
Привет, Хабр! Меня зовут Иван Вахмянин, я – один из сооснователей компании Visiology. Мы разрабатываем и развиваем одноименную аналитическую платформу, и теперь будем делиться нашим опытом, открытиями и интересными историями с вами. Это наш первый пост, и мы начнем с откровенного рассказа, как мы создавали компанию и саму корпоративную BI-платформу Visiology — без купюр, со взлетами и падениями. Если вам интересны реалии пути от стартапа до зрелой софтверной компании или тема Business Intelligence в целом — добро пожаловать под кат!

Дальше будет длинный и полный личных впечатлений рассказ. Но для тех, кто думает, стоит ли подписываться на наш блог — небольшой дисклеймер: мы будем писать в нашем корпоративном блоге о том, в чем мы разбираемся: про технологии анализа данных, про наши разработки и проекты, о том, как мы работаем с партнерами, и вообще о бизнесе российской продуктовой софтверной компании. А теперь давайте вернемся к истории.
Все началось в далеком 2014 году. Я тогда был руководителем центра разработки в системном интеграторе Polymedia, у нас была сильная R&D команда из 23 человек. Мы как раз завершили несколько серьезных проектов, и нужно было решить, куда идти дальше. Самым простым и понятным путем развития могла бы стать стандартная сервисная внедренческая модель (смотрим проблему заказчика, подбираем готовые платформы, создаем решение), но проблема была в том, что именно этим нам не хотелось заниматься.
Хотя мы и были частью интегратора, у команды уже был хороший опыт именно продуктовой разработки. К тому времени мы уже запустили два продукта: Flipbox — оболочка для больших интерактивных дисплеев в переговорных, и Polywall — софт для управления видеостенами в диспетчерских и ситуационных центрах. Эти продукты были действительно качественными. Например, Polywall до сих пор продается по всему миру и является одним из лучших в своей небольшой нише. Но у созданных решений также был недостаток – они быстро достигли потолка в своих специализированных нишах. Поэтому следующим шагом нам хотелось запустить что-то действительно масштабное.
С другой стороны, мы уже выполнили целый ряд проектов по внедрению аналитики, поэтому опыт по части BI у нас тоже был (особенно по ситуационным центрам региональных органов госвласти). Так что паззл сложился сам собой, и мы решили, что будем разрабатывать свою BI-платформу. Так начался путь уже новой компании – Visiology, которая изначально создавалась как чисто продуктовая, то есть Software Vendor.
2015 – Прототип и принятие архитектурных решений
Первый работающий прототип мы собрали очень быстро, буквально за три месяца. Конечно, это был немного “Франкенштейн”, но на нем мы проверяли наши архитектурные решения, а интересные подходы в нем действительно были.
В качестве основного стека технологий мы выбрали C# .NET, потому что у нашей команды уже был серьезный опыт разработки на этой платформе. Тут нам, конечно, сильно повезло, что позже появился .NET Core, с помощью которого мы довольно оперативно портировали платформу на Linux, когда это стало необходимым.
Для OLAP ядра мы взяли (как и подавляющее большинство начинающих разрабатывать свою BI-платформу) открытое решение Pentaho Mondrian, а данные размещали в PostgreSQL. Простое, очевидное и, как потом показал опыт, совершенно неправильное решение.
Поучительная история получилась с библиотекой визуальных компонентов Syncfusion, которую мы взяли для визуализации данных и некоторых UI компонентов, типа таблиц, Property Grid и т. п. Внедрили мы её довольно быстро (надо отдать должное, техподдержка у них работает качественно). Но вот потом все пошло не так – переговоры по лицензированию ушли куда-то совсем не туда, технических проблем тоже вылезло большое количество, и мы решили отказаться от Syncfusion. Однако оказалось, что к этому моменту выпилить ее из продукта гораздо сложнее, и сил на это уйдет больше, чем на добавление. В итоге, последнюю зависимость от Syncfusion мы удалили почти через два года, и все это время нужно было оплачивать лицензию. С тех пор мы очень внимательно относимся ко всем зависимостям, которые мы добавляем в продукт, как к платным, так и к открытым.
Самым нестандартным решением с нашей стороны было применение языка R для скриптов и расширения бизнес-логики системы. Идея заключалась в том, что R изначально очень хорошо подходит для обработки данных, а с расширениями типа dplyr еще и показывает неплохую производительность. Предполагалось, что аналитик будет писать преобразования данных на R, и поэтому первая версия конструктора дашбордов представляла из себя что-то вроде гибрида собственно инструмента верстки и IDE для R. Технически мы сделали форк ядра R и добавили в него интерфейсы, по которым платформа могла отправить код скрипта на исполнение (благо, C++ разработчики у нас тоже были). Мне по-человечески немного жаль, что от этого пришлось в итоге отказаться и выбросить много сделанного, но со временем нам пришлось реализовать много функций преобразования данных прямо в системе, чтобы аналитику приходилось писать код как можно реже, а для случаев, когда скрипты были все-таки нужны, намного более востребованным оказался Python.
Как бы то ни было, в июле 2015 года мы показали первый прототип (и он даже работал). Вдохновленные успехом, мы утвердили архитектурные решения и двинулись вперед. Но тогда мы даже не представляли, насколько недооценен был тот путь, который нам еще предстояло пройти.

2016 – Первая версия, первые внедрения, первые разочарования
В марте 2016 года мы официально презентовали первую версию платформы и сразу приступили к пресейлам и внедрениям. Понятно, что нашими клиентами на тот момент были компании, которых не очень интересовали характеристики Visiology как инструмента, для них был важен конечный результат – дашборды, которые они могут использовать для улучшения своих процессов. Поэтому работой на платформе занимались, в основном, наши коллеги из группы внедрения в Polymedia, они же принимали на себя основной удар проблем, связанных с «сыростью» продукта.
Температура на внутренних демо по итогам спринтов иногда поднималась так, что проектор отключался от перегрева. Внедренцы справедливо жаловались на неудобные моменты и неприятные баги, а мы могли эффективно отработать только небольшую часть их замечаний, потому что в архитектуре продукта и без этого назрели масштабные проблемы…
Производительность и In-Memory OLAP
Самая серьезная из этих проблем – производительность. Как я уже говорил, ядром системы был ROLAP движок Mondrian. Если совсем упростить вопрос, он представлял собой транслятор многомерных OLAP-запросов в обычные SQL-запросы, которые можно выполнить на любой СУБД (лишь бы данные в ней были размещены в определенном формате – т.н. Star Schema). Проблема была в том, что как только объем данных в таблице фактов достигал хотя бы миллионов строк, аналитические запросы начинали выполняться обычными СУБД со строчным дисковым хранением совсем не весело (минуты на обновление дэшборда при целевой метрике - менее 5 секунд).
Пока мы раздумывали, что с этим делать, один из наших ведущих C++ разработчиков предложил собрать прототип своего колоночного In-Memory движка. И даже этот подготовленный за пару недель прототип на синтетических тестах давал прирост скорости больше, чем на порядок, по сравнению с тем, чего мы могли добиться от связки Mondrian+PostgreSQL. Мы оказались перед сложным выбором. С одной стороны было понятно, что вложения в разработку своего In-Memory движка будут немалые. С другой стороны, никаких открытых вариантов или решений с доступным лицензированием на рынке просто не было. Мы смотрели и даже тестировали ClickHouse, который был выпущен Яндексом как раз в тот же период времени – он был максимально близок к тому, что было нужно, но все-таки не подходил (почему – тема, достойная отдельной статьи).
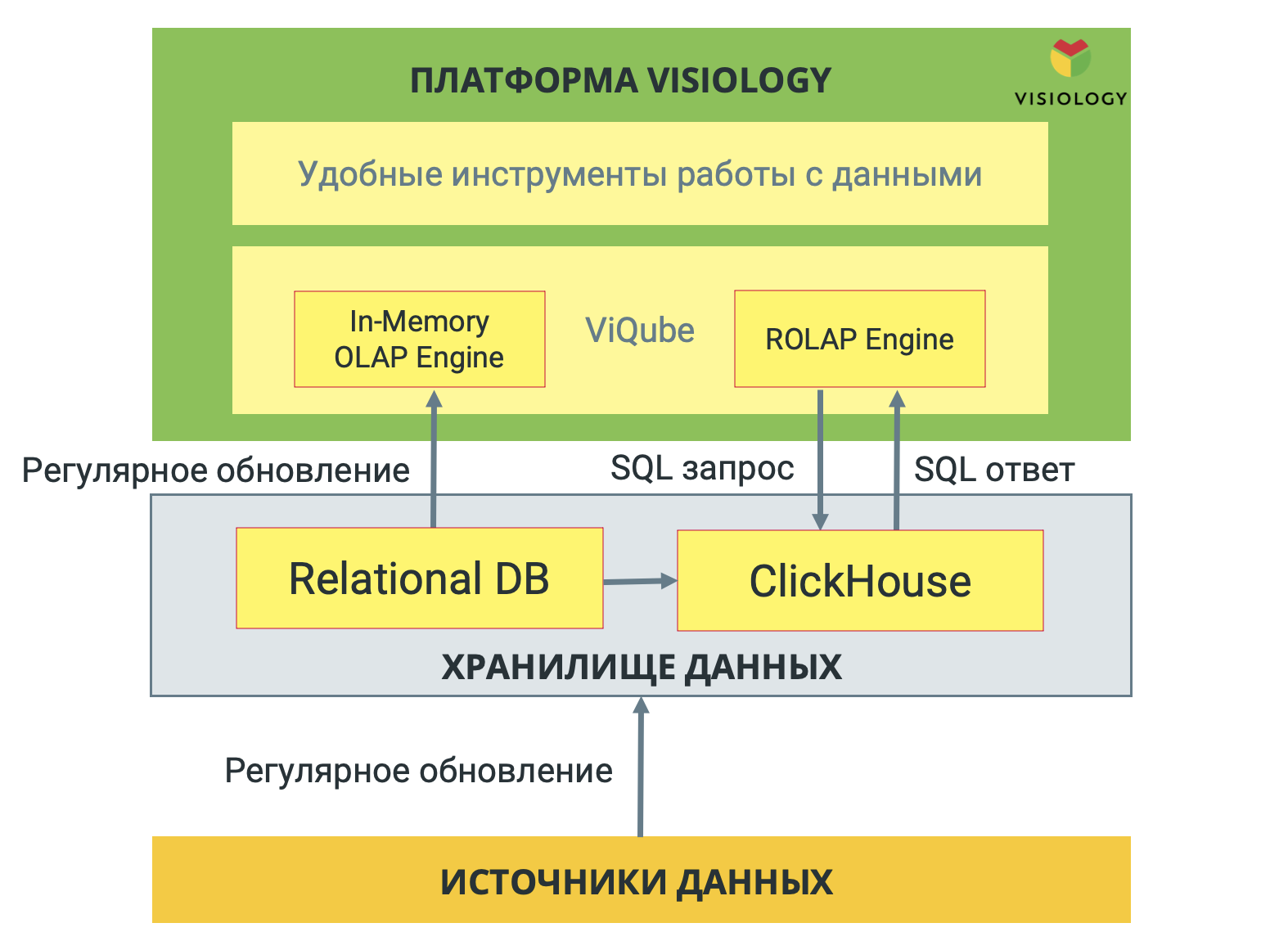
Поэтому, с болью в сердце, но мы все-таки приняли решение писать свой движок, который получил название ViQube. Кстати, именно он сейчас дает нам серьезное конкурентное преимущество. К слову, с ClickHouse мы тоже сделали интеграцию, но уже в 2020 году, и наши клиенты теперь могут использовать его в паре с ViQube в проектах, где объемы сырых данных измеряются в терабайтах.
Как мы и думали, разработка ViQube не была легкой прогулкой – ни в техническом отношении (где пришлось лезть чуть ли не в Assembler для правильного использования векторных регистров CPU), ни в организационном плане. В какой-то момент главный разработчик ViQube решил эмигрировать в Новую Зеландию, и нам пришлось фактически пересоздавать бэкенд команду. А это, прямо скажем, рискованное занятие. К счастью, мы такую возможность обсуждали с ним заранее, и у нас было время на подготовку, поэтому реорганизация прошла успешно.
Формы ввода
Второй проблемой стало отсутствие встроенного инструмента ввода данных. Мы столкнулись с тем, что у подавляющего большинства клиентов нет на 100% хорошо оцифрованных данных, которые можно вытащить из учетной системы и проанализировать. Одна часть всегда живет в Excel файлах разной степени испорченности, а другая — вообще отсутствует.
Опыт показал, что автоматизация загрузки Excel файлов, заполненных вручную, всегда плохо заканчивается. Решение этой проблемы во многих BI-платформах реализовано за счет модуля веб-форм для автоматизации ввода данных. В нем можно создать модель данных и формы, с помощью которых пользователи будут по каким-то регламентам вводить данные в систему. Но это если сильно упростить тему. В реальности корпоративные модули веб-форм – это, по сути, BPM-платформы, позволяющие автоматизировать довольно сложные процессы, например, планирование и бюджетирование. Из наиболее известных примеров — IBM Cognos TM1, Oracle Hyperion и Anaplan.

Какое-то время мы пытались найти партнерское решение, которое можно было бы легко интегрировать и закрыть потребность. Но ни среди российских, ни среди импортных продуктов мы не нашли такого решения с разумной схемой лицензирования. Но поскольку в большой части наших проектов без модуля ввода данных делать было просто нечего, мы решили запустить свою разработку. Очевидно было, что такой модуль – это продукт в продукте, и он требует отдельную команду. Где же ее взять?
Тут помог случай, и на нас вышли люди из Университета Иннополис с предложением открыть подразделение в новом городе Иннополис (республика Татарстан, если кто не знает). На тот момент в Иннополисе был построен только университет и несколько жилых домов, а между ними было разлито необъятное море грязи. Не могу сказать, что это было экономически и стратегически выверенное решение, но мы решили попробовать. Наверное, мы поверили, что сильный ИТ-университет может стать для источником сильных кадров. После оперативного сбора команды началась разработка. Вообще, тема открытия и развития офиса в Иннополисе тоже достойна отдельного поста, и мы вернемся к ней позже. Но если вкратце, то я очень рад, что мы тогда приняли именно такое решение. В первую очередь потому, что в этом офисе удалось построить действительно суперпрофессиональную команду разработки. Ну и сам город с тех пор преобразился, и я с удовольствием провожу там часть своего времени, хотя в последний год вырваться туда и поработать удается реже, чем хотелось бы.

ETL (Extract-Transform-Load), инструменты загрузки данных
Люди любят рассказывать о том, как они приняли решение что-то сделать, но часто на бизнес не меньше (а то и больше) влияют решения, наоборот, чего-то НЕ делать. Для нас таким непростым решением был отказ от разработки собственного ETL-инструмента (Extract-Transform-Load, загрузка и преобразование данных). На тот момент мы уже четко понимали, что на реально качественный крутой ETL у нас ресурсов не хватит, и мы решили, что лучше никакой, чем убогий. Конечно, мы сделали в платформе базовые инструменты загрузки из CSV, Excel файлов и различных СУБД через JDBC (SQL), но для всех сложных преобразований рекомендуем использовать сторонние инструменты, типа Apache Airflow, Pentaho Data Integration или Loginom. Сейчас, больше чем через 3 года, я абсолютно уверен в правильности того решения, как и в том, что для развития бизнеса и продукта определяющую роль играет отказ от чего-то (функции, идеи, партнеры и даже клиенты). На мой взгляд, это и есть фокус, это и есть стратегия.
Правда, мы недавно все-таки запилили ViXtract – бесплатный open-source ETL инструмент на основе Python и Jupyter, но это совсем другая история, да и время тогда было другое.
2017 – Система продаж, отдел Data Science
Параллельно с решением технических проблем, мы активно занимались построением системы продаж. Трудно сказать, что из этого было более сложным. B2B-продажи только со стороны выглядят замечательно – большие бюджеты, масштабные задачи, возможность личного общения с теми, кто принимает решения. Это все так, но еще B2B-продажи – это циклы сделок по 6 месяцев и более (и от 1 года, если стоимость решения требует включения его в годовой бюджет), политика, да и что уж там скрывать, не всегда мотивированные пользователи.
Самая важная история о B2B продажах, которую мы вынесли для себя – ты продаешь не компаниям, а людям. И на принятие решения о покупке в B2B влияет несколько (а иногда и несколько десятков) человек. Поэтому твой продукт должен иметь не просто ценностное предложение, а несколько предложений — по одному для каждой группы заинтересованных людей в компании. В нашем случае таких групп три:
Представители бизнеса (топ-менеджмент, руководители, иногда акционеры). Для этих людей важна выгода, которую их бизнес получит от внедрения – снижение затрат, увеличение выручки, повышение ценности компании в глазах инвесторов. И им, по сути, неважно, на каком инструменте это будет сделано, если только он не требует затрат свыше ожиданий.
Аналитики (те, кто непосредственно работает с BI, исследует данные, готовит дашборды и отчеты). Для аналитиков важнее всего удобство и функциональность инструмента – насколько он экономит его силы и время. Аналитику важно поработать с продуктом, чтобы он почувствовал уверенность, убедился, что сможет эффективно отрабатывать запросы бизнеса в вашей системе.
IT (CIO, IT-специалисты). Для IT важны две основные метрики – надежность решения (ведь за непрерывную работу сервисов им и платят деньги), а также низкий уровень нагрузки на service desk и внутреннюю команду автоматизации. Идеальный BI для IT – в котором аналитики могут полностью выполнить всю свою работу самостоятельно, привлекая IT только для развертывания инфраструктуры и регламентного обслуживания системы.
Наверное, я сейчас упрощаю, но понимание даже этой простой вещи в свое время сэкономило бы немало сил, которые мы тратили на то, чтобы объяснить бизнесу, какая удобная у нас функция вызова R функций, а ИТ-специалистам — как BI может улучшить восприятие компании инвесторами. Осознав свою ошибку, мы расширили метод персон, который до этого использовали только для работы с требованиями. Когда персоны появились в маркетинге и продажах, нам стало намного проще договариваться с нашими клиентами, ведь мы теперь говорили на их языке.
Услуги Data Science
Еще одно из решений, которое определило судьбу компании, был запуск Data Science подразделения. Мы изначально понимали, что без каких-то прорывных функций, технологий и особенностей продукт (и компания) не смогут развиваться. Но я уверен, что нельзя просто так взять и “сделать инновацию”. Любая новая идея – это большой риск, и чисто статистически, скорее всего, она провалится, чем полетит. Поэтому лучше выстроить процесс, когда параллельно с основным бизнесом ты пробуешь новые идеи в расчете, что рано или поздно найдешь ту, которая запустит новый виток развития.
Одной из новых идей стал запуск команды Data Science. По изначальной задумке она должна была оказывать нашим клиентам услуги по разработке сложных матмоделей, в том числе с использованием машинного обучения. Мы надеялись, что на подобных услугах можно будет хорошо заработать, ведь в тот момент конкуренция на этом поле еще не была так велика. Также был расчет, что услуги Data Science помогут продавать саму платформу Visiology.

Но этот путь оказался непростым. Первая проблема не заставила себя долго ждать – как нанять компетентного Data Scientist’а, если у тебя нет компетенций для его собеседования? Нанять через кадровое агентство? По знакомству? Не думаю, что даже сейчас это хорошая идея, а тогда — и подавно.
Мне пришлось стряхнуть пыль со своего университетского математического образования (К-28 МИФИ, привет!) и вникать в тему самому, попутно в очередной раз ощущая гнев и депрессию, сравнивая российские и зарубежные учебники по матстатистике и линейной алгебре. Я, конечно, не стал суперспециалистом по Data Science, но зато у меня получилось разработать процесс отбора кандидатов на позиции по Data Science, который не дал ни одного сбоя. Ключевым критерием было реальное понимание математических основ, а не просто заученные поверхностные определения и опыт подкручивания гиперпараметров в скачанных библиотеках.
Созданная команда реализовала целый ряд проектов, и самый крупный из них — для “Сибура”. Там ребята провели оптимизацию процесса синтеза окиси этилена: была разработана сложнейшая модель, комбинирующая методы машинного обучения с физико-химическим моделированием. Этот подход сейчас, в принципе, стал основным в задачах продвинутой аналитики в промышленности, а тогда приходилось это изобретать с нуля, но мы это сделали!
Впрочем, после ряда сложных задач, мы оглянулись назад и поняли, что это тема не для нас. Во-первых, сама история оказалась абсолютно не масштабируемой, в ней было крайне сложно найти возможность продуктового развития. Во-вторых, каждый раз мы делали почти НИР – а высокие риски заказчик обычно не очень готов брать на себя. В-третьих, большинство крупных компаний пошли по пути создания внутренних (in-house) Data Science подразделений, после чего сразу теряли интерес к работе с внешними подрядчиками. В общем, не хочу сказать, что услуги заказной разработки матмоделей совсем не востребованы, но мы от этого направления решили отказаться. Я бы сказал, что такой профиль лучше подходит для расширения портфеля услуг консалтинговой компании.
После закрытия направления усилия команды Data Science, которая не только сработалась, но и набрала немало опыта, были направлены на продуктовую разработку. В результате этих усилий после серии экспериментов появился ViTalk, виртуальный аналитик, который понимает запросы на естественном языке (типа, «покажи три самых прибыльных категории товара на прошлой неделе»). Сейчас он успешно развивается (например, недавно ViTalk переехал в Telegram и научился сам подбирать подходящие визуализации). С ним, кстати, можно свободно пообщаться в публичной демо-версии.

Крупные заказчики и макеты без продаж
К 2018 году у Visiology уже были и стабильный продукт, и серьезные проекты. Мы всерьез занялись маркетингом, накопили опыт работы с крупными компаниями и госзаказчиками. Самый важный урок, который мы выучили — далеко не каждый пресейл с макетированием приближает нас к продаже (зато каждый пресейл ест ресурсы). Иногда, к сожалению, макет нужен человеку в компании просто для того, чтобы показать какую-то свою деятельность. Мы обжигались на этом неоднократно, делая пресейл для компаний совершенно разного масштаба. В результате стало понятно, что имеет смысл делать макет только тогда, когда клиент тоже готов в него вкладываться – временем своих специалистов, вниманием руководства, ну и, конечно, деньгами. В крупных компаниях такое макетирование/апробация – это, по сути, небольшой проект с функциональным и нагрузочным тестированием. Участие в подобных апробациях требует ресурсов, ничего не гарантирует, но без этого продать в крупную компанию невозможно.
2018 – Импортозамещение, переход на Linux
Время шло, и импортозамещение стало новой реальностью. Серверную часть мы полностью перевели на Docker и Linux, причем удалось это сделать относительно безболезненно, благодаря использованию .NET Core. Хотя сказать, что это вообще не потребовало усилий, тоже нельзя. На момент перехода .NET Core был еще в довольно незрелом состоянии, и далеко не все библиотеки сразу стали в нем полностью поддерживаться. Часть из них пришлось менять из-за отсутствия поддержки, а для некоторых мы писали исправления сами и отправляли PR разработчикам. Внутри самого .NET тоже вылезали проблемы, например, один и тот же сериализатор/десериализатор в .NET Full и .NET Core в сложных кейсах работал по-разному, из-за чего сломалась совместимость между нашим десктопным приложением на .NET Full и сервером на .NET Core. Пришлось очень быстро наращивать компетенции в Linux, Docker и Nginx, потому что весь опыт до этого был связан больше с IIS.
В целом развитие шло довольно бодро, но вместе с тем зрело понимание, что мы должны на чем-то сфокусироваться. Было очевидно, что конкурировать с BI-продуктами из топа рейтингов Gartner на всей BI поляне с нашими ресурсами просто нереально. Мы стали рассматривать разные варианты, выбирать специализацию, максимально используя тот опыт и продукт, который у нас уже был. В топе вариантов был уход на зарубежный рынок с готовым решением под конкретную отрасль и развитие в тренде «отечественного ПО». Тема преференций для российского ПО появилась еще в 2015 году после подписания Постановления Правительства РФ №1236 «Об установлении запрета на допуск программного обеспечения, происходящего из иностранных государств, для целей осуществления закупок для обеспечения государственных и муниципальных нужд», и это выглядело очень заманчиво – «а не будет вашего итальянского сыра! (С) Веселый Молочник». В реальности же все эти законодательные ограничения носили скорее мягкий рекомендательный характер (по крайней мере в нашей отрасли) и до конца 2018 года мы их совсем не чувствовали. Да и сейчас, на самом деле, если госкомпания очень хочет приобрести западное ПО, у нее есть возможность это сделать.
Тем не менее, после подписания директивы Силуанова в конце 2018 года крупные компании оказались готовы, как минимум, смотреть в сторону российских BI решений, причем на это повлияло не только «закручивание гаек импортозамещения», но и вполне прагматичные причины:
Постепенный уход всех западных вендоров в облако и подписку без возможности установки сервера внутри периметра компании с покупкой бессрочной лицензии – в России (и не только, на самом деле) это мало кому нравится;
Возможность иметь вендора «под рукой» и реально влиять на Roadmap продукта;
Снижение TCO за счет использования Linux серверов и лицензирования в рублях;
Регуляторные риски: для некоторых компаний вполне реален риск попасть под санкции и потерять возможность продлять уже закупленные импортные лицензии
Очень хотелось, чтобы наш продукт использовался в действительно крупных проектах, поэтому мы взвесили все за и против, посмотрели на тренды и решили сосредоточиться на локальном рынке. Было понятно, что это тоже будет непросто, ведь на тот момент на нём уже были и российские конкуренты. Локальных BI-разработчиков оказалось вообще на удивление много и новые продолжают появляться даже сейчас, хотя серьезными конкурентами для себя мы считаем лишь единицы из них.
Я не отрицаю множества проблем, которые окружают всю тематику импортозамещения, но этот процесс совершенно точно дает возможности для российских компаний-разработчиков. Конечно, не стоит ожидать, что как только ты внесешь свой софт в Реестр отечественного ПО Минсвязи, тебе сами собой начнут сыпаться заказы, но присмотреться к открывающимся возможностям стоит. Нам очень сильно в этом плане помогло и помогает членство в Ассоциации разработчиков отечественного ПО (АРПП), в которое входят и такие уважаемые компании как InfoWatch, 1С, ЦРТ, ABBYY, Лаборатория Касперского и другие.
2019 – Развитие партнерской сети, крупные Enterprise внедрения
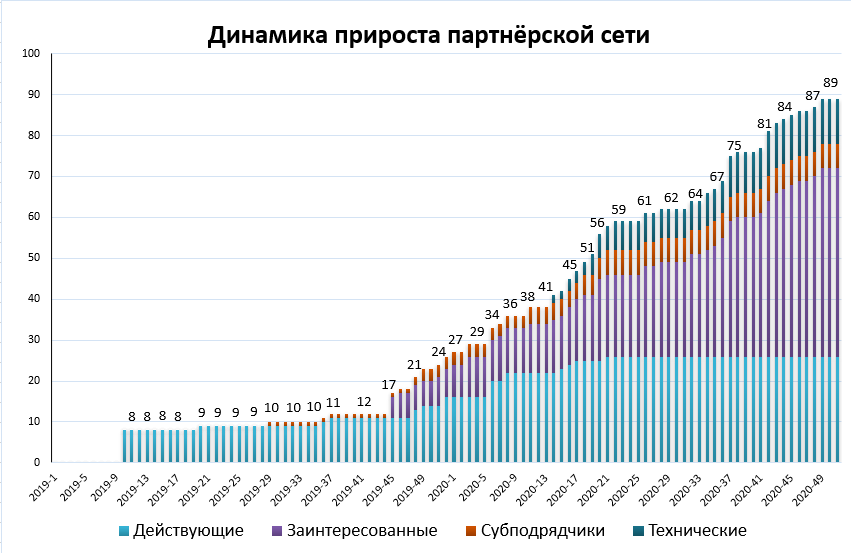
Отдельной историей стало развитие партнерского канала. Мы четко понимали, что хотя наш якорный интегратор – Polymedia и сделал свой вклад в развитие Visiology, но он не сможет помочь нам охватить весь рынок. Нужны были партнеры – реселлеры, интеграторы, дистрибьюторы. Для компании-разработчика идея продавать через партнеров вполне логична и лежит на поверхности – ты разрабатываешь, они продают и внедряют. Проблема в том, что многие разработчики почему-то думают, что стоит им сделать продукт, как все партнеры бросятся их продвигать и продавать. На деле это, конечно же, не так. Цель любой компании – заработать деньги, а не продвигать чужие продукты. Партнерам нужны продукты, которые легко продать (в идеале клиент сам должен за ними прийти), легко внедрить (в идеале вообще ничего не делая и не обучая специалистов) и на которых можно хорошо заработать, при этом без затрат на поддержку. Это означает, что продукт должен набрать очень серьезный уровень зрелости и узнаваемости на рынке, чтобы заинтересовать партнерский канал.
Я говорю все это потому, что мы набили кучу шишек, запуская партнерскую программу для других продуктов. И в случае с аналитической платформой мы уже совсем не торопились. Однако в 2019 году партнеры сами начали приходить с запросами, это был знак – пора! Мы оперативно запустили партнерскую программу и создали всю необходимую экосистему – а это не только (и не столько) продукт, сколько материалы для поддержки продаж, понятная документация, видеоролики, программы обучения и многое другое. Сил было вложено немало, но и результат оказался впечатляющим – за год мы полностью запустили партнерскую сеть, начали работать почти со всеми крупными российскими ИТ-интеграторами, подписали соглашение с двумя дистрибьюторами и даже сделали ряд очень интересных технологических партнерств – с Arenadata, Loginom и Vertica.
Работа с партнерами и апробации в крупных компаниях дали нам огромное количество обратной связи, причем далеко не всегда позитивной. Основной проблемой был проигрыш в сравнении с системами, которые обычно применяются для таких задач (Qlik, Oracle BI/Hyperion, IBM Cognos, SAP BI) по «enterprise» требованиям. Эти нюансы незаметны для пользователя, но без них ни один уважающий себя CIO не поставит систему на промышленную эксплуатацию – предсказуемая производительность, масштабируемость, поддержка сред dev-test-prod, мониторинг, подробное логирование, SSO и многое другое.
Начали мы с оптимизации производительности, и для этого в том же году, наконец, внедрили автоматизированное нагрузочное тестирование (а как иначе оптимизировать то, что не можешь измерить?). Для этого мы даже привлекли внешнюю компанию, специалиста по автотестам, которая написала нам скрипты на JMeter и пользовательские сценарии. Это сильно сэкономило наше время, но потом все равно пришлось самим глубоко вникать в скрипты и даже переписывать часть из них самостоятельно — погрузить подрядчика во все нюансы работы системы оказалось слишком сложной задачей.

Нагрузочное тестирование BI-платформы – это само по себе очень непростое и интересное занятие, достойное отдельной статьи. Основная сложность этого процесса кроется в том, что производительность очень сильно зависит от характера загруженных данных (модель и связи, кардинальность и типы полей в таблицах и многое другое) и от сценариев использования (одновременное редактирование модели, ввод и перезагрузка данных, просмотр дашбордов и т.п.). Причем, данные должны быть максимально приближены к реальным. Сейчас мы используем как тесты на основе TPC-H, так и очищенные от конфиденциальных данных клоны внедрений клиентов. Это позволяет быть уверенными, что у нас нет иллюзий, связанных с синтетическими тестами, отличающимися от реальной жизни.

В каждой крупной компании мы встречались с требованием к горизонтальной масштабируемости, даже в тех случаях, когда, казалось бы, один сервер с запасом закрывал потребности клиента. Сначала мы не могли понять логику этого требования, но потом стало очевидно, что это необходимая страховка на случай роста нагрузки в будущем. Ни один CIO не хочет оказаться в ситуации, когда производительность системы деградировала до неприемлемого уровня, а решить эту проблему добавлением железа он не может — только заменой системы или глубокой работой с разработчиком (а это небыстро). К счастью, основание для масштабируемости у нас было заложено еще тогда, когда мы переходили на Linux, одновременно мигрировав на «почти микросервисную» архитектуру и Docker-контейнеры. Конечно, без доработок ViQube не обошлось, но использование Docker Swarm очень сильно облегчило задачу.
Реализацией этих и других требований мы занимались весь 2019 и большую часть 2020 года. Самое трудное с моральной точки зрения, наверное, было копить в бэклоге задачи и улучшения, связанные с удобством использования. Ты понимаешь, что это нужные вещи, хочешь их сделать, но все ресурсы заняты на задачах по снятию «блокеров» — функций, без которых систему совсем нельзя использовать в крупном проекте… Сейчас уже, наконец, есть возможность изменить приоритеты на UX и, как мы ее называем, «полировку» продукта. Мне это, конечно, очень приятно.
2020 – Масштабирование
2020 был для всех реально непростой (и это он еще не закончился), и Visiology не была исключением. Мы полностью перешли на удаленку еще в марте и до сих пор не возвращались в офис. Многие проекты, на которые рассчитывали в начале года, были отменены или сдвинуты по времени. Сейчас еще рано оценивать качество принятых решений, но лично я уверен, что нам есть чем гордиться. Мы вышли на стабильный ритм выпуска релизов, серьезно поработали над масштабируемостью (кластеризация в Docker Swarm, среды dev-test-prod, мониторинг) и безопасностью, добавили генератор регламентных отчетов, улучшили и перенесли в Telegram виртуального аналитика ViTalk. Количество установок платформы выросло больше, чем в 2,5 раза по сравнению с 2019 годом. И самое главное - наши партнеры даже в такой сложной ситуации стартовали целый ряд действительно масштабных проектов на платформе, о которых мы раньше и мечтать не могли.
А еще мы, наконец, преодолели нашу природную скромность и запустили блог на Хабре! Надеемся, у нас получится вести его так, чтобы многим было полезно и интересно его читать. Кстати, я буду очень признателен, если вы ответите на опрос или напишете в комментарии, на какие темы вы хотели бы видеть публикации в нашем блоге.



NuGan
Интересная статья, хочется пожелать только удачи. Только вот вопрос, а self-hosted BI как класс не вымрет ли в ближайшее время, не заменят его облачные движки? Тот же Power BI отлично отдается из облака и идет как стандарт для тех, кто использует Azure и его сервисы. Будет ли облако Visiology? Нужно ли оно рынку? Чем вы тогда лучше Yandex DataLens, например?
BansheeRotary Автор
Для малого бизнеса облако — отличный вариант, и действительно, многие BI-вендоры активно переходят к SaaS модели (или изначально ее выбирают, как Yandex DataLens). Но крупные компании абсолютно не готовы отдавать свои чувствительные данные в облака. И это характерно не только для России — вот свежий обзор от BARC Research, из которого видно, что по всему миру облачной аналитике сами корпоративные пользователи придают гораздо меньше значения, чем вендоры — http://barc-research.com/research/bi-trend-monitor/. Поскольку наш целевой сегмент — это именно большие компании, то и облачную версию Visiology мы пока делать не планируем, просто нет спроса.
Оговорюсь, что это все касается публичных облачных сервисов, SaaS. Облако в режиме IaaS, конечно, многие применяют. У нас уже сейчас больше половины пилотных проектов живут в Yandex Compute Cloud.