
Привет, меня зовут Роман Вороновский и в этой статье, посвященной Python streaming с использованием Spark и Kafka мы рассмотрим основные шаги, представленные в видео:
Чтобы предоставить вам более подробное описание процесса и помочь при развертывании локального окружения.
Видео,как и статья нацелена на тех, кто только начинает свой путь в Big Data и еще не совсем умеет настраивать различные окружения для легкого старта в профессии.
Итак начнем.
необходимые компоненты и их проверка
Для установки необходимого окружения и проверки компонентов, перед началом работы с Python streaming в связке Spark и Kafka, вам потребуются следующие инструменты и плагины.
0. Docker Desktop (скачать можно по ссылке: https://www.docker.com/products/docker-desktop/)
1. Spark: Apache Spark - это быстрая и мощная платформа для обработки больших объемов данных. Для установки Spark достаточно воспользоваться интерпретатором conda (скачать можно по ссылке: https://www.anaconda.com/download) а не стандартным интерпретатором python, для этого:
в правом нижнем углу жмем по интерпретаторам
выбираем опцию "Add new interpreter"
выбираем опцию "Add local interpreter"
выбираем Conda Environment

С данным интерпретатором Spark работает из коробки и никаких допов в виде Hadoop и тд. разворачивать не прийдется.
2. Kafka: Apache Kafka - это распределенная платформа, предназначенная для обработки потоковых данных. Для установки Kafka достаточно использовать docker-compose.yaml файл, закрепленный в репозитории. Для его запуска можно воспользоваться командой, находясь в корне проекта:
docker-compose up -d3. Python: Python - популярный язык программирования, используемый для разработки приложений и анализа данных. Убедитесь, что на вашем компьютере установлена актуальная версия Python. Вы можете скачать и установить Python с официального сайта (https://www.python.org/downloads). В видео я использую IDE- PyCharm (скачать можно по ссылке: https://www.jetbrains.com/pycharm/?var=1)
4. Для работы с Kafka в Python, вам понадобится установить библиотеку pykafka. Откройте командную строку и выполните команду:
pip install pykafkaдля установки этой библиотеки.
5.PySpark - это Python API для Apache Spark. Чтобы установить PySpark, выполните команду:
pip install pysparkв командной строке.
После установки всех необходимых компонентов и плагинов, проверяем их работоспособность.
Проверка работоспособности
Kafka
После выполнения команды по поднятию контейнера мы должны наблюдать следующую картину:

Запускаем Python скрипт который бы писал сообщения в Kafka(producer.py):
from pykafka import KafkaClient
if __name__ == "__main__":
#хост подключения к кафка
client = KafkaClient(hosts='127.0.0.1:9092')
#имя топика в который мы собираемся отправлять сообщения
topic = client.topics[b'stream_topic']
#создание продюсера, который и будет отправлять сообщения
producer = topic.get_producer()
#отправка самих сообщений
producer.produce(b'Hello, Streaming!')
producer.produce(b'Kafka first Message!')
#остановка продюсера
producer.stop()Следом запускаем скрипт который бы распечатывал сообщения из топика kafka(consumer.py):
from pykafka import KafkaClient
if __name__ == "__main__":
#хост подключения к кафка
client = KafkaClient(hosts='127.0.0.1:9092')
#имя топика из которого мы собираемся получать сообщения
topic = client.topics[b'stream_topic']
#создание простого консьюмера
consumer = topic.get_simple_consumer()
#обработка сообщений если они еще есть в топике
for message in consumer:
if message is not None:
print(message.value.decode('utf-8')) #берется значение сообщений и декодируется по utf-8 для валидного отображенияВ результате все сообщения которые были отправлены должны были распечататься в консоль при помощи consumer.py программы.
Spark+kafka
Для проверки уже в связке необходимо использовать программу - sparkConsumeStreamKafkaWriteToConsole.py :
import os
from pyspark.sql import SparkSession
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.3.0,org.apache.spark:spark-sql-kafka-0-10_2.12:3.3.0 pyspark-shell'
if __name__ == '__main__':
spark = SparkSession \
.builder \
.appName("ProduceConsoleApp") \
.getOrCreate()
source = (spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", "127.0.0.1:9092")
.option("subscribe", "stream_topic")
.option("startingOffsets", "earliest")
.load()
)
#печать схемы - необязательна
source.printSchema()
#работа над получаемыми DataFrame
df = (source
.selectExpr('CAST(value AS STRING)', 'offset'))
# блок записи полученных результатов после действий над DataFrame
console = (df
.writeStream
.format('console'))
console.start().awaitTermination()
Работа над получаемыми DataFrame может максимально отличаться от моего примера, тк данный пример был представлен исключительно в обучающих целях, для реальных проектов данные запросы могут быть гораздо сложнее : )
В блоке записи мы можем указывать различные форматы, так же для примера был выбран самый простой - в консоль. Если хотите усложнить и прописать обратную запись в какой-нибудь результирующий топик, то попробуйте изменить код начиная с .format следующим образом:
.format("kafka") \
.option("kafka.bootstrap.servers", "127.0.0.1:9092") \
.option("topic", "result_topic") \
.option('checkpointLocation', './.local/checkpoint') \
.start().awaitTermination()установка Hadoop_Home
Если возникли ошибки как на видео , связанные с Hadoop, то данный параграф необходимо прочесть.
Первое с чего стоит начать - установить себе папку winutils которую я показывал на видео(скачать можно по ссылке: https://github.com/kontext-tech/winutils). Я использовал другую версию, которая также закреплена линком в репозитории, привожу её и тут: https://github.com/cdarlint/winutils
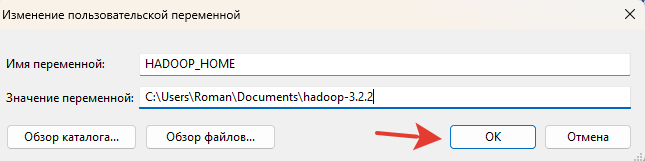
После успешной установки(в моем случае это версия 3.2.2) необходимо задать системную переменную HADOOP_HOME. Делается это следующим образом:
заходим в параметры системы
прописываем: "изменение системных переменных среды"
жмем на кнопку: "переменные среды"
жмем на кнопку: "создать"
в поле имя переменной прописываем: "HADOOP_HOME"
в поле значение переменной прописываем путь до нашего скаченного файла нужной версии ( в моем случае: "C:\Users\Roman\Documents\hadoop-3.2.2"
Находим среди системных переменных- переменную с наименованием: "Path"
изменяем её дописывая следующий текст: "%HADOOP_HOME%\bin"
сохраняем и перезагружаем ПК
Листинг изображениями:



Итог
После проделанных манипуляций ошибка уйдет и проект должен работать корректно, в данном случае мои версии для которых все запускалось:
Python 3.11 - conda interpreter
pyspark 3.4.1
pykafka 2.8.0
Всем спасибо за внимание! Оставляйте комментарии и подписывайтесь!
Репозиторий закреплен под видео.
Комментарии (7)

NightShad0w
09.04.2024 12:01+1И вот все вроде хорошо. Да только в реальной жизни Kafka, Spark и Hadoop живет где-то там, в королевстве кривых платформ корпоративного разлива, администрируются выделенной командой, и настроены согласно их, этой команды, представлениям о прекрасном.
И при попытке использовать эти сервисы, проблема не в том, как контейнеры локально поднять, или пакеты в виртуальное окружение питона установить, а, скорее, в том, чтобы затолкать в свой нормально выглядящий скрипт обработки поддержку stage-развертывания, Kerberos аутентификации, и автосинхронизацию схем топиков, ибо дата продюсеры имеют обыкновение, без объявления, ломать формат сообщений.
И после фарширования скрипта обработки всем этим хозяйством, еще и неплохо уметь его локально запускать для тестов. И воспроизвести локально тот же Kerberos уже не так просто....

v_d_roman Автор
09.04.2024 12:01Тут согласен, но статья нацелена и находится в топике для новичков, чтобы они могли вообще хоть как то погрузиться и что-либо пописать, а когда ты условный junior то развертывание сред и преднастройка, как правило занимает времени +- столько же , сколько отводится времени на практику, когда учишь направление сам , то DevOps как правило дома нет. В целом мой основной язык Java и там как раз все работает почти из коробки с минимальными изменениями относительно гугления и кода из сети, а вот для python к сожалению пришлось немного поплясать с бубном, для этого статья и была создана, чтобы последующим людям, кто только начинает этот путь с данного языка - упростить жизнь, про продакшн, стенды и окружения тут не идет речи, также и про кафку в целом, тут ни консьюмер групп, ни доп конфигов для отказоустойчивости не было, чтобы не перегружать локальную машину, там 1x1 конфиг для кафка кластера, все максимально упрощено : )
VlaKor
Да почему опять питон то на заставке?
v_d_roman Автор
чтобы точно было понятно, что питон, ну и по исторически сложившимся причинам на хабре : )
VlaKor
Дык не питон же, а Пайтон.
Jaffarr
У самого Пайтона на логотипе 2 питона, так что питон тоже легитимен )
VlaKor
А точно! Похоже на две змеи.