
- Общее введение
- ФП
- Введение в ФП
- Основные принципы ФП
- Основные термины
- Встроенное ФП поведение в Python
- Библиотека Xoltar Toolkit
- Библиотека returns
- Литература
- Генераторы
- Введение в итераторы
- Введение в генераторы
- Генераторы vs итераторы
- Генераторы как пайплайн
- Концепт yield from
- Маршрутизация данных на генераторах (мультиплексирование, броадкастинг)
- Пример трейсинга генератора
- Стандартные инструменты генераторы
- Выводы
- Плюсы
- Минусы
- Литература
- Итоги
Общее введение
Говоря о Python, обычно используется процедурный и ООП стиль программирования, однако это не значит, что другие стили невозможны. В презентации ниже мы рассмотрим ещё пару вариантов — Функциональное программирование и программирование с помощью генераторов. Последние, в том числе, привели к появлению сопрограмм, которые позднее помогли создать асинхронность в Python. Сопрограммы и асинхронность выходят за рамки текущего доклада, поэтому, если интересно, можете ознакомиться об этом самостоятельно. Лично я рекомендую книгу "Fluent Python", в которой разговор начинается от итераторов, плавно переходит в темы о генераторах, сопрограммах и асинхронности.
ФП
Введение в ФП
Говоря о ФП сразу следует подчеркнуть, что программирование через функции далеко не всегда ФП, чаще всего это всего лишь процедурный стиль программирования. Чтобы попробовать понять ФП — необходимо разобраться, что это такое, и помогут нам в этом теоретические знания.
Выделяют две крупные парадигмы программирования: императивная и декларативная.
Императивное программирование предполагает ответ на вопрос “Как?”. В рамках этой парадигмы вы задаете последовательность действий, которые нужно выполнить, для того чтобы получить результат. Результат выполнения сохраняется в ячейках памяти, к которым можно обратиться впоследствии.
Декларативное программирование предполагает ответ на вопрос “Что?”. Здесь вы описываете задачу, даете спецификацию, говорите, что вы хотите получить в результате выполнения программы, но не определяете, как этот ответ будет получен. Каждая из этих парадигм включает в себя более специфические модели.
В продуктовой разработке наибольшее распространение получили процедурное и объектно-ориентированное программирование из группы “императивное программирование” и функциональное программирование из группы “декларативное программирование”.
В рамках процедурного подхода к программированию основное внимание сосредоточено на декомпозиции – разбиении программы / задачи на отдельные блоки / подзадачи. Разработка ведётся пошагово, методом “сверху вниз”. Наиболее распространенным языком, который предполагает использование процедурного подхода к программирования является язык C, в нем, основными строительными блоками являются функции.
В рамках объектно-ориентированного (ООП) подхода программа представляется в виде совокупности объектов, каждый из которых является экземпляром определенного класса, классы образуют иерархию наследования. ООП базируется на следующих принципах: инкапсуляция, наследование, полиморфизм, абстракция. Примерами языков, которые позволяют вести разработку в этой парадигме являются C#, Java.
В рамках функционального программирования выполнение программы – процесс вычисления, который трактуется как вычисление значений функций в математическом понимании последних (в отличие от функций как подпрограмм в процедурном программировании). Языки, которые реализуют эту парадигму – Haskell, Lisp.
Языки, которые можно отнести в функциональной парадигме обладают определенным набором свойств. Если язык не является чисто функциональным, но реализует эти свойства, то на нем можно разрабатывать, как говорят, в функциональном стиле.
Основные принципы ФП
- Функции являются объектами первого класса (First Class Object).
Это означает, что с функциями вы можете работать, также как и с данными — передавать их в качестве аргументов другим функциям, присваивать переменным и т.п. - Использование рекурсии в качестве основной структуры контроля потока управления. В некоторых языках не существует иной конструкции цикла, кроме рекурсии.
- Акцент на обработке списков (lists, отсюда название Lisp — LISt Processing). Списки с рекурсивным обходом подсписков часто используются в качестве замены циклов.
- Используются функции высшего порядка (High Order Functions). Функции высшего порядка – функции, которые могут в качестве аргументов принимать другие функции.
Функции высшего порядка принимают в качестве аргументов другие функции. В стандартную библиотеку Python входит достаточно много таких функций, в качестве примера приведем функцию map. Она принимает функцию и Iterable объект, применяет функцию к каждому элементу Iterable объекта и возвращает Iterator объект, который итеративно возвращает все модифицированные после функции элементы.
- Функции являются “чистыми” (Pure Functions) – т.е. не имеют побочных эффектов (иногда говорят: не имеют сайд-эффектов).
В Python это не выполняется. Необходимо самостоятельно следить за тем, чтобы функция была чистой.
- Акцент на том, что должно быть вычислено, а не на том, как вычислять.
Основные термины
Не все термины ниже необходимы для понимания доклада, но необходимы для понимания ФП (спасибо одному другу за их подборку)
Ссылочная прозрачность.
Ссылочная прозрачность — свойство функциональных программ, в котором любое выражение может быть заменено вычисленным им значением без изменения поведения программы. Ссылочная прозрачность позволяет проводить рефакторинг программ без изменения их поведения.
Функции
Детерминированные.
Детерминированная функция возвращает тот же результат для одних и тех же входных данных.
Чистые.
Чистая функция трансформирует входные данные в выходные и не взаимодействует с миром вне функции каким-либо образом, который можно наблюдать. Все чистые функции детерминированы, но не все детерминированные функции чисты.
Тотальные.
Тотальная функция возвращает вывод для каждого ввода.
Тотальные функции всегда завершаются и никогда не вызывают исключений.
Композиция функций — применение одной функции к результату другой
Сайд эффект.
Сайд эффект возникает, когда выполнение выражения делает что-то большее, чем вычисление значения. Сайд эффекты — взаимодействия, которые можно наблюдать за пределами функции или выражения. Распространённые сайд эффекты включают в себя доступ к базе данных, доступ к файлам, доступ к сети, системные вызовы, изменение изменяемой памяти или вызов функций, которые выполняют любое из вышеперечисленных действий.
Полиморфизм.
Полиморфизм — особенность языков программирования, которая позволяет переменной или функции принимать множество различных форм. Рассмотрим один из видов полиморфизма.
Параметрический полиморфизм.
Параметрический полиморфизм, иногда называемый универсальным, является особенностью некоторых языков программирования, который позволяет универсально количественно определять функцию или тип данных по одному или нескольким параметрам типа. Такие полиморфные функции и полиморфные типы данных называются параметризованными их параметрами типа.
Параметрический полиморфизм позволяет создавать общий код, который работает со многими различными типами данных, и универсальными типами данных, таких как коллекции. Параметрически полиморфный код должен вести себя единообразно при любом выборе параметров типа, что дает мощный способ рассуждать о таком коде, называемый параметрическим рассуждением.
Замыкание (closure)
Замыкание — процедура вместе с привязанной к ней совокупностью данных. © Steve Majewski
Замыкание — функция, которая ссылается на свободные переменные в своей области видимости.
Встроенное ФП поведение в Python
Базовые элементы ФП в Python — функции map(), reduce(), filter() и оператор lambda. В Python 1.x введена также функция apply(), удобная для прямого применения функции к списку, возвращаемому другой. Python 2.0 предоставляет для этого улучшенный синтаксис. Начиная с Python 2.3 считается устаревшей, удалена в Python 3.0
Несколько неожиданно, но этих функций и всего нескольких базовых операторов почти достаточно для написания любой программы на Python; в частности, все управляющие утверждения (if, elif, else, assert, try, except, finally, for, break, continue, while, def) можно представить в функциональном стиле, используя исключительно функции и операторы. Несмотря на то, что задача реального удаления всех команд управления потоком, возможно, полезна только для представления на конкурс "невразумительный Python" (с кодом, выглядящим как программа на Lisp'е), стоит уяснить, как ФП выражает управляющие структуры через вызовы функций и рекурсию.
В соответствии с вышесказанным, попробуем сделать несколько хаков, чтобы наш код был более ФПшный. Избавимся от if/elif/else в Python
# Normal statement-based flow control
if <cond1>:
func1()
elif <cond2>:
func2()
else:
func3()
# Equivalent "short circuit" expression
(<cond1> and func1()) or (<cond2> and func2()) or (func3()) Примечание. Как заметил skymorp, эквивалентность соблюдается лишь в том случае, еслиfunc1,func2и (необязательно)func3возвращают non falsy значения. Например, если в качестве func будут принты, то последнее выражение (func3) будет выполняться всегда.
Используем lambda для присваивания таких условных выражений
pr = lambda s:s
namenum = lambda x: (x==1 and pr("one")) or (x==2 and pr("two")) or (pr("other"))
assert namenum(1) == 'one'
assert namenum(2) == 'two'
assert namenum(3) == 'other'Замена циклов на выражения так же проста, как и замена условных блоков. for может быть переписана с помощью map().
for e in lst:
func(e) # statement-based loop
map(func,lst) # map-based loopТо же самое мы можем сделать и с функциями.
do_it = lambda f: f()
# let f1, f2, f3 (etc) be functions that perform actions
map(do_it, [f1,f2,f3])Перевести while впрямую немного сложнее, но вполне получается.
# statement-based while loop
while <cond>:
<pre-suite>
if <break_condition>:
break
else:
<suite>
# FP-style recursive while loop
def while_block():
<pre-suite>
if <break_condition>:
return 1
else:
<suite>
return 0
while_FP = lambda: (<cond> and while_block()) or while_FP()
while_FP()ФП вариант while все еще требует функцию while_block(), которая сама по себе может содержать не только выражения, но и утверждения (statements). Но мы могли бы продолжить дальнейшее исключение утверждений в этой функции (как, например, замену блока if/else в вышеописанном шаблоне).
К тому же, обычная проверка на месте (наподобие while myvar == 7) вряд ли окажется полезной, поскольку тело цикла (в представленном виде) не может изменить какие-либо переменные (хотя глобальные переменные могут быть изменены в while_block()). Один из способов применить более полезное условие — заставить while_block() возвращать более осмысленное значение и сравнивать его с условием завершения.
Стоит взглянуть на реальный пример исключения утверждений:
# imperative version of "echo()"
def echo_IMP():
while 1:
x = input("IMP -- ")
if x == 'quit':
break
else:
print(x)
echo_IMP()
# utility function for "identity with side-effect"
def monadic_print(x):
print(x)
return x
# FP version of "echo()"
echo_FP = lambda: monadic_print(input("FP -- ")) == 'quit' or echo_FP()
echo_FP()Примечание. Как заметил skymorp, в случае с императивным стилем,input("IMP -- ") == 'quit'. В примере с функциональным программированием
Мы достигли того, что выразили небольшую программу, включающую ввод/вывод, циклы и условия в виде чистого выражения с рекурсией (фактически — в виде функционального объекта, который при необходимости может быть передан куда угодно).
Мы все еще используем служебную функцию monadic_print(), но эта функция совершенно общая и может использоваться в любых функциональных выражениях, которые мы создадим позже. Заметим, что любое выражение, содержащее monadic_print(x) вычисляется так же, как если бы оно содержало просто x.
После всей проделанной работы по избавлению от совершенно осмысленных конструкций и замене их на невразумительные вложенные выражения, возникает естественный вопрос — "Зачем?!". Перечитывая описания характеристик ФП, мы можем видеть, что все они достигнуты в Python. Но важнейшая (и, скорее всего, в наибольшей степени реально используемая) характеристика — исключение побочных эффектов или, по крайней мере, ограничение их применения специальными областями наподобие монад. Огромный процент программных ошибок и главная проблема, требующая применения отладчиков, случается из-за того, что переменные получают неверные значения в процессе выполнения программы.
Функциональное программирование обходит эту проблему, просто вовсе не присваивая значения переменным.
# Nested loop procedural style for finding big products
xs = (1,2,3,4)
ys = (10,15,3,22)
bigmuls = []
# ...more stuff...
for x in xs:
for y in ys:
# ...more stuff...
if x*y > 25:
bigmuls.append((x,y))
# ...more stuff...
# ...more stuff...
print(bigmuls)Секции, комментированные как #...more stuff... — места, где побочные эффекты с наибольшей вероятностью могут привести к ошибкам.
В любой из этих точек переменные xs, ys, bigmuls, x, y могут приобрести неожиданные значения в гипотетическом коде. Далее, после завершения этого куска кода все переменные могут иметь значения, которые могут ожидаться, а могут и не ожидаться посдедующим кодом.
Очевидно, что инкапсуляция в функциях/объектах и тщательное управление областью видимости могут использоваться, чтобы защититься от этого рода проблем. Вы также можете всегда удалять (del) ваши переменные после использования.
Но на практике указанный тип ошибок весьма обычен. Функциональный подход к задаче полностью исключает ошибки, связанные с побочными эффектами. Возможное решение могло бы быть таким:
bigmuls = lambda xs,ys: filter(lambda (x,y):x*y > 25, combine(xs,ys))
combine = lambda xs,ys: map(None, xs*len(ys), dupelms(ys,len(xs)))
dupelms = lambda lst,n: reduce(lambda s,t:s+t, map(lambda l,n=n: [l]*n, lst))
print(bigmuls((1,2,3,4),(10,15,3,22)))Реальное преимущество этого функционального примера в том, что в нем абсолютно ни одна переменная не меняет своего значения. Какое-либо неожиданное побочное влияние на последующий код (или со стороны предыдущего кода) просто невозможно. Конечно, само по себе отсутствие побочных эффектов не гарантирует безошибочность кода, но в любом случае это преимущество. Вместо вышеприведенных примеров — императивного или функционального — наилучшая (и функциональная) техника выглядит следующим образом:
print([(x,y) for x in (1,2,3,4) for y in (10,15,3,22) if x*y > 25])Да, всё верно, list, tuple, set, dict comprehensions и generator expressions — изначально ФП техники, которые, как и многое другое, перекочевало в другие не-ФП языки
Библиотека Xoltar Toolkit
Сразу оговоримся, что библиотека достаточно старая и подходит лишь для Python 2, однако для ознакомления её достаточно. Библиотека Xoltar Toolkit Брина Келлера (Bryn Keller) покажет нам больше возможностей ФП.
Основные возможности ФП Келлер представил в виде небольшого эффективного модуля на чистом Python. Помимо модуля functional, в Xoltar Toolkit входит модуль lazy, поддерживающий структуры, вычисляемые "только когда это необходимо". Множество функциональных языков программирования поддерживают отложенное вычисление, поэтому эти компоненты Xoltar Toolkit предоставят вам многое из того, что вы можете найти в функциональном языке наподобие Haskell.
Ничто в Python не запрещает переприсваивания другого значения имени, ссылающемуся на функциональное выражение. В ФП под именами понимается всего лишь буквенное сокращение более длинных выражений, при этом подразумевается, что одно и то же выражение всегда приводит к одному и тому же результату. Если же уже определенному имени присваивается новое значение, это допущение нарушается.
>>> car = lambda lst: lst[0]
>>> cdr = lambda lst: lst[1:]
>>> sum2 = lambda lst: car(lst)+car(cdr(lst))
>>> sum2(range(10))
1
>>> car = lambda lst: lst[2]
>>> sum2(range(10))
5К несчастью, одно и то же выражение sum2(range(10)) вычисляется к разным результатам в двух местах программы, несмотря на то, что аргументы выражении не являются изменяемыми переменными.
К счастью, модуль functional предоставляет класс Bindings, предотвращающий такое переприсваивание.
>>> from functional import *
>>> let = Bindings()
>>> let.car = lambda lst: lst[0]
>>> let.car = lambda lst: lst[2]
Traceback (innermost last):
File "<stdin>",
line 1, in ? File "d:\tools\functional.py",
line 976, in __setattr__ raise BindingError, "Binding '%s' cannot be modified." % name
functional.BindingError: Binding 'car' cannot be modified. >>> car(range(10)) 0Разумеется, реальная программа должна перехватить и обработать исключение BindingError, однако сам факт его возбуждения позволяет избежать целого класса проблем.
Библиотека returns
Уже более современная библиотека, предлагаемая Никитой Соболевым, нашим соотечественником, также позволяет использовать возможности ФП в Python. Декоратор maybe позволяет переходить к следующей итерации только при успешном завершении предыдущей
from returns.maybe import Maybe, maybe
@maybe # decorator to convert existing Optional[int] to Maybe[int]
def bad_function() -> Optional[int]:
...
maybe_number: Maybe[float] = bad_function().map(
lambda number: number / 2,
)
# => Maybe will return Some[float] only if there's a non-None value
# Otherwise, will return NothingБолее реальный пример, из императивного стиля в декларативный можно переписать так:
# Imperative style
user: Optional[User]
discount_program: Optional['DiscountProgram'] = None
if user is not None:
balance = user.get_balance()
if balance is not None:
credit = balance.credit_amount()
if credit is not None and credit > 0:
discount_program = choose_discount(credit)
# same with returns
user: Optional[User]
# Type hint here is optional, it only helps the reader here:
discount_program: Maybe['DiscountProgram'] = Maybe.from_value(
user,
).map( # This won't be called if `user is None`
lambda real_user: real_user.get_balance(),
).map( # This won't be called if `real_user.get_balance()` returns None
lambda balance: balance.credit_amount(),
).map( # And so on!
lambda credit: choose_discount(credit) if credit > 0 else None,
)Или, например, позволяет обходить возможные подводные камни напрямую через пайплайн
# Imperative style
def fetch_user_profile(user_id: int) -> 'UserProfile':
"""Fetches UserProfile dict from foreign API."""
response = requests.get('/api/users/{0}'.format(user_id))
# What if we try to find user that does not exist?
# Or network will go down? Or the server will return 500?
# In this case the next line will fail with an exception.
# We need to handle all possible errors in this function
# and do not return corrupt data to consumers.
response.raise_for_status()
# What if we have received invalid JSON?
# Next line will raise an exception!
return response.json()И то же самое, только с помощью returns
import requests
from returns.result import Result, safe
from returns.pipeline import flow
from returns.pointfree import bind
def fetch_user_profile(user_id: int) -> Result['UserProfile', Exception]:
"""Fetches `UserProfile` TypedDict from foreign API."""
return flow(
user_id,
_make_request,
bind(_parse_json),
)
@safe
def _make_request(user_id: int) -> requests.Response:
response = requests.get('/api/users/{0}'.format(user_id))
response.raise_for_status()
return response
@safe
def _parse_json(response: requests.Response) -> 'UserProfile':
return response.json()Теперь у нас есть чистый, безопасный и декларативный способ выразить потребности нашего бизнеса: Мы начинаем с запроса, который может потерпеть неудачу в любой момент, затем анализирем ответ, если запрос был успешным, а потом возвращаем результат.
Вместо обычных значений возвращаются значения, заключенные в специальный контейнер, благодаря декоратору @safe. Он вернет Success [YourType] или Failure [Exception]. И никогда не бросит нам исключение!
Подробнее об этой библиотеке можно уточнить из её достаточно большой и подробной документации, указанной в литературе.
Прим. Я, как автор этой статьи, не использовал returns в проде и не думаю, что буду когда-либо использовать, но не упомянуть об этой библиотеке в рамках данной статьи просто нельзя.
Литература
- Серия лекций https://devpractice.ru/fp-python-part1-general/
- Две статьи о ФП в Python
- https://degoes.net/articles/fp-glossary большой список терминов ФП
- https://returns.readthedocs.io/en/latest/
Генераторы
Введение в итераторы
Итерация — по сути является перебором значений. Вот обычный пример, который встречается повсюду.
>>> for x in [1,4,5,10]:
... print(x, end=' ')
...
1 4 5 10Также, как мы знаем, итерация может происходить по многим типам объектов (не только спискам). Причина, почему мы можем итерироваться по объектам — реализация специального протокола
>>> items = [1, 4, 5]
>>> it = iter(items)
>>> it.__next__()
1
>>> it.__next__()
4
>>> it.__next__()
5
>>> it.__next__()Внутри под капотом обычной итерации.
for x in obj:
# statementsПроисходит примерно следующее:
_iter = iter(obj) # Get iterator object
while 1:
try:
x = _iter.__next__() # Get next item
except StopIteration: # No more items
break
# statementsФактически, любой объект, который поддерживает конструкцию iter() называется итерируемым. Чтобы добавить его поддержку в своём классе, нам необходимо имплементировать методы __iter__() и __next__().
Например, посмотрим, как имплементировать такое:
>>> for x in Countdown(10):
... print(x, end=' ')
...
10 9 8 7 6 5 4 3 2 1Его реализация будет такова:
class Countdown(object):
def __init__(self,start):
self.start = start
def __iter__(self):
return CountdownIter(self.start)
class CountdownIter(object):
def __init__(self, count):
self.count = count
def __next__(self):
if self.count <= 0:
raise StopIteration
r = self.count
self.count -= 1
return rВведение в генераторы
Генератор — функция, которая генерирует последовательность результатов вместо одного значения
def countdown(n):
while n > 0:
yield n
n -= 1Вместо того, чтобы возвращать значение, мы создаём серию значений (с использованием оператора yield). Вызов функции генератора создает объект-генератор. Однако функция не запускается.
def countdown(n):
print("Counting down from", n)
while n > 0:
yield n
n -= 1
>>> x = countdown(10)
>>> x
<generator object at 0x58490>
>>>Функция генератор выполняется только при вызове __next__().
>>> x = countdown(10)
>>> x
<generator object at 0x58490>
>>> x.__next__()
Counting down from 10
10
>>>yield возвращает значение, но приостанавливает выполнение функции. Функция генератор возобновляется при следующем вызове __next__(). При завершении итератора возбуждается исключение StopIteration.
>>> x.__next__()
9
>>> x.__next__()
8
>>>
...
>>> x.__next__()
1
>>> x.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in ?
StopIteration
>>>Небольшие выводы:
- Функция генератор — более удобный способ написания итератора
- Вам не нужно беспокоиться о реализации протокола итератора (
__next__,__iter__и т. д.), т.к. при создании функции сyieldмагия Python уже добавляет в объект функции нужные методы.
>>> def x():
... return 1
...
>>> def y():
... yield 1
...
>>> [i for i in dir(y()) if i not in dir(x())]
['__del__', '__iter__', '__name__', '__next__', '__qualname__', 'close', 'gi_code', 'gi_frame', 'gi_running', 'gi_yieldfrom', 'send', 'throw']Помимо функции генератора возможно также использовать генераторное выражение, которое также возвращает generator object.
>>> a = [1,2,3,4]
>>> b = (2*x for x in a)
>>> b
<generator object at 0x58760>
>>> for i in b: print(b, end=' ')
...
2 4 6 8Синтаксис генераторного выражения также прост
(expression for i in s if condition)
# the same with
for i in s:
if condition:
yield expressionГенераторы vs итераторы
Функция генератор немного отличается от объекта, поддерживающего итерацию. Генератор — разовая операция. Мы можем перебирать сгенерированные данные один раз, но если мы хотим сделать это снова, мы должны снова вызвать функцию генератор. Это отличается, например, от списка (который мы можем перебирать столько раз, сколько хотим)
Генераторы как пайплайн
Теперь у нас есть два основных строительных блока, которые мы можем применить для создания пайплайна. Например, имеется задача:
Узнайте, сколько байтов данных было передано, суммируя последний столбец данных в журнале веб-сервера Apache. И да, размер лог файла может измеряться в гигабайтах
Каждая строка в логах выглядит примерно так:
81.107.39.38 - ... "GET /ply/ply.html HTTP/1.1" 200 97238
Число байтов находится в последней колонке:
bytes_sent = line.rsplit(None,1)[1]
Это может быть число или отсутствующее значение.
81.107.39.38 - ... "GET /ply/ HTTP/1.1" 304 -
Сконвертируем полученный результат в число
if bytes_sent != '-':
bytes_sent = int(bytes_sent)В итоге, может получиться примерно такой код
with open("access-log") as wwwlog:
total = 0
for line in wwwlog:
bytes_sent = line.rsplit(None,1)[1]
if bytes_sent != '-':
total += int(bytes_sent)
print("Total", total)Мы читаем строка за строкой и обновляем сумму. Но это старый стиль. Посмотрим, как эту задачу можно решить с помощью генераторов.
with open("access-log") as wwwlog:
bytecolumn = (line.rsplit(None,1)[1] for line in wwwlog)
bytes_sent = (int(x) for x in bytecolumn if x != '-')
print("Total", sum(bytes_sent))Этот подход отличается от предыдущего, меньше строк, напоминает функциональный стиль Мы получили пайплайн

На каждом этапе конвейера мы объявляем операцию, которая будет применяться ко всему входному потоку. Вместо того чтобы сосредоточиться на проблеме построчно, мы просто разбиваем ее на большие операции, которые работают со всем файлом. Это декларативный подход.
Безусловно, этот генераторный подход имеет разновидности причудливой медленной магии. Файл из 1.3 ГБ код в старом стиле выполнил за 18.6 секунд, код на генераторах был выполнен за 16,7 секунд.
AWK с той же задачей справился гораздо медленее, за 70.5 секунд
awk '{ total += $NF } END { print total }' big-access-logНебольшие выводы:
- Это не только не медленно, но и на 10% быстрее, чем старый стиль
- Меньше кода
- Код относительно легко читается
- И, честно говоря, мне он нравится в целом больше
- Ни разу в нашем решении с генератором мы не создавали большие временные списки
- Таким образом, это решение не только быстрее, но и может применяться к огромным файлам с данными
- Подход конкурентоспособен с традиционными инструментами
Генераторное решение было основано на концепции конвейерной передачи данных между разными компонентами. Что, если бы у нас были более продвинутые виды компонентов для работы? Возможно, мы могли бы выполнять разные виды обработки, просто подключив различные компоненты друг за другом.
Концепт yield from
'yield from' может использоваться для делегирования итерации
def countdown(n):
while n > 0:
yield n
n -= 1
def countup(stop):
n = 1
while n < stop:
yield n
n += 1
def up_and_down(n):
yield from countup(n)
yield from countdown(n)
>>> for x in up_and_down(3):
... print(x)
...
1
2
3
2
1
>>>Также стоит упомянуть, что в более ранних версиях python (3.5 и ниже) yield from также использовался вместо await, пока await не стал новым ключевым зарезервированными словом, т.к. await — по сути, просто передача контекста управления внутри другой корутины. Чтобы не возлагать много ответственности на yield from и было придумано отдельное зарезервированное слово — await.
Маршрутизация данных на генераторах (мультиплексирование, броадкастинг)
Задача — считать логи в режиме реального времени из разных источников, и транслировать результат нескольким потребителям
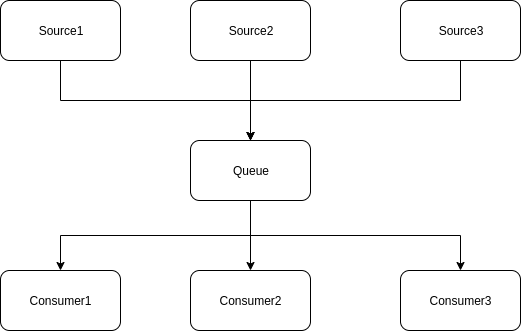
На данной диаграмме видно, что нам потребуется мультиплексирование (всё в одно) и броадкастинг (одно во всё). Что ж, не будем томить и напишем сразу решение.
# same with `tail -f`
def follow(thefile):
thefile.seek(0, os.SEEK_END) # End-of-file
while True:
line = thefile.readline()
if not line:
time.sleep(0.1) # Sleep briefly
continue
yield line
def gen_cat(sources):
# В данном конкретном случае используется для распаковки вложенного списка в плоский
for src in sources:
yield from src
def genfrom_queue(thequeue):
while True:
item = thequeue.get()
if item is StopIteration:
break
yield item
def sendto_queue(source, thequeue):
for item in source:
thequeue.put(item)
thequeue.put(StopIteration)
def multiplex(sources):
in_q = queue.Queue()
consumers = []
for src in sources:
thr = threading.Thread(target=sendto_queue, args=(src, in_q))
thr.start()
consumers.append(genfrom_queue(in_q))
return gen_cat(consumers)
def broadcast(source, consumers):
for item in source:
for c in consumers:
c.send(item)
class Consumer(object):
def send(self,item):
print(self, "got", item)
if __name__ == '__main__':
c1 = Consumer()
c2 = Consumer()
c3 = Consumer()
log1 = follow(open("foo/access-log"))
log2 = follow(open("bar/access-log"))
log3 = follow(open("baz/access-log"))
lines = multiplex([log1, log2, log3])
broadcast(lines,[c1,c2,c3])Как мы видим из этого примера — ничего сложного в этом нет, вполне легко можно решать самые разнообразные задачи.
Пример трейсинга генератора
Тут хотелось бы показать достаточно простой пример, если у тебя используется сотня генераторов и не понятно, в каком из них происходит сбой, например, с помощью принта.
def trace(source):
for item in source:
print(item)
yield item
lines = follow(open("access-log"))
log = trace(apache_log(lines))
r404 = trace(r for r in log if r['status'] == 404)Как мы видим — такой дебаг генератор можно встроить в любой из генераторов, не изменяя его, получив необходимую информацию, например, выведя результат каждый итерации
Стандартные инструменты генераторы
Генераторы встречаются повсюду в стандартной библиотеке. Начиная с 3.0 их стараются внедрять повсеместно. Например, pathlib.Path.rglob, glob.iglob, os.walk, range, map, filter. Есть даже целиком библиотека на генераторах — itertools.
Выводы
Плюсы:
- Генераторы — невероятно полезный инструмент для решения многообразных проблем
- Сила исходит от способности настраивать пайплайны
- Можно создавать компоненты, которые можно переиспользовать в разных пайплайнах
- Небольшие компоненты, которые просто обрабатывают поток данных
- Намного проще, чем это может быть сделано с помощью ООП шаблонов
- Можно расширить идею пайплайнов во многих направлениях (сеть, потоки, корутины)
Минусы
- Использование этого стиля программирования у непосвященных может привести к взрыву головы
- Обработка ошибок сложна, потому что у нас много компонентов, связанных вместе
- Необходимо уделять особое внимание отладке, надежности и другим вопросам.
Литература
- https://www.dabeaz.com/generators/
- https://www.dabeaz.com/generators/Generators.pdf (основной источник)
- https://wiki.python.org/moin/Generators (см. Links)
- https://www.oreilly.com/library/view/fluent-python/9781491946237/
Итоги
В ООП и ФП есть как свои плюсы, так и свои минусы. Например, на чистом ФП не напишешь красивый и выразительный код на Python, в котором можно легко разобраться, из-за чего преимущества Python сходят на нет. Однако, это не значит, что мы не можем использовать преимущества функционального подхода.
Как можно заметить, если мы пишем код на генераторах, то он получается вполне себе декларативным. Можно сказать, что код на генераторах — в некоторой степени ФП, так элегантно вошедший в Python.
Наша главная задача — писать ясный, понятный, красивый, тестируемый код и выбирать для этого подходящие инструменты. ФП — не самоцель, а лишь средство, как и всегда, чтобы мочь написать ещё лучший код!
Если нашли ошибки, пишите в телеграмме Niccolum или на почту lastsal@mail.ru. Буду рад конструктивной критике.



VoidDruid
Спасибо за статью, про функциональные возможности питона часто незаслуженно забывают.
Однако на мой взгляд многое из описанного во второй части статьи, про пакет functional и библиотеку returns, на практике довольно бесполезно.
Код, который мимикрирует под функциональный, вызывая рантайм-исключения при нарушении каких-то условий, только мешает — на его месте мог бы быть более привычной питонячий код, который можно проверить линитерами и mypy, и выявить похожие ошибки «статически», без запуска кода.
Примерно тоже самое применимо и к returns. В частности хаскель, из которого похоже Maybe и притащили, встречая Maybe в коде заставляет тебя проверять везде что именно вернулось — Just T или Nothing, что и даёт серьезные гарантии на уровне типов. В returns не вникал, но судя по примеру из статьи, этот инструмент не даёт никаких «статических» проверок, и вообще будто ломает тайп чекер (mypy), подменяя возвращаемые значения на собственные типы — а если и не ломает, то однозначно усложняет чтение кода.
Я сам функциональную парадигму тоже люблю и уважаю, но объектно-ориентированный, динамически типизированный, интепретируемый Python фундаментально очень от нее далек, несмотря на то что имеет и функции как объекты первого класса, и замыкания, и много чего ещё.
Поэтому на мой взгляд выгоднее внедрять мощь функциональщины в свои Python-программы порционально, там где она решает конкретные проблемы, не выходя далеко за рамки «идиоматического» питона)
VoidDruid
Уточню, что я говорю исключительно про «фреймворки» для функциональной разработки в питоне — с основными выводами статьи я совершенно согласен и большинством из описанного сам активно пользуюсь