Пять подходов к созданию ad-hoc-датафреймов в PySpark +10 13.09.2023 12:35 NigrumKross 0 DevOps Kubernetes Блог компании VK Облачные вычисления Apache Data Engineering
Стайлгайд PySpark: как сделать код элегантным +10 12.09.2023 08:06 NigrumKross 1 Kubernetes Блог компании VK Python Облачные вычисления Apache DevOps
Стайлгайд PySpark: как сделать код элегантным +11 08.09.2023 10:16 waltherman 1 VK corporate blog Cloud computing Блог компании VK Облачные вычисления Apache DevOps Kubernetes
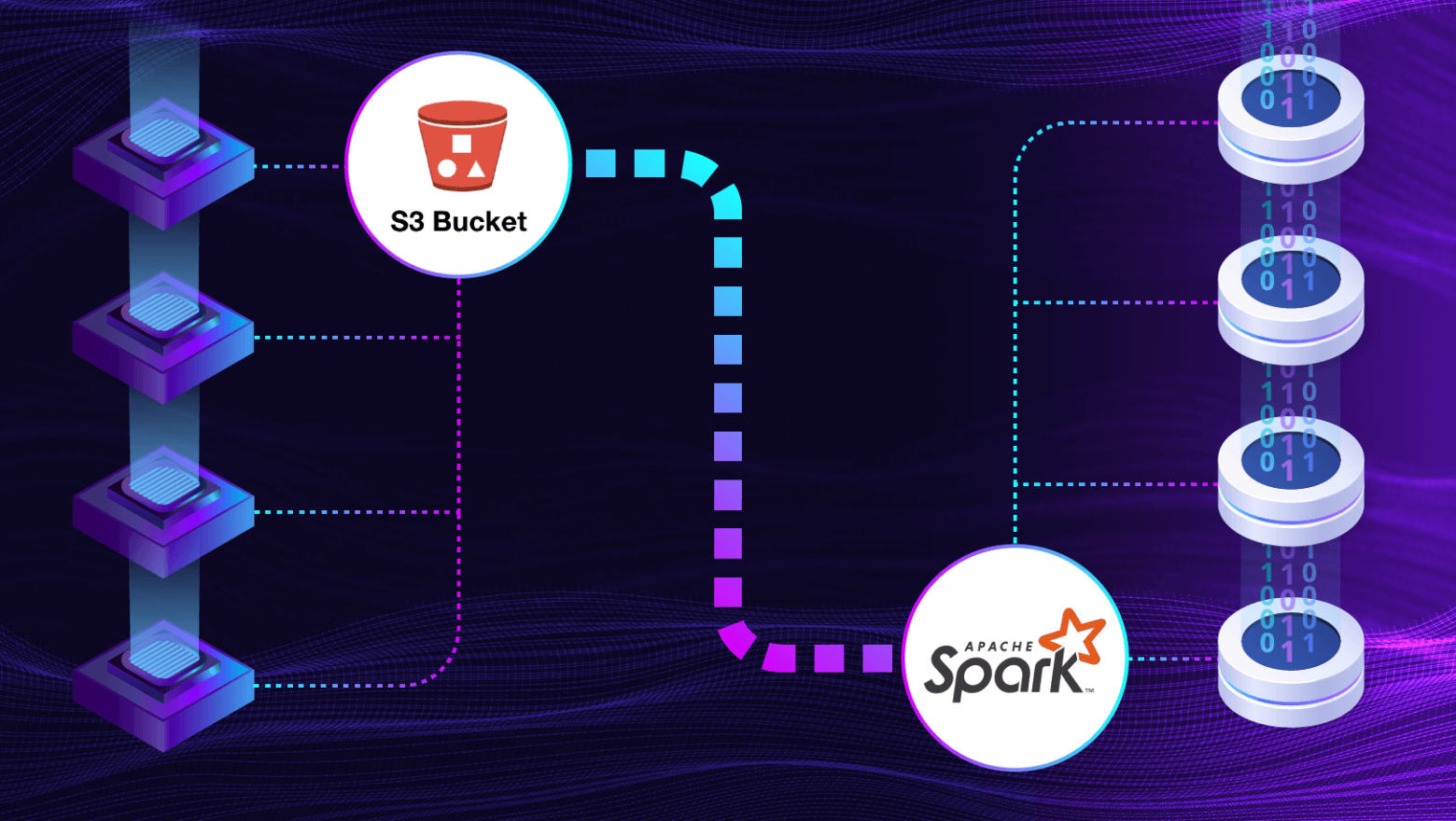
Как подружить Spark и S3 для обработки файлов +1 30.08.2023 08:02 momami 0 Блог компании Neoflex Big Data Data Engineering
Apache Spark для Data Engineering -1 30.08.2023 06:00 alitenicole 2 Блог компании Southbridge Big Data Data Engineering
Какой язык программирования выбрать? Часть 4: Spark +1 15.08.2023 07:00 kamaisha 4 Криптонит corporate blog Programming Блог компании Криптонит Программирование Big Data Processing
Apache Spark 3.4 для Databricks Runtime 13.0 +3 14.08.2023 12:16 alitenicole 0 Блог компании Southbridge IT-инфраструктура Apache Big Data Data Engineering
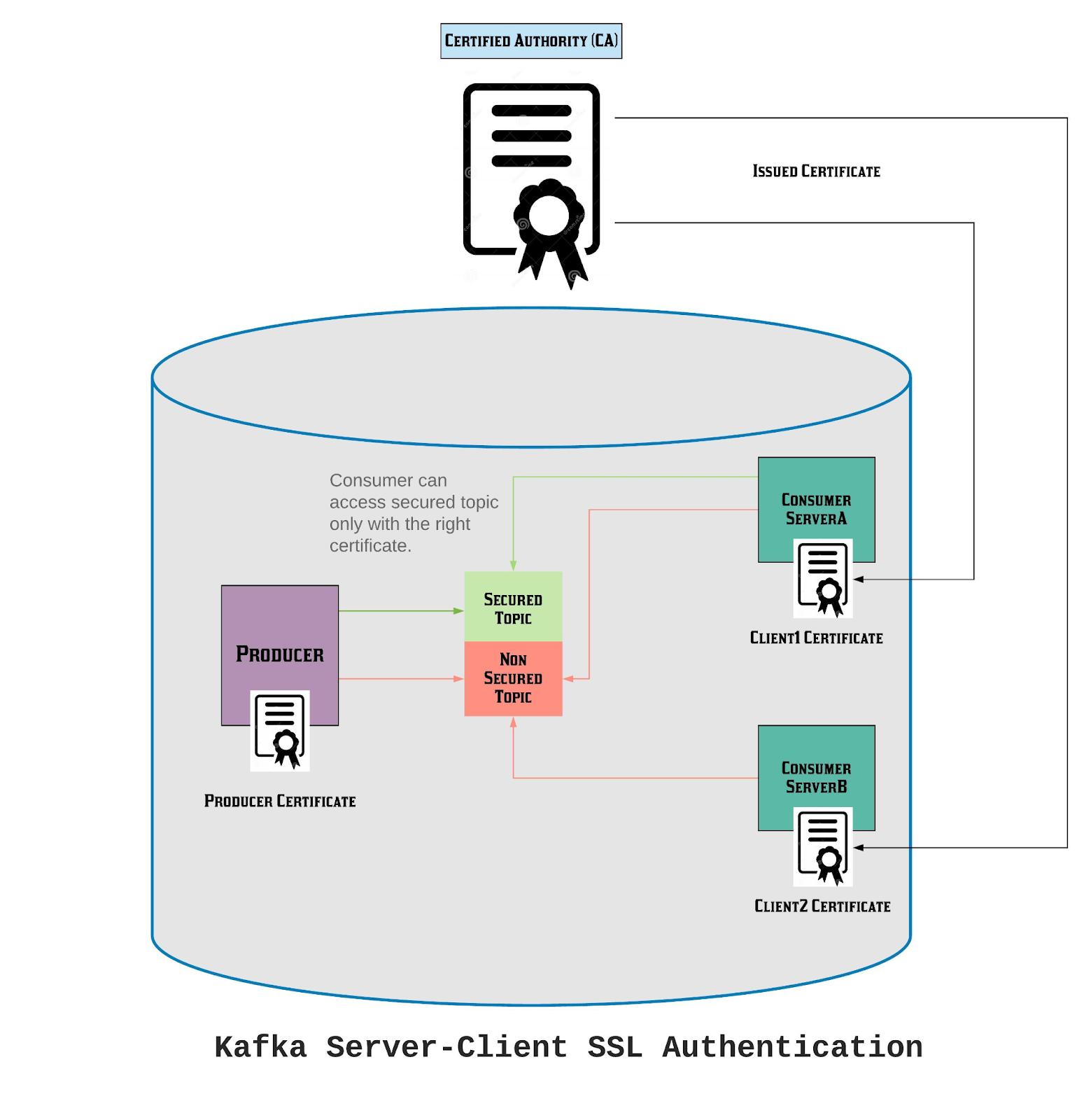
Аутентификация клиента Kafka SSL в мультитенантной архитектуре +3 16.07.2023 06:08 MaxRokatansky 0 Apache Блог компании OTUS
Ближайшие бесплатные мероприятия по разработке (18 июля — 20 июля 2023) +1 15.07.2023 08:14 ITMeeting 0 Programming Studying in IT IT career Conferences Программирование Учебный процесс в IT Карьера в IT-индустрии Конференции
Гарантии доставки и этика телепортации +14 04.07.2023 14:03 MaxRokatansky 5 OTUS corporate blog Distributed systems Блог компании OTUS Распределённые системы
ClickHouse в ритейловом проекте +6 26.06.2023 06:48 ilya-panov 2 Блог компании X5 Tech IT-инфраструктура Big Data IT-компании Data Engineering
Спиливаем spill-ы +17 22.06.2023 11:33 SacredDiablo 3 билайн corporate blog High performance Блог компании билайн Высокая производительность Scala Big Data DevOps
PySpark для аналитика. Как выгружать данные с помощью toPandas и его альтернатив +3 09.06.2023 07:19 aledovskiy 12 Анализ и проектирование систем Аналитика мобильных приложений Блог компании AvitoTech Python Data Mining Big Data
Масштабируемая Big Data система в Kubernetes с использованием Spark и Cassandra +14 03.06.2023 11:36 Dartya 2 JAVA Big Data Kotlin