
Задача
Одна из больших задач приложения для хранения и анализа покупок — поиск одинаковых или очень близких продуктов в базе данных, где собраны разномастные и непонятные наименования продуктов, полученные из чеков. Есть два вида входного запроса:
- Специфичное название с сокращениями, которое может быть понятно только кассирам местного супермаркета, либо заядлым покупателям.
- Запрос на естественном языке, введенный пользователем в поисковую строку
Запросы первого вида как правило исходят из продуктов в самом чеке, когда пользователю нужно подыскать продукты подешевле. Наша задача заключается в том, чтобы подобрать максимально похожий аналог товара из чека в других магазинах поблизости. Здесь важно подобрать наиболее соответствующую марку продукта и по возможности объём.
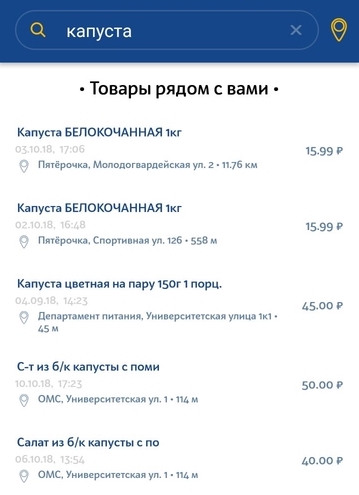
Запрос второго вида — это простой запрос пользователя на поиск определённого продукта в ближайшем магазине. Запрос может быть очень общий, не уникально описывающий продукт. Здесь возможны небольшие отклонения от запроса. Например, если пользователь ищет молоко 3.2%, а у нас в базе только молоко 2.5%, то мы все равно хотим показать хотя бы этот результат.
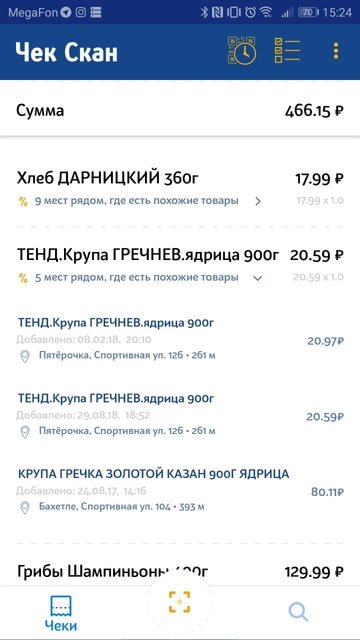
Особенности датасета — проблемы для решения
Информация в чеке о продукте далеко не идеальна. В ней много не всегда понятных сокращений, грамматических ошибок, опечаток, разнообразных транслитов, латинских букв посреди кириллицы и наборов символов, имеющих смысл только для внутренней организации в определенном магазине.
Например, детское яблочно-грушевое пюре с творогом запросто может быть записано в чеке вот так:

О технологии
Elasticsearch — достаточно популярная и доступная технология для имплементации поиска. Это поисковый движок с JSON REST API, использующий Lucene и написанный на Java. Основными преимуществами Elastic’а являются скорость, масштабируемость и отказоустойчивость. Подобные движки используются при сложном поиске по базе документов. Например, поиск с учетом морфологии языка или поиск по geo координатам.
Направления для экспериментов и улучшений
Чтобы понять, как можно улучшить поиск, надо разобрать систему поиска на составляющие настраиваемые компоненты. Для нашего случая структура системы выглядит так.
- Входная строка для поиска проходит через анализатор, который определенным образом разбивает строку на токены — поисковые единицы, по которым ведется поиск среди данных, которые так же хранятся в виде токенов.
- Затем идет непосредственный поиск этих токенов по каждому документу в существующей базе. После нахождения токена в определенном документе (который в базе также представлен в виде сета токенов) высчитывается его релевантность согласно выбранной Similarity model (будем называть её Модель релевантности). Это может быть простой TF/IDF (Term Frequency — Inverse Document Frequency), а могут быть и другие более сложные или специфичные модели.
- На следующем этапе количество очков, набранных каждым отдельным токеном, определенным образом агрегируется. Параметры агрегации задаются семантикой запроса. Примером таких агрегаций могут стать дополнительные веса для определенных токенов (добавочная ценность), условия обязательного присутствия токена и тд. Результатом этого этапа является Score — финальная оценка релевантности определенного документа из базы относительно изначального запроса.

Из устройства поиска можно выделить три отдельно настраиваемых компонента, в каждом из которых можно выделить свои пути и способы улучшения.
- Анализаторы
- Similarity model
- Query-time улучшения
Далее рассмотрим каждый компонент в отдельности и разберём конкретные настройки параметров, которые помогли улучшить поиск в случае с названиями продуктов.
Query-time улучшения
Чтобы понять, что мы можем улучшить в запросе, приведем пример изначального запроса.
{
"query": {
"multi_match": {
"query": "кетчуп хайнц 105г",
"type": "most_fields",
"fields": ["name"],
"minimum_should_match": "70%"
}
},
“size”: 100,
“min_score”: 15
}Мы используем тип запроса most_fields, так как предвидим необходимость в комбинации нескольких анализаторов для поля “название продукта”. Данный тип запроса позволяет комбинировать результаты поиска по разным атрибутам объекта, содержащих один и тот же текст, проанализированный разными способами. Альтернативой этому подходу являются использование запросов best_fields или cross_fields, но они не подходят для нашего случая, так как рассчитаны поиск среди разных атрибутов объекта (н-р: название и описание). Перед нами же стоит задача учесть разные аспекты одного атрибута — названия продукта.
Что можно настроить:
- Взвешенное сочетание различных анализаторов.
Изначально у всех элементов поиска одинаковый вес — а значит, одинаковая значимость. Это можно поменять, добавив параметр ‘boost’, который принимает числовые значения. Если параметр больше 1, элемент поиска будет иметь большее влияние на результаты, соответственно меньше 1 — меньшее. - Разделение анализаторов на ‘should’ и ‘must’.
А именно, определенные анализаторы должны совпасть, а некоторые являться опциональными, то есть недостаточными. В нашем случае примером пользы от такого разделения может стать анализатор чисел. Если в названии продукта в запросе и названии продукта в базе совпадает только число, то это недостаточное условие для их эквивалентности. Мы не хотим видеть такие продукты в результате. В то же время, если запросом являются “сливки 10%”, то мы хотим чтобы у всех сливок с 10% жирности было большое преимущество перед сливками с 20% жирностью. - Параметр minimum_should_match. Какое количество токенов должно обязательно совпадать в запросе и документе из базы? Этот параметр работает сообща с типом нашего запроса (most_fields) и проверяет минимальное количество совпадающих токенов для каждого из полей (в нашем случае — для каждого анализатора).
- Параметр min_score. Порог, отсеивающий документы с недостаточным количеством очков. Загвоздка в том, что нет заранее известного максимального скора. Результирующий Score зависит от конкретного запроса и от конкретной базы документов. Иногда это может быть 150, а иногда 2, но оба эти значения будут означать, что объект из базы релевантен по отношению к запросу. Мы не можем сравнивать скоры результатов разных запросов.
- Константа.
После достаточного наблюдения за итоговыми значениями скора для разных запросов, можно выявить примерную границу, после которой для большинства запросов результаты становятся неподходящими. Это самое легкое, но и самое неумное решение, которое приводит к некачественному поиску. - Попытаться проанализировать полученные скоры для определенного запроса уже после выполнения поиска с минимальным или нулевым min_score.
Идея заключается в том, что после определенного момента можно наблюдать резкий скачок в сторону уменьшения скора. Остается только определить этот скачок, чтобы вовремя остановиться. Такой подход хорошо сработал бы на подобных запросах:
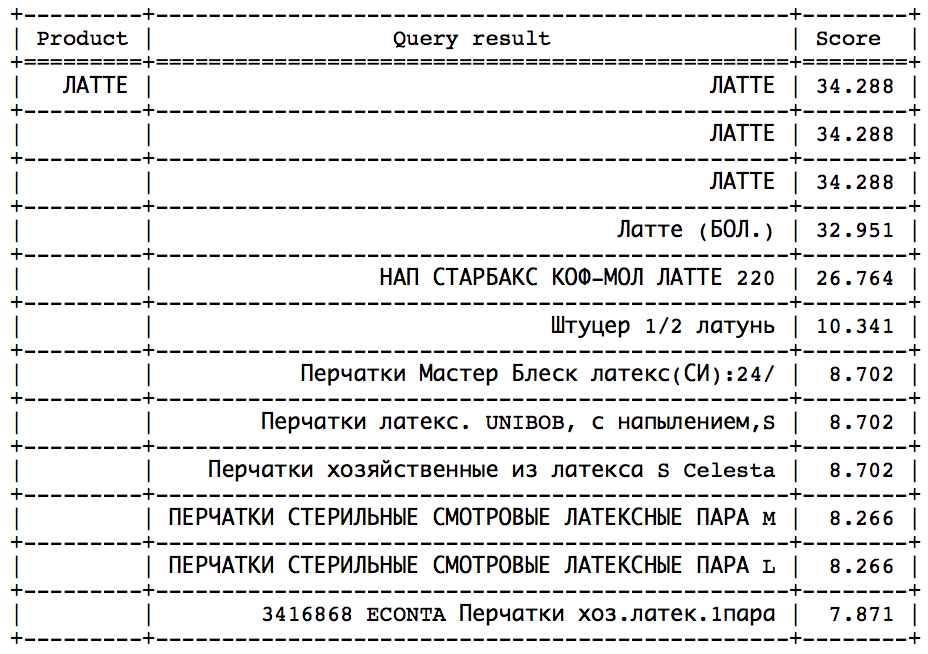
Скачок можно найти путем статистических методов. Но, к сожалению, далеко не во всех запросах этот скачок присутствует и легко определим. - Подсчитать идеальный скор и установить min_score как определенную долю от идеального, что можно сделать двумя путями:
- Из подробного описания вычислений, предоставляемого самим Elastic’ом при установке параметра explain: true. Это трудная задача, требующая исчерпывающего понимания архитектуры запроса и алгоритмов для вычисления, используемых Elastic’ом.
- Путем небольшой хитрости. Получаем запрос, добавляем новый товар в нашу базу с таким же названием, делаем поиск и достаем максимальный скор. Так как будет 100% совпадение по названию, полученное значение будет идеальным. Именно этот подход мы используем в нашей системе, так как опасения по поводу дороговизны данной операции в отношении времени не подтвердились.
- Константа.
- Поменять scoring алгоритм, который отвечает за итоговое значение релевантности. Это может быть учет расстояния до магазина (давать больше очков продуктам, которые ближе), цены товара (давать больше очков продуктам с наиболее вероятной ценой) и тд.
Анализаторы
Анализатор анализирует входную строку в три этапа и на выходе выдает токены — поисковые единицы:

Сначала происходят изменения на уровне символов строки. Это может быть замена, удаление или добавление символов в строку. Затем в игру вступает tokenizer, который призван разделить строку на токены. Стандартный токенизатор разделяет строку на токены согласно знакам препинания. Последним этапом полученные токены фильтруются и обрабатываются.
Рассмотрим, какие вариации этапов стали полезными в нашем случае.
Char filters
- Согласно специфике русского языка было бы полезно обработать такие символы как й и ё и заменить их на и и е соответственно.
- Произвести транслитерацию — передачу знаков одной письменности знаками другой письменности. В нашем случае это обработка названий, написанных латиницей или вперемешку обоими алфавитами. Транслитерацию можно внедрить с помощью плагина (ICU Analysis Plugin) как фильтр токенов (то есть он обрабатывает не изначальную строку, а финальные токены). Мы решили написать свою транслитерацию, так как были не вполне довольны алгоритмом в плагине. Идея заключается в том, чтобы сначала заменить четырехсимвольные установленные вхождения (н-р, "SHCH => щ”), затем трехсимвольные и тд. Порядок применения фильтров символов важен, так как от порядка будет зависеть результат.
- Заменить латинскую c, окруженную кириллицей, на русскую с. Необходимость этого была выявлена после анализа названий в базе данных — очень многие названия на кириллице включали латинскую c, которая имеет в виду кириллическую с. Когда как если название полностью на латинице, то латинская с означает кириллическую к или ц. Поэтому прежде чем производить транслитерацию, необходимо заменить символ c.
- Удаление слишком больших чисел из названий. Иногда в названиях продуктов встречается внутренний идентификационный номер (н-р 3387522 К.Ц.Масло подсолн.раф.0.9л), который не несет никакой смысловой нагрузки в общем случае.
- Замена запятых на точки. Зачем это нужно? Чтобы числительные, например жирности молока 3.2 и 3,2, были эквивалентны
Tokenizer
- Стандартный токенизатор — разделяет строки согласно знакам пробела и препинания (н-р, "твикс экстра 2” -> “твикс”, “экстра”, “2”)
- EdgeNGram токенизатор — разбивает каждое слово на токены заданной длины (как правило диапазон чисел), начиная с первого символа (н-р, для N = [3, 6]: "твикс экстра 2” -> “тви”, “твик”, “твикс”, “экс”, “экст”, “экстр”, “экстра”)
- Токенизатор для чисел — выделяет из строки только числа путем поиска регулярного выражения (н-р, "твикс экстра 2 4.5” -> “2”, “4.5”)
Token filter
- Lowercase фильтр
- Стемминг фильтр — выполняет стемминг алгоритм для каждого токена. Стемминг заключается в том, чтобы определить начальную форму слова (н-р, “риса” -> “рис”)
- Фонетический анализ. Необходим для того, чтобы минимизировать влияние опечаток и разных способов написания одного и того же слова на результаты поиска. В таблице представлены различные доступные алгоритмы для фонетического анализа и результат их работы в проблемных случаях. В первом случае (Шампунь/шампанское/шампиньон/шампиньоны) успех определяется генерацией разных кодировок, в остальных — одинаковых.
| Шампунь/ шампанское/шампиньон/шампиньоны | Хрусteam/хрустим | Маринованные/ маринован | Нютелла/ нутелла/ nutella | ketчуп/ кетчуп | |
|---|---|---|---|---|---|
| Cologne | + | + | + | + | - |
| Metaphone | - | + | + | + | - |
| Soundex | - | + | + | + | - |
| Caverphone | + | + | - | + | - |
| Nysiis | + | + | + | + | + |
Similarity model
Модель релевантности нужна для того, чтобы определить в какой мере совпадение одного токена влияет на релевантность объекта из базы по отношению к запросу. Допустим, если в запросе и продукте из базы совпадает токен ‘для’ — это конечно, неплохо, но о соответствии продукта к запросу говорит мало. Таким образом, совпадение разных токенов несет различную ценность. Для того, чтобы это учитывать и нужна модель релевантности. Elastic предоставляет множество различных моделей. Если правда в них разобраться, то можно подобрать очень специфичную и подходящую под конкретный случай модель. Выбор может основываться на количестве часто употребляемых слов (по типу того же токена ‘для’), оценке важности длинных токенов (длиннее — значит лучше? Хуже? Не имеет значения?), какие результаты мы хотим видеть в конце и тд. Примерами моделей, которые предложены в Elastic’е могут стать TF-IDF (самая простая и понятная модель), Okapi BM25 (улучшенный TF-IDF, модель по умолчанию), Divergence from randomness, Divergence from independence и тд. У каждой модели также имеются настраиваемые параметры. После нескольких экспериментов с моделью, лучший результат показала модель по умолчанию Okapi BM25, но с отличными от предустановленных параметрами.
Использование категорий
По ходу работы с поиском стала доступна очень важная дополнительная информация о продукте — его категория. Подробнее о том, как мы реализовывали категоризацию, можно почитать в статье Как я понял, что ем много сладкого, или классификация товаров по чекам в приложении. До этих пор мы основывали наш поиск только на сопоставлении наименований товаров, теперь стало возможно сравнивать категорию запроса и товаров в базе.
Возможные варианты использования этой информации — обязательное совпадение по полю категория (оформляется как фильтр результатов), дополнительное преимущество в виде очков товарам с совпадающей категорией (как в случае с цифрами) и сортировка результатов по категории (сначала совпадающая, затем все остальные). Для нашего случая последний вариант сработал лучше всего. Это связано с тем, что наш алгоритм категоризации слишком хорош, чтобы использовать второй способ, и недостаточно хорош, чтобы использовать первый. Мы достаточно уверены в алгоритме и хотим, чтобы совпадение по категории было большим преимуществом. В случае добавления дополнительных очков к скору (второй способ) товары с совпадающей категорией будут подниматься по списку, но все так же будут проигрывать некоторым товарам, которые больше совпали по названию. Однако первый способ нам тоже не подходит, так как ошибки в категоризации все-таки не исключены. Иногда запрос может содержать недостаточную информацию для корректного определения категории, или товаров в этой категории в ближайшем радиусе пользователя слишком мало. В этом случае мы все же хотим показать результаты с другой категорией, но все так же релевантные по названию продукта.
Второй способ также хорош тем, что ‘не портит’ скоры продуктов в результате поиска, и позволяет без препятствий продолжать использовать вычисляемый минимальный скор.
Конкретную имплементацию сортировки можно увидеть в финальном запросе.
Финальная модель
Подбор финальной модели поиска включал в себя генерации различных поисковых систем, их оценка и сравнение. Чаще всего сравнение проходило по одному из параметров. Допустим в одном конкретном случае нам необходимо было вычислить лучший размер для токенизатора edgeNgram (то есть подобрать наиболее эффективный диапазон N). Для этого мы генерировали одинаковые поисковые системы с одним лишь различием в размере этого диапазона. После этого было возможно выявить лучшее значение для этого параметра.
Оценка моделей производилась с помощью метрики nDCG (normalized discounted cumulative gain) — метрики для оценивания качества ранжирования. В каждую поисковую модель отправлялись заранее установленные запросы, после чего по полученным результатам поиска рассчитывалась метрика nDCG.
Анализаторы, которые вошли в финальную модель:



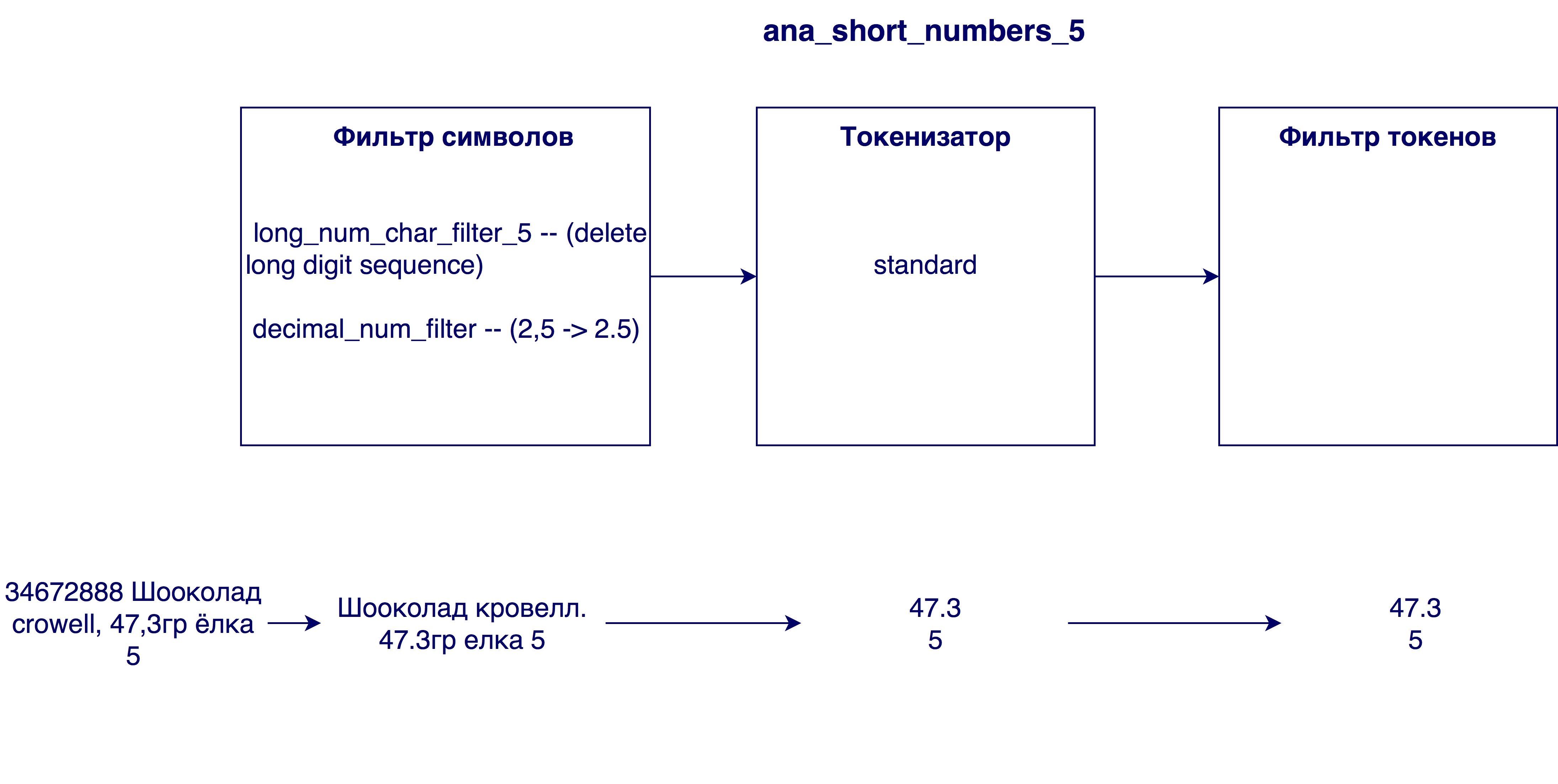
В качестве модели релевантности была выбрана модель по умолчанию (Okapi — BM25) с параметром b = 0.5. Значение по умолчанию — 0.75. Этот параметр показывает в какой степени длина названия продукта нормализует tf (term frequency) переменную. Меньшее число в нашем случае работает лучше, так как длинное название очень часто не влияет на значимость отдельно взятого слова. То есть слово “шоколад” в названии “шоколад с дробленым фундуком в упаковке 25шт” не теряет своей ценности от того, что длина названия достаточно большая.
Финальный запрос выглядит так:
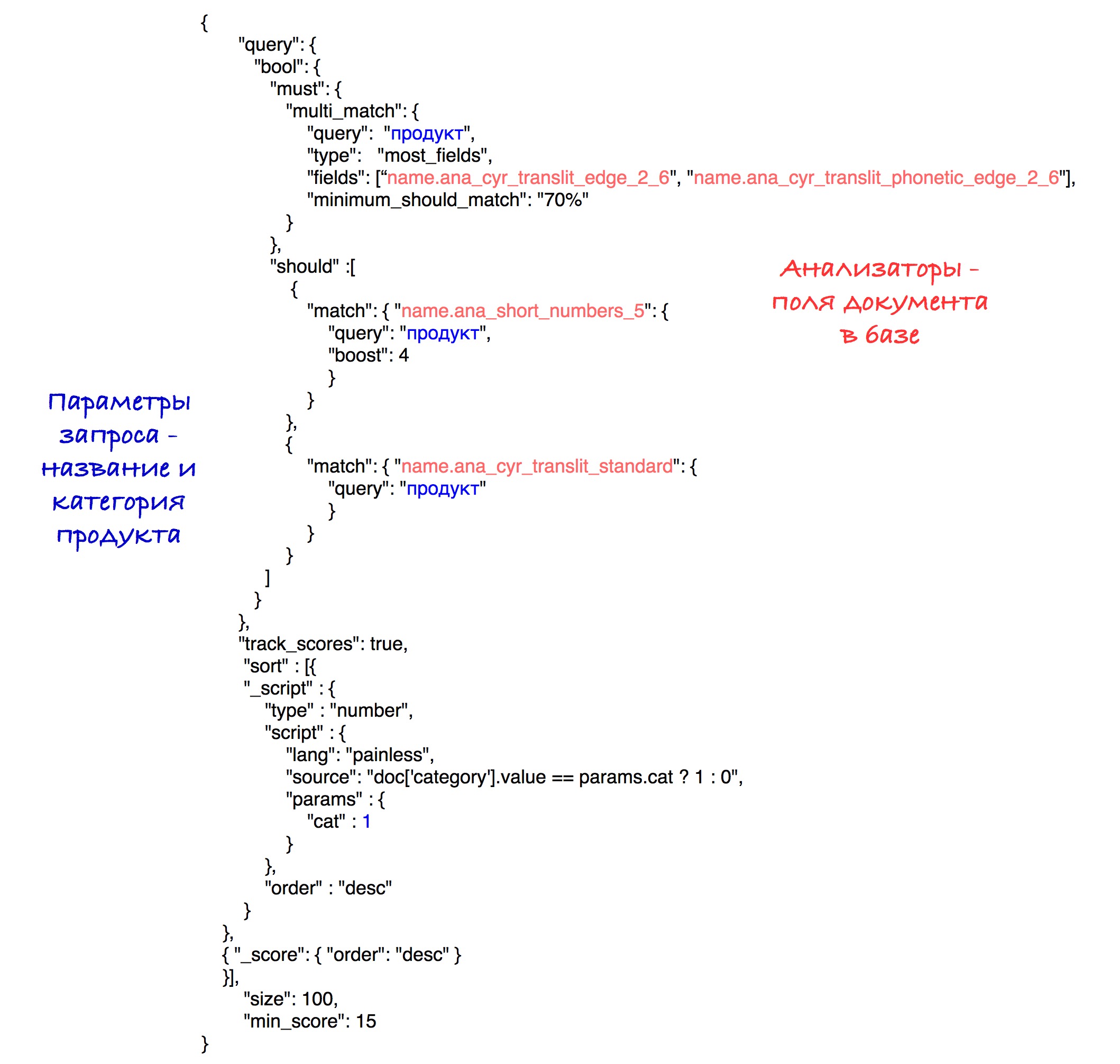
Экспериментальным путем была выявлена лучшая комбинация анализаторов и весов.
В результате сортировки в начало результатов выходят продукты с совпадающей категорией, а затем все остальные. Сортировка по количеству очков (скору) сохраняется внутри каждого подмножества.
Для простоты в данном запросе указан порог для скора в 15, хотя в нашей системе мы используем вычисляемый параметр, который был описан ранее.
В будущем
Есть мысли по улучшению поиска путем решения одной из самых смущающих наш алгоритм проблем, которая заключается в существовании миллиона и одного различного способа сократить слово из 5 букв. Решать её можно путем первоначальной обработки названий с целью раскрыть сокращения. Один из способов решения — попытка сопоставления сокращенного названия из нашей базы с одним из названий из базы с “правильными” полными названиями. Это решение встречает свои определенные препятствия, но кажется многообещающим изменением.
Статья была предложена Альмирой Муртазиной, занимающей должность data scientist в ЧекСкане.