
Что-то всегда идет не по плану. Приходится отвечать на вопросы, «Что сломалось?», «Почему тормозит?» и «Почему мы не увидели этого раньше?». На примере простого приложения Даниил Галиев zefirior из Яндекс.Путешествий показал, как отвечать на эти вопросы и какие инструменты в этом помогут. Настроим логирование, прикрутим трассировку, разложим ошибки, и все это в удобном интерфейсе.
— Давайте начинать. Я расскажу об удобном логировании и инфраструктуре вокруг логирования, которую можно развернуть, чтобы вам с вашим приложением и его жизненным циклом было удобно жить.

Что будем делать? Мы построим небольшое приложение, наш стартап. Потом внедрим в него базовое логирование, это маленькая часть доклада, то, что поставляет Python из коробки. И дальше самая большая часть — мы разберем типичные проблемы, которые встречаются нам во время отладки, выкатки, и инструменты для их решения.
Небольшой дисклеймер: я буду говорить такие слова, как «ручка» и «локаль». Поясню. «Ручка» — возможно, яндексовый сленг, это обозначает ваши API, http или gRPC API или любые другие комбинации букв перед APU. «Локаль» — это когда я разрабатываю на ноутбуке. Вроде бы я рассказал обо всех словах, которые я не контролирую.
Начнем. Наш стартап — это «Книжная лавка». Главной фичей этого приложения будет продажа книг, это все, что мы хотим сделать. Дальше немного начинки. Приложение будет написано на Flask. Все сниппеты кода, все инструменты общие и абстрагированы от Python, поэтому их можно будет интегрировать в большинство ваших приложений. Но в нашем докладе это будет Flask.
Действующие лица: я, разработчик, менеджеры и мой любимый коллега Эраст. Любые совпадения случайны.
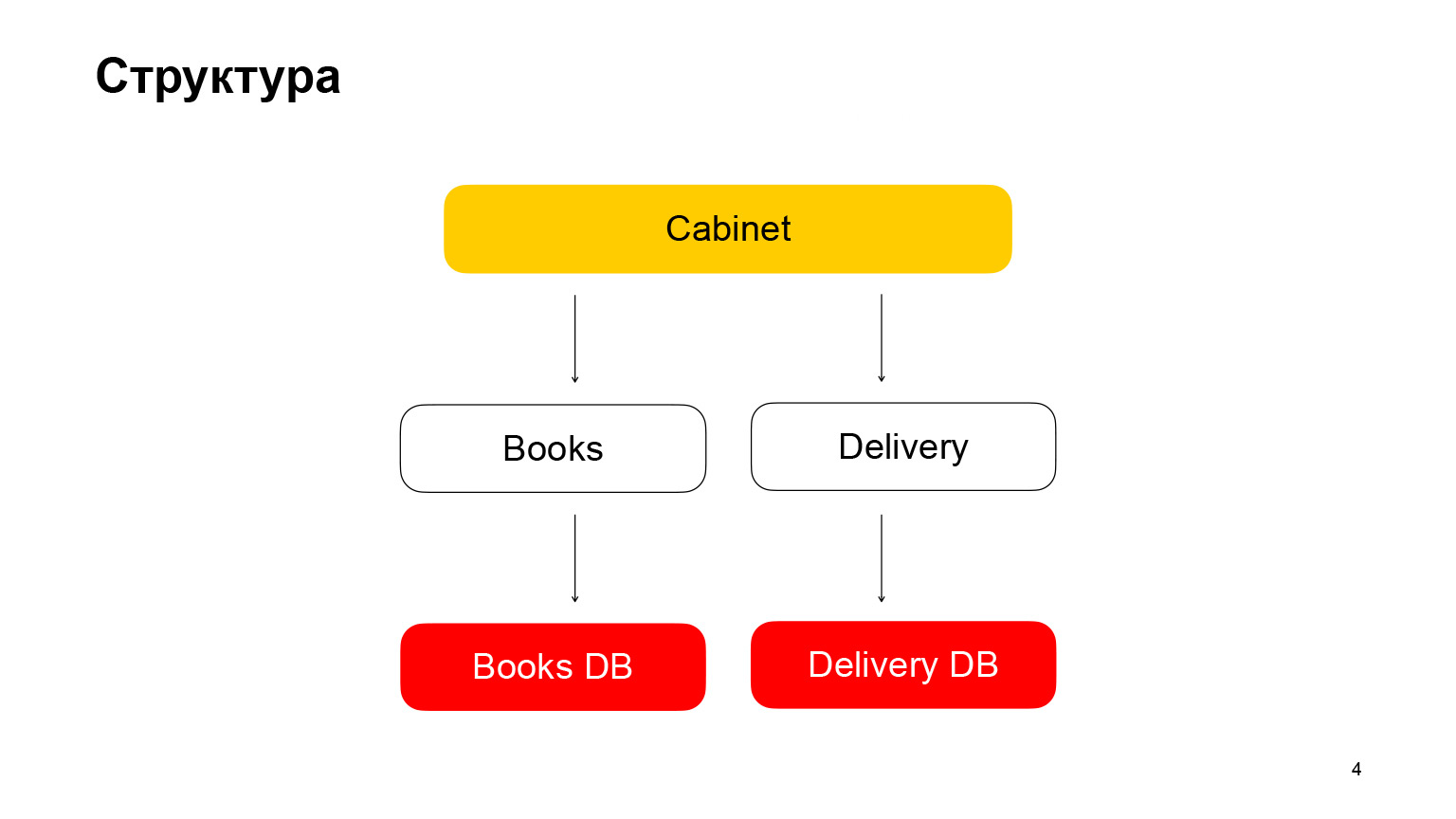
Давайте немного про структуру. Это приложение с микросервисной архитектурой. Первый сервис — Books, хранилище книг с метаданными о книгах. Он использует базу данных PostgreSQL. Второй микросервис — микросервис доставки, хранит метаданные о заказах пользователей. Cabinet — это бэкенд для кабинета. У нас нет фронтенда, в нашем докладе он не нужен. Cabinet агрегирует запросы, данные из сервиса книг и сервиса доставки.

По-быстрому покажу код ручек этих сервисов, API Books. Это ручка выгребает данные из базы, сериализует их, превращает в JSON и отдает.

Пойдем дальше. Сервис доставки. Ручка точно такая же. Выгребаем данные из базы, сериализуем их и отправляем.

И последняя ручка — ручка кабинета. В ней немного другой код. Ручка кабинета запрашивает данные из сервиса доставки и из сервиса книг, агрегирует ответы и отдает пользователю его заказы. Всё. Со структурой приложения мы по-быстрому разобрались.
Теперь давайте про базовое логирование, то, которое мы впилили. Начнем с терминологии.

Что нам дает Python? Четыре базовые, главные сущности:
— Logger, входная точка логирования в вашем коде. Вы будете пользоваться каким-то Logger, писать logging.INFO, и все. Ваш код больше ничего не будет знать о том, куда сообщение улетело и что с ним дальше произошло. За это уже отвечает сущность Handler.
— Handler обрабатывает ваше сообщение, решает, куда его отправить: в стандартный вывод, в файл или кому-нибудь на почту.
— Filter — одна из двух вспомогательных сущностей. Удаляет сообщения из лога. Другой стандартный вариант использования — это наполнение данными. Например, в вашей записи нужно добавить атрибут. Для этого тоже может помочь Filter.
— Formatter приводит ваше сообщение к нужному виду.

На этом с терминологией закончили, дальше к логированию прямо на Python, с базовыми классами, мы возвращаться не будем. Но вот пример конфигурации нашего приложения, которая раскатана на всех трех сервисах. Здесь два главных, важных для нас блока: formatters и handlers. Для formatters, есть пример, который вы можете увидеть здесь, шаблон того, как будет выводиться сообщение.
В handlers вы можете увидеть, что logging.StreamHandler использован. То есть мы выгружаем все наши логи в стандартный вывод. Всё, с этим закончили.
Переходим к проблемам. Для начала проблема первая: логи разбросаны.
Немножечко контекста. Наше приложение мы написали, конфетка уже готова. Мы можем на нем зарабатывать денежку. Мы его выкатываем в продакшен. Конечно, там не один сервер. По нашим скромным подсчетам, нашему сложнейшему приложению нужно порядка трех-четырех машинок, и так для каждого сервиса.
Теперь вопрос. Прибегает к нам менеджер и спрашивает: «Там сломалось, помоги!» Вы бежите. У вас же все логируется, это великолепно. Вы заходите на первую машинку, смотрите — там ничего нет по вашему запросу. Заходите на вторую машинку — ничего. И так далее. Это плохо, это надо как-то решать.

Давайте формализуем результат, который мы хотим увидеть. Я хочу, чтобы логи были в одном месте. Это простое требование. Немного круче то, что я хочу поиск по логам. То есть да, оно лежит в одном месте и я умею грепать, но было бы прикольно, если бы были какие-нибудь tools, крутые фичи помимо простого грепа.
И я не хочу писать. Это Эраст любит писать код. Я не про это, я сразу сделал продукт. То есть хочется меньше дополнительного кода, обойтись одним-двумя файликами, строчками, и всё.

Решение, которое можно использовать, — Elasticsearch. Давайте его попробуем поднять. Какие плюсы Elasticsearch нам даст? Это интерфейс с поиском логов. Сразу из коробки есть интерфейс, это вам не консолька, а единственное место хранения. То есть главное требование мы отработали. Нам не нужно будет ходить по серверам.
В нашем случае это будет довольно простая интеграция, и с недавним релизом у Elasticsearch выпустился новый агент, который отвечает за большинство интеграций. Они там сами впилили интеграции. Очень круто. Я составлял доклад чуть раньше и использовал filebeat, так же просто. Для логов все просто.
Немного об Elasticsearch. Не хочу рекламировать, но там много дополнительных фич. Например, крутая штука — полнотекстовый поиск по логам из коробки. Очень круто звучит. Нам пока достаточно этих плюсов. Прикручиваем.
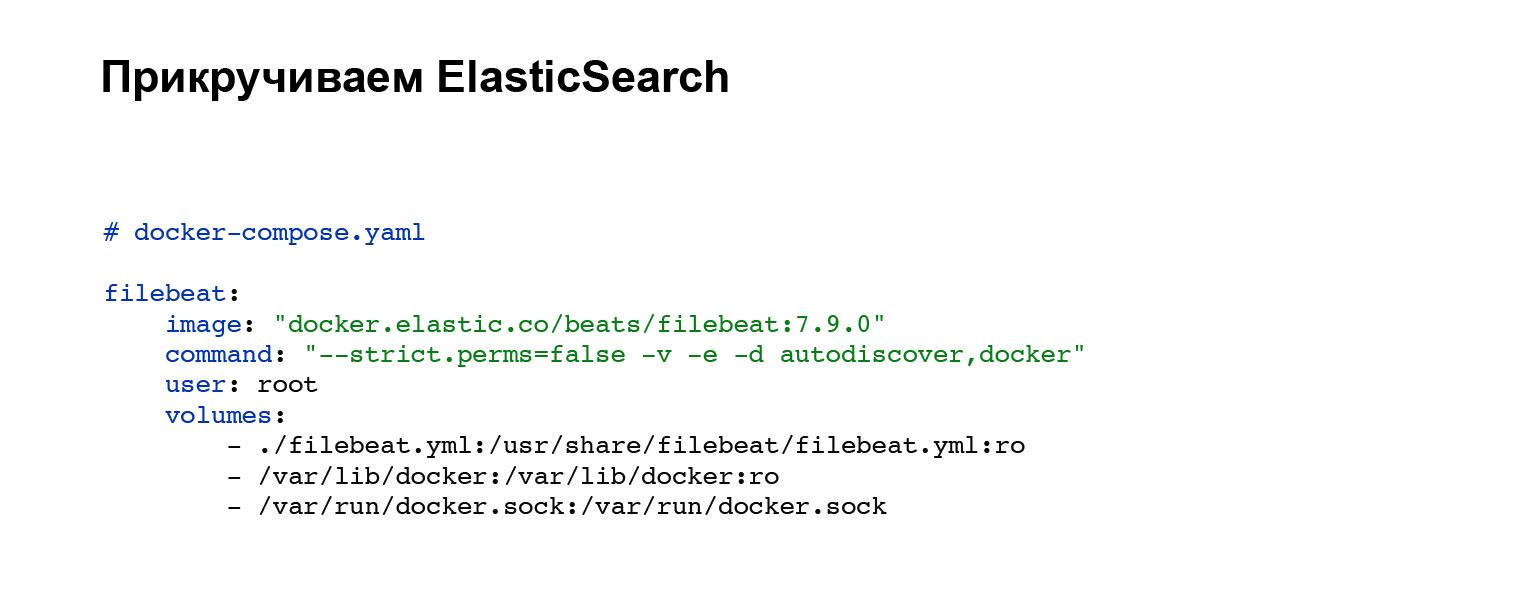
В первую очередь нам нужно будет развернуть агент, который будет отправлять наши логи в Elasticsearch. Вы регистрируете аккаунт в Elasticsearch и дальше добавляете в ваш docker-compose. Если у вас не docker-compose, можете поднимать ручками или в вашей системе. В нашем случае добавляется вот такой блок кода, интеграции в docker-compose. Всё, сервис настроен. И вы можете увидеть в блоке volumes файл конфигурации filebeat.yml.

Вот пример filebeat.yml. Здесь настроен автоматический поиск логов контейнеров docker, которые крутятся рядом. Кастомизован выбор этих логов. По условию можно задавать, вешать на ваши контейнеры лейблы, и в зависимости от этого ваши логи будут отправляться только у определенных контейнеров. С блоком processors:add_docker_metadata все просто. В логи добавляем немножечко больше информации о ваших логах в контексте docker. Необязательно, но прикольно.
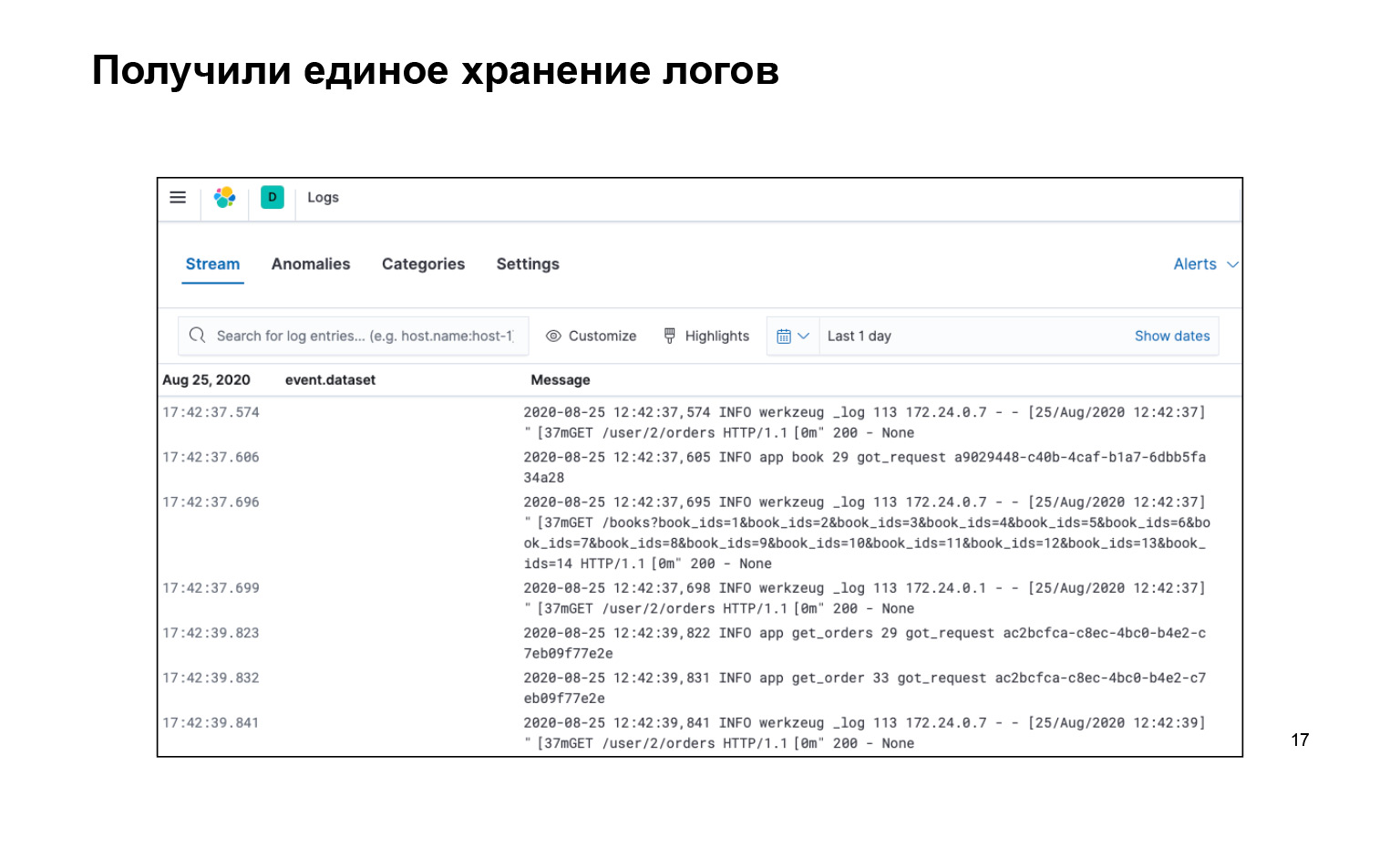
Что мы получили? Это все, что мы написали, весь код, очень круто. При этом мы получили все логи в одном месте и есть интерфейс. Мы можем поискать наши логи, вот плашечка search. Они доставляются. И можно даже в прямом эфире включить так, чтобы стрим летел к нам в логи в интерфейс, и мы это видели.

Тут я бы и сам спросил: а чего, как грепать-то? Что из себя представляет поиск по логам, что там можно сделать?
Да, из коробки в таком подходе, когда у нас текстовые логи, есть небольшой затык: мы можем по тексту задать запрос, например message:users. Это выведет нам все логи, у которых есть подстрока users. Можно пользоваться звездочками, большинством других юниксовых wild cards. Но кажется, этого недостаточно, хочется сделать сложнее, чтобы можно было нагрепать в Nginx раньше, как мы это умеем.

Давайте немного отступим от Elasticsearch и попытаемся сделать это не с Elasticsearch, а с другим подходом. Рассмотрим структурные логи. Это когда каждая ваша запись лога — это не просто текстовая строчка, а сериализованный объект с атрибутами, которые любая ваша сторонняя система может сериализовать, чтобы получить уже готовый объект.
Какие от этого есть плюсы? Это единый формат данных. Да, у объектов могут быть разные атрибуты, но любая внешняя система может прочитать именно JSON и получить какой-то объект.
Какая-никакая типизация. Это упрощает интеграцию с другими системами: не нужно писать десериализаторы. И как раз десериализаторы — это другой пункт. Вам не нужно писать в приложении прозаичные тексты. Пример: «User пришел с таким-то айдишником, с таким-то заказом». И это все нужно писать каждый раз.
Меня это напрягало. Я хочу написать: «Прилетел запрос». Дальше: «Такой-то, такой-то, такой-то», очень просто, очень по-айтишному.

Давайте дальше. Договоримся: логировать будем в формате JSON, это простой формат. Сразу Elasticsearch поддерживается, filebeat, которым мы сериализуем и попробуем впилить. Это не очень сложно. Для начала вы добавляете из библиотеки pythonjsonlogger в блок formatters JSONFormatter файлика settings, где у нас хранится конфигурация. У вас в системе это может быть другое место. И дальше в атрибуте format вы передаете, какие атрибуты вы хотите добавлять в ваш объект.
Блок ниже — это блок конфигурации, который добавляется в filebeat.yml. Здесь из коробки есть интерфейс у filebeat для парсинга JSON-логов. Очень круто. Это все. Для этогов вам больше ничего писать не придется. И теперь ваши логи похожи на объекты.
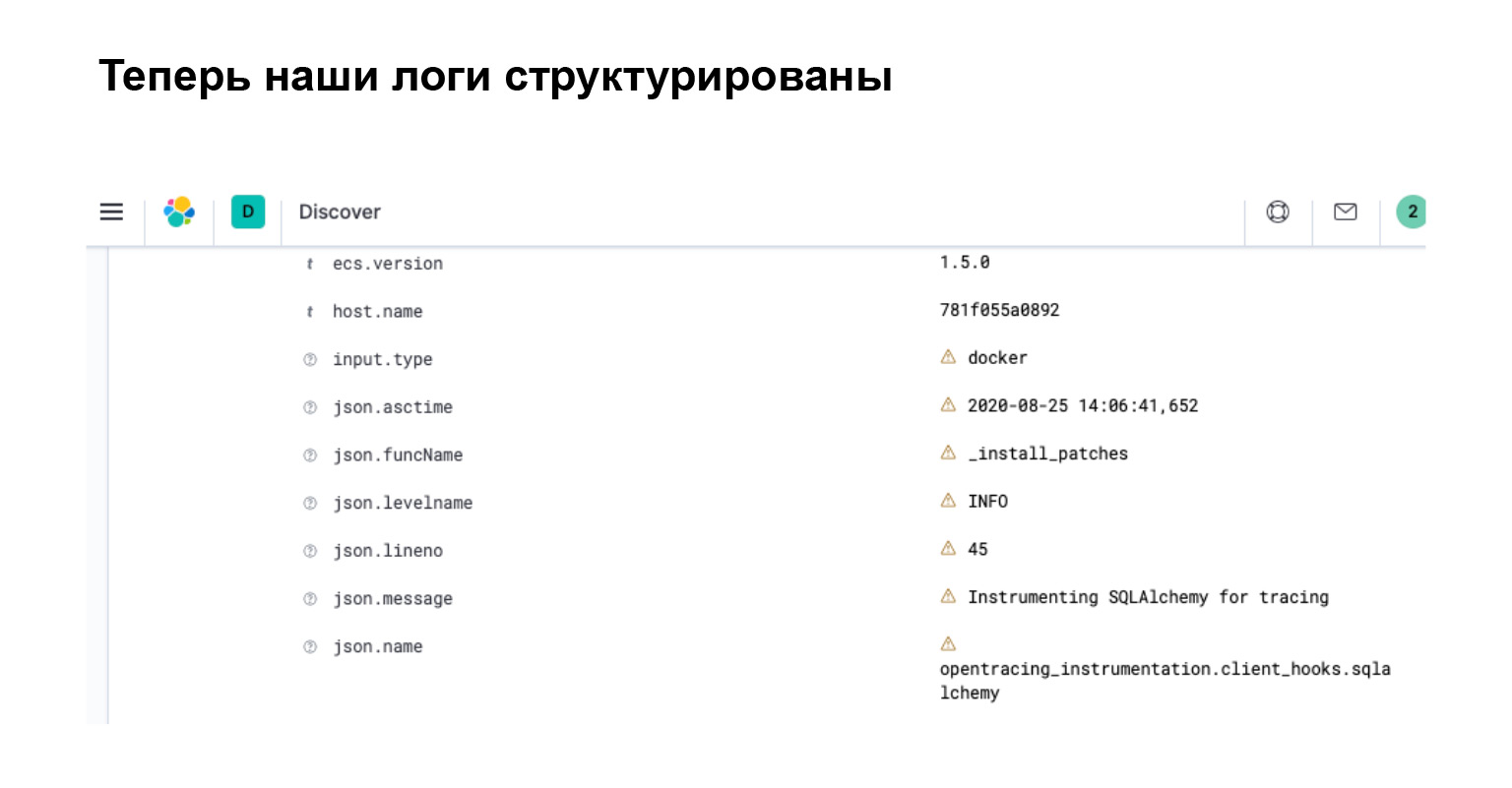
Что мы получили в Elasticsearch? В интерфейсе вы сразу видите, что ваш лог превратился в объект с отдельными атрибутами, по которым вы можете искать, создавать фильтрации и делать сложные запросы.

Давайте подведем итог. Теперь наши логи имеют структуру. По ним несложно грепать и можно писать интеллектуальные запросы. Elasticsearch знает об этой структуре, так как он распарсил все эти атрибуты. А в kibana — это интерфейс для Elasticsearch — можно фильтровать такие логи с помощью специализированного языка запросов, который предоставляет Elasticsearch.
И это проще, чем грепать. Греп имеет довольно сложный и крутой язык. Там очень много можно написать. В kibana можно сделать многие вещи проще. С этим разобрались.
Следующая проблема — тормоза. В микросервисной архитектуре всегда и везде бывают тормоза.

Тут немного контекста, расскажу вам историю. Ко мне прибегает менеджер, главное действующее лицо нашего проекта, и говорит: «Эй-эй, кабинет тормозит! Даня, спаси, помоги!»
Мы пока ничего не знаем, лезем в Elasticsearch в наши логи. Но давайте я расскажу, что, собственно, произошло.

Эраст добавил фичу. В книгах мы теперь отображаем не айдишник автора, а его имя прямо в интерфейсе. Очень круто. Сделал он это вот таким кодом. Небольшой кусок кода, ничего сложного. Что может пойти не так?
Вы наметанным взглядом можете сказать, что с SQLAlchemy так делать нельзя, с другой ORM тоже. Нужно сделать прекэш или что-нибудь еще, чтобы в цикле не ходить в базу с маленьким подзапросиком. Неприятная проблема. Кажется, что такую ошибку вообще нельзя допустить.
Давайте расскажу. У меня был опыт: мы работали с Django, и у нас в проекте был реализован кастомный прекэш. Много лет все шло хорошо. В какой-то момент мы с Эрастом решили: давай пойдем в ногу со временем, обновим Django. Естественно, Django ничего не знает о нашем кастомном прекэше, и интерфейс поменялся. Прикэш отвалился, молча. На тестировании это не отловили. Та же самая проблема, просто ее сложнее было отловить.
Проблема в чем? Как я помогу вам решить проблему?

Давайте расскажу, что я делал до того, как начал решать именно проблему поиска тормозов.
Первое, что делаю, — иду в Elasticsearch, у нас он уже есть, помогает, не нужно бегать по серверам. Я захожу в логи, ищу логи кабинета. Нахожу долгие запросы. Воспроизвожу на ноутбуке и вижу, что тормозит не кабинет. Тормозит Books.
Бегу в логи Books, нахожу проблемные запросы — собственно, он у нас уже есть. Точно так же воспроизвожу Books на ноутбуке. Очень сложный код — ничего не понимаю. Начинаю дебажить. Тайминги довольно сложно отлавливать. Почему? Внутри SQLAlchemy довольно сложно это определить. Пишу кастомные тайм-логгеры, локализую и исправляю проблему.
Мне было больно. Сложно, неприятно. Я плакал. Хочется, чтобы этот процесс поиска проблемы был быстрее и удобнее.
Формализуем наши проблемы. Сложно по логам искать, что тормозит, потому что наш лог — это лог несвязанных событий. Приходится писать кастомные таймеры, которые показывают нам, сколько выполнялись блоки кода. Причем непонятно, как логировать тайминги внешних систем: например, ORM или библиотек requests. Надо наши таймеры внедрять внутрь либо каким-то Wrapper, но мы не узнаем, от чего оно тормозит внутри. Сложно.

Хорошее решение, которое я нашел, — Jaeger. Это имплементация протокола opentracing, то есть давайте внедрим трассировку.
Что дает Jaeger? Это удобный интерфейс с поиском запросов. Вы можете отфильтровать долгие запросы или сделать это по тегам. Наглядное представление потока запросов, очень красивая картинка, чуть позже покажу.
Тайминги логируются из коробки. С ними ничего не надо делать. Если вам нужно про какой-то кастомный блок проверить, сколько он выполняется, вы можете его обернуть в таймеры, предоставляемые Jaeger. Очень удобно.
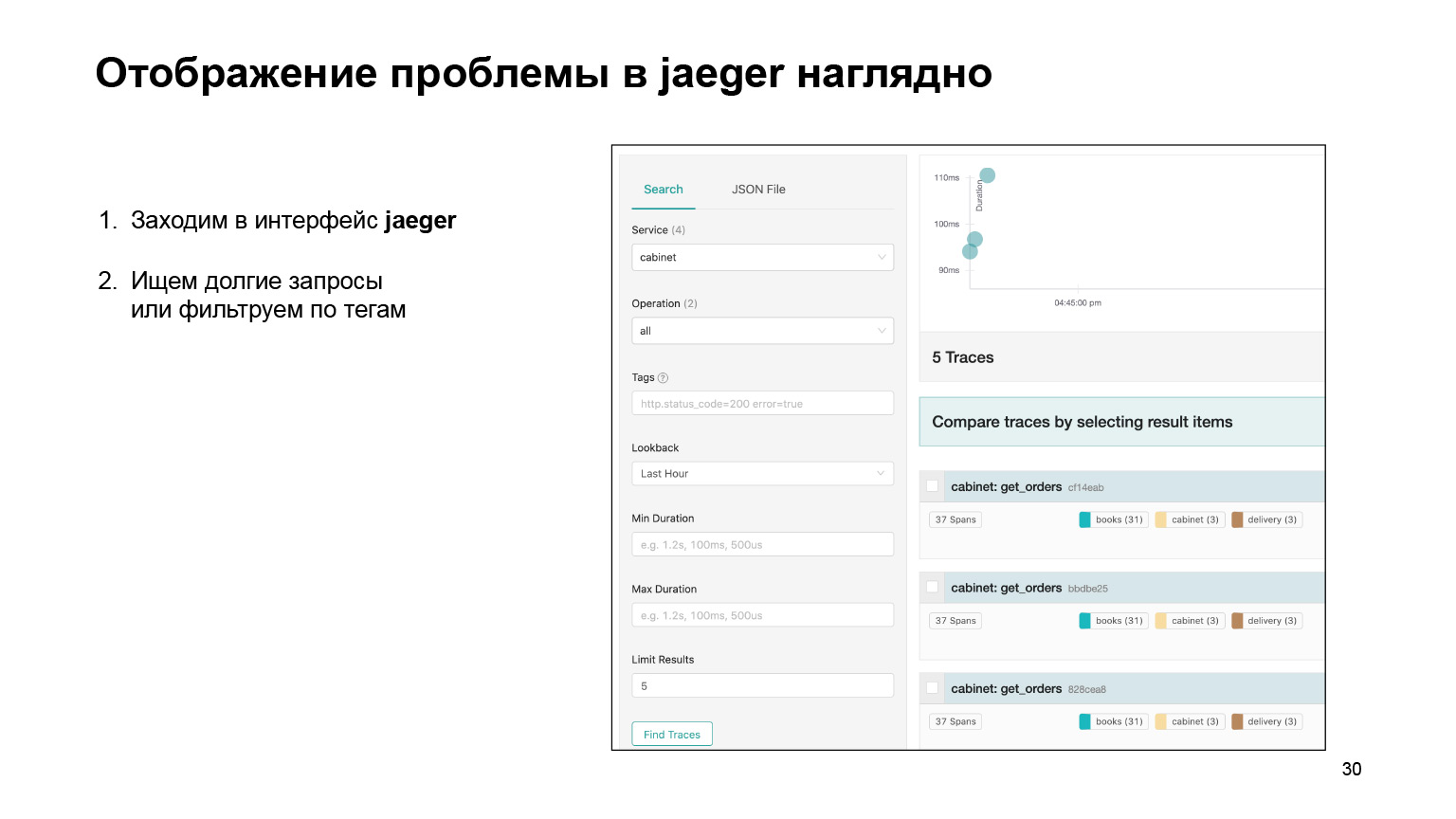
Посмотрим, как вообще можно было найти проблему в интерфейсе и там же ее локализовать. Мы заходим в интерфейс Jaeger. Вот так выглядят наши запросы. Мы можем поискать запросы именно кабинета или другого сервиса. Сразу фильтруем долгие запросы. Нас интересуют именно долгие, их по логам довольно сложно найти. Получаем их список.
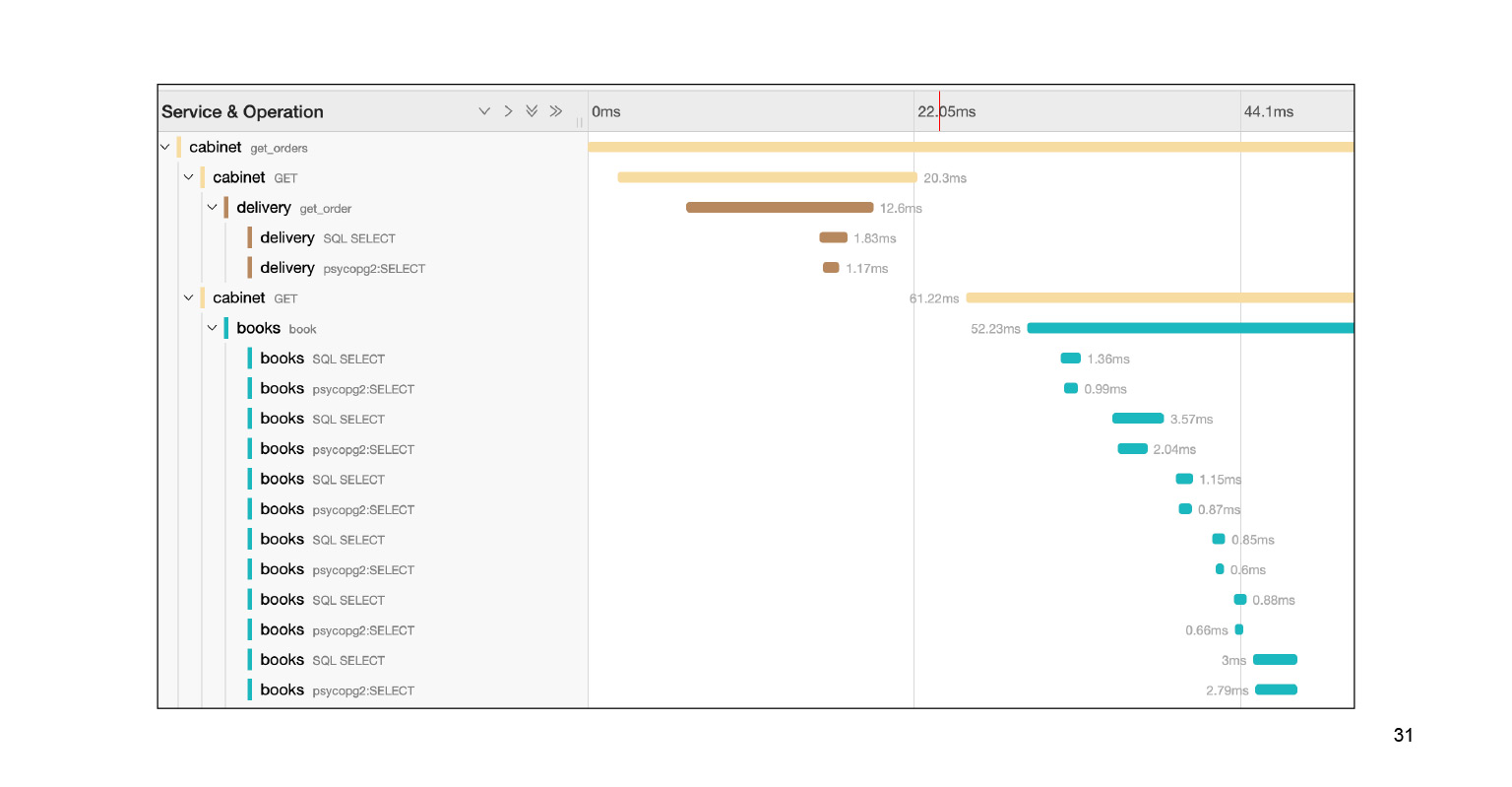
Проваливаемся в этот запрос, и видим большую портянку SQL-подзапросов. Мы прямо наглядно видим, как они исполнялись по времени, какой блок кода за что отвечал. Очень круто. Причем в контексте нашей проблемы это не весь лог. Там есть еще большая портянка на два-три слайда вниз. Мы довольно быстро локализовали проблему в Jaeger. В чем после решения проблемы нам может помочь контекст, который предоставляет Jaeger?
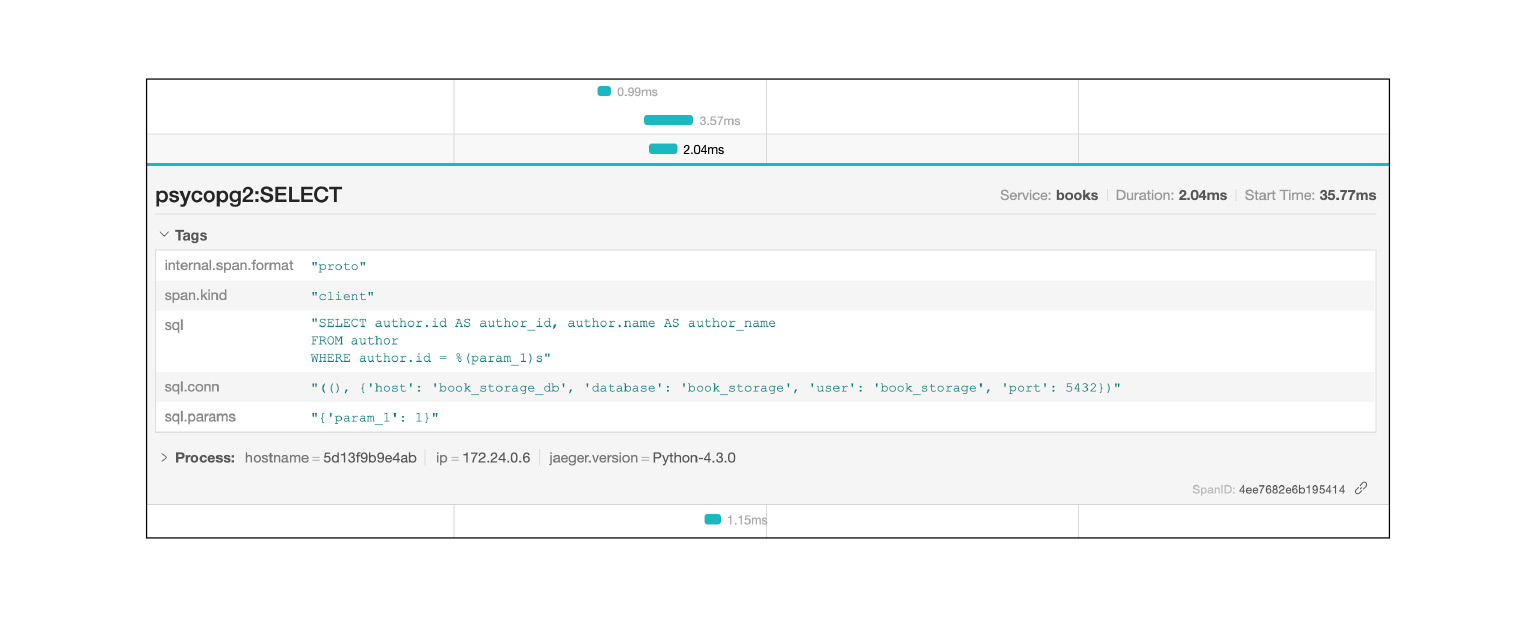
Jaeger логирует, например, SQL-запросы: вы можете посмотреть, какие запросы повторяются. Очень быстро и круто.
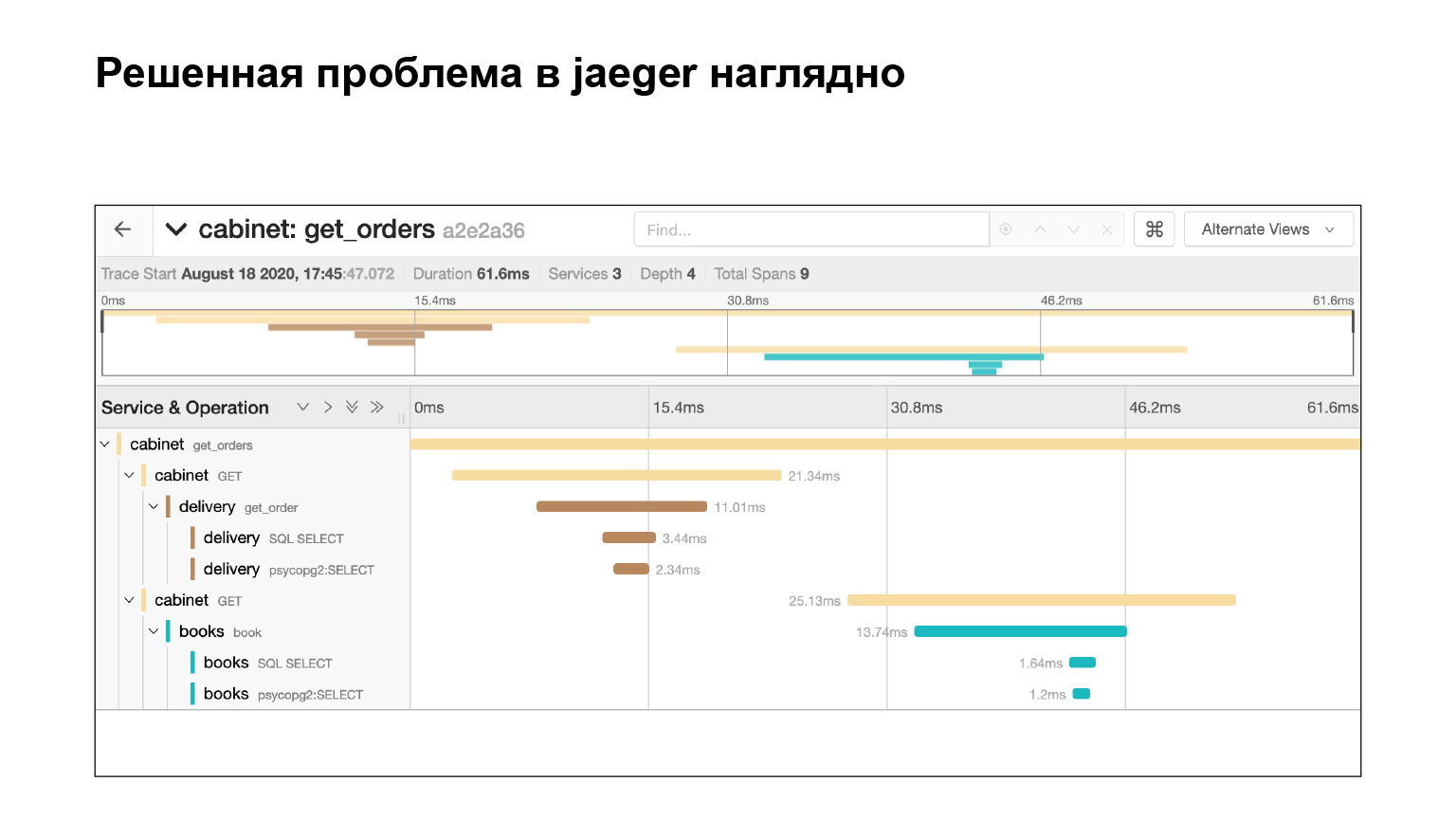
Проблему мы решили и сразу видим в Jaeger, что все хорошо. Мы проверяем по тому же запросу, что у нас теперь нет подзапросов. Почему? Предположим, мы проверим тот же запрос, узнаем тайминг — посмотрим в Elasticsearch, сколько запрос выполнялся. Тогда мы увидим время. Но это не гарантирует, что подзапросов не было. А здесь мы это видим, круто.

Давайте внедрим Jaeger. Кода нужно не очень много. Вы добавляете зависимости для opentracing, для Flask. Теперь о том, какой код мы делаем.
Первый блок кода — это настройка клиента Jaeger.
Затем мы настраиваем интеграцию с Flask, Django или с любым другим фреймворком, на который есть интеграция.
install_all_patches — самая последняя строчка кода и самая интересная. Мы патчим большинство внешних интеграция, взаимодействуя с MySQL, Postgres, библиотекой requests. Мы все это патчим и именно поэтому в интерфейсе Jaeger сразу видим все запросы с SQL и то, в какой из сервисов ходил наш искомый сервис. Очень круто. И вам не пришлось много писать. Мы просто написали install_all_patches. Магия!
Что мы получили? Теперь не нужно собирать события по логам. Как я сказал, логи — это разрозненные события. В Jaeger это одно большое событие, структуру которого вы видите. Jaeger позволяет отловить узкие места в приложении. Вы просто делаете поиск по долгим запросам, и можете проанализировать, что идет не так.
Последняя проблема — ошибки. Да, я лукавлю. Я не помогу вам избавиться от ошибок в приложении, но я расскажу, что с ними можно делать дальше.

Контекст. Вы можете сказать: «Даня, мы логируем ошибки, у нас есть алерты на пятисотки, мы настроили. Чего ты хочешь? Логировали, логируем и будем логировать и отлаживать.
По логам вы не знаете важность ошибки. Что такое важность? Вот у вас есть одна крутая ошибка, и ошибка подключения к базе. База просто флапнула. Хочется сразу видеть, что эта ошибка не так важна, и если нет времени, не обращать на нее внимания, а фиксить более важную.
Частота появления ошибок — это контекст, который может нам помочь в ее отладке. Как отслеживать появление ошибок? Преподолжим, у нас месяц назад была ошибка, и вот она снова появилась. Хочется сразу найти решение и поправить ее или сопоставить ее появление с одним из релизов.
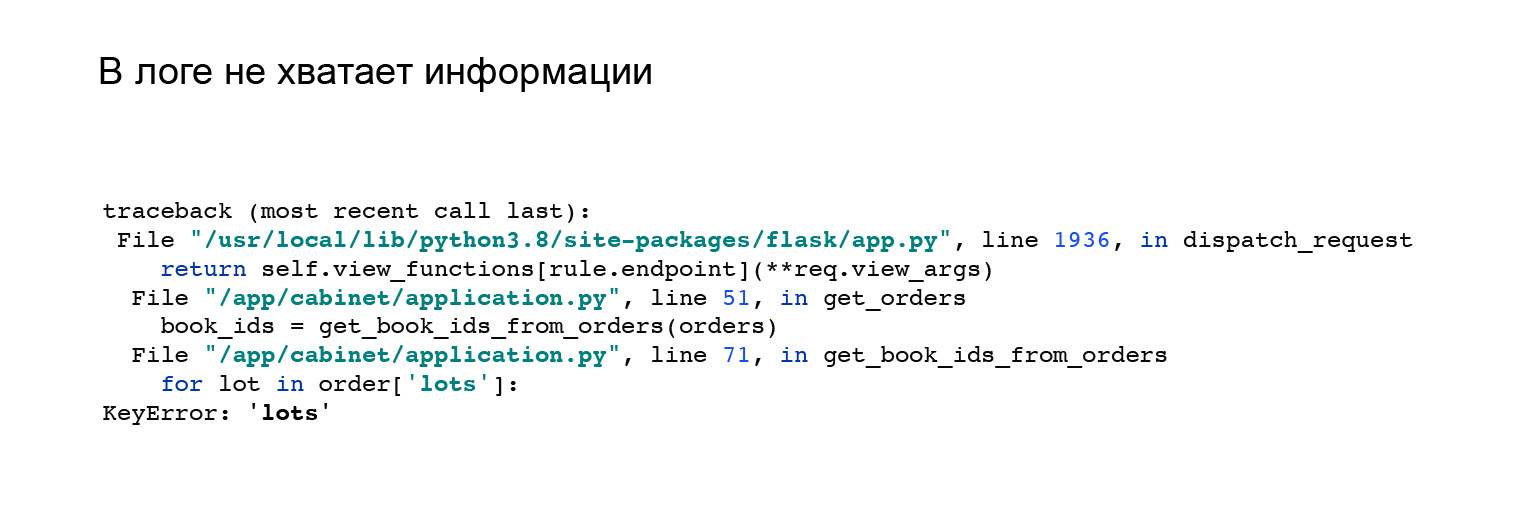
Вот наглядный пример. Когда я впиливал интеграцию с Jaeger, то немного поменял свою API. У меня изменился формат ответа приложения. Я получил вот такую ошибку. Но в ней непонятно, почему у меня нет ключа, lots в объекте order, и нет ничего, что мне бы помогло. Мол, смотри ошибку здесь, воспроизведи и самостоятельно отлови.

Давайте внедрим sentry. Это баг-трекер, который поможет нам в решении подобных проблем и поиске контекста ошибки. Возьмем стандартную библиотеку, поддерживаемую разработчиками sentry. В четыре строчки кода мы ее добавляем в наше приложение. Всё.
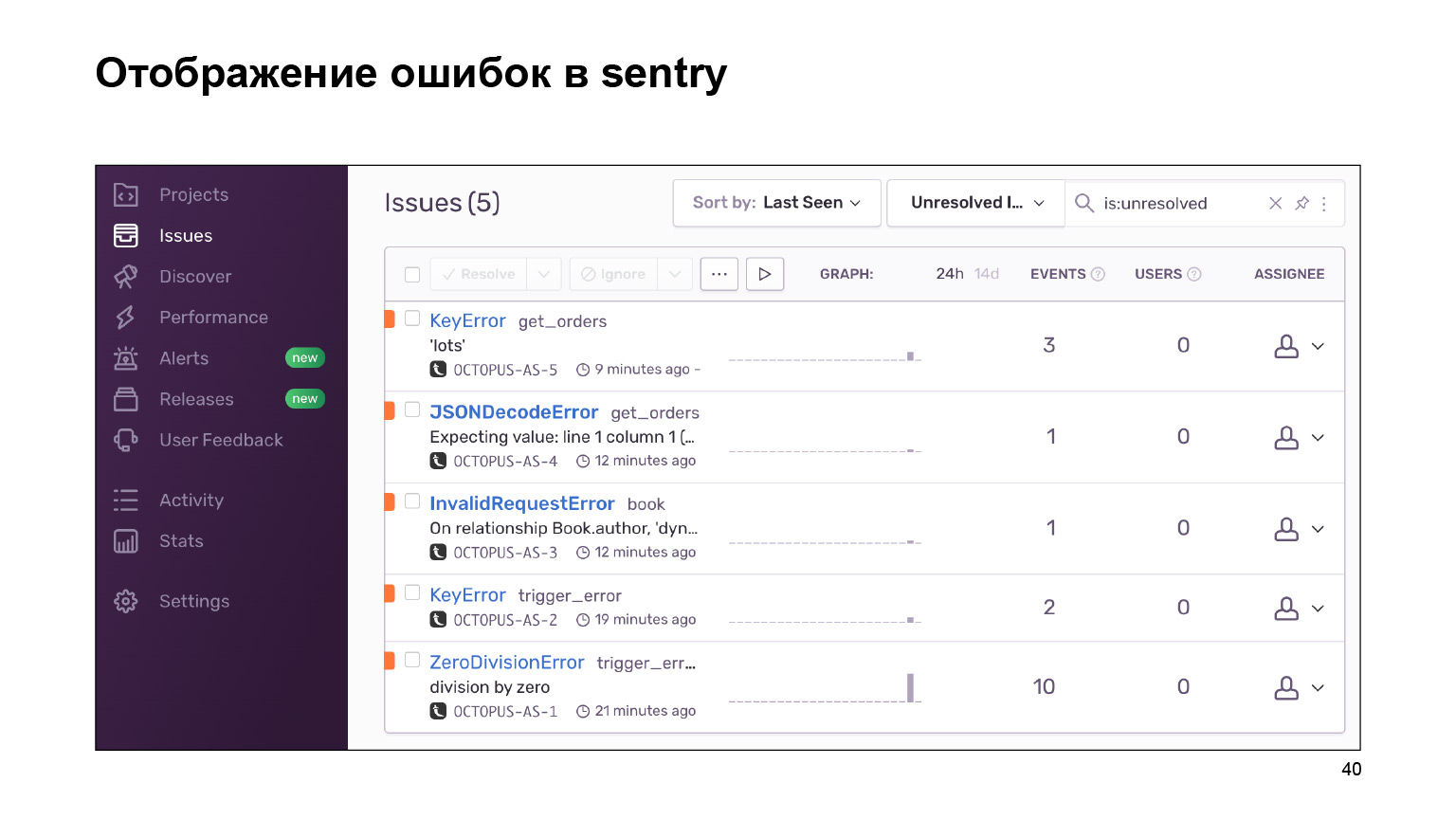
Что мы получили на выходе? Вот такой дашборд с ошибками, которые можно сгруппировать по проектам и за которыми можно следить. Огромная портянка логов с ошибками группируется в одинаковые, похожие. По ним приводится статистика. И вы также можете работать с этими ошибками с помощью интерфейса.
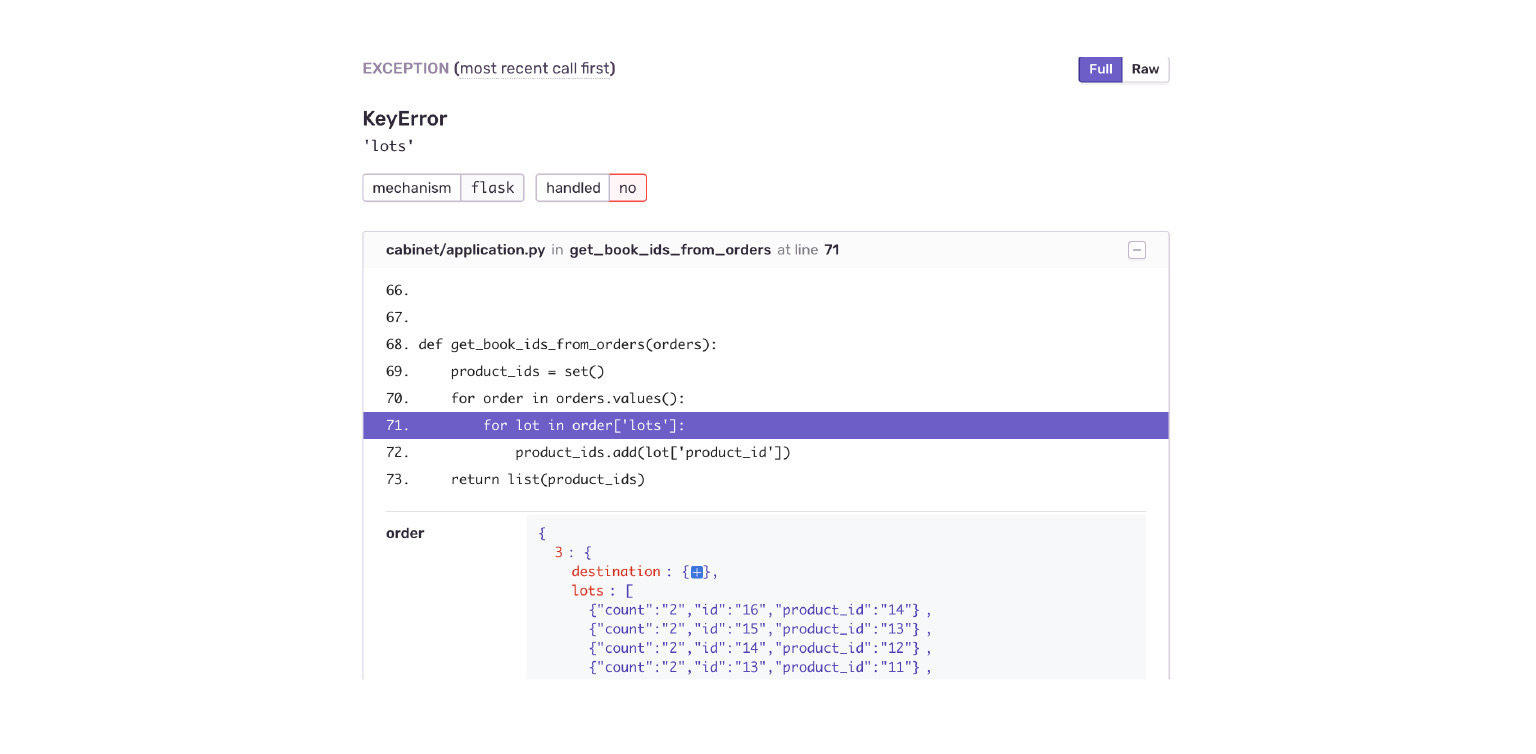
Посмотрим на нашем примере. Проваливаемся в ошибку KeyError. Сразу видим контекст ошибки, что было в объекте order, чего там не было. Я сразу по ошибке вижу, что мне приложение Delivery отдало новую структуру данных. Кабинет просто к этому не готов.

Что дает sentry, помимо того, что я перечислил? Формализуем.
Это хранилище ошибок, в котором можно искать их. Для этого есть удобные инструменты. Есть группировка ошибок — по проектам, по похожести. Sentry дает интеграции с разными трекерами. То есть вы можете следить за вашими ошибками, работать с ними. Вы можете просто добавлять задачу в ваш контекст, и все. Это помогает в разработке.
Статистика по ошибкам. Опять же, легко сопоставить с выкаткой релиза. В этом вам поможет sentry. Похожие события, которые произошли рядом с ошибкой, тоже могут вам помочь в поиске и понимании того, что к ней привело.

Давайте подведем итог. Мы с вами написали приложение, простое, но отвечающее потребностям. Оно помогает вам в разработке и поддержке, в его жизненном цикле. Что мы сделали? Мы собрали логи в одно хранилище. Это дало нам возможность не искать их по разным местам. Плюс у нас появился поиск по логам и сторонние фичи, наши tools.
Интегрировали трассировку. Теперь мы наглядно можем следить за потоком данных в нашем приложении.
И добавили удобный инструмент для работы с ошибками. Они в нашем приложении будут, как бы мы ни старались. Но мы будем фиксить их быстрее и качественнее.
Что еще можно добавить? Само приложение готово, оно есть по ссылке, вы можете посмотреть, как оно сделано. Там поднимаются все интеграции. Например, интеграции с Elasticsearch или трассировки. Заходите, смотрите.
Еще одна крутая штука, которую я не успел осветить, — requests_id. Почти ничем не отличается от trace_id, который используется в трассировках. Но за requests_id отвечаем мы, это самая главная его фича. Менеджер может прийти к нам сразу с requests_id, нам не потребуется его искать. Мы сразу начнем решать нашу проблему. Очень круто.
И не забывайте, что инструменты, которые мы внедряли, имеют overhead. Это проблемы, которые нужно рассматривать для каждого приложения. Нельзя бездумно внедрить все наши интеграции, облегчить себе жизнь, а потом думать, что делать с тормозящим приложением.
Проверяйте. Если на вас это не сказывается, круто. Вы получили только плюсы и не решаете проблемы с тормозами. Не забывайте об этом. Всем спасибо, что слушали.
— Давайте начинать. Я расскажу об удобном логировании и инфраструктуре вокруг логирования, которую можно развернуть, чтобы вам с вашим приложением и его жизненным циклом было удобно жить.
Что будем делать? Мы построим небольшое приложение, наш стартап. Потом внедрим в него базовое логирование, это маленькая часть доклада, то, что поставляет Python из коробки. И дальше самая большая часть — мы разберем типичные проблемы, которые встречаются нам во время отладки, выкатки, и инструменты для их решения.
Небольшой дисклеймер: я буду говорить такие слова, как «ручка» и «локаль». Поясню. «Ручка» — возможно, яндексовый сленг, это обозначает ваши API, http или gRPC API или любые другие комбинации букв перед APU. «Локаль» — это когда я разрабатываю на ноутбуке. Вроде бы я рассказал обо всех словах, которые я не контролирую.
Приложение «Книжная лавка»
Начнем. Наш стартап — это «Книжная лавка». Главной фичей этого приложения будет продажа книг, это все, что мы хотим сделать. Дальше немного начинки. Приложение будет написано на Flask. Все сниппеты кода, все инструменты общие и абстрагированы от Python, поэтому их можно будет интегрировать в большинство ваших приложений. Но в нашем докладе это будет Flask.
Действующие лица: я, разработчик, менеджеры и мой любимый коллега Эраст. Любые совпадения случайны.
Давайте немного про структуру. Это приложение с микросервисной архитектурой. Первый сервис — Books, хранилище книг с метаданными о книгах. Он использует базу данных PostgreSQL. Второй микросервис — микросервис доставки, хранит метаданные о заказах пользователей. Cabinet — это бэкенд для кабинета. У нас нет фронтенда, в нашем докладе он не нужен. Cabinet агрегирует запросы, данные из сервиса книг и сервиса доставки.
По-быстрому покажу код ручек этих сервисов, API Books. Это ручка выгребает данные из базы, сериализует их, превращает в JSON и отдает.
Пойдем дальше. Сервис доставки. Ручка точно такая же. Выгребаем данные из базы, сериализуем их и отправляем.
И последняя ручка — ручка кабинета. В ней немного другой код. Ручка кабинета запрашивает данные из сервиса доставки и из сервиса книг, агрегирует ответы и отдает пользователю его заказы. Всё. Со структурой приложения мы по-быстрому разобрались.
Базовое логирование в приложении
Теперь давайте про базовое логирование, то, которое мы впилили. Начнем с терминологии.
Что нам дает Python? Четыре базовые, главные сущности:
— Logger, входная точка логирования в вашем коде. Вы будете пользоваться каким-то Logger, писать logging.INFO, и все. Ваш код больше ничего не будет знать о том, куда сообщение улетело и что с ним дальше произошло. За это уже отвечает сущность Handler.
— Handler обрабатывает ваше сообщение, решает, куда его отправить: в стандартный вывод, в файл или кому-нибудь на почту.
— Filter — одна из двух вспомогательных сущностей. Удаляет сообщения из лога. Другой стандартный вариант использования — это наполнение данными. Например, в вашей записи нужно добавить атрибут. Для этого тоже может помочь Filter.
— Formatter приводит ваше сообщение к нужному виду.
На этом с терминологией закончили, дальше к логированию прямо на Python, с базовыми классами, мы возвращаться не будем. Но вот пример конфигурации нашего приложения, которая раскатана на всех трех сервисах. Здесь два главных, важных для нас блока: formatters и handlers. Для formatters, есть пример, который вы можете увидеть здесь, шаблон того, как будет выводиться сообщение.
В handlers вы можете увидеть, что logging.StreamHandler использован. То есть мы выгружаем все наши логи в стандартный вывод. Всё, с этим закончили.
Проблема 1. Логи разбросаны
Переходим к проблемам. Для начала проблема первая: логи разбросаны.
Немножечко контекста. Наше приложение мы написали, конфетка уже готова. Мы можем на нем зарабатывать денежку. Мы его выкатываем в продакшен. Конечно, там не один сервер. По нашим скромным подсчетам, нашему сложнейшему приложению нужно порядка трех-четырех машинок, и так для каждого сервиса.
Теперь вопрос. Прибегает к нам менеджер и спрашивает: «Там сломалось, помоги!» Вы бежите. У вас же все логируется, это великолепно. Вы заходите на первую машинку, смотрите — там ничего нет по вашему запросу. Заходите на вторую машинку — ничего. И так далее. Это плохо, это надо как-то решать.
Давайте формализуем результат, который мы хотим увидеть. Я хочу, чтобы логи были в одном месте. Это простое требование. Немного круче то, что я хочу поиск по логам. То есть да, оно лежит в одном месте и я умею грепать, но было бы прикольно, если бы были какие-нибудь tools, крутые фичи помимо простого грепа.
И я не хочу писать. Это Эраст любит писать код. Я не про это, я сразу сделал продукт. То есть хочется меньше дополнительного кода, обойтись одним-двумя файликами, строчками, и всё.
Решение, которое можно использовать, — Elasticsearch. Давайте его попробуем поднять. Какие плюсы Elasticsearch нам даст? Это интерфейс с поиском логов. Сразу из коробки есть интерфейс, это вам не консолька, а единственное место хранения. То есть главное требование мы отработали. Нам не нужно будет ходить по серверам.
В нашем случае это будет довольно простая интеграция, и с недавним релизом у Elasticsearch выпустился новый агент, который отвечает за большинство интеграций. Они там сами впилили интеграции. Очень круто. Я составлял доклад чуть раньше и использовал filebeat, так же просто. Для логов все просто.
Немного об Elasticsearch. Не хочу рекламировать, но там много дополнительных фич. Например, крутая штука — полнотекстовый поиск по логам из коробки. Очень круто звучит. Нам пока достаточно этих плюсов. Прикручиваем.
В первую очередь нам нужно будет развернуть агент, который будет отправлять наши логи в Elasticsearch. Вы регистрируете аккаунт в Elasticsearch и дальше добавляете в ваш docker-compose. Если у вас не docker-compose, можете поднимать ручками или в вашей системе. В нашем случае добавляется вот такой блок кода, интеграции в docker-compose. Всё, сервис настроен. И вы можете увидеть в блоке volumes файл конфигурации filebeat.yml.
Вот пример filebeat.yml. Здесь настроен автоматический поиск логов контейнеров docker, которые крутятся рядом. Кастомизован выбор этих логов. По условию можно задавать, вешать на ваши контейнеры лейблы, и в зависимости от этого ваши логи будут отправляться только у определенных контейнеров. С блоком processors:add_docker_metadata все просто. В логи добавляем немножечко больше информации о ваших логах в контексте docker. Необязательно, но прикольно.
Что мы получили? Это все, что мы написали, весь код, очень круто. При этом мы получили все логи в одном месте и есть интерфейс. Мы можем поискать наши логи, вот плашечка search. Они доставляются. И можно даже в прямом эфире включить так, чтобы стрим летел к нам в логи в интерфейс, и мы это видели.
Тут я бы и сам спросил: а чего, как грепать-то? Что из себя представляет поиск по логам, что там можно сделать?
Да, из коробки в таком подходе, когда у нас текстовые логи, есть небольшой затык: мы можем по тексту задать запрос, например message:users. Это выведет нам все логи, у которых есть подстрока users. Можно пользоваться звездочками, большинством других юниксовых wild cards. Но кажется, этого недостаточно, хочется сделать сложнее, чтобы можно было нагрепать в Nginx раньше, как мы это умеем.
Давайте немного отступим от Elasticsearch и попытаемся сделать это не с Elasticsearch, а с другим подходом. Рассмотрим структурные логи. Это когда каждая ваша запись лога — это не просто текстовая строчка, а сериализованный объект с атрибутами, которые любая ваша сторонняя система может сериализовать, чтобы получить уже готовый объект.
Какие от этого есть плюсы? Это единый формат данных. Да, у объектов могут быть разные атрибуты, но любая внешняя система может прочитать именно JSON и получить какой-то объект.
Какая-никакая типизация. Это упрощает интеграцию с другими системами: не нужно писать десериализаторы. И как раз десериализаторы — это другой пункт. Вам не нужно писать в приложении прозаичные тексты. Пример: «User пришел с таким-то айдишником, с таким-то заказом». И это все нужно писать каждый раз.
Меня это напрягало. Я хочу написать: «Прилетел запрос». Дальше: «Такой-то, такой-то, такой-то», очень просто, очень по-айтишному.
Давайте дальше. Договоримся: логировать будем в формате JSON, это простой формат. Сразу Elasticsearch поддерживается, filebeat, которым мы сериализуем и попробуем впилить. Это не очень сложно. Для начала вы добавляете из библиотеки pythonjsonlogger в блок formatters JSONFormatter файлика settings, где у нас хранится конфигурация. У вас в системе это может быть другое место. И дальше в атрибуте format вы передаете, какие атрибуты вы хотите добавлять в ваш объект.
Блок ниже — это блок конфигурации, который добавляется в filebeat.yml. Здесь из коробки есть интерфейс у filebeat для парсинга JSON-логов. Очень круто. Это все. Для этогов вам больше ничего писать не придется. И теперь ваши логи похожи на объекты.
Что мы получили в Elasticsearch? В интерфейсе вы сразу видите, что ваш лог превратился в объект с отдельными атрибутами, по которым вы можете искать, создавать фильтрации и делать сложные запросы.
Давайте подведем итог. Теперь наши логи имеют структуру. По ним несложно грепать и можно писать интеллектуальные запросы. Elasticsearch знает об этой структуре, так как он распарсил все эти атрибуты. А в kibana — это интерфейс для Elasticsearch — можно фильтровать такие логи с помощью специализированного языка запросов, который предоставляет Elasticsearch.
И это проще, чем грепать. Греп имеет довольно сложный и крутой язык. Там очень много можно написать. В kibana можно сделать многие вещи проще. С этим разобрались.
Проблема 2. Тормоза
Следующая проблема — тормоза. В микросервисной архитектуре всегда и везде бывают тормоза.
Тут немного контекста, расскажу вам историю. Ко мне прибегает менеджер, главное действующее лицо нашего проекта, и говорит: «Эй-эй, кабинет тормозит! Даня, спаси, помоги!»
Мы пока ничего не знаем, лезем в Elasticsearch в наши логи. Но давайте я расскажу, что, собственно, произошло.
Эраст добавил фичу. В книгах мы теперь отображаем не айдишник автора, а его имя прямо в интерфейсе. Очень круто. Сделал он это вот таким кодом. Небольшой кусок кода, ничего сложного. Что может пойти не так?
Вы наметанным взглядом можете сказать, что с SQLAlchemy так делать нельзя, с другой ORM тоже. Нужно сделать прекэш или что-нибудь еще, чтобы в цикле не ходить в базу с маленьким подзапросиком. Неприятная проблема. Кажется, что такую ошибку вообще нельзя допустить.
Давайте расскажу. У меня был опыт: мы работали с Django, и у нас в проекте был реализован кастомный прекэш. Много лет все шло хорошо. В какой-то момент мы с Эрастом решили: давай пойдем в ногу со временем, обновим Django. Естественно, Django ничего не знает о нашем кастомном прекэше, и интерфейс поменялся. Прикэш отвалился, молча. На тестировании это не отловили. Та же самая проблема, просто ее сложнее было отловить.
Проблема в чем? Как я помогу вам решить проблему?
Давайте расскажу, что я делал до того, как начал решать именно проблему поиска тормозов.
Первое, что делаю, — иду в Elasticsearch, у нас он уже есть, помогает, не нужно бегать по серверам. Я захожу в логи, ищу логи кабинета. Нахожу долгие запросы. Воспроизвожу на ноутбуке и вижу, что тормозит не кабинет. Тормозит Books.
Бегу в логи Books, нахожу проблемные запросы — собственно, он у нас уже есть. Точно так же воспроизвожу Books на ноутбуке. Очень сложный код — ничего не понимаю. Начинаю дебажить. Тайминги довольно сложно отлавливать. Почему? Внутри SQLAlchemy довольно сложно это определить. Пишу кастомные тайм-логгеры, локализую и исправляю проблему.
Мне было больно. Сложно, неприятно. Я плакал. Хочется, чтобы этот процесс поиска проблемы был быстрее и удобнее.
Формализуем наши проблемы. Сложно по логам искать, что тормозит, потому что наш лог — это лог несвязанных событий. Приходится писать кастомные таймеры, которые показывают нам, сколько выполнялись блоки кода. Причем непонятно, как логировать тайминги внешних систем: например, ORM или библиотек requests. Надо наши таймеры внедрять внутрь либо каким-то Wrapper, но мы не узнаем, от чего оно тормозит внутри. Сложно.
Хорошее решение, которое я нашел, — Jaeger. Это имплементация протокола opentracing, то есть давайте внедрим трассировку.
Что дает Jaeger? Это удобный интерфейс с поиском запросов. Вы можете отфильтровать долгие запросы или сделать это по тегам. Наглядное представление потока запросов, очень красивая картинка, чуть позже покажу.
Тайминги логируются из коробки. С ними ничего не надо делать. Если вам нужно про какой-то кастомный блок проверить, сколько он выполняется, вы можете его обернуть в таймеры, предоставляемые Jaeger. Очень удобно.
Посмотрим, как вообще можно было найти проблему в интерфейсе и там же ее локализовать. Мы заходим в интерфейс Jaeger. Вот так выглядят наши запросы. Мы можем поискать запросы именно кабинета или другого сервиса. Сразу фильтруем долгие запросы. Нас интересуют именно долгие, их по логам довольно сложно найти. Получаем их список.
Проваливаемся в этот запрос, и видим большую портянку SQL-подзапросов. Мы прямо наглядно видим, как они исполнялись по времени, какой блок кода за что отвечал. Очень круто. Причем в контексте нашей проблемы это не весь лог. Там есть еще большая портянка на два-три слайда вниз. Мы довольно быстро локализовали проблему в Jaeger. В чем после решения проблемы нам может помочь контекст, который предоставляет Jaeger?
Jaeger логирует, например, SQL-запросы: вы можете посмотреть, какие запросы повторяются. Очень быстро и круто.
Проблему мы решили и сразу видим в Jaeger, что все хорошо. Мы проверяем по тому же запросу, что у нас теперь нет подзапросов. Почему? Предположим, мы проверим тот же запрос, узнаем тайминг — посмотрим в Elasticsearch, сколько запрос выполнялся. Тогда мы увидим время. Но это не гарантирует, что подзапросов не было. А здесь мы это видим, круто.
Давайте внедрим Jaeger. Кода нужно не очень много. Вы добавляете зависимости для opentracing, для Flask. Теперь о том, какой код мы делаем.
Первый блок кода — это настройка клиента Jaeger.
Затем мы настраиваем интеграцию с Flask, Django или с любым другим фреймворком, на который есть интеграция.
install_all_patches — самая последняя строчка кода и самая интересная. Мы патчим большинство внешних интеграция, взаимодействуя с MySQL, Postgres, библиотекой requests. Мы все это патчим и именно поэтому в интерфейсе Jaeger сразу видим все запросы с SQL и то, в какой из сервисов ходил наш искомый сервис. Очень круто. И вам не пришлось много писать. Мы просто написали install_all_patches. Магия!
Что мы получили? Теперь не нужно собирать события по логам. Как я сказал, логи — это разрозненные события. В Jaeger это одно большое событие, структуру которого вы видите. Jaeger позволяет отловить узкие места в приложении. Вы просто делаете поиск по долгим запросам, и можете проанализировать, что идет не так.
Проблема 3. Ошибки
Последняя проблема — ошибки. Да, я лукавлю. Я не помогу вам избавиться от ошибок в приложении, но я расскажу, что с ними можно делать дальше.
Контекст. Вы можете сказать: «Даня, мы логируем ошибки, у нас есть алерты на пятисотки, мы настроили. Чего ты хочешь? Логировали, логируем и будем логировать и отлаживать.
По логам вы не знаете важность ошибки. Что такое важность? Вот у вас есть одна крутая ошибка, и ошибка подключения к базе. База просто флапнула. Хочется сразу видеть, что эта ошибка не так важна, и если нет времени, не обращать на нее внимания, а фиксить более важную.
Частота появления ошибок — это контекст, который может нам помочь в ее отладке. Как отслеживать появление ошибок? Преподолжим, у нас месяц назад была ошибка, и вот она снова появилась. Хочется сразу найти решение и поправить ее или сопоставить ее появление с одним из релизов.
Вот наглядный пример. Когда я впиливал интеграцию с Jaeger, то немного поменял свою API. У меня изменился формат ответа приложения. Я получил вот такую ошибку. Но в ней непонятно, почему у меня нет ключа, lots в объекте order, и нет ничего, что мне бы помогло. Мол, смотри ошибку здесь, воспроизведи и самостоятельно отлови.
Давайте внедрим sentry. Это баг-трекер, который поможет нам в решении подобных проблем и поиске контекста ошибки. Возьмем стандартную библиотеку, поддерживаемую разработчиками sentry. В четыре строчки кода мы ее добавляем в наше приложение. Всё.
Что мы получили на выходе? Вот такой дашборд с ошибками, которые можно сгруппировать по проектам и за которыми можно следить. Огромная портянка логов с ошибками группируется в одинаковые, похожие. По ним приводится статистика. И вы также можете работать с этими ошибками с помощью интерфейса.
Посмотрим на нашем примере. Проваливаемся в ошибку KeyError. Сразу видим контекст ошибки, что было в объекте order, чего там не было. Я сразу по ошибке вижу, что мне приложение Delivery отдало новую структуру данных. Кабинет просто к этому не готов.
Что дает sentry, помимо того, что я перечислил? Формализуем.
Это хранилище ошибок, в котором можно искать их. Для этого есть удобные инструменты. Есть группировка ошибок — по проектам, по похожести. Sentry дает интеграции с разными трекерами. То есть вы можете следить за вашими ошибками, работать с ними. Вы можете просто добавлять задачу в ваш контекст, и все. Это помогает в разработке.
Статистика по ошибкам. Опять же, легко сопоставить с выкаткой релиза. В этом вам поможет sentry. Похожие события, которые произошли рядом с ошибкой, тоже могут вам помочь в поиске и понимании того, что к ней привело.
Давайте подведем итог. Мы с вами написали приложение, простое, но отвечающее потребностям. Оно помогает вам в разработке и поддержке, в его жизненном цикле. Что мы сделали? Мы собрали логи в одно хранилище. Это дало нам возможность не искать их по разным местам. Плюс у нас появился поиск по логам и сторонние фичи, наши tools.
Интегрировали трассировку. Теперь мы наглядно можем следить за потоком данных в нашем приложении.
И добавили удобный инструмент для работы с ошибками. Они в нашем приложении будут, как бы мы ни старались. Но мы будем фиксить их быстрее и качественнее.
Что еще можно добавить? Само приложение готово, оно есть по ссылке, вы можете посмотреть, как оно сделано. Там поднимаются все интеграции. Например, интеграции с Elasticsearch или трассировки. Заходите, смотрите.
Еще одна крутая штука, которую я не успел осветить, — requests_id. Почти ничем не отличается от trace_id, который используется в трассировках. Но за requests_id отвечаем мы, это самая главная его фича. Менеджер может прийти к нам сразу с requests_id, нам не потребуется его искать. Мы сразу начнем решать нашу проблему. Очень круто.
И не забывайте, что инструменты, которые мы внедряли, имеют overhead. Это проблемы, которые нужно рассматривать для каждого приложения. Нельзя бездумно внедрить все наши интеграции, облегчить себе жизнь, а потом думать, что делать с тормозящим приложением.
Проверяйте. Если на вас это не сказывается, круто. Вы получили только плюсы и не решаете проблемы с тормозами. Не забывайте об этом. Всем спасибо, что слушали.

DmitryKoterov
Не ElasticSearch, а Elasticsearch. Брэнды надо писать правильно, с точностью до регистра.
BarakAdama
Спасибо, поправим.