
Сегодня я хотел бы поговорить о распаковке вложенных списков неопределённой глубины. Это достаточно нетривиальное занятие, поэтому я бы хотел рассказать тут о том, какие реализации есть, их плюсы и минусы и сравнение их производительности.
Статья будет состоять из нескольких разделов ниже:
- Функции
- Данные
- Результаты
- Выводы
Часть 1. Функции
Заимствованные реализации
outer_flatten_1
def outer_flatten_1(array: Iterable) -> List:
"""
Based on C realization of this solution
More on:
https://iteration-utilities.readthedocs.io/en/latest/generated/deepflatten.html
https://github.com/MSeifert04/iteration_utilities/blob/384948b4e82e41de47fa79fb73efc56c08549b01/src/deepflatten.c
"""
return deepflatten(array)Данную функцию для разбора я взял из внешнего пакета, iteration_utilities.
Реализация выполнена на Си, оставив для питона высокоуровневый интерфейс вызова функции.
Реализация функции на Си является достаточно громоздкой, можете её посмотреть, перейдя по ссылке в спойлере. Функция является итератором.
>>> from typing import Iterator, Generator
>>> from iteration_utilities import deepflatten
>>> isinstance(deepflatten(a), Iterator)
True
>>> isinstance(deepflatten(a), Generator)
FalseСложно сказать про сложность алгоритма, реализованного тут, поэтому оставляю этот интерес на пользователях Хабра.
В целом, также хотелось бы отметить, что все остальные функции из этой библиотеки достаточно быстрые и также реализованы на Си.
outer_flatten_2
def outer_flatten_2(array: Iterable) -> List:
"""
recursive algorithm, vaguely reminiscent of recursion_flatten. Based on next pattern:
.. code:: python
try:
tree = iter(node)
except TypeError:
yield node
more on:
https://more-itertools.readthedocs.io/en/stable/api.html#more_itertools.collapse
"""
return collapse(array)Реализация этого способа распаковки вложенных списков также находится во внешнем пакете, а именно more_itertools.
Функция выполнена на чистом питоне, однако неоптимально, на мой взгляд. Подробную реализацию можно увидеть в ссылке на документацию.
Сложность данного алгоритма O(n*m).
Собственные реализации
niccolum_flatten
def niccolum_flatten(array: Iterable) -> List:
"""
Non recursive algorithm
Based on pop/insert elements in current list
"""
new_array = array[:]
ind = 0
while True:
try:
while isinstance(new_array[ind], list):
item = new_array.pop(ind)
for inner_item in reversed(item):
new_array.insert(ind, inner_item)
ind += 1
except IndexError:
break
return new_arrayКогда как то зашла речь в телеграмм паблике @ru_python_beginners о реализациях распаковки вложенных списков неопределённой вложенности, я предложил свой вариант.
Заключается он в том, что мы копируем исходный список (чтобы не изменять его), а далее в цикле while True проверяем, пока элемент является списком — проходимся по нему и инсёртим результат в самое начало.
Да, сейчас я понимаю, что это выглядит неоптимально и сложно, т.к. каждый раз происходит переиндексирование (т.к. мы добавляем и удаляем из начала списка), однако этот вариант тоже имеет право на жизнь и мы проверим его реализацию вместе с остальными.
Сложность данного алгоритма O(n^3*m) из за перестройки списка дважды за каждую пройденную итерацию
tishka_flatten
def tishka_flatten(data: Iterable) -> List:
"""
Non recursive algorithm
Based on append/extend elements to new list
"""
nested = True
while nested:
new = []
nested = False
for i in data:
if isinstance(i, list):
new.extend(i)
nested = True
else:
new.append(i)
data = new
return dataОдним из первых также реализацию показал Tishka17. Заключается она в том, что внутри цикла while nested идёт перебор по существующему списку с ключом nested = False, и, в случае, если ему хотя бы раз попался лист, он оставляет флаг nested = True и extend'ит этот лист в список. Соответственно получается, что за каждый прогон он раскладывает один уровень вложенности, сколько будет уровней вложенности — столько будет и проходов по циклу. Как видно из описания — не самый оптимальный алгоритм, но всё же, является отличным от остальных.
Сложность данного алгоритма O(n*m).
zart_flatten
def zart_flatten(a: Iterable) -> List:
"""
Non recursive algorithm
Based on pop from old and append elements to new list
"""
queue, out = [a], []
while queue:
elem = queue.pop(-1)
if isinstance(elem, list):
queue.extend(elem)
else:
out.append(elem)
return out[::-1]Алгоритм, также предложенный одним из опытных участников чата. На мой взгляд, является достаточно простым и чистым. Смысл его в том, чтобы в случае, если элемент это список, мы добавляем результат в конец первоначального списка, а в случае, если нет — добавляем в вывод. Буду называть его ниже extend/append механизм. Как результат — выводим перевёрнутый полученный результирующий плоский список, чтобы сохранить первоначальный порядок элементов.
Сложность данного алгоритма O(n*m).
recursive_flatten_iterator
def recursive_flatten_iterator(arr: Iterable) -> Iterator:
"""
Recursive algorithm based on iterator
Usual solution to this problem
"""
for i in arr:
if isinstance(i, list):
yield from recursion_flatten(i)
else:
yield iНаверное, самый распространённый вариант решения данной задачи — через рекурсию и yield from. Мало что можно скзаать — алгоритм кажется достаточно простым и эффективным, не считая того, что он сделан через рекурсию и, при больших вложенностях, может быть достаточно большой стэк вызовов.
Сложность данного алгоритма O(n*m).
recursive_flatten_generator
def recursive_flatten_generator(array: Iterable) -> List:
"""
Recursive algorithm
Looks like recursive_flatten_iterator, but with extend/append
"""
lst = []
for i in array:
if isinstance(i, list):
lst.extend(recursive_flatten_list(i))
else:
lst.append(i)
return lstЭта функция достаточно похожа на прерыдущую, только выполнена не через итератор, а через рекурсивный extend/append механизм.
Сложность данного алгоритма O(n*m).
tishka_flatten_with_stack
def tishka_flatten_with_stack(seq: Iterable) -> List:
"""
Non recursive algorithm
Based on zart_flatten, but build on try/except pattern
"""
stack = [iter(seq)]
new = []
while stack:
i = stack.pop()
try:
while True:
data = next(i)
if isinstance(data, list):
stack.append(i)
i = iter(data)
else:
new.append(data)
except StopIteration:
pass
return newЕщё 1 алгоритм, который предоставил Тишка, который, на самом деле, очень похож на zart_flatten, однако там было реализовано через простой extend/append механизм, то тут — через итерирование в бесконечном цикле, в котором используется этот механизм. Таким образом получилось нечто похожее на zart_flatten, но через итерирование и while True.
Сложность данного алгоритма O(n*m).
Часть 2. Данные
Для проверки эффективности этих алгоритмов нам необходимо создать функции автогенерации списков определённой вложенности, с чем я успешно справился и покажу вам результат ниже:
create_data_decreasing_depth
def create_data_decreasing_depth(
data: Union[List, Iterator],
length: int,
max_depth: int,
_current_depth: int = None,
_result: List = None
) -> List:
"""
creates data in depth on decreasing.
Examples:
>>> data = create_data_decreasing_depth(list(range(1, 11)), length=5, max_depth=3)
>>> assert data == [[[1, 2, 3, 4, 5], 6, 7, 8, 9, 10]]
>>> data = create_data_decreasing_depth(list(range(1, 11)), length=2, max_depth=3)
>>> assert data == [[[1, 2], 3, 4], 5, 6], [[7, 8,] 9, 10]]
"""
_result = _result or []
_current_depth = _current_depth or max_depth
data = iter(data)
if _current_depth - 1:
_result.append(create_data_decreasing_depth(
data=data,
length=length,
max_depth=max_depth,
_current_depth=_current_depth - 1,
_result=_result))
try:
_current_length = length
while _current_length:
item = next(data)
_result.append(item)
_current_length -= 1
if max_depth == _current_depth:
_result += create_data_decreasing_depth(
data=data,
length=length,
max_depth=max_depth)
return _result
except StopIteration:
return _resultДанная функция создаёт вложенные списки с убывающей вложенностью
>>> data = create_data_decreasing_depth(list(range(1, 11)), length=5, max_depth=3)
>>> assert data == [[[1, 2, 3, 4, 5], 6, 7, 8, 9, 10]]
>>> data = create_data_decreasing_depth(list(range(1, 11)), length=2, max_depth=3)
>>> assert data == [[[1, 2], 3, 4], 5, 6], [[7, 8,] 9, 10]]create_data_increasing_depth
def create_data_increasing_depth(
data: Union[List, Iterator],
length: int,
max_depth: int,
_current_depth: int = None,
_result: List = None
) -> List:
"""
creates data in depth to increase.
Examples:
>>> data = create_data_increasing_depth(list(range(1, 11)), length=5, max_depth=3)
>>> assert data == [1, 2, 3, 4, 5, [6, 7, 8, 9, 10]]
>>> data = create_data_increasing_depth(list(range(1, 11)), length=2, max_depth=3)
>>> assert data == [1, 2, [3, 4, [5, 6]]], 7, 8, [9, 10]]
"""
_result = _result or []
_current_depth = _current_depth or max_depth
data = iter(data)
try:
_current_length = length
while _current_length:
item = next(data)
_result.append(item)
_current_length -= 1
except StopIteration:
return _result
if _current_depth - 1:
tmp_res = create_data_increasing_depth(
data=data,
length=length,
max_depth=max_depth,
_current_depth=_current_depth - 1)
if tmp_res:
_result.append(tmp_res)
if max_depth == _current_depth:
tmp_res = create_data_increasing_depth(
data=data,
length=length,
max_depth=max_depth)
if tmp_res:
_result += tmp_res
return _resultДанная функция создаёт вложенные списки с возрастающей вложенностью
>>> data = create_data_increasing_depth(list(range(1, 11)), length=5, max_depth=3)
>>> assert data == [1, 2, 3, 4, 5, [6, 7, 8, 9, 10]]
>>> data = create_data_increasing_depth(list(range(1, 11)), length=2, max_depth=3)
>>> assert data == [1, 2, [3, 4, [5, 6]]], 7, 8, [9, 10]]generate_data
def generate_data() -> List[Tuple[str, Dict[str, Union[range, Num]]]]:
"""
Generated collections of Data by pattern
{amount_item}_amount_{length}_length_{max_depth}_max_depth
where:
.. py:attribute:: amount_item:
len of flatten elements
.. py:attribute:: length:
len of elements at the same level of nesting
.. py:attribute:: max_depth:
highest possible level of nesting
"""
data = []
amount_of_elements = [10 ** i for i in range(5)]
data_template = '{amount_item}_amount_{length}_length_{max_depth}_max_depth'
# amount_item doesn't need to be [1]
for amount_item in amount_of_elements[1:]:
for max_depth in amount_of_elements:
# for exclude flatten list after generate data by create_data_increasing_depth
if amount_item > max_depth:
# generate four types of length
for length in range(0, max_depth + 1, math.ceil(max_depth / 4)):
# min length must be 1
length = length or 1
data_name = data_template.format(
amount_item=amount_item,
length=length,
max_depth=max_depth
)
data_value = {
'data': range(amount_item),
'length': length,
'max_depth': max_depth
}
data.append((data_name, data_value))
# for not to produce more than 1 flat entity
if max_depth == 1:
break
# this order is convenient for me
data = sorted(data, key=lambda x: [x[1]['data'][-1], x[1]['max_depth'], x[1]['length']])
return dataЭта функция непосредственно создаёт шаблоны для тестовых данных. Для этого она генерирует заголовки, созданные по шаблону
data_template = '{amount_item}_amount_{length}_length_{max_depth}_max_depth'Где:
- amount — общее количество элементов в списке
- length — количество элементов на одном уровне вложенности
- max_depth — максимальное количество уровней вложенности
Сами же данные передаются в функции выше для генерации необходимых данных. Соответственно, на выходе, как мы увидим позже, у нас будут следующие данные(заголовки):
10_amount_1_length_1_max_depth
100_amount_1_length_1_max_depth
100_amount_1_length_10_max_depth
100_amount_3_length_10_max_depth
100_amount_6_length_10_max_depth
100_amount_9_length_10_max_depth
1000_amount_1_length_1_max_depth
1000_amount_1_length_10_max_depth
1000_amount_3_length_10_max_depth
1000_amount_6_length_10_max_depth
1000_amount_9_length_10_max_depth
1000_amount_1_length_100_max_depth
1000_amount_25_length_100_max_depth
1000_amount_50_length_100_max_depth
1000_amount_75_length_100_max_depth
1000_amount_100_length_100_max_depth
10000_amount_1_length_1_max_depth
10000_amount_1_length_10_max_depth
10000_amount_3_length_10_max_depth
10000_amount_6_length_10_max_depth
10000_amount_9_length_10_max_depth
10000_amount_1_length_100_max_depth
10000_amount_25_length_100_max_depth
10000_amount_50_length_100_max_depth
10000_amount_75_length_100_max_depth
10000_amount_100_length_100_max_depth
10000_amount_1_length_1000_max_depth
10000_amount_250_length_1000_max_depth
10000_amount_500_length_1000_max_depth
10000_amount_750_length_1000_max_depth
10000_amount_1000_length_1000_max_depthЧасть 3. Результаты
Для профилирования CPU — я использовал line_profiler
Для построения графиков — timeit + matplotlib
CPU Профайлер
$ kernprof -l funcs.py
$ python -m line_profiler funcs.py.lprof
Timer unit: 1e-06 s
Total time: 1.7e-05 s
File: funcs.py
Function: outer_flatten_1 at line 11
Line # Hits Time Per Hit % Time Line Contents
==============================================================
11 @profile
12 def outer_flatten_1(array: Iterable) -> List:
13 """
14 Based on C realization of this solution
15 More on:
16
17 https://iteration-utilities.readthedocs.io/en/latest/generated/deepflatten.html
18
19 https://github.com/MSeifert04/iteration_utilities/blob/384948b4e82e41de47fa79fb73efc56c08549b01/src/deepflatten.c
20 """
21 2 17.0 8.5 100.0 return deepflatten(array)
Total time: 3.3e-05 s
File: funcs.py
Function: outer_flatten_2 at line 24
Line # Hits Time Per Hit % Time Line Contents
==============================================================
24 @profile
25 def outer_flatten_2(array: Iterable) -> List:
26 """
27 recursive algorithm, vaguely reminiscent of recursion_flatten. Based on next pattern:
28
29 .. code:: python
30
31 try:
32 tree = iter(node)
33 except TypeError:
34 yield node
35
36 more on:
37 https://more-itertools.readthedocs.io/en/stable/api.html#more_itertools.collapse
38 """
39 2 33.0 16.5 100.0 return collapse(array)
Total time: 0.105099 s
File: funcs.py
Function: niccolum_flatten at line 42
Line # Hits Time Per Hit % Time Line Contents
==============================================================
42 @profile
43 def niccolum_flatten(array: Iterable) -> List:
44 """
45 Non recursive algorithm
46 Based on pop/insert elements in current list
47 """
48
49 2 39.0 19.5 0.0 new_array = array[:]
50 2 6.0 3.0 0.0 ind = 0
51 2 2.0 1.0 0.0 while True:
52 20002 7778.0 0.4 7.4 try:
53 21010 13528.0 0.6 12.9 while isinstance(new_array[ind], list):
54 1008 1520.0 1.5 1.4 item = new_array.pop(ind)
55 21014 13423.0 0.6 12.8 for inner_item in reversed(item):
56 20006 59375.0 3.0 56.5 new_array.insert(ind, inner_item)
57 20000 9423.0 0.5 9.0 ind += 1
58 2 2.0 1.0 0.0 except IndexError:
59 2 2.0 1.0 0.0 break
60 2 1.0 0.5 0.0 return new_array
Total time: 0.137481 s
File: funcs.py
Function: tishka_flatten at line 63
Line # Hits Time Per Hit % Time Line Contents
==============================================================
63 @profile
64 def tishka_flatten(data: Iterable) -> List:
65 """
66 Non recursive algorithm
67 Based on append/extend elements to new list
68
69 """
70 2 17.0 8.5 0.0 nested = True
71 1012 1044.0 1.0 0.8 while nested:
72 1010 1063.0 1.1 0.8 new = []
73 1010 992.0 1.0 0.7 nested = False
74 112018 38090.0 0.3 27.7 for i in data:
75 111008 50247.0 0.5 36.5 if isinstance(i, list):
76 1008 1431.0 1.4 1.0 new.extend(i)
77 1008 1138.0 1.1 0.8 nested = True
78 else:
79 110000 42052.0 0.4 30.6 new.append(i)
80 1010 1406.0 1.4 1.0 data = new
81 2 1.0 0.5 0.0 return data
Total time: 0.062931 s
File: funcs.py
Function: zart_flatten at line 84
Line # Hits Time Per Hit % Time Line Contents
==============================================================
84 @profile
85 def zart_flatten(a: Iterable) -> List:
86 """
87 Non recursive algorithm
88 Based on pop from old and append elements to new list
89 """
90 2 20.0 10.0 0.0 queue, out = [a], []
91 21012 12866.0 0.6 20.4 while queue:
92 21010 16849.0 0.8 26.8 elem = queue.pop(-1)
93 21010 17768.0 0.8 28.2 if isinstance(elem, list):
94 1010 1562.0 1.5 2.5 queue.extend(elem)
95 else:
96 20000 13813.0 0.7 21.9 out.append(elem)
97 2 53.0 26.5 0.1 return out[::-1]
Total time: 0.052754 s
File: funcs.py
Function: recursive_flatten_generator at line 100
Line # Hits Time Per Hit % Time Line Contents
==============================================================
100 @profile
101 def recursive_flatten_generator(array: Iterable) -> List:
102 """
103 Recursive algorithm
104 Looks like recursive_flatten_iterator, but with extend/append
105
106 """
107 1010 1569.0 1.6 3.0 lst = []
108 22018 13565.0 0.6 25.7 for i in array:
109 21008 17060.0 0.8 32.3 if isinstance(i, list):
110 1008 6624.0 6.6 12.6 lst.extend(recursive_flatten_generator(i))
111 else:
112 20000 13622.0 0.7 25.8 lst.append(i)
113 1010 314.0 0.3 0.6 return lst
Total time: 0.054103 s
File: funcs.py
Function: recursive_flatten_iterator at line 116
Line # Hits Time Per Hit % Time Line Contents
==============================================================
116 @profile
117 def recursive_flatten_iterator(arr: Iterable) -> Iterator:
118 """
119 Recursive algorithm based on iterator
120 Usual solution to this problem
121
122 """
123
124 22018 20200.0 0.9 37.3 for i in arr:
125 21008 19363.0 0.9 35.8 if isinstance(i, list):
126 1008 6856.0 6.8 12.7 yield from recursive_flatten_iterator(i)
127 else:
128 20000 7684.0 0.4 14.2 yield i
Total time: 0.056111 s
File: funcs.py
Function: tishka_flatten_with_stack at line 131
Line # Hits Time Per Hit % Time Line Contents
==============================================================
131 @profile
132 def tishka_flatten_with_stack(seq: Iterable) -> List:
133 """
134 Non recursive algorithm
135 Based on zart_flatten, but build on try/except pattern
136 """
137 2 24.0 12.0 0.0 stack = [iter(seq)]
138 2 5.0 2.5 0.0 new = []
139 1012 357.0 0.4 0.6 while stack:
140 1010 435.0 0.4 0.8 i = stack.pop()
141 1010 328.0 0.3 0.6 try:
142 1010 330.0 0.3 0.6 while True:
143 22018 17272.0 0.8 30.8 data = next(i)
144 21008 18951.0 0.9 33.8 if isinstance(data, list):
145 1008 997.0 1.0 1.8 stack.append(i)
146 1008 1205.0 1.2 2.1 i = iter(data)
147 else:
148 20000 15413.0 0.8 27.5 new.append(data)
149 1010 425.0 0.4 0.8 except StopIteration:
150 1010 368.0 0.4 0.7 pass
151 2 1.0 0.5 0.0 return newГрафики
Общий результат:
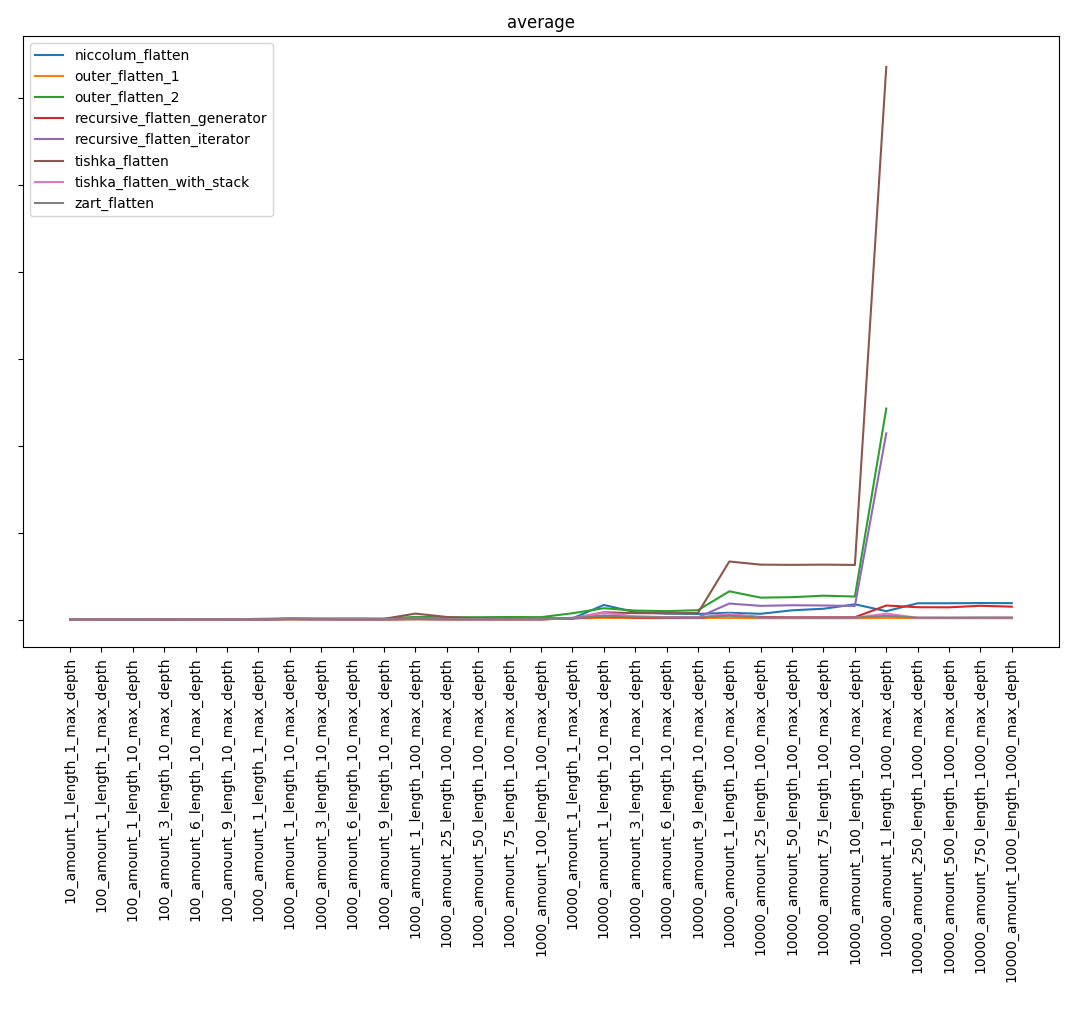
Исключив самые медленные функции, получаем:
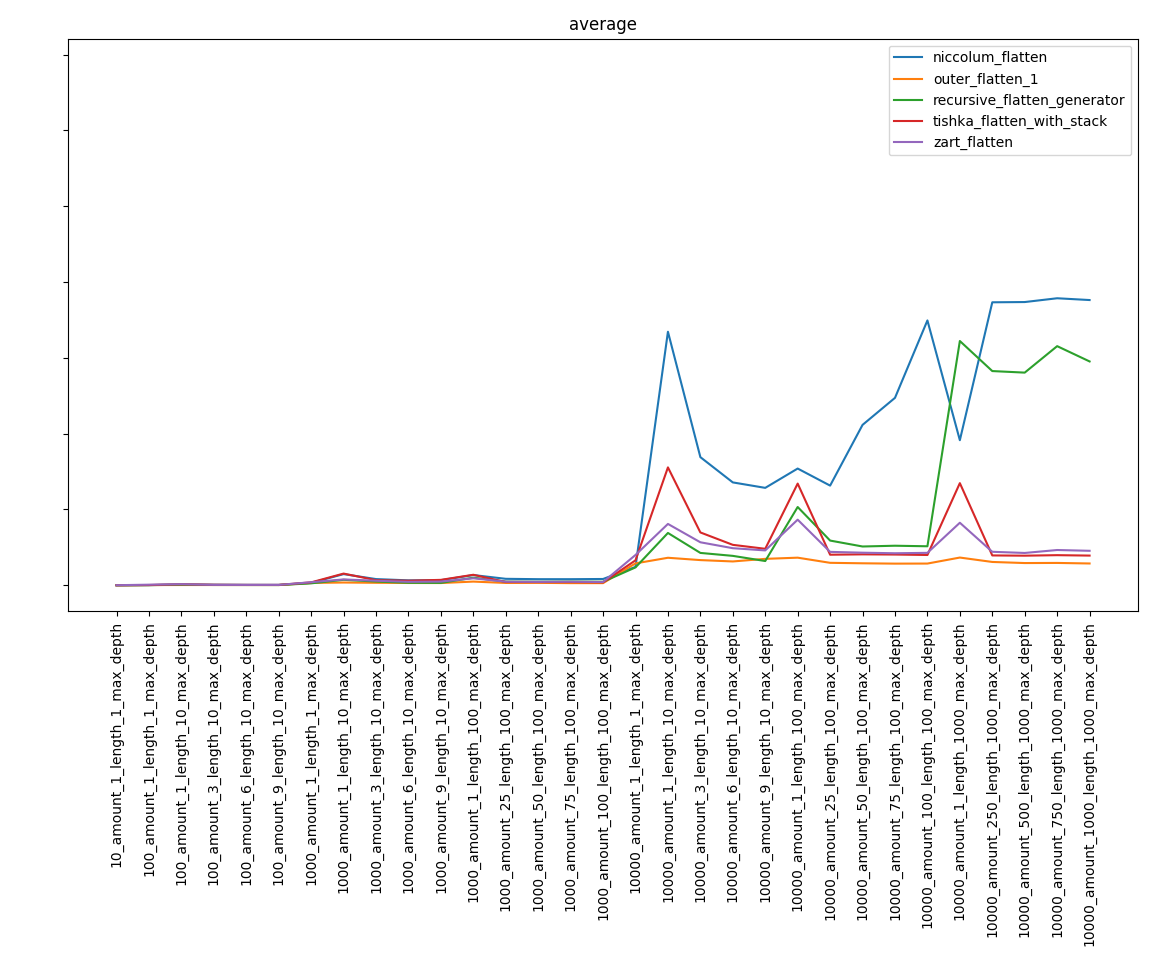
Часть 4. Выводы
Возможно, скажу очевидную вещь, но, несмотря на известную сложность алгоритмов, результат может быть неочевидным. Так, функция niccolum_flatten, сложность которого была самая высокая, попал в финальную стадию и занял далеко не последнее место. А recursive_flatten_generator оказался гораздо быстрее recursive_flatten_iterator.
Подводя итог, хочется прежде всего сказать, что это было скорее учебное исследование, нежели руководство по написанию эффективных алгоритмов по распаковке списка. Обычно, можно написать самую простую реализацию, не думая, самая ли она быстрая, т.к. экономия небольшая.
Полезные ссылки
Более полные результаты можно посмотреть тут
Репозиторий с кодом тут
Документация через sphinx тут
Если нашли ошибки, пишите в телеграмме Niccolum или на почту lastsal@mail.ru.
Буду рад конструктивной критике.
Комментарии (7)

daiver19
30.08.2019 00:49O(n*3m)
Это некорректное использование О нотации. 3 — это всего лишь часть константы скрывающейся за О, так что асимптотически сложность везде одинаковая. Разница в константе обусловлена деталями реализации в принципе.
PiaFraus
30.08.2019 03:38> Это некорректное использование О нотации
А где можно почитать про корректность использования нотации? Сам я как-то только помню определения из вуза и по ним легко выходит, что O(n f(x)) = O( f(x) ), но про «корректность» кажется ничего не было.daiver19
30.08.2019 03:54Ну это я и имею в виду — нет смысла сравнивать O(n) и O(3*n), т.к. они равны.

Niccolum Автор
30.08.2019 10:50Верно говоришь, но у меня там была очепятка
Всё потому, что идёт перестройка индексов при list.pop(0) (все индексы сдвигаются влево) и list.insert(0) — все индексы сдвигаются вправо
Поэтому там таки O(n^3*m), что уже поправил
alexxz
В выводах ничего неожиданного. Сложность алгоритмов в нотации О большого всегда считается для "достаточно больших" входных данных. То есть реально начинает выполняться начиная с какого-то большого значения. Более того, для малых значений, вероятно, будет быстрее алгоритм с большей сложностью. Например, алгоритм линейного поиска в списке из 3 элементов наверняка окажется быстрее хеш-таблицы.