
Как правило, когда нужно что-то сделать быстро и дёшево, мы не задумываемся над отказоустойчивостью и масштабируемостью нашего приложения, что через некоторое время обязательно приводит к боли. Современные решения позволяют быстро и просто решить эту проблему.
На примере перехода от монолитного приложения к микросервисам, я попробую показать все плюсы и минусы каждого подхода. Статья разделена на три части:
- В первой части будет рассмотрено монолитное приложение на веб-фреймворке Dash, т.е. генерация данных и их отображение будут находиться в одном месте.
- Вторая часть посвящена разложению монолитного приложения на микросервисы, т.е. генерацией данных будет заниматься один сервис, отображением другой, а связь между ними будет налажена через брокер сообщений Kafka.
- В третьей части микросервисы будут "упакованы" в Docker контейнеры.
Конечное приложение будет выглядеть, как показано на диаграмме снизу.
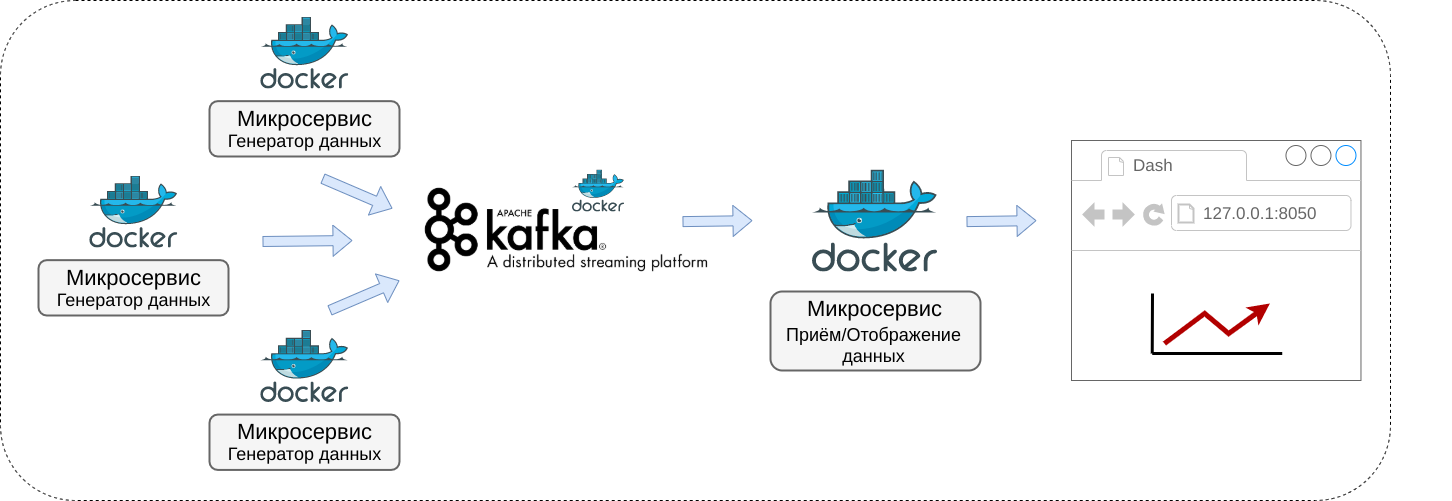
Введение
Для того чтобы лучше понять пример, желательно иметь хотя бы базовые знания в Kafka и Docker, приведу несколько на мой взгляд дельных курсов и статей:
- По Kafka, очень подробно разобрано на youtube канале Stephane Maarek, канал на английском языке.
- Про Docker мне понравился плейлист с youtube канала letsCode на русском языке.
- Статья на хабре Просто о микросервисах от YuryKa.
Полный код проекта залит на github, можно скачать отсюда.
Часть 1. Монолитное приложение
Для примера монолитного приложения я взял код из официальной документации по Dash (Plotly), посмотреть его можно здесь, в исходном коде проекта находится в папке local_app. Это идеальное решение для быстрого прототипирования.
import datetime
import dash
import dash_core_components as dcc
import dash_html_components as html
import plotly
from dash.dependencies import Input, Output
# pip install pyorbital
from pyorbital.orbital import Orbital
satellite = Orbital('TERRA')
external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css']
app = dash.Dash(__name__, external_stylesheets=external_stylesheets)
app.layout = html.Div(
html.Div([
html.H4('TERRA Satellite Live Feed'),
html.Div(id='live-update-text'),
dcc.Graph(id='live-update-graph'),
dcc.Interval(
id='interval-component',
interval=1*1000, # in milliseconds
n_intervals=0
)
])
)
@app.callback(Output('live-update-text', 'children'),
[Input('interval-component', 'n_intervals')])
def update_metrics(n):
lon, lat, alt = satellite.get_lonlatalt(datetime.datetime.now())
style = {'padding': '5px', 'fontSize': '16px'}
return [
html.Span('Longitude: {0:.2f}'.format(lon), style=style),
html.Span('Latitude: {0:.2f}'.format(lat), style=style),
html.Span('Altitude: {0:0.2f}'.format(alt), style=style)
]
# Multiple components can update everytime interval gets fired.
@app.callback(Output('live-update-graph', 'figure'),
[Input('interval-component', 'n_intervals')])
def update_graph_live(n):
satellite = Orbital('TERRA')
data = {
'time': [],
'Latitude': [],
'Longitude': [],
'Altitude': []
}
# Collect some data
for i in range(180):
time = datetime.datetime.now() - datetime.timedelta(seconds=i*20)
lon, lat, alt = satellite.get_lonlatalt(
time
)
data['Longitude'].append(lon)
data['Latitude'].append(lat)
data['Altitude'].append(alt)
data['time'].append(time)
# Create the graph with subplots
fig = plotly.tools.make_subplots(rows=2, cols=1, vertical_spacing=0.2)
fig['layout']['margin'] = {
'l': 30, 'r': 10, 'b': 30, 't': 10
}
fig['layout']['legend'] = {'x': 0, 'y': 1, 'xanchor': 'left'}
fig.append_trace({
'x': data['time'],
'y': data['Altitude'],
'name': 'Altitude',
'mode': 'lines+markers',
'type': 'scatter'
}, 1, 1)
fig.append_trace({
'x': data['Longitude'],
'y': data['Latitude'],
'text': data['time'],
'name': 'Longitude vs Latitude',
'mode': 'lines+markers',
'type': 'scatter'
}, 2, 1)
return fig
if __name__ == '__main__':
app.run_server(debug=True)Приложение каждую секунду обновляет графики и таким образом эмулируется реал-тайм поступление данных. В качестве источника данных используется python пакет pyorbital, с помощью которого можно производить различные астрономические вычисления (в этом примере рассчитывается положение научно-исследовательского спутника Terra (EOS AM-1)). Полученные данные и графики отображаются в браузере через Dash (Plotly) на локальном хосте: 127.0.0.1:8050.
Данные, которые получаются на выходе — это altitude, longitude и latitude (высота, долгота и широта), т.е. координаты спутника в текущий момент времени, первый график показывает изменение высоты, а второй — долготы и широты соответственно.

(На рисунке показана работа монолитного (оригинального) приложения)
К плюсам можно отнести:
- Высокая скорость работы, данные вычисляются и сразу же обновляются.
К минусам:
- Высокая стоимость ошибки, например, если ошибка возникнет при вычислении данных, то и их отображение тоже пострадает, т.к. это повлечет падение всего приложения (хотя конечно можно написать обработчик ошибок, но это усложнит код).
- Невозможность обновить/исправить приложение на лету. Если, например, необходимо изменить алгоритм вычисления данных, необходимо будет перезапустить всё, в том числе и отображение.
Часть 2. Приложение на основе микросервисов
В исходном коде проекта находится в папке local_microservices_app, для удобства туда же я положил сервис Kafka упакованный в Docker, исходный код которого можно посмотреть здесь (взято с github репозитория Stephane Maarek)
Монолитное приложение я разделил на две части, первая часть — backend (producer.py), генерирует данные и отправляет их в Kafka, вторая часть — frontend (consumer.py, graph_display.py) читает сообщения из Kafka и отображает графики в браузере.
backend:
Producer (производитель данных) вычисляет данные и отправляет их в Kafka раз в одну секунду (в оригинальном приложении данные рассчитывались за каждые 20 секунд)
from time import sleep
import datetime
from confluent_kafka import Producer
import json
from pyorbital.orbital import Orbital
satellite = Orbital('TERRA')
topic = 'test_topic'
producer = Producer({'bootstrap.servers': 'localhost:9092'})
def acked(err, msg):
if err is not None:
print("Failed to deliver message: {}".format(err))
else:
print("Produced record to topic {} partition [{}] @ offset {}"
.format(msg.topic(), msg.partition(), msg.offset()))
# send data every one second
while True:
time = datetime.datetime.now()
lon, lat, alt = satellite.get_lonlatalt(time)
record_value = json.dumps({'lon':lon, 'lat': lat, 'alt': alt, 'time': str(time)})
producer.produce(topic, key=None, value=record_value, on_delivery=acked)
producer.poll()
sleep(1)
frontend:
Consumer (потребитель данных) написан в виде класса MyKafkaConnect и находится в файле consumer.py, при инициализации загружает из Kafka последние 180 (или меньше, если их не достаточно) сообщений. При последующих обращениях докачивает все новые сообщения из Kafka.
Изначальное монолитное приложение (monolith.py) не сильно изменилось, ключевое изменение состоит в том, что данные рассчитываются не на месте, а загружаются через класс MyKafkaConnect, все прежние методы работают фактически также.
import datetime
from confluent_kafka import Consumer, TopicPartition
import json
from collections import deque
from time import sleep
class MyKafkaConnect:
def __init__(self, topic, group, que_len=180):
self.topic = topic
self.conf = {
'bootstrap.servers': 'localhost:9092',
'group.id': group,
'enable.auto.commit': True,
}
# the application needs a maximum of 180 data units
self.data = {
'time': deque(maxlen=que_len),
'Latitude': deque(maxlen=que_len),
'Longitude': deque(maxlen=que_len),
'Altitude': deque(maxlen=que_len)
}
consumer = Consumer(self.conf)
consumer.subscribe([self.topic])
# download first 180 messges
self.partition = TopicPartition(topic=self.topic, partition=0)
low_offset, high_offset = consumer.get_watermark_offsets(self.partition)
# move offset back on 180 messages
if high_offset > que_len:
self.partition.offset = high_offset - que_len
else:
self.partition.offset = low_offset
# set the moved offset to consumer
consumer.assign([self.partition])
self.__update_que(consumer)
# https://docs.confluent.io/current/clients/python.html#delivery-guarantees
def __update_que(self, consumer):
try:
while True:
msg = consumer.poll(timeout=0.1)
if msg is None:
break
elif msg.error():
print('error: {}'.format(msg.error()))
break
else:
record_value = msg.value()
json_data = json.loads(record_value.decode('utf-8'))
self.data['Longitude'].append(json_data['lon'])
self.data['Latitude'].append(json_data['lat'])
self.data['Altitude'].append(json_data['alt'])
self.data['time'].append(datetime.datetime.strptime(json_data['time'], '%Y-%m-%d %H:%M:%S.%f'))
# save local offset
self.partition.offset += 1
finally:
# Close down consumer to commit final offsets.
# It may take some time, that why I save offset locally
consumer.close()
def get_graph_data(self):
consumer = Consumer(self.conf)
consumer.subscribe([self.topic])
# update low and high offsets (don't work without it)
consumer.get_watermark_offsets(self.partition)
# set local offset
consumer.assign([self.partition])
self.__update_que(consumer)
# convert data to compatible format
o = {key: list(value) for key, value in self.data.items()}
return o
def get_last(self):
lon = self.data['Longitude'][-1]
lat = self.data['Latitude'][-1]
alt = self.data['Altitude'][-1]
return lon, lat, alt
# for test
if __name__ == '__main__':
connect = MyKafkaConnect(topic='test_topic', group='test_group')
while True:
test = connect.get_graph_data()
print('number of messages:', len(test['time']),
'unique:', len(set(test['time'])),
'time:', test['time'][-1].second)
sleep(0.1)
import datetime
import dash
import dash_core_components as dcc
import dash_html_components as html
import plotly
from dash.dependencies import Input, Output
from consumer import MyKafkaConnect
connect = MyKafkaConnect(topic='test_topic', group='test_group')
external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css']
app = dash.Dash(__name__, external_stylesheets=external_stylesheets)
app.layout = html.Div(
html.Div([
html.H4('TERRA Satellite Live Feed'),
html.Div(id='live-update-text'),
dcc.Graph(id='live-update-graph'),
dcc.Interval(
id='interval-component',
interval=1*1000, # in milliseconds
n_intervals=0
)
])
)
@app.callback(Output('live-update-text', 'children'),
[Input('interval-component', 'n_intervals')])
def update_metrics(n):
lon, lat, alt = connect.get_last()
print('update metrics')
style = {'padding': '5px', 'fontSize': '16px'}
return [
html.Span('Longitude: {0:.2f}'.format(lon), style=style),
html.Span('Latitude: {0:.2f}'.format(lat), style=style),
html.Span('Altitude: {0:0.2f}'.format(alt), style=style)
]
# Multiple components can update everytime interval gets fired.
@app.callback(Output('live-update-graph', 'figure'),
[Input('interval-component', 'n_intervals')])
def update_graph_live(n):
# Collect some data
data = connect.get_graph_data()
print('Update graph, data units:', len(data['time']))
# Create the graph with subplots
fig = plotly.tools.make_subplots(rows=2, cols=1, vertical_spacing=0.2)
fig['layout']['margin'] = {
'l': 30, 'r': 10, 'b': 30, 't': 10
}
fig['layout']['legend'] = {'x': 0, 'y': 1, 'xanchor': 'left'}
fig.append_trace({
'x': data['time'],
'y': data['Altitude'],
'name': 'Altitude',
'mode': 'lines+markers',
'type': 'scatter'
}, 1, 1)
fig.append_trace({
'x': data['Longitude'],
'y': data['Latitude'],
'text': data['time'],
'name': 'Longitude vs Latitude',
'mode': 'lines+markers',
'type': 'scatter'
}, 2, 1)
return fig
if __name__ == '__main__':
app.run_server(debug=True)
К плюсам можно отнести:
- Меньше негативных последствий от ошибок, если ошибка возникнет при вычислении данных в backend микросервисе, то в таком случае отображение графиков продолжится, хотя конечно обновляться они не будут (обратите внимание, графики могут быть лишь не большим модулем большого приложения, которое продолжит работу).
- Возможность обновления/исправления ошибок на лету, т.к. модули работают независимо, то кратковременная остановка backend микросервиса не вызовет падения отображения графиков, хотя и будет небольшой лаг.
- Микросервис может быть написан на любом языке программирования.
К минусам:
- Меньшая скорость работы по сравнению с монолитным приложением, между вычислением данных и их отображением появляется посредник в виде Kafka, на работу которого требуется хоть и не большое, но время.

(На рисунке сверху backend после обновления отправляет вдвое больше сообщений, что видно на графике)
Часть 3. Приложение на основе микросервисов упакованных в Docker
В исходном коде проекта находится в папке docker_microservices_app. От второй части отличается тем, что backend и frontend упакованы в Docker. Также я добавил ещё два микросервиса в backend (ещё два научно-исследовательских спутника Aura (EOS CH-1) и Aqua (EOS PM-1)).
FROM python:3.7
RUN python -m pip install confluent-kafka
RUN python -m pip install pyorbital
WORKDIR /app
COPY producer.py ./
CMD ["python", "producer.py"]
FROM python:3.7
RUN python -m pip install confluent-kafka
RUN python -m pip install dash plotly
WORKDIR /app
COPY consumer.py graph_display.py ./
CMD ["python", "graph_display.py"]
version: '2.1'
# Stephane Maarek's kafka-docker
# https://github.com/simplesteph/kafka-stack-docker-compose/blob/master/zk-single-kafka-single.yml
services:
zoo1:
image: zookeeper:3.4.9
hostname: zoo1
ports:
- "2181:2181"
restart: unless-stopped
environment:
ZOO_MY_ID: 1
ZOO_PORT: 2181
ZOO_SERVERS: server.1=zoo1:2888:3888
volumes:
- ./zk-single-kafka-single/zoo1/data:/data
- ./zk-single-kafka-single/zoo1/datalog:/datalog
kafka1:
image: confluentinc/cp-kafka:5.5.0
hostname: kafka1
ports:
- "9092:9092"
restart: unless-stopped
environment:
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka1:19092,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"
KAFKA_BROKER_ID: 1
KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
volumes:
- ./zk-single-kafka-single/kafka1/data:/var/lib/kafka/data
depends_on:
- zoo1
backend_terra:
build:
context: ./backend
restart: unless-stopped
environment:
BOOTSTRAP_SERVERS: "kafka1:19092"
TOPIC: "terra_topic"
SATELLITE: "TERRA"
depends_on:
- kafka1
backend_aqua:
build:
context: ./backend
restart: unless-stopped
environment:
BOOTSTRAP_SERVERS: "kafka1:19092"
TOPIC: "aqua_topic"
SATELLITE: "AQUA"
depends_on:
- kafka1
backend_aura:
build:
context: ./backend
restart: unless-stopped
environment:
BOOTSTRAP_SERVERS: "kafka1:19092"
TOPIC: "aura_topic"
SATELLITE: "AURA"
depends_on:
- kafka1
frontend:
build:
context: ./frontend
ports:
- "8050:8050"
restart: unless-stopped
environment:
BOOTSTRAP_SERVERS: "kafka1:19092"
depends_on:
- backend_terra
- backend_aqua
- backend_aura
from time import sleep
import datetime
from confluent_kafka import Producer
import json
from pyorbital.orbital import Orbital
import os
topic = os.environ['TOPIC']
bootstrap_servers = os.environ['BOOTSTRAP_SERVERS']
s_name = os.environ['SATELLITE']
satellite = Orbital(s_name)
producer = Producer({'bootstrap.servers': bootstrap_servers})
def acked(err, msg):
if err is not None:
print("Failed to deliver message: {}".format(err))
else:
print("Produced record to topic {} partition [{}] @ offset {}"
.format(msg.topic(), msg.partition(), msg.offset()))
# send data every one second
while True:
time = datetime.datetime.now()
lon, lat, alt = satellite.get_lonlatalt(time)
record_value = json.dumps({'lon':lon, 'lat': lat, 'alt': alt, 'time': str(time)})
producer.produce(topic, key=None, value=record_value, on_delivery=acked)
producer.poll()
sleep(1)import datetime
from confluent_kafka import Consumer, TopicPartition
import json
from collections import deque
from time import sleep
class MyKafkaConnect:
def __init__(self, topic, group, que_len=180):
self.topic = topic
self.conf = {
'bootstrap.servers': 'localhost:9092',
'group.id': group,
'enable.auto.commit': True,
}
# the application needs a maximum of 180 data units
self.data = {
'time': deque(maxlen=que_len),
'Latitude': deque(maxlen=que_len),
'Longitude': deque(maxlen=que_len),
'Altitude': deque(maxlen=que_len)
}
consumer = Consumer(self.conf)
consumer.subscribe([self.topic])
# download first 180 messges
self.partition = TopicPartition(topic=self.topic, partition=0)
low_offset, high_offset = consumer.get_watermark_offsets(self.partition)
# move offset back on 180 messages
if high_offset > que_len:
self.partition.offset = high_offset - que_len
else:
self.partition.offset = low_offset
# set the moved offset to consumer
consumer.assign([self.partition])
self.__update_que(consumer)
# https://docs.confluent.io/current/clients/python.html#delivery-guarantees
def __update_que(self, consumer):
try:
while True:
msg = consumer.poll(timeout=0.1)
if msg is None:
break
elif msg.error():
print('error: {}'.format(msg.error()))
break
else:
record_value = msg.value()
json_data = json.loads(record_value.decode('utf-8'))
self.data['Longitude'].append(json_data['lon'])
self.data['Latitude'].append(json_data['lat'])
self.data['Altitude'].append(json_data['alt'])
self.data['time'].append(datetime.datetime.strptime(json_data['time'], '%Y-%m-%d %H:%M:%S.%f'))
# save local offset
self.partition.offset += 1
finally:
# Close down consumer to commit final offsets.
# It may take some time, that why I save offset locally
consumer.close()
def get_graph_data(self):
consumer = Consumer(self.conf)
consumer.subscribe([self.topic])
# update low and high offsets (don't work without it)
consumer.get_watermark_offsets(self.partition)
# set local offset
consumer.assign([self.partition])
self.__update_que(consumer)
# convert data to compatible format
o = {key: list(value) for key, value in self.data.items()}
return o
def get_last(self):
lon = self.data['Longitude'][-1]
lat = self.data['Latitude'][-1]
alt = self.data['Altitude'][-1]
return lon, lat, alt
# for test
if __name__ == '__main__':
connect = MyKafkaConnect(topic='test_topic', group='test_group')
while True:
test = connect.get_graph_data()
print('number of messages:', len(test['time']),
'unique:', len(set(test['time'])),
'time:', test['time'][-1].second)
sleep(0.1)import datetime
import dash
import dash_core_components as dcc
import dash_html_components as html
import plotly
from dash.dependencies import Input, Output
from consumer import MyKafkaConnect
external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css']
app = dash.Dash(__name__, external_stylesheets=external_stylesheets)
app.layout = html.Div(
html.Div([
html.Div([
html.H4('TERRA Satellite Live Feed'),
html.Div(id='terra-text'),
dcc.Graph(id='terra-graph')
], className="four columns"),
html.Div([
html.H4('AQUA Satellite Live Feed'),
html.Div(id='aqua-text'),
dcc.Graph(id='aqua-graph')
], className="four columns"),
html.Div([
html.H4('AURA Satellite Live Feed'),
html.Div(id='aura-text'),
dcc.Graph(id='aura-graph')
], className="four columns"),
dcc.Interval(
id='interval-component',
interval=1*1000, # in milliseconds
n_intervals=0
)
], className="row")
)
def create_graphs(topic, live_update_text, live_update_graph):
connect = MyKafkaConnect(topic=topic, group='test_group')
@app.callback(Output(live_update_text, 'children'),
[Input('interval-component', 'n_intervals')])
def update_metrics_terra(n):
lon, lat, alt = connect.get_last()
print('update metrics')
style = {'padding': '5px', 'fontSize': '15px'}
return [
html.Span('Longitude: {0:.2f}'.format(lon), style=style),
html.Span('Latitude: {0:.2f}'.format(lat), style=style),
html.Span('Altitude: {0:0.2f}'.format(alt), style=style)
]
# Multiple components can update everytime interval gets fired.
@app.callback(Output(live_update_graph, 'figure'),
[Input('interval-component', 'n_intervals')])
def update_graph_live_terra(n):
# Collect some data
data = connect.get_graph_data()
print('Update graph, data units:', len(data['time']))
# Create the graph with subplots
fig = plotly.tools.make_subplots(rows=2, cols=1, vertical_spacing=0.2)
fig['layout']['margin'] = {
'l': 30, 'r': 10, 'b': 30, 't': 10
}
fig['layout']['legend'] = {'x': 0, 'y': 1, 'xanchor': 'left'}
fig.append_trace({
'x': data['time'],
'y': data['Altitude'],
'name': 'Altitude',
'mode': 'lines+markers',
'type': 'scatter'
}, 1, 1)
fig.append_trace({
'x': data['Longitude'],
'y': data['Latitude'],
'text': data['time'],
'name': 'Longitude vs Latitude',
'mode': 'lines+markers',
'type': 'scatter'
}, 2, 1)
return fig
create_graphs('terra_topic', 'terra-text', 'terra-graph')
create_graphs('aqua_topic', 'aqua-text', 'aqua-graph')
create_graphs('aura_topic', 'aura-text', 'aura-graph')
if __name__ == '__main__':
app.run_server(
host='0.0.0.0',
port=8050,
debug=True)К плюсам можно отнести (кроме тех, что указаны во второй части):
- Изоляция ресурсов, отсутствие конфликтов библиотек различных версий и т.д. (каждый модуль приложения можно упаковать в отдельный Docker-контейнер со всем своим окружением и зависимостями).
- Быстрый и удобный запуск приложения на любом хосте.
- Лёгкая масштабируемость приложения, легко можно добавить новые контейнеры
К минусам:
- Т.к. Docker является дополнительным посредником между ОС и приложением, это приводит к увеличению нагрузки и расходу большего количества ресурсов.
На рисунке ниже показана ситуация, при которой один backend микросервис перестал отправлять данные и так как всё приложение состоит из микросервисов, то оно продолжает работать (в отличие от монолитной конструкции), более того, когда этот микросервис возобновил работу, он подключился на лету, и не потребовалось всё перезапускать.

(Не смотря на то, что один микросервис завис, остальные продолжают работать)
Выводы
В данной статье я рассмотрел, на мой взгляд наиболее очевидные (далеко не все) достоинства и недостатки каждого подхода. Кроме того, хоть внедрение Kafka и кажется дополнительным усложнением проекта, но на самом деле задачи, которые необходимо решить обычно являются типовыми, такими как непрерывное чтение данных из бд или их запись, слив данных из нескольких бд в одну и т.д. Для подобных целей нет необходимости изобретать велосипед, можно использовать готовые решения из Kafka connectors, там есть поддержка для фактически всех хоть сколько-нибудь известных бд.
Дополнительные ссылки по теме:
Python + Kafka =? / Николай Сасковец/ bitnet [Python Meetup 14.09.2019]
Николай Сасковец, Построение микросервисных систем с использованием Kafka
jonSina
Я надеюсь вы знаете что внутри образа cp-kafka:5.5.0 прописан хитрый mount (можете посмотреть через инспект) и ваши монтировки в композе не верны.
DimaFromMai Автор
Кафку взял отсюда, это репозиторий от Stephane Maarek, у него ещё есть youtube канал по Kafka (правда он на английском языке), также ещё на udemy есть его аккаунт, там тоже есть курсы по Kafka, но они платные.