
GTA Online. Многопользовательская игра, печально известная медленной загрузкой. Недавно я вернулся, чтобы завершить несколько ограблений — и был потрясён, что она загружается настолько же медленно, как и в день своего выпуска, 7 лет назад.
Пришло время докопаться до сути.
Сначала я хотел проверить, вдруг кто-то уже решил проблему. Но нашёл только рассказы о великой сложности игры, из-за чего она так долго загружается, истории о том, что сетевая p2p-архитектура — мусор (хотя это не так), некоторые сложные способы загрузки в сюжетный режим, а потом в одиночную сессию, и ещё пару модов, чтобы скипнуть видео с логотипом R* во время загрузки. Ещё немного почитав форумы, я узнал, что можно сэкономить колоссальные 10-30 секунд, если использовать все эти способы вместе!
Тем временем на моём компе…
Знаю, что моё железо устарело, но чёрт возьми, что может замедлить загрузку в 6 раз в онлайн-режиме? Я не мог измерить разницу при загрузке из сюжетного режима в онлайн, как это делали другие. Даже если это сработает, разница небольшая.
Если доверять этому опросу, проблема достаточно широко распространена, чтобы слегка раздражать более 80% игроков. Прошло уже семь лет!

Я немного поискал информацию о тех ~20% счастливчиках, которые загружаются быстрее трёх минут, и нашёл несколько бенчмарков с топовыми игровыми ПК и временем загрузки онлайн-режима около двух минут. Я бы кого-нибудьубил хакнул за такой комп! Действительно похоже на железячную проблему, но что-то не складывается…
Почему у них сюжетный режим по-прежнему загружается около минуты? (кстати, при загрузке с M.2 NVMe не учитывались видео с логотипами). Кроме того, загрузка из сюжетного режима в онлайн занимает у них всего минуту, в то время как у меня около пяти. Я знаю, что их железо гораздо лучше, но не в пять же раз.
Вооружившись таким мощным инструментом, как Диспетчер задач, я приступил к поиску узкого места.

Почти минута уходит на загрузку общих ресурсов, которые нужны и для сюжетного режима, и для онлайна (почти наравне с топовыми ПК), затем GTA в течение четырёх минут полностью нагружает одно ядро CPU, больше ничего не делая.
Использование диска? Нет! Использование сети? Есть немного, но через несколько секунд падает в основном до нуля (кроме загрузки вращающихся информационных баннеров). Использование GPU? Ноль. Память? Вообще ничего…
Что это, майнинг биткоинов или что-то такое? Чую здесь код. Очень плохой код.
На моём старом процессоре AMD восемь ядер, и он ещё молодцом, но это старая модель. Его сделали ещё тогда, когда производительность одного потока у AMD была намного ниже, чем у Intel. Наверное, это главная причина таких различий во времени загрузки.
Что странно, так это способ использования CPU. Я ожидал огромное количество операций чтения с диска или массу сетевых запросов, чтобы организовать сеансы в сети p2p. Но такое? Вероятно, здесь какая-то ошибка.
Профилировщик — отличный способ найти узкие места в CPU. Есть только одна проблема — большинство из них полагаются на инструментирование исходного кода, чтобы получить идеальную картину происходящего в процессе. А у меня нет исходного кода. Мне также не требуются идеальные показания в микросекундах, у меня узкое место на 4 минуты.
Итак, добро пожаловать в образцы стека (stack sampling). Для приложений с закрытым исходным кодом есть только такой вариант. Сбросьте стек запущенного процесса и местоположение указателя текущей инструкции, чтобы построить дерево вызовов в заданные интервалы. Затем наложите их — и получите статистику о том, что происходит. Я знаю только один профилировщик, который может проделать это под Windows. И он не обновлялся уже более десяти лет. Это Люк Stackwalker! Кто-нибудь, пожалуйста, подарите Люку немножко любви :)

Обычно Люк группировал бы одинаковые функции, но у меня нет отладочных символов, поэтому пришлось смотреть на соседние адреса, чтобы искать общие места. И что же мы видим? Не одно, а целых два узких места!
Позаимствовав у моего друга совершенно законную копию стандартного дизассемблера (нет, я действительно не могу его себе позволить… когда-нибудь освою гидру), я пошёл разбирать GTA.

Выглядит совсем неправильно. Да, у большинства топовых игр есть встроенная защита от реверс-инжиниринга, чтобы защититься от пиратов, мошенников и моддеров. Не то чтобы это их когда-то останавливало…
Похоже, здесь применили какую-то обфускацию/шифрование, заменив большинство инструкций тарабарщиной. Не волнуйтесь, нужно просто сбросить память игры, пока она выполняет ту часть, на которую мы хотим посмотреть. Инструкции должны быть деобфусцированы перед запуском тем или иным способом. У меня рядом лежал Process Dump, так что я взял его, но есть много других инструментов для подобных задач.
Дальнейший разбор дампа выявил один из адресов с некоей меткой
Он что-то парсит. Но что? Логический разбор займёт целую вечность, поэтому я решил сбросить некоторые образцы из запущенного процесса с помощью x64dbg. Через несколько шагов отладки выясняется, что это… JSON! Он парсит JSON. Колоссальные десять мегабайт JSON'а с записями 63 тыс. предметов.
Что это? Судя по некоторым ссылкам, это данные для «сетевого торгового каталога». Предполагаю, он содержит список всех возможных предметов и обновлений, которые вы можете купить в GTA Online.
Проясним некоторую путаницу: я полагаю, что это предметы, приобретаемые за игровые деньги, не связанные напрямую с микротранзакциями.
10 мегабайт? В принципе, не так уж и много. Хотя

Да, такая процедура займёт некоторое время… Честно говоря, я понятия не имел, что большинство реализаций
Оказывается, второго преступника вызывают сразу за первым. Даже в одной и той же конструкции

Все метки мои, и я понятия не имею, как на самом деле называются функции/параметры.
Вторая проблема? Сразу после разбора элемента он хранится в массиве (или встроенном списке C++? не уверен). Каждая запись выглядит примерно так:
А перед сохранением? Он проверяет весь массив, сравнивая хэш каждого элемента, есть он в списке или нет. С 63 тыс. записей это примерно

Во время реверс-инжиниринга я назвал его
Всё это конечно классно, но никто не воспримет меня всерьёз, пока я не напишу реальный код для ускорения загрузки, чтобы сделать кликбейтный заголовок для поста.
План такой. 1. Написать .dll, 2. внедрить её в GTA, 3. зацепить некоторые функции, 4. ???, 5. профит. Всё предельно просто.
Проблема с JSON нетривиальная, я не могу реально заменить их парсер. Более реалистичным кажется заменить sscanf на тот, который не зависит от strlen. Но есть ещё более простой способ.
Что-то вроде такого:
А что касается проблемы хэш-массива, то здесь просто полностью пропускаем все проверки и вставляем элементы напрямую, поскольку мы знаем, что значения уникальны.
Полный исходный код PoC здесь.
Ну и как оно работает?
Да, чёрт возьми, получилось! :))
Скорее всего, это не решит всех проблем с загрузкой — в разных системах могут быть и другие узкие места, но это такая зияющая дыра, что я понятия не имею, как R* пропустила её за все эти годы.
Если информация каким-то образом дойдёт до инженеров Rockstar, то проблему можно решить в течение нескольких часов силами одного разработчика. Пожалуйста, ребята, сделайте что-нибудь с этим :<
Вы можете либо перейти на хэш-таблицу для удаления дублей, либо полностью пропустить дедупликацию при запуске как быстрое исправление. Для парсера JSON — просто замените библиотеку на более производительную. Не думаю, что есть более простой вариант.
ty <3
Пришло время докопаться до сути.
Разведка
Сначала я хотел проверить, вдруг кто-то уже решил проблему. Но нашёл только рассказы о великой сложности игры, из-за чего она так долго загружается, истории о том, что сетевая p2p-архитектура — мусор (хотя это не так), некоторые сложные способы загрузки в сюжетный режим, а потом в одиночную сессию, и ещё пару модов, чтобы скипнуть видео с логотипом R* во время загрузки. Ещё немного почитав форумы, я узнал, что можно сэкономить колоссальные 10-30 секунд, если использовать все эти способы вместе!
Тем временем на моём компе…
Бенчмарк
Загрузка сюжетного режима: ~1м 10с Загрузка онлайна: ~6м Без загрузочного меню, от логотипа R* до игрового процесса (без логина в Cоциальный Клуб. Старый, но приличный проц: AMD FX-8350 Дешёвый SSD: KINGSTON SA400S37120G Надо бы прикупить RAM: 2x Kingston 8192 MB (DDR3-1337) 99U5471 Нормальный GPU: NVIDIA GeForce GTX 1070
Знаю, что моё железо устарело, но чёрт возьми, что может замедлить загрузку в 6 раз в онлайн-режиме? Я не мог измерить разницу при загрузке из сюжетного режима в онлайн, как это делали другие. Даже если это сработает, разница небольшая.
Я (не) одинок
Если доверять этому опросу, проблема достаточно широко распространена, чтобы слегка раздражать более 80% игроков. Прошло уже семь лет!
Я немного поискал информацию о тех ~20% счастливчиках, которые загружаются быстрее трёх минут, и нашёл несколько бенчмарков с топовыми игровыми ПК и временем загрузки онлайн-режима около двух минут. Я бы кого-нибудь
Почему у них сюжетный режим по-прежнему загружается около минуты? (кстати, при загрузке с M.2 NVMe не учитывались видео с логотипами). Кроме того, загрузка из сюжетного режима в онлайн занимает у них всего минуту, в то время как у меня около пяти. Я знаю, что их железо гораздо лучше, но не в пять же раз.
Высокоточные измерения
Вооружившись таким мощным инструментом, как Диспетчер задач, я приступил к поиску узкого места.
Почти минута уходит на загрузку общих ресурсов, которые нужны и для сюжетного режима, и для онлайна (почти наравне с топовыми ПК), затем GTA в течение четырёх минут полностью нагружает одно ядро CPU, больше ничего не делая.
Использование диска? Нет! Использование сети? Есть немного, но через несколько секунд падает в основном до нуля (кроме загрузки вращающихся информационных баннеров). Использование GPU? Ноль. Память? Вообще ничего…
Что это, майнинг биткоинов или что-то такое? Чую здесь код. Очень плохой код.
Единственный поток
На моём старом процессоре AMD восемь ядер, и он ещё молодцом, но это старая модель. Его сделали ещё тогда, когда производительность одного потока у AMD была намного ниже, чем у Intel. Наверное, это главная причина таких различий во времени загрузки.
Что странно, так это способ использования CPU. Я ожидал огромное количество операций чтения с диска или массу сетевых запросов, чтобы организовать сеансы в сети p2p. Но такое? Вероятно, здесь какая-то ошибка.
Профилирование
Профилировщик — отличный способ найти узкие места в CPU. Есть только одна проблема — большинство из них полагаются на инструментирование исходного кода, чтобы получить идеальную картину происходящего в процессе. А у меня нет исходного кода. Мне также не требуются идеальные показания в микросекундах, у меня узкое место на 4 минуты.
Итак, добро пожаловать в образцы стека (stack sampling). Для приложений с закрытым исходным кодом есть только такой вариант. Сбросьте стек запущенного процесса и местоположение указателя текущей инструкции, чтобы построить дерево вызовов в заданные интервалы. Затем наложите их — и получите статистику о том, что происходит. Я знаю только один профилировщик, который может проделать это под Windows. И он не обновлялся уже более десяти лет. Это Люк Stackwalker! Кто-нибудь, пожалуйста, подарите Люку немножко любви :)
Обычно Люк группировал бы одинаковые функции, но у меня нет отладочных символов, поэтому пришлось смотреть на соседние адреса, чтобы искать общие места. И что же мы видим? Не одно, а целых два узких места!
Вниз по кроличьей норе
Позаимствовав у моего друга совершенно законную копию стандартного дизассемблера (нет, я действительно не могу его себе позволить… когда-нибудь освою гидру), я пошёл разбирать GTA.
Выглядит совсем неправильно. Да, у большинства топовых игр есть встроенная защита от реверс-инжиниринга, чтобы защититься от пиратов, мошенников и моддеров. Не то чтобы это их когда-то останавливало…
Похоже, здесь применили какую-то обфускацию/шифрование, заменив большинство инструкций тарабарщиной. Не волнуйтесь, нужно просто сбросить память игры, пока она выполняет ту часть, на которую мы хотим посмотреть. Инструкции должны быть деобфусцированы перед запуском тем или иным способом. У меня рядом лежал Process Dump, так что я взял его, но есть много других инструментов для подобных задач.
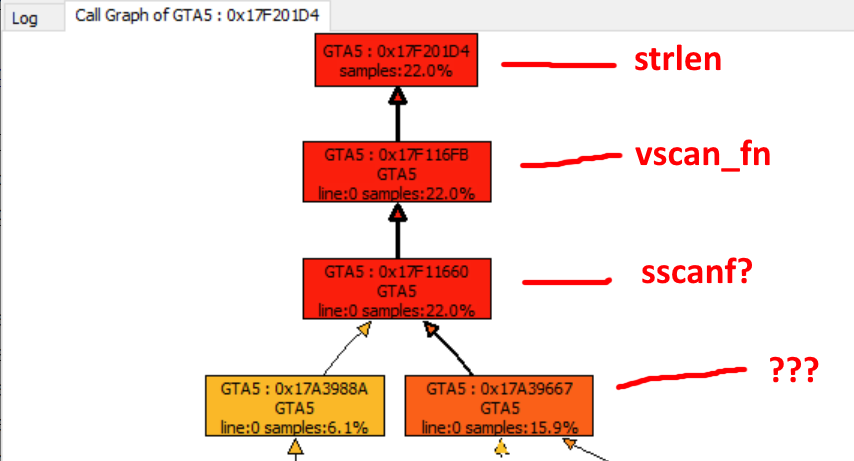
Проблема 1: это что… strlen?!
Дальнейший разбор дампа выявил один из адресов с некоей меткой
strlen, которая откуда-то берётся! Спускаясь вниз по стеку вызовов, предыдущий адрес помечен как vscan_fn, и после этого метки заканчиваются, хотя я вполне уверен, что это sscanf.Он что-то парсит. Но что? Логический разбор займёт целую вечность, поэтому я решил сбросить некоторые образцы из запущенного процесса с помощью x64dbg. Через несколько шагов отладки выясняется, что это… JSON! Он парсит JSON. Колоссальные десять мегабайт JSON'а с записями 63 тыс. предметов.
...,
{
"key": "WP_WCT_TINT_21_t2_v9_n2",
"price": 45000,
"statName": "CHAR_KIT_FM_PURCHASE20",
"storageType": "BITFIELD",
"bitShift": 7,
"bitSize": 1,
"category": ["CATEGORY_WEAPON_MOD"]
},
...Что это? Судя по некоторым ссылкам, это данные для «сетевого торгового каталога». Предполагаю, он содержит список всех возможных предметов и обновлений, которые вы можете купить в GTA Online.
Проясним некоторую путаницу: я полагаю, что это предметы, приобретаемые за игровые деньги, не связанные напрямую с микротранзакциями.
10 мегабайт? В принципе, не так уж и много. Хотя
sscanf используется не самым оптимальным образом, но, конечно, это не так уж плохо? Что ж…Да, такая процедура займёт некоторое время… Честно говоря, я понятия не имел, что большинство реализаций
sscanf вызывают strlen, поэтому не могу винить разработчика, который написал это. Я бы предположил, что он просто сканировал байт за байтом и мог остановиться на NULL.Проблема 2: давайте использовать хэш-…массив?
Оказывается, второго преступника вызывают сразу за первым. Даже в одной и той же конструкции
if, как видно из этой уродливой декомпиляции:Все метки мои, и я понятия не имею, как на самом деле называются функции/параметры.
Вторая проблема? Сразу после разбора элемента он хранится в массиве (или встроенном списке C++? не уверен). Каждая запись выглядит примерно так:
struct {
uint64_t *hash;
item_t *item;
} entry;А перед сохранением? Он проверяет весь массив, сравнивая хэш каждого элемента, есть он в списке или нет. С 63 тыс. записей это примерно
(n^2+n)/2 = (63000^2+63000)/2 = 1984531500, если я не ошибаюсь в расчётах. И это в основном бесполезные проверки. У вас есть уникальные хэши, почему не использовать хэш-таблицу.Во время реверс-инжиниринга я назвал его
hashmap, но это явно не_hashmap. И дальше ещё интереснее. Этот хэш-массив-список пуст перед загрузкой JSON. И все элементы в JSON уникальны! Им даже не нужно проверять, есть они в списке или нет! У них даже есть функция прямой вставки элементов! Просто используйте её! Серьёзно, ну ребята, что за фигня!?Доказательство концепции
Всё это конечно классно, но никто не воспримет меня всерьёз, пока я не напишу реальный код для ускорения загрузки, чтобы сделать кликбейтный заголовок для поста.
План такой. 1. Написать .dll, 2. внедрить её в GTA, 3. зацепить некоторые функции, 4. ???, 5. профит. Всё предельно просто.
Проблема с JSON нетривиальная, я не могу реально заменить их парсер. Более реалистичным кажется заменить sscanf на тот, который не зависит от strlen. Но есть ещё более простой способ.
- зацепить strlen
- подождать длинной строки
- «закэшировать» начало и длину
- если поступит ещё вызов в пределах диапазона строки, вернуть закэшированное значение
Что-то вроде такого:
size_t strlen_cacher(char* str)
{
static char* start;
static char* end;
size_t len;
const size_t cap = 20000;
// если "словили" строку и текущий указатель внутри
if (start && str >= start && str <= end) {
// calculate the new strlen
len = end - str;
// если мы около конца, выгружаемся
// мы не хотим больше ни с чем путаться
if (len < cap / 2)
MH_DisableHook((LPVOID)strlen_addr);
// супербыстрый возврат!
return len;
}
// считаем реальную длину
// нужно минимум одно измерение большого JSON
// или нормального strlen для других строк
len = builtin_strlen(str);
// если это реально большая строка
// сохраняем адреса начала и конца
if (len > cap) {
start = str;
end = str + len;
}
// медленный, скучный возврат
return len;
}А что касается проблемы хэш-массива, то здесь просто полностью пропускаем все проверки и вставляем элементы напрямую, поскольку мы знаем, что значения уникальны.
char __fastcall netcat_insert_dedupe_hooked(uint64_t catalog, uint64_t* key, uint64_t* item)
{
// без реверса структуры
uint64_t not_a_hashmap = catalog + 88;
// без понятия, что это такое, просто повторяем оригинал
if (!(*(uint8_t(__fastcall**)(uint64_t*))(*item + 48))(item))
return 0;
// вставляем напрямую
netcat_insert_direct(not_a_hashmap, key, &item);
// удаляем хуки после хэша последнего предмета
// и выгружаем .dll, мы закончили :)
if (*key == 0x7FFFD6BE) {
MH_DisableHook((LPVOID)netcat_insert_dedupe_addr);
unload();
}
return 1;
}Полный исходный код PoC здесь.
Результаты
Ну и как оно работает?
Прежнее время загрузки онлайн-режима: около 6м Время с патчем проверки дубликатов: 4м 30с Время с парсером JSON: 2м 50с Время с двумя патчами вместе: 1м 50с (6*60 - (1*60+50)) / (6*60) = 69.4% улучшение времени (класс!)
Да, чёрт возьми, получилось! :))
Скорее всего, это не решит всех проблем с загрузкой — в разных системах могут быть и другие узкие места, но это такая зияющая дыра, что я понятия не имею, как R* пропустила её за все эти годы.
Краткое содержание
- При запуске GTA Online есть узкое место, связанное с однопоточным вычислением
- Оказалось, GTA изо всех сил пытается распарсить 1-мегабайтный файл JSON
- Сам парсер JSON плохо сделан/наивен и
- После парсинга происходит медленная процедура удаления дублей
R*, пожалуйста, исправьте
Если информация каким-то образом дойдёт до инженеров Rockstar, то проблему можно решить в течение нескольких часов силами одного разработчика. Пожалуйста, ребята, сделайте что-нибудь с этим :<
Вы можете либо перейти на хэш-таблицу для удаления дублей, либо полностью пропустить дедупликацию при запуске как быстрое исправление. Для парсера JSON — просто замените библиотеку на более производительную. Не думаю, что есть более простой вариант.
ty <3


















LinearLeopard
Извинияюсь за глупый вопрос, сам не играл, но я правильно понял, проблеса с загрузками есть с 2013 года, и никто не догадался (кроме автора поста) попрофайлить её?
STAR
Из статьи следует, что по мере наполнения внутриигрового магазина и роста кол-ва ассортимента, росло и время загрузки. И на данный момент размер конфига достиг до 10Мб (ассортимент магазина до 63к элементов), что с неверно выбранным способом парсинга привело к отложенным проблемам, хотя кол-во и небольшое.
mig126
Проблемы с долгой загрузкой онлайна были с самого старта, особенно страдали консольщики. Как обычно что то пофиксили, что то сломали.
tbl
типичная проблема алгоритмов O(n^2): начальные данные слишком маленькие, чтобы обнаружить проблему на старте, через какое-то время объем данных вырастает, чтобы все начало тормозить, и не очень понятно из-за чего: "раньше работало же".