
В 1993 году, когда появилась Всемирная паутина, World-Wide-Web, веб-страницы были представлены статическими HTML-файлами, содержащими ссылки на другие такие же файлы. Но вскоре, благодаря таким технологиям, как CGI, Perl и Python, веб-сайты стали оснащать динамическим функционалом, который серьёзно расширил их возможности.
Я, с момента появления интернета, создал множество веб-проектов, используя самые разные языки, фреймворки и платформы. Я, кроме прочего, писал системы управления контентом, фреймворки для разработки приложений, движки для блогов, программы, обеспечивающие работу социальных сетей. Среди этих проектов есть такие, которыми я очень горжусь, а вот вспоминая о некоторых других особой гордости я не испытываю.
Недавно я пришёл к выводу о том, что я делал всё неправильно. Я собираюсь прекратить писать серверные веб-приложения, а в этой статье хочу объяснить причины, по которым вам стоит принять такое же решение.

Прекратите писать серверные веб-приложения
Рассмотрим типичный веб-запрос. Некто переходит по ссылке. Браузер выполняет запрос к серверу. Веб-сервер выполняет какой-то код и определяется с тем, что именно хочет увидеть посетитель, и что именно нужно отрендерить. Сервер загружает из базы данных нужную информацию и наполняет ей шаблон страницы. Сервер, наконец, рендерит то, что отправит в ответ на запрос, то есть — HTML-код, и отправляет это браузеру. Выглядит это всё довольно просто. Правда?
Как вам, возможно, известно, любое приложение, вышедшее за пределы «Hello World», очень быстро начинает сильно усложняться. Часто один запрос инициирует несколько обращений к базе данных или к другим внешним API. А чем больше обращений к базе данных и к различным службам — тем выше сетевая задержка. На разных уровнях информационных систем могут присутствовать кеши, нацеленные на решение проблем с производительностью, но усложняющие устройство систем. То, что мы называем «сервером», на самом деле, может быть представлено несколькими серверами, находящимися за балансировщиком нагрузки, что усложняет развёртывание систем.
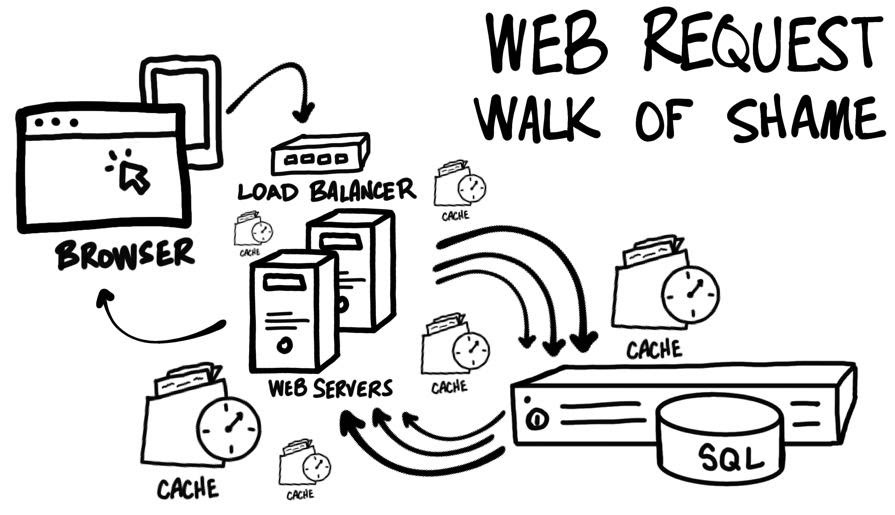
Веб-запрос: путь позора
Обычно монолитные серверные приложения превращаются в монстров. А разбиение монолитного приложения на микросервисы означает необходимость выполнения больших объёмов работы. Это, кроме того, ещё сильнее усложняет информационные системы и плохо отражается на величинах задержек. Что же делать веб-разработчикам?
В последнее время то и дело встречаешься с понятием «JAMstack». Может, и вы что-то об этом слышали? Если предельно просто объяснить суть этого понятия, то окажется, что в JAMstack используются генераторы статических сайтов, с помощью которых создают страницы, содержащие HTML, CSS, JavaScript и другие материалы, а потом размещают это всё на CDN (Content Delivery Network, сеть доставки контента).
«Но это же… статический HTML? Это — всё равно, что размещать на серверах простые HTML-файлы? Шутите, что ли?»
На первый взгляд JAMstack выглядит как шаг назад. Правда?
Когда я впервые услышал о JAMstack, я подумал: «Этот подход к разработке веб-сайтов, возможно, хорошо подойдёт для страниц документации, для маркетинговых лендинговых сайтов и для блогов. Но не для настоящих веб-приложений. Спасибо, конечно, но я буду пользоваться моим собственным стеком технологий».
В общем, я попросту сбросил JAMstack со счетов. Прошу вас — не поступайте так, как я.
Серверы быстрее всего отвечают на запросы браузеров тогда, когда браузеры запрашивают у них обычные файлы. Что-то более сложное требует, в лучшем случае, обработки некоей информации процессором сервера, а в худшем случае всё сводится к «пути позора», о котором мы говорили выше. Быстрее всего клиентам отдаются файлы, которые размещены на CDN, так как файлы, благодаря распределённой природе сетей доставки контента, оказываются, в физическом смысле, ближе к тем, кому они нужны. CDN-провайдеры, кроме того, очень хорошо знают о том, что такое «масштабирование ресурсов», необходимое для поддержания работоспособности систем в моменты пиковых нагрузок и позволяющее предотвращать DDoS-атаки.

Самый быстрый и безопасный код — это его отсутствие
Буквы «JAM» в слове JAMstack — это сокращение от JavaScript, API и Markup (заранее отрендеренная разметка). За JAMstack стоит сравнительно простая идея. Абсолютно всё, что можно, нужно превратить в заранее отрендеренную разметку. Затем, после того, как эта разметка достигнет браузера, нужно, прогрессивно используя JavaScript и обращения к различным API, сделать приложение настолько динамическим и персонализированным, насколько это соответствует нуждам конкретного проекта. Подход к созданию сайтов, реализуемый в рамках JAMstack, перемещает вычисления, необходимые для приведения приложения в работоспособное состояние, с сервера в браузер.
В последнее время генераторы статических сайтов стали чрезвычайно функциональными. Они поддерживают массу возможностей, которые способны удовлетворить широкому спектру потребностей разработчиков. Кроме того, для тех, кому нужны простые инструменты для управления содержимым сайтов, появился новый рынок CMS (Content Management System, система управления контентом) без пользовательского интерфейса. Такие системы отлично дополняют подход к разработке проектов, применяемый в JAMstack. В ходе выполнения сборки проекта генератор статических сайтов может обращаться к API, к базам данных, к CMS, имеющим API, или к чему угодно другому, необходимому для максимизации объёма заранее отрендеренной разметки.
Если вам интересна тема JAMstack — то вот и вот — полезные статьи, а вот — хорошее видео об этом. Здесь можно найти большую коллекцию генераторов статических сайтов.
Веб-разработчик может писать код JAMstack-приложений, пользуясь любимым языком и любимыми платформами! Только теперь фокус его внимания будет смещён на создание как можно более качественных API для его приложений. Навыки разработчика, кроме того, можно использовать в деле автоматизации генерирования статических ресурсов и развёртывания проектов.
Чем больше я узнавал о JAMstack — тем лучше я понимал то, какие именно преимущества этот подход даёт тому, кто его использует:
Рассматривая некоторые из моих прошлых проектов с точки зрения JAMstack, я вижу, как применение этого подхода позволило бы решить множество проблем, особенно — тех, что возникают в сфере масштабирования и развёртывания приложений. А когда я размышляю о приложениях, применение к разработке которых JAMstack-подхода я поначалу считал невозможным, я просто не вижу ничего, что подошло бы для них лучше, чем JAMstack.
Я уверен в том, что фронтенд- и бэкенд-разработчиков ждёт светлое будущее — будущее, где никому больше не придётся писать серверные веб-приложения.
Пользуетесь ли вы JAMstack?

Я, с момента появления интернета, создал множество веб-проектов, используя самые разные языки, фреймворки и платформы. Я, кроме прочего, писал системы управления контентом, фреймворки для разработки приложений, движки для блогов, программы, обеспечивающие работу социальных сетей. Среди этих проектов есть такие, которыми я очень горжусь, а вот вспоминая о некоторых других особой гордости я не испытываю.
Недавно я пришёл к выводу о том, что я делал всё неправильно. Я собираюсь прекратить писать серверные веб-приложения, а в этой статье хочу объяснить причины, по которым вам стоит принять такое же решение.
Прекратите писать серверные веб-приложения
Веб-запрос: путь позора
Рассмотрим типичный веб-запрос. Некто переходит по ссылке. Браузер выполняет запрос к серверу. Веб-сервер выполняет какой-то код и определяется с тем, что именно хочет увидеть посетитель, и что именно нужно отрендерить. Сервер загружает из базы данных нужную информацию и наполняет ей шаблон страницы. Сервер, наконец, рендерит то, что отправит в ответ на запрос, то есть — HTML-код, и отправляет это браузеру. Выглядит это всё довольно просто. Правда?
Как вам, возможно, известно, любое приложение, вышедшее за пределы «Hello World», очень быстро начинает сильно усложняться. Часто один запрос инициирует несколько обращений к базе данных или к другим внешним API. А чем больше обращений к базе данных и к различным службам — тем выше сетевая задержка. На разных уровнях информационных систем могут присутствовать кеши, нацеленные на решение проблем с производительностью, но усложняющие устройство систем. То, что мы называем «сервером», на самом деле, может быть представлено несколькими серверами, находящимися за балансировщиком нагрузки, что усложняет развёртывание систем.
Веб-запрос: путь позора
Обычно монолитные серверные приложения превращаются в монстров. А разбиение монолитного приложения на микросервисы означает необходимость выполнения больших объёмов работы. Это, кроме того, ещё сильнее усложняет информационные системы и плохо отражается на величинах задержек. Что же делать веб-разработчикам?
Веб-разработчикам стоит присмотреться к JAMstack
В последнее время то и дело встречаешься с понятием «JAMstack». Может, и вы что-то об этом слышали? Если предельно просто объяснить суть этого понятия, то окажется, что в JAMstack используются генераторы статических сайтов, с помощью которых создают страницы, содержащие HTML, CSS, JavaScript и другие материалы, а потом размещают это всё на CDN (Content Delivery Network, сеть доставки контента).
«Но это же… статический HTML? Это — всё равно, что размещать на серверах простые HTML-файлы? Шутите, что ли?»
На первый взгляд JAMstack выглядит как шаг назад. Правда?
Когда я впервые услышал о JAMstack, я подумал: «Этот подход к разработке веб-сайтов, возможно, хорошо подойдёт для страниц документации, для маркетинговых лендинговых сайтов и для блогов. Но не для настоящих веб-приложений. Спасибо, конечно, но я буду пользоваться моим собственным стеком технологий».
В общем, я попросту сбросил JAMstack со счетов. Прошу вас — не поступайте так, как я.
Правда о JAMstack
Серверы быстрее всего отвечают на запросы браузеров тогда, когда браузеры запрашивают у них обычные файлы. Что-то более сложное требует, в лучшем случае, обработки некоей информации процессором сервера, а в худшем случае всё сводится к «пути позора», о котором мы говорили выше. Быстрее всего клиентам отдаются файлы, которые размещены на CDN, так как файлы, благодаря распределённой природе сетей доставки контента, оказываются, в физическом смысле, ближе к тем, кому они нужны. CDN-провайдеры, кроме того, очень хорошо знают о том, что такое «масштабирование ресурсов», необходимое для поддержания работоспособности систем в моменты пиковых нагрузок и позволяющее предотвращать DDoS-атаки.
Самый быстрый и безопасный код — это его отсутствие
Буквы «JAM» в слове JAMstack — это сокращение от JavaScript, API и Markup (заранее отрендеренная разметка). За JAMstack стоит сравнительно простая идея. Абсолютно всё, что можно, нужно превратить в заранее отрендеренную разметку. Затем, после того, как эта разметка достигнет браузера, нужно, прогрессивно используя JavaScript и обращения к различным API, сделать приложение настолько динамическим и персонализированным, насколько это соответствует нуждам конкретного проекта. Подход к созданию сайтов, реализуемый в рамках JAMstack, перемещает вычисления, необходимые для приведения приложения в работоспособное состояние, с сервера в браузер.
В последнее время генераторы статических сайтов стали чрезвычайно функциональными. Они поддерживают массу возможностей, которые способны удовлетворить широкому спектру потребностей разработчиков. Кроме того, для тех, кому нужны простые инструменты для управления содержимым сайтов, появился новый рынок CMS (Content Management System, система управления контентом) без пользовательского интерфейса. Такие системы отлично дополняют подход к разработке проектов, применяемый в JAMstack. В ходе выполнения сборки проекта генератор статических сайтов может обращаться к API, к базам данных, к CMS, имеющим API, или к чему угодно другому, необходимому для максимизации объёма заранее отрендеренной разметки.
Если вам интересна тема JAMstack — то вот и вот — полезные статьи, а вот — хорошее видео об этом. Здесь можно найти большую коллекцию генераторов статических сайтов.
Лучшее из двух миров
Веб-разработчик может писать код JAMstack-приложений, пользуясь любимым языком и любимыми платформами! Только теперь фокус его внимания будет смещён на создание как можно более качественных API для его приложений. Навыки разработчика, кроме того, можно использовать в деле автоматизации генерирования статических ресурсов и развёртывания проектов.
Чем больше я узнавал о JAMstack — тем лучше я понимал то, какие именно преимущества этот подход даёт тому, кто его использует:
- Упрощение архитектуры проектов.
- Использование лучших API сторонних разработчиков.
- Применение возможностей CDN.
- Возможность уделять больше внимания удобству приложений для пользователей и соответствию веб-проектов нуждам заказчиков приложений.
Рассматривая некоторые из моих прошлых проектов с точки зрения JAMstack, я вижу, как применение этого подхода позволило бы решить множество проблем, особенно — тех, что возникают в сфере масштабирования и развёртывания приложений. А когда я размышляю о приложениях, применение к разработке которых JAMstack-подхода я поначалу считал невозможным, я просто не вижу ничего, что подошло бы для них лучше, чем JAMstack.
Я уверен в том, что фронтенд- и бэкенд-разработчиков ждёт светлое будущее — будущее, где никому больше не придётся писать серверные веб-приложения.
Пользуетесь ли вы JAMstack?












welovelain
Я не понял, как без сервера приложение будет обращаться к апи. Где это апи крутится-то?
Drag13
JAM это немного не про то. Представьте себе что вы хотите сделать свой блог. Есть несколько вариантов как это сделать.
Вариант №1 — олд скул. Мы берем и пишем статический сайт, Ваши статьи нигде не хранятся, они сразу внутри страниц. Из преимуществ все работает очень быстро. Из минусов, когда вы решите изменить верстку какого то компонента, вам придется делать это для всех страниц. К тому же когда вы захотите сделать мобильное приложение или отдать ваши статьи кому-то еще, окажется что ваши статьи нельзя взять и "просто так" отдать кому-то, они зашиты в разметку.
Вариант №2 — сервер рендер. Теперь наши страницы хранятся в базе, у нас есть шаблоны для компонентов. Из плюсов — верстку можно поменять в одном месте сразу для всех. Можно отдать статьи другому клиенту. Из минусов, все работает немного медленнее, т.к. каждому юзеру мы генерим страницу на лету.
Вариант №3 — рендер на клиенте. Все тоже самое, только еще хуже. Теперь мы сначала отдаем пользователю разметку, выполняем JS, а потом уже делаем запрос за данными. Есть и преимущества но для данного случая они не существенны.
И, наконец, джем стек. Мы смешиваем №1 и №2 подходы. Во время билда! (не в рантайме, это основной момент) мы вытягиваем ваши статьи из БД, берем шаблоны верстки, стили и превращаем это все в статические страницы. На сервер мы ложим именно их. В итоге все очень быстро (т.к. нам нужно только одать статику) и гибко, так как мы работаем с данными и компонентами.
Но нужно понимать что этот подход не всем подходит. Если вид страницы не зависит от пользователя — все отлично. Если зависит сильно, это не ваш вариант скорее всего. Поэтому я бы сказал что заголовок очень кликбейтный и не корректный.
welovelain
А, так понятней, спасибо.
Что-то типа блогов наподобие HEXO, которые рендерят markdown в веб-страницы.
Drag13
Да, именно. Только вместо md — мы используем ответы от апи во время рендера для получения контента. А что оно там вернет (статьи, товары) не важно.
bm13kk
Для сайта с активным добавления информации (например люди мишут блоги и комментарии или есть сторонний источник данных) — тоже не очень подходит. А таких сайтов большинство.
EDIT: пропустил "не"
Drag13
Можете объяснить? В моем понимании как раз не подходит, т.к. мы не знаем основную массу контента во время билда.
bm13kk
поправил
Chamie
Если информация не слишком часто обновляется, то можно просто дописывать её в файлы с данными, которые потом подгрузит JS на стороне клиента.
Dissarion
Для примера далеко ходить не надо. Посмотрите на Smashing Magazine. Они активно создают контент и у них JAMstack.
У них лежит около 4к md файлов и из них генерируются страницы.
shuron
А где можно почитать про их движок и пайплайн?
Dissarion
Об этом не подскажу. Конкретно про JAMStack, MD-файлы и генерацию Виталий Фридман рассказывал в этом мастер-классе на HolyJS Online https://www.youtube.com/watch?v=x7S1YrP8GOg
shai_hulud
А чем это отличается от кеширования отрендереного HTML из «вариант №2»?
Drag13
Статику дешевле обслуживать. Можно положить на хостинг типа "утюг" за 1 доллар и иметь хорошую производительность.
Статику проще положить на CDN и получить еще лучше отклик. С кешем тоже можно но сложнее.
Fell-x27
Это все здорово, только при чем тут веб-приложения? Лендинги, блоги с натяжкой и их родичи типа новостных порталов без поддержки комментариев, допустим. А веб-приложения тут коим боком? Какой-нибудь твиттер или телеграм, или, не знаю, биржа, например? Это вот веб-приложения.
А сайты, динамическая версия которых может быть просто запечена в статическую, к приложениям не имеют никакого отношения, имхо.
Drag13
Зависит от контента, мне кажется. Если он динамический, зависит от пользовтеля то никаким. То что описывается в статье это не серебьрянная пуля, это просто одно из нишевых решений. Кому-то ок, кому-то нет. Просто кто-то поставил очень кликбейтный заголовок вот и поехал вентилятор.
Bigata
Вот именно. Статья как навязчивая реклама. Для приложений, где на странице много что меняется, совершенно не подходящее решение. Как пример — много где рекламные блоки меняют содержимое неоднократно, их что, каждый раз перегонять туда сюда…
Lynn
Реклама как раз отлично меняется js-ом на статических страницах уже лет двадцать
Pro-dev-pm
Хорошую производительность на «хостинге» за 1 доллар вы не получите, поэтому это не преимущество перед кешем
fishHook
А я не понял. Вот, допустим, у нас есть интернет магазин. Есть страница со списком товаров, для каждой единицы товара отображается доступность товара на складе. То есть у нас есть статический шаблон страницы, и есть волатильная информация, которая натягивается поверх шаблона. Натягивание информации на шаблон можно организовать на сервере — серверный рендеринг, или на клиенте. По такому принципу работают, как мне кажется, 95% сайтов. Объясните, пожалуйста, как я могу во время билда чего бы то ни было встроить информацию в страницу, если информация сама по себе не статична (а сайтов с принципиально статическим контентом, я даже себе представить не могу в 2021м году).
Сейчас у меня открыто в браузере: gmail, habr, linux org, jira, fisheye, youtube, confluence и reverso context. Для какого из этих рерурсов актуальна рекламируемая новаторская технология?
Drag13
Ответ теоретический:
Билдаем как статику без реальных цифр (т.е. без цена/количество товара). Раскладываем на CDN. Во время загрузки магазина, делаем запрос на API за данными, обновляем цифры.
Итого: контент юзеру прилетает быстро (т.к. нам нужно просто отдать статику), у сервера нет нагрузки из-за лишнего рендера. Цифры появляются чуть позже (или нет, зависит от организации запроса к АПИ).
Но проблемы в том, что это все так, теория. Перформанс он не любит голых теоретиков. Нужно считать реальный выиграш который мы получим. И отнять время/усилия которые мы потратим вместо использования например SSR+кеш.
За это я и не люблю подобные статьи. На словах все легко и просто, начинаешь думать как это применить в реальном живом проекте и понимаешь что под красивой оберткой пусто.
fishHook
>Билдаем как статику без реальных цифр (т.е. без цена/количество товара). Раскладываем на CDN. Во время загрузки магазина, делаем запрос на API за данными, обновляем цифры.
А чем это отличается от сайта основанного на angular или react? Ну это же, блин, дословно, то же самое.
Rsa97
Я так понимаю, что автор предлагает примерно следующее:
У нас магазин, пусть будет 1000 товаров.
Значит мы генерируем 1000 отдельных статических страниц, по одной для каждого товара, с той информацией, которая практически не меняется или меняется редко — фото, описание, сопутствующие товары. После загрузки такой страницы через JS подтягивается оперативная информация — остатки по складу, цены, скидки и т.д.
То есть получаем смещение в сторону кэшированного SSR, по сравнению с полным CSR в Angular/React/Vue.
Drag13
Не совсем. Разница в том, что в случае с SPA флоу выглядит так:
1 -> отдаем клиенту статику в виде почти пустого index.html
2 -> index.html запрашивает JS. Клиент видит белый экран
3 -> JS приходит и начинает создавать с нуля юай. Клиент видит белый экран.
4 -> JS запрашивает данные. Клиент видит какой то плейсхолдер или частичный юай.
5 -> Данные пришли, мы отрендерили все. Ура.
Здесь идея в том, что мы сразу отдаем Index.html с контентом. И клиент видит что-то пока данные догружаются. Если данных нет, он видит вообще все сразу что прекрасно.
Это очень похоже на SSR, но разница в том, что с SSR мы делаем статику во время запрос (и может быть ее кешируем). А тут мы делаем статику во время билда.
kichik91
Я может что-то не понимаю, но можно же создавать файловый кэш, ложить его на диск, а веб-сервером дёргать файл и возвращать его, то есть готовую страницу, а если страницы в папке с файлами нет, то идём обычным путём…
На примере с магазином всё отлично будет работать… Сервер должен возвращать страницу без цены и наличия, а браузер уже дёргает эту инфу асинхронно…
При изменении товара не нужно перезапускать ребилд проекта, просто при сохранении удаляем файл с кэшем и всё, можно даже удалить файл и в фоне запустить сразу создание файла
У меня такое ощущение, что это просто новый вид кэша =)
fishHook
Такое чувство, что автор инновациооного подхода борется с собсвенным невежеством, а не реальными проблемами.
>Разница в том, что в случае с SPA флоу выглядит так:
Да почему это вдруг? Никто же не запрещает встроить скрипты прям в страницу, и у вас не будет этапа загрузки js. Почему пользователь видит «белую страницу»? Разве SPA приложения определяют такое поведение? Да ничего же подобного, отдавайте страницу с внятным содержимым, изменяйте её по мере поступления данных.
>Здесь идея в том, что мы сразу отдаем Index.html с контентом
А как эта идея противоречит SPA дизайну приложения? Если есть возможность отдать страницу сразу с контентом, то я её отдам сразу с контентом, контент будет встроен в HTML. Далее мои скрипты обращаются к API, получают JSON и изменяют\дополняют контент если требуется.
Что нового то предлагается, я в толк не возьму.
Drag13
Поздравляю, вы убили кэширование скриптов. Если сделаете кэширование index.html — получите проблемы с релизами когда кэшированый юай будет противоречить апи. Да, есть etag но это тоже усложняет систему.
Потому что классический SPA это
script first. Посмотрите AngularJS/ Angular/React/Vue. и другие. SSR появился сильно позже и как раз пытается решить те проблемы о которых я говорил.Это называется SSR. Проблема (условная) в том, что вы тратите серверные ресурсы на рендер на каждый запрос (и, собственно, вам нужен сервер). JAM стек предлагает отказаться от этого в пользу генерации контента разово, во вримя билда. Естественно это возможно далеко не всегда и не всегда имеет смысл.
Создай весь сатический контент в момент билда, остальное накати дополни на клиенте. И это именно то о чем вы говорите. Вопрос терминологии и реализации.
П.С. Я не автор статьи и согласен с тем что этот подход валиден для ограниченого количества сценариев. И не является ни панацеей, ни революцией.
fishHook
>Поздравляю, вы убили кэширование скриптов
я ничего не убивал. Это ваша изначальная претензия к SPA, дескать, вот такой вот флоу и он вам не нравится. Мой ответ — не нравится вам этап загрузки скриптов, не загружайте. Вариантов всего два — загружать скрипты асинхронно или встроить их непосредственно в страницу. Оба этих варианты доступны без изобреиения новых сущностей.
>SSR появился сильно позже и как раз пытается решить те проблемы о которых я говорил.
Вы говорите о проблемах, которые сами же и выдумали, а теперь мужественно боретесь. На какой бы техлогии не был основан ваш сайт, все равно вы должны загрузить HTML самым первым этапом. Почему при использовании ангуляра этот инициализирующий HTML обязан быть белым квадратом — загадка сия есть, это вы просто выдумали.
>JAM стек предлагает отказаться от этого в пользу генерации контента разово, во вримя билда.
Я выше задал вопрос, на который мы сейчас и пытаемсёя получить ответ. Повторю его, каким образом я могу построить интернет магазин, если весь контент обязан быть известен на момент билда.
>Естественно это возможно далеко не всегда и не всегда имеет смысл.
Это никогда не имеет смыла. Так вообще работает весь интернет — контент не известен заранее. У сайтов есть админка, как правило. Персонал заказчика вносит изменения, получает их отражение на сайте. Пользователи работая с сайтом непрерывно изменяют данные, изменения непрерывно влияют на содержимое страницы. CMS на которых работает подавляющее большинство сайтов вообще нельзя постоить на статической основе, даже если страницы выглядят статичными. Я вам дал пример десятка сайтов с которыми работаю, дайте контрпример, покажите сайт, который может быть построен с использованием вашего чего-то там
>Это называется SSR.
Это любое занятие — выдумывать аббревиатуры.
> Вопрос терминологии и реализации.
Именно терминологии, а не реализации. Нет серверным приложениям, вроде так заявлялось? Оказывается, таки да, но давайте это называть немножечко по-другому, мы хотим написать десяток статей на эту тему и провести еще немножечко вебинаров.
Drag13
Вы предложили встроиться что бы уменьшить время ожидания. Я объяснил почему это проблема.
Cпасибо за комплимент, но ни SPA ни SSR я не придумывал. Это то что существует.
Вам уже ответили выше. Генерим статичные страницы для товаров, данные (цена/кол-во) подтягиваем асинхронно с клиента.
Это не правда. Сайты визитки, редко обвновляемые блоги, сайты с инструкциями и просто любым статичным контентом подходят. Твиттер, Хабр, Gmail и еще множество других не подходит.
https://en.wikipedia.org/wiki/Server-side_scripting
Пожалуйста, обратите внимание на:
fishHook
>Вы предложили встроиться что бы уменьшить время ожидания. Я объяснил почему это проблема.
Нет. Я сказал, что есть два варианта — встраивать скрипты или не встраивать. У вас варианта тоже два, и оба вам не нравятся. Вам не нравится флоу СПА приложения, потому что загружаются скрипты, и одновременно не нравится встраивание скриптов. Третьего варианта вы не дали. Так дайте. Ответ «надо чего-то там встраивать на этапе билда» не отвечает на вопрос встраивания или загрузки скриптов. Если же загрузка скриптов никак не относится к теме беседы, то нафига вы это приводите в качестве недостатка SPA.
>Вам уже ответили выше. Генерим статичные страницы для товаров, данные (цена/кол-во) подтягиваем асинхронно с клиента.
Да что это за бред в конце концов? Все данные о товаре диначеские. Приведите пример нединамических данных для товара. Если говорите про изображение, то оно в страницу не встраивается, встраивается ссылка. А ссылка вполне себе вещь динамическая. Страница со списком товаров тоже динамическая по природе своей.
>Это не правда. Сайты визитки, редко обвновляемые блоги, сайты с инструкциями и просто любым статичным контентом подходят.
Ну то есть, имеются никие крохи из всего айсберга, называемого веб. Эти проценты страничек Васи Пупкина с единицами посещений в день не представляются проблемой для серверной производительности. Делаются они на CMS и прекрасно кешируются. Проблемы которую решает статья «Нет чему-то там» не существует. Спасибо, я понял.
Rsa97
И насколько это всё динамическое? Сколько раз в минуту может меняться описание одного товара? А в час? Ну хотя бы оно меняется каждый день? Как правило нет. В большинстве случаев товар описывается один раз и к нему прикрепляется одна или несколько фотографий. После этого такие данные могут оставаться неизменными до исчезновения товара с продажи.
Да, они размещаются в БД и, формально, остаются динамическими. Но по факту они практически статические и на их основе можно периодически (или по факту изменения данных) генерировать новые статические страницы, на которых через JS будут заполняться динамические данные.
fishHook
Сам факт того, что данные размещены в БД делает их строго динамическими. Сколько бы раз в минуту/час/год данные не обновлялись, с точки зрения сайта они обновляются в непредсказуемый момент времени. Вполне допускаю, что теоретически может существовать магазин, в котором цены указанные на сайте и сохраненные в БД могут не совпадать, список товаров может содержать позиции отсутствующие на складе, а одну единицу товара можно продать двум разным покупателям. Я бы хотел посмотреть как сайтостроитель будет объяснять такое поведение владельцу бизнеса! Это я молчу про то, что всегда есть данные рассчитываемые на лету — скидки, акции, всякая шняга из кукисов, есть корзина в которой данные хранятся временно, но тем не менее влияют на список товаров, есть стоимость доставки рассчитываемая на основе размера заказа, и так далее. И вот мы перешагнули в 2021й год, и тут у нас свежая мысль — а давайте прикешируем базку на час! Ну чтобы сэкономить процессорное время. Это пусть где-то в другом мире изобретают ин-мемори хранилища, занимаются всяки нормализациями, оптимизациями, индексы какие-то хитрые изобретают, шардируют чота там, все ради одного — ускорить доступ к данным. А мы пойдем другим путем! Мы вообще откажемся от обмена данными. Как вам мысль? Нет данных, нет проблем. Главное такты ЦПУ сэкономили, одни выгоды для бизнеса.
Вам это шизофренией не кажется? Мне кажется.
Rsa97
Так никто и не предлагает абсолютно все данные делать статическими. Но если данные меняются раз в пятилетку и не требуют особой оперативности, то что мешает сгенерировать статические страницы именно с этими данными, а остальные данные подтягивать динамически?
Насколько часто меняется именно описание товара? И насколько страшно, что корректировка описания (скорее всего из-за ошибки в нём), будет отображаться на сайте не сию же секунду, а, например, на следующие сутки?
Чем плохо, если в блоге при создании/изменении статьи будет генерироваться статическая страница, а комментарии к неё будут грузиться динамически?
DIORTSID
Зачем генерировать статические страницы?
У вас есть данные, вы переживаете, что они медленно выгружаются, потому хотите генерить статику, но это не логично, вы по сути кешируете HTML, в то время, как можно закешировать данные о заказе, а то как он будет отображен, уже дело 10-е и не такое уж и долгое, особенно при серверном рендеринге, у вас же не хайлоады как у яндекса на поиске.
Итого, товар в кеше, сбрасываемый\обновляемый, если данные товара изменились, а рендеринг работает уже по выгруженным данным из кеша, все, в БД ходим крайне редко, скорость работы отличная, для 95% сайтов будет работать оптимально
izogfif
Т.е. вы предлагаете всю (ОК, почти всю) БД держать в кеше?
DIORTSID
Необязательно хранить структуру данных, что в БД в кеше, можно хранить в кеше подготовленные, данные, т.е презентованные, под нужную структуру, выборка из связанных таблиц и тд.
Данные в любом случае будет занимать меньше места, чем хранение HTML. Тем более, можно делать хранение, только основных данных, выборка которых занимает основную часть времени.
Вариантов работы с кешом масса, можно всегда прогревать кеш заранее, а можно делать это только при первом обращении, или только определенных записей, решение индивидуально под проект и проблемы которые возникают с производительностью
Опять же, кеш не панацея, если что-то тупит, надо чинить там, а генерировать готовый шаблон на этапе сборки, как описано в статье это самое последнее, что можно придумать
fishHook
Так тут предлагают ту же самую БД держать в кеше, только не в виде данных, а в виде HTML с внедренными данными.
Chamie
Именно, что если уж хранить все данные, на основе которых строится представление, то почему бы сразу не хранить представление? Если перевод данных в отображение — чистая функция, то нет смысла хранить отдельно функцию, а отдельно заранее аргументы её.
DIORTSID
Это как раз таки не правильно, потому что если хранить уже конечный результат выходит огромное дублирование и оверхед.
Не нужно складывать все в одну корзину, рендиринг это одна функция, данные другая, рендерить данные быстро, а получать данные нет, потому кеширование и оптимизацию решают проблему получения.
Chamie
Ну, так и рассматривайте пре-рендеринг как прогретый файловый кеш с ручной инвалидацией, что не так?
DIORTSID
Дублирование всей верстки, каждый раз делая ПРЕгенерацию всех страниц вы дублируете 1 шаблон на количество страниц с этими данными, пускай у вас магазин, в нем 10 000 товаров, у вас есть 1 шаблон, вы вместо того, чтобы в 1 шаблон врендеривать маленький хешик\json создаете 10 000 HTML страниц
Это неоптимально и в корни неверно. Кешировать надо данные, а не полный HTML страницы. Если прям очень хочется, можно включить кеширование на Nginx
DIORTSID
Изменись у вас 1 атрибут, цена, артикул, да что угодно, вам нужно перерендерить 100500 шаблонов с этими данным. Это затратно по времени и в целом N+1 операция.
В то время, когда кешируются данные (подготовленные к рендерингу, в нужном формате и тд) рендеринг занимает миллисекунды и выполняется только при необходимости, по факту
Chamie
Ага, только скажите, что у вашего сайта случается чаще — обновление основной информации на странице или просмотр? Если просмотров хотя бы не в 100 раз больше, чем обновлений, то да, подход не для вас.
А подход по напихиванию 100500 динамических элементов в рендереную на сервере страницу я видел на реддите — настолько у них всё «отлично», что там даже комментарии одной страницей не посмотреть, а местами и вообще не больше 2-3 за раз.
DIORTSID
Элементарно, товар же явно отображается не только на своем просмотре, а где-то есть превью, где-то еще что-то, везде пойди и перерендели большой HTML ради циферки
Да хоть миллиард просмотров, это решается кешированием данных, а поверх уже оптимизацией рендеринга при необходимости. Redis и Nginx уже закроют основную нагрузку на эту работу
Тогда почему такой идеальны подход не используют все ресурсы? Он ведь так хорошо работает, так давай-те на все будем тулить генерацию HTML и вернемся к сайтам в 90-е
Chamie
P.S. Кстати, во многих серверных движках/CMS пре-рендеринг уже встроен. Причём, в достаточно динамических, вроде движков имиджборд.
DIORTSID
Он будет держать в кеше страницы, которые пользователи посещали, и сбрасывать кеш по необходимости, когда он протухает, это не требует никаких вычислительных мощностей для сервера и никак не замедляет работу деплоев и тд
Chamie
DIORTSID
Как минимум есть время жизни кешированной страницы, это раз, во вторых, если мы вдаемся в оптимизации, можно накручивать свою логику через скрипты, которые будут его сбрасывать
Данные в БД обновились — сразу обновили кеш в редисе, и при необходимости дернули сброс закешированных данных в nginx для них. Как показывает практика, одного редиса достаточно.
Chamie
Вот у нас нагрузка на сервер уже и не нулевая…
Вот просто один в один то же самое, что просто дёрнуть рендеринг. Только ещё и две прослойки лишних в виду редиса и кеша nginx.
DIORTSID
И это по вашему проблема? С каких пор, рендеринг это проблема в 2021 году? Почему такие гиганты как VK, Facebook не делают HTML шаблоны на каждый пост?
Я бы очень хотел посмотреть, как они террабайты текста перегенеривают в шаблоны, да там харды менять нужно будет каждую неделю с такими нагрузками.
Она никогда не будет нулевая, если у вас одностраничная визитка, да.
Оставим к примеру редис. Не суть сейчас
У вас есть 2 ОТДЕЛЬНЫЕ операции — подготовка данных и вывод данных, данные всегда в кеше, их сброс это бекграунд операция, вам и посетитель вообще пофигу на этот механизм — сервер вернул данные — браузер срендерил страницу.
Приложение должно быть разбито на зоны ответственности, а если мешать все в одну кучу, разобьем все яйца…
Советую почитать Роберта Мартина — Чистая архитектура, для начала
Chamie
Не будет нулевая если одностраничная визитка? Где-то тут у вас «не» пропущено?
А теперь просто подвинем это всё назад во времени — после обновления базы происходит сброс и перегенерация файлового кэша. В фоне, вы об этом точно так же ничего не знаете. Только теперь страница отдастся пользователю за микросекунды, потому что генерировать ничего не надо.
Именно — зачем вмешивать генерацию страницы в механизм отдачи HTML пользователю? Генерация страницы отдельно, отдача — отдельно.
DIORTSID
Нет, видимо запутано выразился, 1 HTML страница будет работать без нагузки, а вот уже если их будет 1000, то нагрузка какая никакая все равно будет
Потому что файловый кеш это медленно, если хранить, то хранить в памяти, вот это дает прирост скорости.
Что мешает использовать тогда уже серверный рендеринг и его кеширование? Это абслютно тоже самое с точки зрения браузера, но без ненужных генераций шаблонов
Chamie
Поэтому кэш NGINX — файловый, и быстрее всего он отдаёт статику с диска? Чтобы медленнее было?
Именно, серверный рендеринг и кэширование в файлах. Никаких отдаваемых клиенту шаблонов, не знаю, откуда вы их берёте уже который раз — я говорю про отрендеренные страницы в виде HTML-файлов. С точки зрения веб-сервера (nginx) — это отдача статики, т.е., то, что он умеет делать быстрее всего.
DIORTSID
Плюс, ко всем оптимизациям — если ваш сайт тупит при трафике, это не повод, бежать и генерить странички, значит надо посмотреть:
1 — А не на калькуляторе ли хостится сайт?
2 — А оптимальный ли код?
3 — А оптимальная ли работа с базой?
И вот когда, из всех 3х пунктов можно сказать — да, соки выжаты по максимуму, можно уже начинать крутить кеши и прочие манипуляции
Chamie
2. А не сделал ли я серверный рендеринг на каждый запрос, вместо того, чтобы кэшировать ответы в виде статики?
3. А не зря ли я хожу в базу, когда мог отдавать статику?
DIORTSID
В данном случае, слово «архитектуру» надо взять в кавычки. И сложно представить экономию в серевере для такой задачи, видимо я не в том вебе работаю.
Тут я только развести руками могу, я уже не знаю
А зачем мне вообще база? странички HTML? можно же просто 1 PDF\Word файл скинуть и вуаля, прайс лист готов
Chamie
fishHook
У всех защитников статических страничек сайт какой-то уж очень убогий получается. На словах то просто все — для каждой единицы товара генерируем страничку. Но это UX двадцатилетней давности. У вас нет всплывающих окон, тултипов, и вообще динамически подгружаемого контента. Я бы например хотел иметь список товаров с кратким описанием и возможность при нажатии мышкой получать более детальную информацию. Не перезагружая страницу как при царе Горохе, а используя современные удобные интерфейсы. Ну вот вам дублирование в чистом виде — вам одни и те же данные надо зашить в страницу дважды — к кратком виде в списке и подробном виде в скрытом диве.
Chamie
Вы пропускаете букву A в JAMstack? Никто не отбирает у вас AJAX и асинхронную подгрузку данных. Только серверный рендеринг в рантайме.
VolCh
Слишком громкое название тогда "нет серверным приложениям" если сервер для АПИ всё равно нужен
Chamie
VolCh
Скорее всего автор имеет в виду "использующие серверный рендеринг html хотя бы раз в ответ на http запрос". Но из поста это не совсем очевидно, мягко говоря.
fishHook
Ага. Ну синус и косинус тоже чистые функции, только почему-то никто давно не пользуется таблицами Брадиса. А вы предлагаете именно это, даже еще хуже, потому что по вашим словам получается, что ваша функция это функция одного аргумента. А это не так. Вернемся к нашему интернет-магазину. Допустим, у нас в каталоге 1000 единиц товара. Вы падженируете по десять элементов на страницу и того у нас сто страниц. Не много, можно заранее посчитать чистую функцию. Но откройте любой интернет-магазин. Увидите десятки фильтров. Примените фильтр к списку товаров и вот вы получаете другую страницу. Десять бинарных фильтров дадут вам 10! комбинаций. А если фильтры не бинарные, а скажем вам надо задать диапазон цен «от… до», то боюсь ваша чистая функция охренеет
fishHook
Последние лет двадцать почти все, что происходит в клиент-серверных технологиях, это поиск лучшего способа отделения данных от представления. У вас как-то негласно предполагается, что для каждого товара вам нужна своя отдельная страница. Но чем товар А уникален по сравнению с Б, чтобы создавать собственное представление для него? Ничем. Вы предолгагаете хнанить нагенерированные странички, которые отличаются только текстом, при идентичнорй разметке. Зачем это надо вообще? Ни за чем. Достаточно один раз написать реакт компонент или серверный шаблон — не важно, который будет универсальным для любого товара, а конкретные цифры и текст — то что вы и так предлагаете грузить динамически — будет подставляться в шаблон по мере надобности.
Chamie
fishHook
Представьте себе! У меня есть сайт, у меня есть мобильное приложение, а еще у меня есть бухгалтерская программа, и весь этот зоопарк манипулирует данными в одной базе.
Chamie
И что, нет единого места, через которое осуществляется запись в базу? Все прямо напрямую с СУБД общаются?
swelf
Товар А закончился, казалось небольшое дело, перегенерировали страницу.
Но этот товар А был в рекомендуемых «Так же люди смотрят» еще на 100-1000000 страниц товаров, их тоже перегенерировать? Или продолжать продавать то чего нету в наличии? Бизнесу это понравится, надо включить в презентацию Jamstack=)
Или это была динамическая информация? Итак, у нас цена, доступность, рекомендации, стоимость доставки, коментарии, пользовательский рейтинг, все тянется с сервера. Ради чего «предгенерация» ради названия товара и цвета шапки? Да, много сэкономили
А купить товар тоже можно без сервера?
-Никаких серверов!
-А как же цена товара, доступность, оценки?
-Ну это с сервера
-Но никаких сервров?
-Никаких серверов!
-А если сервер упадет?
-Ну бэкграунд увидите!
-Сирота?
-Сирота((
-Мама папа есть?
-Мама папа есть)))
Chamie
Комментарии и отзывы, кстати, всё равно, обычно, предмодерируются, а цены меняются не руками в базе, а через CMS, которая вполне может запускать перегенерацию страницы. (А если прямо хочется руками в базе править, то можно повесить триггеры, помечающие данные «грязными»).
Если же вы про отдельные цены с персональными скидками, то такие чаще показываются уже в корзине. Которая рисуется джаваскриптом поверх готовой страницы.
Да, серверный код останется, но только там, где он нужен, а не на каждой странице, перерисовывая с нуля всю разметку на каждый запрос.
DIORTSID
Это называется палить из пушки по воробьям, для таких вещей существует кеширование, как данных, так и определенных темплейтов, шапка сайта? ок, ее закешить не вопрос, это данные которые меняются раз в тысячелетие, а каждый раз генерить полную HTML версию под каждый товар, это тоже самое, что для каждой рисинки делать отдельную упаковку
Механизм рендеринга 1 — данных много.
А так получается мы делаем дубликацию шаблонов с заполненными данным, вместо того, чтобы сайт весил 500 мб в вакууме, он будет весить N на M+k, где N размер 1 шаблона и M количество шаблонов и k размер данных
я хотел бы посмотреть, как вы ту же например википедию будете хранить таким образом и сколько места у вас займет
Chamie
DIORTSID
Это были абстрактные цифры, потому и написал, что в вакууме.
Не важно сколько весят все шаблоны, важно то, что при генерации страниц, зря занимается дискове место на сотни, а то и тысячи файлов, что тоже рождает свои проблемы, по деплою, перегенерации
Вот представьте, у вас магазин, в нем 10 000 товаров. Какой-то менеджер делает импорт товаров, новых, 2 000 и изменяет еще 1 000 старых, нужно просто так, сделать генерацию 3-х тысяч шаблонов + шаблоны связанных страниц. Скрыть товар из продажи, что, дропать HTML шаблон?
Лишние и бесполезные действия. Спор не уместен, не сможете убедить, что каждый раз дублировать данные это гениальное решение.
Chamie
3 тысяч страниц по одному шаблону. Вы же сами говоите, что это миллисекунды занимает. Если так уж не нравится, подождать целых 10 секунд, то можно и отложенный рендеринг сделать — при первом обращении.
Шаблон-то зачем? Одну страницу. Удалять или обновлять (ставить метку «нет в продаж»), или просто в подгружаемой цене это выдать — как угодно.
DIORTSID
Только зачем хранить 3 тыс страниц, если достаточно хранить шаблон?
Абстрактно ваш шабло 1 КБ, значит вы на ровном месте сделали 3000 КБ только за счет их дублирования. И спрашивается вопрос — зачем?
Миллисекунды занимает рендаринг шаблона в браузере, каждый рендеринг, перерендеринг шаблона это безсмысленная нагрузка на диск, что черевато проблемами + это нагрузка. В отличии от хранения данных в памяти.
Только вот это лишние действие
Вот послушав такие разговоры, я не удивлен, что большинство ресурсов, особенно на CMS тупят как адовый ад
Chamie
Уже и в браузере, а не на сервере? И на телефонах? А то, что браузеры файлы тоже в дисковый кэш кладут — вы в курсе?
Лишнее действие CMS? Ну, пометила бы она то же самое в базе, какая разница-то?
Потому что на каждое действие ре-рендеринг делают? Давайте без переходов на личности, хорошо?
DIORTSID
Ну да, ну да…
А ничего, что картинка в данных это только ссылка на картинку? а картинки, как раз относятся к статике и кешируются веб-сервером (Nginx) так что этот пример в корни неправильный.
Ах да, в вашем случае нужно под каждый девайс нагенерить отдельный шаблон, забыл, приношу извинения.
Давайте не будем путать представление и данные, данные обновляются когда надо и в каком надо объем и это хранилище. Это отдельная зона отвественности.
Кстати тут не было перехода на личности, это скорее было сожаление по факту, т.к. часто сталкиваюсь с проблемами на сайтах, написанных с использованием CMS и возможно каких-то велосипедов. Так что тут извинения, если не так понято.
Нет, потому что изобретаются неправильные решения, которые выдаются за архитектуру, хотя это костыли и не желание разбираться в конечной проблеме, когда она есть.
О кстати, еще в копилку перерендеринга — фронтещик или кто-то решил шаблон поменять, о нет, нам надо сделать перегенерацию всех товаров, потому что в блоке цены добавился новый CSS класс…
Chamie
Что? Вы уже совсем ёрничаете. Речь шла о серверном рендеринге, а вы, почему-то, вдруг про генерацию в браузере начали писать. Теперь ещё и вот это…Вы предлагаете данные и метаданные в разных местах хранить, или что? Чем ваши хуки на обновление кэша отличаются от хуков на удаление файла?
Решения давно изобретены, называются «файловый кэш», и он есть встроенный в куче движков.
swelf
яснопонятно. Бизнес любит когда программисты делают не то что хочет этот самый бизнес, а то что «чаще» и «обычно».
директор: Наши маркетологи тут прикинули, давайте выводить цены для пользователей с индивидуальными скидками на всех страницах
программист: Знаете, скидки чаще в корзинах
А бывает по другому? но мы все равно назовем это безсервеный рендеринг? Потому что сервер все же у нас есть? логика то в чем?
сервер есть? есть, без него работать что-то будет? нет
как там кэш осуществляется, предварительной генерацией страниц в html файлики или по запросу байтиками в редисе, какая разница, это кэш называется, это не какая-то революционная технология и он от сервера не избавит. Если комуто хочется кэшировать в файлах, то ктож запретит.
допустим сервер на golang, в качестве шаблонного движка используется quicktemplate, он все шаблоны в бинарник загоняет.
Так вот, с какой стати прочитать страницы index.html и home.html с диска и отдать их будет быстрей чем сделать конкатенацию строк
header + indexcontent + footer, все уже в бинаре зашито, а за контентом в базу и так и так идти.
поменяли цену на странице А, запустили перегерацию тысячи связанных страниц, потом поменяли на странице Б и запустили снова перегенерацию тысячи страниц, 900 из которых совпадают с первыми. А не эффективный ли вы менеджер?
Итог: У нас есть сервер приложений, у нас есть кэш. И мы почему-то называем это «нет серверам». без которых на самом деле ничего работать не будет.
Chamie
Оу, вы так пишете, будто это нереализуемо. Собственно, точно так же реализуемо на клиенте, в рантайме. Просто цены будут, например, подсчитываться JS'ом уже после загрузки разметки страницы. Причём, пользователь может об этом и не узнать.
Потому что РЕНДЕРИНГ будет делать НЕ СЕРВЕР. Никто же не говорил «безсерверный сайт»?
Разница в том, что генерация может осуществляться не кодом сайта вообще, а кодом CMS/деплой-скрипта. Ну вот не будет в серверном коде сайта кода, генерирующего HTML-разметку.
Разница в том, что ваш код будет ходить в базу даже за данными, которые заведомо не менялись, парсить их и трансформировать соответствующим образом в разметку. Или он у вас сырой ответ от БД прямо байт в байт отдаёт посреди HTML?
Зачем у вас одна и та же одна цена отображается на тысяче страниц?
Если уж мы генерируем страницы при обновлении данных в CMS, то и кода этого на сайте быть не будет. Он в CMS, а не на сайте. И в отдаче контента клиентам не участвует.
swelf
а как вобще связано
Бизнес:«Я хочу чтоб были скидки»
Программист:«Нет мы их делать не будем»
с каким-то прямым хождением в базу, почему вобще база вызывает такой страх, что она приплетается к месту и не к месту?
1)баннер с «Люди смотревшие это, так же смотрят»
2)Тысячи страниц фильтра «ТВ с диагональю до 50» «ТВ с диагональю до 49»… а наш целевой 30 и везде попадет.
Еще раз, что значит не участвует? Купить товар можно без сервера? Ради чего заниматься перегенерацией тысяч страниц, если от сервера не избавились?
что знач сырой прям в HTML, там вобще может быть не html, а предобработанные данные. И да, если разрешено из конкретно той колонки базы вставлять html, то может быть и он.
ты же сам выше написал «Да, серверный код останется, но только там, где он нужен, а не на каждой странице, перерисовывая с нуля всю разметку на каждый запрос.»
вот тут он и нужен.
Если с базы мы тянем хоть что-то, хоть крохотулечку данных, запрос почти моментальный, вытягиваем допустим цены. что мешает вытянуть еще и название и артикул и описание. Это не повлияет на время ответа, все в одной таблице. и мы уже вместо 10000 страниц, каждая из которых отличается только названием, имеем один шаблон.
я верю что есть такие сайты, только интернет магазины не имеют к ним отношения.
Пользователь купил последний экземпляр товара, нам после действий пользователя надо пересчитать все страницы на которых как-то фигурировал этот товар? А найти эти страницы это очень сложная задача. И таких пользователей десятки сотни и все они как-то влияют, изменили рейтинг явно, изменли рейтинг просто посетив страницу, купили что-то.
Товар сам по себе может пораждать тысячи страниц. Вот появился у нас «Товар А» а у нас уже есть 100500 товаров в этой категории, нам надо создать 100500 новых страниц «сравнение А и Б»? а потом еще 100500**2 «Сравнение А Б и В»?
Chamie
(вообще — да, забыл, почему я именно к этой цитате этот ответ приписал).
Ну, и пусть подгружается динамически. С API придёт список ID связанных товаров, а для которых подгрузятся мини-карточки или просто данные для клиентского рендеринга, если там мало разметки.
Воу, а вы и страницы результатов поиска/фильтрации предполали статикой делать? Все возможные комбинации включая все возможные буквы в поиске? Ну, уж это-то точно динамические данные и работа с API.
В обслуживании read-only активности клиентов он не участвует, в результате нагрузка на него будет только от активных действий типа покупки или поиска, которых, обычно, на порядки меньше.
То и значит, что отдача байтового потока — задача на порядки более простая, чем формирование разметки на основании данных, и отдача уже её. Это же ответ на
Так в том и суть, что цены не меняются непредсказуемо, соответственно, и обновлять ничего до обновления цен не нужно, отдаём готовую страницу и ни базу, ни рендеринг, ни парсинг, ни обработку не трогаем.
Если же будет отдельный функционал, для которого нужна база, то это уже полностью срендеренная страница пойдёт в API endpoint, что не только можно отложить, снизив TFFB в десятки раз, но и не будет задействовать генерацию целой страницы всяких разметок на сервере.
У вас какие-то странные интернет-магазины, в которых все данные всё время непрерывно меняются. На всех, какие я видел, 95%-99% разметки страницы не меняется чаще раза в день. Оставшиеся же 1-5% спокойно себе загружаются асинхронно AJAX'ом.
Как часто такое происходит для товара? Неужели хотя бы несколько раз в день?Он нигде в разметке не должен фигурировать, кроме своей карточки (и мини-карточки, если такая есть). Все остальные места, где он фигурирует — это результат получения с сервера его ID и подгрузки AJAX'ом соответствующей карточки.
swelf
Так оно и щас так, без jamstack.
А че это мы только 1 вариант изменений выдернули из контекста и говорим «а это не часто случается», а как на счет остальных вариантов, оставил комент/оценку, просто своим просмотром поднял автоматический рейтинг интересности?
Я, нет конечно, а вот вы поначалу да, но после вопросов… «Ну это мы с апи дернем, а это динамически сгенерируем, но сервера нам конечно не нужны, да»
Букинг считается за интернет магазин где все время меняются страницы? «этот номер сейчас смотрят 3 человека» «Этот номер только что забронировали».
На любом современно интернет магазине есть динамичсекие данные.
я говорю, что если сервер используется хоть для одного поля рейтнг/оценка/личная скидка/рекомендации, то нет никакого смысла рендерить 100500 страниц чтобы потом все равно с них дергать апи. Если хотим снять нагрузку с бэкэнда то используем кэш, хоть всю страницу хоть данные.
Ради десятков раз можно много че делать. ну например закэшировать реально тяжелый запрос, сам рендеринг не занимает ничего
Fell-x27
Так там потому и единицы посещений в день, что они не на JAM-е! А были бы на JAM-е, там бы отклик был на 2мс ниже и сайт бы смыло волной трафика. Или нет.
DmitryLTL
Думаю что через некоторое время, гугл будет выкручивать руки страницам с inline js. Уменьшать место в поиске, а потом как с сертификатами, будет помечать все такие страницы как unsecure.
eli_l
для решения пунктов 1 и 2 уже какое-то время в ходу PWA, которое позволяет хранить «приложение» или «каркас» (джсник короче) на диске у браузера через удобный и гибкий API: Caching API, CachedDB и, конечно, ServiceWorker.
Проблема медленного рендера давно решена кешированием. Да, не всегда спасает, но деплой 5 часовой 150тыс. страниц Вас тут тоже не сильно спасёт, если поменяв немного лейаут нужно будет их прегенерить заного.
Генерить темплейты в билде не актуально по одной простой причине — слишком быстро всё меняется, быстрые релизы — тоже для многих важны. С этим бегемотом это невозможно.
Блог или новостник — с ростом кол-ва страниц будет увеличиваться длительность билда, хорошо если пропорционально. Если паралелить — этож какой билд сервер нужен чтоб 20к страниц сгенерить.
А еще такой момент — автор, ты видел как выглядит перерисовка страницы, когда рендерится темплейт без данных, как потом весело всё скачет когда данные подставляются. Эта проблема имеет пути решения, но они не тривиальны.
И если в SPA приложении у тебя есть циклы жизни приложения и соответствующий API лдя работы с различными ивентами — то у тебя тут только статика, тонна проверок и спагетти код чтобы контролировать все состояния.
Для личного лендинга, который обновляется раз в три года — может остановится на любой генераторе статики, а еще лучше собрать ручками, потренироваться, так сказать.
Еще один коммент по поводу статика на запрос или статика при билде:
у тебя есть 20к страниц, деплой раз в неделю. Предположим 50% страниц на которые заходят 0-1 посетитель в месяц. Сколько времени, ресурсов и сколько ненужных данных будет сгенерировано за этот месяц? По этому — у тебя есть «генератор» ответа и кеширующий механизм, в котором, помимо того чтобы хранить тот же «сгенерированый контент» ты еще можешь управлять точечно «сроком годности» этого контента. Устарел — сгенерили заного, по запросу.
Такое впечатление, что кто-то не разобравшись в доках и напилив сервисы отвечающие по 10 секунд пытается придумать супер решение. Решение, ИМХО, очень нишевое.
А деплои… всё равно будут сложные, т.к. нужно версионирование и откат на предыдущие версии, так что еще и за дисковое пространство надо будет накинуть.
А API так вообще по-старинке придётся поддерживать.
Chamie
А почему, если не SPA, то сразу спагетти-код и вот это вот всё? Какая связь? Есть же даже и фреймворки готовые примерно к этому, типа React Static.
Ну, и отлично? Генерация по запросу готовых HTML-страниц, обновление кэша через удаление файла из файлового кэша. При этом, пока страницы не обновляются, всё будет происходить как описано у автора.
eli_l
1) Ну сначала нам нужно загрузить основную разметку, скрипты и запустить их — чтобы подтянуть данные. Соответственно нужны какие-то «наполнители». Тот же крутящийся круг — круто, но когда данные подтягиваются с разных API и скорость их загрузки разная — тут или ждать пока мы получим всё, или смотреть на «прыгающую» разметку. Контролировать рендер — всё равно нужно скриптами. Так мы приходи к уже устоявшемуся SPA.
2) Реактивность, если это не SPA, обычно заканчивается кучей невнятного кода. Как и любые попытки посредственных разработчиков создать собственное решения с блэкджеком… ту не конкретно к автору или кому-то, просто так случается. Почти всегда.
3) Есть сомнения насчет «удалить файл из файлового кэша». А новый мы как создадим? А если я правильно понял автора — то нам нужно запустить билд. Билдить приложение, чтобы почистить кэш — это перебор. Если мы генерируем статику точечно… зачем переизобретать кэш (тот же Varnish), который будет работать медленнее (память быстрее FS). Опять же — как нужно автоматизировать весь процесс билда и деплоя, написать обвязку для очистки и новой генерации, сколько железных ресурсов на это нужно — даже думать не хочется.
П.С. Статика есть статика. Где-то — подходит, но в нашем динамичном мире — достаточно редко. Массово применять такой подход — скорее всего не получится, или будет представлять из себя кучу костылей. А для тех, кто боится серверов, деплоев и прочее — есть решения типа serverless, когда всё окружение работает «почти без участия разработчика», в том числе горизонтальное масштабирование. До поры, до времени, конечно :)
Chamie
Почему если скрипты, то сразу SPA-то?
SPA — это всего лишь сайт с одной точкой входа. Никто не мешает вам тот же Реакт использовать хоть на тысяче страниц. Посмотрите, например, на React Static. Он специально для этого и написан.
Только вот кэш NGINX, например — именно файловый. И в состоянии простоя не потребляет ни ЦП ни памяти, переживает перезагрузки и не требует никакого доп. ПО для отдачи его. А кэш в той же MediaWiki — файловый из коробки.
Вы так пишете, как будто про прогрев кэша никто не слышал, и это автора поста его только что придумал, заодно изобретя огонь и колесо. Особенно интересно, что вы боитесь задачи очистки файлового кэша: на секундочку, заключается она в банальном очистки папки с ним.
Это вы же выше написали, что деплоя боитесь =)
0xd34df00d
У меня так блог сделан. Статьи в markdown, компилируются hakyll'ом в статичный HTML, выкладываются на хостинг-утюг.
Но за пределами блога это не сработает, думаю.
anonymous
Я не настоящий сварщик — а вариант когда отдается разметка, параллельно в JSON или иным образом отдается закешированный контент, и на клиенте уже второе вставляется в первое, так не принято?
Опять же, если контент уже скачан, он возьмётся из локального кеша.
Anamelash
Т.е. вы изобрели
велосипедкэширование отрендеренных страниц?Drag13
Про кеширование я уже ответил выше, это все таки другое.
П.С. Я не автор, и не защищаю JAM подход. Я просто ответил про то как это работает на упрощенном примере. Как по мне, JAM применим в довольно узком спектре решений, поэтому заголовок вводит в заблуждение.
Spaceoddity
А зачем что-то генерировать на сервере или клиенте, если можно делать это во время билда?
Т.е. берем вариант №1, делим на компоненты, закладываем контент, например, в локальный json и… собираем статику. При необходимости что-то изменить или собрать приложение, просто вносим нужные изменения и пересобираем проект.
Drag13
Это и есть JAM стек :)
mrzar
Допустим, изменилось описание одного статического элемента (товара), и мы условно "разворачиваем веб сервер заново" (пересобираем проект). Спасибо, но нет.
Chamie
Зачем пересобирать проект чтбоы обновить одну страницу? Частичные билды, вот это вот всё…
VolCh
Описание одного товара может отображаться на каждой странице сайта
Chamie
Но зачем?.. Что это за товар такой, что его на каждой странице нужно показывать?..
Ну, и, кстати, иметь для каждого товара кроме полной карточки ещё и её мини-версию для подгрузки на другие страницы — тоже виданная практика.
VolCh
Флагманская модель, баннер с которой бизнес хочет поместить на каждую страницу.
Chamie
Такие баннеры, обычно, это или картинка (которая просто заменяется по ссылке), или фрейм/подгружаемый AJAX'ом сниппет.
VolCh
Ну вот все страницы со ссылкой надо перегенерировать, да, когда картинку надо поменять?
StanEgo
То, что вы описываете — это SSG. JAMStack пребилдит в основном Markup и может делать пререндеринг страниц, но потом охотно использует API (который в свою очередь общается с базой или Headless CMS) и без труда рендерит на клиенте при помощи JavaScript (после регидрации обычно только так и рендерится). Собственно из подчеркнутых символов и формируется JAM. Кстати, вам до этого задали хороший вопрос, попробуйте добавить в свой пример с блогом комментарии пользователей.
Drag13
Согласен с вами, но SSG — частный случай JAM (если я не прав, поправьте). Пример был упрощенный. Выше идет обсуждение магазина и там я как раз говорю о том, что, если необходимо, данные дотягиваются с клиента.
Моя вина что не указал это сразу, каюсь.
StanEgo
SSG — это один из инструментов JAM. Мы же не называем колеса частным случаем машины. Если я для вашего примера возьму, скажем Hugo или Zola, то там не будет ни "J", ни "A". Странно называть такое решение JAM, не правда ли?)
Myateznik
Но ведь у вас всё равно в итоге получился не JAMstack. Вы всё ещё используете чисто второй подход скатываясь к первому, только рендер перенесли с on-prem на этап сборки. В итоге на выходе у вас только статическая разметка (пусть и сгенерированная). Это путь всевозможных статических генераторов и только часть JAMstack, даже не половина, а скорее треть.
Чтобы получился действительно настоящий JAMstack нужно скрестить все 3 варианта. Причём даже в статье расшифровка приведена JavaScript API Markup. Т.е. к вашему варианту нужно ещё добавить сервер с API (и вот оно расхождение в статье) и клиентский JavaScript код, тогда у вас будет действительно JAMstack.
Фактически сайты на React/Vue/etc, если используют API, гидрацию и будут собирать страницы в статику именно на этапе сборки — настоящий JAMstack.
Чтобы понять что такое JAMstack, оставлю ссылку на JAMstack.wtf. А вообще всё это довольно олдскульно, даже JAMstack существует далеко не 4 года и не 8.
Drag13
Спасибо за комментарий. Пример получился слишком упрощенный, больше про SSG (как мне уже написали) чем про JAM, что и развело флейм. Каюсь, но уже ничего не исправить.
Myateznik
Это правда. Просто получилось, что те кто понимают суть JAM хотя бы частично, горят что пример только часть JAM'а, а те кто не в теме получили либо не полное, либо ложное понимание. Автор оригинальной статьи тоже "молодец" с его "Нет" серверам, и в середине "Да" серверам.
Drag13
Доабвил комментарий, но уже наверняка поздно.
https://habr.com/ru/company/ruvds/blog/537898/#comment_22604640
shamyyl
У JAMstack есть один минус, который проявляется не сразу, но потом начинает сильно раздражать. А именно: дико увеличивающееся время генерации целого сайта.
В итоге на статических сайтах с 1000+ страницами время билда может доходить до получаса. Потому что даже в случае изменении одной страницы новый билд запускается для всего сайта.
Например контент менеджеру надо было добавить пару новых блоков в блоге. Он идет в админку JAMstack CMS, делает правки и отправляет измененную статью на публикацию. Теперь, для того, чтобы убедиться, что изменения дошли до продакшена, он должен полчаса жить в режиме «не забудь проверить продакшен». Вроде, как можно поставить напоминалку и т.д., но по сути в эти полчаса ничем продуктивным заниматься невозможно. А если он что то пропустил, забыл или заметил опечатку? Снова билд на полчаса.
Если несколько менеджеров работают над разными статьями, то каждый будет запускать процесс деплоя для всего сайта.
Разные CMS предлагают различные варианты решения этой проблемы. Gatsby вот например предлагает Incremental Builds, которые те же полчаса могут превратить в 10 сек (согласно рекламе). Но эта опция доступна только на их платном Gatsby Cloud.
Статически сгенерированные сайты определенно несут преимущества для конечного пользователя. Но стоит помнить, что у всего есть своя цена.
Myateznik
На самом деле всё зависит от подхода, можно каждый раз генерировать полностью целый сайт, а можно перегенерировать только изменившиеся страницы (Incremental Build). Это конечно ещё и от инструментов зависит.
Вообще стоит сказать, что JAMstack может быть и без генераторов на самом деле. Если у вас собранная руками html страничка и есть как клиентский JavaScript, так и запросы к API — вы уже используете JAMstack. Даже если страница фактически будет тупо скелетоном это всё ещё JAMstack, хотя больше продвигается "прогрессивный" подход. Тут важно ещё не забывать про клиентскую сторону — мегабайты кода. Всё это всё ещё нужно оптимизировать.
А вот это в рамочку. В зависимости от подхода к JAMstack вы будете платить временем и объёмом хранилища.
Drag13
Важное уточнение. JAM не требует перехода на чистую статику. Мы точно так же можем использовать API для заполнения динамической информации. В примере выше это могли быть быть комментарии, лайки пользователей и так далее.
Простите кого мой комментарий ввел в заблуждение, он был слишком упрощен.
Hheimerd
Вау, так это же практически описание opcache + memchaced!
Перезагружать статические страницы при переходе от одной к другой, где меняется только текст — долго, гораздо лучше использовать кеширование запросов (та же статья в html) + обновление содержимого. Этим вполне успешно занимается livewire или react и ему подобные.
haraldsson
Next.js что ли (олд скул + сервер рендер)? Дико извиняюсь если ляпнул.
MasMaX
Апи не занимается выдачей HTML. Оно выдает грубо говоря JSON с данными и передает его генератору HTML (вебапу)