
Привет Хабр!
Хоум Кредит — это крупная и очень динамичная система, за которой подчас трудно уследить. Чтобы помочь сотрудникам быть в курсе всех новостей и изменений и везде успевать, мы активно внедряем алгоритмы машинного обучения. В нашем Банке чат-боты уже берут на себя часть работы операторов, клиентские отзывы анализируют не только эксперты, но и умные алгоритмы обработки естественного языка.
Сегодня я расскажу, как мы помогли специалистам эксплуатации банковских сервисов избавиться от необходимости непрерывно смотреть в дашборды мониторинговых систем, а именно, призвали на помощь машинное обучение. Вот что у нас получилось.

Типичное рабочее место специалиста по эксплуатации выглядит как на картинке выше, причем большую часть времени он проводит за рассматриванием дашбордов. Любая подозрительная активность в системе, например, когда отвалилась сеть или посыпались NullPointerException, сразу привлечет внимание — немедленно начнется расследование.
Человек не машина. Он может отвлечься, пойти на обед, ответить на телефонный звонок. Да и когда количество графиков переваливает за сотню, связать их всех воедино и докопаться до сути становится трудно.
Еще одна проблема в том, что есть семейство ошибок, которые возникают постоянно, но серьезным образом не затрагивают поведение системы. Например, отвалился сторонний микросервис и дашборды знатно тряхануло, но на самом деле система вне опасности. На первый взгляд, не всегда понятно, насколько аномальное поведение является критическим, и что за этим стоит. Чтобы детально установить причины надо сходить на сервер и основательно покопаться в логах. Такую операцию приходится проделывать десятки раз на дню. Давайте хотя бы частично поручим ее машине.
Есть три основных источника данных: Zabbix, ElasticSearch и внутренняя система мониторинга бизнес-показателей. Zabbix мы используем для мониторинга «железа», сети и доступности различных точек входа в системы. С помощью ElasticSearch парсим и извлекаем лог сообщения. В качестве метрик используются различные ошибки, эксепшены, запросы. Бизнес-аналитики же следят за показателями пользователей: количеством переводов, продаж и прочими бизнес-активностями. Данные собираются с частотой раз в минуту и складываются в базу. Отлично, данные собраны, самое время написать кучу if’ ов пустить в бой машинное обучение.
Сформулируем задачу следующим образом: имея на входе метрики системы, будем классифицировать итоговое состояние системы: штатное или аномальное. В такой постановке задача прекрасно ложится в парадигму обучения с учителем. Это значит, что весь наш обучающий набор данных должен быть размечен. Иначе говоря, каждая минута работы системы должна иметь метку 0 (штатное поведение) или -1 (аномальное поведение).
В жизни оказывается, что не все так радужно, как хотелось бы. Как правило, в JIRA фиксируются не все инциденты, многое остается в почте и не выходит за ее пределы, а иногда временные пределы аномалии размыты или неточны. Получается, что построить качественный датасет на поприще исторических данных нетривиальная задача.
Пока новые данные только начинают размечаться, давайте попробуем выжать пользу из того, что у нас уже есть. Для случаев, когда данные не имеют разметки, используются алгоритмы обучения без учителя. Будем исходить из того, что большую часть времени система работает корректно, но изредка случаются непредвиденные события: баги (куда без них), база отвалилась или, например, экскаваторщик Петр задел кабель датацентра. Поэтому сведем нашу задачу к поиску аномалии, а именно поиску нового поведения системы (Novelty Detection).
Для этого воспользуемся алгоритмом Isolated Forest. Он уже реализован в библиотеке sklearn. В качестве признаков (features) будем использовать метрики из систем мониторинга.
Обучим Isolated Forest на исторических данных, а новые данные, которые уже получилось разметить, будем использовать для оценки качества. Таким образом, остается подобрать гиперпараметры модели и размер датасета для обучения.
Теперь данные о состоянии, которые собираются каждую минуту, поступают на вход обученной модели и получают метку 0 или -1.
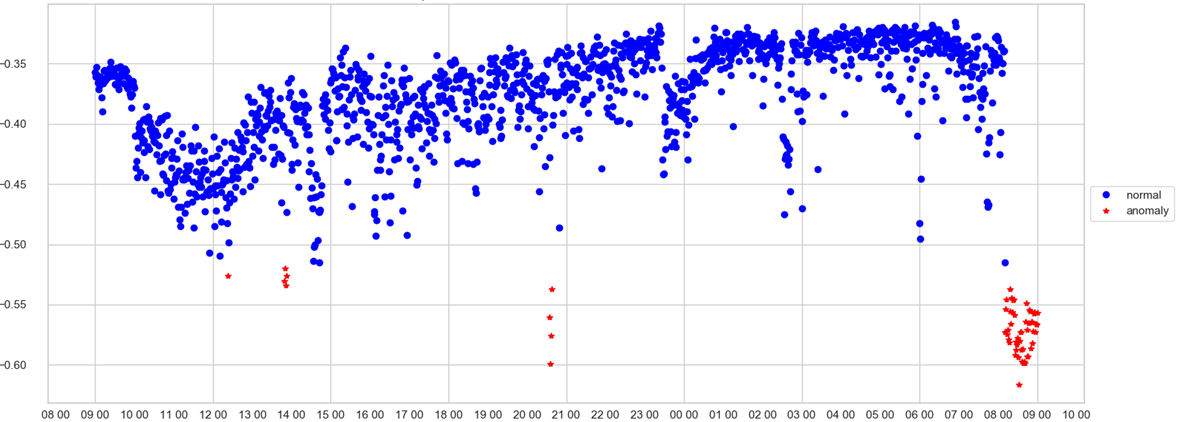
Оператор может отслеживать только один график. По оси Х — время, по Y — anomaly score, то есть, насколько сильно модель посчитала состояние системы в данную минуту аномальным. Если значение скора перевалило через трешхолд (который модель выбирает сама), точка подкрашивается красным и фиксируется аномалия.
Теперь мы узнаем о том, что система функционирует в не свойственном для себя режиме или что случилась внештатная ситуация почти в реальном времени. Это очень приятно, но как быть оператору в момент получения сигнала об аномалии? На какой дашборд смотреть? Давайте попробуем приоткрыть «черный ящик» нашей модели и понять, как она принимает решения.
Существуют разные подходы к тому, как вскрыть «черный ящик» обученной модели и понять, что на уме у машины. С логистической регрессией или решающим деревом все понятно, не составляет труда понять, на основе чего было принято решение. С Isolated Forest дела обстоят сложнее. Во-первых, внутри алгоритма есть случайность, а во-вторых — это алгоритм обучения без учителя.
Первым кандидатом стала библиотека LIME, которая использует model agnostic подход, который помогает интерпретировать любые модели, главное, чтобы на выходе модели было вероятностное распределение по классам. Окей, у нас, конечно, на выходе не вероятности, а скоры, но давайте попробуем их отнормировать в диапазоне от 0 до 1 и трактовать как вероятность. Таким образом нам удалось обеспечить входной формат совместимый с LIME.
То, как LIME интерпретировал результаты, разочаровало. Во-первых, в качестве интерпретации на выходе имелось несколько наиболее важных признаков, причем, в большинстве случаев только один из них реально адекватно отражал суть принятия решения, остальные же добавляли шума. Второй недостаток состоял в том, что интерпретация вела себя нестабильно и от запуска к запуску зачастую выдавала разный списков признаков. Чтобы получить более стабильные результаты, приходилось несколько раз запускать интерпретацию и как-то усреднять результаты. Не очень хотелось это делать.
После этого наш взгляд упал на другую библиотеку для интерпретации моделей — SHAP. Идея, лежащая в основе библиотеки, пришла из теории игр. Также библиотека имеет красивую визуализацию. Посмотрев примеры, мы с досадой поняли, что SHAP не умеет интерпретировать Isolated Forest, а нам так хотелось! Но, зато, SHAP умеет уверенно препарировать XGBoost. Мы подумали, а что если научить делать XGBoost то же самое, что умеет Isolated Forest? Для этого мы взяли весь наш датасет и разметили его с помощью Isolated Forest. Причем, в качестве таргетов взяли не класс, а скор, который присвоил Isolated Forest. Мы будем по всем метрикам предсказывать скор, который бы выдал Isolated Forest, но только XGBootом! Сказано — сделано. Наш размеченный датасет мы прогоним через XGBoost. И вот, теперь он умеет предсказывать скор точно так же, как Isolated Forest. Ура, теперь мы можем использовать SHAP!
Первым делом необходимо создать объект TreeExplainer, передав в качестве параметра саму модель. Далее подсчитываются shap values, которые и позволяют дать объяснение того как модель приняла то или иное решение.
SHAP позволяет интерпретировать и модель в целом, и результаты для конкретных примеров. Например, можно получить объяснение для конкретного примера с помощью метода force_plot(), которому на вход передаются shap values и значения самого примера.
Получается следующий график, который отображает, какие признаки модели и насколько, оказали влияние на принятие решения.

Теперь, зная какие метрики оказали существенный вклад в общий скор аномальности, появляется возможность установить на каком уровне возникла проблема, а главное оказала ли она влияние на конечных пользователей системы.

При каждом выявлении аномалии получается список метрик, которые наибольшим образом повлияли на решение. В случае если в список попали метрики, которые непосредственно отслеживают показатели, связанные с бизнесом, в алерте это упоминается особым образом, тем самым автоматически повышается приоритет аномалии.
Это только первый, но важный шаг усиления и автоматизации системы мониторинга с помощью машинного обучения, позволяющий значительно повысить скорость идентификации причин и влияния аномального поведения системы.
Ссылки:
scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html
github.com/marcotcr/lime
github.com/slundberg/shap
Хоум Кредит — это крупная и очень динамичная система, за которой подчас трудно уследить. Чтобы помочь сотрудникам быть в курсе всех новостей и изменений и везде успевать, мы активно внедряем алгоритмы машинного обучения. В нашем Банке чат-боты уже берут на себя часть работы операторов, клиентские отзывы анализируют не только эксперты, но и умные алгоритмы обработки естественного языка.
Сегодня я расскажу, как мы помогли специалистам эксплуатации банковских сервисов избавиться от необходимости непрерывно смотреть в дашборды мониторинговых систем, а именно, призвали на помощь машинное обучение. Вот что у нас получилось.
Как устроен ручной мониторинг
Типичное рабочее место специалиста по эксплуатации выглядит как на картинке выше, причем большую часть времени он проводит за рассматриванием дашбордов. Любая подозрительная активность в системе, например, когда отвалилась сеть или посыпались NullPointerException, сразу привлечет внимание — немедленно начнется расследование.
Человек не машина. Он может отвлечься, пойти на обед, ответить на телефонный звонок. Да и когда количество графиков переваливает за сотню, связать их всех воедино и докопаться до сути становится трудно.
Еще одна проблема в том, что есть семейство ошибок, которые возникают постоянно, но серьезным образом не затрагивают поведение системы. Например, отвалился сторонний микросервис и дашборды знатно тряхануло, но на самом деле система вне опасности. На первый взгляд, не всегда понятно, насколько аномальное поведение является критическим, и что за этим стоит. Чтобы детально установить причины надо сходить на сервер и основательно покопаться в логах. Такую операцию приходится проделывать десятки раз на дню. Давайте хотя бы частично поручим ее машине.
Машинное обучение как умный ассистент
Есть три основных источника данных: Zabbix, ElasticSearch и внутренняя система мониторинга бизнес-показателей. Zabbix мы используем для мониторинга «железа», сети и доступности различных точек входа в системы. С помощью ElasticSearch парсим и извлекаем лог сообщения. В качестве метрик используются различные ошибки, эксепшены, запросы. Бизнес-аналитики же следят за показателями пользователей: количеством переводов, продаж и прочими бизнес-активностями. Данные собираются с частотой раз в минуту и складываются в базу. Отлично, данные собраны, самое время написать кучу if’ ов пустить в бой машинное обучение.
Сформулируем задачу следующим образом: имея на входе метрики системы, будем классифицировать итоговое состояние системы: штатное или аномальное. В такой постановке задача прекрасно ложится в парадигму обучения с учителем. Это значит, что весь наш обучающий набор данных должен быть размечен. Иначе говоря, каждая минута работы системы должна иметь метку 0 (штатное поведение) или -1 (аномальное поведение).
В жизни оказывается, что не все так радужно, как хотелось бы. Как правило, в JIRA фиксируются не все инциденты, многое остается в почте и не выходит за ее пределы, а иногда временные пределы аномалии размыты или неточны. Получается, что построить качественный датасет на поприще исторических данных нетривиальная задача.
Пока новые данные только начинают размечаться, давайте попробуем выжать пользу из того, что у нас уже есть. Для случаев, когда данные не имеют разметки, используются алгоритмы обучения без учителя. Будем исходить из того, что большую часть времени система работает корректно, но изредка случаются непредвиденные события: баги (куда без них), база отвалилась или, например, экскаваторщик Петр задел кабель датацентра. Поэтому сведем нашу задачу к поиску аномалии, а именно поиску нового поведения системы (Novelty Detection).
Для этого воспользуемся алгоритмом Isolated Forest. Он уже реализован в библиотеке sklearn. В качестве признаков (features) будем использовать метрики из систем мониторинга.
clf = IsolationForest(behaviour='new', max_samples=100,
random_state=rng, contamination='auto')Обучим Isolated Forest на исторических данных, а новые данные, которые уже получилось разметить, будем использовать для оценки качества. Таким образом, остается подобрать гиперпараметры модели и размер датасета для обучения.
Теперь данные о состоянии, которые собираются каждую минуту, поступают на вход обученной модели и получают метку 0 или -1.
Оператор может отслеживать только один график. По оси Х — время, по Y — anomaly score, то есть, насколько сильно модель посчитала состояние системы в данную минуту аномальным. Если значение скора перевалило через трешхолд (который модель выбирает сама), точка подкрашивается красным и фиксируется аномалия.
Теперь мы узнаем о том, что система функционирует в не свойственном для себя режиме или что случилась внештатная ситуация почти в реальном времени. Это очень приятно, но как быть оператору в момент получения сигнала об аномалии? На какой дашборд смотреть? Давайте попробуем приоткрыть «черный ящик» нашей модели и понять, как она принимает решения.
Интерпретация модели с помощью LIME
Существуют разные подходы к тому, как вскрыть «черный ящик» обученной модели и понять, что на уме у машины. С логистической регрессией или решающим деревом все понятно, не составляет труда понять, на основе чего было принято решение. С Isolated Forest дела обстоят сложнее. Во-первых, внутри алгоритма есть случайность, а во-вторых — это алгоритм обучения без учителя.
Первым кандидатом стала библиотека LIME, которая использует model agnostic подход, который помогает интерпретировать любые модели, главное, чтобы на выходе модели было вероятностное распределение по классам. Окей, у нас, конечно, на выходе не вероятности, а скоры, но давайте попробуем их отнормировать в диапазоне от 0 до 1 и трактовать как вероятность. Таким образом нам удалось обеспечить входной формат совместимый с LIME.
То, как LIME интерпретировал результаты, разочаровало. Во-первых, в качестве интерпретации на выходе имелось несколько наиболее важных признаков, причем, в большинстве случаев только один из них реально адекватно отражал суть принятия решения, остальные же добавляли шума. Второй недостаток состоял в том, что интерпретация вела себя нестабильно и от запуска к запуску зачастую выдавала разный списков признаков. Чтобы получить более стабильные результаты, приходилось несколько раз запускать интерпретацию и как-то усреднять результаты. Не очень хотелось это делать.
SHAP — мостик от человека к машине
После этого наш взгляд упал на другую библиотеку для интерпретации моделей — SHAP. Идея, лежащая в основе библиотеки, пришла из теории игр. Также библиотека имеет красивую визуализацию. Посмотрев примеры, мы с досадой поняли, что SHAP не умеет интерпретировать Isolated Forest, а нам так хотелось! Но, зато, SHAP умеет уверенно препарировать XGBoost. Мы подумали, а что если научить делать XGBoost то же самое, что умеет Isolated Forest? Для этого мы взяли весь наш датасет и разметили его с помощью Isolated Forest. Причем, в качестве таргетов взяли не класс, а скор, который присвоил Isolated Forest. Мы будем по всем метрикам предсказывать скор, который бы выдал Isolated Forest, но только XGBootом! Сказано — сделано. Наш размеченный датасет мы прогоним через XGBoost. И вот, теперь он умеет предсказывать скор точно так же, как Isolated Forest. Ура, теперь мы можем использовать SHAP!
Первым делом необходимо создать объект TreeExplainer, передав в качестве параметра саму модель. Далее подсчитываются shap values, которые и позволяют дать объяснение того как модель приняла то или иное решение.
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)SHAP позволяет интерпретировать и модель в целом, и результаты для конкретных примеров. Например, можно получить объяснение для конкретного примера с помощью метода force_plot(), которому на вход передаются shap values и значения самого примера.
shap.force_plot(explainer.expected_value,shap_values[0,:], X.iloc[0,:])Получается следующий график, который отображает, какие признаки модели и насколько, оказали влияние на принятие решения.
Помогаем бизнесу
Теперь, зная какие метрики оказали существенный вклад в общий скор аномальности, появляется возможность установить на каком уровне возникла проблема, а главное оказала ли она влияние на конечных пользователей системы.
При каждом выявлении аномалии получается список метрик, которые наибольшим образом повлияли на решение. В случае если в список попали метрики, которые непосредственно отслеживают показатели, связанные с бизнесом, в алерте это упоминается особым образом, тем самым автоматически повышается приоритет аномалии.
Это только первый, но важный шаг усиления и автоматизации системы мониторинга с помощью машинного обучения, позволяющий значительно повысить скорость идентификации причин и влияния аномального поведения системы.
Ссылки:
scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html
github.com/marcotcr/lime
github.com/slundberg/shap
Комментарии (3)

cosmostarK
14.12.2019 12:07Интересно, но не более как мне показалось. Есть немного интересной информации в разделе «Отчеты» в Zabbix. Там можно посмотреть какие проблемы и с какой периодичностью встречаются и сделать выводы.
SlavikF
Не совсем по теме статьи, но каждый раз когда я читаю
То сразу хочется не иметь с таким банком / сервисом / фирмой…
Те, кто пилят такие «фичи» может и думают, что это типа круто, но каждый раз когда приходится иметь дело с «умным ботом», то уже через 20 секунд хочется сделать «что-то нехорошее» такому умнику.
Kagdilag
а зачем с ним разговаривать? ) пишешь просто «переключите на оператор» — и обычно сразу перекидывает на человека.