличие DWRR от DRR только в том, что в начале цикла каждой очереди выделяется квант, полагающийся именно ей, а не одинаковый для всех.
Выше был описан подход DRR, в котором очереди нельзя уходить в минус — если кредитов не хватает, пакет не пропускается.
Однако есть и более либеральный: пакеты пропускаются, пока очередь не в минусе. В следующий раз пакет пройдёт как только кредит окажется опять положительным.
С DWRR всё же остаётся вопрос с гарантией задержек и джиттера — вес его никак не решает.
Теоретически, здесь можно поступить как и с CB-WFQ, добавив LLQ.
Однако это лишь один из возможных сценариев набирающего сегодня популярность
PB-DWRR — Priority-Based DWRR
Собственно практически мейнстримом сегодня становится PB-DWRR — Priority Based Deficit Weighted Round Robin.
Это тот же старый злой DWRR, в который добавлена ещё одна очередь — приоритетная, пакеты в которой обрабатываются с более высоким приоритетом. Это не значит, что ей отдаётся бoльшая полоса, но то, что оттуда пакеты будут забираться чаще.
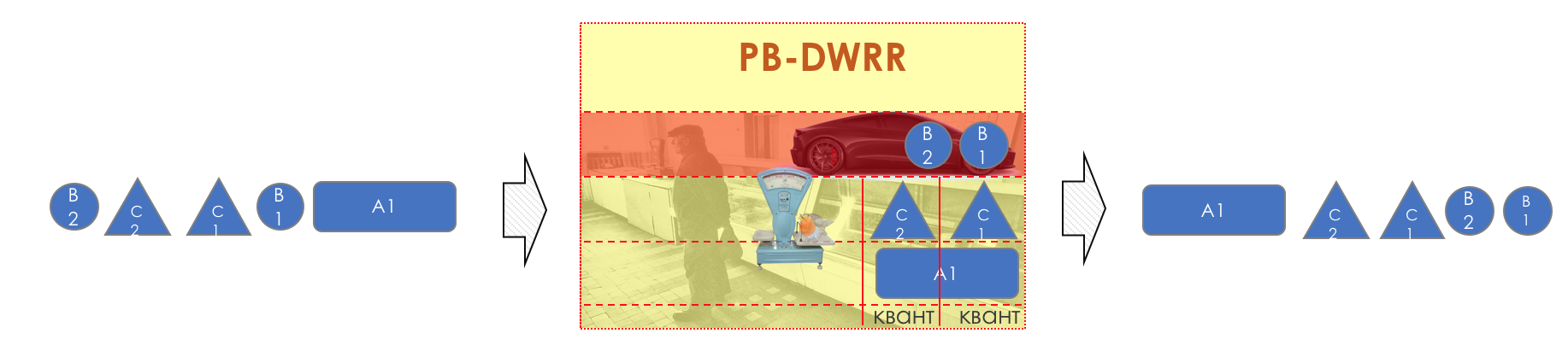
Существует несколько подходов к реализации PB-DWRR. В одних из них, как в PQ, любой пришедший в приоритетную очередь пакет изымается сразу. В других, обращение к ней происходит каждый раз при переходе диспетчера между очередями. В третьих и для неё вводится кредит и квант, чтобы приоритетная очередь не могла отжать всю полосу.
Разбирать мы их, конечно, не будем.
Короткий итог про механизмы диспетчеризации
Десятилетиями человечество пыталось решить сложнейшую проблему обеспечения нужного уровня сервиса и честного распределения полосы. Основным инструментом являлись очереди, вопрос был только в том, как из очередей забирать пакеты, пытаясь их запихнуть в один интерфейс.
Начиная с FIFO, оно изобрело PQ — голос смог сосуществовать с сёрфингом, но не было речи про гарантию полосы.
Появились несколько монструозные FQ, WFQ, работавшие если не per-flow, то почти так. CB-WFQ пришёл к классовому обществу, но не стал от этого проще.
Как альтернатива ему развивался RR. Он превратился в WRR, а затем и в DWRR.
И в глубине каждого из диспетчеров живёт FIFO.
Однако, как видите, нет некоего универсального диспетчера, который все классы обрабатывал так, как они того требуют. Это всегда комбинация диспетчеров, один из которых решает задачу обеспечения задержек, джиттера и отсутствия потерь, а другой распределения полосы.
CBWFQ+LLQ или PB-WDRR или WDRR+PQ.
На реальном оборудовании можно указать какие именно очереди каким диспетчером обрабатывать.
CBWFQ, WDRR и их производные — это сегодняшние фавориты.
PQ, FQ, WFQ, RR, WRR — не скорбим и не помним (если, конечно, не готовимся к CCIE Клиппер).
Итак, гарантировать скорость диспетчеры умеют, но как же ограничить её сверху?
8. Ограничение скорости
Необходимость ограничения скорости трафика на первый взгляд очевидна — не выпустить клиента за пределы его полосы согласно договору.
Да. Но не только. Допустим имеется РРЛ-пролёт шириной в 620 Мб/с, подключенный через порт 1Гб/с. Если пулять в него весь гигабит, то где-то на РРЛ, которая, вполне вероятно, не имеет представления об очередях и QoS, начнутся чудовищные отбрасывания случайного характера, не привязанные к реальным приоритетам трафика.
Однако, если на маршрутизаторе включить шейпинг до 600 Мб/с, то EF, CS6, CS7 не будут отбрасываться совсем, а в BE, AFх полоса и дропы распределятся согласно их весам. До РРЛ будет доходить 600 Мб/с и мы получим предсказуемую картину.
Другой пример — входной контроль (Admission Control). Например, два оператора договорились доверять всей маркировке друг друга, кроме CS7 — если что-то пришло в CS7 — отбрасывать. Для CS6 и EF — давать отдельную очередь с гарантией задержки и отсутствия потерь.
Но, что если хитроумный партнёр начал лить в эти очереди торренты? Прощай телефония. Да и протоколы начнут, скорее всего, разваливаться.
Логично в этом случае договориться с партнёром о полосе. Всё, что укладывается в договор — пропускаем. Что не укладывается — отбрасываем или переводим в другую очередь — BE, например. Таким образом защищаем свою сеть и свои сервисы.
Существует два принципиально разных подхода к ограничению скорости: полисинг и шейпинг. Решают они одну задачу, но по-разному.
Рассмотрим разницу на примере такого профиля трафика:

Traffic Policing
Полисинг ограничивает скорость путём отбрасывания лишнего трафика.
Всё, что превышает установленное значение, полисер срезает и выбрасывает.

Что срезано, то забыто. На картинке видно, что красный пакет отсутствует в трафике после полисера.
И вот как будет выглядеть выбранный профиль после полисера:

Из-за строгости принимаемых мер это называется Hard Policing.
Однако есть и другие возможные действия.
Полисер обычно работает совместно с измерителем трафика. Измеритель красит пакеты, как вы помните, в зелёный, жёлтый или красный.
А на основе уже этого цвета полисер может не отбросить пакет, а поместить в другой класс. Это мягкие меры — Soft Policing.
Применяться может как ко входящему трафику, так и к исходящему.
Отличительная черта полисера — способность абсорбировать всплески трафика и определять пиковую допустимую скорость благодаря механизму Token Bucket.
То есть на самом деле не срезается всё, что выше заданного значения — разрешается немного за него выходить — пропускаются кратковременные всплески или небольшие превышения выделенной полосы.
Название «Policing» диктуется довольно строгим отношением инструмента к лишнему трафику — отбрасывание или разжалование в более низкий класс.
Traffic Shaping
Шейпинг ограничивает скорость путём буферизации лишнего трафика.
Весь приходящий трафик проходит через буфер. Шейпер из этого буфера с постоянной скоростью изымает пакеты.
Если скорость поступления пакетов в буфер ниже выходной, они в буфере не задерживаются — пролетают насквозь.
А если скорость поступления выше выходной, они начинают скапливаться.
Выходная скорость при этом всегда одинакова.
Таким образом всплески трафика складываются в буфер и будут отправлены, когда до них дойдёт очередь.
Поэтому наряду с диспетчеризацией в очередях, шейпинг — второй инструмент, делающий вклад в совокупную задержку.
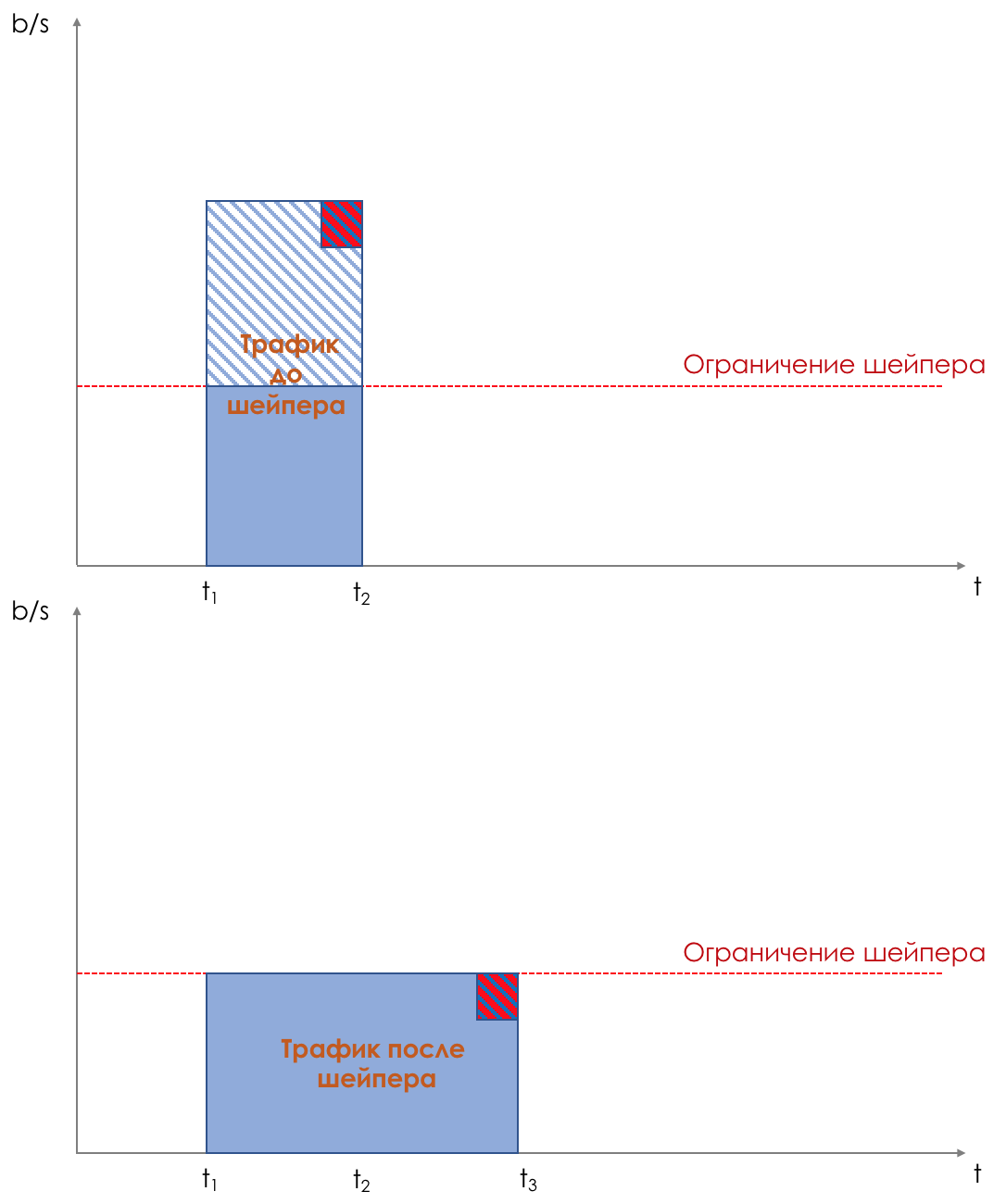
На иллюстрации хорошо видно, как пакет, пришедший буфер в момент времени t2, на выходе оказывается в момент t3. t3-t2 — это задержка, вносимая шейпером.
Шейпер обычно применяется к исходящему трафику.
Так выглядит профиль после шейпера.
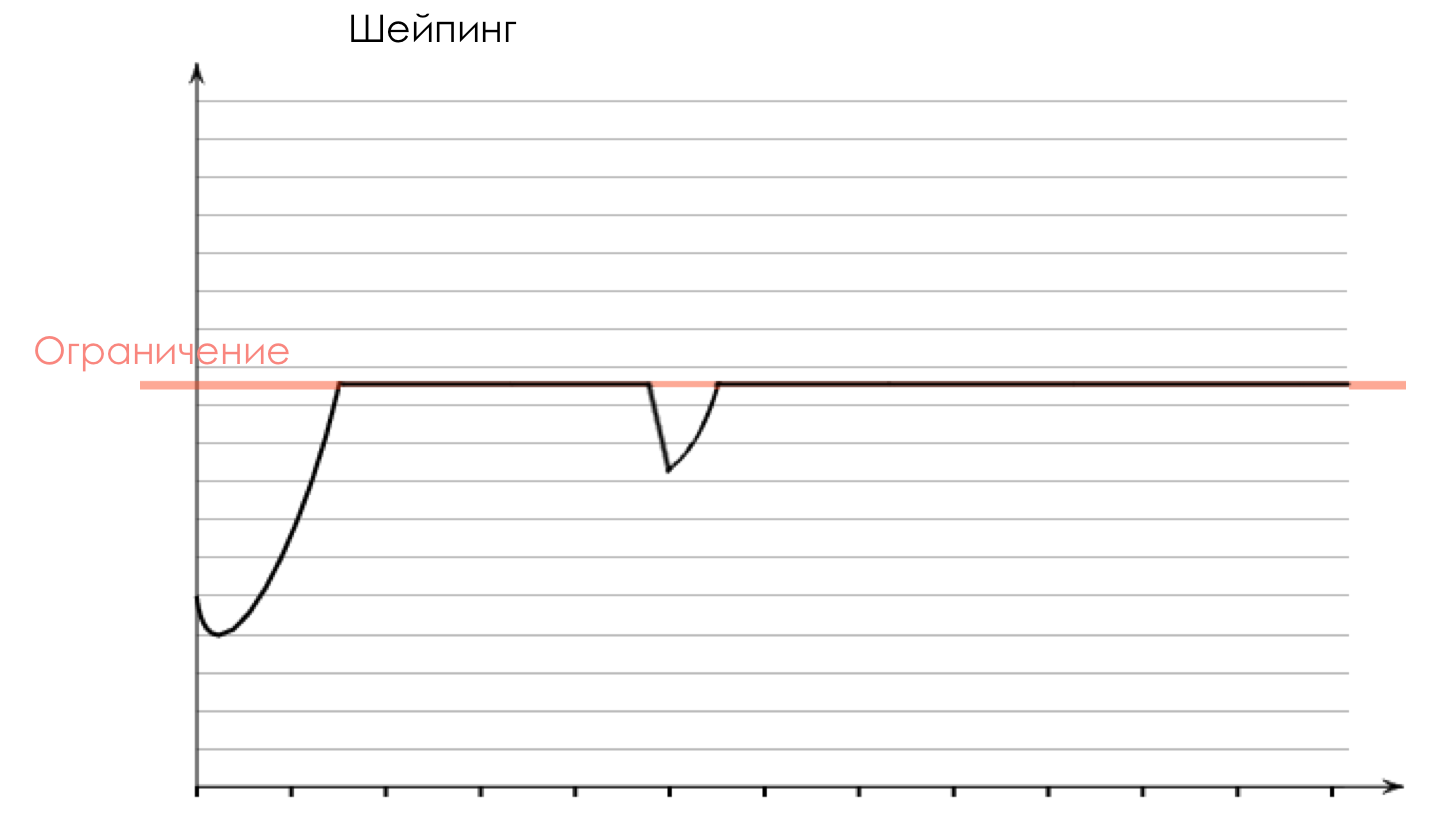
Название «Shaping» говорит о том, что инструмент придаёт профилю трафика форму, сглаживая его.
Главное достоинство такого подхода — оптимальное использование имеющейся полосы — вместо дропа чрезмерного трафика, мы его откладываем.
Главный недостаток — непредсказуемая задержка — при заполнении буфера, пакеты будут томиться в нём долго. Поэтому не для всех типов трафика шейпинг хорошо подходит.
Shaping использует механизм Leaky Bucket.
Шейпинг против полисинга
Работа полисера похожа на нож, который, двигаясь по поверхности масла, срезает острой стороной бугорки.
Работа же шейпера похожа на валик, который разглаживает бугорки, распределяя их равномерно по поверхности.
Шейпер старается не отбрасывать пакеты, пока они помещаются в буфер ценою увеличения задержки.
Полисер не вносит задержек, но с большей готовностью отбрасывает пакеты.
Приложения, нечувствительные к задержкам, но для которых нежелательны потери, лучше ограничивать шейпером.
Для тех же, для которых опоздавший пакет всё равно, что потерянный, лучше его отбросить сразу — тогда полисинг.
Шейпер никак не влияет на заголовки пакетов и их судьбу за пределами узла, в то время как после полисинга устройство может перемарикровать класс в заголовке. Наример, на входе пакет имел класс AF11, метеринг покрасил его в жёлтый цвет внутри устройства, на выходе оно перемаркировало его класс на AF12 — на следующем узле у него будет более высокая вероятность отбрасывания.
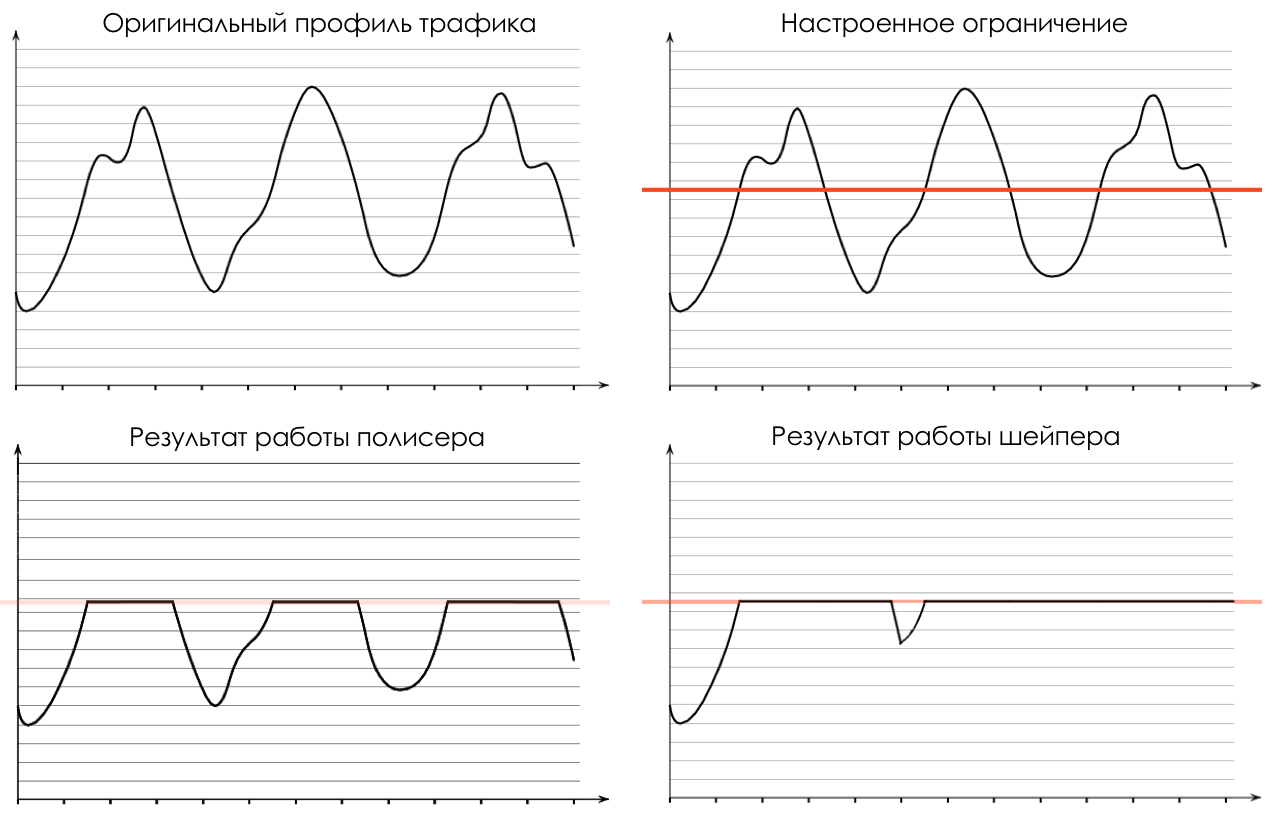
Практика Полисинг и шейпинг
Схема та же:
Файл конфигурации.
Такую картину наблюдаем без применения ограничений:

Мы поступим следующим образом:
- На входном интерфейсе Linkmeup_R2 (e0/1) настроим полисинг — это будет входной контроль. По договору мы даём 10 Мб/с.
- На выходном интерфейсе Linkmeup_R4 (e0/2) настроим шейпинг на 20 Мб/с.
Начнём с шейпера на Linkmeup_R4.
Матчим всё:
class-map match-all TRISOLARANS_ALL_CM
match any Шейпим до 20Мб/с:
policy-map TRISOLARANS_SHAPING
class TRISOLARANS_ALL_CM
shape average 20000000Применяем на выходной интерфейс:
interface Ethernet0/2
service-policy output TRISOLARANS_SHAPING
Всё, что должно покинуть (output) интерфейс Ethernet0/2, шейпим до 20 Мб/с.
Файл конфигурации шейпера.
И вот результат:
Получается достаточно ровная линия общей пропускной способности и рваные графики по каждому отдельному потоку.
Дело в том, что ограничиваем мы шейпером именно общую полосу. Однако в зависимости от платформы отдельные потоки тоже могут шейпиться индивидуально, таким образом получая равные возможности.
Теперь настроим полисинг на Linkmeup_R2.
К существующей политике добавим полисер.
policy-map TRISOLARANS_ADMISSION_CONTROL
class TRISOLARANS_TCP_CM
police cir 10000000 bc 1875000 conform-action transmit exceed-action drop На интерфейс политика уже применена:
interface Ethernet0/1
service-policy input TRISOLARANS_ADMISSION_CONTROLЗдесь указываем среднюю разрешённую скорость CIR (10Mб/с) и разрешённый всплеск Bc (1 875 000 байтов около 14,6 МБ).
Позже, объясняя, как работает полисер, я расскажу, что за CIR да Bc и как эти величины определять.
Файл конфигурации полисера.
Такая картина наблюдается при полисинге. Сразу видно резкие изменения уровня скорости:
А вот такая любопытная картина получается, если мы сделаем слишком маленьким допустимый размер всплеска, например, 10 000 байтов.
police cir 10000000 bc 10000 conform-action transmit exceed-action drop 
Общая скорость сразу упала до примерно 2Мб/с.
Будьте аккуратнее с настройкой всплесков:)
Таблица тестов.
Механизмы Leaky Bucket и Token Bucket
Звучит легко и понятно. Но как работает на практике и реализовано в железе?
Пример.
Ограничение в 400 Мб/с — это много (или мало)? В среднем клиент использует только 320. Но иногда поднимается до 410 на 5 минут. А иногда до 460 на минуту. А иногда до 500 на полсекунды.
Как договоропорядочный провайдер linkmeup может сказать — 400 и баста! Хотите больше, подключайтесь на тариф 1Гб/с+27 аниме-каналов.
А можем повысить лояльность клиента, если это не мешает другим, разрешив такие всплески.
Как разрешить 460Мб/с на всего лишь одну минуту, а не на 30 или навсегда?
Как разрешить 500 Мб/с, если полоса свободна, и прижать до 400, если появились другие потребители?
Теперь передохните, налейте ведро крепкого.
Начнём с более простого механизма, используемого шейпером — протекающее ведро.
Алгоритм Leaky bucket
Leaky Bucket — это протекающее ведро.

Имеем ведро с отверстием заданного размера внизу. В это ведро сверху сыпятся/льются пакеты. А снизу они вытекают с постоянной битовой скоростью.
Когда ведро заполняется, новые пакеты начинают отбрасываться.
Размер отверстия определяется заданным ограничением скорости, которая для Leaky Bucket измеряется в битах в секунду.
Объём ведра, его наполненность и выходная скорость определяют задержку, вносимую шейпером.
Для удобства объём ведра обычно измеряется в мс или мкс.
В плане реализации Leaky Bucket — это обычный буфер на основе SD-RAM.
Даже если явным образом шейпинг не настроен, при наличии всплесков, которые не проходят в интерфейс, пакеты временно складываются в буфер и передаются по мере освобождения интерфейса. Это тоже шейпинг.
Leaky Bucket используется только для шейпинга и не подходит для полисинга.
Алгоритм Token Bucket
Многие считают, что Token Bucket и Leaking Bucket — одно и то же. Сильнее ошибался только Эйнштейн, добавляя космологическую постоянную.
Чипы коммутации не очень-то хорошо понимают, что такое время, ещё хуже они считают сколько битов они за единицу времени передали. Их работа — молотить.
Вот этот приближающийся бит — это ещё 400 000 000 бит в секунду или уже 400 000 001?

Перед разработчиками ASIC стояла нетривиальная инженерная задача.
Её разделели на две подзадачи:
- Собственно ограничение скорости путём отбрасывания лишних пакетов на основе очень простого условия. Выполняется на чипах коммутации.
- Создание этого простого условия, которым занимается более сложный (более специализированный) чип, ведущий счёт времени.
Алгоритм, решающий вторую задачу называется Token Bucket. Его идея изящна и проста (нет).
Задача Token Bucket — пропускать трафик, если он укладывается в ограничение и отбрасывать/красить в красный, если нет.
При этом важно разрешить всплески трафика, поскольку это нормальное явление.
И если в Leaky Bucket всплески амортизировались буфером, то Token Bucket ничего не буферизирует.
Single Rate — Two Color Marking
Пока не обращайте внимания на название =)
Имеем ведро, в которое падают монетки с постоянной скорость — 400 мегамонет в секунду, например.
Объём ведра — 600 миллионов монет. То есть наполняется оно за полторы секунды.
Рядом проходят две ленты конвейера: одна подвозит пакеты, вторая — увозит.
Чтобы попасть на отвозящий конвейер, пакет должен заплатить.
Монетки для этого он берёт из ведра в соответствии со своим размером. Грубо говоря — сколько битов — столько и монеток.
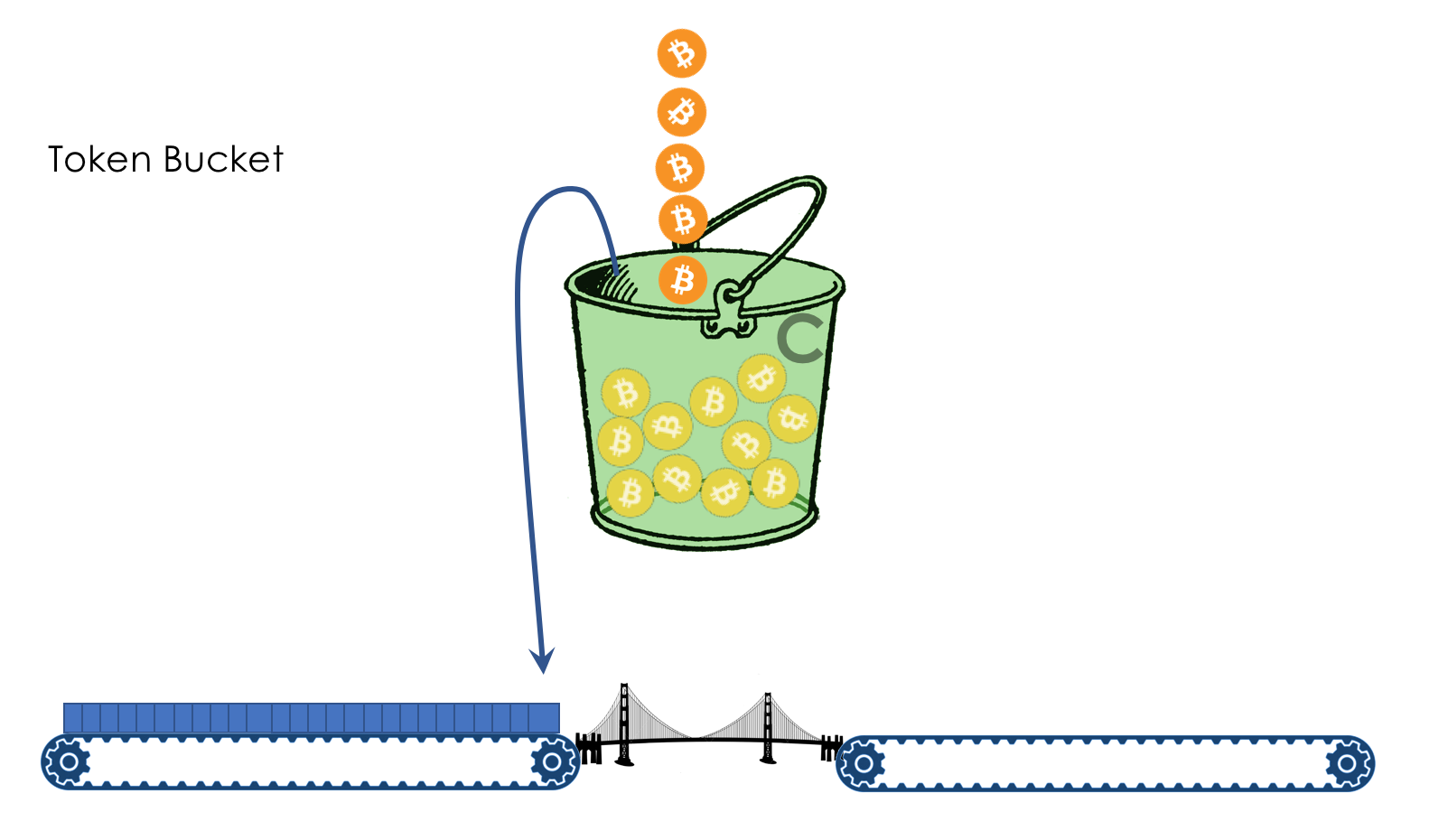

Если ведро опустело и монет пакету не хватило, он окрашивается в красный сигнальный цвет и отбрасывается. Увы-селявы. При этом монеты из ведра не вынимаются.
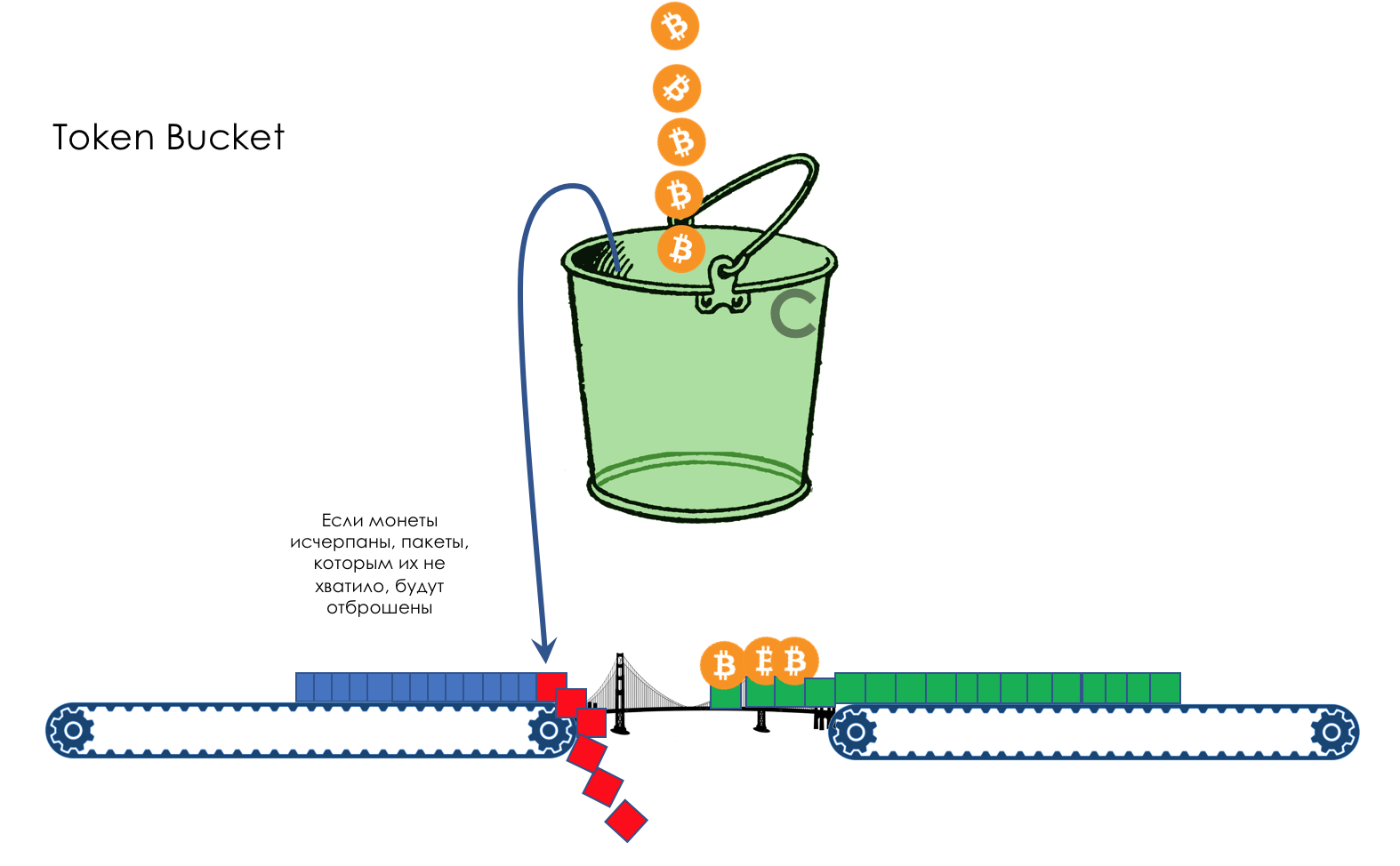
Следующему пакету монет уже может хватить — во-первых, пакет может быть поменьше, а, во-вторых, ещё монет за это время нападает.
Если ведро уже полное, все новые монеты будут выбрасываться.
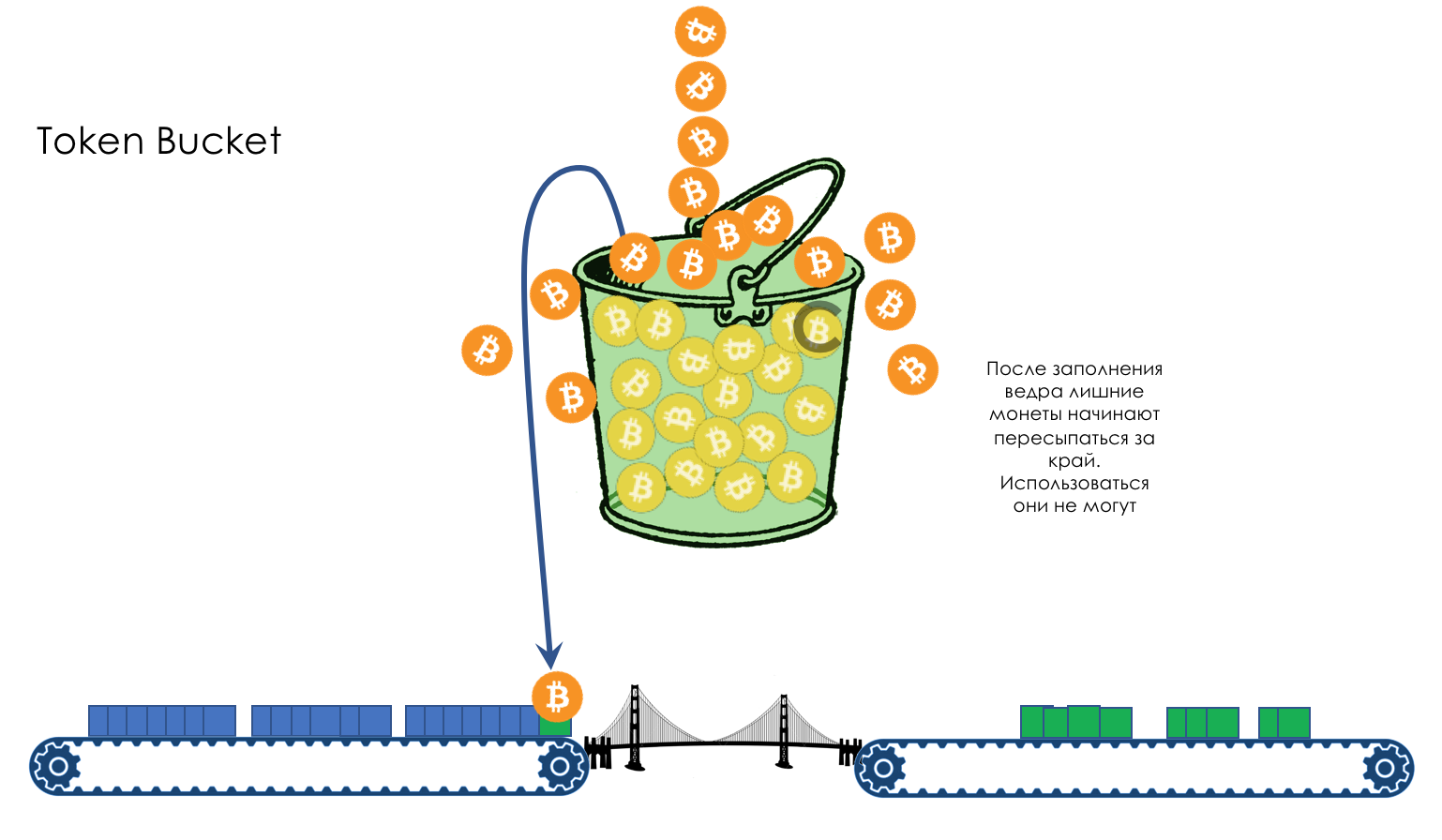
Всё зависит от скорости поступления пакетов и их размера.
Если она стабильно ниже или равна 400 Мб в секунду, значит монет всегда будет хватать.
Если выше, то часть пакетов будет теряться.
Более конкретный пример с гифками, как мы все любим.Зачем ведру объём? Битовый поток не всегда равномерен, это очевидно. Ограничение в 400 Мб/с — это не асимптота — трафик может её пересекать. Объём хранящихся монет позволяет небольшим всплескам пролетать, не будучи отброшенными, однако среднюю скорость сохранить на уровне 400Мб/с.
- Есть ведро ёмкостью 2500 байтов. На начальный момент времени в нём лежит 550 токенов.
На конвейере три пакета по 1000 байтов, которые хотят быть отправлены в интерфейс.
В каждый квант времени в ведро падает 500 байтов (500*8 = 4 000 бит/квант времени — ограничение полисера).- На исходе первого кванта времени в ведро падает 500 токенов. И в это время подходит первый пакет. Его размер 1000 байтов, а в ведре 1050 токенов — хватает. Пакет красится в зелёный цвет и пропускается. 1000 токенов вынимается из ведра.
В ведре остаётся 50 токенов.- На исходе второго кванта времени в ведро падает ещё 500 токенов — итого 550. А размер пришедшего пакета — 1000 — не хватает.
Пакет красится красным и отбрасывается, токены не вынимаются.- На исходе третьего кванта в ведро падает ещё 500 токенов — снова 1050. Размер пришедшего пакета — 1000 — хватает.
Пакет красится в зелёный и пропускается, токены вынимаются из ведра.
Объём ведра в 2500 байтов фактически означает, что через такой полисер ни при каких условиях не пройдёт пакет больше 2500 байтов — ему никогда не будет хватать токенов. Поэтому его объём должен быть не меньше MTU и вообще рекомендуется объём, равный количеству трафика на максимальной скорости, разрешённой полисером, за 1,5-2 секунды.
То есть формула следующая:
CBS = CIR (бит в секунду)*1,5 (секунды)/8 (бит в байте)
Если вернуться к практическому примеру по полисингу, где мы настраивали всплески (Bc), то станет понятно, что при большом значении (1 875 000 байтов) все всплески амортизируются хорошо. А при маленьком (10 000 байтов), несмотря на то, что оно заметно больше MTU, полисер упирается в постоянное заполнение ведра и отбрасывает большое количество пакетов.
{kind=link}
Например, стабильный поток 399 Мб/с за 600 секунд позволит ведру наполниться до краёв.
Далее трафик может подняться до 1000Мб/с и держаться на этом уровне 1 секунду — 600 Мм (Мегамонет) запаса и 400 Мм/с гарантированной полосы.
Или же трафик может подняться до 410 Мб/с и держаться таким на протяжении 60 секунд.
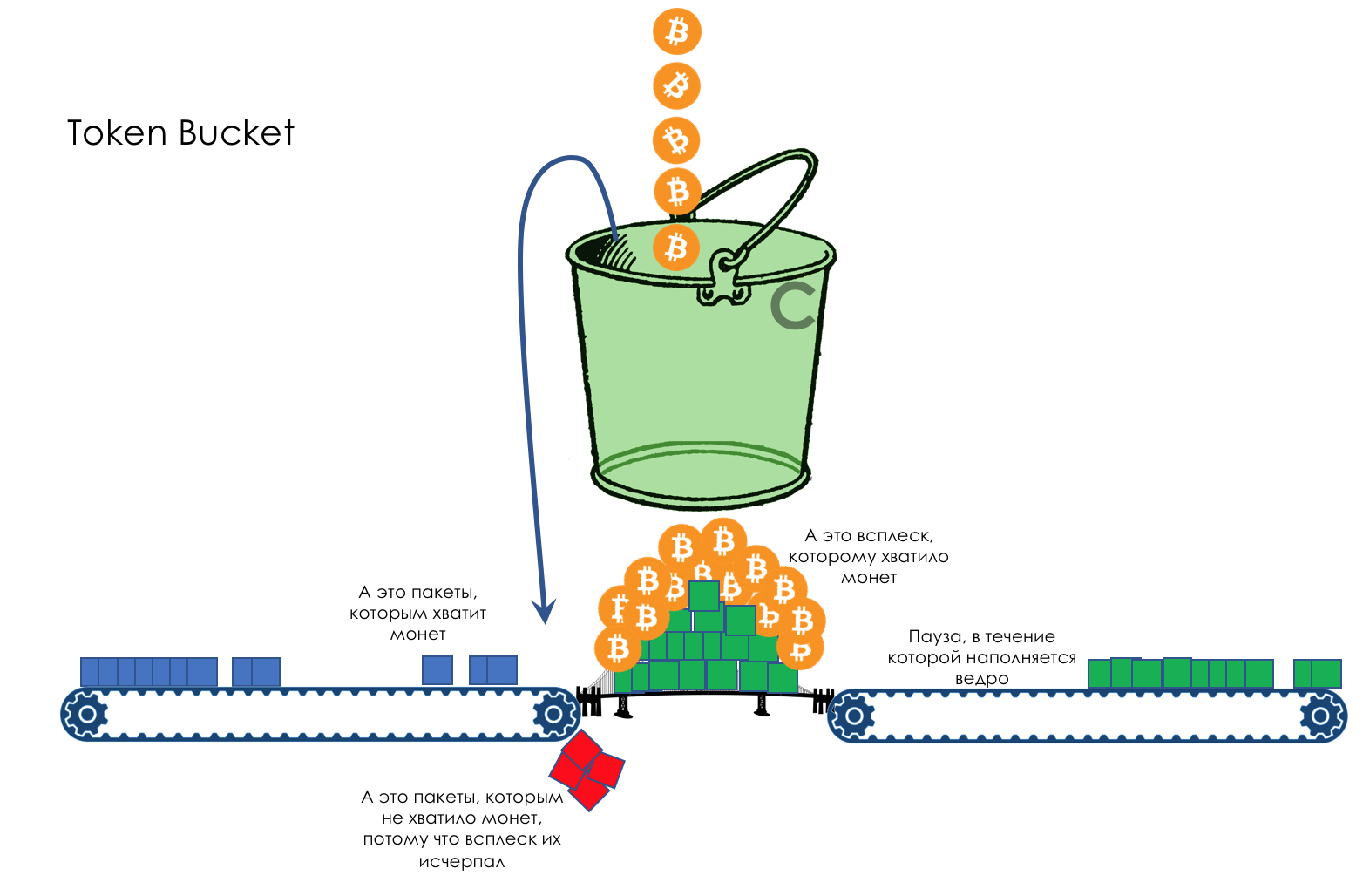
То есть запас монет позволяет слегка выйти за ограничение на продолжительное время или выплеснуть короткий но высокий всплеск.
Теперь к терминологии.
Скорость поступления монет в ведро — CIR — Committed Information Rate (Гарантированная средняя скорость). Измеряется в битах в секунду.
Количество монет, которые могут храниться в ведре — CBS — Committed Burst Size. Разрешённый максимальный размер всплесков. Измеряется в байтах. Иногда, как вы уже могли заметить, называется Bc.
Tc — Количество монет (Token) в ведре C (CBS) в данный момент.
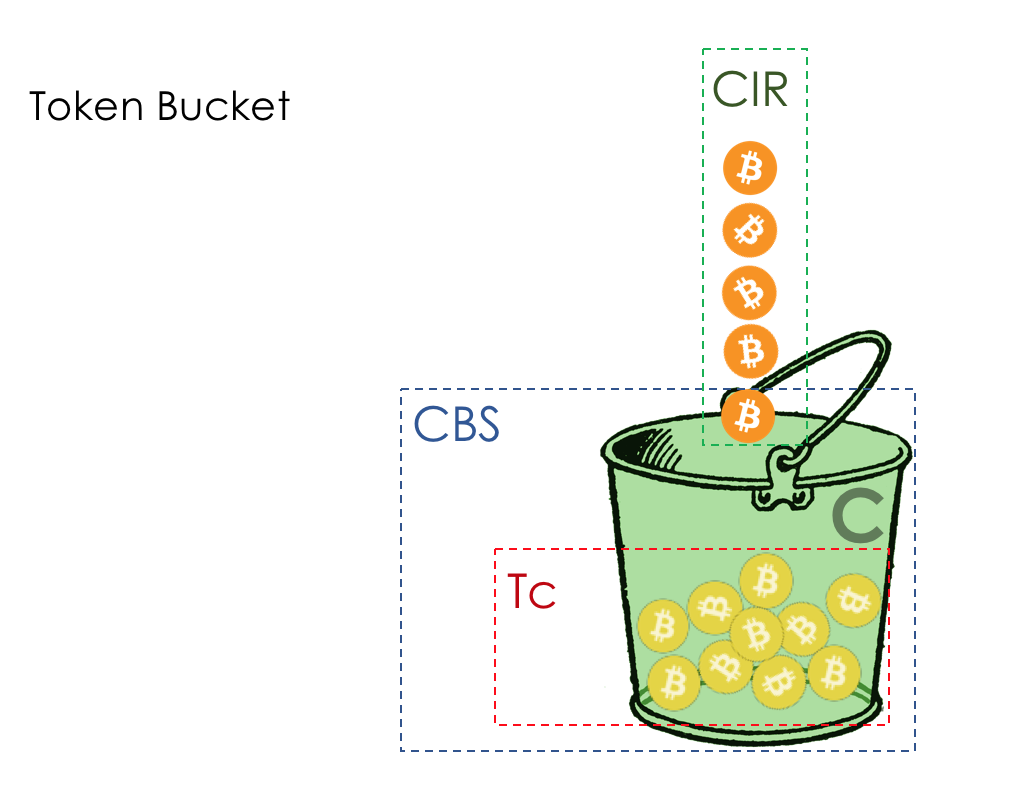
В статье я использую термин "Tc", так же, как он использован в RFC 2697 (A Single Rate Three Color Marker).Это самый простой сценарий. Он называется Single Rate — Two Color.
Однако есть и другой Tc, который описывает интервал времени, когда в ведро ссыпается новая порция монет.
Здесь следует сделать отступление.
Невозможно подстроить скорость интерфейса, чтобы удовлетворить условиям полисера, поэтому и вводится система Token Bucket, реализующая по сути TDM (Time-Division Multiplexing) — она разрешает отправку трафика только в определённые моменты времени.
То есть монеты не льются в ведро непрерывным потоком — современный мир, увы, дискретен.
В первом приближении предлагается один раз в секунду насыпать CIR монет. Потом через секунду итд.
Это работает плохо, потому что всплеск — и секунда молчания, всплеск — и секунда молчания, всплеск — и секунда молчания.
Поэтому во втором приближении секунда делится на интервалы времени, в которые спускается определённое число монет.
Такой интервал времени тоже называется (как минимум в литературе Cisco) Tc, а количество падающих монет — Bc. При этом Bc = CIR*Tc.
То есть в начале каждого интервала Tc в ведро опускается Bc монет.
Single Rate означает, что есть только одна средняя разрешённая скорость, а Two Color — что можно покрасить трафик в один из двух цветов: зелёный или красный.
- Если количество доступных монет (бит) в ведре C больше, чем количество бит, которые нужно пропустить в данный момент, пакет красится в зелёный цвет — низкая вероятность отбрасывания в дальнейшем. Монеты изымаются из ведра.
- Иначе, пакет красится в красный — высокая вероятность дропа (либо, чаще, сиюминутное отбрасывание). Монеты при этом из ведра С не изымаются.
Используется для полисинга в PHB CS и EF, где превышения по скорости не ожидается, но если оно произошло, то лучше сразу отбросить.
Дальше рассмотрим посложнее: Single Rate — Three Color.
Single Rate — Three Color Marking
Недостаток предыдущей схемы в том, что есть только два цвета. Что если мы не хотим отбрасывать всё, что выше средней разрешённой скорости, а хотим быть ещё более лояльными?
sr-TCM (Single Rate — Three Color Marking) вводит второе ведро в систему — E. На этот раз монеты, не поместившиеся в заполненное ведро C, пересыпаются в E.
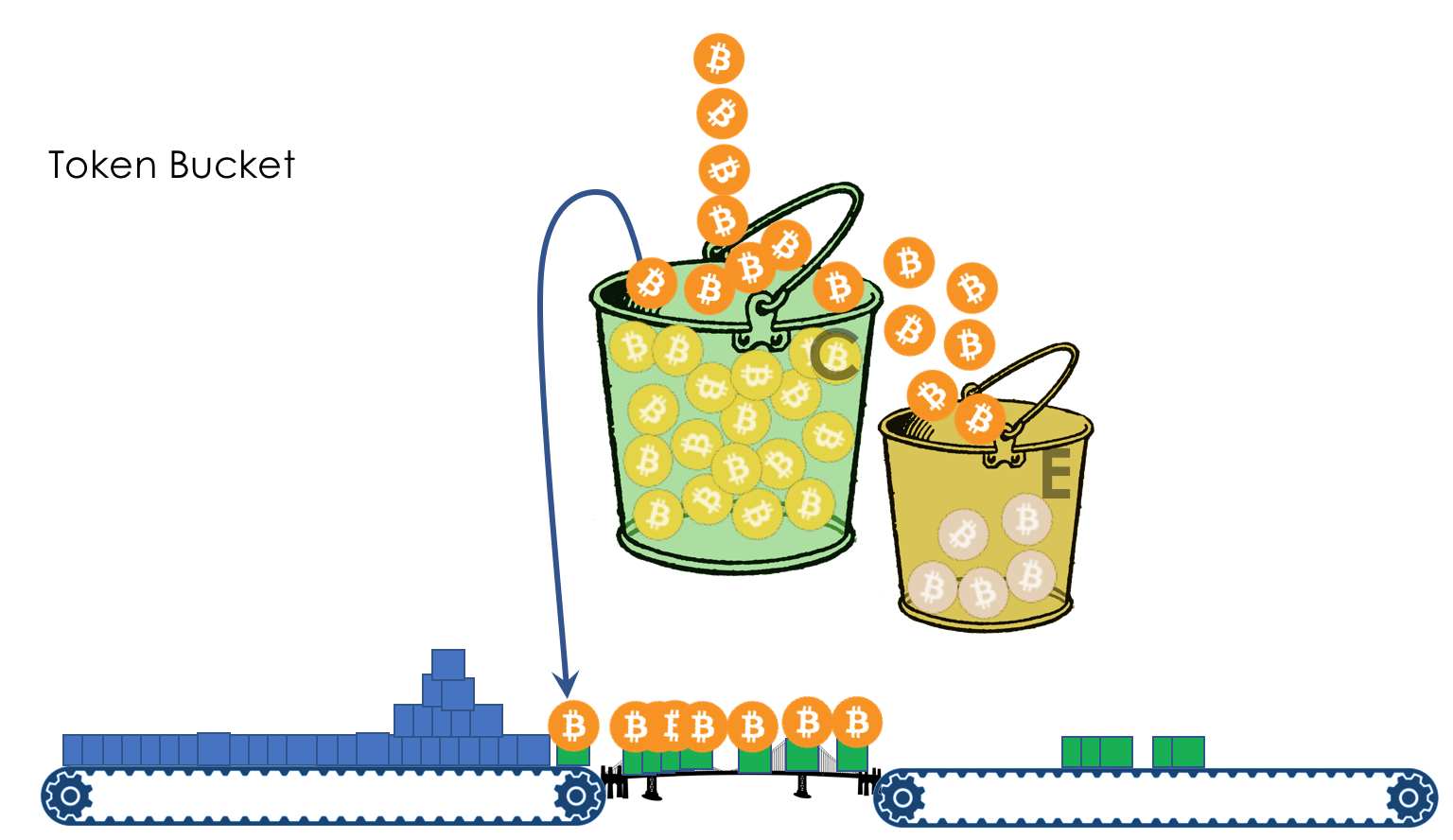
К CIR и CBS добавляется EBS — Excess Burst Size — Разрешённый размер всплесков во время пиков. Te — количество монет в ведре E.

Допустим пакет размера B пришёл по конвейеру. Тогда
- Если монет в ведре C хватает, пакет красится в зелёный и пропускается. Из ведра C вынимается B монет (Остаётся: Tc — B).
- Если монет в ведре C не хватает, проверяется ведро E. Если в нём монет хватает, пакет красится в жёлтый (средняя вероятность дропа), из ведра E вынимается B монет.

- Если и в ведре E не хватает монет, то пакет красится в красный, монеты не вынимаются ниоткуда.

Обратите внимание, что для конкретного пакета Tc и Te не суммируются.
То есть пакет размером 8000 байтов не пройдёт, даже если в ведре C будет 3000 монет, а в E — 7000. В C не хватает, в E не хватает — ставим красное клеймо — шуруй отсюда.
Это очень изящная схема. Весь трафик, который укладывается в среднее ограничение CIR+CBS (автор знает, что нельзя так напрямую складывать биты/с и байты) — проходит зелёным. В пиковые моменты, когда клиент исчерпал монеты в ведре C, у него есть ещё накопленный за время простоя запас Te в ведре E.
То есть можно пропустить чуть больше, но в случае заторов такие с большей вероятностью будут отброшены.
sr-TCM описан в RFC 2697.
Используется для полисинга в PHB AF.
Ну и последняя система — самая гибкая и потому сложная — Two Rate — Three Color.
Two Rate — Three Color Marking
Модель Tr-TCM родилась из идеи, что не в ущерб другим пользователям и типам трафика, почему бы клиенту не дать чуть больше приятных возможностей, а ещё лучше продать.
Скажем ему, что ему гарантировано 400 Мб/с, а если есть свободные ресурсы, то 500. Готовы заплатить на 30 рублей больше?
Добавляется ещё одно ведро P.
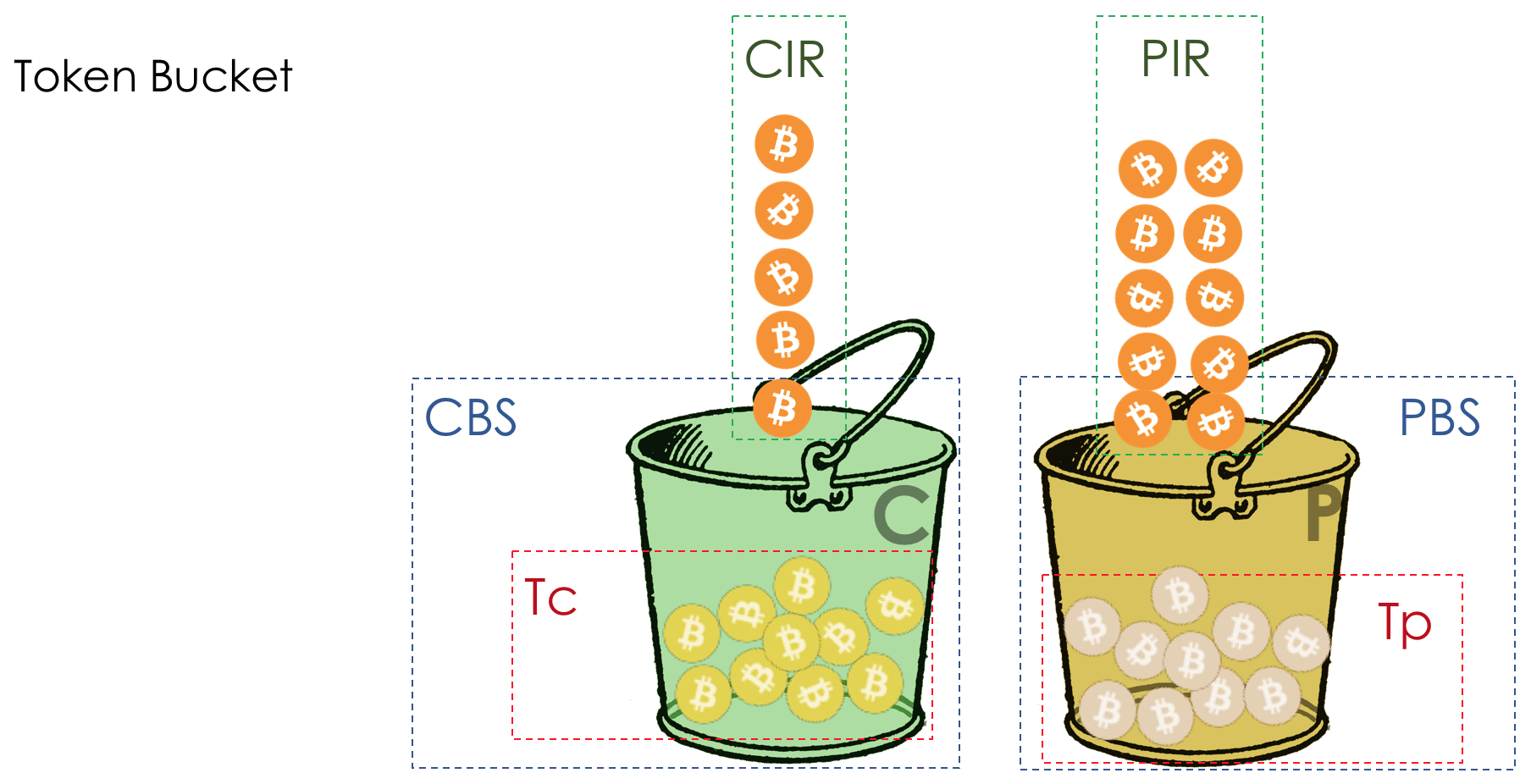
Таким образом:
CIR — гарантированная средняя скорость.
CBS — тот же разрешённый размер всплеска (объём ведра C).
PIR — Peak Information Rate — максимальная средняя скорость.
EBS — разрешённый размер всплесков во время пиков (Объём ведра P).
В отличие от sr-TCM, в tr-TCM в оба ведра теперь независимо поступают монеты. В C — со скоростью CIR, в P — PIR.
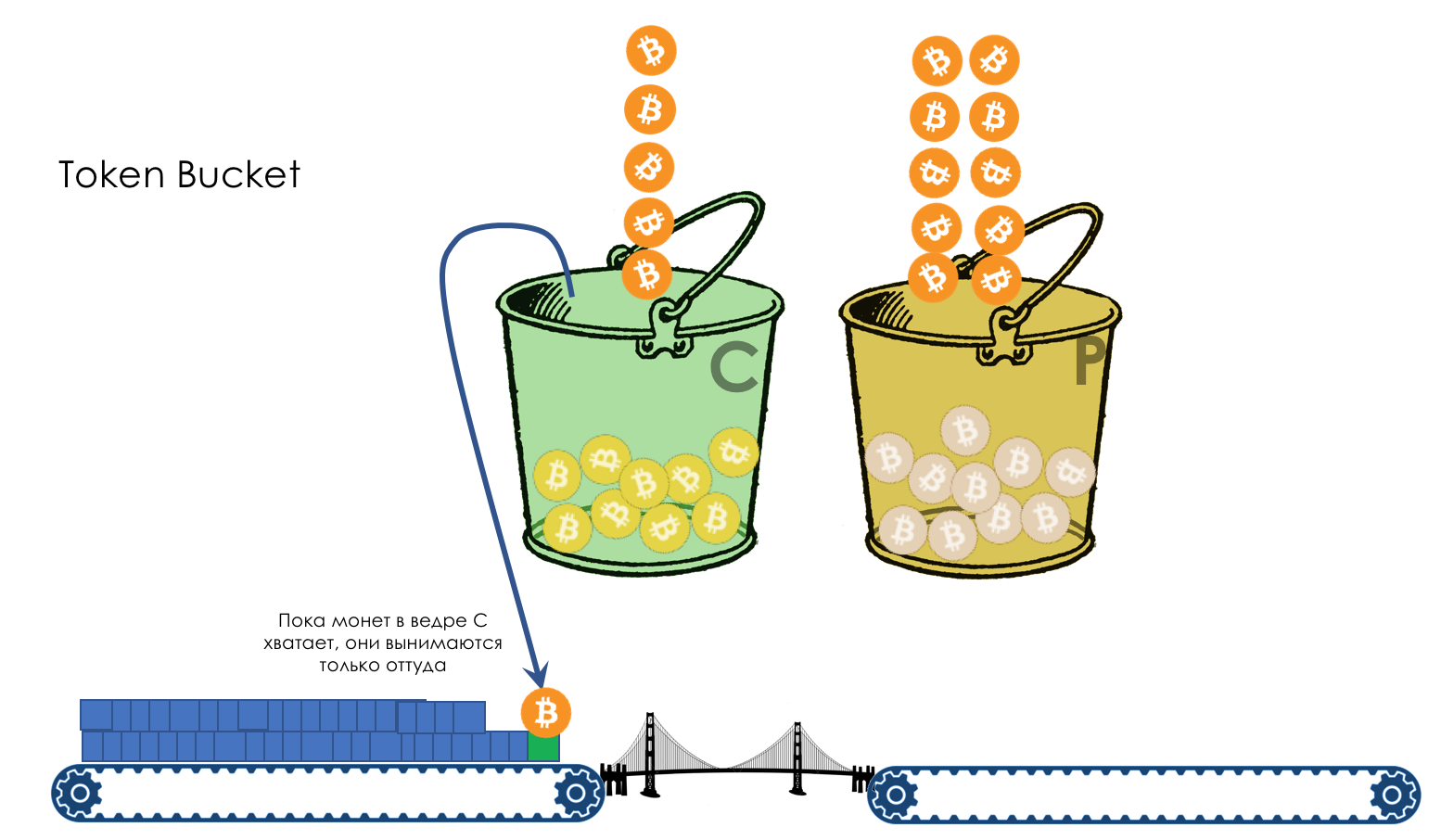
Какие правила?
Приходит пакет размером B байтов.
- Если монет в ведре P не хватает — пакет помечается красным. Монеты не выниваются. Иначе:
- Если монет в ведре C не хватает — пакет помечается жёлтым, и из ведра P вынимаются B монет. Иначе:
- Пакет помечается зелёным и из обоих вёдер вынимаются B монет.

То есть правила в tr-TCM другие.
Пока трафик укладывается в гарантированную скорость, монеты вынимаются из обоих вёдер. Благодаря этому, когда в ведре C монеты кончатся, останутся в P, но ровно столько, чтобы не превысить PIR (если бы вынимались только из C, то P наполнялось бы больше и давало гораздо бо?льшую скорость).
Соответственно, если он выше гарантированной, но ниже пиковой, монеты вынимаются только из P, потому что в C уже нет ничего.
tr-TCM следит не только за всплесками, но и за постоянной пиковой скоростью.
tr-TCM описан в RFC 2698.
Тоже используется для полисинга в PHB AF.
Короткий итог по ограничению скорости
В то время как шейпинг откладывает трафик при превышении, полисинг его отбрасывает.
Шейпинг не подходит для приложений, чувствительных к задержкам и джиттеру.
Для реализации полисинга в железе используется алгоритм Token Bucket, для шейпинга — Leaky Bucket.
Token Bucket может быть:
- С одним ведром — Single Rate — Two Color Marking. Позволяет допустимые всплески.
- С двумя вёдрами — Single Rate — Three Color Marking (sr-TCM). Излишки из ведра C (CBS) пересыпаются в ведро E. Позволяет допустимые и избыточные всплески.
- С двумя вёдрами — Two Rate — Three Color Marking (tr-TCM). Вёдра C и P (PBS) пополняются независимо с разными скоростями. Позволяет пиковую скорость и допустимые и избыточные всплески.
sr-TCM сфокусирован на объёме трафика сверх лимита. tr-TCM — на скорости, с которой он поступает.
Полисинг может использоваться на входе и на выходе с устройства. Шейпинг преимущественно на выходе.
Для PHB CS и EF используется Single Rate Two Color Marking.
Для AF — sr-TCM или tr-TCM.
Для, возможно, лучшего понимания, рекомендую обратиться к оригинальным RFC или почитать тут.
Механизм Token Bucket вполне применим и в быту. Например, если я иду с друзьями в бар, в то время, как жена проводит время с двумя детьми, то каждую минуту из ведра вынимается токен.
Если я вычерпаю всё ведро, то на выходных не могу пойти на пробежку — жду, пока накапает. Если токенов мало, то часок побегать можно, а вот уехать на выходной на работу, чтобы заняться статьёй — уже нет.
Правда рейт наполнения ведра не постоянный, токены выделяются за добрые дела. На самом деле здесь система из двух связанных ведёр — моего и жены. Но так можно и на целую статью материала написать.
Выше я описал все основные механизмы QoS, если не углубляться в иерархический QoS. Сложнейшая система с многочисленными движущимися частями.
Всё хорошо (правда ведь?) звучало до сих пор, но что же творится под ванильной внешней панелью маршрутизатора?
Годами вендоры добавляли всё новые и новые конутры, разрабатывали сложнейшие чипы, расширяли буферы, чтобы с одной стороны поспевать за растущим объёмом трафика и новыми его категориями, а с другой, решать нарастающий проблемы, вызываемые первым пунктом.
Непрекращающаяся гонка. Нельзя терять пакеты, если конкурент их не теряет. Нельзя отказаться от функционала, если соперник стоит с ним под дверями заказчика.
Айда в логово проприетарщины!
9. Аппаратная реализация QoS
В этой главе я беру на себя неблагодарную задачу. Если описывать максимально просто, всегда найдутся те, кто скажет, что всё не так на самом деле.
Если описывать как есть, читатель бросит статью, потому что она превратится в чертёж подводной лодки, точнее чертежи трёх лодок карандашами разного цвета на одном листе.
В общем, сделаю дисклеймер, что в действительности всё не так, как на самом деле, и пойду по варианту простого изложения.
Да простит меня мой попутчик-перфекционист.
Что управляет поведением узла и запускает соответствующие механизмы по отношению к пакету? Приоритет, который он несёт в одном из заголовков? И да, и нет.

Как уже говорилось выше, внутри сетевого устройства обычно перестаёт существовать стандартный коммутирующий заголовок.

Как только пакет попал на чип коммутации, заголовки с него снимаются и отправляются на анализ, а полезная нагрузка томится в каком-то временном буфере.
На основе заголовков происходит классификация (BA или MF) и принимается решение о пересылке.
Через мгновение на пакет навешивается внутренний заголовок с метаданными о пакете.
Эти метаданные несут много важной информации — адреса отправителя и получателя, выходной чип, порядковый номер ячейки, если была фрагментация пакета и обязательно маркировку класса (CoS) и приоритет отбрасывания (Drop Precedence). Только маркировку во внутреннем формате — он может совпадать с DSCP, а может и нет.
В принципе, внутри коробки можно задать произвольную длину маркировки, не привязываясь к стандартам, и определять очень гибко действия с пакетом.
У Cisco внутренняя маркировка зовётся QoS Group, у Juniper — Forwarding Class, Huawei не определился: где-то называет internal priorities, где-то local priorities, где-то Service-Class, а где-то просто CoS. Добавляйте в комментарии названия для других вендоров — я дополню.
Вот эта внутренняя маркировка назначается на основе классификации, которую выполнил узел.
Важно, что если не сказано иного, то внутренняя маркировка работает только внутри узла, но никак потом не отображается на маркировку в заголовках пакета, который будет отправлен с узла — она останется прежней.
Однако, на входе в DS-домен после классификации обычно происходит перемаркировка в определённый класс сервиса, принятый в данной сети. Тогда внутренняя маркировка преобразуется в значение, принятое для данного класса на сети, и записывается в заголовок отправляемого пакета.
Внутренняя маркировка CoS и Drop Precedence определяет поведение только внутри данного узла и никак явным образом не передаётся соседям, кроме перемаркировки заголовков.
CoS и Drop Precedence определяют PHB, его механизмы и параметры: предотвращение перегрузок, управление перегрузками, диспетчеризация, перемаркировка.
Через какие круги проходят пакеты между входным и выходным интерфейсами я рассмотрел в предыдущей статье. Собственно она и оказалась внеплановой, поскольку в какой-то момент стало очевидно, что без понимания архитектуры говорить о QoS преждевременно.
Однако, давайте повторимся.
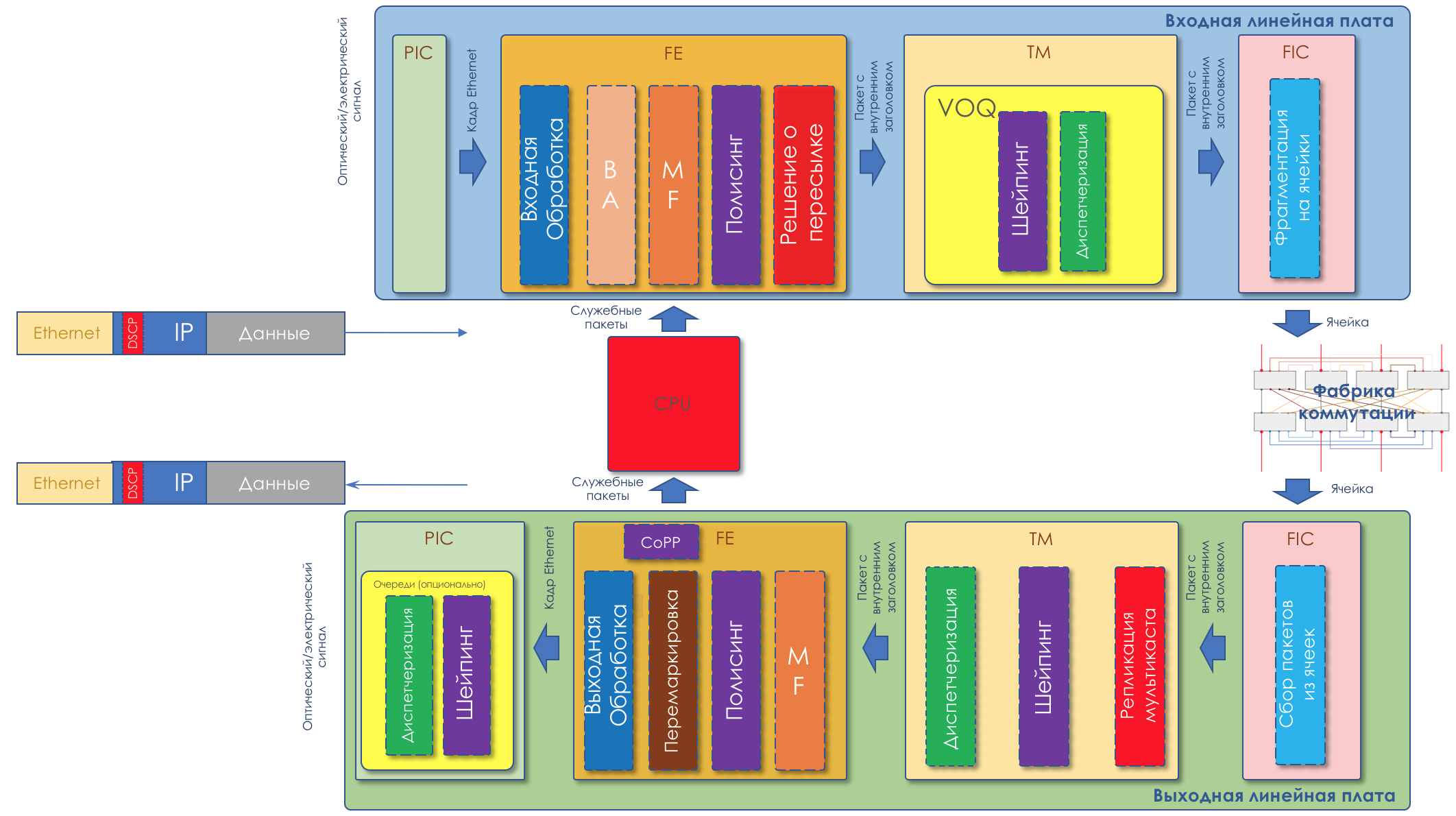
- Сигнал попадает на физический входной интерфейс и его чип (PIC). Из него вналивается битовый поток и потом пакет со всеми заголовками.
- Далее на входной чип коммутации (FE), где заголовки отделяются от тела пакета. Происходит классификация и определяется, куда пакет нужно отправить дальше.
- Далее во входную очередь (TM/VOQ). Уже здесь пакеты раскладываются в разные очереди на основе своего класса.
- Далее на фабрику коммутации (если она есть).
- Далее в выходную очередь (TM).
- Далее в выходной чип коммутации (FE), где навешиваются новые заголовки.
- Далее в выходной интерфейс (возможно, через ещё одну очередь) (PIC).
При этом маршрутизатор должен решить сложное уравнение.
Разложить всё по классам, предоставить кому-то широкую полосу, кому-то низкие задержки, кому-то обеспечить отсутствие потерь.
И при этом успеть пропустить по возможности весь трафик.
Кроме того, нужно сделать шейпинг, возможно, полисинг. Если вдруг имеет место перегрузка, то справиться с ней.
И это не считая лукапов, обработки ACL, подсчёта статистик.
Незавидная доля. Но вкалывают роботы, а не человек.
На самом деле есть всего два места, где работают механизмы QoS — это чип коммутации и чип Traffic Management/очереди.
При этом на чипе коммутации происходят операции, которые требуют анализа или действий с заголовками.
- Классификация
- Полисинг
- Перемаркировка
Остальное берёт на себя TM. В основном это рутинные операции с предопределённым алгоритмом и настраиваемыми параметрами:
- Предотвращение перегрузок
- Управление перегрузками
- Шейпинг
TM — это умный буфер, обычно на основе SD-RAM.
Умный он потому что, а) программируемый, б) с очередями умеет делать всякие хитрые штуки.
Зачастую он распределённый — чипы SD-RAM расположены на каждой интерфейсной плате, и все вместе они объединяются в VOQ (Virtual Output Queue), решающий проблему Head of Line Blocking.
Дело в том, что если чип коммутации или выходной интерфейс захлёбывается, то они просят входной чип притормозить и не отправлять некоторое время трафик. Если там только одна очередь на все направления, то очень обидно, что из-за одного выходного интерфейса страдают все остальные. Это и есть Head of Line Blocking.
VOQ же создаёт на входной интерфейсной плате несколько виртуальных выходных очередей для каждого существующего выходного интерфейса.
Причём эти очереди в современном оборудовании учитывают и маркировку пакета.
Про VOQ достаточно подробно описано в серии заметок здесь.
К слову реально в очереди помещаются, по ним продвигаются, из них изымаются итд не сами пакеты, а только записи о них. Нет смысла делать такое количество телодвижений с большими массивами битов. Пока над записями измывается QoS, пакеты прекрасно себе лежат в памяти и извлекаются оттуда по адресу.
VOQ — это программная очередь (английский термин Software Queue более точен). После него сразу перед интерфейсом находится ещё аппаратная очередь, которая всегда, строго работает по FIFO. Управлять какими-либо её параметры практически невозможно (для примера, Cisco позволяет настроить только глубину командой tx-ring-limit).
Как раз между программной и аппаратной очередью можно запускать произвольные диспетчеры. Именно в программной очереди работают Head/Tail-drop и AQM, полисинг и шейпинг.
Размер аппаратной очереди очень небольшой (единицы пакетов), потому что всю работу по укладыванию в line-rate делает диспетчер.
К сожалению, здесь можно сделать много оговорок, да и вообще всё перечеркнуть красной ручкой и сказать «у вендора Х всё не так».
Хочется сделать ещё одно замечание о служебных пакетах. Они обрабатываются иначе, чем транзитные пользовательские пакеты.
Будучи сгенерированными локально, они не проверяются на подпадание под правила ACL, и ограничения скорости.
Пакеты же извне, предназначенные на CPU, с выходного чипа коммутации попадают в другие очереди — к CPU — на основе типа протокола.
Например, BFD имеет наивысший приоритет, OSPF может подождать подольше, а ICMP и вообще не страшно отбросить. То есть, чем важнее пакет для работоспособности сети, тем выше его класс сервиса при посылке на CPU. Именно поэтому видеть в пинге или трассировке варьирующиеся задержки на транзитных хопах — это нормально — ICMP — не приоритетный для CPU трафик.
Кроме того, на протокольные пакеты применяется CoPP — Control Plane Protection (или Policing) — ограничение скорости во избежание высокой загрузки CPU — опять же, лучше предсказуемые отбрасывания в низкоприоритетных очередях до того, как начались проблемы.
CoPP поможет и от целенаправленного DoS и от аномального поведения сети (например, петли), когда на устройство начинает приходить много широковещательного трафика.
Полезные ссылки
- Лучшая книга по теории и философии QoS: QOS-Enabled Networks: Tools and Foundations.
Некоторые отрывки из неё можно почитать тут, однако я бы рекомендовал читать её от и до, не размениваясь. - На удивление обстоятельная и хорошо написанная книга про QoS от Huawei: Special Edition QoS(v6.0). Очень плотно разбирается архитектура оборудования и работа PHB на разных платах.
- Очень подробное сравнение sr-TCM и tr-TCM от Айни: Understanding Single-Rate and Dual-Rate Traffic Policing.
- Про VOQ: What is VOQ and why you should care?
- Про QoS в MPLS: MPLS and Quality of Service.
- Относительно краткий бриф по QoS на примере Juniper: Juniper CoS notes.
- Практически весь QoS так или иначе ориентирован на специфику TCP и UDP. Не лишним будет досконально разобраться в них: The TCP/IP Guide
- Ну а для тех, кто не чувствует в себе силы одолеть весь этот труд, Лохматый Мамонт для вас написал отдельную заметку: В поисках утерянного гигабита или немного про окна в TCP.
- На этой странице сложно, но подробно описано как работают механизмы группы FQ: Queuing and Scheduling.
А если подняться на уровень выше, то откроется масштабный открытый документ, называющийся An Introduction to Computer Networks, вгоняющий краску, потому что настолько мощный Introduction, что я там половину не знаю. Даже самому захотелось почитать.
- Про WFQ очень научно, но при должно интеллекте, коим, очевидно, я не обладаю, понятно и в цветах: Weighted Fair Queueing: a packetized approximation for FFS/GP.
- Есть ещё механизм LFI, который я затрагивать не стал, потому что сложно и в наших реалиях стогигиабитных интерфейсов не очень актуально, однако ознакомиться может быть интересно: Link Fragmentation and Interleaving.
- tools.ietf.org/html/rfc791 (INTERNET PROTOCOL)
- tools.ietf.org/html/rfc1349 (Type of Service in the Internet Protocol Suite)
- tools.ietf.org/html/rfc1633 (Integrated Services in the Internet Architecture: an Overview)
- tools.ietf.org/html/rfc2474 (Definition of the Differentiated Services Field (DS Field) in the IPv4 and IPv6 Headers)
- tools.ietf.org/html/rfc2475 (An Architecture for Differentiated Services)
- tools.ietf.org/html/rfc2597 (Assured Forwarding PHB Group)
- tools.ietf.org/html/rfc2697 (A Single Rate Three Color Marker)
- tools.ietf.org/html/rfc2698 (A Two Rate Three Color Marker)
- tools.ietf.org/html/rfc3031 (Multiprotocol Label Switching Architecture)
- tools.ietf.org/html/rfc3168 (The Addition of Explicit Congestion Notification (ECN) to IP)
- tools.ietf.org/html/rfc3246 (An Expedited Forwarding PHB (Per-Hop Behavior))
- tools.ietf.org/html/rfc3260 (New Terminology and Clarifications for Diffserv)
- tools.ietf.org/html/rfc3662 (A Lower Effort Per-Domain Behavior (PDB) for Differentiated Services)
- tools.ietf.org/html/rfc4594 (Configuration Guidelines for DiffServ Service Classes)
- tools.ietf.org/html/rfc5462 (Multiprotocol Label Switching (MPLS) Label Stack Entry: «EXP» Field Renamed to «Traffic Class» Field)
Заключение
У этого выпуска было много рецензентов.
Спасибо.
Александру Фатину (LoxmatiyMamont) за вводное слово и ценные советы по выразительности и доходчивости текста.
Александру Клипперу (@metallicat20) за экспертную оценку.
Александру Клименко (@v00lk) за суровую критику и самые массивные изменения в последние дни.
Андрею Глазкову (@glazgoo) за замечания по структуре, терминологии и за запятые.
Артёму Чернобаю за КДПВ.
Антону Клочкову (@NAT_GTX) за контакты с Миран.
Миран (miran.ru) за организацию сервера с Евой и трансляцией. Традиционно моей семье, которая впрочем в этот раз наименее всего пострадала ввиду её отсутствия рядом в самые тяжёлые моменты.
Комментарии (17)

vosi
18.08.2018 19:15Воу, не видел раньше эту серию постов. Это очень круто! Спасибо.
Теперь бы найти время перечитать все старые выпуски.eucariot Автор
18.08.2018 21:40Планирую перенести всё на гитбук. Последние две статьи там уже есть: linkmeup.gitbook.io/sdsm
Поэтому в скором времени все статьи ждёт пересмотр и комментарии приветствуются.
kalininmr
19.08.2018 01:39спасибо. стало хоть что то понятно.
но остатки ауры шаманизма всё ещё есть :)
wlr398
19.08.2018 13:19+1Проблема QoS в том, что его очень не просто поддерживать в полностью рабочем состоянии на реальной сети. Особенно, если сеть не замерла в развитии.
Кто-то забывает на конечных системах маркировать трафик, кто-то путает маркировку, кто-то ставит новое сетевое оборудование и забывает делать настройки чтобы маркировка не сбрасывалась или правильно мапировалась, постоянно меняющиеся полосы арендованных каналов тоже требуют перенастроек и т.д. и т.п.
В общем, пока нет аварий и хватает полосы, то всё хорошо, но регулярно вылезают проблемы.
QoS это не та технология, которую сделал и забыл.
Учитывая нарастающие экономические проблемы у операторов и оптимизации персонала и прочих расходов, все эти непростые технологии вызывают только ощущение печали.eucariot Автор
19.08.2018 23:39Никто и не говорит, что QoS — это волшебная пилюля. Он очень сложен в понимании, дизайне и поддержке.
Но благо, в наш век автоматизации одну часть проблем можно решить шаблонными конфигурациями, а другую мониторингами QoS.
skaleev
19.08.2018 23:35Спасибо за статью, действительно труд огромный.
Хотелось бы конечно еще информации по иерархическому QoS, да и по мониторингу работы QoS.eucariot Автор
19.08.2018 23:35Я даже было думал добавить часть про HQoS, но в нужный момент одумался. Хотя и самому хотелось бы внятный материал про него почитать.
sky-walker
21.08.2018 12:26Спасибо, очень качественная статья. Пользуюсь Linux, как я понимаю, полисинг и шейпинг — это такая себе теоретическая теория, а на практике есть алгоритм (например, HTB), который все и реализует. Ну и еще момент — у нас для качественного доступа в тот же Интернет на маршрутизаторе (linux) пришлось делать буфер поменьше, чтобы пакеты дропались а не ставились в очередь. Если не ошибаюсь, нехорошее явление называется bufferbloat (раздувание буфера), и встречается не так редко.
Собственно, как я понимаю, весь DiffServ QoS строится по сути на одной вещи — на способности TCP сессий понижать скорость при потере пакетов.
eucariot Автор
21.08.2018 12:33полисинг и шейпинг — это такая себе теоретическая теория, а на практике есть алгоритм (например, HTB)
HTB — это ни что иное, как реализация Tokent Bucket.
Вопрос с длиной буфера тревожит каждого инженера и архитектор, разработчика и дизайнера. От вендора до конечного оператора. Это всегда компромис между тем, чтобы дропнуть пакет или доставить любой ценой, даже если поздно.
Собственно, как я понимаю, весь DiffServ QoS строится по сути на одной вещи — на способности TCP сессий понижать скорость при потере пакетов.
Только Congestion avoidance часть строится на особенностях TCP. То, как забирать пакеты из очередей, как шейпить, как классифицировать, на TCP не завязано напрямую. QoS гораздо шире.
Более того, около 10 лет назад функция Congestion Avoidance была вовсе под вопросом, потому что TCP использовался для сёрфинга — короткоживущих сессий с небольшим объёмом передаваемых данных — потеря здесь вызывает только ретрансмит — снижать нечего. Но в наше время видеоконтента его позиции восстановились)
Emily_Rose
Спасибо вам огромное! Спасибо что продолжаете писать «вот это вот все». Это колосальный труд, я готов платить подписку за такие статьи. Вот что для меня был Хабр.
Loxmatiymamont
https://www.patreon.com/linkmeup
А мы и не против если нам трудовым рулём помогают))
12kb
Да, я тоже проникся. Думаю донейт был бы уместнее подписки, ибо это должно быть общедоступно.
eucariot, оставьте, пожалуйста, где-нибудь реквизиты для донейта. Спасибо Вам за ваши статьи! :)
Upd: опоздал с комментарием :) Вижу ссылку, спасибо.
eucariot Автор
Выше мой товарищ дал ссылку на патреон. Это просто возможность поддержать нас (а это ещё несколько серий подкастов) мелким рублём ежемесячно. При этом всё, что мы делаем, публикуется в открытом доступе.
Но есть и другие способы).