
В этой статье я опишу наш опыт миграции Preply в Kubernetes, как и почему мы это сделали, с какими трудностями столкнулись и какие преимущества приобрели.

Kubernetes ради Kubernetes? Нет, бизнес-требования!
Вокруг Kubernetes много хайпа и это неспроста. Многие люди говорят что он решит все проблемы, некоторые утверждают, что скорее всего, Kubernetes вам не нужен. Истина конечно находится где-то посередине.

Однако все эти рассуждения о том где и когда нужен Kubernetes, достойны отдельной статьи. Сейчас же я расскажу немного о наших бизнес-требованиях и как Preply работал до миграции в Kubernetes:
- Когда мы использовали Skullcandy flow у нас было множество веток, все они мержились в общую ветку под названием
stage-rc, деплоились на стейдж. Команда QA тестировала это окружение, после тестирования ветка мержилась в мастер и мастер деплоился на прод. Вся процедура занимала порядка 3-4 часов и у нас получалось деплоиться от 0 до 2 раз в день - Когда мы деплоили сломанный код на прод, нам приходилось откатывать все изменения вошедшие в последний релиз. Также было сложно найти, какое именно изменение сломало нам прод
- Мы использовали AWS Elastic Beanstalk для хостинга нашего приложения. Каждый деплой Beanstalk в нашем случае занимал 45 минут (весь пайплайн вместе с тестами отрабатывал за 90 минут). Откат на предыдущую версию приложения занимал 45 минут
Для улучшения нашего продукта и процессов в компании мы хотели:
- Разбить монолит на микросервисы
- Деплоиться быстрее и чаще
- Откатываться быстрее
- Сменить наш процесс разработки, потому что мы его считали более не эффективным
Наши потребности
Изменяем процесс разработки
Для внедрения наших нововведений со Skullcandy flow нам нужно было создавать динамическое окружение для каждой ветки. В нашем подходе с конфигурацией приложения в Elastic Beanstalk сделать это было сложно и дорого. Нам хотелось создавать окружения которые бы:
- Быстро и легко деплоились (желательно чтобы это были контейнеры)
- Работали на спот-инстансах
- Были максимально похожи на прод
Мы решили переехать на Trunk-Based Development. С его помощью, каждая фича имеет отдельную ветку, которая независимо от остальных может мержиться в мастер. Мастер-ветка может деплоиться в любое время.
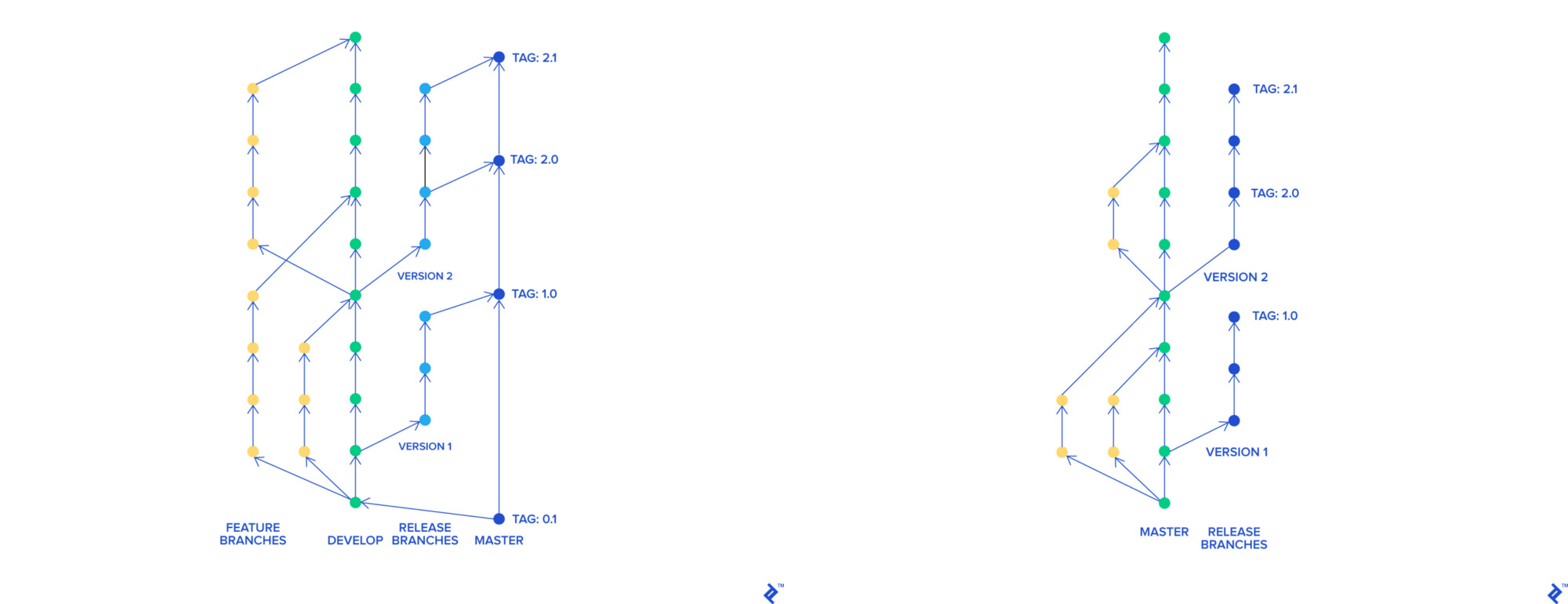
git-flow и Trunk-Based Development
Деплоимся быстрее и чаще
Новый Trunk-Based процесс позволил нам быстрее доставлять нововведения в мастер-ветку одну за другой. Это существенно помогло нам в процессе поиска сломаного кода в проде и его откате. Однако, время деплоя все еще составляло 90 минут, а время отката — 45 минут, из-за этого мы не могли деплоиться чаще 4-5 раз в день.
Также мы столкнулись с трудностями при использовании сервисной архитектуры на Elastic Beanstalk. Наиболее очевидным решением являлось использование контейнеров и инструмента для их оркестрации. К тому же у нас уже был опыт использования Docker и docker-compose для локальной разработки.
Следующим нашим шагом было исследование популярных оркестраторов для контейнеров:
- AWS ECS
- Swarm
- Apache Mesos
- Nomad
- Kubernetes
Мы решили остановиться на Kubernetes, и вот почему. Среди рассматриваемых оркестраторов каждый имел какой-то важный недостаток: ECS является вендорозависимым решение, Swarm уже уступил лавры Kubernetes, Apache Mesos выглядел для нас как космический корабль со своими Zookeeper'ами. Nomad показался интересным, однако полностью себя раскрывал себя только в интеграции с другими продуктами Hashicorp, также нас огорчило то, что неймспейсы в Nomad платные.
Несмотря на высокий порог вхождения, Kubernetes является стандартом де-факто в оркестрации контейнеров. Kubernetes as a Service доступен у большинства крупных облачных провайдеров. Оркестратор находится в активной разработке, имеет большое сообщество пользователей и разработчиков и неплохую документацию.
Мы ожидали мигрировать полностью нашу платформу в Kubernetes за 1 год. Два инженера платформы без опыта работы с Kubernetes занимались миграцией в режиме частичной загрузки.
Используем Kubernetes
Мы начали с proof of concept, создали тестовый кластер, подробно документировали все что мы делали. Решили использовать kops, так как в нашем регионе на то время все еще не был доступен EKS (в Ирландии его анонсировали в сентябре 2018).
В ходе работы с кластером тестировались cluster-autoscaler, cert-manager, Prometheus, интеграции с Hashicorp Vault, Jenkins и многое другое. Мы "игрались" с rolling-update стратегиями, столкнулись с несколькими сетевыми проблемами, в частности с DNS, укрепили знания в траблшутинге кластера.
Для оптимизации затрат на инфраструктуру использовали спот инстансы. Для получения уведомлений о проблемах со спотам использовали kube-spot-termination-notice-handler, Spot Instance Advisor может помочь вам при выборе типа спот-инстанса.
Мы начали миграцию со Skullcandy flow на Trunk-based development, где мы запускали динамический стейдж на каждый пулреквест, это позволило сократить время доставки новых фич с 4-6 до 1-2 часов.
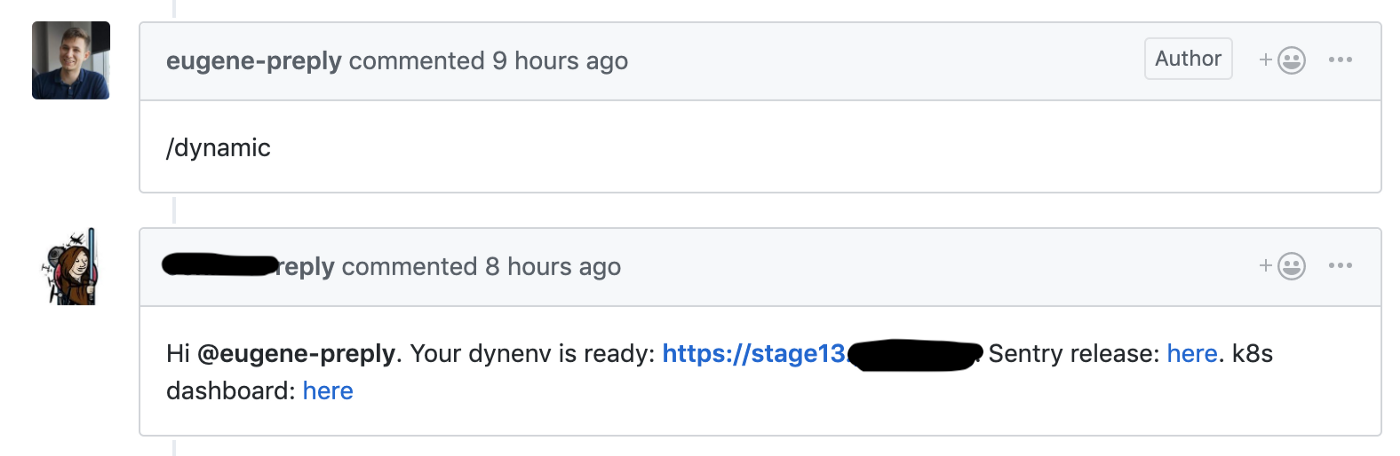
Github-хук запускает создание динамического окружения для пулреквеста
Мы использовали тестовый кластер для этих динамических окружений, каждое окружение находилось в отдельном неймспейсе. Разработчики имели доступ к Kubernetes Dashboard для дебага своего кода.
Мы рады тому, что стали получать пользу от Kubernetes уже спустя 1-2 месяца с начала его использования.
Кластеры для стейджа и прода
Наши настройки стейдж и прод кластеров:
- kops и Kubernetes 1.11 (самая свежая версия на момент создания кластеров)
- Три мастер ноды в разных зонах доступности
- Приватная топология сети с выделенным бастионом, Calico CNI
- Prometheus для сбора метрик, задеплоен в том же кластере с PVC (стоит учесть что мы не храним метрики долго)
- Datadog-агент для APM
- Dex+dex-k8s-authenticator для предоставления доступа к кластеру разработчикам
- Ноды для стейдж кластера работают на спот-инстансах
В ходе работы с кластерами мы столкнулись с несколькими проблемами. К примеру, версии Nginx Ingress и Datadog-агента отличались на кластерах, в связи с этим некоторые вещи работали на стейдж кластере, но не работали на проде. Поэтому мы решили сделать полное соответствие версий ПО на кластерах для избежания подобных случаев.
Мигрируем прод в Kubernetes
Стейдж и прод кластеры готовы, а мы готовы приступить к миграции. Мы используем монорепу с такой структурой:
.
+-- microservice1
¦ +-- Dockerfile
¦ +-- Jenkinsfile
¦ L-- ...
+-- microservice2
¦ +-- Dockerfile
¦ +-- Jenkinsfile
¦ L-- ...
+-- microserviceN
¦ +-- Dockerfile
¦ +-- Jenkinsfile
¦ L-- ...
+-- helm
¦ +-- microservice1
¦ ¦ +-- Chart.yaml
¦ ¦ +-- ...
¦ ¦ +-- values.prod.yaml
¦ ¦ L-- values.stage.yaml
¦ +-- microservice2
¦ ¦ +-- Chart.yaml
¦ ¦ +-- ...
¦ ¦ +-- values.prod.yaml
¦ ¦ L-- values.stage.yaml
¦ +-- microserviceN
¦ ¦ +-- Chart.yaml
¦ ¦ +-- ...
¦ ¦ +-- values.prod.yaml
¦ ¦ L-- values.stage.yaml
L-- JenkinsfileКорневой Jenkinsfile содержит в себе таблицу соответствия имени микросервиса и директории в которой находится его код. Когда разработчик мержит пулреквест в мастер, создается тег в GitHub, этот тег деплоится на прод с помощью Jenkins в соответствии с Jenkinsfile'ом.
В каталоге helm/ располагаются HELM-чарты с двумя отдельными values-файлами для стейджа и прода. Мы используем Skaffold для деплоя множества HELM-чартов на стейдж. Пробовали использовать umbrella chart, но столкнулись с тем что его сложно масштабировать.
В соответствиии с twelve-factor app каждый новый микросервис в проде пишет логи в stdout, читает секреты из Vault и имеет базовый набор алертов (проверка количества работающих подов, пятисотых ошибок и латенси на ингрессе).
В независимости от того, завозим ли мы новые фичи в микросервисы или нет, в нашем случае весь основной функционал находится в Django-монолите и этот монолит все еще работает на Elastic Beanstalk.

Разбиваем монолит на микросервисы // The Vigeland Park в Осло
Мы использовали AWS Cloudfront в качестве CDN и с его помощью мы использовали canary-деплой на протяжении нашей миграции. Мы начали мигрировать монолит на Kubernetes и тестировать его на некоторых языковых версиях и на внутренних страницах сайта (таких как админка). Подобный процесс миграции позволил нам отловить баги на проде и отполировать наши деплои всего за несколько итераций. На протяжении пары недель мы наблюдали за состоянием платформы, нагрузкой и мониторингом, в конце концов 100% трафика прода переключили в Kubernetes.
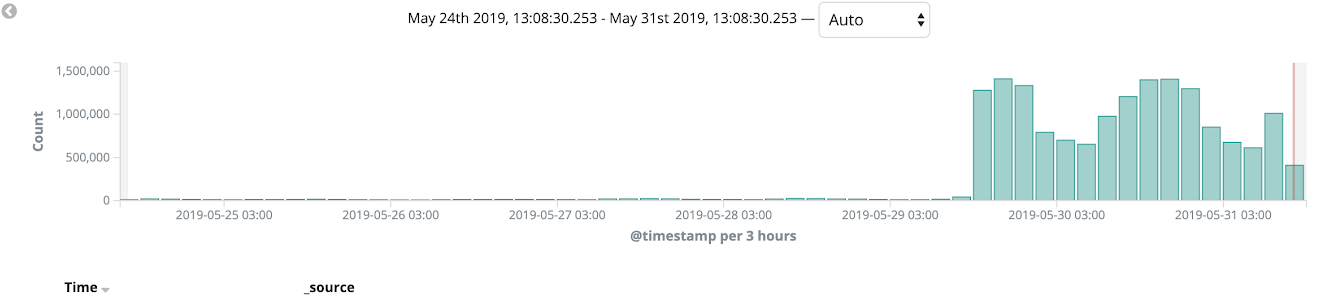
После этого мы полностью смогли отказаться от использования Elastic Beanstalk.
Итоги
Полная миграция у нас заняла 11 месяцев, как я упоминал выше, планировали уложиться в 1 год.
Собственно результаты налицо:
- Время деплоя уменьшилось с 90 мин до 40 мин
- Количество деплоев увеличилось с 0-2 до 10-15 в день (и все еще растет!)
- Время отката уменьшилось с 45 до 1-2 мин
- Мы можем легко доставлять новые микросервисы в прод
- Мы привели в порядок наш мониторинг, логгинг, управление секретами, централизовали их и описали как код
Это был очень крутой опыт по миграции и мы все еще работаем над многими улучшениями платформы. Обязательно прочтите классную статью про опыт работы с Kubernetes от Юры, он был одним из тех YAML-инженеров кто занимался внедрением Kubernetes в Preply.
Комментарии (5)

alex005
27.08.2019 00:58Имеется ввиду, чтобы api, который по semver совместим мог работать только с таким же.

alex005
Интересует возможность авто-обнаружения версий совместимого API? Что для этого нужно сделать, чтобы API всегда был совместим?
Amet13 Автор
Что именно вы подразумеваете под совместимостью? Есть какой-то реальный кейс?
Мы, если что, используем GraphQL.