
Число зверя, штрихи смерти — насколько все это реально? Можно ли зашить в штрихкод видеоролик или фото голой Эммы Уотсон? Бывают ли “неправильные штрихкоды”, и что вообще значит “неправильный штрихкод”?
В “Клеверенсе” мы разрабатываем платформу Mobile SMARTS для создания мобильных решений по учету маркированного товара и постоянно сталкиваемся с детскими ошибками в маркировке. Обычно они вызваны простым нежеланием людей хоть немного разбираться в теме.
Наша платформа тоже не идеальна, но кое-что в своём деле мы понимаем. Статья не к тому, что типа мы крутые и разбираемся, а все вокруг не крутые и не разбираются, нет. У каждого свои задачи, мы тоже часто лажаем. Просто тема набирает популярность и выходит в массы, а любые ошибки стоят денег.
Сначала для затравки расскажем про кассовый штрихкод, а затем про загадочный GS1 DataMatrix, который используется в проекте тотальной маркировки товаров.
Сама статья больше развлекательная, всё изложенное при желании легко гуглится, но может и побудить кого-то изучить тему глубже.

Цифры под штрихкодом — что это такое? Знающие люди говорят, что тут всё просто: именно эти цифры “зашиты” в штрихкод. Девушка на кассе вбивает в программу цифры под штрихкодом — и вуаля — товар найден.
К сожалению, это заблуждение. Цифры под штрихкодом не “зашиты” в штрихкод. Для разговоров у камина сойдет, а для айтишника беда.
Это распространенное заблуждение приводит к тому, что когда встает задача распечатать штрихкод, человек гуглит бесплатный онлайн генератор штрихкода, пихает в поле эти самые цифры, и… получает проблему на ровном месте.
Надписи под штрихкодом называются Human readable interpretation (HRI). Одно только название уже должно наводить на мысль, что тут не всё в порядке.
В самом мягком варианте вера в то, что цифры под штрихкодом повторяют содержимое штрихкода — это примерно как верить в то, что название файла определяет его содержимое. Типа: “Переименовала ваш файл в .doc, но он всё равно не открывается”.
Рассмотрим подробнее, где тут собака зарыта.


Да-да, именно первой цифры, а не последней (чексуммы) как можно было бы подумать. Последняя цифра (чексумма) в полосках этих штрихкодов как раз-таки есть, иначе затея с чексуммой не будет работать.
Рассмотрим поближе, что тут происходит.
В первом приведенном штрихкоде (“4601200000003”) в начале идут две длинные полосочки, они кодируют “начало штрихкода”, далее идут штрихи и пропуски для цифры “6”, затем про цифры “0”, “1”, “2”, “0” и “0”, две длинные полосочки в центре говорят про середину, затем пять одинаковых групп штрихов и пропусков кодируют “00000”, далее идут штрихи и пропуски для цифры “3” и завершающие две длинные полоски про конец штрихкода. Итого, в штрихкоде есть штрихи только про “601200000003”. Цифра “3” (последняя) в полосках штрихкода есть, а первой “4” нет! Откуда же взялась “4”?
Дело в том, что “4” закодирована грязным хаком. Для неё не хватает места, и вообще всё это большой исторический казус.
Изначально такие кассовые штрихкоды появились в США, там они состоят из 12 цифр и называются UPC (Universal Product Code). Для переноса технологии в Европу и адаптации стандарта Европе нужны были дополнительные цифры, потому что американские 12 все уже были заняты.

По американскому стандарту любая из цифр штрихкода может быть записана: а) обычными штрихами и пропусками; б) их зеркальным отражением; в) инверсией черного и белого; г) зеркальной инверсией. Всё это нужно для того, чтобы можно было печатать инверсные штрихкоды (белым по черному) и сканировать штрихкод вверх ногами (зеркальное отражение в случае штрихкода — то же самое, что и поворот на 180°).
В “американском” штрихкоде (который на 12 цифр) первые 6 цифр кодируются обычными штрихами, а вторые 6 цифр инвертированными штрихами (где черные штрихи заменены на белые полоски и наоборот). Это сделано для того, чтобы понимать, перевернут штрихкод или нет, нормально я его сканирую или вверх ногами (и затем декодировать цифры в правильном порядке, а не задом наперед).
В новом “европейском” штрихкоде (который на 13 цифр), первая цифра (например, “4”) кодируется не штрихами, а путем «перетасовывания» способов кодирования следующих за ней 6 цифр из первого блока (второй блок из 6 оставили в покое).
Например, следующая за четверкой “6” выводится как обычно, штрихи следующего за ней “0” выводятся в обратном порядке (зеркально), следующие за ней “1” и “2” выводится снова в обычном виде, следующие два “0” снова зеркально. Общая длина штрихкода и число штрихов в результате этого трюка не меняется.
Для “американского сканера” такая белиберда не имеет смысла, а для Европы это тайный знак того, что в штрихкоде закодирована еще одна цифра! (да, мы всегда знали, что европейцы извращенцы).
Для всех цифр от “1” до “9” были придуманы такие правила тасовки способов кодирования. Для “0” ничего нет, т.е. 13-значный штрихкод с лидирующим нулем визуально ничем не отличается от 12-значного штрихкода без этого лишнего ноля (EAN-13 с лидирующим нулем эквивалентен UPC-А).
Из этого получается первый прикол, что если перед нами “американский” штрихкод (в котором варианты кодирования не “перетасованы”), то “американский сканер” читает 12 цифр, а условный “европейский сканер” может считать, что в нем есть лидирующий «0», и считывать лишний ноль (т.к. для кодирования ноля не предусмотрено никакой “перетасовки”, этого “лидирующего нуля” очевидно в принципе нигде нет в штрихкоде).
Конечно, мир давно глобализован, поэтому “американский” сканер и “европейский” сканер — это просто условности. Сканер один и тот же, но у него есть настройка: нужно ли ему в принципе считывать EAN-13 (Европа) или читать только UPC-А (США), а если считывать EAN-13, то надо ли добавлять лишний ноль к американским штрихкодам UPC-А.
С этим связана одна распространенная проблема при внедрении штрихкодирования: когда в базе данных у компании либо нет нолей в начале штрихкодов, а сканер считывает с “лишним” нолем, либо наоборот, в базе данных есть ноль в начале, а сканер его “не считывает” (хотя, что там считывать, — этого ноля в принципе в штрихкоде нет).
Казалось бы, сложно накосячить в использовании EAN-13/UPC. Тем не менее, люди делают следующие ошибки:
В наших программных продуктах, таких как “Магазин 15” или “Склад 15”, построенных на платформе Mobile SMARTS, мы решаем эту проблему очень просто: сканер устройства всегда автоматически настраивается на возврат ноля, а поиск товара по базе данных производится два раза: и с нолем, и без ноля (чтобы уж точно найти товар).
Сканер мы стараемся настраивать программно, без участия человека. Если сканер нельзя настроить программно — то это всегда проблема, потому что по умолчанию сканером может обрезаться не только 0 (который в начале), но еще и чексумма (которая в конце), тогда в программу придут не 13, а уже 11 символов, зачастую даже без указания типа штрихкода (такие замечательные сканеры тоже бывают).
В этом случае мы бессильны улучшить результат. 11 символов могли прийти от сканирования любого другого типа штрихкода, мы не можем считать все штрихкоды как EAN-13. Чтобы настроить сканер, человеку придется сканировать с листа настроечные штрихкоды или заходить в какие-нибудь меню, а всё это — источники ошибок.
Возьмем тогда другой пример, штрихкод GS1 DataMatrix "(21)abba01(01)04601200000003":

В этом штрихкоде “внутри” нет ни скобок, ни символа «0», ни буквы «a», ни переноса строки.
Что тут происходит?
Во-первых, никакие скобки в штрихкод не кодируются, они печатаются только для удобства прочтения человеком. Это снова называется Human readable interpretation (HRI), привет, кожаный мешок.
Во-вторых, в штрихкоде есть специальные управляющие символы, которые должна расставить та программа, которая формирует данные для штрихкода. Не какая-то бесплатная opensource программа, написанная умными очкариками, а ваша программа, та самая, которую пишете Вы, мой друг. В этот раз символы, которые нужно вставить, не имеют отношения к “коррекции” и т.п., а размечают данные, которые нужно закодировать в штрихкод.
В самом начале в штрихкод вставляется управляющий символ, который называется FNC1 и имеет код 232, что соответствует либо странному печатаемому символу "?" (ANSI), либо русской букве “и” (Windows-1251), смотря какую кодировку использовать. Этот символ говорит, что у нас не просто абы какой DataMatrix, а именно GS1 DataMatrix, данные в котором имеют определенный формат: массив данных из пар (“код поля”, “значение поля”).
Этот управляющий символ FNC1 попадает в самое начало штрихкода, но его нельзя “передать” в штрихкод в составе данных.
Кроме того, непечатаемые символы, вполне очевидно, нельзя копипастить в составе строки, хаха! Страдай, кожаный мешок!
Указание, нужен префикс или не нужен, обычно передают как отдельную настройку (галочку) в программу формирования штрихкода. Если передать префикс как часть данных, то получим либо ошибку, либо два префикса в штрихкоде (в зависимости от используемой программы).
Далее, поскольку в штрихкоде внутри нет скобок, то уже непонятно, где кончается одно поле и начинается другое, где тут номера полей. Без скобок получается “21abba010104601200000003” (тут “01” встречается три раза, ха-ха).
Где заканчивается “01” из значения поля (21) и начинается настоящее (01)?
Это решается следующим способом:
По стандарту GS1 поля имеют формат. Не абы что, а формат значения. Например, значение для (01) должно состоять из 14 цифр и баста (нельзя 13 цифр, нельзя 12 цифр, нельзя не цифры). А поле (21), наоборот, имеет переменную длину, разрешены цифры, латинские буквы обоих регистров, знаки препинания и даже (опачки!) скобки.
Если после значения для (21) штрихкод не закончился, и там еще что-то есть, то в данные вставляется разделитель (это может быть снова или FNC1, или непечатаемый символ GS с кодом 29).
А общее правило звучит так: спецсимвол GS не вставляется, только в случае если AI начинается с пары цифр из этой вот таблицы:
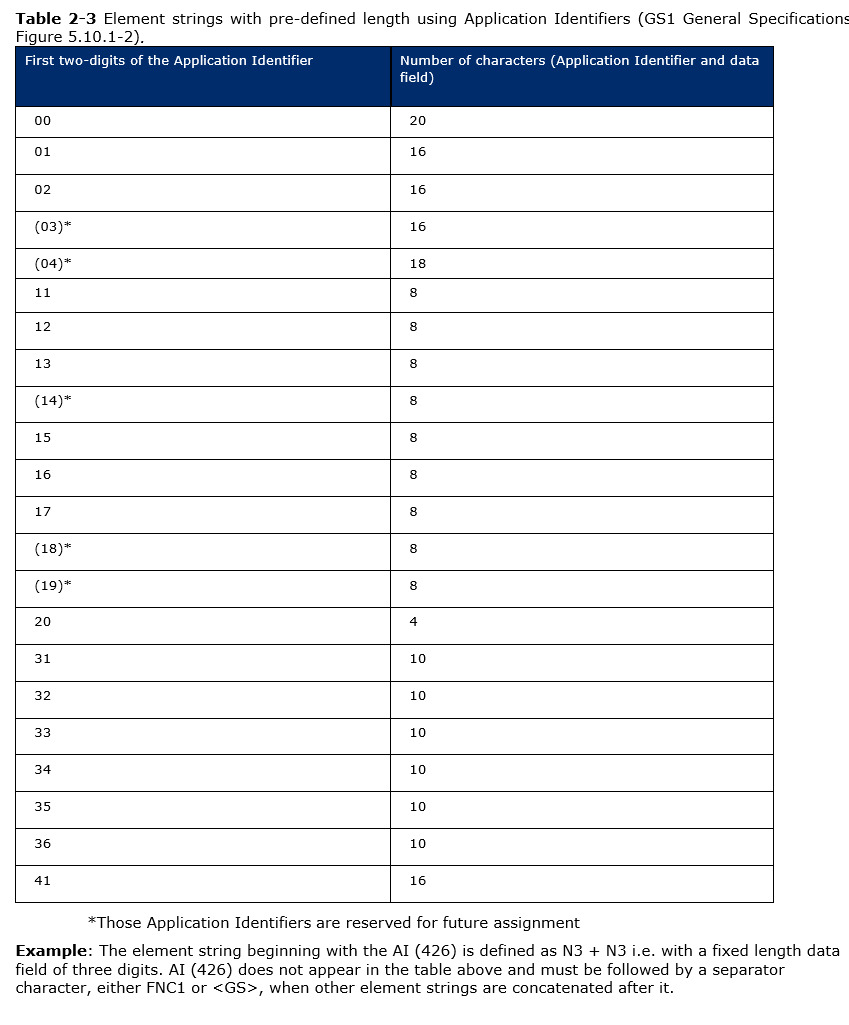
Для всех остальных полей GS1 (не из этой таблицы) в конце значения нужно вставлять GS.
Т.е., мы получим “FNC121abba01GS0104601200000003” (только помним, что первый FNC1 мы не будем передавать в программу формирования штрихкода, а второй GS — это не строка “GS”, а один символ с кодом 29).
Эти требования — именно про данные, а не про штрихкод DataMatrix, потому что в штрихкод DataMatrix можно положить любые данные, они прекрасно закодируются и прочитаются. Тут речь о GS1 DataMatrix, который имеет определенный формат, и ваша программа должна соблюсти этот формат, прежде чем подавать данные в штрихкод.
Вообще говоря, в мире существуют программы печати штрихкодов, которым можно скармливать данные со скобками и они сами всё разрулят. Но это специализированный софт, который стоит денег, а не тот бестолковый и бесплатный онлайн-генератор штрихкодов, которым вы пользуетесь.
И наконец. То, как это будет напечатано и то, как это будет отсканировано, — две большие разницы. То, как данные печатаются под штрихкодом, и как они передаются сканером — это в чистом виде настройки принтера и сканера.
В нашем примере мы закодировали в штрихкод поля порядке: сначала (21), потом (01), а на изображении под штрихкодом распечаталось сначала (01), потом (21). Это снова называется Human readable interpretation (HRI), и порядок вывода в подписи соответствует правилу “потому что так принято”.
Сканер штрихкодов тоже имеет свои настройки, которые заставляют его переставлять поля, вставлять скобки и другие символы, переносить строки и т.п.
В большинстве случаев сканер прочитает наш штрихкод как “21abba01GS0104601200000003”. Никакого лидирующего FNC1, никаких скобок, GS не печатаемый и не виден в “Блокноте” (нужно использовать хотя бы Notepad+).
И принтер, и сканер могут делать со штрихкодами что хотят: добавлять и убирать символы, менять их местами — ради соответствия гайдлайну или для совместимости со сторонней программой.
Что еще интересно: в этом штрихкоде только 16 байт данных (на 24 символа без скобок).
Вот что тут происходит:
Т.е. чтобы закодировать “a”, нужно записать в штрихкод “b”, чтобы закодировать “1”, нужно записать “2” и т.д., именно поэтому прямо в самом штрихкоде нет байта 97 (значение буквы “a” в ASCII).
Итого, в приведенном штрихкоде “закодировано” в байтах 232, 151, 98, 99, 99, 98, 131, 232, 131, 134, 190, 142, 130, 130, 130, 133. И это еще до кодов коррекции и паддинга!
Непонимание процесса кодирования приводит к тому, что, например, для начавшейся обязательной маркировки обуви люди печатают на принтер неправильно сформированные данные и получают неправильные штрихкоды, которые выглядят вполне нормально, читаются приложением “Честный знак”, но данные в них неверные, как минимум это не GS1 DataMatrix.
Штрихкоды неправильно напечатаны, неправильно читаются, и такая обувь не считается правильно промаркированной.
В своем софте “Кировка” мы боремся с этим следующим образом: для печати принимаем в качестве исходных данных любой мусор, пытаемся распарсить его как GS1 DataMatrix, разбираем на косточки. Если всё прошло удачно, то конвертируем в правильный формат, чтобы принтер это понял; а при сканировании перепроверяем данные от сканера, делая таким образом вывод о правильности печати.
Для этого нам, конечно, приходится работать на нативном уровне и со сканером мобильных устройств, и с принтерами, чтобы всё это было правильно ими интерпретировано, а мы собирали максимально полную информацию.
Выполним еще одно упражнение: посмотрим, какого размера должен быть штрихкод GS1 DataMatrix для хранения кода маркировки обуви и легпрома.
На сайте «Честного знака» написано, что код маркировки обуви должен содержать следующие поля (для легпрома те же требования):
Для каждого из этих полей в данных для штрихкода должен быть указан идентификатор применения GS1 (AI, application identifier).
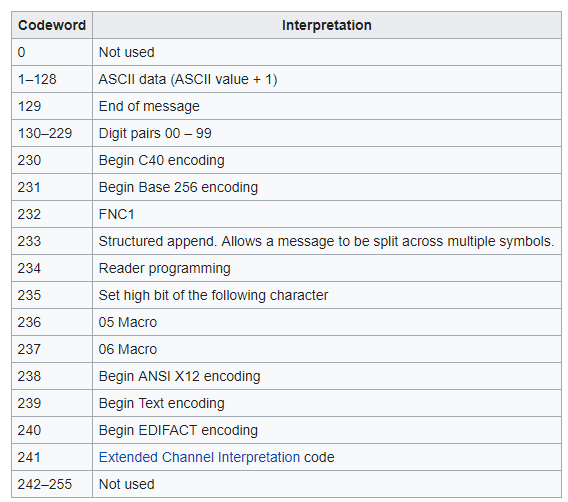
Таблица codeword для DataMatrix
Таблица, объясняющая кодирование КМ обуви в DataMatrix:
* если в данных для штрихкода есть пары подряд идущих цифр, то они будут кодироваться одним байтом, а не двумя (Codewords со [130] по [229]), и это экономит байты.
Как видно, размер данных в теории может меняться в широких пределах от 68 до 118 байт. На практике разброс меньше, длина ближе к 118, потому что в серийном номере и в криптокоде мало цифр и много знаков препинания, включая скобки.
Согласно GS1 DataMatrix Guideline, такие данные укладываются в штрихкоды размером от 36х36 до 44х44 (колонок и строк битов, не миллиметров). В миллиметрах размер будет зависеть от разрешающей способности принтера (обычно это 203-600 dpi).

Таблица из GS1 DataMatrix Guideline
Пожалуй, достаточно.
А как же голая Эмма Уотсон? Рассмотрим в следующей статье.
В “Клеверенсе” мы разрабатываем платформу Mobile SMARTS для создания мобильных решений по учету маркированного товара и постоянно сталкиваемся с детскими ошибками в маркировке. Обычно они вызваны простым нежеланием людей хоть немного разбираться в теме.
Наша платформа тоже не идеальна, но кое-что в своём деле мы понимаем. Статья не к тому, что типа мы крутые и разбираемся, а все вокруг не крутые и не разбираются, нет. У каждого свои задачи, мы тоже часто лажаем. Просто тема набирает популярность и выходит в массы, а любые ошибки стоят денег.
Сначала для затравки расскажем про кассовый штрихкод, а затем про загадочный GS1 DataMatrix, который используется в проекте тотальной маркировки товаров.
Сама статья больше развлекательная, всё изложенное при желании легко гуглится, но может и побудить кого-то изучить тему глубже.
Загадочные цифры под штрихкодом
Цифры под штрихкодом — что это такое? Знающие люди говорят, что тут всё просто: именно эти цифры “зашиты” в штрихкод. Девушка на кассе вбивает в программу цифры под штрихкодом — и вуаля — товар найден.
К сожалению, это заблуждение. Цифры под штрихкодом не “зашиты” в штрихкод. Для разговоров у камина сойдет, а для айтишника беда.
Это распространенное заблуждение приводит к тому, что когда встает задача распечатать штрихкод, человек гуглит бесплатный онлайн генератор штрихкода, пихает в поле эти самые цифры, и… получает проблему на ровном месте.
Надписи под штрихкодом называются Human readable interpretation (HRI). Одно только название уже должно наводить на мысль, что тут не всё в порядке.
В самом мягком варианте вера в то, что цифры под штрихкодом повторяют содержимое штрихкода — это примерно как верить в то, что название файла определяет его содержимое. Типа: “Переименовала ваш файл в .doc, но он всё равно не открывается”.
Рассмотрим подробнее, где тут собака зарыта.
Кассовый штрихкод
Пример про кассовый штрихкод — для затравки. Он на самом деле не вызывает никаких проблем, потому что за 50 лет использования в софте и оборудовании были вставлены 1000 костылей, чтобы обойти все проблемы (ну почти). Зато он хорошо иллюстрирует вопрос.Вот в этих двух штрихкодах (EAN-13) ниже, под которыми написано “4601200000003” и “0123456789128”, в обоих нет штрихов для первой цифры. В первом штрихкоде нет штрихов для “4” (она закодирована другим способом), а во втором штрихкоде вообще в принципе нет лидирующего нуля, хотя он и напечатан под штрихкодом.
Да-да, именно первой цифры, а не последней (чексуммы) как можно было бы подумать. Последняя цифра (чексумма) в полосках этих штрихкодов как раз-таки есть, иначе затея с чексуммой не будет работать.
Рассмотрим поближе, что тут происходит.
В первом приведенном штрихкоде (“4601200000003”) в начале идут две длинные полосочки, они кодируют “начало штрихкода”, далее идут штрихи и пропуски для цифры “6”, затем про цифры “0”, “1”, “2”, “0” и “0”, две длинные полосочки в центре говорят про середину, затем пять одинаковых групп штрихов и пропусков кодируют “00000”, далее идут штрихи и пропуски для цифры “3” и завершающие две длинные полоски про конец штрихкода. Итого, в штрихкоде есть штрихи только про “601200000003”. Цифра “3” (последняя) в полосках штрихкода есть, а первой “4” нет! Откуда же взялась “4”?
Дело в том, что “4” закодирована грязным хаком. Для неё не хватает места, и вообще всё это большой исторический казус.
Изначально такие кассовые штрихкоды появились в США, там они состоят из 12 цифр и называются UPC (Universal Product Code). Для переноса технологии в Европу и адаптации стандарта Европе нужны были дополнительные цифры, потому что американские 12 все уже были заняты.
Первым товаром, приобретенным по штрих-коду на этикетке, стал блок из 10 жевательных резинок Wrigley Juicy Fruit. Это произошло в супермаркете Marsh города Трой (Огайо) в четверг, 26 июня 1974 года в 8.01 утра. В историю вошли и имя покупателя, и имя кассира, открывших новую страницу розничной торговли. Теперь упаковка жвачки, которая тогда обошлась в 67 центов, вместе с чеком хранятся в музее американской истории Смитсоновского института.Чтобы расширить емкость, можно было бы просто добавить еще немного штрихов и пропусков, но в те времена это серьезно ухудшало считываемость. Поэтому вместо того, чтобы просто увеличить штрихкод в ширину, был применен “хак”.
По американскому стандарту любая из цифр штрихкода может быть записана: а) обычными штрихами и пропусками; б) их зеркальным отражением; в) инверсией черного и белого; г) зеркальной инверсией. Всё это нужно для того, чтобы можно было печатать инверсные штрихкоды (белым по черному) и сканировать штрихкод вверх ногами (зеркальное отражение в случае штрихкода — то же самое, что и поворот на 180°).
В “американском” штрихкоде (который на 12 цифр) первые 6 цифр кодируются обычными штрихами, а вторые 6 цифр инвертированными штрихами (где черные штрихи заменены на белые полоски и наоборот). Это сделано для того, чтобы понимать, перевернут штрихкод или нет, нормально я его сканирую или вверх ногами (и затем декодировать цифры в правильном порядке, а не задом наперед).
В новом “европейском” штрихкоде (который на 13 цифр), первая цифра (например, “4”) кодируется не штрихами, а путем «перетасовывания» способов кодирования следующих за ней 6 цифр из первого блока (второй блок из 6 оставили в покое).
Например, следующая за четверкой “6” выводится как обычно, штрихи следующего за ней “0” выводятся в обратном порядке (зеркально), следующие за ней “1” и “2” выводится снова в обычном виде, следующие два “0” снова зеркально. Общая длина штрихкода и число штрихов в результате этого трюка не меняется.
Для “американского сканера” такая белиберда не имеет смысла, а для Европы это тайный знак того, что в штрихкоде закодирована еще одна цифра! (да, мы всегда знали, что европейцы извращенцы).
Для всех цифр от “1” до “9” были придуманы такие правила тасовки способов кодирования. Для “0” ничего нет, т.е. 13-значный штрихкод с лидирующим нулем визуально ничем не отличается от 12-значного штрихкода без этого лишнего ноля (EAN-13 с лидирующим нулем эквивалентен UPC-А).
Из этого получается первый прикол, что если перед нами “американский” штрихкод (в котором варианты кодирования не “перетасованы”), то “американский сканер” читает 12 цифр, а условный “европейский сканер” может считать, что в нем есть лидирующий «0», и считывать лишний ноль (т.к. для кодирования ноля не предусмотрено никакой “перетасовки”, этого “лидирующего нуля” очевидно в принципе нигде нет в штрихкоде).
Конечно, мир давно глобализован, поэтому “американский” сканер и “европейский” сканер — это просто условности. Сканер один и тот же, но у него есть настройка: нужно ли ему в принципе считывать EAN-13 (Европа) или читать только UPC-А (США), а если считывать EAN-13, то надо ли добавлять лишний ноль к американским штрихкодам UPC-А.
С этим связана одна распространенная проблема при внедрении штрихкодирования: когда в базе данных у компании либо нет нолей в начале штрихкодов, а сканер считывает с “лишним” нолем, либо наоборот, в базе данных есть ноль в начале, а сканер его “не считывает” (хотя, что там считывать, — этого ноля в принципе в штрихкоде нет).
Казалось бы, сложно накосячить в использовании EAN-13/UPC. Тем не менее, люди делают следующие ошибки:
- Сохраняют штрихкод в учетной системе без чексуммы (последнего знака).
- Забывают обрабатывать присутствие/отсутствие лидирующего нуля при разработке алгоритма поиска по штрихкоду.
- Требуют ввода 13 символов, а потом приходят сигареты с EAN-8 (с вводом маркировки табака станет неактуально, но пока так).
- Не оставляют положенных широких белых полей справа и слева от штрихкода.
В наших программных продуктах, таких как “Магазин 15” или “Склад 15”, построенных на платформе Mobile SMARTS, мы решаем эту проблему очень просто: сканер устройства всегда автоматически настраивается на возврат ноля, а поиск товара по базе данных производится два раза: и с нолем, и без ноля (чтобы уж точно найти товар).
Сканер мы стараемся настраивать программно, без участия человека. Если сканер нельзя настроить программно — то это всегда проблема, потому что по умолчанию сканером может обрезаться не только 0 (который в начале), но еще и чексумма (которая в конце), тогда в программу придут не 13, а уже 11 символов, зачастую даже без указания типа штрихкода (такие замечательные сканеры тоже бывают).
В этом случае мы бессильны улучшить результат. 11 символов могли прийти от сканирования любого другого типа штрихкода, мы не можем считать все штрихкоды как EAN-13. Чтобы настроить сканер, человеку придется сканировать с листа настроечные штрихкоды или заходить в какие-нибудь меню, а всё это — источники ошибок.
GS1 DataMatrix
Этот пример стал популярным благодаря введению обязательной маркировки товаров. История полна граблей, велосипедов и трупиков мелких животных, как сарай вашей бабушки.Ну ладно, допустим с EAN-13 можно придраться и сказать, что первая цифра всё-таки есть в штрихкоде, просто она закодирована не совсем штрихами (хотя для лидирующего “0” это и не так).
Возьмем тогда другой пример, штрихкод GS1 DataMatrix "(21)abba01(01)04601200000003":
В этом штрихкоде “внутри” нет ни скобок, ни символа «0», ни буквы «a», ни переноса строки.
Что тут происходит?
Во-первых, никакие скобки в штрихкод не кодируются, они печатаются только для удобства прочтения человеком. Это снова называется Human readable interpretation (HRI), привет, кожаный мешок.
Во-вторых, в штрихкоде есть специальные управляющие символы, которые должна расставить та программа, которая формирует данные для штрихкода. Не какая-то бесплатная opensource программа, написанная умными очкариками, а ваша программа, та самая, которую пишете Вы, мой друг. В этот раз символы, которые нужно вставить, не имеют отношения к “коррекции” и т.п., а размечают данные, которые нужно закодировать в штрихкод.
В самом начале в штрихкод вставляется управляющий символ, который называется FNC1 и имеет код 232, что соответствует либо странному печатаемому символу "?" (ANSI), либо русской букве “и” (Windows-1251), смотря какую кодировку использовать. Этот символ говорит, что у нас не просто абы какой DataMatrix, а именно GS1 DataMatrix, данные в котором имеют определенный формат: массив данных из пар (“код поля”, “значение поля”).
Этот управляющий символ FNC1 попадает в самое начало штрихкода, но его нельзя “передать” в штрихкод в составе данных.
Кроме того, непечатаемые символы, вполне очевидно, нельзя копипастить в составе строки, хаха! Страдай, кожаный мешок!
Указание, нужен префикс или не нужен, обычно передают как отдельную настройку (галочку) в программу формирования штрихкода. Если передать префикс как часть данных, то получим либо ошибку, либо два префикса в штрихкоде (в зависимости от используемой программы).
Далее, поскольку в штрихкоде внутри нет скобок, то уже непонятно, где кончается одно поле и начинается другое, где тут номера полей. Без скобок получается “21abba010104601200000003” (тут “01” встречается три раза, ха-ха).
Где заканчивается “01” из значения поля (21) и начинается настоящее (01)?
Это решается следующим способом:
По стандарту GS1 поля имеют формат. Не абы что, а формат значения. Например, значение для (01) должно состоять из 14 цифр и баста (нельзя 13 цифр, нельзя 12 цифр, нельзя не цифры). А поле (21), наоборот, имеет переменную длину, разрешены цифры, латинские буквы обоих регистров, знаки препинания и даже (опачки!) скобки.
Если после значения для (21) штрихкод не закончился, и там еще что-то есть, то в данные вставляется разделитель (это может быть снова или FNC1, или непечатаемый символ GS с кодом 29).
А общее правило звучит так: спецсимвол GS не вставляется, только в случае если AI начинается с пары цифр из этой вот таблицы:
Для всех остальных полей GS1 (не из этой таблицы) в конце значения нужно вставлять GS.
Т.е., мы получим “FNC121abba01GS0104601200000003” (только помним, что первый FNC1 мы не будем передавать в программу формирования штрихкода, а второй GS — это не строка “GS”, а один символ с кодом 29).
Эти требования — именно про данные, а не про штрихкод DataMatrix, потому что в штрихкод DataMatrix можно положить любые данные, они прекрасно закодируются и прочитаются. Тут речь о GS1 DataMatrix, который имеет определенный формат, и ваша программа должна соблюсти этот формат, прежде чем подавать данные в штрихкод.
Вообще говоря, в мире существуют программы печати штрихкодов, которым можно скармливать данные со скобками и они сами всё разрулят. Но это специализированный софт, который стоит денег, а не тот бестолковый и бесплатный онлайн-генератор штрихкодов, которым вы пользуетесь.
И наконец. То, как это будет напечатано и то, как это будет отсканировано, — две большие разницы. То, как данные печатаются под штрихкодом, и как они передаются сканером — это в чистом виде настройки принтера и сканера.
В нашем примере мы закодировали в штрихкод поля порядке: сначала (21), потом (01), а на изображении под штрихкодом распечаталось сначала (01), потом (21). Это снова называется Human readable interpretation (HRI), и порядок вывода в подписи соответствует правилу “потому что так принято”.
Сканер штрихкодов тоже имеет свои настройки, которые заставляют его переставлять поля, вставлять скобки и другие символы, переносить строки и т.п.
В большинстве случаев сканер прочитает наш штрихкод как “21abba01GS0104601200000003”. Никакого лидирующего FNC1, никаких скобок, GS не печатаемый и не виден в “Блокноте” (нужно использовать хотя бы Notepad+).
И принтер, и сканер могут делать со штрихкодами что хотят: добавлять и убирать символы, менять их местами — ради соответствия гайдлайну или для совместимости со сторонней программой.
Что еще интересно: в этом штрихкоде только 16 байт данных (на 24 символа без скобок).
Вот что тут происходит:
- пары подряд идущих цифр кодируются одним байтом;
- все отдельно стоящие цифры, не парные, а также все символы из таблицы ASCII (а это символы с кодами с 0 по 127, без русских букв, и печатаемые, и непечатаемые) кодируются в штрихкод как (значение байта символа)+1.
Т.е. чтобы закодировать “a”, нужно записать в штрихкод “b”, чтобы закодировать “1”, нужно записать “2” и т.д., именно поэтому прямо в самом штрихкоде нет байта 97 (значение буквы “a” в ASCII).
Итого, в приведенном штрихкоде “закодировано” в байтах 232, 151, 98, 99, 99, 98, 131, 232, 131, 134, 190, 142, 130, 130, 130, 133. И это еще до кодов коррекции и паддинга!
Непонимание процесса кодирования приводит к тому, что, например, для начавшейся обязательной маркировки обуви люди печатают на принтер неправильно сформированные данные и получают неправильные штрихкоды, которые выглядят вполне нормально, читаются приложением “Честный знак”, но данные в них неверные, как минимум это не GS1 DataMatrix.
Штрихкоды неправильно напечатаны, неправильно читаются, и такая обувь не считается правильно промаркированной.
В своем софте “Кировка” мы боремся с этим следующим образом: для печати принимаем в качестве исходных данных любой мусор, пытаемся распарсить его как GS1 DataMatrix, разбираем на косточки. Если всё прошло удачно, то конвертируем в правильный формат, чтобы принтер это понял; а при сканировании перепроверяем данные от сканера, делая таким образом вывод о правильности печати.
Для этого нам, конечно, приходится работать на нативном уровне и со сканером мобильных устройств, и с принтерами, чтобы всё это было правильно ими интерпретировано, а мы собирали максимально полную информацию.
Выполним еще одно упражнение: посмотрим, какого размера должен быть штрихкод GS1 DataMatrix для хранения кода маркировки обуви и легпрома.
На сайте «Честного знака» написано, что код маркировки обуви должен содержать следующие поля (для легпрома те же требования):
- Кода товара, 14 цифровых символов (GTIN).
- Индивидуального серийного номера единицы товара, который генерируется оператором системы или участником оборота товаров, 13 символов (s/n).
- Ключ проверки, предоставляемый оператором системы, 4 символа.
- Код проверки, предоставляемый оператором системы, 88 символов.
Для каждого из этих полей в данных для штрихкода должен быть указан идентификатор применения GS1 (AI, application identifier).
Таблица codeword для DataMatrix
Таблица, объясняющая кодирование КМ обуви в DataMatrix:
| Что | Формат | Codewords | Сколько байт | Всего байт, минимум | Всего байт, максимум |
|---|---|---|---|---|---|
| <FNC1> | - | Codeword [232] | 1 | 1 | 1 |
| AI (00) | - | Codeword [130] | 1 | 2 | 2 |
| GTIN | 14 цифр | Codeword со [130] по [229] | 7 | 9 | 9 |
| AI (21) | - | Codeword [141] | 1 | 10 | 10 |
| s/n | 13 знаков ASCII | Codewords с [1] по [128] и со [130] по [229] | от 7 до 13* | 17 | 23 |
| <GS> | - | Codeword 30 | 1 | 18 | 24 |
| AI (91) | - | Codeword 221 | 1 | 19 | 25 |
| Ключ проверки | 4 цифры | Codeword с 130 по 229 | 4 | 23 | 29 |
| AI (92) | - | Codeword 222 | 1 | 24 | 30 |
| Код проверки | 88 знаков ASCII | Codewords с [1] по [128] и со [130] по [229] | от 44 до 88* | 28 | 118 |
* если в данных для штрихкода есть пары подряд идущих цифр, то они будут кодироваться одним байтом, а не двумя (Codewords со [130] по [229]), и это экономит байты.
Как видно, размер данных в теории может меняться в широких пределах от 68 до 118 байт. На практике разброс меньше, длина ближе к 118, потому что в серийном номере и в криптокоде мало цифр и много знаков препинания, включая скобки.
Согласно GS1 DataMatrix Guideline, такие данные укладываются в штрихкоды размером от 36х36 до 44х44 (колонок и строк битов, не миллиметров). В миллиметрах размер будет зависеть от разрешающей способности принтера (обычно это 203-600 dpi).
Таблица из GS1 DataMatrix Guideline
Пожалуй, достаточно.
А как же голая Эмма Уотсон? Рассмотрим в следующей статье.




teology
Жду в следующей статье инфу, подтверждающую какую-нибудь галиматью и в QR-кодах…