
В этой статье я хочу рассказать об алгоритме, который помогает ответить на извечный вопрос всех проектов:
Когда проект будет закончен?
Более формально проблема звучит так: "Проект состоит из задач, которые могут зависеть друг друга, а также могут иметь один и тех же исполнителей. Когда проект может быть закончен?"

Небольшая предыстория
С прошлого года я работаю в роли техлида. В моменте я отвечал за 3 различных проекта в команде с 11 разработчиками, 2 продактами, 2 дизайнерами и рядом смежников из других отделов. Проекты крупные, один из них, например, к запуску содержал около 300 тикетов.
Для работы с задачами мы используем Яндекс.Трекер. Увы, Трекер не содержит инструментов, которые могут дать ответ на извечный вопрос: "Когда?". Поэтому время от времени мы руками синхронизируем задачи с Omniplan, что увидеть общую картину по срокам. Оказывается, этот инструмент решает практически все наши проблемы планирования. Самая полезная для нас фича — это авто-планирование задач таким образом, чтобы ни один сотрудник не был загружен единовременно больше чем на 100%.
Однако, Omniplan имеет свои минусы:
- Медленная и ненадежная синхронизация между членами команды, основанная на модификации локальной копии.
- Только для MacOS
- Довольно непросто синхронизировать с внешним трекером
- Дороговат: $200 или $400 за Pro редакцию.
Я решил попробовать сделать свой собственный Omniplan c блэкджеком и пр.:
- Работает в вебе
- Простая синхронизация с нашим трекером
- Real-time совместная работа над проектом
Самая веселая часть — это разработка алгоритма авто-планирования задач. Я изучил довольно много других сервисов и не понимал, почему только Omniplan имеет эту жизненно важную фичу. Теперь понимаю.
Предварительные исследования
Итак, не найдя подходящих сервисов, я решил написать свой сервис с функцией авто-планирования задач. Мне нужно было уметь импортировать задачи из нашего трекера и планировать их таким образом, чтобы у разработчиков не было загрузки больше 100%.
Для начала я поисследовал вопрос, ведь всё уже придумано до нас.
Нашел довольно много информации про диаграммы Ганта, PERT, но не нашел ни одной работы про реализацию нужного мне алгоритма.
Затем поискал open-source библиотеки и нашел только одну: Bryntum Chronograph. Похоже, это было то, что нужно! У них даже есть бенчмарки. Но, честно говоря, я вообще не понял код этого решения, и отсутствие документации также не сильно помогло. В общем, надо писать свое.
Как всегда, сначала я попробовал изобразить проблему.
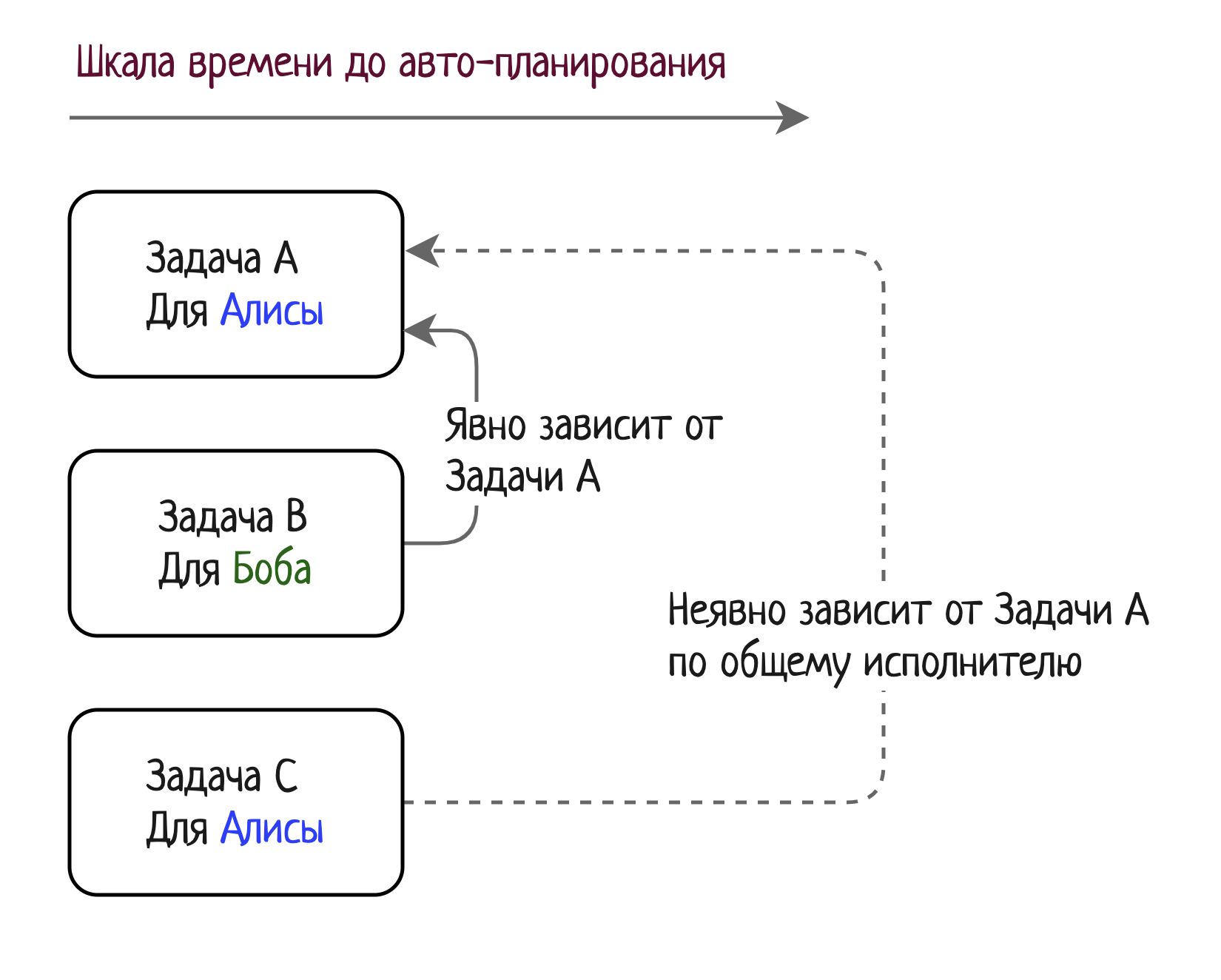
Пока я рисовал картинку, меня осенило: а ведь задачи можно представить как направленный граф, где ребра — это не только явные зависимости между задачами, но и неявные. Неявные зависимости появляются из-за того, что на разные задачи может быть назначен один и тот же исполнитель.
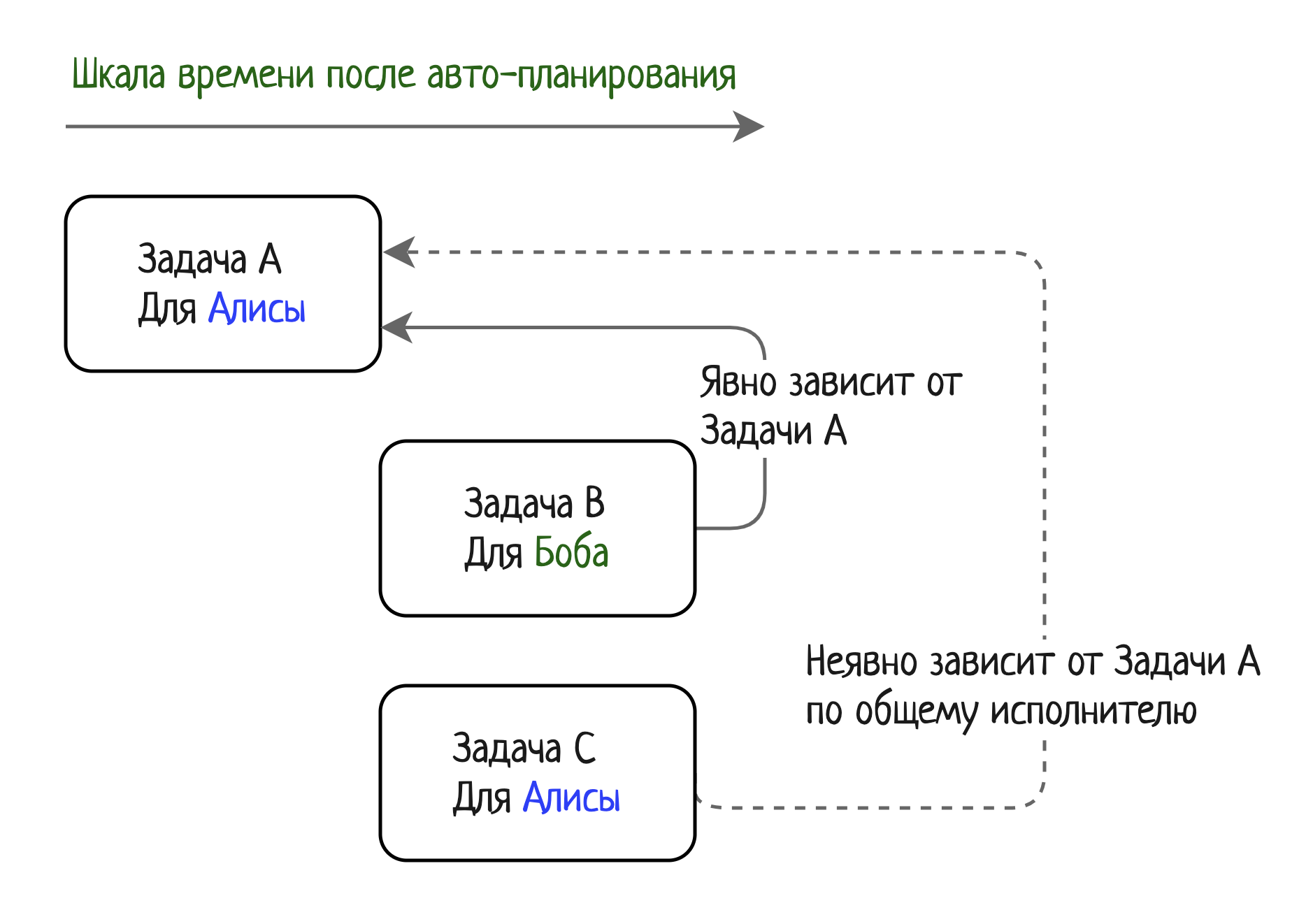
Алгоритм должен привести к такой расстановке задач во времени:
Анатомия задачи
Давайте рассмотрим, из чего состоит задача:
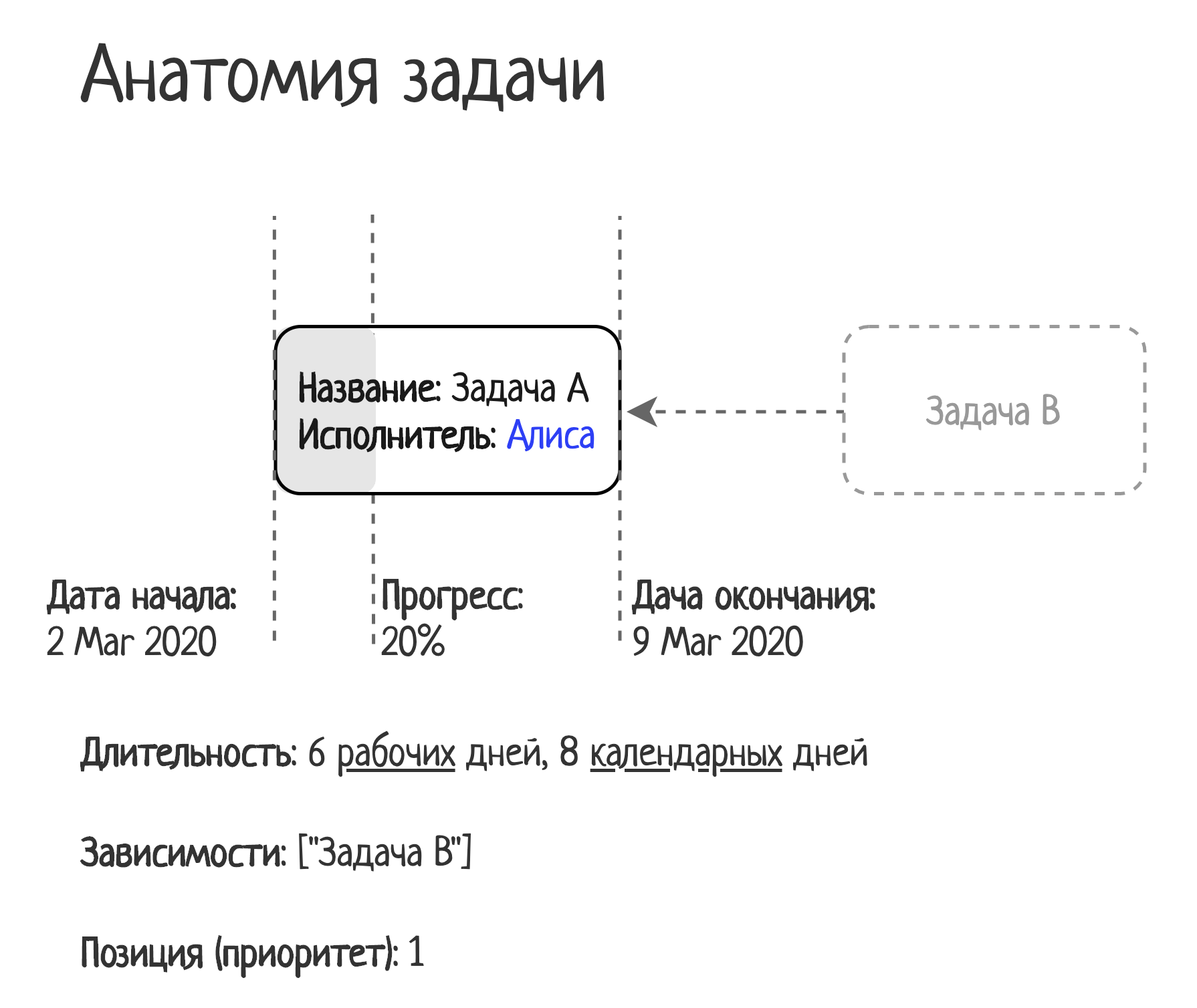
Есть ряд на таких уж очевидных свойств у задачи:
- Длительность. Задача выполняется только в рабочие дни. Оценка задачи — число рабочих дней. В этом примере задача стартует 2 марта, имеет оценку в 6 рабочих дней и её выполнение заканчивается 9 марта. Важно, что не 7 Марта, т.к. 7 и 8 марта — выходные.
- Приоритет задачи. Будем считать, что чем выше позиция задачи в списке, тем раньше она должна быть сделана, другими словами она более приоритетна.
- Прогресс выполнения. Прогресс в процентах отражает выполненную часть задачи. Фактически это число дней, которые уже потратили на задачу. Например, если оценили задачу в 4 дня, а ее прогресс 75%, значит задачу осталось делать 1 день.
В нотации Typescript задача выглядит следующим образом:
export type Task = {
id: ID; // ID — alias for string
title: string;
start: Date;
end: Date;
duration: number;
position: number; // Приоритет
progress: number;
resourceId: ID;
dependencies?: ID[];
};Алгоритм
Алгоритм должен менять начальную и конечную даты задач следующим образом:
- Задачи должны начинаться от текущего дня, если это возможно.
- Задачу невозможно начать сегодня, если есть другие незавершенные задачи, от которых она зависят, явно или неявно. Таким образом задача должна начаться сразу после того, как все предварительные задачи закончатся.
На практике алгоритм состоит из следующих шагов:
1) Сначала построим граф задач. Создадим ребра с учетом явных зависимостей или неявных по общему исполнителю.
/**
* Graph respects explicit dependencies
* and implicit by resources (via positions)
*/
export const makeGraphFromTasks = (tasks: Task[]): Graph => {
const graph: Graph = new Map();
const resources = new Map<ID, Task[]>();
// add edges for deps by resourceId and explicit dependencies
for (const t of tasks) {
const tasksForResource = resources.get(t.resourceId) ?? [];
tasksForResource.push(t);
resources.set(t.resourceId, tasksForResource);
graph.set(t.id, new Set(t.dependencies ?? []));
}
for (const tasksForResource of resources.values()) {
// sort by position
tasksForResource.sort((a, b) => a.position - b.position);
// add to graph such edges so first node has second as dependency
let prevTask: Task | undefined;
for (const task of tasksForResource) {
if (prevTask) {
graph.get(prevTask.id)?.add(task.id);
}
prevTask = task;
}
}
return graph;
};2) Сделаем обратный (транспонированный) граф. Этот граф нам поможет найти стоки (вершины только с входящими ребрами), истоки (вершины только с исходящими ребрами) и изолированные вершины (без ребер).
Для прохода по всем вершинам воспользуемся поиском в глубину. Я привел универсальную функцию-генератор для прохождения по графу.
export const makeReverseGraph = (graph: Graph): Graph => {
const reverseGraph: Graph = new Map();
for (const [id, parentId] of dfs(graph, { withParentId: true })) {
const prerequesitions = reverseGraph.get(id) ?? new Set();
if (parentId) {
prerequesitions.add(parentId);
}
reverseGraph.set(id, prerequesitions);
}
return reverseGraph;
};
/**
* Iterate over every node.
* If withParentId = true, than it is possible to visit same not more then once
* @yields {[string, string?]} [nodeId, parentNodeId?]
*/
export function* dfs(
graph: Graph,
options: { withParentId: boolean } = { withParentId: false }
): Generator<readonly [string, string?], void, void> {
const visited = new Set<ID>();
// DFS interative
// iterate over all nodes in case of disconnected graph
for (const node of graph.keys()) {
if (visited.has(node)) {
continue;
}
const stack: ID[] = [node];
while (stack.length > 0) {
const currentNode = stack.pop();
assertIsDefined(currentNode);
yield [currentNode];
visited.add(currentNode);
const dependencies = graph.get(currentNode);
if (!dependencies) {
continue;
}
for (const dependencyId of dependencies) {
if (options.withParentId) {
// possible to yield same nodeId multiple times (needed for making reverse graph)
yield [dependencyId, currentNode];
}
if (visited.has(dependencyId)) {
continue;
}
stack.push(dependencyId);
}
}
}
}
export const makeReverseGraph = (graph: Graph): Graph => {
const reverseGraph: Graph = new Map();
for (const [id, parentId] of dfs(graph, { withParentId: true })) {
const prerequisites = reverseGraph.get(id) ?? new Set();
if (parentId) {
prerequisites.add(parentId);
}
reverseGraph.set(id, prerequisites);
}
return reverseGraph;
};
/**
* Iterate over every node.
* If withParentId = true, than it is possible to visit same not more then once
* @yields {[string, string?]} [nodeId, parentNodeId?]
*/
export function* dfs(
graph: Graph,
options: { withParentId: boolean } = { withParentId: false }
): Generator<readonly [string, string?], void, void> {
const visited = new Set<ID>();
// DFS interative
// iterate over all nodes in case of disconnected graph
for (const node of graph.keys()) {
if (visited.has(node)) {
continue;
}
const stack: ID[] = [node];
while (stack.length > 0) {
const currentNode = stack.pop();
assertIsDefined(currentNode);
yield [currentNode];
visited.add(currentNode);
const dependencies = graph.get(currentNode);
if (!dependencies) {
continue;
}
for (const dependencyId of dependencies) {
if (options.withParentId) {
// possible to yield same nodeId multiple times (needed for making reverse graph)
yield [dependencyId, currentNode];
}
if (visited.has(dependencyId)) {
continue;
}
stack.push(dependencyId);
}
}
}
}3) Посетим каждую вершину графа (задачу) и обновим даты начала и конца. Посещение вершин должно начинаться с задач с более высоким приоритетом.
Если задача — исток (не зависит от других задач и у исполнителя нет других задач, которые нужно сделать раньше) или если задача — это изолированная вершина (нет зависимостей и сама задача не является зависимостью), то начинаем задачу сегодня.
В противном случае у задачи есть предварительные задачи и она должна начаться в момент когда закончатся все предварительные задачи.
Также важно корректно обновлять даты окончания задач в момент, когда меняем дату начала задачи. Надо учитывать выходные дни и текущий прогресс выполнения задачи.
Ниже по коду встретите отсылку к алгоритму Беллмана-Форда. Тут используется похожая техника: запускаем алгоритм обновления дат начала и конца задач до тех пор, пока даты не перестанут меняться.
export const scheduleTasks = (tasks: Task[], today?: Date) => {
const graph = makeGraphFromTasks(tasks);
const tasksById = tasks.reduce((map, task) => {
map[task.id] = task;
return map;
}, {} as { [id: string]: Task });
// @TODO: 0. Detect cycles, if present throw error
// 1. Make reverse graph, to detect sinks and sources
const reverseGraph = makeReverseGraph(graph);
// 2. If node is source, t.start = max(today, t.start)
// Repeat until dates remains unchanged, max graph.size times.
// Similar to optimization in Bellman-Ford algorithm
// @see https://en.wikipedia.org/wiki/Bellman–Ford_algorithm#Improvements
for (let i = 0; i <= graph.size; i++) {
let datesChanged = false;
for (const [id] of dfs(graph)) {
const t = tasksById[id];
const isSource = reverseGraph.get(id)?.size === 0;
const isSink = graph.get(id)?.size === 0;
const isDisconnected = isSource && isSink;
if (isSource || isDisconnected) {
datesChanged = updateStartDate(t, today ?? new Date());
} else {
const prerequesionsEndDates = Array.from(
reverseGraph.get(id) ?? []
).map((id) => tasksById[id].end);
datesChanged = updateStartDate(
t,
addBusinessDays(max(prerequesionsEndDates), 1)
);
}
}
if (datesChanged === false) {
break;
}
}
return tasks;
};
/**
* Update task dates, according to startDate change
* @returns false if date didn't change, true if it changed
*/
export const updateStartDate = (task: Task, startDate: Date) => {
const correctedStartDate = shiftToFirstNextBusinessDay(startDate);
const daysSpent = Math.floor(task.duration * task.progress);
const newStartDate = subBusinessDays(correctedStartDate, daysSpent);
if (isEqual(task.start, newStartDate)) {
return false;
}
task.start = subBusinessDays(correctedStartDate, daysSpent);
// -1 because every task is minimum 1 day long,
// say it starts and ends on same date, so it has 1 day duration
task.end = addBusinessDays(task.start, task.duration - 1);
return true;
};Что можно улучшить
- Обнаружение циклических зависимостей. Если задача А зависит от задачи Б и задача Б зависит от задач А, то в графе есть циклическая зависимость. Пользователи должны сами вручную разруливать эти проблемы, а нам надо только явно сказать, где она найдена. Это известный алгоритм, который надо запустить после получения графа задач, однажды я его туда добавлю.)
- Потенциально, одна из наиболее важных функций — это добавление желаемой даты старта задачи. Если однажды это все вырастет в веб-сервис, думаю, это нужно будет сделать в первую очередь. Сейчас это можно примерно поправить, выставив правильный приоритет у задач.
- Для полноценного решения также надо добавить поддержку отпусков и праздников. Думаю, это несложно будет добавить в функцию updateStartDate.
- Использование одного дня в качестве наименьшего кванта времени хорошо подходит для моих задач. Но кому-то может быть важно использовать почасовое планирование.
Заключение
Код с тестами вы можете найти на моем GitHub. Можно скачать как NPM-пакет. Еще некий Дастин зачем-то переписал его на Rust :)
Интересно, есть ли какие-то ошибки в предложенном алгоритме. С удовольствием с вами это обсужу тут или в issues секции на GitHub.


Ndochp
А про автовыравнивание ресурсов в MSПроджекте не вспоминалось? хотя денег хотят много.
Кстати, у вас задачи могут рваться?
Например:
у Алисы задача А:3дня и задача С:10 дней
у Боба Б:2 дня, но от неё зависит А
Алиса будет:
1. 2 дня балду пинать, а потом возмется за А
2. будет делать 2 дня С, потом А, потом С
3. Сделает С целиком, потом возьмется за А
Ну и я бы получив граф задач ходил не по нему, а по исполнителям/квантам времени(далее — датам) — в конце концов их надо работой загрузить. (неявные зависимости в этом случае не нужны)
1. Отсортировать пары исполнитель/дата по дате
2. Для текущей верхней пары выбрать задачи исполнителя без входящих связей
3. Назначить на дату самую приоритетную
4. Сократить ей время на день
5. Если задача завершилась, убрать из графа
6 GOTO 2 если граф не пуст.
Как вариант условие выхода — достижение горизонта планирования. Тогда можно отвечать на вопрос «а что вы успеете за месяц»
sky2high0 Автор
Да, точно, в MS Project тоже такое умеет! Забыл упомянуть, т.к. на маке уже не первый десяток лет работаю, а там MS Project нет.
Разрыв задачи — интересная штука. На практике, правда, редко когда так делаем, т.к. уходит дополнительное время на переключения, да и сами задачи стараемся короче формулировать. Поэтому сильно про такую штуку не думал.
В вашем алгоритме надо еще как-то отслеживать занятость исполнителя и временные сроки. Кажется, это довольно все усложнит.
Ndochp
Занятость исполнителя надо отслеживать в любом случае. Мы же ради этого алгоритм делаем. У меня описание конечно под разрыв задач сделано.
Какие сроки нужно отслеживать? (да, мой алгоритм только под явные связи начало — окончание и задачи начинать "как можно раньше" под экзотику нужно доделывать, но кажется не сильно усложнит)
Если задачи не рвем, то можно по исполнителям сделать иначе:
1 если таких нет, то дата освобождения сдвигается на день (квант) го 2
2 Назначить самую приоритетную задачу
По сути работаем с 3 объектами:
sky2high0 Автор
На шаге 5 «Исключить назначенную задачу из графа» получается будут теряться зависимости между задачами, разве нет? Типа Задача Б зависит от Задачи А. Задачу А отдали Васе и, получается, можно Оле сразу отдать задачу Б, а ведь надо дождаться окончания А сначала.
Ndochp
Угу…
Значит поле "начинать не раньше" для задачи нужно обязательно. Так разговоры кончатся тем, что напишу таки свой вариант "в железе". Давно задумывался, уж больно проджект дорог в проф варианте.