
Мы заканчиваем мини-серию статей о работе с агрегатами в PostgreSQL:
И сегодня поговорим о том, как можно снизить суммарные задержки на вставку множества изменений в таблицы агрегатов за счет использования промежуточных таблиц и внешней обработки.

Поговорим об этом на примере коллектора нашего сервиса анализа PostgreSQL-логов, о котором я уже рассказывал в предыдущих статьях:
C точки зрения дальнейшей работы с таблицей агрегатов, всегда выгодно все-таки иметь единственный экземпляр записи в ней, а не пытаться перезаписывать его многократно, поэтому в нашем распоряжении оказываются варианты промежуточной агрегации в памяти процесса и отдельного "накатывания" изменений.
Если первая оптимизация достаточно очевидна (посылать в базу не "10 раз +1", а "1 раз +10"), то о второй стоит рассказать подробнее.
"Все, что нажито непосильным трудом!.."
Итак, мы хотим достаточно оперативно видеть статистику из какой таблицы/индекса насколько активно (и бессмысленно) читают. Примерно вот такая картинка должна получиться:

Давайте посмотрим, из чего конкретно состоит время вставки нового экземпляра записи агрегата.
Я уже рассказывал, что для вставки в агрегаты мы используем тот же самый COPY, что и в таблицы "фактов" + триггер, который преобразует вставку в INSERT ON CONFLICT ... DO UPDATE. Агрегатов у нас существенно меньше, чем летящих в них фактов - то есть, практически каждая вставка приводит к UPDATE! А что это у нас "технически"?..
накладываем RowExclusiveLock
находим по индексу и вычитываем текущий образ записи
прописываем служебное поле xmax в нем
вставляем новый образ записи с измененными данными в WAL-файл и heap таблицы
вписываем изменения во все относящиеся индексы - если повезло, будет HOT update с чуть меньшей нагрузкой
Как-то очень много всяких "читаем" и "пишем" получается. А в активный агрегат через секунду прилетит следующий UPDATE, и следующий...
Создаем прокси-таблицу
А вот было бы хорошо, если бы можно было вставлять сразу в такую табличку - чтобы ни индексов, ни WAL-файлов, ни UPDATE'ов - только "чистые" INSERT... А ведь так можно сделать!
Давайте породим промежуточную таблицу по формату целевой:
CREATE UNLOGGED TABLE px$agg(
LIKE agg
);Зачем нужен UNLOGGED и что он дает, можно подробно прочитать в статье "DBA: грамотно организовываем синхронизации и импорты".
Теперь все что мы хотим записать - будем писать прямо сюда без всяких триггеров и индексов.
Обрабатываем прокси-таблицу
Но в целевую-то таблицу данные у нас теперь никак не попадают - значит, надо кому-то это поручить. Причем, чтобы нам не пришлось решать никаких конфликтов параллельности, поручим это кому-то одному, вообще постороннему относительно вставки данных.
В нашей архитектуре для этого как раз удачно оказался диспетчер-балансировщик, описанный в статье "Динамическая балансировка нагрузки в pull-схеме".
Мы можем каждые 10 секунд вычитывать все содержимое в прокси-таблице (да, это будет Seq Scan, но это самый быстрый способ доступа ко "всем" данным таблицы), динамически агрегировать в памяти процесса PostgreSQL без передачи на клиента, и сразу вставлять в целевую таблицу за один запрос.
Если не знаете, как совместить вычисление разных агрегатов в одном запросе, стоит прочитать "SQL HowTo: 1000 и один способ агрегации".
После того, как мы все вычитали, сагрегировали и вставили - просто и быстро зачистим прокси с помощью TRUNCATE:
BEGIN;
INSERT INTO agg
SELECT
pk1
...
, pkN
, <aggfunc>(val1) -- sum/min/max/...
, <aggfunc>(val2)
...
FROM
px$agg -- тот самый Seq Scan
GROUP BY -- агрегация в памяти в разрезе PK таблицы агрегатов = (pk1, ..., pkN)
pk1
...
, pkN;
TRUNCATE px$agg;
COMMIT;Замечу, что это надо делать в одной транзакции, поскольку мало ли какие ошибки могут произойти при вставке, а TRUNCATE вне этой транзакции все зачистит, и данные - потеряем.
Защита от параллельной вставки
Но вот беда, пока мы читали-агрегировали, в таблицу кто-то мог что-то еще записать. А мы это зачистим, не обработав.
Можно, конечно, повесить перед началом LOCK на всю таблицу, чтобы уж никто точно ничего не смог ничего с ней сделать, но это не наш вариант - ведь ждать будет слишком много вставок.
Зато... мы можем практически мгновенно подменить ее на пустую такую же!
BEGIN;
SET LOCAL lock_timeout = '100ms'; -- ждем блокировку не дольше 100мс
LOCK TABLE px$agg IN ACCESS EXCLUSIVE MODE; -- собственно, блокируем от всех
ALTER TABLE px$agg RENAME TO px$agg_swap; -- обменяли имена двух табличек
ALTER TABLE px$agg_ RENAME TO px$agg;
ALTER TABLE px$agg_swap RENAME TO px$agg_;
COMMIT;Как только мы дождемся блокировку, так сразу и переименование пройдет. Если не дождемся - то попробуем в следующий раз, не страшно.
В принципе, можно обойтись и двумя RENAME, но прокси-таблиц тогда должно быть больше:
px -> px0, px1 -> px
px -> px1, px0 -> px
Примерно так же живет внутренняя "механика" брокера очередей PgQ и базирующейся на ней репликации Londiste.
Пруфы
Теперь самое интересное - сколько это все дало:
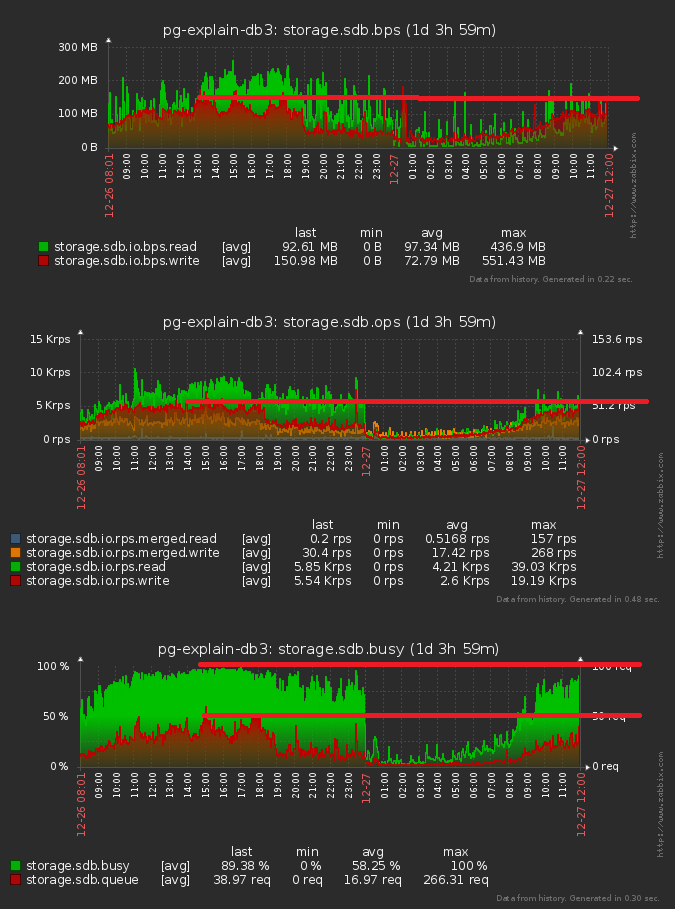
Мы получили снижение примерно на 10% по дисковой нагрузке, ускорили вставку в таблицу агрегатов и избавились от ожидания блокировок на них.
Мини-серия "Агрегаты в БД":
Kwisatz
Не сравнивали с гипертаблицами? Объем то у вас для экспериментов само то.
Зы благодарю за очередную публикацию по работе с пг
Kilor Автор
Гипертаблицы — это Timescale? Пока не довелось.
Kwisatz
Они самые. Я пробовал, мне очень понравилось, особенно после того как они добавили агрегаты реального времени. Но на серьезном объеме данных (действительно серьезном) пока не довелось 8(
ЗЫ хотя документация там местами — туши свет