
Перевод статьи подготовлен в преддверии старта курса «Промышленный ML на больших данных»

Amazon SageMaker дает не просто возможность управлять notebook-ами в Jupyter, а предоставляет конфигурируемый сервис, который позволяет создавать, обучать, оптимизировать и разворачивать модели машинного обучения. Распространённое заблуждение особенно в начале работы с SageMaker заключается в том, что для использование этих сервисов вам нужен SageMaker Notebook Instance или SageMaker (Studio) Notebook. На самом деле вы можете запустить все сервисы непосредственно с вашего локального компьютера или даже вашей любимой IDE.
Прежде чем мы пойдем дальше, давайте разберемся как взаимодействовать с сервисами Amazon SageMaker. У вас есть два API:
SageMaker Python SDK – высокоуровневый API на Python, который абстрагирует код для построения, обучения и развертывания моделей машинного обучения. В частности, он предоставляет оценщиков для алгоритмов первого класса или встроенных алгоритмов, а также поддерживает фреймворки, такие как TensorFlow, MXNET и т.д. В большинстве случаев вы будете использовать его для взаимодействия с интерактивными задачами машинного обучения.
AWS SDK – это низкоуровневый API, который используется для взаимодействия со всеми поддерживаемыми сервисами AWS не обязательно для SageMaker. AWS SDK доступен для большинства популярных языков, таких как Java, Javascript, Python (boto) и т.д. В большинстве случаев вы будете использовать этот API для таких вещей, как создание ресурсов для автоматизации или взаимодействия с другими сервисами AWS, которые не поддерживаются SageMaker Python SDK.
Стоимость – это первое, что приходит в голову, но также немаловажную роль играет гибкость использования вашей родной IDE и возможность работать в автономном режиме и запускать задачи в облаке AWS по готовности.
Вы пишите код для построения модели, но вместо экземпляра SageMake Notebook или SageMaker Studio Notebook вы делаете это на своей локальной машине в Jupyter или из своей IDE. Затем, когда все готово, вы начнете обучение на экземплярах SageMaker на AWS. После обучения модель будет храниться в AWS. Затем можно запустить развертывание или пакетное преобразование с локальной машины.
Рекомендуется настроить виртуальную среду Python. В нашем случае мы будем использовать conda для управления виртуальными средами, но вы можете воспользоваться virtualenv. Опять же Amazon SageMaker использует conda для управления средами и пакетами. Предполагается, что у вас уже установлена conda, если нет – то вам сюда.

Чтобы установить пакеты, воспользуйтесь командами
Установим AWS SDK для Python (boto), awscli и SageMaker Python SDK. SageMaker Python SDK недоступен в качестве пакета conda, поэтому тут просто воспользуемся
Если вы впервые используете awscli, вам нужно его настроить. Здесь вы можете посмотреть, как это сделать.
По умолчанию будет установлена вторая версия SageMaker Python SDK. Обязательно проверьте наличие критических изменений во второй версии SDK.
Запустите Jupyter через jupyter lab и выберите ядро
Затем проверьте версии в notebook и убедитесь, что это именно те, которые нужны.
Теперь вы можете начать создавать свою модель локально и начать обучение на AWS, когда будете готовы.
Импортируйте необходимые пакеты и укажите роль. Ключевое отличие здесь заключается в том, что нужно указать напрямую
Создайте оценщик и установите гиперпараметры как вы делаете это обычно. В приведенном ниже примере мы обучаем классификатор изображений с использованием встроенного алгоритма классификации изображений. Также вы указываете тип экземпляра Stagemaker и количество экземпляров, которые вы хотите использовать для обучения.
Укажите каналы обучения так, как вы делаете это всегда, тут тоже нет никаких изменений по сравнению с тем, как вы сделали бы это на своем экземпляре notebook.
Начните задачу по обучению на SageMaker, вызвав метод fit, который начнет обучение на экземплярах SageMaker AWS.
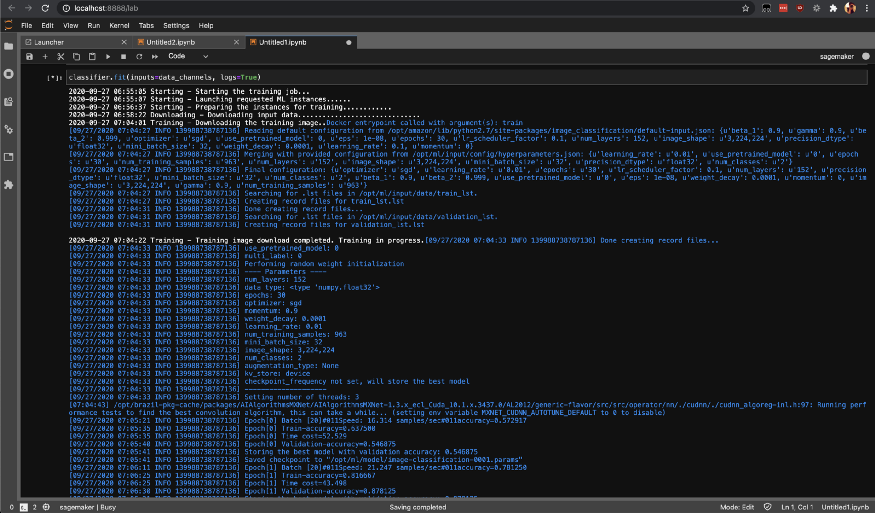
Вы можете проверить статус задач обучения с помощью list-training-jobs.
Вот и все. Сегодня мы разобрались с тем, как локально настроить среду SageMaker и собрать модели машинного обучения на локальной машине с помощью Jupyter. Помимо Jupyter вы можете сделать то же самое из собственной IDE.
Удачного обучения!

Amazon SageMaker дает не просто возможность управлять notebook-ами в Jupyter, а предоставляет конфигурируемый сервис, который позволяет создавать, обучать, оптимизировать и разворачивать модели машинного обучения. Распространённое заблуждение особенно в начале работы с SageMaker заключается в том, что для использование этих сервисов вам нужен SageMaker Notebook Instance или SageMaker (Studio) Notebook. На самом деле вы можете запустить все сервисы непосредственно с вашего локального компьютера или даже вашей любимой IDE.
Прежде чем мы пойдем дальше, давайте разберемся как взаимодействовать с сервисами Amazon SageMaker. У вас есть два API:
SageMaker Python SDK – высокоуровневый API на Python, который абстрагирует код для построения, обучения и развертывания моделей машинного обучения. В частности, он предоставляет оценщиков для алгоритмов первого класса или встроенных алгоритмов, а также поддерживает фреймворки, такие как TensorFlow, MXNET и т.д. В большинстве случаев вы будете использовать его для взаимодействия с интерактивными задачами машинного обучения.
AWS SDK – это низкоуровневый API, который используется для взаимодействия со всеми поддерживаемыми сервисами AWS не обязательно для SageMaker. AWS SDK доступен для большинства популярных языков, таких как Java, Javascript, Python (boto) и т.д. В большинстве случаев вы будете использовать этот API для таких вещей, как создание ресурсов для автоматизации или взаимодействия с другими сервисами AWS, которые не поддерживаются SageMaker Python SDK.
Почему локальная среда?
Стоимость – это первое, что приходит в голову, но также немаловажную роль играет гибкость использования вашей родной IDE и возможность работать в автономном режиме и запускать задачи в облаке AWS по готовности.
Как работает локальная среда
Вы пишите код для построения модели, но вместо экземпляра SageMake Notebook или SageMaker Studio Notebook вы делаете это на своей локальной машине в Jupyter или из своей IDE. Затем, когда все готово, вы начнете обучение на экземплярах SageMaker на AWS. После обучения модель будет храниться в AWS. Затем можно запустить развертывание или пакетное преобразование с локальной машины.
Настройка среды с помощью conda
Рекомендуется настроить виртуальную среду Python. В нашем случае мы будем использовать conda для управления виртуальными средами, но вы можете воспользоваться virtualenv. Опять же Amazon SageMaker использует conda для управления средами и пакетами. Предполагается, что у вас уже установлена conda, если нет – то вам сюда.
Создаем новую среду conda
conda create -n sagemaker python=3Активируем и верифицируем среду
Устанавливаем необходимые пакеты
Чтобы установить пакеты, воспользуйтесь командами
conda или pip. Выберем вариант с conda.conda install -y pandas numpy matplotlibУстанавливаем пакеты AWS
Установим AWS SDK для Python (boto), awscli и SageMaker Python SDK. SageMaker Python SDK недоступен в качестве пакета conda, поэтому тут просто воспользуемся
pip.pip install boto3 awscli sagemakerЕсли вы впервые используете awscli, вам нужно его настроить. Здесь вы можете посмотреть, как это сделать.
По умолчанию будет установлена вторая версия SageMaker Python SDK. Обязательно проверьте наличие критических изменений во второй версии SDK.
Устанавливаем Jupyter и создаем ядро
conda install -c conda-forge jupyterlab
python -m ipykernel install --user --name sagemakerВерифицируем среду и проверяем версии
Запустите Jupyter через jupyter lab и выберите ядро
sagemaker, которое мы создали выше.Затем проверьте версии в notebook и убедитесь, что это именно те, которые нужны.
Создаем и обучаем
Теперь вы можете начать создавать свою модель локально и начать обучение на AWS, когда будете готовы.
Импортируем пакеты
Импортируйте необходимые пакеты и укажите роль. Ключевое отличие здесь заключается в том, что нужно указать напрямую
arn роли, а не get_execution_role(). Поскольку вы запускаете все с локального компьютера с учетными данными AWS, а не экземпляр notebook с ролью, функция get_execution_role() работать не будет.from sagemaker import image_uris # Use image_uris instead of get_image_uri
from sagemaker import TrainingInput # Use instead of sagemaker.session.s3_input
region = boto3.Session().region_name
container = image_uris.retrieve('image-classification',region)
bucket= 'your-bucket-name'
prefix = 'output'
SageMakerRole='arn:aws:iam::xxxxxxxxxx:role/service-role/AmazonSageMaker-ExecutionRole-20191208T093742'Создаем оценщик
Создайте оценщик и установите гиперпараметры как вы делаете это обычно. В приведенном ниже примере мы обучаем классификатор изображений с использованием встроенного алгоритма классификации изображений. Также вы указываете тип экземпляра Stagemaker и количество экземпляров, которые вы хотите использовать для обучения.
s3_output_location = 's3://{}/output'.format(bucket, prefix)
classifier = sagemaker.estimator.Estimator(container,
role=SageMakerRole,
instance_count=1,
instance_type='ml.p2.xlarge',
volume_size = 50,
max_run = 360000,
input_mode= 'File',
output_path=s3_output_location)
classifier.set_hyperparameters(num_layers=152,
use_pretrained_model=0,
image_shape = "3,224,224",
num_classes=2,
mini_batch_size=32,
epochs=30,
learning_rate=0.01,
num_training_samples=963,
precision_dtype='float32')
Каналы обучения
Укажите каналы обучения так, как вы делаете это всегда, тут тоже нет никаких изменений по сравнению с тем, как вы сделали бы это на своем экземпляре notebook.
train_data = TrainingInput(s3train, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
validation_data = TrainingInput(s3validation, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
train_data_lst = TrainingInput(s3train_lst, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
validation_data_lst = TrainingInput(s3validation_lst, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
data_channels = {'train': train_data, 'validation': validation_data,
'train_lst': train_data_lst, 'validation_lst': validation_data_lst}Начинаем обучение
Начните задачу по обучению на SageMaker, вызвав метод fit, который начнет обучение на экземплярах SageMaker AWS.
classifier.fit(inputs=data_channels, logs=True)Вы можете проверить статус задач обучения с помощью list-training-jobs.
Вот и все. Сегодня мы разобрались с тем, как локально настроить среду SageMaker и собрать модели машинного обучения на локальной машине с помощью Jupyter. Помимо Jupyter вы можете сделать то же самое из собственной IDE.
Удачного обучения!
lair
Некое противоречие. Данные в S3, обучаемся на инстансах AWS, а в начале статьи обещают "возможность работать в автономном режиме и запускать задачи в облаке AWS по готовности". Нет, я понимаю, что автор имел в виду, но с учетом реальности эти обещания выглядят немножко иначе.
При этом, афаик, у SageMaker была возможность полного локального запуска, по крайней мере, для пользовательских контейнеров, только вот под Windows она у меня так и не завелась.