
Иногда при выполнении длительных или плохо написанных запросов в PostgreSQL происходят разные неприятные вещи типа внезапного сбоя процесса или краша всего сервера.
В таких случаях на носителе могут остаться "мертвые души" - файлы (иногда совсем немаленькие, а вполне сравнимые по объему со всей остальной базой), которые были созданы во время работы процесса в качестве временного хранилища промежуточных данных.
Эти данные уже никому не нужны, никем не могут быть использованы, но сервер все равно не торопится избавиться от них как Плюшкин.

Сегодня посмотрим, как их можно найти и безболезненно "зачистить".
Разыскиваем temp buffers
Первая категория возникающих проблем - временное использование дискового пространства при выполнении узла плана, если необходимый объем памяти не уместился в work_mem.
Получить такой эффект достаточно просто - забыть поставить или выбрать слишком большой предел рекурсии:
explain (analyze, buffers)
WITH RECURSIVE T AS (
SELECT
0 i
, '' s
UNION ALL
SELECT
i + 1
, repeat('a', i + 1)
FROM
T
WHERE
i < 1e4 -- 10k итераций
)
TABLE T ORDER BY s DESC LIMIT 1;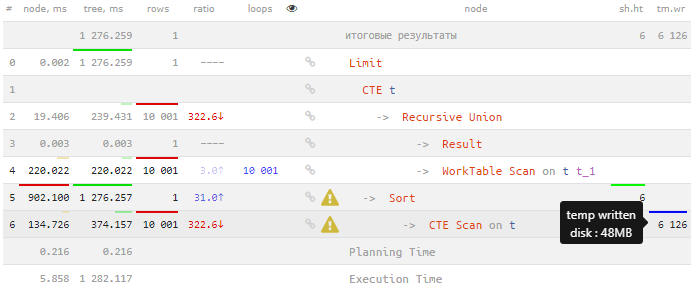
[просмотреть на explain.tensor.ru]
Корень беды заключается в том, что для сортировки рекурсивной выборки T необходимо вычислить и куда-то записать ее полностью, что и показывает атрибут temp written:
-> CTE Scan on t (actual time=0.008..374.157 rows=10001 loops=1)
Buffers: temp written=6126Давайте теперь сэмулируем неприятность, случившуюся во время выполнения запроса - увеличим для этого ограничение рекурсии на порядок:
SELECT pg_backend_pid();
-- 15004 - это PID процесса, обслуживающего наше клиентское соединение
explain (analyze, buffers)
WITH RECURSIVE T AS (
SELECT
0 i
, '' s
UNION ALL
SELECT
i + 1
, repeat('a', i + 1)
FROM
T
WHERE
i < 1e5 -- 100k итераций
)
TABLE T ORDER BY s DESC LIMIT 1;kill -9 15004
Сервер быстро упал - быстро поднялся. Но место на диске у нас убыло почти на 4GB - где же они?
Найти их нам поможет функция получения списка временных файлов pg_ls_tmpdir:
SELECT * FROM pg_ls_tmpdir(); name | size | modification
pgsql_tmp15004.0 | 1073741824 | 2021-05-12 10:46:10+03
pgsql_tmp15004.1 | 1073741824 | 2021-05-12 10:46:38+03
pgsql_tmp15004.2 | 1073741824 | 2021-05-12 10:47:06+03
pgsql_tmp15004.3 | 958078976 | 2021-05-12 10:47:31+03Данная функция появилась только в PostgreSQL 12, поэтому если версия вашего сервера младше, придется воспользоваться pg_ls_dir по <data>/base/pgsql_tmp - это как раз то место, где сохраняются временные файлы, которые мы ищем.
Эти файлы в имени содержат PID процесса, который их породил. Поэтому, чтобы не зачистить лишнего, сразу проверим, что среди активных запросов такого идентификатора нет:
WITH dir AS (
SELECT
current_setting('data_directory') || '/base/pgsql_tmp' dir
)
, ls AS (
SELECT
*
, pg_ls_dir(dir) fn
FROM
dir
)
, tmp AS (
SELECT
*
, regexp_replace(fn, '^pgsql_tmp(\d+).*$', '\1')::integer pid
, (pg_stat_file(dir || '/' || fn)).*
FROM
ls
)
SELECT
dir || '/' || fn
FROM
tmp
LEFT JOIN
pg_stat_activity sa
USING(pid)
WHERE
sa IS NOT DISTINCT FROM NULL;Теперь осталось пройти по полученному списку и поудалять. Замечу, что если "прибивать" запрос через pg_terminate_backend(pid), то и сервер не "падает", и подобного "мусора" в каталоге не остается.
Ничейные TEMPORARY TABLE
CREATE TEMPORARY TABLE x AS
SELECT
i
, repeat('a', i::integer) s
FROM
generate_series(1, 1e5) i;Теперь в списке схем нашего соединения появилась pg_temp_5:
SELECT current_schemas(true);
-- {pg_temp_5,pg_catalog,public}Именно на эту схему проецируется обращение к псевдосхеме pg_temp - то есть в этом соединении запросы TABLE x, TABLE pg_temp.x и TABLE pg_temp_5.x будут эквивалентны, пока эта временная таблица существует.
Но раз эта таблица полноценная, а не "полуфабрикат", как в случае temp buffers, то мы должны бы увидеть ее и в pg_class:
SELECT
oid
, relnamespace::regnamespace
, relname
, relfilenode
FROM
pg_class
WHERE
relnamespace::regnamespace::text ~ '^pg(_toast)?_temp'; oid | relnamespace | relname | relfilenode
66112 | pg_toast_temp_5 | pg_toast_66109 | 66112
66114 | pg_toast_temp_5 | pg_toast_66109_index | 66114
66109 | pg_temp_5 | x | 66109Выяснение такой странной нумерации схем приводит к письму Tom Lane аж от февраля 2003:
> What is the origin of these schemas? local temporary tables? sorts?
Right, they're made to hold temporary tables. The first time a givenbackend does CREATE TEMP TABLE, it looks for a pg_temp_n schema, and makes it if it's not there. On shutdown, it removes the temp tables, but it seemed like a waste of cycles to remove the pg_temp_n schema itself.
(ObTrivialFact: the 'n' is the backend's pgproc slot number, so it's known not to be in use by any concurrently running backend. But it will certainly be used again in future.)
Итак, при штатном гашении сервера сами файлы временных таблиц должны быть вычищены. Собственно, а где они?
В отличие от temp buffers, относящихся ко всему серверу, файлы временных таблиц и индексов относятся к конкретной базе, но имеют несколько другой формат имени:
WITH dir AS (
SELECT
current_setting('data_directory') || '/base/' || oid dir
FROM
pg_database
WHERE
datname = current_database()
)
, ls AS (
SELECT
*
, pg_ls_dir(dir) fn
FROM
dir
)
SELECT
*
FROM
ls
WHERE
fn ~ '^t'; dir | fn
.../data/base/16393 | t5_66109
.../data/base/16393 | t5_66112
.../data/base/16393 | t5_66114То есть имя файла временного объекта выглядит как t<temp schema N>_<temp object OID>. Если сейчас мы "уроним" сервер снова, эти файлы останутся, как и записи в pg_class.
Чтобы избавиться от них, можно прогнать VACUUM FULL по всей базе, но это практически невозможно, если она достаточно велика. Или просто подождать когда то же самое доберется сделать autovacuum:
LOG: autovacuum: found orphan temp table "tst.pg_temp_5.x"Но если таблиц в базе немало, это может наступить ой как нескоро, а дисковое пространство по-прежнему будет занято.
Поэтому, чтобы выловить заведомо "ничейные" временные таблицы, сравним время последней модификации их файлов со временем перезагрузки сервера, которое в обычных условиях можно определить как время сброса статистики по "нулевой" базе:
WITH dir AS (
SELECT
current_setting('data_directory') || '/base/' || oid dir
FROM
pg_database
WHERE
datname = current_database()
)
, ls AS (
SELECT
*
, pg_ls_dir(dir) fn
FROM
dir
)
, lsid AS (
SELECT
*
, (pg_stat_file(dir || '/' || fn)).*
FROM
ls
WHERE
fn ~ '^t'
)
, sch AS (
SELECT DISTINCT
regexp_replace(fn, '^t(\d+)_.*$', '\1') sch
FROM
lsid
WHERE
modification < (
SELECT
stats_reset
FROM
pg_stat_database
WHERE
datid = 0
)
)
SELECT
string_agg('DROP SCHEMA ' || nspname || ' CASCADE;', E'\n') s
FROM
sch
JOIN
pg_namespace nsp
ON nsp.nspname IN ('pg_temp_' || sch, 'pg_toast_temp_' || sch);Получаем готовый текст запроса, который останется только выполнить:
DROP SCHEMA pg_temp_5 CASCADE;
DROP SCHEMA pg_toast_temp_5 CASCADE;
Melkij
Корректный способ — штатный перезапуск базы.
При crash recovery временные файлы база оставляла на диске намеренно, а не «забывала». Разработчики считали, что эти файлы могут быть полезны для дебага краха СУБД.
Я пишу об этом в прошедшем времени, т.к. в марте это поведение было изменено и postgresql 14 будет вычищать эти временные файлы сам при crash recovery, так же как и при обычном старте.
Kilor Автор
1. Если простой базы/ее рестарт приводит к дополнительной трате ресурсов, ошибкам в приложениях, потере денег,… Это не всегда оправдано повторно, даже если сервер уже выключался перед этим аварийно.
2. Как правильно сказано в описании к тому же патчу, само наличие этих файлов может усугублять проблему
"disk usage may grow over time due to repeated backend failures (possibly.even hitting ENOSPC)"
Melkij
Да, об этом десятке секунд даунтайма на рестарт базы бывает проблемно договориться. Но и потери в (далеко не самом невозможном) случае «упс, я ошибся в команде и грохнул не тот файл» будут куда больше.