
Про принцип единственной ответственности (The Single Responsibility Principle, SRP) уже было написано множество статей. В большинстве из них даётся лишь поверхностное его описание мало чем отличающееся от информации в википедии. А те немногие статьи что затрагивают ключевые особенности SRP делают это вскользь, не акцентируя на них внимания и не развивая тему дальше.
Эта статья — попытка дать более глубокое объяснение принципу единственной ответственности, а также показать как его всё таки можно применять на практике. Кому интересно — добро пожаловать под кат.
Первоначально, автор принципа — Дядя Боб, дал ему такую формулировку:
Рассмотрим следующий пример класса и попробуем оценить (субъективно конечно же) соответствует ли он SRP согласно определению выше:
Примечание: весь код в статье не высосан из пальца, а взят из реальных проектов автора.
Как нетрудно догадаться этот класс умеет строить SELECT запрос и выполнять его. Сразу же бросается в глаза что у класса есть две группы методов: методы для генерации SQL кода и методы для выполнения этого кода. А значит у нас могут появиться две разных причины для изменения этого класса. Например, мы можем добавить новый метод having() для генерации HAVING условий. Это изменение никак не затронет методы выполняющие запрос. С другой стороны, мы можем добавить метод groupByKey() позволяющий группировать извлечённые данные по ключу и это в свою очередь никак не скажется на первой группе методов.
Налицо нарушение SRP. Решить проблему можно было бы, например, разделением класса на два:
Теперь вроде всё в порядке. Каждый класс делает ровно одну вещь и имеет ровно одну причину для изменений.
А вот другой пример:
Как следует из названия класс используется для поиска различных сущностей и больше ничего не делает, а значит соответствует SRP. Ведь так?
А как вам такой пример:
Ну ActiveRecord известный антипатерн. Он точно нарушает SRP. Или нет?
На самом деле во всех этих примерах нарушение или не нарушение SRP зависит от того, что мы будем считать причиной для изменений. При этом, варьируя широту этого понятия мы сможем обосновать как создание классов содержащих ровно по одному методу (из одной строки кода), так и создание «божественных объектов». А значит озвученное выше определение принципа единственной ответственности бесполезно.
По видимому, Дядя Боб в какой-то момент пришёл к тому же выводу и поэтому в своей недавней книге Clean Architecture даёт новое определение этого принципа:
Это определение гораздо лучше предыдущего, т.к., во-первых, оно акцентирует внимание не на классе, а на модуле, что явно указывает на то, что SRP применим к любой части системы и не зависит от используемой парадигмы программирования. Во-вторых, из него следует важное практическое следствие:
Оценим с этой точки зрения наш первый пример — класс SelectQuery. Объективно он может использоваться в двух контекстах (т.е. у него есть два актора): генерация SQL кода и выполнение этого кода. Если у нас есть оба этих актора, т.е. если класс в каких-то сценариях используется только для генерации SQL, а в каких-то для выполнения запросов, то первая реализация класса не соответствует SRP. Если же у нас лишь один актор (как в проекте автора) — контекст выполнения запросов, то тогда исходная реализация не противоречит SRP. Действительно, в этом случае с точки зрения применения SelectQuery не будет никакой разницы содержится ли весь нужный функционал для построения и выполнения запросов в одном классе или в двух связанных классах. Сценарий использования будет всегда одним и тем же — строим запрос и потом выполняем:
Заметим, что классы из второй реализации SelectQuery не противоречат принципу единственной ответственности как для одного так и для двух акторов. А значит в случае одного актора отвечающего за выполнение запросов обе реализации эквивалентны с точки зрения следования SRP.
Что на счёт следующего класса SearchService. Одного кода класса недостаточно. Во-первых, неизвестно, что представляют собой сущности Athlete, Association и т.д. А во-вторых, неясен контекст использования класса. Например, может быть такой вариант что сущности это простые DTO, а контекст использования поиск различимых, но почти однородных данных. Тогда этот класс имеет одного актора и следовательно удовлетворяет SRP. Но если возвращаемые сущности это бизнес сущности, а методы класса используются в разных контекстах соответствующих каждой бизнес сущности (как в проекте автора), то тогда класс имеет кучу акторов, по одному на каждый метод, и следовательно жёстко нарушает принцип единственной ответственности.
В каких контекстах может использоваться наш ActiveRecord? На самом деле только в одном — сохранение записи в источнике данных. Никак иначе использовать этот класс нельзя. Таким образом, ActiveRecord прекрасно согласуется с SRP.
Постойте! Что мы вообще делаем? На каком основании мы выделяем контексты (акторов) использования модуля. Каков критерий разграничения акторов? Чем это принципиально отличается от «причины для изменений»? Собственно ничем. Да, мы теперь знаем, что нужно изучать то как мы используем программные модули, но в остальном трактовка принципа единственной ответственности в его актуальной формулировке всё также субъективна и находится в прямой зависимости от опыта и интуиции разработчика. Хотелось бы какого-то более формального подхода к проблеме, что-нибудь померить и посчитать в конце концов. Что ж, такой подход есть.
Принцип единственной ответственности возник как попытка объединения двух важных понятий структурного анализа и проектирования: coupling (сопряжение, зацепление, связанность) и cohesion (сплочённость, связность, прочность модуля).
Оба понятия неформально определяются следующим образом:
В стандарте ISO/IEC/IEEE 24765-2010 определены (неформально) следующие виды связности и сопряжения (от худшего к лучшему):
Несмотря на обилие метрик, не существует какого-то единственного способа для вычисления сопряжения и связности модулей. Отчасти это связано с отсутствием строгой формализации этих понятий. С другой стороны разновидностей связей между программными модулями великое множество. Какие-то связи считаются «полезными», а какие-то «вредными» (зависимости). И какую связь какой считать во многом зависит от того на каком языке программирования написана программа, какая парадигма программирования использовалась или в каком архитектурном стиле велась разработка.
Тем не менее не всё так плохо. Существуют интегральные метрики позволяющие объединить всё, что мы считаем «полезным» в отношении связей и рассчитать связность и сопряжение для всей системы. Один из таких подходов описан в Measuring Software Coupling. Хотя этот метод предлагается использовать для вычисления сопряжения, он также подходит и для вычисления связности модулей.
Суть метода заключается в следующем: необходимо составить список того, что мы считаем зависимостями, далее по формулам рассчитываем связность или сопряжение. Расчёт будет настолько точным насколько адекватным и полным будет наш список видов зависимостей. Из-за диалектической природы сопряжения и связности списки зависимостей для них могут быть противоположными.
Описание алгоритма расчёта
Пользуясь вышеописанным алгоритмом попробуем рассчитать сопряжение и связность. Для примера возьмём код на PHP:
Прежде чем рассчитывать сопряжение составим список возможных связей между классами в PHP. Каждому типу связи присвоим вес в диапазоне от 0 до 1 (0 — соответствует отсутствию связи, 1 — соответствует максимально «жёсткой» связи).
Приведённый список зависимостей не является исчерпывающим, а скорее показывает качественную картину: какая из зависимостей является более «жёсткой» по отношению к другой. Можно также спорить по поводу весов. Однако наша задача получить не точное значение сопряжения, а качественно оценить на сколько код плох или хорош в этом отношении.
Итак, описание зависимостей есть, можно приступать к расчёту сопряжения. Всего у нас есть 11 модулей:
Составим матрицу описания связей, где будет определять степень зависимости между и . Таким образом столбцы в матрице связей это веса рёбер графа зависимостей рассчитанные в прямом и обратном направлении:
Матрица описания связей:
Выполняем расчёты и получаем матрицу зависимостей:
Общая зависимость классов , а средняя степень зависимости
Как и следовало ожидать, самым зависимым модулем оказался ChatSessionApplicationService, за ним следуют репозитории, UserAccessService, AbstractApplicationService и наконец все остальные классы. Средняя степень зависимости между классами небольшая, что говорит нам о том, что в основном классы слабо связанны между собой.
Попробуем теперь вычислить связность ChatSessionApplicationService и понять на сколько он удовлетворяет SRP. Здесь также можно было бы составить иерархию видов связей внутри модуля (класса) с точки зрения связности его подмодулей (методов). Но поскольку в нашем случае методы внутри ChatSessionApplicationService связаны исключительно через зависимости класса условимся в целях упрощения расчётов считать использование конкретной зависимости методом за 1. Таким образом, строки матрицы описаний связей будут соответствовать методам класса, а столбцы — использованию конкретной зависимости:
Матрица связей:
Матрица зависимостей:
Общая связность класса , а средняя степень связности методов
Сразу бросается в глаза низкая степень связности методов друг с другом. Об этом также свидетельствует средняя связность. При этом первый метод почти не связан с третьим, а второй в два раза сильнее связан с первым методом чем с третьим. Третий метод слабо связан с первыми двумя. Всё это означает, что ChatSessionApplicationService плохо соответствует SRP и, следовательно, должен быть разбит на три класса. К тому же такое разбиение только улучшит показатели сопряжения между классами (кто не верит — посчитайте сами) в силу слабой независимости сервиса с остальными классами.
Едва ли. Исследования в области контроля качества и сложности программного кода ведутся до сих пор и останавливаться не собираются. А значит применение принципов управления сложностью программного кода, к которым в частности относится SRP, будет становиться всё более приближенным к стандартным инженерным практикам.
Эта статья — попытка дать более глубокое объяснение принципу единственной ответственности, а также показать как его всё таки можно применять на практике. Кому интересно — добро пожаловать под кат.
Уровень 0
Первоначально, автор принципа — Дядя Боб, дал ему такую формулировку:
A class should have one, and only one, reason to change.
Класс должен иметь лишь одну причину для изменений.Это наиболее часто цитируемое определение принципа и оно крайне туманно. Проблема в том, что никто точно не понимает, что есть причина для изменений. Отсюда возникают различные субъективные трактовки «причины», а также стойкое ощущение того, что применение принципа единственной ответственности в разработке ПО это удел матёрых архитекторов и вообще что-то из области искусства. А ведь применение принципов проектирования на практике это именно то, что хочется в первую очередь освоить в процессе их изучения.
Рассмотрим следующий пример класса и попробуем оценить (субъективно конечно же) соответствует ли он SRP согласно определению выше:
Примечание: весь код в статье не высосан из пальца, а взят из реальных проектов автора.
class SelectQuery
{
public function __construct(QueryExecutor $executor) {...}
public function select($column, $alias = null): self {...}
public function from($table, $alias = null): self {...}
public function join(string $type, $table, $conditions = null): self {...}
public function where($column, $operator = null, $value = null): self {...}
public function orderBy($column, $order = null): self {...}
public function groupBy($column, $order = null): self {...}
public function limit(?int $limit): self {...}
public function offset(?int $offset): self {...}
public function build(): string {...}
public function rows(): array {...}
public function row(): array {...}
public function column(): array {...}
public function scalar() {...}
public function count() {...}
}
Как нетрудно догадаться этот класс умеет строить SELECT запрос и выполнять его. Сразу же бросается в глаза что у класса есть две группы методов: методы для генерации SQL кода и методы для выполнения этого кода. А значит у нас могут появиться две разных причины для изменения этого класса. Например, мы можем добавить новый метод having() для генерации HAVING условий. Это изменение никак не затронет методы выполняющие запрос. С другой стороны, мы можем добавить метод groupByKey() позволяющий группировать извлечённые данные по ключу и это в свою очередь никак не скажется на первой группе методов.
Налицо нарушение SRP. Решить проблему можно было бы, например, разделением класса на два:
class SelectQuery
{
public function select($column, $alias = null): self {...}
public function from($table, $alias = null): self {...}
public function join(string $type, $table, $conditions = null): self {...}
public function where($column, $operator = null, $value = null): self {...}
public function orderBy($column, $order = null): self {...}
public function groupBy($column, $order = null): self {...}
public function limit(?int $limit): self {...}
public function offset(?int $offset): self {...}
public function build(): string {...}
}
class ExecutableSelectQuery extends SelectQuery
{
public function __construct(QueryExecutor $executor) {...}
public function rows(): array {...}
public function row(): array {...}
public function column(): array {...}
public function scalar() {...}
public function count() {...}
}
Теперь вроде всё в порядке. Каждый класс делает ровно одну вещь и имеет ровно одну причину для изменений.
А вот другой пример:
@Transactional
class SearchService {
public List<Athlete> searchAthlete(SearchCriteria criteria)
public List<User> searchUser(SearchCriteria criteria)
public List<Association> searchAssociation(SearchCriteria criteria)
public List<Orgaization> searchOrganization(SearchCriteria criteria)
public List<Club> searchClub(SearchCriteria criteria)
public List<Team> searchTeam(SearchCriteria criteria)
public List<Game> searchGame(SearchCriteria criteria)
}
Как следует из названия класс используется для поиска различных сущностей и больше ничего не делает, а значит соответствует SRP. Ведь так?
А как вам такой пример:
class ActiveRecord
{
private $properties = [];
public function __get($property) {...}
public function __set($property, $value) {...}
public function create() {...}
public function update() {...}
public function delete() {...}
public function read() {...}
}
Ну ActiveRecord известный антипатерн. Он точно нарушает SRP. Или нет?
На самом деле во всех этих примерах нарушение или не нарушение SRP зависит от того, что мы будем считать причиной для изменений. При этом, варьируя широту этого понятия мы сможем обосновать как создание классов содержащих ровно по одному методу (из одной строки кода), так и создание «божественных объектов». А значит озвученное выше определение принципа единственной ответственности бесполезно.
Уровень -1
По видимому, Дядя Боб в какой-то момент пришёл к тому же выводу и поэтому в своей недавней книге Clean Architecture даёт новое определение этого принципа:
A module should be responsible to one, and only one, actor.
Модуль должен отвечать перед одним и только одним актором.Под актором здесь понимается группа, состоящая из одного или нескольких лиц, желающих изменения поведения программного модуля.
Это определение гораздо лучше предыдущего, т.к., во-первых, оно акцентирует внимание не на классе, а на модуле, что явно указывает на то, что SRP применим к любой части системы и не зависит от используемой парадигмы программирования. Во-вторых, из него следует важное практическое следствие:
Для определения соответствия программного модуля принципу единственной ответственности не всегда достаточно изучения лишь кода этого модуля. Требуется изучить также как этот модуль используется во внешнем по отношению к нему коде.Иными словами, каждый актор определяет контекст использования модуля или, что тоже самое, набор сценариев использования модуля. Это может показаться неочевидным сразу, но каждый сценарий использования модуля отражает чьё-либо желание зафиксированное в коде.
Докажем это
Каждый актор, или что тоже самое, группа лиц желающих изменения поведения модуля выступает в роли заказчика этого изменения. Чтобы изменение не было бесполезным оно должно как-то и где-то проявляться. Единственный способ это сделать это задействовать это изменение в одном или нескольких сценариях использования модуля. Если же изменение поведения программного модуля никак не проявляет себя в сценариях использования, то это означает одно из двух: либо это изменение не касается поведения модуля (например, рефакторинг приватных методов класса), а значит не относится к SRP вообще, либо оно сделано «на перспективу», что напрямую нарушает принцип YAGNI и следовательно такое изменение бесполезно.
Оценим с этой точки зрения наш первый пример — класс SelectQuery. Объективно он может использоваться в двух контекстах (т.е. у него есть два актора): генерация SQL кода и выполнение этого кода. Если у нас есть оба этих актора, т.е. если класс в каких-то сценариях используется только для генерации SQL, а в каких-то для выполнения запросов, то первая реализация класса не соответствует SRP. Если же у нас лишь один актор (как в проекте автора) — контекст выполнения запросов, то тогда исходная реализация не противоречит SRP. Действительно, в этом случае с точки зрения применения SelectQuery не будет никакой разницы содержится ли весь нужный функционал для построения и выполнения запросов в одном классе или в двух связанных классах. Сценарий использования будет всегда одним и тем же — строим запрос и потом выполняем:
$rows = (new SelectQuery(new QueryExecutorImpl()))
->select(...)
->from(...)
->where(...)
->rows();
Заметим, что классы из второй реализации SelectQuery не противоречат принципу единственной ответственности как для одного так и для двух акторов. А значит в случае одного актора отвечающего за выполнение запросов обе реализации эквивалентны с точки зрения следования SRP.
Что на счёт следующего класса SearchService. Одного кода класса недостаточно. Во-первых, неизвестно, что представляют собой сущности Athlete, Association и т.д. А во-вторых, неясен контекст использования класса. Например, может быть такой вариант что сущности это простые DTO, а контекст использования поиск различимых, но почти однородных данных. Тогда этот класс имеет одного актора и следовательно удовлетворяет SRP. Но если возвращаемые сущности это бизнес сущности, а методы класса используются в разных контекстах соответствующих каждой бизнес сущности (как в проекте автора), то тогда класс имеет кучу акторов, по одному на каждый метод, и следовательно жёстко нарушает принцип единственной ответственности.
В каких контекстах может использоваться наш ActiveRecord? На самом деле только в одном — сохранение записи в источнике данных. Никак иначе использовать этот класс нельзя. Таким образом, ActiveRecord прекрасно согласуется с SRP.
Для тех кто не верит
Приведённая выше реализация ActiveRecord действительно не нарушает SRP (кто думает иначе, приведите пример использования отличный от сохранение данных в источнике данных). Однако в оригинальном определении этого патерна заложено нарушение SRP: как минимум два контекста — бизнес логика и взаимодействие с источником данных.
Постойте! Что мы вообще делаем? На каком основании мы выделяем контексты (акторов) использования модуля. Каков критерий разграничения акторов? Чем это принципиально отличается от «причины для изменений»? Собственно ничем. Да, мы теперь знаем, что нужно изучать то как мы используем программные модули, но в остальном трактовка принципа единственной ответственности в его актуальной формулировке всё также субъективна и находится в прямой зависимости от опыта и интуиции разработчика. Хотелось бы какого-то более формального подхода к проблеме, что-нибудь померить и посчитать в конце концов. Что ж, такой подход есть.
Уровень -2
Принцип единственной ответственности возник как попытка объединения двух важных понятий структурного анализа и проектирования: coupling (сопряжение, зацепление, связанность) и cohesion (сплочённость, связность, прочность модуля).
Как это было
- В 1972 году Дэвид Парнас публикует статью в которой он высказывает идею декомпозиции системы на модули основываясь на том как они могут изменяться в будущем.
- В 1974 Эдсгер Дейкстра
вводит новый термин: The Separation of Concerns (Разделение ответственности). - В конце 70х Том Демарко популяризирует понятия coupling и cohesion предложенные ранее (в 1974) Ларри Константином.
- В конце 90х — начале 2000х Дядя Боб объединяет все эти идеи в принцип единственной ответственности.
Оба понятия неформально определяются следующим образом:
Coupling — степень взаимозависимости между программными модулями.
Cohesion — степень взаимозависимости между структурными составляющими программного модуля (подмодулями).Введём также определение связи и зависимости между программными модулями:
Модуль A связан с модулем B, или что тоже самое, модуль B связан с модулем А, только тогда когда существует передача информации между ними.
Модуль A зависит от модуля B, а модуль B не зависит от A, если изменения в спецификации А никогда не приведут к изменениям кода в B, а изменения в спецификации B могут приводить к изменениям кода в A.Где под спецификацией модуля понимается некоторая его часть доступная для прямого обращения извне (программный интерфейс модуля). Существует также альтернативная формулировка:
Модуль A зависит от модуля B, а модуль B не зависит от A, если удаление модуля B приводит к нарушениям в работе A.Таким образом программные модули могут быть связанными, но при этом независимыми. При этом несвязанные модули всегда независимы. Чего не скажешь про зависимые модули, они всегда связанны. Заметим, что информация (например, вызов метода, класса, обращение к переменной, отправка сообщения и т.д.) может передаваться как от зависимого модуля к независимому так и наоборот. Обратите также внимание на то, что связность это по сути то же самое что и сопряжение, но применительно к подмодулям рассматриваемых модулей. При этом в хорошо спроектированной системе низкое сопряжение между модулями подразумевает высокую связность внутри этих модулей (смотри, например, GRASP).
Нет ли тут подвоха?
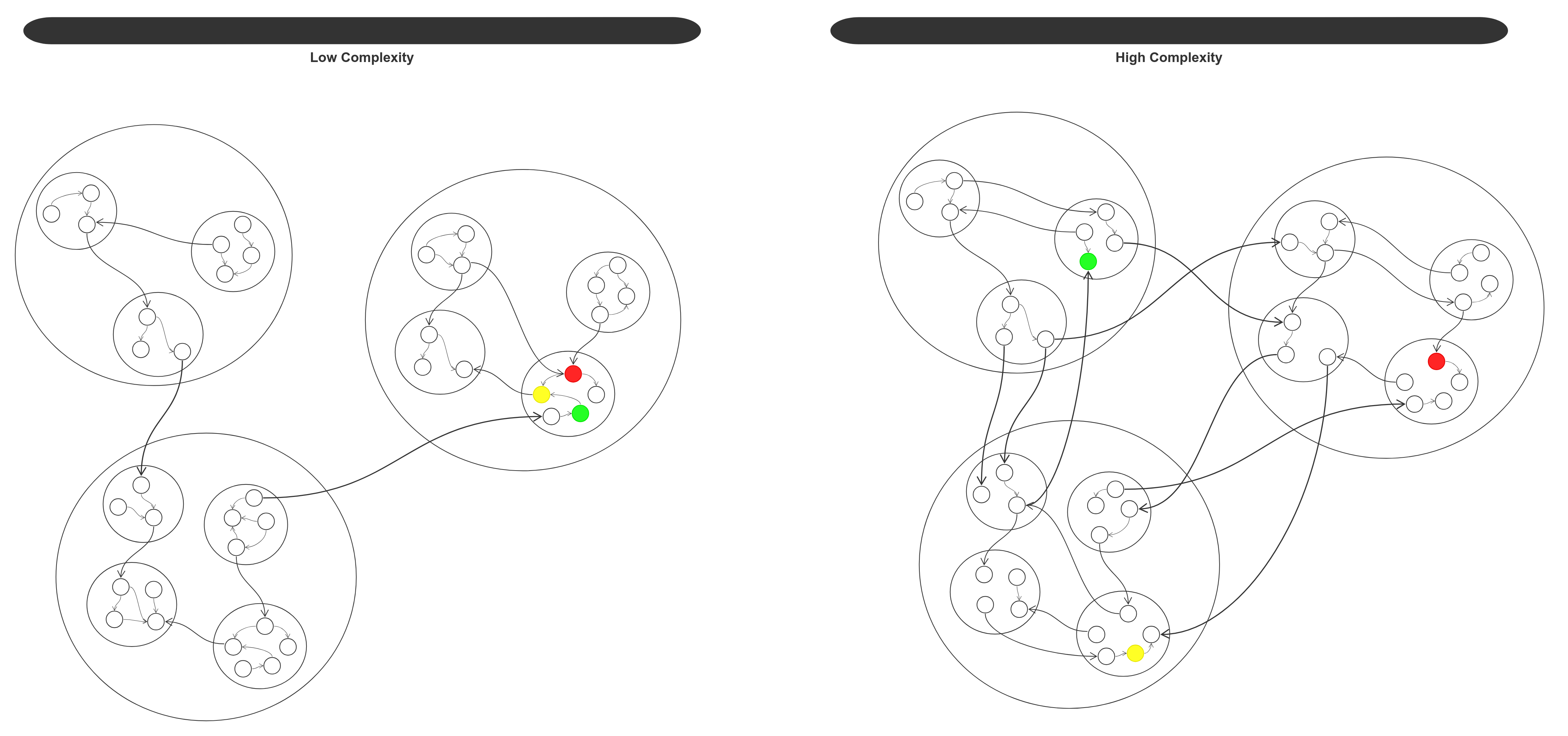
Если связность это тоже самое что и сопряжение, то получается, что для некоторого набора модулей входящих в состав более крупного модуля их взаимозависимость должна быть одновременно высокой (модули являются подмодулями более крупного модуля, а значит должны обладать высокой связностью) и низкой (сопряжение между модулями). Как такое возможно? Возможно, если взаимозависимость подмодулей каждого модуля будет не меньше взаимозависимости между модулями более высокого уровня. При этом самые низкоуровневые модули будут обладать наибольшей взаимозависимостью, а самые высокоуровневые (из которых состоит вся программа) — наименьшей. Следующий рисунок демонстрирует хорошую и плохую декомпозицию программы на модули (разноцветные модули изменяются в одно и то же время):
В стандарте ISO/IEC/IEEE 24765-2010 определены (неформально) следующие виды связности и сопряжения (от худшего к лучшему):
- Связность
- Случайная (coincidental)
Подмодули модуля в этом случае никак не взаимодействуют друг с другом и выполняют функционально не связанные задачи. Примером такой связности может быть весь тот код, который часто приводят для демонстрации нарушения принципа единственной ответственности:
class UserManager { public function writeToFile(...) {...} public function calculatePaymentAmount(...) {...} public function authenticateUser(...) {...} }
- Логическая (logical)
Также как и в случае случайной связности подмодули модуля никак не взаимодействуют друг с другом (либо взаимодействуют слабо), однако наблюдается их логическое сходство по какому-либо признаку (например, по сходству решаемых подмодулями задач). Примером логической связности может служить класс SearchService, при условии, что все его методы возвращают различные экземпляры бизнес сущностей. Тогда все методы класса имеют одно общее свойство — все они выполняют поиск некоторой сущности хотя каждый метод функционально принадлежит разным модулям.
- Временная (temporal)
Тип связности при котором подмодули объединены в модуль по причине их совместного использования в некоторый момент времени выполнения программы, а порядок обращения к ним не важен. При этом подмодули никак функционально не связаны между собой.
class ExceptionProcessor { public function logException(Exception $e) {...} public function notifyAdminAboutException(Exception $e) {...} public function showFormattedException(Exception $e) {...} } // Далее, где-то в коде $exceptionProcessor = new ExceptionProcessor(); ... try { ... } catch (Exception $e) { $exceptionProcessor->logException($e); $exceptionProcessor->notifyAdminAboutException($e); $exceptionProcessor->showException($e); }
- Процедурная (procedural)
Тип связности при котором подмодули объединены в модуль по причине их совместного использования в некоторый момент времени выполнения программы. Обращение к модулям происходит в определённом порядке. Подмодули могут быть функционально связаны между собой.
class Concole { public static function hasColorSupport(): bool {...} public static function highlight(string $text): string {...} } // Далее, где-то в коде $consoleText = '...'; if (Console::hasColorSupport()) { $consoleText = Console::highlight($consoleText); } $this->write($consoleText);
- Коммуникационная/информационная (communicational/informational)
Подмодули модуля функционально связаны между собой и обрабатывают одни и те же данные. Порядок обращения к подмодулям не имеет значения. Примером этого типа связности может служить класс SelectQuery (до разделения), ActiveRecord (только CRUD), большинство классов бизнес сущностей и сервисов, при условии их правильной реализации, воплощающих сценарии использования бизнес логики.
- Последовательностная (sequential)
Подмодули модуля функционально связаны между собой. При этом выходные данные одного подмодуля становятся входными данными другого подмодуля, т.е. важен порядок обращения к подмодулям. Как правило такой модуль имеет одну точку входа.
class ExpressionExecutor { public function execute(string $expression) { $ast = $this->parse( $this->lexer( $this->characterIterator($expression) ) ); return $ast->evaluate(); } protected function parse(Lexer $lexer) {...} protected function lexer(Iterator $iterator): Lexer {...} protected function characterIterator($expression): Iterator {...} }
- Функциональная (functional)
Все подмодули модуля функционально связаны между собой и выполняют одну хорошо определённую задачу. Этот тип связности прямая противоположность случайной связности.
class Lexer { public function __construct(CharacterIterator $charIterator) {...} public function getTokens(): Generator {...} }
- Случайная (coincidental)
- Сопряжение
- Патологическое (pathological)
Программный модуль оказывает влияние или зависит от внутренней реализации другого модуля. Как правило, этот тип зацепления связан с нарушением принципа сокрытия информации (information hiding).
class Hash: ... def hashOfText(self, text): self.__hashFromCache(text, self.__textHashCache) def __hashFromCache(text, cache): ... class OrderId: ... def hash(self): return Hash()._Hash__hashFromCache(self.__id, dict())
- По содержимому (content)
Часть или все содержимое одного программного модуля включены в содержимое другого модуля. Примером такого зацепления могут служить вложенные или анонимные классы.
public class BitSet implements Cloneable, java.io.Serializable { ... public IntStream stream() { class BitSetSpliterator implements Spliterator.OfInt { ... } return StreamSupport.intStream( new BitSetSpliterator(0, -1, 0, true), false ); } }
class EventPublisher { private $subscribers = []; public function __construct() { $this->subscribers[] = new EventSubscriberContract { public function handle(Event $event) { ... } } } }
- По общей области данных (common, common-environment)
Два или более модулей совместно используют общую область данных (глобальную по отношению к модулям).
$board = []; class Bot implements Player { ... public function move() { global $board; ... if ($board[$x][$y] === $this->shape['o']) { ... } ... $board[$x][$y] = $this->shape['x']; ... } } class Game { private $player1; private $player2; public function __construct(Player $player1, Player $player2) { $this->player1 = $player1; $this->player2 = $player2; } public funciton next(): bool { $this->player1->move(); if ($this->isGameOver()) { return true; } $this->player2->move(); if ($this->isGameOver()) { return true; } return false; } public function isGameOver(): bool { global $board; if ($board[$x][$y] === 'x' || ... ) { return true; } return false; } }
- Смешанное (hybrid)
Различные подмножества значений некоторого элемента данных используются в нескольких программных модулях для разных и несвязанных целей. Тут можно придумать такой искусственный пример: есть некоторый DTO содержащий данные потребляемыми двумя совершенно разными модулями.
- По управлению (control coupling)
Один модуль взаимодействует с другим модулем с целью повлиять на его поведение путём передачи ему управляющей информации.
class SortedCollection { private $items; private $comparator; public function __construct(array $items, callable $comparator) { $this->items = $items; $this->comparator = $comparator; } public function items(): array { $this->sort(); return $this->items; } private function sort(): void { usort($this->items, $this->comparator); } } ... $collection = new SortedCollection([3, 5, 2, 1], function (int $a, int $b) { return $a <=> $b; }); $sortedItems = $collection->items();
- По данным (data)
Данные одного программного модуля поступают на вход другого модуля.
class UserController { public function userDetails(string $userId, UserQueryService $service) { return $service->getUserDetails($userId); } }
- Патологическое (pathological)
Ссылки для примера
Несмотря на обилие метрик, не существует какого-то единственного способа для вычисления сопряжения и связности модулей. Отчасти это связано с отсутствием строгой формализации этих понятий. С другой стороны разновидностей связей между программными модулями великое множество. Какие-то связи считаются «полезными», а какие-то «вредными» (зависимости). И какую связь какой считать во многом зависит от того на каком языке программирования написана программа, какая парадигма программирования использовалась или в каком архитектурном стиле велась разработка.
Уровень — 3
Тем не менее не всё так плохо. Существуют интегральные метрики позволяющие объединить всё, что мы считаем «полезным» в отношении связей и рассчитать связность и сопряжение для всей системы. Один из таких подходов описан в Measuring Software Coupling. Хотя этот метод предлагается использовать для вычисления сопряжения, он также подходит и для вычисления связности модулей.
Суть метода заключается в следующем: необходимо составить список того, что мы считаем зависимостями, далее по формулам рассчитываем связность или сопряжение. Расчёт будет настолько точным насколько адекватным и полным будет наш список видов зависимостей. Из-за диалектической природы сопряжения и связности списки зависимостей для них могут быть противоположными.
Описание алгоритма расчёта
- Составляем матрицу описания связей для m модулей связанных посредством n видов связей: где число характеризующее степень влияния вида связи j на модуль i. Чем больше это число тем сильнее модуль i связан с какими-то другими модулями через связь j. Если равен нулю, то это означает что вид связи j не относится к модулю i.
Следует заметить, что матрица описаний применима только к модулям граф зависимостей которых связный, т.е. есть существует путь передачи информации из любого модуля в любой другой модуль. Или другими словами в матрице описаний не должно быть строк или колонок состоящих из одних нулей.
- Вычисляем матрицу зависимостей: по следующим формулам:
где — сумма всех элементов i-й строки матрицы описаний, а — величина обратная сумме элементов k-го столбца матрицы связей.
- Анализируем получившуюся матрицу зависимостей. При этом имеем:
- , для всех i и j.
- — степень зависимости между модулями i и j, если .
- — степень независимости модуля i от остальных модулей, если .
- — зависимость модуля от других модулей.
- — общая степень взаимозависимости модулей.
- — средняя степень взаимозависимости модулей.
Пользуясь вышеописанным алгоритмом попробуем рассчитать сопряжение и связность. Для примера возьмём код на PHP:
<?php
class User {...}
class Chat {...}
class ChatSession {...}
interface UserRepository
{
public function getMostLowLoadedOperator(): ?User;
}
interface ChatRepository
{
public function chatFrom($chatId): Chat;
}
interface ChatSessionRepository
{
public function sessionFrom($sessionId): ChatSession;
public function save(ChatSession $session): void;
}
interface BotService {...}
class ChatSessionApplicationService extends AbstractApplicationService
{
public function __construct(
ChatSessionRepository $sessionRepository,
ChatRepository $chatRepository,
UserRepository $userRepository,
BotService $botService,
UserAccessService $accessService
) {
...
}
public function startSession(StartSessionCommand $command): string
{
// Используются Chat, ChatRepository, ChatSession, ChatSessionRepository,
// BotService и функционал из AbstractApplicationService
...
}
public function switchChatSessionToFreeOperator($sessionId): void
{
// Используются ChatSession, ChatSessionRepository, User и UserRepository
// и функционал из AbstractApplicationService
...
}
public function changeName($sessionId, string $name): void
{
// Используются ChatSession, ChatSessionRepository и UserAccessService
...
}
}
Прежде чем рассчитывать сопряжение составим список возможных связей между классами в PHP. Каждому типу связи присвоим вес в диапазоне от 0 до 1 (0 — соответствует отсутствию связи, 1 — соответствует максимально «жёсткой» связи).
| Вид связи | Вес связи |
|---|---|
| Класс наследует не абстрактный класс или использует каким либо образом не абстрактный класс. | 1.0 |
| Класс использует трейт. | 0.8 |
| Класс наследует абстрактный класс или использует каким либо образом абстрактный класс. | 0.6 |
| Класс реализует интерфейс или использует каким либо образом интерфейс. | 0.4 |
| Класс взаимодействует с другим классом через посредника — функцию или другой класс или используется каким-либо образом другим классом будучи при этом независимым от него. | 0.2 |
| Класс взаимодействует с другим классом через несколько посредников или не взаимодействует вовсе. | 0.0 |
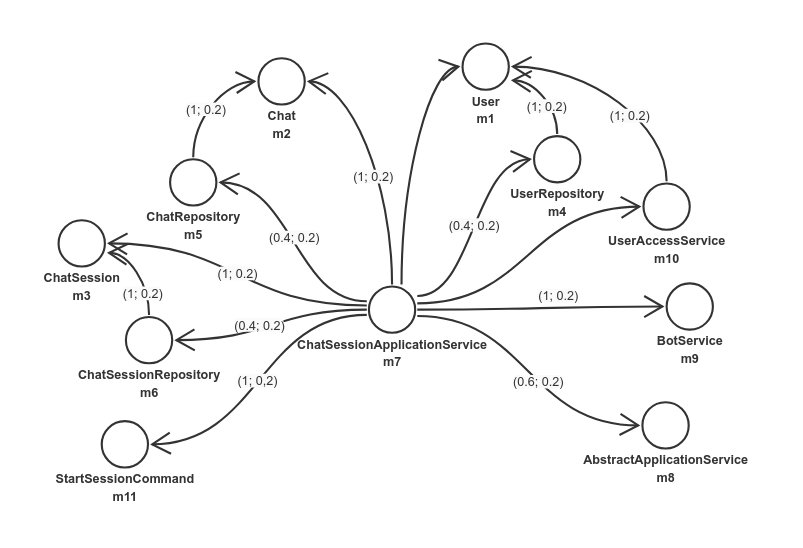
Итак, описание зависимостей есть, можно приступать к расчёту сопряжения. Всего у нас есть 11 модулей:
- — User
- — Chat
- — ChatSession
- — UserRepository
- — ChatRepository
- — ChatSessionRepository
- — ChatSessionApplicationService
- — AbstractApplicationService
- — BotService
- — UserAccessService
- — StartSessionCommand
Составим матрицу описания связей, где будет определять степень зависимости между и . Таким образом столбцы в матрице связей это веса рёбер графа зависимостей рассчитанные в прямом и обратном направлении:
Матрица описания связей:
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.4 | 0.2 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0.4 | 0.2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0.4 | 0.2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0.2 | 0.2 | 0.2 | 0 | 0.2 | 0 | 0.2 | 0.2 | 0.2 | 0 | 0.2 | 0 | 0.2 | 0.2 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.6 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0.2 | 0 | 0 | |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Выполняем расчёты и получаем матрицу зависимостей:
Общая зависимость классов , а средняя степень зависимости
Как и следовало ожидать, самым зависимым модулем оказался ChatSessionApplicationService, за ним следуют репозитории, UserAccessService, AbstractApplicationService и наконец все остальные классы. Средняя степень зависимости между классами небольшая, что говорит нам о том, что в основном классы слабо связанны между собой.
Попробуем теперь вычислить связность ChatSessionApplicationService и понять на сколько он удовлетворяет SRP. Здесь также можно было бы составить иерархию видов связей внутри модуля (класса) с точки зрения связности его подмодулей (методов). Но поскольку в нашем случае методы внутри ChatSessionApplicationService связаны исключительно через зависимости класса условимся в целях упрощения расчётов считать использование конкретной зависимости методом за 1. Таким образом, строки матрицы описаний связей будут соответствовать методам класса, а столбцы — использованию конкретной зависимости:
- Метод использует UserRepository
- Метод использует ChatRepository
- Метод использует ChatSessionRepository
- Метод использует UserAccessService
- Метод использует BotService
- Метод использует AbstractApplicationService
Матрица связей:
Матрица зависимостей:
Общая связность класса , а средняя степень связности методов
Сразу бросается в глаза низкая степень связности методов друг с другом. Об этом также свидетельствует средняя связность. При этом первый метод почти не связан с третьим, а второй в два раза сильнее связан с первым методом чем с третьим. Третий метод слабо связан с первыми двумя. Всё это означает, что ChatSessionApplicationService плохо соответствует SRP и, следовательно, должен быть разбит на три класса. К тому же такое разбиение только улучшит показатели сопряжения между классами (кто не верит — посчитайте сами) в силу слабой независимости сервиса с остальными классами.
Дно?
Едва ли. Исследования в области контроля качества и сложности программного кода ведутся до сих пор и останавливаться не собираются. А значит применение принципов управления сложностью программного кода, к которым в частности относится SRP, будет становиться всё более приближенным к стандартным инженерным практикам.






andreyverbin
Вы лучше найдите где дядя Боб берет траву под которой он все эти определения пишет. Или может у него исследования есть или теорема какая-то доказана? Все это игра слов — что такое «модуль», что такое «актор» и так о каждом слове в определении.
Делать нужно как в нормальной науке. Выводим из эксперимента несколько величин. Даём модель, которая их связь описывает. Не пытаемся определить базовые понятия через друг друга, а говорим абстрактно об объектах, которые обладают измеримыми свойствами и поведением, которое можно показать экспериментально. Вот тогда будут получаться принципы, которые не нужно в каждой новой книге править и по поводу которых никто спорить не будет.
samizdam
Я думаю всё это будет, вопрос времени. Дядя Боб исходит из практического опыта коммерческой разработки. Его практический опыт начинается в 70-ых. Самим технологиям несколько десятков лет, по меркам серьёзных наук это немного. Мне кажется мы в этом вопросе находимся на уровне античных философов, которые эмперически выводили основные наблюдаемые связи в окружающей природе. А вы уже требуете подходов основанных Ньютоном 2000 лет спустя)
ApeCoder
Делайте. Или приведите пример того, кто делает (в именно в дизайне).
Если такого нет, то приходится интуитивно передавать знания при помощи того, кто это делает неясными определениями. Если уж другого нет.
lair
Начинаем с того, что находим какие-нибудь объективно измеримые величины и объективно воспроизводимый эксперимент.
playermet
lair
Подождите, а как понять, что значение одно, если возможны разные трактовки?
playermet
В данном случае, прочитать книгу самого автора (Clean Architecture), который прям так и пишет, что альтернативная трактовка — неверная.
lair
конкретная альтернативная трактовка. Но не все альтернативные трактовки. А это, в свою очередь, возвращает нас к вопросу "как же понять, сколько значений у SRP".
(И это еще не вдаваясь в тот маленький нюанс, что мнение автора тоже может меняться.)
playermet
lair
Вот в том-то и дело, что "приблизиться". Мы опять попали в царство субъективных оценок.
И тем не менее, некоторые другие отрасли знания почему-то не страдают от проблем с пониманием терминов. Почему бы?
playermet
lair
Может быть, надо начинать с построения терминологии до открытия зоопарка?
Что, собственно, и приводит нас к проблеме подтверждаемости этих принципов.
playermet
Имхо, пора уже пробовать менять некоторые укоренившиеся десятилетия назад вещи в программировании. Например, перестать использовать текст как внутреннее представление программного кода при хранении и редактировании.
lair
Неа, не придется. Если новая терминология будет однозначной, трактовка старых языков и инструментов в рамках этой терминологии тоже будет однозначной. Зачем перепиливать, если можно просто составить словарь?
… зачем?
playermet
Потому что текст это лишь человекочитаемое представление программы. Использование его в качестве основы для всех инструментов программирования вмешивает проблемы уровня текстового представления во все другие уровни, и на каждом соответствующий инструмент решает их заново. Разделение программы и ее представления позволило бы этого избежать, а заодно добавить новые возможности.
lair
Ну и что? В натуральных языках одна и та же вещь называется по-разному, но однако человечество не занимается перепиливанием всех языков под одну гребенку.
Ну то есть лишь самое важное — с моей, конечно, точки зрения — в программе.
Это какие проблемы?
… давно есть — это разделение между исполняемой программой и ее исходным кодом.
Какие?
И да, вы забыли упомянуть недостатки отказа от текста.
playermet
Важное для программиста в момент чтения кода, но абсолютно бесполезное для внутренних алгоритмов работы инструментов.
Тысячи их. Обработка текста — медленно, открытие проекта — медленно, поиск по проекту — медленно, постоянный парсинг — медленно, повторный парсинг разными инструментами — кратно медленно, пересчет подстветки IDE — медленно, потребляемая память — высоко, толкование изменений кода — ужасно, код-стайл — холиварно, отступы — холиварно, окончания строк — холиварно, файловая структура проекта — холиварно, сцепления синтаксиса и ЯП — высоко, хороший синтаксис — сложно, написание парсеров — сложно, однозначность трактовки синтаксиса — плохо, толкование синтаксических ошибок — дно дна, количество языков которые не отличаются почти ничем кроме синтаксиса и имен — миллион. И это только первое что пришло в голову.
Это не то о чем я говорю. Я имею ввиду что код на диске и во внутренних структурах IDE/компиляторов/анализаторов должен быть представлен графом. А текстовое представление должно генерироваться лишь по необходимости, когда программист читает или редактирует конкретные элементы программы.
Возможность менять синтаксис, код-стайл, и все остальное на ходу, никак не мешая при этом соседнему программисту, который в это время редактирует этот же самый класс в IDE с поддержкой совместного редактирования. Возможность читать код на любом языке выучив один общий синтаксис и лишь доучивая новые фичи. Возможность легко эмулировать синтаксические фичи которые не поддерживает конкретный язык (например += или тернарный оператор). Возможность легко писать обобщенный код независимо от языка. Возможность автогенерации осмысленной истории изменений, т.е. воспринимающей и отображающей переименование как переименование, а не гадающее на кофейной гуще что есть что. Возможность легкой генерации/модификации программного кода. Возможность динамически упорядочивать код чтобы программист видел рядом все важное в конкретный момент времени. Возможность расширять и оптимизировать работу инструментов за счет информации которая не записывается в тексте проекта.
В принципе эти фичи можно получить и сейчас. Но это будет очень сложно сделать и это будет крайне медленно работать, поэтому никто этого не делает.
Невозможность делиться кодом через текстовые сообщения, невозможность редактировать программу вне специальных IDE. Необходимость наполовину переписать весь стек инструментов.
lair
Это то же самое, что в естественных языках. И ничего, справляются.
… а именно этот момент мне и важен.
Все, что "медленно" — решаемо ресурсами. Все, что холиварно, не решаемо отменой текста — вы просто замените одни холивары на другие.
Это не проблема текста.
… и оно будет разным для разных программистов, что лишает программиста выразительного инструмента.
Синтаксис на ходу менять не получится. Все остальное… а зачем?
Для этого нужен semantic merge, отказываться от текста не нужно.
Для этого нужен один язык, один синтаксис. Вы не добьетесь этого отказом от текста, надо сначала этот один язык придумать.
Все остальное есть — или возможно — и сейчас.
Полностью написать стек инструментов. И этот стек не будет совместим с соседним стеком, который работает с текстом (версионирование — самый яркие пример).
Текст — это общий делитель, позволяющий как-то уравнять опыт работы с разными языками и подходами. А вы предлагаете заменить его на один язык.
playermet
Почти все решаемо ресурсами. Можно отказаться хоть от качества кода в пользу ресурсов. Это не значит что это хорошо.
Ну и в конце концов. Чтобы написать парсер нужно больше ресурсов, чем чтобы написать генератор кода из графа. Чтобы написать IDE для текстового кода нужно больше ресурсов чем для IDE для графа. Чтобы написать инструменты работающие с текстом всегда нужно больше ресурсов, потому что всегда нужен парсинг, алгоритмы двигающие символы, дополнительные проверки на корректность, и т.д. и т.п. Но в итоге получаем что например при переименовании класса в проекте из текста нужно обойти весь проект, найти все файлы с упоминаниями (хорошо если есть индекс), загрузить эти файлы в память, двигать мегабайты символов в буфере при замене текста, сохранять это все обратно, потом это все еще будет перепарситься, обновляться подсветка синтаксиса, статически анализироваться, автоформатироваться, и чего только еще не делает IDE в процессе. А с другой стороны просто меняется одна строчка в одной ноде в графе, возможно обновляется крошечный сгенерированный кусочек текста на экране, миллисекунда прошла, готово.
Ресурсов на создание стека затрачено меньше, скорость работы стека вышла значительно больше.
Я не говорил про отмену текста, я говорил про перенос работы с ним на отдельный уровень. Соотвественно, он не добавляет новых тем для холиваров, но делает менее важными старые темы, ведь теперь выбор каждого члена команды (например касаемо форматирования) трогает остальную команду не больше, чем выбор шрифта или темы в собственной IDE.
Не имеет значения, чья это проблема, если это решаемо отказом от переноса текста на другой уровень.
А что плохого в том, что каждый программист видит код таким, каким ему удобно?
Почему нет? Если текст это только генерируемое по надобности представление графа, его можно хоть на блоксхему менять. Это как переключение локализации.
Потому что у каждого программиста есть свое мнение по поводу того как удобней читать код.
Не нужно, но при работе с кодом как с графом это будет сделать намного проще, и работать оно будет быстрее.
Нет. Для этого нужен один набор чего-то вроде AST. Синтаксисов можно придумать сколько угодно: C-like, Python-like, Pascal-like, Rust-like и т.д. При этом поскольку за текстовым отображением будет стоять древовидная иерархия блоков, вещи вроде неоднозначностей или конфликтов парсинга в принципе невозможны, что дает полную свободу в придумывании удобного человеку синтаксиса. Не нравятся точки с запятой — пожалуйста, не нравятся круглые скобки в if () {} — без проблем.
Этот стек может генерировать код для старых языков, с которыми может работать старый стек. Даже больше того, он может расширять возможности старого стека, например добавить более строгие проверки типов, проверять время жизни и освобождение объектов, эмулировать новые синтаксические конструкции, создавать темплейты для обобщенного кода, проводить оптимизацию уровня графа, а потом полученный граф транслировать хоть в C, хоть в JS, хоть в оба сразу.
Не, я предлагаю отделить отделить синтаксис от языка, и вынести все что его касается на уровень IDE. А общим делителем языков станет подобие AST, с которым намного проще работать внутренним алгоритмам инструментов, и которое намного «ровнее» между языками чем бесконечный зоопарк синтаксисов.
Главная проблема в том, что никто не захочет уходить со старого стека в виду полной неизвестности нового. Это как раскладка DVORAK, на которой можно печатать проще и быстрей, но почти никто не пользуется потому что большинство привыкли к QWERTY, а потому ее и спрос и предложение.
lair
В ИТ пока и словаря нет, поэтому достаточно бесполезно сравнивать.
Это, прямо скажем, неправда.
Вы так говорите, как будто этот "кусочек текста" не придется каждый раз отрисовывать из графа заново. С форматированием и прочим счастьем.
Добавляет. Какие узлы в графе использовать? Вот вам и холивар.
Ну так не решаемо же.
То, что он теряет интент другого программиста.
Потому что разный синтаксис требует разного нижележащего графа. Не всегда, но часто.
AST, тем не менее, привязан к синтаксису языка.
Они невозможны только если неоднозначностей нет ни в AST, ни в целевом синтаксисе.
"Пожалуйста" — это в смысле "пожалуйста, напишите"?
А обратно как?
… и заставить все IDE работать с вашим AST, да. Не, не выйдет.
А вот последнее утверждение нуждается в доказательстве, потому что на мой скромный взгляд, вы в разработку этого "универсального AST" вобьете бесконечное число ресурсов.
playermet
Рендеринг сотен строк занимающих всю ширину экрана на каком нибудь медленном GDI методом в лоб само по себе занимает меньше 10мс, и это на средненькой машине. Выполнение операций над текстом достаточно долгое, чтобы современным IDE пришлось рисовать фейковое обновление текста перед выполнением всех этих операций, чтобы после их выполнения нарисовать все по честному. И это даже при вводе одного символа, а про пример с переименованием класса в проекте я вообще молчу, это может десятки секунд длиться.
Граф всегда будет проще и быстрее текста, на любых операциях и в любых алгоритмах. Потому что:
1) Компактность. Текстовый код это суть избыточное повторение одного и того же — табуляции, форматирования, имен переменных, типов, инструкций. В графе досточно хранить каждое имя в своем узле, а остальные узлы просто ссылаются на него. При конвертации одного в другое выигрыш минимум десятикратный, даже без особых оптимизаций. Это значит что при любых операциях в среднем нужно обрабатывать намного меньший объем памяти, при этом в кеш будет вмещаться намного больше данных кода. По сути, небольшой проект полностью и с запасом влезает в кеш первого уровня.
2) Локальность изменений. Операции над узлами графа обычно трогают только эти сами узлы. Вставка или удаления символа в среднем сдвигает половину содержимого буфера символов представляющего текстовый файл. Современные редакторы всячески откладывают это хитрыми структурами, но так или иначе это все равно приходится сделать, рано или поздно.
3) Атомарность изменений. В графе можно вставить, удалить или изменить узел или ссылку. При этом эти операции нельзя недовыполнить. В тексте атомом является символ, который лишь часть какого-то изменения.
4) Идентифицируемость изменений. Следствие из предыдущего. Любая операция над графом имеет четкое понятное значение — например элемент добавился, элемент удалился, изменилось имя объекта или значение литерала. Операции над текстом ортогональны значению вложенному в синтаксис ЯП. Кавычка закрывающая управляющую инструкцию легко метаморфирует в кавычку закрывающую класс, от того что добавился новый текст где-то выше.
5) Согласованность. Граф всегда находится в каком-то корректном, осмысленном, однозначном состоянии, а почти любая операция на нем легко проверяется на непротиворечивость. В тексте же настоящий ад. Пользователь может добавить что угодно, куда угодно, и когда угодно, в том числе текстовым редактором вне самой IDE. Начиная от любых бессмысленных символов в любом месте и заканчивая вставкой цикла прямо в имя аргумента функции, т.е. вообще любой белиберды. И IDE ничего не может с этим сделать, даже внутри себя, потому что она не может определить какое изменение делает пользователь пока он не завершит его до какой-то корректной формы. И что хуже, IDE должна постоянно что-то делать с некорректным состоянием текста, додумывать намерения программиста, и как-то раскрашивать и отображать код.
6) Семантика. Граф уже имеет семантическое значение, выступая в роли готового подобия AST. Чтобы определить семантическое значение текста (для подсветки, автоподстановки, поиска, анализа, компиляции), его нужно парсить, все равно приходя к AST, а потом еще и хранить к индексе (для поиска), и постоянно все это обновлять и согласовывать из текста. Т.е. выполнять очень сложную в реализации и медленную работу, которая в первом случае вообще не нуждается в выполнении, и только для того чтобы выполнять абсолютно те же самые функции. Прошу прощения за такую аналогию, но это похоже на удаление гланд через задний проход.
В моем представлении работы IDE такого вопроса не может возникнуть. Программист по прежнему видит код, ему не нужно думать об узлах. Просто маппинг будет направлен не от синтаксису к AST а от графа к синтаксису с подхватом изменений узлов.
Решаемо. Программист видит синтаксис, который является представлением универсального графа, которому все равно в какой язык он будет транслирован. Т.е. если два языка не имеют критических семантических отличий, которые не могут быть сэмулированы, они сводимы к одному одинаковому синтаксису. А как минимум часть неэмулируемых отличий сводятся к множеству-подмножеству синтаксиса. Таким образом человек может выучить наибольшее синтаксическое подмножество, и использовать все языки которые с ним совместимы. А даже если ему нужен несовместимый язык, он не учит вообще все с нуля, а доучивает лишь необходимую разницу.
Интент программиста выражен не синтаксисом, а значением под этим синтаксисом. А оно одинаково независимо от синтаксиса, потому что синтаксис лишь представление.
При этом в VCS графовое представление наоборот лучше отражает интент. Если мы перенесем класс в другой файл, переименуем его и отрефакторим что в текстовом представлении это выглядит как удаление одного класса и добавление совсем другого. При графовом представлении читающий историю увидит переименование и рефакторинг. А переноса может вообще не быть, потому что классы принадлежат неймспейсам, а не файлам.
Так у нас же обратная зависимость. Граф всегда один.
Поэтому я и говорю «подобие AST». Просто подходящего термина сейчас вроде как нет. Не уверен, подходит ли «семантическое дерево».
В данном случае они невозможны в принципе, потому что IDE никогда не пытается выводить структуру из символов. Даже если все без исключения инструкции отображаются одними только пробелами и переносами строк, IDE все равно знает что находится под каждым символом на экране. Само собой в таком крайнем случае о читабельности человеком речи не идет, но на то он и крайний случай.
Написать не сложно, ведь правила генерации пишутся не сложнее чем локализация со строковой интерполяцией. Но я имел в виду другое. Если сделать подобное изменение в синтаксисе скажем С++, то это просто не сможет работать из-за заведомо известной неоднозначности. Я конечно не предлагаю делать именно такое изменение, но например лямбды в С++ сейчас выглядят совершенно уродскими, потому что его синтаксис загнал сам себя в угол.
Распарсить код уже существующими парсерами, и привести полученное к графу.
Я и не предлагаю переписывать существующие IDE. Я предлагаю в будущем создать новое поколение IDE. Не думаю что это хуже, чем создавать новые IDE на старом принципе, или писать плагины для кучи IDE для каждого нового языка. Да и уже сейчас есть применение подобного подхода с децентрализацией — Language Server Protocol.
retran
А с чего вы взяли что это не так?
playermet
Потому что это так и есть. Код на диске хранится в текстовом виде, даже не уверен, должен ли я писать о том как это проверить. Соответственно и IDE с ними работают как с текстом, но если такого следствия вам не достаточно, вы можете посмотреть их исходники, или например почитать вот эту статью от авторов одной популярной IDE.
LonelyDeveloper97
Не трогайте текст!
Это лучшее что случилось с человечеством)
playermet
А что в нем хорошего, кроме возможности обмена через текстовые сообщения и возможности программирования из блокнота?
lair
Гм, что хорошего в письменной культуре, насчитывающей тысячелетия?
Она эффективна.
playermet
Она эффективна для общения между людьми. Но кроме чтения человеком кода и его редактированием, есть еще 100500 процессов которые необходимо выполнять инструментам (например IDE), и вместо того чтобы пользоваться для этого представлением которое удобно им, они используют текст, который на этом уровне не имеет ни единого преимущества.
lair
Это самая важная часть в разработке. Ну, на мой личный вкус.
LonelyDeveloper97
А у вас есть предложения получше?
Я абсолютно серьезно, если есть — давайте, это же революцию в коммуникациях совершит.
playermet
Есть, описал выше, но особого отношения к коммуникации это не имеет.
MaxVetrov
от каждого гиганта ИТ — три индуса по одному.