
В повседневной жизни мы пользуемся готовыми интерпретаторами и компиляторами — и редко кому придёт в голову написать их самостоятельно. Во-первых, это же сложно, во-вторых — зачем.
В Surf мы написали собственный интерпретатор и используем его на клиенте мобильного приложения — хотя изначально, казалось бы, это вообще слабо относится к мобильной разработке. На самом деле интерпретаторы и компиляторы — инструменты для решения задач, которые могут встретиться где угодно. Поэтому понимать, как это работает, и уметь писать свои — полезно.
Сегодня на примере перевода масок из одного в формата в другой познакомимся с основами построения интерпретаторов и посмотрим, как использовать формальные грамматики, абстрактное синтаксическое дерево, правила перевода — в том числе для того, чтобы решать задачи бизнеса.

Маски — это круто и удобно. Но есть проблема, неизбежная в определённых условиях: когда на клиенте — один формат масок, а на сервере — много разных провайдеров данных и у каждого свой формат. Рассчитывать на то, что у нас будет один и тот же формат, мы не можем. Просить сервер: «Подгони нам маски, как мы любим», — тоже. Нужно уметь с этим жить.
Возникает задача: есть спецификация бэкенда, нужно написать фронтенд — мобильное приложение. Можно вручную написать все маски для приложения — и это хороший вариант, когда провайдер один и масок мало. Программисту, конечно, придётся потратить время, чтобы разобраться как минимум в двух спецификациях на маски: бэкенда и фронта. Потом ему нужно перевести конкретные маски бэкенда в соответствующие маски фронтенда. Это тоже занимает время, тут есть человеческий фактор — можно ошибиться. Это непростая работа, перевод тяжёлый: некоторые языки масок написаны в первую очередь для компьютеров, а не для людей.
Если вдруг на сервере маска изменилась или появилась новая, то приложение, во-первых, может перестать работать. Во-вторых, тяжёлую работу по переводу нужно проделать ещё раз, зарелизить новое приложение, это отнимает время, силы, деньги. Возникает вопрос: как минимизировать работу программиста? Похоже, что всем этим должна заниматься машина, а занимается почему-то человек.
Ответ — «да», у нас есть решение. Маски написаны на языке компьютеров — и это одна из причин, почему человеку тяжело с ним работать и переводить с одного языка на другой. Нужно переложить эту работу на компьютер. Поскольку маска представляется формальной грамматикой, то самый верный способ транслировать одну грамматику в другую:
Это то, для чего и пишутся компиляторы и трансляторы.
Теперь подробно рассмотрим наше решение на основе формальных грамматик.
В нашем приложении довольно много разнообразных экранов, которые формируются по backend driven принципу: полное описание экрана вместе с данными приходит с сервера.

Большая часть экранов содержит разнообразные формы ввода. Сервер определяет, какие поля есть в форме и как они должны быть отформатированы. Для описания этих требований используются в том числе и маски.
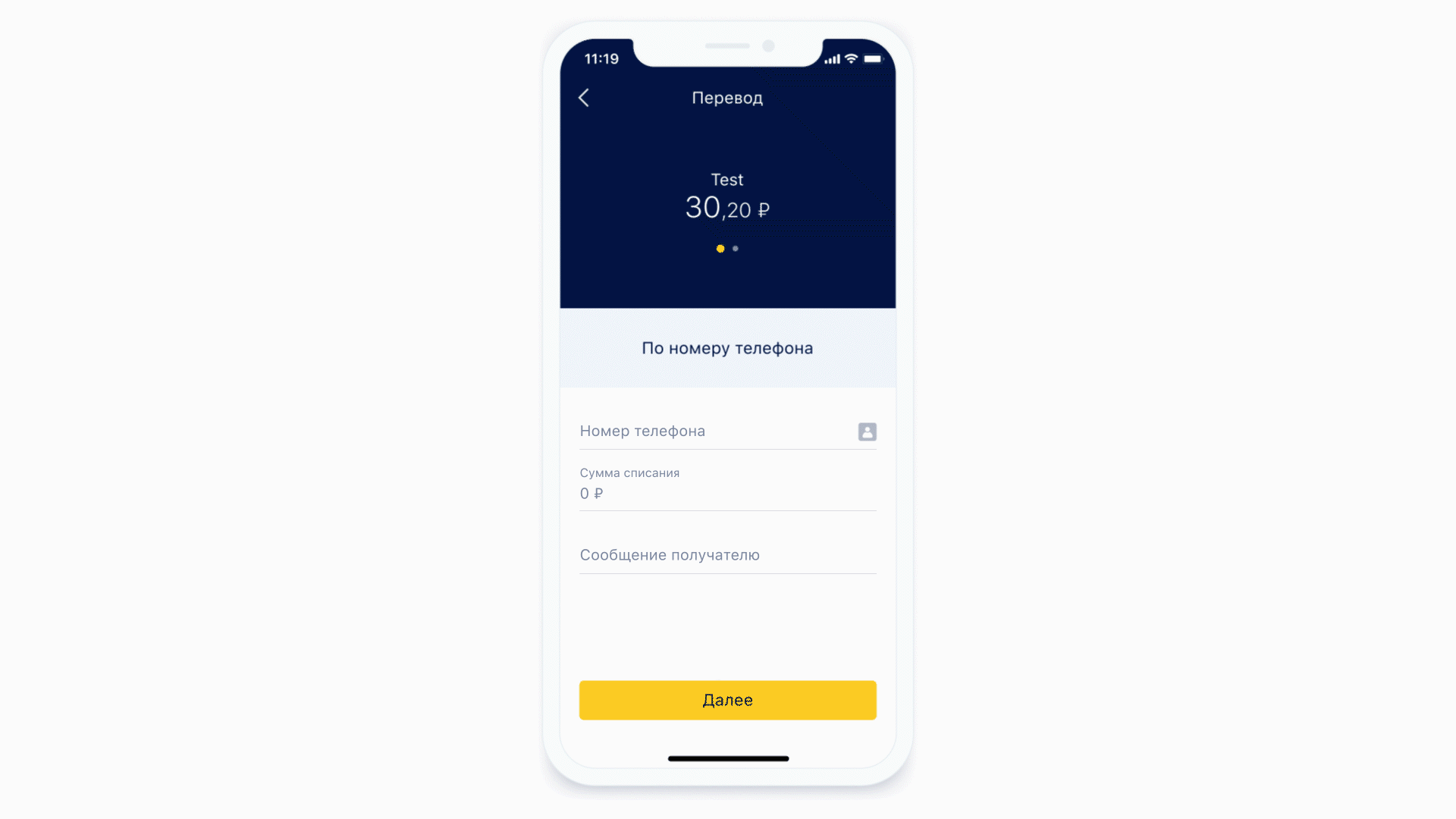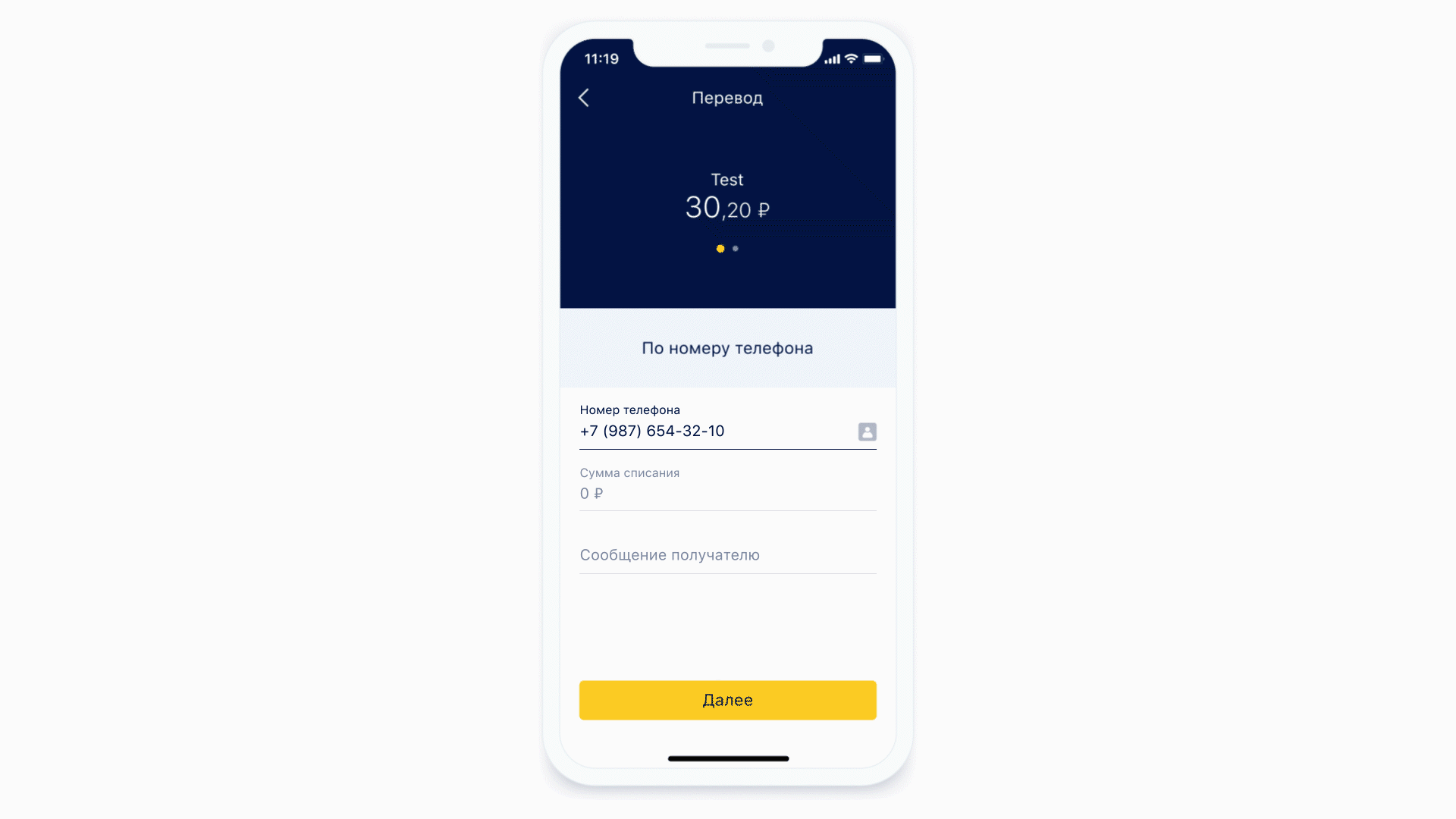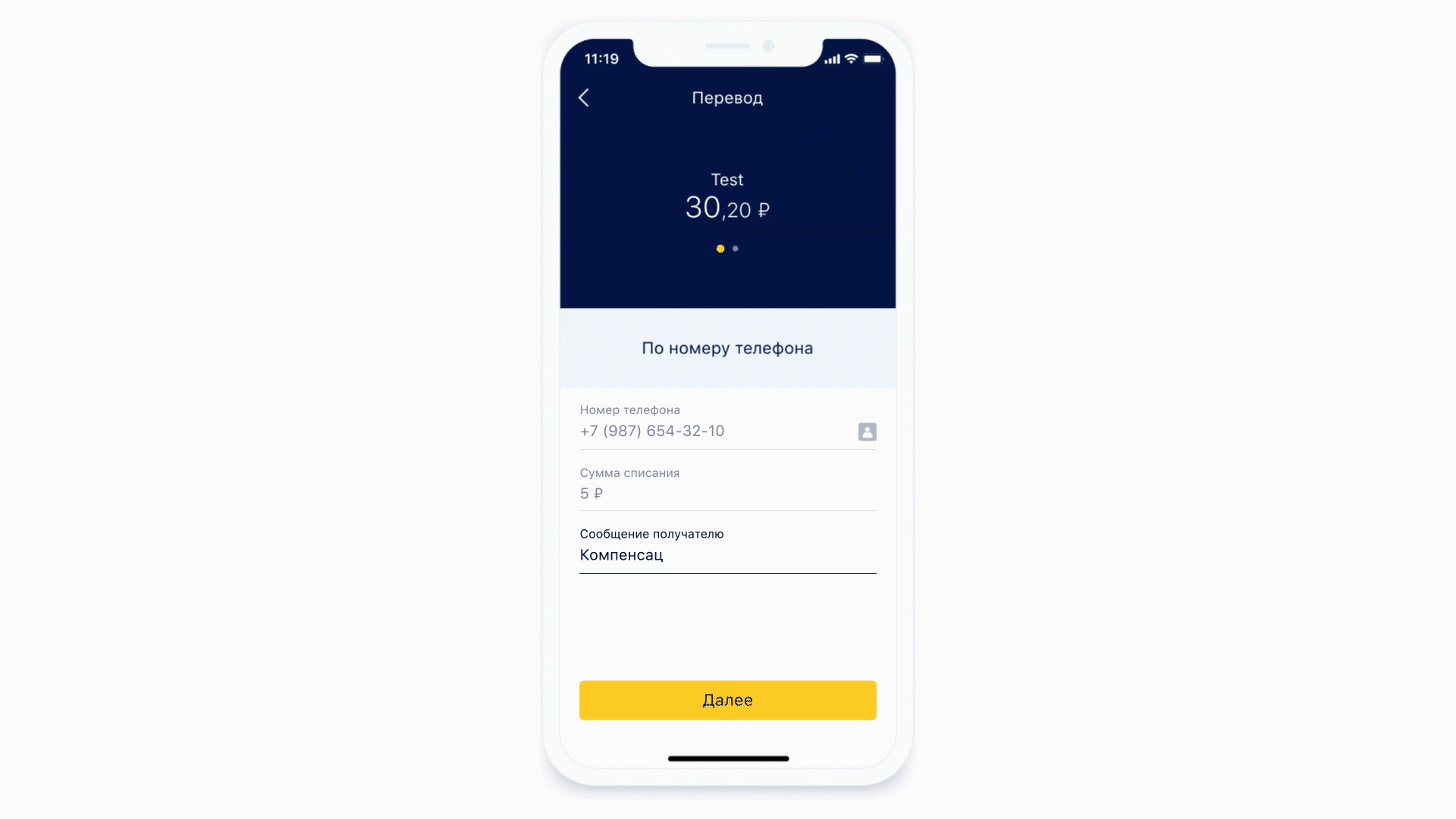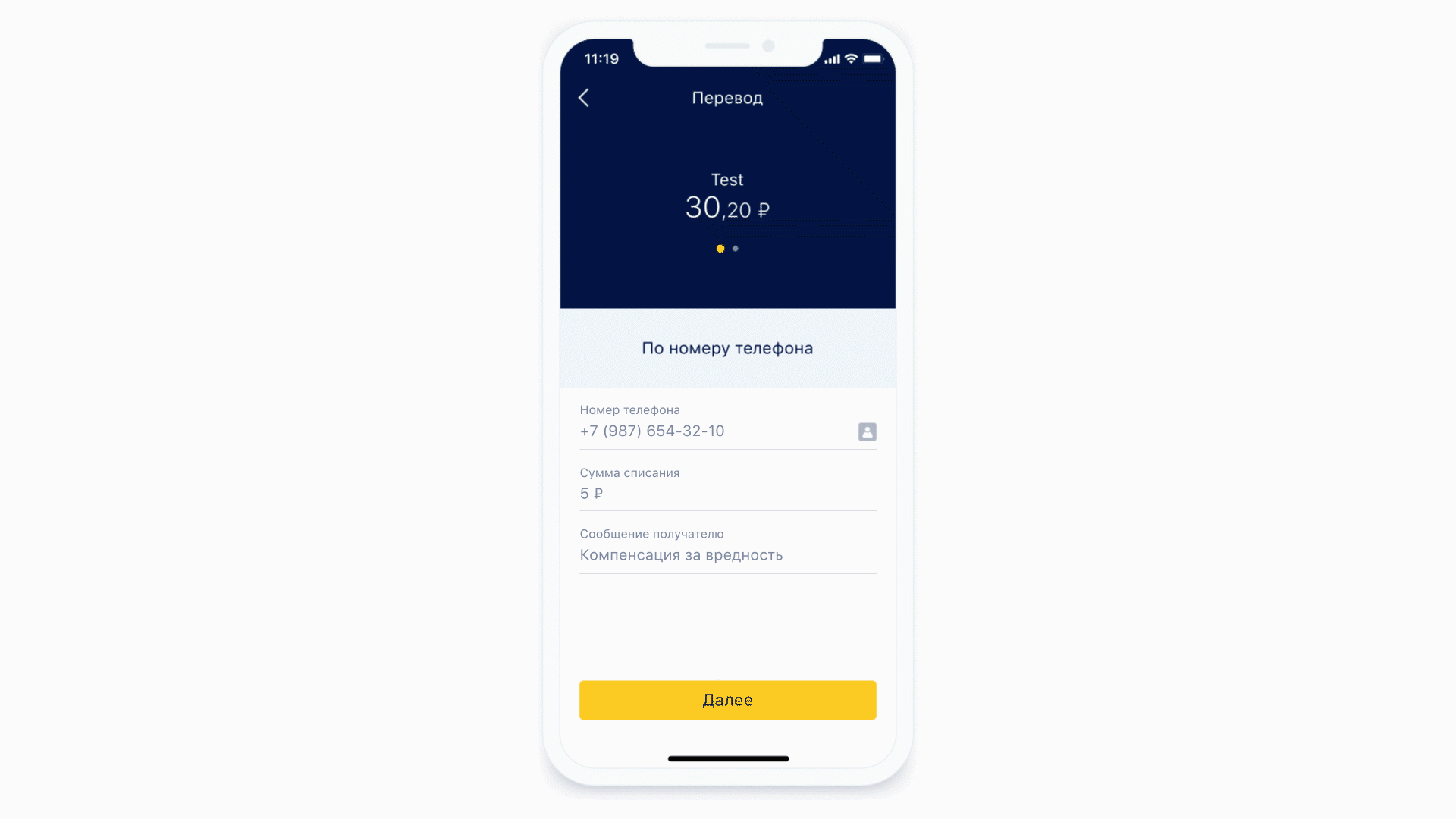
Давайте посмотрим, как устроены маски.
В качестве первого примера возьмём всё ту же форму ввода номера телефона. Маска для такой формы может выглядеть так.

С одной стороны, маска сама добавляет разделители, скобочки и запрещает вводить неправильные символы. С другой стороны, эта же маска из отформатированного ввода достаёт полезную информацию для отправки на сервер.
Красным выделена часть, которая называется константа. Это символы, которые появятся автоматически, — пользователь их вводить не должен:

Дальше идёт динамическая часть — она всегда выделена угловыми скобками:

Здесь записано выражение, по которому мы будем форматировать наш ввод:

Красным выделены кусочки, отвечающие за содержимое динамической части.
\\d — любая цифра.
+ — обычный репитер: повторить минимум один раз.
${3} — символ метаинформации, который уточняет количество повторений. В данном случае должно быть три символа.
Тогда выражение \\d+${3} означает, что должно быть три цифры.
В данном формате масок внутри динамической части может быть только один репитер:

Это ограничение появилось не просто так — сейчас объясню почему.
Допустим, у нас есть ДВ, в котором жёстко указан размер: 4 элемента. И мы задаём ему 2 элемента с репитером: `<!^\\d+\\v+${4}>`. Под такое ДВ попадают следующие сочетания:
Получается, что такое ДВ не даёт нам однозначного ответа, чего ожидать на месте второго символа: цифру или букву.
Берём маску, складываем её с пользовательским вводом. Получаем отформатированный номер телефона:

На клиенте формат у масок может выглядеть по-другому. Например, в библиотеке Input Mask от Redmadrobot маска для номера телефона имеет следующий вид:

Выглядит она симпатичнее и понимать её проще.
Получается, что маска для сервера и маска для клиента записываются по-разному, а делают одно и то же.

Нам нужно эти маски друг с другом совместить — или как-то из одной получить вторую.
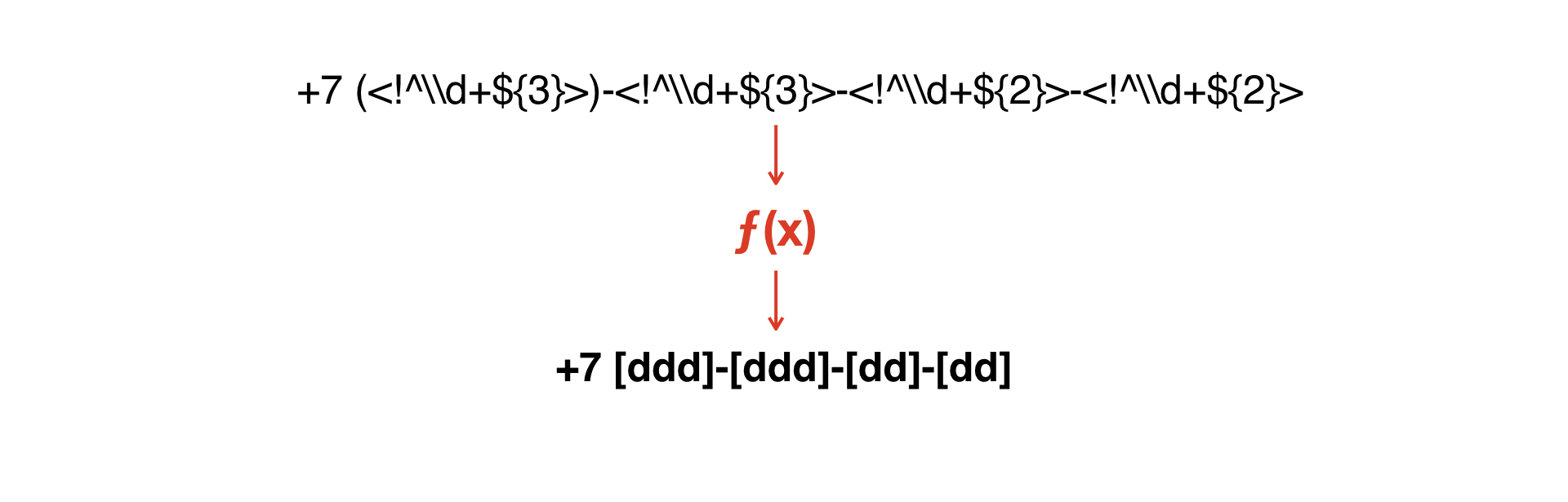
Нужно построить функцию, которая бы преобразовывала одну маску во вторую.
И здесь пришла идея написать очень простой интерпретатор, который позволит из одной грамматики получить вторую грамматику.
Так как мы дошли до интерпретатора, давайте поговорим про грамматики.
Сначала у нас есть поток символов — наша маска. По сути это строка, которой мы оперируем. Но так как символы не формализованы, нужно формализовать строку: разбить её на элементы, которые будут понятны интерпретатору.
Этот процесс называется токенизация: поток символов превращается в поток токенов. Количество токенов ограничено, они формализованы, следовательно, можно их анализировать.
Далее, исходя из правил грамматики, по потоку токенов строим абстрактное синтаксическое дерево. Из дерева получаем поток символов в нужной нам грамматике.
Есть выражение. Смотрим на него и видим, что у нас есть константа, про которую я говорил выше:

Все константы представим как токен CS, у которого аргумент — сама константа:

Следующий вид токенов — это начало ДВ:

Далее все подобные токены будем трактовать как специальные символы. В нашем примере их немного, в реальных масках их может быть значительно больше.

Затем у нас идёт репитер.
Потом — несколько символов, которые считаются метаданными. Мы схитрим и представим их одним токеном, потому что так проще.

Конец ДВ. Таким образом, мы разложили всё по токенам.

Чтобы посмотреть, как в принципе происходит процесс токенизации и как будет работать интерпретатор, возьмём маску для номера телефона и преобразуем её в поток токенов.

Сначала — символ +. Преобразуем в константный символ +. Далее то же самое мы делаем для семёрки и для всех остальных символов. Получаем массив из токенов. Это ещё не структура — далее будем этот массив анализировать.
Теперь более сложная часть — это лексер.

Слева описана легенда — специальные символы, которые используются для описания лексических правил. Справа — сами правила.
Правило symbolRule описывает какой-то символ. Если это правило применимо, если оно верно, это значит что мы встретили либо специальный символ, либо константный символ. Можно сказать, что это функция.
Дальше — repeaterRule. Это правило описывает ситуацию, когда встречается какой-то символ, а за ним токен репитера.
Дальше всё похожим образом выглядит. Если это ДВ, то это либо symbol, либо repeater. В нашем случае это правило шире. И в конце обязательно должен быть токен с метаданными.
Последнее правило – maskRule. Это последовательность из символов и ДВ.
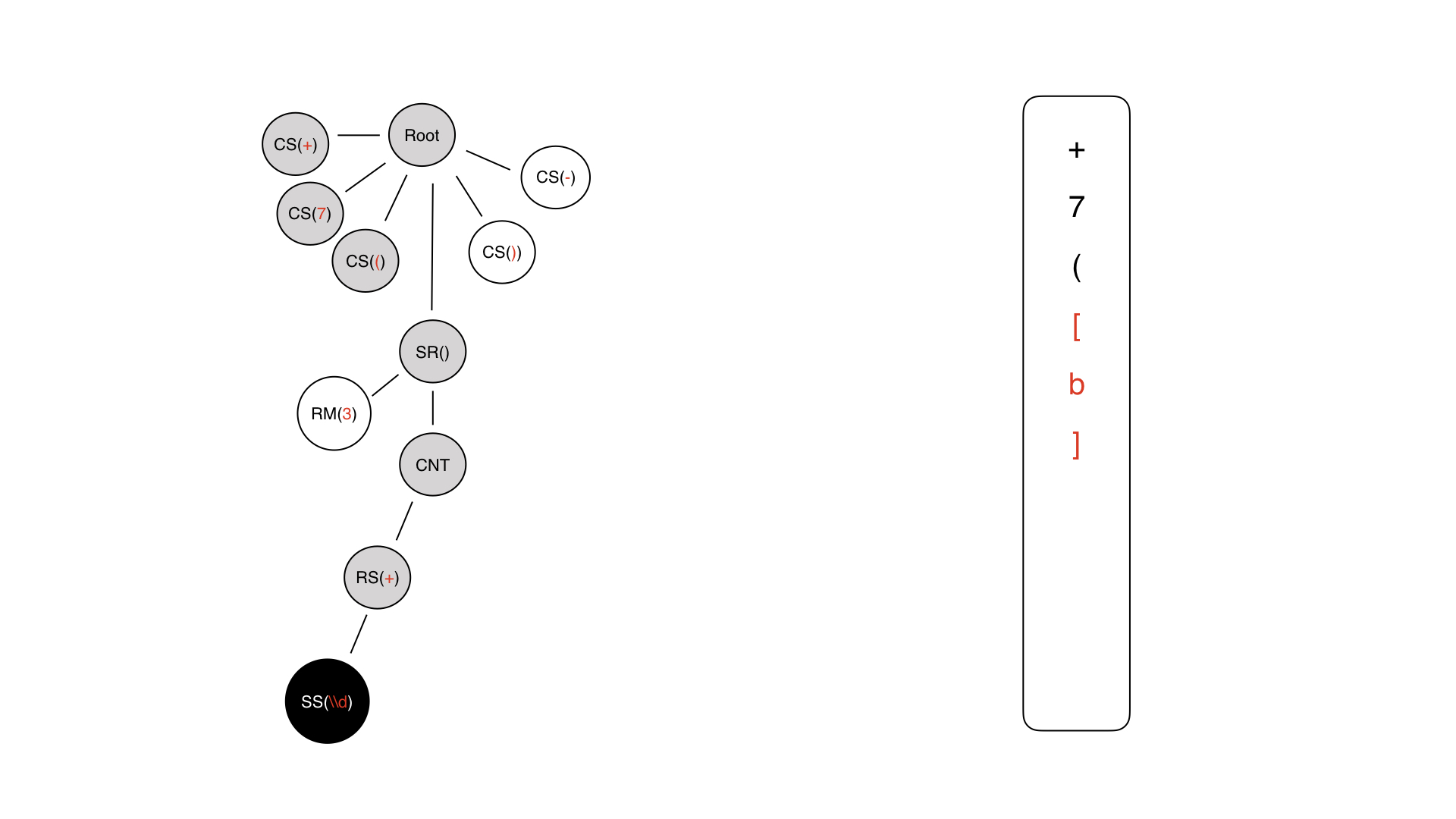
Теперь построим абстрактное синтаксическое дерево (АСД) из массива токенов.
Вот список токенов. Первый узел дерева — корневой, с которого начнём построение. Он не несёт никакого смысла, просто дереву нужен корень.

У нас есть первый токен +, значит, мы просто добавляем дочерний узел, и все.

То же самое делаем со всеми остальными константными символами, но дальше — сложнее. Мы наткнулись на токен ДВ.

Это не просто обычный узел — мы знаем, что у него обязательно должен быть какой-то контент.

Узел контента — это просто технический узел, на который мы сможем ориентироваться в дальнейшем. У него есть свои дочерние узлы и какой узел у него будет следующим? Следующий токен у нас в потоке это специальный символ. Будет ли он дочерним узлом?

На самом деле, в данном случае, нет. У нас дочерним узлом будет репитер.

Почему? Потому что так удобнее работать с деревом в будущем. Допустим, мы хотим распарсить это дерево и построить по нему какую-то грамматику. Во время парсинга дерева мы смотрим на типы узлов. Если у нас CS узел, то мы и разбираем его в тот же самый CS узел, но уже для другой грамматики. Условно, мы итерируем по вершинам дерева и запускаем какую-то логику.
Логика зависит от типа узла — или от типа токена, который лежит в узле. Для разбора сильно удобнее сразу понимать, какой токен перед тобой: составной, как репитер, или простой, как CS. Это нужно, чтобы не возникало двойных трактовок или постоянных поисков дочерних узлов.
Особенно это было бы заметно на группах символов: например, [abcde]. В том случае, очевидно, должен быть какой-то родительский узел GROUP, у которого будет список дочерних узлов CS(a)CS(b) и т.д.
Возвращаемся к токену с метаданными. Он не включается в контент, он находится сбоку.

Это необходимо для того, чтобы было просто проще работать с деревом, чтобы мы не считали этот узел контентом — потому что на самом деле он к нему не относится.
Закончилось ДВ, и мы не считаем это каким-то узлом: это был токен, который теперь можно выкинуть. Мы не будем превращать его в узел дерева.
У нас уже есть поддерево, корнем которого является узел SR — то есть та самая динамическая часть. Токен конца ДВ очень нам помогает в процессе построения дерева — мы можем понять, когда закончено построение поддерева для ДВ. Но никакой ценности для логики этот токен не несёт: глядя на построчное дерево, мы и так понимаем, когда ДВ закончится, потому что оно как бы закрыто узлом SR.
Дальше — просто обычные константные символы.

Мы получили дерево. Теперь пройдёмся по этому дереву в глубину и построим на его основе какую-то другую грамматику: нужно зайти в узел, посмотреть, что это за узел, и сгенерировать элемент другой грамматики из этого узла.
Рассмотрим синтаксис библиотеки Redmadrobot.

Здесь — то же самое выражение. +7 — константа, которая добавится автоматически. Внутри фигурных скобок описано ДВ — динамическая часть. Внутри ДВ — специальный символ d. У Redmadrobot это дефолтная нотация, которая обозначает цифру.
Так выглядит нотация:

Нотация состоит из трёх частей:
Смотрим, у нас сейчас будет такая маска.

Если нужно записать правило, когда символов может быть от одного до десяти, то один символ будет не опциональный. А девять символов будут опциональными. То есть в нотации из примера они будут записаны большими буквами. В итоге это правило будет выглядеть так: [cCCCCCCCCC]
Вот дерево, которое мы получили на прошлом этапе. Нам нужно по нему пройтись. Первое, куда мы попадаем, это корень.

Дальше от корня мы попадаем в константный символ + — генерируем сразу +. Справа записывается маска в формате InputMask.

Следующий символ понятный — просто 7, а за ним — открывающая скобка.
Дальше генерируется кусок динамической части, но он пока не заполнен.

Идём внутрь, у нас контент, это технический узел. Ничего не пишем никуда.

Здесь у нас репитер, мы тоже ничего никуда не пишем, потому что в маске нет такого символа. Нельзя записать такое правило.

Доходим, наконец, до какого-то контентного символа.
Контентым символом может быть либо константный символ, либо специальный. В данном случае используется специальный, потому что только он несёт какую-то смысловую нагрузку для ввода.
Вот мы его написали, возвращаемся и идём как раз за метаинформацией.

Смотрим, что у нас там был репитер и здесь у нас 3 — жёсткое ограничение. Поэтому повторяем его три раза и получаем такой вот динамический кусок. Дальше мы дописываем наши константные символы.

В результате мы получаем маску, которая похожа на маску в формате роботов.
На практике мы взяли одну грамматику и сгенерировали из неё другую грамматику.
Теперь немного про правила генерации. Это важно.
Могут быть такие непростые случаи: внутри динамической части несколько разных кусочков ДВ. Внутри фигурные скобки: это то же самое, как в ДВ, — один из множества. Давайте разберём, как интерпретатор будет обрабатывать эту ситуацию.

Сначала идёт набор символов, и мы должны конвертировать его в какую-то нотацию с точки зрения InputMask. Почему? Потому что это какой-то ограниченный набор символов, которые нам нужно матчить. Нам нужно совместить пользовательский ввод и символ, и поэтому здесь у нас будет записана какая-то определённая нотация.
Дальше у нас идёт символ \\d.
Дальше — ДВ с опциональным размером.

Первый, получается, какой-то символ b. У него будет Character Set, содержащий abcd.
Далее понятно, что будет другой уже символ, потому что не сматчишь иначе, или сматчишь неправильно. И дальше у нас это выражение превращается вот в такое.
В последней части обязательно должен быть хотя бы один символ. Обозначим это требование как d. Но также пользователь может ввести два дополнительных символа, и тогда они обозначаются как DD.
Соберём всё вместе.

Здесь приведён пример Character Set, которые генерируются. Видно, что b соответствует Character Set abcd, для цифр — соответствующий предустановленный Character Set. Для d и D соответствующий Character Set содержит 12vf.
Мы научились автоматически конвертировать одну грамматику в другую: теперь в нашем приложении работают маски по спецификации сервера.
Ещё одна фишка, которую мы получили бесплатно, — это возможность проводить статический анализ маски, которая нам пришла. То есть мы можем понять, какой тип клавиатуры нужен для этой маски и какое максимальное количество символов может быть в этой маске. И это ещё круче, потому что теперь мы не показываем всё время одну и ту же клавиатуру на каждый элемент формы — мы показываем нужную клавиатуру под нужный элемент формы. И также мы можем условно точно определить, что какое-то поле — это поле ввода телефона.
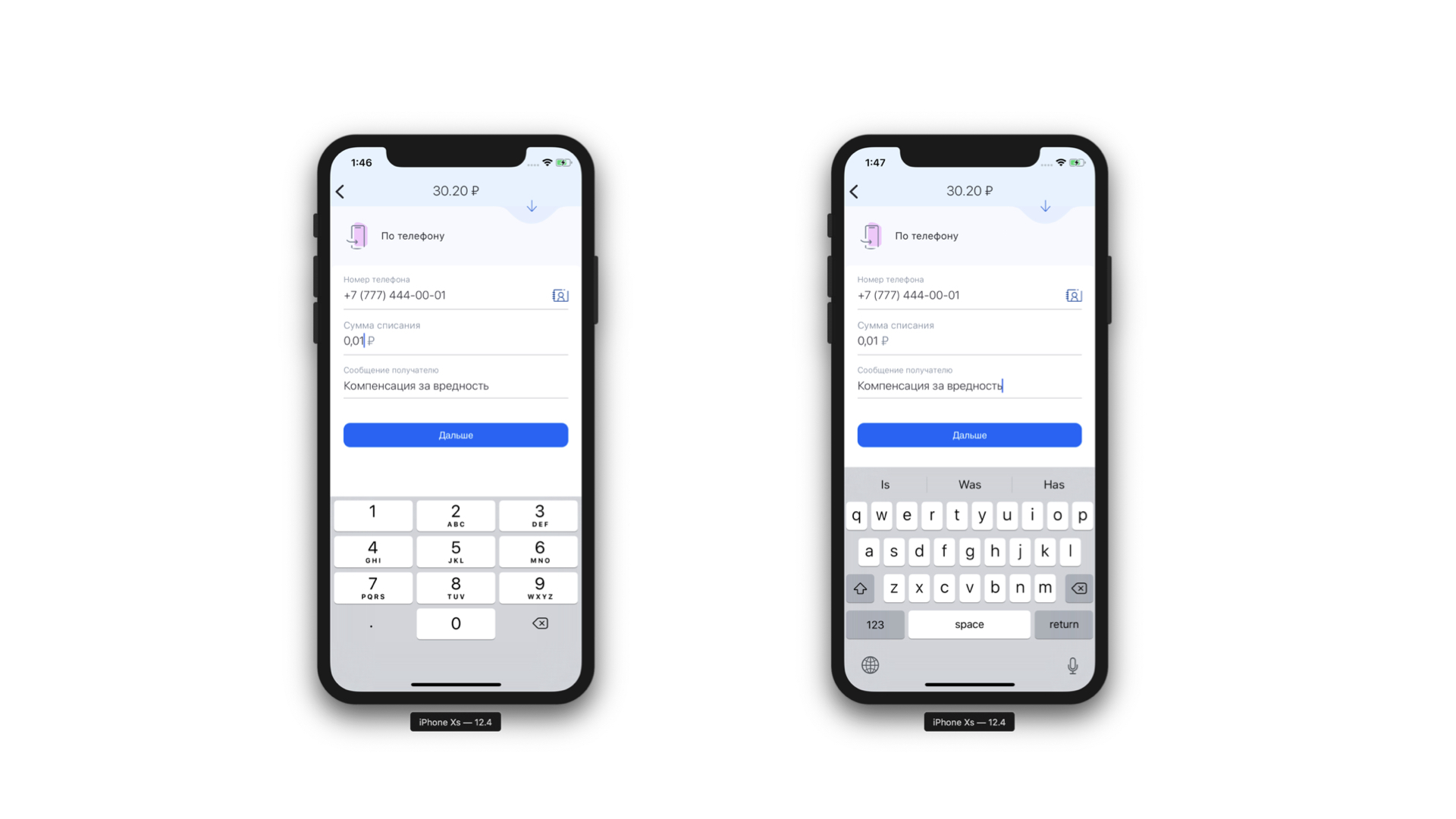
Слева: вверху у поля ввода телефона есть иконка (на самом деле кнопка), которая отправит пользователя в список контактов. Справа: пример клавиатуры для обычного текстового сообщения.
Можете посмотреть на то, как мы реализовали вышеописанный подход. Библиотека лежит на Гитхабе.
Это первая маска, которую мы смотрели в самом начале. Она интерпретируется в такое RedMadRobot представление.

А это вторая маска — просто маска ввода чего-то. Она конвертируется в такое представление.

В Surf мы написали собственный интерпретатор и используем его на клиенте мобильного приложения — хотя изначально, казалось бы, это вообще слабо относится к мобильной разработке. На самом деле интерпретаторы и компиляторы — инструменты для решения задач, которые могут встретиться где угодно. Поэтому понимать, как это работает, и уметь писать свои — полезно.
Сегодня на примере перевода масок из одного в формата в другой познакомимся с основами построения интерпретаторов и посмотрим, как использовать формальные грамматики, абстрактное синтаксическое дерево, правила перевода — в том числе для того, чтобы решать задачи бизнеса.
Немного о масках: что это и зачем нужно
Пользователь заполняет форму. В форме есть инпут, и мы ожидаем, что пользователь в него введет что-то конкретное — например, номер телефона. Номер телефона можно ввести по-разному: с плюсом или двойным нулем, со скобочками или без, с минусами или пробелами и так далее.
В конце концов, заполненную форму мобильное приложение отправляет на сервер. В этот момент важно, чтобы данные были правильно отформатированы. Например, API интернет-банка будет требовать, чтобы номер выглядел вот так: 9161234567 — без 8, скобочек и минусов.
Если форма пассивно обрабатывает пользовательские данные, то номер телефона она принимает в любом формате, но возникают проблемы:
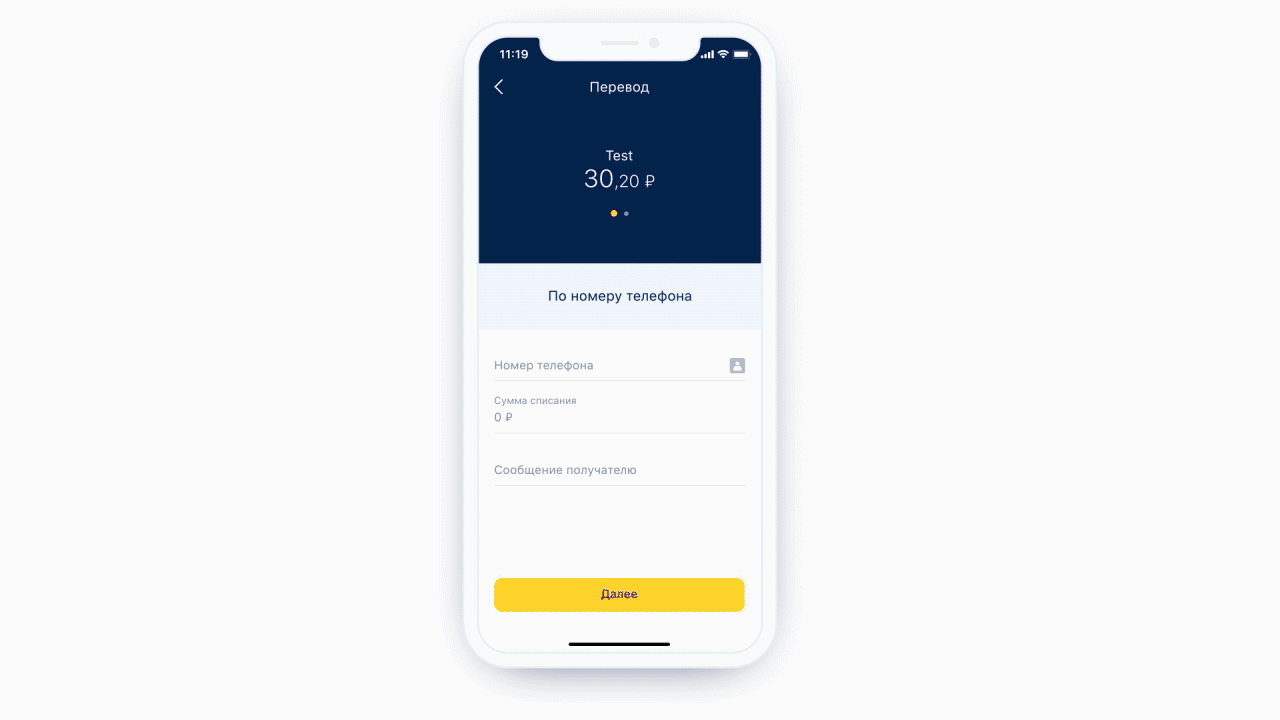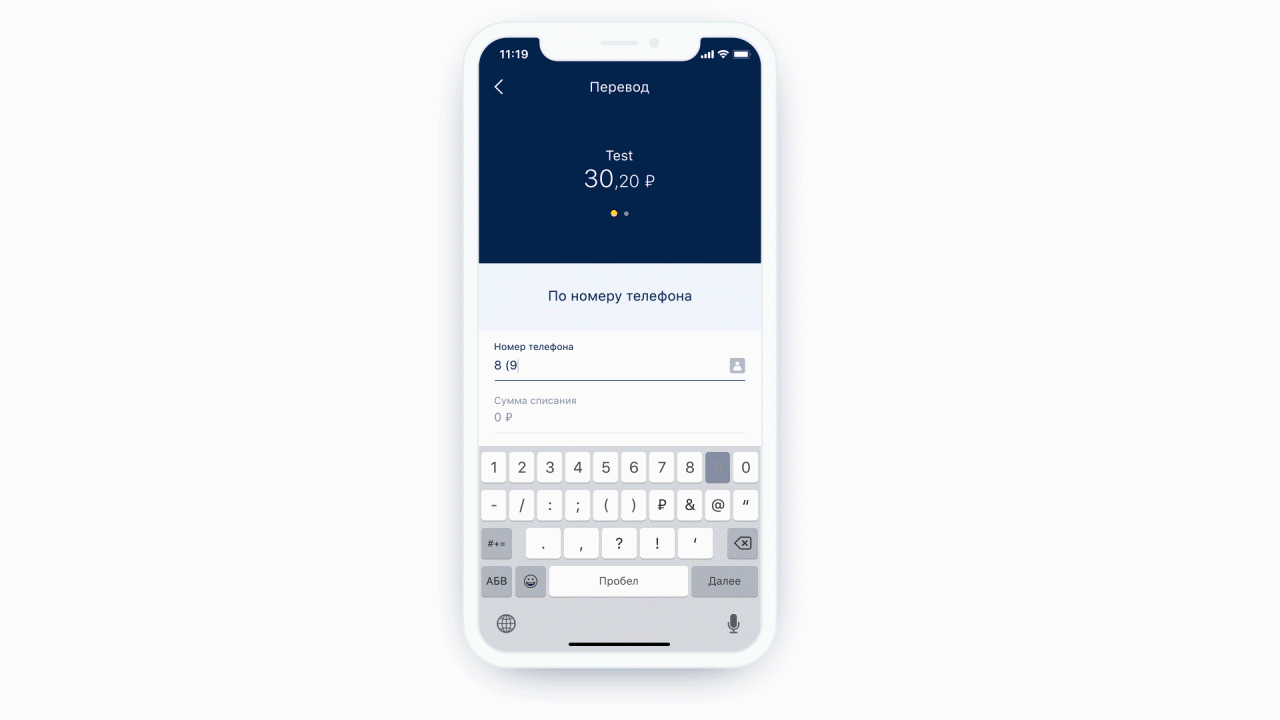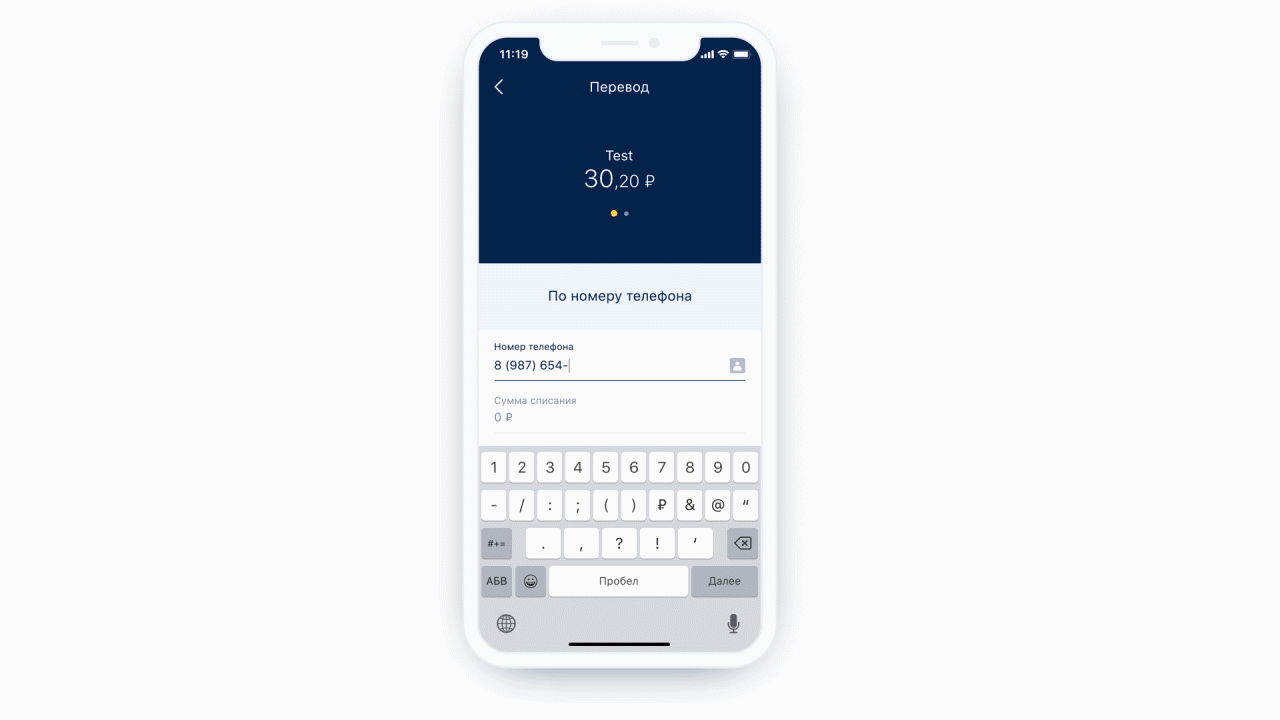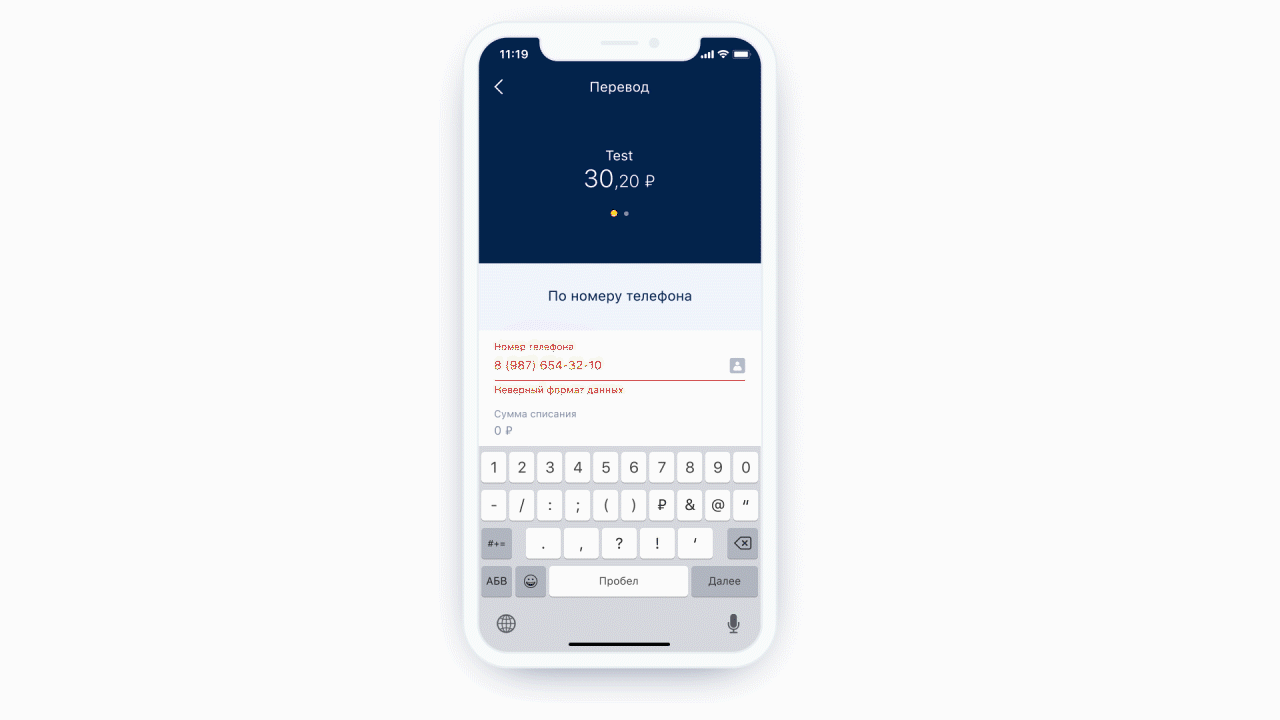
Конечно, если в форме одно или два поля, особых неудобств пользователь не почувствует. Другое дело, когда нужно заполнить сложную форму, например, для банка — с большим количеством разных полей. Как облегчить пользователю жизнь? Одно из решений — активно обрабатывать пользовательский ввод с помощью масок.
Маска — это описание того, как должно выглядеть отформатированное поле ввода в зависимости от контента. С их помощью мы можем быть уверены, что введенные данные будут соответствовать требуемому формату.
Если продолжать пример с номером телефона, использование маски даст следующие преимущества:

Как видим, маски помогают пользователю легко и безошибочно вводить сложные данные, а программисту упрощают жизнь: всю тяжелую работу по форматированию пользовательского ввода берёт на себя библиотека по работе с масками на стороне клиентского приложения. Программисту всего лишь нужно описать саму маску.
В конце концов, заполненную форму мобильное приложение отправляет на сервер. В этот момент важно, чтобы данные были правильно отформатированы. Например, API интернет-банка будет требовать, чтобы номер выглядел вот так: 9161234567 — без 8, скобочек и минусов.
Если форма пассивно обрабатывает пользовательские данные, то номер телефона она принимает в любом формате, но возникают проблемы:
- Мы вынуждаем пользователя разбираться в том, как нужно правильно отформатировать номер телефона, чтобы система его приняла.
- Мы вынуждаем пользователя набирать на клавиатуре труднодоступные символы: переключать раскладку клавиатуры, чтобы набрать цифры или, например, знак плюса.
- Нам нужно точно объяснить пользователю, в чем он ошибся.
Конечно, если в форме одно или два поля, особых неудобств пользователь не почувствует. Другое дело, когда нужно заполнить сложную форму, например, для банка — с большим количеством разных полей. Как облегчить пользователю жизнь? Одно из решений — активно обрабатывать пользовательский ввод с помощью масок.
Маска — это описание того, как должно выглядеть отформатированное поле ввода в зависимости от контента. С их помощью мы можем быть уверены, что введенные данные будут соответствовать требуемому формату.
Если продолжать пример с номером телефона, использование маски даст следующие преимущества:
- Пользователю не нужно разбираться с особенностями форматирования. Человек нажимает только цифры, а приложение автоматически подставляет плюс в начале, скобочки вокруг префикса оператора и разделяет длинные последовательности цифр пробелами или минусом.
- Маски выполняют задачу форматирования ввода и простой валидации «на лету»: у пользователя просто нет шансов ввести что-то, не похожее на номер телефона.
- Отформатированный ввод удобен для восприятия пользователем и снижает вероятность ошибки.
Как видим, маски помогают пользователю легко и безошибочно вводить сложные данные, а программисту упрощают жизнь: всю тяжелую работу по форматированию пользовательского ввода берёт на себя библиотека по работе с масками на стороне клиентского приложения. Программисту всего лишь нужно описать саму маску.
Маски — это по сути UX-сахар
Почему нельзя просто взять и описать маску
Маски — это круто и удобно. Но есть проблема, неизбежная в определённых условиях: когда на клиенте — один формат масок, а на сервере — много разных провайдеров данных и у каждого свой формат. Рассчитывать на то, что у нас будет один и тот же формат, мы не можем. Просить сервер: «Подгони нам маски, как мы любим», — тоже. Нужно уметь с этим жить.
Возникает задача: есть спецификация бэкенда, нужно написать фронтенд — мобильное приложение. Можно вручную написать все маски для приложения — и это хороший вариант, когда провайдер один и масок мало. Программисту, конечно, придётся потратить время, чтобы разобраться как минимум в двух спецификациях на маски: бэкенда и фронта. Потом ему нужно перевести конкретные маски бэкенда в соответствующие маски фронтенда. Это тоже занимает время, тут есть человеческий фактор — можно ошибиться. Это непростая работа, перевод тяжёлый: некоторые языки масок написаны в первую очередь для компьютеров, а не для людей.
Если вдруг на сервере маска изменилась или появилась новая, то приложение, во-первых, может перестать работать. Во-вторых, тяжёлую работу по переводу нужно проделать ещё раз, зарелизить новое приложение, это отнимает время, силы, деньги. Возникает вопрос: как минимизировать работу программиста? Похоже, что всем этим должна заниматься машина, а занимается почему-то человек.
Ответ — «да», у нас есть решение. Маски написаны на языке компьютеров — и это одна из причин, почему человеку тяжело с ним работать и переводить с одного языка на другой. Нужно переложить эту работу на компьютер. Поскольку маска представляется формальной грамматикой, то самый верный способ транслировать одну грамматику в другую:
- понять правила построения исходной грамматики,
- понять правила построения целевой грамматики,
- написать правила перевода из исходной грамматики в целевую,
- реализовать всё это в коде.
Это то, для чего и пишутся компиляторы и трансляторы.
Теперь подробно рассмотрим наше решение на основе формальных грамматик.
Предыстория
В нашем приложении довольно много разнообразных экранов, которые формируются по backend driven принципу: полное описание экрана вместе с данными приходит с сервера.
Большая часть экранов содержит разнообразные формы ввода. Сервер определяет, какие поля есть в форме и как они должны быть отформатированы. Для описания этих требований используются в том числе и маски.
Давайте посмотрим, как устроены маски.
Примеры масок в разных форматах
В качестве первого примера возьмём всё ту же форму ввода номера телефона. Маска для такой формы может выглядеть так.
С одной стороны, маска сама добавляет разделители, скобочки и запрещает вводить неправильные символы. С другой стороны, эта же маска из отформатированного ввода достаёт полезную информацию для отправки на сервер.
Красным выделена часть, которая называется константа. Это символы, которые появятся автоматически, — пользователь их вводить не должен:
Дальше идёт динамическая часть — она всегда выделена угловыми скобками:
Далее в тексте я буду называть это выражение «динамическим выражением» — или ДВ сокращённо
Здесь записано выражение, по которому мы будем форматировать наш ввод:
Красным выделены кусочки, отвечающие за содержимое динамической части.
\\d — любая цифра.
+ — обычный репитер: повторить минимум один раз.
${3} — символ метаинформации, который уточняет количество повторений. В данном случае должно быть три символа.
Тогда выражение \\d+${3} означает, что должно быть три цифры.
В данном формате масок внутри динамической части может быть только один репитер:
Это ограничение появилось не просто так — сейчас объясню почему.
Допустим, у нас есть ДВ, в котором жёстко указан размер: 4 элемента. И мы задаём ему 2 элемента с репитером: `<!^\\d+\\v+${4}>`. Под такое ДВ попадают следующие сочетания:
- 1abc
- 12ab
- 123a
Получается, что такое ДВ не даёт нам однозначного ответа, чего ожидать на месте второго символа: цифру или букву.
Берём маску, складываем её с пользовательским вводом. Получаем отформатированный номер телефона:
На клиенте формат у масок может выглядеть по-другому. Например, в библиотеке Input Mask от Redmadrobot маска для номера телефона имеет следующий вид:
Выглядит она симпатичнее и понимать её проще.
Получается, что маска для сервера и маска для клиента записываются по-разному, а делают одно и то же.
Переформулируем задачу: как совместить маски разных форматов
Нам нужно эти маски друг с другом совместить — или как-то из одной получить вторую.
Нужно построить функцию, которая бы преобразовывала одну маску во вторую.
И здесь пришла идея написать очень простой интерпретатор, который позволит из одной грамматики получить вторую грамматику.
Так как мы дошли до интерпретатора, давайте поговорим про грамматики.
Как проводится синтаксический анализ
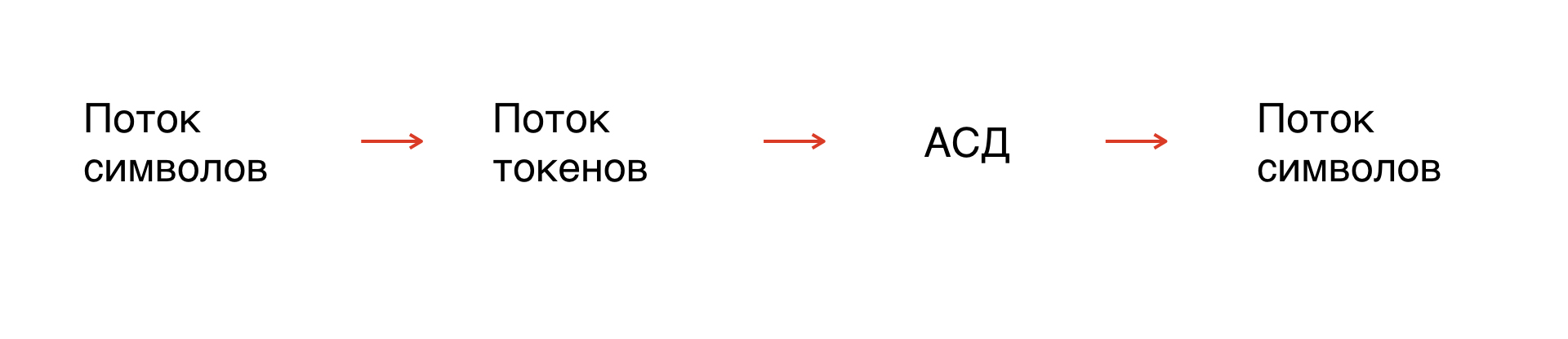
Сначала у нас есть поток символов — наша маска. По сути это строка, которой мы оперируем. Но так как символы не формализованы, нужно формализовать строку: разбить её на элементы, которые будут понятны интерпретатору.
Этот процесс называется токенизация: поток символов превращается в поток токенов. Количество токенов ограничено, они формализованы, следовательно, можно их анализировать.
Далее, исходя из правил грамматики, по потоку токенов строим абстрактное синтаксическое дерево. Из дерева получаем поток символов в нужной нам грамматике.
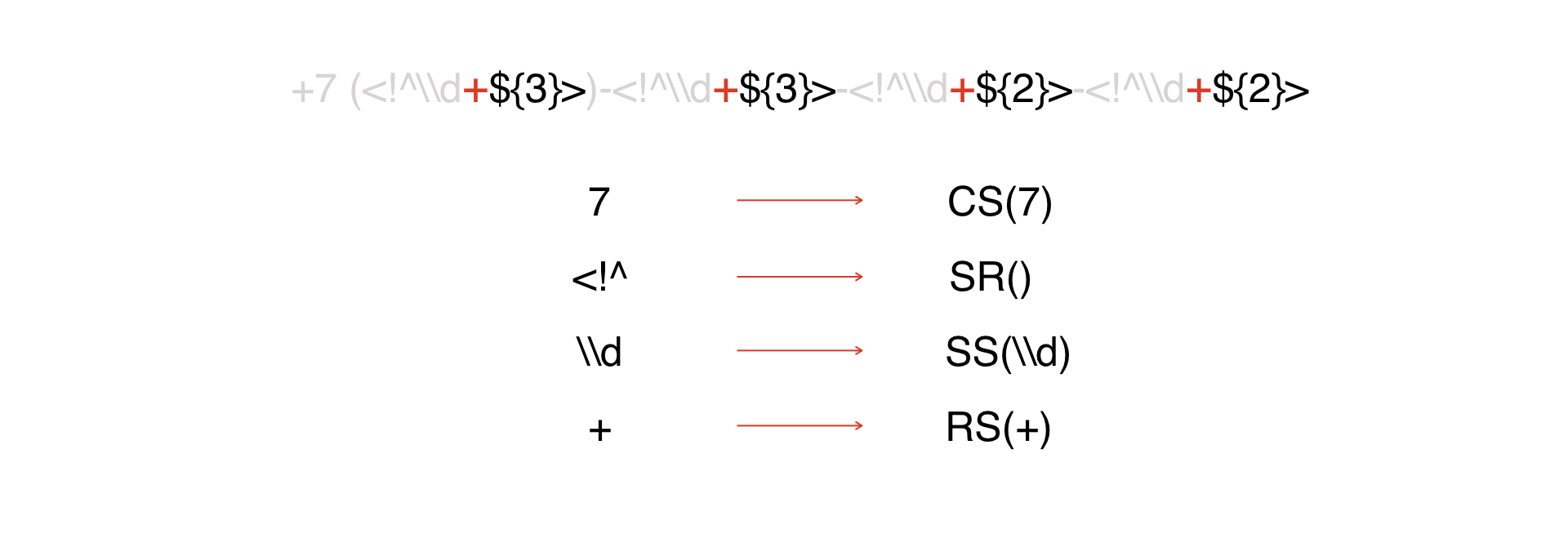
Есть выражение. Смотрим на него и видим, что у нас есть константа, про которую я говорил выше:
Все константы представим как токен CS, у которого аргумент — сама константа:
Следующий вид токенов — это начало ДВ:
Далее все подобные токены будем трактовать как специальные символы. В нашем примере их немного, в реальных масках их может быть значительно больше.
Затем у нас идёт репитер.
Потом — несколько символов, которые считаются метаданными. Мы схитрим и представим их одним токеном, потому что так проще.
Конец ДВ. Таким образом, мы разложили всё по токенам.
Пример токенизации маски для номера телефона
Чтобы посмотреть, как в принципе происходит процесс токенизации и как будет работать интерпретатор, возьмём маску для номера телефона и преобразуем её в поток токенов.
Сначала — символ +. Преобразуем в константный символ +. Далее то же самое мы делаем для семёрки и для всех остальных символов. Получаем массив из токенов. Это ещё не структура — далее будем этот массив анализировать.
Лексер и построение АСД
Теперь более сложная часть — это лексер.
Слева описана легенда — специальные символы, которые используются для описания лексических правил. Справа — сами правила.
Правило symbolRule описывает какой-то символ. Если это правило применимо, если оно верно, это значит что мы встретили либо специальный символ, либо константный символ. Можно сказать, что это функция.
Дальше — repeaterRule. Это правило описывает ситуацию, когда встречается какой-то символ, а за ним токен репитера.
Дальше всё похожим образом выглядит. Если это ДВ, то это либо symbol, либо repeater. В нашем случае это правило шире. И в конце обязательно должен быть токен с метаданными.
Последнее правило – maskRule. Это последовательность из символов и ДВ.
Теперь построим абстрактное синтаксическое дерево (АСД) из массива токенов.
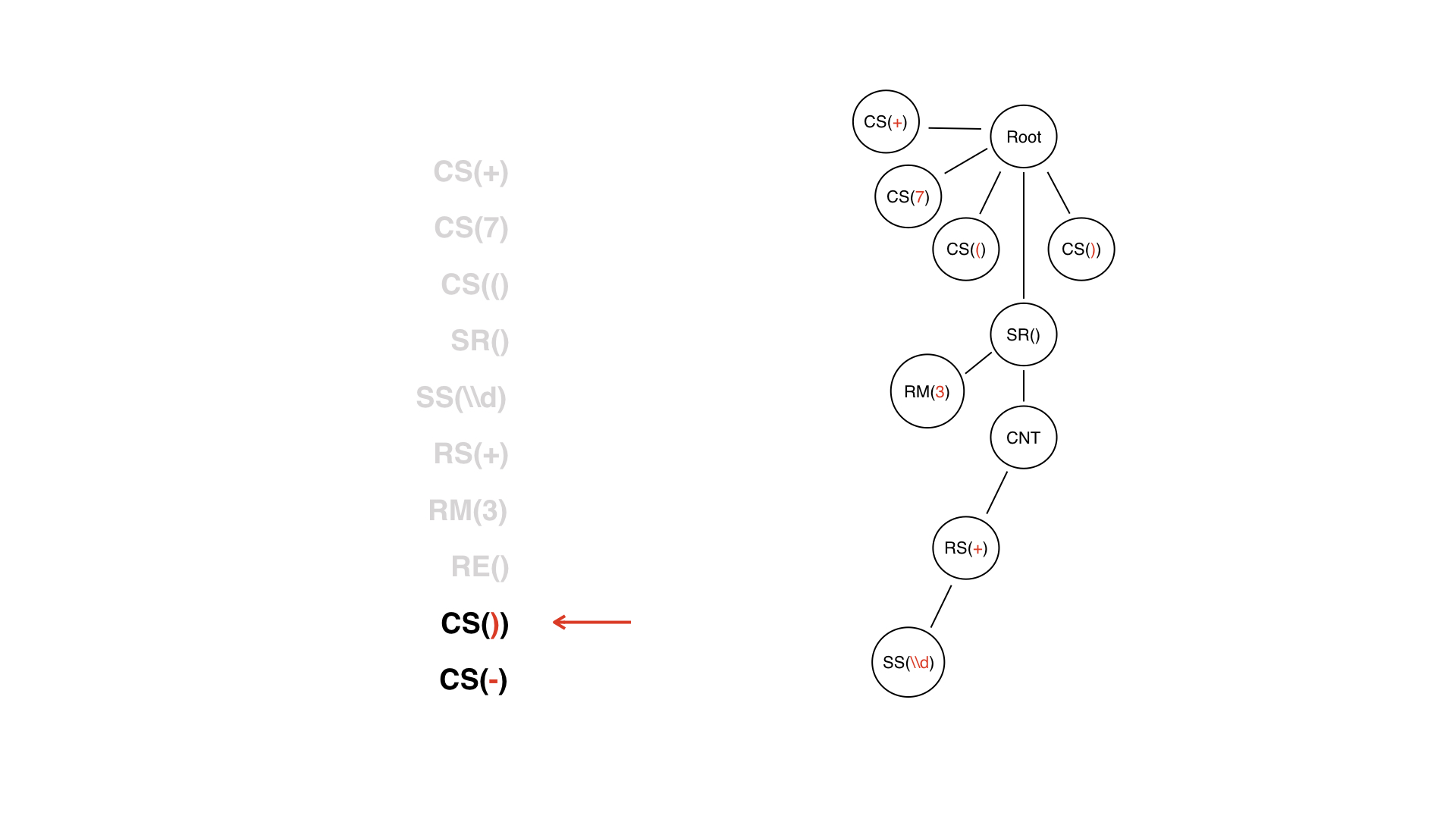
Вот список токенов. Первый узел дерева — корневой, с которого начнём построение. Он не несёт никакого смысла, просто дереву нужен корень.
У нас есть первый токен +, значит, мы просто добавляем дочерний узел, и все.
То же самое делаем со всеми остальными константными символами, но дальше — сложнее. Мы наткнулись на токен ДВ.
Это не просто обычный узел — мы знаем, что у него обязательно должен быть какой-то контент.
Узел контента — это просто технический узел, на который мы сможем ориентироваться в дальнейшем. У него есть свои дочерние узлы и какой узел у него будет следующим? Следующий токен у нас в потоке это специальный символ. Будет ли он дочерним узлом?
На самом деле, в данном случае, нет. У нас дочерним узлом будет репитер.
Почему? Потому что так удобнее работать с деревом в будущем. Допустим, мы хотим распарсить это дерево и построить по нему какую-то грамматику. Во время парсинга дерева мы смотрим на типы узлов. Если у нас CS узел, то мы и разбираем его в тот же самый CS узел, но уже для другой грамматики. Условно, мы итерируем по вершинам дерева и запускаем какую-то логику.
Логика зависит от типа узла — или от типа токена, который лежит в узле. Для разбора сильно удобнее сразу понимать, какой токен перед тобой: составной, как репитер, или простой, как CS. Это нужно, чтобы не возникало двойных трактовок или постоянных поисков дочерних узлов.
Особенно это было бы заметно на группах символов: например, [abcde]. В том случае, очевидно, должен быть какой-то родительский узел GROUP, у которого будет список дочерних узлов CS(a)CS(b) и т.д.
Возвращаемся к токену с метаданными. Он не включается в контент, он находится сбоку.
Это необходимо для того, чтобы было просто проще работать с деревом, чтобы мы не считали этот узел контентом — потому что на самом деле он к нему не относится.
Закончилось ДВ, и мы не считаем это каким-то узлом: это был токен, который теперь можно выкинуть. Мы не будем превращать его в узел дерева.
У нас уже есть поддерево, корнем которого является узел SR — то есть та самая динамическая часть. Токен конца ДВ очень нам помогает в процессе построения дерева — мы можем понять, когда закончено построение поддерева для ДВ. Но никакой ценности для логики этот токен не несёт: глядя на построчное дерево, мы и так понимаем, когда ДВ закончится, потому что оно как бы закрыто узлом SR.
Дальше — просто обычные константные символы.
Мы получили дерево. Теперь пройдёмся по этому дереву в глубину и построим на его основе какую-то другую грамматику: нужно зайти в узел, посмотреть, что это за узел, и сгенерировать элемент другой грамматики из этого узла.
Синтаксис библиотеки InputMask от Redmadrobot
Рассмотрим синтаксис библиотеки Redmadrobot.
Здесь — то же самое выражение. +7 — константа, которая добавится автоматически. Внутри фигурных скобок описано ДВ — динамическая часть. Внутри ДВ — специальный символ d. У Redmadrobot это дефолтная нотация, которая обозначает цифру.
Так выглядит нотация:
Нотация состоит из трёх частей:
- character — символ, который мы будем использовать, чтобы записать маску. То, из чего состоит алфавит маски. Например, d.
- characterSet — какие набранные пользователем символы матчатся этой нотацией. Например, 0, 1, 2, 3, 4 и так далее.
- isOptional — обязательно ли пользователь должен ввести один из символов characterSet или можно ничего не вводить.
Смотрим, у нас сейчас будет такая маска.
- У символа «b» специальная нотация цифры и он не опциональный.
- У символа «c» другая нотация — CharacterSet другой. Он тоже не опциональный.
- И символ «C» – это то же самое что «c», только он опциональный. Это нужно для того, чтобы в маске мы посмотрели на метаданные и увидели, что там не жёсткое ограничение, а слабое.
Если нужно записать правило, когда символов может быть от одного до десяти, то один символ будет не опциональный. А девять символов будут опциональными. То есть в нотации из примера они будут записаны большими буквами. В итоге это правило будет выглядеть так: [cCCCCCCCCC]
Пример: перевод маски номера телефона из формата бекэнда в формат InputMask
Вот дерево, которое мы получили на прошлом этапе. Нам нужно по нему пройтись. Первое, куда мы попадаем, это корень.
Дальше от корня мы попадаем в константный символ + — генерируем сразу +. Справа записывается маска в формате InputMask.
Следующий символ понятный — просто 7, а за ним — открывающая скобка.
Дальше генерируется кусок динамической части, но он пока не заполнен.
Идём внутрь, у нас контент, это технический узел. Ничего не пишем никуда.
Здесь у нас репитер, мы тоже ничего никуда не пишем, потому что в маске нет такого символа. Нельзя записать такое правило.
Доходим, наконец, до какого-то контентного символа.
Контентым символом может быть либо константный символ, либо специальный. В данном случае используется специальный, потому что только он несёт какую-то смысловую нагрузку для ввода.
Вот мы его написали, возвращаемся и идём как раз за метаинформацией.
Смотрим, что у нас там был репитер и здесь у нас 3 — жёсткое ограничение. Поэтому повторяем его три раза и получаем такой вот динамический кусок. Дальше мы дописываем наши константные символы.
В результате мы получаем маску, которая похожа на маску в формате роботов.
На практике мы взяли одну грамматику и сгенерировали из неё другую грамматику.
Правила генерации клиентской грамматики из серверной
Теперь немного про правила генерации. Это важно.
Могут быть такие непростые случаи: внутри динамической части несколько разных кусочков ДВ. Внутри фигурные скобки: это то же самое, как в ДВ, — один из множества. Давайте разберём, как интерпретатор будет обрабатывать эту ситуацию.
Сначала идёт набор символов, и мы должны конвертировать его в какую-то нотацию с точки зрения InputMask. Почему? Потому что это какой-то ограниченный набор символов, которые нам нужно матчить. Нам нужно совместить пользовательский ввод и символ, и поэтому здесь у нас будет записана какая-то определённая нотация.
Дальше у нас идёт символ \\d.
Дальше — ДВ с опциональным размером.
Первый, получается, какой-то символ b. У него будет Character Set, содержащий abcd.
Далее понятно, что будет другой уже символ, потому что не сматчишь иначе, или сматчишь неправильно. И дальше у нас это выражение превращается вот в такое.
В последней части обязательно должен быть хотя бы один символ. Обозначим это требование как d. Но также пользователь может ввести два дополнительных символа, и тогда они обозначаются как DD.
Соберём всё вместе.
Здесь приведён пример Character Set, которые генерируются. Видно, что b соответствует Character Set abcd, для цифр — соответствующий предустановленный Character Set. Для d и D соответствующий Character Set содержит 12vf.
Итоги
Мы научились автоматически конвертировать одну грамматику в другую: теперь в нашем приложении работают маски по спецификации сервера.
Ещё одна фишка, которую мы получили бесплатно, — это возможность проводить статический анализ маски, которая нам пришла. То есть мы можем понять, какой тип клавиатуры нужен для этой маски и какое максимальное количество символов может быть в этой маске. И это ещё круче, потому что теперь мы не показываем всё время одну и ту же клавиатуру на каждый элемент формы — мы показываем нужную клавиатуру под нужный элемент формы. И также мы можем условно точно определить, что какое-то поле — это поле ввода телефона.
Слева: вверху у поля ввода телефона есть иконка (на самом деле кнопка), которая отправит пользователя в список контактов. Справа: пример клавиатуры для обычного текстового сообщения.
Работающая библиотека по переводу масок
Можете посмотреть на то, как мы реализовали вышеописанный подход. Библиотека лежит на Гитхабе.
Примеры перевода разных масок
Это первая маска, которую мы смотрели в самом начале. Она интерпретируется в такое RedMadRobot представление.
А это вторая маска — просто маска ввода чего-то. Она конвертируется в такое представление.
agent10
Привет. А можете привести некоторые примеры когда и у каких полей приходилось менять маску/форматирования на сервере?