
Доброго всем.
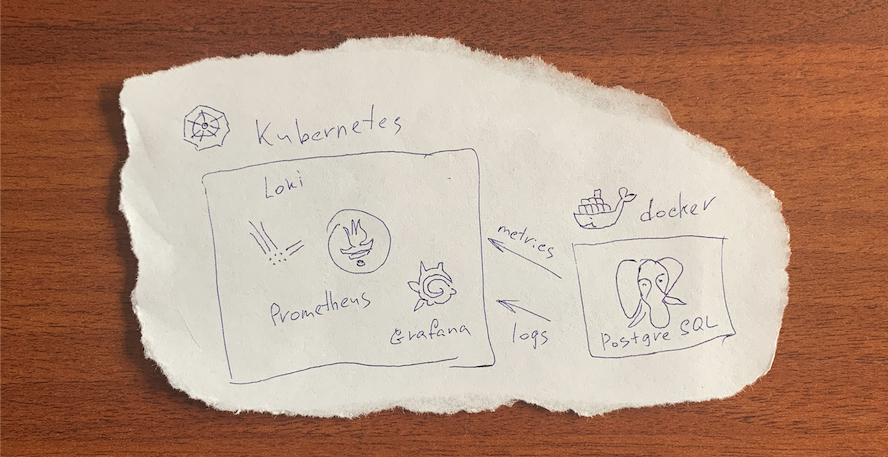
Я не нашел в сети обобщенного руководства по логированию и сбору метрик со сторонних сервисов в системы развернутые в Kubernetes. Публикую свое решение. Данная статья подразумевает, что у вас уже имеется рабочий Prometheus и другие службы. В качестве примера источника данных внешнего stateful-сервиса будет использоваться СУБД PostgreSQL в контейнере Docker. В компании используется пакетный менеджер Helm, ниже по тексту будут примеры на нем. Для всего решения мы готовим собственный чарт, включающий в себя вложенные чарты всех используемых сервисов.
Логирование
Многие компании для сбора и просмотра и централизации логов используется стэк технологий Elasticsearch + Logstash + kibana, сокращённо ELK. В нашем случае нет необходимости индексировать контент и я применил более легковесный Loki. Он доступен в виде пакета Helm, мы добавили его как subchart изменив values для ingress и pv под нашу систему.
values.yaml
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: nginx
hosts:
- host: kube-loki.example.domain
paths:
- /
tls: []
....
persistence:
type: pvc
enabled: true
accessModes:
- ReadWriteOnce
size: 100Gi
finalizers:
- kubernetes.io/pvc-protection
existingClaim: "pv-loki"
Для отправки логов на инстанс Loki используем Loki Docker Logging Driver.
Необходимо установить это дополнение на все Docker хосты, с которых желаете получать логи. Есть несколько способов указать демону, как использовать дополнение. Я выбор драйвера произвожу в yaml Docker Compose, который является частью Ansible playbook.
postgres.yaml
где loki_url: kube-loki.example.domain/loki/api/v1/push
- name: Run containers
docker_compose:
project_name: main-postgres
definition:
version: '3.7'
services:
p:
image: "{{ postgres_version }}"
container_name: postgresql
restart: always
volumes:
- "{{ postgres_dir }}/data:/var/lib/postgresql/data"
- "{{ postgres_dir }}/postgres_init_scripts:/docker-entrypoint-initdb.d"
environment:
POSTGRES_PASSWORD: {{ postgres_pass }}
POSTGRES_USER: {{ postgres_user }}
ports:
- "{{ postgres_ip }}:{{ postgres_port }}:5432"
logging:
driver: "loki"
options:
loki-url: "{{ loki_url }}"
loki-batch-size: "{{ loki_batch_size }}"
loki-retries: "{{ loki_retries }}"
...
где loki_url: kube-loki.example.domain/loki/api/v1/push
Метрики
Собираются метрики с PostgreSQL с помощью postgres_exporter для Prometheus. Продолжение вышеуказанного файла Ansible playbook.
postgres.yaml
...
pexp:
image: "wrouesnel/postgres_exporter"
container_name: pexporter
restart: unless-stopped
environment:
DATA_SOURCE_NAME: "postgresql://{{ postgres_user }}:{{ postgres_pass }}@p:5432/postgres?sslmode=disable"
ports:
- "{{ postgres_ip }}:{{ postgres_exporter_port }}:9187"
logging:
driver: "json-file"
options:
max-size: "5m"
...
Для большей наглядности имен внешних stateful-сервисов пропишем через Endpoints.
postgres-service.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: postgres-exporter
subsets:
- addresses:
- ip: {{ .Values.service.postgres.ip }}
ports:
- port: {{ .Values.service.postgres.port }}
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: postgres-exporter
labels:
chart: "{{ .Chart.Name }}-{{ .Chart.Version | replace "+" "_" }}"
spec:
ports:
- protocol: TCP
port: {{ .Values.service.postgres.port }}
targetPort: {{ .Values.service.postgres.port }}
Настройка Prometheus для получения данных postgres_exporter производится правкой values в subchart.
values.yaml
scrape_configs:
...
- job_name: postgres-exporter
static_configs:
- targets:
- postgres-exporter.applicationnamespace.svc.cluster.local:9187
labels:
alias: postgres
...
Для визуализации полученных данных установите соответствующий Dashboard в
Grafana и настройте источники данных. Это так же можно сделать через values в subchart Grafana.
Как это выглядит

Надеюсь, что эта краткая статья помогла вам понять основные идеи, заложенные в данном решении, и сохранит время при настройке мониторинга и логирования внешних сервисов для Loki/Prometheus в кластере Kubernetes.
gecube
Я вообще не понял смысла этой статьи. С какой целью городился огород с Service/Endpoints? Постгрес разве нельзя затащить в прометеус как отдельный эндпойнт (по внешнему имени, короче) через правку scrape config? Прометеус как развернут — как говорится дьявол в деталях — а это очень существенно. Предполагаю, что через оператор? Но тогда зачем править скрейп конфиг? ServiceMonitor и вперед. Декларативненько.
Ну, окей, затащили мы метрики внешнего сервиса во внутрикластерный прометеус. Что с алертами делаем? И еще вопрос отказоустойчивости самого прометеуса?
tnt4brain
Это не про смысл, это про «хоп, хоп — и в продакшн!» :-))))
alexovchinnicov Автор
Вы не внимательно прочитали, в самом начале статьи я писал, что все ставиться через коммунити чарт. Давайте, попробую объяснить. Вы же не будете отрицать, что Kubernetes удел не только крупных корпораций. Многие компании меньших размеров, тоже не спешно переводят свои легаси приложения на эту платформу. У компаний может быть не только одно приложение, а несколько копий для разных заказчиков в различных неймспейсах. Postgres, Redis, Kafkа, etc могут быть у каждого свои, на выделенных серверах и доступны исключительно по IP адресу, без внешних имен или иметь не человеко-читаемые имена. Мой «огород с Service/Endpoints» как я и писал, как раз для большей наглядности в Grafana. Он позволяет задать удобно-читаемое имя. Надеюсь, вам стало более понятно, для чего это было сделано в моем случае. Отдельное спасибо за ServiceMonitor. Упустил, возможно, вы правы и можно зарефакторить.
gecube
Первую половину аргументации я понимаю. Вторая часть — не полностью согласен — как минимум — вся эта история с засовыванием внешних эндпойнтов в кластер раздувает его. Увеличивает размер етсд. Увеличивает количество правил файрволла (а service именно через них работают). И в какой-то момент вы выясняете, что кластер "тормозит" по неведомой причине.
В результате вроде бы — пока действительно с одной стороны это удобно (мы унифицируем работу с ресурсами), а с другой — мы создаем себе какие-то потенциальные фантомные боли в будущем. И моя реакция связана с тем, что вроде бы да — мы нечто сделали, но не дошли до конца — коли уж так рассуждать — дальше ServiceMonitor, а еще дальше — вообще все засунуть в кубернетес и получить "плоский" пул сетевых ресурсов.
да, посмотрите, пожалуйста.
тоже объясню. Есть несколько разных чартов. Есть несколько разных способов установки. Мне лично нравится prometheus-operator. Кто-то же может ставит вообще stand-alone prometheus через helm, потому что хочет все крутить руками. Какого-то общего и стандартного способа установки нет, все-таки кубернетес — это конструктор. А от способа установки зависит то, как будешь настраивать прометеус....
а еще может быть… а еще могут инстансы, которые попилены между несколькими клиентами или проектами (разделяемые). Такой DBaaS в 0-й стадии развития. Еще интересный вопрос — удалось ли Вам завести Service не через IP, а через доменное имя (предполагаю, что нет).
это вообще холиварный вопрос. Потому что "кубернетес — это просто" и "кубернетес — это сложно" — оба утверждения будут справедливы. Но вероятнее всего, что маленькие вообще отдадут поддержку этой машинерии либо на аутсорсеров (типа Фланта, айти-суммы), либо возьмут кубер в облаке (где бОльшая часть проблем уже решена). А если самому готовить, то Вы абсолютно правы, что нужно иметь человеческий ресурс на поддержку/обслуживание этой платформы )
alexovchinnicov Автор
Теперь я вас не очень понимаю, что именно вы пытаетесь до меня донести? Есть реальная компания, в которой свои устои. В ней ни кто не хочет революций, эволюция всех устраивает. Выбрали эволюционировать в Kubernetes. Знаю ли я про DNS? Знаю. В курсе ли я про Type ExternalName? В курсе и пробовал. Желает ли моя компания «поддержку … аутсорсеров»? Не могу знать! :)
Мое решение вполне рабочее, вместо IP и абракадабр сотрудники моей компании в единой точке Grafana, видят осмысленные названия и логи при расследовании инцидентов.
Я с вами полностью согласен, что «все-таки кубернетес — это конструктор». Отмечу, что это справедливо и для многих других продуктов, в том числе и для Prometheus.
От себя, буду благодарен, если от вас получу URL на материалы, по которым вами сделаны выводы о увеличенном размере etcd, увеличенном количестве правил файрволла, приводящим к тому, что кластер «тормозит» при описании внешних Service/Endpoint против описания, когда stateful-сервисы «все засунуты в кубернетес». Учиться и познавать новое ведь никогда не поздно.
ЗЫ: Без обид.
Сейчас же минусы статьи и некоторые комментарии, выглядят как попытка наказать музыканта, который исполнил произведение другого композитора. И который выбрал флейту и поле вместо органа и зала, за не имением последних. Но по мнению знатоков органной музыки исполнение полное …
gecube
я то тут причем? Думаете, специально нагнал минусующих — вот реально заняться нечем.
логика? Потому что с проблемами на маленьких кластерах вы и так и так не столкнетесь скорее всего, но действительно каждый объект типа Service создает пачку правил файрволла (если мы говорим о просто прописать внешний урл в scrape_config против завести внутреннее имя для внешнего сервиса) — это в самой доке кубернетеса написано и каких-либо дополнительных ссылок на это не требуется.
anonymous
Вопрос без подвоха, правда интересно: А в чём проблема с алертами и отказоустойчивостью при таком подходе к прокидыванию внешних сервисов в прометеус внутри кластера? По вашему прометеус должен быть только вне кластера?
Статья, вроде, не претендует на полноту раскрытия вопроса настройки прометеуса в продакшне.
gecube
проблемы как таковой нет. Просто те же алерты мне, например, удобнее писать в PrometheusRule. Кому-то может удобнее конфигурацию как-то шаблонизировать.
как минимум две реплики прометеуса, по понятным причинам, нужно
по остальному см. также мой комментарий автору
gecube
еще очень интересный вопрос — у вас после установки этого плагина работает команда docker logs? Поясню — для наших dev/ops очень критично в удобном виде смотреть логи на удаленных серверах, если мало ли центральное хранилище сдохло/тормозит/etc., либо для отладки. Мне известно только два варианта получить работоспособную docker logs команду — либо штатный драйвер json-file (или journald драйвер), либо перекатываться на docker ee
alexovchinnicov Автор
Да, логи по «docker logs» и в Grafana идентичны и вывод в консоле работает.
gecube
попробую, тогда отпишусь )
anonymous
А можете пруф?
Не поймите неправильно, сам сейчас с этим борюсь. Настроил по статье — daemon.json натравил на Локи сервер. Так вот, doker logs пуст.
И с этим можно жить, когда уже пайплайны отработаны, но у меня есть тесты, на основе которых (allure) формируется ответ и стату джобы в дженкинсе.
Хочу поиграться с указанием драйвера не в конфиге докера, а в композ-файле. По типу, сервисы драйвер: Локи, тесты — дефолт
alexovchinnicov Автор
Я понял из документации, что через daemon.json настраивается логгирование по умолчанию для демона хоста. Мне это не нужно и поэтому указываю в Docker Compose только для конкретных приложений. Попробуйте вообще ничего не писать в daemon.json.
gecube
Все так )
я именно поэтому выразил сомнение в верности действия (установка плагина Loki + переключение на него), дал аргументы, почему это может быть плохо.
Кратко история такая:
docker run --log-driver ...или через docker-compose)