
 Удобно сфотографировать на смартфон страницу из паспорта, визитку коллеги, договор с банком или чек из ресторана. Важные документы всегда будут под рукой, и их можно распечатать или переслать. Но быстро найти нужные файлы в галерее мобильного телефона становится все сложнее. Как правило, у пользователей копится целая коллекция мемчиков и картинок с котиками вперемешку с фотографиями счетов на оплату электричества, СНИЛС и др. У сотрудников компаний, например, выездных менеджеров банка или юридической фирмы, тоже бывают похожие ситуации. Только вместо изображений пушистиков – сотни фотографий клиентских договоров и других документов. Как отыскать необходимый экземпляр, чтобы отправить коллегам в офис, или как распечатать фото водительского удостоверения в правильном масштабе, а не на весь А4? Придется повозиться.
Удобно сфотографировать на смартфон страницу из паспорта, визитку коллеги, договор с банком или чек из ресторана. Важные документы всегда будут под рукой, и их можно распечатать или переслать. Но быстро найти нужные файлы в галерее мобильного телефона становится все сложнее. Как правило, у пользователей копится целая коллекция мемчиков и картинок с котиками вперемешку с фотографиями счетов на оплату электричества, СНИЛС и др. У сотрудников компаний, например, выездных менеджеров банка или юридической фирмы, тоже бывают похожие ситуации. Только вместо изображений пушистиков – сотни фотографий клиентских договоров и других документов. Как отыскать необходимый экземпляр, чтобы отправить коллегам в офис, или как распечатать фото водительского удостоверения в правильном масштабе, а не на весь А4? Придется повозиться. Гораздо проще решать все эти задачи с помощью одного приложения. Поэтому мы и обновили ABBYY FineScanner AI. Теперь он умеет автоматически сортировать фотографии из галереи смартфона на 7 групп документов и быстро ищет нужные фото по текстовым запросам.
Сегодня мы подробно расскажем, как создавали каждую из этих фич, какие технологии при этом использовали и как в этом помог фреймворк ABBYY NeoML. Также покажем, как это работает в приложении. А в конце – поделимся нашими планами по развитию FineScanner и зададим вам несколько вопросов.
Разложить все по полочкам папочкам
Согласно исследованию Appsflyer, в 2020 году резко выросло использование мобильных устройств и объем скачивания приложений, в том числе и неигровых. Для совместной удаленной работы сотрудникам нужны не только корпоративные мессенджеры, но и удобные мобильные инструменты для эффективной обработки информации, печати, удаленного документооборота и хранения данных.
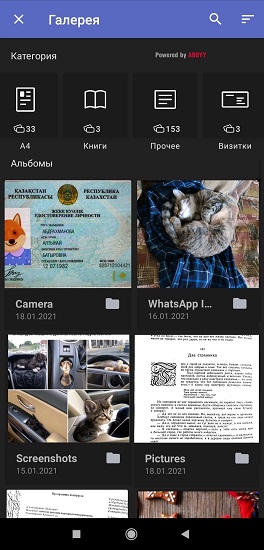
По данным опросов пользователей FineScanner и интервью с ними, чаще всего с помощью приложения сканируют одно- и многостраничные A4 (договоры, счета, официальные письма и др.), паспорта и водительские удостоверения, книги, чеки и визитки. 40% опрошенных фотографируют документы примерно раз в месяц, а 20% – раз в неделю. На основе статистики мы составили список тех типов документов, которые пользователи чаще всего снимают на камеру и хранят в галерее смартфона для себя или по работе. А затем мы научили FineScanner разделять фотографии на группы. Процесс состоит из двух этапов, полностью происходит в фоновом режиме и не требует интернет-подключения.
1). Сначала FineScanner классифицирует фотографии из галереи пользователя
После первого запуска приложения и получения всех разрешений от пользователя встроенные нейросети автоматически анализируют фотографии на смартфоне и распределяют их по 7 категориям: формат А4, книги, визитки, удостоверения личности, чеки, рукописный текст и «другое» (в этой папке хранятся афиши, открытки, цветные журналы и пр.).

Над интеллектуальной классификацией изображений трудится наша нейронная сеть на движке ABBYY NeoML, о котором мы подробно рассказывали на Хабре. Механизм состоит из двух нейросетей: первая – выявляет наличие текста на изображении, вторая – определяет типы документов. Основа архитектуры сетей – блоки MobilenetV3.
Нам важно было разделять рукописные документы от печатных, поэтому первая сетка разделяет файлы на 3 класса:
- изображение с рукописным текстом,
- изображение с печатным текстом,
- изображение без текста (котики, селфи и окружающая среда).
В первой сетке мы дополнительно использовали информацию о центральном кропе (кусок изображения из центра, вырезанный в большом разрешении), чтобы определить наличие текста на снимке. Мы взяли именно такой кроп, потому что в выборке (о ней расскажем чуть ниже) на всех фотографиях текст в основном был в центральной части. Это изображение подается вместе с миниатюрой в отдельную ветвь сети и помогает ей принять решение, есть ли текст на картинке или нет.
Вторая сетка определяет типы документов:
- документ А4 (с небольшим количеством рисунков),
- другие документы формата А4 (с цветным фоном, большим количеством иллюстраций — например, страница журнала),
- классический двухстраничный разворот книги (разворот книги с небольшим количеством черно-белых иллюстраций),
- цветной разворот книги (с большим количеством иллюстраций и цветным фоном, например, разворот журнала),
- визитка,
- ID (паспорта, водительские удостоверения и т.д) – любые документы, на которых есть фотография лица,
- чек (длинные и короткие магазинные чеки. Не инвойсы и не квитанции).
Датасет для обучения нейросеток собирали и размечали наши сотрудники. Выборка состояла примерно из 40 тыс. фотографий (визитки, флаеры, банковские карты, справки, страховки и т.д.), сделанных на смартфон.
За счет нейросетки вес приложения увеличился незначительно – всего на 3МБ. Мы специально старались сделать нейросеть компактной. Не хотелось сильно раздувать приложение ради такой отчасти «экспериментальной» фичи.
2). После классификации происходит распознавание текстов на найденных фотографиях документов.
Для этого используется наша технология ABBYY Mobile Capture SDK, которая работает и в TextGrabber для распознавания текста или видеоряда, и в Business Card Reader для обработки визиток. В FineScanner этот SDK использовался и ранее – для быстрого офлайн-распознавания документов. В этот раз мы использовали его по полной программе: он может распознавать текст на тысячах картинок. Конечно, стараемся делать это нежно и аккуратно, чтобы процесс не загружал девайс и не пожирал батарейку. Кроме того, мы решили пока не скачивать фотографии пользователя, выгруженные в облака, а обрабатываем только те, что доступны локально на девайсе.
Общее время всей обработки галереи зависит от количества фотографий и документов среди них, а также от поколения телефона и в среднем составляет 10-30 минут для первого раза. В дальнейшем сканироваться будут только новые фотографии, а их уже будет значительно меньше, не тысячи штук.
Найти документ по его тексту
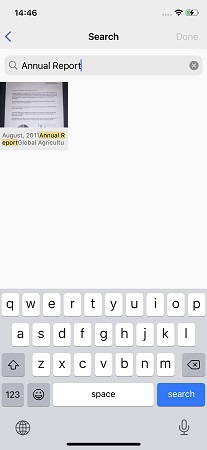 Сортировка изображений по типам – хорошая вещь, но что если в папке «Книги» – сотня снимков, а нужно найти один, например, рецепт пряной шакшуки, сфотографированный из редкой кулинарной энциклопедии? Или отыскать в папке «А4» договор аренды жилья, заключенный два года назад?
Сортировка изображений по типам – хорошая вещь, но что если в папке «Книги» – сотня снимков, а нужно найти один, например, рецепт пряной шакшуки, сфотографированный из редкой кулинарной энциклопедии? Или отыскать в папке «А4» договор аренды жилья, заключенный два года назад?Для таких случаев мы научили FineScanner поиску по тексту документа. Причем вариант с поиском по точному запросу, слово в слово, отбросили сразу же. Как правило, искать текст на качественно сфотографированных документах нетрудно, но в галерее на смартфоне может быть что угодно – сильно повернутые или размытые фото. Организовать по ним так называемый «четкий поиск» несложно, но результаты будут грустные. Капитализацию (применение заглавных букв), конечно же, можно и нужно игнорировать, но бывают, например, орфографические ошибки пользователей при написании запроса.
Чтобы приложение проглатывало этот спектр ошибок, мы сделали «нечеткий поиск». Свой полноценный поисковый движок писать не собирались, поэтому смотрели на существующие подходы и библиотеки. В итоге для решения нашей задачи неплохо подошел дифф-алгоритм Юджина Майерса (Myer's diff algorithm).
Дифф-алгоритм служит не для поиска, а для сравнения двух текстов или двух версий одного и того же документа.
Реализацию взяли готовую, отсюда. Правда, пришлось добавить поверх нее вычисление расстояния Левенштейна между поисковым запросом и найденной подстрокой и подобрать пороги, чтобы не было совсем уж диких вариантов. В результате наш текстовый поиск работает четко, быстро и в режиме реального времени.
AR-линейка в iOS-версии, или как определить размер документа без танцев с бубном
 Когда мы разрабатывали новые фичи в FineScanner, то учитывали и пожелания пользователей. Например, им часто нужно распечатать документы не только привычных размеров (A4, A5, A6, визитка), но и нестандартных: листовки, флаеры, СНИЛС и др. А с печатью таких файлов возникают трудности: например, фото растягивается на весь А4, хотя оригинальные пропорции у него другие.
Когда мы разрабатывали новые фичи в FineScanner, то учитывали и пожелания пользователей. Например, им часто нужно распечатать документы не только привычных размеров (A4, A5, A6, визитка), но и нестандартных: листовки, флаеры, СНИЛС и др. А с печатью таких файлов возникают трудности: например, фото растягивается на весь А4, хотя оригинальные пропорции у него другие.Самые распространенные размеры документов можно выбрать из готового списка в приложении, их 8 типов. Любые другие – открытки, визы и т.п. – теперь можно измерить автоматически. Для этого в новую версию FineScanner для iOS мы встроили ARKit (линейку в дополненной реальности). Для ее разработки использовали API Apple совместно с нашим crop-модулем ABBYY Mobile Capture SDK, который позволяет определять границы документа даже на белом фоне и достраивает их, если они закрыты руками. Линейка определяет физический размер документа, чтобы указать его в свойствах и получить его корректное отображение на бумаге при печати на принтере.
Вот как это работает:
Как используют FineScanner наши бизнес-заказчики
Первыми новую функциональность попробуют наши B2C-клиенты, а бизнес начнет использовать приложение чуть позже. Это связано, в первую очередь, со строгими политиками в области корпоративной безопасности.
Наши заказчики из крупных компаний используют свои версии ABBYY FineScanner под управлением различных платформ MDM (Mobile Device Management, то есть решения, которые позволяют настраивать уровни защиты корпоративной информации от несанкционированного доступа и распространения, а также определяют, будет ли доступна сохраненная на мобильном устройстве информация для сторонних приложений). Например, сотрудники практик аудита или бизнес-консультирования PwC применяют мобильный сканер для быстрой оцифровки любых документов. Во время аудиторских проверок они всего за несколько секунд фотографируют, например, договоры или приказы, преобразовывают их в PDF с возможностью поиска и отправляют в корпоративные хранилища для дополнительной проверки и анализа данных.
Для удобства наших заказчиков сейчас мы готовим к выпуску версию FineScanner с поддержкой самых популярных MDM-систем – Microsoft InTune, Mobile Iron, Workspace One и других.
На будущее
Надеемся, обновленный FineScanner поможет упростить задачи по оцифровке и распознаванию документов и книг прямо на смартфоне, а также по быстрому поиску нужных файлов в галерее и их печати.
Мы регулярно собираем пожелания пользователей к FineScanner, чтобы понимать, как развивать продукт дальше. Согласно нашему последнему опросу, половина юзеров отправляют сфотографированные документы на свою или другую почту и продолжают работать с ними на компьютере, например, распечатывают или хранят. Причем свыше 70% ожидают, что у FineScanner будет интеграция с ABBYY FineReader PDF. Нам стало интересно узнать, что об этом думают хабровчане.




{kind=link}
ClearAirTurbulence
Как неспециалист прошу уточнить: оно это делает локально, или такие коннектится к серверу и сливает туда фото\часть фото? У некоторых юзеров, очевидно, в галерее есть фото, которые они вряд ли хотели бы анализировать "на стороне" (конфиденциальные документы, запрещенные на территории РФ комиксы, интим-фото и т.п.).
ABBYYTeam
ClearAirTurbulence все происходит локально, на устройстве.