
Общепринятый и проверенный временем подходом к построению Data Warehouse (DWH) — это схема «Звезда» или «Снежинка». Такой подход каноничен, фундаментален, вотрфоллен и совсем не отвечает той гибкости, к которой призывает Agile. Чтобы сделать структуру DWH гибкой, существуют современные подходы к проектированию: Data Vault и Anchor modeling — похожие и разные одновременно. Задавшись вопросом, какую из двух методологий выбрать, руководители в Яндекс Go Евгений Ермаков и Николай Гребенщиков пришли к неожиданному ответу: выбирать надо не между подходами, а лучшее из двух подходов.
Темы доклада:
— DV и AM: в чем разница и где точки соприкосновения
— Гибридный подход к построению хранилища
— Сильные и слабые стороны этого подхода
— Примеры кода
— Дальнейший вектор развития hNhM
— Меня зовут Евгений Ермаков, я руководитель Data Warehouse в Яндекс Go.
Я расскажу историю о том, как два руководителя объединились и сделали нечто крутое — как минимум, по мнению этих двух руководителей. Расскажу про наш подход к хранению данных в детальном слое. Мы его называем highly Normalized hybrid Model. Надеюсь, что корректно произнес по-английски, я тренировался.
Мы это сокращаем до hNhM — не пугайтесь, если услышите эту странную аббревиатуру. Можно еще «гибридная модель» или «двухстульная модель». А почему двухcтульная, я обязательно расскажу на примере одного мема.

Рассказ у нас будет достаточно долгий, из двух глав. Первая глава будет моя — я расскажу, как мы вообще к этому пришли. Она, наверное, будет для тех, кто сведущ в этой теме, или послужит повторением того, что вы уже знаете.
Также я расскажу про архитектуру хранилища Яндекс Go в целом, вместе с детальным слоем, где как раз эта модель и применяется. Потом сравню Data Vault и якорное моделирование так, как мы у себя их сравнивали, и объясню, почему мы из этого сравнения сделали вывод, что нужно создавать нечто свое. И расскажу базисные основы про hNhM.

А во второй главе я передам слово Коле.
Николай Гребенщиков:
— Я расскажу о нашем фреймворке, который позволяет нам описывать сущности и загружать данные. Покажу, как мы с ним работаем, как загружаем используем и строим витрины над нашим детальным слоем.
— В конце мы подведем итоги, самое главное, что можно из этого доклада почерпнуть. посмотрим, куда мы пришли, что сделали и как это можно переиспользовать.

Итак, архитектура Data Warehouse (DWH) в Яндекс Go. Расскажу об архитектуре слоев данных, какая она у нас, какие инструменты хранения и обработки информации есть, и покажу место детального слоя во всей этой архитектуре.
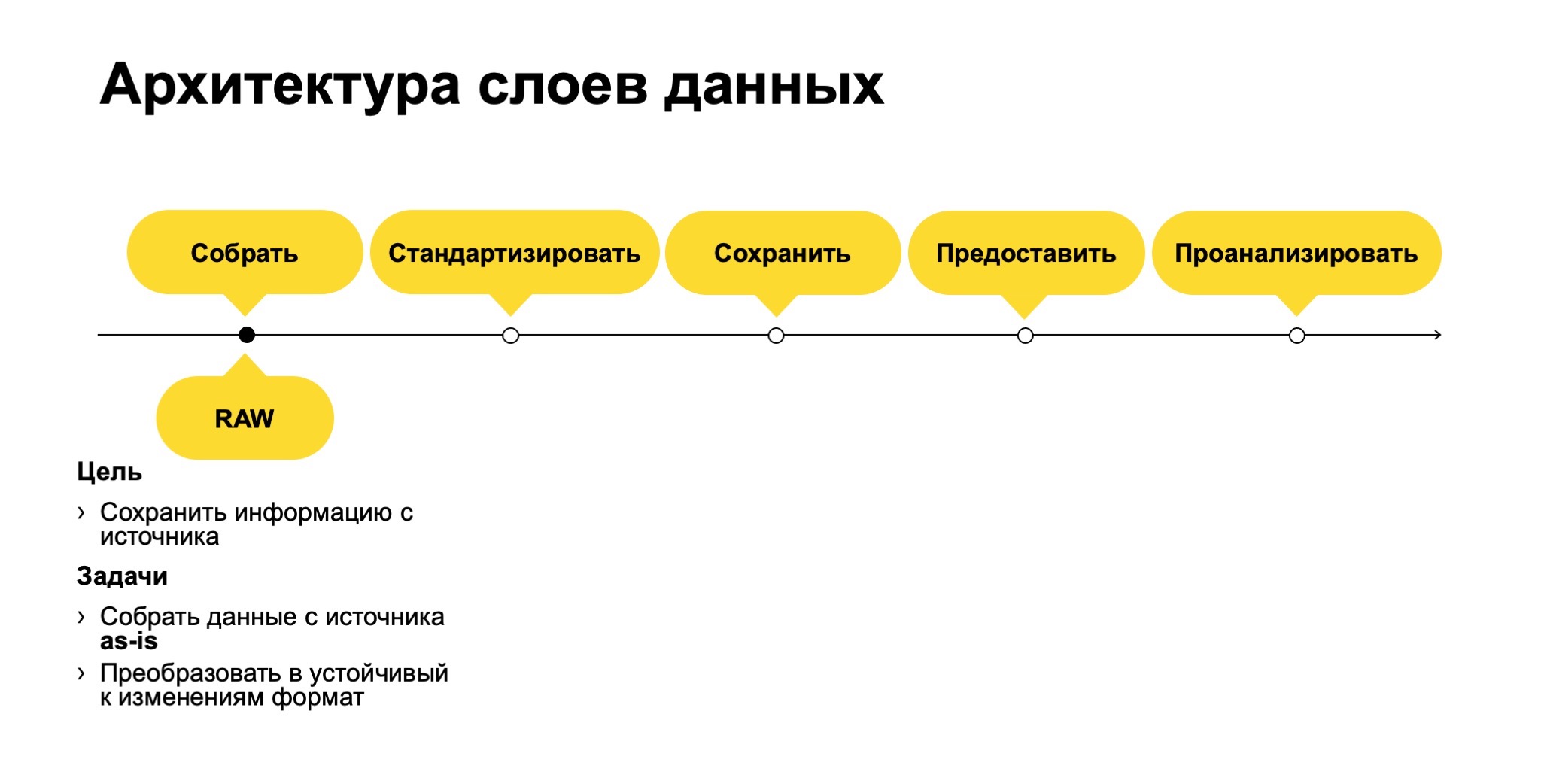
По моему мнению, архитектура слоев данных в нашем хранилище максимально классическая. Мы шли от глаголов действий над данными, которые происходят с хранилищами. Что мы делаем с данными?
Мы их собираем, стандартизируем, сохраняем в нашем хранилище. При этом сохраняем максимально долго, лучше бесконечно или в пределах того, насколько бесконечен наш бюджет на хранение этих данных.
Потом мы предоставляем эти данные для анализа, непосредственно анализируем и все. Классика.
Отсюда родились наши слои на логическом уровне сверху. Первый слой — RAW. Здесь мы сохраняем информацию с источников. Важно, что мы собираем данные как есть. Здесь мы не преобразовываем именно содержимое, но при этом преобразовываем информацию в устойчивый к изменению формат.
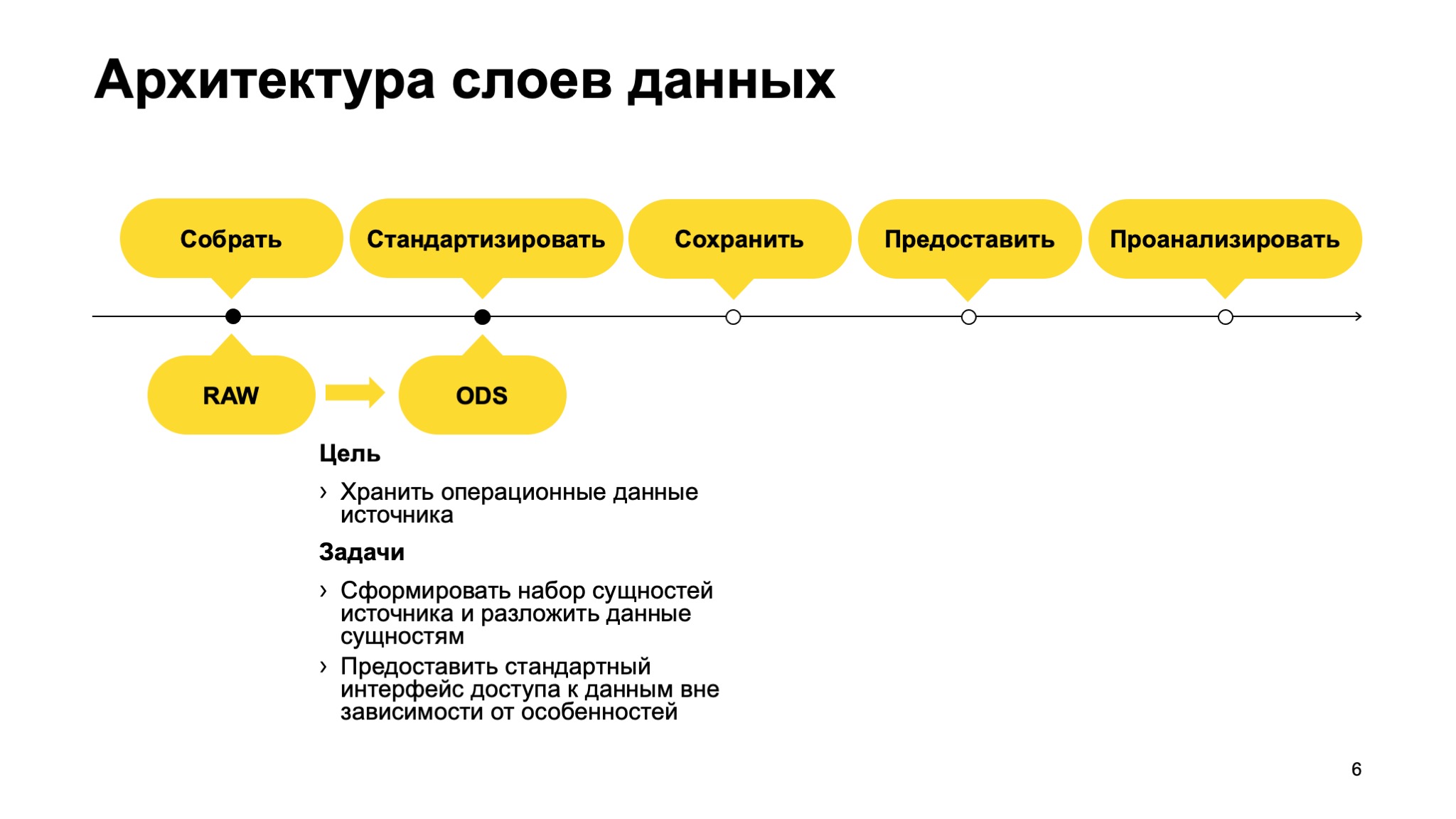
Дальше мы все это стандартизируем в операционном слое. Здесь мы храним операционные данные из источника без истории. Возможно, с какой-то ротацией, например год или месяц, зависит от источника и его объема.
Задача этого слоя — сформировать набор сущностей источника и предоставить стандартный интерфейс доступа к этим данным, вне зависимости от особенностей источника. Все примерно в стандартном виде.
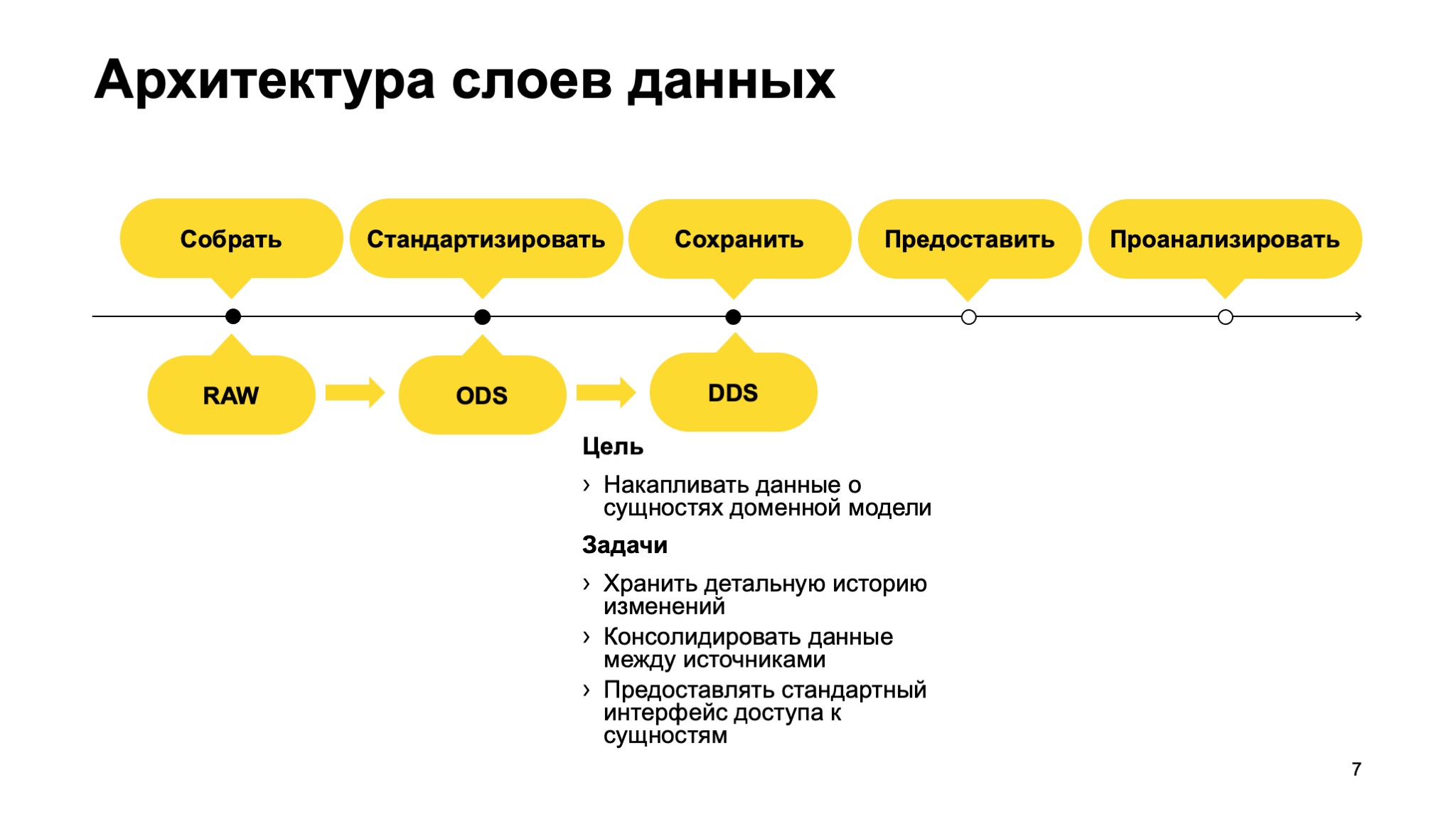
Дальше детальный слой. Ядро хранилища. Здесь мы храним детальную историю изменений и консолидируем данные между всеми источниками.
На базе этого детального слоя есть слой витрин Common Data Marts.
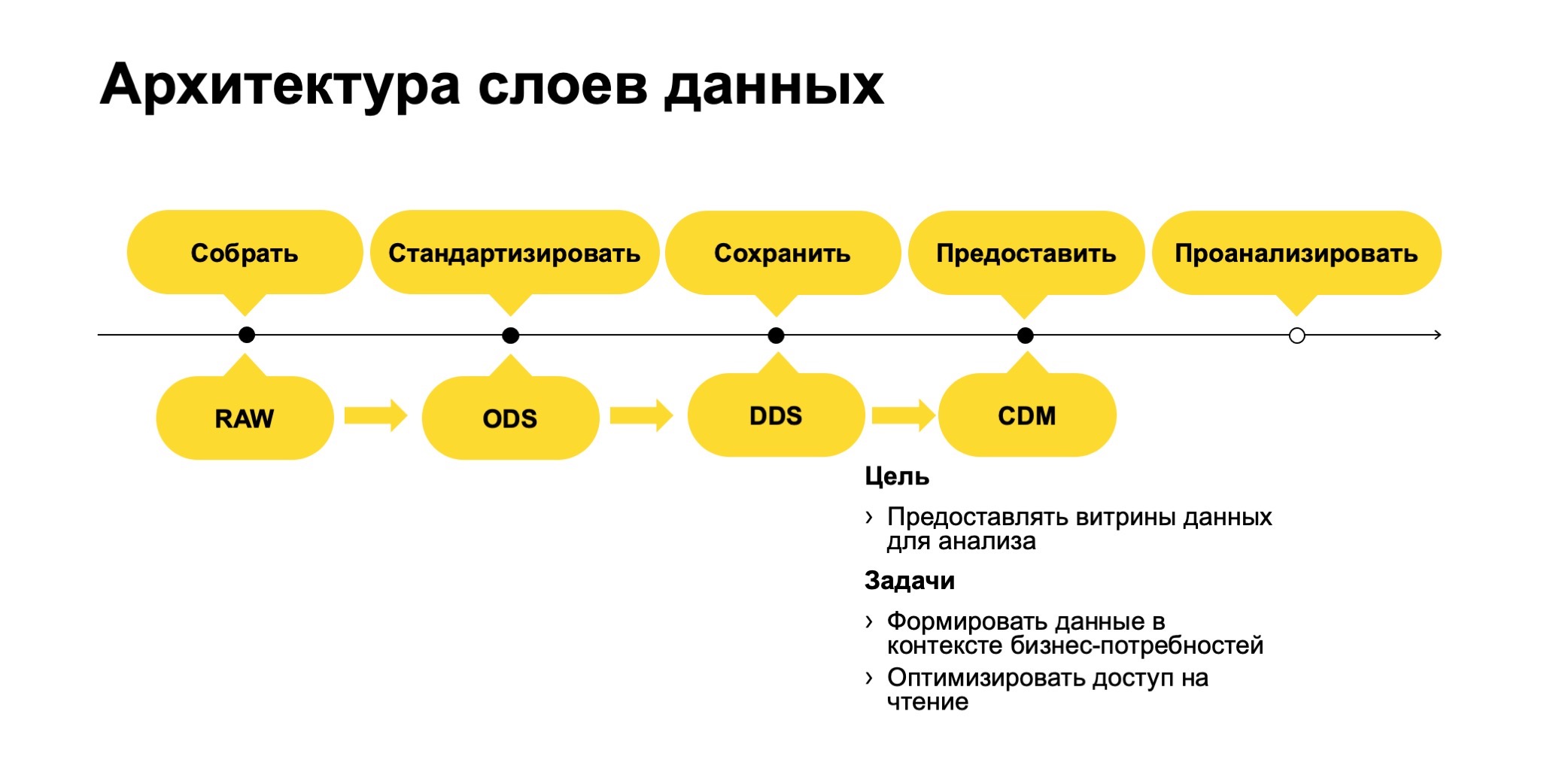
Здесь мы уже формируем плоские, удобные для аналитиков витрины и оптимизируем доступ на чтение.

В слое отчетов мы храним отчетные срезы в контексте без потребителя, агрегаты, нечто более понятное для потребителя.

В итоге — классика, все по слоям, от RAW до REP. Данные протекают в хранилище, все как завещали Кимбалл и Инмон в своих подходах.
Если это рассматривать прямо по системам, то для того, чтобы захватывать данные, у нас есть сервис репликации данных. Он забирает инкременты и снепшоты из источников самых разных типов, которые есть в Яндексе. И преобразовывает эти данные к устойчивому формату.

RAW, ODS — это такой Data Lake. Здесь у нас полуструктурированные данные, каркас MapReduce и всевозможные внутренние аналоги экосистемы Hadoop.
Центр хранилища — это непосредственно Data Warehouse. Здесь у нас слои ODS, DDS, CDM.

Основные цели — давать ответ на всевозможные ad-hoc-запросы наших аналитиков, выдерживать большое количество Join и достаточно малое время отклика на всевозможные вопросы.
И витрины. Помимо того, что они служат Data Warehouse, мы еще отгружаем их содержимое в системы анализа и визуализации данных. Это кубы данных, отчеты, дашборды, Tableau.

Если мы эти слои разложим по системам, то получится приблизительно такая картина.
То есть RAW, ODS и части CDM-слоя на супербольших данных — это у нас Data Lake.

Маленькая ремарка: в Яндексе много внутренних инструментов, которые мы делаем сами. У нас есть своя собственная платформа, есть такие внутренние инструменты, как YT. Можно проводить аналоги: YT — это как Hadoop. И в принципе, есть всевозможные аналоги Hadoop-стека.
На Greenplum у нас находятся часть слоя ODS, детальный слой и витрины. Построенные в Greenplum витрины мы затем отгружаем в MS SSAS или ClickHouse для ряда пользователей. Некоторым удобно пользоваться кубами данных, некоторым — широкимb плоскими таблицами, и ClickHouse здесь прямо идеален.
Часть витрин доступно для биосистем, или мы делаем из них агрегаты, доступные для нашего BI. BI у нас — это Tableau.
Ремарка: я прямо не рассказываю про наш инструментарий, не рассказываю про те возможности платформы, которые у нас есть. Очень советую посмотреть доклад Владимира Верстова, это руководитель разработки нашей платформы, где он подробно расскажет, зачем наша платформа управления данными создавалась, какие задачи она решает и что вообще делает.
Однако я немного слукавил, что не буду про это рассказывать, потому что во второй главе Коле придется коснуться платформы, чтобы показать, какое место наша разработка в этой платформе находит.
Если посмотреть на детальный слой, он не зря находится в самом центре хранилища, потому что это ядро, сердце, ключевое для построения всей доменной модели хранилища.

Основные требования к детальному слою — хранить историю изменений всех сущностей и связей между ними по всему нашему бизнесу. Консолидировать данные между источниками.
Два важных пункта. Детальный слой должен быть устойчив к изменению в бизнесе. Это достаточно сложно: допустим, мы изменили кардинальные связи или добавили новые сущности. Или у нас полностью изменился подход к бизнесу.
Очень хочется, чтобы детальный слой при этом не приходилось каждый раз перестраивать, чтобы он был модульным, масштабируемым, чтобы можно было добавить связи, сущности и чтобы весь проделанный труд до этого не был уничтожен.
Когда мы начали проектировать детальный слой, то провели анализ — а какие подходы к построении детального слоя вообще есть? Первое, что приходит на ум, — это когда нет «никакого» детального слоя или подхода.
Отсутствие детального слоя, когда витрина строится прямо по ODS, — это нормально по Кимбаллу. Это нормально, если у вас немного источников, если вы небольшой стартап. Но при росте количества источников взаимосвязи между ними и построением витрин становятся настолько большими, что приходится выделять детальный слой, чтобы унифицировать процесс построения витрин.
А подход, который называется «никакого подхода», — это когда мы просто сваливаем данные в кучку и потом пытаемся их них что-то извлечь. Если огрублять, это что-то вроде болота данных.
К сожалению, такой подход тоже имеет право на жизнь только потому, что он часто встречается. Так-то он, конечно, не имеет права на жизнь. Тем не менее, тут у нас денормализация. Можно использовать без подготовки в том плане, что легко селектить. Однако здесь нет устойчивости к изменениям, при любых изменениях в источнике придется все это перестраивать.

Пойдем дальше. Следующий подход — классическая звезда и снежинка. Нормализация до третьей нормальной формы, то, что описывал у себя Билл Инмон. Это можно использовать с минимальной подготовкой — нужно понимать, что такое первичный ключ, внешний ключ, join-таблички, SCD2, если мы говорим про измерения. И понимать, какие SCD вообще существуют.
Это может быть неудобно перестраивать при изменении кардинальности. Например, есть клиент и заказ. У одного клиента может быть много заказов, но у одного заказа только один клиент. Бизнес поменялся, у одного заказа теперь может быть несколько клиентов, и клиенты могут делить между собой заказ, как это, например, реализовано в такси. Перестраивать все это крайне больно.
При этом минимальное дублирование информации, если мы используем SCD. И какое-то приемлемое количество join. Если аналитики работают с SQL, они должны уметь работать и с этим.
Следующие походы — Data Vault и Anchor modeling. Почему я их вывел одновременно? Потому что они предлагают, на самом деле, нечто очень похожее. Это достаточно строгая нормализация, их сложно использовать без подготовки, без понимания, какие таблицы и какие правила они накладывают.

Обе методологии обещают, что их не надо перестраивать. Для Data Vault это работает с ограничениями, я дальше проговорю, какими. Здесь ультрабольшое количество join. При этом обе методологии относительно современны и обещают гибкость.
Посмотрим на эксплуатацию. Все, что справа, — Data Vault и якорное моделирование — достаточно сложно эксплуатировать из-за большого количества join. Чем больше join, тем сложнее писать SQL-запросы и в целом получать отсюда информацию. При этом проще вносить изменения в модель. Во всяком случае, обе методологии это обещают.
И наоборот, если у нас никакого подхода нет и мы всё вкладываем в плоскую табличку или нормализуем, то эксплуатировать проще. join или вообще нет, или их приемлемо малое количество. Но при этом вносить изменения, перестраивать сложно.
Когда мы начали смотреть на Data Vault и якорное моделирование, они показались нам крайне близкими и мы решили сравнить их между собой.

Здесь я перехожу ко второй части своей главы — к сравнению Data Vault и якорного моделирования, плюсам, минусам и итогу — что из них выбрать.
Предлагаю откатиться назад и представить себя в образе такого классического мастера по DWH, дэвэхашника. Это который все делает строго по слоям, все сразу проектирует, у него есть красивые витринки, все лежит аккуратненько в третьей нормальной форме.
Сперва стоит спрогнозировать требования, а потом подумать, согласовать, подумать еще. Я уверен, что все, кто работал с классическими DWH, которые построены не по Data Vault или по якорю, понимают, что DWH — это не быстро.
Но здесь классический дэвэхашник сталкивается с проблемой: заказчик не знает, чего хочет. Готов смотреть на результат, а потом уточнять, что ему хочется. Его желания постоянно меняются.
И вообще, у нас Agile, мы гибкие, давайте все переделывать максимально быстро. Желательно, завтра. Примерно так выглядит классический дэвэхашник, когда попадает в Agile-среду, в которой невозможно использовать Waterfall.
Логичные вопросы: откуда родились методологии Data Vault и якорь; может ли DWH быть agile; можно ли подходить к разработке хранилища гибко?
Ответ — да, можно. Модели, как я говорил, достаточно похожи, у них есть общие черты. Они повышают градус нормализации выше третьей нормальной формы, вплоть до предельной шестой в якоре. Они вводят свои типы таблиц и накладывают достаточно жесткие ограничения на их использование и на то, что они содержат. При использовании этих моделей можно нагенерить буквально тысячи таблиц. В якорной модели это буквально так, не какое-то преувеличение.

Взамен они обещают уменьшить постоянное дублирование данных в SCD2, если у нас меняется только один атрибут. Те, кто работают с SCD2, знают, что если у нас большое измерение, много атрибутов, а меняется только один, то нам приходится снова эту строчку вставлять. И это больно. Обе модели обещают избавить от деструктивных изменений, только расширять модель и позволить дорабатывать хранилище легко и быстро. Мистика для любого хранилищного аксакала.

Кратко пройдусь по каждой из методологий, чтобы потом их можно было сравнить.
Data Vault вводит и регламентирует несколько основных тип таблиц. Ключевые — это Hub, Link и Satellite, дальше я буду о них говорить. Hub хранит сущности, Link обеспечивает связь между хабами, Satellite предоставляет атрибуты и описания Data Vault.
Data Vault 2.0 я не буду касаться. Есть еще специальные таблицы типа bridge и point-in-time. Они упрощают или соединение данных через несколько связей, или получение информации из сателлитов с разной частотой обновления. Это скорее расширяющие, упрощающие модель сущности. Ключевые таблицы — это все-таки Hub, Link и Satellite.
Hub — отдельная таблица, которая содержит как минимум список бизнес-ключей. У нас есть бизнес-ключи сущности из внешней системы, суррогатный ключ, которым измерили хранилище, и техническая информация — отметка даты загрузки и код источника.

Link или связь — это физическое представление отношения между сущностями. При этом они всегда реализованы в виде таблиц «многие-ко-многим», в виде отдельных таблиц. Атрибуты Link включают в себя суррогатный ключ Link, ключи хабов в зависимости от того, какие хабы связаны через эту связь, и техническую информацию — временную отметку даты загрузки и код источника.
Satellite или сателлит — это описательная информация хаба, обычно с историзмом по SCD2. Здесь есть информация о ключе связи или хаба, в зависимости от описательных характеристик того, что находится в этом сателлите, сама информация и технические записи: SCD2, временная отметка даты загрузки, код источника данных.
Если на это посмотреть с точки зрения третьей нормальной формы, то есть вот такая неплохая картинка из презентации самого автора Data Vault:

Ссылка со слайда
Посмотрим на третью нормальную форму. Видно, что бизнес-ключи мигрируют в хабы. Все внешние ключи мигрируют и фактически являются связями. А все описательное, все наши поля, которые несут какой-то смысл, уходят в сателлиты. Сателлитов может быть несколько. Нет явных правил, как правильно разбить атрибуты на сателлит. Есть разные подходы: можно бить по частоте изменений, по источнику, по чтению — это такой творческий момент в Data Vault.

Если мы посмотрим на якорное моделирование, то я бы его сформулировал как такую крайнюю форму Data Vault, когда у нас правила еще строже и нормализация еще выше.
У этой методологии есть четыре основных типа таблиц — якорь, атрибут, связь и узел. Про узел я не буду подробно рассказывать, фактически это словарь ключ-значение. А про якорь, атрибут и связь сейчас коротко расскажу.
Якорь — фактический аналог хаба с важным отличием: здесь нет бизнес-ключей, есть только суррогатный ключ и временная отметка даты загрузки, техническая информация. Все бизнес-ключи фактически являются атрибутами и хранятся в таблицах атрибутов.

Tie — связь «многих ко многим», один в один как в Data Vault. Внешние таблицы — это принципиальный момент, даже если кардинальность связи другая. Но в якорном моделировании есть отличие — у связи принципиально не может быть атрибутов.
Сами атрибуты, как и сателлиты, хранят описательную информацию нашей сущности. Важное отличие: это шестая нормальная форма, один атрибут — одна таблица. Такое кажется, с одной стороны, странным, а с другой, расширение атрибутивного состава сущности проходит легко и просто. Мы добавляем новые таблицы, ничего не удаляем, изумительно и прекрасно.
Но расплачиваться за это приходится дорого. Даже очень простая схема, которая загружена на слайде, превращается в гигантское, просто неимоверное количество таблиц.
Скриншот взят с самого сайта якорного моделирования. Понятно, что это не само физическое представление таблиц. Все таблицы, которые с двойным кружком, историзируемые. Все остальное — это якоря и связи.

Если мы рассмотрим нашу таблицу в третьей нормальной форме, то суррогатные ключи находятся в якорях. Это не тот суррогатный ключ, который нам приходит, а которые мы сгенерировали в хранилище.

Внешние ключи находятся в наших связях.

Ссылка со слайдов
А вся описательная характеристика, в том числе бизнес-ключи и атрибуты, находятся каждый в отдельной таблице. Причем достаточно строго — одна таблица, один атрибут.
Возникает вопрос: нельзя ли хоть как-нибудь прохачить систему и навесить атрибут на связь? Можно через словарь. Но это именно что словарик, некий типизатор связи. Ничего более сложного на связь в якорной модели навесить нельзя.
Посмотрим на стандартный тест TPC-H. Я уверен, что многие из вас знают, что это такое, но кратко напомню: это стандартный тест для проверки аналитических хранилищ, внизу на слайде есть ссылка на одну из его версий.
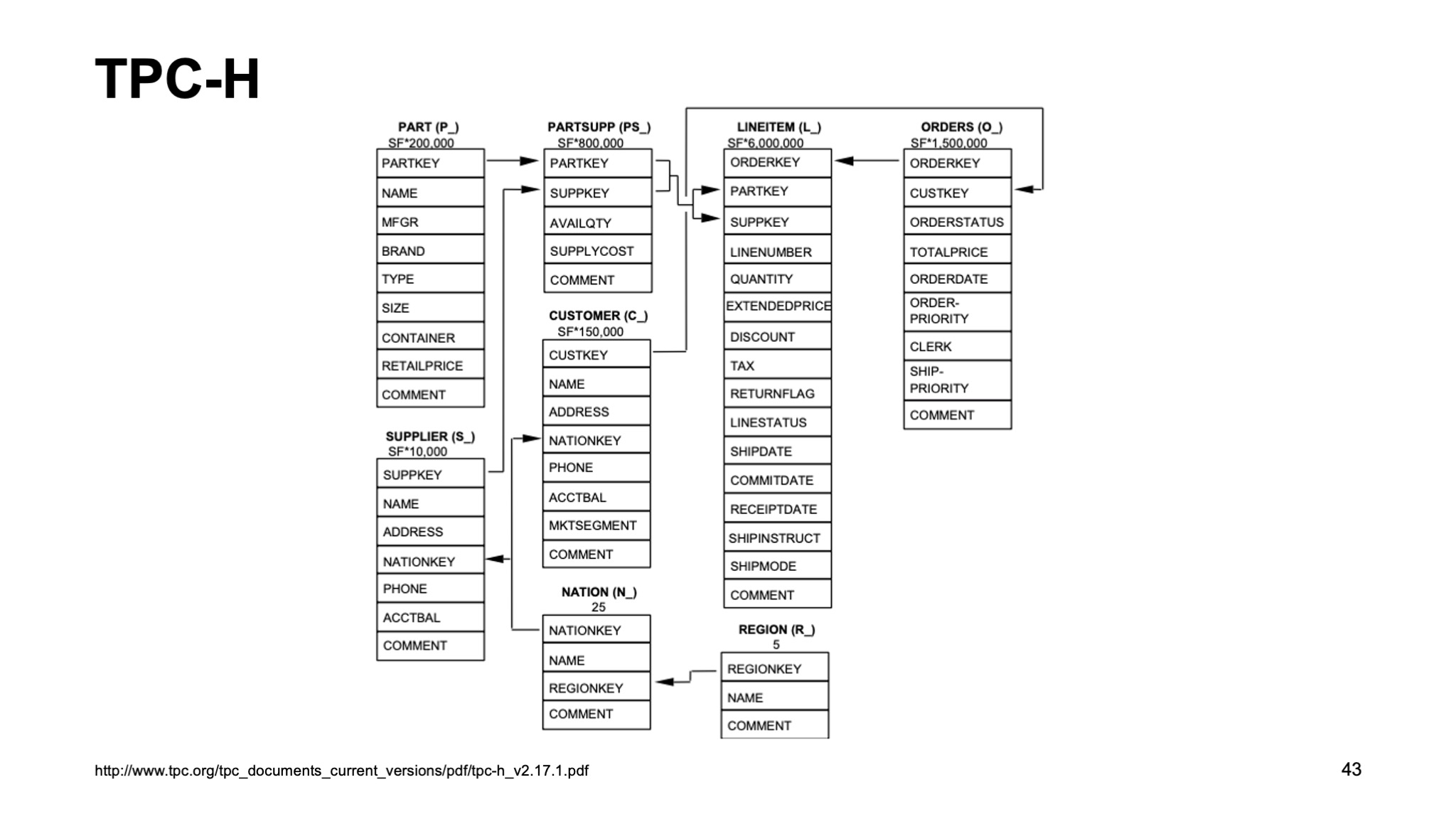
Ссылка со слайда
Сейчас на слайде схема в третьей нормальной форме. Здесь есть таблица фактов, таблица измерений, все это связано между собой. Ключи не помечены, но их можно прочитать.
Если мы эту схему преобразуем в Data Vault, то видно, насколько больше таблиц становится, появляются отдельные хабы, отдельные Link. Причем Link сделаны в виде таблиц «многие-ко-многим».
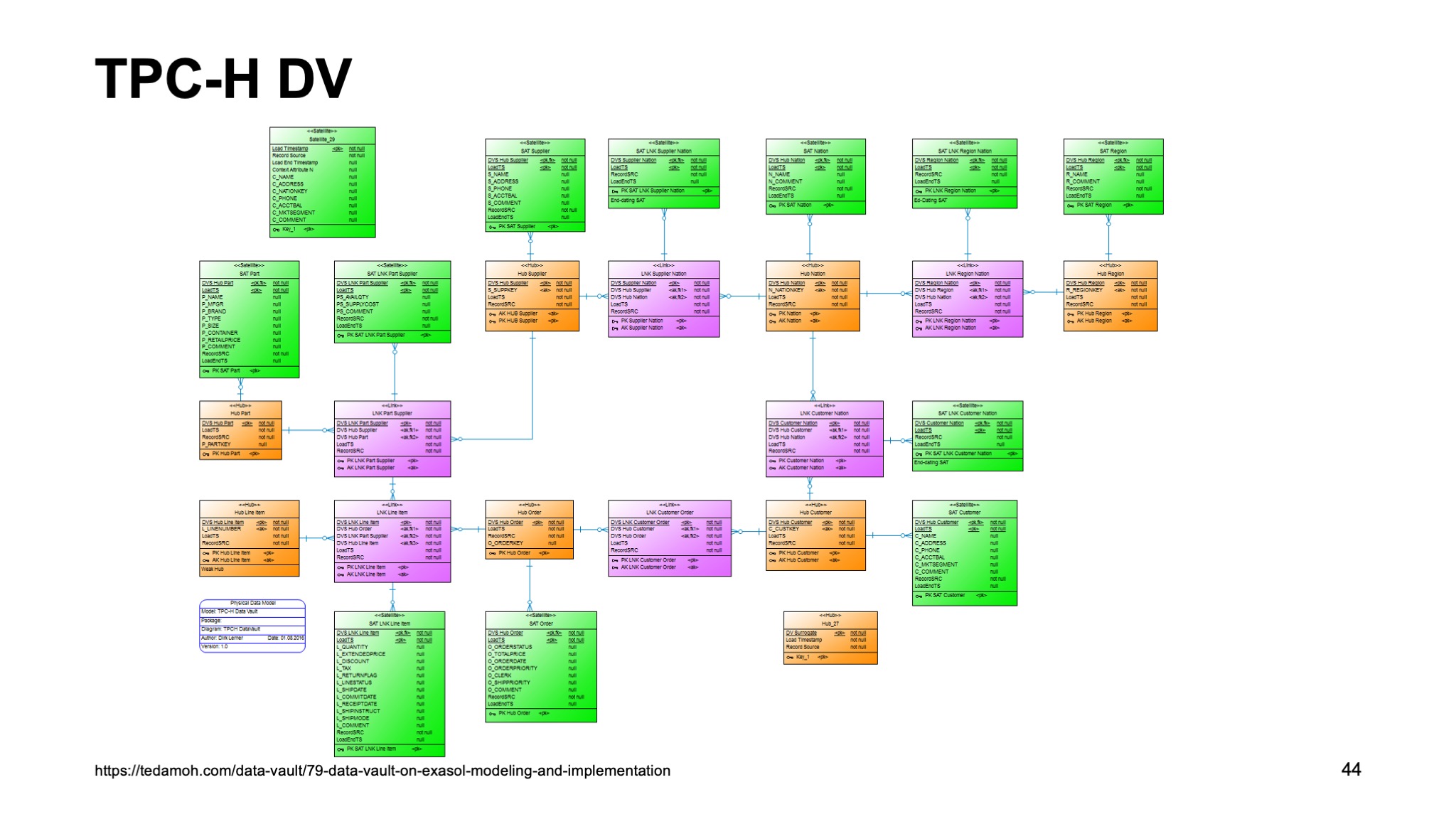
Ссылка со слайда
У нас вешаются сателлиты — как на Link, так и на отдельные хабы. И в целом, таблица становится больше.
Если мы это конвертируем в якорную модель, получится нечто подобное.
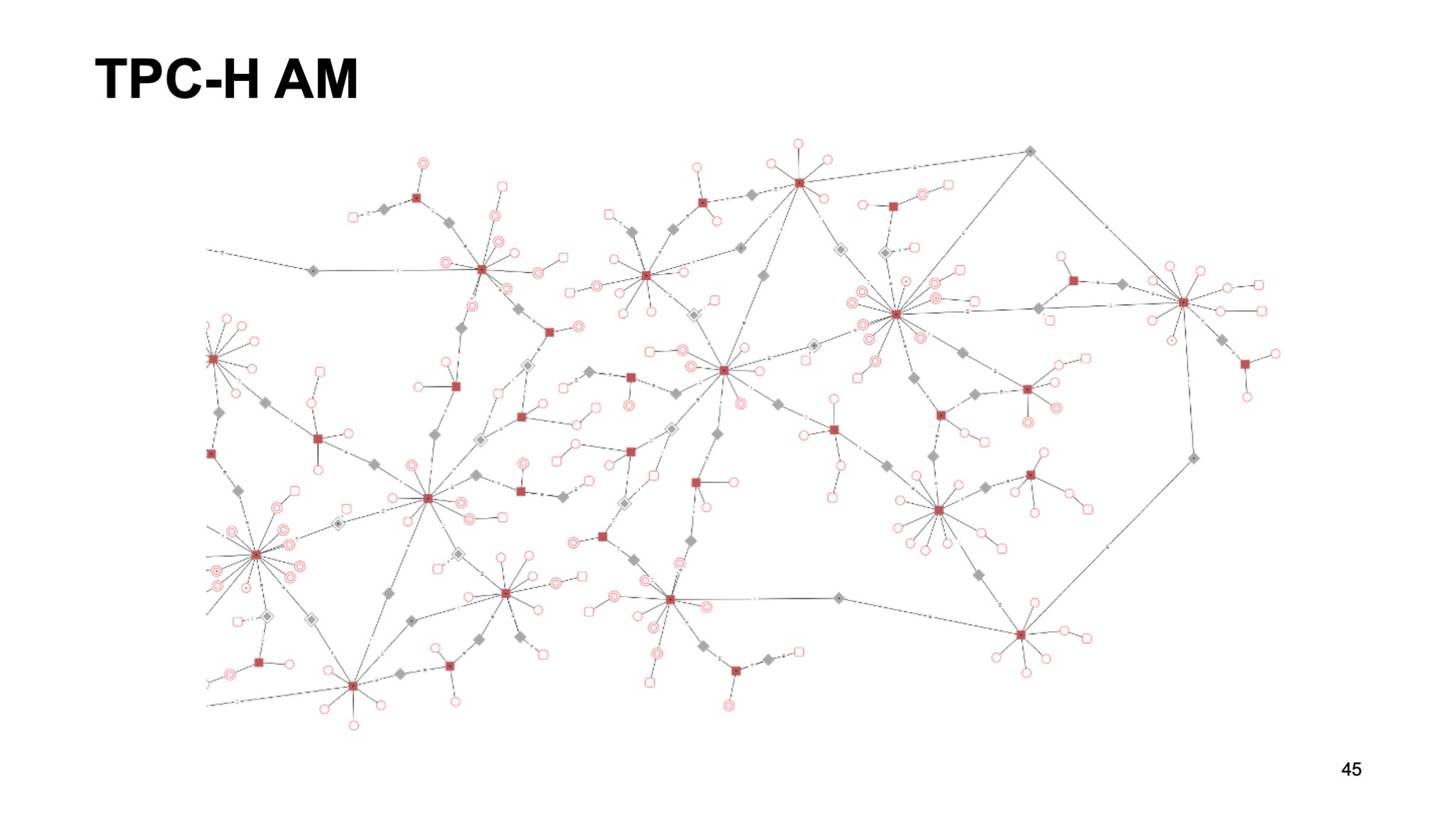
Честно говоря, на этом слайде есть небольшое лукавство в том смысле, что я не нашел якорной модели в TPC-H, хотя пытался найти. Взял просто абстрактную схему с сайта якорного моделирования. Но, тем не менее, таблиц должно быть примерно столько, если не больше.
В чем же схожести и различия, если их в лоб сравнивать?

И в Data Vault, и в якоре создается специальная таблица на сущность. В Data Vault это Hub, в якоре это якорь. Разница в том, что в хабе есть бизнес-ключ, а в якоре бизнес-ключ — это атрибут.
В Data Vault атрибуты группируются в таблицы-сателлиты. В якоре все строже: один атрибут — одна таблица, шестая нормальная форма, все раскладываем на отдельные кубики-элементы.
Связи через отдельные таблицы — и там и там, физическая реализация — «многие-ко-многим». Но в якоре нельзя навешивать никакие атрибуты на связи. Если и возникает такое желание, значит, скорее всего, нам нужно выделить под это какую-нибудь сущность.
И есть специальные таблицы, в Data Vault — point in time и bridge, в якоре — knot.
Когда мы вот так, в лоб, их сравнили, ощущение было — что выбрать? В чем-то лучше якорь, в чем-то — Data Vault. У каждого достаточно цельная методология. Якорь построже, но, с другой стороны, возникает меньше вопросов и больше пространства для автоматизации.
В общем, как-то так. Яндекс славится тем, что создает свои инструменты. Почему бы нам не создать свою модель?
Идея простая. Надо выбирать не между методологиями, а лучшее из каждой методологии и уметь применять это лучшее в каждом конкретном случае.

Из этой идеи и родилась наша гибридная модель highly Normalized hybrid Model, hNhM. Здесь я кратко расскажу ключевые идеи модели. (...)

Ключевая идея — выбирать оптимальный формат хранения. Мы не ограничиваем себя ни Data Vault, ни строгостью якоря. Но при этом позволяем выбрать либо одно, либо другое. А если мы позволяем это выбрать, то с точки зрения методологии классно было бы разделить логическое и физическое моделирование.
Еще есть требование, которое мы сами себе ставили: параллельная загрузка из разных источников, идемпотентность при повторной загрузке тех же данных. Стандартная для Data Vault и якоря устойчивость к изменению в бизнесе, модульность и масштабируемость.
И удобство построения витрин. Потому что да, таблиц очень много, есть большой риск написать не оптимально. Это даже не то чтобы риск. Просто вокруг тебя раскиданы мины. Очень хочется дать инструментарий, чтобы со всем этим было удобно работать.
Если пойти по этим идеям, посмотреть очень верхнеуровнево, то мы это представляли так.

У нас есть слои, про которые я рассказывал, RAW. ODS — это наш Data Lake. В RAW мы захватили данные, они лежат как есть. В ODS мы их чуть почистили, но это операционные данные, без истории. В детальном слое мы фактически разложили это все на маленькие кубики-сущности. С точки зрения логического проектирования это сущности-связи между ними. С точки зрения физического хранения на нашем Greenplum это скрыто с точки зрения использования.
Дальше мы на базе DDS, где все наши данные уже слились, строим витрины — и плоские, и кубы, как нам хочется. Делаем из этого срезы. В общем, DDS — это такой конструктор Lego.
То есть мы сначала разбираем все на кубики, а потом из этих кубиков собираем что-то красивое. Во всяком случае, мы себе так это рисовали на старте. К концу доклада вы сможете понять, получилось у нас сделать это так, как мы это изначально планировали, или нет.
Про разделение логического и физического уровня. Мы хотели на старте их разделить явным образом.
Логический уровень — это всем известные ER-диаграммы. Уверен, что все, кто работает с данными, про ER-диаграммы знает. Здесь есть сущности и их ключи, связи между сущности и атрибутивный состав сущностей. Мы еще добавили необходимость их историзации, но это как дополнительная информация к атрибутам.
Логический уровень — когнитивно сложная часть проектирования. Он не зависит от СУБД в общем виде и достаточно сложен. Трудно выделить сущности и домены в бизнесе, особенно если ты его не знаешь так, как основатели этого бизнеса.

Физический уровень — это скрипты DDL. Здесь выполняется партицирование сущностей, объединение атрибутов в группы, дистрибьюция в системах MPP. И индексы для ускорения запросов. Все перечисленное мы хотели скрыть. Во-первых, оно зависит от СУБД и технических ограничений, которые у нас есть. Во-вторых, нам хотелось сделать так, чтобы этот физический уровень был невидим, чтобы мы могли переключаться между Data Vault и якорем, если захотим.

Разделяя так логический и физический уровень, мы фактически делим задачи между нашими ролями. У нас есть две роли:
Внизу есть платформа, это наши разработчики ядра. Они каждый день задают себе один и тот же вопрос: как сделать инструментарий по работе с данными удобным, чтобы наши партнеры по данным и инженеры данных работали лучше?

В итоге, базируясь на ER-диаграммах, мы используем сущность и связь. Сущность — базовый кубик любого описания домена. Здесь, на логическом уровне, мы хотели сделать так, чтобы сущности описывались наименованием и комментарием; именем сущности и его описанием; бизнес-ключом, который обязателен для любой сущности, чтобы понимать, что его определяет; и каким-то набором атрибутов.
Сам атрибут описывается наименованием и комментарием, типом и необходимостью хранить историю. Мы можем хотеть или не хотеть хранить историю, это нормальный вопрос на логическом уровне.
А на физическом уровне каждая сущность состоит из таблицы хаба, которая содержит техническую информацию и суррогатный ключ. Это хэш от бизнес-ключа в указанном порядке.
Атрибут — это таблица. Она содержит информацию об одном атрибуте, может содержать историю, а может не содержать. Group — это группа атрибутов, как сателлит в Data Vault. Она может содержать информацию о нескольких атрибутах. Важное ограничение на уровне модели: все атрибуты должны приходить в эту группу сателлита из нового источника и иметь один тип историзма.

Связь. На уровне ER-диаграммы понятно, что это такое. С точки зрения логического уровня это список связанных сущностей и кардинальность связи. Здесь мы пошли по жесткой модели якоря и не позволили хранить у связи никаких атрибутов. Если хочется повесить на связь атрибут, то для этого должна быть отдельная сущность.
На физическом уровне это абсолютно то же самое, что и в Data Vault, и в якоре: таблицы «многие-ко-многим», которые содержат суррогатные ключи всех входящих сущностей, поля историзма, если они нужны, и поля партии сущностей, если связь гипербольшая.
Итого мы получаем примерно такую картинку: На логическом уровне рисуем ER-диаграмму или описываем нашу сущность.
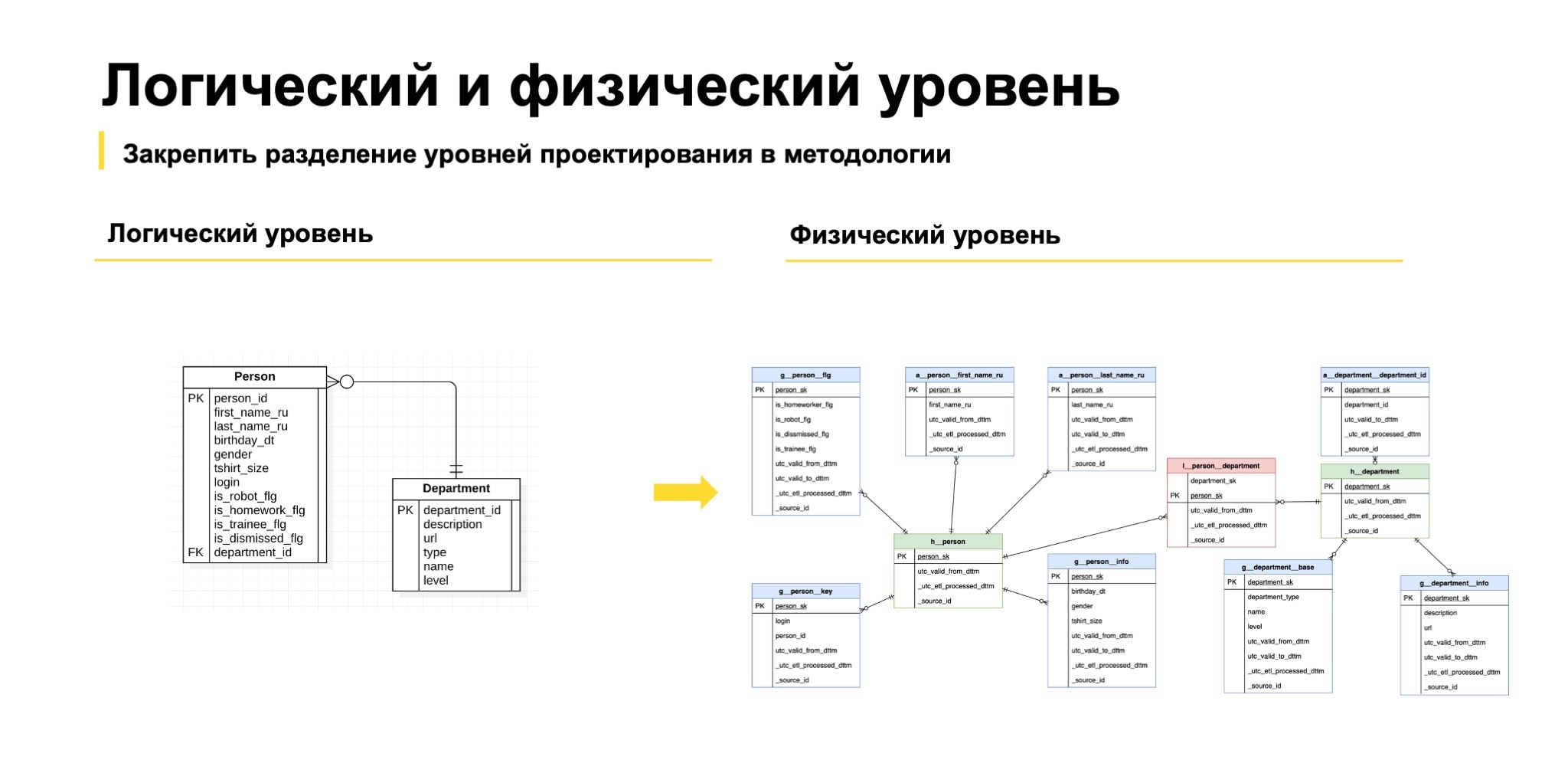
А на физическом уровне получаем вот такой набор таблиц. Видно, что тут есть и группы атрибутов, и просто атрибуты, и связи. Хотелось бы, чтобы все это было скрыто. Причем на обоих уровнях работы с DDS: и на загрузке данных, и на построении витрин.

Мы скрываем физическую реализацию загрузки. Загрузка данных должна обеспечить идемпотентность, то есть мы можем загружать одни и те же данные сколько угодно раз, не ломая наш детальный слой. Грузиться должны параллельно все таблицы, это крайне желательно.
Мы хотим скрыть сложности загрузки SCD2. Если приходят данные, то мы в этом месте требуем, чтобы в слое DDS обязательно помимо ключа была еще дата, актуальная с точки зрения бизнеса, по которой мы простраиваем SCD2 в детальном слое.
На уровне построения витрин скрываем сложность групп, связей, хабов. Мы работаем с сущностями на логическом уровне, а они — с таблицами на физическом уровне. Это нам позволяет скрыть сложности исторической обработки записей и максимизировать простоту работы с инкрементом.
Всего тут есть три концептуальные идеи:
Если возвращаться к Data Vault и якорю, то фактически из Data Vault мы взяли сателлиты и назвали их у себя «группой атрибутов». Позволили отойти от этой строгости якоря, где один атрибут — одна таблица.
Из якоря мы взяли к ебе сам якорь. То есть мы не храним бизнес-ключи в ключевой таблице, а смотрим на них как на еще одни атрибуты. Связи идут через отдельную таблицу, как в Data Vault или якоре, но мы запретили вешать на них атрибуты. В перспективе хотим разрешить.

Но с точки зрения простоты внедрения проще не думать, вешать ли атрибут на связь, а сразу знать: если на связь потребуется выделить атрибуты — создай новую сущность. Или подумай, что за сущность с этими атрибутами должна существовать.
Из Data Vault мы взяли специальные таблицы point in time и bridge для упрощения своей собственной внутренней работы с hNhM.
И если подводить итог, этим всем категорически невозможно управлять без фреймворка. Если вы попробуете все это воссоздать полуавтоматически или DDL-скриптами, то можно буквально убиться об количество таблиц и весь объем данных, метаданных, которыми надо управлять.

Поэтому мы разработали так называемый hNhM-фреймворк. Здесь я передаю слово Коле. Он подробно расскажет, что мы конкретно разработали и как мы этим пользуемся у себя внутри.
— Да, я расскажу о нашем фреймворке — что сделали, как храним и как с этим работаем.
Поскольку детальный слой данных является частью нашей платформы по управлению данными, то вначале я хотел бы показать, как, собственно, выглядит наша платформа. Про нее будет отдельный рассказ Владимира Верстова.
В левой части — сервис репликации, написанный в Go на базе MongoDB, которая позволяет получать данные из всех возможных источников. Это может быть как реляционная база данных, так и нереляционная. Это может быть API, при этом и мы можем читать из API, и API может к нам пушить данные. То есть перед нами вещь, которая в себе собирает изменения.

В центральной части находится наш Data Lake, который хранится на YT. Это аналог экосистемы Hadoop, в нем мы храним слои RAW и ODS. Сейчас у нас объем данных — около двух петабайт.
И само хранилище на Greenplum, в котором находится частично ODS за очень небольшое количество времени и слой DDS. Сейчас Greenplum у нас весит, по-моему, около пол-петабайта. На каждом слое мы умеем вычислять инкремент, что позволяет ускорить загрузку, избавиться от лишней работы по чтению и обработке данных.
Детальный слой — основной элемент хранилища на Greenplum. На его основе мы строим все наши витрины.

Отличительная особенность платформы: все сущности на всех слоях описываются в питонячем коде, но это видно и на слайде. Особенности описания сущностей в DDS мы рассмотрим на основе сущностей Person — «сотрудник».

Сущность определяет название класса. Название должно быть уникальным внутри домена данных. Для каждого класса мы пишем подробную документацию. В данном случае мы ее немножко сократили, чтобы все влезло на слайд.
Для чего нам нужна документация? На ее основе во время релиза платформа собирает документацию по всем нашим объектам и автоматически выкладывает на внутренний ресурс, это удобно для пользователей. Потому что им не надо следить за анонсами по изменению структуры. Они могут пойти в документацию, попробовать найти то, что им нужно, и начать пользоваться данными.

Далее необходимо описать технические параметры layout. С помощью трех полей — Layer, Group и Name — мы определяем путь до места хранения объекта в нашем хранилище. Неважно, будет ли это YT, Greenplum или что-то еще в будущем.

Следующим шагом мы начинаем описывать все атрибуты, которые есть в сущности. Для этого мы используем предопределенные типы, которые также едины во всей платформе. Для каждого атрибута нужно обязательно указать документацию. Я уже говорил, что это сделано для удобства пользователей.
Для каждого атрибута указываем тип историчности.

Сейчас у нас есть три типа. Ignore — это когда пришедшее значение записывается, а мнение с большей бизнес-датой игнорируется. Update — когда при изменении значение перезаписывается. New — исторический атрибут.
Атрибуты с Ignore и Update не хранят историю изменений и отличаются тем, что в Ignore предпочтение отдается значению с меньшей бизнес-датой, а в Update — с большей.

Также для каждой сущности мы указываем логический ключ.
На слайде видно, во что физически превращается каждая сущность.

Тут, наверное, сложно сходу что-то понять, поэтому я детально опишу основные особенности каждой таблицы. В каждой таблице есть поле SK, это суррогатный ключ, который мы получаем из натурального ключа. Используем хэш, это удобно, потому что при загрузке любого атрибута, любой сущности, любого хаба, мы можем на основе данных из системы источника сгенерить хэш и иметь внутренний ключ в хранилище.
Также в каждой таблице есть поля, в которых хранятся даты действия атрибута.

Если у данного атрибута историчность New, то это два столбца — utc_valid_from_dttm и utc_valid_to_dttm. То есть это метка во времени, с которой определяется действие конкретной записи.
Для атрибутов типа историчности Update и Ignore действует только один столбец: utc_valid_from. Это бизнес-дата, с которой мы узнали, что атрибут имеет текущее значение.

Также в каждой из таблиц находится два системных столбца: дата последнего изменения записи и система источника, из которой пришел этот атрибут.
В якорной модели каждый атрибут должен храниться в отдельной таблице, но в реальной жизни это оказалось не очень удобно для таблиц фактов.

Например, для финансовых транзакций, где все атрибуты приходят из одного источника. Самих транзакций крайне много, и соединять между собой таблицы атрибутов достаточно дорого. А в отчетности очень редко бывает, что атрибуты и транзакции должны быть по отдельности.
Поэтому мы решили, что круто уметь атрибуты объединять в группы, чтобы их хранить в одном месте. Это позволит и ускорить загрузку и упростить чтение данных. Для этого мы добавили свойства групп — их надо задавать у атрибутов, которые должны быть объединены в группу.
В группы можно объединять только атрибуты с одинаковой историчностью. И важно понимать минус этого решения: атрибуты должны приходить все вместе, иначе мы будем терять информацию. И желательно, с одинаковой частотой изменения. Потому что если один атрибут имеет гораздо большую частоту изменений, то при создании исторических данных все атрибуты будут лишний раз дублироваться.
Структура после объединения части атрибутов в группы выглядит уже гораздо более компактно.

Например, все флаги мы объединили в группу flg, общую информацию — в группу info, ключевые атрибуты — в группу key.
Теперь поговорим про объявление связей. Каждая связь тоже описывается в отдельном классе.

Атрибутами связи являются сами сущности, поэтому атрибуты Link должны быть объединены с объектами специального класса. Также обязательно для Link указывать ключ. Ключ определяет набор сущностей, которые однозначно идентифицируют строку в Link.
Каждый Link по умолчанию является историческим. Таким образом, в нем всегда есть два поля: utc_valid_from и utc_valid_to.
В этом примере мы делаем Link между департаментом и сотрудником. В данном случае ключом Link является сотрудник.

На слайде мы видим, как это физически реализовано.

Видно, что у Link нет суррогатного ключа, потому что его суррогатным ключом являются все те сущности, которые входят в ключ Link.
Теперь мы обсудим, как загружаем сущности.
Для загрузки был разработан ETL-кубик, который является частью нашего ETL-процесса. Он также описывается на Python. Мы описываем, что подается на вход, как данные распределяются по атрибутам и что является полем с бизнес-датой.

В самом простом случае этот кубик выглядит так.

В самом начале мы описываем источник. Это stage-таблица, для которой есть точно такой же класс, написанный отдельно в платформе.
Также мы указываем поле, в котором хранится бизнес-дата и система-источник.
Далее мы делаем маппинг между атрибутами. Описание таргета состоит из двух частей — указание сущности, куда мы загружаем атрибуты, и маппинг самих атрибутов.

Как мы видим, в качестве таргета указана таблица Person. Дальше следует маппинг атрибутов. Это самый простой вариант описания. В реальной жизни все выглядит гораздо сложнее. Например, так.

Мы видим, что из одной stage-таблицы данные грузятся в несколько сущностей. Одна сущность может грузиться несколько раз. Это в данном случае e-mail, он может быть в stage-таблице и персональным, и рабочим.
В большинстве случаев при загрузке Link не обязательно указывать маппинг, так как на основе этой информации мы можем понять, какие сущности указаны в Link, и найти маппинг этих сущностей в таргетах.
А если нет, то, скорее всего, это ошибка и мы об этом сообщаем пользователю.

Но в ряде случаев мы не можем автоматически этого сделать. Например, в stage-таблицу приходит и персональный почтовый ящик, и рабочий. Но и в обоих Link используется одна и та же сущность — e-mail. Мы их специально не разделяем, потому что в реальном мире e-mail — единая сущность. В то же время нам надо понять, какое здесь поле, какой Link грузить. Мы добавили специальный параметр, который позволяет определить, какое поле куда идет.
Дальше есть вот такой граф загрузки. Для каждой такой загрузки, для каждого такого лоудера генерится свой граф загрузки, который состоит из атомарных загрузок атрибутов Hub Link. Суррогатный ключ генерится как хэш, поэтому он может создаваться на каждом этапе самостоятельно.

Все задачи внутри графа выполняются параллельно, в зависимости от типа изменений. Это либо Insert\Update по SCD2, либо Insert. Данные из разных источников также могут загружаться параллельно.

Дальше я расскажу, как мы используем наш hNhM.
На основе DDS мы строим витрины. Пользователи напрямую могут обращаться к нашим сущностям и просматривать данные.

У нас есть два основных типа потребления данных DDS: ad-hoc-запросы от бизнес-пользователей и построение витрин. ad-hoc-запрос реализован двумя способами — либо view, либо через функции. И то и то скрывает реализацию от пользователей.
Витрины мы строим с помощью нашего фреймворка и тоже полностью скрываем реализацию.
Почему нельзя писать чистый SQL для детального слоя? В первую очередь потому, что дата-инженер должен знать о всех сущностях и атрибутах, должен знать, какой тип историчности у конкретного атрибута, и правильно это использовать в запросе.
После изменения описания сущности все витрины, которые использует тот или иной атрибут, теоретически могут развалиться, потому что атрибут был исторический, стал не исторический, и это изменит структуру таблицы.
В конце концов, это просто очень сложно — написать что-то с select, где будет 20-30 join.
Как у нас происходит доступ к сущностям из Python?

Было разработано несколько классов, которые позволяют сформировать SQL-запрос к определенной сущности и затем использовать его в построении витрины. Как это выглядит?

Мы описываем CTE. Оно может быть либо историческое, либо актуальное.

В первую очередь мы указываем сущность, которую хотим использовать.

После этого указываем необходимые атрибуты, которые мы будем использовать для витрины.

Прямо здесь мы можем сделать переименования, чтобы лишний не делать их в коде.
А так выглядит SQL-запрос для построения витрины. Есть переменные постановки, которые полностью скрывают реализацию. Потом идет сам запрос, который их использует. При этом можно использовать переменные как в визе, так и во временных таблицах. Это уже зависит от объема данных.

Как происходит доступ к сущностям из СУБД?

У нас есть вьюхи и есть две специальные процедуры. Первая — get_entity. Она получает в качестве параметров сущность, столбцы и создает временную таблицу, в которой будут, собственно, все необходимые данные процедуры.
И вторая процедура — это когда мы от entity к существующей таблице через Link добавляем дополнительную сущность и расширяем нашу табличку. Теоретически ключ у нее даже может поменяться.
А сейчас чуть более подробно покажу, как это работает.

Мы вызываем специальную функцию.

Указываем сущность.

Указываем столбцы, которые необходимо получить. Получить все столбцы сейчас нельзя, потому что для больших сущностей достаточно дорого считать всё вместе. Поэтому мы заставляем пользователя указать конкретные атрибуты, которые он хочет получить.

Дальше указываем временную таблицу, в которую надо положить данные.
Затем выполняется эта процедура. В ней создается таблица, куда вставляются данные. После этого можно просто селектить таблицу и смотреть подготовленные данные.

Примерно так же выглядит добавление сущности к уже созданной таблице.

Мы указываем таблицу, в которой уже есть сущность.

Указываем Link, через который мы хотим подключить дополнительную сущность.

Указываем саму сущность, которую мы хотим добавить.

И столбцы этой новой сущности. При этом мы можем как положить данные в уже существующую таблицу, так и создать новую.

Дальше мы расскажем, какие задачи оптимизации мы решали. Тут я передам слово Жене.
— Спасибо. Расскажу про оптимизацию и атрибуты против групп. Задача, на мой взгляд, очень интересная.
Посмотрим на объявление класса. Например, на объявление сущности Person.

В физическом мире мы можем представить ее в виде «один атрибут — одна табличка».

Это будет вполне нормально с точки зрения якорной модели. А можем ли мы сгруппировать атрибут? Здесь часть сгруппирована: флаги отдельно, информация о персоне отдельно, ключи отдельно, атрибуты отдельно.

Какая схема лучше? С точки зрения загрузки данных все то же самое. С точки зрения чтения данных все это скрыто, Коля про это рассказал. И с точки зрения использования будет одинаково.Не можем ли мы сделать так, чтобы эта физическая модель выбиралась наилучшим, оптимальным образом?

Мы постарались это свести к оптимизационной задаче. У нас буквально стояла проблема с объемом данных на Greenplum. Сейчас она не стоит. У нас действительно полупетабайтовый кластер на Greenplum, это достаточно много. Но еще буквально год-полтора назад даже такого не было.
Перед нами стоял вопрос: как оптимально объединить атрибуты по группам так, чтобы минимизировать объем хранения информации. У нас были метаданные объектов, это все наше описание того, что за объекты у нас есть. Маппинги полей и загрузчиков, количество строк в объекте и инкремент, а также накопленное знание о частоте изменений. У нас свой metaDWH, в который мы складываем всю эту информацию, и могли бы ее переиспользовать.
Существует набор ограничений, набор полей в метаданных объектов и эти маппинги, загрузчики. Как вы помните, группа должна загружаться из одного источника и иметь общий тип историзма.
Будем минимизировать занимаемое место на диске. Вот такую задачу мы себе поставили. Как мы ее решали?

Прежде всего мы формализовали и стандартизовали операции, меняющие схему, но не меняющие логику. Они совсем простые и очевидные. Можем объединять группы атрибутов в какую-нибудь еще группу, еще более крупную. Можем разъединять набор групп или вообще разъединить до атрибутов.
Фактически эта миграция, которая на слайде, никак не поменяет логическое устройство данных. Но при этом каждую из них мы можем хотя бы приблизительно оценить — узнать, сколько места они будут занимать в нашем случае.
Дальше мы взяли наше исходное состояние и из каждого состояния с помощью этих атомарных операций могли получить другое состояние физической системы, не меняя логическую архитектуру.

Из них следующие, из них следующие — так мы получаем пространство всех возможных состояний, в которые мы можем этими атомарными операциями попасть.
Дальше все просто. Мы из нашего состояния генерим новое мутациями — атомарными преобразованиями. Чтобы не обходить все, мы ограничиваем выборку и оцениваем каждое состояние.
Берем лучшие, скрещиваем их между собой, проводим новые мутации и так далее, классический генетический алгоритм.
В итоге при признаках какой-то сходимости мы останавливаемся, получаем итоговое состояние, которое лучше текущего по нашей оптимизационной функции. Сравниваем метаданные между собой и генерируем скрипт миграции. Как проходит миграция, как аккуратненько смигрировать так, чтобы пользователь не заметил, что у него физически что-то поменялось, — это отдельный большой вопрос на целый доклад, мы специально его не освещаем.
Я делаю акцент на том, что оптимизация была по месту, потому что применимость этого подхода гораздо шире. Гораздо интереснее оптимизировать не место, которое мы фактически сейчас закупили, это не для нас не проблема, а скорость чтения и скорость вставки информации. Усложнить нашу матмодель так, чтобы мы оценивали не только по месту, но и как-нибудь более сложно.
У нас есть наработки в этом направлении, но, честно говоря, мы не готовы про них рассказывать, потому что еще ничего не применяли на практике. Наверное, мы это сделаем и тогда поделимся, насколько мы смогли оптимизировать построение витрины и загрузку данных с помощью такой оптимизации.

К чему мы пришли, зачем мы сюда пришли и стоит ли вообще повторять наш путь?
Первый, на наш взгляд, инсайт от доклада — сравнение Data Vault и якоря. Мы поняли, что нам нужен детальный слой, что есть современные методологии Data Vault и якорь, и провели между ними сравнение. Они очень похожи. Я воспринимаю якорь как более жесткую форму Data Vault: в последнем есть правила, а в якоре эти правила еще более сложные.

Мы провели сравнение и сделали вывод: можно взять лучшее из каждой методологии. Не стоит слепо идти по одной из них и разрезать, например, clickstream на отдельные атрибуты. Стоит взять лучшее из Data Vault и из якоря.

Наш вариант — это гибридная модель, мы ее назвали hNhM. Требования я не буду перечислять, они на слайде. Основных идей три. Логическое и физическое проектирование, физический мир полностью скрыть как с точки зрения загрузки информации, так и с точки зрения ее получения.
Раз мы все это скрыли, то можем для физического мира выбирать нечто наиболее оптимальное. Оптимизировали именно хранение информации, но можно сделать нечто более интересное, например чтение.
На слайде показано, что мы взяли из Data Vault, а что из якоря.
Стоит ли за этим повторять? Пожалуйста, можете взять и полностью повторить, использовать точно так же. Кажется, что это вполне рабочая вещь, потому что мы ее используем уже года полтора.

Всем этим невозможно управлять без фреймворка. На явный вопрос, сколько у нас это заняло времени, Коля ответил — квартал. Но именно потому, что мы базировались на существующем внутреннем решении. На схеме было видно, что мы лишь маленький кубик в нашей общей платформе. Однако квартал — это не совсем честно. У нас был еще квартал на проектирование, размышление, не то чтобы это абсолютно чистая разработка.
Этот путь мы не советуем повторять. Если у вас нет свободной горы разработчиков, которые настолько круто прокачаны в Python, что готовы все это повторить и аккуратно сделать так же, как у нас, — лучше не вступать на этот скользкий путь. Вы просто убьете очень много времени и не получите того бизнес-результата, который можно получить, используя Data Vault, якорь или гибридную модель, как мы.

Что же делать? У нас есть большой roadmap развития. Можно добавить больше гибкости — например, я говорил, что на связь мы не вешаем ни атрибуты, ни группы. Но здесь можно это реализовать и воссоздать все типы таблиц Data Vault и якоря.
В нашем коде мы сейчас сильно завязаны на Greenplum. Хотелось бы от этого оторваться, сделать так, чтобы можно было применять модель где угодно именно с точки зрения фреймворка.
DSL у нас хоть и есть, но хотелось бы полноценный язык, который позволит строить витрины с учетом инкремента так, чтобы была полная кодогенерация. Пока она частичная.
Можно оптимизировать не только хранение, но и скорость выполнения запросов, делать автоматизированные миграции, потому что сейчас они еще полуручные, мы все еще боимся делать это аккуратно. И совсем фантастика — это визуальное редактирование метаданных.
Что делать, если у вас нет разработчиков? Дождаться, когда мы это заопенсорсим. У нас есть такие мечты. Вполне возможно, что мы свои фантазии осуществим и заопенсорсим этот продукт.
Следите за обновлениями или, если не хотите следить, приходите к нам и создавайте гибридную модель вместе с нами. На этом все. Спасибо за внимание.
Темы доклада:
— DV и AM: в чем разница и где точки соприкосновения
— Гибридный подход к построению хранилища
— Сильные и слабые стороны этого подхода
— Примеры кода
— Дальнейший вектор развития hNhM
— Меня зовут Евгений Ермаков, я руководитель Data Warehouse в Яндекс Go.
Я расскажу историю о том, как два руководителя объединились и сделали нечто крутое — как минимум, по мнению этих двух руководителей. Расскажу про наш подход к хранению данных в детальном слое. Мы его называем highly Normalized hybrid Model. Надеюсь, что корректно произнес по-английски, я тренировался.
Мы это сокращаем до hNhM — не пугайтесь, если услышите эту странную аббревиатуру. Можно еще «гибридная модель» или «двухстульная модель». А почему двухcтульная, я обязательно расскажу на примере одного мема.
Рассказ у нас будет достаточно долгий, из двух глав. Первая глава будет моя — я расскажу, как мы вообще к этому пришли. Она, наверное, будет для тех, кто сведущ в этой теме, или послужит повторением того, что вы уже знаете.
Также я расскажу про архитектуру хранилища Яндекс Go в целом, вместе с детальным слоем, где как раз эта модель и применяется. Потом сравню Data Vault и якорное моделирование так, как мы у себя их сравнивали, и объясню, почему мы из этого сравнения сделали вывод, что нужно создавать нечто свое. И расскажу базисные основы про hNhM.
А во второй главе я передам слово Коле.
Николай Гребенщиков:
— Я расскажу о нашем фреймворке, который позволяет нам описывать сущности и загружать данные. Покажу, как мы с ним работаем, как загружаем используем и строим витрины над нашим детальным слоем.
— В конце мы подведем итоги, самое главное, что можно из этого доклада почерпнуть. посмотрим, куда мы пришли, что сделали и как это можно переиспользовать.
Итак, архитектура Data Warehouse (DWH) в Яндекс Go. Расскажу об архитектуре слоев данных, какая она у нас, какие инструменты хранения и обработки информации есть, и покажу место детального слоя во всей этой архитектуре.
По моему мнению, архитектура слоев данных в нашем хранилище максимально классическая. Мы шли от глаголов действий над данными, которые происходят с хранилищами. Что мы делаем с данными?
Мы их собираем, стандартизируем, сохраняем в нашем хранилище. При этом сохраняем максимально долго, лучше бесконечно или в пределах того, насколько бесконечен наш бюджет на хранение этих данных.
Потом мы предоставляем эти данные для анализа, непосредственно анализируем и все. Классика.
Отсюда родились наши слои на логическом уровне сверху. Первый слой — RAW. Здесь мы сохраняем информацию с источников. Важно, что мы собираем данные как есть. Здесь мы не преобразовываем именно содержимое, но при этом преобразовываем информацию в устойчивый к изменению формат.
Дальше мы все это стандартизируем в операционном слое. Здесь мы храним операционные данные из источника без истории. Возможно, с какой-то ротацией, например год или месяц, зависит от источника и его объема.
Задача этого слоя — сформировать набор сущностей источника и предоставить стандартный интерфейс доступа к этим данным, вне зависимости от особенностей источника. Все примерно в стандартном виде.
Дальше детальный слой. Ядро хранилища. Здесь мы храним детальную историю изменений и консолидируем данные между всеми источниками.
На базе этого детального слоя есть слой витрин Common Data Marts.
Здесь мы уже формируем плоские, удобные для аналитиков витрины и оптимизируем доступ на чтение.
В слое отчетов мы храним отчетные срезы в контексте без потребителя, агрегаты, нечто более понятное для потребителя.
В итоге — классика, все по слоям, от RAW до REP. Данные протекают в хранилище, все как завещали Кимбалл и Инмон в своих подходах.
Если это рассматривать прямо по системам, то для того, чтобы захватывать данные, у нас есть сервис репликации данных. Он забирает инкременты и снепшоты из источников самых разных типов, которые есть в Яндексе. И преобразовывает эти данные к устойчивому формату.
RAW, ODS — это такой Data Lake. Здесь у нас полуструктурированные данные, каркас MapReduce и всевозможные внутренние аналоги экосистемы Hadoop.
Центр хранилища — это непосредственно Data Warehouse. Здесь у нас слои ODS, DDS, CDM.
Основные цели — давать ответ на всевозможные ad-hoc-запросы наших аналитиков, выдерживать большое количество Join и достаточно малое время отклика на всевозможные вопросы.
И витрины. Помимо того, что они служат Data Warehouse, мы еще отгружаем их содержимое в системы анализа и визуализации данных. Это кубы данных, отчеты, дашборды, Tableau.
Если мы эти слои разложим по системам, то получится приблизительно такая картина.
То есть RAW, ODS и части CDM-слоя на супербольших данных — это у нас Data Lake.
Маленькая ремарка: в Яндексе много внутренних инструментов, которые мы делаем сами. У нас есть своя собственная платформа, есть такие внутренние инструменты, как YT. Можно проводить аналоги: YT — это как Hadoop. И в принципе, есть всевозможные аналоги Hadoop-стека.
На Greenplum у нас находятся часть слоя ODS, детальный слой и витрины. Построенные в Greenplum витрины мы затем отгружаем в MS SSAS или ClickHouse для ряда пользователей. Некоторым удобно пользоваться кубами данных, некоторым — широкимb плоскими таблицами, и ClickHouse здесь прямо идеален.
Часть витрин доступно для биосистем, или мы делаем из них агрегаты, доступные для нашего BI. BI у нас — это Tableau.
Ремарка: я прямо не рассказываю про наш инструментарий, не рассказываю про те возможности платформы, которые у нас есть. Очень советую посмотреть доклад Владимира Верстова, это руководитель разработки нашей платформы, где он подробно расскажет, зачем наша платформа управления данными создавалась, какие задачи она решает и что вообще делает.
Смотреть доклад Владимира
Однако я немного слукавил, что не буду про это рассказывать, потому что во второй главе Коле придется коснуться платформы, чтобы показать, какое место наша разработка в этой платформе находит.
Если посмотреть на детальный слой, он не зря находится в самом центре хранилища, потому что это ядро, сердце, ключевое для построения всей доменной модели хранилища.
Основные требования к детальному слою — хранить историю изменений всех сущностей и связей между ними по всему нашему бизнесу. Консолидировать данные между источниками.
Два важных пункта. Детальный слой должен быть устойчив к изменению в бизнесе. Это достаточно сложно: допустим, мы изменили кардинальные связи или добавили новые сущности. Или у нас полностью изменился подход к бизнесу.
Очень хочется, чтобы детальный слой при этом не приходилось каждый раз перестраивать, чтобы он был модульным, масштабируемым, чтобы можно было добавить связи, сущности и чтобы весь проделанный труд до этого не был уничтожен.
Когда мы начали проектировать детальный слой, то провели анализ — а какие подходы к построении детального слоя вообще есть? Первое, что приходит на ум, — это когда нет «никакого» детального слоя или подхода.
Отсутствие детального слоя, когда витрина строится прямо по ODS, — это нормально по Кимбаллу. Это нормально, если у вас немного источников, если вы небольшой стартап. Но при росте количества источников взаимосвязи между ними и построением витрин становятся настолько большими, что приходится выделять детальный слой, чтобы унифицировать процесс построения витрин.
А подход, который называется «никакого подхода», — это когда мы просто сваливаем данные в кучку и потом пытаемся их них что-то извлечь. Если огрублять, это что-то вроде болота данных.
К сожалению, такой подход тоже имеет право на жизнь только потому, что он часто встречается. Так-то он, конечно, не имеет права на жизнь. Тем не менее, тут у нас денормализация. Можно использовать без подготовки в том плане, что легко селектить. Однако здесь нет устойчивости к изменениям, при любых изменениях в источнике придется все это перестраивать.
Пойдем дальше. Следующий подход — классическая звезда и снежинка. Нормализация до третьей нормальной формы, то, что описывал у себя Билл Инмон. Это можно использовать с минимальной подготовкой — нужно понимать, что такое первичный ключ, внешний ключ, join-таблички, SCD2, если мы говорим про измерения. И понимать, какие SCD вообще существуют.
Это может быть неудобно перестраивать при изменении кардинальности. Например, есть клиент и заказ. У одного клиента может быть много заказов, но у одного заказа только один клиент. Бизнес поменялся, у одного заказа теперь может быть несколько клиентов, и клиенты могут делить между собой заказ, как это, например, реализовано в такси. Перестраивать все это крайне больно.
При этом минимальное дублирование информации, если мы используем SCD. И какое-то приемлемое количество join. Если аналитики работают с SQL, они должны уметь работать и с этим.
Следующие походы — Data Vault и Anchor modeling. Почему я их вывел одновременно? Потому что они предлагают, на самом деле, нечто очень похожее. Это достаточно строгая нормализация, их сложно использовать без подготовки, без понимания, какие таблицы и какие правила они накладывают.
Обе методологии обещают, что их не надо перестраивать. Для Data Vault это работает с ограничениями, я дальше проговорю, какими. Здесь ультрабольшое количество join. При этом обе методологии относительно современны и обещают гибкость.
Посмотрим на эксплуатацию. Все, что справа, — Data Vault и якорное моделирование — достаточно сложно эксплуатировать из-за большого количества join. Чем больше join, тем сложнее писать SQL-запросы и в целом получать отсюда информацию. При этом проще вносить изменения в модель. Во всяком случае, обе методологии это обещают.
И наоборот, если у нас никакого подхода нет и мы всё вкладываем в плоскую табличку или нормализуем, то эксплуатировать проще. join или вообще нет, или их приемлемо малое количество. Но при этом вносить изменения, перестраивать сложно.
Когда мы начали смотреть на Data Vault и якорное моделирование, они показались нам крайне близкими и мы решили сравнить их между собой.
Здесь я перехожу ко второй части своей главы — к сравнению Data Vault и якорного моделирования, плюсам, минусам и итогу — что из них выбрать.
Предлагаю откатиться назад и представить себя в образе такого классического мастера по DWH, дэвэхашника. Это который все делает строго по слоям, все сразу проектирует, у него есть красивые витринки, все лежит аккуратненько в третьей нормальной форме.
Сперва стоит спрогнозировать требования, а потом подумать, согласовать, подумать еще. Я уверен, что все, кто работал с классическими DWH, которые построены не по Data Vault или по якорю, понимают, что DWH — это не быстро.
Но здесь классический дэвэхашник сталкивается с проблемой: заказчик не знает, чего хочет. Готов смотреть на результат, а потом уточнять, что ему хочется. Его желания постоянно меняются.
И вообще, у нас Agile, мы гибкие, давайте все переделывать максимально быстро. Желательно, завтра. Примерно так выглядит классический дэвэхашник, когда попадает в Agile-среду, в которой невозможно использовать Waterfall.
Логичные вопросы: откуда родились методологии Data Vault и якорь; может ли DWH быть agile; можно ли подходить к разработке хранилища гибко?
Ответ — да, можно. Модели, как я говорил, достаточно похожи, у них есть общие черты. Они повышают градус нормализации выше третьей нормальной формы, вплоть до предельной шестой в якоре. Они вводят свои типы таблиц и накладывают достаточно жесткие ограничения на их использование и на то, что они содержат. При использовании этих моделей можно нагенерить буквально тысячи таблиц. В якорной модели это буквально так, не какое-то преувеличение.
Взамен они обещают уменьшить постоянное дублирование данных в SCD2, если у нас меняется только один атрибут. Те, кто работают с SCD2, знают, что если у нас большое измерение, много атрибутов, а меняется только один, то нам приходится снова эту строчку вставлять. И это больно. Обе модели обещают избавить от деструктивных изменений, только расширять модель и позволить дорабатывать хранилище легко и быстро. Мистика для любого хранилищного аксакала.
Кратко пройдусь по каждой из методологий, чтобы потом их можно было сравнить.
Data Vault вводит и регламентирует несколько основных тип таблиц. Ключевые — это Hub, Link и Satellite, дальше я буду о них говорить. Hub хранит сущности, Link обеспечивает связь между хабами, Satellite предоставляет атрибуты и описания Data Vault.
Data Vault 2.0 я не буду касаться. Есть еще специальные таблицы типа bridge и point-in-time. Они упрощают или соединение данных через несколько связей, или получение информации из сателлитов с разной частотой обновления. Это скорее расширяющие, упрощающие модель сущности. Ключевые таблицы — это все-таки Hub, Link и Satellite.
Hub — отдельная таблица, которая содержит как минимум список бизнес-ключей. У нас есть бизнес-ключи сущности из внешней системы, суррогатный ключ, которым измерили хранилище, и техническая информация — отметка даты загрузки и код источника.
Link или связь — это физическое представление отношения между сущностями. При этом они всегда реализованы в виде таблиц «многие-ко-многим», в виде отдельных таблиц. Атрибуты Link включают в себя суррогатный ключ Link, ключи хабов в зависимости от того, какие хабы связаны через эту связь, и техническую информацию — временную отметку даты загрузки и код источника.
Satellite или сателлит — это описательная информация хаба, обычно с историзмом по SCD2. Здесь есть информация о ключе связи или хаба, в зависимости от описательных характеристик того, что находится в этом сателлите, сама информация и технические записи: SCD2, временная отметка даты загрузки, код источника данных.
Если на это посмотреть с точки зрения третьей нормальной формы, то есть вот такая неплохая картинка из презентации самого автора Data Vault:
Ссылка со слайда
Посмотрим на третью нормальную форму. Видно, что бизнес-ключи мигрируют в хабы. Все внешние ключи мигрируют и фактически являются связями. А все описательное, все наши поля, которые несут какой-то смысл, уходят в сателлиты. Сателлитов может быть несколько. Нет явных правил, как правильно разбить атрибуты на сателлит. Есть разные подходы: можно бить по частоте изменений, по источнику, по чтению — это такой творческий момент в Data Vault.
Если мы посмотрим на якорное моделирование, то я бы его сформулировал как такую крайнюю форму Data Vault, когда у нас правила еще строже и нормализация еще выше.
У этой методологии есть четыре основных типа таблиц — якорь, атрибут, связь и узел. Про узел я не буду подробно рассказывать, фактически это словарь ключ-значение. А про якорь, атрибут и связь сейчас коротко расскажу.
Якорь — фактический аналог хаба с важным отличием: здесь нет бизнес-ключей, есть только суррогатный ключ и временная отметка даты загрузки, техническая информация. Все бизнес-ключи фактически являются атрибутами и хранятся в таблицах атрибутов.
Tie — связь «многих ко многим», один в один как в Data Vault. Внешние таблицы — это принципиальный момент, даже если кардинальность связи другая. Но в якорном моделировании есть отличие — у связи принципиально не может быть атрибутов.
Сами атрибуты, как и сателлиты, хранят описательную информацию нашей сущности. Важное отличие: это шестая нормальная форма, один атрибут — одна таблица. Такое кажется, с одной стороны, странным, а с другой, расширение атрибутивного состава сущности проходит легко и просто. Мы добавляем новые таблицы, ничего не удаляем, изумительно и прекрасно.
Но расплачиваться за это приходится дорого. Даже очень простая схема, которая загружена на слайде, превращается в гигантское, просто неимоверное количество таблиц.
Скриншот взят с самого сайта якорного моделирования. Понятно, что это не само физическое представление таблиц. Все таблицы, которые с двойным кружком, историзируемые. Все остальное — это якоря и связи.
Если мы рассмотрим нашу таблицу в третьей нормальной форме, то суррогатные ключи находятся в якорях. Это не тот суррогатный ключ, который нам приходит, а которые мы сгенерировали в хранилище.
Внешние ключи находятся в наших связях.
Ссылка со слайдов
А вся описательная характеристика, в том числе бизнес-ключи и атрибуты, находятся каждый в отдельной таблице. Причем достаточно строго — одна таблица, один атрибут.
Возникает вопрос: нельзя ли хоть как-нибудь прохачить систему и навесить атрибут на связь? Можно через словарь. Но это именно что словарик, некий типизатор связи. Ничего более сложного на связь в якорной модели навесить нельзя.
Посмотрим на стандартный тест TPC-H. Я уверен, что многие из вас знают, что это такое, но кратко напомню: это стандартный тест для проверки аналитических хранилищ, внизу на слайде есть ссылка на одну из его версий.
Ссылка со слайда
Сейчас на слайде схема в третьей нормальной форме. Здесь есть таблица фактов, таблица измерений, все это связано между собой. Ключи не помечены, но их можно прочитать.
Если мы эту схему преобразуем в Data Vault, то видно, насколько больше таблиц становится, появляются отдельные хабы, отдельные Link. Причем Link сделаны в виде таблиц «многие-ко-многим».
Ссылка со слайда
У нас вешаются сателлиты — как на Link, так и на отдельные хабы. И в целом, таблица становится больше.
Если мы это конвертируем в якорную модель, получится нечто подобное.
Честно говоря, на этом слайде есть небольшое лукавство в том смысле, что я не нашел якорной модели в TPC-H, хотя пытался найти. Взял просто абстрактную схему с сайта якорного моделирования. Но, тем не менее, таблиц должно быть примерно столько, если не больше.
В чем же схожести и различия, если их в лоб сравнивать?
И в Data Vault, и в якоре создается специальная таблица на сущность. В Data Vault это Hub, в якоре это якорь. Разница в том, что в хабе есть бизнес-ключ, а в якоре бизнес-ключ — это атрибут.
В Data Vault атрибуты группируются в таблицы-сателлиты. В якоре все строже: один атрибут — одна таблица, шестая нормальная форма, все раскладываем на отдельные кубики-элементы.
Связи через отдельные таблицы — и там и там, физическая реализация — «многие-ко-многим». Но в якоре нельзя навешивать никакие атрибуты на связи. Если и возникает такое желание, значит, скорее всего, нам нужно выделить под это какую-нибудь сущность.
И есть специальные таблицы, в Data Vault — point in time и bridge, в якоре — knot.
Когда мы вот так, в лоб, их сравнили, ощущение было — что выбрать? В чем-то лучше якорь, в чем-то — Data Vault. У каждого достаточно цельная методология. Якорь построже, но, с другой стороны, возникает меньше вопросов и больше пространства для автоматизации.
В общем, как-то так. Яндекс славится тем, что создает свои инструменты. Почему бы нам не создать свою модель?
Идея простая. Надо выбирать не между методологиями, а лучшее из каждой методологии и уметь применять это лучшее в каждом конкретном случае.
Из этой идеи и родилась наша гибридная модель highly Normalized hybrid Model, hNhM. Здесь я кратко расскажу ключевые идеи модели. (...)
Ключевая идея — выбирать оптимальный формат хранения. Мы не ограничиваем себя ни Data Vault, ни строгостью якоря. Но при этом позволяем выбрать либо одно, либо другое. А если мы позволяем это выбрать, то с точки зрения методологии классно было бы разделить логическое и физическое моделирование.
Еще есть требование, которое мы сами себе ставили: параллельная загрузка из разных источников, идемпотентность при повторной загрузке тех же данных. Стандартная для Data Vault и якоря устойчивость к изменению в бизнесе, модульность и масштабируемость.
И удобство построения витрин. Потому что да, таблиц очень много, есть большой риск написать не оптимально. Это даже не то чтобы риск. Просто вокруг тебя раскиданы мины. Очень хочется дать инструментарий, чтобы со всем этим было удобно работать.
Если пойти по этим идеям, посмотреть очень верхнеуровнево, то мы это представляли так.
У нас есть слои, про которые я рассказывал, RAW. ODS — это наш Data Lake. В RAW мы захватили данные, они лежат как есть. В ODS мы их чуть почистили, но это операционные данные, без истории. В детальном слое мы фактически разложили это все на маленькие кубики-сущности. С точки зрения логического проектирования это сущности-связи между ними. С точки зрения физического хранения на нашем Greenplum это скрыто с точки зрения использования.
Дальше мы на базе DDS, где все наши данные уже слились, строим витрины — и плоские, и кубы, как нам хочется. Делаем из этого срезы. В общем, DDS — это такой конструктор Lego.
То есть мы сначала разбираем все на кубики, а потом из этих кубиков собираем что-то красивое. Во всяком случае, мы себе так это рисовали на старте. К концу доклада вы сможете понять, получилось у нас сделать это так, как мы это изначально планировали, или нет.
Про разделение логического и физического уровня. Мы хотели на старте их разделить явным образом.
Логический уровень — это всем известные ER-диаграммы. Уверен, что все, кто работает с данными, про ER-диаграммы знает. Здесь есть сущности и их ключи, связи между сущности и атрибутивный состав сущностей. Мы еще добавили необходимость их историзации, но это как дополнительная информация к атрибутам.
Логический уровень — когнитивно сложная часть проектирования. Он не зависит от СУБД в общем виде и достаточно сложен. Трудно выделить сущности и домены в бизнесе, особенно если ты его не знаешь так, как основатели этого бизнеса.
Физический уровень — это скрипты DDL. Здесь выполняется партицирование сущностей, объединение атрибутов в группы, дистрибьюция в системах MPP. И индексы для ускорения запросов. Все перечисленное мы хотели скрыть. Во-первых, оно зависит от СУБД и технических ограничений, которые у нас есть. Во-вторых, нам хотелось сделать так, чтобы этот физический уровень был невидим, чтобы мы могли переключаться между Data Vault и якорем, если захотим.
Разделяя так логический и физический уровень, мы фактически делим задачи между нашими ролями. У нас есть две роли:
- Партнер по данным, Data Partner. Мы так переименовали Data steward. Да, слово steward имеет здравое значение в переводе: распорядитель чего-то чужого, а данные в этом смысле чужие. Но все равно «партнер по данным» звучит гораздо лучше.
Партнер по данным на логическом уровне должен ответить на вопрос концептуальной модели: какие вообще направления бизнеса и взаимосвязи между ними у нас есть, как часто будут меняться атрибуты. И из этого построить логическую модель, прямо по классике. - И инженер данных, здесь все классически. Он отвечает на вопросы физической модели: как хранить атрибуты, нужны ли партиции, нужно ли закрытие SCD2. И обеспечивает сам расчет данных по инкременту, а также пересчет истории, то есть фактически ETL-процесс.
Внизу есть платформа, это наши разработчики ядра. Они каждый день задают себе один и тот же вопрос: как сделать инструментарий по работе с данными удобным, чтобы наши партнеры по данным и инженеры данных работали лучше?
В итоге, базируясь на ER-диаграммах, мы используем сущность и связь. Сущность — базовый кубик любого описания домена. Здесь, на логическом уровне, мы хотели сделать так, чтобы сущности описывались наименованием и комментарием; именем сущности и его описанием; бизнес-ключом, который обязателен для любой сущности, чтобы понимать, что его определяет; и каким-то набором атрибутов.
Сам атрибут описывается наименованием и комментарием, типом и необходимостью хранить историю. Мы можем хотеть или не хотеть хранить историю, это нормальный вопрос на логическом уровне.
А на физическом уровне каждая сущность состоит из таблицы хаба, которая содержит техническую информацию и суррогатный ключ. Это хэш от бизнес-ключа в указанном порядке.
Атрибут — это таблица. Она содержит информацию об одном атрибуте, может содержать историю, а может не содержать. Group — это группа атрибутов, как сателлит в Data Vault. Она может содержать информацию о нескольких атрибутах. Важное ограничение на уровне модели: все атрибуты должны приходить в эту группу сателлита из нового источника и иметь один тип историзма.
Связь. На уровне ER-диаграммы понятно, что это такое. С точки зрения логического уровня это список связанных сущностей и кардинальность связи. Здесь мы пошли по жесткой модели якоря и не позволили хранить у связи никаких атрибутов. Если хочется повесить на связь атрибут, то для этого должна быть отдельная сущность.
На физическом уровне это абсолютно то же самое, что и в Data Vault, и в якоре: таблицы «многие-ко-многим», которые содержат суррогатные ключи всех входящих сущностей, поля историзма, если они нужны, и поля партии сущностей, если связь гипербольшая.
Итого мы получаем примерно такую картинку: На логическом уровне рисуем ER-диаграмму или описываем нашу сущность.
А на физическом уровне получаем вот такой набор таблиц. Видно, что тут есть и группы атрибутов, и просто атрибуты, и связи. Хотелось бы, чтобы все это было скрыто. Причем на обоих уровнях работы с DDS: и на загрузке данных, и на построении витрин.
Мы скрываем физическую реализацию загрузки. Загрузка данных должна обеспечить идемпотентность, то есть мы можем загружать одни и те же данные сколько угодно раз, не ломая наш детальный слой. Грузиться должны параллельно все таблицы, это крайне желательно.
Мы хотим скрыть сложности загрузки SCD2. Если приходят данные, то мы в этом месте требуем, чтобы в слое DDS обязательно помимо ключа была еще дата, актуальная с точки зрения бизнеса, по которой мы простраиваем SCD2 в детальном слое.
На уровне построения витрин скрываем сложность групп, связей, хабов. Мы работаем с сущностями на логическом уровне, а они — с таблицами на физическом уровне. Это нам позволяет скрыть сложности исторической обработки записей и максимизировать простоту работы с инкрементом.
Всего тут есть три концептуальные идеи:
- Закрепить разделение логического и физического проектирования в методологии, полностью закрыть физическое проектирование.
- Сокрытие физического проектирования провести как при загрузке данных, так и при использовании модели, чтобы было удобно загружать и строить витрины.
- И так как мы все сокрыли с физической точки зрения, то нужно еще выбирать оптимальный формат хранения для каждого конкретного случая: группировать и догруппировать атрибуты. Все это скрыто внутри.
Если возвращаться к Data Vault и якорю, то фактически из Data Vault мы взяли сателлиты и назвали их у себя «группой атрибутов». Позволили отойти от этой строгости якоря, где один атрибут — одна таблица.
Из якоря мы взяли к ебе сам якорь. То есть мы не храним бизнес-ключи в ключевой таблице, а смотрим на них как на еще одни атрибуты. Связи идут через отдельную таблицу, как в Data Vault или якоре, но мы запретили вешать на них атрибуты. В перспективе хотим разрешить.
Но с точки зрения простоты внедрения проще не думать, вешать ли атрибут на связь, а сразу знать: если на связь потребуется выделить атрибуты — создай новую сущность. Или подумай, что за сущность с этими атрибутами должна существовать.
Из Data Vault мы взяли специальные таблицы point in time и bridge для упрощения своей собственной внутренней работы с hNhM.
И если подводить итог, этим всем категорически невозможно управлять без фреймворка. Если вы попробуете все это воссоздать полуавтоматически или DDL-скриптами, то можно буквально убиться об количество таблиц и весь объем данных, метаданных, которыми надо управлять.
Поэтому мы разработали так называемый hNhM-фреймворк. Здесь я передаю слово Коле. Он подробно расскажет, что мы конкретно разработали и как мы этим пользуемся у себя внутри.
— Да, я расскажу о нашем фреймворке — что сделали, как храним и как с этим работаем.
Поскольку детальный слой данных является частью нашей платформы по управлению данными, то вначале я хотел бы показать, как, собственно, выглядит наша платформа. Про нее будет отдельный рассказ Владимира Верстова.
Смотреть доклад Владимира
В левой части — сервис репликации, написанный в Go на базе MongoDB, которая позволяет получать данные из всех возможных источников. Это может быть как реляционная база данных, так и нереляционная. Это может быть API, при этом и мы можем читать из API, и API может к нам пушить данные. То есть перед нами вещь, которая в себе собирает изменения.
В центральной части находится наш Data Lake, который хранится на YT. Это аналог экосистемы Hadoop, в нем мы храним слои RAW и ODS. Сейчас у нас объем данных — около двух петабайт.
И само хранилище на Greenplum, в котором находится частично ODS за очень небольшое количество времени и слой DDS. Сейчас Greenplum у нас весит, по-моему, около пол-петабайта. На каждом слое мы умеем вычислять инкремент, что позволяет ускорить загрузку, избавиться от лишней работы по чтению и обработке данных.
Детальный слой — основной элемент хранилища на Greenplum. На его основе мы строим все наши витрины.
Отличительная особенность платформы: все сущности на всех слоях описываются в питонячем коде, но это видно и на слайде. Особенности описания сущностей в DDS мы рассмотрим на основе сущностей Person — «сотрудник».
Сущность определяет название класса. Название должно быть уникальным внутри домена данных. Для каждого класса мы пишем подробную документацию. В данном случае мы ее немножко сократили, чтобы все влезло на слайд.
Для чего нам нужна документация? На ее основе во время релиза платформа собирает документацию по всем нашим объектам и автоматически выкладывает на внутренний ресурс, это удобно для пользователей. Потому что им не надо следить за анонсами по изменению структуры. Они могут пойти в документацию, попробовать найти то, что им нужно, и начать пользоваться данными.
Далее необходимо описать технические параметры layout. С помощью трех полей — Layer, Group и Name — мы определяем путь до места хранения объекта в нашем хранилище. Неважно, будет ли это YT, Greenplum или что-то еще в будущем.
Следующим шагом мы начинаем описывать все атрибуты, которые есть в сущности. Для этого мы используем предопределенные типы, которые также едины во всей платформе. Для каждого атрибута нужно обязательно указать документацию. Я уже говорил, что это сделано для удобства пользователей.
Для каждого атрибута указываем тип историчности.
Сейчас у нас есть три типа. Ignore — это когда пришедшее значение записывается, а мнение с большей бизнес-датой игнорируется. Update — когда при изменении значение перезаписывается. New — исторический атрибут.
Атрибуты с Ignore и Update не хранят историю изменений и отличаются тем, что в Ignore предпочтение отдается значению с меньшей бизнес-датой, а в Update — с большей.
Также для каждой сущности мы указываем логический ключ.
На слайде видно, во что физически превращается каждая сущность.
Тут, наверное, сложно сходу что-то понять, поэтому я детально опишу основные особенности каждой таблицы. В каждой таблице есть поле SK, это суррогатный ключ, который мы получаем из натурального ключа. Используем хэш, это удобно, потому что при загрузке любого атрибута, любой сущности, любого хаба, мы можем на основе данных из системы источника сгенерить хэш и иметь внутренний ключ в хранилище.
Также в каждой таблице есть поля, в которых хранятся даты действия атрибута.
Если у данного атрибута историчность New, то это два столбца — utc_valid_from_dttm и utc_valid_to_dttm. То есть это метка во времени, с которой определяется действие конкретной записи.
Для атрибутов типа историчности Update и Ignore действует только один столбец: utc_valid_from. Это бизнес-дата, с которой мы узнали, что атрибут имеет текущее значение.
Также в каждой из таблиц находится два системных столбца: дата последнего изменения записи и система источника, из которой пришел этот атрибут.
В якорной модели каждый атрибут должен храниться в отдельной таблице, но в реальной жизни это оказалось не очень удобно для таблиц фактов.
Например, для финансовых транзакций, где все атрибуты приходят из одного источника. Самих транзакций крайне много, и соединять между собой таблицы атрибутов достаточно дорого. А в отчетности очень редко бывает, что атрибуты и транзакции должны быть по отдельности.
Поэтому мы решили, что круто уметь атрибуты объединять в группы, чтобы их хранить в одном месте. Это позволит и ускорить загрузку и упростить чтение данных. Для этого мы добавили свойства групп — их надо задавать у атрибутов, которые должны быть объединены в группу.
В группы можно объединять только атрибуты с одинаковой историчностью. И важно понимать минус этого решения: атрибуты должны приходить все вместе, иначе мы будем терять информацию. И желательно, с одинаковой частотой изменения. Потому что если один атрибут имеет гораздо большую частоту изменений, то при создании исторических данных все атрибуты будут лишний раз дублироваться.
Структура после объединения части атрибутов в группы выглядит уже гораздо более компактно.
Например, все флаги мы объединили в группу flg, общую информацию — в группу info, ключевые атрибуты — в группу key.
Теперь поговорим про объявление связей. Каждая связь тоже описывается в отдельном классе.
Атрибутами связи являются сами сущности, поэтому атрибуты Link должны быть объединены с объектами специального класса. Также обязательно для Link указывать ключ. Ключ определяет набор сущностей, которые однозначно идентифицируют строку в Link.
Каждый Link по умолчанию является историческим. Таким образом, в нем всегда есть два поля: utc_valid_from и utc_valid_to.
В этом примере мы делаем Link между департаментом и сотрудником. В данном случае ключом Link является сотрудник.
На слайде мы видим, как это физически реализовано.
Видно, что у Link нет суррогатного ключа, потому что его суррогатным ключом являются все те сущности, которые входят в ключ Link.
Теперь мы обсудим, как загружаем сущности.
Для загрузки был разработан ETL-кубик, который является частью нашего ETL-процесса. Он также описывается на Python. Мы описываем, что подается на вход, как данные распределяются по атрибутам и что является полем с бизнес-датой.
В самом простом случае этот кубик выглядит так.
В самом начале мы описываем источник. Это stage-таблица, для которой есть точно такой же класс, написанный отдельно в платформе.
Также мы указываем поле, в котором хранится бизнес-дата и система-источник.
Далее мы делаем маппинг между атрибутами. Описание таргета состоит из двух частей — указание сущности, куда мы загружаем атрибуты, и маппинг самих атрибутов.
Как мы видим, в качестве таргета указана таблица Person. Дальше следует маппинг атрибутов. Это самый простой вариант описания. В реальной жизни все выглядит гораздо сложнее. Например, так.
Мы видим, что из одной stage-таблицы данные грузятся в несколько сущностей. Одна сущность может грузиться несколько раз. Это в данном случае e-mail, он может быть в stage-таблице и персональным, и рабочим.
В большинстве случаев при загрузке Link не обязательно указывать маппинг, так как на основе этой информации мы можем понять, какие сущности указаны в Link, и найти маппинг этих сущностей в таргетах.
А если нет, то, скорее всего, это ошибка и мы об этом сообщаем пользователю.
Но в ряде случаев мы не можем автоматически этого сделать. Например, в stage-таблицу приходит и персональный почтовый ящик, и рабочий. Но и в обоих Link используется одна и та же сущность — e-mail. Мы их специально не разделяем, потому что в реальном мире e-mail — единая сущность. В то же время нам надо понять, какое здесь поле, какой Link грузить. Мы добавили специальный параметр, который позволяет определить, какое поле куда идет.
Дальше есть вот такой граф загрузки. Для каждой такой загрузки, для каждого такого лоудера генерится свой граф загрузки, который состоит из атомарных загрузок атрибутов Hub Link. Суррогатный ключ генерится как хэш, поэтому он может создаваться на каждом этапе самостоятельно.
Все задачи внутри графа выполняются параллельно, в зависимости от типа изменений. Это либо Insert\Update по SCD2, либо Insert. Данные из разных источников также могут загружаться параллельно.
Дальше я расскажу, как мы используем наш hNhM.
На основе DDS мы строим витрины. Пользователи напрямую могут обращаться к нашим сущностям и просматривать данные.
У нас есть два основных типа потребления данных DDS: ad-hoc-запросы от бизнес-пользователей и построение витрин. ad-hoc-запрос реализован двумя способами — либо view, либо через функции. И то и то скрывает реализацию от пользователей.
Витрины мы строим с помощью нашего фреймворка и тоже полностью скрываем реализацию.
Почему нельзя писать чистый SQL для детального слоя? В первую очередь потому, что дата-инженер должен знать о всех сущностях и атрибутах, должен знать, какой тип историчности у конкретного атрибута, и правильно это использовать в запросе.
После изменения описания сущности все витрины, которые использует тот или иной атрибут, теоретически могут развалиться, потому что атрибут был исторический, стал не исторический, и это изменит структуру таблицы.
В конце концов, это просто очень сложно — написать что-то с select, где будет 20-30 join.
Как у нас происходит доступ к сущностям из Python?
Было разработано несколько классов, которые позволяют сформировать SQL-запрос к определенной сущности и затем использовать его в построении витрины. Как это выглядит?
Мы описываем CTE. Оно может быть либо историческое, либо актуальное.
В первую очередь мы указываем сущность, которую хотим использовать.
После этого указываем необходимые атрибуты, которые мы будем использовать для витрины.
Прямо здесь мы можем сделать переименования, чтобы лишний не делать их в коде.
А так выглядит SQL-запрос для построения витрины. Есть переменные постановки, которые полностью скрывают реализацию. Потом идет сам запрос, который их использует. При этом можно использовать переменные как в визе, так и во временных таблицах. Это уже зависит от объема данных.
Как происходит доступ к сущностям из СУБД?
У нас есть вьюхи и есть две специальные процедуры. Первая — get_entity. Она получает в качестве параметров сущность, столбцы и создает временную таблицу, в которой будут, собственно, все необходимые данные процедуры.
И вторая процедура — это когда мы от entity к существующей таблице через Link добавляем дополнительную сущность и расширяем нашу табличку. Теоретически ключ у нее даже может поменяться.
А сейчас чуть более подробно покажу, как это работает.
Мы вызываем специальную функцию.
Указываем сущность.
Указываем столбцы, которые необходимо получить. Получить все столбцы сейчас нельзя, потому что для больших сущностей достаточно дорого считать всё вместе. Поэтому мы заставляем пользователя указать конкретные атрибуты, которые он хочет получить.
Дальше указываем временную таблицу, в которую надо положить данные.
Затем выполняется эта процедура. В ней создается таблица, куда вставляются данные. После этого можно просто селектить таблицу и смотреть подготовленные данные.
Примерно так же выглядит добавление сущности к уже созданной таблице.
Мы указываем таблицу, в которой уже есть сущность.
Указываем Link, через который мы хотим подключить дополнительную сущность.
Указываем саму сущность, которую мы хотим добавить.
И столбцы этой новой сущности. При этом мы можем как положить данные в уже существующую таблицу, так и создать новую.
Дальше мы расскажем, какие задачи оптимизации мы решали. Тут я передам слово Жене.
— Спасибо. Расскажу про оптимизацию и атрибуты против групп. Задача, на мой взгляд, очень интересная.
Посмотрим на объявление класса. Например, на объявление сущности Person.
В физическом мире мы можем представить ее в виде «один атрибут — одна табличка».
Это будет вполне нормально с точки зрения якорной модели. А можем ли мы сгруппировать атрибут? Здесь часть сгруппирована: флаги отдельно, информация о персоне отдельно, ключи отдельно, атрибуты отдельно.
Какая схема лучше? С точки зрения загрузки данных все то же самое. С точки зрения чтения данных все это скрыто, Коля про это рассказал. И с точки зрения использования будет одинаково.Не можем ли мы сделать так, чтобы эта физическая модель выбиралась наилучшим, оптимальным образом?
Мы постарались это свести к оптимизационной задаче. У нас буквально стояла проблема с объемом данных на Greenplum. Сейчас она не стоит. У нас действительно полупетабайтовый кластер на Greenplum, это достаточно много. Но еще буквально год-полтора назад даже такого не было.
Перед нами стоял вопрос: как оптимально объединить атрибуты по группам так, чтобы минимизировать объем хранения информации. У нас были метаданные объектов, это все наше описание того, что за объекты у нас есть. Маппинги полей и загрузчиков, количество строк в объекте и инкремент, а также накопленное знание о частоте изменений. У нас свой metaDWH, в который мы складываем всю эту информацию, и могли бы ее переиспользовать.
Существует набор ограничений, набор полей в метаданных объектов и эти маппинги, загрузчики. Как вы помните, группа должна загружаться из одного источника и иметь общий тип историзма.
Будем минимизировать занимаемое место на диске. Вот такую задачу мы себе поставили. Как мы ее решали?
Прежде всего мы формализовали и стандартизовали операции, меняющие схему, но не меняющие логику. Они совсем простые и очевидные. Можем объединять группы атрибутов в какую-нибудь еще группу, еще более крупную. Можем разъединять набор групп или вообще разъединить до атрибутов.
Фактически эта миграция, которая на слайде, никак не поменяет логическое устройство данных. Но при этом каждую из них мы можем хотя бы приблизительно оценить — узнать, сколько места они будут занимать в нашем случае.
Дальше мы взяли наше исходное состояние и из каждого состояния с помощью этих атомарных операций могли получить другое состояние физической системы, не меняя логическую архитектуру.
Из них следующие, из них следующие — так мы получаем пространство всех возможных состояний, в которые мы можем этими атомарными операциями попасть.
Дальше все просто. Мы из нашего состояния генерим новое мутациями — атомарными преобразованиями. Чтобы не обходить все, мы ограничиваем выборку и оцениваем каждое состояние.
Берем лучшие, скрещиваем их между собой, проводим новые мутации и так далее, классический генетический алгоритм.
В итоге при признаках какой-то сходимости мы останавливаемся, получаем итоговое состояние, которое лучше текущего по нашей оптимизационной функции. Сравниваем метаданные между собой и генерируем скрипт миграции. Как проходит миграция, как аккуратненько смигрировать так, чтобы пользователь не заметил, что у него физически что-то поменялось, — это отдельный большой вопрос на целый доклад, мы специально его не освещаем.
Я делаю акцент на том, что оптимизация была по месту, потому что применимость этого подхода гораздо шире. Гораздо интереснее оптимизировать не место, которое мы фактически сейчас закупили, это не для нас не проблема, а скорость чтения и скорость вставки информации. Усложнить нашу матмодель так, чтобы мы оценивали не только по месту, но и как-нибудь более сложно.
У нас есть наработки в этом направлении, но, честно говоря, мы не готовы про них рассказывать, потому что еще ничего не применяли на практике. Наверное, мы это сделаем и тогда поделимся, насколько мы смогли оптимизировать построение витрины и загрузку данных с помощью такой оптимизации.
К чему мы пришли, зачем мы сюда пришли и стоит ли вообще повторять наш путь?
Первый, на наш взгляд, инсайт от доклада — сравнение Data Vault и якоря. Мы поняли, что нам нужен детальный слой, что есть современные методологии Data Vault и якорь, и провели между ними сравнение. Они очень похожи. Я воспринимаю якорь как более жесткую форму Data Vault: в последнем есть правила, а в якоре эти правила еще более сложные.
Мы провели сравнение и сделали вывод: можно взять лучшее из каждой методологии. Не стоит слепо идти по одной из них и разрезать, например, clickstream на отдельные атрибуты. Стоит взять лучшее из Data Vault и из якоря.
Наш вариант — это гибридная модель, мы ее назвали hNhM. Требования я не буду перечислять, они на слайде. Основных идей три. Логическое и физическое проектирование, физический мир полностью скрыть как с точки зрения загрузки информации, так и с точки зрения ее получения.
Раз мы все это скрыли, то можем для физического мира выбирать нечто наиболее оптимальное. Оптимизировали именно хранение информации, но можно сделать нечто более интересное, например чтение.
На слайде показано, что мы взяли из Data Vault, а что из якоря.
Стоит ли за этим повторять? Пожалуйста, можете взять и полностью повторить, использовать точно так же. Кажется, что это вполне рабочая вещь, потому что мы ее используем уже года полтора.
Всем этим невозможно управлять без фреймворка. На явный вопрос, сколько у нас это заняло времени, Коля ответил — квартал. Но именно потому, что мы базировались на существующем внутреннем решении. На схеме было видно, что мы лишь маленький кубик в нашей общей платформе. Однако квартал — это не совсем честно. У нас был еще квартал на проектирование, размышление, не то чтобы это абсолютно чистая разработка.
Этот путь мы не советуем повторять. Если у вас нет свободной горы разработчиков, которые настолько круто прокачаны в Python, что готовы все это повторить и аккуратно сделать так же, как у нас, — лучше не вступать на этот скользкий путь. Вы просто убьете очень много времени и не получите того бизнес-результата, который можно получить, используя Data Vault, якорь или гибридную модель, как мы.
Что же делать? У нас есть большой roadmap развития. Можно добавить больше гибкости — например, я говорил, что на связь мы не вешаем ни атрибуты, ни группы. Но здесь можно это реализовать и воссоздать все типы таблиц Data Vault и якоря.
В нашем коде мы сейчас сильно завязаны на Greenplum. Хотелось бы от этого оторваться, сделать так, чтобы можно было применять модель где угодно именно с точки зрения фреймворка.
DSL у нас хоть и есть, но хотелось бы полноценный язык, который позволит строить витрины с учетом инкремента так, чтобы была полная кодогенерация. Пока она частичная.
Можно оптимизировать не только хранение, но и скорость выполнения запросов, делать автоматизированные миграции, потому что сейчас они еще полуручные, мы все еще боимся делать это аккуратно. И совсем фантастика — это визуальное редактирование метаданных.
Что делать, если у вас нет разработчиков? Дождаться, когда мы это заопенсорсим. У нас есть такие мечты. Вполне возможно, что мы свои фантазии осуществим и заопенсорсим этот продукт.
Следите за обновлениями или, если не хотите следить, приходите к нам и создавайте гибридную модель вместе с нами. На этом все. Спасибо за внимание.