
Привет, Хабр!
Я не являюсь каким-то очень известным экспертом, однако мне очень интересен процесс обработки данных, а также написания кода для обработки этих самых данных. В процессе написания различных методов обработки этих самых данных у меня родилась идея частичной автоматизации, кхм, написания методов обработки.
Введение
Предположим, у нас есть набор инструментов(сущностей) для обработки какого-то потока данных, или построения других комплексных сущностей, а также постоянно меняющиеся условия последовательности композиции этих сущностей для воспроизведения алгоритма обработки.
На примере транспортных средств
Есть у нас набор атомарных компонентов:
class EngineA;
class EngineB;
class WingsA;
class WingsB;
class FrameA;
class FrameB;
class WheelsA;
class WheelsB;и т.д.
Если нам нужна машина - мы просто объявляем класс Car, в котором есть нужный корпус, колеса, двигатель и т.д. Аналогично с какой-нибудь лодкой, мы бы объявили класс Boat, и быстренько набросали агрегацию нужных частей лодки.
Если же нам нужна и лодка, и машина, и даже самолет - мы можем воспользоваться паттерном фабрика, но что делать, если нам нужны машины, лодки, самолеты, и мы заранее не знаем сколько, когда, и в каком порядке.
Можно под каждую задачу писать отдельную агрегацию, предусмотрев классы Car, Boat, Plane с общим интерфейсом ITransport. Если нам нужно 2 машины, и 5 лодок - мы можем через цикл создать необходимое количество объектов. Однако, если нам важна последовательность, создавать подряд однотипные объекты через циклы уже не так просто. И чем больше параметров - тем больше времени нужно будет на написание того или иного кода для очередного шаблонного транспортного средства
Попробуем сэкономить это время, поставив создание объектов на поток!
Положим, у нас есть некий интерфейс ITransport
class ITransport
{
public:
virtual void move() = 0;
};реализованный в таких классах как Car, Boat, Plane.
class Car final : public virtual ITransport
{
public:
Car() = default;
~Car() = default;
void move() override
{
std::cout << "Car is move" << std::endl;
// do something with parts
}
private:
std::unique_ptr < IFrame > _frame;
std::unique_ptr < IWheels > _wheels;
std::unique_ptr < IEngine > _engine;
};
class Boat final : public virtual ITransport
{
public:
Boat() = default;
~Boat() = default;
void move() override
{
std::cout << "Boat is move" << std::endl;
// do something with parts
}
private:
std::unique_ptr < IFrame > _frame;
std::unique_ptr < IEngine> _engine;
};
class Plane final : public virtual ITransport
{
public:
Plane() = default;
~Plane() = default;
void move() override
{
std::cout << "Plane is move" << std::endl;
// do something with parts
}
private:
std::unique_ptr < IFrame > _frame;
std::unique_ptr < IEngine> _engine;
std::unique_ptr < IWings > _wings;
};И нам нужно сделать 2 машины, лодку, 3 самолета и еще одну лодку, и именно в такой последовательности.
Перед самим классом конвейера будет необходимо объявить словарь с видами транспорта, который наш конвейер должен уметь производить. Для универсальности будем все необходимые параметры хранить в виде строк.
enum class VehTypes
{
Car,
Boat,
Plane
};
static std::map < std::string, VehTypes > VehCast{
{"Car", VehTypes::Car},
{"Boat", VehTypes::Boat},
{"Plane", VehTypes::Plane}
};
Теперь, сам класс конвейера.
class Conveyor final
{
public:
using _TyParameters = std::map < std::string, std::string >;
using _TyStorage = std::vector < _TyParameters >;
Conveyor(const _TyStorage& blueprints)
: _blueprints(blueprints) { }
~Conveyor() = default;
std::vector < Vehicles::ITransport* > vehicles()
{
std::vector < Vehicles::ITransport* > result;
for (auto&& blueprint : _blueprints)
{
switch (VehCast[blueprint["type"]])
{
case VehTypes::Car: result.emplace_back(new Vehicles::Car());
break;
case VehTypes::Boat: result.emplace_back(new Vehicles::Boat());
break;
case VehTypes::Plane: result.emplace_back(new Vehicles::Plane());
break;
}
}
return result;
}
private:
_TyStorage _blueprints;
};Исходя из нежелания сильно переусложнять пример я опущу код интерпретатора для построения объекта из текстовых данных, а также прочие однотипные моменты касательно создания объектов.
Для удобства понимания переопределяем два новых типа:
Параметры - словарь с информацией о транспортном средстве
Хранилище - массив с информацией об объектах, в нужной нам последовательности.
using _TyParameters = std::map < std::string, std::string >;
using _TyStorage = std::vector < _TyParameters >;В конструктор мы лишь передаем информацию о том, какие транспортные средства нам нужны(их описание).
Дальше, единственное что нам нужно - пройтись циклом по данным описаниям, и на их основе заполнить наш массив транспортных средств сконструированными объектами конкретных видов.
Проверяем
Создаем необходимый список(над этим можно отдельно поработать) транспортных средств с их параметрами.
Создаем конвейерный класс и передаем ему этот список.
Получаем набор готовых объектов.
Conveyor::_TyStorage blueprints
{
{
{"type", "Car"}, {"engineType", "EngineA"}, {"wheelsType", "WheelsB"}, etc..
},
{
{"type", "Car"},
},
{
{"type", "Boat"},
},
{
{"type", "Plane"},
},
{
{"type", "Plane"},
},
{
{"type", "Plane"}
},
{
{"type", "Boat"}
},
};
Conveyor conveyor(blueprints);
for (auto&& transport : conveyor.vehicles())
{
transport->move();
}Результат
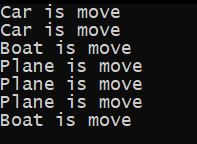
В итоге
И хотя мы тратим не сильно меньше времени на описание композиции атомарных объектов для каждой операции, суммарно, мы потратим на много меньше времени на процесс описания всего набора операций.
Данный способ не отличается идеальной производительностью, и по началу требует время на описание всех необходимых компонентов, однако в дальнейшем снижает суммарное время на описание новых последовательностей обработки данных/конструирования сущностей.
Из слабых мест данного подхода к конструированию объектов могу отметить необходимость каждый раз добавлять новые типы в словарь, а также постоянно дописывать интерпретатор новых текстовых параметров, если у вас постоянно добавляются новые атомарные компоненты.

ruomserg
Следующим этапом заводятся классы типа GenericContext (или NVPL — name-value pair list), и все описанные классы делаются Configurable из GenericContext-а. Потом пишутся адаптеры на GenericContext из XML и JSON. В результате, получается приложение с функционалом, определяемым конфигурацией. Это очень мощная и красивая вещь, но надо понимать, что в какой-то момент конфигурация становится этаким специфичным (в клинических случаях — тьюринг-полным) языком программирования, описывающим существенные свойства классов и их взаимоотношения. Если это не пугает и оправдано сложностью решаемой задачи — почему бы и нет? На Java можно посмотреть в сторону Spring, где через XML-файл (или аннотации) можно вшивать одни Beans (экземпляры классов) в другие. Так вот, людей которые могли бы («с нуля», не с шаблона или предыдущей версии) написать конфиги spring/hibernate/maven — оказывается, не так и много! :-)
nekitak Автор