
Эта публикация — перевод поста Романа Елизарова «Shared flows, broadcast channels». Опубликовано с одобрения автора оригинала. Примечания переводчика выделены курсивом.
Давным-давно в Kotlin были представлены корутины, одной из особенностей которых является легковесность (создание корутин дешевле, чем с запуск новых Threads). Мы можем запускать несколько корутин, и нам нужен способ взаимодействия между ними избегая “mutable shared state” (неконсистентности данных при записи и чтении из разных корутин).
Для этого был придуман Channel как примитив для связи между корутинами. Channels — отличное изобретение. Они поддерживают связь между корутинами «один к одному», «один ко многим», «многие к одному» и «многие ко многим», но каждое значение, отправляемое в Channel, принимается один раз (в одной из корутин с запущенной подпиской).
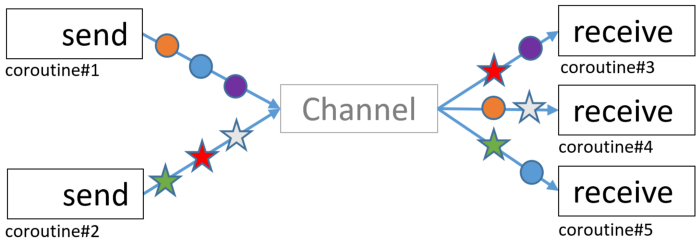
Вы не можете использовать Channel для распространения событий или обновлений состояния так, чтобы несколько подписчиков могли независимо получать и реагировать на них.
Для решения этой проблемы был дополнительно добавлен интерфейс BroadcastChannel, хранящий состояние, доступное каждому подписчику, и его реализацию — ConflatedBroadcastChannel. Некоторое время они хорошо выполняли свою задачу, но их развитие оказалось тупиковым. Начиная с версии kotlinx-coroutines 1.4, мы представили новое решение — shared flows. Это была предыстория, а теперь поехали!
В ранних версиях библиотеки у нас были только Channels, и мы пытались реализовать различные преобразования последовательностей данных как функции, которые принимают один Channel в качестве аргумента и в результате возвращают другой Channel. Это означает, что, например, оператор filter будет работать в своей собственной корутине.

Производительность такого подхода была далека от идеала, особенно по сравнению с простым написанием оператора if. И это неудивительно, потому что Channel — это примитив синхронизации доступа к данным (в общем случае из разных потоков). Любой Channel, даже реализация, оптимизированная для одного producer и одного consumer, должен поддерживать консистентный доступ к данным из разных потоков, а значит между ними требуется синхронизация, которая в современных многоядерных системах обходится дорого. Когда вы начинаете строить архитектуру приложения на основе асинхронных потоков данных, почти сразу возникает необходимость в преобразованиях данных, приходящих от producer. Тяжеловесность решения с каждым преобразованием возрастает.
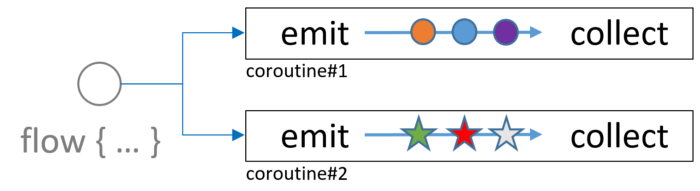
Первым решением это проблемы можно назвать Flow, который позволяет эффективно добавлять операторы преобразования. По умолчанию данные передаются, преобразуются и собираются в одной корутине без необходимости в синхронизации.

Синхронизация возникает только в том случае, когда producer и consumer работают в разных корутинах (при этом emit и filter из примера на картинке будут работать в одной корутине, что лучше ситуации, описанной двумя абзацами выше).
Однако вычисления данных для Flow обычно холодные (cold) — Flow, созданный билдером flow {…}, является пассивной сущностью. Рассмотрим следующий код:
Сами Flow не начинают вычисляться и не хранят состояния пока на них не подпишется collector. Каждая корутина с collector-ом создает новый экземпляр кода, упаковывающего данные во Flow. Статья “Cold flow, hot channels” описывает причины, лежащие в основе такой работы Flows, и показывает примеры использования, для которых они подходят лучше, чем Channels.
Но что насчет таких событий, как действия пользователя, события из операционной системы от датчиков устройства или о изменении состояния? Они появляются независимо от того, есть ли сейчас какой-либо collector, который в них потенциально заинтересован. Они также должны поддерживать нескольких collectors внутри приложения. Это так называемые горячие источники данных…
Вот здесь-то и появляется концепция SharedFlow. Shared Flow существует независимо от того, есть-ли сейчас collectors или нет. Collector у SharedFlow называется подписчиком (observer). Все observers получают одинаковую последовательность значений. Он работает как BroadcastChannel, но эффективнее и делает концепцию BroadcastChannel устаревшей.
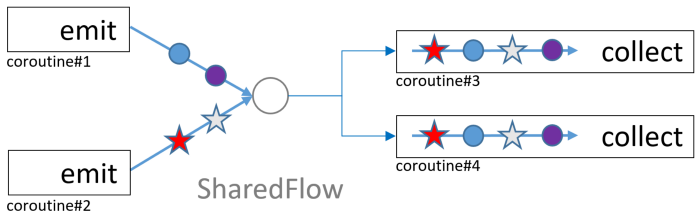
SharedFlow — это легковесная широковещательный event bus, который вы можете создать и использовать в своей архитектуре приложения.
Он имеет параметры для настройки, такие как количество старых событий, которые нужно сохранить и воспроизвести для новых подписчиков, и extraBufferCapacity, чтобы настроить поведение в случае быстрых emmiters и медленных observers.
Все observers SharedFlow асинхронно собирают данные в своем собственном coroutine context. Emmiter не ждет, пока подписчики закончат обработку данных. Однако, когда общий буфер SharedFlow заполнен, emmiter приостанавливается, пока в буфере не появится место. Альтернативные стратегии работы с переполненным буфером настраиваются параметром BufferOverlow.
Частый способ справиться с переполнением буфера — отбрасывать старые данные и сохранять только новые. В частности, при единичном размере буфера мы имеем дело со state variable. Это настолько распространенный вариант использования, что у него есть собственный специализированный тип — StateFlow. Он служит заменой ConflatedBroadcastChannel, который также устарел.
Смотрите на StateFlow как на изменяемую переменную, на изменения которой можно подписаться. Его последнее значение всегда доступно, и, фактически, последнее значение — единственное, что важно для observers.
Разница в производительности StateFlow с Channel и обычным Flow становится очевидной — StateFlow обновляет состояние без выделения памяти.
По мере того, как разные виды Flow заменяют разные виды BroadcastChannel, возникает популярный вопрос: что произойдет с Channels? Они останутся в следующих версиях языка по многим причинам. Одна из причин заключается в том, что Channels представляют из себя низкоуровневые примитивы, которые используются для реализации многих сложных операторов, на которых базируется Flow.
Но у Channels также есть свои варианты использования. Channels могут быть использованы для обработки событий, которые должны быть обработаны ровно один раз. Это происходит в проекте с типом события, которое обычно имеет одного подписчика, но периодически (при запуске или во время некоторой реконфигурации) подписчиков вообще нет, и есть требование, чтобы все опубликованные события сохранялись до тех пор, пока не появился подписчик.
Оба примера, BroadcastEventBus, который написан с SharedFlow, и этот SingleShotEventBus, который написан с Channel, выставляют наружу данные в виде Flow , но у них есть важное отличие.
В SharedFlow события транслируются неизвестному количеству (?0) подписчиков. При отсутствии подписчика любое опубликованное событие немедленно удаляется. Это шаблон проектирования можно использовать для событий, которые должны обрабатываться немедленно или не обрабатываться вообще.
С помощью Channel каждое событие доставляется только одному подписчику. Попытка опубликовать событие без подписчиков будет приостановлена, как только буфер канала заполнится, ожидая появления подписчика. По умолчанию опубликованные события не удаляются.
Знайте разницу и правильно используйте как SharedFlow, так и Channels. Они оба полезны и предназначены для совместной работы. Однако BroadcastChannels — это пережитки прошлого, которые в будущем будут удалены.
Давным-давно в Kotlin были представлены корутины, одной из особенностей которых является легковесность (создание корутин дешевле, чем с запуск новых Threads). Мы можем запускать несколько корутин, и нам нужен способ взаимодействия между ними избегая “mutable shared state” (неконсистентности данных при записи и чтении из разных корутин).
Для этого был придуман Channel как примитив для связи между корутинами. Channels — отличное изобретение. Они поддерживают связь между корутинами «один к одному», «один ко многим», «многие к одному» и «многие ко многим», но каждое значение, отправляемое в Channel, принимается один раз (в одной из корутин с запущенной подпиской).
Вы не можете использовать Channel для распространения событий или обновлений состояния так, чтобы несколько подписчиков могли независимо получать и реагировать на них.
Для решения этой проблемы был дополнительно добавлен интерфейс BroadcastChannel, хранящий состояние, доступное каждому подписчику, и его реализацию — ConflatedBroadcastChannel. Некоторое время они хорошо выполняли свою задачу, но их развитие оказалось тупиковым. Начиная с версии kotlinx-coroutines 1.4, мы представили новое решение — shared flows. Это была предыстория, а теперь поехали!
Flows are simple
В ранних версиях библиотеки у нас были только Channels, и мы пытались реализовать различные преобразования последовательностей данных как функции, которые принимают один Channel в качестве аргумента и в результате возвращают другой Channel. Это означает, что, например, оператор filter будет работать в своей собственной корутине.
Производительность такого подхода была далека от идеала, особенно по сравнению с простым написанием оператора if. И это неудивительно, потому что Channel — это примитив синхронизации доступа к данным (в общем случае из разных потоков). Любой Channel, даже реализация, оптимизированная для одного producer и одного consumer, должен поддерживать консистентный доступ к данным из разных потоков, а значит между ними требуется синхронизация, которая в современных многоядерных системах обходится дорого. Когда вы начинаете строить архитектуру приложения на основе асинхронных потоков данных, почти сразу возникает необходимость в преобразованиях данных, приходящих от producer. Тяжеловесность решения с каждым преобразованием возрастает.
Первым решением это проблемы можно назвать Flow, который позволяет эффективно добавлять операторы преобразования. По умолчанию данные передаются, преобразуются и собираются в одной корутине без необходимости в синхронизации.
Синхронизация возникает только в том случае, когда producer и consumer работают в разных корутинах (при этом emit и filter из примера на картинке будут работать в одной корутине, что лучше ситуации, описанной двумя абзацами выше).
Flows are cold
Однако вычисления данных для Flow обычно холодные (cold) — Flow, созданный билдером flow {…}, является пассивной сущностью. Рассмотрим следующий код:
val coldFlow = flow {
while (isActive) {
emit(nextEvent)
}
}Сами Flow не начинают вычисляться и не хранят состояния пока на них не подпишется collector. Каждая корутина с collector-ом создает новый экземпляр кода, упаковывающего данные во Flow. Статья “Cold flow, hot channels” описывает причины, лежащие в основе такой работы Flows, и показывает примеры использования, для которых они подходят лучше, чем Channels.
Но что насчет таких событий, как действия пользователя, события из операционной системы от датчиков устройства или о изменении состояния? Они появляются независимо от того, есть ли сейчас какой-либо collector, который в них потенциально заинтересован. Они также должны поддерживать нескольких collectors внутри приложения. Это так называемые горячие источники данных…
Shared flows
Вот здесь-то и появляется концепция SharedFlow. Shared Flow существует независимо от того, есть-ли сейчас collectors или нет. Collector у SharedFlow называется подписчиком (observer). Все observers получают одинаковую последовательность значений. Он работает как BroadcastChannel, но эффективнее и делает концепцию BroadcastChannel устаревшей.
SharedFlow — это легковесная широковещательный event bus, который вы можете создать и использовать в своей архитектуре приложения.
class BroadcastEventBus {
private val _events = MutableSharedFlow<Event>()
val events = _events.asSharedFlow() // read-only public view
suspend fun postEvent(event: Event) {
_events.emit(event) // suspends until subscribers receive it
}
}Он имеет параметры для настройки, такие как количество старых событий, которые нужно сохранить и воспроизвести для новых подписчиков, и extraBufferCapacity, чтобы настроить поведение в случае быстрых emmiters и медленных observers.
Все observers SharedFlow асинхронно собирают данные в своем собственном coroutine context. Emmiter не ждет, пока подписчики закончат обработку данных. Однако, когда общий буфер SharedFlow заполнен, emmiter приостанавливается, пока в буфере не появится место. Альтернативные стратегии работы с переполненным буфером настраиваются параметром BufferOverlow.
State flows
Частый способ справиться с переполнением буфера — отбрасывать старые данные и сохранять только новые. В частности, при единичном размере буфера мы имеем дело со state variable. Это настолько распространенный вариант использования, что у него есть собственный специализированный тип — StateFlow. Он служит заменой ConflatedBroadcastChannel, который также устарел.
class StateModel {
private val _state = MutableStateFlow(initial)
val state = _state.asStateFlow() // read-only public view
fun update(newValue: Value) {
_state.value = newValue // NOT suspending
}
}Смотрите на StateFlow как на изменяемую переменную, на изменения которой можно подписаться. Его последнее значение всегда доступно, и, фактически, последнее значение — единственное, что важно для observers.
Разница в производительности StateFlow с Channel и обычным Flow становится очевидной — StateFlow обновляет состояние без выделения памяти.
Что будет с Channels
По мере того, как разные виды Flow заменяют разные виды BroadcastChannel, возникает популярный вопрос: что произойдет с Channels? Они останутся в следующих версиях языка по многим причинам. Одна из причин заключается в том, что Channels представляют из себя низкоуровневые примитивы, которые используются для реализации многих сложных операторов, на которых базируется Flow.
Но у Channels также есть свои варианты использования. Channels могут быть использованы для обработки событий, которые должны быть обработаны ровно один раз. Это происходит в проекте с типом события, которое обычно имеет одного подписчика, но периодически (при запуске или во время некоторой реконфигурации) подписчиков вообще нет, и есть требование, чтобы все опубликованные события сохранялись до тех пор, пока не появился подписчик.
class SingleShotEventBus {
private val _events = Channel<Event>()
val events = _events.receiveAsFlow() // expose as flow
suspend fun postEvent(event: Event) {
_events.send(event) // suspends on buffer overflow
}
}Оба примера, BroadcastEventBus, который написан с SharedFlow, и этот SingleShotEventBus, который написан с Channel, выставляют наружу данные в виде Flow , но у них есть важное отличие.
В SharedFlow события транслируются неизвестному количеству (?0) подписчиков. При отсутствии подписчика любое опубликованное событие немедленно удаляется. Это шаблон проектирования можно использовать для событий, которые должны обрабатываться немедленно или не обрабатываться вообще.
С помощью Channel каждое событие доставляется только одному подписчику. Попытка опубликовать событие без подписчиков будет приостановлена, как только буфер канала заполнится, ожидая появления подписчика. По умолчанию опубликованные события не удаляются.
Заключение
Знайте разницу и правильно используйте как SharedFlow, так и Channels. Они оба полезны и предназначены для совместной работы. Однако BroadcastChannels — это пережитки прошлого, которые в будущем будут удалены.




Nihiroz
Подскажите пожалуйста, как можно с помощью
SharedFlowреализовать подписку на события вSTARTEDсостоянии Activity? То есть обычно во всех примерах описываетсяActivityScope, в котором мы подписываемся наFlow, это просто и удобно. Но мы остаемся подписанными наFlowв течении всего времени жизниActivity, даже когда приложение свернуто. А мне бы хотелось обрабатывать события только когда приложение видно пользователю.Можно конечно подписаться на
FlowвActivityScopeи при получении событий проверять находится лиActivityв состоянииSTARTED, но это во-первых костыль, а во-вторых неуниверсальное решение.То есть хотелось бы иметь возможность подписываться на
Flowне вCoroutineScope, а вFlow<CoroutineScope?>или вFlow<Boolean>. То есть что бы была функцияFlow<T>.launchIn(scopes: Flow<CoroutineScope>)agent10
lifecycleScope.launchWhenStarted может вам помочь
Nihiroz
Да, спасибо, для данной задачи то что нужно. Не учел, что корутины можно не только отменять, но ещё и ставить на паузу. Правда постановка на паузу в данном решении прибита к Lifecycle, для более абстрактного решения придется либой свой велосипед пилить с оглядкой на
lifecycleScope.launchWhenStarted, либо искать готовое.Вообще изначально вопрос был задан для того, что бы понять как подобное сделать для обработки Flow внутри Custom View. Хотелось бы получать новые значения из Flow, только когда View видна пользователю. Думал решение для Activity подойдет и для View. Но View Lifecycle не соответствует жизненному циклу Activity
agent10
Самое примитивное внутри view — сохранять джобу после collect, и отменять её, когда вью детачится от window
Nihiroz
Да, в текущей реализации так и есть, но хотелось бы некую утилитку использовать, не в каждой же View прописывать эту логику.
Кстати идея с приостановкой корутины на время сокрытия View, наверное, не подойдет, т.к. В отличии от Activity, в View мы не можем знать завершилась ли работа с ней полностью, или может ее ещё раз пользователю покажут, так что мы не можем ни в какой момент времени завершить корутину, а только поставить ее на паузу. А это опасно утечками
agent10
Посмотрите как работает ViewModel внутри. Там похожая идея внутри. Может вам внутри вью создавать собственный скоуп, который вы будет использовать, и который будете закрываться когда вью детачится.
Nihiroz
ViewModelимеет методonClear, то есть уViewModelжизненный цикл, как и уActivityконечный. И вonClearможно завершить скоуп и память не утечет. А при работе сViewвидимо придется завершать его каждый раз, когдаViewскрывается, потому как не знаем, появится ли ещё она на экране или уже можно собирать ее сборщиком.agent10
Ну либо надо менять подход. Не делать умную View, а передавать данные в неё из вне..
Nihiroz
Вроде да, так обычно и делается. Но мне очень нравится подход, что изображение на экране это функция от состояния. В этом подходе можно делать View без публичных методов, просто передать Flow состояния в конструкторе, а View уже сам его будет актуально отображать
Guitariz
launchWhenStarted — не наглядно? :)
Nihiroz
А внутри View как ими пользоваться?
Guitariz
activity.lifecycleScope.launchWhenStarted.
У вьюх в следующей версии lifecycle такая фича появится
Nihiroz
Надо ещё обработать ситуацию, что View может быть откреплена от Activity, да хотя бы тот же фрагмент сменился. И нам надо отписаться от
Flow, хотяactivity.lifecycleScopeещё активенGuitariz
Надо, но это не проблема flow)
Сейчас разрабатывается lifecycle экстеншн для этого. но пока надо делать это вручную. В местах удаления с экрана, убивать и скоуп.
Nihiroz
Вот вопрос и есть про то, как аккуратно это делать. А не копировать логику по созданию и завершению скоупов в каждую кастомную вьюху. Кстати, а что за экстеншен? По какой логике он будет работать?
Guitariz
developer.android.com/jetpack/androidx/releases/lifecycle#2.3.0-beta01
Tepex
Вот есть полезная статья про SharedFlow/StateFlow.