
Appodeal — это компания из ~100 человек, которые работают в Москве, Сан-Франциско, Барнауле, Луцке, Кирове, Барселоне, а с июня 2018 года — еще и в Минске.
Мы занимаемся монетизацией мобильных приложений с помощью показа рекламы пользователям. Начинали мы с медиации рекламы, но стек технологий постоянно растет, поэтому к медиации добавились и другие продукты из отрасли Ad Tech.

Для тех, кто еще не знаком с Ad Tech — это область работы технологичных компаний, которые работают в сфере рекламы. Когда рассказываешь кому-то, что ты работаешь в сфере мобильной рекламы, то люди часто реагируют скептически — видимо, на ум приходит надоедливая реклама «Азино три топора». На самом деле это лишь верхушка айсберга, и вся эта “дикая” реклама не имеет никакого отношения к настоящему рекламному бизнесу. А мобильный сегмент, которым мы и занимаемся, уже давно перерос сегмент рекламы в вебе:

Разумеется, на создание приложений тратится много ресурсов — и создатели/владельцы хотят, чтобы потраченные время и усилия окупались. Владельцев мобильных приложений, которые выкладывают свое приложение в App store/Google Play называют издателями или паблишерами. Паблишеры применяют разные модели монетизации, от внутриигровых покупок (In-App Purchases) до монетизации с помощью рекламы. Но из всех этих способов только последний позволяет пользователю не платить за использование приложения — и это дает наибольший охват аудитории.
Да, если рекламы слишком много, это будет всех раздражать и негативно скажется на удержании пользователя. Что, конечно же, никому не нужно. Поэтому рекламу всегда стараются интегрировать с умом, чтобы заработать на своем приложении максимум денег и при этом не брать с пользователей ни копейки.
Как только паблишер решает монетизироваться с помощью рекламы, он приходит к той компании, которая может максимально облегчить для него эту задачу. Как это происходит в случае с Appodeal? После регистрации на сайте мы интегрируем его приложение с нашим сервисом. Делается это через клиентский SDK, который связывает приложение с серверной частью и осуществляет общение с серверной частью посредством API.
Если свести детали к минимуму, то цель взаимодействия сводится к двум этапам:
а. Определить, какую рекламу нужно показать прямо сейчас;
б. Отправить информацию о том, какая реклама была показана, а какая нет, и отобразить это в статистике.
На данный момент Appodeal обслуживает несколько тысяч активных приложений, которые осуществляют примерно 400-450 млн. показов рекламы в день, получаемых в ответ на около 1 млрд. запросов к рекламным сетям (которые и являются поставщиками рекламы). Чтобы все это работало, наши сервера суммарно обслуживают около 125 тыс. запросов в секунду, т.е. примерно 10.8 млрд запросов в день.

Мы используем различные технологии, чтобы обеспечивать скорость, надежность и при этом гибкость разработки и поддержки. На данный момент мы пишем код на следующих языках:

Appodeal конкурирует в своем сегменте с очень крупными игроками, поэтому приспосабливаться под изменения рынка приходится быстро. Часто это по ощущениям напоминает смену колес у автомобиля на скорости в 100 км/ч. Ruby on Rails позволил нам выдержать гонку и закрепиться на рынке достаточно, чтобы быть лидером в своем сегменте. Основные плюсы Rails на наш взгляд:

Из явных минусов:

Данных у нас много. Очень. Речь идет о миллиардах / десятках / сотнях миллиардов записей. Поскольку данные абсолютно разные, то и храним мы их по-разному. Никогда не стоит ограничиваться в архитектуре каким-то одним решением, которое якобы является универсальным. Практика показывает, что, во-первых, в Highload'е универсальных решений практически не бывает. Универсальность означает средние (или значительно ниже средних) показатели по скорости доступа / чтения / размеру хранения данных как плату за эту самую универсальность. Во-вторых, нужно все время пробовать что-то новое, экспериментировать и искать нетривиальные решения для поставленных задач. Итого:

Такой набор может показаться перегруженным, но во-первых, Appodeal — это большой конгломерат из нескольких команд разработки и нескольких проектов внутри одного. А во-вторых, это суровые реалии ad tech — далеко не мы одни используем многоэтажный стек внутри одной компании.
Поскольку потоки данных большие, чтобы их обрабатывать, данные нужно складывать в очередь. В качестве очереди мы используем Kafka. Это отличное надежное решение, написанное на Scala, которое нас еще ни разу не подвело.
Единственное требование к пользователю в данном случае заключается в том, чтобы он успевал разгребать постоянно увеличивающуюся очередь быстрее, чем она растет. Простое и очевидное правило. Поэтому для этих целей мы в основном используем GoLang. Однако, это не отменяет того, что оперативной памяти на этом сервере должно быть с избытком.
Чтобы следить за всем этим хозяйством, приходится мониторить и делегировать буквально все подряд. Для этого мы используем:

Нужно понимать, что грамотно построенный мониторинг — это ваши глаза и уши. Вслепую работать невозможно. Нужно видеть, что происходит на ваших серверах в конкретный момент времени, поэтому стабильность и надежность вашего продукта будет зависеть во многом от того, насколько вы грамотно построите систему сбора и отображения метрик.
Кстати, говоря о надежности, мы содержим несколько staging-серверов для предварительного выкатывания и проверки релизов, которые стабильно держим под нагрузкой, дублируя туда часть настоящего трафика. Каждую неделю мы синхронизируем базы данных между продакшеном и стейджингом. Это дает нам некое «зеркало», позволяющее тестировать те вещи, которые не удается проверить локально, а также выявить проблемы на уровне нагрузочного тестирования.
Получается, что так. Как писал Илон Маск в своей книге: «Лучшие умы моего поколения заняты тем, как заставить людей кликать мышью по рекламным объявлениям, — сказал мне Джефф Хаммербахер, ранее инженер Facebook. — Ужас...». Краткий список того, что делает Appodeal:

В данном случае так называемые биддеры торгуются друг с другом онлайн на аукционе за право показать на выбранном устройстве свою рекламу. Очень интересный момент, достойный отдельной статьи. Многие биржи, как например Google AdExchange, устанавливают жесткие рамки на время ответа сервера (например, в 50мс), что ставит вопрос производительности ребром. В случае неповиновения — штраф в тысячи долларов. Это как раз то, что делает ядро, написанное на Scala в связке с Druid.
Каждый охотник желает знать, где сидит фазан, а наши клиенты (как и мы) желают знать, кому была показана реклама, когда и почему. Поэтому всю кучу данных, которая у нас есть, нам приходится ставить в очередь (Kafka), постепенно обрабатывать и складывать в OLAP базу данных (ClickHouse). Многие думают, что PostgreSQL вполне справится с этой задачей не хуже всяких «хипстерских» решений, но это не так. PostgreSQL хорош, но классическое решение построения индексов для скорости доступа к данным перестает работать, когда количество полей для фильтрации и сортировки переваливает за 10, а количество хранимых данных приближается к 1 млрд. записей. У вас попросту не хватит памяти для хранения всех этих индексов или же возникнут проблемы с обновлением этих индексов. В любом случае, добиться такой же производительности, как у колонко-ориентированных решений, для аналитических запросов вам не удастся.
В этой статье я попытался хотя бы вкратце рассказать то, чем мы занимаемся, как мы храним и обрабатываем данные. Рассказывайте в комментариях, какой стек используете вы, задавайте вопросы и запрашивайте новые статьи — мы с удовольствием поделимся своим опытом.
Мы занимаемся монетизацией мобильных приложений с помощью показа рекламы пользователям. Начинали мы с медиации рекламы, но стек технологий постоянно растет, поэтому к медиации добавились и другие продукты из отрасли Ad Tech.
Для тех, кто еще не знаком с Ad Tech — это область работы технологичных компаний, которые работают в сфере рекламы. Когда рассказываешь кому-то, что ты работаешь в сфере мобильной рекламы, то люди часто реагируют скептически — видимо, на ум приходит надоедливая реклама «Азино три топора». На самом деле это лишь верхушка айсберга, и вся эта “дикая” реклама не имеет никакого отношения к настоящему рекламному бизнесу. А мобильный сегмент, которым мы и занимаемся, уже давно перерос сегмент рекламы в вебе:
Зачем нужно интегрировать рекламу в приложениях?
Разумеется, на создание приложений тратится много ресурсов — и создатели/владельцы хотят, чтобы потраченные время и усилия окупались. Владельцев мобильных приложений, которые выкладывают свое приложение в App store/Google Play называют издателями или паблишерами. Паблишеры применяют разные модели монетизации, от внутриигровых покупок (In-App Purchases) до монетизации с помощью рекламы. Но из всех этих способов только последний позволяет пользователю не платить за использование приложения — и это дает наибольший охват аудитории.
Да, если рекламы слишком много, это будет всех раздражать и негативно скажется на удержании пользователя. Что, конечно же, никому не нужно. Поэтому рекламу всегда стараются интегрировать с умом, чтобы заработать на своем приложении максимум денег и при этом не брать с пользователей ни копейки.
Как это работает?
Как только паблишер решает монетизироваться с помощью рекламы, он приходит к той компании, которая может максимально облегчить для него эту задачу. Как это происходит в случае с Appodeal? После регистрации на сайте мы интегрируем его приложение с нашим сервисом. Делается это через клиентский SDK, который связывает приложение с серверной частью и осуществляет общение с серверной частью посредством API.
Если свести детали к минимуму, то цель взаимодействия сводится к двум этапам:
а. Определить, какую рекламу нужно показать прямо сейчас;
б. Отправить информацию о том, какая реклама была показана, а какая нет, и отобразить это в статистике.
На данный момент Appodeal обслуживает несколько тысяч активных приложений, которые осуществляют примерно 400-450 млн. показов рекламы в день, получаемых в ответ на около 1 млрд. запросов к рекламным сетям (которые и являются поставщиками рекламы). Чтобы все это работало, наши сервера суммарно обслуживают около 125 тыс. запросов в секунду, т.е. примерно 10.8 млрд запросов в день.
На чем все это построено?
Мы используем различные технологии, чтобы обеспечивать скорость, надежность и при этом гибкость разработки и поддержки. На данный момент мы пишем код на следующих языках:
- /Ruby / Ruby on Rails + React.JS (front-end)/: Все еще большая часть API и вся веб-часть, которую видят пользователи и наши сотрудники
- /GoLang/: Обработка больших массивов данных по статистике и не только
- /Scala/: Realtime-обработка запросов для работы с биржами торговли трафика по протоколу RTB (подробнее о нем читайте в конце статьи)
- /Elixir / Phoenix/: Скорее, экспериментальная часть. Построение некоторых микро-сервисов для обработки части статистики и API.
Почему изначально Ruby и Ruby on Rails?
Appodeal конкурирует в своем сегменте с очень крупными игроками, поэтому приспосабливаться под изменения рынка приходится быстро. Часто это по ощущениям напоминает смену колес у автомобиля на скорости в 100 км/ч. Ruby on Rails позволил нам выдержать гонку и закрепиться на рынке достаточно, чтобы быть лидером в своем сегменте. Основные плюсы Rails на наш взгляд:
- Большое количество квалифицированных разработчиков
- Отличное коммьюнити. Огромное количество готовых решений и библиотек
- Скорость внедрения новых фич и изменение/удаление старых
Из явных минусов:
- Производительность в целом оставляет желать лучшего. Также сказывается отсутствие JIT (на данный момент), отсутствие возможности параллелить код (если не брать в расчет JRuby). До какой-то степени это остается терпимым, потому что “бутылочным горлышком”, как правило, становится база данных и кэш. Что мы и видим на снимке из NewRelic:
- Рельсовый монолит не слишком хорошо пилится на микросервисы — сказывается высокая степень связности бизнес-логики и логики доступа к данным (ActiveRecord).
Как хранятся данные?
Данных у нас много. Очень. Речь идет о миллиардах / десятках / сотнях миллиардов записей. Поскольку данные абсолютно разные, то и храним мы их по-разному. Никогда не стоит ограничиваться в архитектуре каким-то одним решением, которое якобы является универсальным. Практика показывает, что, во-первых, в Highload'е универсальных решений практически не бывает. Универсальность означает средние (или значительно ниже средних) показатели по скорости доступа / чтения / размеру хранения данных как плату за эту самую универсальность. Во-вторых, нужно все время пробовать что-то новое, экспериментировать и искать нетривиальные решения для поставленных задач. Итого:
- /PostgreSQL/: Мы любим Postgre. Считаем его лучшим на данный момент OLTP решением для хранения данных. Данные о юзерах, приложениях, рекламных кампаниях и так далее храним там. Используем Primary-Replica репликацию. Бэкапы делаем только по рождественским праздникам, потому что это для слабаков (шутка).
- /VerticaDB/: Колонко-ориентированная база данных. Используем для хранения миллиардов записей по статистике. Если кратко, то считали какое-то время “Вертику”лучшим OLAP решением для хранения аналитики. Основной минус — огромная (индивидуальная) цена за лицензию.
- /ClickHouse/: Тоже колонко-ориентированная база данных. Постепенно переходим на нее с VerticaDB. Считаем лучшим OLAP решением на данный момент. Не стоит ни копейки. Работает очень быстро и надежно. Главный минус — данные нельзя удалять и обновлять (об этом расскажем в отдельной статье, если кому-то будет интересно).
Ничоси! Как это нельзя удалять и изменять данные?!
- /Aerospike/: Самый быстрый NoSQL key-value storage на наш взгляд. Есть ряд минусов, но в целом нас устраивает. По Aerospike есть даже сравнительная таблица на их сайте по производительности с другими решениями: [When to use Aerospike NoSQL database vs. Redis](https://www.aerospike.com/when-to-use-aerospike-vs-redis/)
- /Redis/: Про “Редис”, я думаю, отдельно рассказывать нет смысла. Как ни парадоксально, его главный плюс в простоте использования и однопоточности, что позволяет избежать race conditions, например, при работе с банальными счетчиками.
- /Druid/: Используем для больших массивов данных в работе с RTB биржами. По сути, в большинстве своем, играет на одном поле с ClickHouse, но исторически сложилось, что перейти на какой-то один инструмент мы пока не смогли.
Такой набор может показаться перегруженным, но во-первых, Appodeal — это большой конгломерат из нескольких команд разработки и нескольких проектов внутри одного. А во-вторых, это суровые реалии ad tech — далеко не мы одни используем многоэтажный стек внутри одной компании.
Как вы за этим следите?
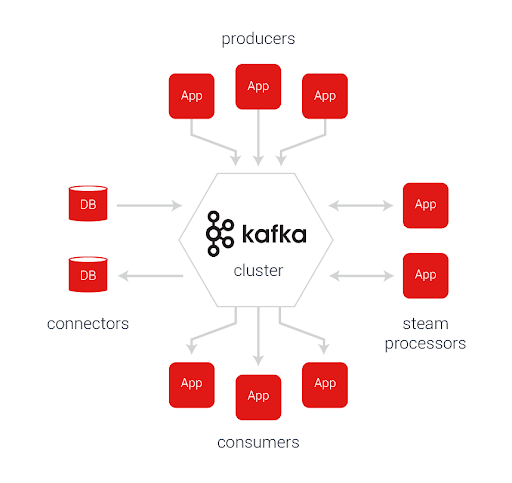
Поскольку потоки данных большие, чтобы их обрабатывать, данные нужно складывать в очередь. В качестве очереди мы используем Kafka. Это отличное надежное решение, написанное на Scala, которое нас еще ни разу не подвело.
Единственное требование к пользователю в данном случае заключается в том, чтобы он успевал разгребать постоянно увеличивающуюся очередь быстрее, чем она растет. Простое и очевидное правило. Поэтому для этих целей мы в основном используем GoLang. Однако, это не отменяет того, что оперативной памяти на этом сервере должно быть с избытком.
Чтобы следить за всем этим хозяйством, приходится мониторить и делегировать буквально все подряд. Для этого мы используем:
- /NewRelic/: Проверенное временем решение, отлично интегрируется с Ruby on Rails и микро-сервисами на GoLang. Единственный минус NewRelic — это его цена. Поэтому NewRelic стоит у нас не везде. В большинстве своем мы стараемся заменять его собственноручно собираемыми метриками — их мы складываем в Grafana.
- /Statsd + Grafana/: Хорошая штука для сбора своих метрик. С тем лишь минусом, что все приходится настраивать самому и «повторять» функционал NewRelic из коробки.
- /ElasticSearch + Fluentd + Kibana/: В логи мы складываем все подряд. От медленных запросов PostgreSQL, до каких-то системных сообщений Rails. Собственно, такое решение как Kibana на базе ElasticSearch позволяет удобным образом собирать все логи в одном месте и потом проводить по ним поиск нужных сообщений.
- /Airbrake/: Обязательным в этом всем является процесс сбора ошибок вместе со stacktrace'ами сообщений. В данный момент мы съезжаем с Airbrake на одно из бесплатных решений. По причине, опять-таки, цены.
Нужно понимать, что грамотно построенный мониторинг — это ваши глаза и уши. Вслепую работать невозможно. Нужно видеть, что происходит на ваших серверах в конкретный момент времени, поэтому стабильность и надежность вашего продукта будет зависеть во многом от того, насколько вы грамотно построите систему сбора и отображения метрик.
Кстати, говоря о надежности, мы содержим несколько staging-серверов для предварительного выкатывания и проверки релизов, которые стабильно держим под нагрузкой, дублируя туда часть настоящего трафика. Каждую неделю мы синхронизируем базы данных между продакшеном и стейджингом. Это дает нам некое «зеркало», позволяющее тестировать те вещи, которые не удается проверить локально, а также выявить проблемы на уровне нагрузочного тестирования.
Неужели все настолько сложно?
Получается, что так. Как писал Илон Маск в своей книге: «Лучшие умы моего поколения заняты тем, как заставить людей кликать мышью по рекламным объявлениям, — сказал мне Джефф Хаммербахер, ранее инженер Facebook. — Ужас...». Краткий список того, что делает Appodeal:
- Мы интегрированы с двумя десятками рекламных сетей и агентств. В автоматическом режиме мы регистрируем приложения в этих сетях, а также настраиваем различные параметры, чтобы эти сети работали с максимальной производительностью. Не у каждой сети есть соответствующие API, где-то приходится делать это «роботами».
- Каждая сеть выплачивает пользователям доход за показы, который необходимо получить, разбить по различным параметрам и обработать. Делается это в режиме нон-стоп. Где-то, опять-таки, роботами.
- Чтобы предоставить пользователю максимальный доход, мы «заставляем» сетки конкурировать между собой, выстраивая из рекламных предложений так называемый «водопад». Водопад построен на базе различных показателей, например, eCPM (средняя цена за 1000 показов), которые мы различными способами предсказываем. Чем выше в водопаде рекламное предложение, тем выше мы прогнозируем цену за него. Отдается на устройство этот водопад настолько часто, насколько это требуется. Как вы уже могли догадаться, реклама, на которую никто не нажмет, и которая всех будет только раздражать, никого не интересует. Исключение составляет только т.н. «брендовая» баннерная реклама от Coca-Cola, Pepsi и прочих корпоративных гигантов, которые привыкли говорить о себе всегда и везде.
- Часть из этого взаимодействия построено по так называемому протоколу RTB (Real-Time Bidding):
В данном случае так называемые биддеры торгуются друг с другом онлайн на аукционе за право показать на выбранном устройстве свою рекламу. Очень интересный момент, достойный отдельной статьи. Многие биржи, как например Google AdExchange, устанавливают жесткие рамки на время ответа сервера (например, в 50мс), что ставит вопрос производительности ребром. В случае неповиновения — штраф в тысячи долларов. Это как раз то, что делает ядро, написанное на Scala в связке с Druid.
Каждый охотник желает знать, где сидит фазан, а наши клиенты (как и мы) желают знать, кому была показана реклама, когда и почему. Поэтому всю кучу данных, которая у нас есть, нам приходится ставить в очередь (Kafka), постепенно обрабатывать и складывать в OLAP базу данных (ClickHouse). Многие думают, что PostgreSQL вполне справится с этой задачей не хуже всяких «хипстерских» решений, но это не так. PostgreSQL хорош, но классическое решение построения индексов для скорости доступа к данным перестает работать, когда количество полей для фильтрации и сортировки переваливает за 10, а количество хранимых данных приближается к 1 млрд. записей. У вас попросту не хватит памяти для хранения всех этих индексов или же возникнут проблемы с обновлением этих индексов. В любом случае, добиться такой же производительности, как у колонко-ориентированных решений, для аналитических запросов вам не удастся.
Заключение
В этой статье я попытался хотя бы вкратце рассказать то, чем мы занимаемся, как мы храним и обрабатываем данные. Рассказывайте в комментариях, какой стек используете вы, задавайте вопросы и запрашивайте новые статьи — мы с удовольствием поделимся своим опытом.