
Сегодня поговорим о том, как лучше хранить данные в мире, где сети пятого поколения, сканеры геномов и беспилотные автомобили производят за день больше данных, чем всё человечество породило в период до промышленной революции.

Наш мир генерирует всё больше информации. Какая-то её часть мимолётна и утрачивается так же быстро, как и собирается. Другая должна храниться дольше, а иная и вовсе рассчитана «на века» — по крайней мере, так нам видится из настоящего. Информационные потоки оседают в дата-центрах с такой скоростью, что любой новый подход, любая технология, призванные удовлетворить этот бесконечный «спрос», стремительно устаревают.
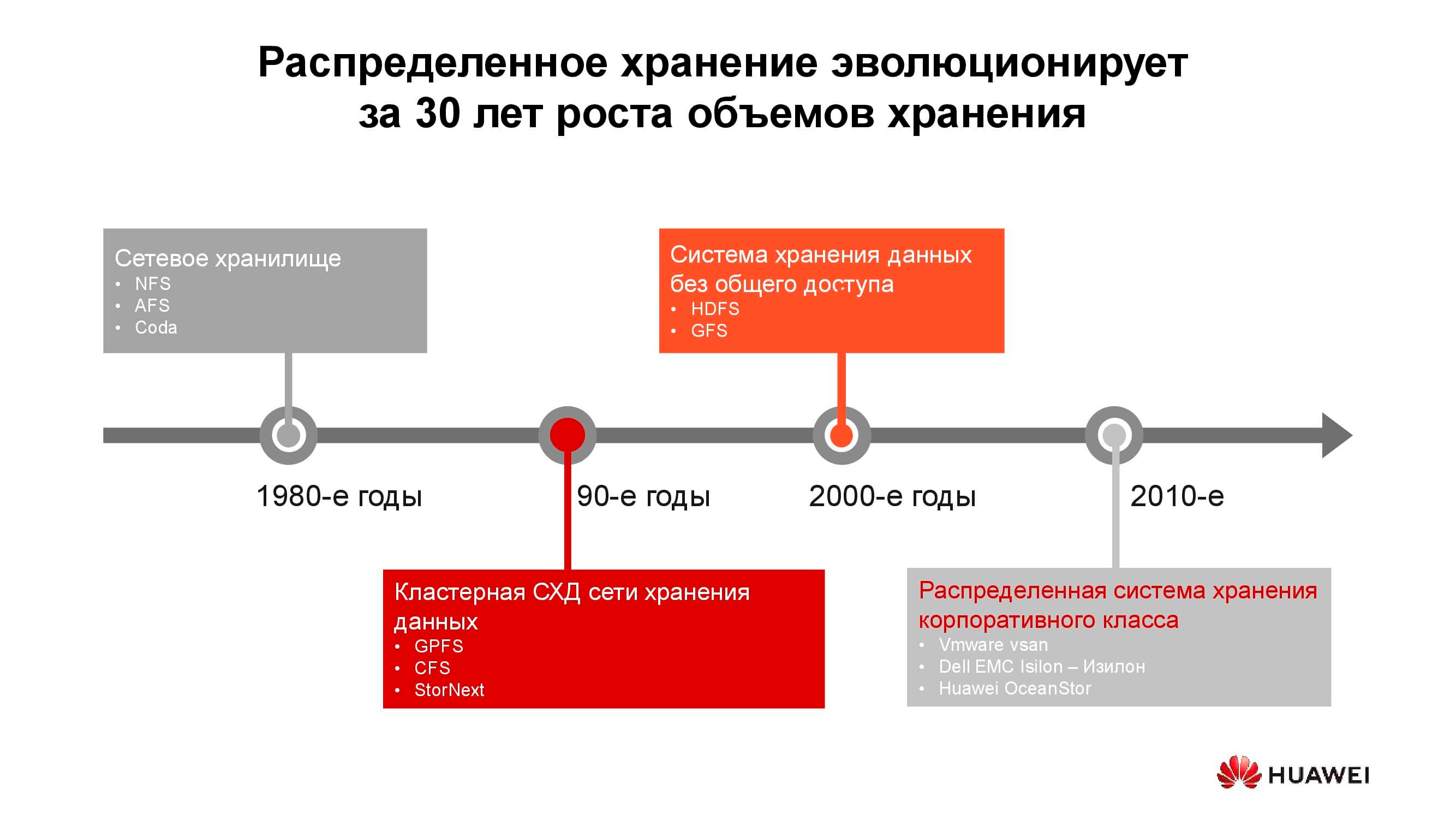
Первые сетевые хранилища в привычном нам виде появились в 1980-х. Многие из вас сталкивались с NFS (Network File System), AFS (Andrew File System) или Coda. Спустя десятилетие мода и технологии изменились, а распределённые файловые системы уступили место кластерным СХД на основе GPFS (General Parallel File System), CFS (Clustered File Systems) и StorNext. В качестве базиса использовались блочные хранилища классической архитектуры, поверх которых с помощью программного слоя создавалась единая файловая система. Эти и подобные решения до сих пор применяются, занимают свою нишу и вполне востребованы.
На рубеже тысячелетий парадигма распределённых хранилищ несколько поменялась, и на лидирующие позиции вышли системы с архитектурой SN (Shared-Nothing). Произошёл переход от кластерного хранения к хранению на отдельных узлах, в качестве которых, как правило, выступали классические серверы с обеспечивающим надёжное хранение ПО; на таких принципах построены, скажем, HDFS (Hadoop Distributed File System) и GFS (Global File System).
Ближе к 2010-м заложенные в основу распределённых систем хранения концепции всё чаще стали находить отражение в полноценных коммерческих продуктах, таких как VMware vSAN, Dell EMC Isilon и наша Huawei OceanStor. За упомянутыми платформами стоит уже не сообщество энтузиастов, а конкретные вендоры, которые отвечают за функциональность, поддержку, сервисное обслуживание продукта и гарантируют его дальнейшее развитие. Такие решения наиболее востребованы в нескольких сферах.
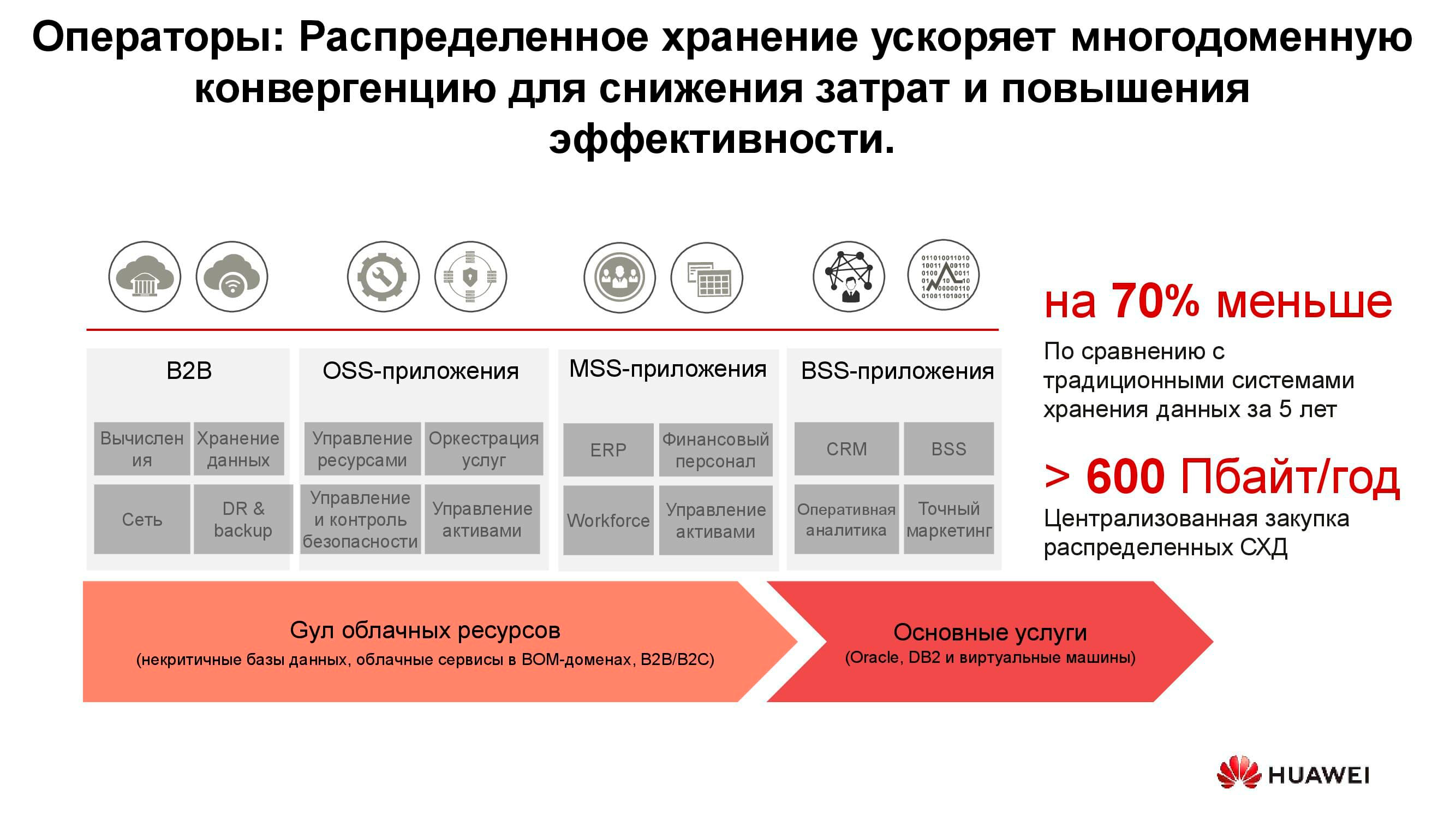
Пожалуй, одними из старейших потребителей распределённых систем хранения являются операторы связи. На схеме видно, какие группы приложений производят основной объём данных. OSS (Operations Support Systems), MSS (Management Support Services) и BSS (Business Support Systems) представляют собой три дополняющих друг друга программных слоя, необходимых для предоставления сервиса абонентам, финансовой отчётности провайдеру и эксплуатационной поддержки инженерам оператора.
Зачастую данные этих слоев сильно перемешаны между собой, и, чтобы избежать накопления ненужных копий, как раз и используются распределённые хранилища, которые аккумулируют весь объём информации, поступающей от работающей сети. Хранилища объединяются в общий пул, к которому и обращаются все сервисы.
Наши расчёты показывают, что переход от классических СХД к блочным позволяет сэкономить до 70% бюджета только за счёт отказа от выделенных СХД класса hi-end и использования обычных серверов классической архитектуры (обычно x86), работающих в связке со специализированным ПО. Сотовые операторы уже довольно давно начали приобретать подобные решения в серьезных объёмах. В частности, российское операторы используют такие продукты от Huawei более шести лет.
Да, ряд задач с помощью распределённых систем выполнить не получится. Например, при повышенных требованиях к производительности или к совместимости со старыми протоколами. Но не менее 70% данных, которые обрабатывает оператор, вполне можно расположить в распределённом пуле.
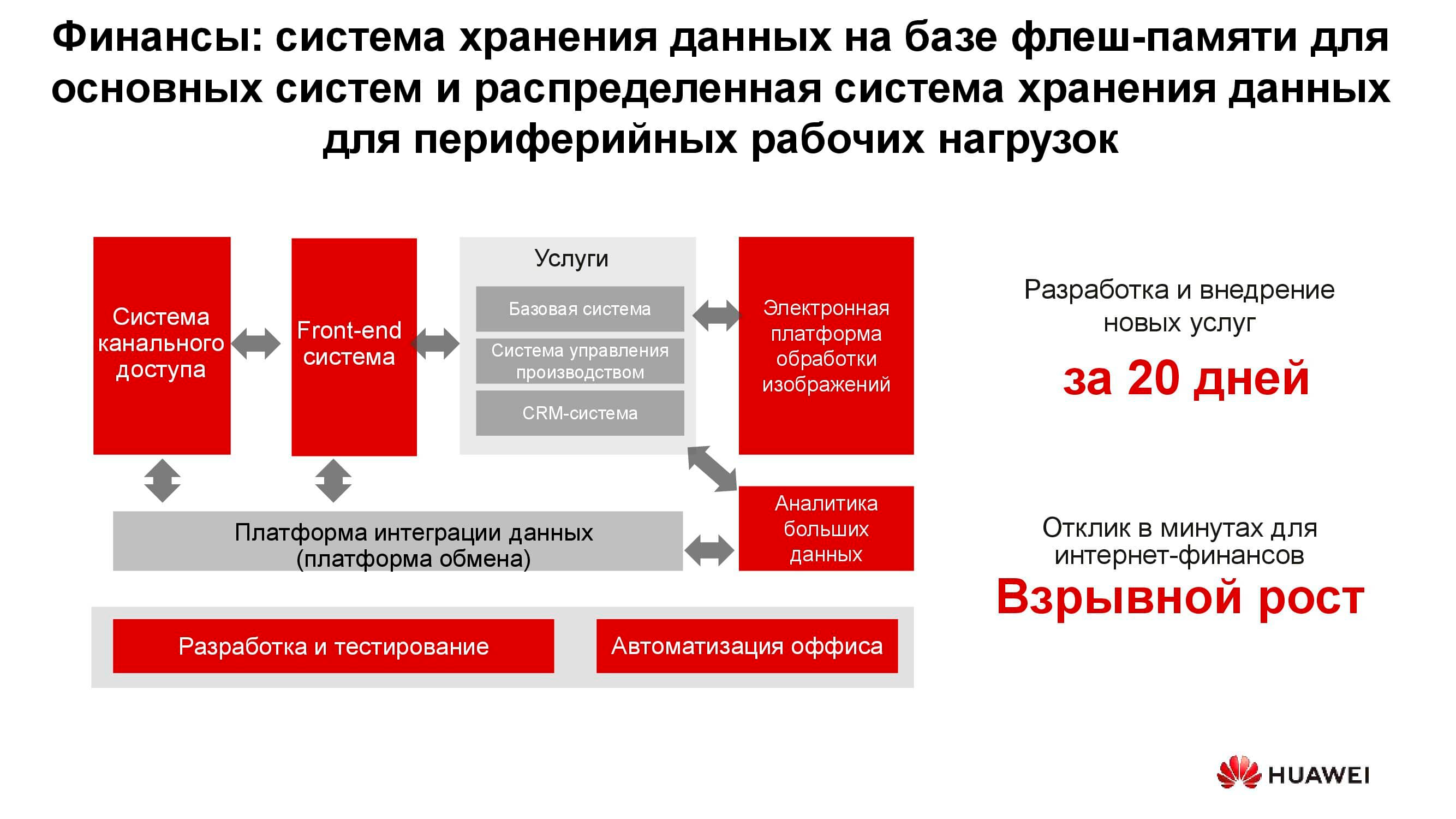
В любом банке соседствует множество разношёрстных IT-систем, начиная с процессинга и заканчивая автоматизированной банковской системой. Эта инфраструктура тоже работает с огромным объёмом информации, при этом большая часть задач не требует повышенной производительности и надёжности систем хранения, например разработка, тестирование, автоматизация офисных процессов и пр. Здесь применение классических СХД возможно, но с каждым годом всё менее выгодно. К тому же в этом случае отсутствует гибкость расходования ресурсов СХД, производительность которой рассчитывается из пиковой нагрузки.
При использовании распределённых систем хранения их узлы, по факту являющиеся обычными серверами, могут быть в любой момент конвертированы, например, в серверную ферму и использованы в качестве вычислительной платформы.
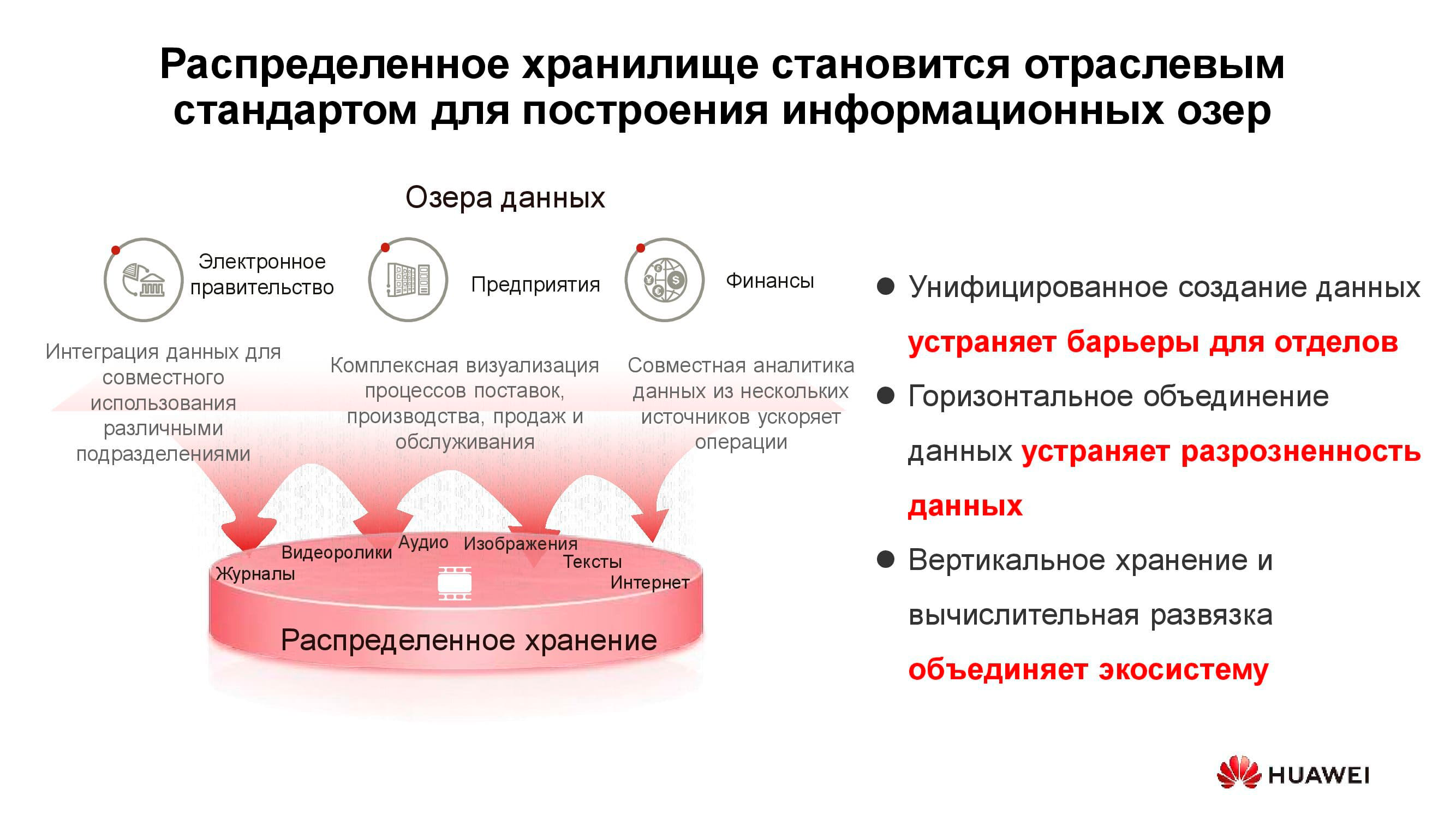
На схеме выше приведён перечень типичных потребителей сервисов data lake. Это могут быть службы электронного правительства (допустим, «Госуслуги»), прошедшие цифровизацию предприятия, финансовые структуры и др. Всем им необходимо работать с большими объёмами разнородной информации.
Эксплуатация классических СХД для решения таких задач неэффективна, так как требуется и высокопроизводительный доступ к блочным базам данных, и обычный доступ к библиотекам сканированных документов, хранящихся в виде объектов. Сюда же может быть привязана, допустим, система заказов через веб-портал. Чтобы всё это реализовать на платформе классической СХД, потребуется большой комплект оборудования под разные задачи. Одна горизонтальная универсальная система хранения вполне может закрывать все ранее перечисленные задачи: понадобится лишь создать в ней несколько пулов с разными характеристиками хранения.

Количество хранимой в мире информации растёт примерно на 30% в год. Это хорошие новости для поставщиков систем хранения, но что же является и будет являться основным источником этих данных?
Десять лет назад такими генераторами стали социальные сети, это потребовало создания большого количества новых алгоритмов, аппаратных решений и т. д. Сейчас выделяются три главных драйвера роста объёмов хранения. Первый — cloud computing. В настоящее время примерно 70% компаний так или иначе используют облачные сервисы. Это могут быть электронные почтовые системы, резервные копии и другие виртуализированные сущности.
Вторым драйвером становятся сети пятого поколения. Это новые скорости и новые объёмы передачи данных. По нашим прогнозам, широкое распространение 5G приведёт к падению спроса на карточки флеш-памяти. Сколько бы ни было памяти в телефоне, она всё равно кончается, а при наличии в гаджете 100-мегабитного канала нет никакой необходимости хранить фотографии локально.
К третьей группе причин, по которым растёт спрос на системы хранения, относятся бурное развитие искусственного интеллекта, переход на аналитику больших данных и тренд на всеобщую автоматизацию всего, чего только можно.
Особенностью «нового трафика» является его неструктурированность. Нам надо хранить эти данные, никак не определяя их формат. Он требуется лишь при последующем чтении. К примеру, банковская система скоринга для определения доступного размера кредита будет смотреть выложенные вами в соцсетях фотографии, определяя, часто ли вы бываете на море и в ресторанах, и одновременно изучать доступные ей выписки из ваших медицинских документов. Эти данные, с одной стороны, всеобъемлющи, а с другой — лишены однородности.

Какие же проблемы влечет за собой появление «новых данных»? Первейшая среди них, конечно, сам объём информации и расчётные сроки её хранения. Один только современный автономный автомобиль без водителя каждый день генерирует до 60 Тбайт данных, поступающих со всех его датчиков и механизмов. Для разработки новых алгоритмов движения эту информацию необходимо обработать за те же сутки, иначе она начнёт накапливаться. При этом храниться она должна очень долго — десятки лет. Только тогда в будущем можно будет делать выводы на основе больших аналитических выборок.
Одно устройство для расшифровки генетических последовательностей производит порядка 6 Тбайт в день. А собранные с его помощью данные вообще не подразумевают удаления, то есть гипотетически должны храниться вечно.
Наконец, всё те же сети пятого поколения. Помимо собственно передаваемой информации, такая сеть и сама является огромным генератором данных: журналов действий, записей звонков, промежуточных результатов межмашинных взаимодействий и пр.
Всё это требует выработки новых подходов и алгоритмов хранения и обработки информации. И такие подходы появляются.
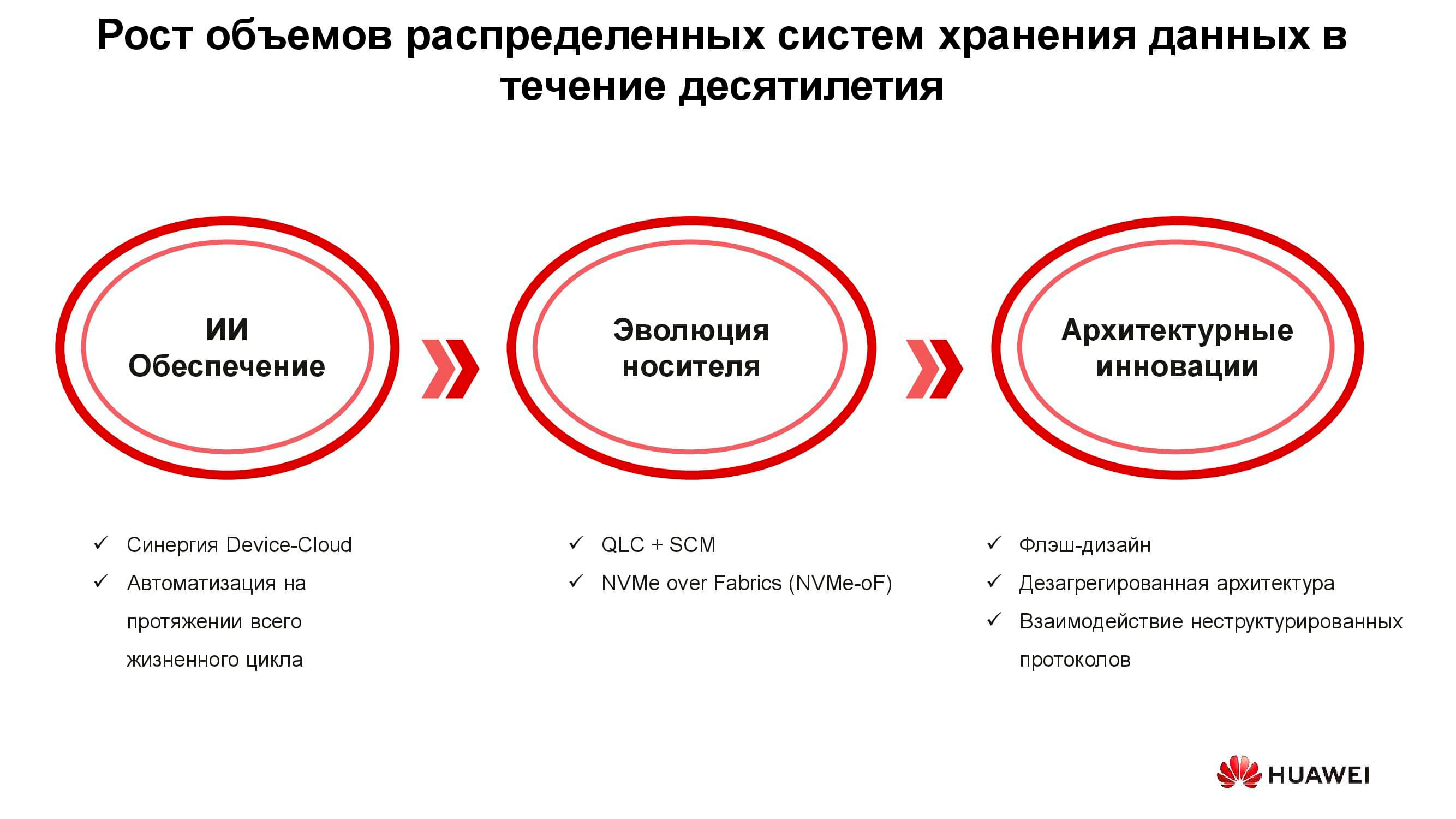
Можно выделить три группы решений, призванных справиться с новыми требованиями к системам хранения информации: внедрение искусственного интеллекта, техническая эволюция носителей данных и инновации в области системной архитектуры. Начнём с ИИ.

В новых решениях Huawei искусственный интеллект используется уже на уровне самого хранилища, которое оборудовано ИИ-процессором, позволяющим системе самостоятельно анализировать своё состояние и предсказывать отказы. Если СХД подключить к сервисному облаку, которое обладает значительными вычислительными способностями, искусственный интеллект сможет обработать больше информации и повысить точность своих гипотез.
Помимо отказов, такой ИИ умеет прогнозировать будущую пиковую нагрузку и время, остающееся до исчерпания ёмкости. Это позволяет оптимизировать производительность и масштабировать систему ещё до наступления каких-либо нежелательных событий.

Теперь об эволюции носителей данных. Первые флеш-накопители были выполнены по технологии SLC (Single-Level Cell). Основанные на ней устройства были быстрыми, надёжными, стабильными, но имели небольшую ёмкость и стоили очень дорого. Роста объёма и снижения цены удалось добиться путём определённых технических уступок, из-за которых скорость, надёжность и срок службы накопителей сократились. Тем не менее тренд не повлиял на сами СХД, которые за счёт различных архитектурных ухищрений в целом стали и более производительными, и более надёжными.
Но почему понадобились СХД класса All-Flash? Разве недостаточно было просто заменить в уже эксплуатируемой системе старые HDD на новые SSD того же форм-фактора? Потребовалось это для того, чтобы эффективно использовать все ресурсы новых твердотельных накопителей, что в старых системах было попросту невозможно.
Компания Huawei, например, для решения этой задачи разработала целый ряд технологий, одной из которых стала FlashLink, позволившая максимально оптимизировать взаимодействия «диск — контроллер».
Интеллектуальная идентификация дала возможность разложить данные на несколько потоков и справиться с рядом нежелательных явлений, таких как WA (write amplification). Вместе с тем новые алгоритмы восстановления, в частности RAID 2.0+, повысили скорость ребилда, сократив его время до совершенно незначительных величин.
Отказ, переполненность, «сборка мусора» — эти факторы также больше не влияют на производительность системы хранения благодаря специальной доработке контроллеров.
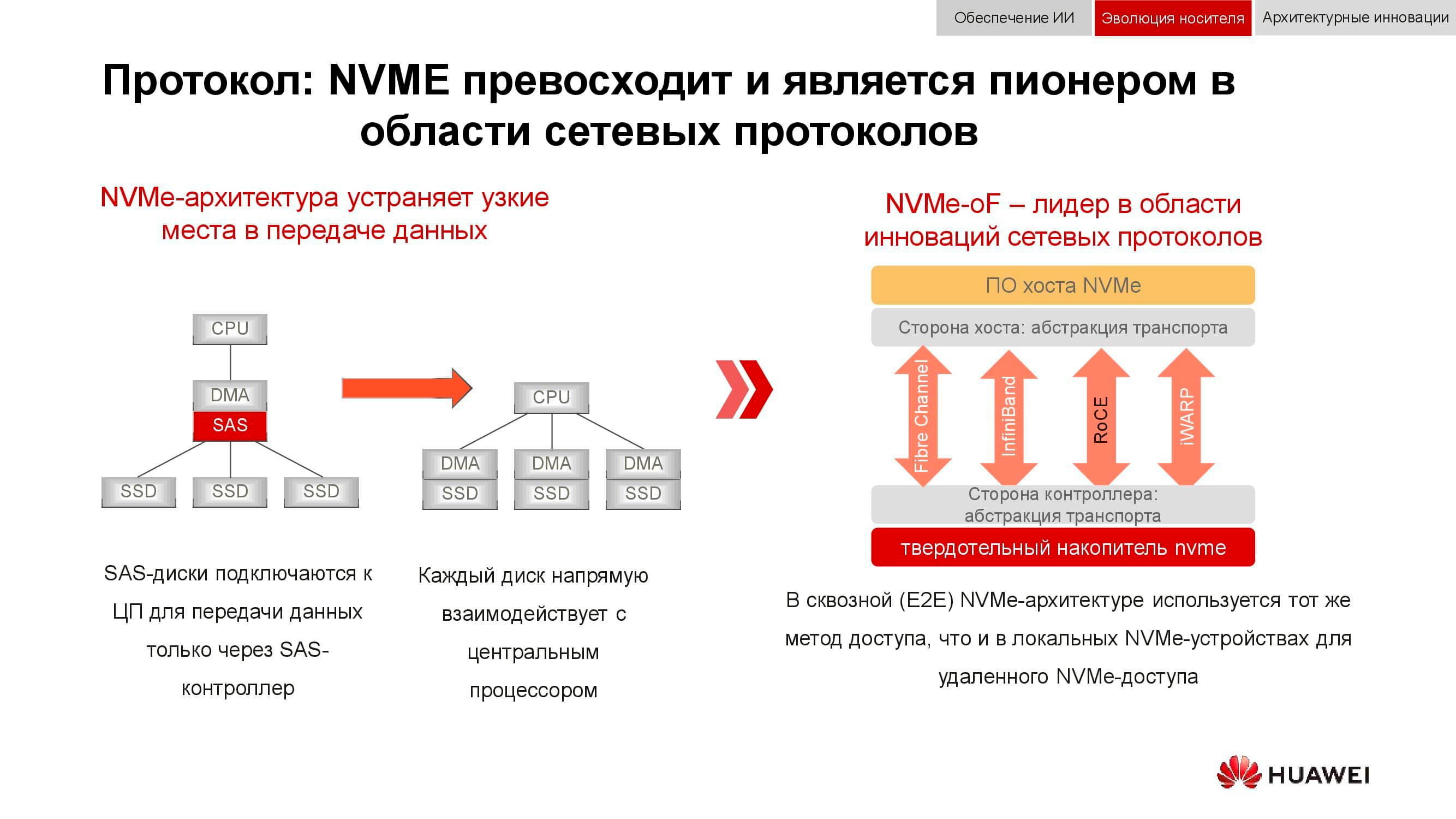
А ещё блочные хранилища данных готовятся встретить NVMe. Напомним, что классическая схема организации доступа к данным работала так: процессор обращался к RAID-контроллеру по шине PCI Express. Тот, в свою очередь, взаимодействовал с механическими дисками по SCSI или SAS. Применение NVMe на бэкенде заметно ускорило весь процесс, однако несло в себе один недостаток: накопители должны были иметь непосредственное подключение к процессору, чтобы обеспечить тому прямой доступ в память.
Следующей фазой развития технологии, которую мы наблюдаем сейчас, стало применение NVMe-oF (NVMe over Fabrics). Что касается блочных технологий Huawei, они уже сейчас поддерживают FC-NVMe (NVMe over Fibre Channel), и на подходе NVMe over RoCE (RDMA over Converged Ethernet). Тестовые модели вполне функциональны, до официальной их презентации осталось несколько месяцев. Заметим, что всё это появится и в распределённых системах, где «Ethernet без потерь» будет весьма востребован.
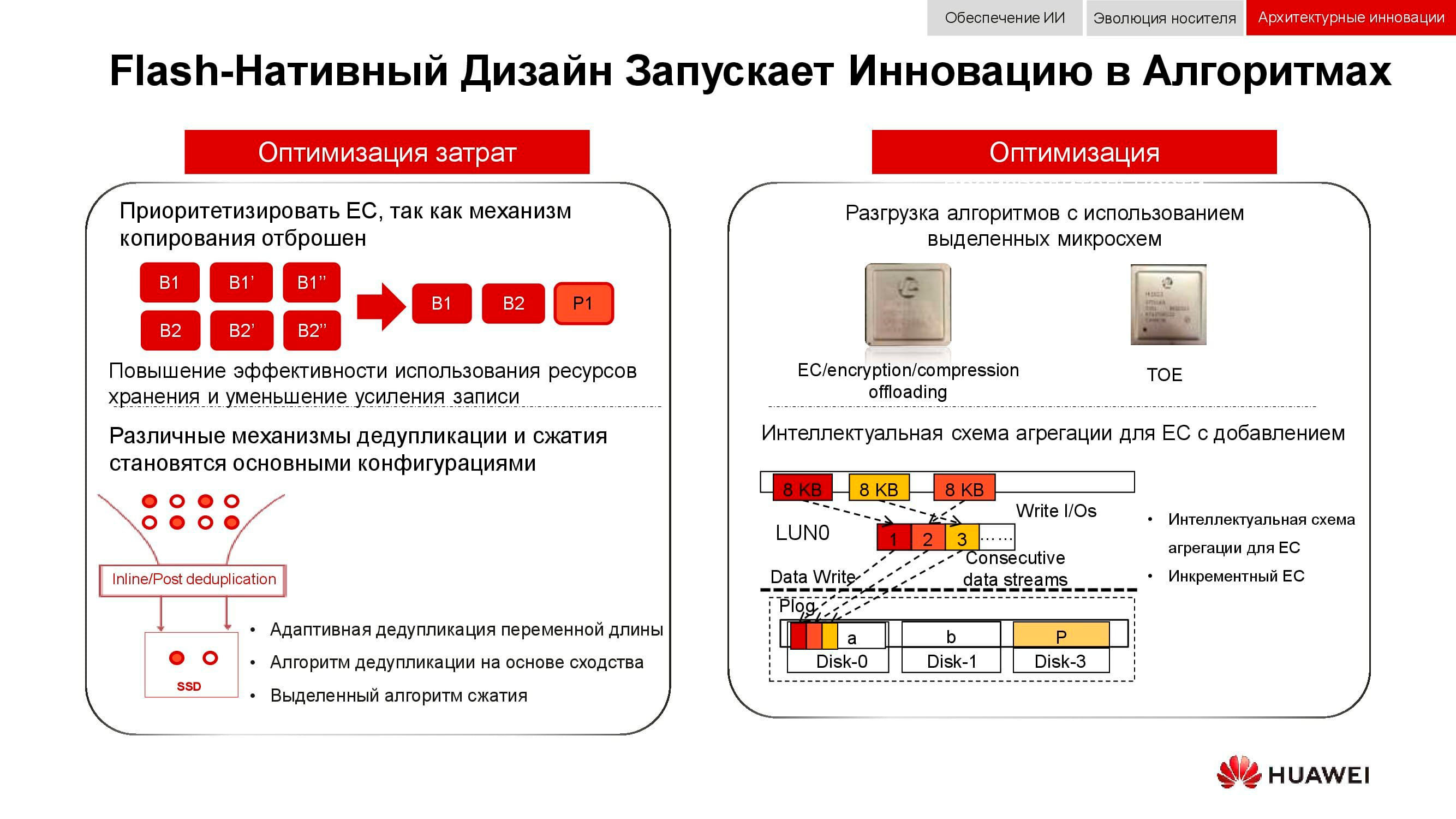
Дополнительным способом оптимизации работы именно распределённых хранилищ стал полный отказ от зеркалирования данных. Решения Huawei больше не используют n копий, как в привычном RAID 1, и полностью переходят на механизм EC (Erasure coding). Специальный математический пакет с определённой периодичностью вычисляет контрольные блоки, которые позволяют восстановить промежуточные данные в случае их потери.
Механизмы дедупликации и сжатия становятся обязательными. Если в классических СХД мы ограничены количеством установленных в контроллеры процессоров, то в распределённых горизонтально масштабируемых системах хранения каждый узел содержит всё необходимое: диски, память, процессоры и интерконнект. Этих ресурсов достаточно, чтобы дедупликация и компрессия оказывали на производительность минимальное влияние.
И об аппаратных методах оптимизации. Здесь снизить нагрузку на центральные процессоры удалось с помощью дополнительных выделенных микросхем (или выделенных блоков в самом процессоре), играющих роль TOE (TCP/IP Offload Engine) или берущих на себя математические задачи EC, дедупликации и компрессии.
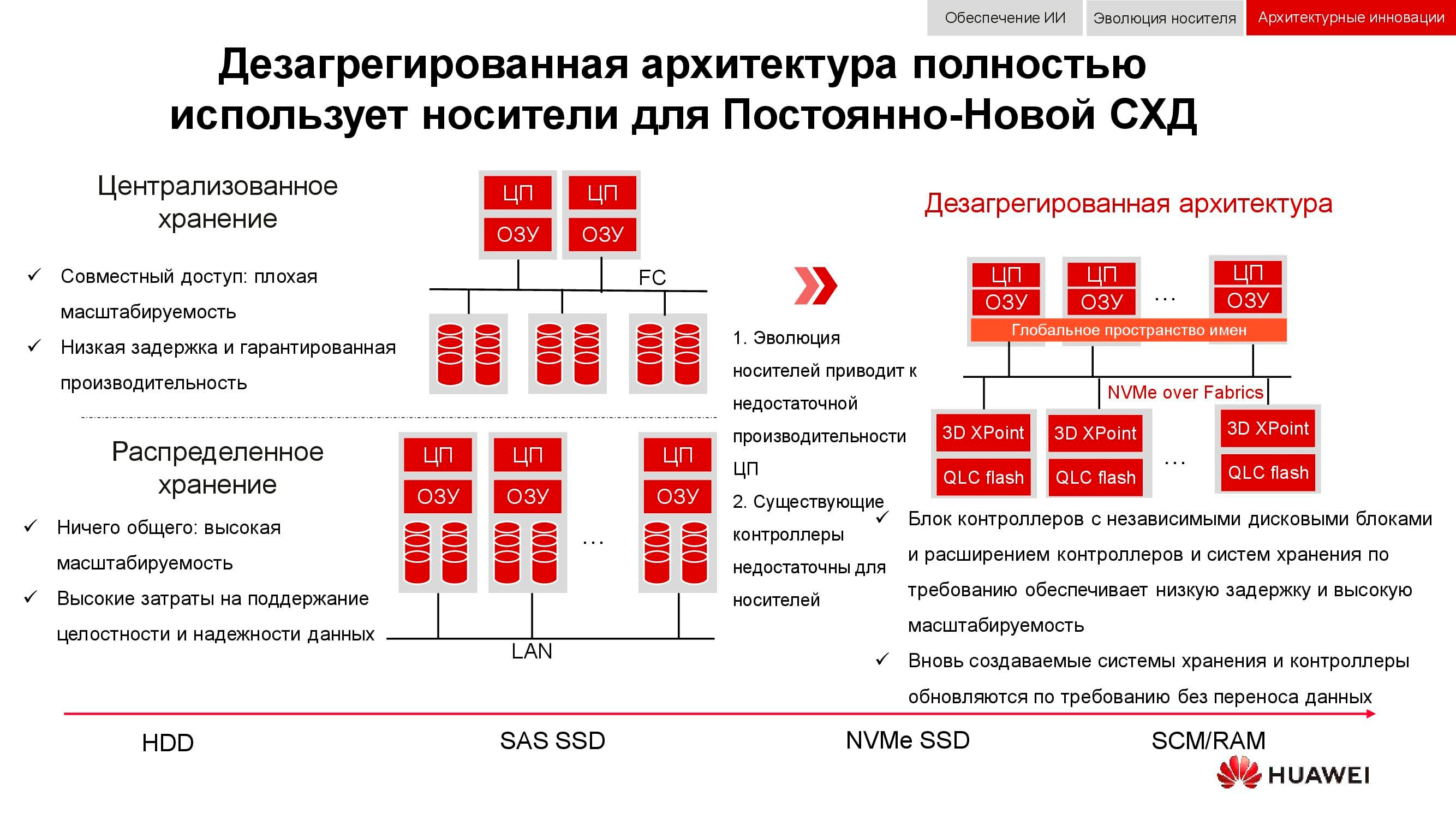
Новые подходы к хранению данных нашли воплощение в дезагрегированной (распределённой) архитектуре. В системах централизованного хранения имеется фабрика серверов, по Fibre Channel подключённая к SAN с большим количеством массивов. Недостатками такого подхода являются трудности с масштабированием и обеспечением гарантированного уровня услуги (по производительности или задержкам). Гиперконвергентные системы используют одни и те же хосты — как для хранения, так и для обработки информации. Это даёт практически неограниченный простор масштабирования, но влечёт за собой высокие затраты на поддержание целостности данных.
В отличие от обеих вышеперечисленных, дезагрегированная архитектура подразумевает разделение системы на вычислительную фабрику и горизонтальную систему хранения. Это обеспечивает преимущества обеих архитектур и позволяет практически неограниченно масштабировать только тот элемент, производительности которого не хватает.
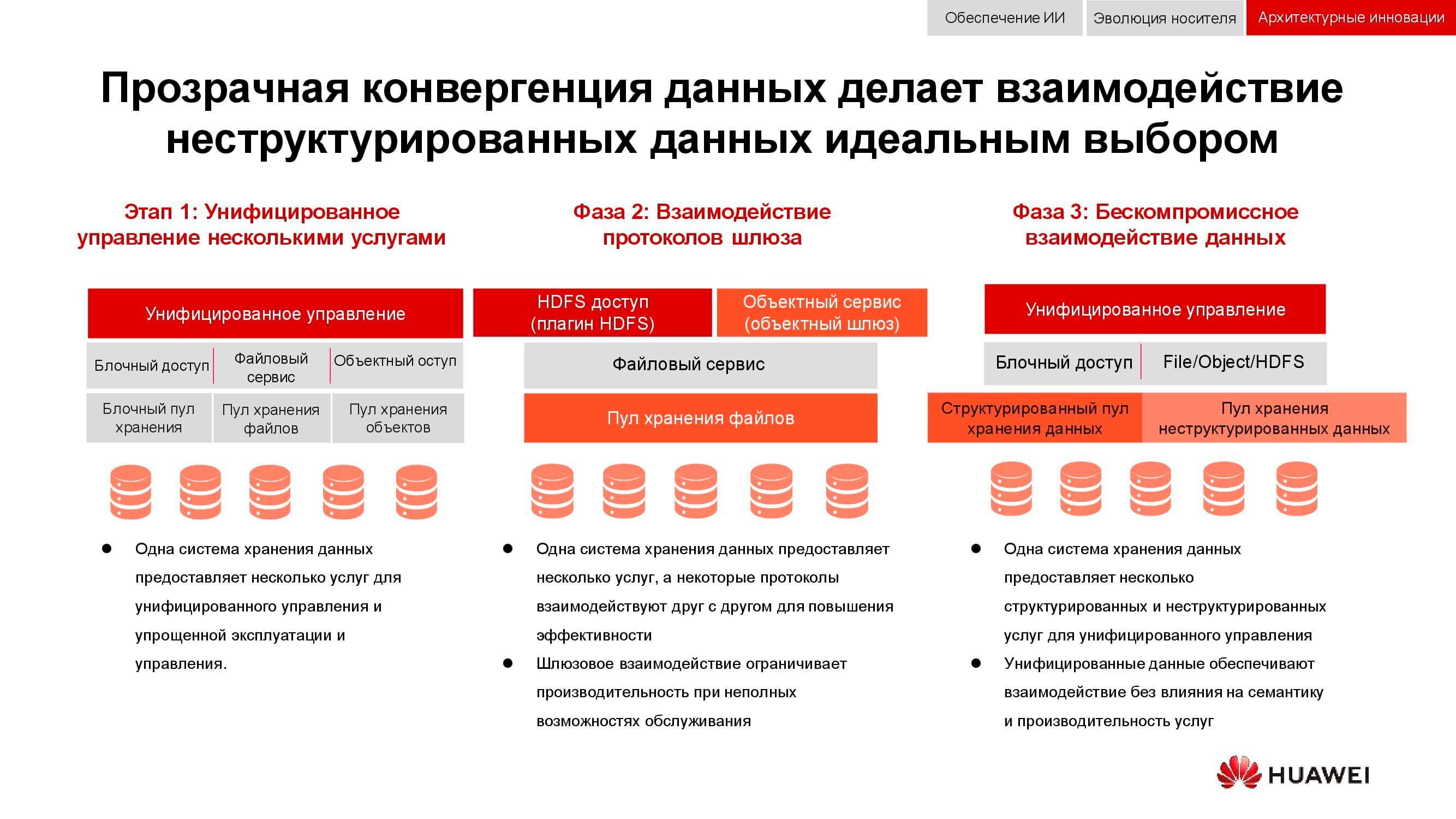
Классической задачей, актуальность которой последние 15 лет лишь росла, является необходимость одновременно обеспечить блочное хранение, файловый доступ, доступ к объектам, работу фермы для больших данных и т. д. Вишенкой на торте может быть ещё, например, система бэкапа на магнитную ленту.
На первом этапе унифицировать удавалось только управление этими услугами. Разнородные системы хранения данных замыкались на какое-либо специализированное ПО, посредством которого администратор распределял ресурсы из доступных пулов. Но так как аппаратно эти пулы были разными, миграция нагрузки между ними была невозможна. На более высоком уровне интеграции объединение происходило на уровне шлюза. При наличии общего файлового доступа его можно было отдавать через разные протоколы.
Самый совершенный из доступных нам сейчас методов конвергенции подразумевает создание универсальной гибридной системы. Именно такой, какой должна стать наша OceanStor 100D. Универсальный доступ использует те же самые аппаратные ресурсы, логически разделённые на разные пулы, но допускающие миграцию нагрузки. Всё это можно сделать через единую консоль управления. Таким способом нам удалось реализовать концепцию «один ЦОД — одна СХД».
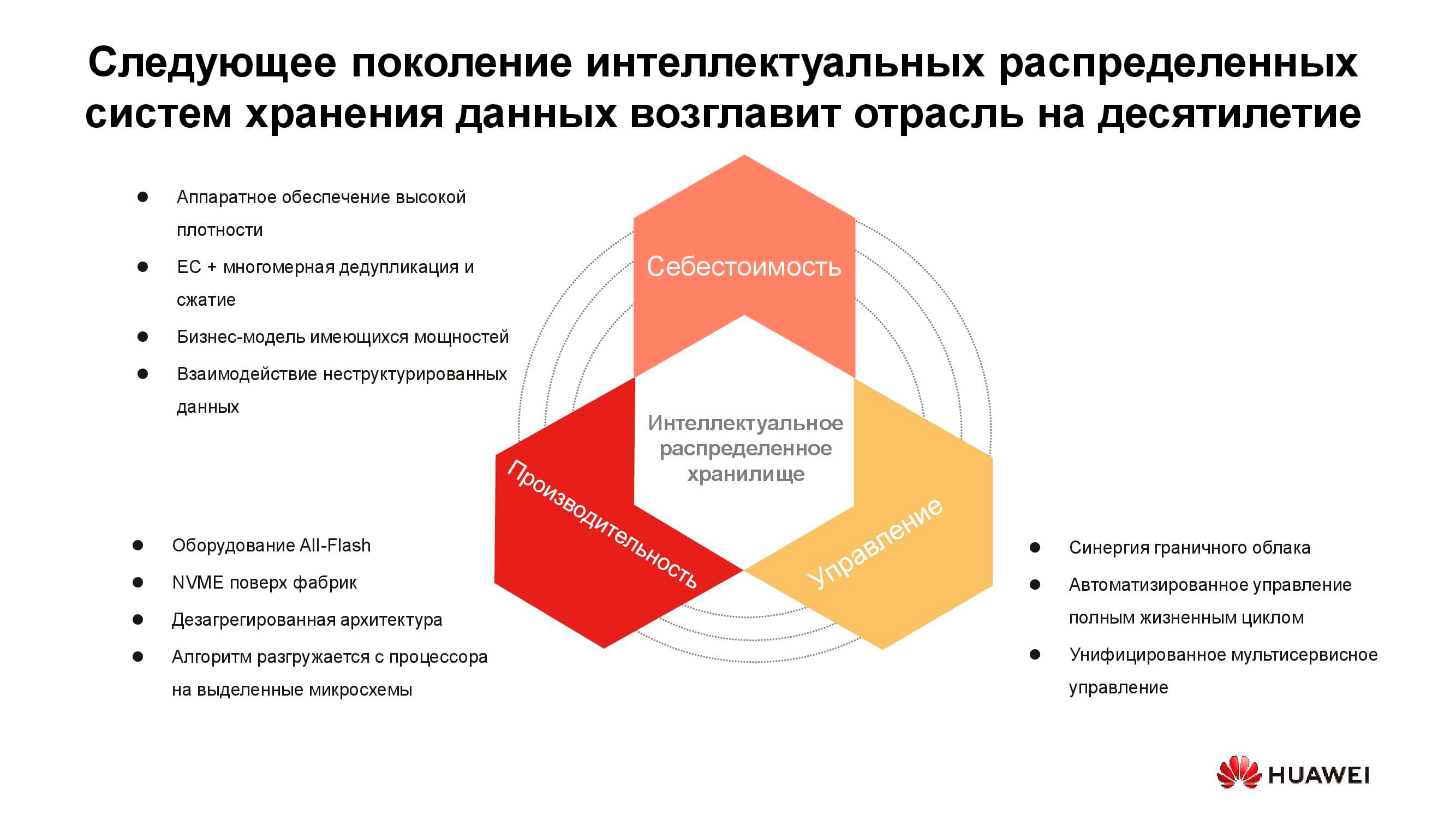
Стоимость хранения информации сейчас определяет многие архитектурные решения. И хотя её можно смело ставить во главу угла, мы сегодня обсуждаем «живое» хранение с активным доступом, так что производительность тоже необходимо учитывать. Ещё одним важным свойством распределённых систем следующего поколения является унификация. Ведь никто не хочет иметь несколько разрозненных систем, управляемых из разных консолей. Все эти качества нашли воплощение в новой серии продуктов Huawei OceanStor Pacific.
OceanStor Pacific отвечает требованиям надёжности на уровне «шести девяток» (99,9999%) и может использоваться для создания ЦОД класса HyperMetro. При расстоянии между двумя дата-центрами до 100 км системы демонстрируют добавочную задержку на уровне 2 мс, что позволяет строить на их основе любые катастрофоустойчивые решения, в том числе и с кворум-серверами.
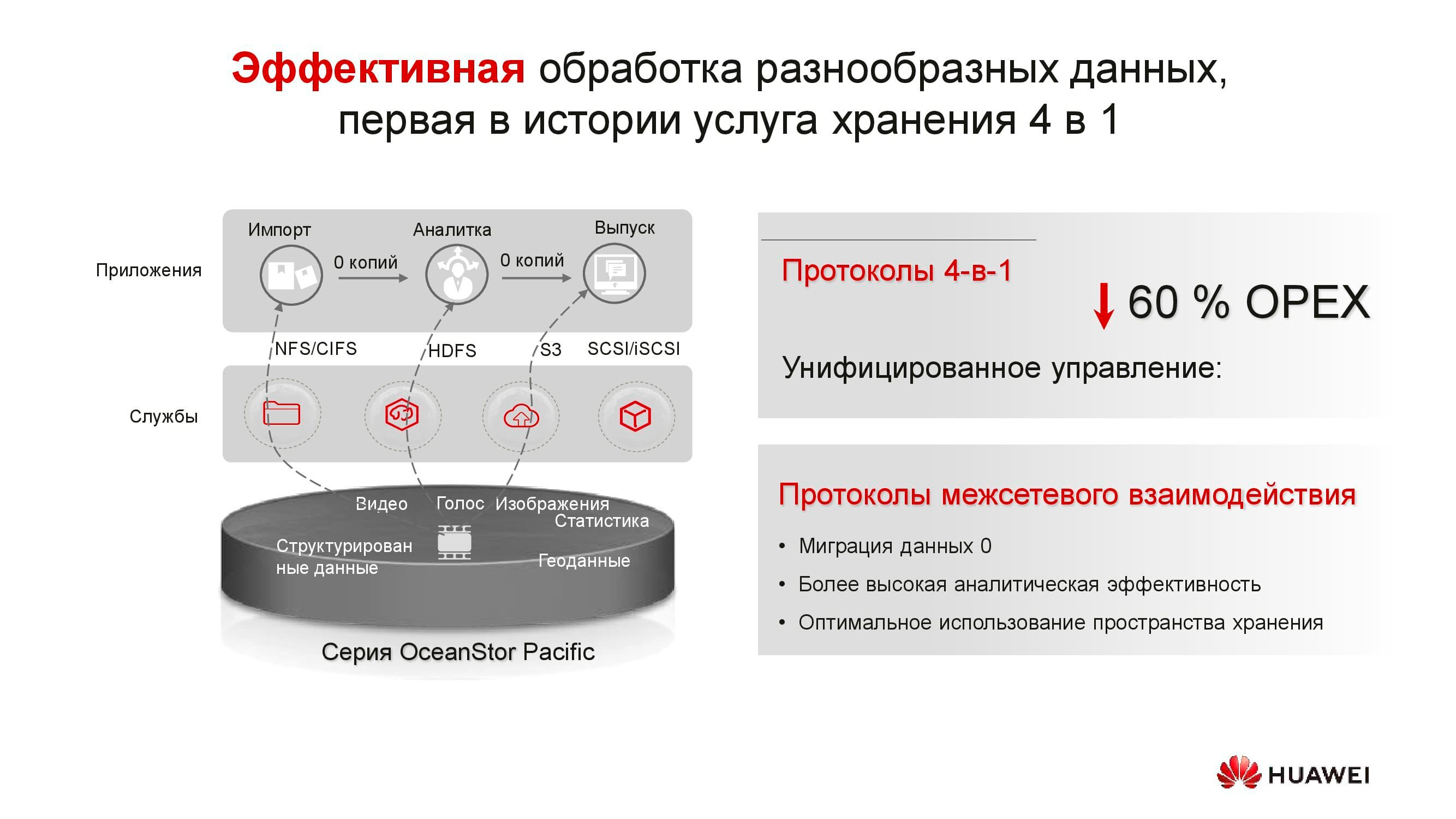
Продукты новой серии демонстрируют универсальность по протоколам. Уже сейчас OceanStor 100D поддерживает блочный доступ, объектовый доступ и доступ Hadoop. В ближайшее время будет реализован и файловый доступ. Нет нужды хранить несколько копий данных, если их можно выдавать через разные протоколы.
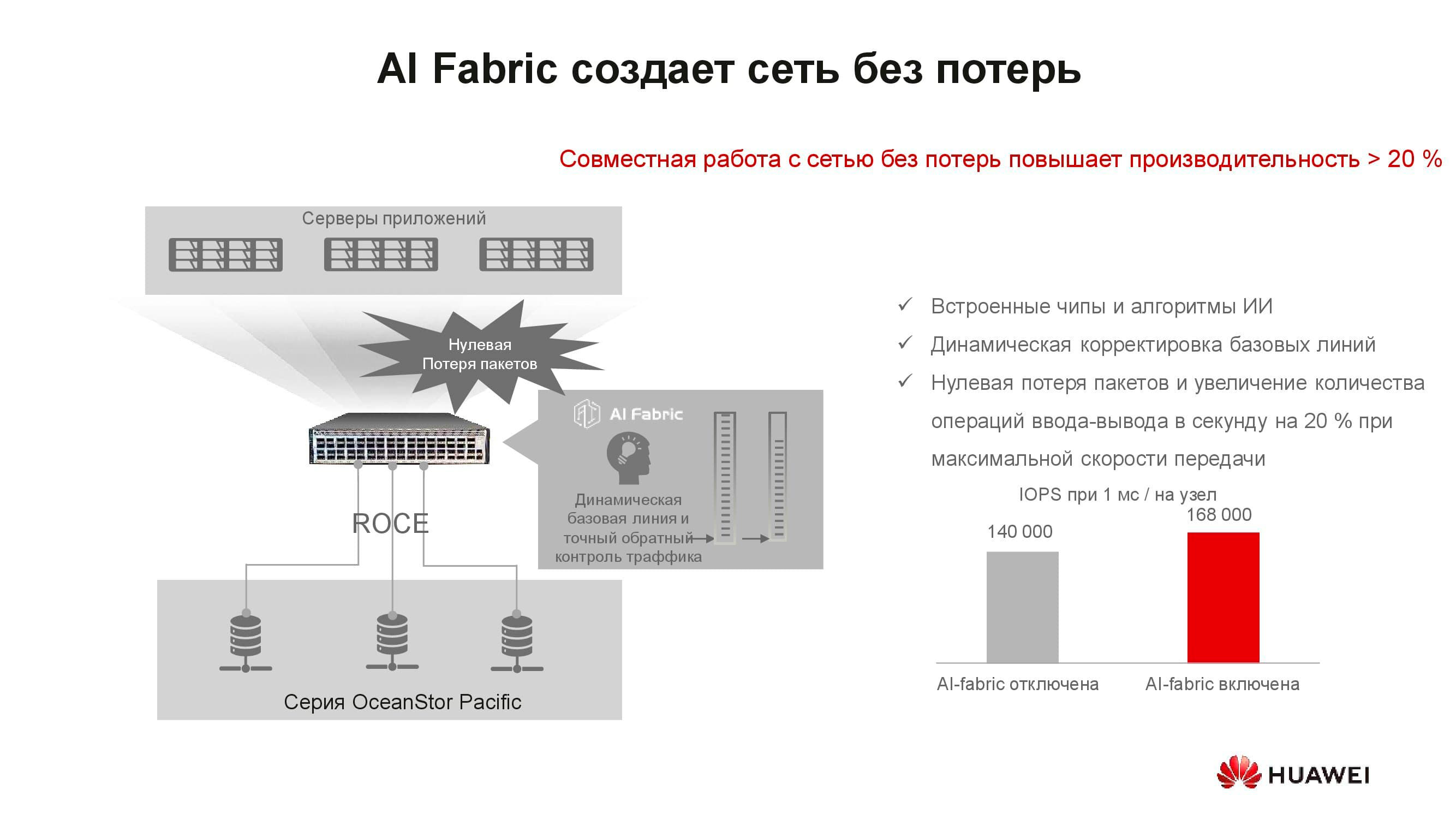
Казалось бы, какое отношение концепция «сеть без потерь» имеет к СХД? Дело в том, что распределённые системы хранения данных строятся на основе быстрой сети, поддерживающей соответствующие алгоритмы и механизм RoCE. Дополнительно увеличить скорость сети и снизить задержки помогает поддерживаемая нашими коммутаторами система искусственного интеллекта AI Fabric. Выигрыш производительности СХД при активации AI Fabric может достигать 20%.
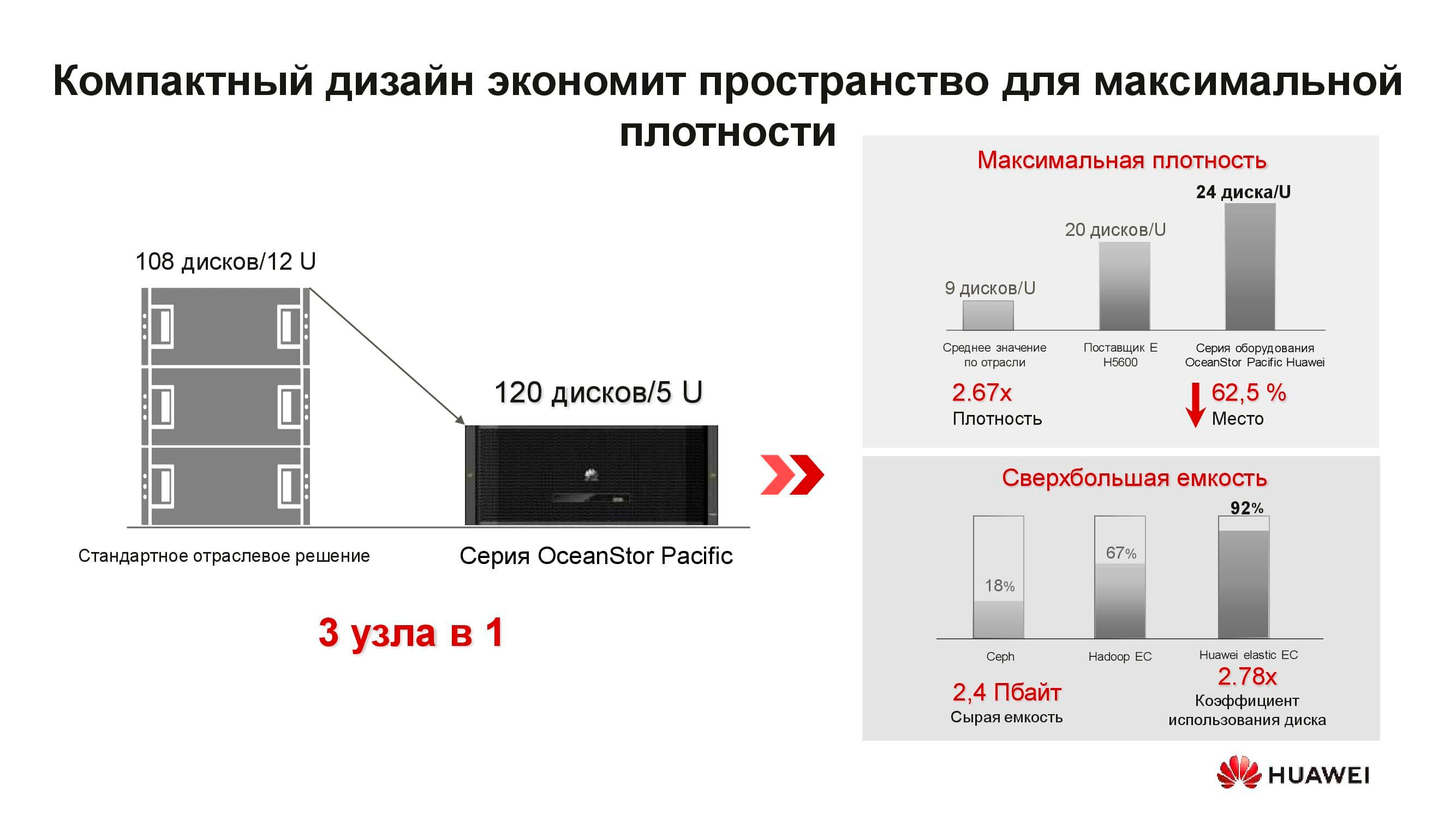
Что же представляет собой новый узел распределённой СХД OceanStor Pacific? Решение форм-фактора 5U включает в себя 120 накопителей и может заменить три классических узла, что даёт более чем двукратную экономию места в стойке. За счёт отказа от хранения копий КПД накопителей ощутимо возрастает (до +92%).
Мы привыкли к тому, что программно-определяемая СХД — это специальное ПО, устанавливаемое на классический сервер. Но теперь для достижения оптимальных параметров это архитектурное решение требует и специальных узлов. В его состав входят два сервера на базе ARM-процессоров, управляющие массивом трёхдюймовых накопителей.
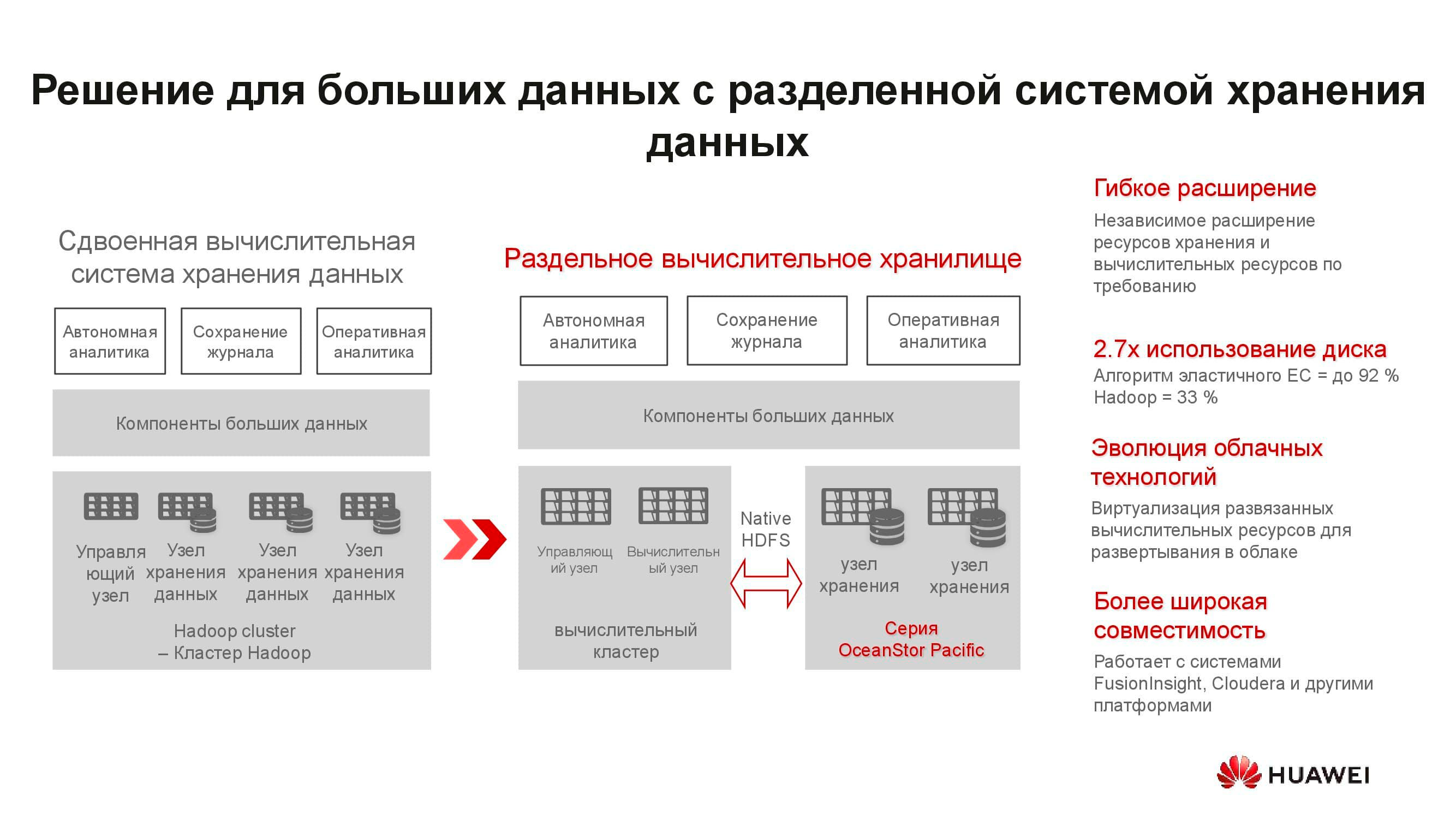
Эти серверы мало подходят для гиперконвергентных решений. Во-первых, приложений для ARM достаточно мало, а во-вторых, трудно соблюсти баланс нагрузки. Мы предлагаем перейти к раздельному хранению: вычислительный кластер, представленный классическими или rack-серверами, функционирует отдельно, но подключается к узлам хранения OceanStor Pacific, которые также выполняют свои прямые задачи. И это себя оправдывает.
Для примера возьмём классическое решение для хранения больших данных с гиперконвергентной системой, занимающее 15 серверных стоек. Если распределить нагрузку между отдельными вычислительными серверами и узлами СХД OceanStor Pacific, отделив их друг от друга, количество необходимых стоек сократится в два раза! Это снижает затраты на эксплуатацию дата-центра и уменьшает совокупную стоимость владения. В мире, где объём хранимой информации растет на 30% в год, подобными преимуществами не разбрасываются.
Больше информации о решениях Huawei и сценариях их применения вы можете получить на нашем сайте или обратившись непосредственно к представителям компании.
Наш мир генерирует всё больше информации. Какая-то её часть мимолётна и утрачивается так же быстро, как и собирается. Другая должна храниться дольше, а иная и вовсе рассчитана «на века» — по крайней мере, так нам видится из настоящего. Информационные потоки оседают в дата-центрах с такой скоростью, что любой новый подход, любая технология, призванные удовлетворить этот бесконечный «спрос», стремительно устаревают.
40 лет развития распределённых СХД
Первые сетевые хранилища в привычном нам виде появились в 1980-х. Многие из вас сталкивались с NFS (Network File System), AFS (Andrew File System) или Coda. Спустя десятилетие мода и технологии изменились, а распределённые файловые системы уступили место кластерным СХД на основе GPFS (General Parallel File System), CFS (Clustered File Systems) и StorNext. В качестве базиса использовались блочные хранилища классической архитектуры, поверх которых с помощью программного слоя создавалась единая файловая система. Эти и подобные решения до сих пор применяются, занимают свою нишу и вполне востребованы.
На рубеже тысячелетий парадигма распределённых хранилищ несколько поменялась, и на лидирующие позиции вышли системы с архитектурой SN (Shared-Nothing). Произошёл переход от кластерного хранения к хранению на отдельных узлах, в качестве которых, как правило, выступали классические серверы с обеспечивающим надёжное хранение ПО; на таких принципах построены, скажем, HDFS (Hadoop Distributed File System) и GFS (Global File System).
Ближе к 2010-м заложенные в основу распределённых систем хранения концепции всё чаще стали находить отражение в полноценных коммерческих продуктах, таких как VMware vSAN, Dell EMC Isilon и наша Huawei OceanStor. За упомянутыми платформами стоит уже не сообщество энтузиастов, а конкретные вендоры, которые отвечают за функциональность, поддержку, сервисное обслуживание продукта и гарантируют его дальнейшее развитие. Такие решения наиболее востребованы в нескольких сферах.
Операторы связи
Пожалуй, одними из старейших потребителей распределённых систем хранения являются операторы связи. На схеме видно, какие группы приложений производят основной объём данных. OSS (Operations Support Systems), MSS (Management Support Services) и BSS (Business Support Systems) представляют собой три дополняющих друг друга программных слоя, необходимых для предоставления сервиса абонентам, финансовой отчётности провайдеру и эксплуатационной поддержки инженерам оператора.
Зачастую данные этих слоев сильно перемешаны между собой, и, чтобы избежать накопления ненужных копий, как раз и используются распределённые хранилища, которые аккумулируют весь объём информации, поступающей от работающей сети. Хранилища объединяются в общий пул, к которому и обращаются все сервисы.
Наши расчёты показывают, что переход от классических СХД к блочным позволяет сэкономить до 70% бюджета только за счёт отказа от выделенных СХД класса hi-end и использования обычных серверов классической архитектуры (обычно x86), работающих в связке со специализированным ПО. Сотовые операторы уже довольно давно начали приобретать подобные решения в серьезных объёмах. В частности, российское операторы используют такие продукты от Huawei более шести лет.
Да, ряд задач с помощью распределённых систем выполнить не получится. Например, при повышенных требованиях к производительности или к совместимости со старыми протоколами. Но не менее 70% данных, которые обрабатывает оператор, вполне можно расположить в распределённом пуле.
Банковская сфера
В любом банке соседствует множество разношёрстных IT-систем, начиная с процессинга и заканчивая автоматизированной банковской системой. Эта инфраструктура тоже работает с огромным объёмом информации, при этом большая часть задач не требует повышенной производительности и надёжности систем хранения, например разработка, тестирование, автоматизация офисных процессов и пр. Здесь применение классических СХД возможно, но с каждым годом всё менее выгодно. К тому же в этом случае отсутствует гибкость расходования ресурсов СХД, производительность которой рассчитывается из пиковой нагрузки.
При использовании распределённых систем хранения их узлы, по факту являющиеся обычными серверами, могут быть в любой момент конвертированы, например, в серверную ферму и использованы в качестве вычислительной платформы.
Озёра данных
На схеме выше приведён перечень типичных потребителей сервисов data lake. Это могут быть службы электронного правительства (допустим, «Госуслуги»), прошедшие цифровизацию предприятия, финансовые структуры и др. Всем им необходимо работать с большими объёмами разнородной информации.
Эксплуатация классических СХД для решения таких задач неэффективна, так как требуется и высокопроизводительный доступ к блочным базам данных, и обычный доступ к библиотекам сканированных документов, хранящихся в виде объектов. Сюда же может быть привязана, допустим, система заказов через веб-портал. Чтобы всё это реализовать на платформе классической СХД, потребуется большой комплект оборудования под разные задачи. Одна горизонтальная универсальная система хранения вполне может закрывать все ранее перечисленные задачи: понадобится лишь создать в ней несколько пулов с разными характеристиками хранения.
Генераторы новой информации
Количество хранимой в мире информации растёт примерно на 30% в год. Это хорошие новости для поставщиков систем хранения, но что же является и будет являться основным источником этих данных?
Десять лет назад такими генераторами стали социальные сети, это потребовало создания большого количества новых алгоритмов, аппаратных решений и т. д. Сейчас выделяются три главных драйвера роста объёмов хранения. Первый — cloud computing. В настоящее время примерно 70% компаний так или иначе используют облачные сервисы. Это могут быть электронные почтовые системы, резервные копии и другие виртуализированные сущности.
Вторым драйвером становятся сети пятого поколения. Это новые скорости и новые объёмы передачи данных. По нашим прогнозам, широкое распространение 5G приведёт к падению спроса на карточки флеш-памяти. Сколько бы ни было памяти в телефоне, она всё равно кончается, а при наличии в гаджете 100-мегабитного канала нет никакой необходимости хранить фотографии локально.
К третьей группе причин, по которым растёт спрос на системы хранения, относятся бурное развитие искусственного интеллекта, переход на аналитику больших данных и тренд на всеобщую автоматизацию всего, чего только можно.
Особенностью «нового трафика» является его неструктурированность. Нам надо хранить эти данные, никак не определяя их формат. Он требуется лишь при последующем чтении. К примеру, банковская система скоринга для определения доступного размера кредита будет смотреть выложенные вами в соцсетях фотографии, определяя, часто ли вы бываете на море и в ресторанах, и одновременно изучать доступные ей выписки из ваших медицинских документов. Эти данные, с одной стороны, всеобъемлющи, а с другой — лишены однородности.
Океан неструктурированных данных
Какие же проблемы влечет за собой появление «новых данных»? Первейшая среди них, конечно, сам объём информации и расчётные сроки её хранения. Один только современный автономный автомобиль без водителя каждый день генерирует до 60 Тбайт данных, поступающих со всех его датчиков и механизмов. Для разработки новых алгоритмов движения эту информацию необходимо обработать за те же сутки, иначе она начнёт накапливаться. При этом храниться она должна очень долго — десятки лет. Только тогда в будущем можно будет делать выводы на основе больших аналитических выборок.
Одно устройство для расшифровки генетических последовательностей производит порядка 6 Тбайт в день. А собранные с его помощью данные вообще не подразумевают удаления, то есть гипотетически должны храниться вечно.
Наконец, всё те же сети пятого поколения. Помимо собственно передаваемой информации, такая сеть и сама является огромным генератором данных: журналов действий, записей звонков, промежуточных результатов межмашинных взаимодействий и пр.
Всё это требует выработки новых подходов и алгоритмов хранения и обработки информации. И такие подходы появляются.
Технологии новой эпохи
Можно выделить три группы решений, призванных справиться с новыми требованиями к системам хранения информации: внедрение искусственного интеллекта, техническая эволюция носителей данных и инновации в области системной архитектуры. Начнём с ИИ.
В новых решениях Huawei искусственный интеллект используется уже на уровне самого хранилища, которое оборудовано ИИ-процессором, позволяющим системе самостоятельно анализировать своё состояние и предсказывать отказы. Если СХД подключить к сервисному облаку, которое обладает значительными вычислительными способностями, искусственный интеллект сможет обработать больше информации и повысить точность своих гипотез.
Помимо отказов, такой ИИ умеет прогнозировать будущую пиковую нагрузку и время, остающееся до исчерпания ёмкости. Это позволяет оптимизировать производительность и масштабировать систему ещё до наступления каких-либо нежелательных событий.
Теперь об эволюции носителей данных. Первые флеш-накопители были выполнены по технологии SLC (Single-Level Cell). Основанные на ней устройства были быстрыми, надёжными, стабильными, но имели небольшую ёмкость и стоили очень дорого. Роста объёма и снижения цены удалось добиться путём определённых технических уступок, из-за которых скорость, надёжность и срок службы накопителей сократились. Тем не менее тренд не повлиял на сами СХД, которые за счёт различных архитектурных ухищрений в целом стали и более производительными, и более надёжными.
Но почему понадобились СХД класса All-Flash? Разве недостаточно было просто заменить в уже эксплуатируемой системе старые HDD на новые SSD того же форм-фактора? Потребовалось это для того, чтобы эффективно использовать все ресурсы новых твердотельных накопителей, что в старых системах было попросту невозможно.
Компания Huawei, например, для решения этой задачи разработала целый ряд технологий, одной из которых стала FlashLink, позволившая максимально оптимизировать взаимодействия «диск — контроллер».
Интеллектуальная идентификация дала возможность разложить данные на несколько потоков и справиться с рядом нежелательных явлений, таких как WA (write amplification). Вместе с тем новые алгоритмы восстановления, в частности RAID 2.0+, повысили скорость ребилда, сократив его время до совершенно незначительных величин.
Отказ, переполненность, «сборка мусора» — эти факторы также больше не влияют на производительность системы хранения благодаря специальной доработке контроллеров.
А ещё блочные хранилища данных готовятся встретить NVMe. Напомним, что классическая схема организации доступа к данным работала так: процессор обращался к RAID-контроллеру по шине PCI Express. Тот, в свою очередь, взаимодействовал с механическими дисками по SCSI или SAS. Применение NVMe на бэкенде заметно ускорило весь процесс, однако несло в себе один недостаток: накопители должны были иметь непосредственное подключение к процессору, чтобы обеспечить тому прямой доступ в память.
Следующей фазой развития технологии, которую мы наблюдаем сейчас, стало применение NVMe-oF (NVMe over Fabrics). Что касается блочных технологий Huawei, они уже сейчас поддерживают FC-NVMe (NVMe over Fibre Channel), и на подходе NVMe over RoCE (RDMA over Converged Ethernet). Тестовые модели вполне функциональны, до официальной их презентации осталось несколько месяцев. Заметим, что всё это появится и в распределённых системах, где «Ethernet без потерь» будет весьма востребован.
Дополнительным способом оптимизации работы именно распределённых хранилищ стал полный отказ от зеркалирования данных. Решения Huawei больше не используют n копий, как в привычном RAID 1, и полностью переходят на механизм EC (Erasure coding). Специальный математический пакет с определённой периодичностью вычисляет контрольные блоки, которые позволяют восстановить промежуточные данные в случае их потери.
Механизмы дедупликации и сжатия становятся обязательными. Если в классических СХД мы ограничены количеством установленных в контроллеры процессоров, то в распределённых горизонтально масштабируемых системах хранения каждый узел содержит всё необходимое: диски, память, процессоры и интерконнект. Этих ресурсов достаточно, чтобы дедупликация и компрессия оказывали на производительность минимальное влияние.
И об аппаратных методах оптимизации. Здесь снизить нагрузку на центральные процессоры удалось с помощью дополнительных выделенных микросхем (или выделенных блоков в самом процессоре), играющих роль TOE (TCP/IP Offload Engine) или берущих на себя математические задачи EC, дедупликации и компрессии.
Новые подходы к хранению данных нашли воплощение в дезагрегированной (распределённой) архитектуре. В системах централизованного хранения имеется фабрика серверов, по Fibre Channel подключённая к SAN с большим количеством массивов. Недостатками такого подхода являются трудности с масштабированием и обеспечением гарантированного уровня услуги (по производительности или задержкам). Гиперконвергентные системы используют одни и те же хосты — как для хранения, так и для обработки информации. Это даёт практически неограниченный простор масштабирования, но влечёт за собой высокие затраты на поддержание целостности данных.
В отличие от обеих вышеперечисленных, дезагрегированная архитектура подразумевает разделение системы на вычислительную фабрику и горизонтальную систему хранения. Это обеспечивает преимущества обеих архитектур и позволяет практически неограниченно масштабировать только тот элемент, производительности которого не хватает.
От интеграции к конвергенции
Классической задачей, актуальность которой последние 15 лет лишь росла, является необходимость одновременно обеспечить блочное хранение, файловый доступ, доступ к объектам, работу фермы для больших данных и т. д. Вишенкой на торте может быть ещё, например, система бэкапа на магнитную ленту.
На первом этапе унифицировать удавалось только управление этими услугами. Разнородные системы хранения данных замыкались на какое-либо специализированное ПО, посредством которого администратор распределял ресурсы из доступных пулов. Но так как аппаратно эти пулы были разными, миграция нагрузки между ними была невозможна. На более высоком уровне интеграции объединение происходило на уровне шлюза. При наличии общего файлового доступа его можно было отдавать через разные протоколы.
Самый совершенный из доступных нам сейчас методов конвергенции подразумевает создание универсальной гибридной системы. Именно такой, какой должна стать наша OceanStor 100D. Универсальный доступ использует те же самые аппаратные ресурсы, логически разделённые на разные пулы, но допускающие миграцию нагрузки. Всё это можно сделать через единую консоль управления. Таким способом нам удалось реализовать концепцию «один ЦОД — одна СХД».
Стоимость хранения информации сейчас определяет многие архитектурные решения. И хотя её можно смело ставить во главу угла, мы сегодня обсуждаем «живое» хранение с активным доступом, так что производительность тоже необходимо учитывать. Ещё одним важным свойством распределённых систем следующего поколения является унификация. Ведь никто не хочет иметь несколько разрозненных систем, управляемых из разных консолей. Все эти качества нашли воплощение в новой серии продуктов Huawei OceanStor Pacific.
Массовая СХД нового поколения
OceanStor Pacific отвечает требованиям надёжности на уровне «шести девяток» (99,9999%) и может использоваться для создания ЦОД класса HyperMetro. При расстоянии между двумя дата-центрами до 100 км системы демонстрируют добавочную задержку на уровне 2 мс, что позволяет строить на их основе любые катастрофоустойчивые решения, в том числе и с кворум-серверами.
Продукты новой серии демонстрируют универсальность по протоколам. Уже сейчас OceanStor 100D поддерживает блочный доступ, объектовый доступ и доступ Hadoop. В ближайшее время будет реализован и файловый доступ. Нет нужды хранить несколько копий данных, если их можно выдавать через разные протоколы.
Казалось бы, какое отношение концепция «сеть без потерь» имеет к СХД? Дело в том, что распределённые системы хранения данных строятся на основе быстрой сети, поддерживающей соответствующие алгоритмы и механизм RoCE. Дополнительно увеличить скорость сети и снизить задержки помогает поддерживаемая нашими коммутаторами система искусственного интеллекта AI Fabric. Выигрыш производительности СХД при активации AI Fabric может достигать 20%.
Что же представляет собой новый узел распределённой СХД OceanStor Pacific? Решение форм-фактора 5U включает в себя 120 накопителей и может заменить три классических узла, что даёт более чем двукратную экономию места в стойке. За счёт отказа от хранения копий КПД накопителей ощутимо возрастает (до +92%).
Мы привыкли к тому, что программно-определяемая СХД — это специальное ПО, устанавливаемое на классический сервер. Но теперь для достижения оптимальных параметров это архитектурное решение требует и специальных узлов. В его состав входят два сервера на базе ARM-процессоров, управляющие массивом трёхдюймовых накопителей.
Эти серверы мало подходят для гиперконвергентных решений. Во-первых, приложений для ARM достаточно мало, а во-вторых, трудно соблюсти баланс нагрузки. Мы предлагаем перейти к раздельному хранению: вычислительный кластер, представленный классическими или rack-серверами, функционирует отдельно, но подключается к узлам хранения OceanStor Pacific, которые также выполняют свои прямые задачи. И это себя оправдывает.
Для примера возьмём классическое решение для хранения больших данных с гиперконвергентной системой, занимающее 15 серверных стоек. Если распределить нагрузку между отдельными вычислительными серверами и узлами СХД OceanStor Pacific, отделив их друг от друга, количество необходимых стоек сократится в два раза! Это снижает затраты на эксплуатацию дата-центра и уменьшает совокупную стоимость владения. В мире, где объём хранимой информации растет на 30% в год, подобными преимуществами не разбрасываются.
***
Больше информации о решениях Huawei и сценариях их применения вы можете получить на нашем сайте или обратившись непосредственно к представителям компании.
VaalKIA
Скучная статья, где много воды. Но Акеанохрон (OceanStor) — очень поэтично!