
Привет, Хабр!
Меня зовут Антон Маркелов, я ops-инженер компании United Traders. Мы занимаемся проектами, так или иначе связанными с инвестициями, биржами и прочими финансовыми делами. Компания мы не очень большая, около 30 инженеров разработки, масштабы соответствующие – чуть меньше сотни серверов. В ходе количественного и качественного роста нашей инфраструктуры классическое решение «держим на одном сервере и приложение, и его базу» перестало нас устраивать как в плане надежности, так и в плане быстродействия. Со стороны аналитиков возникла потребность создавать кроссбазные запросы, отделу эксплуатации надоело возиться с бэкапом и мониторингом большого количества серверов БД. Вдобавок ко всему, хранение стейта на одной машине с самим приложением сильно снижала гибкость планирования ресурсов и отказоустойчивость инфраструктуры.
Процесс перехода на текущую архитектуру шел эволюционно, апробировались разные решения как по предоставлению удобного интерфейса для разработчиков и аналитиков, так и по повышению надежности и управляемости всего этого хозяйства. Я хочу рассказать об основных этапах модернизации наших СУБД, на какие грабли мы наступили и к каким решениям пришли, получив в итоге отказоустойчивую независимую среду, предоставляющую удобные способы взаимодействия инженерам эксплуатации, разработчикам и аналитикам. Надеюсь, наш опыт окажется полезным инженерам из компаний нашего масштаба.
Данная статья является конспектом моего доклада на конференции UPTIMEDAY, может быть формат видео будет кому-то комфортнее, хотя писатель руками из меня чуть лучше, чем говоритель ртом.
«Человек-снежинка» с КДПВ бессовестно позаимствован у Максима Дорофеева.
Болезни роста
У нас микросервисная архитектура, сервисы написаны в основном на Java или Kotlin с использованием фреймворка Spring. Рядом с каждым микросервисом – база PostgreSQL, сверху все прикрыто nginx для обеспечения доступа. Типовой микросервис — приложение на Spring Boot, которое пишет свои данные в PostgreSQL (часть приложений заодно и в ClickHouse), общается с соседями через Kafka и имеет какие-нибудь REST или GraphQL эндпойнты для связи с внешним миром.
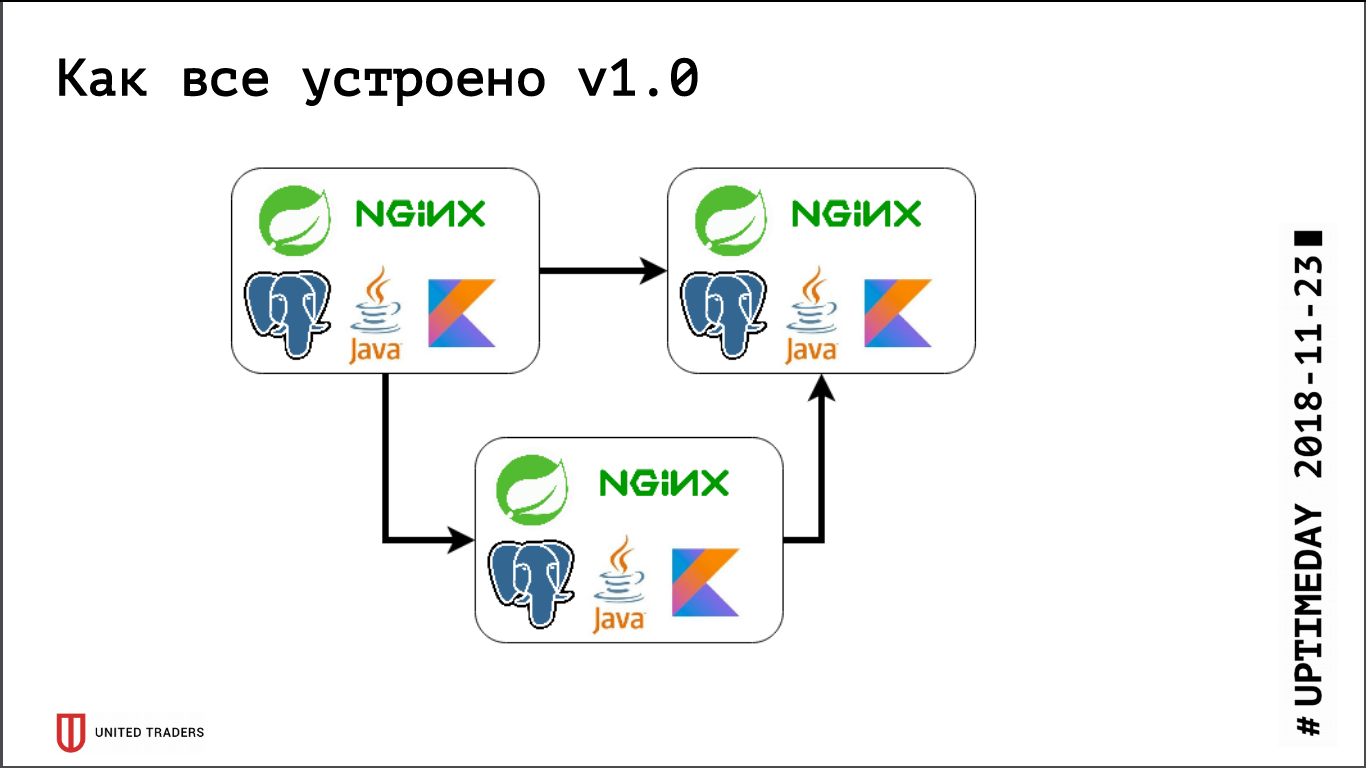
Раньше, когда мы были совсем маленькими, мы просто держали несколько серверов в DigitalOcean, Kafka еще не было, все общение было через REST. То есть мы брали дроплет, ставили туда Java, PostgreSQL, nginx, запускали туда Zabbix, чтобы он мониторил серверные ресурсы и доступность эндпойнтов сервиса. Деплоили все с помощью Ansible, у нас были унифицированные плейбуки, четыре-пять ролей раскатывали весь сервис. Пока у нас было, условно говоря, 6 серверов на продакшне и 3 на тесте — с этим как-то можно было жить.
Потом началась фаза активной разработки, росло количество приложений, десять микросервисов превратились в сорок, начал меняться их функционал, плюс появилась интеграция с внешними системами типа CRM, клиентскими сайтами и тому подобное. У нас появилась первая боль. Некоторые приложения стали потреблять больше ресурсов, перестали влезать на имеющиеся серверы, мы добирали дроплеты, таскали приложения туда-сюда, много ковырялись руками. Болело довольно сильно – никто не любит тупую механическую работу, – решить хотелось быстро. Поэтому пошли «в лоб» – просто взяли 3 больших dedicated сервера вместо 10 облачных дроплетов. Это на какое-то время закрыло проблему, но стало очевидно, что пора прорабатывать варианты какой-то оркестрации и ребалансировки серверов. Мы начали присматриваться к решениям типа DC/OS и Kubernetes, потихоньку наращивать экспертизу в этом направлении.
Примерно в это же время у нас появился аналитический отдел, которому понадобилось регулярно делать тяжелые запросы, готовить отчеты, иметь красивые дашборды, и это принесло нам вторую боль. Во-первых, аналитики сильно нагружали базу, а во-вторых, им потребовались кроссбазные запросы, т.к. каждый микросервис хранил довольно узкий срез данных. Мы оттестировали несколько систем, сначала пытались решить это все через репликацию на уровне таблиц (дело было еще во времена девятого PostgreSQL, там не было логической репликации из коробки), но получившиеся поделки на базе pglogical, Presto, Slony-I и Bucardo нас совершенно не устроили. Например, pglogical не поддерживал миграции – выкатилась новая версия микросервиса, изменилась структура БД, Java сама поменяла структуру с помощью Flyway, а на репликах в pglogical все надо менять вручную. В остальном либо чего-то не хватало, либо было слишком сложно.
Супер-раб
В итоге изысканий родилось простое и брутальное решение под названием Superslave: мы взяли отдельный сервер, настроили на нем по слейву для каждого продакшн сервера на разных портах и создали виртуальную базу данных, объединяющую в себе базы со слейвов через postgres_fdw (foreign data wrapper). То есть все это было реализовано стандартными средствами постгреса без введения дополнительных сущностей, просто и надежно: одним запросом можно было получать данные из нескольких баз. Эту виртуальную кроссбазу мы выдали аналитикам. Дополнительный плюс в том, что реплика read-only, даже при ошибке с правами доступа что-либо туда записать было невозможно.
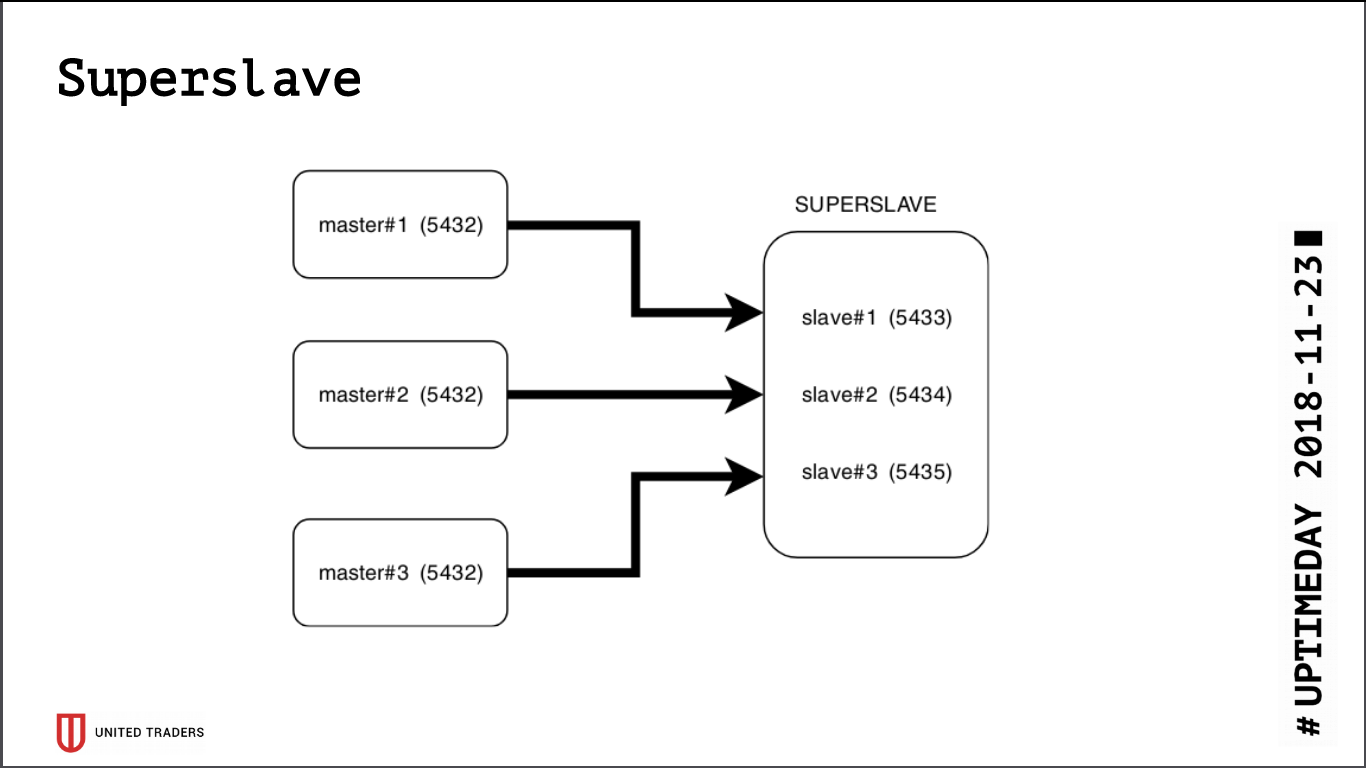
Для визуализации взяли Redash, он умеет рисовать графики, выполнять запросы по расписанию, например раз в сутки, и обладает развесистой системой прав, поэтому мы пускаем туда и аналитиков, и разработчиков.

Параллельно продолжался рост, в инфраструктуре появились Kafka в качестве шины и ClickHouse для хранения аналитики. Они легко кластеризуются из коробки, наш суперслейв на их фоне выглядел неповоротливой окаменелостью. Плюс ко всему, PostgreSQL, по факту, оставался единственным стейтом, который надо было таскать вслед за приложением (если его все-таки надо было переносить на другой сервер), а нам очень хотелось получить stateless приложение, чтобы вплотную заняться экспериментами с Kubernetes и ему подобными платформами.
Мы начали искать решение, отвечающее следующим требованиям:
- отказоустойчивость: при падении N серверов кластер продолжает работу;
- для приложений все должно остаться как прежде, никаких изменений в коде;
- простота развертывания и управления;
- поменьше слоев абстракции над обычным PostgreSQL;
- в идеале – балансировка нагрузки, чтобы не все запросы шли на один сервер;
- в идеале – написано на знакомом нам языке.
Кандидатов было не особо много:
- стандартная потоковая репликация (repmgr, Patroni, Stolon);
- репликация на основе триггеров (Londiste, Slony);
- репликация запросов в среднем слое (pgpool-II);
- синхронная репликация с несколькими главными серверами (Bucardo).
Со значительной частью мы уже имели неудачный опыт во время строительства кроссбазы, так что оставались Patroni и Stolon. Patroni написан на Python, Stolon на Go, у нас хватает экспертизы в обоих языках. Более того, у них схожая архитектура и функционал, поэтому выбор был сделан по субъективным причинам: Patroni разрабатывает компания Zalando, а мы когда-то пытались работать с их проектом Nakadi (REST API к Kafka), где столкнулись с сильной нехваткой документации.
Stolon
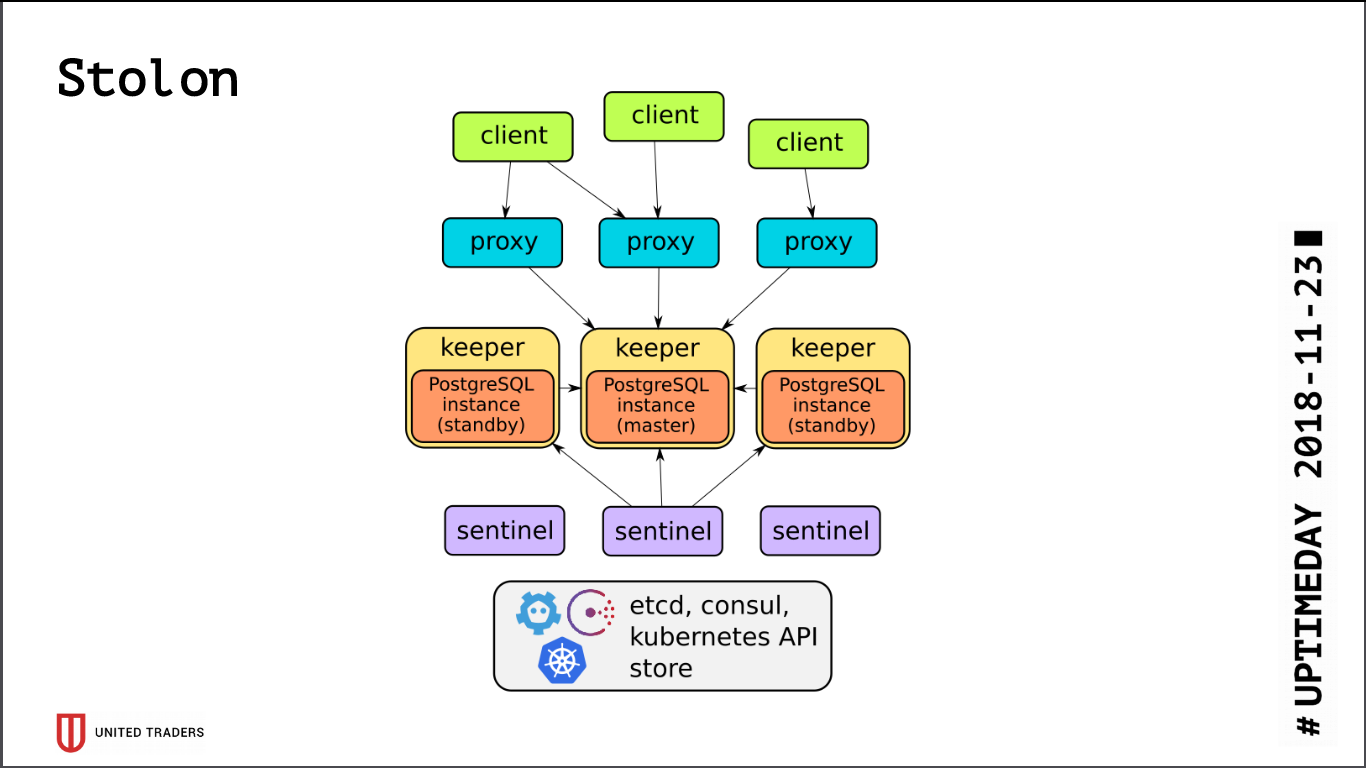
Архитектура у Stolon довольно простая: имеется N серверов, с помощью etcd/consul выбирается лидер, на нем запускается PostgreSQL в режиме мастера и реплицируется на остальные серверы. Потом в этот PostgreSQL-мастер ходят столон-прокси, прикидывающиеся для приложений обычным постгресом, а клиенты ходят в эти прокси. В случае пропадания мастера происходят перевыборы, кто-то другой становится мастером, остальные — стендбаями. Слоев абстракции немного, PostgreSQL ставится как обычно, единственный нюанс – конфиг PostgreSQL хранится в etcd, и конфигурируется несколько иначе.
При тестировании кластера мы выловили довольно много проблем:
- Stolon не умеет работать поверх ZooKeeper, только consul или etcd;
- etcd очень чувствителен к IO. Если держать PostgreSQL и etcd на одном сервере, однозначно нужны быстрые SSD;
- даже на SSD надо настраивать таймауты etcd, иначе под нагрузкой все сломается – кластер будет думать, что мастер отвалился, и постоянно рвать коннекты;
- по умолчанию max_connections на PostgreSQL невелико (200), надо увеличивать под свои потребности;
- кластер из трех etcd переживет смерть только одного сервера, в идеале надо иметь конфигурацию, например 5 etcd + 3 Stolon;
- из коробки все коннекты идут на мастер, слейвы недоступны для коннекта.
Так как все коннекты к PostgreSQL идут на мастер, мы опять уперлись в проблему с тяжелыми запросами аналитиков. etcd временами болезненно реагировал на высокую нагрузку на мастер и переключал его. А переключение мастера – это всегда разрыв коннектов. Запрос перезапускался, все начиналось сначала. Для обхода был написан скрипт на Python, который запрашивал у stolonctl адреса живых слейвов и генерировал конфиг для HAProxy, перенаправляющий запросы на них.
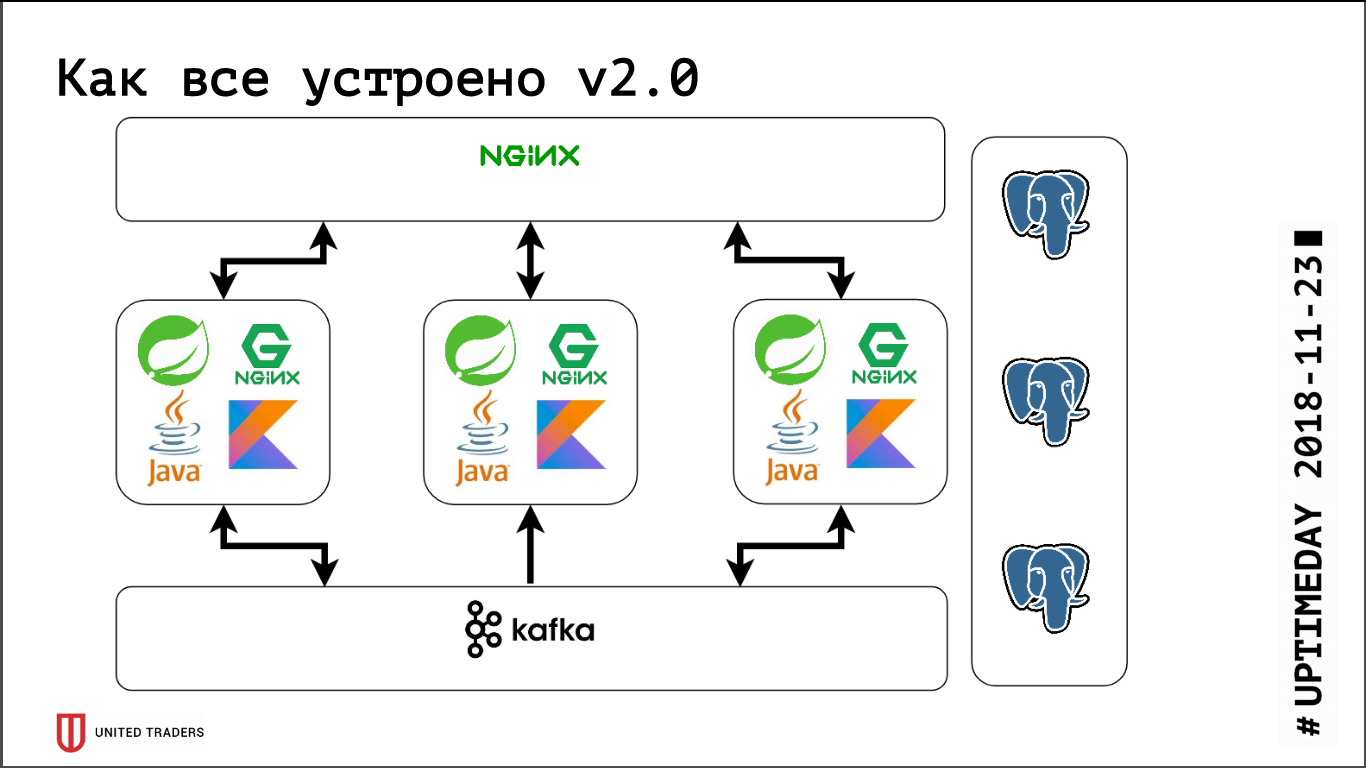
Получилась следующая картина: запросы от приложений идут на порт stolon-proxy, который перенаправляет их на мастер, а запросы от аналитиков (они всегда read-only) — на порт HAProxy, который перекидывает их на какой-нибудь слейв.
Также, буквально сегодня, в Stolon был принят PR, который позволил отдавать информацию об инстансах Stolon в сторонний service discovery.
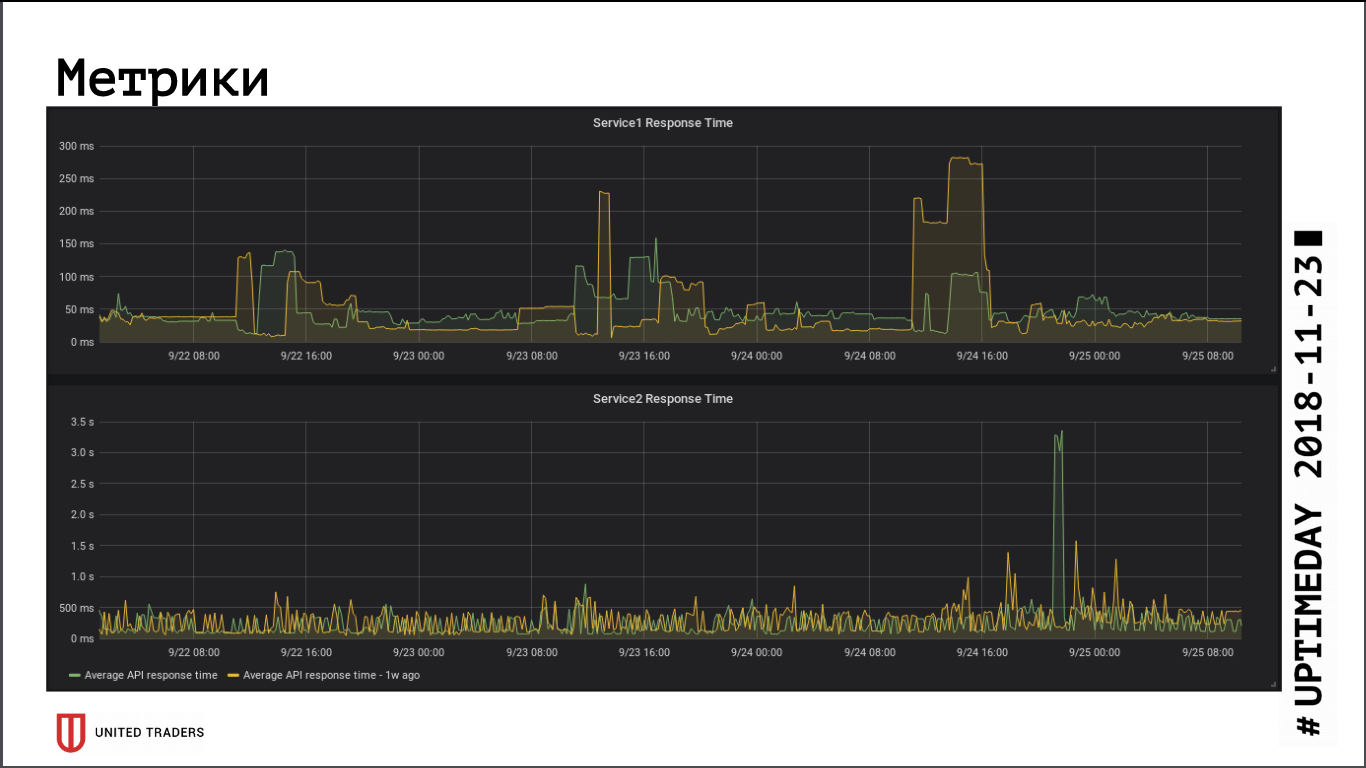
Насколько можно судить по метрикам скорости ответа приложений, переход на удаленный кластер не оказал существенного влияния на быстродействие, среднее время ответа практически не изменилось. Возникшее сетевое latency, видимо, скомпенсировалось тем, что БД теперь на выделенном сервере.
Stolon без проблем переживает аварию мастера (потеря сервера, потеря сети, потеря диска), когда сервер оживает — он сам автоматически переналивает реплику. Самое слабое место в Stolon – это etcd, сбои в нем кладут кластер. У нас была типичная авария: кластер из трех нод etcd, две вырубились. Все, нарушился кворум, etcd перешел в статус unhealthy, кластер Stolon не принимает любые коннекты, включая запросы от stolonctl. Схема восстановления: превращаем etcd на выжившем сервере в single-node кластер, потом добавляем мемберов обратно. Вывод: чтобы переживать смерть двух серверов, надо иметь как минимум 5 инстансов etcd.
Мониторинг и ловля ошибок
С ростом инфраструктуры и сложности микросервисов, захотелось собирать больше информации о том, что происходит внутри приложения и Java-машины. Приспособить Zabbix к новой среде нам не удалось: он очень неудобен в условиях изменяющейся инфраструктуры. Приходилось либо городить костыли через его API, либо лезть внутрь руками, что еще хуже. Его БД плохо приспособлена к большим нагрузкам, да и в целом очень неудобно все это складывать в реляционную базу данных.
В итоге мы выбрали для мониторинга Prometheus. У него из коробки есть актуатор для Spring-приложений для предоставления метрик, для Kafka прикрутили JMX Exporter, также обеспечивающий метрики в комфортном виде. Те экспортеры, что не нашлись «в коробке», мы написали сами на Python, их порядка десяти. Визуализируем Grafana, логи собираем Graylog’ом (благо он теперь поддерживает Beats).
Для сбора ошибок используем Sentry. Он все записывает в структурированном виде, рисует графики, показывает, что случалось чаще, что реже. Обычно разработчики сразу после деплоя идут в Sentry, смотрят, не идет ли какой-то пик, не нужно ли срочно откатить. Получается оперативно отлавливать ошибки без ковыряния в логах.
На этом пока все, если формат статей устроит читателей, мы продолжим рассказывать про нашу инфраструктуру дальше, там еще много веселого: Kafka и решения для аналитики проходящих сквозь нее событий, CI/CD тракт для Windows-приложений и приключения с Openshift.
Комментарии (4)

Hixon10
13.03.2019 21:39Привет!
если формат статей устроит читателей
Формат — бомба! Подробности, размышления, и ни грамму маркетинга :)

strangeman Автор
14.03.2019 03:52Привет! Спасибо! Мое дело с серверами развлекаться, а не маркетинг маркетить, вот и пишу про что мне интересно. :)
shurup
Очень перекликается с докладом «Базы данных и Kubernetes» от коллеги, где рассказывалось про эволюцию инфраструктуры под БД и заканчивалось как раз на Stolon ;-)
strangeman Автор
До уровня Димы мне еще далеко, конечно, плюс мы сознательно решили вынести весь стейт «в сторонку» от K8S/Openshift. Но да, там у него очень много ценного про хранение стейта в кубере. :)