
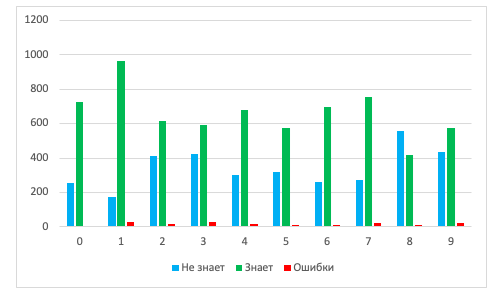
Мы, небольшая команда разработчиков одного из отделов компании ЯКурьер, очень хотели внести свою лепту в стремительно развивающееся пространство беспилотных технологий. Купили Prius для экспериментов, немного периферии, задумали свою фишечку с сосредоточением внимания интеллектуальной системы, имитирующим внимание водителя. Начали. И что же интеллектуальная система компьютерного зрения сама и вместе с ней «подинтеллектуальная» система, обеспечивающая детекцию новизны, то есть это самое внимание?
TensorFlow или что-то похожее – готовое? Несколько экспериментов дают понять, что для динамических многофакторных случаев с перестройками входных массивов, множеством подзадач, явной неопределенностью множества классов распознаваемых данных, неизбежной масштабируемостью системы в течение разработки, с желанием внести свои авторские свёртки и слои вариант «всё готовенькое», как ни странно, требует пота, крови, бюджетов и разочарований от ошибок на первых шагах, которые всё портят, и которые уже не исправишь (разве что надоедливыми костылями). А так как мы команда довольно наивная, то решили сыграть по-своему. Есть мнение, что дело не в TensorFlow, а в реализуемой им технологии, и нам удастся что-то упростить, что-то улучшить, а что-то вовсе изменить.
Поговорим сперва о подходах к классификации и распознаванию образов, уверены вы все о них знаете, но куда же без подводки. Будем придерживаться более человечных абстракций и визуализаций взамен разговора на строгом математическом языке и возьмём отвлеченный случай распознавания условных огурцов и помидоров.
Классификация и распознавание образов
Явно опустив методы извлечения каких-либо признаков подопытных объектов, рассмотрим случай, когда мы чудесно умеем измерять два из них: цвет (от красного через желтый до зеленого) и эллиптичность формы (как отношение осей). Сказав «измерять», любой инженер подразумевает, что умеет явно сопоставить признаку/явлению/величине число, а, так как у нас их два, и они достаточно независимые, то есть цвет не может свидетельствовать о форме, мы можем изобразить прямоугольную систему координат и говорить о точках или векторах в ней, соответствующих своим цвету x_1 и форме x_2.
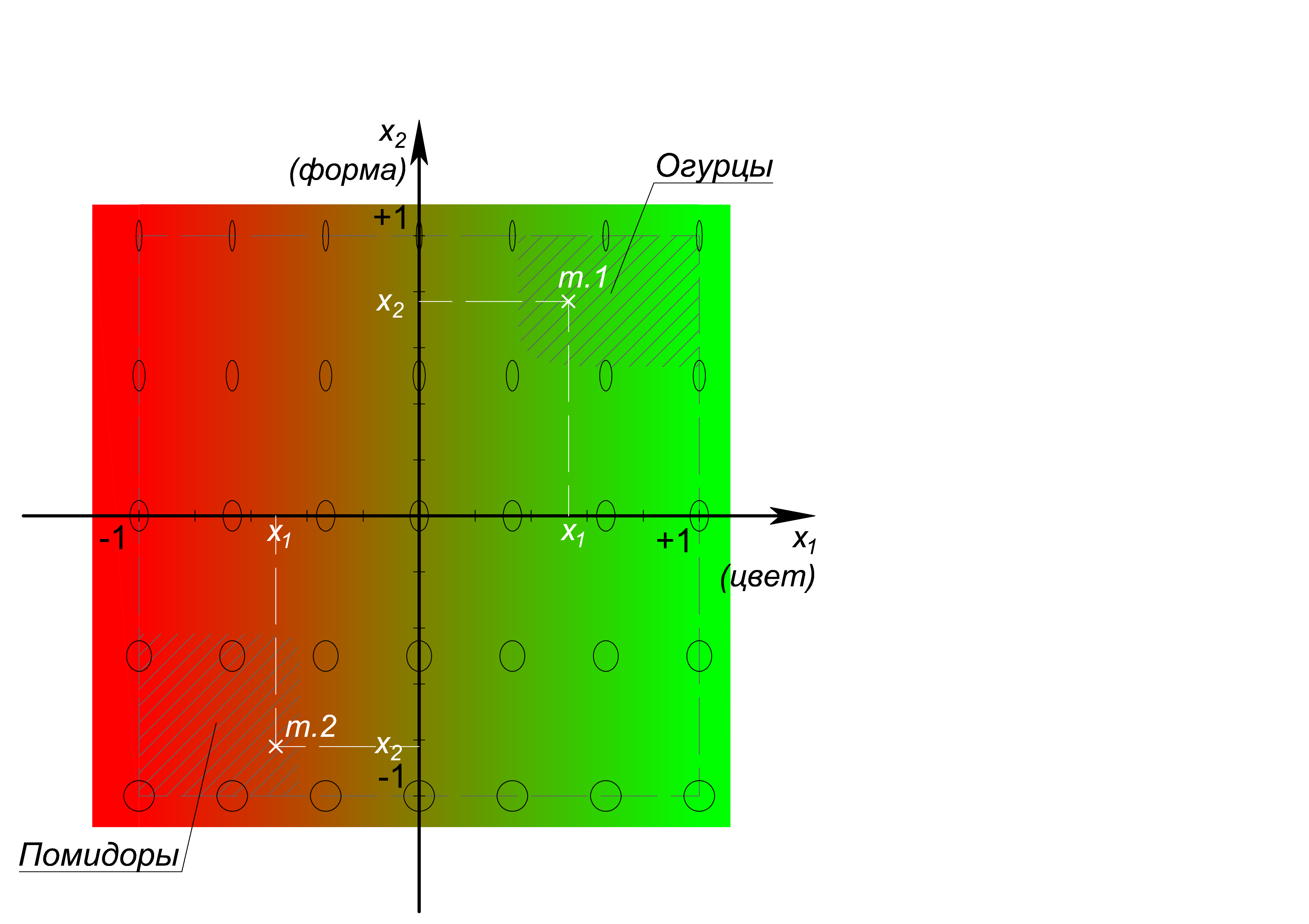
Итак, по цвету, отложенному вдоль x_1: красному соответствует значение (-1), зеленому (+1); по форме вдоль x_2: кругу соответствует значение (-1), эллипсу с коэффициентом сжатия (эллиптичностью) 1/5 соответствует (+1). В представленных координатах явно выделяются область огурцов – справа, вверху и область помидоров – слева, внизу. То есть объект, измерение которого, дает результат по двум нашим признакам, а равно точку с координатами, например, точки 1 рисунка {(x_1=0,53@x_2=0,77)} – мы уверенно относим к классу огурцов, а объект с признаковыми координатами точки 2 рисунка {(x_1=-0,51@x_2=-0,82)} – к классу помидоров.
На всякий случай упомянем, что распознаванием является вовсе не измерение цвета и формы, а определение к какой области – классу – в системе координат признаков относятся полученные 2 бездушных числа. Кажется, что задача банальная, но её, во-первых, нужно решать вычислениями а, во-вторых, например, в случае с непосредственной классификацией объектов на изображениях, где за отдельные признаки принимаются яркости отдельных пикселей, у нас может оказаться, ну, пусть, 900 (30х30 px) чисел и осей, и мы очутимся не на плоскости в 900-мерном пространстве. Плюс, если так присмотреться, в нашем примере непосильную сложность представляют необходимые предзадачи измерения цвета и формы, которые должны сворачивать многомерность реальных объектов на плоскость (заметили, здесь этот глагол не случаен).
Что же здесь ещё ключевого? Ясно, что прежде чем разделять классы необходимо определиться с их количеством и формой ограничивающих областей. Подходы к такому определению мы не рассматриваем, нам интересно, каковыми они окажутся на реальных объектах и различных совокупностях признаков, можно ли ожидать каких-то закономерностей? Это важно, чтобы выделить общие, удобные для большинства случаев сепарационные алгоритмы и функции. Можно догадываться, что воля автора в выборе таковых и их настройке практически не ограничена. На рисунке далее, слева направо, показано лишь небольшое разнообразие сепараторов: линейная ортогональная совокупность, оптимизируемая по положениям вдоль осей, нелинейная совокупность, оптимизируемая по параметрам различных нелинейных функций и по их вариациям, и совокупность окружностей, оптимизируемая по положениям центров и радиусам:
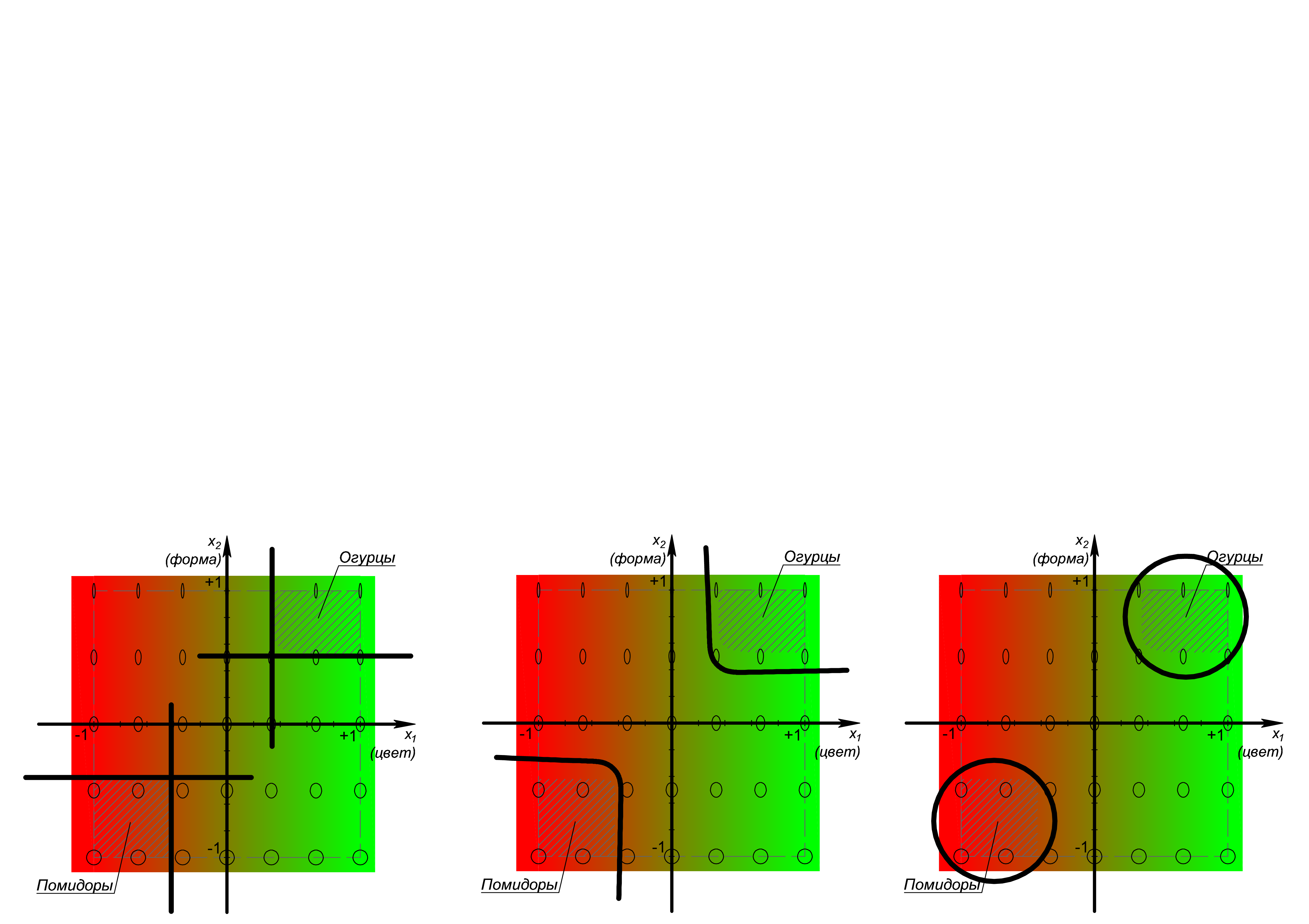
Линии могут быть усложнены до аналогичных поверхностей, поверхности до тел в 4-хмерных пространствах, и т.д. до N-мерных пространств.
Персептрон и первичные нейронные сети II-го поколения
Перейдём на некоторое время к классическому персептрону, являющемуся общим случаем линейного сепаратора, из которого состоит подавляющее большинство нейронных сетей у нас на слуху. Терминологически, персептрон, в целом, и считают основной разновидностью нейрона. Взглянем на решающую границу и вычислительный граф персептрона:
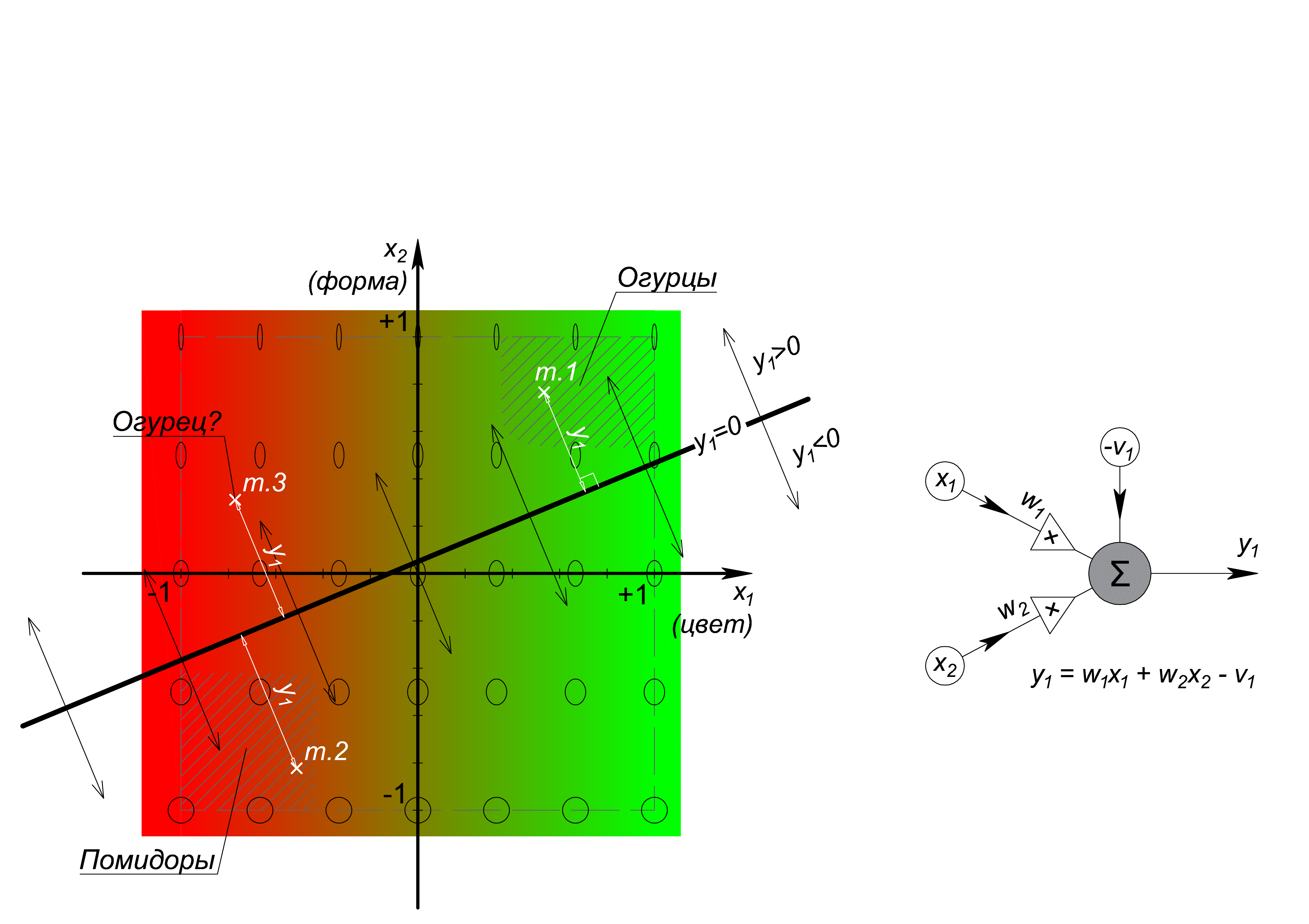
Двумерный персептрон реализует левую часть нормализованного уравнения прямой на плоскости: Ax+By+C=0, где чисто графически на месте коэффициентов A, B и C стоят называемые весами коэффициенты w_1, w_2 и -v_1, а обозначения координат {x;y} заменены на {x_1;x_2 }. Уже трехмерный персептрон с тремя входами реализует левую часть уравнения плоскости, N-мерный – гиперплоскости размерности N-1. Если результат вычисления левой части уравнения равен 0, то точка с измерениями объекта (вектор) лежит на решающей границе, что логично, если больше – объект «над ней», если меньше – «под ней», при этом величина (модуль) результата – это расстояние от точки объекта до сепаратора. Для задачи классификации достаточно знать «над», «под» или «где-то рядом» находится точка, для чего на выходе персептрона используют какую-либо ступенькообразную функцию, называемую пороговой (см. Интернет). Чтобы разрешить два рассматриваемых нами класса одного линейного сепаратора недостаточно и с этого момента из них начинает развиваться сеть. Ведь также недостаточно и одного слоя, так как линия решающей границы второго персептрона разбивает плоскость на четыре сектора, и требуется далее по пути распознать нужный сектор. Смотрим.
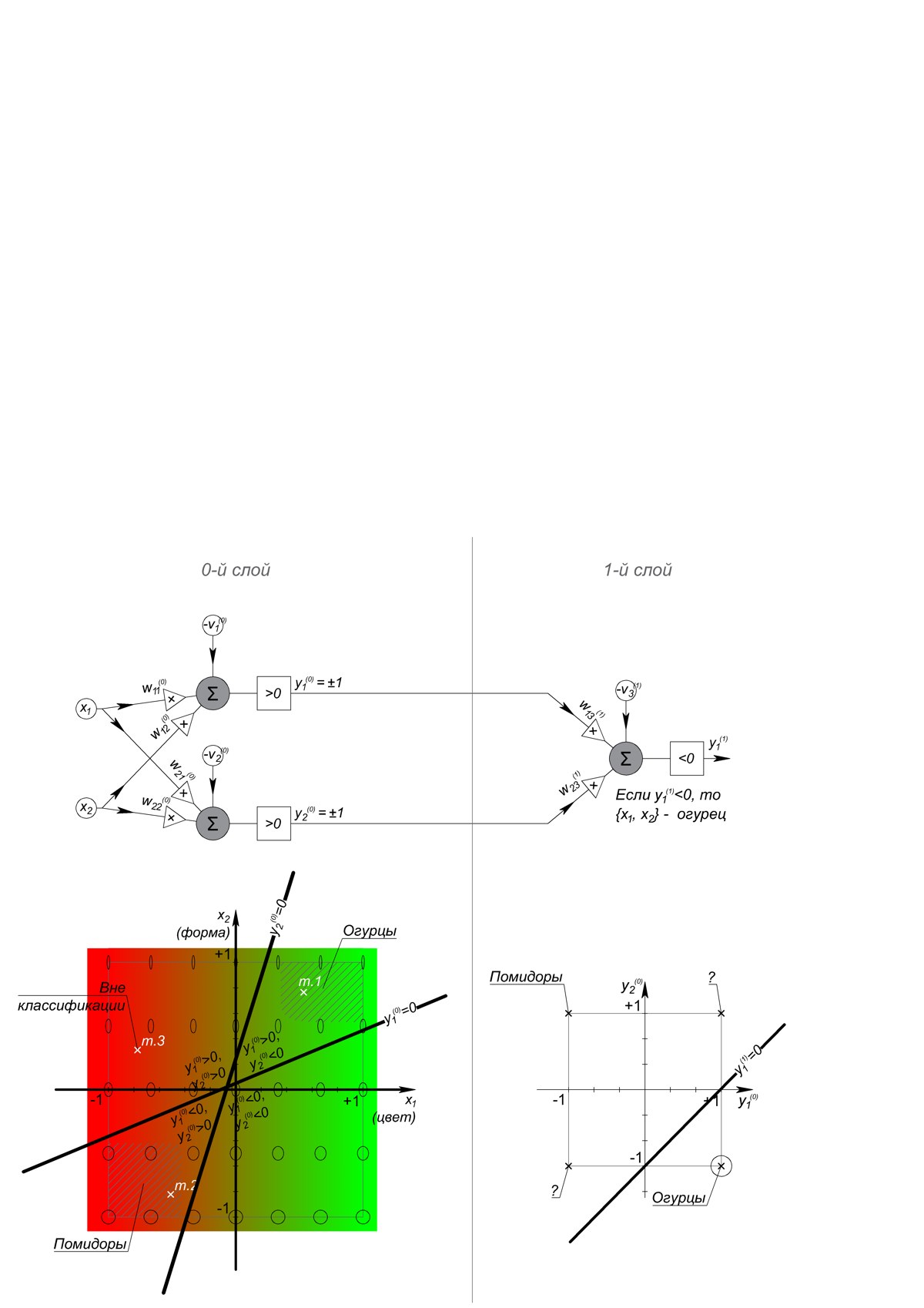
Показанная сеть в качестве пороговой функции использует обычное сравнение с 0, различает «огурцы» и «не огурцы», тогда как для различения «огурцы», «помидоры» и «не то и не другое» нужен еще один персептрон «на помидоры» в 1-м слое.
Оптимизация или обучение такой сети осуществляется настройкой весов w (k)/j, что в геометрическом смысле означает вращения и смещения прямых линий решающих границ отдельных персептронов, а в N-мерном пространстве – вращения и смещения гиперплоскостей решающих границ. Настройка, разумеется, целенаправленный и осмысленный процесс, потому что должна привести к выстраиванию сепараторов в нужных для задачи положениях. Коротко взглянем на трехмерный случай для огурцов, в который третьей осью мы добавили массу объекта от 0 до 1 кг.
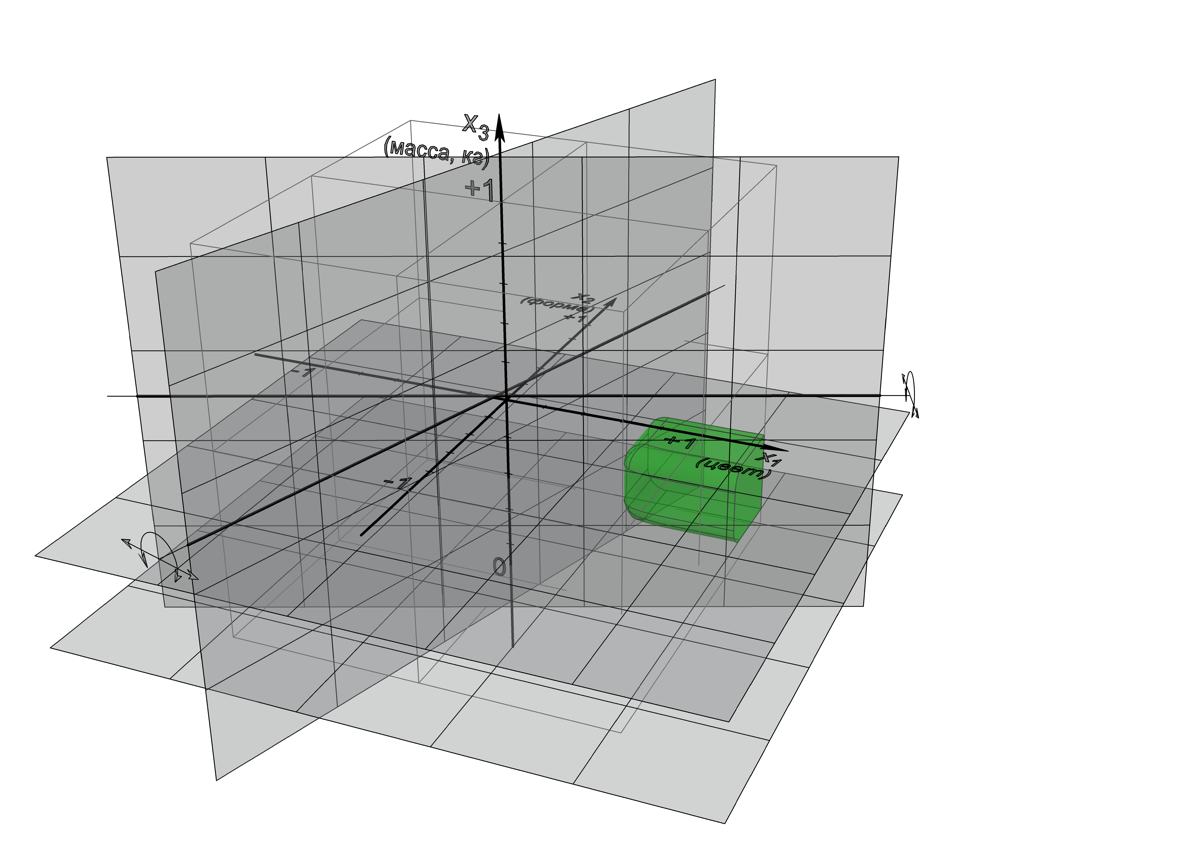
Здесь решающие границы – это плоскости, а соответствующая сеть имеет следующую структуру (слева показаны минимально необходимая логика, справа – общий паттерн):

Замена линейных сепараторов – персептронов в структуре сети на любые другие, например, на эллиптические (к ним относится окружность), описываемые уравнениями второго порядка вида Ax2+By2+Cxy+Dx+Ey+F=0, никак не изменит основной траектории решения задачи классификации. Нейроны-сепараторы текущего слоя различают признаковое входное пространство на полупространства, каждый на свои, а нейроны последующих слоев различают пересечения между этими полупространствами (к слову, также разделяя уже свои входные пространства на половинки). Особенность заключается в том, что типичный и понятный алгоритм оптимизации/обучения подобных сетей, называемый методом градиентного спуска, имеет наиболее адекватную форму только в случае с линейной сепарацией и эффективно здесь применяется. Для нелинейного сепарирования ситуация значительно усложняется.
Любопытно, что при этом в научно-популярной и научной литературе можно встретить аналогии на работу и устройство обсуждаемых многослойных нейронных сетей такого рода. Нулевой входной слой – это рецепторный или сенсорный слой, промежуточные слои или, правильно сказать, скрытые – это ассоциативные слои, а выходной слой – это реакционный слой. Существуют специальные обозначения для нейронов этих слоев: S-, A-, R- элементы. Ну, и по итогу, на примере распознавания рукописных цифр популярного датасета MNIST, вы сможете прочесть следующее рассуждение: нейроны входного слоя, воспринимая изображение, обучаются выделять его отдельные части похожим образом:
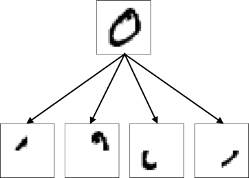
далее нейроны следующего ассоциативного слоя детектируют какие из частей присутствуют/отсутствуют в изображении…
Нет! в действительности, если попытаться изобразить веса нейронов 1-го скрытого слоя в местах подключения к входному вы увидите нечто следующее:

Хаос и случайность. Но тому есть множество объяснений. Во-первых, сеть обучается ровно настолько, насколько ей достаточно для успешной классификации на заведомо ограниченных обучающих данных, при чём результат обучения никогда не детерминирован в объективном смысле, здесь также существенно и то, что функция ошибки (cost function) минимизируется методом градиентного спуска, как правило, только до локального минимума, удовлетворяющего выбранному датасету. Например, поведение показанной огуречно-помидорной сети покажется странным, если ей на вход попадёт точка объекта из основания «огуречного» сектора, такое, скорее всего не произойдёт, ведь такие объекты редки в реальности, но такой же эффект нас ожидает, когда в сеть, натренированную на цифры, попадёт буква или, как в нашумевших ранее публикациях о слепых пятнах, когда придут особые входные данные, очень близкие на человеческий взгляд к тому, чтобы быть классифицированными верно, и распознаются ошибочно – вот настолько близкие (нечетные колонки – верно, четные – неверно):

Во-вторых, и, на наш взгляд, это важнее, нейронная сеть, сотканная из нейронов-сепараторов оптимизирует и хранит в себе не параметры распознаваемых классов, а параметры и особенности границ между ними. Это первоочередная причина для нередко упоминаемой особенности нейронных сетей, что они принципиально не могут изобразить то, что распознают, а являются черным ящиком между входными данными и выходными суждениями, содержимое которого человек понять не может, но зато может обучить. Иногда люди придают этому некие магические смыслы. Но смотрите. Вот легко получаемые уравнения сепараторов нашей 2-х-слойной огуречно-помидорной сети:
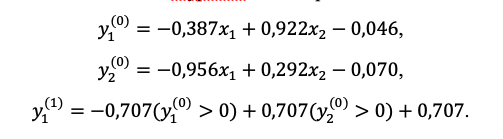
Что означают веса каждого отдельного нейрона? Напоминаем, по оси цвета x_1: красный – это (-1), зеленый – (+1); по оси формы x_2: круг – это (-1), эллипс с коэффициентом сжатия 1/5 – (+1). Да, для линий в 2-хмерном пространстве ещё можно что-то уловить, попробуйте, а для гиперплоскостей в 900-мерном пространстве? Также обратите внимание, сколько различных решающих линейных границ можно провести для нейрона 1-го слоя нашей сети, отделяющих нижнюю правую точку от трёх других – при достижении любой из них обучение продолжать бесполезно. Думаем, с чернотой ящиков с более сложными эллиптическими или нелинейными сепараторами всё ясно заранее. Итак, свойства нейронных сетей II-го поколения – это свойства границ, достаточных для получения удовлетворительного решения по разделению принятых на выбранном датасете классов, и именно от этого мы в своей работе хотели бы уйти.
Вернемся к благополучно оставленной форме классов. Здесь нам важно закрепить, что чем более независимыми, не влияющими на значения друг друга признаками образована их система координат, тем более прямоугольными мы ожидаем области, ограничивающие классы и наоборот. При этом вблизи границ таких областей мы можем ожидать неоднозначности и сомнения. Для размышлений по этой теме мы сделали фаски в наших классах огурцов и помидоров, подумайте, есть ли в них смысл.
Вкратце заметив, что развитие независимости признаков достигается, в основном, различными свёрточными преобразованиями, переходим непосредственно к нашим разработкам.
Своя собственная интеллектуальная нейронная сеть
Мы, как уже было упомянуто, хотели, чтобы классифицирующая интеллектуальная сеть была заполнена именно параметрами и свойствами самих классов, что даёт многое: упрощает масштабируемость сети во времени, то есть становится возможным мягко и вживую её доучивать или переучивать, не теряя и не изменяя ранее полученных полезных способностей, позволяет переносить классы и/или их части на новые структуры и, что любопытно, допускает использование такой сети в качестве вторичного источника обучающих данных. Ещё мы хотели, чтобы её структурная единица, объединенная общим выходом, реагирующим на появление своего образа, могла бы по входам расширяться на разные, независимые источники данных, как в смысле происхождения, так и в смысле их значений, например, общий образ некоторой цифры может быть на картинке, в звуке или где-то возникнуть внутри самой сети.
Но первое важнее. Как это сделать? Во-первых, в первом приближении рассмотрения параметров самих классов мы можем пользоваться прямоугольными их границами, присваивая соответствующим интервалам вдоль осей условленные величины или коды, во-вторых, мы должны учитывать, что класс, представляющий общий образ, в общем случае не является топологически связным в признаковом пространстве. Что ж, давайте смотреть на равномерно разделенное трехмерное признаковое пространство с кодированными интервалами на осях, для которого селекционеры дополнительно вывели особые зеленые тяжелые помидоры. Сектора, ограничивающие несвязный класс помидоров, ограничены красными рамками, сектор огурцов – зелёными.
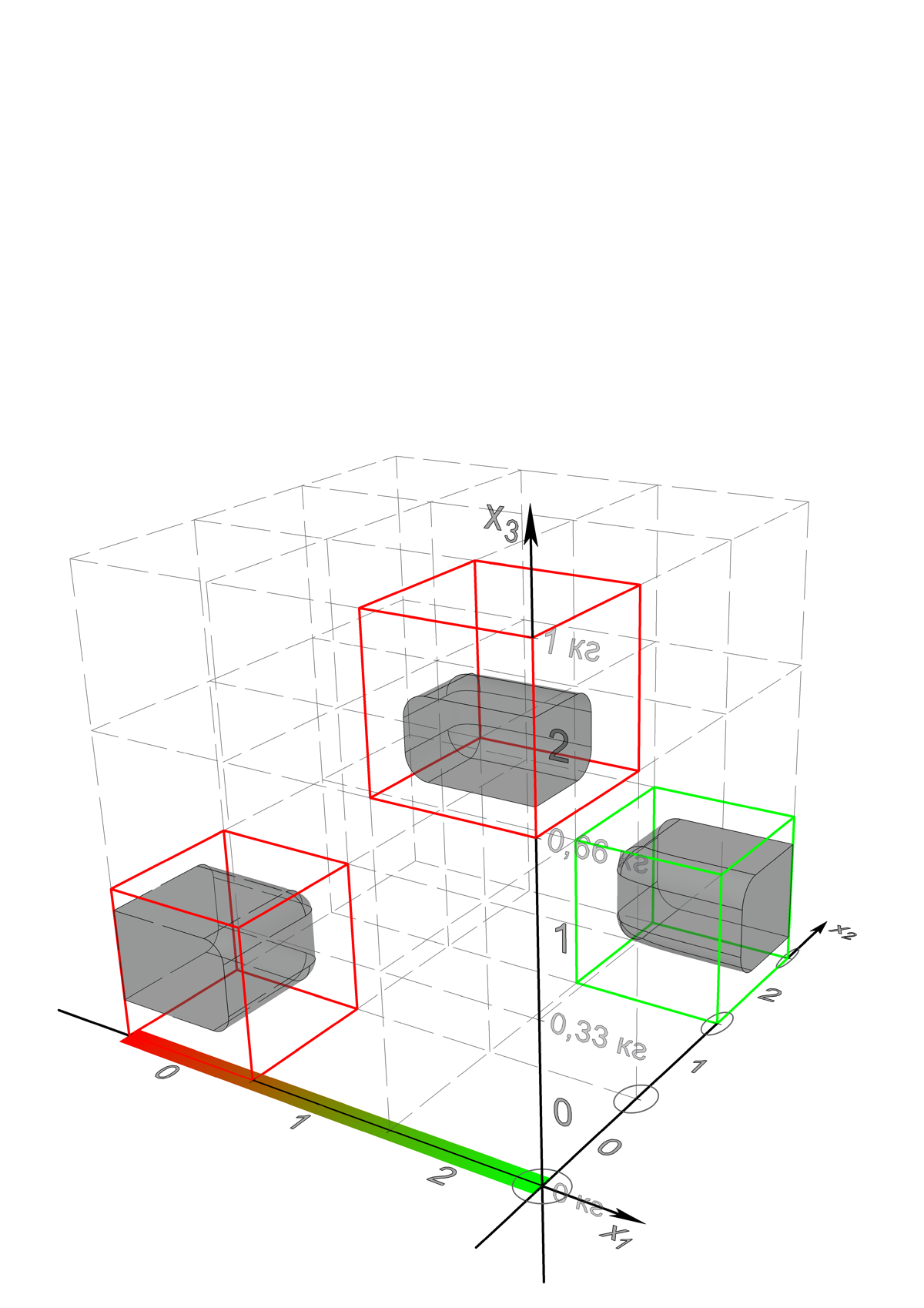
Что получается? Тройки чисел {0;0;0} и {2;0;2} соответствуют помидорам, тройка {2;2;0} – огурцам. Таким образом, необходимо измерять распознаваемый экземпляр, определять в какие интервалы попадают соответствующие признаки и сопоставлять. Подход кажется простым и тривиальным, но в этом изюминка, такими совокупностями чисел легко манипулировать, их можно собирать в единые структуры, сцеплять разные кодировки, добавлять и удалять, легко воспроизводить то, что распознается и т.д. Однако, за простотой на первый взгляд поджидают неочевидные трудности. Совокупности чисел, мы назовем их гипотезами, необходимо эффективно объединять и организовывать, ранжировать между собой, в многомерных пространствах и при зашумлении данных неизбежно возникает проблема с их захватом и формированием, можно говорить, в целом, о сложности обучения системы, построенной на гипотезах.
Кратко о терминах. Мы не называем рассматриваемую совокупность чисел вектором, подразумевая, что в общем случае она является совокупностью векторов, при чем произвольных размерностей, и называем эту совокупность гипотезой, исходя из того, что, оказавшись первично сформированной, она подлежит проверке в ходе обучения.
Простую сборку наших гипотез можно осуществить по наитию:


Здесь w_i – веса, b_i – бинарные триггеры гипотез, срабатывающие при их удовлетворении. Выходной сигнал также бинарный и определяется по превышению весовой суммы над порогом h. Мы смело рассматриваем такую сборку как нейрон, объединенный общим смыслом/образом, множество дендритов которого является множеством элементов гипотез, аксон – выходным полем.
Как обучать такие нейроны и сеть из них? Если разглядеть в совокупностях элементов гипотез некий, не побоимся этого слова, генетический или, что уж, интеллектуальный код, то ответ напрашивается сам – с помощью эволюционного алгоритма и конкурентного отбора. Мы его разработали. А также разработали ядро, включающее модель памяти, для сборки, обучения и запуска в работу интеллектуальных сетей, собранных из таких нейронов, на GPU с помощью CUDA.
Перейдем к знакомству с полученными нами результатами на известном и уже упомянутом датасете MNIST, содержащем рукописные цифры на изображениях 28x28 px. В системе 10 цифр и 10 нейронов, они крупные и фактически являются массивами памяти, никакой предобработки для увеличения признаковой независимости или снижения межпиксельной корреляции – напрямую. Параметры отбора оптимизированы на глазок, хотелось, чтобы просто работало.
Для начала наиболее исследуем любопытные качества, а именно, изображения отдельных гипотез, уверенно победивших в конкурентной эволюционной борьбе и их усредненных совокупностей по нейронам, кстати, в среднем скапливалось около 30?60 таковых.
Штрих цифры изображен красным на черном фоне, белым показаны безразличные пиксели изображений, яркость в которых может принимать любые значения, по мнению сети. Слева – пример цифры MNIST, в середине – одна из выживших гипотез, справа – среднее по гипотезам.
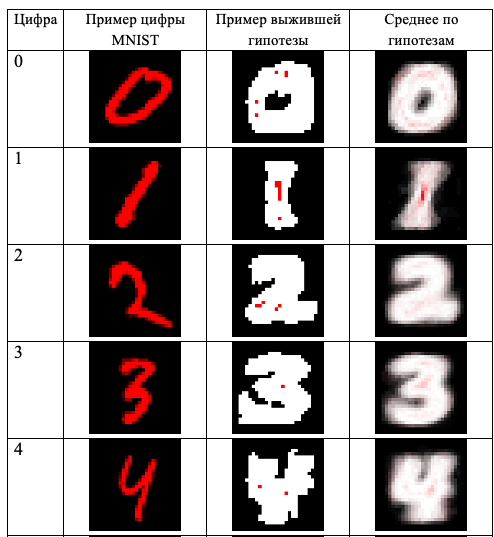
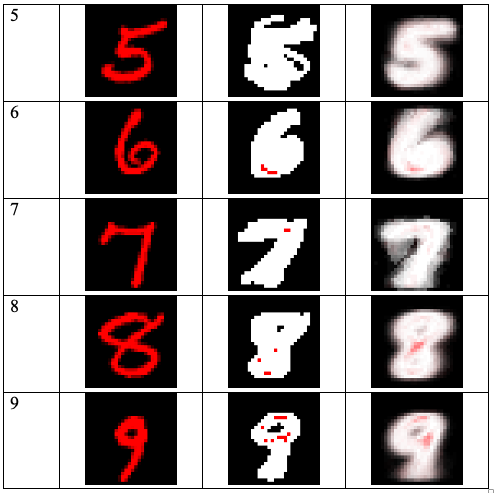
Правая колонка показывает, как нейроны видят то, что распознают. Отметим, что основную роль в распознавании играет не сам штрих письма, а окружающая его область.
Демонстрируемая интеллектуальная сеть имеет особенность в формировании устойчивого состояния «не знаю» по всем выходам даже в случае наименьшего возможного порога детекции.
Это связано и с несепарационным принципом распознавания (нейрон «узнает своего»), и с выработанным алгоритмом эволюционного отбора, где для гипотез равно губительными устраиваются стратегии «спасительного молчания» и «наглой болтливости». Однако, с другой стороны, такая реализация позволяет мягко доучивать нейроны, переносить между ними отдельные гипотезы и масштабировать распознаваемые ими паттерны, так как полностью игнорирует на любых порогах детекции практически всё «чужое».
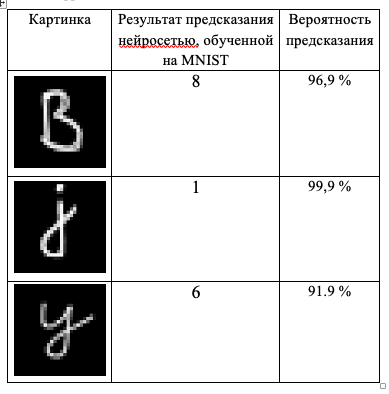
Так, известно, что нейронные сети, основанные на персептронах (сепараторах), склонны допускать уверенные предсказания и для данных, совершенно посторонних по отношению к обучающему набору, но идентично организованных (в наших терминах, они склонны болтать лишнее). Для примера, мы с помощью TensorFlow собрали сеть с 2-мя скрытыми слоями, также без предобработок, обучили её на MNIST до уровня ошибки на проверочной части в 2,6%, и давали ей на вход буквы. Вероятность, с которой такая сеть видит в различных буквах цифры показана ниже.
Смотрим результаты распознавания нашей интеллектуальной сетью с гипотезами по проверочному набору MNIST (10 000 цифр) с учетом состояния «не знаю».
Порог распознавания, равный целевому при отборе + 25%:

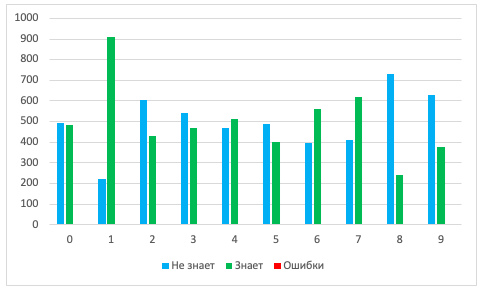
Минимально возможный порог распознавания:
Какие недостатки:
- тяжеловесность и медленное обучение;
- явная чувствительность к межпризнаковой корреляции и необходимость уменьшать её предобработкой, к слову, разработка эволюционного алгоритма проводилась на псевдослучайных данных, в которые вводились искусственные закономерности.
Какие преимущества:
- ярковыраженная возможность масштабировать, мягко доучить, переучить, добавить новые источники данных, сохраняя и не изменяя накопленное;
- нечувствительность к чужеродным входным данным;
- гибкая архитектура, доступность постоптимизации, межнейронного переноса и внутринейронного переноса;
- способность нейронов работать в качестве источников полезных и обучающих данных.
Разумеется, очень многое не изучено и почти всё не опробовано, например, любопытно, возможно ли нашим подходом выполнять кластеризацию или осуществлять самоорганизацию нейронов, включая генерацию новых.
Краткое заключение
Хм, а при чем здесь беспилотные технологии, о которых упомянуто в начале? Мы уверены, что именно в этой сфере наша интеллектуальная сеть найдет свои основные применения, позволив преодолеть существующие барьеры, связанные с множественностью, изменчивостью и разнородностью при восприятии и распознавании окружающей обстановки.


Akon32
Пара вопросов:
1) А не переизобрели ли вы сеть Кохонена или даже kernel trick? Ну, грубо говоря, считаем расстояние от входного изображения до шаблонов (усреднённых образов классов) и выбираем например номер шаблона, который даёт наименьшее расстояние.
2) Когда вы обучали "классическую" сеть на MNIST, предусмотрели ли в ней выход "не цифра" и обучали ли сеть на "не цифрах"?
Ну и вообще, странно пытаться улучшить перцептрон, когда картинки уже принято распознавать свёрточными сетями.
kraidiky
Это просто другой вид деятельности. Я в своё время переизобретал перцептрон, и знаете что? На некоторых синтетических задачах мой перцептрон рвал общепринятые существующие как стоячих. Так что если вам нужна быстрая коммерциализация — берите тензорфлоу и кучу суперкомпьютеров, но если вы хотите качественно изменить ситуацию, надо переизобретать перцептрон, правда у вас, скорее всего, не получится. Не все мы Хинтоны, потому что.
Robert87 Автор
Ключевое отличие в эволюционном и конкурентном методе извлечения и оценки шаблонов из поступающих данных, когда отбор настраивается на развитие их устойчивого, дифференцированного и взвешенного множества в пределах одного нейрона.
Robert87 Автор
Akon32
Получается, вы тренировали классическую нейросеть на одной задаче, а тестировали на другой. Множества выходов при обучении и при тестах разные. Это примерно как спрашивать "
вы перестали пить коньяк по утрамкакой сегодня день недели, да или нет?"