

Вступление
Привет!
В данной статье я поделюсь опытом построения микросервисной архитектуры для проекта, использующего нейронные сети.
Поговорим о требованиях к архитектуре, посмотрим на различные структурные диаграммы, разберем каждый из компонентов готовой архитектуры, а также оценим технические метрики решения.
Приятного чтения!
Пару слов о задаче и ее решении
Основная идея – на основе фото дать оценку привлекательности человека по десятибалльной шкале.
В данной статье мы отойдем от описания как используемых нейронных сетей, так и процесса подготовки данных, обучения. Однако, в одной из следующих публикаций, мы обязательно вернемся к разбору пайплайна оценки на углубленном уровне.
Сейчас же мы верхнеуровнево пройдемся по пайплайну оценки, а упор сделаем на взаимодействие микросервисов в контексте общей архитектуры проекта.
При работе над пайплайном оценки привлекательности, задача была декомпозирована на следующие составляющие:
- Выделение лиц на фото
- Оценка каждого из лиц
- Рендер результата
Первое решается силами предобученной MTCNN. Для второго была обучена сверточная нейросеть на PyTorch, в качестве backbone был использован ResNet34 – из баланса «качество / скорость инференса на CPU»

Функциональная диаграмма пайплайна оценки
Анализ требований к архитектуре проекта
В жизненном цикле ML проекта этапы работы над архитектурой и автоматизацией развертывания модели, зачастую, одни из самых затратных по времени и ресурсам.

Жизненный цикл ML проекта
Данный проект не исключение – было принято решение обернуть пайплайн оценки в онлайн-сервис, для этого требовалось погрузиться в архитектуру. Были обозначены следующие базовые требования:
- Единое хранилище логов – все сервисы должны писать логи в одно место, их должно быть удобно анализировать
- Возможность горизонтального масштабирования сервиса оценки — как наиболее вероятного Bottleneck
- На оценку каждого изображения должно быть выделено одинаковое кол-во ресурсов процессора — во избежание выбросов в распределении времени на инференс
- Быстрое (пере)развертывание как конкретных сервисов, так и стэка в целом
- Возможность, при необходимости, использовать в разных сервисах общие объекты
Архитектура
После анализа требований стало очевидно, что микросервисная архитектура вписывается практически идеально.
Для того, чтобы избавиться от лишней головной боли, в качестве фронтенда был выбран Telegram API.
Для начала рассмотрим структурную диаграмму готовой архитектуры, далее перейдем к описанию каждого из компонентов, а также формализуем процесс успешной обработки изображения.
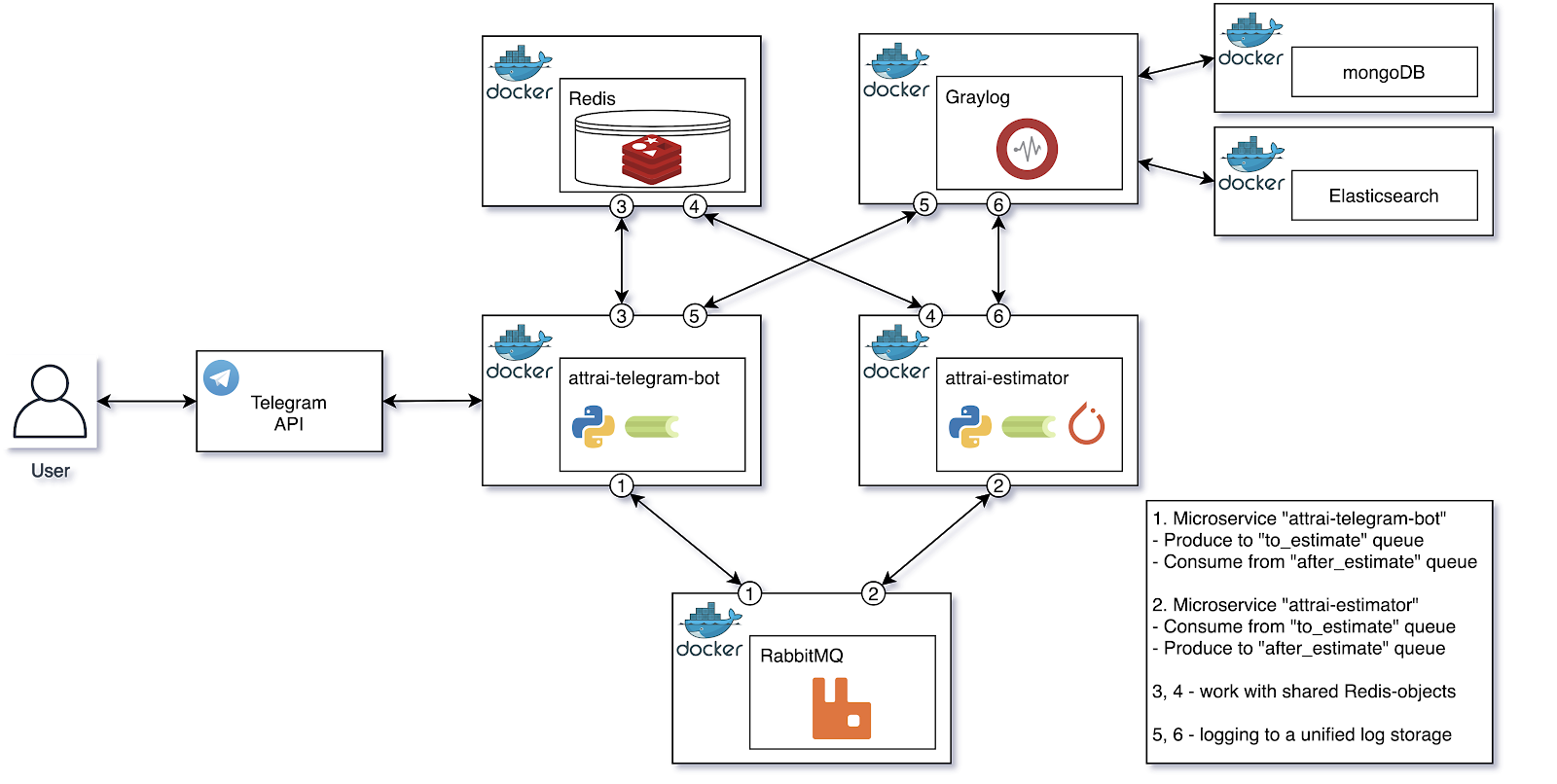
Структурная диаграмма готовой архитектуры
Поговорим подробнее о каждом из компонентов диаграммы, обозначим их Single Responsibility в процессе оценки изображения.
Микросервис «attrai-telegram-bot»
Данный микросервис инкапсулирует все взаимодействия с Telegram API. Можно выделить 2 основных сценария – работа с пользовательским изображением и работа с результатом пайплайна оценки. Разберем оба сценария в общем виде.
При получении пользовательского сообщения с изображением:
- Производится фильтрация, состоящая из следующих проверок:
- Наличия оптимального размера изображения
- Количества изображений пользователя, уже находящихся в очереди
- При прохождении первичной фильтрации изображение сохраняется в docker volume
- В очередь “to_estimate” продьюсится таска, в которой, в том числе, фигурирует путь до изображения, лежащего в нашем volume
- Если вышеперечисленные этапы пройдены успешно – пользователь получит сообщение с примерным временем обработки изображения, которое рассчитывается на основе количества тасков в очереди. В случае ошибки пользователь будет явным образом об этом оповещен – путем отправки сообщения с информацией о том, что могло пойти не так.
Также, данный микросервис, как celery worker, слушает очередь «after_estimate», которая предназначается для тасков, прошедших через пайплайн оценки.
При получении новой таски из “after_estimate”:
- Если изображение обработано успешно – отправляем результат пользователю, если нет – оповещаем об ошибке
- Удаляем изображение, являющееся результатом пайплайна оценки
Микросервис оценки «attrai-estimator»
Данный микросервис является celery worker и инкапсулирует в себе всё, что связано с пайплайном оценки изображения. Алгоритм работы тут один – разберем его.
При получении новой таски из “to_estimate”:
- Прогоняем изображение через пайплайн оценки:
- Загружаем изображение в память
- Приводим изображение к нужному размеру
- Находим все лица (MTCNN)
- Оцениваем все лица (оборачиваем найденные в прошлом пункте лица в батч и инференсим ResNet34)
- Рендерим итоговое изображением
- Отрисоваем bounding boxes
- Отрисовываем оценки
- Удаляем пользовательское (исходное) изображение
- Сохраняем выход с пайплайна оценки
- Кладем таску в очередь “after_estimate”, которую слушает разобранный выше микросервис “attrai-telegram-bot”
Graylog (+ mongoDB + Elasticsearch)
Graylog — это решение для централизованного управления логами. В данном проекте, он использовался по своему прямому назначению.
Выбор пал именно на него, а не на привычный всем ELK стэк, по причине удобства работы с ним из под Python. Все, что необходимо сделать для логирования в Graylog, это добавить GELFTCPHandler из пакета graypy к остальным root logger handlers нашего python-микросервиса.
Я, как человек, который до этого работал только с ELK стэком, в целом, получил позитивный опыт во время работы с Graylog. Единственное, что удручает – превосходство по фичам Kibana над веб-интерфейсом Graylog.
RabbitMQ
RabbitMQ — это брокер сообщений на основе протокола AMQP.
В данном проекте он использовался как наиболее стабильный и проверенный временем брокер для Celery и работал в durable режиме.
Redis
Redis — это NoSQL СУБД, работающая со структурами данных типа «ключ — значение»
Иногда возникает необходимость использовать в разных python-микросервисах общие объекты, реализующие какие-либо структуры данных.
Например, в Redis хранится hashmap вида «telegram_user_id => количество активных тасок в очереди», что позволяет ограничить количество запросов от одного пользователя определенным значением и, тем самым, предотвратить DoS-атаки.
Формализуем процесс успешной обработки изображения
- Пользователь отправляет изображение в Telegram бота
- «attrai-telegram-bot» получает сообщение от Telegram API и разбирает его
- Таск с изображением добавляется в асинхронную очередь «to_estimate»
- Пользователь получает сообщение с планируемым временем оценки
- «attrai-estimator» берет таск из очереди «to_estimate», прогоняет через пайплайн оценки и продьюсит таск в очередь «after_estimate»
- «attrai-telegram-bot», слушающий очередь «after_estimate», отправляет результат пользователю
DevOps
Наконец, после обзора архитектуры, можно перейти к не менее интересной части — DevOps
Docker Swarm

Docker Swarm - система кластеризации, функционал которой реализован внутри Docker Engine и доступен из коробки.
При помощи «роя», все ноды нашего кластера можно разделить на 2 типа – worker и manager. На машинах первого типа разворачиваются группы контейнеров (стэки), машины второго типа отвечают за скалирование, балансировку и другие классные фичи. Менеджеры по умолчанию являются и воркерами.
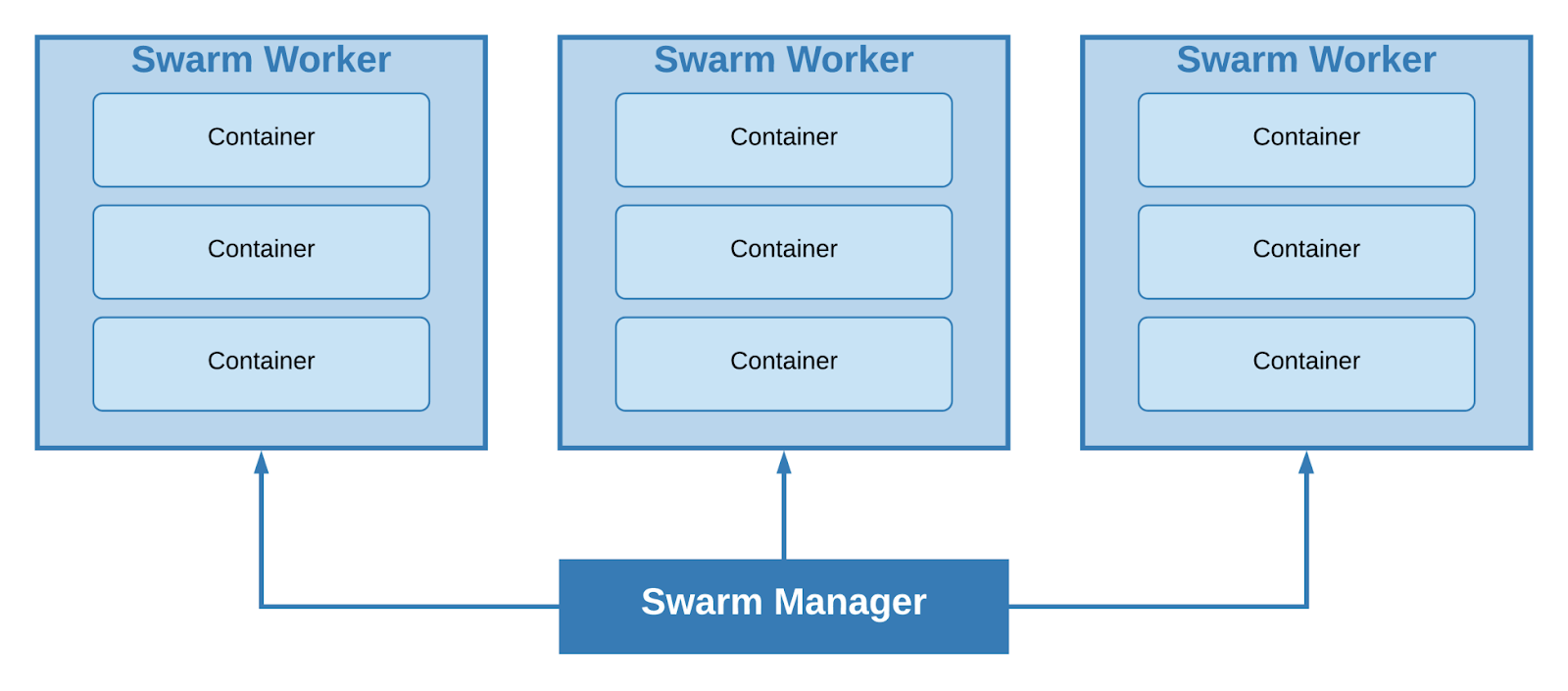
Кластер с одним leader manager и тремя worker
Минимально возможный размер кластера – 1 нода, единственная машина будет одновременно выступать как leader manager и worker. Исходя из размера проекта и минимальных требований к отказоустойчивости, было принято решение использовать именно этот подход.
Забегая вперед, скажу, что с момента первой production-поставки, которая была в середине июня, проблем, связанных с данной организацией кластера, не было (но это не значит, что подобная организация хоть сколько-нибудь допустима в любых средне-крупных проектах, на которые накладываются требования по отказоустойчивости).
Docker Stack
В режиме «роя» за развертывание стэков (наборов docker services) отвечает docker stack
Он поддерживает docker-compose конфиги, позволяя дополнительно использовать deploy параметры.
Например, при помощи данных параметров были ограничены ресурсы на каждый из инстансов микросервиса оценки (выделяем на N инстансов N ядер, в самом микросервисе ограничиваем кол-во ядер, используемое PyTorch`ем, одним)
attrai_estimator:
image: 'erqups/attrai_estimator:1.2'
deploy:
replicas: 4
resources:
limits:
cpus: '4'
restart_policy:
condition: on-failure
…Важно отметить, что Redis, RabbitMQ и Graylog — stateful сервисы и масштабировать их так же просто, как «attrai-estimator», не получится
Предвещая вопрос — почему не Kubernetes?
Кажется, что использование Kubernetes в проектах маленького и среднего размера – оверхед, весь необходимый функционал можно получить от Docker Swarm, который довольно user friendly для оркестратора контейнеров, а также имеет низкий порог вхождения.
Инфраструктура
Развертывалось это все на VDS со следующими характеристиками:
- CPU: 4 ядра Intel® Xeon® Gold 5120 CPU @ 2.20GHz
- RAM: 8 GB
- SSD: 160 GB
После локального нагрузочного тестирования, казалось, что при серьезном наплыве пользователей, данной машинки будет хватать впритык.
Но, сразу после деплоя, я запостил ссылку на одну из самых популярных в СНГ имиджборд (ага, ту самую), после чего люди заинтересовались и за несколько часов сервис успешно обработал десятки тысяч изображений. При этом в пиковые моменты ресурсы CPU и RAM не были использованы даже наполовину.

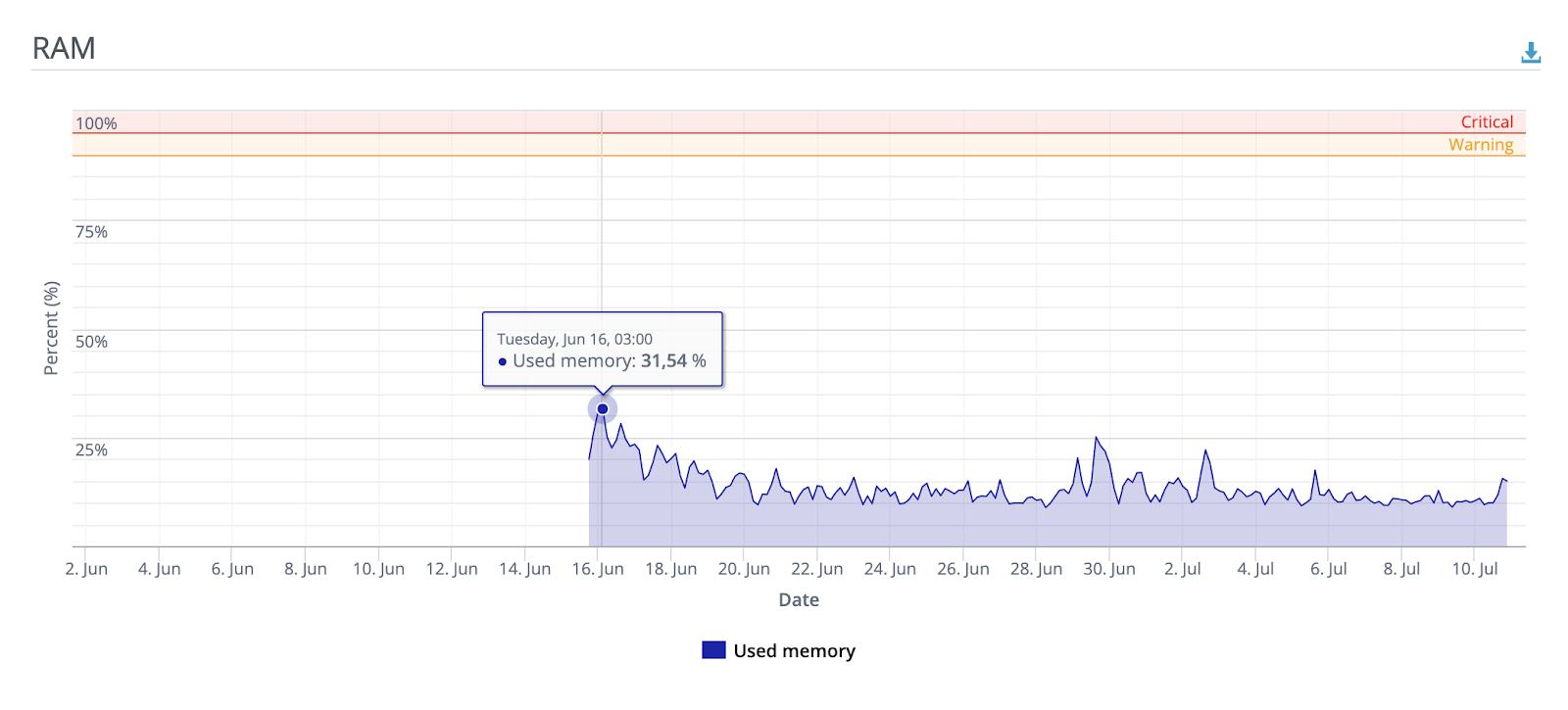
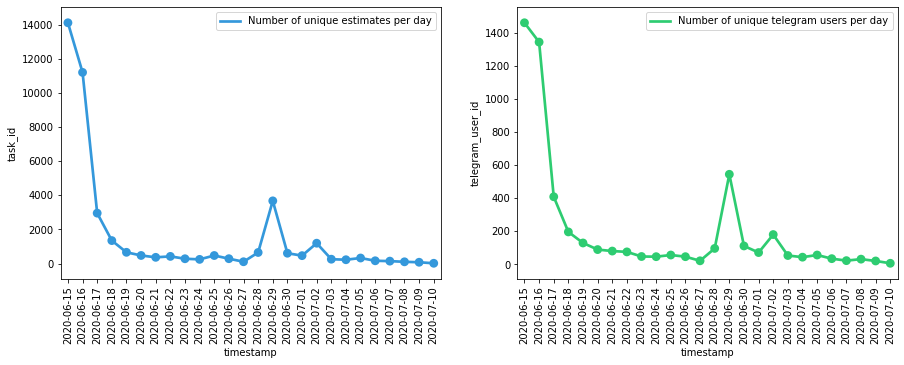
Еще немного графики
Количество уникальных пользователей и запросов на оценку, с момента деплоя, в зависимости от дня
Распределение времени инференса пайплайна оценки

Выводы
Резюмируя, могу сказать, что архитектура и подход к оркестрации контейнеров полностью себя оправдали — даже в пиковые моменты не было падений и проседаний по времени обработки.
Думаю, проекты маленького и среднего размеров, использующие в своем процессе реалтайм инференс нейронных сетей на CPU, успешно могут перенять практики, описанные в данной статье.
Добавлю, что изначально статья была больше, но, дабы не постить лонгрид, решил некоторые моменты в данной статье опустить — вернемся к ним в следующих публикациях.
Потыкать бота можно в Telegram — @AttraiBot, работать будет, как минимум, до конца осени 2020 года. Напомню — никакие пользовательские данные не хранятся — ни исходные изображения, ни результаты пайплайна оценки — все сносится после обработки.
Matshishkapeu
Если на двух приведенных картинках 7.71 и 5.46 это показатель няшности, можно запостить несколько примеров с оценкой >9.5 и <2.5?
morozovsk
Тоже стало интересно, поэтому загуглил «самая красивая девушка» — нашёл мисс вселенную и загуглил «самая страшная девушка» — нашёл рекордсменку из книги рекордов Гиннесса (но это не точно).
anonymous Автор
Первая картинка ~200x200, кроп лица еще меньше. Попробуйте загрузить изображение с приемлемым разрешением.
Начет второго — боюсь, в таких случаях сетка и правда может работать не совсем корректно, т.к в обучающей выборке были лица «обычных» людей. Тем не менее, 5.41 — это меньше, чем 10-й перцентиль по обучающей выборке (распределение оценок при этом гауссово, но немного «сдвинуто» вправо).
Третье, с вашего позволения, комментировать не буду :)
morozovsk
Ок, взял фотку с википедии побольше.
Matshishkapeu
Ну теперь то у мисс мира хотя бы выше чем у официально самой страшной, было же меньше :)
morozovsk
Это просто у самой страшной теперь разрешение фотки ниже :)
Matshishkapeu
Алгоритм ширину фотки в пикселях на 100 делит?
Matshishkapeu
Но все еще уступает по няшности Валуеву. Он, конечно, красавчик, но любим все таки не за это. Опять же если мисс мира не дотягивает внешностью до боксера-тяжеловеса, это какой-то альтернативный конкурс красоты.
alexey_c
Но здесь, на конкретно этом фото, дейтвительно, если скропить только лицо и убрать серьги, то эта «мисс» сильно похожа на мужика.
Что даёт к её привлекательности минус 100500%
Matshishkapeu
Трансвестит, ну если не знать, кабы не симпатишнее мисс мира (кто ее выбрал?). К слову самой страшноватой красавицей пока признан паренек в боковом мониторе слева от трансвестита, по шкале женской сипатишности ему дали 4.
morozovsk
Причём если просто мужиков загружать, то оценка не выставляется. А здесь его на стене нашло и оценило :)
anonymous Автор
На самом деле сетка и мужчин оценивает. В обучающей выборке у мужчин и женщин равная доля. Вероятно, в вашем случае просто face detection не сработал.
Matshishkapeu
Не-не-не, если не оценило то просто качество низкое. Вот у меня брутального Карелина посчитало нечеловечески (Ubermensch?) брутальным, вот а Валуева выше вполне себе сьела, больше чем Мисс-Мира баллов получил.
morozovsk
Итоги моего эксперимента.
Алгоритм на первое место ставит толирантность и политкорректность:
самая страшная женщина мира — 9,15
трансвистит — 8,47
чернокожая женщина — 7,21
мисс вселенная — 5,78
PS: зато не засудят :)
PPS: за статью всё равно спасибо, особенно за телеграмм-бота. Всем бы так делать демки. Ловите 3 плюса.
Matshishkapeu
Может это не оценка, а штрафные балы? Или там гандикап, который надо прибавлять к объективной оценке выданной безжалостным искусственным интеллектом?
anonymous
Не думаю, что алгоритм обращает внимание на цвет кожи — скорее всего, картинки перед «оценкой» становятся черно-белыми.
ramzes2
Вообще не понятно, на каких данных учили, как размечали и что эти оценки значат? Возможно тут классический garbage in — garbage out.
algotrader2013
Да. Намного интереснее было бы почитать о том, как датасет собрали, чем почему docker-swarm вместо k8s и подробные штуки.
Задача ведь реально нетривиальная. База условного тиндера с фотками и историей лайков была бы кстати, но фиг достанешь (хотя, хз, может в слитых базах Ashley Madison и были фотки).
Наверное, сразу ещё приходит мысль инстаграм парсить, но, тоже, очень сомнительная тема. Там лайкают далеко не за идеальность лица
adictive_max
El_Kraken_Feliz
Самой красивой девушкой тогда будет кот же!
adictive_max
Не, кот будет, если обучать на видео с ютуба.
anonymous Автор
Ответил на вопрос о структуре обучающей выборки в другой ветке.
anonymous
Интересна другая сторона сервиса)
Как отреагируют некоторые слои населения на то, что нейросеть поставила низкие оценки их внешности и позволят ли это выкатить на рынок?
В телеграме это, конечно, возможно, но скорее всего многие активисты не оценят такую инициативу)
algotrader2013
Да, это боль последних лет. Общество неблагодарно. Делаешь бесплатную фичу по распознаванию фоток и их описанию, описываешь людям сотни миллионов фоток, но стоит на одной фотке афроамериканцев дать описание "гориллы", как тебя заваливает говном пол интернета
anonymous
Не совсем понятно, как делалось обучение сети. Как делалась изначальная разметка данных? Привлекательность — это ну очень субъективный параметр, один человек скажет 4, другой 8, кто прав?
anonymous Автор
Хотел уделить время на описание таких подробностей в следующей публикации, но что-то уж слишком много вопросов по даней теме.

Обучающая выборка основана на кропах лиц из публичного некоммерческого датасета “SCUT-FBP5500”, который был обогащен дополнительными данными для привидения распределения оценок к нормальному. Дополнительные данные были получены, в основном, при помощи Semi-supervised подхода (обучаемся на датасете -> скорим картинки без рейтинга -> самые адекватные добавляем в обучающую выборку -> замеряем метрики на тестовой выборке -> если необходимо, повторяем цикл)
Насчет субъективности — вы абсолютно правы, но все-таки есть определенные “стандарты красоты”, навязываемые обществом. Например, датасет, о котором я писал выше, основан на перекрестной оценке (N разметчиков разных полов, каждый из них оценивает каждое фото в выборке) и позволяет увидеть следующую картину:
algotrader2013
5500 фоток всего, из которых 4000 это азиаты, — да, ниочем. Понятно, почему результаты столь слабые
morozovsk
Спасибо за развёрнутый ответ.
Mobile1
Хороший, добрый бот…

5.11 — обычная внешность: