
Каждый день мне приходится добавлять место на одном, двух, трех, пяти, а бывает – и десяти database серверах. Почему? Потому что для них характерен естественный рост баз. Серверов сотни, все они виртуалки с дисками на thin provisioning. Если им заранее выдать много места, то будет обязательно какой нибудь “runaway”, типа апгрейда с переливом таблиц, который пожрет все это место, а если не пожрет, то поднадкусает. Как вы знаете, thin provisioning – это путь в одну сторону, если место сожрано, но то его назад не вернуть.
В итоге большинство серверов болтаются где то у границы 90% space used – именно потому, что на границе 90% срабатывает алерт. Как только я даю немного, именно немного места – сервер отправляется в район 80%-85% used, и через месяц другой место надо добавлять снова. И, тем не менее, много сразу давать не буду – слишком много прецедентов с runaways.
Я так часто делал механическую работу по расширению места на дисках, что мне это надоело и я решил это автоматизировать с помощью Jenkins:
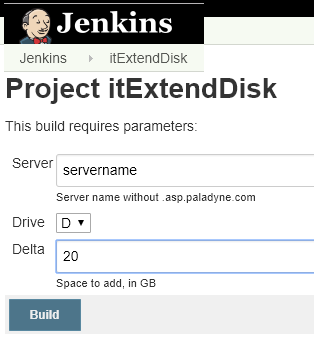
Прошу прощения за несколько занудное и детализированное описание ниже, но если это может быть полезно кому-то, то важны как раз мелкие детали – именно на них всегда тратишь больше всего времени. Если детали не важны, сразу прокрутите на последнюю картинку.
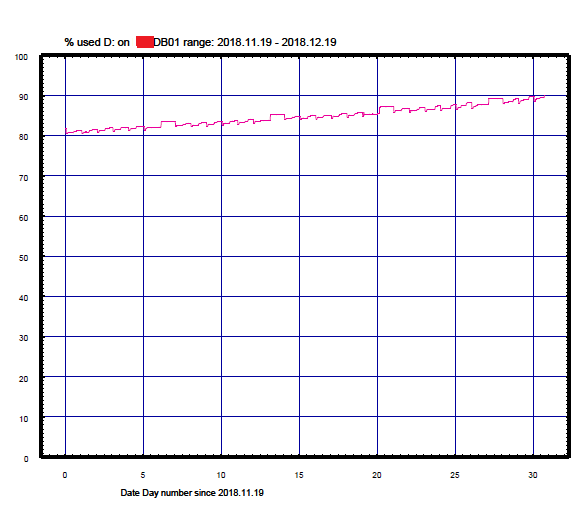
Разумеется, прежде чем добавлять место я смотрю историю роста space used %, автоматически приложенную к алерту моей тайной системой мониторинга. Чаще всего рост естественный:
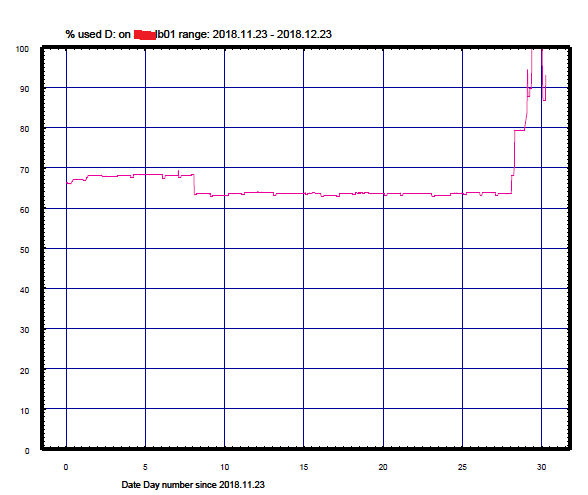
А вот тут лучше вначале разобраться:
Вернемся к Jenkins, который есть лишь интерфейс к Powershell script. У нас много VMware Vcenters, так что специальная процедура на SQL по имени сервера определяет, где находится данный сервер и коннектится именно к нему:
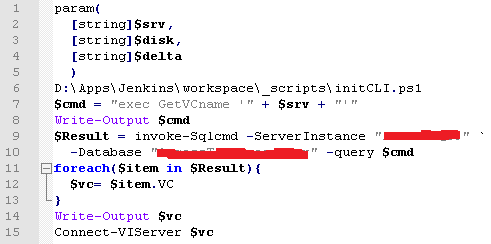
Теперь мы считываем размер диска, добавляем дельту и устанавливаем новое значение.

Правда, я нагло пользуюсь тем, что все сервера у нас отлиты подобным образом, например, D: всегда Hard disk 2. Если у вас это не так, то придется помучиться.
Теперь диск расширен с точка зрения VMware, но не с точки зрения guest (Windows). Мы должны выделенное место использовать. Для этого надо выполнить внутри guestа команды DISKPART.

Мы нагло запихиваем в корень D: файл BAT и IN, и с помощью WMIC заставляем машинку выполнить эти команды. Файл doresizeX.bat (X – название драйва) содержит лишь
А doresizeX.in содержит:
Теперь все готово, надо только чуть подождать (команда то асинхронная!) и прочитать результат, отфильтровав ненужное:

И ждем письма от Jenkins:

В итоге большинство серверов болтаются где то у границы 90% space used – именно потому, что на границе 90% срабатывает алерт. Как только я даю немного, именно немного места – сервер отправляется в район 80%-85% used, и через месяц другой место надо добавлять снова. И, тем не менее, много сразу давать не буду – слишком много прецедентов с runaways.
Я так часто делал механическую работу по расширению места на дисках, что мне это надоело и я решил это автоматизировать с помощью Jenkins:
Прошу прощения за несколько занудное и детализированное описание ниже, но если это может быть полезно кому-то, то важны как раз мелкие детали – именно на них всегда тратишь больше всего времени. Если детали не важны, сразу прокрутите на последнюю картинку.
Разумеется, прежде чем добавлять место я смотрю историю роста space used %, автоматически приложенную к алерту моей тайной системой мониторинга. Чаще всего рост естественный:
А вот тут лучше вначале разобраться:
Вернемся к Jenkins, который есть лишь интерфейс к Powershell script. У нас много VMware Vcenters, так что специальная процедура на SQL по имени сервера определяет, где находится данный сервер и коннектится именно к нему:
Теперь мы считываем размер диска, добавляем дельту и устанавливаем новое значение.
Правда, я нагло пользуюсь тем, что все сервера у нас отлиты подобным образом, например, D: всегда Hard disk 2. Если у вас это не так, то придется помучиться.
Теперь диск расширен с точка зрения VMware, но не с точки зрения guest (Windows). Мы должны выделенное место использовать. Для этого надо выполнить внутри guestа команды DISKPART.
Мы нагло запихиваем в корень D: файл BAT и IN, и с помощью WMIC заставляем машинку выполнить эти команды. Файл doresizeX.bat (X – название драйва) содержит лишь
diskpart <d:\doresizeX.in >d:\doresize.out
А doresizeX.in содержит:
rescan
select volume X
extend
exit
Теперь все готово, надо только чуть подождать (команда то асинхронная!) и прочитать результат, отфильтровав ненужное:
И ждем письма от Jenkins:
Комментарии (15)

johnfound
29.12.2018 13:11Вообще-то время полу-заполнения всегда константа, как бы не было большое доступное пространство. Так что выделять понемногу, вполне разумное решение. Только мне кажется, что этот процесс можно и еще более автоматизировать, чтобы скорость заполнения держалась хотя бы в полиномиальных границах...
VMichael
«Если им заранее выдать много места, то будет обязательно какой нибудь “runaway”, типа апгрейда с переливом таблиц, который пожрет все это место, а если не пожрет, то поднадкусает. Как вы знаете, thin provisioning – это путь в одну сторону, если место сожрано, но то его назад не вернуть. » — и что? Что в этом ужасного? Стоимость ГБ снижается, почему админ решил, что нужно место «зажимать»? Если это клиенты, они за место заплатят, если внутренние подразделения у них тоже могут быть резоны и они могут сами позаботится о бюджете.
Сисадмин типа красава, экономит место. А базовики извращаются из-за нехватки места, чтобы выполнить свои задачи, потому, что админ ощущает себя «раздающим ресурс».
С нашими, на текущем месте работы тоже боремся.
Первый раз столкнулся с таким, что место на дисках для работы БД жмут, админ апологет религии автора статьи, похоже.
Вопрос: У тебя бюджета не хватает, чтобы диски нарастить? Давай напишу заяву, бюджет выделят. Нет, он считает, что много места, это зло, базовики захапают все равно, поэтому выделять нужно по чуть чуть.
Как итог регулярные остановы, когда место закончится на диске и база встает. И авральное добавление место по ночам. Какие то БД оперативные удалось проломить твердолобость и увеличить место в разы, а какие то (отчетные, архивные) приходится работать частями. Компания типа «бирюзовая», договаривайтесь мол сами, самоорганизуйтесь, блин. В итоге базовики машут руками и извращаются.
Tzimie Автор
Место на NetApp, а еще и реплицируемом для disaster recovery не просто дорогое, а золотое.
А бюджетные игры довольно сложны у нас, куда сложнее чем "напиши заяву получишь бюджет"
VMichael
Просто наболело. У нас деньги есть. Но нет воли и желания админа.
Не было бы денег, бюджета, другой вопрос и претензий к админам не было бы, с моей стороны.
У вас может быть, другая ситуация, обобщать не буду. Хотя в статье причины, по которой место не дается не было обозначено, кроме мыслей сисадмина.
Sergey-S-Kovalev
Я в целом поддерживаю схему работы автора (возможно акромя тонких дисков под сами базы). Просто потому что если не ограничивать ни базовиков, ни 1Сников — сервера баз данных резко наполняются внезапными бэкапами перед обновлениями, которые никто не спешит удалять, непонятными дубликатами баз, копиями и прочими вещами коих быть на продуктовых серверах не должно. Это создает ненужный беспорядок и потребление. Весь этот избыток вместе с виртуальной машиной улетает бэкапом в какой нить Data Domain или StoreOnce и занимает место в хранилище на весь цикл ротации попутно ухудшая RTO.
Создание ограничения на доступное место устраняет этот эффект, а негативную сторону этой реализации автор весьма эффективно решил. Честь ему и хвала.
VMichael
Автор решил негативную сторону только со своей стороны. У остальных она осталась. И вы смотрите на это чисто с «сисадминской стороны».
Как насчет накатить обновление без предварительного бэкапа, потому, что места для бэкапа просто нет?
А ведь так делают, точно знаю, потому как сроки поджимают, админ где то «решает» свои негативные эффекты и вообще запаришься его уговаривать место накинуть.
А если нужно сделать разработчикам копии БД для отработки — нет, нельзя, места нет.
Т.е. в цепочке, производственной, админ выцепил свой кусок и оптимизирует его, не глядя на процесс по всей цепочке.
Хотя, как вариант, в регламент перед «улетом бэкапа в Data Domain» достаточно добавить шаг проверки его содержания.
Или бэкапы перед обновлением могут лежать на дисках, которые очищаются после тестов и контрольного срока работы обновления.
В общем, все решаемо, если не закукливаться в рамках одной лишь «экономии места».
Да и психологическая проблема. Значимость сисадмина уменьшается, если ему не нужно будет решать, когда выделить немножко места по просьбам трудящихся. А так важный человек, решает, кому, сколько отмерить. ЧСВ растет.
Sergey-S-Kovalev
— в сетевую папку;
— на ленточку;
— специализированные системы с поддержкой дедупликации на лету (читай DDBoost, Catalyst, etc)
Сетевая папка прям простейшее и общедоступное решение. При правильной настройке прав в базе, бэкап выполняется кем нужно и именно туда куда нужно. К примеру простым скриптом. Или кнопкой в вебинтерфейсе. Вообще не вижу проблем.
Ну я лично смотрю с позиции корпоративного аутсорсера, который админит множество серверов, включая базоводы, где в каждой организации свой набор 1Сников, техсуппортов и даже админов. Правильно разданные права, строгий подход к контролю ресурсов избавляет меня от ответственности за простой вверенных нам на обслуживание систем. Мы не оправдаемся за простой, тем что Ваши 1Сники наделали бэкапов и все резко встало колом. Мы просто не даем им возможности сломать, но даем возможность делать бэкапы и прочие изменения как им угодно часто поскольку этого требует рабочий процесс.
Нас интересует скорость работы сервисов и время их доступности. Мы не экономим место, но мы оптимизируем потребляемые ресурсы по максимуму экономя деньги заказчика. У собственных ИТ команд заказчика эти задачи не являются приоритетными, от них требуется развитие функционала.
Любой процесс взаимодействия между командами должен быть понятен всем сторонам, и никто не должен простаивать из-за коллег. В дополнение, мы делаем так что бы никто не мог сломать, даже если бы захотел, то за что мы отвечаем.
VMichael
У вас набор противоречивых заявлений:
А с чего вы решили, что на другом сервере место выделено?
Чистая экономия это бухгалтерский подход. Вы экономите деньги на объеме дисков, и это легко посчитать. Но сколько денег теряется на телодвижениях лишних разработчиков, это уже сложнее и на это частенько забивают. Экономя на дисках, можно потерять темп развития. Что может оказаться гораздо больнее в текущих реалиях.
Впрочем я не спорю по поводу вашего подхода. Дьявол кроется в деталях.
Вполне может быть, что я экстраполирую мой опыт в текущей организации, когда меня так зажали по дискам, что очень много времени уходит, на то, что бы работать в текущих объемах, а вы свой опыт в текущей организации, с проблемами, которых я не знаю.
Но! Когда то бились за каждый кб в памяти, сейчас этого нет и думаю ситуация со временем не поменяется. Места нужно будет больше и больше и ГБ места будет дешевле и дешевле, это нужно учитывать и вовремя расширяться, без фанатичной экономии места на дисках, в ущерб развитию.
Tzimie Автор
>Вы экономите деньги на объеме дисков
Диск диску рознь. У нас часто жалуются — вот ты жмотишься 100Gb дать, да я 1Tb в магазине за копейки возьму. Приходиться объяснять что netApp с лицензиями, DR replication (умножить место на 2) плюс 24 снэпшота (умножить непонятно насколько с учетом дельт и дедупликации) совсем другое дело
Поэтому все бэкапы «на всякий случай» — на шары на дешевых файловых помойках
VMichael
Понимаете, начинать статью нужно было так: «При дефиците финансирования, средств на расширение дисков не хватает, поэтому...».
Но у вас этого нет.
У нас, руководство заявляет: У ИТ — бюджетный безлимит. Нам нужно, что бы все бегало без запинки, в средствах не ограничиваем.
Но у сисадминов, свое видение. И идут «частые жалобы».
Ситуация другая совсем.
В других компаниях, где я работал, мы (базовики) выдвигали требования по объему, согласовывали бюджет, деньги выделялись и размер дисков не был узким местом и «частых жалоб» не было. Редких тоже.
Проходило время, мы ощущали, что начнется напряг с дисками и цикл повторялся.
И не было ситуации, когда, например сотрудник аутсорсера запустил чистку БД 1С, сделал удаление циклами по 10 млн. лог разбух и база встала. Не хватило 5-10 гб на диске. Конечно это ночью. Склад встал. Комплектация в магазины встала. Отгрузка машин встала. Суета, нервы, перезвоны.
Зато сисадмин сэкономил диски, хотя его об этом никто не просил.
Таже фигня с темпдб рабочего сервера.
Пока стрелки за остановки на админов не перевели, не желали выделять место для лога. Им казалось, что достаточно и так.
Вы из своего уютного мирка выйдите, сходите на остановившееся производство и послушайте, что об вас (ИТ) говорят во время, когда база встала. Может взглянете на мир по другому.
А то, кругом враги, желающие все «ваше» место отобрать.
Впрочем если вам навесили KPI экономии места, тогда да, ваши действия отлично вписываются в систему.
Tzimie Автор
Бюджетный безлимит? Ну значит вы в раю
У нас не то чтобы ограничены средства, но если каждому давать — то
развалитсябизнесы окажутся неприбыльнымиЧто касается событий, когда место кончилось — то да, при экономии таких событий потенциально больше, но у нас и саппорт реагирует на алерты 24/7 еще на подступах, при 90%
Sergey-S-Kovalev
Не вижу противоречия.
Нисколько. Отдельные виртуалки с тестовыми базами не влияющие на прод на ресурсах подешевле. Загрузка любого бэкапа в тестовую инфраструктуру по запросу или расписанию. Отдельные сервера под олап-кубы и генерацию отчетности для финансово экономических отделов.Да. Мы экономим деньги заказчика не давая создавать непонятные копии баз данных в которых работает один человек или складировать бэкапы внутри виртуалок расположенных на allflash массивах. Они очень быстрые, но очень дорогие, и их нужно использовать рационально.
Ну, главное не терять веру в людей. И уметь писать техзадания.
VMichael
А заказчик об этом просил?
Это не так.
Так вы в реальности выделяете место, столько, сколько нужно, по запросу, о чем тогда спор вообще?
И кстати:
А обработка запроса это не работа человека, которая денег стоит?
Или ожидание обработки запроса, когда кто то простаивает и ждет выполнения запроса, это не потери?
И потом, почему вы решили, что я говорю про прод? Мне жмут место везде.
Реальная причина моих проблем — админам нужно совершать телодвижения, что бы изменить инфраструктуру и нарастить место серьезно. Допускаю, что у них нет ресурсов человеческих для этого, но этот вопрос нужно поднимать. Я как внутренний клиент очень не доволен сервисом, предоставляемым мне.
Я напишу любое требуемое техзадание. Но этого от меня не требуют. Мне просто ограничивают ресурс, от чего страдает дело.
На работе мне нужна не вера в людей, а четко настроенные процессы, что бы я занимался своим делом, а не преодолевал устроенные мне искусственные трудности.
В данной ситуации, мне нужно место, я делаю заявку, мне говорят, что бы удовлетворить нужен такой то бюджет, я согласовываю расходы с лицом, принимающим решение, и все, поехало. Я так это вижу.
А не ходить уговаривать сисадмина проникнутся моими проблемами.
Когда то я работал нач. управления бизнес процессов, и мы периодически наталкивались на такую психологию собственника ресурса, когда кто то заполучив ресурс жал его. Типа не желания выписать дополнительные коробки со склада, оправдывая это некоей «экономией», не понимая при этом потребности бизнес подразделений. И убрав такие «мини плотины» бизнес бежал быстрее.
Tzimie Автор
Бэкапы надо делать у нас на специальные файловые шары. нет ничего хуже чем бэкап сделанный локально — netApp хранит 24 снэпшота дисков плюс все это реплицируется в другой датацентр. Поэтому бэкапы на локальные диски я запретил на уровне MS SQL
Tzimie Автор
«что если не ограничивать ни базовиков» — спасибо, видно что вы тоже все это вкусили