Быстрая Data Quality проверка на базе алгоритма adversarial validation 27.05.2024 15:08 MaximML 2 Блог компании МТС Data Mining Математика Машинное обучение Искусственный интеллект
Рулим запуском Spark-приложений в Airflow с помощью самописного оператора 07.05.2024 08:03 andbul 0 Lamoda Tech corporate blog Блог компании Lamoda Tech Python Big Data Hadoop Data Engineering
[Перевод] Почему стоит начать писать собственные Spark Native Functions? 24.04.2024 09:34 Ninil 12 Scala Big Data Hadoop Data Engineering
SPARK для «малышей» 17.04.2024 13:57 vladislav_shevchenko 0 Блог компании Альфа-Банк Hadoop Data Engineering
Python streaming (spark+kafka) 08.04.2024 22:12 v_d_roman 7 Python Big Data Микросервисы Data Engineering
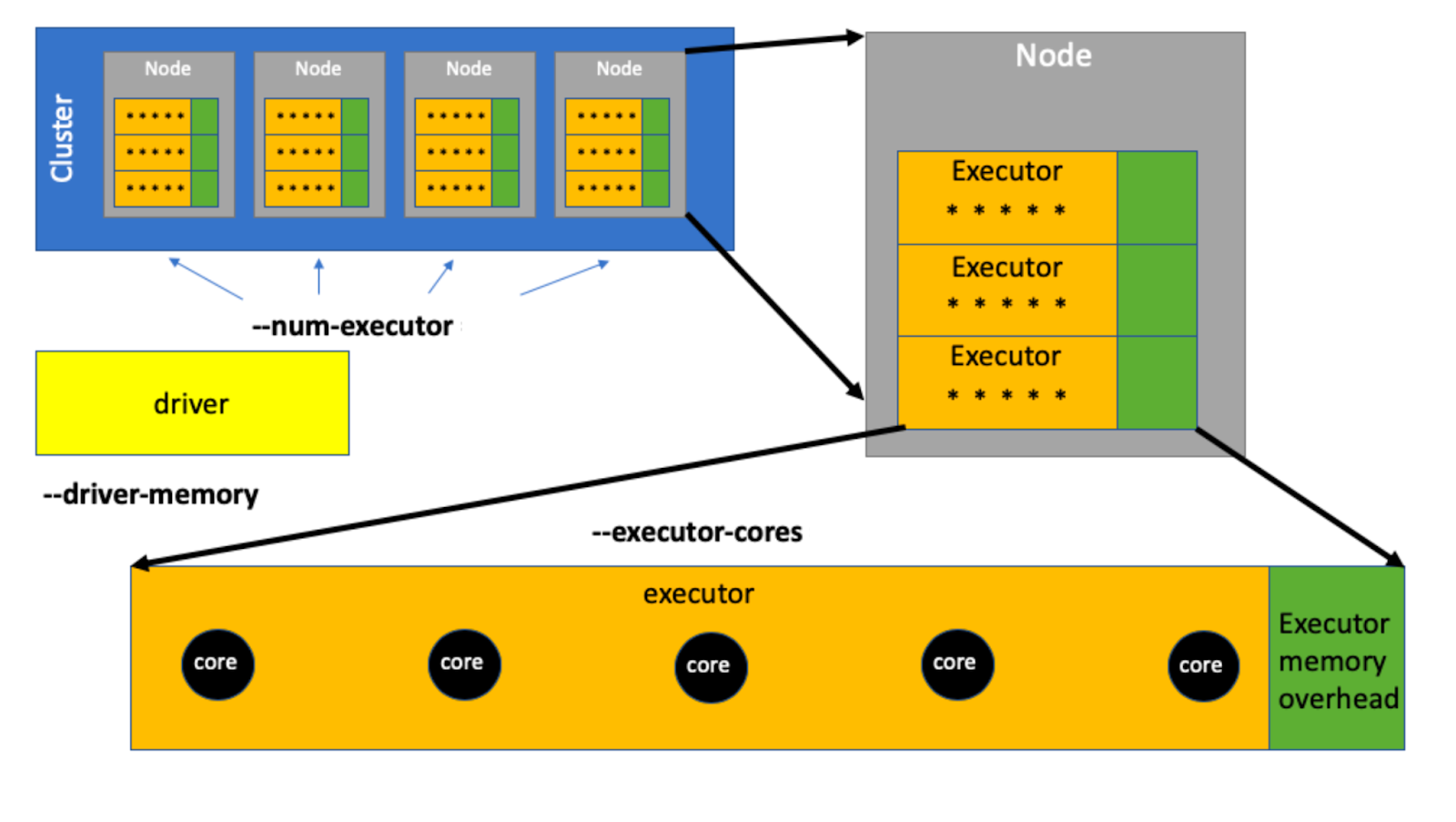
Оптимизируем параметры запуска приложения Spark. Часть первая 04.04.2024 15:09 centerco 0 Блог компании билайн Big Data Хранилища данных Data Engineering
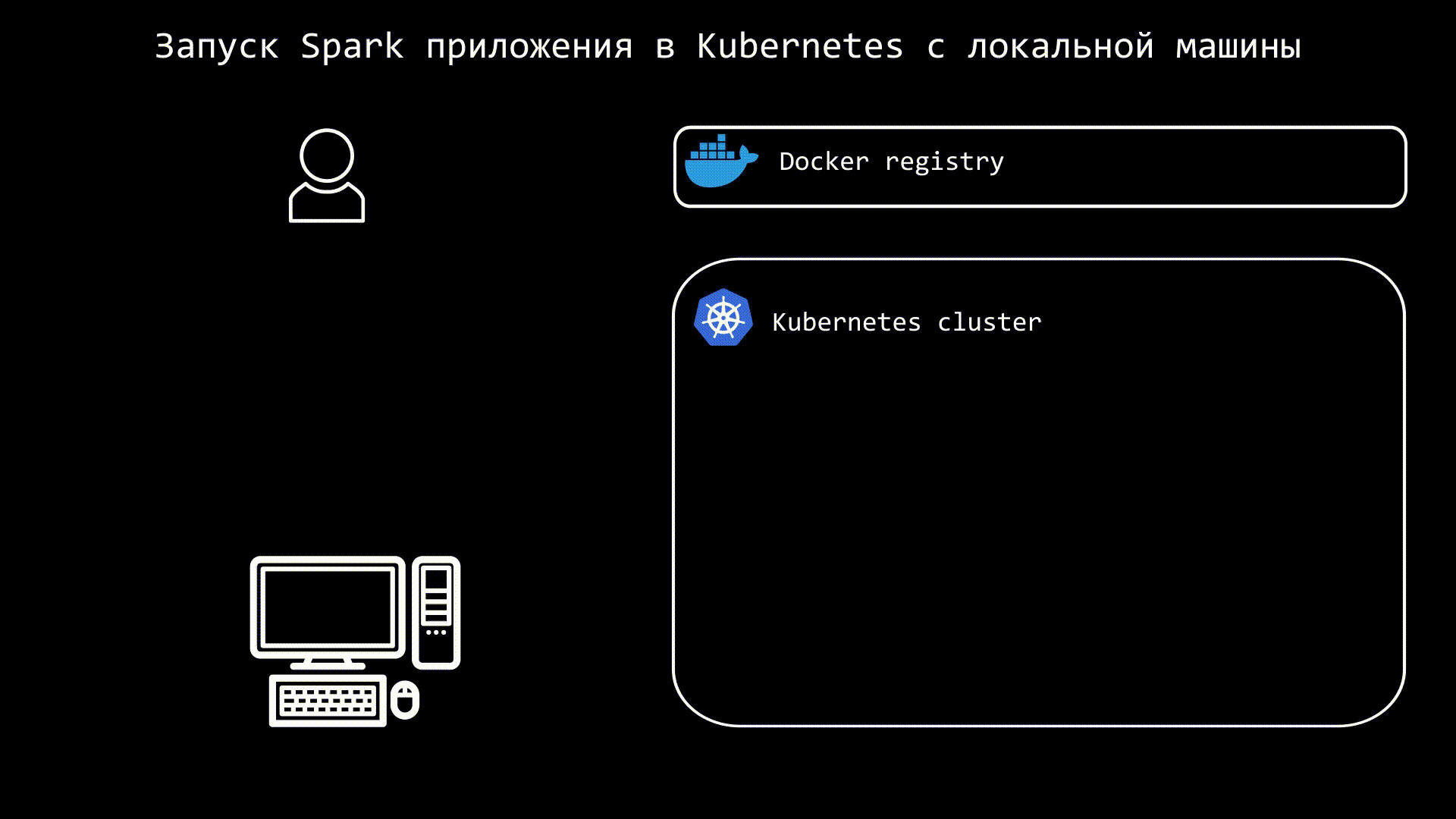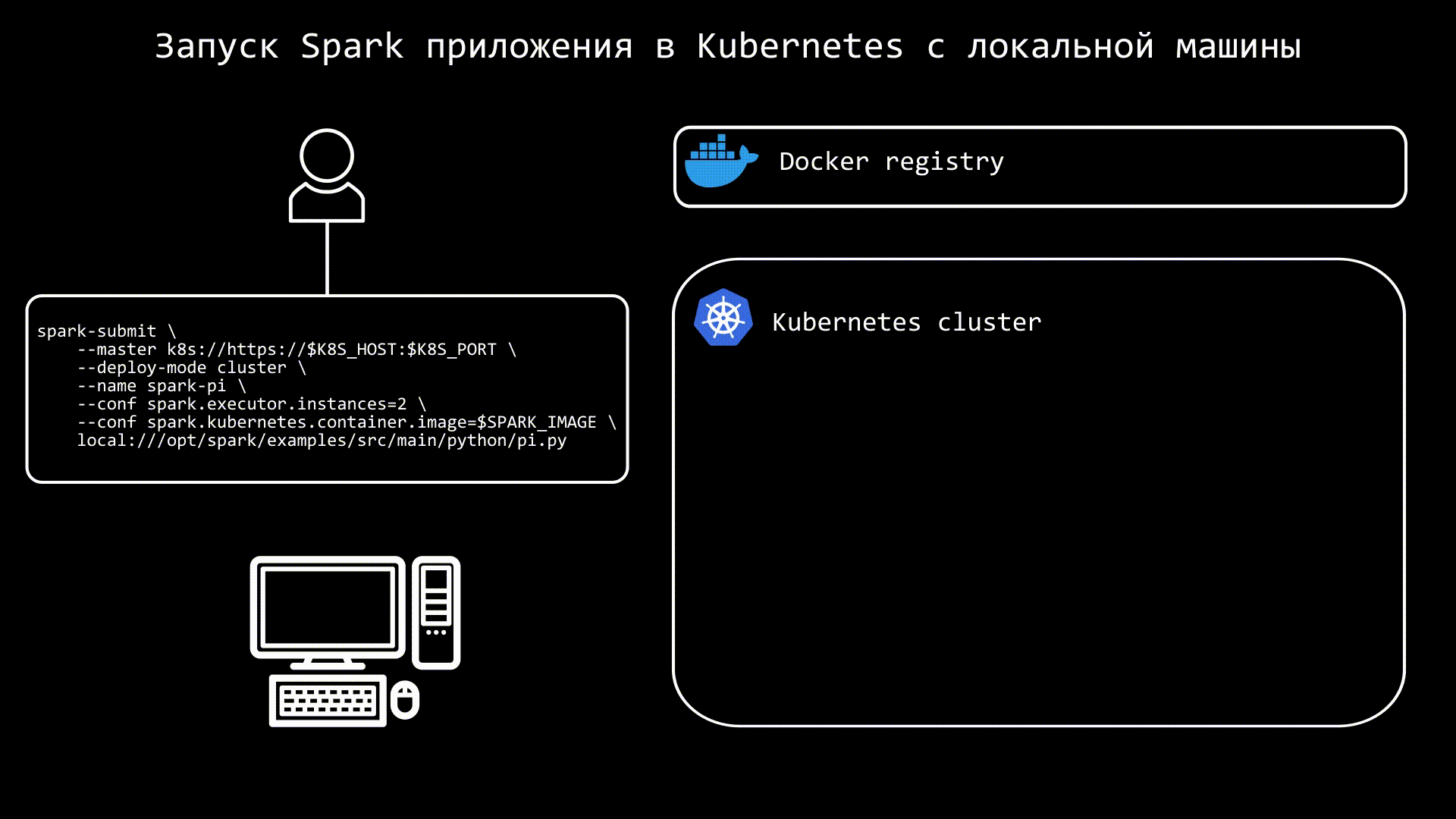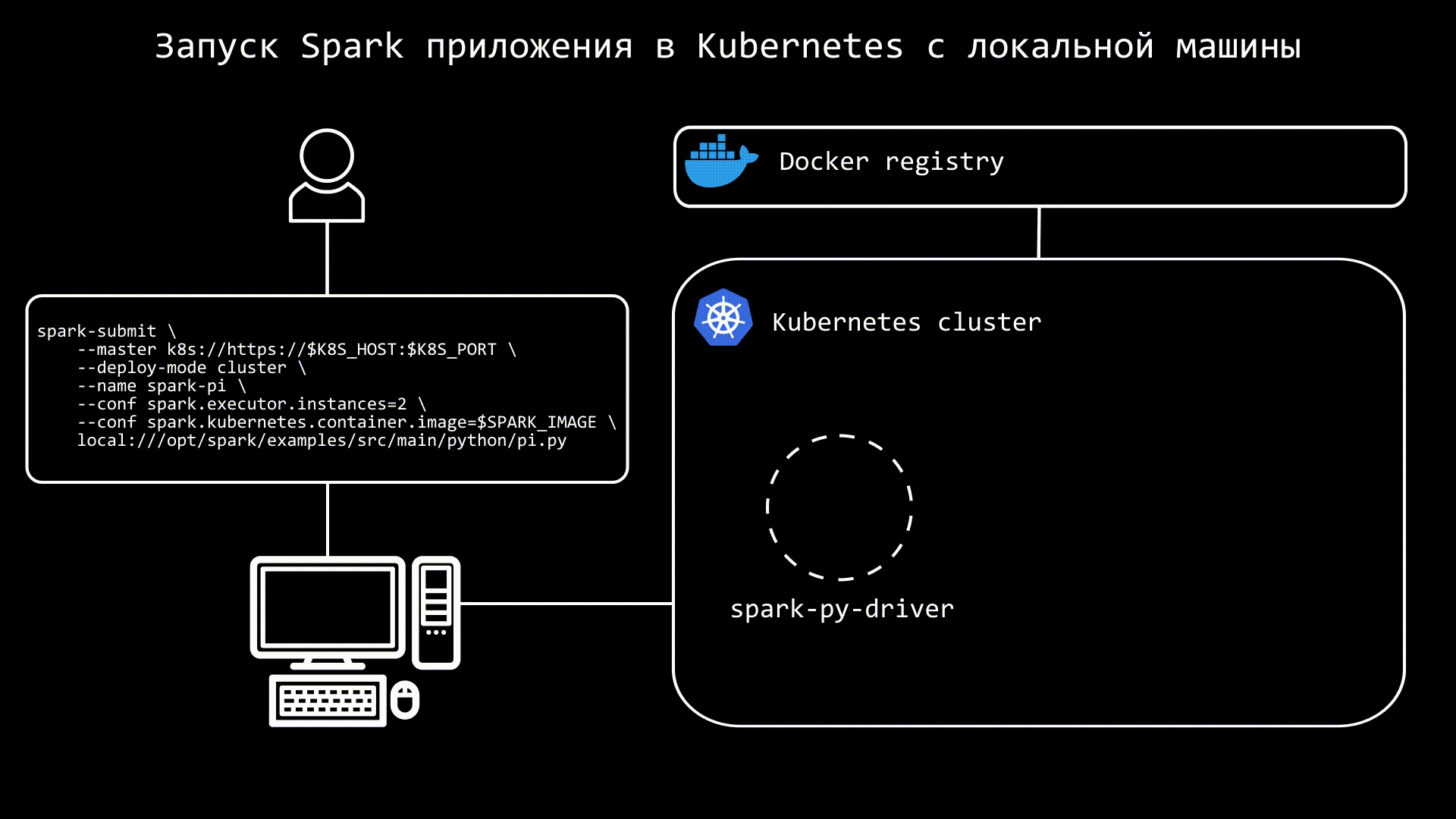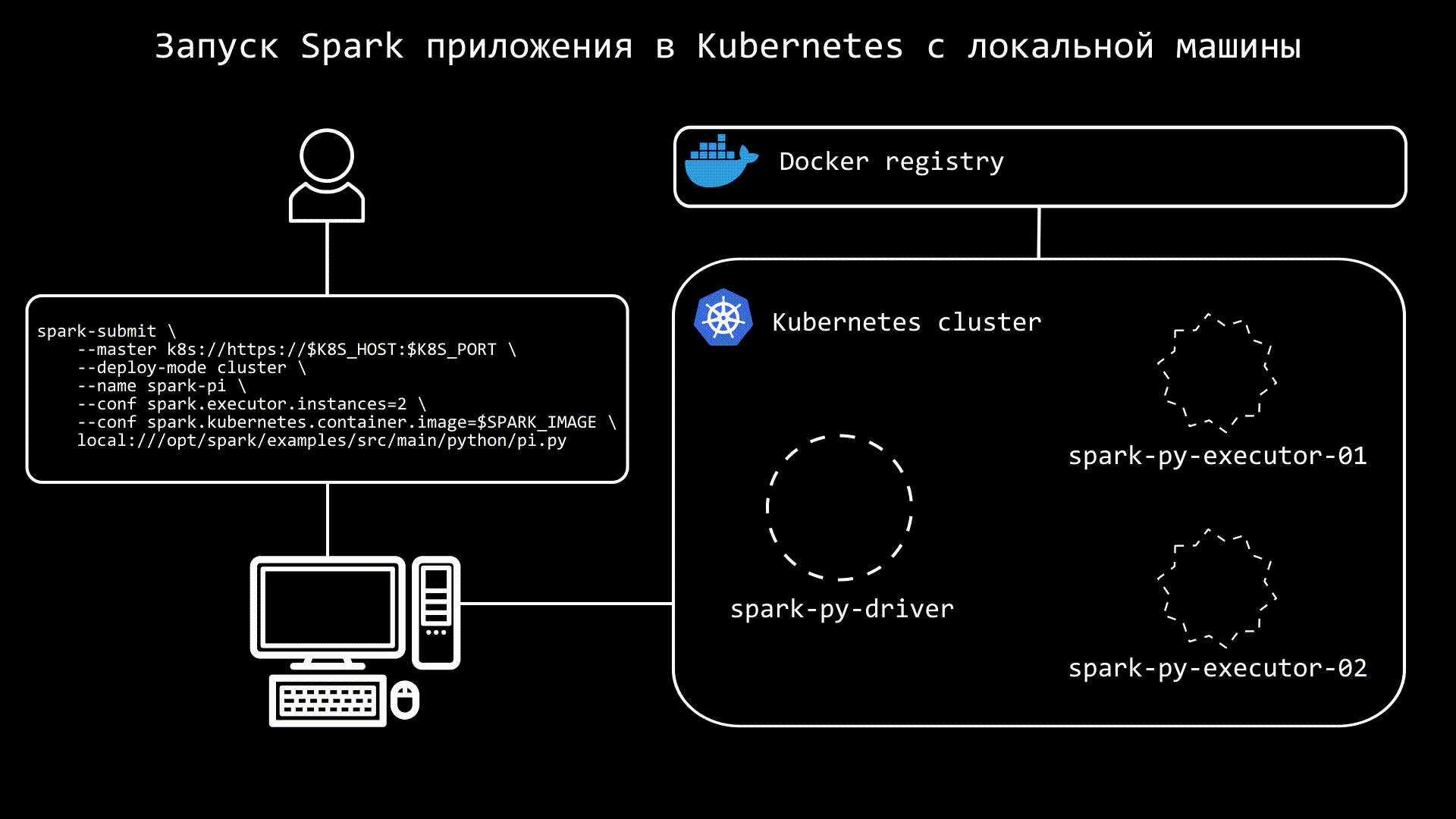
3 способа запуска Spark в Kubernetes из Airflow 03.04.2024 16:52 SiplatovKirill 0 Big Data Kubernetes Data Engineering
Что такое MLOps и как мы внедряли каскады моделей 21.03.2024 15:57 IAlexOps 5 Блог компании Альфа-Банк Big Data Data Engineering
Как сделать Spark в Kubernetes простым в использовании: опыт команды VK Cloud 18.01.2024 11:01 matyunin_as 0 Блог компании VK Big Data Машинное обучение Kubernetes
Spark не для чайников: где? 16.01.2024 07:36 Ninil 12 Big Data Учебный процесс в IT Карьера в IT-индустрии Data Engineering
Дежурный data-инженер: рабочие хроники +9 10.11.2023 13:17 NigrumKross 0 Блог компании VK Big Data Хранилища данных
Подбираем параметры сессии в Apache Spark, чтобы не стоять в очереди +12 07.11.2023 10:53 vladislav_shevchenko 7 Блог компании Альфа-Банк Apache Big Data DevOps Data Engineering
Руководство для начинающих по Spark UI: Как отслеживать и анализировать задания Spark +4 31.10.2023 12:19 Liloon21 0 Блог компании Слёрм Big Data Data Engineering
Apache Spark и PySpark для аналитика. Учимся читать и понимать план запроса в SparkUI +8 06.10.2023 09:00 aledovskiy 0 Блог компании AvitoTech Python Data Mining Big Data