
Этапы получения, обработки и записи данных занимают время. Немного, но для крупной системы это может выливаться в большие задержки. Проблема хранения — это вопрос доступа к данным. Они используются для отчетов, проверок и триггеров. Задержки при доступе к данным также влияют на производительность. Когда БД разрастаются, неактуальные данные приходится удалять. Удаление — это тяжелая операция, которая также съедает часть ресурсов.

Проблемы задержек при сборе и хранении в Zabbix решаются кэшированием: несколько видов кэшей, кэширование в БД. Для решения третьей проблемы кэширование не подходит, поэтому в Zabbix применили TimescaleDB. Об этом расскажет Андрей Гущин — инженер технической поддержки Zabbix SIA. В поддержке Zabbix Андрей больше 6 лет и напрямую сталкивается с производительностью.
Как работает TimescaleDB, какую производительность может дать по сравнению с обычным PostgreSQL? Какую роль играет Zabbix для БД TimescaleDB? Как запустить с нуля и как мигрировать с PostgreSQL и производительность какой конфигурации лучше? Обо всем этом под катом.
Вызовы производительности
Каждая система мониторинга встречается с определенными вызовами производительности. Я расскажу о трех из них: сбор и обработка данных, хранение, очистка истории.
Быстрый сбор и обработка данных. Хорошая система мониторинга должна оперативно получать все данные и обрабатывать их согласно триггерным выражениям — по своим критериям. После обработки система должна также быстро сохранить эти данные в БД, чтобы позже их использовать.
Хранение истории. Хорошая система мониторинга должна хранить историю в БД и предоставлять удобный доступ к метрикам. История нужна, чтобы использовать ее в отчетах, графиках, триггерах, пороговых значениях и вычисляемых элементах данных для оповещения.
Очистка истории. Иногда наступает день, когда вам не нужно хранить метрики. Зачем вам данные, которые собраны за 5 лет назад, месяц или два: какие-то узлы удалены, какие-то хосты или метрики уже не нужны, потому что устарели и перестали собираться. Хорошая система мониторинга должна хранить исторические данные и время от времени их удалять, чтобы БД не разрослась.
Очистка устаревших данных — острый вопрос, который сильно отражается на производительности базы данных.
Кэширование в Zabbix
В Zabbix первый и второй вызовы решены с помощью кэширования. Для сбора и обработки данных используется оперативная память. Для хранения — истории в триггерах, графиках и вычисляемых элементах данных. На стороне БД есть определенное кэширование для основных выборок, например, графиков.
Кэширование на стороне самого Zabbix-сервера это:
- ConfigurationCache;
- ValueCache;
- HistoryCache;
- TrendsCache.
Рассмотрим их подробнее.
ConfigurationCache
Это основной кэш, в котором мы храним метрики, хосты, элементы данных, триггеры — все, что нужно для PreProcessing и для сбора данных.
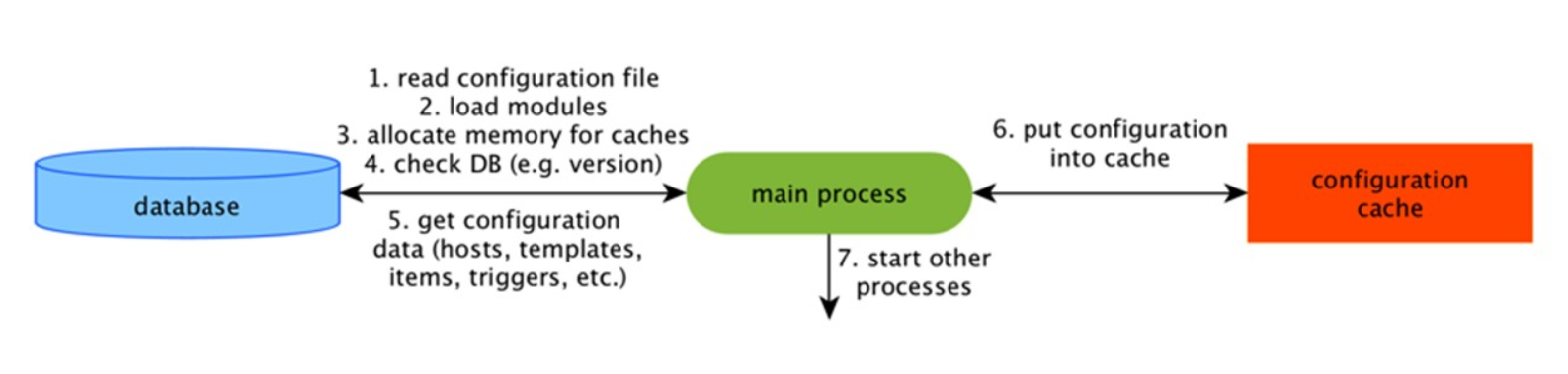
Все это хранится в ConfigurationCache, чтобы не создавать лишних запросов в БД. После старта сервера мы обновляем этот кэш, создаем и периодически обновляем конфигурации.
Сбор данных
Схема достаточно большая, но основное в ней — это сборщики. Это различные «pollers» — процессы сборки. Они отвечают за разные виды сборки: собирают данные по SNMP, IPMI, и передают это все на PreProcessing.
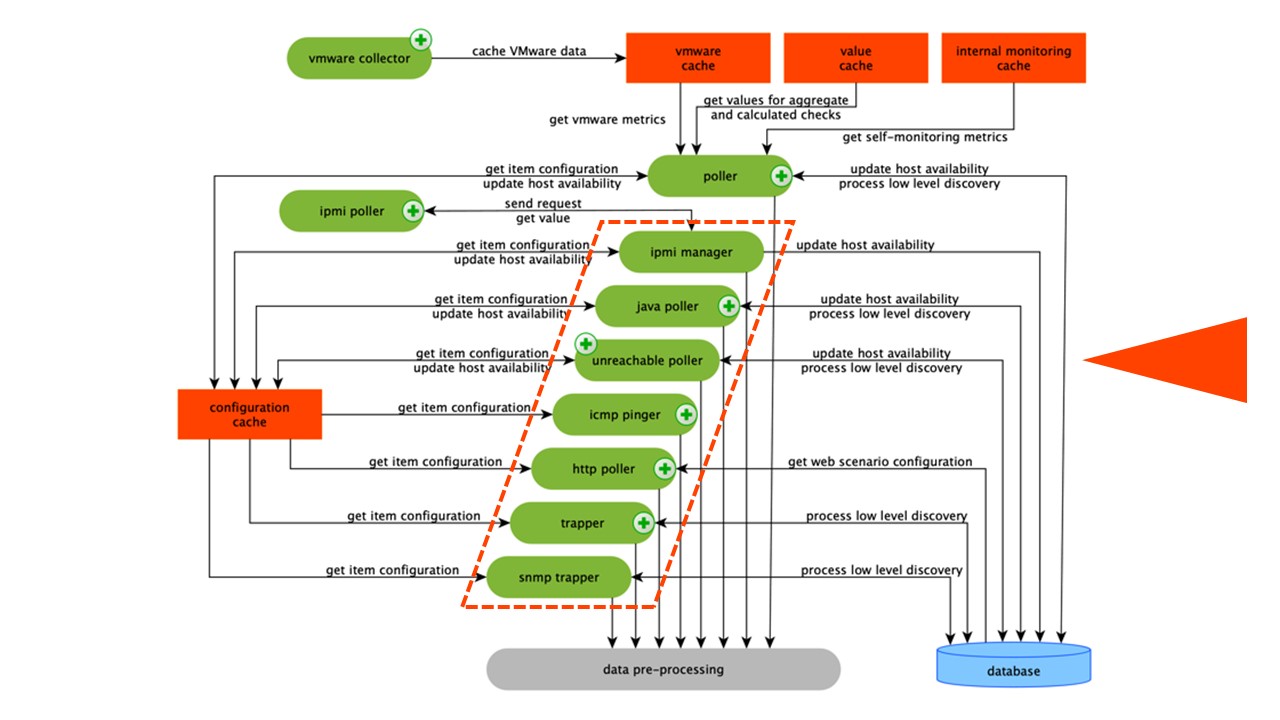 Сборщики обведены оранжевой линией.
Сборщики обведены оранжевой линией.В Zabbix есть вычисляемые агрегационные элементы данных, которые нужны, чтобы агрегировать проверки. Если у нас они есть, мы забираем данные для них напрямую из ValueCache.
PreProcessing HistoryCache
Все сборщики используют ConfigurationCache, чтобы получать задания. Дальше они передают их на PreProcessing.

PreProcessing использует ConfigurationCache, чтобы получать шаги PreProcessing. Он обрабатывает эти данные различными способами.
После обработки данных с помощью PreProcessing, сохраняем их в HistoryCache, чтобы обработать. На этом заканчивается сбор данных и мы переходим к главному процессу в Zabbix — history syncer, так как это монолитная архитектура.
Примечание: PreProcessing достаточно тяжелая операция. С v 4.2 он вынесен на proxy. Если у вас очень большой Zabbix с большим количеством элементов данных и частотой сбора, то это сильно облегчает работу.
ValueCache, history & trends cache
History syncer — это главный процесс, который атомарно обрабатывает каждый элемент данных, то есть каждое значение.
History syncer берет значения из HistoryCache и проверяет в Configuration наличие триггеров для вычислений. Если они есть — вычисляет.
History syncer создает событие, эскалацию, чтобы создать оповещения, если требуется по конфигурации, и записывает. Если есть триггеры для последующей обработки, то это значение он запоминает в ValueCache, чтобы не обращаться в таблицу истории. Так ValueCache наполняется данными, которые необходимы для вычисления триггеров, вычисляемых элементов.
History syncer записывает все данные в БД, а она — в диск. Процесс обработки на этом заканчивается.
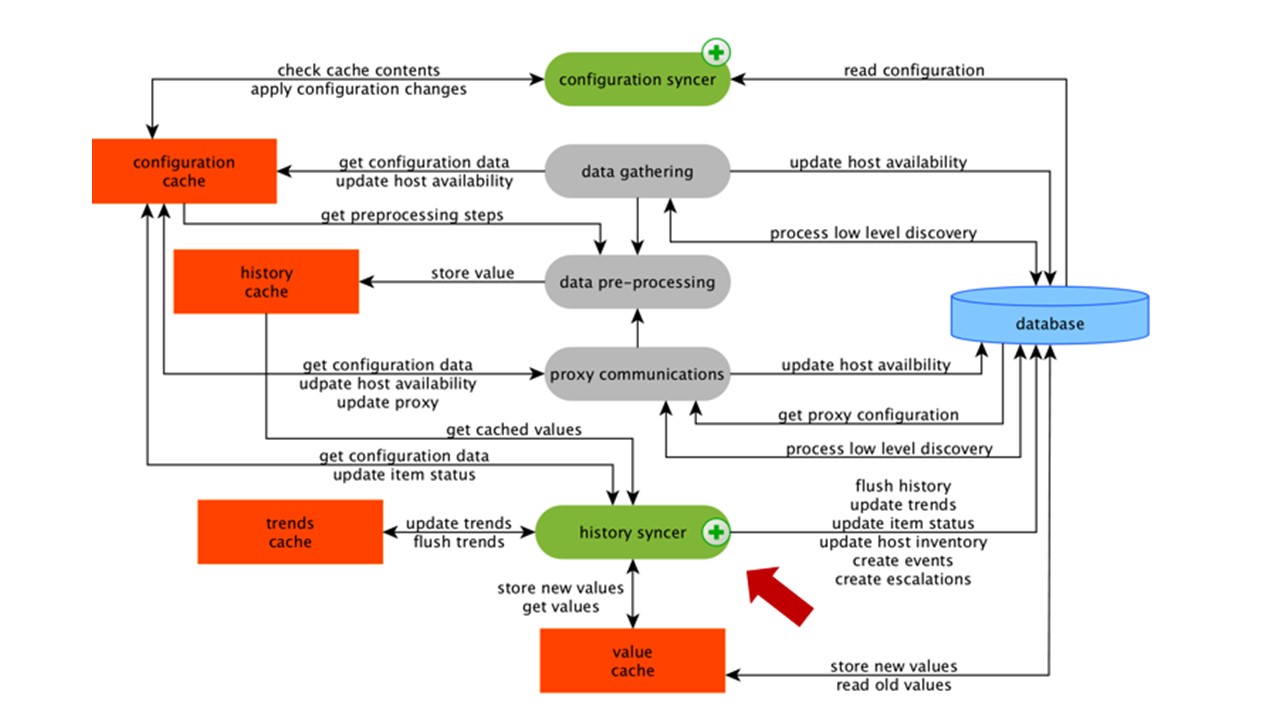
Кэширование в БД
На стороне БД есть различные кэши, когда вы хотите смотреть графики или отчеты по событиям:
Innodb_buffer_poolна стороне MySQL;shared_buffersна стороне PostgreSQL;effective_cache_sizeна стороне Oracle;shared_poolна стороне DB2.
Есть еще много других кэшей, но это основные для всех БД. Они позволяют держать в оперативной памяти данные, которые часто необходимы для запросов. У них свои технологии для этого.
Производительность БД критически важна
Zabbix-сервер постоянно собирает данные и записывает их. При перезапуске он тоже читает из истории для наполнения ValueCache. Скрипты и отчеты использует Zabbix API, который построен на базе Web-интерфейса. Zabbix API обращается в базу данных и получает необходимые данные для графиков, отчетов, списков событий и последних проблем.
Для визуализации — Grafana. Среди наших пользователей это популярное решение. Она умеет напрямую отправлять запросы через Zabbix API и в БД, и создает определенную конкурентность для получения данных. Поэтому нужна более тонкая и хорошая настройка БД, чтобы соответствовать быстрой выдаче результатов и тестирования.
Housekeeper
Третий вызов производительности в Zabbix — это очистка истории с помощью Housekeeper. Он соблюдает все настройки — в элементах данных указано, сколько хранить динамику изменений (трендов) в днях.
TrendsCache мы вычисляем на лету. Когда поступают данные, мы их агрегируем за один час и записываем в таблицы для динамики изменений трендов.
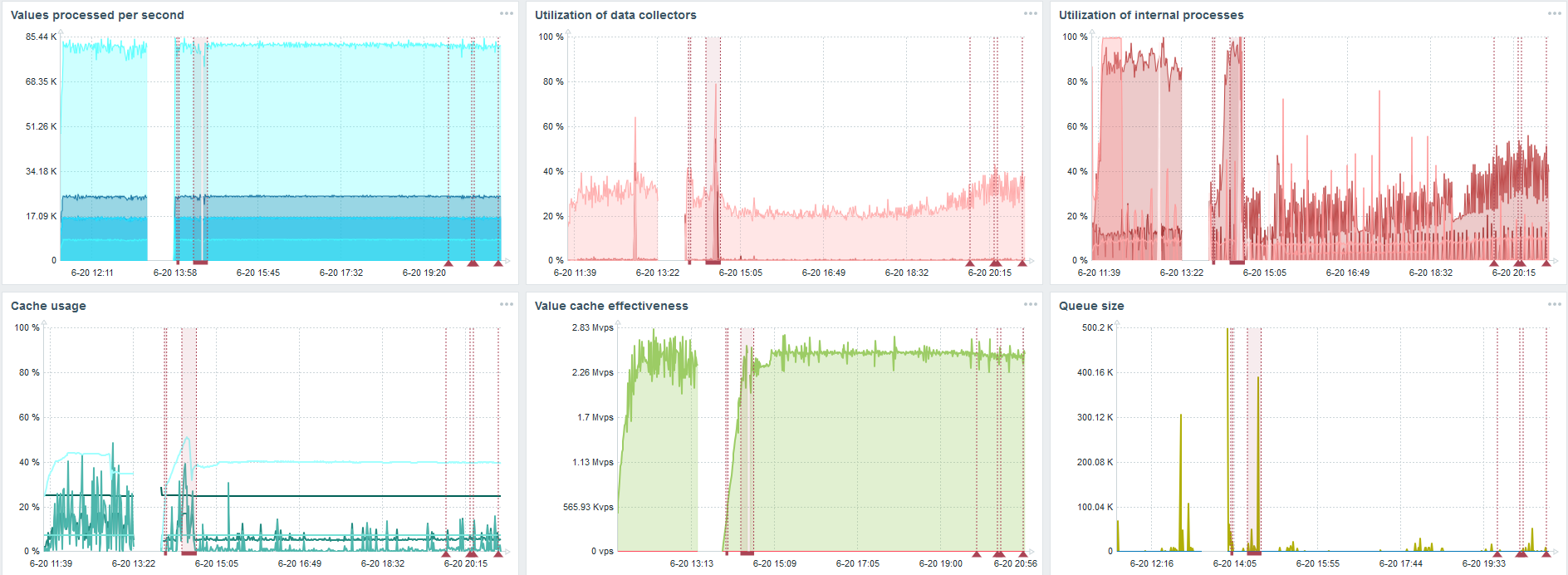
Housekeeper запускается и удаляет информацию из БД обычными «selects». Это не всегда эффективно, что можно понять по графикам производительности внутренних процессов.
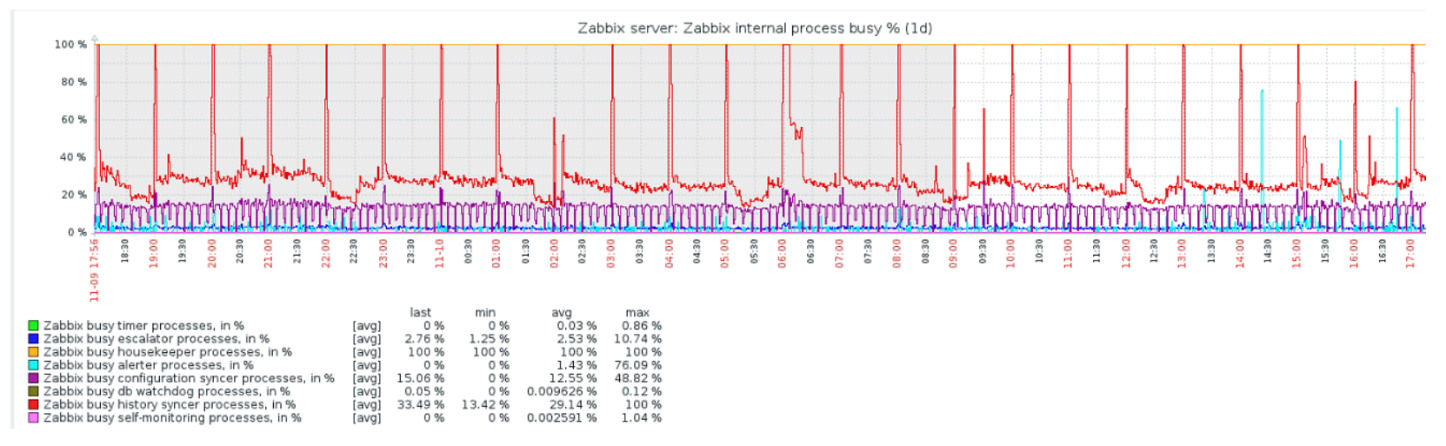
Красный график показывает, что History syncer постоянно занят. Оранжевый график сверху — это Housekeeper, который постоянно запускается. Он ждет от БД, когда она удалит все строки, которые он задал.
Когда стоит отключить Housekeeper? Например, есть «Item ID» и нужно удалить последние 5 тысяч строк за определенное время. Конечно, это происходит по индексам. Но обычно dataset очень большой, и БД все равно считывает с диска и поднимает в кэш. Это всегда очень дорогая операция для БД и, в зависимости от размеров базы, может приводить к проблемам производительности.
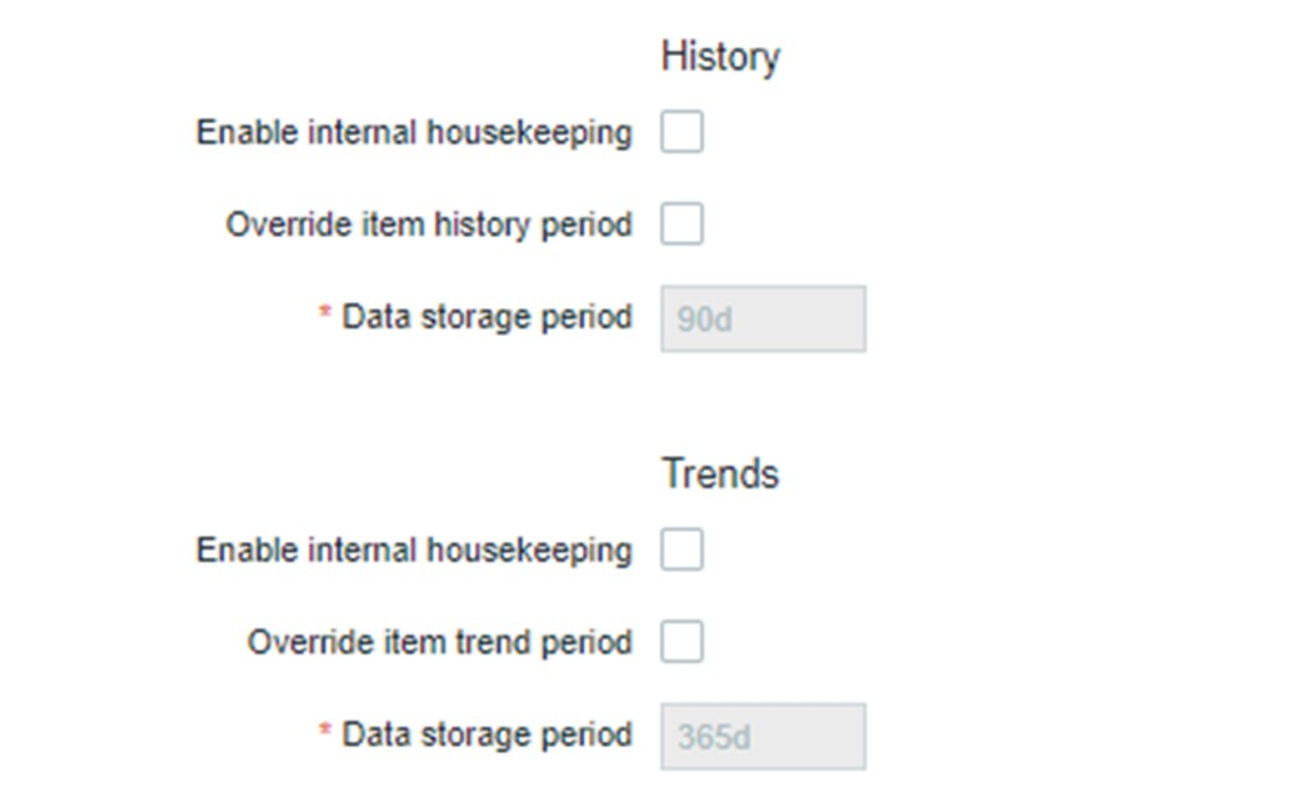
Housekeeper просто отключить. В Web-интерфейсе есть настройка в «Administration general» для Housekeeper. Отключаем внутренний Housekeeping для внутренней истории трендов и он больше не управляет этим.
Housekeeper отключили, графики выровнялись — какие в этом случае могут быть проблемы и что может помочь в решении третьего вызова производительности?
Partitioning — секционирование или партиционирование
Обычно партиционирование настраивается различным способом на каждой реляционной БД, которые я перечислил. У каждой своя технология, но они похожи, в целом. Создание новой партиции часто приводит к определенным проблемам.
Обычно партиции настраивают в зависимости от «setup» — количества данных, которые создаются за один день. Как правило, Partitioning выставляют за один день, это минимум. Для трендов новой партиции — за 1 месяц.
Значения могут изменяться в случае очень большого «setup». Если малый «setup» — это до 5 000 nvps (новых значений в секунду), средний — от 5 000 до 25 000, то большой — выше 25 000 nvps. Это большие и очень большие инсталляции, которые требуют тщательной настройки именно базы данных.
На очень больших инсталляциях отрезок в один день может быть не оптимальным. Я видел на MySQL партиции по 40 ГБ и больше за день. Это очень большой объем данных, который может приводить к проблемам, и его нужно уменьшать.
Что дает Partitioning?
Секционирование таблиц. Часто это отдельные файлы на диске. План запросов более оптимально выбирает одну партицию. Обычно партиционирование используется по диапазону — для Zabbix это тоже верно. Мы используем там «timestamp» — время с начала эпохи. У нас это обычные числа. Вы задаете начало и конец дня — это партиция.
Быстрое удаление —
DELETE. Выбирается один файл/субтаблица, а не выборка строк на удаление.Заметно ускоряет выборку данных
SELECT — использует одну или более партиций, а не всю таблицу. Если вы обращаетесь за данными двухдневной давности, они выбираются из БД быстрее, потому что нужно загрузить в кэш и выдать только один файл, а не большую таблицу.Зачастую многие БД также ускоряет
INSERT — вставки в child-таблицу.TimescaleDB
Для v 4.2 мы обратили внимание на TimescaleDB. Это расширение для PostgreSQL с нативным интерфейсом. Расширение эффективно работает с time series данными, при этом не теряя преимуществ реляционных БД. TimescaleDB также автоматически партицирует.
В TimescaleDB есть понятие гипертаблица (hypertable), которую вы создаете. В ней находятся чанки — партиции. Чанки — это автоматически управляемые фрагменты гипертаблицы, который не влияет на другие фрагменты. Для каждого чанка свой временной диапазон.
TimescaleDB vs PostgreSQL
TimescaleDB работает действительно эффективно. Производители расширения утверждают, что они используют более правильный алгоритм обработки запросов, в частности, <code>inserts</code>. Когда размеры dataset-вставки растут, алгоритм поддерживает постоянную производительность.
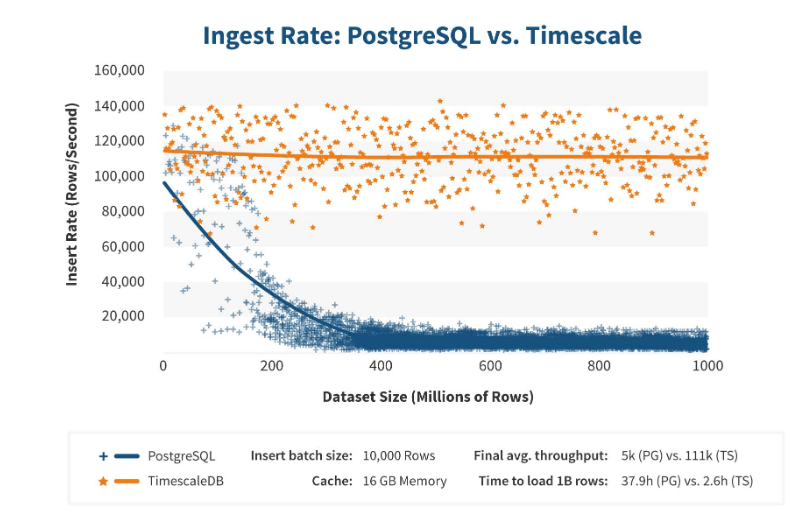
После 200 млн строк PostgreSQL обычно начинает сильно проседать и теряет производительность до 0. TimescaleDB позволяетэффективно вставлять «inserts» при любом объеме данных.
Установка
Установить TimescaleDB достаточно просто для любых пакетов. В документации все подробно описано — он зависит от официальных пакетов PostgreSQL. TimescaleDB также можно собрать и скомпилировать вручную.
Для БД Zabbix мы просто активируем расширение:
echo "CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;" | sudo -u postgres psql zabbixВы активируете
extension и создаете его для БД Zabbix. Последний шаг — создание гипертаблицы.Миграция таблиц истории на TimescaleDB
Для этого есть специальная функция
create_hypertable:SELECT create_hypertable(‘history’, ‘clock’, chunk_time_interval => 86400, migrate_data => true);
SELECT create_hypertable(‘history_unit’, ‘clock’, chunk_time_interval => 86400, migrate_data => true);
SELECT create_hypertable(‘history_log’, ‘clock’, chunk_time_interval => 86400, migrate_data => true);
SELECT create_hypertable(‘history_text’, ‘clock’, chunk_time_interval => 86400, migrate_data => true);
SELECT create_hypertable(‘history_str’, ‘clock’, chunk_time_interval => 86400, migrate_data => true);
SELECT create_hypertable(‘trends’, ‘clock’, chunk_time_interval => 86400, migrate_data => true);
SELECT create_hypertable(‘trends_unit’, ‘clock’, chunk_time_interval => 86400, migrate_data => true);
UPDATE config SET db_extension=’timescaledb’, hk_history_global=1, hk_trends_global=1У функции три параметра. Первый — таблица в БД, для которой нужно создать гипертаблицу. Второй — поле, по которому надо создать
chunk_time_interval — интервал чанков партиций, которые нужно использовать. В моем случае интервал это один день — 86 400.Третий параметр —
migrate_data. Если выставить true, то все текущие данные переносятся в заранее созданные чанки. Я сам использовал migrate_data. У меня было около 1 ТБ, что заняло больше часа. Даже в каких-то случаях при тестировании я удалял необязательные к хранению исторические данные символьных типов, чтобы их не переносить.Последний шаг —
UPDATE: в db_extension ставим timescaledb, чтобы БД понимала, что есть это расширение. Zabbix его активирует и правильно использует синтаксис и запросы уже к БД — те фичи, которые необходимы для TimescaleDB.Конфигурация железа
Я использовал два сервера. Первый — VMware-машина. Она достаточно маленькая: 20 процессоров Intel® Xeon® CPU E5-2630 v 4 @ 2.20GHz, 16 ГБ оперативной памяти и SSD-диск на 200 ГБ.
Я установил на ней PostgreSQL 10.8 с ОС Debian 10.8-1.pgdg90+1 и файловой системой xfs. Все минимально настроил, чтобы использовать именно эту базу данных, за вычетом того, что будет использовать сам Zabbix.
На этой же машине стоял Zabbix-сервер, PostgreSQL и нагрузочные агенты. У меня было 50 активных агентов, которые использовали
LoadableModule, чтобы очень быстро генерировать различные результаты: числа, строки. Я забивал базу большим количеством данных.Изначально конфигурация содержала 5 000 элементов данных на каждый хост. Почти каждый элемент содержал триггер, чтобы это было схоже с реальными инсталляциями. В некоторых случаях было больше одного триггера. На один узел сети приходилось 3 000-7 000 триггеров.
Интервал обновления элементов данных — 4-7 секунд. Саму нагрузку я регулировал тем, что использовал не только 50 агентов, но добавлял еще. Также, с помощью элементов данных я динамических регулировал нагрузку и снижал интервал обновления до 4 с.
PostgreSQL. 35 000 nvps
Первый запуск на этом железе у меня был на чистом PostgreSQL — 35 тыс значений в секунду. Как видно, вставка данных занимает фракции секунды — все хорошо и быстро. Единственное, что SSD диск на 200 ГБ быстро заполняется.
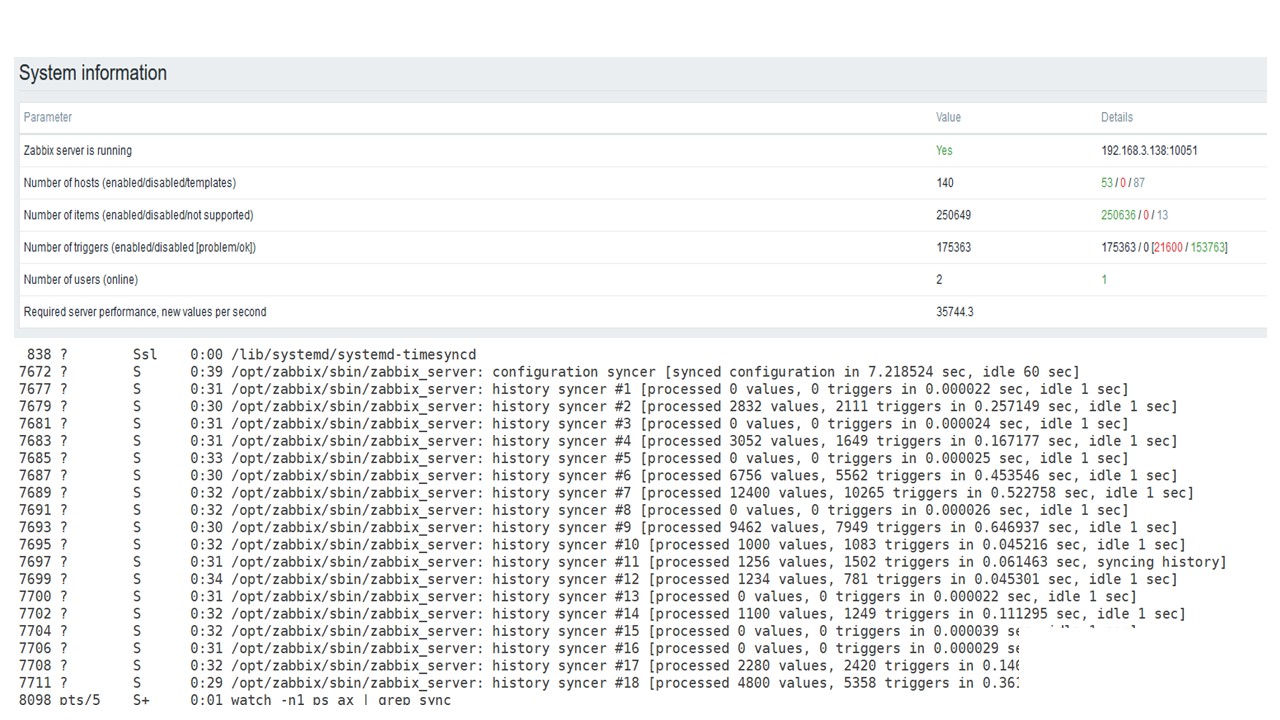
Это стандартный dashboard производительности Zabbix — сервера.
Первый голубой график — количество значений в секунду. Второй график справа — загрузка процессов сборки. Третий — загрузка внутренних процессов сборки: history syncers и Housekeeper, который здесь выполнялся достаточное время.
Четвертый график показывает использование HistoryCache. Это некий буфер перед вставкой в БД. Зеленый пятый график показывает использование ValueCache, то есть сколько хитов ValueCache для триггеров — это несколько тысяч значений в секунду.
PostgreSQL. 50 000 nvps
Дальше я увеличил нагрузку до 50 тыс значений в секунду на этом же железе.
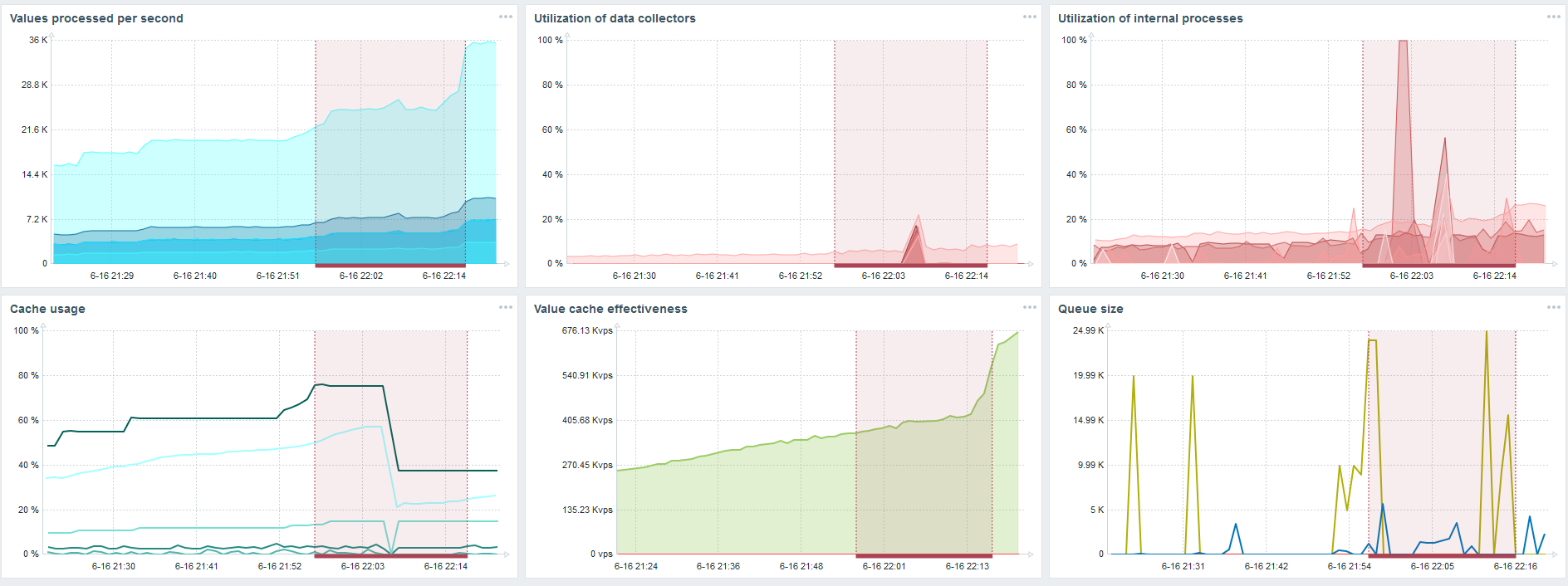
При загрузке с Housekeeper вставка 10 тыс значений записывалась 2-3 с.
Housekeeper уже начинает мешать работе.
По третьему графику видно, что, в целом, загрузка трапперов и history syncers пока еще на уровне 60%. На четвертом графике HistoryCache во время работы Housekeeper уже начинает достаточно активно заполняться. Он заполнился на 20% — это около 0,5 ГБ.
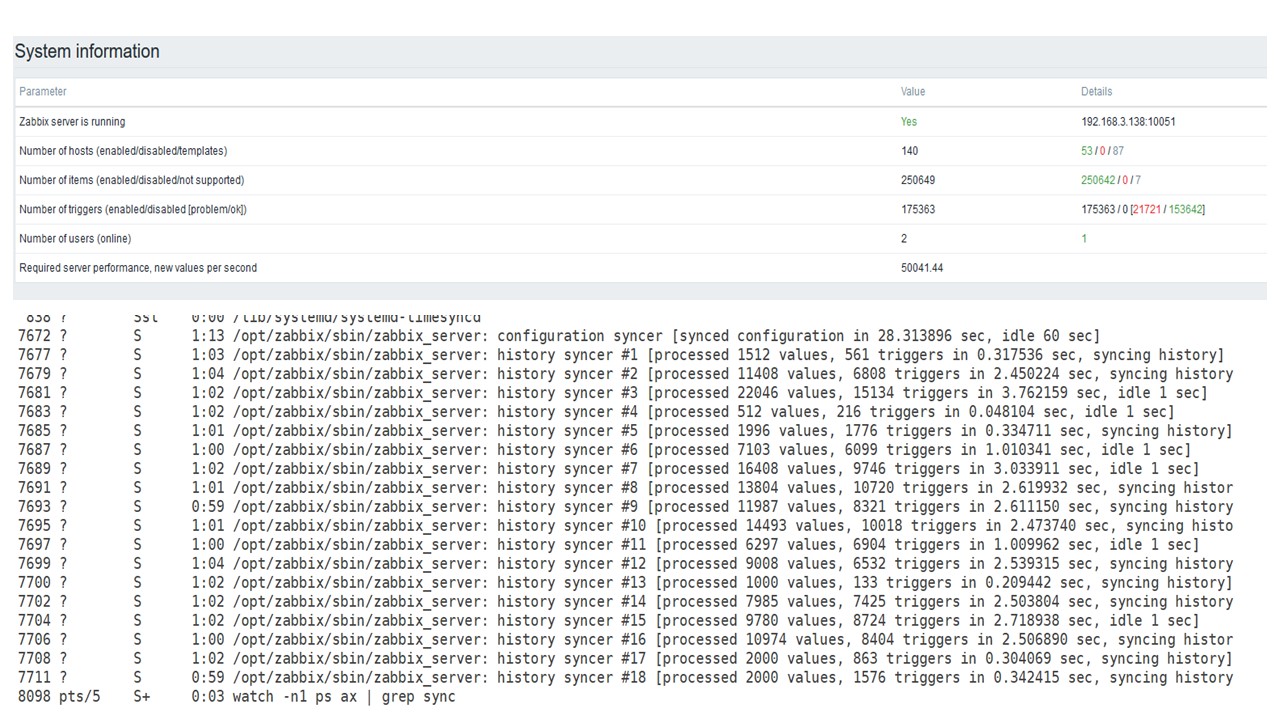
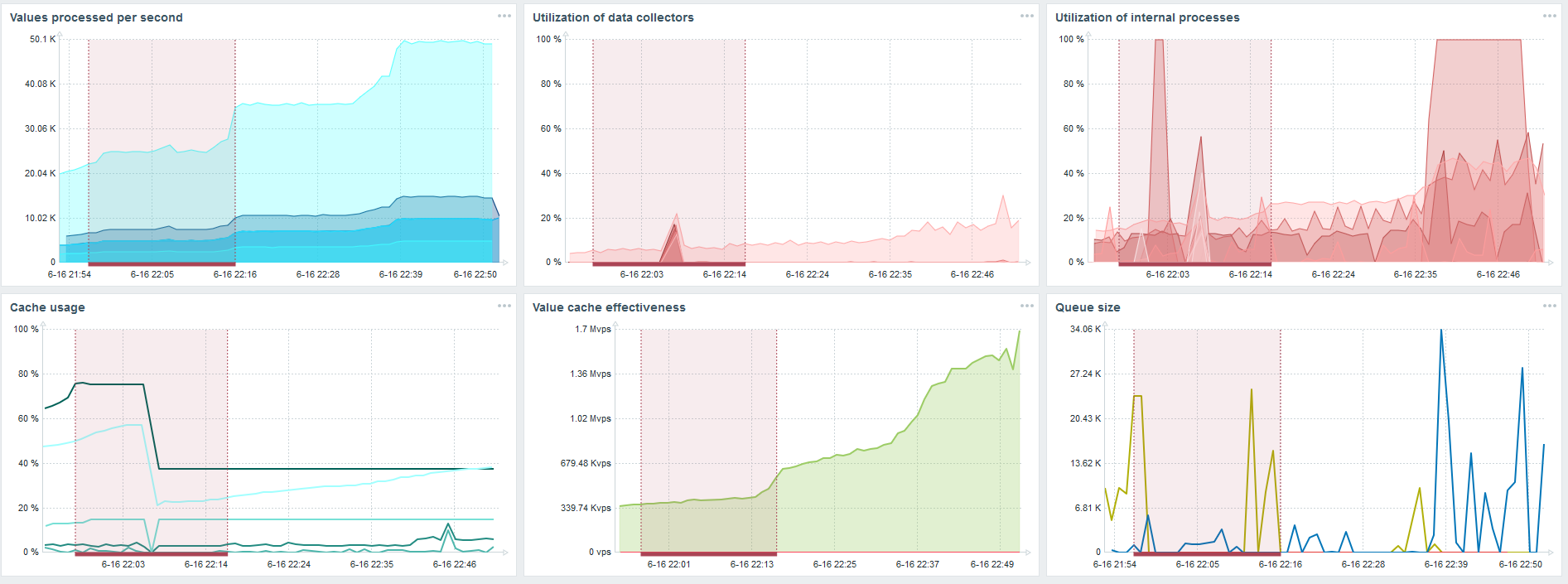
PostgreSQL. 80 000 nvps
Дальше я увеличил нагрузку до 80 тыс значений в секунду. Это примерно 400 тыс элементов данных и 280 тыс триггеров.
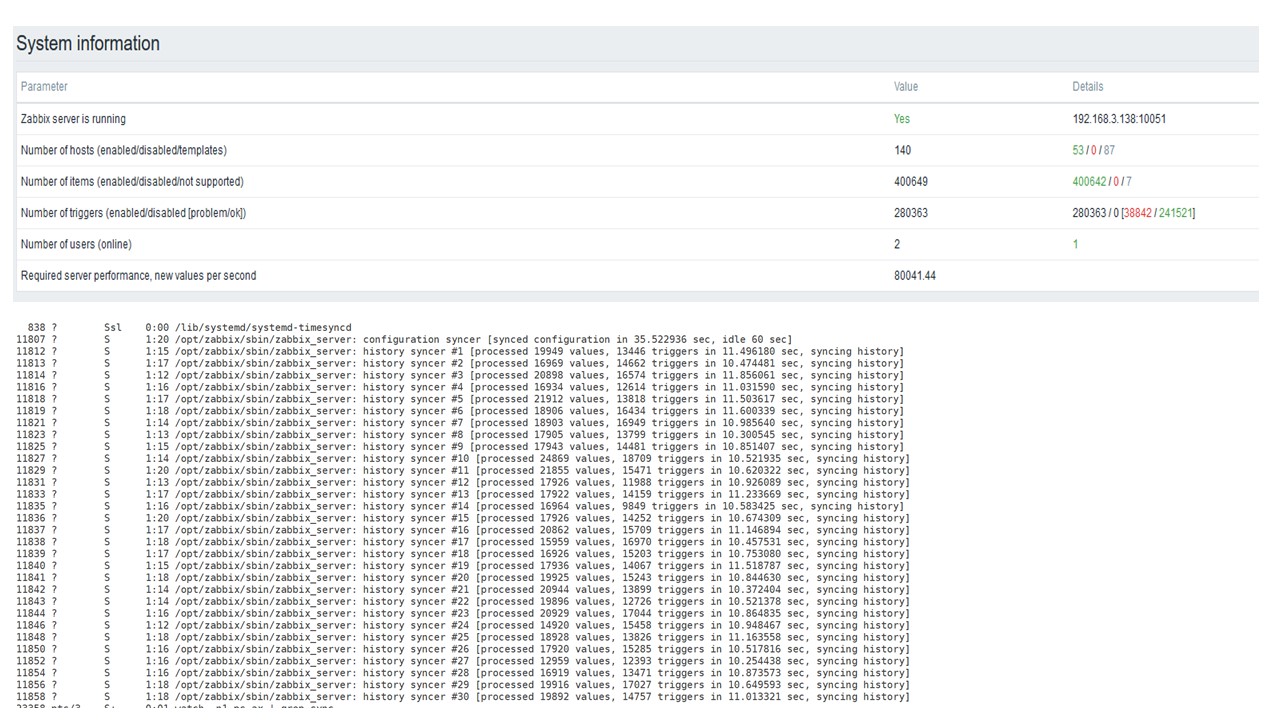
Вставка по загрузке тридцати history syncers уже достаточно высокая.
Также я увеличивал различные параметры: history syncers, кэши.
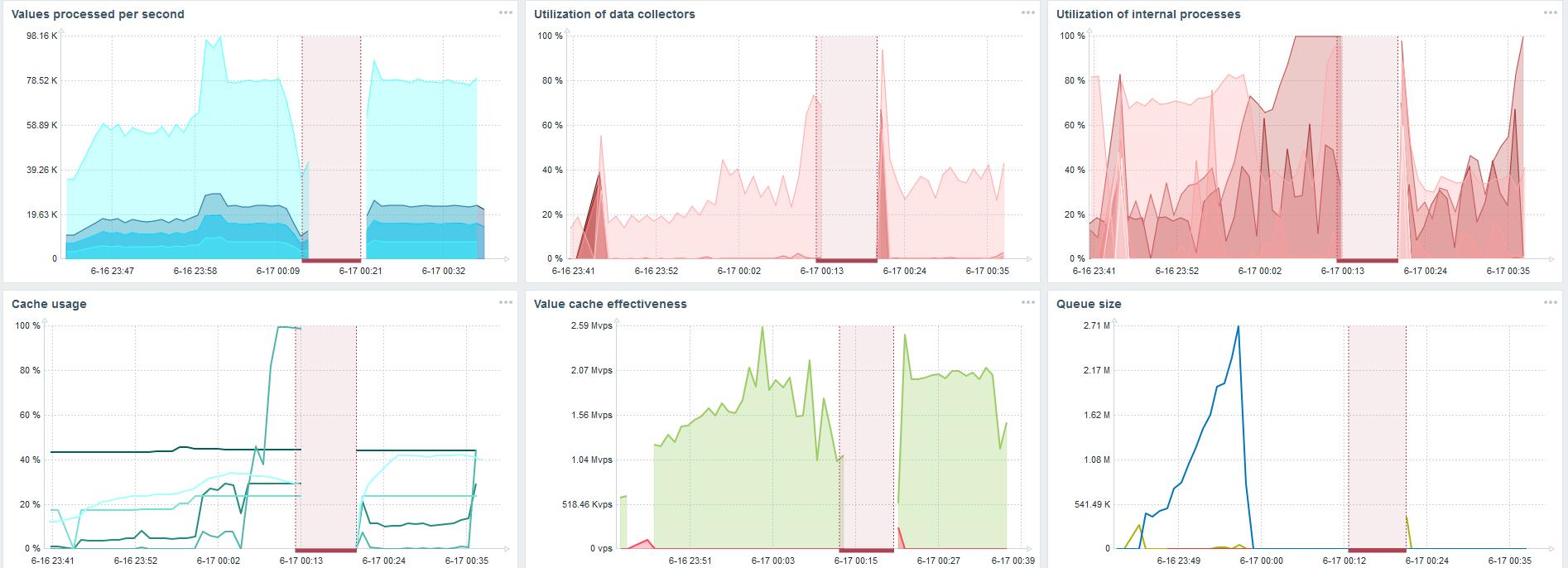
На моем железе загрузка history syncers увеличивалась до максимума. HistoryCache быстро заполнился данными — в буфере накопились данные для обработки.
Все это время я наблюдал, как используется процессор, оперативная память и другие параметры системы, и обнаружил, что утилизация дисков была максимальна.
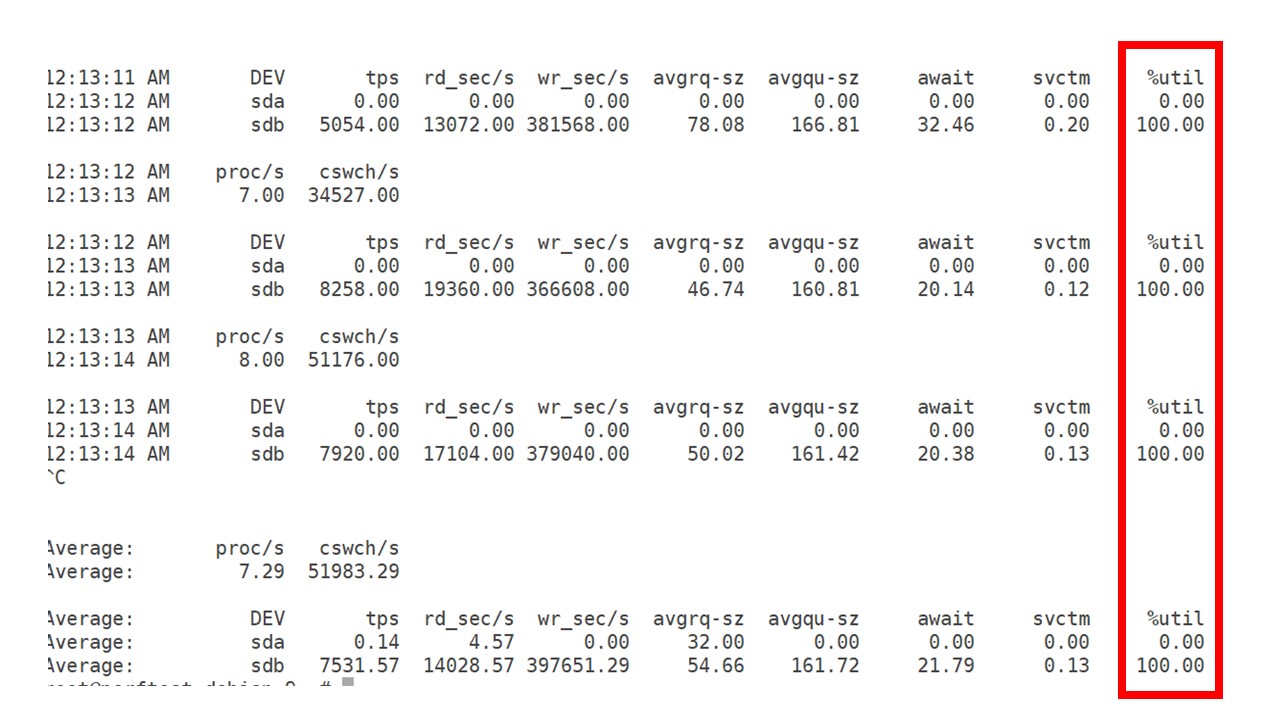
Я добился использования максимальных возможностей диска на этом железе и на этой виртуальной машине. При такой интенсивности PostgreSQL начал сбрасывать данные достаточно активно, и диск уже не успевал работать на запись и чтение.
Второй сервер
Я взял другой сервер, который имел уже 48 процессоров и 128 ГБ оперативной памяти. Затюнинговал его — поставил 60 history syncer, и добился приемлемого быстродействия.
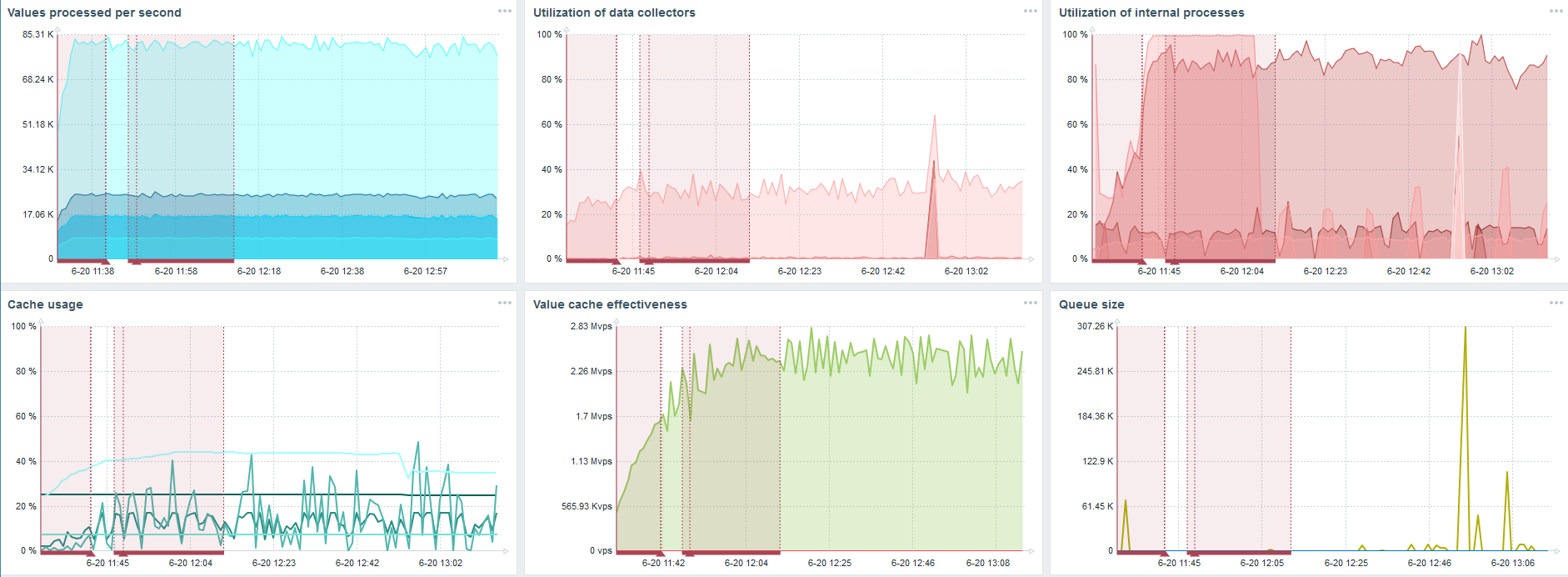
Фактически, это уже предел производительности, где необходимо что-то предпринимать.
TimescaleDB. 80 000 nvps
Моя главная задача — проверить возможности TimescaleDB от нагрузки Zabbix. 80 тыс значений в секунду — это много, частота сбора метрик (кроме Яндекса, конечно) и достаточно большой «setup».
На каждом графике есть провал — это как раз миграция данных. После провалов в Zabbix-сервере профиль загрузки history syncer очень сильно изменился — упал в три раза.
TimescaleDB позволяет вставлять данные практически в 3 раза быстрее и использовать меньше HistoryCache.
Соответственно, у вас своевременно будут поставляться данные.
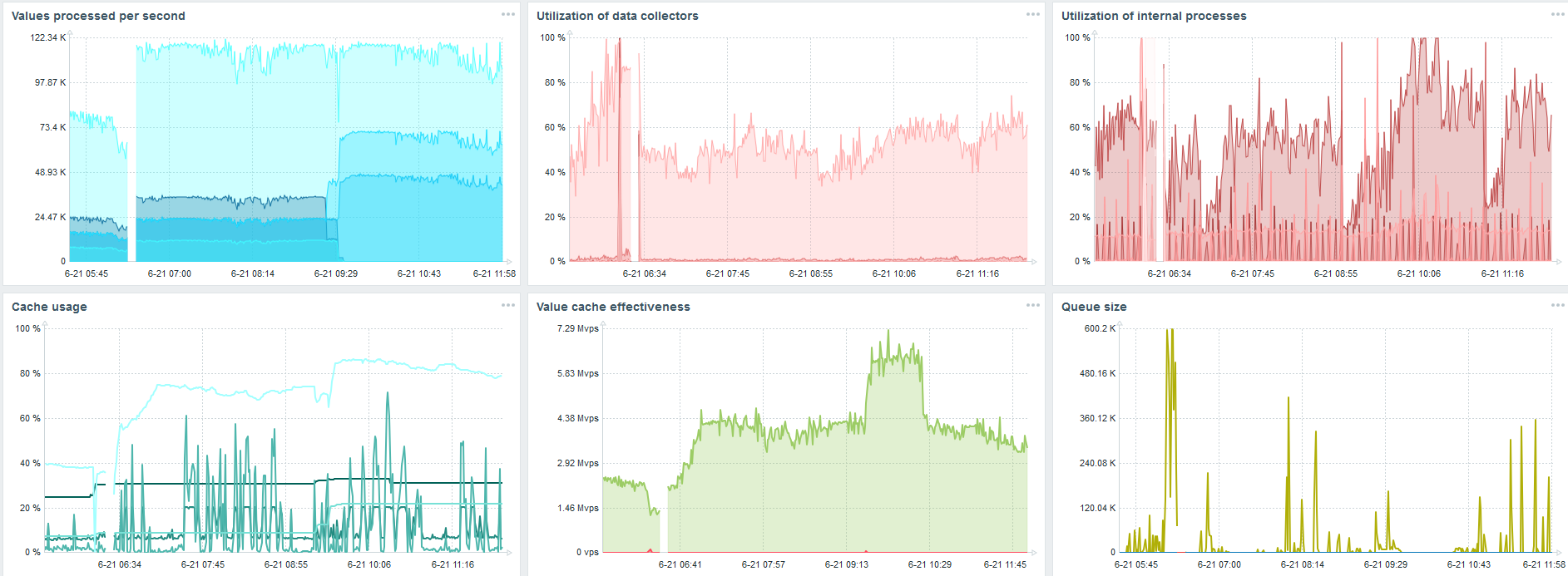
TimescaleDB. 120 000 nvps
Дальше я увеличил количество элементов данных до 500 тыс. Главная задача была проверить возможности TimescaleDB — я получил расчетное значение 125 тыс значений в секунду.
Это рабочий «setup», который может долго работать. Но так как мой диск был всего на 1,5 ТБ, то я его заполнил за пару дней.
Самое важное, что в это же время создавались новые партиции TimescaleDB.
Для производительности это совершенно незаметно. Когда создаются партиции в MySQL, например, все иначе. Обычно это происходит ночью, потому что блокирует общую вставку, работу с таблицами и может создавать деградацию сервиса. В случае с TimescaleDB этого нет.
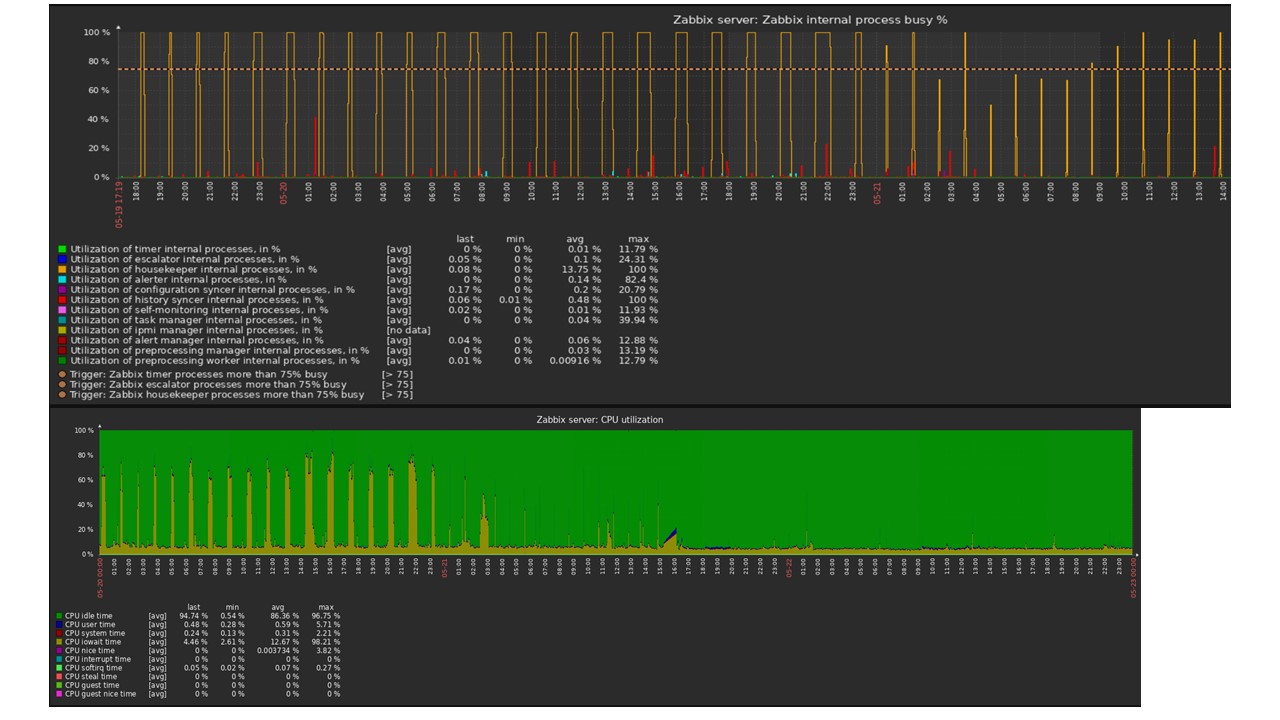
Для примера покажу один график из множества в community. На картинке включен TimescaleDB, благодаря этому загрузка по использованию io.weight на процессоре упала. Использование элементов внутренних процессов тоже снизилось. Причем это обычная виртуалка на обычных блинных дисках, а не SSD.
Выводы
TimescaleDB хорошее решение для маленьких «setup», которые упираются в производительность диска. Оно позволит неплохо продолжать работать до миграции БД на железо побыстрее.
TimescaleDB прост в настройке, дает прирост производительности, хорошо работает с Zabbix и имеет преимущества по сравнению с PostgreSQL.
Если вы применяете PostgreSQL и не планируете его менять, то рекомендую использовать PostgreSQL с расширением TimescaleDB в связке с Zabbix. Это решение эффективно работает до средних «setup».
Говорим «высокая производительность» — подразумеваем HighLoad++. Ждать, чтобы познакомиться с технологиями и практиками, позволяющими сервисам обслуживать миллионы пользователей, совсем недолго. Список докладов на 7 и 8 ноября мы уже составили, а вот митапы еще можно предложить.
Подписывайтесь на нашу рассылку и telegram, в которых мы раскрываем фишки предстоящей конференции, и узнайте, как извлечь максимум пользы.
Комментарии (2)

iddqda
16.10.2019 14:33Спасибо большое за статью!
По результату прочтения уже запланировал сделать партиционирование в своем сетапе.
Есть два вопроса:
1. Отключили housekeeping, графики выровнялись…
И как мы теперь будем убивать устаревшие ненужные данные? Место на диске не бесконечно
2. Если я применяю MySQL и не собираюсь погружаться в Postgres могу ли я использовать TimescaleDB?
achekalin
Можно такой момент прояснить: вы на маленькой виртуалке поставили Дебиан, но ФС там xfs. Скажем так, я бы не удивился набору CentOS + xfs (как дефолтной ФС для CentOS), или Debian + ext4 (по той же причине), но у вас явно выбор сознательный. Можно попросить написать пару слов по выбору ОС, ФС и версий?