
Для проверки технологии я записал несколько обращений в разные колл-центры. Дальше они будут фигурировать под кодовыми названиями: water, mosenergo, rigla, transaero и worldclass.
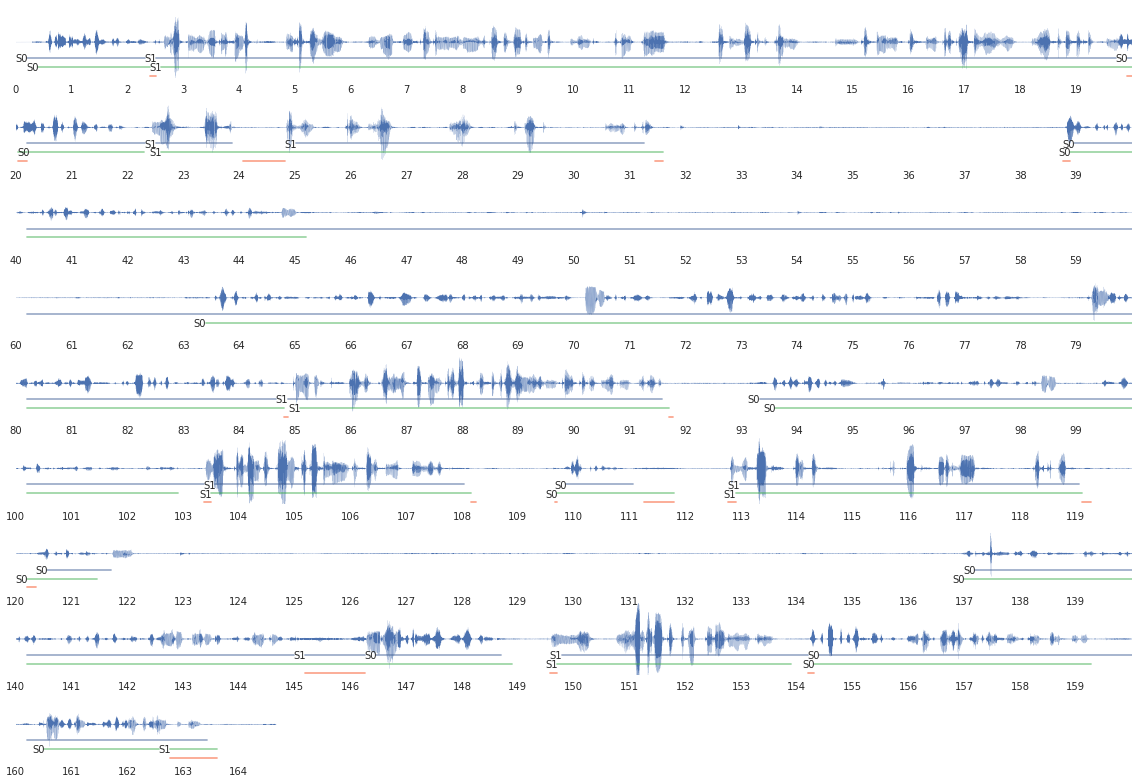
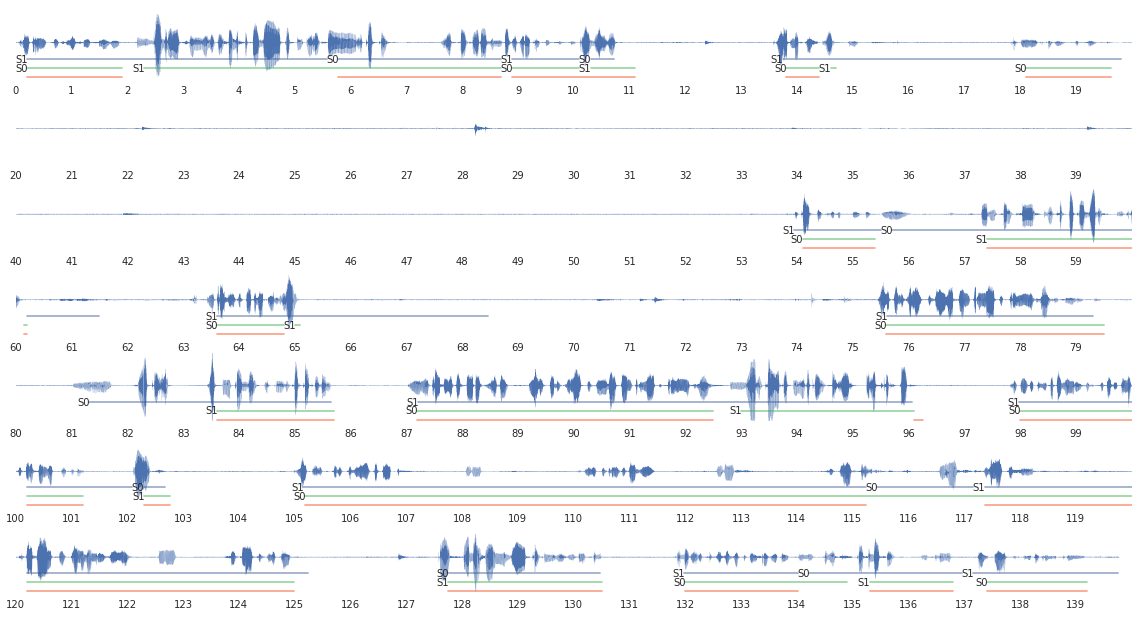
Первым делом нужно разбить запись на реплики. Как оказалось, этот процесс называется диаризацией. Есть несколько готовых инструментов: LIUM, ALIZE, SDT. Я выбрал LIUM, потому что он выглядел солиднее остальных. Написал небольшую обёртку и разметил свои треки. Качество получилось нормальное, на картинке показана разметка для water:

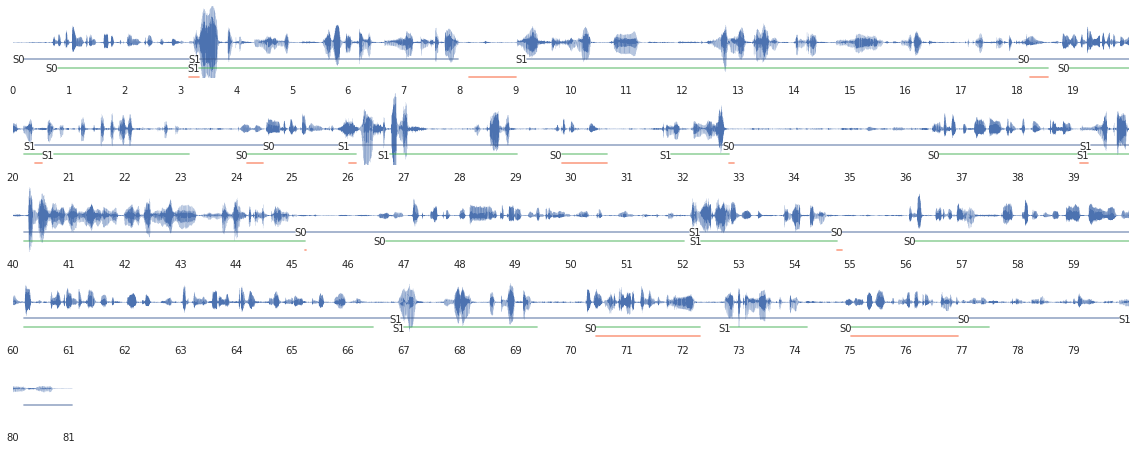
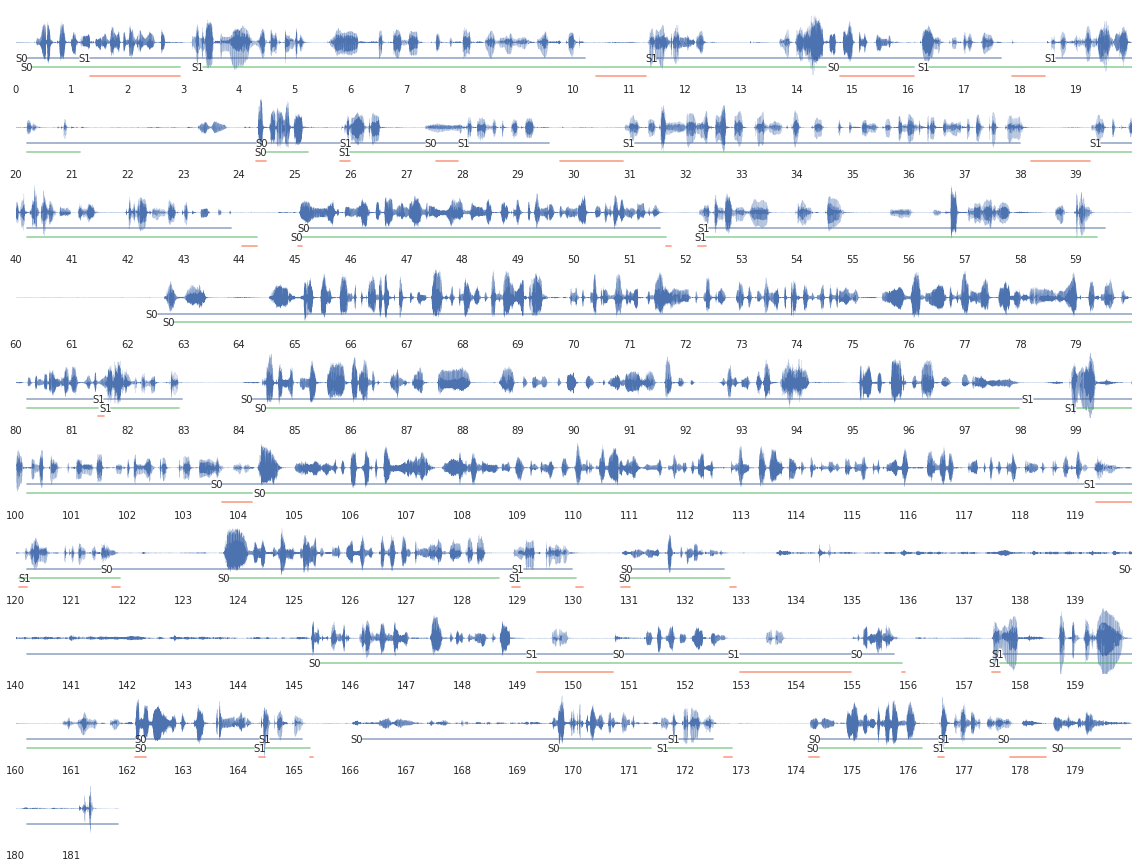
Для расшифровки реплик я использовал яндексовый SpeechKit. Чтобы оценить ошибку работы их API, я сначала скормил туда реплики, полученные по эталонной ручной разметке. Ошибки значительные, но жить можно. На картинке показана расшифровка для water:




Потом я расшифровал реплики, полученные автоматически. Убедился, что ошибки сильно не изменились, представил себя владельцем колл-центра и попробовал извлечь какую-то пользу:
По-моему, технология жизнеспособная и может принести некоторую пользу.
Первым делом нужно разбить запись на реплики. Как оказалось, этот процесс называется диаризацией. Есть несколько готовых инструментов: LIUM, ALIZE, SDT. Я выбрал LIUM, потому что он выглядел солиднее остальных. Написал небольшую обёртку и разметил свои треки. Качество получилось нормальное, на картинке показана разметка для water:
- Зелёным отмечена эталонная разметка, синим — автоматическая, красным — ошибки.
- SO — это оператор, S1 — я. Видно, что короткие ответы S1 часто подклеиваются к S0. Это не очень страшно, обычно там ничего содержательного нет, только фразы вида: «да», «верно», «нет», «хорошо».
- Более или менее корректно выделяются паузы в разговоре.
mosenergo, rigla, transaero и worldclass.
mosenergo
rigla
transaero
worldclass
rigla
transaero
worldclass
Для расшифровки реплик я использовал яндексовый SpeechKit. Чтобы оценить ошибку работы их API, я сначала скормил туда реплики, полученные по эталонной ручной разметке. Ошибки значительные, но жить можно. На картинке показана расшифровка для water:
- Слева текст, который пришёл от API, справа — то, что на самом деле было в записи. Всё что не попало в пересечение подчёркнуто красным.
- Ошибки слева — это слова, которых в записи на самом деле не было. Мне кажется, они нестрашные потому что часто совсем выбиваются из контекста разговора: «даже смерть», «лопаточные кольца», «до скольких женщин», «ленина седого», «вечер вашей страны», и к ошибкам второго рода не приведут.
- Ошибки в правой колонке — это слова, которые потерялись при расшифорвке. Их 30%-50%. Это, конечно, печально.
mosenergo, rigla, transaero и worldclass.
mosenergo

rigla

transaero

worldclass


rigla
transaero
worldclass
Потом я расшифровал реплики, полученные автоматически. Убедился, что ошибки сильно не изменились, представил себя владельцем колл-центра и попробовал извлечь какую-то пользу:
- Попробовал оценить успешность обращений по ключевым словам:
show_query_results(query_transcripts(u'спасибо большое пожалуйста', transcripts, top=10))
show_query_results(query_transcripts(u'не получается не могу нет', transcripts, top=5))
show_query_results(query_transcripts(u'заявку оформил', transcripts))
show_query_results(query_transcripts(u'будем ждать', transcripts))
- Проверил скилы операторов по впариванию услуг:
show_query_results(query_transcripts(u'у нас есть скидки', transcripts))
show_query_results(query_transcripts(u'рекомендую заключить договор на техническое обслуживание', transcripts))
show_query_results(query_transcripts(u'мы предлагаем замену труб и радиаторов на выгодных условиях', transcripts))
show_query_results(query_transcripts(u'завтра завтрашний день', transcripts))
show_query_results(query_transcripts(u'за выезд мастера никто денег не возьмёт', transcripts))
show_query_results(query_transcripts(u'в любое время когда вам удобно', transcripts))
show_query_results(query_transcripts(u'приходите поговорим о ценах акциях подберем выгодный вариант', transcripts))
show_query_results(query_transcripts(u'у нас принято встречать гостей', transcripts))
show_query_results(query_transcripts(u'скажите вашу фамилию и телефон', transcripts))
- Попробовал определить цель звонка:
show_query_results(query_transcripts(u'хотел бы оформить узнать сколько стоит сколько платить подключить посмотреть посещать уточнить наличие', transcripts, top=5))
show_query_results(query_transcripts(u'горные лыжи', transcripts))
По-моему, технология жизнеспособная и может принести некоторую пользу.
Stas911
А можно подробнее — где хранили, чем обрабатывали?
alexkuku Автор
Хранил в файликах, обрабатывал кодом на Питоне