
Дмитрий Стогов из Zend Technologies на HighLoad++ рассказал, благодаря чему повысилась производительность. В расшифровке: о внутреннем устройстве PHP, об идеях в основе версии 7.0, об изменениях в базовых структурах данных и алгоритмах, которые и определили успех.
Disclaimer: На март 2019 года 80% сайтов работают на PHP, и 70% из них — на PHP 5, хотя с 1 января 2019 эта версия не поддерживается. Доклад Дмитрия от 2016 года про принципы, благодаря которым произошел двукратный скачок производительности между PHP 5 и 7, — актуален и в марте 2019. Для половины сайтов — точно.
О спикере: Дмитрий Стогов начал программировать еще в 80-х: «Электроника Б3-34», Basic, ассемблер. В 2002 Дмитрий познакомился с PHP и вскоре, начал работать над его усовершенствованием: разработал Turck MMCache для PHP, руководил проектом PHPNG и играл важную роль в работе над JIT для PHP. Последние 14 лет Principal Engineer в Zend Technologies.
Zend Technologies занимается разработкой PHP и коммерческих решений на его основе. В 1999 её основали израильские программисты Энди Гутманс и Зеев Сураски, которые за два года до этого создали PHP 3. Эти люди стояли у истоков разработки PHP и во многом определили текущий вид языка и успех технологии.
Zend Technologies разрабатывает ядро PHP и приложения для него, и за время работы мне приходилось писать расширения, влезать во все подсистемы и даже заниматься коммерческими проектами, иногда с PHP совсем не связанными. Но самой интересной темой для меня всегда была производительность.
Искать пути ускорения PHP я начал еще до прихода в Zend, работая над своим собственным проектом, который конкурировал с компанией. За время работы над проектом я досконально разобрался в языке и понял, что работая не с мейнстримным проектом, можно влиять только на отдельные аспекты исполнения скрипта, а все самое интересное и эффективное можно создать только в ядре. Это понимание и стечение обстоятельств привели меня в Zend.
Небольшой экскурс в историю PHP
PHP – это не совсем и не только язык программирования. PHP переводится как Personal Home Page — инструмент создания персональных веб-страниц и динамических веб-сайтов. Язык – только одна из его основных частей. PHP — это огромная библиотека функций, множество расширений для работы с другими сторонними библиотеками, например, для доступа к БД или к парсерам XML, а также набор модулей для связи с различными веб-серверами.
Датский программист Расмус Лердорф представил PHP в июне 1995. На тот момент это был просто набор CGI-скриптов, написанных на Perl. В апреле 96 Расмус представил PHP/FI, а уже в июне вышла версия PHP/FI 2.0. Впоследствии эту версию существенно переработали Энди Гутманс и Зеев Сураски, и в 98-м выпустили PHP 3.0. К 2000 году язык пришел к тому виду, который мы привыкли видеть сегодня как с точки зрения языка, так и внутренней архитектуры — PHP 4, основанный на Zend Engine.
С 4-й версии PHP развивается эволюционно. Переломным моментом был выход PHP 5 в 2004, когда полностью обновилась объектная модель. Именно она открыла эру PHP фреймворков и поставила вопрос о производительности на новый уровень. Предвидя это, сразу после выхода 5.0 мы в Zend задумались об ускорении PHP и принялись работать над повышением производительности.
Версия 7.1, которая вышла в ноябре 2016 на синтетических тестах в 25 раз быстрее версии 2002 года. По графику изменения производительности в разных ветках, основные прорывы видны в 5.1 и 7.0.

В версии 5.1 мы только запустили работу над производительностью, и все за что брались — получалось, но после 5.3 — уперлись в стену, все попытки усовершенствовать интерпретатор ни к чему не приводили.
Тем не менее мы нашли, куда копать, и получили даже больше, чем ожидали, — 2,5-кратное ускорение по сравнению с предыдущей версией 5.6 на тестах. Но самое интересное, что то же 2,5-кратное ускорение мы получили и на неизменных реальных приложениях. Это феномен, потому что предыдущий фактор 2 мы нарабатывали в течении всей жизни пятерки за 10 лет.
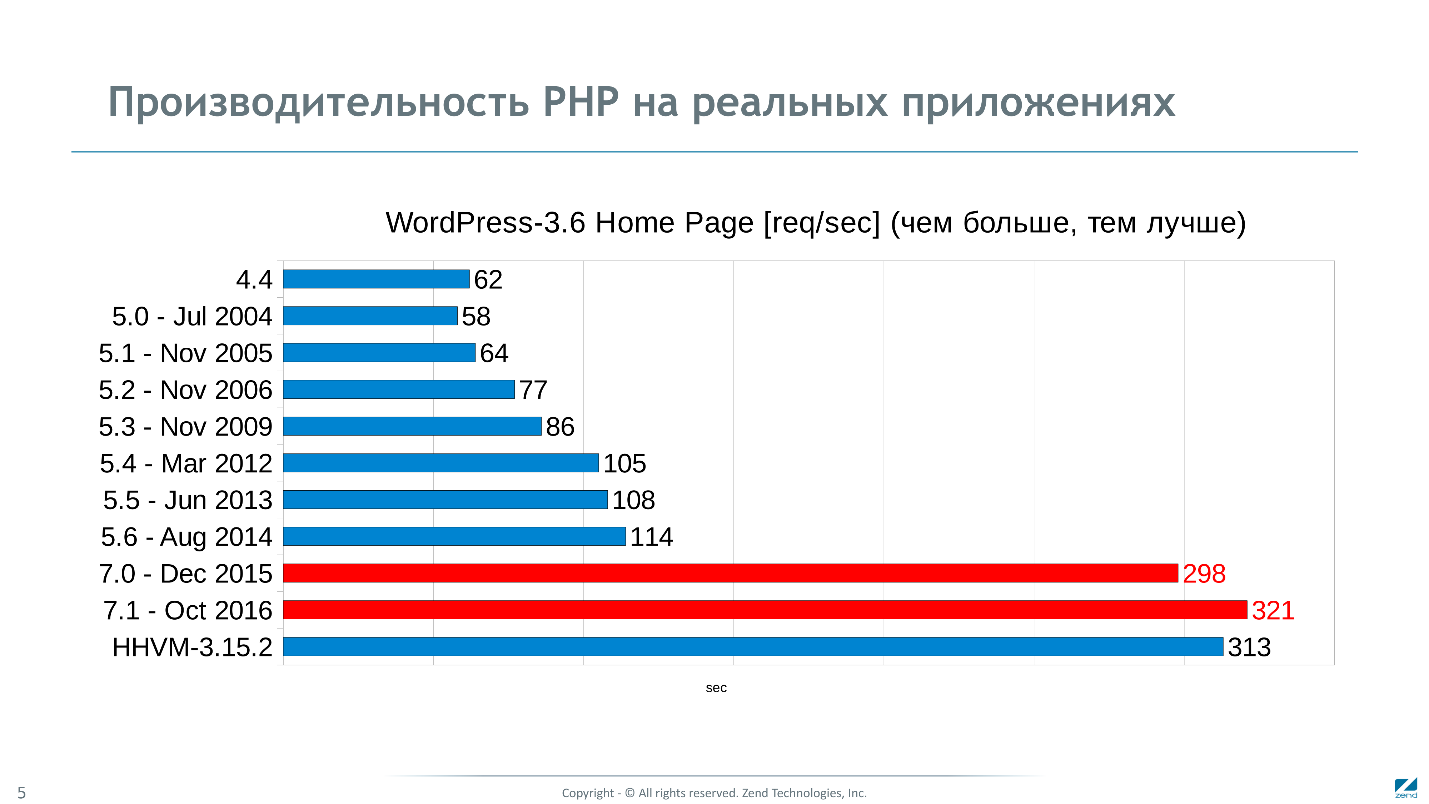
Огромный скачок в 5.1 на синтетических тестах, на реальных приложениях не заметен. Причина в том, что при разных использованиях производительность PHP упирается в тормоза, связанные с разными подсистемами.
История PHP 7 начинается с трехлетнего застоя, который начался в 2012, а закончился в 2015 с релизом седьмой версии. Тогда мы поняли, что не можем больше увеличивать производительность мелкими усовершенствованиями нашего интерпретатора и обратились в сторону JIT.
Блуждание около JIT
Почти два года мы потратили на прототип JIT для PHP-5.5. Сначала мы генерировали очень простой код – последовательность вызовов для стандартных обработчиков, что-то наподобие сшитого кода Форта. Затем написали собственный Runtime Assembler, инлайнили отдельный код для обходов, но поняли, что такие низкоуровневые оптимизации не дают практического эффекта даже на тестах.
Тогда мы задумались о выводе типов переменных, используя методы статического анализа. Реализовав вывод, сразу же получили 2-кратное ускорение на тестах. Воодушевленные, попытались написать глобальные register alocator, но потерпели неудачу. Мы использовали достаточно высокоуровневое представление, а для распределения регистров применять его было практически невозможно.
Чтобы избежать проблем с низким уровнем, решили попробовать LLVM, и через год у нас получилось 10-кратное ускорение для bench.php, а на реальных приложениях — ничего. Кроме того, компиляция реальных приложений теперь занимала минуты, например, первый реквест к Wordpress занимал 2 минуты и не давал ускорения. Конечно, это совершенно не подходило для реальной практики.
Хороший код возможен при правильном предсказании типов, которое в реальных приложениях работает плохо, а использование структур данных РНР делает генерируемый код неэффективным.
Что же тормозит?
Мы переосмыслили причины неудач и решили еще раз посмотреть, почему тормозит PHP. На картинке результат профилирования нескольких запросов к домашней странице Wordpress.
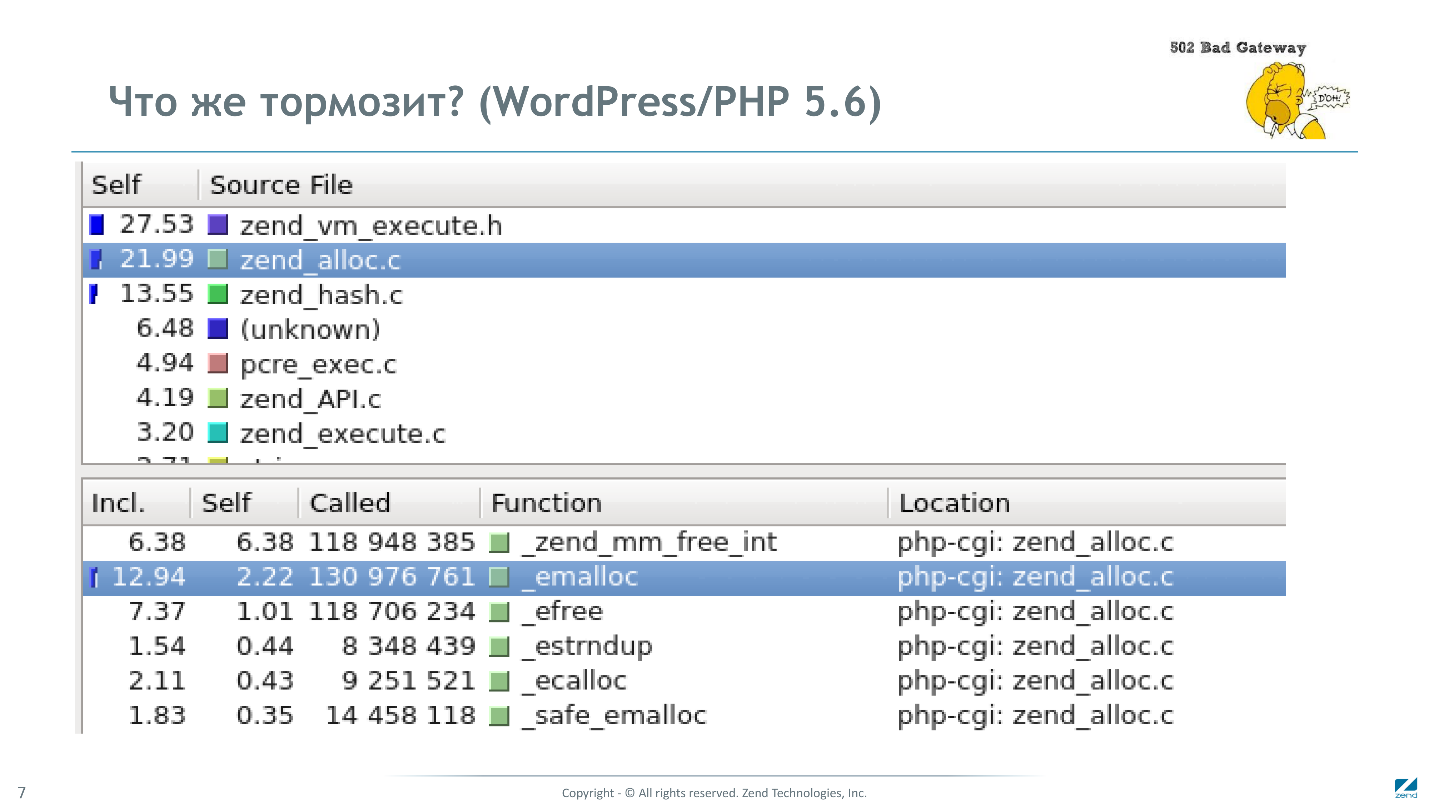
На интерпретацию байт-кода тратится меньше 30%, 20% — это накладные расходы memory-менеджера, 13% — это работа с хэш-таблицами, и 5% — работа с регулярными выражениями.
Работая на JIT, мы избавлялись только от первых 30%, а все остальное лежало мертвым грузом. Практически везде мы были вынуждены использовать стандартные структуры данных PHP, которые влекли за собой накладные расходы: распределение памяти, подсчет ссылок, и т.п. Это понимание и привело к выводу о необходимости замены ключевых структур данных в PHP. С этой подмены фундамента и начался проект PHPNG.
PHPNG. New Generation
Проект получил развитие после безрезультатных попыток создать JIT для PHP. Основная цель — достичь нового уровня производительности и заложить базу для будущих улучшений.
Мы обещали себе какое-то время больше не использовать для измерения производительности синтетические тесты — это как правило небольшие вычислительные программы, которые используют ограниченный объем данных, полностью помещающийся в кэш процессора. Реальные приложения, наоборот, подвержены тормозам, связанным с подсистемной памяти, и одно чтение из памяти может стоить 100 вычислительных инструкций. Проект PHPNG — это рефакторинг ключевых структур данных PHP для оптимизации обращения к памяти. Никаких нововведений, 100% совместимость с PHP 5.
Как менять эти структуры было понятно. Но объем зависимых изменений был огромен, потому что само ядро PHP – это 150 000 строк, и почти каждая третья нуждалась в изменении. Прибавьте ещё сотню расширений, которые входят в base distribution, десяток модулей для разных веб-серверов, и вы поймете грандиозность проекта.
Мы даже не были уверены, что доведем проект до конца. Поэтому запустили проект в тайне и открыли его, только когда появились первые оптимистичные результаты. Две недели ушло на то, чтобы просто скомпилировать ядро. Еще через две недели заработал bench.php. Полтора месяца потратили для обеспечения работы Wordpress. Еще через месяц мы открыли проект — это был май 2014 года. На тот момент у нас было ускорение на 30% на Wordpress. Это уже казалось грандиозным событием.
PHPNG сразу вызвал волну интереса, и в августе 2014 принят, как основа для будущего PHP 7. Это был уже другой проект, с другим набором целей, где производительность была только одной из них.
PHP 7.0
Сам номер версии 7 был под вопросом. Предыдущая версия была пятая. А шестая разрабатывалась несколько лет назад и была полностью посвящена нативной поддержке Unicode, но неудачные решения, принятые на ранних этапах разработки, привели к чрезмерному усложнению кода ядра и каждого расширения. В конце концов было принято решение о заморозке проекта.
К этому времени уже было накоплено много материала, посвящённого PHP 6: выступления на конференциях, опубликованные книги. Чтобы никого не путать, мы назвали проект PHP 7, пропустив PHP 6. Этой версии повезло куда больше — PHP 7 вышел в декабре 2015, почти по плану.
Кроме производительности, в PHP 7 появились некоторые давно востребованные нововведения:
- Возможность определять скалярные типы параметров и возвращаемых значений.
- Исключения вместо ошибок — теперь мы можем их ловить и обрабатывать.
- Появились
Zero-cost assert(), анонимные классы, чистка неконсистентностей, новые операторы и функции (<=>, ??).
Нововведения это хорошо, но вернемся ко внутренним изменениям. Поговорим о пути, который прошел PHP 7, и о том, куда этот путь нас может завести.
zval
Это основная структура данных PHP. Она используется для представления любого значения в PHP. Так как язык у нас динамически типизированный и тип переменных может меняться во выполнения программы, нам необходимо хранить поле типа (zend_uchar type), которое может принимать значения IS_NULL, IS_BOOL, IS_LONG, IS_DOUBLE, IS_ARRAY, IS_OBJECT и т.д., и собственно значение, представленное union-ом (value), где может храниться целое, вещественное число, строка, массив или объект.
zval в PHP 5
Память под каждую такую структуру выделялась отдельно в Heap. Помимо типа и значения в ней же хранился счетчик ссылок на структуру. Так структура занимала 24 байта, не считая накладные расходы memory-менеджера и указателя на нее.
На картинке справа сверху показаны структуры данных, которые создавались в памяти PHP 5 для простого скрипта.

На стеке выделилась память под 4 переменные, представленные указателями. Сами же значения (zval) лежат в куче. В нашем случае это всего два zval, на каждый из которых ссылаются две переменные, и соответственно их счетчики ссылок установлены равными 2.
Для доступа к типу или к скалярному значению нужно как минимум два чтения: сначала прочитать значение указателя, а потом значение структуры. Если же надо прочитать не скалярное значение, а например, часть строки или массива, то потребуется как минимум еще на одно чтение больше.
zval в PHP 7
Там, где раньше мы использовали указатели, в семерке мы стали встраивать zval. Мы ушли от подсчета ссылок для скалярных типов. Поля тип и значение остались без существенных изменений, но добавились еще некоторые флаги и зарезервированное место, про которые расскажу чуть позже.

Слева — как это выглядело в PHP 5, а справа — в PHP 7.

Теперь на стеке лежат сами zval. Для чтения типов и скалярных значений достаточно всего одной машинной инструкции. Все значения сгруппированы в одной области памяти, а это значит, что при работе с локальными переменными у нас практически не будет потерь из-за промахов кэша процессора. Но настоящая мощь нового представления включается при необходимости копирования.
Копирование записи
В верхней строчке скрипта добавилось еще одно присваивание.

В PHP5 мы выделяли из кучи память под новый zval, инициализировали его int(2), изменяли значение указателя переменной b и уменьшали reference counter того значения, на которое b ссылалось раньше.
В PHP 7 мы просто инициализировали переменную b прямо по месту с помощью нескольких инструкций, в то время как в PHP 5 это требовало сотен инструкций. Так zval выглядит сейчас в памяти.
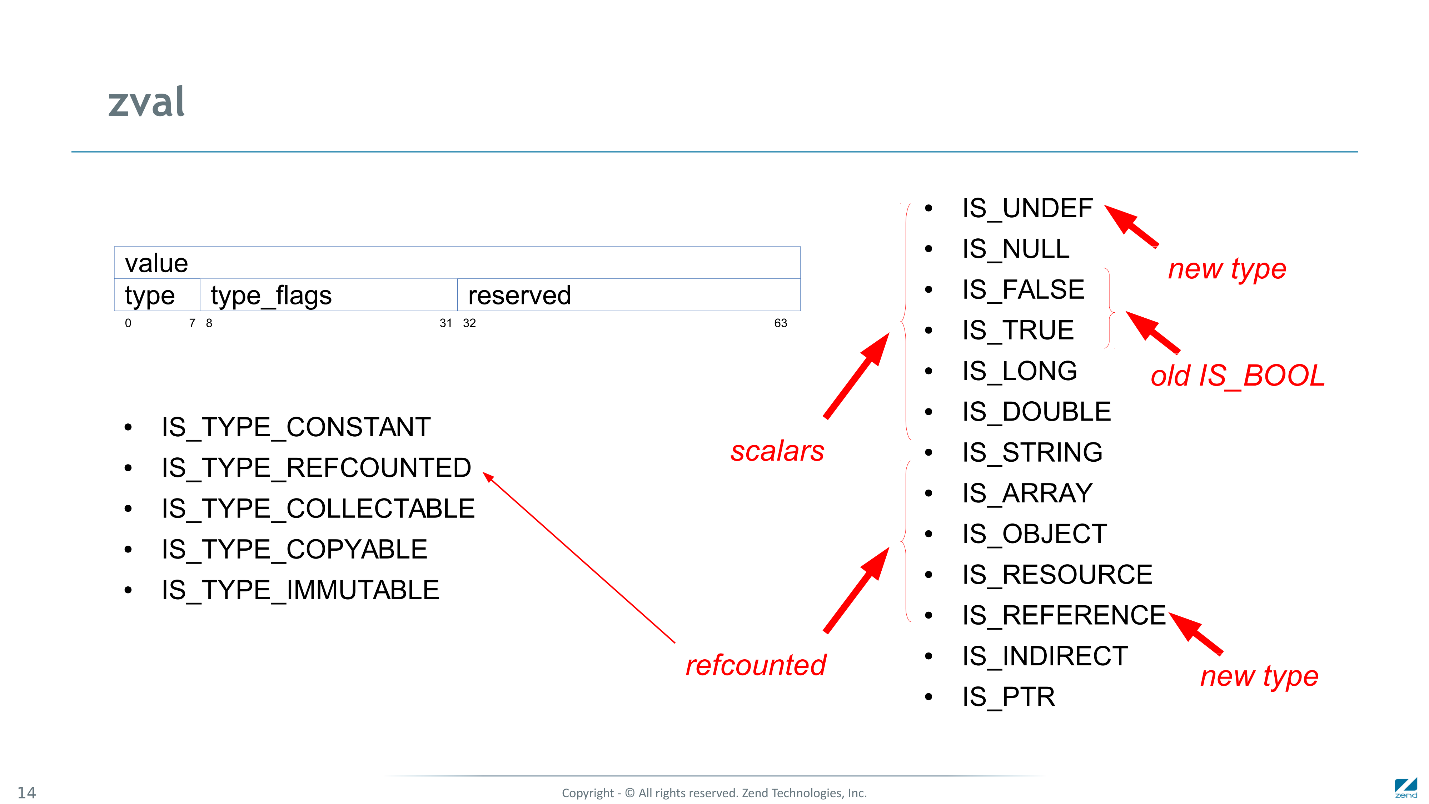
Это два 64-битных слова. Первое слово — значение: целое число, вещественное или указатель. Во втором слове тип (он говорит, как интерпретировать значение), флаги, и зарезервированное место, которое все равно добавилось бы при выравнивании. Но оно не пропадает, а используется разными подсистемами для хранения косвенно связанных значений.
Флаги — это набор битов, где каждый бит говорит о том, поддерживает ли zval какой-то протокол. Например, если стоит
IS_TYPE_REFCOUNTED, то при работе с данным zval, engine должен заботиться о значении счетчика ссылок. При присваивании — увеличивать, при выходе из области видимости — уменьшать, если reference counter достиг нуля — уничтожать зависимую структуру.Из типов, по сравнению с PHP 5, появилось несколько новых.
IS_UNDEF— маркер неинициализированной переменной.- На смену единому
IS_BOOLпришли раздельныеIS_FALSEиIS_TRUE. - Добавился отдельный тип для ссылок и еще несколько магических типов.
Типы от
IS_UNDEF до IS_DOUBLE — скалярные, и не требуют дополнительной памяти. Для их копирования достаточно скопировать первое машинное 64-битное слово со значением и половину второго с типом и флагами.Refcounted
С другими типами сложнее. Все они представлены подчиненной структурой, и в zval хранится просто ссылка на эту структуру. Для каждого из типов эта структура своя, но в терминах ООП все они имеют общего абстрактного предка или структуру zend_refcounted. Она определяет формат первого 64-битного слова, где хранится счетчик ссылок и другая информация для сборщика мусора.

Это слово можно рассматривать просто как информацию для сборщика мусора, а структуры для конкретных типов добавляют свои поля вслед за этим первым словом.
Строки
В семёрке для строки мы храним вычисленное значение хэш-функции, её длину и сами символы. Размер такой структуры переменный и зависит от длины строки. Хэш-функция вычисляется для строки один раз, при первой необходимости. В PHP 5 она заново вычислялась при каждой потребности.

Теперь строки стали reference countable, и если в PHP 5 мы копировали сами символы, то теперь достаточно увеличить счетчик ссылок на данную структуру.
Так же как и в PHP 5 у нас осталось понятие неизменяемых или interned-строк. Они обычно существуют в одном экземпляре, живут до конца запроса и могут вести себя как скалярные значения. Нам незачем заботиться о счетчике ссылок на них, и для копирования достаточно скопировать только сам zval с помощью четырех машинных инструкций.
Массивы
Массивы представлены встроенной хэш-таблицей и мало чем отличаются от PHP 5. Сама хэш-таблица изменилась, но об этом отдельно.

Массивы теперь — это адаптивная структура, которая немного меняет свою внутреннюю структуру и поведение в зависимости от хранимых данных. Если мы храним только элементы с близкими числовыми ключами, то получаем доступ к элементам непосредственно по индексу со скоростью, сравнимой со скоростью массивов в С. Но стоит в этот же самый массив добавить элемент со строковым ключом — он превращается в настоящий хэш с разрешением коллизий.
Так хэш-таблица выглядит в PHP 5.
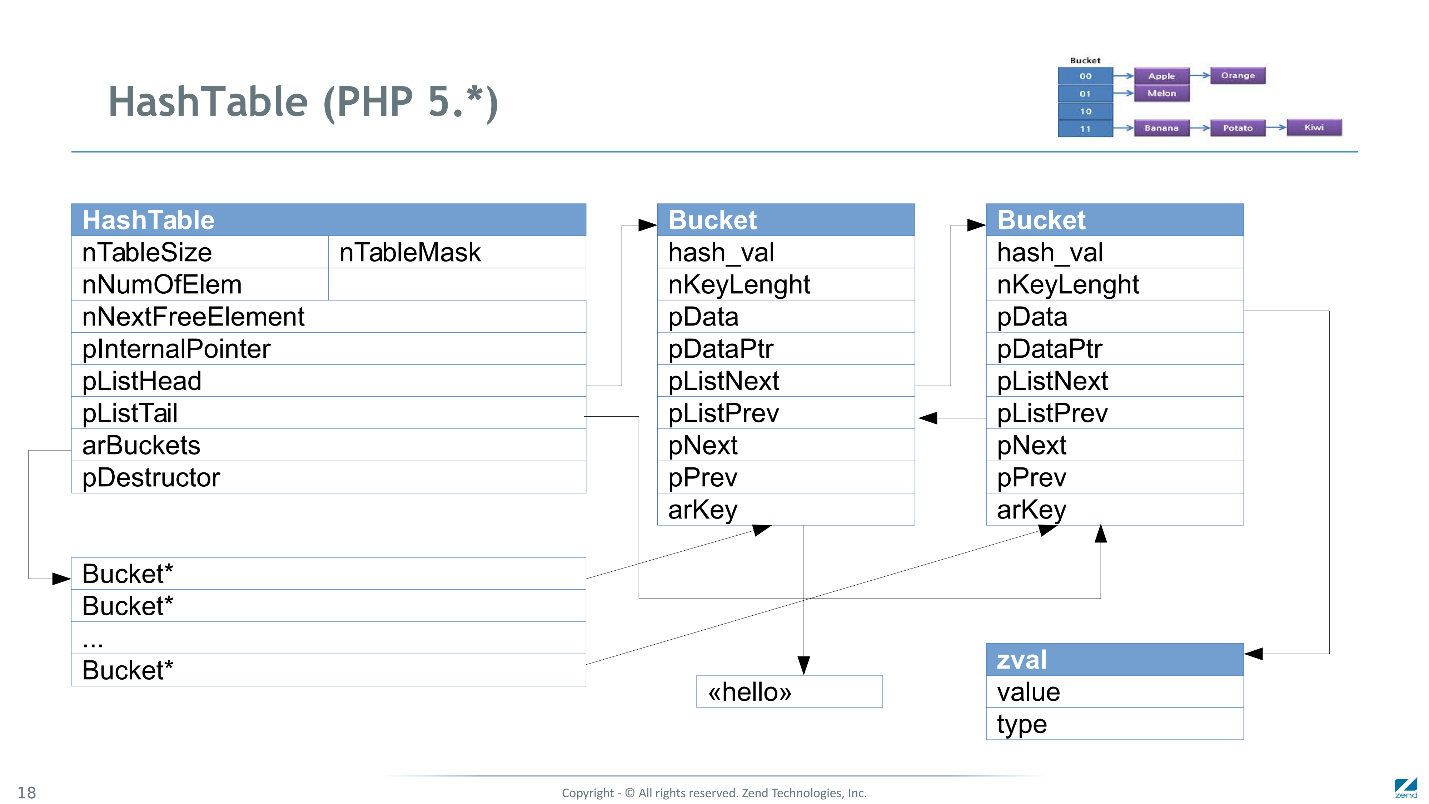
Это классическая реализация хэш-таблицы с разрешением коллизий с помощью линейных списков (показана в правом верхнем углу). Каждый элемент представлен Bucket. Все Buckets связаны двусвязными списками для разрешения коллизий, и связаны еще другим двусвязным списком для итерации по порядку. Значения под каждый zval выделяются отдельно — в Bucket мы храним только ссылку на него. Также строковые ключи могут выделяться отдельно.
Таким образом, под каждую хэш-таблицу нужно выделять очень много мелких блоков памяти, а чтобы потом что-то найти, приходится бегать по указателям. Каждый такой переход может вызвать cahce miss и задержку на ~10-100 циклов процессора.
Вот что получилось в PHP 7.

Логическая структура осталась без изменений, изменилась только физическая. Теперь под хэш-таблицу память выделяется с помощью одной операции.
На картинке, внизу от базового указателя лежат элементы, а вверху — хэш-массив, который адресуется по хэш-функции. Для плоских или упакованных массивов, когда мы храним только элементы с числовыми индексами, верхняя часть вообще не выделяется, и мы адресуемся к Bucket-ам непосредственно по номеру.
Для обхода элементов мы последовательно перебираем их сверху вниз или снизу вверх, что современные процессоры делают безупречно. Значения встроены в Buckets, а вот зарезервированное место в них как раз используется для разрешения коллизий. Там хранится индекс другого Bucket с тем же значением хэш-функции либо маркер конца списка.
Память под строковые значения ключей выделяется отдельно, но это все те же zend_string. При вставке в массив достаточно увеличить reference counter строки, хотя раньше нам приходилось копировать непосредственно символы, а при поиске мы теперь можем сравнивать не символы, а сами указатели на строки.
Неизменяемые массивы
Раньше у нас были неизменяемые строки, а теперь появились еще и неизменяемые массивы. Как и строки они не используют счетчик ссылок и не уничтожаются до конца запроса. Это простой скрипт, который создает массив из миллиона элементов, а каждый элемент — это один и тот же массив с единственным элементом «hello».

В PHP 5 на каждой итерации цикла создавался новый пустой массив, в него записывалось «hello», и все это добавлялось в результирующий массив. В PHP 7 на этапе компиляции мы создаем всего один неизменяемый массив, который ведет себя как скаляр, и добавляем его в результирующий. На представленном примере это позволяет добиться более чем 10-кратного уменьшения потребления памяти и почти 10-кратного ускорения.
Константные массивы из миллионов элементов в реальных приложениях, конечно, встречаются не часто, но небольшие — довольно часто. На каждом из них вы получите небольшой, но выигрыш.
Объекты
Ссылки на все объекты в PHP 5 лежали в отдельном хранилище, а в zval был только handle — уникальному ID объекта.
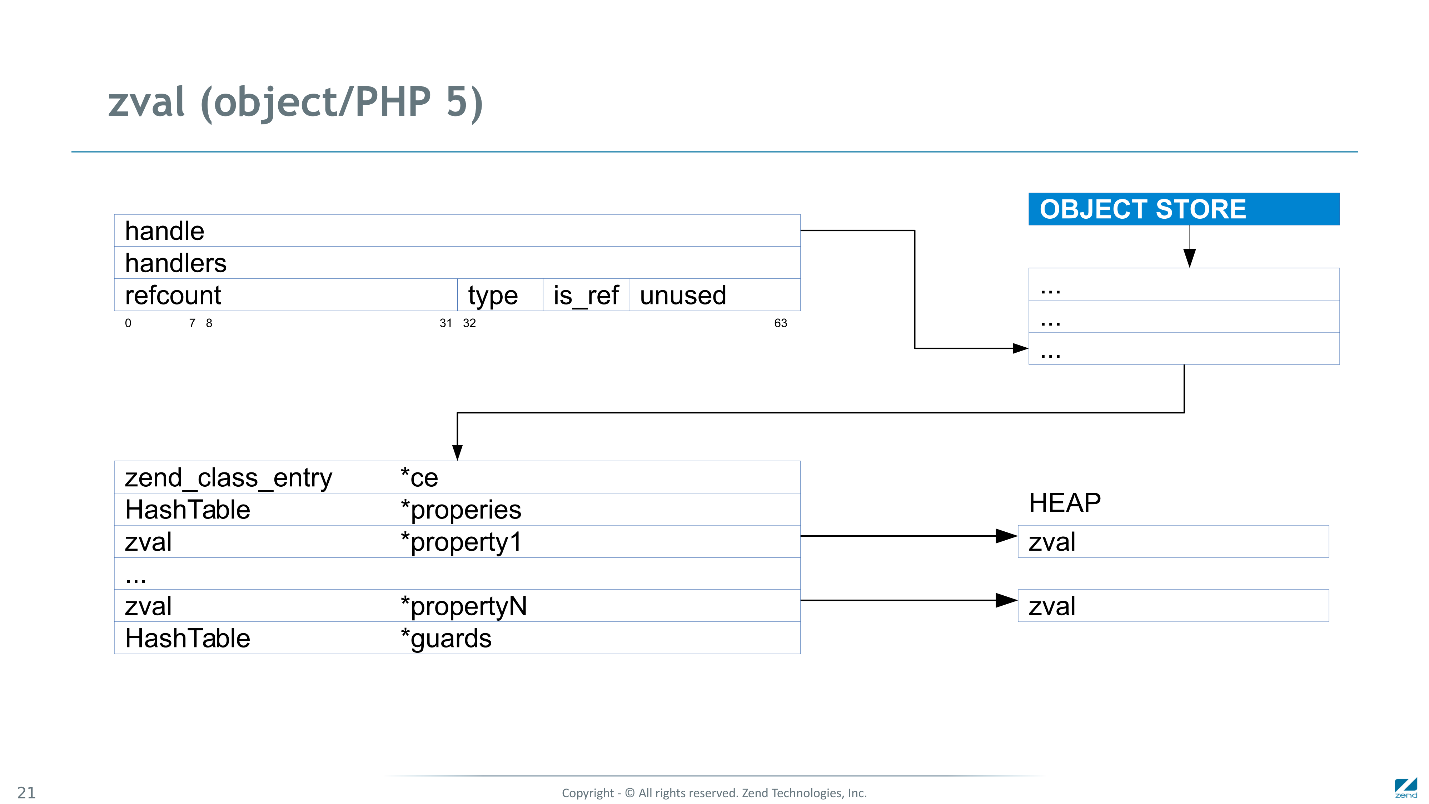
Чтобы добраться до объекта, мы производили как минимум 3 чтения. Кроме того, память под значение каждого свойства объекта распределялась отдельно, и нам требовалось еще как минимум 2 чтения, чтобы прочитать его.
В PHP 7 мы смогли перейти к прямой адресации.

Теперь адрес
zend_object доступен с помощью одной машинной инструкции. А Property встроены и для их чтения нужно всего одно дополнительное чтение. Также они сгруппированы вместе, что улучшает data locality и помогает современным процессорам не спотыкаться.Кроме предопределенных property здесь же хранится ссылка на класс данного объекта, некие handlers — аналог таблиц виртуальных методов, и хэш-таблица для property, которые не были определены. В PHP к любому объекту можно добавить property, которые изначально не были определены, и если для доступа к предопределенным property достаточно нескольких машинных инструкций, то для не предопределенных придется обращаться к хэш-таблице, что потребует десятков машинных инструкций. Конечно, это намного дороже.
Reference
Наконец, нам пришлось ввести отдельный тип для представления PHP ссылок.

Это абсолютно прозрачный тип. Он не виден PHP скриптам. Скрипты видят другой zval, который встроен в структуру zend_reference. Подразумевается, что на одну такую структуру у нас ссылаются как минимум из двух мест, и reference counter этой структуры всегда больше 1. Как только счетчик падает до 1, ссылка превращается в обычное скалярное значение. Встроенный в ссылку zval копируется в последний ссылающийся на него zval, а сама структура удаляется.
Кажется, что теперь работа с reference намного сложнее, чем с другими типами (и это действительно так), но на самом деле в PHP 5 нам приходилось выполнять сопоставимую по сложности работу при обращении к любому значению (даже простому целому числу). Теперь же мы применяем более сложные протоколы только к одному типу и тем самым ускорили работу со всеми другими, особенно со скалярными значениями.
IS_FALSE и IS_TRUE
Я уже говорил, что единый тип IS_BOOL был разбит на отдельные IS_FALSE и IS_TRUE. Эта идея была подсмотрена в реализации LuaJIT, а сделана для ускорения одной из наиболее частых операций — условного перехода.

Если в PHP 5 требовалось прочитать тип, проверить на boolean, прочитать значение, узнать true оно или false и сделать переход на основании этого, то теперь достаточно просто проверить тип и сравнить его с true:
- если он равен true, то идем по одной ветке;
- если он меньше true, идем по другой ветке;
- если он больше true, идем на так называемый slow path (медленный путь) и там проверяем, что это за тип пришел и что с ним делать: если это integer, то мы должны сравнить его значение с 0, если float — опять с 0 (но вещественным), и т.д.
Calling Convention
Изменение в Calling Convention или соглашении о вызовах функций — важная оптимизация, которая затрагивает не только структуры данных, но и в базовые алгоритмы. На картинке слева небольшой скрипт, состоящий из функции foo() и ее вызова. Ниже — байт-код, в который этот скрипт был скомпилирован PHP 5.

Сначала расскажу, как это работало в PHP 5.
Calling Convention в PHP 5
Первая инструкция
SEND_VAL должна была отправить значение «3» в функцию foo. Для этого она была вынуждена аллоцировать новый zval на куче, копировать туда значение (3) и записать на стек значение указателя на эту структуру.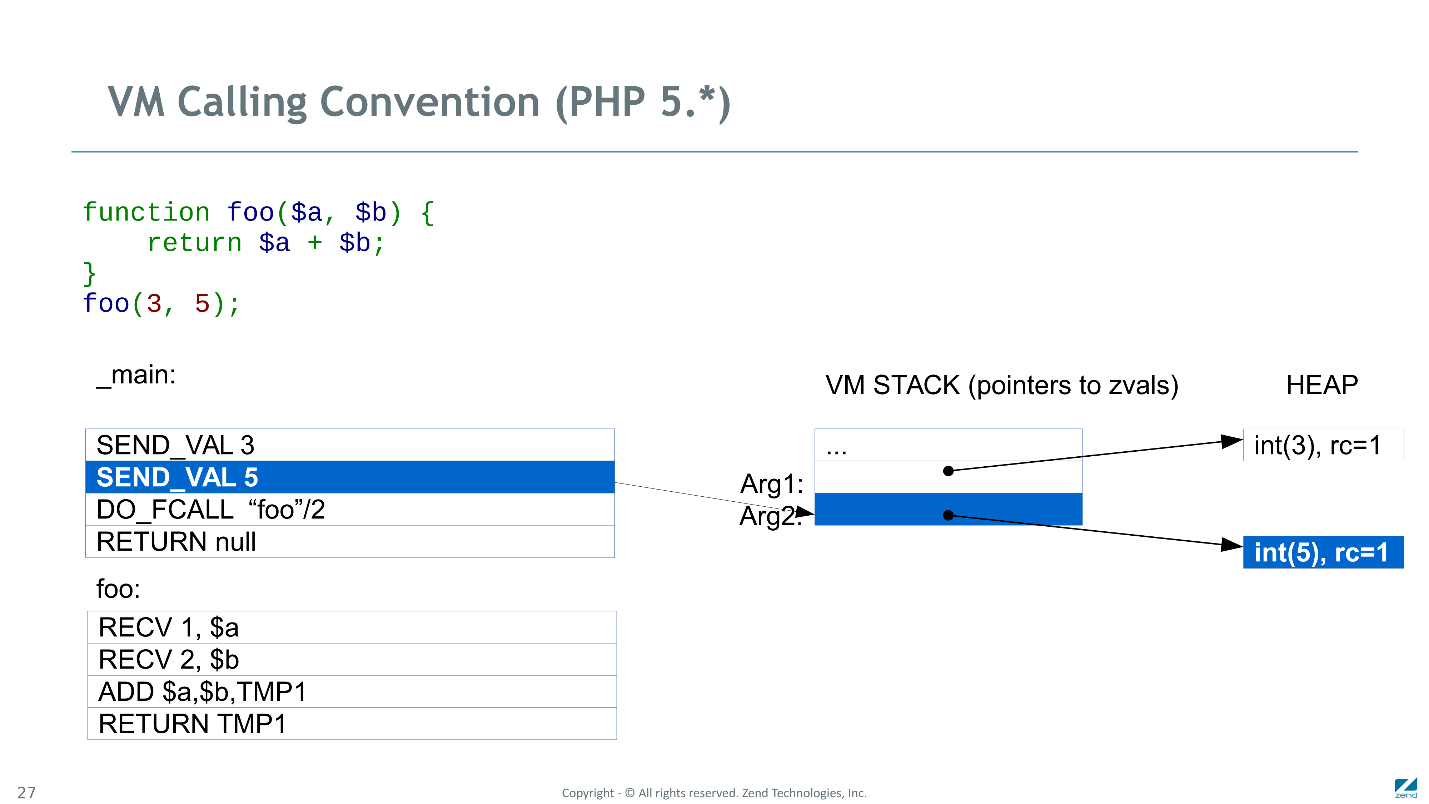
Аналогично со второй инструкцией. Дальше
DO_FCALL инициализировал CALL FRAME, резервировал место под локальные и временные переменные, и передавал управление на вызываемую функцию.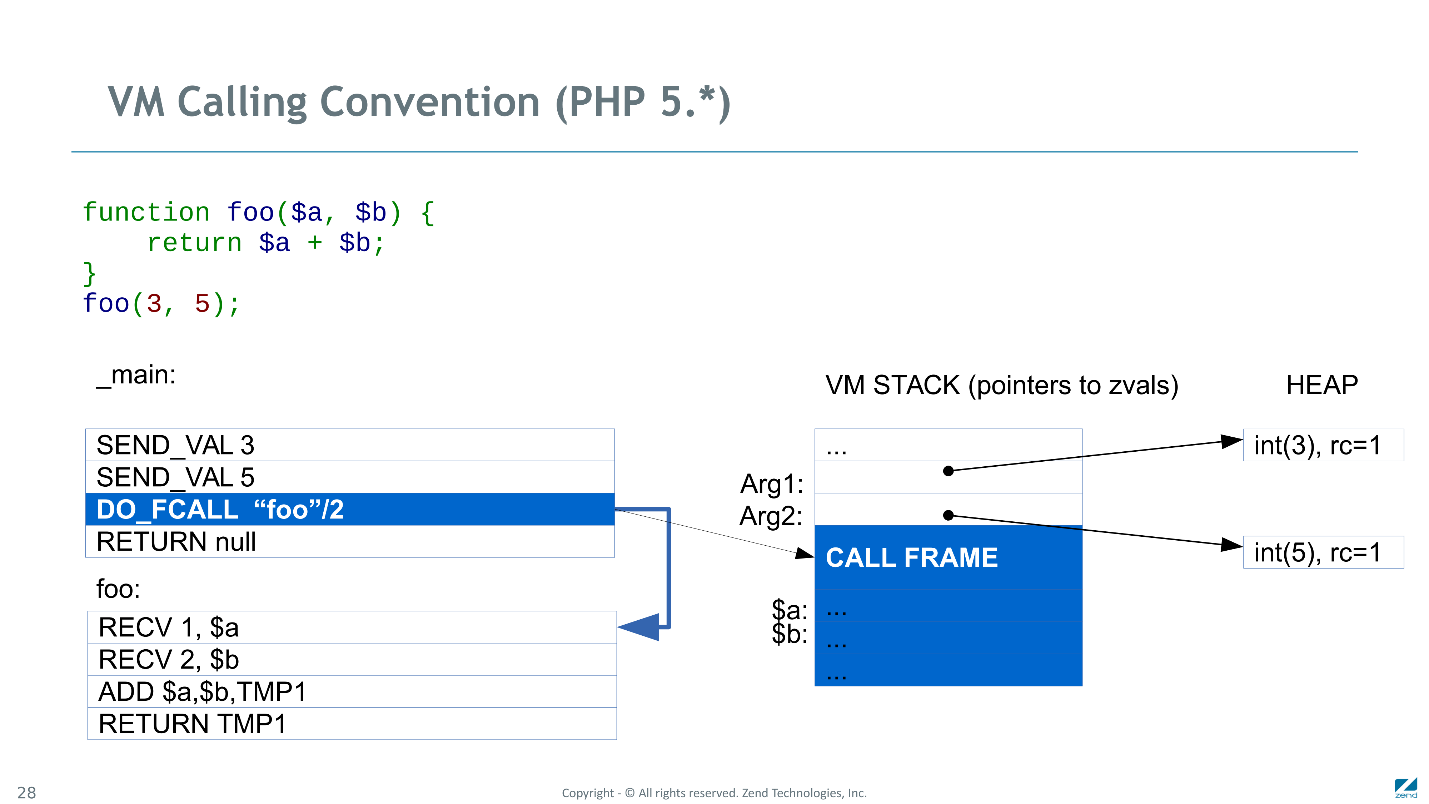
Первый оператор
RECV проверял первый аргумент и инициализировал на стеке слот соответствующей локальной переменной ($a). Тут мы обошлись без копирования и просто увеличили счетчик ссылок соответствующего параметра (zval со значением 3). Аналогично второй оператор RECV устанавливал связь между переменной $b и параметром 5.
Дальше тело функции. Произошло сложение 3 + 5 — получилось 8. Это временная переменная и ее значение хранилось непосредственно на стеке.

RETURN и мы возвращаемся из функции.

При возврате освобождаем все переменные и аргументы, которые вышли из области видимости. Для этого проходим по всем zval на которые ссылаются слоты из освобождаемого фрейма, и для каждого уменьшаем счетчик ссылок. Если он достиг 0, то уничтожаем соответствующую структуру.
Как видно, даже такая простая операция, как посылка константы в функцию требует распределения новой памяти, копирования и увеличения счетчика ссылок, а потом еще и двойного уменьшения и удаления.
Calling Convention в PHP 7
В PHP 7 эти проблемы исправили — теперь на стеке храним не указатели на zval-ы, а сами zval-ы.

Также мы ввели новую инструкцию
INIT_FCALL, которая теперь отвечает за инициализацию и выделение памяти под CALL FRAME, и резервацию места под аргументы и временные переменные.
SEND_VAL 3 теперь просто копирует аргумент в первый слот за CALL FRAME. Следующий SEND_VAL 5 во второй слот.
Дальше самое интересное. Казалось бы,
DO_FCALL должна передать управление на первую инструкцию вызываемой функции. Но аргументы уже попали в слоты, которые зарезервированы для переменных параметров $a и $b, и инструкциям RECV просто ничего делать. Поэтому можно их просто пропустить. Мы посылали два параметра, поэтому пропускаем две инструкции. Если бы посылали три — пропустили бы три.
Так что мы переходим непосредственно на тело функции, производим сложение и возвращаемся.

При возврате чистим все локальные переменные, но теперь только для двух слотов, а поскольку там у нас скаляры, нам опять ничего не требуется делать.

Мой рассказ чуть-чуть упрощен, он не учитывает функции с переменным числом аргументов и необходимость проверки типов и некоторые другие моменты.
Новый Calling Convention немного сломал совместимость. В PHP есть такие функции, как
func_get_arg и func_get_args. Если раньше они возвращали оригинальное значение посланного параметра, то теперь возвращают текущее значение соответствующей локальной переменной, потому что мы просто не храним оригинальные значения. Так же как делают отладчики C.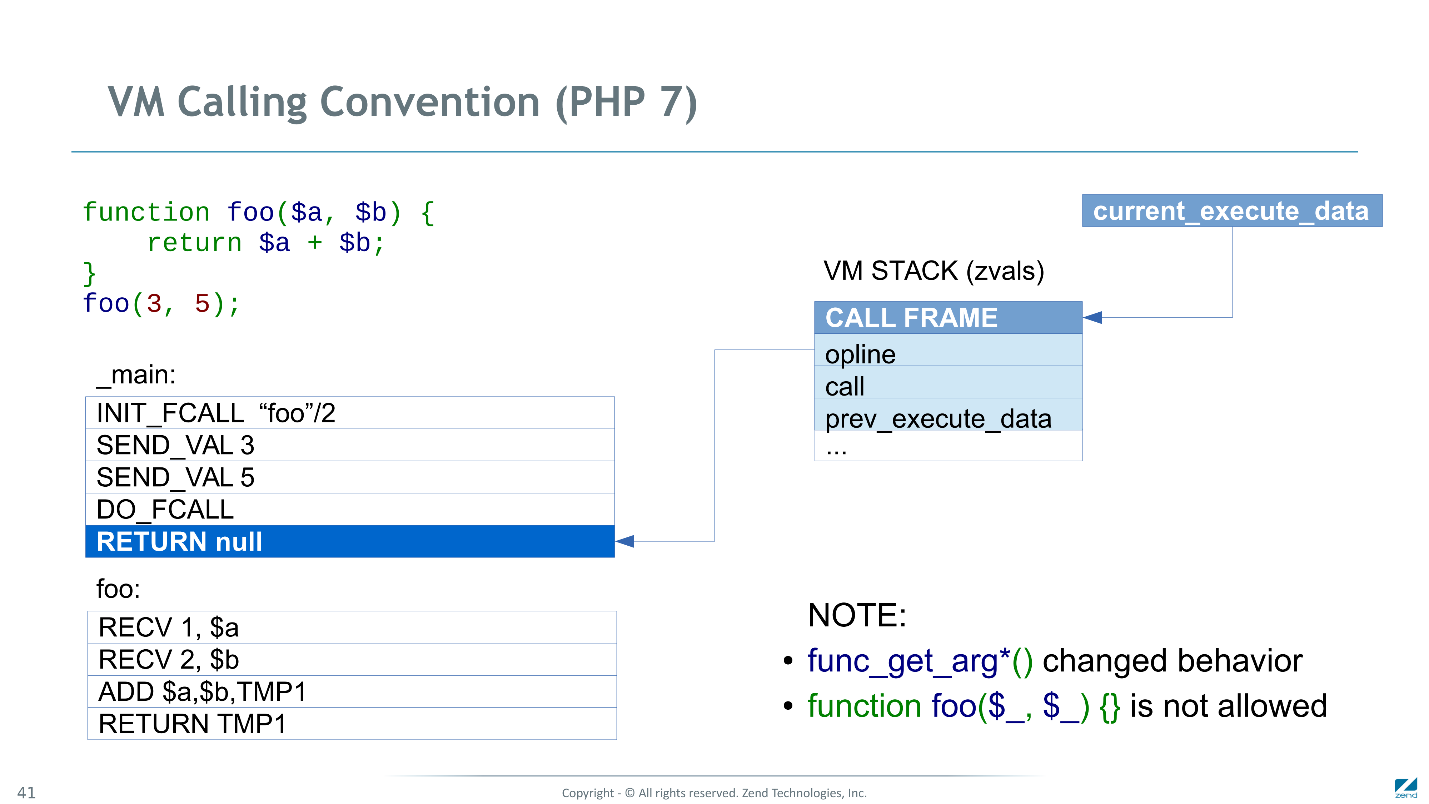
Кроме того, функция теперь не может иметь несколько параметров с одинаковым именем. Смысла в этом не было и раньше, но такой PHP код
foo($_, $_) я встречал. На что это похоже? (Я узнал Prolog)Новый менеджер памяти
Закончив с оптимизацией структур данных и базовых алгоритмов, мы еще раз обратили внимание на все тормозящие подсистемы. Менеджер памяти в PHP 5 занимал почти 20% процессорного времени на Wordpress.
После того, как мы избавились от множества аллокаций, его накладные расходы стали меньше, но все равно существенны — и не потому что он делал какую-то существенную работу, а потому, что спотыкался на кэше. Происходило это из-за того, что мы использовали классический алгоритм Doug Lea's malloc, который подразумевал поиск подходящих свободных участков памяти с помощью путешествия по ссылкам и деревьям, а все эти путешествия неминуемо вызывали промахи кэша.
Сегодня существуют новые алгоритмы управления памятью, которые учитывают особенности современных процессоров. Например: jemalloc и ptmalloc от Google. Сначала, мы попытались использовать их в неизменном виде, но не получили выигрыша, поскольку отсутствие специфичного для PHP функционала удорожало полное освобождение памяти в конце реквеста. В итоге мы отказались от dlmalloc и написали что-то свое, скомбинировав идеи из старого memory manager и jemalloc.
Мы сократили накладные расходы Memory Manager до 5%, уменьшили издержки памяти на служебную информацию и улучшили использование кэша CPU. Подходящие блоки памяти теперь ищутся по битовым картам, память под блоки небольшого размера выделяется из отдельных страниц и кэшируется при освобождении, добавлены специализированные функции для часто используемых размеров блоков.
Множество мелких усовершенствований
Я рассказал только о самых главных усовершенствованиях, но мелких было куда больше. Могу отметить некоторые из них.
- Быстрый API для разбора параметров внутренних функций и новый API для итерации по HashTable.
- Новые инструкции VM: конкатенация строк, специализация, супер-инструкции.
- Некоторые внутренние функции были превращены в инструкции VM: strlen, is_int.
- Использование регистров CPU под регистры VM: IP и FP.
- Оптимизация функций дублирования и удаления массивов.
- Использование счетчиков ссылок вместо копирования везде, где можно.
- PCRE JIT.
- Оптимизация внутренних функций и serialize().
- Уменьшение размера кода и обрабатываемых данных.
Одни были очень простыми, например, потребовалось всего три строчки кода, чтобы включить JIT в регулярных перловских выражениях, и это сразу принесло видимое (2-3%) ускорение почти всем приложениям. Другие оптимизации затрагивали какие-то узкие аспекты определенных PHP функций, и не особо интересны, хотя суммарный вклад всех этих мелких усовершенствований вполне значим.
К чему пришли
Это вклад различных подсистем на WordPress/PHP 7.0.
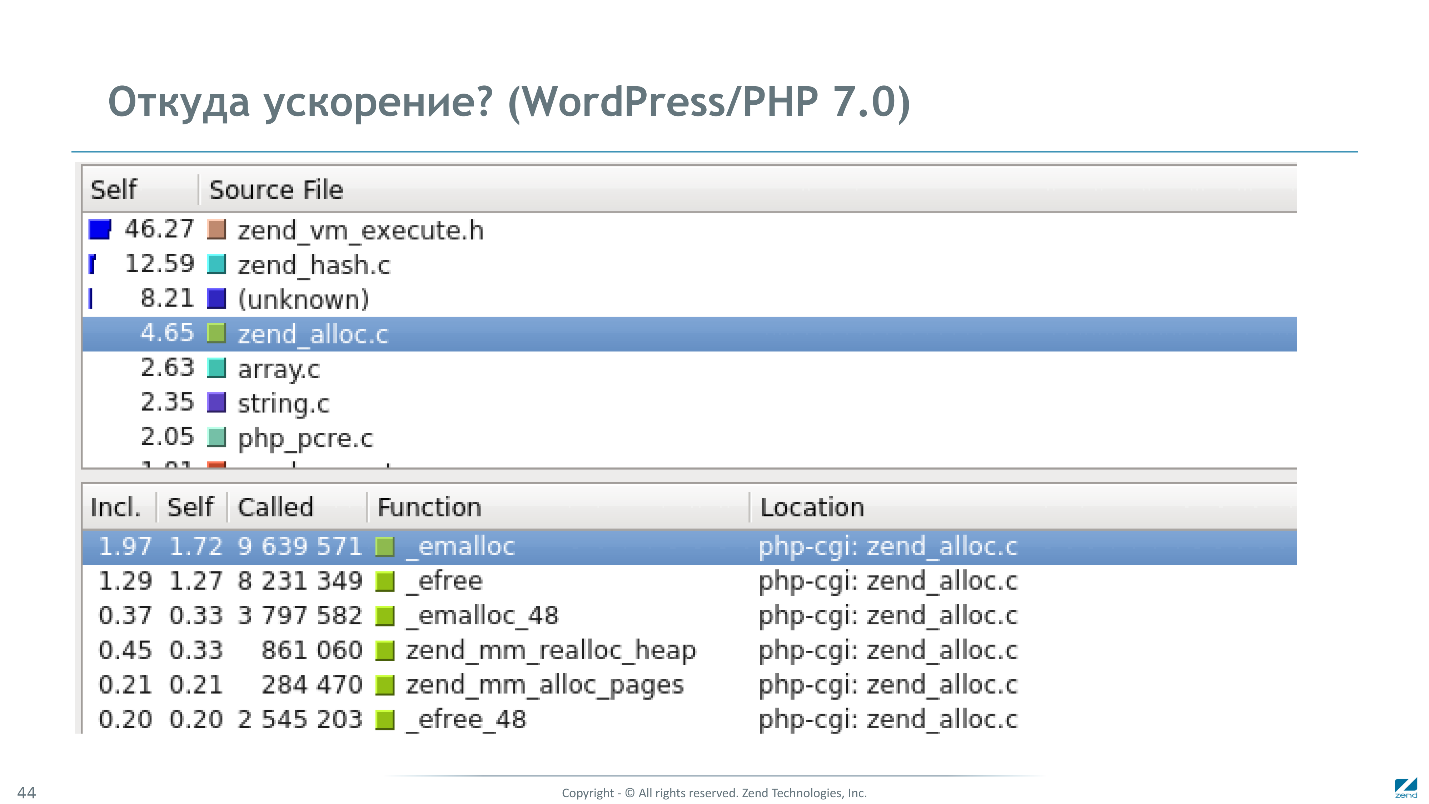
Вклад виртуальной машины увеличен до 50%. Memory Manager потребляет уже меньше 5% — и в основном не за счет оптимизаций самого Memory Manager, а за счет уменьшения количества обращений к нему. Если раньше на этом же тесте память выделялась 130 млн. раз, то сейчас только 10 млн. Может показаться, что все основное ускорение достигнуто за счет уменьшения накладных расходов Memory Manager и уменьшения количества обращений к нему за счет улучшения структур данных, но на самом деле все подсистемы были существенно усовершенствованы.

Основные источники ускорения:
- Интерпретатор стал работать лучше в 2 раза.
- Накладные расходы MM уменьшились в 17 раз.
- Хэш-таблицы стали работать быстрее в 4 раза.
- Общая производительность на WordPress выросла в 3,5 раза.
В начале статьи мы говорили о 2,5-кратном реальном ускорении, а сейчас цифры другие. Почему так? Дело в том, что реальную скорость мы измеряли в запросах в секунду, а здесь скорость измерена профилировщиком в терминах CPU time, по сути — тактах процессора, когда он не простаивает. Когда PHP ждет ответа от базы данных, процессор стоит и это время здесь не учитывается.
Производительность PHP 7
WordPress 3.6 был для нас основным бенчмарком — на нём мы мониторили производительность с первых дней работы. В какой-то момент, когда из PHP 7 выкинули расширение mysql, нам пришлось его специально поддерживать, просто чтобы продолжить этот график.

На графике видно, что основные прорывы произошли в первые месяцы работы над PHPNG. К августу было набрано 2/3 улучшений. Дальше мы двигались маленькими шажками, и набрали оставшуюся треть.
Разумеется, мы измеряли производительность не только на WordPress, но и на других популярных приложениях, и практически везде мы видим — от 1,5 до 2-кратное ускорение.
PHP 7 и HHVM
По нашей версии мы почти везде обгоняли даже актуальные на тот момент версии HHVM.
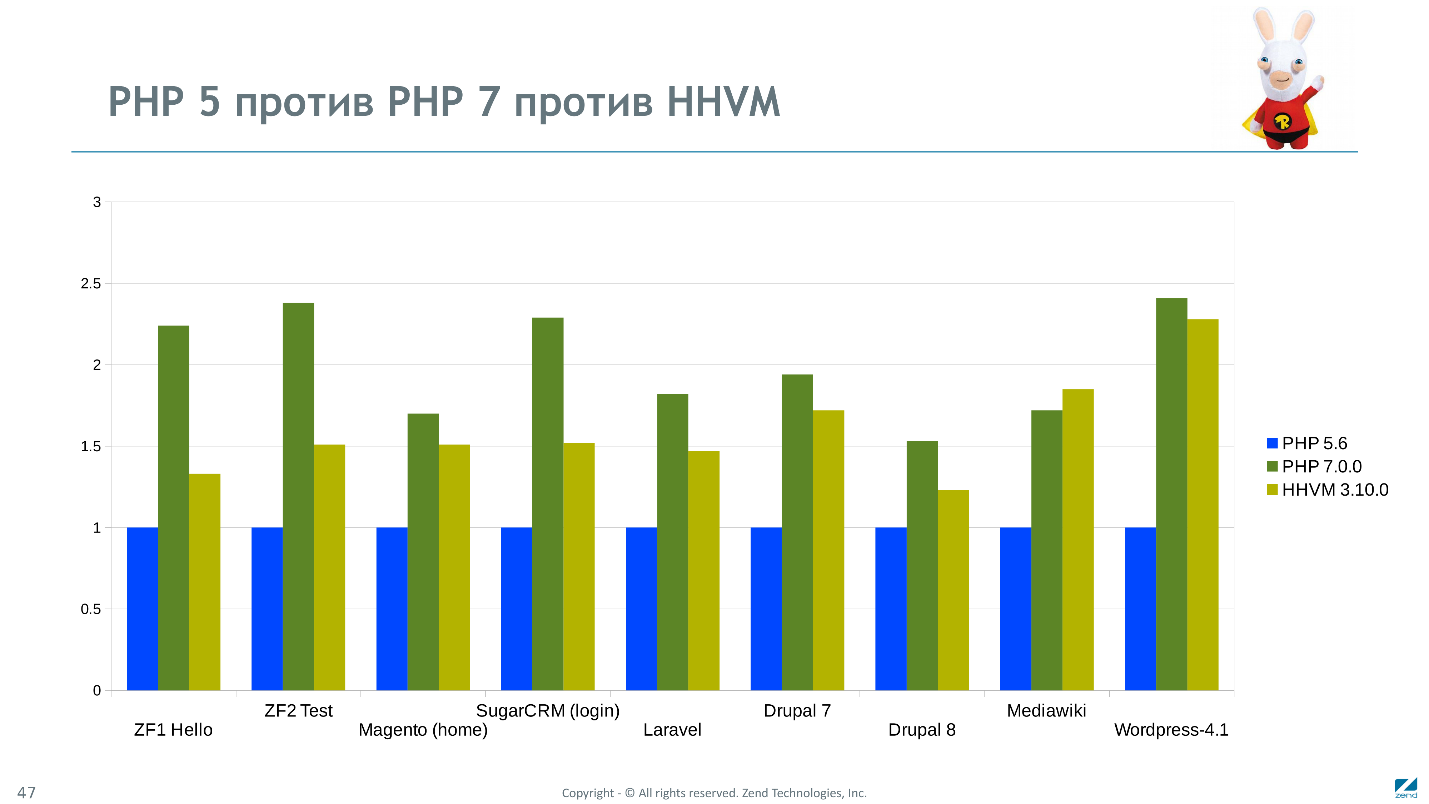
Но сравнение со сторонним продуктом — неблагодарное занятие. Всегда выигрыш в пользу измеряющего. Версия команды Facebook показывает другие результаты. На графике HHVM везде пропорционально быстрее. Возможно, это связано с разными процедурами замера, тестированием на разных аппаратных платформах, разницы в тонких настройках, а может повлияли и субъективные факторы.

Апофеоз PHP 7 — начало использования крупными сайтами. Пионерами были китайский Vebia, американский Etsy и Badoo. Highload-проверка вскрыла несколько существенных проблем, но они были быстро локализованы и пофикшены.
Переход на PHP 7.0 для Etsy и Badoo позволил выключить практически половину серверов в веб-фермах. Badoo оценил экономию в миллион долларов.
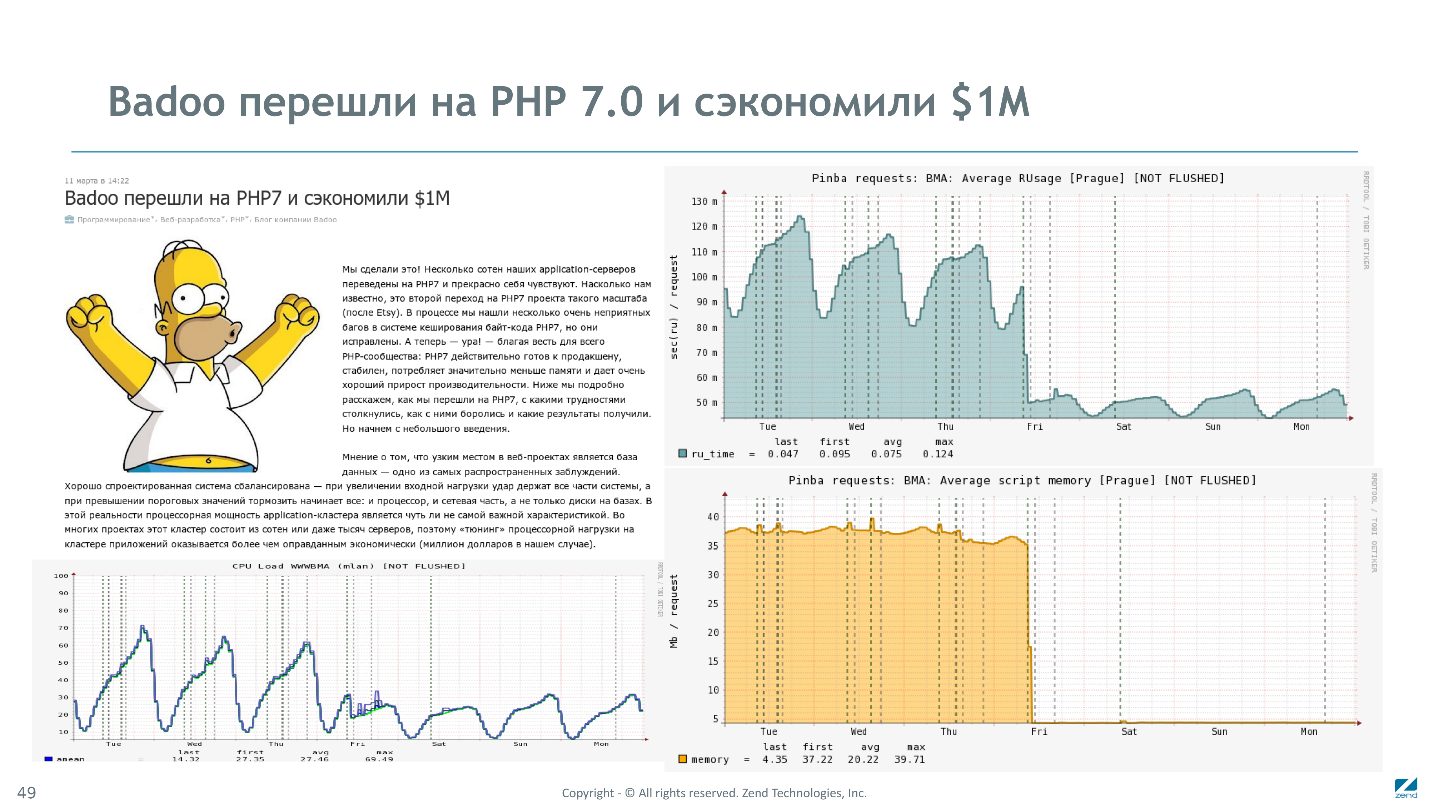
Показательны графики, что на момент перехода суммарная загрузка процессоров уменьшилась в 2 раза, а потребление памяти — аж в 7 раз.
На этой радостной ноте закончим сегодняшний разговор о PHP 7.0. Но продолжим его совсем скоро с PHP 7.1, в оптимизации которого пошли существенно дальше структур данных.
В мае на PHP Russia Дмитрий Стогов выступит с докладом о самых интересных новых технологиях разрабатываемых для PHP 8. Если и ваш опыт во многом связан с PHP, вы знаете, как его правильно готовить, и готовы поделиться своими наработками — присылайте заявки до 1 апреля. И помните, главное, что мы ищем — живой полезный опыт, а с докладом поможем, зададим правильные вопросы и подскажем, куда двигаться.
Комментарии (18)

iproger
20.03.2019 21:09Это действительно круто. Редко где можно увидеть чтобы новая версия была в 2 раза быстрее старой без каких-либо ограничений.

ZurgInq
20.03.2019 22:03-7Есть похожий лайфхак с базами данных. Вначале создаёшь голые таблички. Потом когда спустя какое то время (в зависимости от нагрузок), всё начинает тормозить — вешаешь индексы, и вот у тебя с лёгкой руки уже ускорение даже не в разы, а на порядок!
CyberSEO
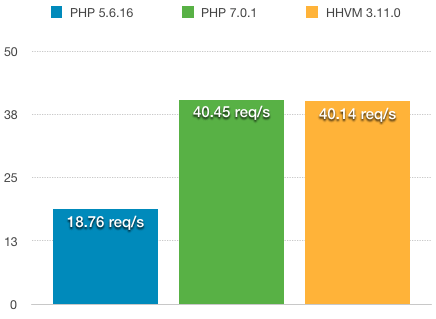
20.03.2019 23:01+2Спасибо за интересную статью. Кстати, WordPress, например, с PHP 7 в 2 раза быстрее прямо из коробки шурует.

EvilBeaver
20.03.2019 23:19+1Спасибо, очень классно. Мне, как мейнтейнеру скриптового движка, будет над чем подумать.

Dimensi
20.03.2019 23:43-1Мало, что понял, так как все эти оптимизации далеки от меня, но читать было бы интересно.
Если бы php причесали бы, улучшили стандартную библиотеку (убрали текущий цирк) и поубивали старый синтаксис, то была бы уже радость от использования языка, но такой поворот наверно превратил бы php в python 3.JekaMas
21.03.2019 01:48+2Python… Только с константами, объектной моделью, менеджером зависимостей, трейтами, статическими полями, теперь уже и контролем над типами...
Dimensi
21.03.2019 09:08Я имел ввиду, что переход на питон 3 для многих был болезненным, а не в том, что пхп станет выглядить как питон.

mihmig
21.03.2019 10:11Скажите — а при работе php (в качестве модуля apache или php-fpm+nginx) парсинг php-файла происходит при каждом запросе клиента или есть какое-никакое кеширование байткода?

Urvin
21.03.2019 10:37Opcache есть, конечно.
mihmig
21.03.2019 10:53Он (Opcache) встроен в стандартную поставку? А если я поменял файл и нажал обновил страничку — ка PHP об этом догадывается? Он проверяет дату изменения файла при каждом запросе?
Urvin
21.03.2019 11:01Opcache в стандартной поставке с PHP 5.5, до этого был APC. При большом желании его можно выключить или накриворучить настройками.
Стандартно, да, следит на временем изменения файла, если этот файл закеширован. Из кеша можно выпилиться засчет переполнения максимального отведенного объема памяти или количества файлов.
На проде устанавливают
opcache.validate_timestamps=0
и при деплое сбрасывают кеш, искренне считая, что тут код не должен меняться и нечего тратить время на проверки всякие.

Lailore
21.03.2019 11:14+1Довольно забавно видеть эту эволюцию. Как сначала не типизированность показываться как супер пупер киллер фича во множество языках. а через некоторое время — ой, нам нужны типы для читаемости, ой нам нужны типы для производительности
bat
21.03.2019 13:07Такая информация из первых рук бесценна. Дмитрий выступал с похожим докладом в 2017 на кодефесте, была возможность послушать в живую. огонь.
Кому интересны еще подробности, на хабре была статья хардкорная статья про внутрянку массивов в семерке: habr.com/ru/company/mailru/blog/308240



Compolomus
21.03.2019 19:27Было бы интересно почитать об встроенном сервере, который появился в 5.4
Хотелось бы узнать будет ли расти стандартная библиотека SPL, например хотелось бы увидеть там класс для работы с сокетами, по типу SPLFileObject
Какие расширение планируются добавиться в common
Какие расширения будут выпилены, есть куча расширении для xml
Enmar
Офигенная статья, респект автору!
Очень интересно читать, хоть я и не php developer.