

Airflow в Lamoda Tech играет роль оркестратора процессов обработки данных. Ежедневно с его помощью мы запускаем 1 800+ тасок на проде, примерно половина из которых являются Spark-приложениями.
Все Spark-приложения сабмитятся из Docker-контейнеров. И здесь сталкиваемся с проблемой: в нашем случае не существует готовых решений для запуска Spark-приложений, позволяющих легко править конфигурацию и следить за количеством потребляемых ресурсов.
Меня зовут Андрей Булгаков, я лид команды разработчиков Big Data в Lamoda Tech. Вместе с разработчиком Иваном Васенковым @vasenkovid в этой статье мы поделимся историей создания Airflow-оператора для запуска Spark-приложений.
Как выглядят наши Airflow и пайплайны
Прежде чем начать разбирать особенности запуска Spark-приложений, хочу немного рассказать про наш подход к конфигурации пайплайнов в Airflow. Это даст возможность посмотреть на процесс сверху.
Подробно о том, как мы оркестрируем процессы обработки данных, мы уже рассказывали в статье. Если вы хорошо знакомы с этой темой, блок можно пропустить.
Для начала коротко про наш Airflow. В PROD-контуре работает 370+ активных дагов (DAG — Directed Acyclic Graph), а в DEV-контуре команды разработчиков Big Data, дата-сайентистов и продуктовых аналитиков на своих стендах разрабатывают и тестируют наработки перед выкатом на PROD.
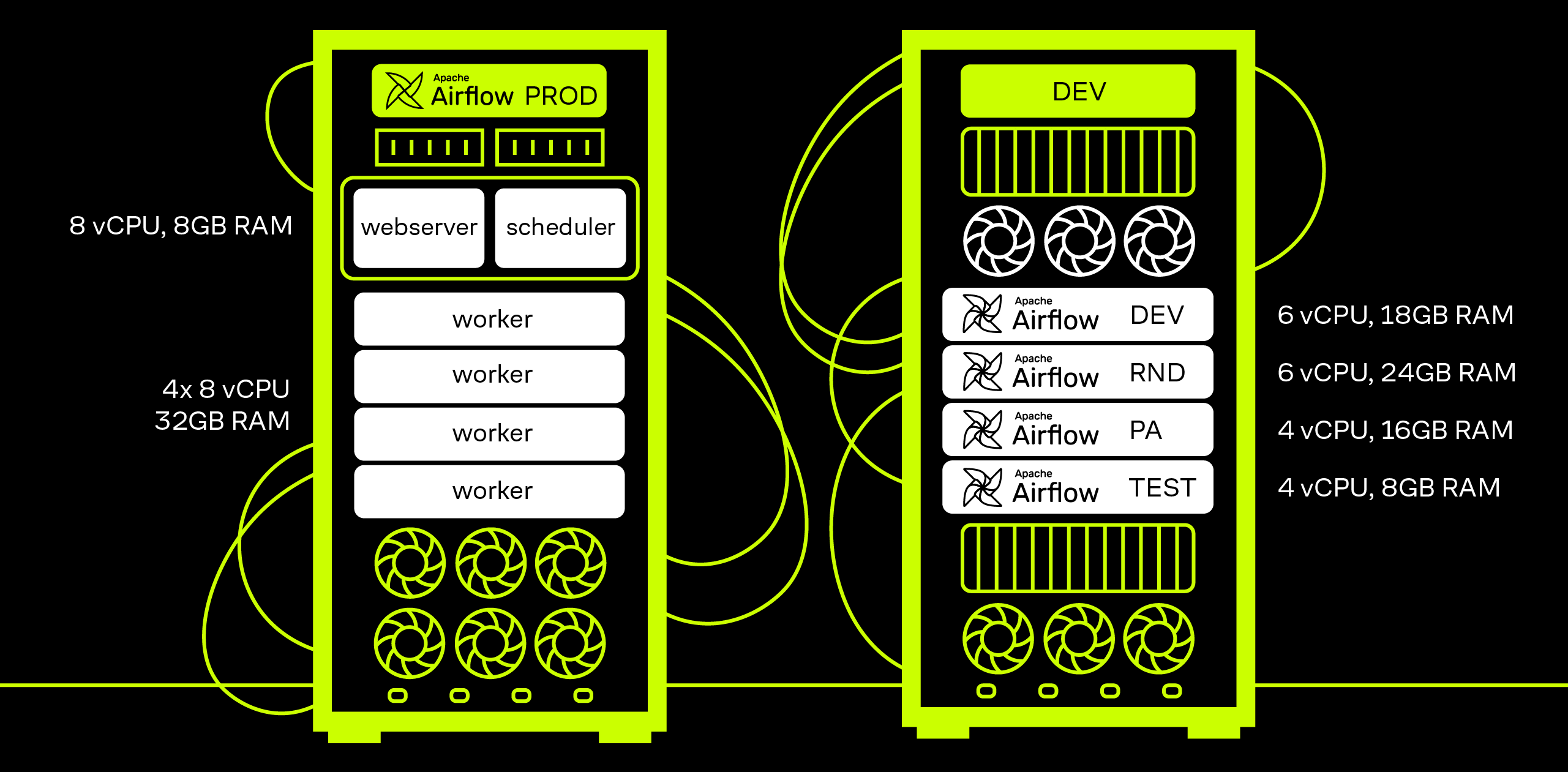
Под каждый стенд создана своя ветка в репозитории. Чтобы поддерживать актуальность при внесении изменений в master-ветку, отвечающую за PROD, автоматически происходит merge в ветки, которые используются в DEV-контуре.
Тестовый стенд мы используем в основном для тестирования новых версий Airflow, чтобы принять решение о безопасности переезда. На момент написания статьи на всех стендах используется версия Airflow 2.7.3 на Celery Executor.
Для удобного создания пайплайнов мы описываем даги не в коде, а в конфигурационных файлах.
Конфигурации задаем в формате HOCON (Human-Optimized Config Object Notation) — более удобной для чтения и редактирования человеком версии JSON. Среди особенностей формата HOCON для нас есть несколько преимуществ:
минималистичный синтаксис,
возможность импорта других HOCON-файлов,
возможность ссылаться на другие части конфигурации.
Настройки уровня пайплайна определяем в начале конфига. В них входят параметры дага, информация о владельце данных и список рассылки по почте оповещений о его падении. Также информация о падении всегда приходит дежурному дата-инженеру, и можно настроить оповещения в чаты корпоративного мессенджера.
include "../../generics/emails.conf"
dags {
main_pa_metrics {
owner = "RND-PA"
name = "main_pa_metrics"
start_date = "20220327"
emails = ${PRODUCT_ANALYSTS_TEAM}
schedule_interval = "30 9 * * *"
catchup = true
notify_on_failure = {
title = "{dag_id} FAILED",
message = "Упал расчет основных продуктовых метрик. Что делать смотри в конфлюенс. Важно его переподнять до 12 дня.",
to = {
pachca = [{
connection= "pachca_alerts_etl"
}, {
connection= "pachca_alerts_pa_automation"
}]
}
}
description = "Даг для обновления таблицы pa_db.main_pa_metrics с расчетом главных продуктовых метрик"
tags = [
"critical", "pa"
]
В этом примере описаны два шага: ожидание завершения процедуры в Oracle и выполнение запроса в Trino.
tasks {
await_visitor_activity_ready {
type = "oracle_sensor"
sensor_type = "job_code"
conn_id = "dwh"
job_code = "ORA_VISITOR_ACTIVITY"
dt = "{{ ds_nodash }}"
}
load_trino {
type = "trino"
sql_params {
hive_schema = "{{ var.value.HIVE_DB_PA }}"
start_dt = "{{ ds }}"
end_dt = "{{ next_ds }}"
}
sql_file = "trino/main_pa_metrics.sql"
}
task_order = [
"await_visitor_activity_ready",
"load_trino"
]
}Для подстановки нужных значений параметров в зависимости от даты запуска и стенда Airflow в конфиге через Jinja-шаблоны можно использовать макросы, переменные и коннекшены:
в первой таске прописать коннекшн для Oracle, имя приложения и дату, за которую она должна отработать;
во второй таске — указать, где лежит код запроса и параметры, которые необходимо подставить в запрос.
Последовательность тасок задается в виде списка. Можно объединить их в дополнительный список внутри основного и настроить параллельное выполнение задач.
Пример кода дага целиком
include "../../generics/emails.conf"
dags {
main_pa_metrics {
owner = "RND-PA"
name = "main_pa_metrics"
start_date = "20220327"
emails = ${PRODUCT_ANALYSTS_TEAM}
schedule_interval = "30 9 * * *"
catchup = true
notify_on_failure = {
title = "{dag_id} FAILED",
message = "Упал расчет основных продуктовых метрик. Что делать смотри в конфлюенс. Важно его переподнять до 12 дня.",
to = {
pachca = [{
connection= "pachca_alerts_etl"
}, {
connection= "pachca_alerts_pa_automation"
}]
}
}
description = "Даг для обновления таблицы pa_db.main_pa_metrics с расчетом главных продуктовых метрик"
tags = [
"critical", "pa"
]
tasks {
await_visitor_activity_ready {
type = "oracle_sensor"
sensor_type = "job_code"
conn_id = "dwh"
job_code = "ORA_VISITOR_ACTIVITY"
dt = "{{ ds_nodash }}"
}
load_trino {
type = "trino"
sql_params {
hive_schema = "{{ var.value.HIVE_DB_PA }}"
start_dt = "{{ ds }}"
end_dt = "{{ next_ds }}"
}
sql_file = "trino/main_pa_metrics.sql"
}
task_order = [
"await_visitor_activity_ready",
"load_trino"
]
}
}
}
После генерации получаем даг, состоящий из двух последовательных тасок.

Как мы варим Spark
В платформе данных Lamoda Tech мы применяем «докеризированный» Spark. Docker позволяет создать отдельное окружение, которое будет работать в независимом контейнере, и упаковать в него все необходимые исходники и зависимости для запуска Spark-приложения.
Таким образом, единственное требование, которое предъявляется к машине, с которой запускается Spark, — это наличие на ней Docker.
У нас есть базовый образ для запуска Spark. На его основе мы строим финальные версии образов, которые используем для запуска приложений на кластере. В базовом образе содержатся собранный Spark, конфиги Hadoop и объявляются необходимые переменные окружения.
Пример Dockerfile для базового образа:
FROM docker-registry.lamoda.ru/centos:7.9.2009
# Устанавливаем Python и OpenJDK
RUN yum install -y curl python3-3.6.8 java-1.8.0-openjdk && \
yum clean all && \
rm -rf /var/cache/yum
# Добавляем исходники Spark
COPY build/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz "./"
RUN tar -xzf spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz && \
mv spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION} $SPARK_HOME && \
rm spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz
ENV PATH $SPARK_HOME/bin:$PATH
# Копируем конфиги
COPY configs/datalake/hadoop/conf /opt/hadoop/conf
COPY ["configs/spark-defaults.conf", "configs/spark-env.sh", "configs/log4j.properties", "$SPARK_HOME/conf/"]
# Устанавливаем переменные окружения
ENV HADOOP_CONF_DIR /opt/hadoop/conf
ENV YARN_CONF_DIR /opt/hadoop/conf
ENV HIVE_CONF_DIR /opt/hadoop/conf
# Задаем дефолтные jvm options для использования в приложениях. Могут быть переопределены
ENV SPARK_JVM_OPTS "-Dhdp.version=current -XX:+UseNUMA -XX:+UseG1GC"
ENTRYPOINT ["/bin/bash"]Как получить готовый для применения образ:
Если код написан на Scala/Java, то мы добавляем в базовый образ JAR с приложением.
Если на Python, то добавляем скрипты вместе со сторонними зависимостями, необходимыми для исполнения PySpark-кода.
Пример Dockerfile для образа с приложением на Scala/Java:
# начинаем построение с базового образа (собранного выше)
FROM docker-registry.lamoda.ru/base/lmd-spark:3.3.1-51
# копируем в образ jar с приложением
COPY target/scala-2.12/aerospike-loader.jar /aerospike-loader.jar
ENTRYPOINT ["/bin/bash"]Пример Dockerfile для образа с приложением на Python:
# начинаем построение с базового образа (собранного выше)
FROM docker-registry.lamoda.ru/base/lmd-spark:3.3.1-51
COPY . /tmp/build/
# пакуем зависимости
RUN python3.6 -m venv tmp_venv --clear && \
. tmp_venv/bin/activate && \
python3.6 -m pip install pip==21.3.1 && \
pip install -r /tmp/build/requirements.txt && \
deactivate && \
cd tmp_venv && \
zip -rq /app/dependencies.zip * && \
rm -rf /tmp/build /app/tmp_venv
# копируем скрипты с кодом приложения
COPY py_scripts /app/py_scripts
ENTRYPOINT ["/bin/bash"]
Сабмитим приложения в кластерном режиме через YARN.
Работать со Spark в Docker удобно по многим причинам:
Простота обновления. При переезде на новую версию Spark нет необходимости проводить апгрейд кластера Hadoop и переживать, продолжат ли нормально работать существующие приложения на новой версии.
Участие разработчиков платформы данных для выкатки приложений на прод сводится к минимуму: пользователи системы приходят с готовым образом и конфигом. Остается только провести минимальное ревью, нажать апрув, и приложение побежит в Airflow без дополнительных манипуляций.
На локальной машине разработчика достаточно иметь Docker, чтобы самостоятельно собирать образы и так же локально при их помощи запускать Spark-приложения для тестирования в процессе разработки.
Kuber Friendly: можно достаточно легко перенести приложения на Kubernetes (проверяли при пилотировании проекта Spark on K8s).
Можно использовать несколько версий Spark одновременно.
Но у этого подхода есть один недостаток: не существует удобного способа запустить Spark в docker-образе из Airflow при помощи существующих инструментов.
Почему не подошли готовые решения
Так как мы держим Spark в Docker и не хотим устанавливать пакеты для запуска Spark на воркеры Airflow, то мы не можем использовать доступные через Airflow Spark Provider SparkSubmitOperator, SparkJDBCOperator и SparkSqlOperator. Точно так же не получится просто запускать код на PySpark через PythonOperator или триггерить spark-submit через BashOpertator.
Мы решили попробовать использовать DockerOperator для запуска Docker-контейнеров в Airflow. Он доступен через Airflow Docker Provider. DockerOperator позволяет добавить в даг таску, при старте которой на воркере Airflow будет поднят Docker-контейнер и выполнена переданная команда.
Процесс настройки регулярного запуска Spark-приложений на основе DockerOperator выглядел следующим образом:
Добавляем в образ при сборке .sh файл с кодом скрипта spark-submit. В нем нужно указать параметры запуска приложения, JAR или Python-файл, а также параметры приложения. Называем его, например, submit.sh. При необходимости в него можно подставлять значения из переменных окружения, используя синтаксис работы с переменными в Bash.
Пример скрипта spark-submit в кодблоке:
spark-submit \
--master "yarn" \
--queue "apps" \
--deploy-mode "cluster" \
--class "tech.lamoda.dwh.etl.executor.spark_sql.SparkSqlExecutor" \
--name "ip_geo_snapshot" \
--driver-cores "1" \
--driver-memory "2G" \
--executor-cores "1" \
--executor-memory "1G" \
--num-executors "3" \
--files "/app/metrics.conf" \
--conf "spark.yarn.maxAppAttempts=1" \
--conf "spark.driver.extraJavaOptions=${SPARK_JVM_OPTS}" \
--conf "spark.executor.extraJavaOptions=${SPARK_JVM_OPTS}" \
--conf "spark.yarn.am.extraJavaOptions=${SPARK_JVM_OPTS}" \
--conf "spark.metrics.conf=metrics.conf" \
--conf "spark.metrics.namespace=ip_geo" \
--conf "spark.sql.broadcastTimeout=1200" \
/data-processing-etl.jar \
--out-db "$OUT_DB" \
--out-table "$OUT_TABLE" \
--mode "$MODE" \
--partitions-num "$PARTITIONS_NUM" \
—-partitions-cols "$PARTITIONS_COLS" \
--sql "$SQL" В конфиг дага добавляем таску, вызывающую DockerOperator:
ip_geo_snapshot {
type = "docker"
image = ${data-processing-etl-spark3.3}
command = "./submit.sh" # путь в образе до .sh файла
environment { # словарь env переменных, которые будут использоваться для подстановки в код spark-submit при запуске оператора
OUT_DB = "{{ var.value.HIVE_DB_DERIVATIVES }}"
OUT_TABLE = "ip_geo_snapshot"
MODE = "overwrite"
PARTITIONS_NUM = "1
PARTITIONS_COLS = "dt"
SQL = """{{ sql('spark/ip_geo_snapshot.sql', params={
'ds_nodash': ds_nodash,
'hive_db_derivatives': var.value.HIVE_DB_DERIVATIVES
}) }}"""
}
}В результате вызов оператора произойдет со следующими параметрами:
new_task = DockerOperator(
dag=dag,
task_id="ip_geo_snapshot",
image="docker-registry.lamoda.ru/data-processing-etl:1.0.0",
environment=**environment,
auto_remove="success",
command="./submit.sh"
)Но у такого способа оказались свои недостатки:
По коду репозитория с дагами зачастую нельзя определить, сколько ресурсов будет выдано приложению и какие еще параметры используются. За безобидным с первого взгляда выполнением
command = "./submit.sh"может скрываться что-то вроде num-executors=100500 или executor-memory=2TBНебольшие изменения в параметрах приложения доезжают до прода минимум через 2 пулл-реквеста. Например, чтобы добавить в spark-submit параметр
"spark.sql.adaptive.coalescePartitions.initialPartitionNum" = "1000", нужно сначала поправить файлsubmit.shв репозитории приложения, а затем поднять в репозитории с конфигами дагов версию образа, получившегося на предыдущем шаге.
Более удобного способа запуска Spark без доработок мы найти не смогли. Поэтому пришлось написать свое решение.

Как выглядит наше решение
Мы разработали новый Airflow-оператор, который не имеет проблем стандартных инструментов и решает наши задачи. Унаследовали его от стандартного DockerOperator — и назвали SparkSubmitDockerOperator.
При его вызове в оператор передаются все необходимые параметры для запуска приложения. Из них можно создать полноценную команду spark-submit и дальше использовать ее в качестве команды при старте Docker-контейнера.
Помимо генерации команды, оператор также реализует дополнительные вспомогательные функции, о которых расскажем дальше в этом разделе.
Конфигурация
Типичная конфигурация таски при применениии SparkSubmitDockerOperator выглядит так:
ip_geo_snapshot {
image = ${data-processing-etl-spark3.3}
type = "spark_submit_v2"
spark-params = {
driver-cores = 1
driver-memory = 2G
executor-cores = 1
executor-memory = 1G
num-executors = 3
files = "/app/metrics.conf"
class = "tech.lamoda.dwh.etl.executor.spark_sql.SparkSqlExecutor"
conf {
"spark.metrics.conf" = "metrics.conf"
"spark.metrics.namespace" = "ip_geo"
"spark.sql.broadcastTimeout" = "1200"
}
}
program-path = "/data-processing-etl.jar"
job-params {
out-db = "{{ var.value.HIVE_DB_DERIVATIVES }}"
out-table = "ip_geo_snapshot"
mode = "overwrite"
partitions-num = 1
partitions-cols = "dt"
sql = """{{ sql('spark/ip_geo_snapshot.sql', params={
'ds_nodash': ds_nodash,
'hive_db_derivatives': var.value.HIVE_DB_DERIVATIVES
}) }}"""
}
spark-files {
"/app/metrics.conf" = """
master.source.jvm.class=org.apache.spark.metrics.source.JvmSource
worker.source.jvm.class=org.apache.spark.metrics.source.JvmSource
driver.source.jvm.class=org.apache.spark.metrics.source.JvmSource
executor.source.jvm.class=org.apache.spark.metrics.source.JvmSource
*.sink.statsd.class=org.apache.spark.metrics.sink.StatsdSink
*.sink.statsd.prefix={{ var.value.STATSD_PREFIX_BATCH }}
*.sink.statsd.period=10
*.sink.statsd.unit=seconds
*.sink.statsd.host={{ var.value.STATSD_HOST }}
*.sink.statsd.port={{ var.value.STATSD_PORT }}
"""
}
}Эти блоки будут преобразованы в аргументы, используемые при вызове SparkSubmitDockerOperator.
После генерации дага из конфига в Airflow будет создана таска. У ее инстансов в разделе Rendered template появится поле rendered_command, содержащее пример команды, исполняемой в Docker-контейнере:
# Этот сгенерированный sh-скрипт можно применять для локального запуска и отслеживания параметров запуска приложения через rendered template в Airflow. Процесс запуска в докер контейнере происходит по незначительно отличающимся правилам. \
export PYTHONPATH="../:"; \
export LMD_ENV_TYPE="dev"; \
echo "master.source.jvm.class=org.apache.spark.metrics.source.JvmSource
worker.source.jvm.class=org.apache.spark.metrics.source.JvmSource
driver.source.jvm.class=org.apache.spark.metrics.source.JvmSource
executor.source.jvm.class=org.apache.spark.metrics.source.JvmSource
*.sink.statsd.class=org.apache.spark.metrics.sink.StatsdSink
*.sink.statsd.prefix=de_spark.batch
*.sink.statsd.period=10
*.sink.statsd.unit=seconds
*.sink.statsd.host=thor.dev.dwh.lamoda.tech
*.sink.statsd.port=9126" > /app/metrics.conf; \
spark-submit \
--master "yarn" \
--queue "apps" \
--deploy-mode "cluster" \
--name "ip_geo__ip_geo_snapshot" \
--driver-cores "1" \
--driver-memory "2G" \
--executor-cores "1" \
--executor-memory "1G" \
--num-executors "3" \
--files "/app/metrics.conf" \
--class "tech.lamoda.dwh.etl.executor.spark_sql.SparkSqlExecutor" \
--conf "spark.yarn.maxAppAttempts=1" \
--conf "spark.driver.extraJavaOptions=${SPARK_JVM_OPTS}" \
--conf "spark.executor.extraJavaOptions=${SPARK_JVM_OPTS}" \
--conf "spark.yarn.am.extraJavaOptions=${SPARK_JVM_OPTS}" \
--conf "spark.metrics.conf=metrics.conf" \
--conf "spark.metrics.namespace=ip_geo" \
--conf "spark.sql.broadcastTimeout=1200" \
/data-processing-etl.jar \
--out-db "dev_derivatives_db" \
--out-table "ip_geo_snapshot" \
--mode "overwrite" \
--partitions-num "1" \
--partitions-cols "dt" \
--sql "select ip,
country,
region_aoid,
region_name,
region_abbr,
city_aoid,
city_name,
'20240403' as dt
from \\\`dev_derivatives_db\\\`.ip_geo"
Обратим внимание на предупреждение: данная команда отличается от того, что сабмитится в Doker. Это действительно так. Этот блок специально сгенерирован для удобства локального воспроизведения и дебага запуска Spark-приложений. Передаваемая в Docker-контейнер команда не сильно отличается от представленной: в ней будут другие правила для экранирования, а env-переменные и файлы будут переданы через специальные параметры оператора.
Чтобы воспроизвести запуск приложения, выводимую команду можно скопировать и запустить, например, в контейнере на локальном компьютере.
Запуск приложения
При инициализации оператора мы сразу задаем стандартные параметры Spark и объединяем их с поступившими из конфигурации тасками. Это позволяет нам массово управлять стандартными параметрами приложений. Например, с помощью этого поля мы смогли постепенно включить KryoSerializer для всех дагов.
class SparkSubmitDockerOperatorV2(LamodaDockerOperator):
default_spark_params = {
"master": "yarn",
"queue": "{{ var.value.YARN_QUEUE }}",
"deploy-mode": "cluster",
"conf": {
'"spark.yarn.maxAppAttempts"': 1,
'"spark.hadoop.orc.overwrite.output.file"': "true",
'"spark.serializer"': 'org.apache.spark.serializer.KryoSerializer',
'"spark.kryoserializer.buffer.max"': '2047m'
},
}Нарисовать команду для локального запуска можно с помощью нехитрого трюка. Для этого необходимо переопределить метод render_template_fields и добавить в кортеж template_fields новое значение 'rendered_command', являющиеся именем атрибута класса self.rendered_command .
Демонстрация с кусочками кода:
class SparkSubmitDockerOperator(DockerOperator):
...
# Поля оператора, в которых могут использоваться jinja шаблоны для подстановки. Если поля нет в кортеже, то шаблоны подставлены не будут
template_fields = (
'rendered_command',
'environment',
'spark_params',
'spark_conf_params',
'program_path',
'job_params',
'job_flags',
'container_name',
)
template_fields_renderers: Dict[str, str] = {
'rendered_command': 'bash'
}
...
# Переопределяем метод оператора
def render_template_fields(self, context: Dict, jinja_env: Optional[jinja2.Environment] = None) -> None:
logger.info("Заполняем шаблоны в требуемых полях, используя родительский метод")
super().render_template_fields(context=context, jinja_env=jinja_env)
logger.info("Подготавливаем sh команду для запуска")
result_command = self.create_command(
spark_params=self.spark_params,
spark_conf_params=self.spark_conf_params,
program_path=self.program_path,
job_params=self.job_params,
job_flags=self.job_flags,
files=self.spark_files,
)
logger.info("Подготавливаем команду для отображения в UI")
self.rendered_command = self.render_ui_view(result_command, environment=self.environment, files=self.spark_files)
logger.info("Подготавливаем команду для запуска в Docker")
self.command = self.prepare_docker_command(result_command)
В блоке кода видно, что отдельно генерируется команда, выводимая на UI, и отдельно — команда для запуска. При старте контейнера DockerOperator возьмет команду, которая лежит в поле self.command, в то время как rendered_command отправится на UI.
Добавление файлов
Мы хотели иметь возможность передавать файлы или их контент в параметрах таски в поле spark-files. Проблема заключалась в том, что в файлах тоже могут быть Jinja-шаблоны, которые необходимо подставить.
Также мы хотели, чтобы на странице Rendered template эти файлы выводились в итоговом виде, в том, в каком они отправятся в Docker. Чтобы файлы прошли через процесс рендеринга и вывелись на странице, необходимо, чтобы информация о них появилась в поле template_fields . Для этого в init-методе мы создаем атрибуты класса с именами, соответствующими именам файлов, и значениями, соответствующими содержимому файлов. После этого добавляем их имена в template_fields и расширение файла в template_fields_renderers (оно нужно для подсветки синтаксиса):
class SparkSubmitDockerOperatorV2(LamodaDockerOperator):
...
template_fields = (
'rendered_command',
'environment',
'spark_params',
'spark_conf_params',
'program_path',
'job_params',
'job_flags',
'container_name',
)
template_fields_renderers: Dict[str, str] = {
'rendered_command': 'bash'
}
def __init__(
self,
image,
...
):
...
for file_name, content in spark_files.items():
logger.info(f"Добавляем файлы в template {file_name}")
setattr(self, file_name, content)
# Добавляем атрибуты с котентом файлов и их расширения в Renderred UI
file_extension = get_file_extension(file_name)
self.template_fields += (file_name,)
self.template_fields_renderers[file_name] = file_extension
Запуск самого контейнера происходит в методе-родителе DockerOperator.run_image. Чтобы файлы попали в образ, необходимо добавить его в mount. Для этого создаем временную директорию, подготовим в ней файл и добавим его к атрибуту mounts:
def _run_image(self) -> Optional[str]:
with TemporaryDirectory(prefix='spark_files', dir=self.host_tmp_dir) as spark_files_temp_dir:
for spark_file_path in self.spark_files.keys():
rendered_content = getattr(self, spark_file_path)
filename = Path(spark_file_path).name
temp_file_path = Path(spark_files_temp_dir, filename)
with open(temp_file_path, "w") as spark_file:
spark_file.write(rendered_content)
self.mounts += [Mount(target=spark_file_path, source=str(temp_file_path), type="bind")]
return super()._run_image()Дальше базовый класс DockerOperator запускает образ, используя определенный в нем метод _run_image. Он автоматически подхватывает такие поля, как self.command, self.environment, переданные для mount файлы из полей оператора, запускает контейнер и мониторит его состояние.
Локальный запуск приложений
Не всем разработчикам удобно тестировать приложения на dev-стендах, ведь после каждого коммита нужно дожидаться, пока в проекте отработают тесты, пройдут билды и деплой. Для них проще скачать образ на свой компьютер и выполнить docker run. При запуске Docker-контейнера локально функционал SparkSubmitDockerOperator оказывается недоступным, поэтому задавать параметры Spark-приложения при помощи HOCON-конфигов без вспомогательных инструментов невозможно. Остается пользоваться .sh файлами или передавать команду текстом, что приводит к необходимости совершать двойную работу. Первый раз пишем код запуска spark-submit при помощи .sh файла или текста, а во второй раз переносим написанное на рельсы дагогенерации.
Чтобы решить эту проблему и везде использовать HOCON-конфиги, разработали Python-библиотеку spark_submit_runner. Она повторяет основную логику SparkSubmitDockerOperator.
Помимо установки библиотеки понадобится создать два файла — airflow_builtins.conf и task_conf.conf (вы можете придумать ему более оригинальное имя). Первый — это своего рода заглушка, необходимая для подстановки значений переменных, макросов и коннекшенов Airflow в Jinja-шаблоны при локальном запуске. Второй — это файл с таким же конфигом таски, какой будет использоваться в Airflow.
Пример заполнения airflow_builtins.conf:
airflow-macros {
ds = "2023-03-22"
}
airflow-vars {
HIVE_DB_DERIVATIVES = "derivatives_db"
}
airflow-connections {
connection_id {
conn_type = "conn_type"
host = "host"
login = "login"
password = "password"
schema = "schema"
port = "port"
extra_dejson {
extra__jdbc__drv_clsname = "oracle.jdbc.driver.OracleDriver"
extra_connection_type = "service_name"
}
}
}Также во время установки либы в консоль добавляется команда spark-submit-runner. Она позволяет запускать приложение локально в Docker-образе. Например, так:
spark-submit-runner -i image_name -c local_runner_confs/task_conf.conf
Если все сделано правильно, после нажатия на Enter вы увидите те же логи, что отображаются во вкладке logs в Airflow, но у себя в консоли.
Что нам это дало
Такой способ запуска приложений имеет несколько преимуществ:
Прозрачность в управлении Spark-приложениями. Теперь, когда пользователи делают Pull Request в репозиторий с конфигурациями дагов, мы понимаем, сколько ресурсов кластера они берут и с какими параметрами.
Возможность легко и быстро определить новые конфигурации и переопределить существующие. Мы можем рулить параметрами всех Spark-приложений из конфига. Это позволило включить KryoSerializer во все Spark-приложения буквально в несколько строк кода. Также мы смогли сделать механизм постепенной раскатки для массового добавления нового параметра.
-
Генерация имени Spark-приложения. Теперь не пользователь определяет, какой будет spark.name у приложения, а мы. Добавили проброску параметров name из Airflow в следующем виде <dag_name>__<task_name> — и наша Grafana показывает, какой даг в Airflow сколько ресурсов потребляет. Раньше приходилось искать это руками по коду.

Упрощение локального запуска приложений. Теперь пользователь пишет конфигурацию таски в том же формате, в каком она представлена в репозитории с конфигурациями. Это значительно уменьшило время выкатки новых приложений в прод (ТТМ). Выкатка стала представлять из себя ctrl+c ctrl+v в основной репозиторий конфигураций.
Мы довольны своим решением. Следующие шаги в наших планах — опубликовать оператор и код библиотеки на GitHub в виде opensource-провайдера для Airflow и выложить библиотеку в PyPi, как только согласуем все внутри.