
We thought about building the infrastructure for large load tests a year ago when we reached the mark of 12,000 simultaneously active online users. In three months, we made the first version of the test, which showed us the limits of the service.
The irony is that simultaneously with the launch of the test, we reached the limits on the production server, resulting in two-hour service downtime. This further encouraged us to move from making occasional tests to establishing an effective load testing infrastructure. By infrastructure, I mean all tools for working with load testing: tools for launching the test (manual and automatic), the cluster that creates the load, a production-like cluster, metrics and reporting services, scaling services, and the code to manage it all.
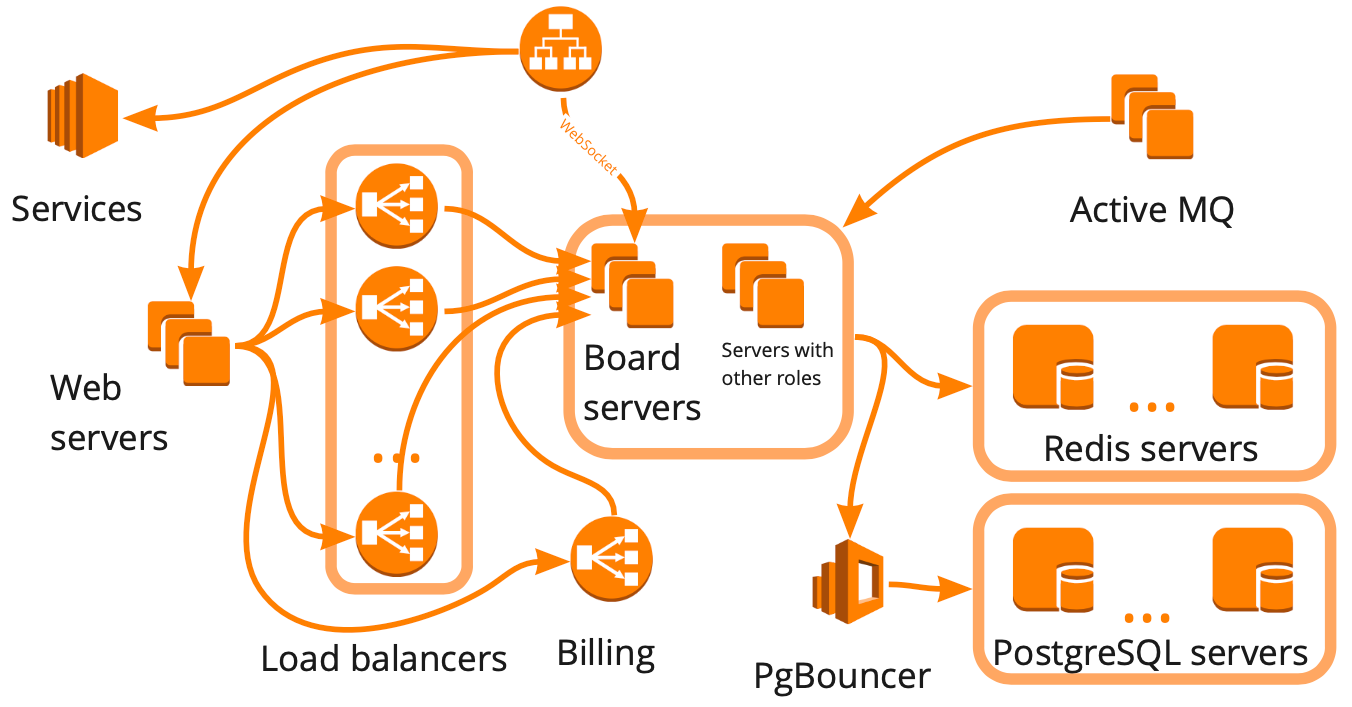
Simplified, this is what our structure looks like: a collection of different servers that somehow interact with each other, each server performing specific tasks. It seemed that to build the load testing infrastructure, it was enough for us to make this diagram, take account of all interactions, and start creating test cases for each block one by one.
This approach is right, but it would have taken many months, which was not suitable for us because of our rapid growth — over the past twelve months, we have grown from 12,000 to 100,000 simultaneously active online users. Also, we didn’t know how our service infrastructure would respond to the increased load: which blocks would become the bottleneck, and which would scale linearly?
In the end, we decided to test the service with virtual users simulating real activity — that is, to build a clone of the production environment and make a big test that will:
In this article, I will talk about creating a realistic test scenario, plugins (WS, Stress-client, Taurus), a load-generating cluster, and a production cluster, and I will show examples of using tests. In the next article, I will describe how we manage hundreds of load-generating servers.
To create a realistic test scenario, we need to:
Now, more details about each item.
In our service, users can create whiteboards and work on them with different content: photos, texts, mockups, stickers, diagrams, etc. The first metric we need to collect is the number of whiteboards and the distribution of content on them.
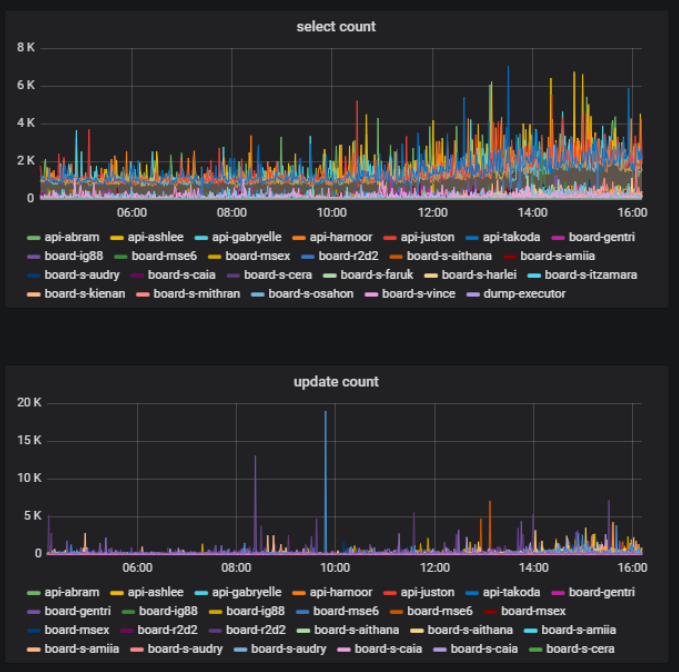
On the same whiteboard at the same time, some users can be actively doing something — creating, editing, deleting the content — and some can simply be viewing the content. The ratio of users changing the content on the whiteboard to the total number of users of that whiteboard is also an important metric. We can derive this data from database usage statistics.
In our backend, we use a component approach. We call the components “models.” We break our code into models so that each model is responsible for a specific part of the business logic. We can count the number of database calls that occur through each model and identify the part of the logic that creates the heaviest load.
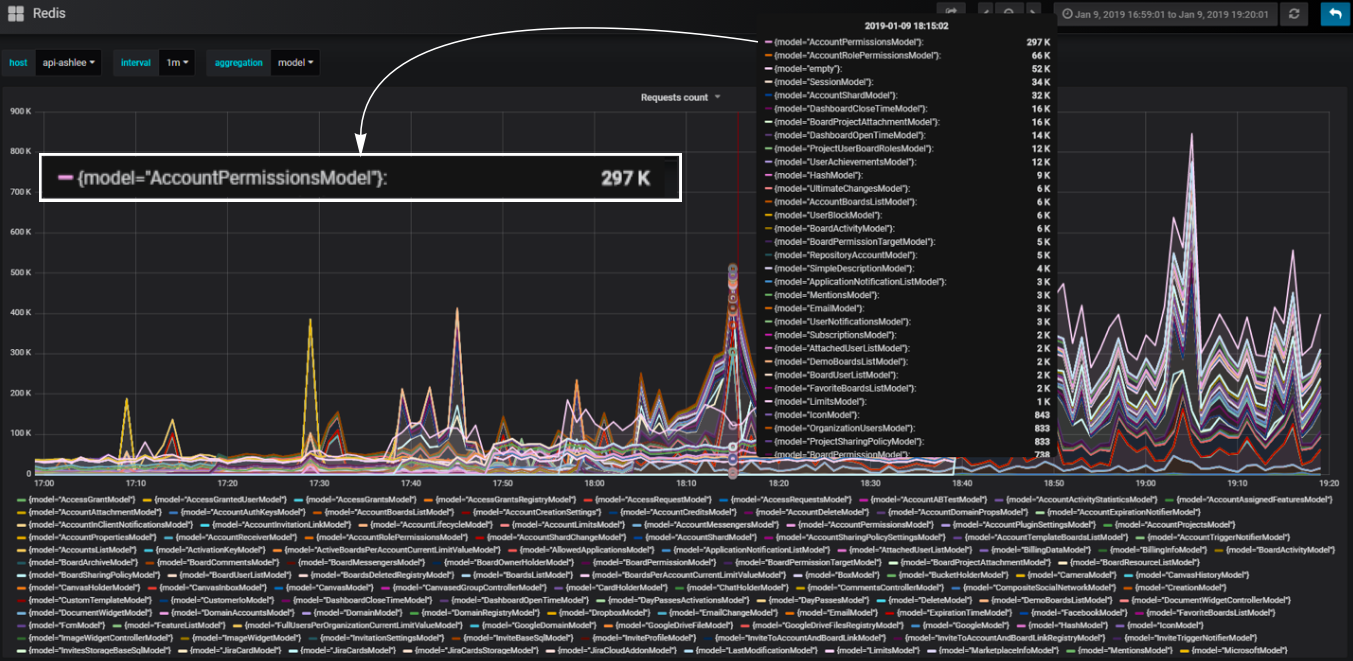
For example, we need to add a block to the test scenario that will create a load on our service identical to the load that happens when you open a dashboard page with a list of user whiteboards. When this page loads, HTTP requests containing a large amount of data are sent: the number of whiteboards, accounts to which the user has access, all users of the account, and so on.

How to create an efficient load on a dashboard? When analyzing the behavior of the production environment, we saw database usage spikes during the opening of the dashboard of a large account. We can create an identical account and change the intensity of its data usage in the test case, effectively loading the dashboard with a small number of calls. We can also create an uneven load for better realism.
At the same time, it is crucial for us that the number of virtual users and the load generated by them are as similar as possible to the users and the load in the production environment. For this, we also recreate the background load on an average dashboard in the test. Thus, most virtual users work on small average dashboards, and only a few users create a destructive load, as happens in the production environment.
From the start, we did not want to cover each server role and each interaction with a different test case. This can be seen in the dashboard example — during the test, we simply repeat what happens when a user opens a dashboard in the production environment. We do not cover what it affects with synthetic test cases. This allows us to cover nuances that we didn’t even expect with the test by default. Thus, we approach the creation of an infrastructure test from the side of business logic.
This is the logic we used to efficiently load all other blocks of the service. At the same time, each block may not be realistic from functional logic; the important part is that it provides a realistic load according to server metrics. Then, using these blocks, we can create a test scenario that simulates real users’ activity.

It is important to keep in mind that data is also part of the test case, and the code logic itself heavily depends on it. When building an extensive database for the test — and it obviously should be large for a large infrastructure test — we need to learn how to create data that will not distort the test during the execution. If we put bad data into the database, the test scenario can become unrealistic, and in an extensive database, that would be hard to fix. Therefore, we started creating data in the same way our users do use the REST API.
For example, to create whiteboards with existing data, we make API requests that load the whiteboard from the backup. As a result, we get genuine real data — different whiteboards of different sizes. At the same time, the database is being filled relatively quickly because our script is making requests in multiple threads. In terms of speed, this is comparable to the generation of garbage data.
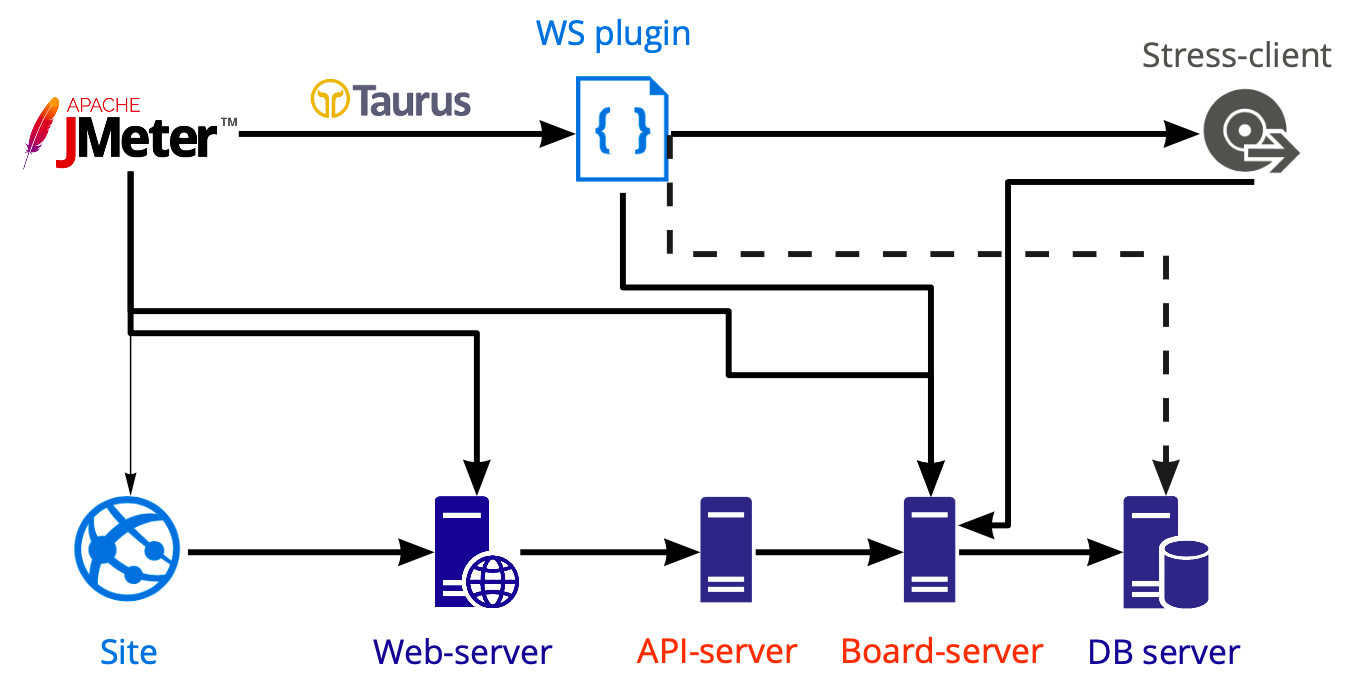 Our load-generating tooling
Our load-generating tooling
In JMeter, we create a test that we launch using Taurus to create a load on various servers: web, API, and board servers. We perform database tests separately using PostgreSQL, not JMeter, so the diagram shows a dashed line.
Work on the whiteboard takes place inside a WebSocket connection, and it is on the whiteboard that multiuser work is possible. Nowadays, JMeter Plugins Manager has several plugins for working with WebSocket connections. The logic is the same everywhere — the plugin simply opens a WebSocket connection, and every action that occurs inside it, in any case, you have to write yourself. Why is that? Because it is impossible to work with WebSocket connections similarly to HTTP requests, that is, we cannot create a test case, extract dynamic values, and pass them along.
The work inside a WebSocket connection is usually very customized: you invoke specific custom methods passing specific custom data, and therefore, you need your means of understanding whether the request was executed correctly and how long it took to execute. You also have to write the Listeners inside that plugin yourself — we haven’t found an excellent ready-made solution.
We want to make it as easy as possible to replicate what real users do. But we do not yet know how to record and replay everything that is happening in WebSocket inside the browser. If we recreate everything inside WebSocket from scratch, then we would get a new client, not the one that is used by real users. There is no incentive to write a new client if we already have one working.
So we decided to put our client inside JMeter. And we faced several difficulties. For example, JavaScript execution inside JMeter is a whole other topic, because it uses a very specific version of the language. And if you want to use your existing client code, you probably won’t be able to do that, because modern JavaScript features are not supported, and you’ll have to rewrite parts of your code.
The second difficulty is that we don’t want to support the entire client code for load tests. Therefore, we removed everything from the client but the client-server interaction. This allowed us to use client-server methods and do everything that our client can do. The advantage of this is that client-server interaction very rarely changes, which means that the code support inside the test case is seldom required. For instance, over the last six months, I haven’t made any changes to the code because it works perfectly.
The third difficulty is that the introduction of large scripts significantly complicates the test case. First, it can become a bottleneck in the test. Second, we most likely will not be able to run a large number of threads from one machine. Right now, we are only able to run 730 threads.
Our example at the Amazon instance
Next, the question arises: 730 threads from one machine, but we want 50,000 — where can we get so many servers? We are creating a cloud-based solution, so buying servers to test a cloud solution seems odd. Plus, there is always a certain slowness in buying new hardware. Therefore, we need to deploy them in the cloud as well, so we ended up choosing between cloud providers and cloud-based load testing tools.
We decided not to use cloud-based load testing tools like Blazemeter and RedLine13 because their usage restrictions did not suit us. We have different test sites, so we wanted to find a universal solution that would allow us to reuse 90 percent of the work in local testing as well.
Hence, in the end, we were choosing between cloud service providers.

Our platform is AWS-based, and almost all testing is done there, so we want the test bench to be as similar as possible to the production environment. Amazon has a lot of paid features, some of which, like load balancers, we use in production. If you don’t need these features in AWS, you can get them 17 times cheaper in Hetzner. Or you can get servers at Hetzner, use OpenStack, and write the balancers and other features yourself since with OpenStack, you can replicate the entire infrastructure. We managed to do just that.
Testing of 50,000 users using 69 AWS instances costs us about $3,000 per month. How do we save money? One way is to use temporary AWS instances — Spot instances. Their main benefit is that instead of keeping instances running all the time, we only launch them for tests, and they cost much less. One important detail, however, is that somebody can outbid your offer right at the time of testing. Fortunately, this has never happened to us, and we already save at least 60 percent of the cost thanks to them.
We use the default JMeter cluster. It works perfectly; it does not have to be modified in any way. It has several launch options. We use the simplest option, where one master launches N number of instances, and there can be hundreds of them.
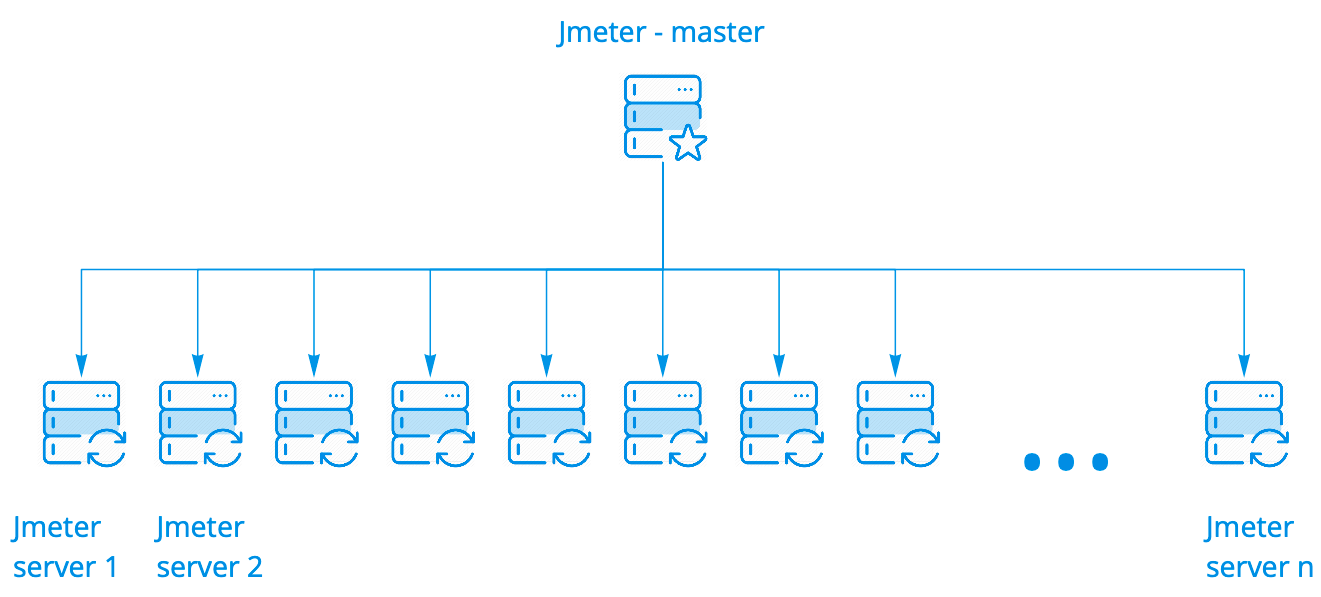
The master runs a test scenario on the JMeter servers, keeps communicating with them, collects general statistics from all instances in real-time, and displays it in the console. Everything looks the same as running the test scenario on a single server, even though we see the results of running it on a hundred servers.
For a detailed analysis of the results of test scenario execution in all instances, we use Kibana. We parse the logs with Filebeat.

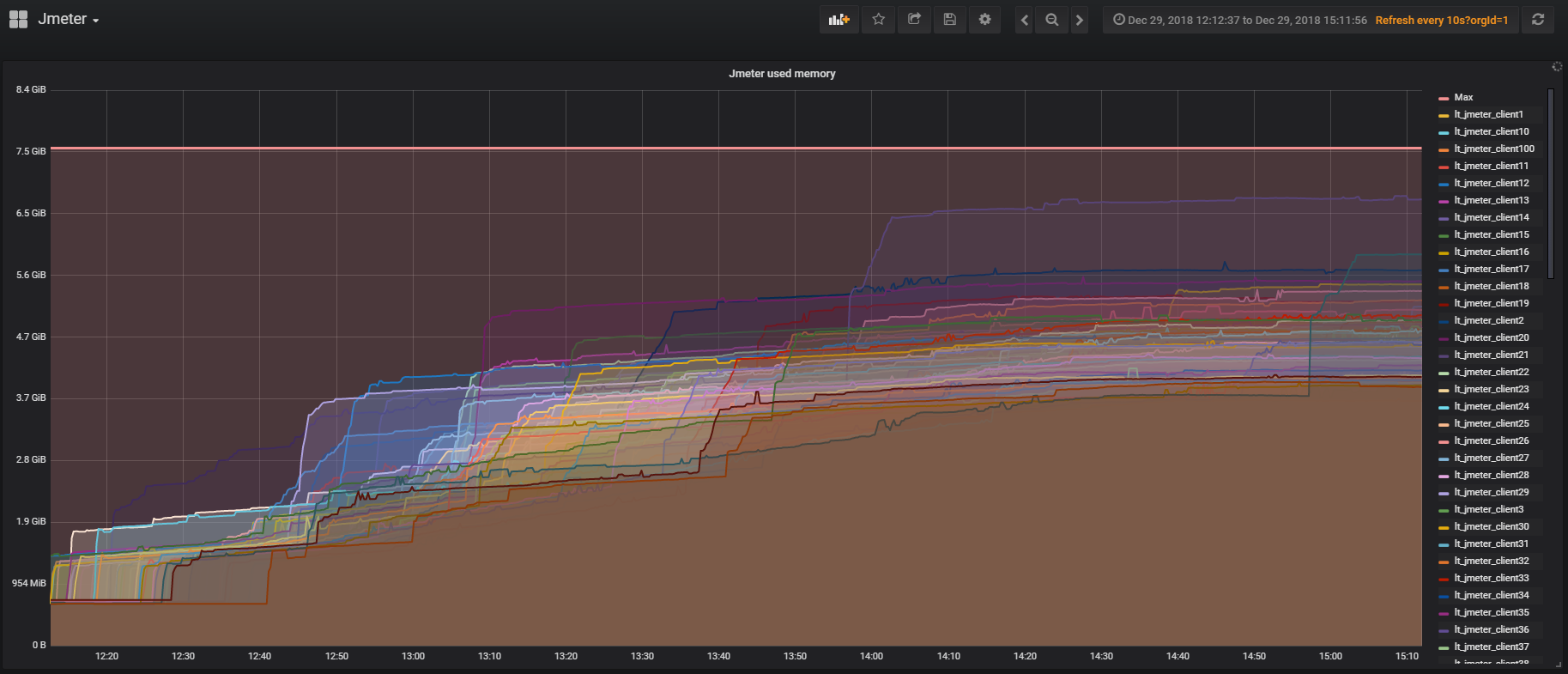
JMeter has a plugin for working with Prometheus, which out of the box provides all JVM and thread usage statistics inside the test. This allows you to see how often users log in, log out, and so on. The plugin can be customized to send the test scenario run data to Prometheus and display it in real-time in Grafana.
We want to solve some current problems with Taurus, but we haven’t started that yet:
The whole story above is largely about creating a realistic case to test the limits of the service. The examples below show how you can reuse the work you have done on the load testing infrastructure to solve local problems. I will talk in detail about two out of about ten types of load tests that we conduct periodically.
What can we load test in the database? Big queries are an unlikely target because we can test them in a single-threaded mode if we just look at the query plans.
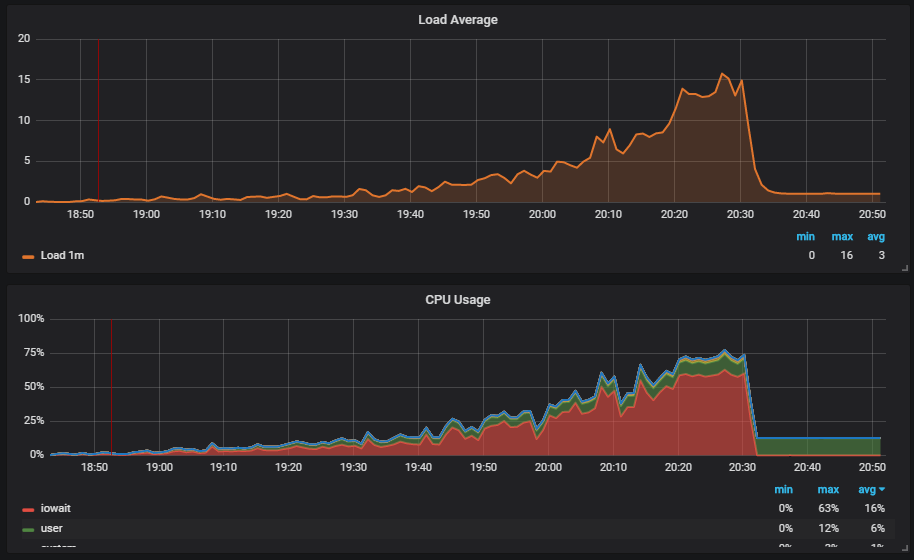
More interesting is the situation where we run the test and see the load on the disk. The graph shows an increase in iowait.
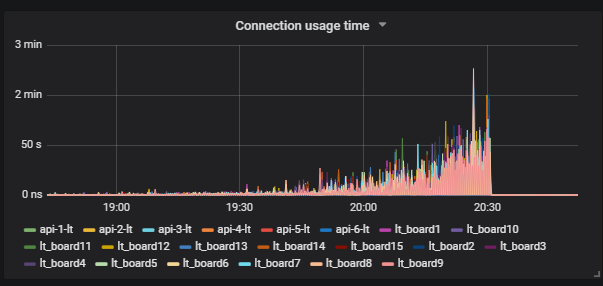
Next, we see that this affects users.
Then we understand the reason: VACUUM did not run and did not remove the garbage data from the database. If you’re not familiar with PostgreSQL, VACUUM is similar to Garbage Collector in Java.

The next thing we see is that CHECKPOINT started to trigger out of schedule. For us, this is a signal that the PostgreSQL configs do not adequately match the intensity of the database usage.
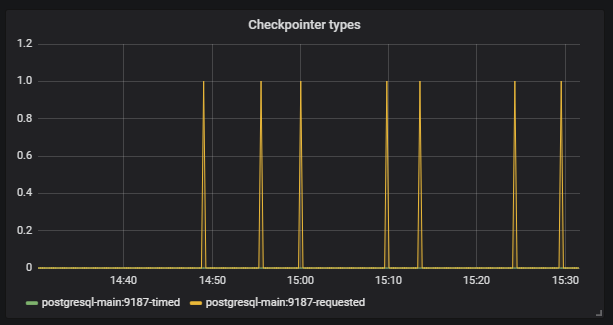
Our task is to adjust the database configuration so that such situations do not happen again. PostgreSQL, for instance, has many settings. For fine-tuning, you need work in short iterations: change the settings, launch the server, evaluate, repeat. For that, of course, you need to provide a good load on the database, and this requires extensive infrastructure tests.
One thing is that for the test to carry on normally without any unnecessary crashes, it must take a long time. In our case, the test takes about three hours, which no longer looks like a short iteration.
We look for a solution. We find a tool for PostgreSQL called pgreplay. It can reproduce — using multiple threads — exactly what is written in log files, exactly the way it happened at the time of writing. How can we use it effectively? We make a dump of the database, then log everything that happens to the database after the dump, and then we can deploy the dump and replay everything that happened to the database using multiple threads.
Where to write logs? A popular solution for logging is to collect logs in the production environment, as this gives the most realistic and reproducible test case. But there are some problems with that:
Our approach to large-scale testing helps us here. We make a database dump on the test environment, run a sizeable realistic test, and log everything that happens during the execution of that test. Then we use our tool called Marucy to run the database test:
When launching Marucy, we can pass a few parameters that can change, for example, the intensity of the test.
In the end, we use our realistic test scenario to create a database test, and then run this test without using a large cluster. It is important to note that to test any SQL database, the test case must be uneven, otherwise, the database will behave differently than it will in the production environment.
For degradation tests, we use our realistic test scenario. The idea is that we need to ensure that the service has not become slower after another release. If our developers change something in the code that leads to increased response times, we can compare the new values with the reference values and signal if there is an error in the build. For the reference values, we use the current values that suit us.
Controlling the response times is useful, but we went further. We wanted to check that the response times during real users’ activity have not increased after the release. We thought that we could probably test something manually during the load testing, but that would only be dozens of cases. It’s more efficient to run the existing functional tests and check a thousand cases at the same time.

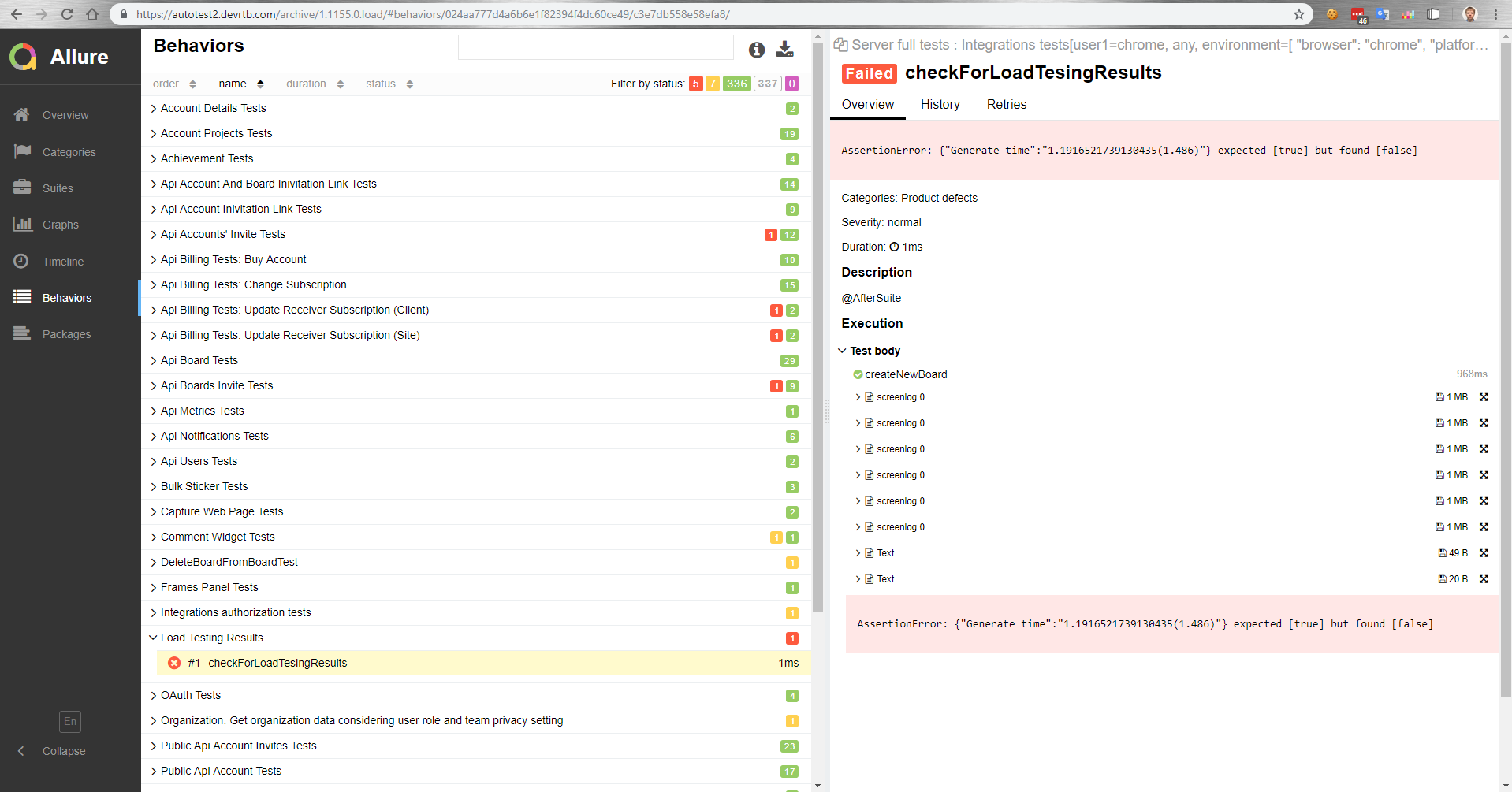
How did we set it up? There is a master that gets deployed to the test bench after the build. Then, the functional tests are automatically run in parallel with the load tests. After that, we get a report in Allure on how the functional tests performed under load.
In this report, for example, we see that the comparison with the reference value has failed.
We can also measure browser performance with functional tests. Or, a functional test will simply fail due to an increase in operation execution time under load, because a timeout on the client-side will be triggered.
P.S.: This article was first published on Medium.
The irony is that simultaneously with the launch of the test, we reached the limits on the production server, resulting in two-hour service downtime. This further encouraged us to move from making occasional tests to establishing an effective load testing infrastructure. By infrastructure, I mean all tools for working with load testing: tools for launching the test (manual and automatic), the cluster that creates the load, a production-like cluster, metrics and reporting services, scaling services, and the code to manage it all.
Simplified, this is what our structure looks like: a collection of different servers that somehow interact with each other, each server performing specific tasks. It seemed that to build the load testing infrastructure, it was enough for us to make this diagram, take account of all interactions, and start creating test cases for each block one by one.
This approach is right, but it would have taken many months, which was not suitable for us because of our rapid growth — over the past twelve months, we have grown from 12,000 to 100,000 simultaneously active online users. Also, we didn’t know how our service infrastructure would respond to the increased load: which blocks would become the bottleneck, and which would scale linearly?
In the end, we decided to test the service with virtual users simulating real activity — that is, to build a clone of the production environment and make a big test that will:
- create a load on a cluster that is structurally identical to the production cluster but which surpasses it in terms of performance;
- give us all the data for making decisions;
- show that the entire infrastructure is capable of withstanding the necessary load;
- become the basis for load tests that we may need in the future.
- The only disadvantage of such a test is its cost because it will require an environment more extensive than the production environment.
In this article, I will talk about creating a realistic test scenario, plugins (WS, Stress-client, Taurus), a load-generating cluster, and a production cluster, and I will show examples of using tests. In the next article, I will describe how we manage hundreds of load-generating servers.
Creating a realistic test scenario
To create a realistic test scenario, we need to:
- analyze users’ activity in the production environment, and to do this, identify essential metrics, start collecting them, and analyze the peaks;
- create convenient, customizable blocks that we can use to effectively create a load on the right part of the business logic;
- verify the realism of the test scenario by using server metrics.
Now, more details about each item.
Analyzing users’ activity in the production environment
In our service, users can create whiteboards and work on them with different content: photos, texts, mockups, stickers, diagrams, etc. The first metric we need to collect is the number of whiteboards and the distribution of content on them.
On the same whiteboard at the same time, some users can be actively doing something — creating, editing, deleting the content — and some can simply be viewing the content. The ratio of users changing the content on the whiteboard to the total number of users of that whiteboard is also an important metric. We can derive this data from database usage statistics.
In our backend, we use a component approach. We call the components “models.” We break our code into models so that each model is responsible for a specific part of the business logic. We can count the number of database calls that occur through each model and identify the part of the logic that creates the heaviest load.
Convenient, customizable blocks
For example, we need to add a block to the test scenario that will create a load on our service identical to the load that happens when you open a dashboard page with a list of user whiteboards. When this page loads, HTTP requests containing a large amount of data are sent: the number of whiteboards, accounts to which the user has access, all users of the account, and so on.
How to create an efficient load on a dashboard? When analyzing the behavior of the production environment, we saw database usage spikes during the opening of the dashboard of a large account. We can create an identical account and change the intensity of its data usage in the test case, effectively loading the dashboard with a small number of calls. We can also create an uneven load for better realism.
At the same time, it is crucial for us that the number of virtual users and the load generated by them are as similar as possible to the users and the load in the production environment. For this, we also recreate the background load on an average dashboard in the test. Thus, most virtual users work on small average dashboards, and only a few users create a destructive load, as happens in the production environment.
From the start, we did not want to cover each server role and each interaction with a different test case. This can be seen in the dashboard example — during the test, we simply repeat what happens when a user opens a dashboard in the production environment. We do not cover what it affects with synthetic test cases. This allows us to cover nuances that we didn’t even expect with the test by default. Thus, we approach the creation of an infrastructure test from the side of business logic.
This is the logic we used to efficiently load all other blocks of the service. At the same time, each block may not be realistic from functional logic; the important part is that it provides a realistic load according to server metrics. Then, using these blocks, we can create a test scenario that simulates real users’ activity.
Data is part of the test case
It is important to keep in mind that data is also part of the test case, and the code logic itself heavily depends on it. When building an extensive database for the test — and it obviously should be large for a large infrastructure test — we need to learn how to create data that will not distort the test during the execution. If we put bad data into the database, the test scenario can become unrealistic, and in an extensive database, that would be hard to fix. Therefore, we started creating data in the same way our users do use the REST API.
For example, to create whiteboards with existing data, we make API requests that load the whiteboard from the backup. As a result, we get genuine real data — different whiteboards of different sizes. At the same time, the database is being filled relatively quickly because our script is making requests in multiple threads. In terms of speed, this is comparable to the generation of garbage data.
Summary of this part
- Use realistic cases if you want to test everything at once;
- Analyze real user behavior to design the structure of the test cases;
- From the very start, create convenient blocks to customize the testing process;
- Configure the tests according to the real server metrics, not the usage analytics;
- Do not forget that data is part of the test case.
Load-generating cluster
Our load-generating toolingIn JMeter, we create a test that we launch using Taurus to create a load on various servers: web, API, and board servers. We perform database tests separately using PostgreSQL, not JMeter, so the diagram shows a dashed line.
Custom work inside a WebSocket
Work on the whiteboard takes place inside a WebSocket connection, and it is on the whiteboard that multiuser work is possible. Nowadays, JMeter Plugins Manager has several plugins for working with WebSocket connections. The logic is the same everywhere — the plugin simply opens a WebSocket connection, and every action that occurs inside it, in any case, you have to write yourself. Why is that? Because it is impossible to work with WebSocket connections similarly to HTTP requests, that is, we cannot create a test case, extract dynamic values, and pass them along.
The work inside a WebSocket connection is usually very customized: you invoke specific custom methods passing specific custom data, and therefore, you need your means of understanding whether the request was executed correctly and how long it took to execute. You also have to write the Listeners inside that plugin yourself — we haven’t found an excellent ready-made solution.
Stress-client
We want to make it as easy as possible to replicate what real users do. But we do not yet know how to record and replay everything that is happening in WebSocket inside the browser. If we recreate everything inside WebSocket from scratch, then we would get a new client, not the one that is used by real users. There is no incentive to write a new client if we already have one working.
So we decided to put our client inside JMeter. And we faced several difficulties. For example, JavaScript execution inside JMeter is a whole other topic, because it uses a very specific version of the language. And if you want to use your existing client code, you probably won’t be able to do that, because modern JavaScript features are not supported, and you’ll have to rewrite parts of your code.
The second difficulty is that we don’t want to support the entire client code for load tests. Therefore, we removed everything from the client but the client-server interaction. This allowed us to use client-server methods and do everything that our client can do. The advantage of this is that client-server interaction very rarely changes, which means that the code support inside the test case is seldom required. For instance, over the last six months, I haven’t made any changes to the code because it works perfectly.
The third difficulty is that the introduction of large scripts significantly complicates the test case. First, it can become a bottleneck in the test. Second, we most likely will not be able to run a large number of threads from one machine. Right now, we are only able to run 730 threads.
Our example at the Amazon instance
JMeter server type in AWS: m5.large ($0.06 per hour)
vCPU: 2
Mem (GiB): 8
Dedicated EBS Bandwidth (Mbps): Up to 3,500
Network Performance (Gbps): Up to 10
> ~730 threadsWhere to get hundreds of servers and how to save money
Next, the question arises: 730 threads from one machine, but we want 50,000 — where can we get so many servers? We are creating a cloud-based solution, so buying servers to test a cloud solution seems odd. Plus, there is always a certain slowness in buying new hardware. Therefore, we need to deploy them in the cloud as well, so we ended up choosing between cloud providers and cloud-based load testing tools.
We decided not to use cloud-based load testing tools like Blazemeter and RedLine13 because their usage restrictions did not suit us. We have different test sites, so we wanted to find a universal solution that would allow us to reuse 90 percent of the work in local testing as well.
Hence, in the end, we were choosing between cloud service providers.
Our platform is AWS-based, and almost all testing is done there, so we want the test bench to be as similar as possible to the production environment. Amazon has a lot of paid features, some of which, like load balancers, we use in production. If you don’t need these features in AWS, you can get them 17 times cheaper in Hetzner. Or you can get servers at Hetzner, use OpenStack, and write the balancers and other features yourself since with OpenStack, you can replicate the entire infrastructure. We managed to do just that.
Testing of 50,000 users using 69 AWS instances costs us about $3,000 per month. How do we save money? One way is to use temporary AWS instances — Spot instances. Their main benefit is that instead of keeping instances running all the time, we only launch them for tests, and they cost much less. One important detail, however, is that somebody can outbid your offer right at the time of testing. Fortunately, this has never happened to us, and we already save at least 60 percent of the cost thanks to them.
Load-generating cluster
We use the default JMeter cluster. It works perfectly; it does not have to be modified in any way. It has several launch options. We use the simplest option, where one master launches N number of instances, and there can be hundreds of them.
The master runs a test scenario on the JMeter servers, keeps communicating with them, collects general statistics from all instances in real-time, and displays it in the console. Everything looks the same as running the test scenario on a single server, even though we see the results of running it on a hundred servers.
For a detailed analysis of the results of test scenario execution in all instances, we use Kibana. We parse the logs with Filebeat.
Prometheus Listener for Apache JMeter
JMeter has a plugin for working with Prometheus, which out of the box provides all JVM and thread usage statistics inside the test. This allows you to see how often users log in, log out, and so on. The plugin can be customized to send the test scenario run data to Prometheus and display it in real-time in Grafana.
Taurus
We want to solve some current problems with Taurus, but we haven’t started that yet:
- Configurations instead of test scenario clones. If you have worked with JMeter, you have probably faced the need to run test scenarios with different sets of source parameters, for which you had to create clones of the test scenarios. In Taurus, you can have one test scenario and manage its launch parameters using configurations;
- Configs for controlling JMeter servers when working with a cluster;
- An online results analyzer that allows you to collect the results separately from the JMeter threads and not to complicate the test scenario itself;
- Easy integration with CI;
- Capability to test a distributed system.
Summary of this part
- If we use custom code inside JMeter, it is better to think about its performance right away, because otherwise, we will end up testing JMeter and not our product;
- The JMeter cluster is a beautiful thing: it is easy to set up, and it’s easy to add monitoring to;
- A large cluster can be maintained on AWS Spot instances; it will be much cheaper;
- Be careful with Listeners in JMeter so that the test scenario does not slow down with a large number of servers.
Examples of using infrastructure tests
The whole story above is largely about creating a realistic case to test the limits of the service. The examples below show how you can reuse the work you have done on the load testing infrastructure to solve local problems. I will talk in detail about two out of about ten types of load tests that we conduct periodically.
Database testing
What can we load test in the database? Big queries are an unlikely target because we can test them in a single-threaded mode if we just look at the query plans.
More interesting is the situation where we run the test and see the load on the disk. The graph shows an increase in iowait.
Next, we see that this affects users.
Then we understand the reason: VACUUM did not run and did not remove the garbage data from the database. If you’re not familiar with PostgreSQL, VACUUM is similar to Garbage Collector in Java.
The next thing we see is that CHECKPOINT started to trigger out of schedule. For us, this is a signal that the PostgreSQL configs do not adequately match the intensity of the database usage.
Our task is to adjust the database configuration so that such situations do not happen again. PostgreSQL, for instance, has many settings. For fine-tuning, you need work in short iterations: change the settings, launch the server, evaluate, repeat. For that, of course, you need to provide a good load on the database, and this requires extensive infrastructure tests.
One thing is that for the test to carry on normally without any unnecessary crashes, it must take a long time. In our case, the test takes about three hours, which no longer looks like a short iteration.
We look for a solution. We find a tool for PostgreSQL called pgreplay. It can reproduce — using multiple threads — exactly what is written in log files, exactly the way it happened at the time of writing. How can we use it effectively? We make a dump of the database, then log everything that happens to the database after the dump, and then we can deploy the dump and replay everything that happened to the database using multiple threads.
Where to write logs? A popular solution for logging is to collect logs in the production environment, as this gives the most realistic and reproducible test case. But there are some problems with that:
- You have to use production data for testing, which is not always possible;
- This process uses the syslog feature, which is expensive;
- Disk usage is increased.
Our approach to large-scale testing helps us here. We make a database dump on the test environment, run a sizeable realistic test, and log everything that happens during the execution of that test. Then we use our tool called Marucy to run the database test:
- An AWS instance is created;
- The dump we need is deployed;
- pgreplay is launched to replay the logs that we need;
- We use our Prometheus/Grafana monitoring to evaluate the results. There are also dashboard examples in the repository.
When launching Marucy, we can pass a few parameters that can change, for example, the intensity of the test.
In the end, we use our realistic test scenario to create a database test, and then run this test without using a large cluster. It is important to note that to test any SQL database, the test case must be uneven, otherwise, the database will behave differently than it will in the production environment.
Degradation monitoring
For degradation tests, we use our realistic test scenario. The idea is that we need to ensure that the service has not become slower after another release. If our developers change something in the code that leads to increased response times, we can compare the new values with the reference values and signal if there is an error in the build. For the reference values, we use the current values that suit us.
Controlling the response times is useful, but we went further. We wanted to check that the response times during real users’ activity have not increased after the release. We thought that we could probably test something manually during the load testing, but that would only be dozens of cases. It’s more efficient to run the existing functional tests and check a thousand cases at the same time.
How did we set it up? There is a master that gets deployed to the test bench after the build. Then, the functional tests are automatically run in parallel with the load tests. After that, we get a report in Allure on how the functional tests performed under load.
In this report, for example, we see that the comparison with the reference value has failed.
We can also measure browser performance with functional tests. Or, a functional test will simply fail due to an increase in operation execution time under load, because a timeout on the client-side will be triggered.
Summary of this part
- A realistic test allows you to test the database cheaply and easily configure it;
- Functional testing under load is possible.
P.S.: This article was first published on Medium.