
Как нормальные DBA, мы подождали выпуск пары минорных версий к PostgreSQL 13, который должен порадовать нас многими полезными вещами, и теперь готовы перенести базу нашего сервиса мониторинга этой СУБД с 12-й версии на 13-ю.
Но как это сделать с минимальным простоем, а лучше вообще без него? На помощь придет функционал Foreign Data Wrappers, а точнее - postgres_fdw.

Структура исходной базы
Некоторые детали об устройстве базы нашего сервиса, которые помогают нам очень быстро записывать приходящие данные, я рассказывал в статьях "Пишем в PostgreSQL на субсветовой: 1 host, 1 day, 1TB" и "Экономим копеечку на больших объемах в PostgreSQL". Если в двух словах, то грамотное секционирование БД решает массу проблем производительности.
Мы применяем секционирование по дням в силу того, что у нас приходит по 100-150GB данных ежедневно. Давайте смоделируем структуру нашей базы tst на PostgreSQL 12:
CREATE TABLE archive(
dt
date
, val
integer
)
PARTITION BY RANGE(dt); -- секционирование по диапазонам
CREATE TABLE archive_20210401 -- секция конкретного дня
PARTITION OF archive
FOR VALUES FROM ('2021-04-01') TO ('2021-04-02');
-- dt >= '2021-04-01' AND dt < '2021-04-02'
CREATE TABLE archive_20210402
PARTITION OF archive
FOR VALUES FROM ('2021-04-02') TO ('2021-04-03');Хоть каждый день и представлен конкретным значением dt, мы все равно предпочитаем использовать PARTITION BY RANGE с указанием FOR VALUES FROM (dt) TO (dt + 1) вместо PARTITION BY LIST, поскольку этот вариант допускает определенную гибкость - например, можно слить некоторые архивные секции до месячных вместо суточных.
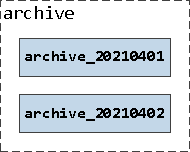
Проверим, как раскладываются по секциям записи при вставке в такую таблицу:
INSERT INTO archive
VALUES
('2021-04-01', 1)
, ('2021-04-02', 2)
RETURNING
tableoid::regclass
, *; tableoid | dt | val
archive_20210401 | 2021-04-01 | 1
archive_20210402 | 2021-04-02 | 2tableoid - это одно из системных полей записи, представляющее ссылку на конкретную таблицу (в нашем случае - секцию), в которой она находится. Подробнее можно прочитать в статье "PostgreSQL Antipatterns: уникальные идентификаторы".
"Подцепляем" старые данные
К особенностям нашей базы, как и многих баз мониторинга, можно отнести доминирующую активность только 1-2 последних секций и постепенное "отмирание" с течением времени более не требующихся блоков "сырых" данных.
Поэтому мы можем спокойно развернуть PostgreSQL 13 прямо на том же сервере, не создавая никакой избыточной нагрузки. Для определенности примем, что v12 доступна на :5439, а v13 будет на :5440.
Сначала повторим структуру базы для новых секций на новом сервере:
CREATE TABLE archive(
dt
date
, val
integer
)
PARTITION BY RANGE(dt);
CREATE TABLE archive_20210403
PARTITION OF archive
FOR VALUES FROM ('2021-04-03') TO ('2021-04-04');
Чтобы не создавать проекции всех старых секций с помощью IMPORT FOREIGN SCHEMA, ограничимся единственной вспомогательной секцией на определенный вид данных (планы, запросы, ...). Но раз таких видов у нас много, сразу настроим полный доступ к старому серверу, чтобы не копипастить параметры каждый раз:
CREATE EXTENSION postgres_fdw;
CREATE SERVER postgresql_12
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host '127.0.0.1', port '5439', dbname 'tst');
CREATE USER MAPPING FOR postgres
SERVER postgresql_12
OPTIONS (user 'postgres', password 'postgres');Теперь остается всего лишь создать служебную секцию, обеспечивающую доступ к старым данным:
CREATE FOREIGN TABLE archive_old
PARTITION OF archive
FOR VALUES FROM ('-infinity') TO ('2021-04-03')
-- dt < '2021-04-03'
SERVER postgresql_12
OPTIONS(table_name 'archive');Тут нам снова удачно помогло использование PARTITION BY RANGE вместо BY LIST, позволив опереться на неравенство.
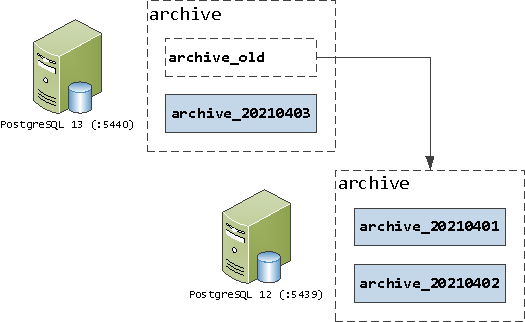
Проверим, как на новом сервере отработает аналогичная вставка данных:
INSERT INTO archive
VALUES
('2021-04-01', 1)
, ('2021-04-02', 2)
, ('2021-04-03', 3)
RETURNING
tableoid::regclass
, *; tableoid | dt | val
archive_old | 2021-04-01 | 1 -- старый сервер
archive_old | 2021-04-02 | 2
archive_20210403 | 2021-04-03 | 3 -- новая секцияДополнительные настройки FDW
Если в течение какого-то времени нам необходимо поддерживать возможность записи в старые секции, убедитесь в правильном задании значения FDW-параметра updatable, а если планируете активно читать оттуда - обратите внимание на use_remote_estimate и fetch_size.
Ровно таким же способом, с помощью FDW-секций, можно распределять дисковую нагрузку на другие серверы - только тут уже лучше использовать PARTITION BY HASH, конечно.
Kwisatz
Я уже спрашивал почему без гипертаблиц?)
Kilor Автор
Пока не довелось. ))
Пробовали Citus для аналитических запросов, но с «выточкой» конкретных запросов «руками» получается эффективнее пока.
Kwisatz
Эх(
Кстати читаю ваши статьи очень пристально, довольно основательный подход хоть и с нюансами. Но параллельно работаю по доработки интеграции СБИС и 1с, я малость в ужасе. Не чувствуется даже близко такой проработки вопроса.
Kilor Автор